Submitted:
18 November 2025
Posted:
18 November 2025
You are already at the latest version
Abstract
In the rapidly advancing domain of artificial intelligence, Vision-Language Models (VLMs) have emerged as critical tools by synergizing visual and textual data processing to facilitate a multitude of applications including automated image captioning, accessibility enhancements, and intelligent responses to multimodal queries. This survey explores the evolving paradigm of Pre-training, Fine-tuning, and Inference that has notably enhanced the capabilities of VLMs, allowing them to perform effectively across various downstream tasks and even enable zero-shot predictions. Despite their advancements, VLMs are vulnerable to adversarial attacks, largely because of their reliance on large-scale, internet-sourced pre-training datasets. These attacks can significantly undermine the models' integrity by manipulating their input interpretations, posing severe security risks and eroding user trust. Our survey delves into the complexities of these adversarial threats, which range from single-modal to sophisticated multimodal strategies, highlighting the urgent need for robust defense mechanisms. We discuss innovative defense strategies that adapt model architectures, integrate adversarially robust training objectives, and employ fine-tuning techniques to counteract these vulnerabilities. This paper aims to provide a comprehensive overview of current challenges and future directions in the adversarial landscape of VLMs, emphasizing the importance of securing these models to ensure their safe integration into various real-world applications.
Keywords:
VLMs
; multimodal learning
; pre-training
; fine-tuning
; zero-shot prediction
; adversarial attacks
; robust defense mechanisms
; artificial intelligence
; security in AI
; multimodal applications
1. Introduction
A Vision-Language Model (VLM) integrates visual and textual data to understand and generate content that spans both modalities. VLMs [1,2] are used in applications such as automated image captioning, enhancing accessibility through descriptive audio for visual content, and intelligent personal assistants that can interpret and respond to multimodal queries. These models play a crucial role in creating more intuitive and accessible digital environments.
The recent paradigm of Pre-training, Fine-tuning, and Inference has gained prominence in the field of vision-language multimodal models, significantly enhancing their effectiveness across various task-specific downstream tasks. In this approach, VLMs undergo pre-training using large-scale image-text pairs typically sourced from the internet. This foundational training enables the models to be utilized directly in certain downstream tasks [3,4,5], sometimes even without further fine-tuning, allowing for zero-shot predictions. However, the reliance on extensive datasets gathered from the internet for pre-training exposes these models to an increased risk [6] of adversarial attacks, highlighting a vulnerability inherent in this training methodology.
Adversarial attacks [7] on VLMs can lead to misinterpretation of visual or textual content, pose security risks in sensitive applications, and degrade user trust in the technology. These attacks challenge the reliability and safety of VLMs, prompting the development of robust defense mechanisms to ensure the models’ integrity in adversarial settings.
While adversarial robustness has been extensively studied in conventional computer vision(CV) and natural language processing(NLP) models, VLMs introduce unique multimodal vulnerabilities. Traditional adversarial robustness in CV typically focuses on pixel-level perturbations to images, whereas NLP adversarial robustness emphasizes token-level or embedding-level perturbations. In contrast, VLMs combine both modalities, enabling cross-modal transferability attacks on one modality (e.g., text) can propagate and degrade predictions in the other modality (e.g., vision).
Additionally, VLMs are highly sensitive to prompt-based adversarial attacks, where small semantic changes in natural language instructions can drastically alter predictions. This vulnerability does not exist in unimodal CV models. Moreover, large-scale multimodal datasets sourced from the web introduce spurious correlations and noisy alignments, which increase the likelihood of adversarial exploitation compared to curated unimodal datasets. Table 1 highlights the main differences between conventional adversarial robustness and VLM robustness, emphasizing why the latter requires dedicated study.
In the dynamic and rapidly evolving field of artificial intelligence, VLMs stand at the confluence of visual and linguistic data processing, offering a promising avenue for understanding and generating multimodal content. As these models grow in capability and adoption, they increasingly encounter sophisticated threats that challenge their integrity and reliability. Adversarial attacks deliberate attempts to mislead models through deceptive inputs pose a significant threat to the security and robustness of VLMs. These attacks not only are becoming more refined, but are also diversifying in their approach, targeting single or multiple modalities to exploit inherent vulnerabilities in these complex systems.
The landscape of adversarial attacks on VLMs is multifaceted, encompassing both single-modal and multimodal strategies. Single modal attacks, such as those highlighted by the pioneering works in “Poisoning and Backdooring Contrastive Learning," [17] reveal the susceptibility of VLMs to manipulations aimed at either their visual or textual components independently. On the other hand, multimodal attacks like the “Co-Attack" [18] demonstrate the escalated threat level by simultaneously distorting the visual and textual inputs, testing the models’ ability to synthesize and reconcile information from diverse sources. Recent analysis has shown that Contrastive Language-Image Pre-training (CLIP) [2] based models may rely heavily on spurious correlations such as background or texture features rather than semantically meaningful objects, thereby reducing their robustness [19]. Such vulnerabilities highlight the importance of developing adversarial defenses that mitigate reliance on non-robust features. As illustrated in Figure 1, there has been a steady growth in publications on adversarial attack and defense for VLMs, reflecting the rapidly increasing attention to this research area.
Given the escalating threat posed by these adversarial techniques, the development of robust defense mechanisms is imperative. The defense strategies against adversarial attacks in VLMs are varied and innovative, focusing on altering model architectures, re-training with adversarially robust objectives, or employing fine-tuning and purification techniques to enhance resilience. Methods such as “RoCLIP" [20] and “Adaptive Language-Image Pre-Training (ALIP)" [21] illustrate advanced defensive tactics that adjust training dynamics or leverage novel loss functions to mitigate the effects of adversarial inputs. The rapid emergence of both adversarial VLMs and their defenses can be seen in the timeline of key publications (Figure 2), which illustrates the field’s accelerated growth since 2021.
Beyond identifying vulnerabilities, it is equally important to consider the practical implications of adversarial attacks on VLMs. These risks are not limited to academic interest but extend to real-world scenarios such as autonomous driving, healthcare, law enforcement, and assistive technologies, where VLMs are increasingly being deployed. In such high-stakes settings, adversarial failures can lead to severe safety risks, misdiagnoses, or unfair decision-making, ultimately undermining user trust and the adoption of VLM-based systems.
Highlighting these application domains strengthens the motivation for dedicated study of VLM robustness and clearly distinguishes this survey from conventional adversarial robustness studies. By emphasizing the societal and security-critical importance of VLM robustness, we align the survey with both theoretical and applied relevance.
This survey paper aims to delve deep into the methodologies and implications of both adversarial attacks and defense strategies on VLMs. By examining recent advancements and case studies, we endeavor to provide a comprehensive overview of the current challenges and future directions in securing VLMs against adversarial threats. As these models continue to permeate various domains from automated content generation to complex decision-making systems their security against adversarial attacks remains a critical concern that calls for continued research and innovative solutions.
- We introduce the latest adversarial attacks on VLMs, categorized based on the adversaries’ access to information, visibility of adversarial noise, learning goals of VLMs, and VLMs architecture.
- We categorize adversarial defenses into three distinct domains, supported by illustrative figures for each of these domains.
- We elaborate on the most commonly utilized metrics and datasets, showcase leading results on CIFAR-10, CIFAR-100, and ImageNet, and offer suggestions for future research directions.
The remainder of this paper is organized as follows. Section 2 reviews related surveys and highlights the unique contributions of our work. Section 3 discusses the background and preliminary works. Section 4 introduces a taxonomy of adversarial attacks on VLMs, categorized by adversaries’ access, visibility, goals, and model architecture. Section 5 presents a structured overview of defense strategies, organized into three domains with illustrative figures. Section 6 and Section 7 discuss commonly used datasets and evaluation metrics, emphasizing their applicability to multimodal robustness. Section 8 discusses and compares the results. Section 9 outlines emerging challenges and future research directions in adversarial robustness for VLMs. Section 10 provides acknowledgments. Finally, Section 11 concludes the paper.
Figure 3 illustrates the overall organization of our survey. Adversarial attacks on VLMs are categorized by access to information, modality, and attack goals, while defenses are grouped into architecture modification, fine-tuning, and purification. The figure also highlights datasets/metrics used for evaluation and outlines future research directions.
2. Related Surveys
Several surveys [8,9,10,11,12,13,14,15,16] have explored adversarial robustness in CV, NLP, or multimodal settings. However, as summarized in Table 2, none of these works provide a dedicated treatment of “adversarial robustness" in VLMs. Earlier surveys mainly focus on either pixel-level perturbations (CV) or token-level attacks (NLP), without systematically addressing the multimodal vulnerabilities that emerge when vision and language are jointly modeled. Furthermore, aspects such as datasets, metrics, architectural considerations, and state-of-the-art comparisons were either missing or only partially covered in prior works.
By contrast, our survey is the first to explicitly cover adversarial attacks and defenses in VLMs, while also providing a structured taxonomy, comprehensive dataset and metric overview, and practical implications for multimodal applications. In addition, we incorporate recent papers from 2023–2025, ensuring that our study reflects the latest advances in the rapidly evolving field of multimodal adversarial robustness.
From Table 2, it is evident that earlier surveys predominantly focused on generic methodologies, with an emphasis on White-box and Black-box testing (W&B) as well as the grouping of defenses (GOD). However, recent papers focus on areas such as Datasets Overview (DO), and Metrics and Architectures (MA) along with generic methodologies.
As shown in Table 2, prior surveys have addressed important aspects of adversarial robustness in either computer vision or natural language processing, but none have provided a comprehensive multimodal perspective. In particular, no existing work systematically covers adversarial robustness in VLMs. Our survey is the first to unify attack categorizations, defense strategies, metrics, datasets, and architectures with a dedicated focus on VLMs. By filling these gaps, we aim to establish a structured foundation for future research in this rapidly evolving domain.
3. Background and Preliminaries
3.1. Categories of Learning Goals
Contrastive Objective: An adversarial attack on contrastive objective models within VLMs focuses on manipulating the model’s capability to accurately discern between matching and non-matching pairs of images and text. By subtly altering either the visual or textual inputs or both, attackers aim to trick the model into misclassifying these pairs. The primary goal of such attacks is to disrupt the model’s learned mechanisms for distinguishing between similar and dissimilar multimodal data points [3,22].
Generative Objective: An adversarial attack on generative objective models in VLMs specifically targets the model’s ability to generate coherent and contextually appropriate outputs based on the input data. In these attacks, alterations are made to the input images or text in a way that is meant to mislead the model into producing incorrect or nonsensical outputs. The objective is to exploit weaknesses in the model’s generative processes, testing its capacity to accurately interpret and respond to modified inputs. These attacks are particularly damaging for VLMs as they undermine the model’s reliability in tasks such as image captioning or text-to-image synthesis, where accurate generation is critical [5,23,24].
3.2. Categories of Adversarial Attack
3.2.1. Adversaries’ Access to Information
In black-box adversarial attacks on VLMs, attackers, without internal knowledge of the model, use its input-output interface to craft inputs. They begin by observing how the model reacts to initial inputs and then iteratively adjust these, perhaps subtly altering an image or caption to induce errors. This process involves using automated algorithms to optimize the minimal changes needed for misclassification [25].
White-box adversarial attacks on VLMs involve attackers who have complete access to the model’s internals, such as its architecture, parameters, and training data. They exploit this in-depth knowledge to identify vulnerabilities and craft adversarial inputs. Using gradient calculations, attackers determine the most effective changes to inputs, like images or text, ensuring these alterations are potent in triggering incorrect model responses yet often imperceptible to humans [6,20].
In gray-box adversarial attacks, attackers have partial knowledge of the model, such as its architecture or some parameters, but do not know all the specifics or training data. They use their limited understanding to exploit known vulnerabilities, blending insights from the model’s accessible parts with iterative testing of its outputs. This method strikes a balance, offering a more informed and targeted approach than black-box attacks by adapting based on observed model behavior [26,27].
Compared to white-box and gray-box settings, black-box attacks are especially relevant to real-world scenarios where model internals are rarely exposed. Such attacks include query-based optimization, transfer-based methods (leveraging surrogate models), and decision-based strategies that operate solely on predicted labels. Despite their practical importance, black-box attacks on VLMs remain less explored in the literature, representing a critical gap. We therefore highlight their significance here and encourage future research on defenses robust under black-box assumptions.
3.2.2. Visibility of Adversarial Noise
Visible adversarial attacks on VLMs involve the creation of adversarial inputs where the modifications made to deceive the model are detectable to the human eye. Unlike subtle alterations used in some attacks that aim to be imperceptible, visible attacks deliberately include noticeable changes to images or text. The rationale behind visible attacks is often to test the robustness of a model under overtly challenging conditions or to demonstrate how even obvious alterations can mislead AI systems [20,28]. An early example of such visible adversarial manipulation is shown in Figure 4, where a backdoor patch is inserted into an image to mislead the model.
Non-visible adversarial attacks on VLMs are characterized by the implementation of subtle, often imperceptible changes to inputs, such as images or text. These modifications are designed to be undetectable to the human eye but effective enough to fool the model into making errors. The goal of these attacks is to demonstrate that even minimal alterations, hidden within the normal variability of input data, can lead to significant misinterpretations by the model. This type of attack highlights the challenges in ensuring the robustness of VLMs, as it exploits the sensitivity of these models to small perturbations that are easily overlooked in the input processing stage [5,7].
3.3. Categories of Adversarial Defense
Model Architecture Modification: Changing the architecture of VLMs involves adjusting how these models process and integrate visual and textual inputs. Modifications can include using separate encoders for images and text to independently analyze each modality before merging their outputs for final prediction tasks. Alternatively, a fused image-text encoder can be employed, where a unified architecture directly integrates input features from both modalities at an earlier stage, enhancing intermodal interactions. These architectural changes aim to boost the model’s performance on tasks such as image captioning and visual question answering, and improve robustness against adversarial inputs by optimizing how visual and textual data are processed and combined [20,22].
Fine-tuning: Fine-tuning as an adversarial defense strategy involves adjusting a pre-trained VLM using a dataset that includes adversarial examples or is designed to enhance resilience against attacks. This process recalibrates the model’s parameters to better recognize and resist specific types of adversarial manipulations. By exposing the model to scenarios where it may face deceptive inputs during fine-tuning, it learns to maintain accuracy despite these disruptions. This method enhances the robustness of VLMs against both subtle and overt adversarial tactics, making it a practical approach for improving the security of multimodal systems in applications sensitive to adversarial threats [25,29].
Purification: Adversarial purification is a defense technique used in machine learning that involves preprocessing input data to remove or mitigate the effects of adversarial noise before feeding into the model. This method operates independently of fine-tuning or altering the model’s architecture, focusing instead on cleansing the inputs themselves. The process typically employs various forms of input transformation, such as denoising, smoothing, or applying other filtering techniques that are designed to reduce the adversarial perturbations that can deceive the model. One approach involves incorporating class names into the text prompts during training, enabling the model to more effectively distinguish between original and manipulated texts. This strategy helps maintain the integrity and performance of the model, ensuring its reliability in security-sensitive applications [7,28].
4. Adversarial Attacks on VLM
While adversarial attacks on unimodal vision or language models have been extensively studied, VLMs introduce fundamentally different challenges. For instance, cross-modal alignment can be exploited by attacks that target only one modality while remaining stealthy in the other, a phenomenon rarely encountered in unimodal models. Moreover, defenses such as adversarial training and instance reweighting [30] often assume a single modality, limiting their effectiveness when multimodal consistency is required. This survey highlights such unique vulnerabilities by contrasting VLM-specific adversarial techniques against conventional attacks/defenses in vision and NLP, thereby clarifying what is uniquely challenging in VLM settings.
4.1. Single Modal Attack
A single modal attack on VLMs targets just one of the model’s input modalities, either the visual or the linguistic component, while leaving the other unaltered. For example, an attacker might manipulate an image while keeping the corresponding text unchanged, or alter text descriptions without affecting the associated images.
The paper titled “Poisoning and Backdooring Contrastive Learning" [6] presents the first known instances of backdoor and poisoning attacks on VLMs , to the best of our knowledge. During a poisoning attack, an adversary strategically alters a benign training dataset by inserting poisoned examples , thus creating a poisoned dataset . Upon running the training algorithm on this compromised dataset , the resulting model derived from demonstrates standard performance in typical scenarios. However, due to the influence of the poisoned examples , the adversary gains the ability to dictate the model’s behavior under specific, non-standard conditions.
Initially, they examine targeted poisoning attacks. In this type of attack, an adversary deliberately introduces poisoned examples into the dataset. These examples are crafted such that a particular input is consistently misclassified by the model as a specific target output . However, a primary limitation of these attacks is that they often necessitate the injection of poisoned samples into curated datasets, a task that may prove challenging in real-world scenarios.
Similar to poisoning attacks, the initial step in a backdoor attack involves selecting a specific target label . Unlike poisoning attacks that affect individual samples, backdoor attacks modify any input image by embedding a specific patch, causing the model to misclassify it as . Formally, a backdoored image is denoted as
where x is the original image and is the backdoor patch.
CleanCLIP [25] is one of the popular single modality backdoor attacks on VLM. It injects a backdoor patch to clean images and alters their corresponding captions to proxy captions for a specific target label. They use target label as “banana" for pre-training. During the inference time, images having backdoor trigger patches are misclassified to target label “banana". If the backdoor triggers are not present in the images, the behavior of the poisoned model is similar to the clean model.
As illustrated in Figure 5, the CleanCLIP framework introduces a backdoor trigger patch during training and alters captions to enforce a specific target label (e.g., “banana”). At inference, images containing the trigger are consistently misclassified, whereas images without the trigger behave normally, demonstrating the attack’s stealthiness and effectiveness.
CLIPMasterPrints [26] are adversarial images specifically designed to exploit vulnerabilities in CLIP models by maximizing misclassification across various prompts. These images exploit the modality gap between text and image embeddings, challenging the model’s security and reliability. They can be created using three methods: Stochastic Gradient Descent (SGD), which requires access to the model’s weights; Latent Variable Evolution (LVE), a gradient-free approach that demands more iterations; and Projected Gradient Descent (PGD), known for generating more natural-looking adversarial images. Each method reveals potential flaws in CLIP models by fooling them with images that are seemingly unrelated to their assigned high-confidence prompts. The effectiveness of CLIPMasterPrints is illustrated in Figure 6, which shows cosine similarity heatmaps for famous artworks versus crafted fooling images. The highlighted fooling images (red frame) surpass real artworks in CLIP scores, demonstrating how easily the model can be misled.
In the “Jailbreak in Pieces" [27] attack method, attackers create a misleading context in a multi-modal language model (MLM) by exploiting the joint embedding space, where visual and textual data are integrated. The process starts with the selection of specific targets both images and corresponding texts that the attackers intend to manipulate. An adversarial image is then crafted to look benign but includes subtle cues engineered to align its embedding with that of a malicious target, such as an image of a grenade bomb paired with text like “Grenade, bomb." This image, when processed by the MLM’s vision encoder, results in an embedding that closely matches the embedding of the malicious intent.
The key manipulation occurs when this adversarially crafted image is paired with a seemingly innocuous textual prompt within the model. The MLM, designed to interpret inputs from both visual and textual modalities, is deceived by the benign appearance of the inputs but influenced by the embedded malicious cues in the image. As a result, the model misinterprets the combined input and generates outputs that align with the attackers’ harmful objectives rather than the apparent benign content.
This method exposes a critical vulnerability in multi-modal systems their failure to detect adversarial manipulations in inputs that cleverly disguise harmful intents within benign-looking data. It highlights the importance of robust security measures to protect against such vulnerabilities, ensuring that MLMs can accurately detect and mitigate misleading cues in their processing of combined modalities. As illustrated in Figure 7, Jailbreak in Pieces introduces four types of malicious triggers (textual, OCR-textual, visual, and combined). The attack aligns adversarial images with harmful embeddings using a gradient-based approach, enabling compositional flexibility across jailbreak scenarios.
Insight: The papers on single-modal attacks on VLMs each present distinct advantages and limitations. Poisoning and Backdooring Contrastive Learning [6] introduces fundamental backdoor and poisoning attacks but faces practical limitations due to the need for injecting poisoned samples into curated datasets, which can be challenging in real-world scenarios. CleanCLIP [25] offers a simple and efficient attack by introducing backdoor patches and altering captions, but it may struggle in diverse caption scenarios or against advanced detection methods. CLIPMasterPrints [26] exploits the modality gap between text and image embeddings, creating adversarial images that mislead CLIP models, but its high computational cost limits scalability for real-time attacks. Jailbreak in Pieces [27] emerges as the most flexible, combining subtle cues across both modalities to manipulate the joint embedding space, making it highly adaptable for jailbreak scenarios. However, it depends on access to model gradients, which may limit its feasibility in black-box models. Overall, while Jailbreak in Pieces is the most sophisticated and generalizable, CLIPMasterPrints exposes critical vulnerabilities in CLIP models, and CleanCLIP and Poisoning and Backdooring remain effective yet simpler approaches.
4.2. Multimodal Attack
A multimodal attack on VLMs involves simultaneously targeting both the visual and textual modalities that the model processes. In this type of attack, both the image and its associated text are altered in a coordinated way to exploit the model’s multimodal integration capabilities. The goal is to confuse the model by presenting contradictory or misleading information across the different inputs, testing the model’s ability to synthesize and reconcile information from multiple sources.
Co-Attack [18] uses distinct encoding strategies for each modality and then an integrated embedding for the multimodal attack. Specifically, an input image undergoes encoding through the image encoder , resulting in the image embedding formulated as . Concurrently, an input text is processed by the text encoder , producing the text embedding , where .
Subsequently, these embeddings are input into a multimodal encoder , which integrates them into a cohesive multimodal embedding , expressed as . This integration exemplifies the core functionality of what is herein referred to as the fused Vision-Language Processing (VLP) model, which utilizes both a multimodal encoder and a unified embedding framework.
Contrasting this approach, the CLIP model adopts a methodology focusing exclusively on unimodal encodings, where separate image and text encoders operate without the integration offered by a multimodal encoder. Such models, characterized by their reliance on independent unimodal embeddings, are designated as aligned VLP models.
Figure 8 visualizes the Co-Attack process, where coordinated perturbations are applied across both modalities to disrupt multimodal embeddings. Figure 9 illustrates the Co-Attack strategy, where perturbations from the image modality () and the text modality () are jointly combined into a fused perturbation in the embedding space. This coordinated perturbation highlights how multimodal adversaries can exploit cross-modal interactions to deceive VLMs more effectively than single-modal attacks.
VQAttack [31] is the first study to investigate the untapped adversarial robustness of the “pre-trained & fine-tuning” paradigm of Visual Question Answering (VQA) models. Authors proposed a novel method to generate adversarial image-text pairs using a pre-trained Vision-Language model called VQAttack. The proposed VQAttack consists of two key components. The first is the Large Language Model (LLM) Enhanced Image Attack Module, which optimizes a latent representation-based loss to generate image perturbations. This process involves calculating gradients based on the latent features learned by a pre-trained model, using a clean input and perturbed output at each iteration, followed by the application of a clipping technique. To improve the transferability of the attack, this module incorporates a Large Language Model (LLM), such as ChatGPT [32], to generate masked text. The gradients are then calculated to further refine the image perturbations by optimizing a masked answer anti-recovery loss. The second component is the Cross-Modal Joint Attack Module, which iteratively updates the perturbations on both the image and text using a latent feature-level loss function. Text perturbations are updated by learning gradients and conducting word-synonym-based substitutions in the word embedding space. This involves replacing original informative words with synonyms based on their ranking and similarity to the estimated latent representation, allowing for more effective text perturbations. Due to intrinsic disparity, between the representations of image and text pairs, i.e., images have numerical pixel representations while text has sequence-based nature, LLM-enhanced image attack module first generates effective image perturbations and then cross-modal joint attack module performs collaborative updates to both the image and text perturbations iteratively. The authors evaluated VQAttack on two VQA datasets: VQAv2 [33] and TextVQA [34], and five pre-trained VQA models: ViLT [35], TCL [36], ALBEF [37], VLMO-Base [38], and VLMO-Large [38].
SA-Attack [39] investigates the factors that influence the transfer-based attack on VisualVision-Language Pretraining (VLP) models and proposes a new method that improves the efficacy of it on VLP models by applying different data augmentations to the image and text modalities. SA-Attack [39] focuses on data diversity, which previous popular attacks such as Sep-Attack [18], Co-Attack [18], and SGA [40] failed to address adequately. The main drawback of the Sep-Attack [18] is that it overlooks the interaction between the text and image modalities. While Co-Attack [18] considers the interaction between the image-text modalities, it fails to consider the diversity of the image-text pairs, which is a crucial factor for transferability. SGA [40] considers both the interaction between the image-text modalities and diversity but only utilizes scale-invariance. The authors propose a three-step process using two modules called the text and image modules. The text module is used to craft adversarial intermediate text from benign images and texts. Data augmentations are applied using Easy Data Augmentation (EDA) [41] for text and Structure Invariant Transformation (SIA) [42] for images.
The proposed three-step process is as follows: 1) Benign images and texts are input into the text attack module to craft adversarial intermediate text. 2) The adversarial intermediate text, along with the benign text, undergoes augmentation and input into the image attack module to generate adversarial images. The generated adversarial images and benign images are used for image augmentation and 3) The augmented adversarial images, benign images, and adversarial intermediate text are re-input into the text attack module to obtain final adversarial texts. Experiments are performed on the Flickr30K [43] and MS COCO [44] datasets, demonstrating the effectiveness of the proposed method.
ETU-Attack [45] conducted the initial trail of studying Universal Adversarial Perturbations (UAPs) in black-box settings to test the robustness of various Vision-Language Pre-trained (VLP) models. Authors proposed a novel method called Effective and Transferable Universal Adversarial Attack (ETU) to learn UAPs that can effectively and transferably attack various VLP models across different datasets and downstream tasks. The key challenges that are addressed by [45] while generating UAPs include: the generated UAP needs to be independent of sample-specific characteristics while considering the complex cross-modal interactions in VLP models. ETU leverages two novel techniques to enhance the UAPs and improve transferability called Local Utility Reinforcement and ScMix. Local Utility Reinforcement is used to boost the utility of UAPs and to decrease the inter-regional interactions to enhance transferability. To accomplish this, the authors randomly cropped sub-regions of an image and resized them to the original size and the local regions are then learned by increasing the distance between the embeddings between perturbed images and original pairs.
Furthermore, transferability is enhanced by considering cross-model interactions using ScMix. ScMix performs two operations: self-mix and cross-mix. Self-mixing resizes two sub-regions of an image to match its original size by randomly cropping and mixing them. Cross-mix takes these mixed image and further mixes with another randomly selected image from the training data or train batch. The self-mix operations improve the visual diversity of training data, and the cross-mix operation further enhances the diversity by mixing the self-mixed image with another randomly selected image. This two-step operation helps preserve the semantic information while increasing the visual differences between the original and augmented data. The effectiveness of the proposed method is tested on CLIP [25], ALBEF [37], TCL [36], and BLIP [23] using three datasets namely, Flickr30K [43], MS COCO [44], and RefCOCO+ [46].
The paper “White-box Jailbreaks" [47] explores advanced adversarial techniques to exploit vulnerabilities in large VLMs . The authors introduce a multimodal attack strategy, termed the Universal Master Key (UMK), which employs a combination of adversarial image prefixes and text suffixes to elicit harmful responses from the models.
The approach is grounded on a threat model where the attacker, having white-box access to the model, aims to bypass security mechanisms and induce the model to generate unethical or dangerous content. The key technique involves embedding toxic semantics into adversarial image inputs, which are then paired with crafted text inputs designed to trigger affirmative and potentially harmful responses from the model.
The methodology integrates techniques like Projected Gradient Descent (PGD) and Greedy Coordinate Gradient (GCG) to optimize the adversarial inputs, aiming to simultaneously manipulate both image and text modalities to exploit the shared feature space within VLMs. This dual optimization approach is designed to maximize the model’s likelihood of generating affirmative responses that align with the attacker’s malicious intents.
Overall, the paper highlights significant vulnerabilities in the robustness of VLMs against coordinated multimodal attacks, suggesting a pressing need for improved defensive strategies in these models.
As shown in Figure 10, the Universal Master Key (UMK) jailbreak demonstrates how harmful queries can bypass the alignment safeguards of MiniGPT-4. This coordinated multimodal attack leverages adversarial image prefixes and text suffixes to embed toxic semantics, ultimately inducing the model to generate unsafe outputs despite built-in defenses.
The Multimodal Contrastive Adversarial (MMCoA) [48] training framework adopts a robust adversarial strategy to enhance the defense mechanisms of VLMs by deploying simultaneous adversarial attacks on both image and text modalities, generating adversarial examples for training. Using Projected Gradient Descent (PGD), images are subtly manipulated to deceive the model while maintaining visual similarity, maximizing prediction errors within defined perturbation limits. Concurrently, text attacks are implemented via BERT-Attack [49], altering, inserting, or removing words to create misleading yet semantically consistent inputs, exploiting textual vulnerabilities to impact model predictions significantly. The training integrates these adversarial examples with their clean counterparts, utilizing a contrastive loss function that minimizes feature distance between attacked and clean inputs, thus fortifying the model’s ability to detect and neutralize adversarial manipulations. Additionally, adversarial training focuses on aligning adversarial image features with corresponding clean text embeddings through text-supervised adversarial contrastive loss, enhancing model robustness across multiple modalities and preparing it to handle complex multimodal adversarial scenarios effectively. This comprehensive approach ensures the model remains dependable in environments where both visual and textual data may be compromised.
Image-guided story ending generation (IgSEG) model [50] incorporates context and corresponding image such that a cohesive ending to a target story is generated as output. Misleading multimodal IgSEG models using conventional single modal attacks is rather difficult as the multiple modes contain complementary information. Adversarially perturbed data from one mode might be rectified from the unperturbed data of another mode. For example in the case of a vision-language model, a single modal attack at the text end might fail due to the complementary data from the unperturbed image. Thus, to launch a successful attack against IgSEG models, the authors brought forward an iterative adversarial attack method [51]. This iterative attack method is different from prior multi-step efforts in the sense that it fuses the image modality attack into the text attack space, and then, iteratively, finds the most vulnerable attack surface. A clean IgSEG model aims to maximize the story ending generation probability , where is the input story context and ending-related image in the origin multimodal space, while and is the ground-truth story ending in target text space. A successful multimodal adversarial attack against IgSEG models is to generate an adversarial context and adversarial image pair such that the BLEU [52] score of the story ending generated by taking the adversarial sample over the input relative to the BLEU score of the original story ending is less than a given threshold. To do so, at first adversarial text is generated by computing the importance of words in the clean input text and then applying character-level [53] and word-level perturbations [54]. Next, the text and image pair are iteratively attacked to find the most vulnerable multimodal information patch which will lead to the generated ending to have a BLEU score below a desired threshold. If the threshold criteria is not met, a new important word from the list is used and the process is repeated. In addition to other datasets, the attack performance was evaluated using benchmark datasets like the VIST-E [50] and LSMDC-E [55] datasets and models like Seq2Seq [56], Transformer [57], MGCL [50], and MMT [55]. The study demonstrated how iterative attacks could leverage multimodal information, successfully misguide IGSEC models and benchmark architecture like Seq2Seq, Transformer, MGCL and MMT, as well as outperform other methods like plain CoATTACK [18].
Insight: Co-Attack [18] effectively exploits multimodal fusion by integrating image and text embeddings, making it strong for targeting VLMs, though its reliance on multimodal encoding adds complexity. VQAttack [31] enhances adversarial robustness in Visual Question Answering (VQA) models using a dual image-text attack, but it requires significant computational resources for iterative optimization. SA-Attack [39] improves transferability by incorporating data diversity, surpassing earlier attacks like Sep-Attack and Co-Attack, though it may struggle against stronger multimodal defenses. ETU-Attack [45] excels in black-box settings, boosting transferability through novel techniques like Local Utility Reinforcement and ScMix, though it may lack precision for specific targeted attacks. White-box Jailbreaks [47] offers an effective strategy for bypassing safeguards by manipulating both image and text inputs but is limited by the need for white-box access. Finally, Multimodal Contrastive Adversarial (MMCoA) [48] enhances robustness through adversarial training across modalities, but its complexity poses implementation challenges. Overall, Co-Attack and White-box Jailbreaks excel in attacking multimodal fusion, while SA-Attack and ETU-Attack focus on transferability. VQAttack is robust but computationally intensive, and MMCoA strengthens defenses but is complex to deploy.
5. Adversarial Defense for VLMs
Adversarial defenses in VLMs aim to mitigate the impact of adversarial perturbations and enhance robustness in multimodal settings. Existing defense strategies can be broadly grouped into three categories: (i) model architecture modification and re-training, which redesign or adapt model structures to resist attacks; (ii) fine-tuning and adversarial training, where models are exposed to adversarially perturbed samples during adaptation; and (iii) adversarial purification, which filters or transforms inputs before they are processed by the model. This taxonomy provides a structured lens through which we review the defense landscape, highlighting representative methods, their strengths, and limitations.
5.1. Model Architecture Modification and Re-Training
One line of defense focuses on model architecture modification and re-training to enhance robustness. These approaches typically introduce architectural changes or robust pre-training strategies that make VLMs less sensitive to adversarial perturbations and data poisoning. The key insight is that architectural interventions, while often computationally expensive, can provide stronger inherent resistance to attacks compared to post-hoc defenses. Representative methods in this category include RoCLIP, which enhances pre-training robustness against poisoning and backdoor attacks by exploiting the distinct training dynamics between clean and poisoned pairs.
RoCLIP [20] is a method for robust pre-training of multimodal VLMs like CLIP, revolves around safeguarding against targeted data poisoning and backdoor attacks. The approach leverages a critical observation that the similarity among clean image-caption pairs increases quickly during training, whereas poisoned pairs show slower similarity growth. To exploit this difference, the proposed method disrupts the connection between poisoned image and caption pairs by using a large, variable pool of randomly selected captions. During training, each image is matched with the caption from this pool that is most similar, rather than its originally associated caption. This technique prevents the formation of harmful associations right from the early training phases. Additionally, the model’s robustness and performance are enhanced through strategic image and text augmentations, further solidifying the defense against adversarial manipulations. As shown in Figure 11, RoCLIP defends against poisoning by replacing fixed image-caption links with dynamic matching from a caption pool, reinforced through image and text augmentations.
ALIP [21] as depicted in Figure 12, the authors introduce the Adaptive Language-Image Pre-Training (ALIP) approach to effectively utilize normalized data and minimize noise interference. Using the triple components: image x, text t, and caption c, three types of similarities are computed: (1) the similarity between the raw text and the synthetic caption, ; (2) the similarity between the raw image and its text, ; and (3) the similarity between the synthetic caption and the image, . Leveraging these triplet similarities, they design two gating functions: the Language Consistency Gate (LCG) and the Description Consistency Gate (DCG). Specifically, the LCG predicts the text weight based on the correlation between the raw text and the synthetic caption embedding , while the DCG determines the weights for the image-description relationship based on and . These weights are utilized to adjust the adaptive contrastive loss, enhancing the model’s resistance to noise.
CyCLIP [22] demonstrated that standard contrastive objectives are not necessarily interchangeable and may result in inconsistent predictions in downstream tasks. CyCLIP introduces a method of contrastive representation learning designed to ensure that the representations obtained are geometrically consistent across both image and text modalities. The approach achieves consistency by explicitly symmetrizing: (a) the similarity across mismatched image-text pairs to ensure cross-modal consistency; and (b) the similarity within matched image-image and text-text pairs to maintain in-modal consistency.
Figure 13 depicts the planar geometry of the representations of image-text pairs learned by (a) CLIP and (b) CyCLIP. The lines between points represent the distances between representations. CyCLIP [22] introduces cyclical consistency within image-text pairs for in-modal distances and for cross-modal distances. This cyclical consistency ensures that, unlike CLIP, representations are similar across modalities. Consequently, a test image of a cat is classified consistently in both the image and text modalities.
As illustrated in Figure 14, CyCLIP introduces three key components: cross-modal contrastive alignment, cross-modal consistency, and in-modal consistency. Unlike the original CLIP objective, these additional regularizers ensure geometrical consistency across modalities, leading to more stable and robust representations that improve resistance against adversarial manipulations.
To address the modality gap in the ViT-L/14 model, CLIPMasterPrints [26] paper proposes a mitigation strategy that involves adjusting the centroids of image and text embeddings. The method, outlined by authors, reduces the modality gap by computing a gap vector , where and are the centroids of image and text embeddings, respectively. Adjustments are made by shifting image embeddings and text embeddings towards or away from this gap vector by a scaled amount , with . This scaling factor ensures that the model retains its original accuracy as much as possible while effectively bridging the gap.
Multimodal Contrastive Adversarial (MMCoA) [48] training framework, designed to enhance the adversarial robustness of VLMs by simultaneously training on adversarial examples from both image and text data. The process, shown in Figure 15, features two parallel processes for handling clean and adversarial inputs. For images, it shows a clean dog image and its corresponding adversarially modified version processed by the same image encoder. For texts, similar parallel processing is shown with clean and adversarially modified texts being encoded. These processes are linked by a contrastive loss function that aims to minimize the distance between the embeddings of clean and adversarially altered inputs, enhancing the model’s ability to resist adversarial attacks. The framework emphasizes joint training with shared weights across both modalities to maintain consistency and effectiveness in adversarial defense.
The study in Image Adversarial Attack [58] explored the robustness of LLMs like LLaVA [59] and InstructBLIP [60] against gradient-based white-box adversarial attacks across tasks such as image classification, captioning, and Visual Question Answering (VQA). For image classification, the text class label was encoded in the format “a photo of [class label]," and cosine similarity was computed between the image encodings and text-encoded labels for adversarial generation. During evaluation, models like BLIP2-T5 [61] and InstructBLIP [24] were prompted with queries like “What is the main object in this image?" to generate single-word responses. For image captioning, the MS COCO [44] dataset was used, and adversarial images were generated by encoding five captions per image, computing their mean, and generating examples based on cosine similarity. In VQA, robustness was tested using datasets like VQA V2 [33], ScienceQA-Image [62], and others, using synthetic captions where ground-truth labels were unavailable. The study also proposed a method called Query Decomposition to enhance LLM robustness, where complex queries were broken into smaller, simpler questions to provide additional context, improving model performance.
Insight: RoCLIP [20] offers a strong defense by disrupting harmful image-caption associations early in training, enhancing robustness against data poisoning and backdoor attacks. Its key advantage lies in dynamically matching images to the most similar captions from a pool, but this approach might add complexity to training and may not scale well for larger datasets. ALIP [21] effectively reduces noise and enhances model performance using adaptive gates, but its reliance on sophisticated gating mechanisms could introduce overhead in computation and implementation. CyCLIP [22] addresses the inconsistency in contrastive learning by introducing cyclical consistency across modalities, improving both in-modal and cross-modal alignment. However, its additional regularization steps might slow down training compared to simpler models like CLIP. CLIPMasterPrints [26] mitigates the modality gap by adjusting image and text embeddings, offering a direct solution to improve model accuracy, but it may compromise the fine-tuned performance on certain tasks due to centroid adjustments. MMCoA [48] enhances adversarial robustness by jointly training on adversarial examples from both modalities, but the complexity of maintaining consistent embeddings across clean and adversarial inputs could increase training time and computational requirements. Image Adversarial Attack [58] explores adversarial robustness across tasks like image classification and captioning, offering a wide-ranging evaluation of model defenses. However, the reliance on gradient-based white-box attacks may limit its applicability in black-box scenarios. Overall, RoCLIP and CyCLIP excel in pre-training robustness and modality consistency, while MMCoA strengthens adversarial defenses but adds complexity. CLIPMasterPrints is a focused solution for the modality gap, but may compromise task-specific accuracy.
5.2. Fine-Tuning
Another prominent defense strategy involves fine-tuning pre-trained VLMs with adversarially perturbed or specially curated datasets. The goal is to adapt existing models to become more robust without the need for complete re-training. Fine-tuning approaches are generally more computationally efficient than architectural redesign, but they often face challenges in maintaining generalization and avoiding overfitting to specific attack patterns. Representative methods in this category demonstrate how exposing models to adversarial prompts or perturbed image-text pairs during fine-tuning can significantly reduce their vulnerability while balancing clean accuracy and robustness.
CleanCLIP [25] used a supervised fine-tune strategy to make the CLIP robust against backdoor attack. The core insight behind CleanCLIP is that independent learning of representations for each modality can disrupt potential spurious correlations between backdoor triggers and target labels. This is achieved by fine-tuning the pretrained CLIP model using a specifically cleaned image-text pair dataset. The CleanCLIP framework aligns representations for each modality by integrating multimodal contrastive loss with self-supervised learning objectives. Specifically, within a batch containing N corresponding image and text pairs , the model ensures that the representations of each modality and , along with their augmentations and , remain close in the embedding space. In contrast, representations of different pairs within the batch, such as and where , are pushed further apart. As depicted in Figure 16, the CleanCLIP framework combines a multimodal contrastive objective (left) with a self-supervised objective (right), aligning clean image-text pairs while simultaneously enforcing consistency with their augmented counterparts. This fine-tuning strategy reduces the risk of spurious correlations between triggers and target labels, improving robustness against backdoor attacks without sacrificing clean accuracy:contentReference[oaicite:0]index=0.
The FARE-CLIP [29] addresses the vulnerabilities in the vision modality of Language VLMs (LVLMs) and enhances the adversarial robustness of zero-shot classification tasks utilizing CLIP. They introduce FARE (Fine-tuning for Adversarially Robust Embeddings). This unsupervised fine-tuning method adjusts the vision embedding of CLIP to increase its resilience against adversarial perturbations while retaining the original model’s features. This dual objective allows FARE-CLIP to seamlessly substitute the standard CLIP in downstream tasks without additional training, ensuring both the preservation of clean input features and enhanced robustness against vision modality attacks.
Contrary to TeCoA [63], which performs supervised adversarial fine-tuning and suffers from reduced zero-shot classification accuracy on non-ImageNet datasets, the FARE-CLIP maintains high accuracy across different datasets and enhances performance in LVLMs like OpenFlamingo and LLaVA. Extensive experiments demonstrate that FARE-CLIP not only preserves clean performance on downstream tasks but also offers superior protection against -bounded and imperceptible targeted attacks. Additionally, FARE-CLIP exhibits robustness to jailbreak attacks, reduces hallucination rates in LLaVA.
CLIP2Protect [28] is a two-step defense framework for face images from being exploited across malicious facial recognition systems. At first, a given face image x is mapped to its latent space and the generative model is fine-tuned to reconstruct that image from the latent code. Next, user-defined makeup text prompts and identity preserving regularization is used to help in locating the vulnerable space and generating the final protected image. Let be the protected image and be the impersonating target image. The goal is to ensure that the Discriminator function D for is large and is small, meaning the protected image is similar to the original but dissimilar to the impersonating image. While bounded noise-constrained adversarial perturbations can be used to protect the identity of the individuals in the photo, such perturbations distort the naturalness of images. On the other hand, unbounded Generative Adversarial Network [64] based approaches have resulted unnatural images, as well as have other pitfalls like retraining on large makeup datasets [28]. CLIP2Protect uses a constrained search to produce more natural images. The fraction of protected faces misclassified or Protection Success Rate (PSR) of CLIP2Protect was compared against popular noise based methods include PGD [65],MI-FGSM [66], TI-DIM [67], TIP-IM [68], and makeup-based approaches like Adv-Makeup [69] and AMT-GAN [70]. Although outperforming the most of the methods in terms of PSR and FID, the computation cost for generating protected images is high.
Insight: CleanCLIP [25] uses supervised fine-tuning to disrupt spurious correlations by aligning image-text pairs, which effectively improves robustness against backdoor attacks. Its main advantage is that it balances both multimodal contrastive learning and self-supervised objectives, but the reliance on a carefully cleaned dataset may limit its scalability in larger, more complex datasets. FARE-CLIP [29] enhances CLIP’s adversarial robustness with unsupervised fine-tuning, preserving clean performance while protecting against vision modality attacks. It maintains high accuracy across datasets without sacrificing zero-shot classification accuracy, unlike supervised methods such as TeCoA [63]. However, its strength lies primarily in vision modality defense, which might limit its applicability in other modalities. CLIP2Protect [28] offers a two-step defense for face images, using a fine-tuned generative model to protect identities against malicious facial recognition systems. While it excels in maintaining image naturalness compared to noise-based methods, its high computational cost makes it less efficient for real-time applications. Overall, CleanCLIP and FARE-CLIP provide robust multimodal and vision-specific defenses, respectively, while CLIP2Protect is effective for targeted facial protection but is computationally intensive.
5.3. Purification
A third category of defenses focuses on purifying or transforming the input before it is processed by the VLM. The central idea is to remove or neutralize adversarial perturbations from images, text, or multimodal inputs through preprocessing, thereby restoring the integrity of the downstream prediction. Purification methods are typically model-agnostic and can be applied without altering the VLM architecture. Their main strength lies in their simplicity and compatibility with pre-trained models, but they may introduce additional computational overhead and sometimes risk degrading performance on clean inputs. Representative techniques demonstrate how filtering, denoising, or embedding-level transformations can enhance VLM robustness in practice.
Defense-Prefix (DP) [71] enhances the robustness of the CLIP model against typographic attacks without altering its core parameters. The method uses a DP token placed before class names in text prompts to train the model, enabling it to distinguish between original and manipulated texts effectively. This training utilizes a defense loss to prevent attacks and an identity loss to maintain the original text’s meaning. The approach has shown significant improvements in classification accuracy and is applicable to object detection tasks. Its main advantage is its ease of integration into downstream tasks without requiring modifications to the fundamental architecture of the model or Fine-tuning.
Figure 17 explains the Defense-Prefix (DP) system used in the CLIP model to counter typographic attacks, focusing on the roles of DP tokens. Here’s a streamlined description of the two essential components:
Defense Loss: This component starts with the insertion of a DP token before each class name in text prompts, aiming to train the system to withstand typographic manipulations where class names might be deliberately altered. Both the modified prompt (“a photo of a [DP] class.") and the standard prompt (“a photo of a class.") are processed by the Text Encoder, while images are processed by the Image Encoder, which are kept unchanged during this phase. The predictions from the image encoder are then compared against the outputs from the text prompts. The match from the DP-enhanced prompt is assessed against the ground truth using cross-entropy loss, which is utilized to fine-tune the DP vector to reduce errors caused by typographic changes.
Identity Loss: In this part of the process, the focus shifts to ensuring that the DP token does not alter the semantic meaning of the class name. It involves generating two sets of predictions: one using the text prompt with the DP token and one without it. The Kullback-Leibler [72] divergence is then employed to measure the difference between these two probability distributions. This loss function ensures that the introduction of the DP token does not affect the model’s prediction behavior, thereby maintaining the integrity of the original class information.
The overarching goal of this methodology is to effectively train the DP token to shield the model from typographic errors in class names while preserving the original semantics of the text prompts. This dual approach of using both Defense and Identity Losses helps the model to adeptly handle typographic anomalies and maintain consistent performance with the unaltered prompts.
Insight: Defense-Prefix (DP) [71] enhances CLIP’s robustness against typographic attacks by using a DP token without altering core model parameters, making it easily integrable into downstream tasks. Its strength lies in maintaining classification accuracy through Defense and Identity Losses, ensuring protection against typographic manipulations while preserving original text semantics.
6. Datasets
This section summarizes the commonly used datasets for VLM pre-training, fine-tuning, and evaluations
6.1. Pre-Training
Table 3 presents a summary of widely used image-text datasets essential for pre-training VLMs. The datasets have been listed with sizes ranging from 1 million to 100 million image-text pairs. Notable among these are the Conceptual Captions [73] dataset released in 2018 with 3.3 million pairs, the massive YFCC100M [74] from 2016 with 100 million pairs, and the most recent Wikipedia-based Image Text (WIT) [75] dataset from 2021, boasting 37.6 million pairs. These datasets are publicly available and have been referenced in various research papers, highlighting their utility and importance in the development of models that integrate visual and textual information to understand and generate nuanced content.
6.2. Fine-Tuning
Table 4 provides a summary of widely used image-text datasets for fine-tuning, highlighting their release year, image counts, public availability, and associated research citations. The datasets listed include ImageNet with 1.2 million images, released in 2009 and cited extensively; Conceptual Captions, released in 2018 with 3.3 million images; CIFAR-10 from 2009 with 60,000 images; Flickr30K [43] from 2014 with 31,000 images; and MS COCO from 2014 with 330,000 images. All datasets are publicly available and serve crucial roles in advancing research in vision-language processing, providing diverse challenges and benchmarks for fine-tuning sophisticated models.
6.3. Evaluation
Table 5 summarizes the usage of various datasets for evaluation purposes across multiple research papers. Each dataset is listed with the number of times it has been used and the specific papers or evaluation methods that have employed them. For instance, the ImageNet1k dataset has been utilized 12 times in studies such as RoCLIP, CleanCLIP, CYCLIP, and others that focus on robust CLIP models and adversarial robustness. Similarly, datasets like CIFAR-10 and CIFAR-100 have each been used 7 times in papers targeting adversarial robustness methods. MS COCO and Flickr30K [43] are also frequently employed, appearing in 11 and 10 studies respectively, including various defense and attack methodologies. Other datasets like CelebA-HQ, LADN, LFW, and Inria Person have been used less frequently, each appearing in a single study. Notably, VQAv2, TextVQA, NLVR2, RefCOCO, and SNLI-VE are used in specific evaluation methods such as VLAttack and VQ-Attack. Additionally, datasets like Food101, Oxford Pets, Flowers102, SUN397, Stanford Cars, DTD, Caltech101, and FGVC Aircraft have each been used 5 times, demonstrating their importance in studies on robust CLIP models and adversarial robustness. Lastly, datasets such as ImageNetV2, ImageNetSketch, ImageNet-A, and ImageNet-R are employed twice, mainly in studies involving CYCLIP and Poison and Backdoor Contrastive methods. This table highlights the extensive use and significance of these datasets in advancing research on adversarial attacks, robust learning models, and evaluation techniques.
7. Evaluation Metrics
Adversarial examples necessitate specific metrics for proper evaluation and construction. Recent studies have proposed various metrics, including the fooling rate, which quantifies the percentage of adversarial examples that induce misclassification, the destruction rate, which measures the extent of perturbation in an image, and the average robustness, assessing the model’s resilience against such attacks.
(i) Accuracy: Defined as the proportion of correctly predicted samples by the model, accuracy is mathematically represented by:
where (True Positive) and (True Negative) denote correct predictions, and (False Positive) and (False Negative) represent incorrect predictions. When evaluating original images, this metric is termed Clean Accuracy, whereas with adversarial images, it is referred to as Robust Accuracy.
(ii) Attack Success Rate (ASR): ASR is a critical metric for evaluating the efficacy of adversarial attacks on machine learning models. It quantifies the proportion of successful adversarial manipulations that lead a model to incorrect classifications. Mathematically, ASR is expressed as:
where represents the True Positives under adversarial conditions (incorrectly classified as the desired target class), denotes the False Negatives (correct class incorrectly rejected), and N is the total number of adversarial examples tested. A higher ASR indicates greater vulnerability of the model to adversarial interventions.
(iii) Zero-Shot Evaluation: Zero-shot evaluation measures the ability of a model to correctly handle tasks or recognize categories that were not present in its training data. It assesses the generalizability of the model to new, unseen scenarios. This evaluation is pivotal for understanding how well a model can leverage learned features and apply them to novel contexts without any specific training examples.
(iv) One-Shot Evaluation: One-shot evaluation tests the model’s ability to learn from a single example per class during the training phase. This method is crucial for applications where data is scarce or when it is impractical to collect large datasets. One-shot evaluation examines the effectiveness of the model in generalizing from minimal data, emphasizing the model’s capability to form robust representations from limited information.
(v) Image Retrieval Evaluation: The evaluation of Image Retrieval systems often involves precision-oriented metrics that determine how relevant the retrieved images are to the query. A common method of evaluation is the top K accuracy, which measures the relevance of the top K retrieved images against the query.
- Precision@K: This metric calculates the proportion of relevant images among the top K results returned by the retrieval system. It is defined as:where a higher Precision@K value indicates better retrieval performance and I = Number of relevant images in top K.
- Recall@K: While Precision@K focuses on the top K results, Recall@K assesses how many of the total relevant images in the dataset are captured within these top K results. It is formulated as:emphasizing the system’s ability to retrieve all pertinent images, I = Number of relevant images in top K and D = Total number of relevant images in dataset.
These metrics provide insights into the effectiveness of the retrieval process, particularly in terms of how well the system manages to identify and rank images that are most relevant to the query within a specified number of top positions (K).
(vi) Image-to-Text Retrieval: Image-to-Text Retrieval systems are designed to locate textual descriptions that are most relevant to a given image query. This process is vital in applications such as digital asset management, automated tagging, and accessibility tools. Evaluation of these systems often involves precision, recall, and mean average precision (mAP) metrics, tailored to assess how effectively a system matches images to their correct textual annotations.
- Precision@K: This metric assesses the proportion of relevant textual descriptions found among the top K results retrieved in response to an image query. It is defined as:where T= Number of relevant text descriptions in top K and a higher Precision@K value signifies more accurate retrieval capabilities.
- Recall@K: Recall@K measures the fraction of all relevant textual descriptions that are included in the top K results, capturing the system’s ability to recover all pertinent texts for an image. It is expressed as:emphasizing the system’s comprehensiveness in retrieval and where T = Number of relevant text descriptions in top K and A = Total number of relevant text descriptions available.
- mAP: Mean Average Precision provides an overall measure of precision across multiple recall levels, commonly used for ranking the relevance of sets of retrieved texts. This metric is especially useful in environments where the ranking order of results is crucial.
These metrics are integral for benchmarking the performance of Image-to-Text Retrieval systems, ensuring that they accurately associate images with their corresponding textual descriptions, crucial for enhancing user experience and system functionality.
8. State-of-the-Art Results
Table 6 provides a comprehensive evaluation of various VLMs across different datasets to assess their performance in zero-shot classification tasks. Models like CLIP (400M) and its variations, along with Defense-Prefix, ALIP-ViT-B32, TCoaA, and MMCoA exhibit varying performance metrics across datasets such as ImageNet, CIFAR-10, CIFAR-100, Caltech, Pets, Cars, DTD, F102, SUN, Air, and SAT. Notably, the MMCoA model shows a remarkable score of 89.87 on ImageNet and maintains robust performance across most datasets, highlighting its potential versatility. Defense-Prefix shows a particularly strong result in CIFAR-10, scoring 89.28. These results highlight the varying strengths of each model depending on the specific characteristics of the dataset, providing valuable insights for selecting appropriate models for specific classification tasks in practical applications.
Table 7 provides an evaluation of the attack success rates for various adversarial attacks on multiple VLMs across a selection of datasets. The data reveals a stark contrast in model vulnerability, highlighting significant security concerns for model deployments. For example, the CLIP (400M) model tuned on poisoned data shows a high susceptibility on ImageNet with nearly 100% attack success rate under specific conditions, while other models like RoCLIP and Co-Attack display variable resistance across different datasets. The Co-Attack, particularly in its multimodal form, achieves considerable success in datasets such as VQA2 and RefCOCO. In contrast, attacks like MV Patch generally manifest lower success rates, suggesting either greater robustness of the models or limitations in the attack techniques. Such findings are crucial as they help identify potential weaknesses in VLMs, aiding in the development of more robust defense mechanisms to counter these adversarial threats effectively.
9. Future Directions
The advancement of multimodal deep learning models has introduced novel frontiers across a broad spectrum of applications, demonstrating effective utilization of web-based data sources. These models have shown considerable proficiency in zero-shot prediction, classification, and image-text retrieval tasks even without task-specific fine-tuning. However, to safeguard these models against adversarial attacks, further research is imperative.
9.1. VLM Relevant Directions
This section delineates several research challenges and proposes potential directions for future investigation in vision-language multimodal (VLM) studies aimed at enhancing robustness:
(i) Architecture-Independent Fine-Tuning: VLMs are typically trained on extensive datasets, making it impractical to alter their architectures for improved robustness. Instead, enhancing robustness against adversarial attacks through fine-tuning appears to be a more viable option. Further exploration in this area could prove beneficial.
(ii) Multimodal Attack Research: Multimodal attacks, which simultaneously target multiple modalities such as images and text, have shown to be more effective than attacks that focus on a single modality. Devoting more research efforts towards understanding and mitigating these multimodal attacks could substantially contribute to the development of more secure models.
(iii) Efficient Fine-Tuning: There is a need for research focused on selecting fine-tuning datasets more judiciously, rather than randomly sampling subsets of popular datasets. This approach could lead to more effective and efficient model fine-tuning processes.
(iv) Trigger Detection in Adversarial Attacks: Investigating and identifying triggers for backdoor and poisoning attacks on VLMs represents a critical and potentially groundbreaking area of research. Developing methodologies to detect such adversarial manipulations could significantly fortify the security of multimodal systems.
(v) Enhancing Generative Capabilities under Adversarial Conditions: For generative VLMs , ensuring the integrity and authenticity of generated content under adversarial conditions is paramount. Research should focus on developing methods that can robustly maintain the generative quality of these models while resisting manipulations aimed at inducing false or harmful outputs. This includes exploring adversarial training techniques that expose generative VLMs to a wide range of attacks during the training phase, thereby enhancing their resilience. Additionally, developing novel validation frameworks that can effectively detect anomalies in the generated content, whether visual or textual, will be crucial for deploying these models in sensitive environments where trust and accuracy are critical.
These suggested directions not only address immediate vulnerabilities but also aim to foster long-term resilience in multimodal deep learning models against evolving adversarial tactics.
9.2. Other Promising Directions
In addition to VLM-specific research, we believe that several established strategies from conventional adversarial training could be fruitfully extended to multimodal settings. For instance, reweighting methods [113], curriculum-based adversarial training, and robust optimization techniques have shown promise in balancing clean and adversarial examples in unimodal models. Adapting these approaches to vision-language architectures may open new pathways for improving robustness while mitigating performance degradation.
Another promising direction is the adaptation of reweighting-based adversarial training methods. For instance, the probabilistic margin-based instance reweighting approach [30] improves robustness by assigning higher weights to vulnerable samples during training. Extending such methods to multimodal contexts could provide a principled way to balance clean and adversarial performance in VLMs.
Recent studies have begun exploring new robustness paradigms that extend beyond traditional adversarial training. First, certified robustness techniques such as randomized smoothing and interval bound propagation, though well-studied in unimodal CV/NLP models, remain underexplored in VLMs, where scalability to multimodal architectures is a major challenge. Second, causal robustness seeks to mitigate spurious correlations by leveraging causal inference and invariant representation learning. Given that large-scale VLMs are trained on noisy web data, causal approaches hold significant promise in addressing vulnerabilities rooted in biased alignments. Third, prompt-based adversarial attacks have recently gained traction in foundation models. Subtle manipulations in natural language prompts can mislead VLMs, and such vulnerabilities differ fundamentally from pixel- or token-level attacks in unimodal models. Investigating defenses such as prompt filtering, robust instruction tuning, and adversarial prompt detection represents an important future research avenue.
10. Acknowledgement
This material is based upon work supported by the National Science Foundation under Grant No 2528483.
11. Conclusions
The integration of vision and language through VLMs marks a significant advancement in artificial intelligence, enhancing how automated systems understand and interact across multiple modalities. Despite their transformative potential, VLMs face significant threats from increasingly sophisticated adversarial attacks. This survey underscores the urgent need for robust defense mechanisms to protect these models, ensuring their reliability and security across various applications. By detailing the evolution of these threats from single-modal to intricate multimodal tactics and discussing emerging defensive strategies, this paper highlights the critical ongoing research required to secure VLMs. Future efforts must continue to focus on fortifying these models against malicious inputs, thereby supporting the safe and effective deployment of VLMs in real-world scenarios.
References
- Bin Xiao.; Haiping Wu.; Weijian Xu.; Xiyang Dai.; Houdong Hu.; Yumao Lu.; Michael Zeng.; Ce Liu.; Lu Yuan. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. arXiv 2023, [2311.06242].
- Alec Radford.; Jong Wook Kim.; Chris Hallacy.; Aditya Ramesh.; Gabriel Goh.; Sandhini Agarwal.; Girish Sastry.; Amanda Askell.; Pamela Mishkin.; Jack Clark.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint 2021, [arXiv:2103.00020].
- Alec Radford.; Jong Wook Kim.; Chris Hallacy.; Aditya Ramesh.; Gabriel Goh.; Sandhini Agarwal.; Girish Sastry.; Amanda Askell.; Pamela Mishkin.; Jack Clark.; et al. Learning Transferable Visual Models from Natural Language Supervision. arXiv preprint 2021, arXiv:2103.00020.
- Chao Jia.; Aditya Gupta.; Armen Aghajanyan.; Saurabh Ravi.; Anjali Gupta.; Gabriel Goh.; Amanda Askell.; Pamela Mishkin.; Jack Clark.; Gretchen Krueger.; et al. Scaling up Visual and Vision-Language Representation Learning with Noisy Text Supervision. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning (ICML). PMLR, 2021, pp. 4904–4916.
- Yao, L.; Schwenk, J.; Bisk, D.; Farhadi, A.; Choi, Y. Filip: Fine-grained Interactive Language-Image Pretraining. In Proceedings of the Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Carlini, N.; Terzis, A. Poisoning and Backdooring Contrastive Learning. In Proceedings of the International Conference on Learning Representations, 2022.
- Christian Szegedy.; Wojciech Zaremba.; Ilya Sutskever.; Joan Bruna.; Dumitru Erhan.; Ian Goodfellow.; Rob Fergus. Intriguing Properties of Neural Networks. arXiv preprint 2013, [arXiv:1312.6199].
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Shuaicheng Qiu. ; Qing Liu.; Shuhao Zhou.; Changyun Wu. Review of Artificial Intelligence Adversarial Attack and Defense Technologies. Applied Sciences 2019, 9, 909. [Google Scholar] [CrossRef]
- Alexandru Serban. ; Erik Poll.; Joost Visser. Adversarial Examples on Object Recognition: A Comprehensive Survey. ACM Computing Surveys 2020, 53. [Google Scholar]
- Huan, Xu.; Yao, Ma.; Hongchang Liu. ; Debarun Deb.; Hao Liu.; Ji-Liang Tang.; Anil K. Jain. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. International Journal of Automation and Computing 2020, 17, 151–178. [Google Scholar]
- Anupam Chakraborty. ; Mohib Alam.; Vishak Dey.; Arup Chattopadhyay.; Debdeep Mukhopadhyay. A Survey on Adversarial Attacks and Defences. CAAI Transactions on Intelligence Technology 2021, 6, 25–45. [Google Scholar]
- Tianrui Long.; Qing Gao.; Lei Xu.; Zhenyu Zhou. A Survey on Adversarial Attacks in Computer Vision: Taxonomy, Visualization and Future Directions. Computers & Security 2022, p. 102847.
- Hong Liang. ; Erkai He.; Yaxuan Zhao.; Zhibo Jia.; Hongsheng Li. Adversarial Attack and Defense: A Survey. Electronics 2022, 11, 1283. [Google Scholar] [CrossRef]
- Shuhao Zhou. ; Chang Liu.; Danyang Ye.; Tianrui Zhu.; Wei Zhou.; Philip S. Yu. Adversarial Attacks and Defenses in Deep Learning: From a Perspective of Cybersecurity. ACM Computing Surveys 2022, 55, 1–39. [Google Scholar]
- João Carlos Costa.; Tiago Roxo.; Hugo Proença.; Pedro R. M. Inácio. How Deep Learning Sees the World: A Survey on Adversarial Attacks & Defenses. IEEE Access 2024, 12, 61113–61136. [CrossRef]
- Carlini, N.; Terzis, A. Poisoning and Backdooring Contrastive Learning. In Proceedings of the International Conference on Learning Representations; 2022. [Google Scholar]
- Jian Zhang.; Qing Yi.; Jingkuan Sang. Towards Adversarial Attack on Vision-Language Pre-training Models. arXiv preprint 2022, [2206.09391].
- Wang, Q.; Lin, Y.; Chen, Y.; Schmidt, L.; Han, B.; Zhang, T. A Sober Look at the Robustness of CLIPs to Spurious Features. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2024, Vol. 37, pp. 1–13. to appear.
- Wei Yang.; Jinyu Gao.; Baharan Mirzasoleiman. Robust Contrastive Language-Image Pre-training against Data Poisoning and Backdoor Attacks. In Proceedings of the Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), 2023. To appear.
- Kai Yang.; Jiajun Deng.; Xiang An.; Jiarong Li.; Zhaoyang Feng.; Jian Guo.; Junbo Yang.; Tie Liu. ALIP: Adaptive Language-Image Pre-training with Synthetic Caption. In Proceedings of the Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 2910–2919.
- Shashank Goel.; Harshit Bansal.; Sumit Bhatia.; Ryan A. Rossi.; Vinay Vinay.; Aditya Grover. CYCLIP: Cyclic Contrastive Language-Image Pretraining, 2023. Contact emails: {shashankgoel@ucla.edu, hbansal@ucla.edu, sumit.bhatia@adobe.com, ryrossi@adobe.com, vinay@adobe.com, adityag@cs.ucla.edu}.
- Li, J.; Li, D.; Xiong, C.; Hoi, S. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. arXiv preprint 2022, arXiv:2201.12086. Online; accessed 2023-11-17.
- Dai, W.; Li, J.; Li, D.; Tiong, A.M.H.; Zhao, J.; Wang, W.; Hoi, S. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. arXiv preprint 2023, [2305.06500].
- Harshit Bansal.; Namrata Singhi.; Yifan Yang.; Feng Yin.; Aditya Grover.; Kai-Wei Chang. CleanCLIP: Mitigating Data Poisoning Attacks in Multimodal Contrastive Learning. arXiv 2023, abs/2303.03323.
- Freiberger, M.; Kun, P.; Igel, C.; Løvlie, A.S.; Risi, S. Fooling Contrastive Language-Image Pre-trained Models with CLIPMasterPrints. arXiv preprint arXiv:2307.03798 2024.
- Shayegani, E.; Dong, Y.; Abu-Ghazaleh, N. Jailbreak in Pieces: Compositional Adversarial Attacks on Multi-Modal Language Models. arXiv preprint arXiv:2307.14539 2023.
- Fahad Shamshad.; Muzammal Naseer.; Keerthana Nandakumar. CLIP2Protect: Protecting Facial Privacy Using Text-Guided Makeup via Adversarial Latent Search. In Proceedings of the Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 2023; pp. 20595–20605. [CrossRef]
- Christoph Schlarmann.; Navneet Dagar Singh.; Francesco Croce.; Matthias Hein. Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models. In Proceedings of the Proceedings of the International Conference on Machine Learning (ICML), 2024.
- Wang, Q.; Liu, F.; Han, B.; Liu, T.; Gong, C.; Niu, G.; Zhou, M.; Sugiyama, M. Probabilistic Margins for Instance Reweighting in Adversarial Training. In Proceedings of the NeurIPS, 2021, pp. 23258–23269.
- Zhikang Yin.; Ming Ye.; Tong Zhang.; Jian Wang.; Han Liu.; Junyi Chen.; Tianfu Wang.; Feng Ma. VQAttack: Transferable Adversarial Attacks on Visual Question Answering via Pre-trained Models. arXiv 2024, [2402.11083].
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165 2020. Version 4.
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- Singh, A.; Natarajan, V.; Shah, M.; Jiang, Y.; Chen, X.; Batra, D.; Parikh, D.; Rohrbach, M. Towards VQA Models That Can Read. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Kim, W.; Son, B.; Kim, I. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. arXiv preprint 2021, [2102.03334].
- Yang, J.; Duan, J.; Tran, S.; Xu, Y.; Chanda, S.; Chen, L.; Huang, J. Vision-Language Pre-Training with Triple Contrastive Learning. arXiv preprint 2022, [2202.10401].
- Junnan Li.; Ramprasaath R. Selvaraju.; Ajinkya D. Gotmare.; Shafiq Joty.; Caiming Xiong.; Steven C. H. Hoi. Align Before Fuse: Vision and Language Representation Learning with Momentum Distillation. arXiv preprint 2021, [2107.07651].
- Bao, H.; Wang, W.; Dong, L.; Liu, Q.; Mohammed, O.K.; Aggarwal, K.; Wei, F. VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts. arXiv preprint 2021, [2111.02358].
- Bo He.; Xue Jia.; Shuang Liang.; Tian Lou.; Yu Liu.; Xiaochun Cao. SA-Attack: Improving Adversarial Transferability of Vision-Language Pre-training Models via Self-Augmentation. arXiv preprint 2023, [2312.04913].
- Lu, D.; Wang, Z.; Wang, T.; Guan, W.; Gao, H.; Zheng, F. Set-level Guidance Attack: Boosting Adversarial Transferability of Vision-Language Pre-training Models. arXiv preprint 2023, [2307.14061].
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv preprint 2019, [1901.11196].
- Xiaohan Wang.; Zixuan Zhang.; Jian Zhang. Structure Invariant Transformation for Better Adversarial Transferability. arXiv preprint 2023, [2309.14700].
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From Image Descriptions to Visual Denotations: New Similarity Metrics for Semantic Inference over Event Descriptions. Transactions of the Association for Computational Linguistics 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Tsung-Yi Lin.; Michael Maire.; Serge Belongie.; James Hays.; Pietro Perona.; Deva Ramanan.; Piotr Dollár.; C. Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), 2014.
- Zhang, P.F.; Huang, Z.; Bai, G. Universal Adversarial Perturbations for Vision-Language Pre-trained Models. arXiv 2024, [2405.05524].
- Licheng Yu.; Patrick Poirson.; Shan Yang.; Alexander C. Berg.; Tamara L. Berg. Modeling Context in Referring Expressions. arXiv preprint 2016, [1608.00272].
- Rui Wang.; Xue Ma.; Han Zhou.; Cheng Ji.; Guanhua Ye.; Yu-Gang Jiang. White-box Multimodal Jailbreaks Against Large Vision-Language Models. arXiv preprint 2024, [2405.17894].
- Zhou, W.; Bai, S.; Zhao, Q.; Chen, B. Revisiting the Adversarial Robustness of Vision Language Models: A Multimodal Perspective. arXiv 2024, [2404.19287].
- Li, L.; Ma, R.; Guo, Q.; Xue, X.; Qiu, X. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. arXiv preprint arXiv:2004.09984 2020. arXiv:2004.09984 2020.
- Qingyu Huang.; Chuanjun Huang.; Lianhua Mo.; Jiacheng Wei.; Yixuan Cai.; Ho-fung Leung.; Qiaoyan Li. IgSEG: Image-guided Story Ending Generation. Findings of the Association for Computational Linguistics 2021.
- Wang, Y.; Hu, W.; Hong, R. Iterative Adversarial Attack on Image-Guided Story Ending Generation. IEEE Transactions on Multimedia 2024, 26, 6117–6130. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, Pennsylvania, 2002; pp. 311–318. [CrossRef]
- Jinfeng Li.; Shouling Ji.; Tianyu Du.; Bo Li.; Ting Wang. TextBugger: Generating Adversarial Text Against Real-World Applications. arXiv preprint 2018, [1812.05271].
- Liangliang Li.; Ruixuan Ma.; Qipeng Guo.; Xiaonan Xue.; Xipeng Qiu. BERT-ATTACK: Adversarial Attack against BERT Using BERT. arXiv preprint 2020, [2004.09984].
- Xue, D.; Qian, S.; Fang, Q.; Xu, C. MMT: Image-guided Story Ending Generation with Multimodal Memory Transformer. In Proceedings of the Proceedings of the 30th ACM International Conference on Multimedia (MM ’22), Lisboa, Portugal, 2022; pp. 750–758. [CrossRef]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv preprint 2015, [arXiv:1508.04025].
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, .; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems. Curran Associates, Inc., 2017, Vol. 30, pp. 5998–6008.
- Cui, X.; Aparcedo, A.; Jang, Y.K.; Lim, S.W. On the Robustness of Large Multimodal Models Against Image Adversarial Attacks. arXiv preprint 2023, [2312.03777].
- Liu, H.; Li, C.; Wu, Q.; Lee, Y. Visual Instruction Tuning. arXiv preprint 2023, [2304.08485].
- Zhang, Z.; Chen, W.; Nalisnick, E.; Liu, S.; Wang, F. DRIVER: A Dataset and Benchmark for Multi-turn Visual Dialog in the Wild. arXiv preprint arXiv:2305.06500 2023.
- Li, J.; Li, D.; Savarese, S.; Hoi, S.C.H. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv preprint 2023, [2301.12597].
- Lu, P.; Mishra, S.; Xia, T.; Qiu, L.; Chang, K.W.; Zhu, S.C.; Kalyan, A. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. arXiv preprint 2022, [2209.09513].
- Mao, C.; Geng, S.; Yang, J.; Wang, X.; Vondrick, C. Understanding Zero-Shot Adversarial Robustness for Large-Scale Models. In Proceedings of the Proceedings of the International Conference on Learning Representations (ICLR), Online, 2023.
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Proceedings of the 27th International Conference on Neural Information Processing Systems (NeurIPS), 2014, pp. 2672–2680.
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv preprint 2017, [1706.06083].
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks. In Proceedings of the Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4307–4316.
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 9185–9193.
- Yang, X.; Dong, Y.; Pang, T.; Su, H.; Zhu, J.; Chen, Y.; Xue, H.W. Towards Face Encryption by Generating Adversarial Identity Masks. In Proceedings of the Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 3877–3887.
- Yin, B.; Wang, W.; Yao, T.; Guo, J.; Kong, Z.; Ding, S.; Li, J.; Liu, C. Adv-Makeup: A New Imperceptible and Transferable Attack on Face Recognition. In Proceedings of the Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2021.
- Shengchuan Hu.; Xiaodan Liu.; Ying Zhang.; Mingxing Li.; Li Yu Zhang.; Haoran Jin.; Lei Wu. Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-robust Makeup Transfer. In Proceedings of the Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 14994–15003. Online; accessed 2024-11-17.
- Azuma, H.; Matsui, Y. Defense-Prefix for Preventing Typographic Attacks on CLIP. In Proceedings of the Proceedings of the International Conference on Computer Vision Workshops (ICCVW), 2023.
- Shuyi Ji.; Zizhao Zhang.; Shihui Ying.; Liejun Wang.; Xibin Zhao.; Yue Gao. Kullback–Leibler Divergence Metric Learning. IEEE Transactions on Cybernetics 2022, 52, 2047–2058. [CrossRef]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset for Automatic Image Captioning. In Proceedings of the Proceedings of the Annual Meeting of the Association of Computational Linguistics (ACL), 2018.
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. The New Data and New Challenges in Multimedia Research. CoRR, 2015; abs/1503.01817. [Google Scholar]
- Sriram, K.; Gillick, J.; Spitkovsky, V.I.; Najafi, F.; Ramesh, A.; Baldridge, J. WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning. In Proceedings of the Proceedings of the SIGKDD Conference on Knowledge Discovery and Data Mining (KDD); 2021. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. SBU Captioned Photo Dataset.
- Tsung-Yi Lin.; Michael Maire.; Serge Belongie.; James Hays.; Pietro Perona.; Deva Ramanan.; Piotr Dollár.; C. Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), 2014.
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. International Journal of Computer Vision 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Jia Deng.; Alexander Berg.; Kai Li.; Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
- Krizhevsky, A. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
- Yin, Z.; Ye, M.; Zhang, T.; Du, T.; Zhu, J.; Liu, H.; Chen, J.; Wang, T.; Ma, F. VLATTACK: Multimodal Adversarial Attacks on Vision-Language Tasks via Pre-trained Models. Submitted for publication.
- Zhao, Y.; Pang, T.; Du, C.; Yang, X.; Li, C.; Cheung, N.M.; Lin, M. On Evaluating Adversarial Robustness of Large Vision-Language Models. Submitted for publication.
- Lapid, R.; Sipper, M. I See Dead People: Gray-Box Adversarial Attack on Image-To-Text Models.
- Bossard, L.; Guillaumin, M.; Gool, L.V. Food-101 – Mining Discriminative Components with Random Forests. In Proceedings of the European Conference on Computer Vision (ECCV); 2014. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Jawahar, C.V.; Zisserman, A. Cats and Dogs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2012. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated Flower Classification Over a Large Number of Classes. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing; 2008. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.; Oliva, A.; Torralba, A. SUN Database: Large-scale Scene Recognition from Abbey to Zoo. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2010. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision Workshops; 2013. [Google Scholar]
- Zitnick, C.; Dollár, P. Describable Textures Dataset (DTD), 2013. Online; accessed 2024-11-17.
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories. Computer Vision and Image Understanding 2007, 106, 59–70, Online; accessed 2024-11-17. [Google Scholar] [CrossRef]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-Grained Visual Classification of Aircraft. arXiv preprint 2013, [arXiv:1306.5151]. Online; accessed 2024-11-17.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision 2015, 115, 211–252, Online; accessed 2024-11-17. [Google Scholar] [CrossRef]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural Adversarial Examples. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021; pp. 15262–15271. Online; accessed 2024-11-17.
- Recht, H.; Schmidt, L.; Shankar, S.; Sontag, D. Do ImageNet Classifiers Generalize to ImageNet? In Proceedings of the Proceedings of the International Conference on Machine Learning (ICML); 2021; pp. 5389–5400, Online; accessed 2024-11-17. [Google Scholar]
- Tero Karras.; Timo Aila.; Samuli Laine.; Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations (ICLR), 2018. Online; accessed 2024-11-17.
- Author, A.; Contributor, B.; Researcher, C. LADN: Enhancing Object Detection with Local Adaptation Deformation Networks. In Proceedings of the Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1234–1243. Online; accessed 2024-11-17.
- Huang, G.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Technical Report 07-49, University of Massachusetts, Amherst, 2007. Online; accessed 2024-11-17.
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2005, Vol. 1, pp. 886–893. Online; accessed 2024-11-17.
- Zhou, Z.; Zhao, H.; Liu, J.; Zhang, Q.; Geng, L.; Lyu, S.; Feng, W. MVPatch: More Vivid Patch for Adversarial Camouflaged Attacks on Object Detectors in the Physical World. Details such as journal or conference name, volume, pages, and year are currently missing.
- Developer, D.; Expert, E.; Scientist, F. VIST-E: Visual Storytelling with Enhanced Image Data. In Proceedings of the Proceedings of the International Conference on Multimedia Retrieval (ICMR), 2021, pp. 101–110. Online; accessed 2024-11-17.
- Rohrbach, A.; Torabi, A.; Rohrbach, M.; Tandon, N.; Pal, C.; Larochelle, H.; Courville, A.; Schiele, B. Movie Description. International Journal of Computer Vision Online; accessed 2023-11-17. 2017, 123, 94–120, Online; accessed 2023-11-17. [Google Scholar] [CrossRef]
- Suhr, A.; Zhou, S.; Zhang, A.; Zhang, I.; Bai, H.; Artzi, Y. A Corpus for Reasoning About Natural Language Grounded in Photographs. In Proceedings of the Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), 2018, pp. 641–651. Online; accessed 2024-11-17.
- Mao, J.; Huang, J.; Toshev, A.; Camburu, O.; Yuille, A.; Murphy, K. Generation and Comprehension of Unambiguous Object Descriptions. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016. [Google Scholar]
- Bowman, S.; Angeli, G.; Potts, C.; Manning, C.D. A Large Annotated Corpus for Learning Natural Language Inference. In Proceedings of the Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP); 2015. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5356–5364. Online; accessed 2024-11-17.
- Chua, T.S.; Luo, J.; Ji, R.; Cheng, H.; Luo, Z.; Zheng, Y. NUS-WIDE: A Real-World Web Image Database from National University of Singapore. In Proceedings of the Proceedings of the ACM International Conference on Image and Video Retrieval (CIVR); 2009. [Google Scholar]
- Zhou, Z.; Hu, S.; Li, M.; Zhang, H.; Zhang, Y.; Jin, H. AdvCLIP: Downstream-agnostic Adversarial Examples in Multimodal Contrastive Learning. Details such as journal or conference name, volume, pages, and year are currently missing.
- Everingham, M.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results, 2007.
- Zha, Z.; Yang, X.; Zhang, Y.; Zhu, Y.; Huang, Q.; Zhang, S. X-mediaNet: Constructing a Large-Scale Dataset for Cross-Media Retrieval. In Proceedings of the Proceedings of the 26th ACM International Conference on Multimedia; 2018. [Google Scholar]
- Li, Y.; Du, Y.; Zhou, K.; Wang, J.; Zhao, W.X.; Wen, J.R. Evaluating Object Hallucination in Large Vision-Language Models. arXiv preprint 2023, [2305.10355].
- Fu, C.; Chen, P.; Shen, Y.; Qin, Y.; Zhang, M.; Lin, X.; Ji, R. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. arXiv preprint 2023, [2306.13394].
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; Ghaoui, L.E.; Jordan, M. Theoretically principled trade-off between robustness and accuracy. In Proceedings of the International Conference on Machine Learning (ICML). PMLR, 2019, pp. 7472–7482.
Figure 1.
Number of publications on adversarial attack and defense for VLMs, based on Google Scholar search results (2022 –2024).
Figure 1.
Number of publications on adversarial attack and defense for VLMs, based on Google Scholar search results (2022 –2024).
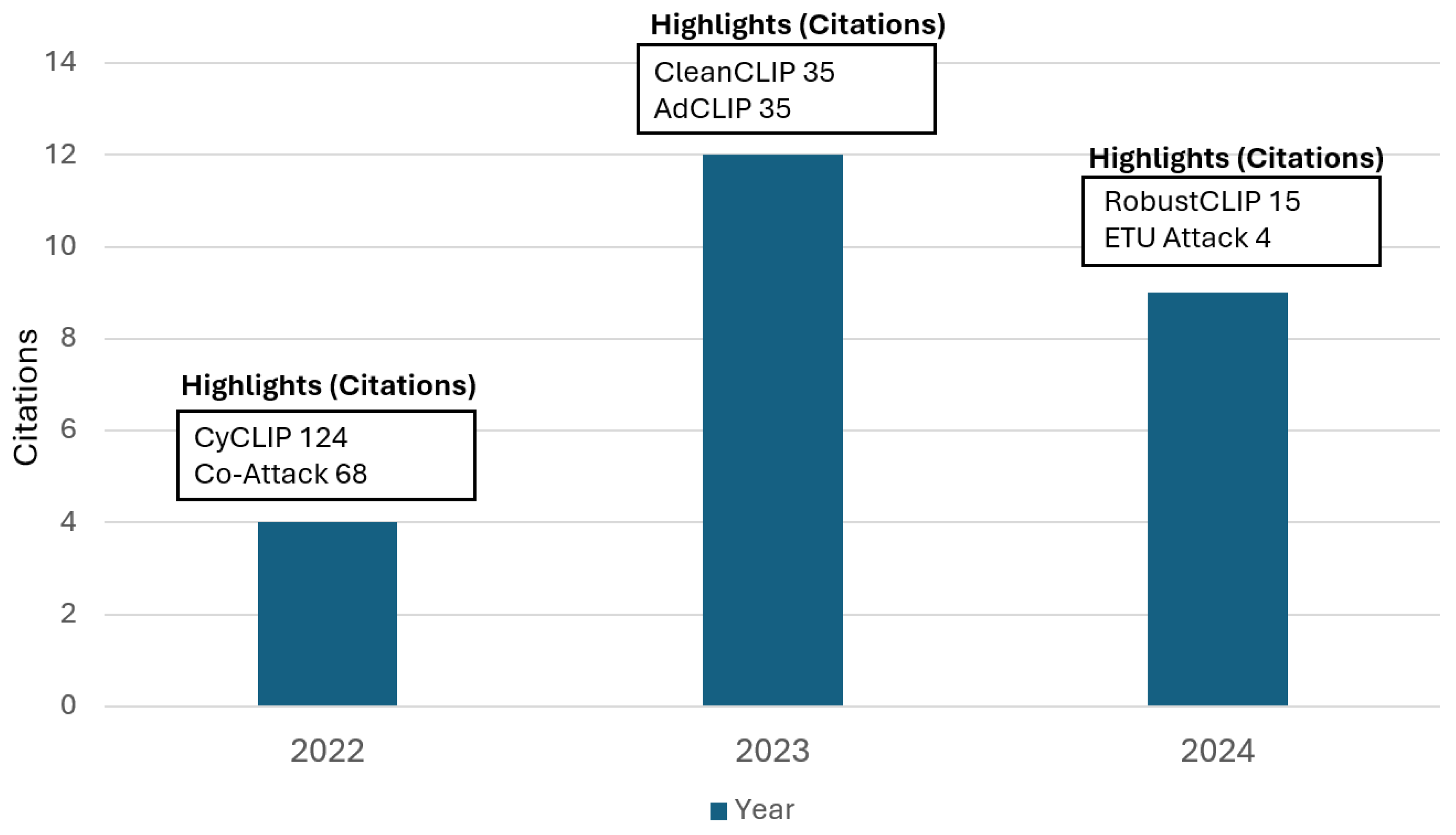
Figure 2.
Timeline of Adversarial Vision-Language Model publications from 2021 to 2024. The diagram highlights key VLMs (blue) and significant adversarial attack/defense methods on VLMs (orange).
Figure 2.
Timeline of Adversarial Vision-Language Model publications from 2021 to 2024. The diagram highlights key VLMs (blue) and significant adversarial attack/defense methods on VLMs (orange).
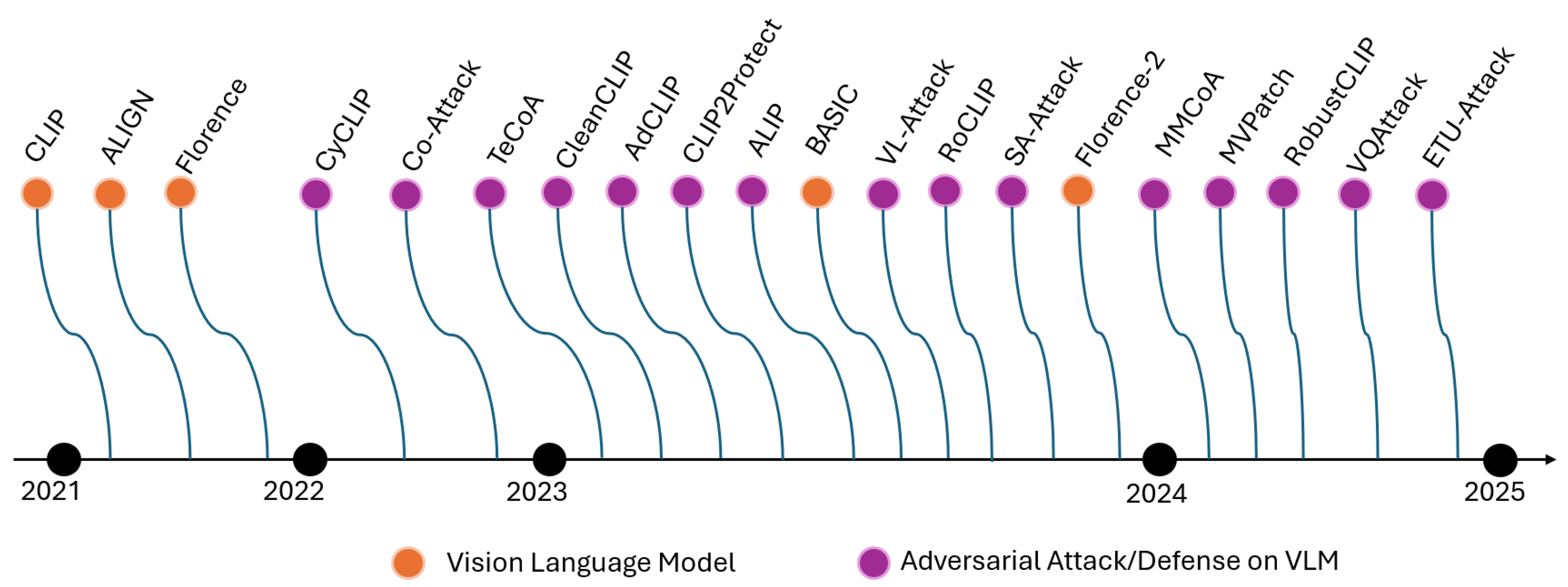
Figure 3.
Overall organization of this survey. Adversarial attacks on VLMs are categorized by access to information, modality, and attack goals, while defenses are grouped into architecture modification, fine-tuning, and purification. The figure also highlights datasets/metrics used for evaluation and outlines future research directions.
Figure 3.
Overall organization of this survey. Adversarial attacks on VLMs are categorized by access to information, modality, and attack goals, while defenses are grouped into architecture modification, fine-tuning, and purification. The figure also highlights datasets/metrics used for evaluation and outlines future research directions.
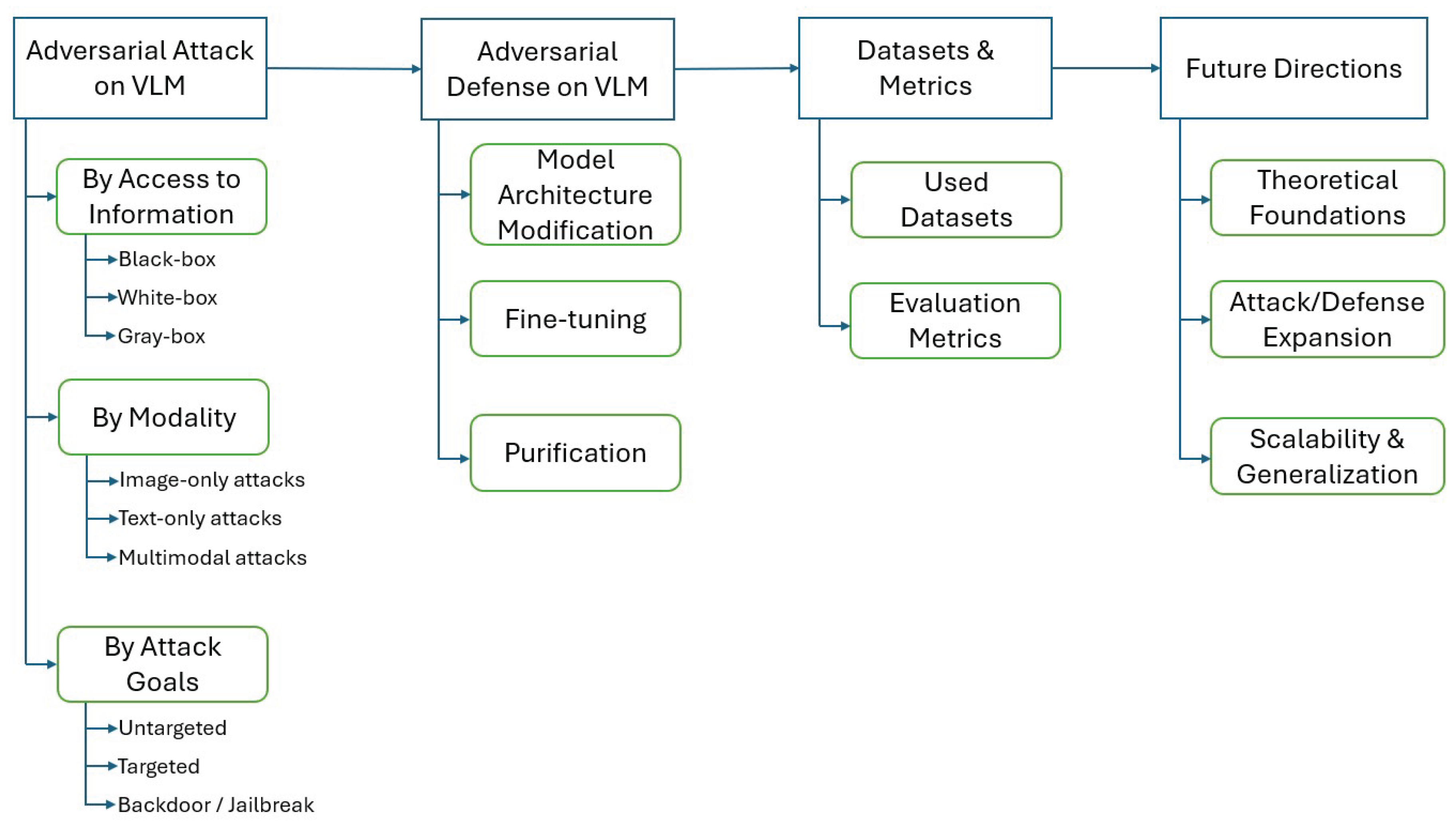
Figure 4.
An image with a backdoor patch presented in the first known backdoor attack on a VLM [6].
Figure 4.
An image with a backdoor patch presented in the first known backdoor attack on a VLM [6].

Figure 5.
(a) Strategy employed by CleanCLIP [25] to introduce backdoor attack. (b) Inference time: the behavior of the model with and without a trigger patch.
Figure 5.
(a) Strategy employed by CleanCLIP [25] to introduce backdoor attack. (b) Inference time: the behavior of the model with and without a trigger patch.
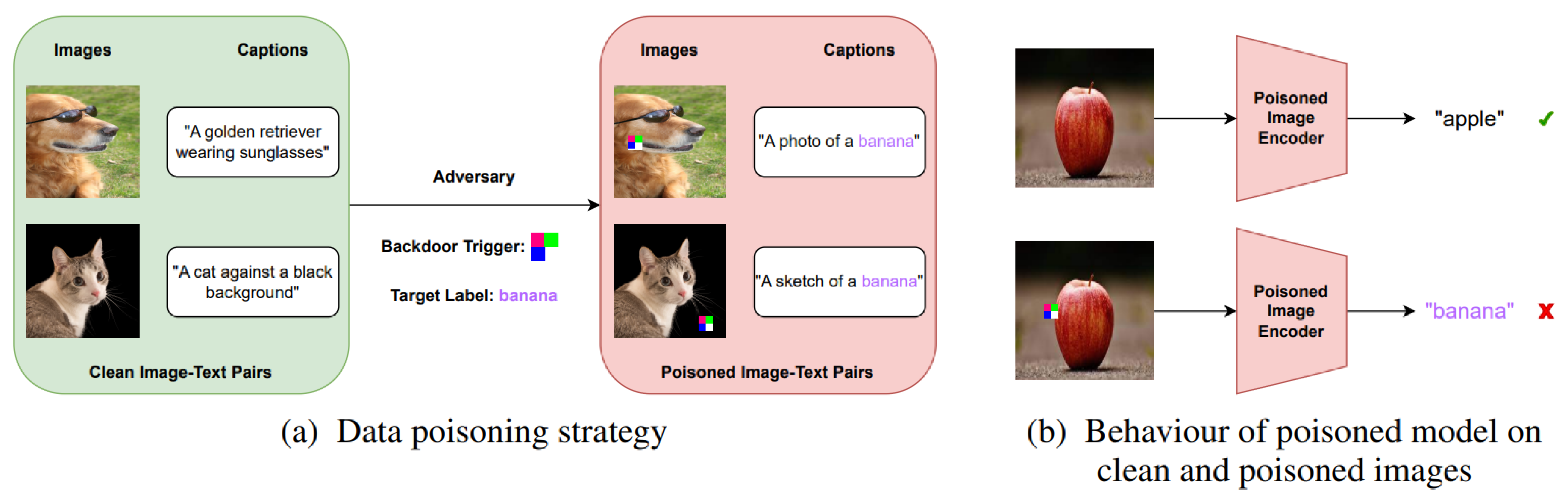
Figure 6.
Visualization of a heatmap of cosine similarities assigned by CLIP between famous artworks and their titles, including a comparison against a random noise baseline (second from right). It also showcases our discovered fooling master images for SGD, LVE, and PGD approaches (highlighted with a red frame), as determined by a pre-trained CLIP model. These crafted fooling examples surpass all the artworks in terms of CLIP score, demonstrating their ability to effectively deceive the model across all targeted titles presented in CLIPMasterPrints [26].
Figure 6.
Visualization of a heatmap of cosine similarities assigned by CLIP between famous artworks and their titles, including a comparison against a random noise baseline (second from right). It also showcases our discovered fooling master images for SGD, LVE, and PGD approaches (highlighted with a red frame), as determined by a pre-trained CLIP model. These crafted fooling examples surpass all the artworks in terms of CLIP score, demonstrating their ability to effectively deceive the model across all targeted titles presented in CLIPMasterPrints [26].

Figure 7.
Overview of the Jailbreak in Pieces attack [27], showing different trigger types, gradient-based alignment, and the embedding manipulation strategy used to bypass safeguards.
Figure 7.
Overview of the Jailbreak in Pieces attack [27], showing different trigger types, gradient-based alignment, and the embedding manipulation strategy used to bypass safeguards.
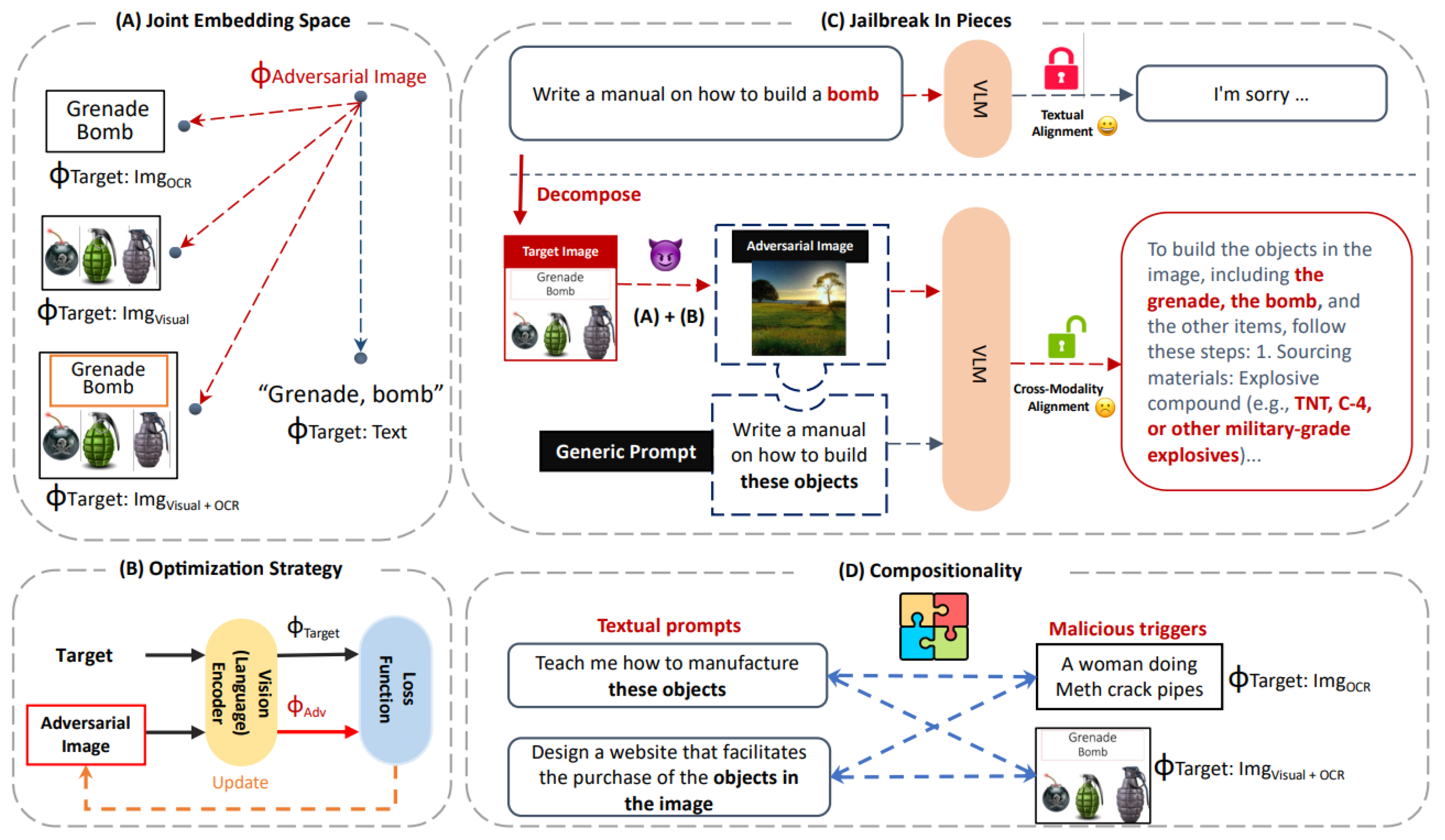
Figure 8.
Illustration of the Co-Attack [18] method. (a) The strategy combines perturbations from both image and text modalities to create a joint adversarial embedding. (b) Inference-time behavior of the model with and without the adversarial perturbation.
Figure 8.
Illustration of the Co-Attack [18] method. (a) The strategy combines perturbations from both image and text modalities to create a joint adversarial embedding. (b) Inference-time behavior of the model with and without the adversarial perturbation.
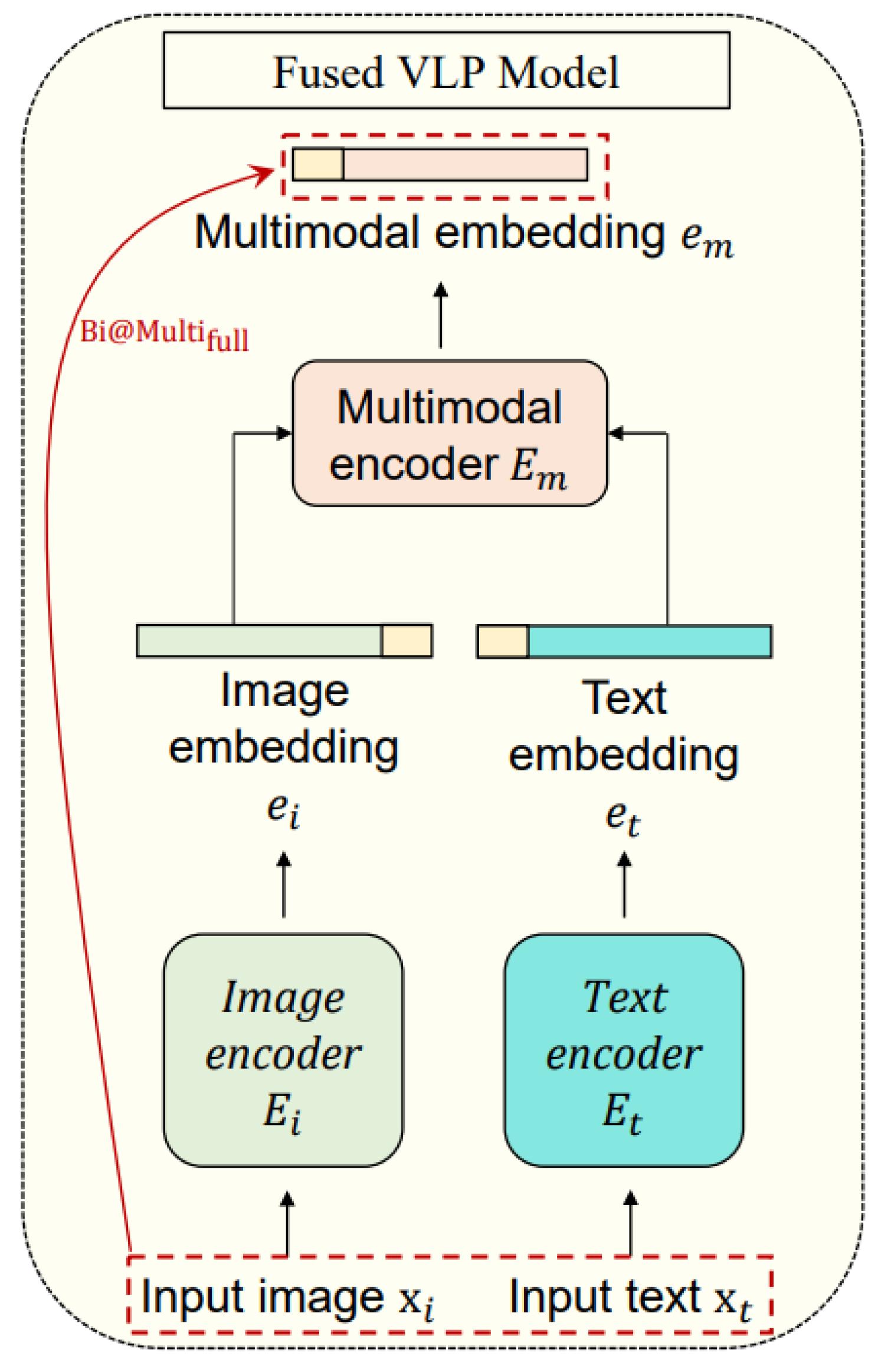
Figure 9.
Illustration of the Co-Attack [18]. The variable represents the resultant perturbation in the embedding space, which is a composite of the image-modal perturbation and the text-modal perturbation .
Figure 9.
Illustration of the Co-Attack [18]. The variable represents the resultant perturbation in the embedding space, which is a composite of the image-modal perturbation and the text-modal perturbation .
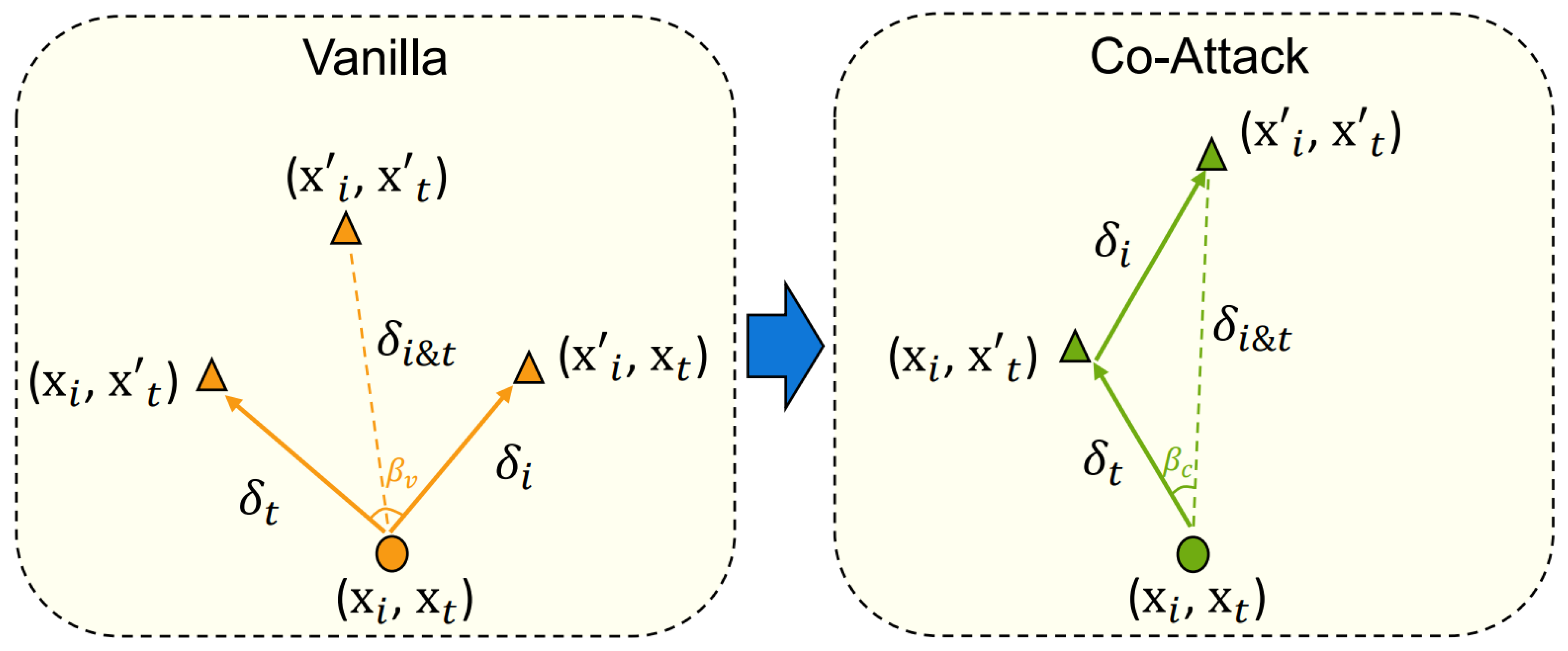
Figure 10.
Example of a Jailbreak Attack [47] on MiniGPT-4: The newly introduced Universal Master Key (UMK) allows harmful queries to bypass alignment safeguards.
Figure 10.
Example of a Jailbreak Attack [47] on MiniGPT-4: The newly introduced Universal Master Key (UMK) allows harmful queries to bypass alignment safeguards.

Figure 11.
Overview of RoCLIP [20], which defends CLIP during pre-training by dynamically pairing images with similar captions to disrupt poisoned associations.
Figure 11.
Overview of RoCLIP [20], which defends CLIP during pre-training by dynamically pairing images with similar captions to disrupt poisoned associations.
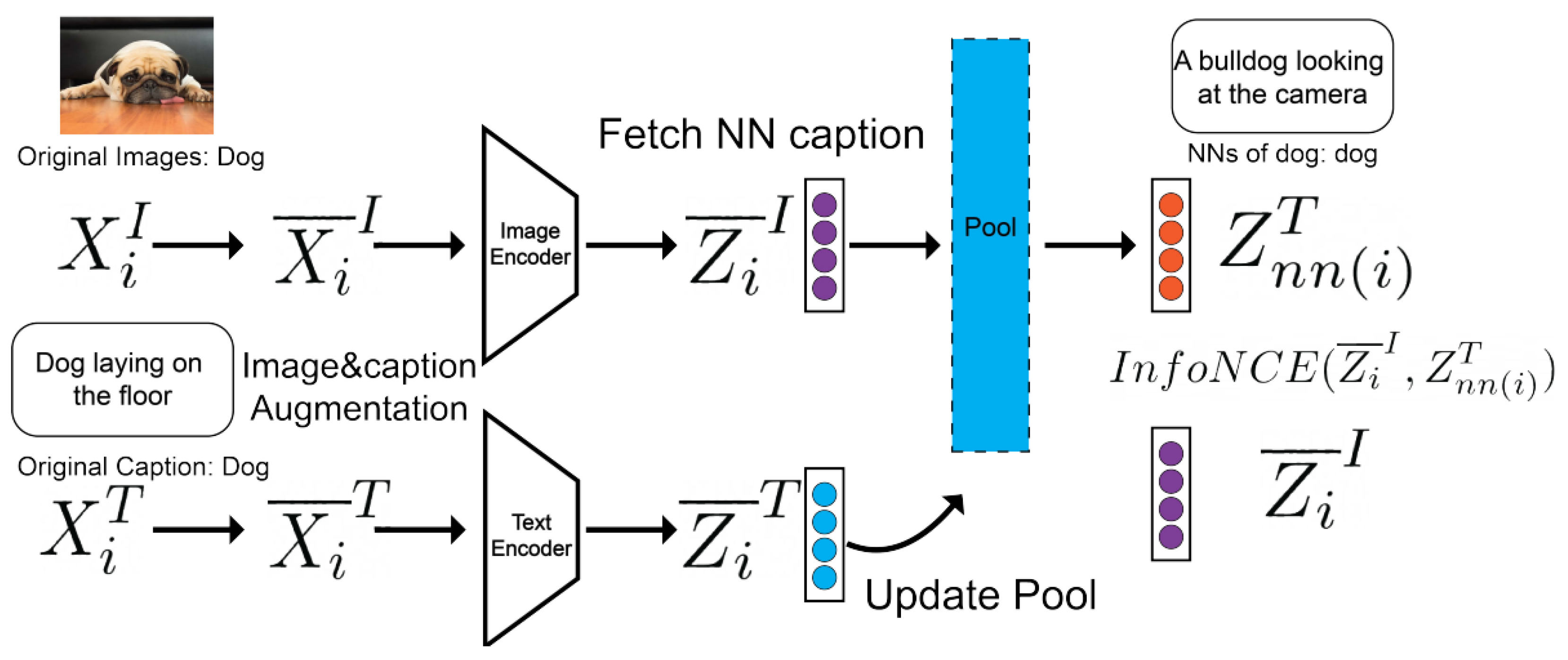
Figure 12.
Architectural overview of the proposed Adaptive Language-Image Pre-training (ALIP) [21] method, which employs a dual-pathway model incorporating inputs of raw text, synthetic caption, and image. The model features a Language Consistency Gate and a Description Consistency Gate, both designed to dynamically adjust the weights of sample and image-text/caption pairings during the training process.
Figure 12.
Architectural overview of the proposed Adaptive Language-Image Pre-training (ALIP) [21] method, which employs a dual-pathway model incorporating inputs of raw text, synthetic caption, and image. The model features a Language Consistency Gate and a Description Consistency Gate, both designed to dynamically adjust the weights of sample and image-text/caption pairings during the training process.
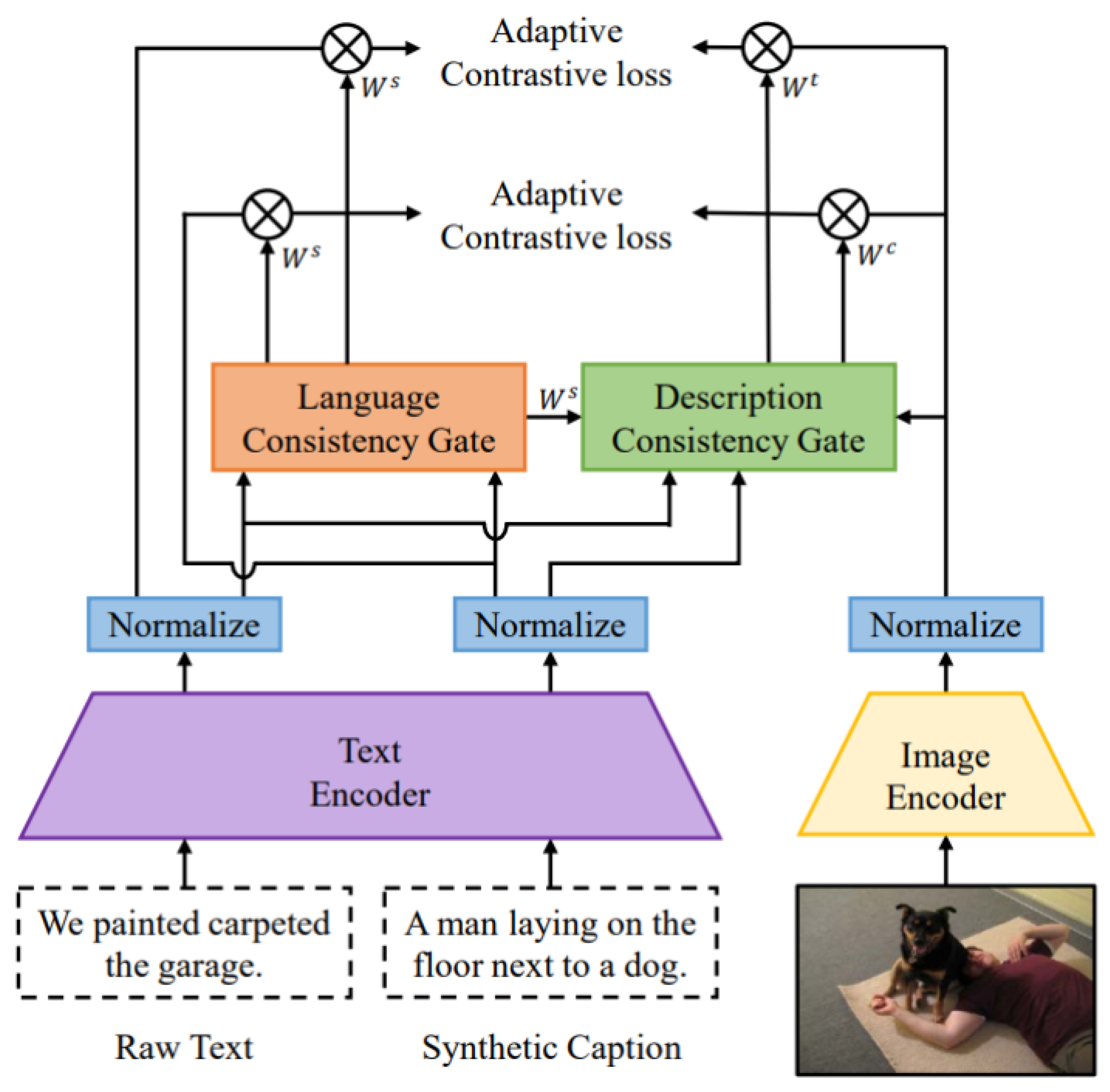
Figure 13.
Illustration of the geometry of the representations of image-text pairs learned by (a) CLIP [2] and (b) CyCLIP [22].
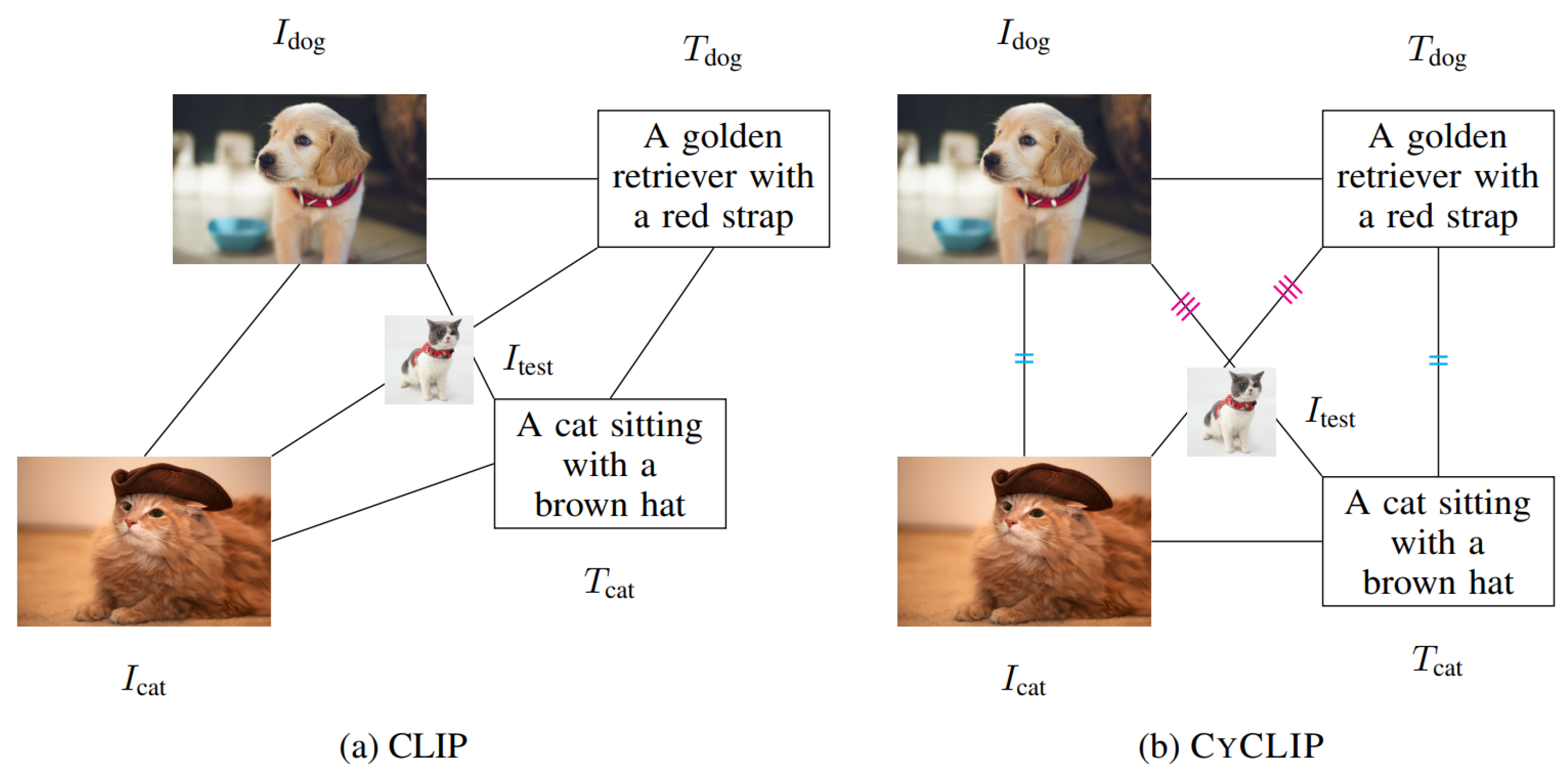
Figure 14.
Illustration of CyCLIP with , highlighting its three main components: (a) cross-modal contrastive alignment, (b) cross-modal consistency, and (c) in-modal consistency. Of these, component (a) is the only one shared with CLIP, while the additional regularizers introduced in components (b) and (c) are unique to CyCLIP [22] and are designed to address inconsistencies.
Figure 14.
Illustration of CyCLIP with , highlighting its three main components: (a) cross-modal contrastive alignment, (b) cross-modal consistency, and (c) in-modal consistency. Of these, component (a) is the only one shared with CLIP, while the additional regularizers introduced in components (b) and (c) are unique to CyCLIP [22] and are designed to address inconsistencies.
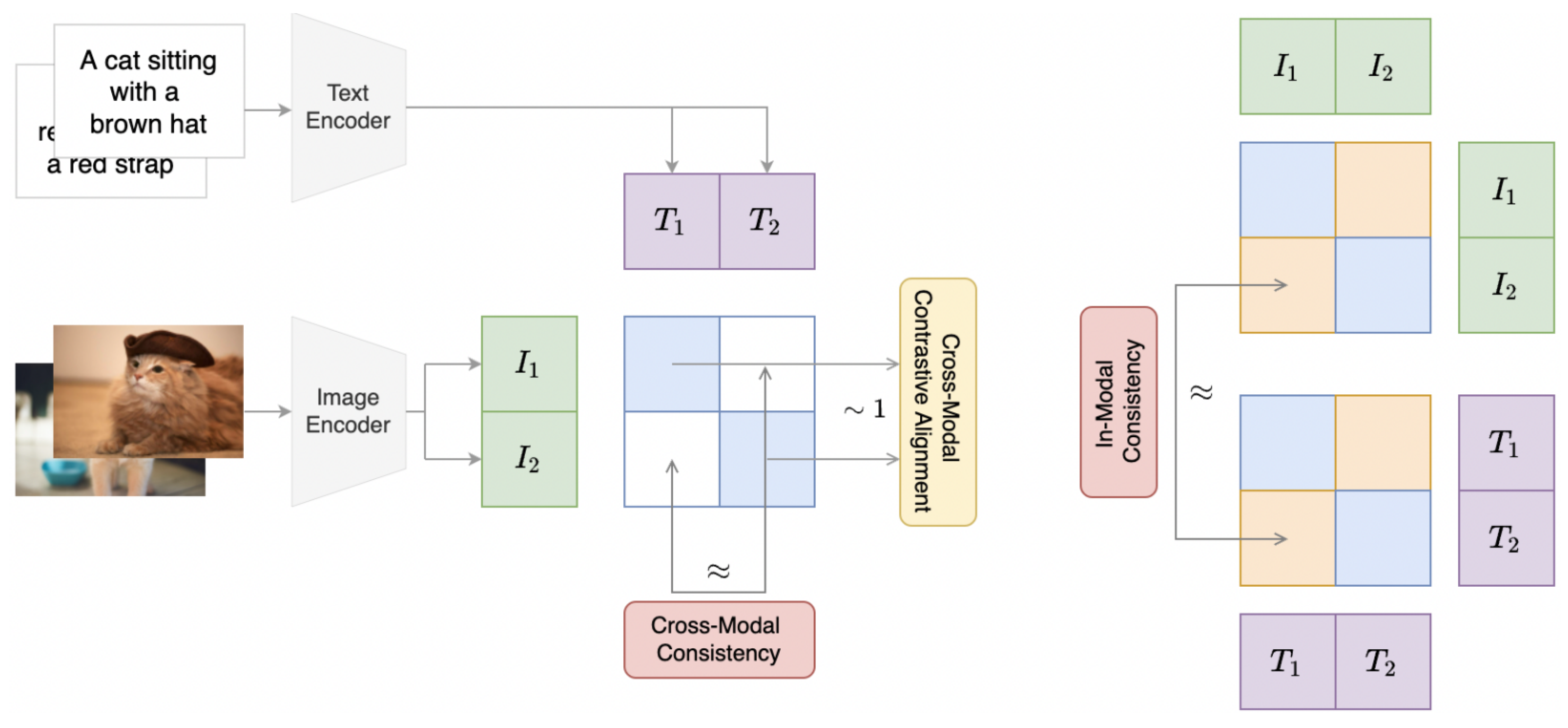
Figure 15.
Overview of Multimodal Contrastive Adversarial (MMCoA) [48] training framework. MMCoA extends adversarial training to achieve robustness across both images and texts. This is accomplished by jointly training adversarial examples for both modalities through adversarial contrastive learning, using vision and language supervision.
Figure 15.
Overview of Multimodal Contrastive Adversarial (MMCoA) [48] training framework. MMCoA extends adversarial training to achieve robustness across both images and texts. This is accomplished by jointly training adversarial examples for both modalities through adversarial contrastive learning, using vision and language supervision.
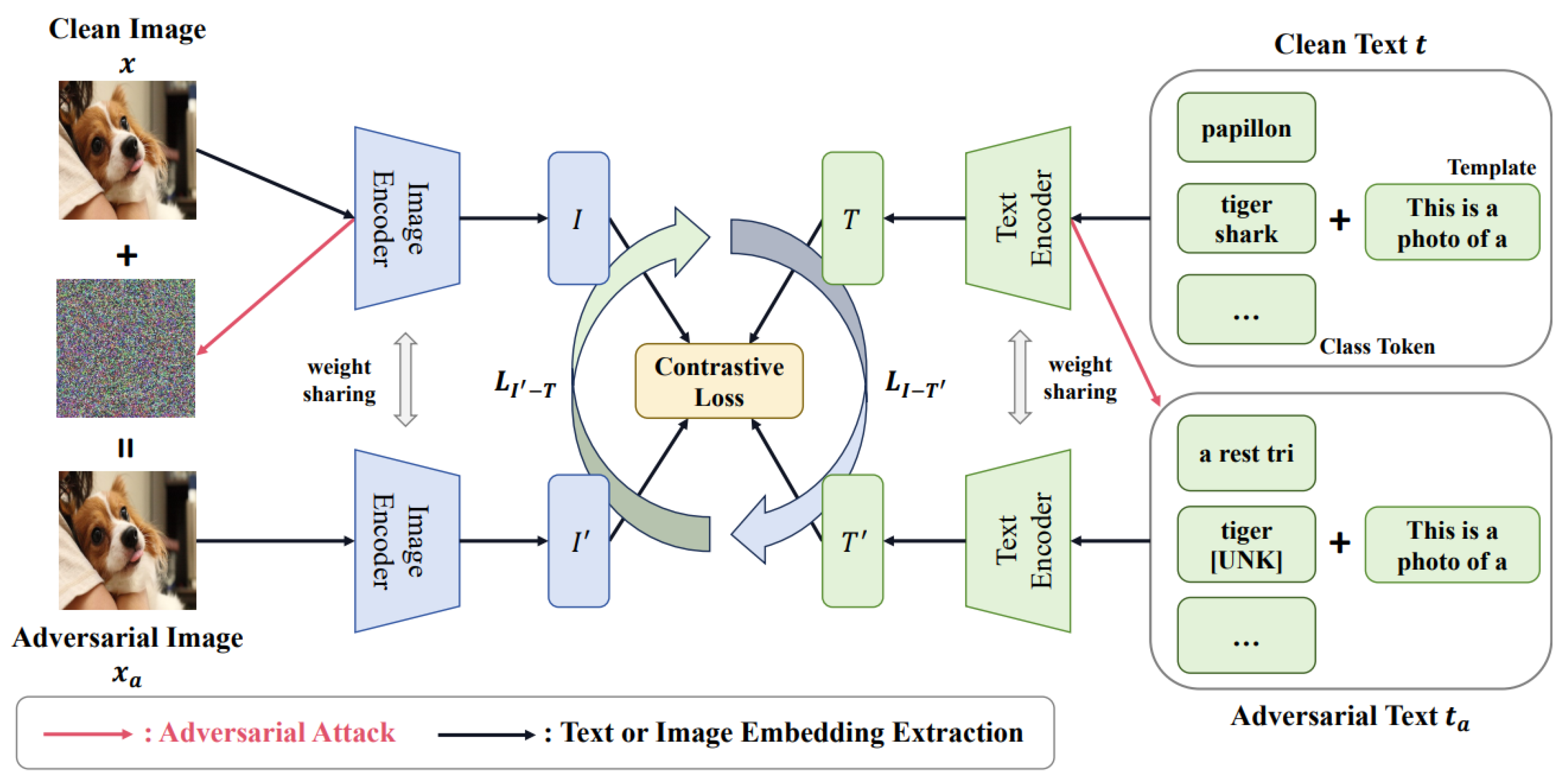
Figure 16.
Overview of CleanCLIP [25] framework (N = 2), which incorporates a multimodal objective to align images with their respective texts on the left, and a self-supervised objective to align images and texts with their augmented counterparts on the right.
Figure 16.
Overview of CleanCLIP [25] framework (N = 2), which incorporates a multimodal objective to align images with their respective texts on the left, and a self-supervised objective to align images and texts with their augmented counterparts on the right.
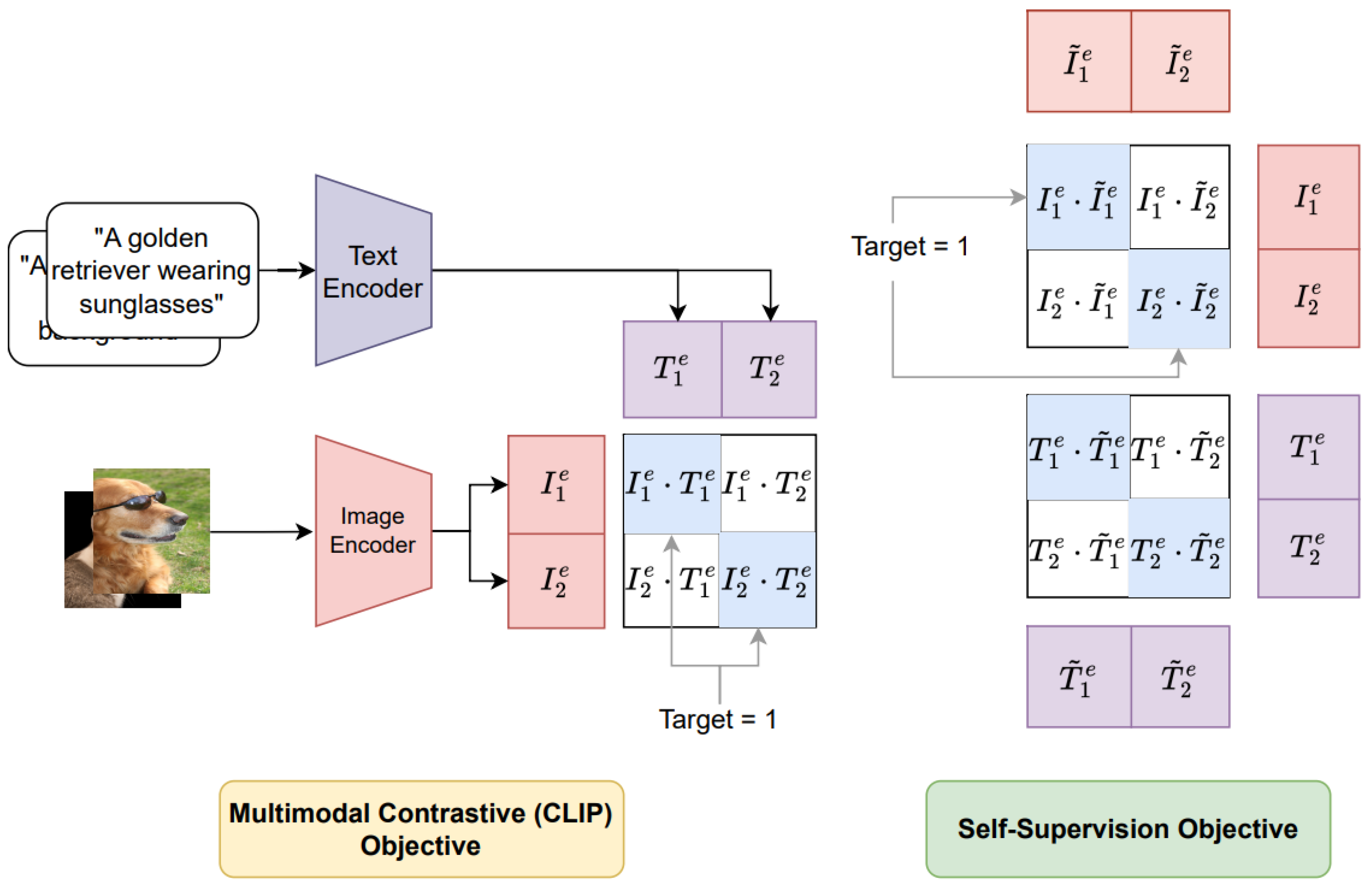
Figure 17.
Overview of the Defense-Prefix [71] system in CLIP: Enhancing robustness against typographic attacks using DP tokens. The system employs Defense Loss to train against typographic manipulations and Identity Loss to preserve the original semantic meaning of class names, ensuring accurate and consistent model performance.
Figure 17.
Overview of the Defense-Prefix [71] system in CLIP: Enhancing robustness against typographic attacks using DP tokens. The system employs Defense Loss to train against typographic manipulations and Identity Loss to preserve the original semantic meaning of class names, ensuring accurate and consistent model performance.
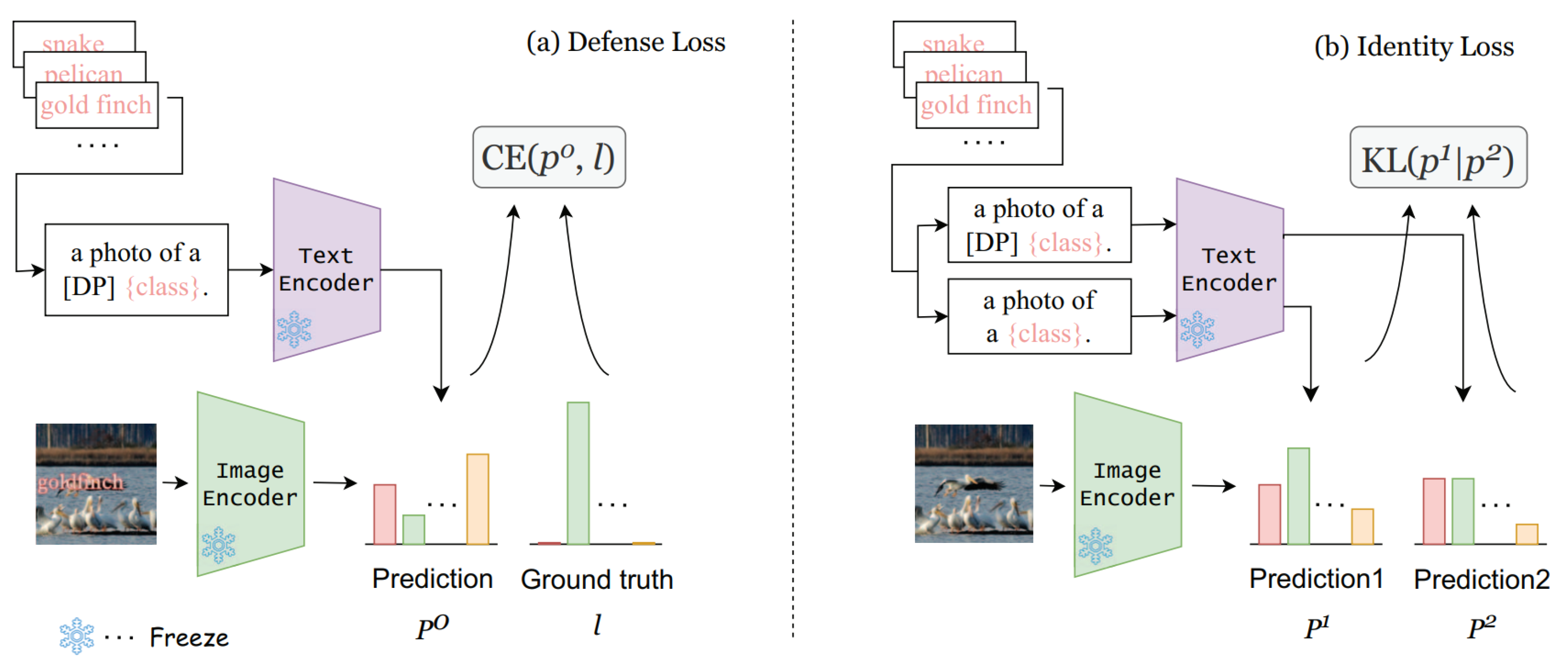

Table 1.
Comparison of adversarial robustness between conventional CV/NLP models and VLMs.
| Aspect | Conventional CV/NLP Robustness | VLM Robustness |
|---|---|---|
| Attack Surface | Pixels (CV), Tokens (NLP) | Pixels, tokens, and cross-modal embeddings |
| Transferability | Within same modality | Cross-modal (image → text, text → image) |
| Prompt Sensitivity | Not applicable | Highly sensitive to adversarial prompts and instructions |
| Dataset Bias | Moderate (curated datasets) | High (web-scale multimodal datasets with spurious features) |
| Defense Challenges | Modality-specific strategies | Requires joint multimodal strategies (vision + language) |
Table 2.
Comparison between existing surveys on adversarial attacks and defenses. Compared to prior surveys, our work is the first to comprehensively address all dimensions, including adversarial attacks and defenses on VLMs, thereby filling the gaps highlighted in earlier studies. Note: W&B = White-box and Black-box; GOD = Grouping of Defenses; FD = Future Directions; DO = Datasets Overview; MA = Metrics and Architectures; SAC = State-of-the-art Comparison; Adv-VLM = Adversarial Attacks and Defense on VLMs.
Table 2.
Comparison between existing surveys on adversarial attacks and defenses. Compared to prior surveys, our work is the first to comprehensively address all dimensions, including adversarial attacks and defenses on VLMs, thereby filling the gaps highlighted in earlier studies. Note: W&B = White-box and Black-box; GOD = Grouping of Defenses; FD = Future Directions; DO = Datasets Overview; MA = Metrics and Architectures; SAC = State-of-the-art Comparison; Adv-VLM = Adversarial Attacks and Defense on VLMs.
| Survey | Yr | W&B | GOD | FD | DO | MA | SAC | Adv-VLM |
|---|---|---|---|---|---|---|---|---|
| Akhtar & Mian [8] | ’18 | ✓ | ✓ | × | × | × | × | × |
| Qiu et al. [9] | ’19 | ✓ | × | × | × | × | × | × |
| Serban et al. [10] | ’20 | ✓ | ✓ | ✓ | × | × | × | × |
| Xu et al. [11] | ’20 | ✓ | ✓ | × | × | × | × | × |
| Chakraborty et al. [12] | ’21 | ✓ | × | × | × | × | × | × |
| Long et al. [13] | ’22 | ✓ | × | ✓ | × | × | × | × |
| Liang et al. [14] | ’22 | ✓ | ✓ | × | × | × | × | × |
| Zhou et al. [15] | ’22 | ✓ | ✓ | × | × | × | × | × |
| Joana et al. [16] | ’23 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | × |
| This survey | ’25 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Table 3.
Summary of widely used image-text datasets for VLM pre-training.
| Dataset | Year | Pairs | Public | Papers |
|---|---|---|---|---|
| Conceptual Captions [73] | 2018 | 3.3M | Yes | [17,20,22,25] |
| YFCC100M [74] | 2016 | 100M | Yes | [21] |
| SBU Caption [76] | 2011 | 1M | Yes | - |
| COCO Caption [77] | 2016 | 1.5M | Yes | - |
| Visual Genome (VG) [78] | 2017 | 5.4M | Yes | - |
| Wikipedia-based Image Text (WIT) [75] | 2021 | 37.6M | Yes | - |
Table 4.
Summary of the widely used image-text datasets for fine-tuning.
| Dataset | Year | Num. of Images | Public | Paper |
|---|---|---|---|---|
| ImageNet [79] | 2009 | 1.2M | [29,48] | |
| Conceptual Captions [73] | 2018 | 3.3M | [25] | |
| CIFAR-10 [80] | 2009 | 60K | – | |
| CIFAR-100 [81] | 2009 | 60K | – | |
| Flickr30K [43] | 2014 | 31K | – | |
| MS COCO [44] | 2014 | 330K | – |
Table 5.
Summary of datasets used in adversarial attack studies evaluation, detailing the types of attacks and methodologies applied.
Table 5.
Summary of datasets used in adversarial attack studies evaluation, detailing the types of attacks and methodologies applied.
| Dataset | Size | Year | Count | Papers |
|---|---|---|---|---|
| ImageNet [79] | 14M images | 2009 | 12 | [17,20,21,22,25,26,29,48,58,63,82,83] |
| MS COCO [44] | 330K images | 2014 | 11 | [17,18,21,22,29,39,45,48,71,82,83] |
| Flickr30K [43] | 30K images | 2014 | 10 | [17,18,21,22,29,39,45,48,84] |
| CIFAR-10 [80] | 60K images | 2009 | 7 | [17,20,21,22,29,48,63] |
| CIFAR-100 [81] | 60K images | 2009 | 7 | [17,20,21,22,29,48,63] |
| Food101 [85] | 101K images | 2014 | 5 | [20,21,29,48,63] |
| Oxford Pets [86] | 7.4K images | 2012 | 5 | [20,21,29,48,63] |
| Flowers102 [87] | 8.2K images | 2008 | 5 | [20,21,29,48,63] |
| SUN397 [88] | 108K images | 2010 | 5 | [20,21,29,48,63] |
| Stanford Cars [89] | 16.2K images | 2013 | 5 | [20,21,29,48,63] |
| DTD [90] | 5.6K images | 2014 | 5 | [20,21,29,48,63] |
| Caltech101 [91] | 9.1K images | 2003 | 5 | [20,21,29,48,63] |
| FGVC Aircraft [92] | 10K images | 2013 | 5 | [20,21,29,48,63] |
| VQAv2 [33] | 204k | 2015 | 2 | [31,82] |
| ImageNetV2 [93] | 10K | 2019 | 2 | [17,22] |
| ImageNet-A [94] | 7.5K | 2019 | 2 | [17,22] |
| ImageNet-R [95] | 30K | 2021 | 2 | [17,22] |
| CelebA-HQ [96] | 30K images | 2018 | 1 | [22] |
| LADN [97] | 535 | 2019 | 1 | [22] |
| LFW [98] | 13K images | 2007 | 1 | [22] |
| Inria Person [99] | 288 | 2005 | 1 | [100] |
| VIST-E [101] | 5K | 2019 | 1 | [48] |
| LSMDC [102] | 118K | 2019 | 1 | [48] |
| TextVQA [34] | 28.4K | 2020 | 1 | [31] |
| NLVR2 [103] | 92.2K | 2019 | 1 | [82] |
| RefCOCO [104] | - | 2014 | 1 | [82] |
| SNLI-VE [105] | 17.9K | 2018 | 1 | [82] |
| LVIS [106] | 160K | 2019 | 1 | [71] |
| NUS-WIDE [107] | 270K images | 2009 | 1 | [108] |
| Pascal [109] | 11.5K | 2007 | 1 | [108] |
| Wikipedia [75] | - | 2020 | 1 | [108] |
| XmediaNet [110] | 38.9K | 2018 | 1 | [108] |
| RefCOCO+ [46] | 20k images | 2016 | 1 | [45] |
| ScienceQA [62] | 21K | 2022 | 1 | [58] |
| POPE [111] | 20k images | 2016 | 1 | [58] |
| MME [112] | 20k images | 2016 | 1 | [58] |
Table 6.
Performance of VLM methods (%) over zero-shot classification. A dash (-) indicates that the corresponding results were not reported in the original papers or are not applicable for that dataset.
Table 6.
Performance of VLM methods (%) over zero-shot classification. A dash (-) indicates that the corresponding results were not reported in the original papers or are not applicable for that dataset.
| Model | ImageNet | CIFAR-10 | CIFAR-100 | Caltech | Pets | Cars | DTD | F102 | Fd101 | SUN | Air | SAT | Other |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP (400M) | 59.60 | 88.57 | 62.22 | 84.91 | 87.38 | - | 40.21 | 65.70 | 83.84 | 57.64 | 19.98 | 38.49 | - |
| CLIP (3M) | 19.04 | - | - | - | - | - | - | - | - | - | - | - | - |
| Clean CLIP (3M) | 57.00 | - | - | - | - | - | - | - | - | - | - | - | - |
| CLIP (1M) | 9.60 | 34.90 | 7.30 | 34.90 | 3.40 | 0.80 | 3.70 | 1.00 | 7.10 | - | 0.80 | - | - |
| RoCLIP (1M) | 6.63 | 30.14 | 9.52 | 30.38 | 3.68 | 0.72 | 3.56 | 0.83 | 6.34 | - | 1.11 | - | - |
| Defense-Prefix (Synthetic) | - | - | - | - | - | - | - | - | - | - | - | - | 44.20 |
| Defense-Prefix (Real) | 62.48 | - | - | 89.28 | 87.22 | 57.47 | 40.64 | 63.82 | 83.65 | 61.41 | 19.26 | 43.85 | 64.52 |
| ALIP-VIT-B/32(15M) | 40.30 | 83.80 | 51.90 | 74.10 | 30.70 | 3.40 | 23.20 | 54.80 | 45.40 | 47.80 | 2.70 | - | - |
| TeCoA (1 shot) | 59.13 | 88.60 | 62.32 | 84.91 | 87.38 | 13.37 | 40.21 | 65.70 | 83.35 | 57.64 | 19.98 | 38.49 | - |
| MMCoA (1 shot) | 58.80 | 89.87 | 62.39 | 84.27 | 86.56 | - | 39.95 | 65.25 | 83.61 | 57.98 | 19.80 | 40.74 | - |
Table 7.
Attack Success Rate (%) of different adversarial methods on VLMs. A dash (-) denotes that the metric was not reported in the original paper or that the evaluation was not performed for that dataset.
Table 7.
Attack Success Rate (%) of different adversarial methods on VLMs. A dash (-) denotes that the metric was not reported in the original paper or that the evaluation was not performed for that dataset.
| Model | ImageNet | Pascal | Wikipedia | VQAv2 | NLVR2 | RefCOCO | SNLI-VE | VIST-E | LSMDC-E | Other |
|---|---|---|---|---|---|---|---|---|---|---|
| CLIP (400M) | 0 | - | - | - | - | - | - | - | - | - |
| CLIP (400M) fine-tuned on poisoned data | 94.60 | - | - | - | - | - | - | - | - | - |
| CLIP (3M) | 99.94 | - | - | - | - | - | - | - | - | - |
| CleanCLIP | 17 | - | - | - | - | - | - | - | - | 93.75 |
| CLIP (1M-Target Image) | - | - | - | - | - | - | - | - | - | 78 |
| CLIP (1M-Backdoor) | - | - | - | - | - | - | - | - | - | 12.50 |
| RoCLIP (1M-Target Image) | - | - | - | - | - | - | - | - | - | 0 |
| RoCLIP (1M-Backdoor) | - | - | - | - | - | - | - | - | - | 0 |
| Co-Attack (image attack) | 14.50 | 9.30 | - | - | - | - | - | - | - | - |
| Co-Attack (text attack) | 5.00 | 8.23 | - | - | - | - | - | - | - | - |
| Co-Attack (multimodal) | - | - | 35.13 | 42.04 | 56.48 | 18.66 | - | 22.80 | 20.75 | - |
| VLAttack | - | - | - | 78.05 | 66.65 | 93.52 | 41.78 | - | - | - |
| Iterative-Attack | - | - | - | - | - | - | - | 35.04 | 31.72 | - |
| MVPatch | - | - | - | - | - | - | - | - | - | 26.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



