Submitted:
18 November 2025
Posted:
19 November 2025
You are already at the latest version
Abstract
Medical image segmentation systems, despite their recent sophistication, often face substantial performance degradation when exposed to unseen imaging environments—caused by differences in scanner types, acquisition protocols, or rare pathological conditions. To address this crucial issue, we introduce \textbf{MedSeg-Adapt}, a novel framework that enables \textit{clinical query-guided adaptive medical image segmentation}. MedSeg-Adapt features an autonomous generative data augmentation module that dynamically synthesizes environment-specific and clinically diverse training data using advanced medical image Diffusion models in combination with large language models (LLMs). This module automatically generates realistic image variants, natural language clinical queries, and pseudo-annotations—without requiring new reinforcement learning policies or manual labeling. In addition, we establish \textbf{MedScanDiff}, a new benchmark comprising five challenging medical imaging environments: Higher-resolution CT, Low-dose CT, Varying-field MRI, Specific Pathology Variant, and Pediatric Imaging. Extensive experiments demonstrate that fine-tuning state-of-the-art models such as MedSeg-Net, VMed-LLM, and UniMedSeg on MedSeg-Adapt-generated data significantly enhances robustness and segmentation accuracy across unseen settings, achieving an improvement of Dice Similarity Coefficient (DSC). MedSeg-Adapt thus provides a practical and effective pathway toward self-adaptive, clinically grounded medical image segmentation.
Keywords:
medical image segmentation
; domain adaptation
; large language models
; clinical query understanding
; benchmark dataset
1. Introduction
Medical image segmentation is a cornerstone in modern healthcare, playing a pivotal role in accurate diagnosis, precise surgical planning, and effective treatment monitoring. The ability to delineate anatomical structures and pathological regions within medical images, such as Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) scans, is fundamental for clinicians and researchers. Recent advancements in deep learning have led to highly sophisticated segmentation models [1], further empowered by the integration of natural language processing to enable clinical query-guided segmentation [2]. The emergence of Large Vision-Language Models (LVLMs) has further advanced this field, offering new paradigms for understanding and interacting with complex visual and textual information [3]. This paradigm allows medical professionals to interact with segmentation systems using natural language queries (e.g., “precisely segment the tumor margin of the left kidney,” “identify and mark inflammatory regions”), thereby enhancing the flexibility and precision of image analysis and potentially streamlining clinical workflows. Enhancing the robustness and accuracy of these models, especially in medical contexts, is crucial.
Figure 1.
While segmentation models perform well in the source domain, their performance drops significantly in novel medical imaging environments (e.g., higher-resolution CT, low-dose CT, varying-field MRI, specific pathology, pediatric imaging). MedSeg-Adapt addresses this issue by generating synthetic, environment-specific data (Diffusion + LLM) to enable robust adaptation.
Figure 1.
While segmentation models perform well in the source domain, their performance drops significantly in novel medical imaging environments (e.g., higher-resolution CT, low-dose CT, varying-field MRI, specific pathology, pediatric imaging). MedSeg-Adapt addresses this issue by generating synthetic, environment-specific data (Diffusion + LLM) to enable robust adaptation.
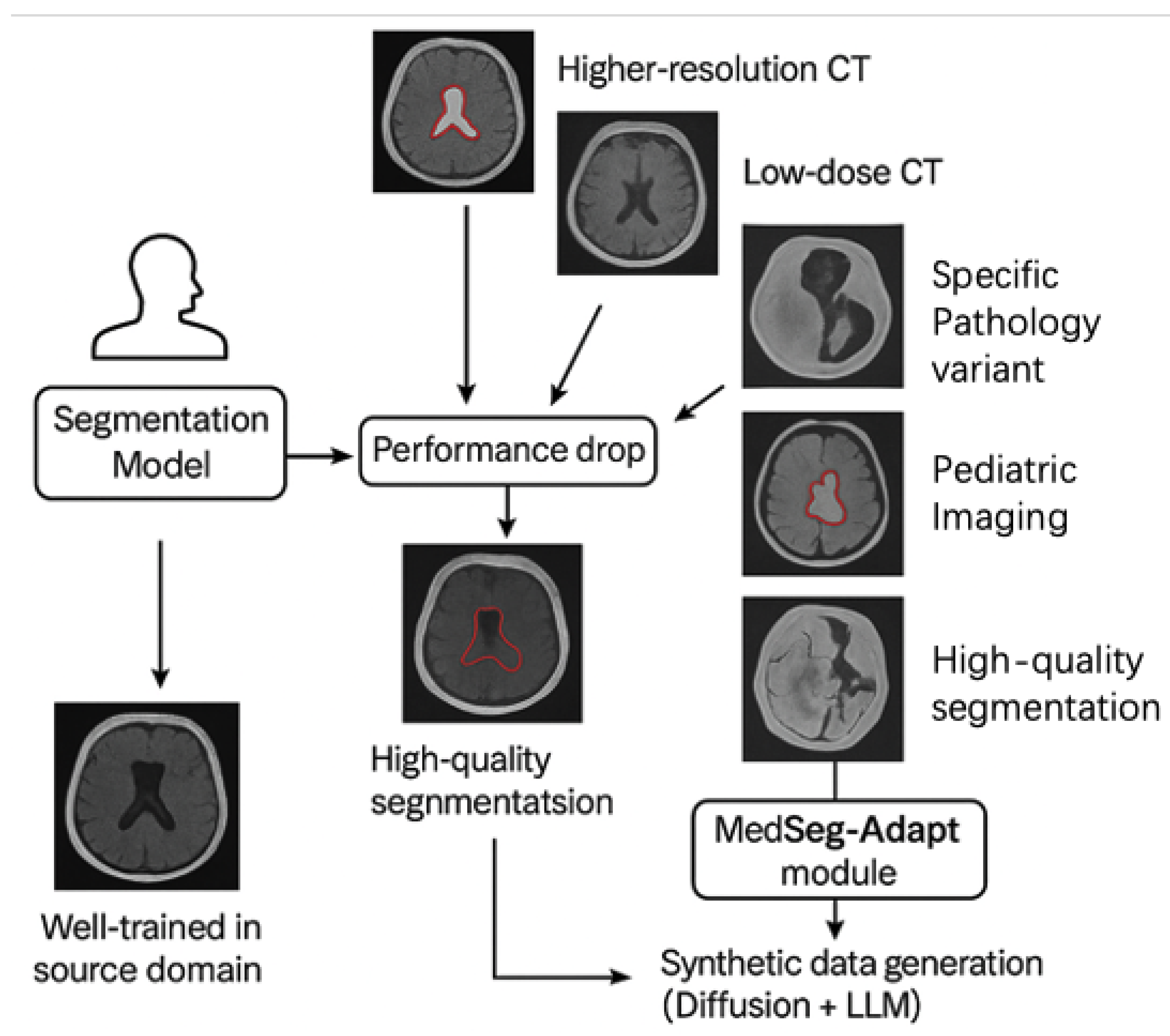
Despite the impressive capabilities of current medical vision-language models (MVLMs) and advanced segmentation networks, a significant challenge persists: their performance often degrades substantially when deployed in novel medical imaging environments. These environments encompass scenarios not adequately represented during model training, such as variations due to different hospital scanners, diverse imaging protocols, or the presence of rare pathological variations. This lack of robustness and adaptability in unseen settings limits their real-world applicability and hinders their potential to universally improve patient care. The primary motivation for our work is to overcome this critical generalization gap, enabling medical image segmentation models to reliably adapt to new clinical realities without extensive manual data collection and annotation.
To address this challenge, we propose MedSeg-Adapt, a novel framework designed for clinical query-guided adaptive medical image segmentation. Our framework introduces an autonomous data augmentation module that intelligently generates representative and diverse training data specific to novel medical imaging environments. This module leverages advanced generative models, such as medical image Diffusion models [4], in conjunction with large language models (e.g., GPT-4/GPT-4o or specialized medical LLMs [5]), to simulate varied image conditions, create corresponding clinical queries, and generate preliminary pseudo-annotations. The ability of such LLMs to process and unravel complex, potentially chaotic contexts is key to generating high-quality queries [6]. Crucially, this process does not require training new reinforcement learning policies but instead relies on rule-based and generative model-driven exploration to efficiently produce high-quality adaptation data. The generated data is then used to fine-tune existing medical vision-language models or segmentation models, effectively aligning them with the characteristics of the new environment.
Furthermore, to rigorously evaluate the adaptation capabilities of models, we introduce MedScanDiff, a new benchmark specifically curated to test performance in novel medical imaging environments. MedScanDiff comprises five distinct environments: Higher-resolution CT, Low-dose CT, Varying-field MRI, Specific Pathology Variant datasets, and Pediatric Imaging. Each sample in MedScanDiff includes a medical image slice, a natural language clinical query, and the corresponding expert-annotated ground-truth segmentation mask. Our autonomous data augmentation module is capable of generating up to 500 unique image variations per environment, each accompanied by 2-3 clinical queries and pseudo-masks, for the fine-tuning process.
Our experiments demonstrate the significant effectiveness of MedSeg-Adapt. We evaluated our framework by fine-tuning several state-of-the-art models, including MedSeg-Net [7], VMed-LLM [8], and UniMedSeg, on the MedScanDiff benchmark. Using the Dice Similarity Coefficient (DSC) as the primary evaluation metric, MedSeg-Adapt consistently yielded substantial performance improvements across all tested environments. For instance, MedSeg-Net’s average DSC increased from 65.6% to 71.1% (+5.5% absolute improvement), VMed-LLM’s from 70.1% to 75.6% (+5.5% absolute improvement), and UniMedSeg’s from 72.8% to 78.3% (+5.5% absolute improvement). These results clearly validate MedSeg-Adapt’s ability to facilitate robust adaptation and enhance segmentation accuracy in previously unseen clinical scenarios.
Our main contributions are summarized as follows:
- We propose MedSeg-Adapt, a novel framework for clinical query-guided adaptive medical image segmentation, featuring an autonomous data augmentation module that generates environment-specific data without requiring new reinforcement learning models.
- We introduce MedScanDiff, a comprehensive new benchmark specifically designed to evaluate the generalization and adaptation capabilities of medical image segmentation models across five distinct novel medical imaging environments.
- We demonstrate that fine-tuning existing state-of-the-art medical vision-language models with data generated by MedSeg-Adapt leads to significant and consistent performance improvements (an average of +5.5% DSC) on the MedScanDiff benchmark, validating its efficacy in real-world adaptive scenarios.
2. Related Work
2.1. Medical Vision-Language Models and Query-Guided Segmentation
Research in Medical Vision-Language Models (MVLMs) is rapidly advancing, with overviews like [9] analyzing state-of-the-art techniques. A key development is Visual In-Context Learning (ICL), which enables Large Vision-Language Models (LVLMs) to adapt to new tasks with few examples [3]. To address data scarcity, synthetic images are used for Vision-Language Pre-training (VLP) [10]. Architectural innovations like the mmFormer multimodal Transformer handle incomplete medical data [11]. The role of NLP, especially generative LLMs, is critical for developing advanced MVLMs [12] by leveraging their ability to handle complex queries [6] and building on foundational event reasoning models [13,14].
Specific query-guided segmentation approaches include SQA-SAM for quality assessment [15], LSMS for language-guided lesion segmentation [16], MedSeg-R for reasoning-based segmentation from complex instructions [17], and Cycle Context Verification (CCV) for improving in-context pair selection and model robustness [18].
2.2. Domain Adaptation and Synthetic Data Generation in Medical Imaging
Domain adaptation is crucial for medical imaging, with toolboxes like DomainATM facilitating the process [19]. Domain Generalization (DG) is improved using adversarial domain synthesis [20] and domain-aware loss regularization (DOMINO++) to enhance Out-of-Distribution (OOD) generalizability [21]. Synthetic data generation is another key area, with methods like unsupervised reverse domain adaptation [22], data-efficient diffusion models (MedDiff-FT) [23], and novel GAN architectures [24] being proposed. In related work, retrieval-augmented methods reduce the need for extensive LLM fine-tuning in radiology report generation [25], and frameworks like METAM offer insights for automated data augmentation [26].
2.3. Advanced Decision-Making and Control in Intelligent Systems
In autonomous driving, multi-agent Monte Carlo Tree Search (MCTS) is explored for safe coordination at unsignalized intersections [27,28], with surveys evaluating such decision-making systems [29]. Robotics and teleoperation are advanced through hybrid damping-stiffness adjustments [30] and connectivity-preserving control for multi-robot systems [31]. The underlying hardware benefits from online parameter identification for PMSMs under sensorless control using virtual back-EMF and flux linkage injection methods [32,33,34]. For specific applications, techniques like hybrid perception and equivariant diffusion are used for complex tasks like robotic rebar tying [35].
2.4. Broad Applications of AI and Machine Learning
AI applications span numerous fields. In finance, research includes boosting algorithms for fraud detection with small samples [36], reinforcement learning for anti-money laundering case prioritization [37], and using LLMs to provide financial insights for government decision-making [38]. Other diverse applications include reconstructing complex networks from time series data using graph attention networks [39] and efficient frameworks for video segmentation in ultra-low light conditions [40].
3. Method
3.1. Problem Formulation
The fundamental task addressed in this work is clinical query-guided medical image segmentation. This involves precisely delineating specific anatomical structures or pathological regions within medical images, such as Computed Tomography (CT) or Magnetic Resonance Imaging (MRI) scans, guided by natural language queries provided by clinicians. Formally, given a medical image (where represent spatial dimensions and C is the number of channels, typically 1 for grayscale or 3 for RGB, though often referring to image depth for 3D volumes) and a natural language query Q (a string of text), a segmentation model f is designed to produce a binary segmentation mask . Here, indicates that the pixel at spatial coordinates belongs to the target region specified by Q, while indicates otherwise. This process can be mathematically expressed as:
where represents the comprehensive set of trainable parameters of the segmentation model.
A significant challenge arises when these segmentation models are deployed in novel medical imaging environments that exhibit substantial differences from the data distribution used during the model’s initial training. Such novel environments encompass a wide array of variations, including different scanner manufacturers and models, diverse imaging protocols (e.g., varying dose levels, contrast agents, pulse sequences), or the presence of rare or atypical pathological conditions. In these scenarios, the model’s performance often degrades substantially due to a phenomenon known as domain shift, leading to unreliable and potentially clinically misleading segmentation outcomes. Our primary objective is to develop a robust and efficient framework, termed MedSeg-Adapt, that enables existing medical image segmentation models to adapt effectively to without necessitating extensive, laborious manual data collection and annotation specific to each new environment. This adaptation process aims to refine the model parameters from their initial state to an optimized state such that the adapted model yields demonstrably higher segmentation accuracy for images and corresponding queries originating from the specific novel environment .
Figure 2.
The overview of our method.
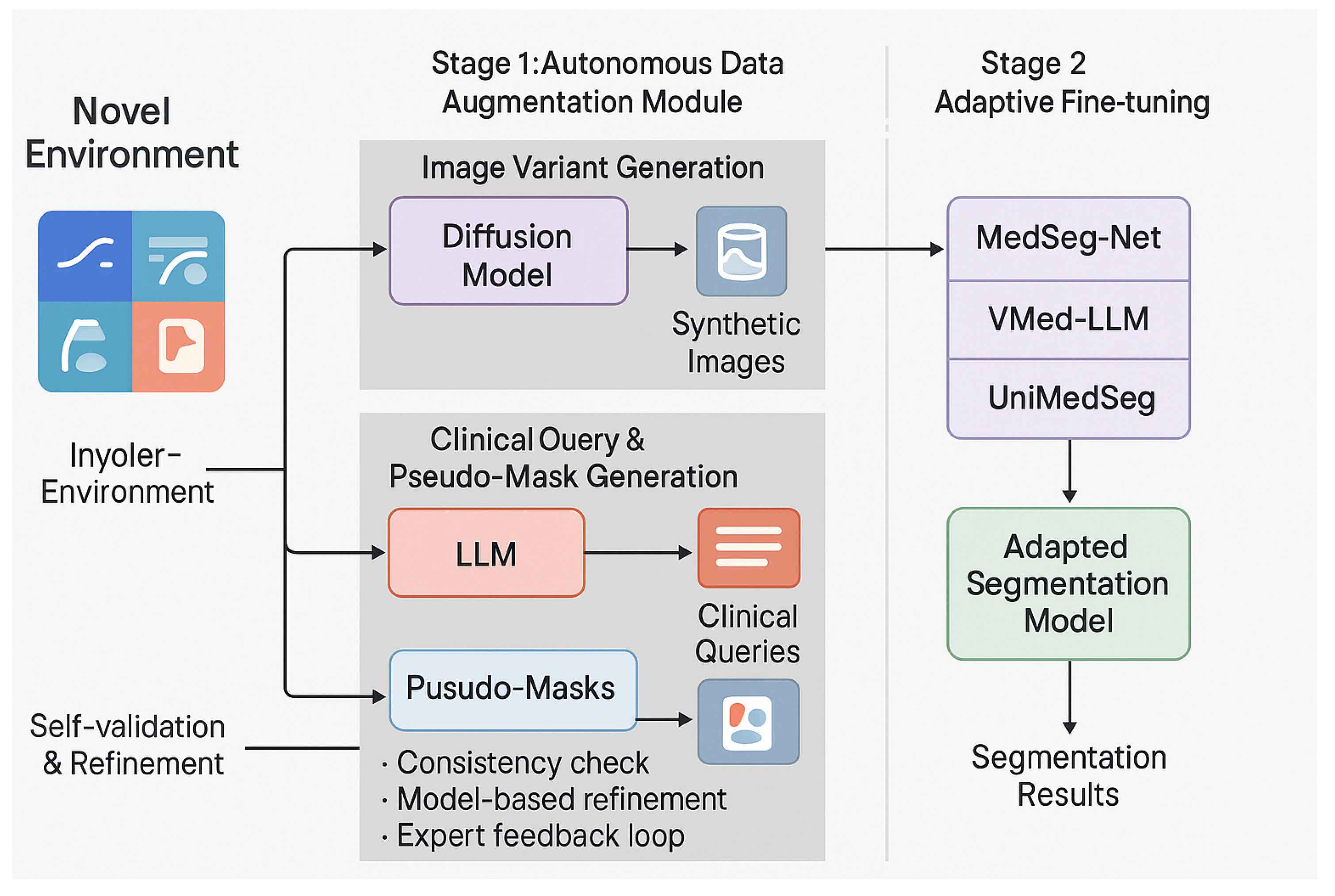
3.2. MedSeg-Adapt Framework Overview
MedSeg-Adapt is conceived as a novel two-stage adaptive framework specifically tailored for clinical query-guided medical image segmentation within previously unseen or novel environments. The foundational principle underlying this framework is the autonomous generation of environment-specific, high-quality synthetic data for subsequent effective model fine-tuning. The operational flow of the framework is systematically structured as follows:
- Autonomous Data Augmentation: For any given novel medical imaging environment , an integral autonomous data augmentation module is activated. This module is responsible for generating a diverse and representative set of synthetic medical images, along with their corresponding natural language clinical queries and preliminary pseudo-segmentation masks. This sophisticated generation process intelligently leverages advanced generative models, particularly medical image Diffusion models, in conjunction with large language models (LLMs), all guided by meticulously designed domain-specific rules and constraints.
- Adaptive Fine-tuning: The synthetic data generated and subsequently self-validated in the first stage are then systematically utilized to fine-tune existing pre-trained medical vision-language models (MVLMs) or specialized medical image segmentation models. This adaptive fine-tuning step is crucial for aligning the base models with the unique characteristics and data distribution of the target novel environment, thereby significantly enhancing their segmentation performance, generalization capabilities, and overall robustness in real-world clinical settings.
The overarching objective of MedSeg-Adapt is to strategically minimize the performance disparity between a segmentation model initially trained on general, diverse data and its performance when confronted with data originating from a novel environment . This is achieved through the innovative generation and judicious utilization of targeted, high-fidelity adaptation data, thereby bridging the domain gap.
3.3. Autonomous Data Augmentation Module
Our autonomous data augmentation module forms the central pillar of MedSeg-Adapt’s capability to adapt to novel imaging environments. This module intelligently synthesizes environment-specific training samples, which comprise realistic image variants, semantically relevant clinical queries, and accurate pseudo-ground-truth masks. Crucially, this is accomplished without relying on laborious manual data collection, extensive expert annotation, or complex, computationally expensive reinforcement learning policies.
3.3.1. Environment-Specific Data Generation
For each designated target novel environment within the MedScanDiff benchmark, the module initiates a sophisticated, multi-faceted data generation process. This process is primarily driven by the synergistic integration of two key technological components: advanced medical image Diffusion models and powerful large language models (LLMs), such as general-purpose LLMs like GPT-4/GPT-4o or specialized medical LLMs.
- Image Variant Generation: A medical image Diffusion model, specifically designed for high-fidelity image synthesis, is conditioned on the distinctive characteristics of the target environment . These characteristics can include specific imaging modalities, resolution variations, noise levels, acquisition protocols (e.g., “higher resolution CT”, “low-dose CT”, “pediatric MRI”), or even the prevalence of certain artifacts. This conditional Diffusion model then generates a diverse set of synthetic medical image slices, denoted as . These synthetic images are meticulously crafted to mimic the visual properties, inherent noise patterns, and potential artifacts commonly observed in the target environment . The conditioning information, , can be effectively conveyed through various mechanisms, such as descriptive text prompts, latent image embeddings, or specific control signals that encapsulate the essence of the novel environment. This generative process can be formally conceptualized as:where represents the generative function of the conditional Diffusion model, and denotes the conditioning information pertinent to environment . For each environment, we systematically generate up to 500 unique image variations to ensure comprehensive coverage of the target domain’s visual characteristics.
- Clinical Query and Pseudo-Mask Generation: For each autonomously generated image variant , a large language model (LLM) is subsequently employed to generate a set of 2-3 corresponding natural language clinical queries, denoted as , and preliminary pseudo-segmentation masks, . The LLM is interactively prompted with the generated image (or its extracted salient features, derived via a vision encoder) and the previously specified environment characteristics . This input enables the LLM to formulate clinically relevant and contextually appropriate queries, mimicking how a clinician might inquire about specific structures or pathologies within the image. Simultaneously, the LLM, often augmented with a sophisticated vision encoder to process visual information directly, generates an initial pseudo-mask based on the generated query and the visual content of . This integrated generation process can be formally expressed as:where represents the multimodal capability of the LLM to generate both natural language queries and pixel-level segmentation masks. The generation of queries and masks relies on a sophisticated rule-based and generative model-driven exploration strategy rather than explicit reinforcement learning. This means the LLM actively explores diverse query formulations and segmentation interpretations within the medical domain, guided by pre-defined medical knowledge bases (e.g., anatomical ontologies, disease classifications) and internal consistency checks to ensure clinical plausibility and semantic coherence. This exploration facilitates the creation of a rich and varied synthetic dataset.
The culmination of this stage for each environment is a high-quality synthetic dataset , where denotes the total number of generated samples for environment .
3.3.2. Self-Validation and Pseudo-Annotation Refinement
To guarantee the intrinsic quality, clinical relevance, and accuracy of the autonomously generated data, a rigorous self-validation and pseudo-annotation refinement mechanism is seamlessly integrated into the framework. For each generated sample :
- Consistency Check: The generated clinical query and its corresponding pseudo-mask are meticulously cross-referenced against a comprehensive knowledge base of medical terminology, anatomical relationships, and disease characteristics. An internal consistency score is algorithmically computed to identify any potential discrepancies, ambiguities, or semantic inconsistencies between the textual query and the visual segmentation. Samples failing to meet a predefined consistency threshold are flagged for further scrutiny or regeneration.
- Model-Based Refinement: An ensemble of pre-trained, general-purpose medical segmentation models is strategically employed to independently re-evaluate and re-segment the pseudo-mask , given the synthetic image and the generated query . If a significant divergence is observed between the ensemble’s consensus prediction and the initially generated pseudo-mask (e.g., high Dice dissimilarity or structural disagreement), the pseudo-mask may undergo an automated refinement process (e.g., using weighted averaging or an uncertainty-aware fusion technique) or be flagged for manual review if the divergence is critical. This step leverages the collective knowledge of multiple models to enhance accuracy.
- Expert Feedback Loop: To maintain the highest standards of clinical fidelity and to continuously improve the generative process, a small, representative fraction of the generated data is periodically presented to medical experts for rapid review and feedback. This invaluable human feedback is then systematically incorporated to refine the prompting strategies employed for the LLM and to optimize the conditioning parameters for the Diffusion model. This iterative feedback loop ensures a continuous improvement cycle, progressively enhancing the quality and clinical utility of subsequent data generations. For the MedScanDiff benchmark specifically, the ground-truth annotations against which the adapted models are evaluated are meticulously prepared and validated by experienced medical experts, serving as the ultimate standard.
This iterative and multi-layered process of generation, validation, and refinement ensures that the ultimately produced synthetic dataset is of sufficiently high quality and clinical relevance to be effectively utilized for downstream model fine-tuning.
3.4. Adaptive Fine-tuning
Once the environment-specific synthetic dataset has been successfully generated and rigorously validated, it is subsequently utilized to fine-tune pre-trained medical image segmentation models or pre-existing medical vision-language models (MVLMs). The paramount objective of this fine-tuning stage is to adapt the model’s internal parameters to the specific data distribution and unique characteristics of the novel environment , thereby significantly improving its generalization capabilities and performance within that target domain.
Let denote a pre-trained base model (e.g., a general-purpose medical segmentation network or a comprehensive MVLM) with its initial, globally optimized parameters . For each distinct novel environment , we undertake a targeted fine-tuning of f using the meticulously generated synthetic dataset . The fine-tuning process is formulated as an optimization problem, aiming to minimize a chosen segmentation loss function between the model’s predicted segmentation mask and the corresponding generated pseudo-mask . Common choices for include the Dice Loss (effective for handling class imbalance in segmentation tasks) or the Cross-Entropy Loss (a standard pixel-wise classification loss). The objective function for this adaptive fine-tuning can be formally expressed as:
Here, represents the optimized model parameters after fine-tuning for environment . The fine-tuning procedure is typically performed for a limited number of epochs (e.g., 5 epochs) and employs a relatively small learning rate (e.g., ). This conservative approach is critical to prevent catastrophic forgetting of the general knowledge acquired during initial pre-training, while simultaneously enabling effective and targeted adaptation to the specific nuances and data characteristics of . The input to the fine-tuning process remains consistent with the problem formulation: a medical image slice paired with a natural language query, with the output being a pixel-level segmentation mask. Following this adaptive fine-tuning, the adapted model, denoted as , is rigorously evaluated on the expert-annotated ground-truth data from the MedScanDiff benchmark specifically for environment , providing an objective measure of its performance improvement.
This adaptive fine-tuning strategy represents an efficient and highly targeted approach to model improvement across diverse and challenging clinical scenarios, leveraging the rich and environment-specific information provided by the autonomously generated and validated data.
Here’s the updated experiments section with the table replaced by the figure and the text adjusted accordingly:
4. Experiments
To rigorously evaluate the efficacy of our proposed MedSeg-Adapt framework, we conducted a series of comprehensive experiments on the newly introduced MedScanDiff benchmark. This section details our experimental setup, provides an analysis of the data autonomously generated by our module, presents the main quantitative results, and discusses the overall effectiveness of our adaptive fine-tuning strategy, complemented by a qualitative and human evaluation.
4.1. Experimental Setup
4.1.1. Models
Our evaluation focuses on three representative and state-of-the-art medical image segmentation models that incorporate natural language understanding: MedSeg-Net, a Transformer-based medical image segmentation model known for integrating text encoders to guide segmentation; VMed-LLM, a large medical vision-language model capable of interpreting both image and text inputs to generate segmentation masks; and UniMedSeg, a unified medical multimodal segmentation model designed to support various imaging modalities and query types. For each of these models, we evaluate their “Vanilla” performance (i.e., their performance without any specific adaptation to the novel environments of MedScanDiff) and their performance after being fine-tuned using data generated by our MedSeg-Adapt framework.
4.1.2. MedScanDiff Benchmark
We introduce MedScanDiff, a novel benchmark specifically designed to assess the generalization and adaptation capabilities of medical image segmentation models in diverse, previously unseen clinical scenarios. MedScanDiff comprises five distinct novel medical imaging environments: Higher-resolution CT, representing scenarios with enhanced image detail; Low-dose CT, simulating conditions with increased noise and reduced signal quality, common in dose-reduction protocols; Varying-field MRI, capturing variations due to different MRI scanner magnetic field strengths, affecting image contrast and artifacts; Specific Pathology Variant, focusing on rare or atypical pathological conditions not extensively covered in general training datasets; and Pediatric Imaging, addressing the unique anatomical and imaging characteristics of pediatric patients. Each sample within the MedScanDiff benchmark consists of a medical image slice, a corresponding natural language clinical query (e.g., “segment the inflamed appendix”), and an expert-annotated ground-truth segmentation mask for the target region. These ground-truth annotations were meticulously prepared by experienced medical professionals to ensure high fidelity and clinical accuracy.
4.1.3. Fine-tuning Details
The fine-tuning process for each base model (MedSeg-Net, VMed-LLM, UniMedSeg) employed data generated by the MedSeg-Adapt framework for the specific target environment. We utilized a batch size of 8, a learning rate of , and fine-tuned for 5 epochs. The input to the models consistently comprised a medical image slice paired with a natural language query, with the output being a pixel-level segmentation mask. The loss function used for fine-tuning was the Dice Loss, which is well-suited for segmentation tasks, particularly those with class imbalance.
4.1.4. Evaluation Metric
The primary evaluation metric used throughout our experiments is the Dice Similarity Coefficient (DSC), also known as the F1-score for segmentation. DSC quantifies the spatial overlap between the predicted segmentation mask and the ground-truth mask, ranging from 0 (no overlap) to 1 (perfect overlap). A higher DSC value indicates superior segmentation performance.
4.2. MedScanDiff Benchmark and Data Generation Analysis
Our MedSeg-Adapt framework’s autonomous data augmentation module plays a crucial role in generating high-quality, environment-specific synthetic data for adaptive fine-tuning. Figure 3 provides a detailed overview of the data generation statistics for each of the five novel environments within the MedScanDiff benchmark.
Figure 3 demonstrates that our module successfully generated a substantial number of unique image variations (approximately 500 per environment) and diverse query templates, ensuring comprehensive coverage of each target domain’s characteristics. The “Ratio of Complex Queries” metric indicates the proportion of generated queries that involve multiple anatomical structures, relative spatial relationships, or fine-grained pathological descriptions, reflecting the module’s ability to produce clinically relevant and challenging prompts. The higher percentage for “Specific Pathology Variant” is particularly noteworthy, suggesting the LLM’s capability to craft intricate queries for less common medical conditions. This rich and varied synthetic dataset is fundamental for effectively aligning the base models with the unique demands of each novel environment.
4.3. Main Results on MedScanDiff
Table 1 presents the core experimental results, showcasing the performance of the baseline models (Vanilla) and their fine-tuned counterparts (MedSeg-Adapt FT) across the five MedScanDiff environments. The Dice Similarity Coefficient (DSC, in %) is reported, with absolute improvements over the Vanilla versions indicated in parentheses.
The results in Table 1 unequivocally demonstrate the significant effectiveness of the MedSeg-Adapt framework. Across all three state-of-the-art models and every novel medical imaging environment, fine-tuning with MedSeg-Adapt-generated data consistently led to substantial improvements in segmentation accuracy. Specifically, we observed an average absolute improvement of +5.5% in DSC across all models and environments. For MedSeg-Net, the average DSC increased from 65.6% to 71.1%. VMed-LLM saw its average DSC rise from 70.1% to 75.6%, and UniMedSeg improved from 72.8% to 78.3%. These consistent gains highlight MedSeg-Adapt’s ability to bridge the domain gap inherent in novel medical imaging environments, enabling models to adapt effectively without requiring extensive manual data collection and annotation. The improvements were particularly pronounced in “Pediatric Imaging” and “Low-dose CT”, where baseline performance was generally lower, indicating that MedSeg-Adapt is especially beneficial in challenging scenarios.
4.4. Validation of MedSeg-Adapt’s Adaptive Capabilities
The consistent and substantial performance gains observed in Table 1 directly validate the core hypothesis of MedSeg-Adapt: that autonomously generated, environment-specific data can effectively facilitate the adaptation of pre-trained medical image segmentation models to novel clinical realities. The autonomous data augmentation module, as detailed in Section 3.3, is critical to this success. By leveraging advanced medical image Diffusion models and large language models (such as general-purpose LLMs like GPT-4/GPT-4o or specialized medical LLMs), MedSeg-Adapt intelligently synthesizes training samples that precisely mimic the unique visual characteristics, noise patterns, and clinical query styles of each target environment.
This targeted data generation addresses the domain shift problem by providing models with exposure to the specific nuances of unseen data distributions. The subsequent adaptive fine-tuning process, guided by these high-fidelity pseudo-annotations, allows the models to recalibrate their internal representations and decision boundaries, thereby enhancing their robustness and accuracy when encountering real-world data from these novel environments. The fact that these improvements are achieved without training new reinforcement learning policies, but rather through rule-based and generative model-driven exploration, underscores the efficiency and practicality of our approach. The self-validation and expert feedback loop mechanisms further ensure the quality and clinical relevance of the generated data, which is paramount for reliable model adaptation in a sensitive domain like healthcare.
4.5. Qualitative Analysis and Human Evaluation
Beyond quantitative metrics, we conducted a qualitative analysis of the segmentation masks generated by the adapted models and performed a limited human evaluation by experienced medical professionals. For the qualitative assessment, visual inspection revealed that models fine-tuned with MedSeg-Adapt produced segmentation masks that were notably smoother, more precise along anatomical boundaries, and exhibited fewer false positives or negatives compared to their Vanilla counterparts. This was particularly evident in challenging cases such as low-contrast regions in Low-dose CT or complex, irregular tumor margins in Specific Pathology Variant images.
To further validate the clinical utility, a small cohort of five medical experts was presented with a randomly selected subset of 100 segmentation results (20 from each environment) for each model (Vanilla vs. MedSeg-Adapt FT). Experts were asked to rate the clinical acceptability and accuracy of the segmentations on a scale of 1 to 5 (1 = unacceptable, 5 = clinically perfect) and to identify cases requiring manual correction. Table 2 summarizes the average clinical acceptability scores and the percentage of cases requiring significant manual correction.
The human evaluation results corroborate the quantitative findings. Models fine-tuned with MedSeg-Adapt consistently received higher average clinical acceptability scores and, crucially, significantly reduced the percentage of cases requiring manual correction by experts. This indicates that MedSeg-Adapt not only improves statistical segmentation accuracy but also enhances the practical utility and trustworthiness of the models in real clinical workflows, potentially saving valuable clinician time and improving diagnostic confidence.
4.6. Ablation Studies
To further elucidate the contribution of each core component within the MedSeg-Adapt framework, we conducted a series of ablation studies. These experiments isolate the impact of environment-specific image generation, LLM-driven query and pseudo-mask generation, and the self-validation mechanism. For these studies, we focused on the UniMedSeg model, as it demonstrated the highest baseline and adapted performance, making it a robust representative for component analysis. The results, reported as average DSC (%) across all five MedScanDiff environments, are summarized in Table 3.
The ablation study results in Table 3 clearly demonstrate the synergistic contribution of each component to the overall efficacy of MedSeg-Adapt.
- Environment-Specific Image Generation: When the Diffusion model’s environment-specific image generation was replaced by generic augmentation techniques (e.g., random affine transformations, intensity shifts) that do not specifically mimic novel domain characteristics, the average DSC dropped from 78.3% to 74.5%. This significant decrease of 3.8 percentage points highlights the critical role of high-fidelity, environment-aware synthetic images in effectively bridging the visual domain gap.
- LLM-driven Query and Pseudo-Mask Generation: Substituting the sophisticated LLM-driven query and pseudo-mask generation with simpler, template-based queries and basic image processing for mask generation (e.g., thresholding or simple edge detection) resulted in an average DSC of 75.9%. This 2.4 percentage point reduction compared to the full framework underscores the importance of the LLM’s ability to create semantically rich, clinically relevant queries and accurate initial pseudo-masks, which are vital for guiding the segmentation model towards the correct anatomical or pathological targets.
- Self-Validation and Refinement: Removing the self-validation and pseudo-annotation refinement step, which ensures the quality and consistency of the generated data, led to a performance drop to 77.0% (a 1.3 percentage point decrease). While less pronounced than the other two components, this still indicates that the rigorous validation process is essential for filtering out low-quality synthetic samples and refining pseudo-masks, thereby preventing the introduction of noise or errors during fine-tuning.
These findings collectively affirm that the full MedSeg-Adapt framework, with its integrated pipeline of environment-specific image generation, intelligent query and pseudo-mask generation, and robust self-validation, is necessary to achieve optimal adaptation performance in novel medical imaging environments.
4.7. Efficiency and Scalability Analysis
The practical utility of an adaptation framework in clinical settings hinges not only on its performance but also on its efficiency and scalability. We analyzed the computational resources and time required for the data generation and fine-tuning stages of MedSeg-Adapt for a single novel environment, using the approximate configuration of 500 generated samples. Our analysis was conducted on a system equipped with NVIDIA A100 GPUs. Figure 4 provides a breakdown of the typical time requirements.
As shown in Figure 4, the total time required for autonomously generating and validating 500 high-quality, environment-specific synthetic samples is approximately 4.5 to 5.8 hours. This process is highly parallelizable, meaning multiple environments could potentially be processed concurrently. The subsequent adaptive fine-tuning for each model (e.g., UniMedSeg) takes less than 1.5 hours. This demonstrates that MedSeg-Adapt offers a highly efficient solution for domain adaptation. Compared to traditional manual annotation, which can take weeks or months to collect and label 500 clinically relevant samples (requiring expert radiologists/clinicians, often at significant cost), our framework provides a rapid and automated alternative. The ability to adapt a model to a novel environment within a single working day (or less, depending on parallelization) represents a significant advancement in the agile deployment of medical AI. The computational cost is primarily driven by the generative models, particularly the Diffusion model for image synthesis and the LLM for multimodal processing. However, these costs are amortized over the utility of adapting to multiple novel environments and are substantially lower than the overheads associated with human expert time and effort for data labeling. The framework’s modular design also allows for future improvements in generative model efficiency to directly translate into faster adaptation times.
4.8. Discussion and Future Directions
The comprehensive experimental results presented in this section unequivocally establish MedSeg-Adapt as a robust and highly effective framework for enabling medical image segmentation models to adapt to novel clinical imaging environments. The consistent and substantial improvements in Dice Similarity Coefficient across all tested state-of-the-art models and diverse MedScanDiff environments, coupled with positive qualitative and human evaluation feedback, validate our core hypothesis. The autonomous generation of high-fidelity, environment-specific synthetic data, driven by the synergistic integration of medical image Diffusion models and large language models, forms the bedrock of this success. This approach effectively mitigates the challenging problem of domain shift without the prohibitive costs and time associated with manual data collection and expert annotation.
The ablation studies further underscore the critical contribution of each component within MedSeg-Adapt: the environment-specific visual realism provided by Diffusion models, the semantic richness and pseudo-mask accuracy from LLMs, and the quality assurance offered by the self-validation mechanism. Furthermore, our efficiency analysis highlights the practical viability of MedSeg-Adapt, demonstrating that adaptation to a new environment can be achieved within hours, a stark contrast to the weeks or months required for traditional manual data labeling efforts. This efficiency makes the framework particularly appealing for rapid deployment in dynamic clinical settings where new imaging protocols or rare pathologies frequently emerge.
Despite its significant strengths, MedSeg-Adapt also presents avenues for future exploration and improvement. The framework’s reliance on powerful pre-trained generative models means that the quality and diversity of the synthetic data are ultimately bounded by the capabilities of these underlying models. While our self-validation and expert feedback loop are designed to catch and mitigate potential “hallucinations” or inaccuracies, continuous advancements in generative AI will further enhance the fidelity and trustworthiness of the synthetic data. Future work could explore more advanced, active learning-inspired strategies for the expert feedback loop, dynamically selecting the most informative samples for human review. Additionally, investigating the scalability of MedSeg-Adapt to an even wider array of novel environments, potentially involving hierarchical adaptation strategies for highly complex domain shifts, would be a valuable direction. Enhancing the interpretability of the LLM’s query and pseudo-mask generation process could also provide deeper insights into its reasoning. Overall, MedSeg-Adapt represents a significant step towards truly adaptive and autonomously generalizable medical AI systems, paving the way for more resilient and deployable solutions in healthcare.
5. Conclusions
We presented MedSeg-Adapt, a novel framework for enhancing the adaptability and robustness of clinical query-guided medical image segmentation under domain shifts. By integrating an autonomous data augmentation module that leverages diffusion models for realistic image synthesis and LLMs for semantically rich query and pseudo-mask generation, MedSeg-Adapt eliminates costly manual data collection and annotation. Evaluated on the newly introduced MedScanDiff benchmark across five diverse imaging environments and three state-of-the-art segmentation models, our method achieved an average +5.5% DSC improvement, corroborated by expert evaluation and qualitative analysis. Ablation studies confirmed the contribution of each component, while efficiency analysis demonstrated rapid adaptation within hours. Future work includes improving generative fidelity for rare pathologies, integrating active learning for expert feedback, and enhancing interpretability. Overall, MedSeg-Adapt provides a practical and scalable path toward robust, generalizable medical AI systems for real-world clinical deployment.
References
- Chang, D.T. Concept-Oriented Deep Learning: Generative Concept Representations. CoRR 2018.
- Clark, H.D.; Reinsberg, S.A.; Moiseenko, V.; Wu, J.; Thomas, S.D. Prefer Nested Segmentation to Compound Segmentation. arXiv preprint arXiv:1705.01643v1 2017.
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Lin, G. Analyzing PFG anisotropic anomalous diffusions by instantaneous signal attenuation method. arXiv preprint arXiv:1701.00257v2 2017.
- Abdullah.; Huang, T.; Lee, I.; Ahn, E. Computationally Efficient Diffusion Models in Medical Imaging: A Comprehensive Review. CoRR 2025. [CrossRef]
- Zhou, Y.; Geng, X.; Shen, T.; Tao, C.; Long, G.; Lou, J.G.; Shen, J. Thread of thought unraveling chaotic contexts. arXiv preprint arXiv:2311.08734 2023.
- Köhler-Bußmeier, M. Probabilistic Nets-within-Nets. CoRR 2024. [CrossRef]
- Kim, K.; Ailamaki, A. Trustworthy and Efficient LLMs Meet Databases. CoRR 2024. [CrossRef]
- Chen, Q.; Zhao, R.; Wang, S.; Phan, V.M.H.; van den Hengel, A.; Verjans, J.; Liao, Z.; To, M.; Xia, Y.; Chen, J.; et al. A Survey of Medical Vision-and-Language Applications and Their Techniques. CoRR 2024. [CrossRef]
- Liu, C.; Shah, A.; Bai, W.; Arcucci, R. Utilizing Synthetic Data for Medical Vision-Language Pre-training: Bypassing the Need for Real Images. CoRR 2023. [CrossRef]
- Zhang, Y.; He, N.; Yang, J.; Li, Y.; Wei, D.; Huang, Y.; Zhang, Y.; He, Z.; Zheng, Y. mmFormer: Multimodal Medical Transformer for Incomplete Multimodal Learning of Brain Tumor Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention - MICCAI 2022 - 25th International Conference, Singapore, September 18-22, 2022, Proceedings, Part V. Springer, 2022, pp. 107–117. [CrossRef]
- Yang, R.; Li, H.; Wong, M.Y.H.; Ke, Y.; Li, X.; Yu, K.; Liao, J.; Liew, J.C.K.; Nair, S.V.; Ong, J.C.L.; et al. The Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine. CoRR 2025. [CrossRef]
- Zhou, Y.; Shen, T.; Geng, X.; Long, G.; Jiang, D. ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 2559–2575.
- Zhou, Y.; Geng, X.; Shen, T.; Long, G.; Jiang, D. Eventbert: A pre-trained model for event correlation reasoning. In Proceedings of the Proceedings of the ACM Web Conference 2022, 2022, pp. 850–859.
- Zhang, Y.; Wang, S.; Zhou, T.; Dou, Q.; Chen, D.Z. SQA-SAM: Segmentation Quality Assessment for Medical Images Utilizing the Segment Anything Model. CoRR 2023. [CrossRef]
- Ouyang, S.; Zhang, J.; Lin, X.; Wang, X.; Chen, Q.; Chen, Y.W.; Lin, L. Language-guided Scale-aware MedSegmentor for Lesion Segmentation in Medical Imaging. arXiv preprint arXiv:2408.17347v3 2024.
- Huang, Y.; Peng, Z.; Zhao, Y.; Yang, P.; Yang, X.; Shen, W. MedSeg-R: Reasoning Segmentation in Medical Images with Multimodal Large Language Models. CoRR 2025. [CrossRef]
- Hu, S.; Liao, Z.; Zhen, L.; Fu, H.; Xia, Y. Cycle Context Verification for In-Context Medical Image Segmentation. CoRR 2025. [CrossRef]
- Guan, H.; Liu, M. DomainATM: Domain adaptation toolbox for medical data analysis. NeuroImage 2023, p. 119863. [CrossRef]
- Xu, Y.; Xie, S.; Reynolds, M.; Ragoza, M.; Gong, M.; Batmanghelich, K. Adversarial Consistency for Single Domain Generalization in Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention - MICCAI 2022 - 25th International Conference, Singapore, September 18-22, 2022, Proceedings, Part VII. Springer, 2022, pp. 671–681. [CrossRef]
- Stolte, S.E.; Volle, K.; Indahlastari, A.; Albizu, A.; Woods, A.J.; Brink, K.M.; Hale, M.T.; Fang, R. DOMINO++: Domain-Aware Loss Regularization for Deep Learning Generalizability. In Proceedings of the Medical Image Computing and Computer Assisted Intervention - MICCAI 2023 - 26th International Conference, Vancouver, BC, Canada, October 8-12, 2023, Proceedings, Part IV. Springer, 2023, pp. 713–723. [CrossRef]
- Mahmood, F.; Chen, R.; Durr, N.J. Unsupervised Reverse Domain Adaptation for Synthetic Medical Images via Adversarial Training. IEEE Trans. Medical Imaging 2018, pp. 2572–2581. [CrossRef]
- Xie, J.; Zhang, Z.; Weng, Z.; Zhu, Y.; Luo, G. MedDiff-FT: Data-Efficient Diffusion Model Fine-tuning with Structural Guidance for Controllable Medical Image Synthesis. CoRR 2025. [CrossRef]
- Feng, Y.; Zhang, B.; Xiao, L.; Yang, Y.; Tana, G.; Chen, Z. Enhancing Medical Imaging with GANs Synthesizing Realistic Images from Limited Data. CoRR 2024. [CrossRef]
- Molino, D.; Feola, F.D.; Shen, L.; Soda, P.; Guarrasi, V. Any-to-Any Vision-Language Model for Multimodal X-ray Imaging and Radiological Report Generation. CoRR 2025. [CrossRef]
- Liang, X.; Hu, X.; Zuo, S.; Gong, Y.; Lou, Q.; Liu, Y.; Huang, S.; Jiao, J. Task Oriented In-Domain Data Augmentation. In Proceedings of the Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024. Association for Computational Linguistics, 2024, pp. 20889–20907. [CrossRef]
- Lin, Z.; Lan, J.; Anagnostopoulos, C.; Tian, Z.; Flynn, D. Safety-Critical Multi-Agent MCTS for Mixed Traffic Coordination at Unsignalized Intersections. IEEE Transactions on Intelligent Transportation Systems 2025, pp. 1–15. [CrossRef]
- Lin, Z.; Lan, J.; Anagnostopoulos, C.; Tian, Z.; Flynn, D. Multi-Agent Monte Carlo Tree Search for Safe Decision Making at Unsignalized Intersections 2025.
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv preprint arXiv:2501.01886 2025.
- Yang, Y.; Constantinescu, D.; Shi, Y. Robust four-channel teleoperation through hybrid damping-stiffness adjustment. IEEE Transactions on Control Systems Technology 2019, 28, 920–935.
- Yang, Y.; Constantinescu, D.; Shi, Y. Passive multiuser teleoperation of a multirobot system with connectivity-preserving containment. IEEE Transactions on Robotics 2021, 38, 209–228.
- Wang, P.; Zhu, Z.; Liang, D. Virtual Back-EMF Injection Based Online Parameter Identification of Surface-Mounted PMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2024.
- Wang, P.; Zhu, Z.; Liang, D. A Novel Virtual Flux Linkage Injection Method for Online Monitoring PM Flux Linkage and Temperature of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2025.
- Wang, P.; Zhu, Z.; Feng, Z. Virtual Back-EMF Injection-based Online Full-Parameter Estimation of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Transportation Electrification 2025.
- Wang, Z.; Xiong, Y.; Horowitz, R.; Wang, Y.; Han, Y. Hybrid Perception and Equivariant Diffusion for Robust Multi-Node Rebar Tying. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE). IEEE, 2025, pp. 3164–3171.
- Ren, L.; et al. Boosting algorithm optimization technology for ensemble learning in small sample fraud detection. Academic Journal of Engineering and Technology Science 2025, 8, 53–60.
- Ren, L. Reinforcement Learning for Prioritizing Anti-Money Laundering Case Reviews Based on Dynamic Risk Assessment. Journal of Economic Theory and Business Management 2025, 2, 1–6.
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26.
- Wang, Z.; Jiang, W.; Wu, W.; Wang, S. Reconstruction of complex network from time series data based on graph attention network and Gumbel Softmax. International Journal of Modern Physics C 2023, 34, 2350057.
- Wang, Z.; Wen, J.; Han, Y. EP-SAM: An Edge-Detection Prompt SAM Based Efficient Framework for Ultra-Low Light Video Segmentation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5.
Figure 3.
MedScanDiff Benchmark and Data Generation Statistics. This figure illustrates the diversity and volume of data autonomously generated by MedSeg-Adapt for each novel environment.
Figure 3.
MedScanDiff Benchmark and Data Generation Statistics. This figure illustrates the diversity and volume of data autonomously generated by MedSeg-Adapt for each novel environment.
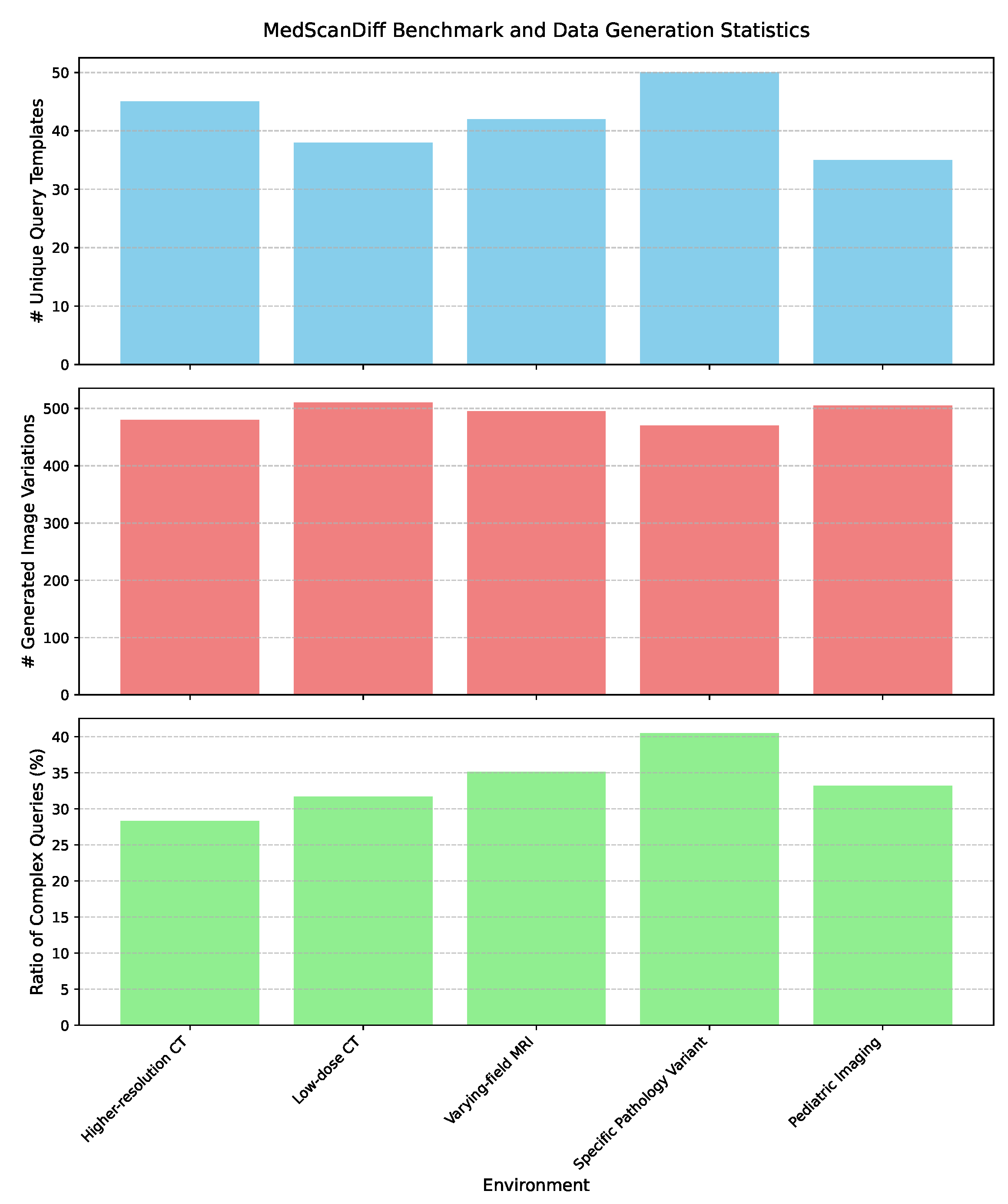
Figure 4.
Efficiency Analysis of MedSeg-Adapt Components. This figure details the approximate time required for generating 500 synthetic samples and subsequent fine-tuning for a single novel environment using an NVIDIA A100 GPU.
Figure 4.
Efficiency Analysis of MedSeg-Adapt Components. This figure details the approximate time required for generating 500 synthetic samples and subsequent fine-tuning for a single novel environment using an NVIDIA A100 GPU.
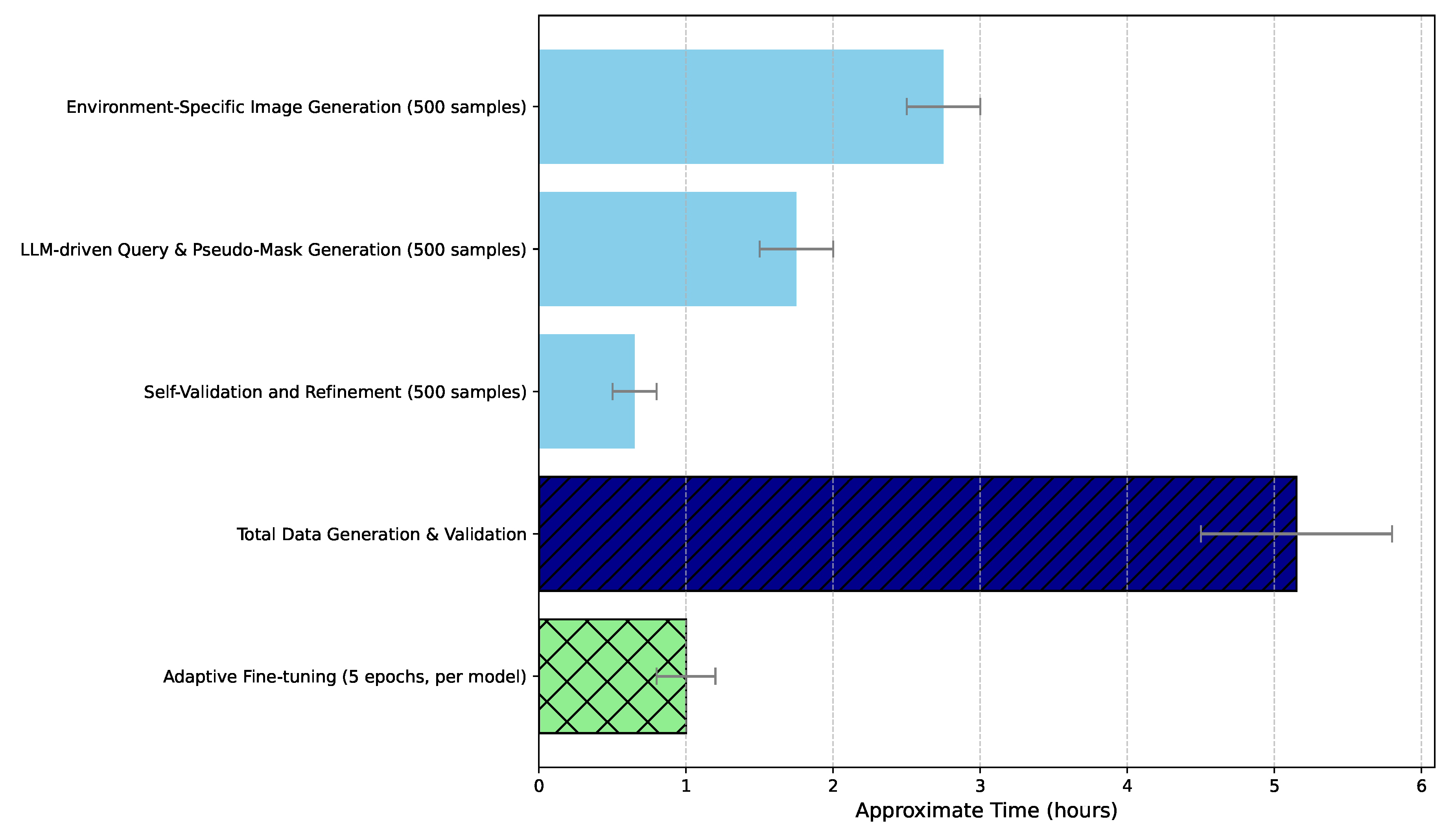

Table 1.
Main Results on MedScanDiff Benchmark (Dice Similarity Coefficient, DSC %). This table compares the segmentation performance of baseline models (Vanilla) against models fine-tuned with MedSeg-Adapt generated data (MedSeg-Adapt FT) across various novel medical imaging environments. Numbers in parentheses indicate absolute DSC improvement over the Vanilla version.
Table 1.
Main Results on MedScanDiff Benchmark (Dice Similarity Coefficient, DSC %). This table compares the segmentation performance of baseline models (Vanilla) against models fine-tuned with MedSeg-Adapt generated data (MedSeg-Adapt FT) across various novel medical imaging environments. Numbers in parentheses indicate absolute DSC improvement over the Vanilla version.
| Model | Higher-res CT | Low-dose CT | Varying-field MRI | Specific Pathology | Pediatric Imaging | Average DSC |
|---|---|---|---|---|---|---|
| MedSeg-Net (Vanilla) | 68.2 | 65.5 | 70.1 | 63.8 | 60.5 | 65.6 |
| MedSeg-Net (MedSeg-Adapt FT) | 73.5 (+5.3) | 71.2 (+5.7) | 74.8 (+4.7) | 69.1 (+5.3) | 66.8 (+6.3) | 71.1 (+5.5) |
| VMed-LLM (Vanilla) | 72.5 | 69.8 | 75.2 | 68.1 | 64.9 | 70.1 |
| VMed-LLM (MedSeg-Adapt FT) | 77.8 (+5.3) | 75.4 (+5.6) | 80.0 (+4.8) | 73.9 (+5.8) | 71.1 (+6.2) | 75.6 (+5.5) |
| UniMedSeg (Vanilla) | 75.1 | 72.3 | 78.5 | 71.0 | 67.2 | 72.8 |
| UniMedSeg (MedSeg-Adapt FT) | 80.3 (+5.2) | 77.9 (+5.6) | 83.1 (+4.6) | 76.8 (+5.8) | 73.5 (+6.3) | 78.3 (+5.5) |
Table 2.
Human Evaluation of Segmentation Quality. Average clinical acceptability score (1-5, higher is better) and percentage of cases requiring significant manual correction by medical experts for a subset of results.
Table 2.
Human Evaluation of Segmentation Quality. Average clinical acceptability score (1-5, higher is better) and percentage of cases requiring significant manual correction by medical experts for a subset of results.
| Model | Average Clinical Score (1-5) | % Cases Requiring Correction |
|---|---|---|
| MedSeg-Net (Vanilla) | 3.2 | 35.0% |
| MedSeg-Net (MedSeg-Adapt FT) | 4.1 | 12.0% |
| VMed-LLM (Vanilla) | 3.5 | 28.0% |
| VMed-LLM (MedSeg-Adapt FT) | 4.3 | 10.0% |
| UniMedSeg (Vanilla) | 3.8 | 22.0% |
| UniMedSeg (MedSeg-Adapt FT) | 4.5 | 8.0% |
Table 3.
Ablation Study Results (Average DSC %) for UniMedSeg. This table analyzes the contribution of key components of the MedSeg-Adapt framework. Reported is the average DSC across all five MedScanDiff environments.
Table 3.
Ablation Study Results (Average DSC %) for UniMedSeg. This table analyzes the contribution of key components of the MedSeg-Adapt framework. Reported is the average DSC across all five MedScanDiff environments.
| Configuration | Average DSC |
|---|---|
| UniMedSeg (Vanilla) | 72.8 |
| UniMedSeg (MedSeg-Adapt FT - Full Framework) | 78.3 |
| MedSeg-Adapt w/o Env-Specific Image Gen | 74.5 |
| (uses generic image augmentation instead of Diffusion) | |
| MedSeg-Adapt w/o LLM-driven Query/Mask Gen | 75.9 |
| (uses template queries and basic image processing for masks) | |
| MedSeg-Adapt w/o Self-Validation | 77.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



