Submitted:
13 November 2025
Posted:
14 November 2025
You are already at the latest version
Abstract
In the domain of low-light image enhancement, both transformer- based approaches, such as Retinexformer and Mamba-based frame- works, such as MambaLLIE, have demonstrated distinct advantages alongside inherent limitations. Transformer-based methods, in com- parison with mamba-based methods, can capture local interactions more effectively, albeit often at a high computational cost. In con- trast, Mamba-based techniques provide efficient global information modeling with linear complexity, yet they encounter two significant challenges: (1) inconsistent feature representation at the margins of each scanning row and (2) insufficient capture of fine-grained local interactions. To overcome these challenges, we propose an innovative enhancement to the Mamba framework by increasing the Hausdorff dimension of its scanning pattern through a novel Hilbert Selective Scan mechanism. This mechanism explores the feature space more effectively, capturing intricate fine-scale details and improving overall coverage. As a result, it mitigates informa- tion inconsistencies while refining spatial locality to better capture subtle local interactions without sacrificing the model’s ability to handle long-range dependencies. Extensive experiments on publicly available benchmarks demonstrate that our approach significantly improves both the quantitative metrics and qualitative visual fidelity of existing Mamba-based low-light image enhancement methods, all while reducing computational resource consumption and short- ening inference time. We believe that this refined strategy not only advances the state-of-the-art in low-light image enhancement but also holds promise for broader applications in fields that leverage Mamba-based techniques.
Keywords:
low-light image enhancement
; mamba-based methods
; Hausdorff dimension
1. Introduction
Low-light image enhancement is an essential but challenging topic in computer vision. It aims to restore the image degradation with low brightness, improve the visual quality of images captured under low-light conditions, and aid high-level visual tasks (e.g., object detection, face recognition, and action detection).
Numerous traditional methods, such as histogram equalization [6,23] and Retinex theory [12,32], have been proposed to enhance low-light images. With the development of deep learning, many learning-based methods [4,33,40,47,60,75,79,80] have emerged, which improve visual quality by learning the mapping between low-light and normal-light images using end-to-end models or deep Retinex-based models to make them more robust than tradi- tional approaches. Recently, some methods [30,66] have explored wavelet transformation for low-light image enhancement, inte- grating wavelet information into convolutional neural networks (CNNs) or transformer models to achieve impressive results. How- ever, CNNs [79] have limitations in modeling long-range dependen- cies and non-local self-similarity, resulting in challenges in address- ing image degradation effectively in low-light scenarios. In addition, the quadratic growth of the complexity of transformer models [4] results in inefficient use of computational resources. Both the CNN model [15] and the transformer model [68] achieve average per- formance only in both aspects of performance, as indicated by the PSNR scores and inference time.
To overcome these issues, Mamba [10] is designed to model long- range dependencies and enhance the efficiency of training and inference through a selection mechanism and a hardware-aware al- gorithm. For now, numerous studies have explored the applications of Mamba in computer vision. Vision Mamba [86] introduces the Vim block, incorporating a bidirectional state space model for effi- cient learning. Meanwhile, VMamba [42] introduces a CSM module to traverse the spatial domain, combining the advantages of CNNs and Visual Transformers (ViTs) while achieving computational effi- ciency in linear complexity without sacrificing the global receptive field. Additionally, U-Mamba [46] combines U-Net and Mamba mod- els to enhance medical image segmentation. SegMamba [65] utilises Mamba’s efficient reasoning and linear scalability to enable fast and accurate processing of large-scale 3D medical data. Additionally, WaveMamba [88], RetinexMamba [1], and MambaLLIE [61] demon- strate marvelous performance of Mamba in the field of low-light image enhancement, all of which generally applies Mamba along with U-Net backbone, significantly reducing the computational complexity compared with Retinexformer [4].
However, several challenges arise when incorporating Mamba with vision tasks. The primary challenge originates from the mis- match between the causal sequential modeling of Mamba and the two-dimensional (2D) data structure of images. Mamba is designed for one-dimensional (1D) causal modeling for sequential signals, which cannot be directly leveraged for modeling two-dimensional image tokens [3,25,26,27,28,29,41,67,76,82,83,84,87]. A simple solution is to use the raster-scan order to convert 2D data into 1D sequences. However, it restricts the receptive field of each location to only the previous locations in the raster-scan order, which means such type of raster scan, in some cases, fails to capture local interactions when dealing with features with more extensive areas in the images. Moreover, in the raster-scan order, the ending of the current row is followed by the beginning of the next row, while they do not share spatial continuity.
To accurately evaluate the ability of a scanning path to cap- ture complicated patterns in an image, we propose the Hausdorff Dimension Measurement Method. The Hausdorff dimension of a scanning curve directly reflects its inherent complexity and capac- ity to capture local interactions [2,5,16,17,18,19,20,21,35,36,51,52,53,56,81]. A higher Hausdorff dimension indicates that the curve is not simply a smooth, predictable path but rich in intricate detail and subtle fluctuations. This complexity enables the scanning pattern to more effectively perceive local variations, ensuring that fine-scale inter- actions within the scanned area are not overlooked. In other words, as the Hausdorff dimension increases, it signals a more nuanced and densely packed trajectory that can more effectively capture local features while maintaining the ability of Mamba to understand long-range dependencies.
Besides, we conduct extensive experiments to show that Mamba scanning patterns with higher Hausdorff dimension, Hilbert scan, and Peano scan, inspired by Hilbert curve [22] and Peano curve [50], can effectively prompt the performance of previous Mamba-based low-light image enhancement methods on several paired datasets. Hilbert and Peano scans not only leverage the Hausdorff Dimension of 2 but also map neighboring 2D points to nearby positions in the 1D sequence, which minimizes discontinuities and improves cache performance and data coherence. The visual presentations of different scanning patterns are provided in the supplementary material.
Our main contributions are summarized as follows:
• We propose an innovative method for evaluating scanning paths by employing the Hausdorff dimension. This met- ric measures the inherent complexity of a scanning curve, thereby assessing its capacity to capture intricate, fine-scale local variations and to effectively navigate complex image structures.
• We proved that scanning patterns with high Hausdorff Di- mension (eg, Hilbert scan, and Peano scan) leverage the curve’s intrinsic properties to capture local features effec- tively in larger regions, mapping neighboring 2D points to adjacent positions in the 1D sequence.
• Experimental results on a comprehensive set of benchmark datasets consistently demonstrate the reliability of the mea- sure of Hausdorff Dimension and the effectiveness of Hilbert scan and Peano scan on improving the performance of exist- ing Mamba-based low-light image enhancement methods.
2. Related Work
2.1. Low-light Image Enhancement
Following the development of learning-based image restoration methods [37,38,57,70], LLNet [43] synthesizes paired data by applying gamma adjustment and randomly adding noise to clean images. MBLLEN [45] extracts features at different levels using a multi-scale network structure to achieve better results. LightenNet [34] directly estimates the illumination map based on the input.
RetinexNet [60] utilizes the Retinex theory to decompose low-light images into reflection and illumination components. ZeroDCE [13] proposed to transform LLIE into a curve estimation problem and designed a zero-reference learning strategy for training. Enlighten- GAN [31] adopted unpaired images for training for the first time by using the generative adverse network as the main framework. KinD++ [79] utilizes a layer-wise decomposition strategy for bright- ness adjustment and detail reconstruction to suppress noise in the reflection layer further. LLFlow [58] uses conditional normalization flows for low-light image enhancement. Restormer [73] designs a lightweight transformer for image restoration tasks. SNRNet [68] introduces an SNR-aware CNN-transformer hybrid network for low- light image enhancement. MBPNet [77] introduces a multi-branch progressive network for low-light image enhancement. Bread [15] decomposes low-light images into texture and chrominance com- ponents and suppresses complex noise through adjustable noise suppression networks. Retinexformer [4] combined the Retinex the- ory with the design of a one-stage transformer, further refining and optimizing this approach. Diff-Retinex [72] designed a transformer- based decomposition network and adopted generative diffusion networks to reconstruct the results. Overall, they typically applied the Retinex theory directly, which may be limited for low light enhancement problems.
2.2. Mamba-based Methods
Recently, the success of State Space Models (SSMs) [11] has been increasingly recognized as a promising direction in research, which is proposed as a novel alternative to CNNs or Transformers to model long-range dependency. Contemporary SSMs such as Mamba [10] not only establish long-distance dependency relations but also demonstrate linear complexity with respect to input size. Other methods introduce the state space models for visual applications. UMamba [46] proposes a hybrid CNN-SSM architecture to han- dle the long-range dependencies in biomedical image segmenta- tion. Vision Mamba [86] suggests that pure SSM models can serve as a generic visual backbone. SegMamba [65] introduces a novel 3D medical image segmentation model designed to capture long- range dependencies within volume features at every scale effec- tively. Swin-UMamba [39] introduces a medical image segmentation model based on Mamba, which utilizes pre-trained models from ImageNet to improve the performance of medical image segmen- tation tasks. Furthermore, LocalMamba [24] was focused on the local scanning strategy and preservation of local context depen- dencies. EfficientVMamba [54] designed a lightweight SSMs with an additional convolution branch to learn both global and local representational features. MambaIR [14] employed convolution and channel attention to enhance the capabilities of the Mamba. WaveMamba [88] focuses on applying Wavelet Transform along- side Mamba to mitigate information loss and address the limitation ofSSMs, which struggle to model noise effectively. In the case of low-light image enhancement, this insensitivity could lead to the inability to detect or leverage subtle noise patterns that carry im- portant information effectively. RetinexMamba [1] uses SS2D to replace Transformers in capturing long-range dependencies. Mam- baLLIE [61] introduces a novel global-then-local state space block that integrates a local-enhanced state space module and an implicit
Larger Hausdorff Dimension in Scanning Pattern Facilitates Mamba-Based Methods in Low-Light Image Enhancement Retinex-aware selective kernel module. This design effectively cap- tures intricate global and local dependencies. However, although a number of applications of the Mamba-based image restoration approach have been proposed, none of them have researched the fac- tors determining the effectiveness of a scanning pattern of Mamba.
3. Preliminaries
3.1. State Space Model
SSMs, such as the structured state space sequence models (S4) [11] and Mamba [10], can be interpreted as continuous linear time- invariant (LTI) systems [62]. Given a one-dimensional input se- quence x (t) ∈ R, these models map it to an output sequence y (t) ∈ R by means of a hidden state h(t) ∈ Rm, where m is the dimension of the hidden state. The entire system is governed by the following linear ordinary differential equations:
h/(t) = A h(t) + B x (t),
y (t) = C h(t) + Dx (t). (1)
Here, A ∈ Rm×m is the state matrix, B ∈ Rm×1 represents the input projection, C ∈ R1×m is the output projection, and D ∈ R denotes the feedthrough parameter.
Since these state-space models are inherently continuous, they must be discretized for implementation on a computer. Using the zero-order hold (ZOH) method, the continuous matrices A and B
are converted into their discrete counterparts and as follows:
= exp (Δ A) , = (Δ A)−1 (exp (Δ A) − I) · Δ B, (2)
where Δ is the step size. Thus, the discrete formulation becomes:
ht = ht −1 + xt, y t = C h t + Dx t . (3)
However, this formulation remains static with respect to vary- ing inputs. To overcome this limitation, Mamba [10] introduces selective state-space models, where the parameters dynamically adapt based on the input, which is formulated as:
B = fB (xt), C = fC (xt), Δ = θA (P + fA (xt)), (4)
with fB (xt), fC (xt), and fA (xt) being linear functions that expand the input features into the hidden state space. Although SSMs are effective at modeling long sequences, they may struggle to capture complex local details. To address this challenge in visual data, meth- ods such as VMamba [42] and Vim [86] employ specialized location- aware scanning strategies that preserve the two-dimensional struc- ture of images.
3.2. Hausdorff Dimension
The Hausdorff dimension provides a robust and precise method of quantifying the complexity of geometric objects, including fractals, whose dimensions are often non-integer and, therefore, cannot be described by traditional geometric measures [8,48].
To understand Hausdorff Dimension, we must first introduce the definition of Hausdorff Measure. Let s ⊆ Rn be a subset, a geometric object. For each real number d ≥ 0 and every E > 0, define the d-dimensional Hausdorff content (s) by:
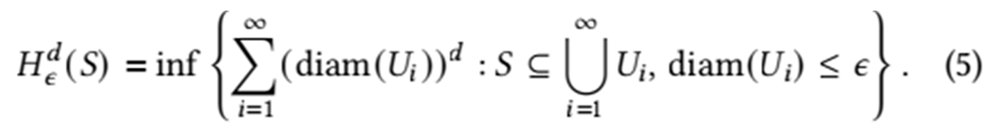
where diam(ui) is defined as diam(ui) = sup{|x − y | : x, y ∈ ui} represents the greatest distance between any two points within within subset ui. ui are subsets that “cover” the set s. The set s must be fully contained within the union = 1 ui. Typically, these can be intervals, balls, or cubes. E is a positive real number representing the scale we measure. Smaller E means subsets ui have smaller sizes. The infimum is then taken over all countable coverings {ui} ofs [8] as a measure of the total size of set s.
Then the d-dimensional Hausdorff measure Hd (s) is defined as:
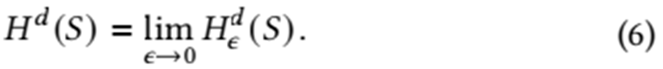
Given the Hausdorff measure, the Hausdorff dimension dimH(s) of the set s ⊆ Rn is defined as:
dimH(s) = inf{d : Hd (s) = 0} = sup{d : Hd (s) = ∞}. (7)
Referring to equation 5, as E → 0, the value of diam(ui) will be very small, which means when d becomes too large, the value of Hd (s) would become 0. Vice versa, when d becomes too small, the value of Hd (s) becomes infinite. Intuitively, this dimension identifies a critical threshold separating two regimes: dimensions for which the measure is infinite and dimensions for which it collapses to zero [8].
4. Methodology
In this section, we first introduce how the Hausdorff Dimension of a scanning pattern of Mamba influences Mamba-based low-light image enhancement methods and then move on to the explanation of the superiority of the Hilbert scan and Peano scan in Mamba- based low-light enhancement methods.
4.1. Hausdorff Dimension’s Implications for
Vision Mamba
In many vision applications, image processing and feature extrac- tion depend on how well a discrete set of samples approximates a continuous image function. In particular, the scanning pattern used to traverse the spatial domain of an image can have significant implications for the performance of downstream tasks. This section investigates the effect of employing a scanning pattern with a high Hausdorff dimension. This intuitively leads to more uniform and space-filling coverage, thus reducing the worst-case approximation error.
Spatial Domain & Sampling Set: We define Ω as the spatial domain of the original input images:
Ω ⊂ Rn ,
where n denotes the number of spatial dimensions. For example,
for a two-dimensional image of height H and width W, we have
Ω = {(x, y) | 0 ≤ x < H, 0 ≤ y < W}.
described as a function.
f : Ω → Rc ,
where c is the number of channels, e.g., c = 3 for an RGB image.
Note that Ω does not include any feature content of the image; it
merely defines the locations over which the image f is defined.
We define P as the sampling set of the spatial domain Ω:
P ⊂ Ω,
where P is a collection of points from which the scanning algorithm extracts data. While a full ordinary raster scan in Mamba might have P = Ω in a discrete sense, advanced architectures such as Vision Mamba often employ selective or non-uniform scanning strategies. In such cases, P is a proper subset of Ω, and the distribu- tion of points in P, their density, uniformity, and fractal properties, directly influence the quality of the approximation of the continu- ous function f , which represents the original image.
Function Spaces and Smoothness Conditions: To rigorously analyze how well the continuous image function f : Ω → Rc is approximated by its samples, we place f within appropriate function spaces and assume certain smoothness conditions. These conditions, such as L2 integrability, Lipschitz continuity, and Hölder continuity, provide a mathematical framework that allows us to derive error bounds on the approximation quality. In this subsection, we describe these spaces and conditions in detail.
A function f belongs to L2(Ω) if
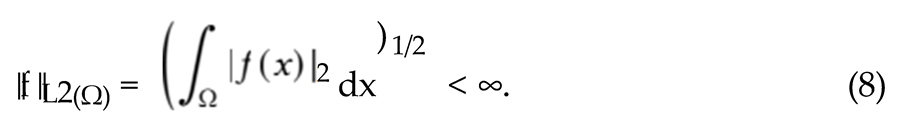
This condition ensures that f has finite energy, a natural re- quirement in signal processing and machine learning.
A function f : Ω → R is said to be Lipschitz continuous if there exists a constant Lf > 0 such that
|f (x) − f (y)| ≤ Lf ∥x − y∥ ∀ x, y ∈ Ω . (9)
This condition bounds the rate at which f can change between any two points in Ω, ensuring that the function does not exhibit abrupt transitions.
More generally, f is Hölder continuous with exponent α ∈ (0, 1] if there exists a constant cf > 0 such that
|f (x) − f (y)| ≤ cf ∥x − y∥α ∀ x, y ∈ Ω . (10)
When α = 1, Hölder continuity is equivalent to Lipschitz conti- nuity. For α < 1, the condition allows for more gradual variations in f . These smoothness properties are essential for establishing rigorous error estimates in function approximation.
Worst-Case Approximation Error from Sparse Sampling: This subsection examines the error incurred when approximating a con- tinuous function from discrete samples, which is central to under- standing the performance impact of different scanning patterns.
Dispersion & Worst-Case Approximation Error: The dispersion of a sampling set P in Ω is defined as
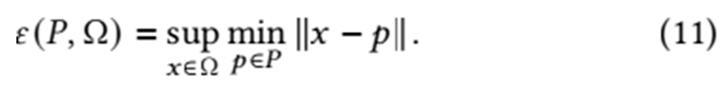
For each point x ∈ Ω, the term minp ∈p ∥x − p ∥ is the distance from x to its nearest sample in P. Taking the supremum over x ∈ Ω yields the largest distance, quantifying the worst-case gap in the sampling coverage. A smaller ε(P, Ω) indicates that every point in Ω is close to at least one sample, which is critical for accurate approximation.
Let F denote the class of functions defined on Ω that belong to L2(Ω) and satisfy Lipschitz or Hölder continuity. When approx- imating a function f ∈ F using only its values at points in P, interpolation theory provides a pointwise error bound:
|f (x) − fˆ(x)| ≤ K ε(P, Ω)α , ∀ x ∈ Ω, (12)
where fˆ(x) is an interpolant off from the samples P, and K is a constant dependent on the smoothness constants (e.g., cf or Lf)
[7], and α is the Hölder exponent. Integrating this error over Ω in the L2 norm yields the worst-case approximation error:
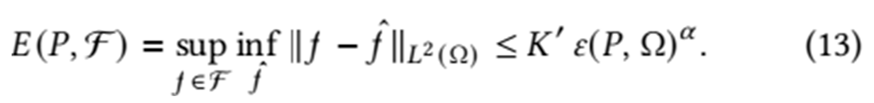
This relation indicates that minimizing the dispersion ε(P, Ω) is key to reducing the overall approximation error in any f ∈ F [7]. If the sampling points P are sparse or irregularly distributed, ε(P, Ω) will be larger, leading to a higher worst-case error. Hence, having a scanning pattern that minimizes this worst-case error is critical for faithful approximation.
Scanning Patterns & Hausdorff Dimension: In this subsection, we discuss how the fractal properties of a scanning pattern, as measured by its Hausdorff dimension, impact the dispersion and, consequently, the approximation error.
The Hausdorff dimension dimH(P) of a set P is defined using the s-dimensional Hausdorff measure:
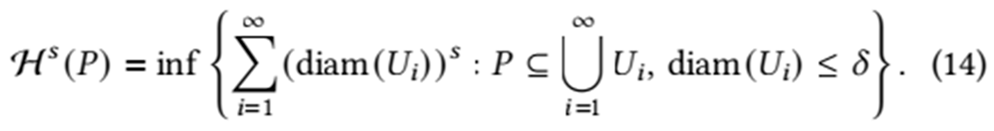
where δ → 0, and
dimH(P) = inf{s : Hs (P) = 0}.
A higher Hausdorff dimension implies that P is more space- filling and provides a more uniform coverage of Ω . This concept has been thoroughly discussed in the literature [9,48] and plays a key role in determining the uniformity of the sampling.
Under reasonable uniformity assumptions, if two sampling sets P1 and P2 satisfy
dimH(P2) > dimH(P1),
Then generally, according to [7,9,48], as scanning patterns with higher Hausdorff Dimensions cover the continuous image func- tion f more uniformly, higher Hausdorff Dimensions lead to lower dispersion value:
ε(P2, Ω) ≤ ε(P1, Ω).
which directly leads to a lower worst-case approximation error.
Consider two scanning methods: ordinary raster scan and Hilbert scan. Raster scan follows a simple row-by-row order. Its continuous parameterization is effectively one-dimensional (Haus- dorff dimension of one) even though it visits all discrete points. In contrast, Hilbert scan is a space-filling curve with Hausdorff dimension of two [9,48], designed to preserve more input features with its fractal nature.
While both methods may visit every pixel in a discrete grid, in scenarios of selective scan in Mamba, the Hilbert curve typically yields a lower dispersion, thereby providing a more robust recon- struction of the underlying image function [9,48,49]. The same principle can also be applied to evaluate the effectiveness of the Peano scan.
Figure 1.
Visualization of self-similar nature of Hilbert curve [22]. Proper rotation and duplication can transform the pat- tern in (a) into (b), the second-order Hilbert curve. Vice versa for (c) and (d).
Figure 1.
Visualization of self-similar nature of Hilbert curve [22]. Proper rotation and duplication can transform the pat- tern in (a) into (b), the second-order Hilbert curve. Vice versa for (c) and (d).

4.2. Hilbert Scan & Peano Scan
In this subsection, we introduce two distinct low-light enhancement methods, HilbertMamba and PeanoMamba, that leverage the supe- riority of the Hilbert curve [22] and Peano curve [50]. The Hilbert Scan builds on the principles of space-filling curves. It leverages the fractal geometry of the Hilbert curve and Peano curve [22,48,50] to address the challenges associated with mapping two-dimensional image data to a one-dimensional sequence. Both methods are based on WaveMamba [88], where we replace its raster-scanning strategy with Hilber-scanning and Peano-scanning strategy, respectively. HilbertMamba: Based on WaveMamba [88], HilbertMamba lever- ages the superiority of the Hilbert scan, a scanning strategy inspired by the Hilbert curve [22], which is defined as a continuous mapping:
H : [0, 1] → [0, 1]2, (15)
that fills the unit square. In our context, the Hilbert Scan reorders the pixels of an H ×W image grid into a one-dimensional sequence, denoted by I(x, y), such that adjacent 2D coordinates are mapped to nearby positions in the sequence. As shown in Figure 1, the Hilbert curve has a self-similar nature, which means the Hilbert curve at higher orders can always be formed by proper rotation and duplication of patterns of lower orders. Formally, for a pixel at spatial location (x, y) ∈ Ω, the Hilbert Scan assigns an index:
I(x, y) = H-1 (x, y), (16)
Figure 2.
Visualization of self-similar nature of Peano curve [50]. Proper rotation and duplication can transform the pat- tern in (a) into (b), the second-order Peano curve. Vice versa for (c) and (d).
Figure 2.
Visualization of self-similar nature of Peano curve [50]. Proper rotation and duplication can transform the pat- tern in (a) into (b), the second-order Peano curve. Vice versa for (c) and (d).
thereby preserving the continuity of the spatial domain and ensur- ing that local neighborhoods remain coherent after transformation. PeanoMamba: PeanoMamba utilizes the Peano scan, inspired by the Peano curve [50], another space-filling curve, offering a distinct fractal approach compared to the Hilbert curve. The Peano curve similarly provides a continuous mapping:
P : [0, 1] → [0, 1]2, (17)
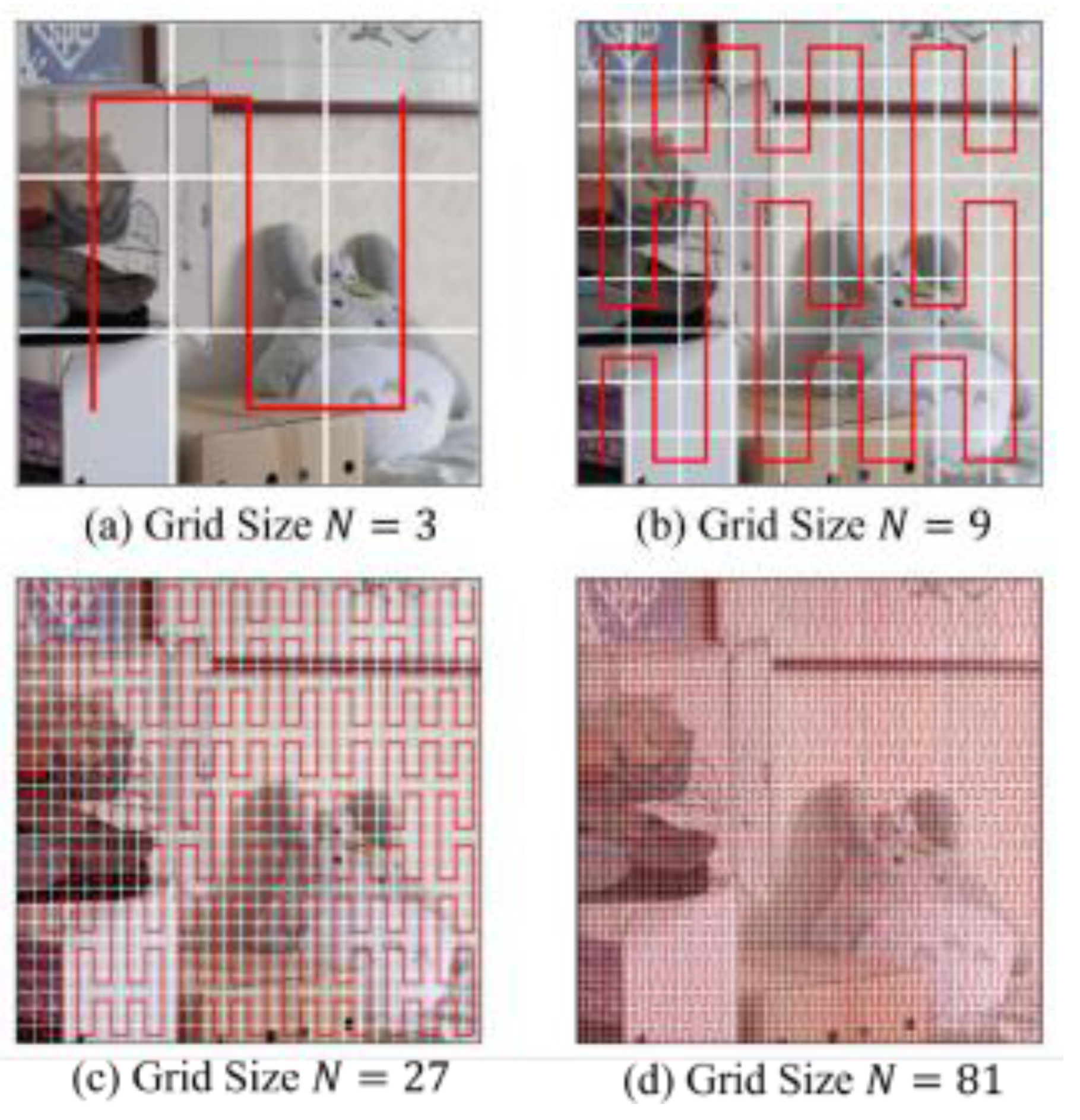
and ensures comprehensive coverage of the image domain through a unique traversal pattern. The Peano scanning patterns with differ- ent grid sizes are demonstrated in 2. Analogous to HilbertMamba, PeanoMamba transforms a two-dimensional image into a one- dimensional sequence, preserving local spatial coherence through the indexing:
I(x, y) = P-1 (x, y). (18)
Peano scan’s distinct fractal structure effectively maintains both fine-grained local details and global dependencies, contributing uniquely to low-light image enhancement.
Superiority of HilbertMamba & PeanoMamba: The superiority of HilbertMamba and PeanoMamba becomes solid when addressing the two challenges in low-light image enhancement: 1) preserving fine-grained local interactions and 2) maintaining global depen- dency modeling.
Their advantages include: 1) The continuity of the Hilbert and Peano scans ensures that subtle local image features, such as tex- tures and edges, are sampled with high fidelity. This is particularly important in low-light conditions, where minor details significantly impact the perceived visual quality. 2)By providing a more uni- form sampling of the spatial domain Ω, Hilbert Scan lowers the dispersion ε(P, Ω). Under the assumption that the underlying image function f is Hölder continuous with exponent α, the worst-case error bound
E(P, F) ≤ K′ ε(P, Ω)α ,
is directly minimized, resulting in higher fidelity in the recon- structed features.

Table 1.
Quantitative comparisons of different methods on LOLv1 [60], LOLv2-real [71] and LOLv2-synthetic [71]. The best and second-best results are highlighted in bold and underlined, respectively. Note that we download the pre-trained models from the authors’ websites.
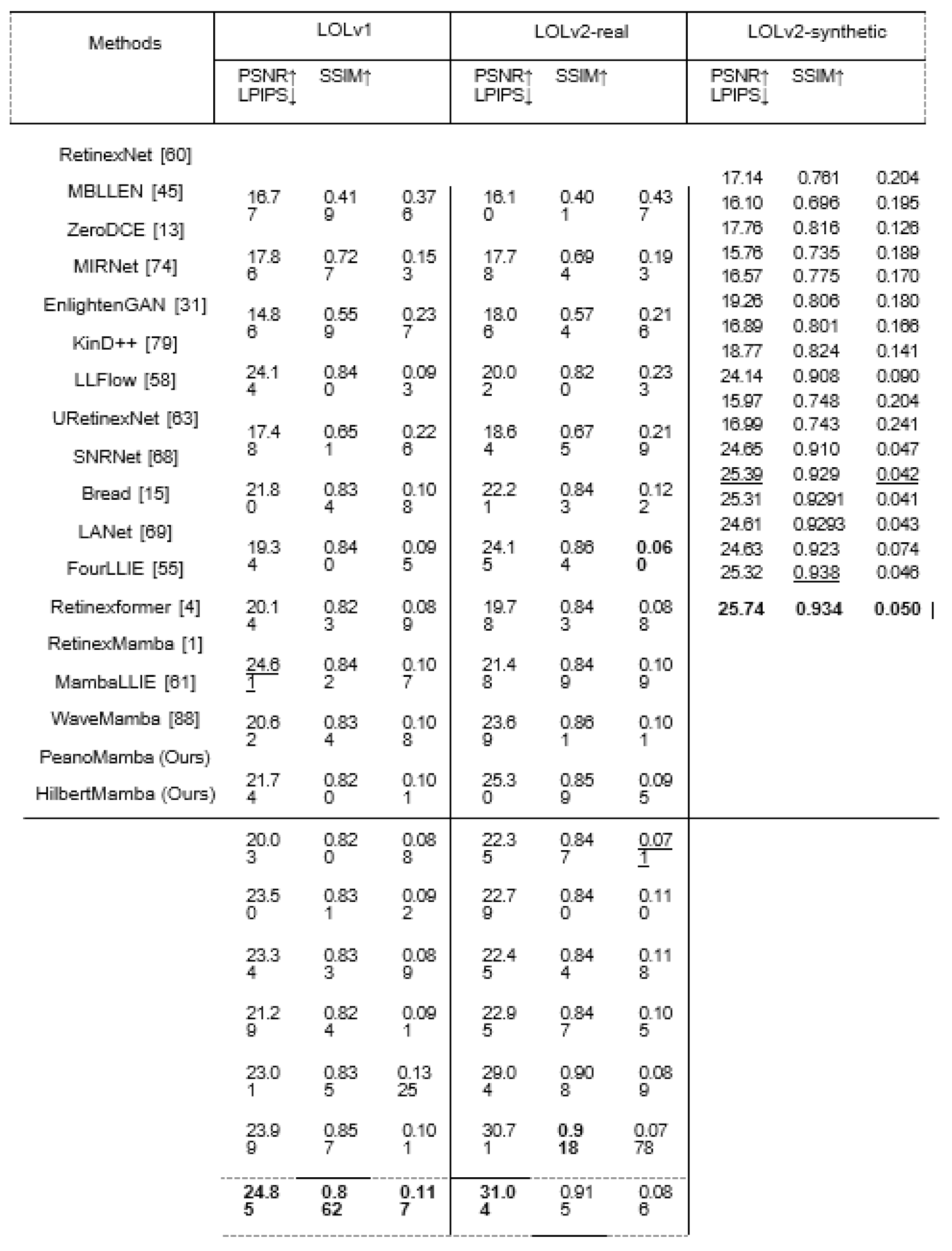 |
Figure 3.
Visual comparisons ofthe enhanced results by different methods on LOLv2-real.

In summary, the Hilbert and Peano scans, by their space-filling and fractal properties, offer mathematically rigorous strategies that significantly enhance the performance of Vision Mamba.
We also introduce a spatial dispersion metric that quantifies discontinuities in scanning patterns by jointly considering the mag- nitude and frequency of index jumps. For full details and derivations, please refer to the supplementary material.
5. Experiment
5.1. Experiment Settings
Datasets: We trained several Mamba-based low-light image en- hancement methods [1, 61, 88] on two datasets: LOLv1 [60] and LOLv2 [71]. LOLv1 contains 500 real-world low/normal-light image pairs, with 485 pairs for training and 15 for testing. LOLv2 is divided into LOLv2-real and LOLv2-synthetic subsets. LOLv2-real contains 689 paired images for training and 100 pairs for testing, collected by adjusting the exposure time and ISO. LOLv2-synthetic contains 900 paired images for training and 100 pairs for testing.
Evaluation metrics: To evaluate the performance of different methods and validate the effectiveness of the proposed method, we adopt full-reference image quality evaluation metrics to evaluate various low-light image enhancement approaches. We employ peak signal-to-noise ratio (PSNR), structural similarity (SSIM) [59], and learned perceptual image patch similarity (LPIPS) [78] as evaluation metrics to assess the model’s performance. Higher PSNR and SSIM values and lower LPIPS scores generally indicate more significant similarity between two images.
Methods Comparisons: To demonstrate the superiority of the
Mamba-based low-light image enhancement methods reinforced by
scanning patterns with Hausdorff dimensions equal to 2, PeanoMamba and HilbertMamba, we compare these prompted baseline meth- ods with a great variety of state-of-the-art methods both quan- titatively and qualitatively, including RetinexNet [60], MBLLEN
[45], ZeroDCE [13], MIRNet [74], EnlightenGAN [31], KinD++ [79], LLFlow [58], URetinexNet [63], SNRNet [68], Bread [15], LANet [69], FourLLIE [55], Retinexformer [4]. For fair comparison, all codes are downloaded from the authors’ GitHub repositories, and all comparison results are gained from retraining based on their recommended experimental configurations.
Figure 4.
Visual comparisons ofthe enhanced results by different methods on LOLv2-synthetic.

Scanning Paths Comparisons: To demonstrate the superiority of the scanning patterns with Hausdorff dimensions equal to 2 in Mamba-based low-light image enhancement methods, we compare our proposed Hilbert Scan and Peano Scan with other mainstream types of scans: raster scan [86], continuous scan [85], local scan [24], and tree scan [64]. We implement these scans on three differ- ent Mamba-based low-light image enhancement methods: Retinex- Mamba [1], MambaLLIE [61], and WaveMamba [88], respectively, to show the generalizability of the Hilbert Scan and Peano Scan in Mamba-based low-light image enhancement methods. For fair comparison, all codes are downloaded from the authors’ websites, and all comparison results are based on their recommended experi- mental configurations.
Implementation details: We implement our HilbertMamba and PeanoMamba models using PyTorch and train it for 500000 itera- tions on an NVIDIA GeForce RTX 4090D GPU. The AdamW [44] optimizer (β1 = 0.9, β2 = 0.99) is adopted for optimization. initial learning rate 5× 10-4 gradually reduced to 1× 10-7 with the cosine annealing. During training, input images are cropped to 256×256 pixels to serve as training samples, with a batch size of 32. For the augmented training data, we use random rotations of 90, 180, 270, random flips, and random cropping to 256 × 256 size. To constrain the training of HilbertMamba and PeanoMamba, we use the L1 loss function.
5.2. Comparison with State-of-the-Art Methods
Results on paired datasets:Table 1 displays the quantitative re- sults obtained from comparison methods, where it can be observed that our proposed methods outperform others in most cases, nearly securing the second-best results where they fall short. When com- pared with the recent transformer-based approaches, SNR [68] and Retinexformer [4], our method achieves 1.11, 5.94, and 3.10 dB im- provement on LOLv1, LOLv2-real, and LOLv2-synthetic datasets. Especially on LOLv2-real, the improvement is over 5 dB, as shown in Table 1. Compared with the recent Fourier-based method, FourL- LIE [55], our WaveletMamba yields 5.23, 6.38, and 4.12 dB on the three benchmarks. When compared with the recent CNN-based approaches, Bread [15] and LANet [69], our WaveletMamba gains 4.52, 3.43, and 11.78 dB on the three datasets in Table 1. Particularly, our method yields the best visually appealing results in real-world images, as shown in Fig. 3and Fig. 4, where our method effectively suppresses noise and restores image details, resulting in visuals that closely resemble the original scene. Please zoom in for a better view. The visual results on LOLv1 are provided in the supplementary material. All these results suggest the outstanding effectiveness and efficiency advantage of our HilbertMamba and PeanoMamba.
5.3. Comparison with Different Scanning Paths
Results with Different Scanning Patterns:Table 2 summa- rizes the performance of RetinexMamba [1], MambaLLIE [61], and WaveMamba [88] on the LOLv1, LOLv2-real, and LOLv2-synthetic datasets using various 2D scanning paths. Our results clearly show that the dimension-2 scans, PS2D (Peano) and HS2D (Hilbert), con- sistently outperform the dimension-1 scans (SS2D, CS2D, LS2D, TS2D) in terms of PSNR, SSIM, and LPIPS.
For example, RetinexMamba with PS2D yields PSNRs of 23.8 dB (LOLv1), 29.25 dB (LOLv2-real), and 25.54 dB (LOLv2-synthetic). Similarly, MambaLLIE achieves PSNRs of 22.62 dB and 23.36 dB on LOLv1 and 29.76 dB and 29.99 dB on LOLv2-real using PS2D and HS2D, respectively. Notably, WaveMamba with HS2D reaches the highest PSNRs of 24.85 dB on LOLv1 and 31.04 dB on LOLv2-real, surpassing its performance with any dimension-1 scan. The quali- tative comparisons implemented on the method WaveMamba [88] are shown in Fig 5, Fig 6and Fig 7. The qualitative comparisons of the other two methods are provided in the supplementary material.
6. Conclusion
In this paper, we rigorously demonstrate both mathematically and empirically that the performance of Mamba-based low-light image enhancement methods can be significantly improved by adopting scanning patterns with higher Hausdorff dimensions. By introduc- ing HilbertMamba and PeanoMamba, our work pioneers a novel scanning paradigm that transforms the way state space models (SSMs) handle two-dimensional image data. Leveraging the frac- tal and space-filling properties of Hilbert and Peano curves, our approach reorders image pixels into a one-dimensional sequence in a manner that preserves delicate local features and enhances the reconstruction of fine-scale details under challenging low-light conditions. Our methodology effectively overcomes the inherent limitations of conventional raster scanning by reducing the ap- proximation errors typical in traditional mapping strategies. This allows SSMs to capture long-range dependencies while faithfully reconstructing local textures and edges critical for perceptual image quality. Extensive experiments on standard low-light benchmarks validate the theoretical benefits of high Hausdorff dimension scan- ning patterns, with our methods consistently achieving superior quantitative metrics and visually pleasing enhancement results compared to state-of-the-art approaches. In summary, by bridging the gap between fractal geometry and state space modeling, Hilbert- Mamba and PeanoMamba not only advance the state-of-the-art in low-light image enhancement but also offer a versatile framework that could reshape how we approach sampling and representation in a wide range of vision applications.
Table 2.
Quantitative comparisons of different scans implemented on Mamba-based low-light image enhancement methods, Retinexmamba[1], MambaLLIE[61], and WaveMamba[88] on LOLv1, LOLv2-real, and LOLv2-synthetic. SS2D[42] represents raster scan, CS2D[85] represents continuous scan, LS2D[24] represents local scan, TS2D[64] represents tree scan, PS2D represents Peano scan and HS2D represents Hilbert scan.
Table 2.
Quantitative comparisons of different scans implemented on Mamba-based low-light image enhancement methods, Retinexmamba[1], MambaLLIE[61], and WaveMamba[88] on LOLv1, LOLv2-real, and LOLv2-synthetic. SS2D[42] represents raster scan, CS2D[85] represents continuous scan, LS2D[24] represents local scan, TS2D[64] represents tree scan, PS2D represents Peano scan and HS2D represents Hilbert scan.
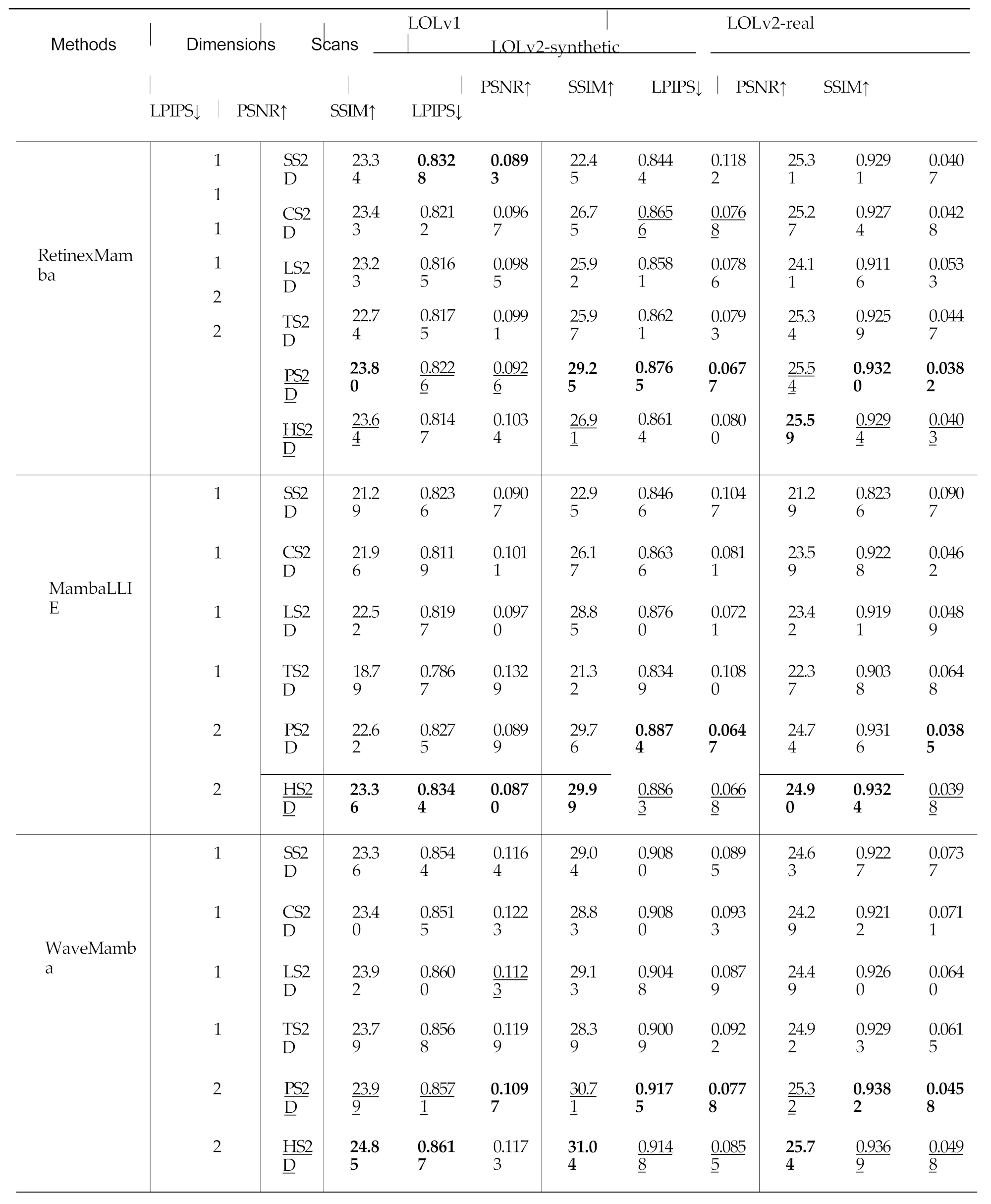 |
Figure 5.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv1.
Figure 5.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv1.

Figure 6.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv2-real.
Figure 6.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv2-real.

Figure 7.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv2-synthetic.
Figure 7.
Visual comparisons of results of different scanning paths (based on WaveMamba[88]) on LOLv2-synthetic.

References
- Jiesong Bai, Yuhao Yin, Qiyuan He, Yuanxian Li, and Xiaofeng Zhang. 2024. Retinexmamba: Retinex-based Mamba for Low-light Image Enhancement. arXiv:2405.03349 [cs.CV] https://arxiv.org/abs/2405.03349.
- Steven Bart, Zepeng Wu, YE Rachmad, Yuze Hao, Lan Duo, and X. Zhang. 2025. Frontier AI Safety Confidence Evaluate. Cambridge Open Engage (2025). [CrossRef]
- Jiang Bian, Helai Huang, Qianyuan Yu, and Rui Zhou. 2025. Search-to-Crash: Gen- erating safety-critical scenarios from in-depth crash data for testing autonomous vehicles. Energy (2025), 137174.
- Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang. 2023. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In ICCV. 12504–12513.
- Jie Chen, Ziyi Li, Lu Li, Jialing Wang, Wenyan Qi, Chong-Yu Xu, and Jong-Suk Kim. 2020. Evaluation of multi-satellite precipitation datasets and their error propagation in hydrological modeling in a monsoon-prone region. Remote Sensing 12, 21 (2020), 3550.
- Heng-Da Cheng and XJ Shi. 2004. A simple and effective histogram equalization approach to image enhancement. Digit. Signal Process. 14, 2 (2004), 158–170.
- Ronald, A. DeVore and George G. Lorentz. 1993. Constructive Approximation. Springer.
- Gerald, A. Edgar. 2007. Measure, Topology, and Fractal Geometry. Springer.
- Kenneth, J. Falconer. 2003. Fractal Geometry: Mathematical Foundations and Applications. John Wiley & Sons.
- Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023).
- Albert Gu, Karan Goel, and Christopher Ré . 2021. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021).
- Zhihao Gu, Fang Li, Faming Fang, and Guixu Zhang. 2019. A novel retinex-based fractional-order variational model for images with severely low light. IEEE TIP 29 (2019), 3239–3253.
- Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. 2020. Zero-reference deep curve estimation for low-light image enhancement. In CVPR. 1780–1789.
- Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. 2024. MambaIR: A Simple Baseline for Image Restoration with State-Space Model. arXiv preprint arXiv:2402.15648 (2024).
- Xiaojie Guo and Qiming, Hu. 2023. Low-light image enhancement via breaking down the darkness. IJCV 131, 1 (2023), 48–66.
- Yuze Hao. 2024. Comment on’Predictions of groundwater PFAS occurrence at drinking water supply depths in the United States’ by Andrea K. Tokranov et al., Science 386, 748-755 (2024). Science 386 (2024), 748–755.
- Yuze Hao. 2025. Accelerated Photocatalytic C–C Coupling via Interpretable Deep Learning: Single-Crystal Perovskite Catalyst Design using First-Principles Calculations. In AI for Accelerated Materials Design-ICLR 2025.
- Yuze Hao, Lan Duo, and Jinlu He. 2025. Autonomous Materials Synthesis Labora- tories: Integrating Artificial Intelligence with Advanced Robotics for Accelerated Discovery. ChemRxiv (2025). [CrossRef]
- Yuze Hao and Yueqi Wang. 2023. Quasi liquid layer-pressure asymmetrical model for the motion of of a curling rock on ice surface. arXiv preprint arXiv:2302.11348 (2023).
- Yuze Hao and Yueqi Wang. 2025. Unveiling Anomalous Curling Stone Trajec- tories: A Multi-Modal Deep Learning Approach to Friction Dynamics and the Quasi-Liquid Layer.
- Yuze Hao, X Yan, Lan Duo, H Hu, and J He. 2025. Diffusion Models for 3D Molecular and Crystal Structure Generation: Advancing Materials Discovery through Equivariance, Multi-Property Design, and Synthesizability. (2025).
- David Hilbert. 1891. Ueber die stetige Abbildung einer Linie aufein Flächenstück. Math. Ann. 38 (1891), 459–460.
- Shih-Chia Huang, Fan-Chieh Cheng, and Yi-Sheng Chiu. 2012. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE TIP 22, 3 (2012), 1032–1041.
- Tao Huang, Xiaohuan Pei, Shan You, Fei Wang, Chen Qian, and Chang Xu. 2024. Localmamba: Visual state space model with windowed selective scan. arXiv preprint arXiv:2403.09338 (2024).
- Xinyue Huang, Ziqi Lin, Fang Sun, Wenchao Zhang, Kejian Tong, and Yunbo Liu. 2025. Enhancing Document-Level Question Answering via Multi-Hop Retrieval- Augmented Generation with LLaMA 3. arXiv:2506.16037 [cs.CL] https://arxiv. org/abs/2506.16037.
- Xinyue Huang, Chen Zhao, Xiang Li, Chengwei Feng, and Wuyang Zhang. 2025. GAM-CoT Transformer: Hierarchical Attention Networks for Anomaly Detection in Blockchain Transactions. INNO-PRESS: Journal of Emerging Applied AI 1, 3 (2025).
- XinyuJia, Weinan Hou, Shi-Ze Cao, Wang-Ji Yan, and Costas Papadimitriou. 2025. Analytical hierarchical Bayesian modeling framework for model updating and uncertainty propagation utilizing frequency response function data. Computer Methods in Applied Mechanics and Engineering 447 (2025), 118341.
- XinyuJia and Costas Papadimitriou. 2025. Data features-based Bayesian learning for time-domain model updating and robust predictions in structural dynamics. Mechanical Systems and Signal Processing 224 (2025), 112197.
- Xinyu Jia, Omid Sedehi, Costas Papadimitriou, Lambros S Katafygiotis, and Babak Moaveni. 2022. Nonlinear model updating through a hierarchical Bayesian modeling framework. Computer Methods in Applied Mechanics and Engineering 392 (2022), 114646.
- Hai Jiang, Ao Luo, Haoqiang Fan, Songchen Han, and Shuaicheng Liu. 2023. Low-light image enhancement with wavelet-based diffusion models. ACM Trans. Graph. 42, 6 (2023), 1–14.
- Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jian- chao Yang, Pan Zhou, and Zhangyang Wang. 2021. EnlightenGAN: Deep light enhancement without paired supervision. IEEE TIP 30 (2021), 2340–2349.
- Daniel J Jobson, Zia-ur Rahman, and Glenn A Woodell. 1997. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE TIP 6, 7 (1997), 965–976.
- Chongyi Li, Chunle Guo, Linghao Han, Jun Jiang, Ming-Ming Cheng, Jinwei Gu, and Chen Change Loy. 2021. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 44, 12 (2021), 9396–9416.
- Chongyi Li, Jichang Guo, Fatih Porikli, and Yanwei Pang. 2018. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 104 (2018), 15–22.
- Ziyi Li, Kaiyu Guan, Wang Zhou, Bin Peng, Zhenong Jin, Jinyun Tang, Robert F Grant, Emerson D Nafziger, Andrew J Margenot, Lowell E Gentry, et al. 2022. Assessing the impacts of pre-growing-season weather conditions on soil nitrogen dynamics and corn productivity in the US Midwest. Field Crops Research 284 (2022), 108563.
- Ziyi Li, Kaiyu Guan, Wang Zhou, Bin Peng, Emerson D Nafziger, Robert F Grant, Zhenong Jin, Jinyun Tang, Andrew J Margenot, DoKyoung Lee, et al. 2025. Com- paring continuous-corn and soybean-corn rotation cropping systems in the US central Midwest: Trade-offs among crop yield, nutrient losses, and change in soil organic carbon. Agriculture, Ecosystems & Environment 393 (2025), 109739.
- Dong Liang, Ling Li, Mingqiang Wei, Shuo Yang, Liyan Zhang, Wenhan Yang, Yun Du, and Huiyu Zhou. 2022. Semantically contrastive learning for low-light image enhancement. In AAAI, Vol. 36. 1555–1563.
- Seokjae Lim and Wonjun Kim. 2020. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE TMM 23 (2020), 4272–4284.
- Jiarun Liu, Hao Yang, Hong-Yu Zhou, Yan Xi, Lequan Yu, Yizhou Yu, Yong Liang, Guangming Shi, Shaoting Zhang, Hairong Zheng, et al. 2024. Swin- UMamba: Mamba-based unet with imagenet-based pretraining. arXiv preprint arXiv:2402.03302 (2024).
- Risheng Liu, Long Ma, Jiaao Zhang, Xin Fan, and Zhongxuan Luo. 2021. Retinex- inspired unrolling with cooperative prior architecture search for low-light image enhancement. In CVPR. 10561–10570.
- Xichang Liu, Helai Huang, Jiang Bian, Rui Zhou, Zhiyuan Wei, and Hanchu Zhou. 2025. Generating intersection pre-crash trajectories for autonomous driving safety testing using Transformer Time-Series Generative Adversarial Networks. Engineering Applications of Artificial Intelligence 160 (2025), 111995.
- Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. 2024. VMamba: Visual state space model. arXiv preprint arXiv:2401.10166 (2024).
- Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. 2017. LLNet: A deep autoencoder approach to natural low-light image enhancement. PR 61 (2017), 650–662.
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Feifan Lv, Feng Lu, Jianhua Wu, and Chongsoon Lim. 2018. MBLLEN: Low- light image/video enhancement using CNNs.. In BMVC, Vol. 220. Northumbria University, 4.
- Jun Ma, Feifei Li, and Bo Wang. 2024. U-Mamba: Enhancing long-range de- pendency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024).
- Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, and Zhongxuan Luo. 2022. Toward fast, flexible, and robust low-light image enhancement. In CVPR. 5637–5646.
- Benoit B. Mandelbrot. 1982. The Fractal Geometry of Nature. W.H. Freeman and Company.
- Jiří Matoušek. 1999. Geometric Discrepancy: An Illustrated Guide. Springer.
- Giuseppe Peano. 1890. Sur une courbe, qui remplit toute une aire. Math. Ann. 36, 1 (1890), 157–160.
- Jiaming Pei, Jinhai Li, Zhenyu Song, Maryam Mohamed Al Dabel, Mohammed JF Alenazi, Sun Zhang, and Ali Kashif Bashir. 2025. Neuro-VAE-Symbolic Dynamic Traffic Management. IEEE Transactions on Intelligent Transportation Systems (2025).
- Jiaming Pei, Wenxuan Liu, Jinhai Li, Lukun Wang, and Chao Liu. 2024. A review of federated learning methods in heterogeneous scenarios. IEEE Transactions on Consumer Electronics 70, 3 (2024), 5983–5999.
- Jiaming Pei, Marwan Omar, Maryam Mohamed Al Dabel, Shahid Mumtaz, and Wei Liu. 2025. Federated Few-Shot Learning With Intelligent Transportation Cross-Regional Adaptation. IEEE Transactions on Intelligent Transportation Sys- tems (2025).
- Xiaohuan Pei, Tao Huang, and Chang Xu. 2024. Efficientvmamba: Atrous selective scan for light weight visual mamba. arXiv preprint arXiv:2403.09977 (2024).
- Chenxi Wang, Hongjun Wu, and Zhi Jin. 2023. FourLLIE: Boosting low-light im- age enhancement by fourier frequency information. In ACMInt. Conf. Multimedia. 7459–7469.
- Lukun Wang, Xiaoqing Xu, and Jiaming Pei. 2025. Communication-Efficient Federated Learning via Dynamic Sparsity: An Adaptive Pruning Ratio Based on Weight Importance. IEEE Transactions on Cognitive Communications and Networking (2025).
- Wenjing Wang, Chen Wei, Wenhan Yang, and Jiaying Liu. 2018. GLADNet: Low- light enhancement network with global awareness. In IEEE Conf. Autom. Face Gesture Recognit. (FG). IEEE, 751–755.
- Yufei Wang, Renjie Wan, Wenhan Yang, Haoliang Li, Lap-Pui Chau, and Alex Kot. 2022. Low-light image enhancement with normalizing flow. In AAAI, Vol. 36. 2604–2612.
- Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE TIP 13, 4 (2004), 600–612.
- Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. 2018. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018).
- Jiangwei Weng, Zhiqiang Yan, Ying Tai, Jianjun Qian, Jian Yang, and Jun Li. 2024. MambaLLIE: Implicit Retinex-Aware Low Light Enhancement with Global-then- Local State Space. NeurIPS 2024 (2024).
- Jan C Willems. 1986. From time series to linear system—Part I. Finite dimensional linear time invariant systems. Automatica 22 (1986), 561–580.
- Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wenhan Yang, and Jianmin Jiang. 2022. URetinex-Net: Retinex-based deep unfolding network for low-light image enhancement. In CVPR. 5901–5910.
- Yicheng Xiao, Lin Song, Shaoli Huang, Jiangshan Wang, Siyu Song, Yixiao Ge, Xiu Li, and Ying Shan. 2024. GrootVL: Tree Topology is All You Need in State Space Model. arXiv preprint arXiv:2406.02395 (2024).
- Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. 2024. SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation. arXiv preprint arXiv:2401.13560 (2024).
- Jingzhao Xu, Mengke Yuan, Dong-Ming Yan, and Tieru Wu. 2022. Illumination guided attentive wavelet network for low-light image enhancement. IEEE TMM 25 (2022), 6258–6271.
- Shuo Xu, Yuchen ***, Zhongyan Wang, and Yexin Tian. 2025. Fraud Detec- tion in Online Transactions: Toward Hybrid Supervised–Unsupervised Learning Pipelines. In Proceedings of the 2025 6th International Conference on Electronic Communication and Artificial Intelligence (ICECAI 2025), Chengdu, China. 20–22.
- Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, and Jiaya Jia. 2022. SNR-aware low-light image enhancement. In CVPR. 17714–17724.
- Kai-Fu Yang, Cheng Cheng, Shi-Xuan Zhao, Hong-Mei Yan, Xian-Shi Zhang, and Yong-Jie Li. 2023. Learning to adapt to light. IJCV 131, 4 (2023), 1022–1041.
- Wenhan Yang, Shiqi Wang, Yuming Fang, Yue Wang, and Jiaying Liu. 2020. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In CVPR. 3063–3072.
- Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu. 2021. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE TIP 30 (2021), 2072–2086.
- Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Jiayi Ma. 2023. Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model. In ICCV. IEEE, 12268–12277.
- Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. 2022. Restormer: Efficient transformer for high- resolution image restoration. In CVPR. 5728–5739.
- Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. 2020. Learning enriched features for real image restoration and enhancement. In ECCV. Springer, 492–511.
- Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. 2022. Learning enriched features for fast image restoration and enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 45, 2 (2022), 1934–1948.
- Hongwei Zhang, Meixia Tao, Yuanming Shi, and Xiaoyan Bi. 2022. Federated multi-task learning with non-stationary heterogeneous data. In ICC 2022-IEEE International Conference on Communications. IEEE, 4950–4955.
- Kaibing Zhang, Cheng Yuan, Jie Li, Xinbo Gao, and Minqi Li. 2023. Multi-branch and progressive network for low-light image enhancement. IEEE TIP 32 (2023), 2295–2308.
- Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR. 586–595.
- Yonghua Zhang, Xiaojie Guo, Jiayi Ma, Wei Liu, and Jiawan Zhang. 2021. Beyond brightening low-light images. IJCV 129 (2021), 1013–1037.
- Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. 2019. Kindling the darkness: A practical low-light image enhancer. In ACM Int. Conf. Multimedia. 1632–1640.
- Kaiyang Zhong, Yifan Wang, Jiaming Pei, Shimeng Tang, and Zonglin Han. 2021. Super efficiency SBM-DEA and neural network for performance evaluation. Information Processing & Management 58, 6 (2021), 102728.
- Rui Zhou, Weihua Gui, Helai Huang, Xichang Liu, Zhiyuan Wei, and Jiang Bian. 2025. DiffCrash: Leveraging Denoising Diffusion Probabilistic Models to Expand High-Risk Testing Scenarios Using In-Depth Crash Data. Expert Systems with Applications (2025), 128140.
- Rui Zhou, Helai Huang, Guoqing Zhang, Hanchu Zhou, and Jiang Bian. 2025. Crash-based safety testing of autonomous vehicles: Insights from generating safety-critical scenarios based on in-depth crash data. IEEE Transactions on Intelligent Transportation Systems (2025).
- Rui Zhou, Guoqing Zhang, Helai Huang, Zhiyuan Wei, Hanchu Zhou, Jieling Jin, Fangrong Chang, and Jiguang Chen. 2024. How would autonomous vehicles behave in real-world crash scenarios? Accident Analysis & Prevention 202 (2024), 107572.
- Weilian Zhou, Sei-Ichiro Kamata, Haipeng Wang, Man-Sing Wong, Huiying, and Hou. 2024. Mamba-in-Mamba: Centralized Mamba-Cross-Scan in Tokenized Mamba Model for Hyperspectral Image Classification. arXiv:2405.12003 [cs.CV] https://arxiv.org/abs/2405.12003.
- Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. 2024. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 (2024).
- J Zhuang, G Li, H Xu, J Xu, and R Tian. 2024. TEXT-TO-CITY Controllable 3D Urban Block Generation with Latent Diffusion Model. In Proceedings of the 29th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Singapore. 20–26.
- Wenbin Zou, Hongxia Gao, Weipeng Yang, and Tongtong Liu. 2024. Wave- Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement. In ACM Multimedia 2024. https://openreview.net/forum?
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



