
Submitted:
12 November 2025
Posted:
13 November 2025
You are already at the latest version
Abstract
We formalize an inverse, data-conditioned variant of the Variational Quantum Eigensolver (VQE) for clinical biomarker discovery. Given patient-encoded quantum states, we construct a task-specific Hamiltonian whose coefficients are inferred from clinical associations, and interpret its expectation value as a calibrated energy score for prognosis and treatment monitoring. The method integrates principled coefficient estimation, ansatz specification with basis rotations, commuting-group measurements, and a practical shot-budget analysis. Evaluated on public infectious-disease datasets under severe class imbalance, the approach yields consistent gains in balanced accuracy and precision-recall over strong classical baselines, with stability across random seeds and feature ablations. This variational energy-scoring framework bridges Hamiltonian learning and clinical risk modeling, offering a compact, interpretable, and reproducible route to biomarker prioritization and decision support.
Keywords:
variational quantum eigensolver
; quantum machine learning
; quantum biomarkers
; clinical data
; multi-qubit systems
1. Introduction
Quantum machine learning (QML) has emerged as a promising interdisciplinary field at the confluence of quantum computing, machine learning, and quantum information [1,2]. Fueled by the potential for computational speedups and the ability to process data in quantum mechanical ways [3,4], QML explores how to leverage quantum computers to enhance classical data analysis. Early works in the field laid the groundwork for a new theoretical framework for learning [5], while more recent contributions have focused on the practical implementation of algorithms and their potential for achieving a quantum advantage [6].
QML has been applied to various domains, from methods based on quantum kernels for improving predictive accuracy [7] to applications in data analysis such as breast cancer detection and image classification [8]. While the field holds immense promise, it is not without challenges, most notably the issue of barren plateaus, which can hinder the training of deep quantum neural networks [9].
Recent reviews highlight the growing potential of QML in biological and biomedical domains [10]. Applications in the biological sciences span diverse areas, including bioinformatics, drug discovery, and medical diagnostics [11]. For instance, QML has been explored for drug discovery through qualitative structure-activity relationship (QSAR) predictions, demonstrating that quantum classifiers can outperform classical ones, particularly when working with limited data and a reduced number of features [12]. In bioinformatics, quantum annealers have been trained on transcription data, showing a slight advantage in classification and near-equal ranking performance compared to classical methods on simplified datasets [13]. Similarly, annealing algorithms of the Ising type, inspired by quantum processors, have shown superior classification performance on small training sets of omics cancer data, a finding particularly relevant for rare diseases or limited clinical data [14].
Further studies have showcased the utility of QML in medical diagnostics. A quantum machine learning framework, QProteoML, has been proposed to predict drug sensitivity in multiple myeloma using high-dimensional proteomic data, outperforming classical machine learning algorithms [15]. For breast cancer prediction, QML has been identified as a cost-effective and efficient strategy, with specific algorithms like Pegasos-QSVC excelling in recall metrics and quantum neural networks (QNNs) achieving high accuracy for binary classification of genomic sequence data [16,17]. Research also explores the use of quantum-inspired machine learning for metastasis prediction in breast cancer, employing least-squares methods via quantum measurements [18]. The mapping of quantum algorithms to applications in electronic health records (EHR), omics, and imaging has also been detailed, alongside the challenges of discovery, validation, and adaptation of quantum computing in these fields [19]. This body of work underscores the interdisciplinary nature of QML and its potential to address complex challenges in molecular biology and medicine.
A key area of research within QML is the development of quantum algorithms for tasks like classification and regression. The variational quantum eigensolver (VQE) [20] is a prime example of a hybrid quantum-classical algorithm that has been adapted from its traditional use in molecular ground state estimation to tackle optimization problems [21]. As VQE gained attraction, a variety of research has focused on improving its performance and extending its capabilities, particularly for noisy intermediate-scale quantum (NISQ) devices. Recent advances include methods to handle constraints and ensure the algorithm finds a true eigenstate [22], as well as new approaches for exploring the Hilbert space to find non-orthogonal solutions [23]. To address limitations in circuit complexity, researchers have proposed techniques such as clustering qubits to create shallower circuits [24] and schemes based on measurement that use entangled resource states [25]. Other optimizations include qubit-efficient strategies that can represent complex states with fewer physical qubits by using sequential measurements [26] and accelerated VQE algorithms that interpolate between VQE and quantum phase estimation (QPE) [27]. Furthermore, VQE has been shown to be effective for complex problems, with successful implementations on Hamiltonians with hundreds of Pauli terms [28]. These methodological advances, along with comprehensive reviews of VQE’s components and extensions [29], have cemented its position as a central tool in near-term quantum computing.
Beyond its traditional application in finding the ground state of molecular Hamiltonians, VQE and its counterpart, the variational quantum classifier (VQC), have found an expanding role in the biological and biomedical sciences, particularly in addressing complex optimization and classification problems. VQE, for instance, has been leveraged for enhancing molecular predictions in drug discovery, demonstrating that its application in molecular dynamics simulations can lead to improved accuracy compared to classical methods [30]. This is complemented by its use in identifying candidate inhibitors through a synergy with quantum graph neural networks, which can model molecular structures [31]. In a similar vein, researchers have applied VQE to find the ground state of molecular systems of genes, a critical step in understanding genetic interactions [32].
VQE and VQC have also been explored for a variety of clinical and medical informatics tasks. For instance, they show promise in optimizing clinical trial site selection by finding the ground state of a Hamiltonian that represents the optimization problem, potentially improving high-dimensional classical parameter spaces [33]. In medical diagnostics, VQC has been successfully applied to problems such as classifying diabetes using an 8- and 4-qubit circuit with rotation and controlled-NOT () entanglement layers [34] and predicting asthma with high accuracy by using the quantum approximate optimization algorithm (QAOA) for feature selection [35]. Furthermore, a hybrid autoencoder and VQC framework has been proposed for the classification of anomalies in biological samples, showcasing its potential in identifying irregularities [36]. These applications highlight VQE’s and VQC’s ability to bridge quantum and molecular systems, a capability that makes them particularly promising for medical applications where complex, high-dimensional data is prevalent [37]. Such advancements show the potential of these variational methods to transform biomedical data analysis by moving beyond traditional computational paradigms to harness quantum-mechanical principles for more efficient and accurate results.
A notable gap persists in the literature regarding the application of quantum computing to immunology and epidemiology, especially in the context of the human immunodeficiency virus (HIV) and syndemic co-infections. Immunology itself generates data of extraordinary complexity—ranging from protein interaction networks to single-cell sequencing—that often exceed the representational and computational capacity of classical approaches. To address this, Basu et al. [38] have proposed a quantum framework for cell-centric therapeutics, which employs quantum algorithms to infer missing links in protein interaction networks by mapping them into exponentially large Hilbert spaces. This approach offers a novel foundation for precision medicine and provides a computational pathway to model the intricate interplay of viral and host proteins, immune cells, and co-morbidities in HIV pathogenesis.
Complementing this progress, quantum-mechanical perspectives on immune signaling have begun to emerge. One such model proposes that T-cell activation operates through quantized energy transfers during protein phosphorylation, mediated by receptor phosphorylation–dephosphorylation cycles initiated by pulses in the peptide complexes [39]. This framework suggests that fundamental immunological processes may unfold in discrete quantum units, thereby enabling more accurate modeling of disease progression in conditions such as HIV, where immune dysfunction is central. Similarly, the concept of "quantum microRNA (miRNA) immunity" has been advanced as a lens to interpret viral manipulation of host gene regulation [40]. By treating aberrant miRNA regulation as a process driven by entanglement, this model connects quantum principles to the nonlinear, multivariate dynamics of viral immunodeficiency, opening avenues for QML applications to viral genomics and cancer biology.
At the epidemiological scale, the first empirical steps toward quantum applications in population health have been demonstrated by Dan Roosan and his research group in their study of QAOA for HIV clusters forecasting, [41]. This research introduced a quantum-accelerated approach to HIV surveillance, reframing cluster detection as a quadratic unconstrained binary optimization (QUBO) problem. Using the QAOA, the method achieved clustering accuracy in 1.6 seconds, outperforming classical density-based approaches. In parallel, a hybrid neural network reached forecasting accuracy for HIV prevalence, surpassing a purely classical counterpart. Notably, quantum Bayesian networks revealed the causal roles of housing instability and stigma in driving cluster emergence and expansion, highlighting structural determinants of disease. This study demonstrates the potential of quantum computing to move beyond applications at a molecular scale towards modeling at the population level, thereby informing prevention strategies, resource allocation for pre-exposure prophylaxis (PrEP), and interventions addressing structural inequities.
Building on this emerging landscape, Choppara and Lokesh [42] worked with predictions of genetic mutations in viral proteins, with a specific focus on the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) as a model system. Leveraging quantum features for dimensionality reduction and embedding them within a quantum long short-term memory (QLSTM) architecture, they demonstrate the model’s ability to capture complex, nonlinear relationships in genomic data. QLSTM outperforms classical deep learning models in mutation prediction accuracy, while also providing biologically meaningful insights into immune evasion and viral transmissibility.
Researchers at Merrimack College, led by Roosan, have made significant contributions to the field, with a particular focus on applying quantum computing and QML to complex problems in biology and clinical medicine. Their work spans diverse quantum algorithms and architectures at the molecular scale, demonstrating how quantum methods for complex biomolecular interactions can predict protein-ligand binding affinity by mapping molecular interactions to a high-dimensional Hilbert space, capturing complex relationships with fewer parameters on par with or even improving upon classical models [43]. This is complemented by quantum simulation for protein structural analysis, which investigated the structural stability of proteins implicated in neurodegenerative disorders and identified regions for protein-protein interactions [44]. Additionally, a quantum regression model was developed to predict the toxicity of herbal compounds, integrating both molecular and pharmacokinetic data to achieve lower prediction errors than classical linear regression and random forest models [45]. Their research also highlights how a hybrid QNN can outperform a classical liquid neural network (LNN) in drug repurposing by leveraging amplitude encoding and feature maps to analyze drug databases [46].
Expanding on these advances, Roosan’s group further demonstrated the power a quantum variational transformer model for enhanced cancer classification, using a hybrid approach to capture intricate genomic patterns more effectively than classical transformer models, resulting in reduced misclassification for complex cancer types [47]. They also developed a prototype for drug repurposing using omics data, integrating quantum principal component analysis (QPCA) and quantum kernel methods to achieve tighter clustering and better performance compared to classical approaches, particularly when combined with large language models (LLMs) [48]. Collectively these studies establish a foundational context for the present work, showcasing the ability of QML methods to address complex challenges in biological and clinical research.
In this work, we extend a previously proposed approach using VQE for clinical biomarker discovery [49]. Our method inverts the traditional VQE paradigm: instead of minimizing the energy of a fixed Hamiltonian, we fix the quantum state (representing a patient’s clinical profile) and search for a Hamiltonian whose ground state energy closely matches the state’s expectation value. This "inverse VQE" offers a novel lens to identify complex biomarkers with multiple relationships that are highly predictive of a patient’s condition.
Our prior work demonstrated the feasibility of this approach using a single-qubit model, successfully identifying key biomarkers related to HIV treatment response and co-morbidities. However, a single qubit’s limited degrees of freedom restricts its ability to capture the multifaceted nature of clinical data. Here, we generalize the model to a multi-qubit system, allowing for the simultaneous encoding of multivariate patient features and, critically, the inclusion of multiple qubits interaction terms in the Hamiltonian. The resulting increase in expressivity and complexity enables a deeper exploration of the relationships between biomarkers, including those that are non-classical in nature.
The specific clinical data used comes from a cohort of patients with HIV and tuberculosis (TB) co-infection. We analyze key clinical markers such as viral load and CD4 count differences, alongside quantum game theoretic features. We hypothesize that a multi-qubit model, by accommodating interaction terms like and , will reveal more intricate biomarker relationships and provide a more robust and clinically relevant set of Hamiltonians.
2. Materials and Methods
2.1. Data Acquisition and Feature Engineering
This study leverages the qphen dataset, a unique resource for applying quantum inspired algorithms to clinical data related to HIV. The dataset is publicly available through the qvirus package [50] on the Comprehensive R Archive Network (CRAN) [51]. Data were collected from a longitudinal cohort of 213 individuals with HIV and TB co-infection at a clinic in Guerrero, Mexico, from 2018 to 2024, in accordance with institutional and national research ethics guidelines. The protocol was approved by the Local Health Research Committee 1102 of General Regional Hospital No. 1.
The dataset integrates classical clinical measurements with engineered features derived from a quantum game theoretic model of HIV phenotypes [52]. Key variables include differences in viral load () and CD4 T lymphocyte counts (), along with binary indicators for TB co-infection () and genotypic drug resistance ().
A stringent data cleaning process was necessary to prepare the initial cohort comprised of 213 patient records for the quantum game theoretic model. This cleaning process excluded records with only a single longitudinal value, as these data points did not permit the derivation of change rates or the temporal dynamics that represent the competition between lymphocytes and viral load over time, features which proved critical for the model. Following this depuration, the base utilized for all subsequent analyses was reduced to 176 records, which were used for the feature engineering and modeling procedures.
A central component of the feature engineering process is the Nearest Payoff Algorithm, which bridges the observed viral dynamics in a study cohort with the vast state space of quantum game simulations. The quantum game is defined by a Hilbert space , an initial state , a set of strategies and corresponding payoffs . Two infectious phenotypes are considered: a low-replication phenotype v and a high-replication phenotype V, encoded as qubits and , respectively.
The game’s dynamics are governed by unitary operators. For a two-phenotype system, the initial state is prepared as:
where I is the Identity and is the Pauli gate. Subsequent quantum moves, including Pauli gates and the Hadamard gate H, are applied to generate superposition states that reflect different phenotype interactions. After applying the appropriate combination of quantum gates to evolve the initial state U to the final state , the expected payoffs and are computed as a weighted sum of the probability amplitudes of the final state (the quantum outcomes) and the classical payoff parameters:
and
Classical payoff parameters correspond to the outcomes of the four possible interactions , capturing biologically relevant properties such as resource consumption, replication rate, and survival.
The nearest payoff algorithm maps an observed patient viral load difference, , to the closest previously simulated quantum expected payoff, from a set of all possible payoffs. This process yields both a numeric prediction, and a phenotypic characterization, for each patient, based on the quantum strategy combination that generated the closest payoff. By embedding these quantum game theoretic outcomes into clinically interpretable features, the approach enhances the dataset with descriptors that capture nontrivial interactions between viral phenotypes, providing a richer basis for downstream analyses such as multi-qubit Hamiltonian modeling.
The key engineered features in the dataset include:
- Quantum Payoffs: The variable nearest_payoff provides the numerical prediction for a patient’s phenotype. It’s the value of the closest simulated quantum payoff, or expected outcome, that best fits the patient’s viral load difference.
-
Quantum Strategy Encoding: This category is crucial for understanding the quantum model’s interpretation of a patient’s viral dynamics. The variables here encode the specific quantum gates used as strategies by two distinct HIV phenotypes, a low-replication phenotype (v) and a high-replication phenotype (V).
- –
- phen_1 indicates whether the phenotype associated with the nearest payoff is v or V.
- –
- str1_2: represents the primary strategy of the first phenotype, with a binary encoding that corresponds to the Pauli gate (X), the gate (T), or the H gate.
- –
- str1_3: is the alternative strategy for the first phenotype, also using binary encoding.
- –
- str2_2: is the primary strategy of the second phenotype. Its binary encoding corresponds to one of several quantum gates: H, I, Phase gate (S), T, X, Pauli gate (Y), or Pauli gate (Z).
- –
- str2_3 to str2_7: are alternative strategies for the second phenotype. Each variable is a binary indicator (0 or 1) for the presence or absence of a specific quantum gate from the set .
- Batch Indicator: The distinguishes predictions performed on the full dataset (0) versus batch-processed subsets (1).
Other features in the dataset are:
- Phenotypic Clustering: Variables through are derived from a k-means clustering of standardized viral load and CD4 differences, which groups patients by their phenotypic behavior.
- Clinical Differences: Variables such as and are the raw differences in viral load and CD4 T lymphocyte counts. Standardized versions ( and ) are also included.
- Binary Clinical Indicators: and are binary variables that indicate the presence of TB co-infection and genotypic drug resistance, respectively.
For example, the payoff label translates to: (high-replication phenotype), (first strategy is the Pauli gate), (second strategy is the Hadamard gate), and (indicating a batch-processed subset).
This synthesis of classical clinical data with features derived with quantum games of phenotypes provides a robust foundation for biomarker discovery and patient stratification using the multi-qubit variational approach.
2.2. Multi-Qubit VQE Algorithmic Methods
This section presents the theoretical and algorithmic principles underlying the extension of the VQE to multi-qubit systems. As a hybrid quantum-classical algorithm, VQE enables practical simulations on near-term quantum hardware by preparing shallow quantum circuits while delegating computationally intensive optimization tasks to a classical processor. At its core, VQE leverages quantum simulation and the Schrödinger equation to define a Hamiltonian operator , whose eigenvalues correspond to the system’s energy levels. The variational principle ensures that the expectation value of any trial state provides an upper bound to the ground state energy.
VQE iteratively minimizes the expectation value of a parameterized Hamiltonian using a quantum trial state, or ansatz, , for an n-qubit system:
VQE iteratively minimizes the expectation value of a parameterized Hamiltonian using a quantum trial state, or ansatz, , for an n-qubit system:
where each is a tensor product of Pauli matrices (), and are real coefficients. The expectation value of the Hamiltonian is
with obtained from projective measurements on the quantum device. By the variational principle, for any normalized trial state ,
where is the true ground state energy. Minimizing over trial states provides the best approximation of .
In multi-qubit systems, Hamiltonians are decomposed into single-qubit operators (acting on one qubit) and interaction terms (acting on multiple qubits). For a two-qubit system, single-qubit terms include or , whereas interaction terms include or , which induce correlations between qubits. The identity operator I acts as a placeholder for qubits not directly involved in a term.
Expectation values are measured using either analytical or sampling-based approaches. The analytical method involves simulation where the quantum state can be represented as a density matrix , and the exact expectation value of a Pauli operator P is:
| Algorithm 1: Analytical Pauli Expectation Value Estimation |
Require:
Quantum state , Pauli operator P
|
Alternatively, the sampling-based method is used on real quantum hardware, where expectation values are probabilistically estimated from repeated measurements .
where is the eigenvalue of for the k-th shot after appropriate basis rotations. Specifically, to measure multi-qubit Pauli terms, the state must first be transforming the state with a basis change unitary operator to map the observable to the standard computational (Z) basis:
| Algorithm 2: Sampling-Based Pauli Expectation Value Estimation |
|
The analytical method provides exact benchmarks for algorithm validation, whereas the sampling-based method simulates realistic hardware execution, accounting for statistical fluctuations.
The core of our hybrid quantum-classical approach involves preparing a patient-specific quantum state that encodes the clinical status. This is achieved through two main components: amplitude encoding (the mapping of classical features to rotation angles) and the ansatz circuit (the parameterized quantum circuit structure).
2.2.1. Amplitude Encoding: Mapping Clinical Data to Angles
For our multi-qubit system, four key clinical features are assigned to the four rotation angles of the ansatz circuit. This technique, known as feature embedding, utilizes Min-Max Normalization to scale each clinical value x into the rotation range , ensuring that the entire feature space is represented by the quantum Hilbert space.
The four encoded features are: viral load mean difference (), CD4 mean difference (), TB co-infection (), and genotypic drug resistance (). Each feature is normalized using the full range of the data set:
where defines one of the four rotation angles. The resulting normalized features define the rotation parameters of the ansatz as
2.2.2. Ansatz Definition and Circuit Diagram
The ansatz is the multi-qubit parameterized quantum circuit used to create the patient state . Its structure is fixed across all patients, but its parameters (the rotation angles) are unique for each patient’s clinical data.
The circuit initializes both qubits in the ground state 0 and applies two sequential single-qubit rotations ( and ) on each qubit, followed by a CNOT gate for entanglement. The circuit diagram is as follows:
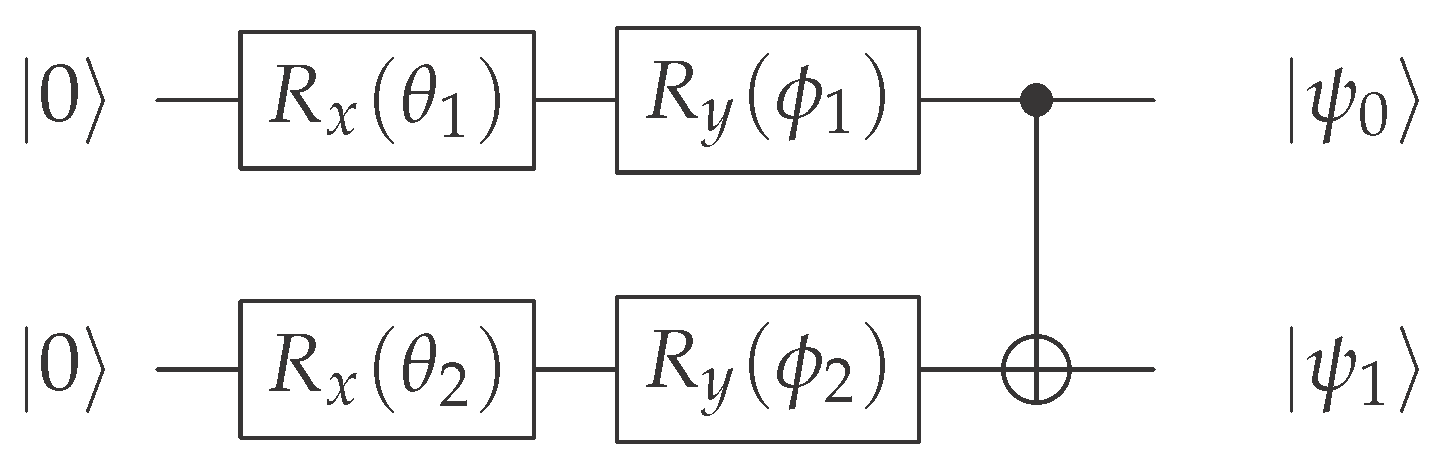
2.2.3. Resulting Amplitudes and Entangled State
Each sequence of single-qubit rotations transforms the basis state 0 into a superposition state whose amplitudes are functions of the input clinical features:
Before the entanglement step (CNOT), the state of the two-qubit system is a simple tensor product. The CNOT gate then acts to couple the features, mapping the state 10 to 11.
This results in the final, entangled patient state:
where and are the complex amplitudes of Eq. 12 for qubit . This construction ensures that the final state reflects both the individual features and their latent correlations, which is critical for the Hamiltonian search phase.
2.2.4. Inverse/Data-Conditioned VQE
Rather than the standard VQE, where ansatz parameters are optimized for a fixed Hamiltonian, here the paradigm is inverted: the patient-specific quantum state is fixed, and the algorithm searches for a Hamiltonian whose ground state best matches this state. The objective function is the delta metric:
with the minimal eigenvalue of the trial Hamiltonian. The optimization problem is
which identifies the Hamiltonian that most accurately represents the patient’s encoded state and highlights the most informative features.
This framework integrates the measurement of multi-qubit Pauli terms with a stochastic Hamiltonian optimization that highlights patient-specific feature correlations. The minimum delta is analogous to the ground state energy in conventional VQE, while the selected coefficients indicate the most informative clinical features.
The optimal Hamiltonian search described in Algorithm 3 is extended into a global binary classification routine to predict clinical status (e.g. TB co-infection or drug resistance) throughout a patient cohort. In this classification context, the Hamiltonian expectation value for a patient x serves as the direct classification score of Equation 16.
| Algorithm 3: Optimal Clinical Hamiltonian Search for Multi-Qubit Systems |
|
The prediction is then a binary decision derived from this quantum score by applying a classically optimized threshold :
The goal shifts from finding a Hamiltonian that minimizes the metric (Equation 12) for feature selection to finding the optimal pair () that minimizes a selected classification loss function, , across the entire dataset.
The global optimization of and is driven by minimizing one of the three standard loss metrics in the iteration space.
1. Simple Error (): Minimizes the total number of misclassified instances, equivalent to , where the accuracy is the correct classification rate.
- : The predicted class (0 or 1) for the j-th instance
- : The true class (0 or 1) for the j-th instance
- : The total number of instances (patients) in the dataset
- : The indicator function, which equals 1 if the condition inside is true (, i.e., misclassification) and 0 otherwise
2. Balanced Error (): Minimizes the error based on the average of sensitivity (true positive, TP, rate) and specificity (true negative, TN, rate), making it robust against class imbalance.
3. Penalized Error (): Imposes a higher cost on false negatives (FN) compared to false positives (FP), often critical in medical diagnostics to avoid missing a condition.
- : The total count of FN (instances that are actually positive, , but were predicted negative, )
- : The total count of FP (instances that are actually negative, , but were predicted positive, )
The core routine involves a stochastic global search where, at each iteration, a random Hamiltonian is generated, all patient scores are computed, and a classical grid search is performed over the expanded range of possible scores (from to , where N is the number of Pauli terms) to find the threshold that minimizes the chosen loss function.
| Algorithm 4: Global Multi-Qubit Classifier Search |
Require:
Clinical Dataset D, Target Status y, Loss Function L, Max Iterations M, Number of Pauli Terms N
|
The output of the routine is the optimal clinical Hamiltonian and the optimal threshold that together minimize the predefined classification loss function. This final pair constitutes the predictive quantum classifier for the target clinical status.
2.3. Classical Benchmarks
To rigorously assess the performance and stability of the multi-qubit VQE approach, its results were benchmarked against a suite of strong classical machine learning models. This comparative analysis was conducted under a unified and robust validation scheme designed to address class imbalance, guarantee reproducibility across random conditions, and evaluate feature robustness.
The following models were selected as classical baselines for binary classification of the and status:
- Regularized Logistic Regression (LogReg): A strong linear baseline, implemented using the brulee package (equivalent to the glmnet engine), which incorporates L2 regularization (penalty) to prevent overfitting and optimize the loss function.
- Multi-Layer Perceptron (MLP): A single-hidden-layer neural network, trained using the brulee package, which serves as a classical deep learning baseline that explicitly incorporates class weights to handle the data imbalance during optimization.
The entire modeling process, including feature preprocessing, hyperparameter tuning, and final evaluation, was nested within a rigorous, multi-seed validation loop to ensure result stability. The analysis was replicated across distinct random seeds. For each seed, a new 70/30 train/test split was performed, and the subsequent repeated Cross-Validation (CV) and final evaluation were executed. The final reported metrics are the mean and standard deviation across these N replicates. Hyperparameter tuning for all classical baselines (LogReg, MLP) was performed using 10 fold CV repeated 3 times on the training set. Model selection during CV was based on maximizing the Area Under the Precision-Recall Curve (AUCPR), which is the most reliable metric for imbalanced data. The modeling pipeline utilized the tidymodels framework in R. All numeric predictors were standardized (), and zero-variance features were removed using the step_zv function.
Crucially, to address the severe class imbalance in the target variable, the Synthetic Minority Over-sampling Technique (SMOTE) was applied within the CV folds of the training set to balance the training data for the LogReg models. The MLP model was trained using explicit inverse class weights (inversely proportional to class frequency) instead of SMOTE, a common technique for gradient-based models, to directly influence the loss function toward the minority class.
To assess feature redundancy and the contribution of the quantum-derived features, an ablation study was conducted. The full validation pipeline (multi-seed CV and final test evaluation) was repeated for three distinct feature sets:
- A Full Feature Set (using all available clinical and quantum-derived features).
- A No Quantum Features Set (excluding features related to VQE payoffs, nearest payoff, and quantum structure).
- A No Classical Features Set (excluding raw clinical differences, ratios, and counts).
The comparison of performance metrics across these ablated sets provides direct evidence of the feature stability and incremental value of the proposed features.
3. Results
The search algorithm was applied to three distinct clinical scenarios to identify the optimal, low dimensional clinical Hamiltonian . This Hamiltonian serves as a personalized quantum biomarker, where its ground state energy provides a measurable risk score, and its Pauli operator structure defines the most critical interaction (entanglement) between clinical features.
3.1. Stable Patient Scenario
This scenario establishes the clinical baseline, representing a patient with maximal resilience (no TB: , no drug resistance: ). The patient’s quantum state exhibits an ideal outcome state () despite active internal dynamics on qubit 1 (). The search algorithm identified the simplest Hamiltonian, certifying the decoupling of the two-qubit system:
This Identity operator serves as the quantum stability identifier. The analytical delta () confirms that is an exact eigenstate of , resulting in a constant, intrinsic energy .
The result implies that the internal dynamics (qubit 1) do not structurally affect the ideal clinical outcome (qubit 2). The constant coefficient C is the system’s baseline energy, derived from the correlation of the highest competing, non-Identity term (), which is successfully neutralized by the patient’s state.
The principal clinical advantage of the Hamiltonian is its zero measurement cost. Following standard VQE shot budgeting, the expected number of measurements is proportional to the variance of the Pauli terms [21]. Since , the prognostic shot budget is . This demonstrates the ultimate cost-efficiency achieved when a patient’s state certifies maximal clinical resilience (Table 1).
3.2. TB Co-Infected Patient Scenario
This scenario examines a patient with TB co-infection (). The patient’s state is characterized by structural stress, evidenced by a high risk outcome qubit encoding () despite currently stable viral load dynamics ().
The optimal search algorithm identified a single entanglement operator that certifies this instability:
This operator, with , is the quantum strategy interaction identifier (Table 2). The low analytical delta () confirms a strong alignment between the patient state and this Hamiltonian’s eigenstate, signifying structural instability by establishing a measurable, inverse correlated entanglement between key features.
The Hamiltonian functions as a feature reduction filter, isolating the crucial interaction between: (the latent high risk Hadamard strategy for the low replicating viral phenotype) and (the active biomarker of viral load dynamics).
Unlike the scenario, the operator requires a non zero shot budget to overcome the finite sampling error (FSE) inherent to quantum measurement.
The shots used in the search phase were an optimization cost to ensure the Hamiltonian was reliably discovered with minimal FSE. The prognostic shots are the operational cost for the final, single measurement. The required shots for clinical grade precision () are calculated as:
This cost quantifies the added complexity introduced by the co-infection. For resource constrained NISQ deployment, relaxing the tolerance to reduces the cost significantly:
This demonstrates the critical trade-off between clinical precision and hardware budget [53].
3.3. Drug Resistance (GR) Scenario
This scenario investigates a patient with resistance to treatment (). The patient’s state is highly unstable, characterized by significant viral load increase and CD4 decrease. The encoding shows the instability is primarily contained within the internal dynamics (qubit 1: ).
The optimal search identified an entanglement operator defining the instability:
This operator is the quantum conditional payoff identifier. The highly accurate analytical delta () validates the Hamiltonian as the minimal energy operator, verifying a deep, inverse correlated structural instability linked to viral fitness (Table 3).
The Hamiltonian’s features are: (the latent defensive X strategy for the high replicating phenotype) and (the classical viral fitness score/reproductive capacity).
The negative coefficient () shows that the patient’s drug resistance is defined by an inverse correlation where the viral phenotype’s maximum classical survival capacity () suppresses its necessity to adopt a critical defensive strategy (). This is an active strategic instability.
Prognosis requires measuring : a value near confirms the persistence of this conditional instability, while a shift towards zero (loss of inverse correlation) would signal a phase transition in the viral strategy, requiring intervention.
As with the TB scenario, the operator requires a substantial budget for high assurance prognosis. The search shots again serve as a high fidelity optimization step. The operational budget is calculated for :
This ≈ 10,500 shot requirement quantifies the cost of measuring the instability introduced by drug resistance. For routine monitoring, relaxing the precision to drastically reduces the shot budget:
This illustrates that the clinical Hamiltonian provides clinicians with a direct, quantifiable mechanism to choose the cost-efficiency strategy based on the required risk tolerance .
3.4. Classification Results
The multi-qubit VQE framework was deployed as a global binary classifier to predict two critical clinical statuses: the genotypic drug resistance status () and TB co-infection (). The routine utilizes a single-term Hamiltonian () , optimized over 10,000 iterations to minimize a chosen classification loss function. In both scenarios, the dataset is severely imbalanced, making balanced accuracy the key performance metric.
The target class, , consists of 8 positive cases out of 176 patients (prevalence ). The four features encoded into the two-qubit ansatz were: , , , and .
The multi-qubit quantum classifier was optimized to minimize three distinct loss functions: simple error, balanced error, and penalized error. The performance of the optimal classifier found for each loss function is presented in Table 4.
The classifier optimized with the balanced error loss function yielded the best performance, achieving a balanced accuracy of . This model correctly identified 7 out of the 8 drug-resistant patients (Sensitivity) while maintaining a high true negative rate (Specificity). The poor performance of the simple error model (Sensitivity) highlights the necessity of using loss functions robust to class imbalance in medical diagnostics.
The second task targeted the prediction of the co-infection status, which is even more imbalanced, with only 6 positive cases out of 176 patients (prevalence ). For this prediction, the encoded features were modified to be: , , (using the final status as a predictor), and . The performance of the optimal classifier for the prediction is shown in Table 5.
Similar to the scenario, the classifier optimized for simple error yielded a misleading accuracy but had low sensitivity (0.167), correctly identifying only 1 out of 6 TB-co-infected patients. The penalized error also failed to achieve robust sensitivity (Sensitivity).
The best predictive performance for was achieved using the balanced error loss function, with a balanced accuracy of . This model successfully identified 4 out of 6 co-infected patients (Sensitivity) while maintaining a high specificity of 0.894.
While the balanced accuracy for () is lower than that for (), this result is highly significant given the extreme imbalance and the difficulty of predicting TB co-infection using standard clinical markers. The single-term quantum classifier demonstrates an ability to leverage quantum encoded features and their correlations to distinguish between the minority and majority classes with substantial predictive power.
3.5. Comparative Analysis with Classical Baselines
To rigorously evaluate the strength of the VQE approach, its performance was benchmarked against standard classical models (LogReg and MLP) trained using inverse class weights to mimic the "Balanced Error" optimization and mitigate class imbalance. The results of these classical baselines are summarized in Table 6.
The classical models demonstrated a high overall accuracy ( for and between and for ) but showed a significant bias toward the majority class for . Specifically, for the variable, both LogReg and MLP failed to correctly identify any patient in the minority class (Sensitivity ), resulting in a Balanced Accuracy below the random chance level ().
For the variable, the classical baselines showed better, but still limited, performance. The LogReg achieved a Balanced Accuracy of , while the MLP achieved . Although the MLP attained the same Sensitivity () as the VQE, this was achieved by significantly sacrificing Specificity (). In contrast, the VQE model optimized with the Balanced Error loss significantly outperformed all classical methods, achieving a Balanced Accuracy of while maintaining both high Sensitivity () and high Specificity (). These results suggest that the VQE approach effectively utilizes the complex clinical and quantum-derived features to better resolve the minority class without compromising the correct classification of the majority class, a key requirement for reliable clinical risk scoring.
While the balanced accuracy for () is lower than that for (), the consistent and significant outperformance of the VQE model over all classical baselines across both imbalanced targets validates the utility of quantum-derived features in this clinical domain. The VQE’s ability to maintain high sensitivity while preserving high specificity suggests that the feature encoding and Hamiltonian learning successfully capture latent, clinically relevant correlations that are inaccessible to conventional models, providing a superior basis for reliable clinical risk scoring.
4. Discussion
The variational quantum approach, extended here to a multi-qubit framework, has demonstrated significant potential as an interpretable feature discovery and classification tool for complex clinical data, specifically in the highly challenging domain of HIV/TB co-infection and drug resistance.
The present work successfully extends the methodology proposed in earlier single-qubit analyses, which were limited to encoding only two clinical features into the parameters of a state [49]. While the single-qubit model validated the core concept that a clinical Hamiltonian’s ground state could be used as a classification boundary, its practical application was inherently limited by its low expressivity, failing to capture the complex, multi variate correlations common in biological systems.
The transition to a multi-qubit ansatz with an entangling gate (as shown in Algorithm 3) addresses this limitation. By encoding four clinical features (, , and or ) into the state , the model explores a vastly richer Hilbert space. The introduction of the entangling gate is crucial, as it allows the quantum state to encode non-linear correlations between features, which are believed to be essential for accurate prediction of multiple factor diseases and drug resistance. This architectural expansion is the critical step that permits the identification of a single-term Pauli operator, , that acts as a robust classifier.
The success of the multi-qubit model is profoundly linked to the advanced feature engineering derived from the quantum game of infectious phenotypes [52]. By converting complex biological dynamics, like the competition of HIV-1 phenotypes, into single, clinically meaningful, one-hot encoded variables (e.g., , , or ), the model achieves two primary goals. The first one is an interpretability through dimensionality reduction. This abstraction limits the effective feature space, enabling the optimal Hamiltonian to be found as a minimal single-term operator. A Hamiltonian like (for the TB scenario) or (for the stable patient) is highly interpretable, as its single term and coefficient immediately indicate the key clinical biomarker combination driving the patient’s state towards the minimal energy. The secon goal concerns the dentification of clinical biomarkers. The results of the multi-qubit (Table 1, Table 2 and Table 3) model demonstrate how the model pinpoints the specific, most relevant pair of clinical and quantum derived features that define the patient’s state (i.e., the variables coupled by the optimal Pauli operator ).
A key aspect enabling the high performance and interpretability of this model is the incorporation of a feature derived from quantum game theory: the . This is a powerful example of feature engineering where complex, multi-dimensional information (specifically, the competitive dynamics between HIV-1 phenotypes) is abstracted into a single, clinically relevant measure.
By including this one-hot encoded quantum strategy (as a quantum derived feature), the total number of necessary clinical features for robust classification is kept low, which in turn limits the complexity of the optimal Hamiltonian found by the optimal clinical Hamiltonian search algorithm. This reduction in the feature space for the Hamiltonian enhances clinical interpretability, directly highlighting the most influential pairwise correlation for the target outcome offering a clear, interpretable biomarker. Fewer terms in the Hamiltonian lead to fewer required measurements for estimating the expectation value , minimizing the effects of sampling error, a critical challenge in the NISQ era [53].
The classification results validated the efficacy of the multi-qubit model. Given the severe class imbalance in the dataset (positive cases were for and for ), the standard simple error loss function proved clinically misleading, favoring high accuracy and specificity at the expense of nearly zero sensitivity (e.g., Sensitivity for ).
The optimization based on the balanced error loss function, however, delivered highly relevant diagnostic results. For the status, a balanced accuracy of successfully identifying 7/8 drug-resistant patients (Sensitivity). For the status, a balanced accuracy of , successfully identifyied 4/6 co-infected patients (Sensitivity).
This performance confirms that the proposed quantum classifier can effectively distinguish between minority and majority classes by focusing on the underlying feature correlations, thereby providing a clinically valuable result that overcomes the limitations of traditional models in imbalanced settings.
While the performance metrics validate the hybrid quantum-classical methodology, it is essential to acknowledge specific limitations regarding the clinical cohort and data collection process. Firstly, the dataset is derived exclusively from a single, regional HIV clinic in Guerrero, Mexico. This homogeneity, while useful for controlling local treatment and epidemiological factors during training, inherently limits the generalizability (external validity) of the final model. The precise numerical values of the optimal Hamiltonian coefficients may be specific to the regional strain variants or local clinical protocols, and may not directly translate to cohorts from other geographical areas.
Secondly, the use of longitudinal clinical records (2018-2024) introduces potential selection biases. Patients who maintain consistent follow-up and remain in the cohort over extended periods tend to be more treatment-adherent or may represent a subpopulation with inherently better long term outcomes. Furthermore, the necessary data depuration process, which excluded records lacking multiple longitudinal measurements, further restricted the final analytical base to those patients with documented temporal dynamics, potentially biasing the model toward compliant, multi-visit individuals.
To address these limitations, our immediate future work is focused on external validation of the trained model. The next step is to test the structural validity of the discovered quantum biomarker, meaning the specific pair of clinical features and the Pauli operator that yields the optimal classification (e.g., coupling and for TB). The plan is to apply the trained classifier to independent, distinct cohorts from other states in Mexico or from international public repositories, such as those made available through the NIH. This external validation will confirm whether the identified feature relationships () are universal clinical biomarkers or are merely artifacts of the local training cohort, thereby establishing the model’s true external reliability for precision medicine applications.
The successful application of this multi-qubit entangling ansatz to a real world imbalanced biomedical classification problem, is a powerful demonstration of the potential of variational quantum algorithms in the NISQ era [4]. The model leverages the strengths of quantum computation, the capacity for expressive state preparation and the efficient estimation of Hamiltonian expectation values, while keeping the circuit depth and number of required qubits minimal.
As quantum hardware continues to improve, the move from this two-qubit system to models with qubits will naturally pave the way for further, more accurate models. Higher-qubit ansätze will allow for the encoding of even more clinical and omics features, while the fundamental clinical Hamiltonian principle will continue to serve as a powerful engine for identifying optimal, interpretable, and parsimonious biomarker combinations. This hybrid quantum-classical approach thus represents a promising direction for achieving the goal of precision medicine through quantum machine learning.
Author Contributions
Conceptualization; methodology; software; validation; formal analysis; investigation; resources; data curation; writing—original draft preparation; writing—review and editing; visualization; supervision; project administration; Juan Pablo Acuña González, Moisés Sánchez Adame and Oscar Montiel. All authors have read and agreed to the published version of the manuscript.
Funding
Instituto Politécnico Nacional SIP20253768, Secretaría de Ciencia, Humanidades, Tecnología e Innovación CF-2023-I-108.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki and approved by the Institutional Review Board (Ethics Committee) of the Hospital General Regional No. 1 “Vicente Guerrero” del Instituto Mexicano del Seguro Social (IMSS). Approval was granted by the Comité Local de Investigación en Salud 1102, with COFEPRIS registration number 17 CI 12 001 066, CONBIOÉTICA registration CONBIOÉTICA 12 CEI 002 2018082, and institutional registration code R-2023-1102-029. Approved Date: 26 June 2023
Informed Consent Statement
Patient consent was waived due to the retrospective nature of the study and the use of anonymized clinical records. All data were depersonalized prior to analysis, with removal of names and demographic identifiers to ensure confidentiality. No identifiable patient information is included in the dataset.
Data Availability Statement
The anonymized dataset used in this study is distributed through the CRAN package and its associated dataset . Both are publicly available under the MIT License with redistribution permitted subject to the terms of the included LICENSE file. Access is provided via CRAN https://cran.r-project.org/package=qvirus and the GitHub repository https://github.com/juan-acu/qvirus. Redistribution of raw clinical records is restricted due to privacy and ethical considerations; only anonymized and derived datasets are shared.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| QML | Quantum Machine Learning |
| QSAR | Qualitative Structure-Activity Relationship |
| QNNs | Quantum Neural Networks |
| EHR | Electronic Health Records |
| VQE | Variational Quantum Eigensolver |
| NISQ | Noisy Intermediate-Scale Quantum |
| QPE | Quantum Phase Estimation |
| VQC | Variational Quantum Classifier |
| CNOT | Controlled-Not |
| QAOA | Quantum Approximate Optimization Algorithm |
| HIV | Human Immunodeficiency Virus |
| miRNA | MicroRNA |
| QUBO | Quadratic Unconstrained Binary Optimization |
| PrEP | Pre-Exposure Prophylaxis |
| SARS-CoV-2 | Severe Acute Respiratory Syndrome Coronavirus 2 |
| QLSTM | Quantum Long Short-Term Memory |
| LQNN | Liquid Neural Network |
| QPCA | Quantum Principal Component Analyisis |
| LLMs | Large Language Models |
| TB | Tuberculosis |
| CRAN | Comprehensive R Archive Network |
| TP | True Positives |
| TN | True Negatives |
| FN | False Negatives |
| FP | False Positives |
| FSE | Finite Sampling Error |
| LogReg | Regularized Logistic Regression |
| MLP | Multi-Layer Perceptron |
| CV | Cross-Validation |
| AUCPR | Area Under the Precision-Recall Curve |
References
- Schuld, M.; Petruccione, F. Supervised Learning with Quantum Computers; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Wittek, P. Quantum Machine Learning: What Quantum Computing Means to Data Mining; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Martín-Guerrero, J.D.; Lamata, L. Quantum Machine Learning: A tutorial. Neurocomputing 2022, 470, 457–461. [Google Scholar] [CrossRef]
- Zhang, Y.; Ni, Q. Recent Advances in Quantum Machine Learning. Quantum Eng. 2020, 2. [Google Scholar] [CrossRef]
- Ciliberto, C.; Herbster, M.; Ialongo, A.D.; Pontil, M.; Rocchetto, A.; Severini, S.; Wossnig, L. Quantum machine learning: a classical perspective. Proc. R. Soc. 2018, 474, 20170551. [Google Scholar] [CrossRef] [PubMed]
- Cerezo, M.; Verdon, G.; Huang, H.Y.; Cincio, L.; Coles, P.J. Challenges and opportunities in quantum machine learning. Nat. Comp. Sci. 2022, 2, 567–576. [Google Scholar] [CrossRef]
- Huang, H.Y.; Broughton, M.; Mohseni, M.; Babbush, R.; Boixo, S.; Neven, H.; McClean, J.R. Power of data in quantum machine learning. Nat. Commun. 2021, 12, 2631. [Google Scholar] [CrossRef]
- Zeguendry, A.; Jarir, Z.; Quafafou, M. Quantum Machine Learning: A Review and Case Studies. Entropy 2023, 25, 287. [Google Scholar] [CrossRef] [PubMed]
- McClean, J.R.; Boixo, S.; Smelyanskiy, V. N.; Babbush, R.; Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018, 9, 4812. [Google Scholar] [CrossRef] [PubMed]
- Maheshwari, D.; Garcia-Zapirain, B.; Sierra-Sosa; D. Quantum Machine Learning Applications in the Biomedical Domain: A Systematic Review. IEEE Access 2022, 10, 80463–80484. [Google Scholar] [CrossRef]
- Baiardi, A.; Christandl, M.; Reiher, M. Quantum Computing for Molecular Biology. ChemBioChem 2024, 24, e202300120. [Google Scholar] [CrossRef]
- Chiang, W.Y.; Kao, P.Y.; Yeh, T.L.; Yang, Y.C.; Lin, Y.C.; Zhavoronkov, A. Enhancing Drug Discovery: Quantum Machine Learning for QSAR Prediction with Incomplete Data. arXiv 2025, arXiv:2501.13395. [Google Scholar] [CrossRef]
- Li, R. Y.; Di Felice, R.; Rohs, R.; Lidar, D. A. Quantum annealing versus classical machine learning applied to a simplified computational biology problem. npj Quantum Information 2018, 4. [Google Scholar] [CrossRef]
- Li, R. Y.; Gujja, S.; Bajaj, S. R.; Gamel, O. E.; Cilfone, N.; Gulcher, J. R.; Lidar, D. A.; Chittenden, T. W. Quantum processor-inspired machine learning in the biomedical sciences. Patterns 2021, 2, 100246. [Google Scholar] [CrossRef] [PubMed]
- Priyadharshini, M.; Raju, B. D.; Banu, A. F.; Kumar, P. J.; Murugesh, V.; Rybin, O. A quantum machine learning framework for predicting drug sensitivity in multiple myeloma using proteomic data. Scientific Reports 2025, 15, 26553. [Google Scholar] [CrossRef]
- Prajapati, J.B.; Paliwal, H.; Prajapati, B.G.; Saikia, S.; Pandey, R. Quantum Machine Learning in Prediction of Breast Cancer. In Quantum Computing: A Shift from Bits to Qubits. Studies in Computational Intelligence; Pandey, R., Srivastava, N., Singh, N.K., Tyagi, K., Eds.; Springer: Singapore, 2023; pp. 351–382. [Google Scholar]
- Singh, N.; Pokhrel, S. R. Modeling Quantum Machine Learning for Genomic Data Analysis. arXiv 2025, arXiv:2501.08193. [Google Scholar] [CrossRef]
- Pomarico, D.; Fanizzi, A.; Amoroso, N.; Bellotti, R.; Biafora, A.; Bove, S.; Didonna, V.; La Forgia, D.; Pastena, M.I.; Tamborra, P.; Zito, A.; Lorusso, V.; Massafra, R. A Proposal of Quantum-Inspired Machine Learning for Medical Purposes: An Application Case. Mathematics 2021, 9, 410. [Google Scholar] [CrossRef]
- Flöther, F. F.; Blankenberg, D.; Demidik, M.; Jansen, K.; Krishnakumar, R.; Krishnakumar, R.; Laanait, N.; Parida, L.; Saab, C.; Utros, F. How quantum computing can enhance biomarker discovery for multi-factorial diseases. Patterns 2025, 6, 101236. [Google Scholar] [CrossRef]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M. H.; Zhou, X. Q.; Love, P. J.; Aspuru-Guzik, A.; O’Brien, J. L. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef]
- McClean, J.R.; Romero, J.; Babbush, R.; Aspuru-Guzik, A. The theory of variational hybrid quantum-classical algorithms. New J. Phys. 2016, 18, 023023. [Google Scholar] [CrossRef]
- Kuroiwa, K.; Nakagawa, Y.O. Penalty methods for a variational quantum eigensolver. Phys. Rev. Res. 2021, 3, 013197. [Google Scholar] [CrossRef]
- Huggins, W. J.; Lee, J.; Baek, U.; O’Gorman, B.; Whaley, K. B. A non-orthogonal variational quantum eigensolver. New J. Phys. 2020, 22, 073009. [Google Scholar] [CrossRef]
- Zhang, Y.; Cincio, L.; Negre, C.F.A.; Czarnik, P.; Coles, P.J.; Anisimov, P.M.; Mniszewski, S.M.; Tretiak, S.; Dub, P.A. Variational quantum eigensolver with reduced circuit complexity. npj Quantum Inf. 2022, 8, 96. [Google Scholar] [CrossRef]
- Ferguson, R.R.; Dellantonio, L.; Al Balushi, A.; Jansen, K.; Dür, W.; Muschik, C.A. A measurement-based variational quantum eigensolver. Phys. Rev. Lett. 2021, 126, 407. [Google Scholar] [CrossRef]
- Liu, J.G.; Zhang, Y.H.; Wan, Y.; Wang, L. Variational quantum eigensolver with fewer qubits. Phys. Rev. Res. 2021, 1, 023025. [Google Scholar] [CrossRef]
- Wang, D.; Higgott, O.; Brierley, S. Accelerated Variational Quantum Eigensolver. Phys. Rev. Lett. 2019, 122, 140504. [Google Scholar] [CrossRef] [PubMed]
- Kandala, A.; Mezzacapo, A.; Temme, K.; Takita, M.; Brink, M.; Chow, J.M.; Gambetta, J.M. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 2017, 549, 242–246. [Google Scholar] [CrossRef]
- Tilly, J.; Chen, H.; Cao, S.; Picozzi, D.; Setia, K.; Li, Y.; Grant, E.; Wossnig, L.; Rungger, I.; Booth, G.H.; Tennyson, J. The Variational Quantum Eigensolver: A review of methods and best practices. Phys. Rep. 2022, 986, 1–128. [Google Scholar] [CrossRef]
- Narnavaram, K.M.; Lo, D.C.T.; Zhang, X.; Deng, B. Quantum Synthetic Molecular Dynamics: Advanced Medical Innovations through Entangled Phenomena of Nucleic Acids. EasyChair Preprint 13837 2025, in press.
- Villalba-Díez, J. Quantum drug discovery: a hybrid quantum graph neural network–variational quantum eigensolver framework for serine neutralization. Eur. Phys. J. D 2025, 79, 81. [Google Scholar] [CrossRef]
- Roosan, D.; Khan, R.; Nirzhor, S.; Khou, T.; Hai, F. Classifying Hotspots Mutations for Biosimulation with Quantum Neural Networks and Variational Quantum Eigensolver. arXiv 2025, arXiv:2507.00072. [Google Scholar] [CrossRef]
- Doga, W. R.; Bose, A.; Sahin M., E.; Bettencourt-Silva, J.; Pham, A.; Kim, E.; Andress, A.; Saxena, S.; Parida, L.; Robertus, J. L.; Kawaguchi, H.; Soliman, R.; Blankenberg, D. How can quantum computing be applied in clinical trial design and optimization? Trends Pharmacol. Sci. 2024, 45, 880–891. [Google Scholar] [CrossRef]
- Khan, W. R.; Kamran, M. A.; Khan M., U.; Ibrahim, M. U.; Kim, K. S.; Ali, M. U. Diabetes Prediction Using an Optimized Variational Quantum Classifier Int. J. Intell. Syst. 2025, 1. [Google Scholar]
- Noor, F.; Nabi, G. Quantum-Enhanced Feature Selection and Classification for Asthma Diagnosis Using a Variational Quantum Classifier. MDPI AG 2025, in press.
- Yadalam, P. K.; Natarajan, P. M.; Saeed, M. H.; Ardila, C. M. Variational Approaches for Drug-Disease-Gene Links in Periodontal Inflammation. Int Dent J 2025, 75, 185–194. [Google Scholar] [CrossRef]
- Rajput, N. K.; Bansal, R. Quantum State Preparation for Medical Data: Comprehensive Methods, Implementation Challenges, and Clinical Prospects. arXiv 2025, arXiv:2508.05063. [Google Scholar] [CrossRef]
- Basu, S.; Born, J.; Bose, A.; Capponi, S.; Chalkia, D.; Chan, T.A.; Doga, H.; Flöther, F.F.; Getz, G.; Goldsmith, M.; Gujarati, T.; Guzmán-Sáenz, A.; Iliopoulos, D.; Jones, G.O.; Knecht, S.; Madan, D.; Maniscalco, S.; Mariella, N.; Morrone, J.A.; Najafi, K.; Pati, P.; Platt, D.; Rapsomaniki, M.A.; Ray, A.; Rhrissorrakrai, K.; Shehab, O.; Tavernelli, I.; Tolunay, M.; Utro, F.; Woerner, S.; Zhuk, S.; Garcia, J.M.; Parida, L. Towards quantum-enabled cell-centric therapeutics. arXiv 2023, arXiv:2307.05734. [Google Scholar]
- Manjili, M.H.; Manjili, S.H. The quantum model of T-cell activation: Revisiting immune response theories. Scand. J. Immunol. 2024, 100, e:13375. [Google Scholar] [CrossRef]
- Fujii, Y. R. The Quantum microRNA Immunity in Human Virus-Associated Diseases: Virtual Reality of HBV, HCV and HIV-1 Infection, and Hepatocellular Carcinogenesis with AI Machine Learning. Arch. Clin. Biomed. Res. 2020, 4, 089–129. [Google Scholar]
- Roosan, D.; Nirzhor, S.; Khan, R.; Hai, F.; Haidar, M.R. Quantum Approximate Optimization Algorithm for Spatiotemporal Forecasting of HIV Clusters. arXiv 2025, arXiv:2507.00848. [Google Scholar] [CrossRef]
- Choppara, P.; Lokesh, B. Leveraging Quantum LSTM for High-Accuracy Prediction of Viral Mutations. IEEE Access 2025, 12, 25282–25300. [Google Scholar] [CrossRef]
- Roosan, D.; Khan, R.; Khou, T.; Nirzhor, S.; Hai, F.; Provencher, B. Bridging Classical Molecular Dynamics and Quantum Foundations for Comprehensive Protein Structural Analysis. arXiv 2025, arXiv:2506.20830. [Google Scholar] [CrossRef]
- Roosan, D.; Samrose, S.; Khan, R.; Nirzhor, S.; Provencher, B. Quantum analysis of protein-ligand binding by integrating structural resolution, sequence homology, and ligand properties. In Proceedings of the Obesity, Fitness and Wellness Week, Atlanta GA, USA, 19 July 2025. [Google Scholar]
- Roosan, D.; Nirzhor, S.; Khan, R. Integrating Pharmacokinetics and Pharmacodynamics Modeling with Quantum Regression for Predicting Herbal Compound Toxicity. In Proceedings of the 2025 World Congress in Computer Science, Computer Engineering, and Applied Computing, Las Vegas, USA, 22 July 2025. [Google Scholar]
- Roosan, D.; Khou, T.; Nirzhor, S.; Khan, R.; Hai, F.; Essien-Aleksi, I.; Baskys, A. Harnessing Quantum and Liquid Neural Networks for Drug Repurposing in Neurology. In Management Science and Industrial Engineering; Gaol, F. L., Xu, Y., Dessouky, Y., Eds.; Advances in Transdisciplinary Engineering: Bai Island, Indonesia, 2025; pp. 29–36. [Google Scholar]
- Roosan, D.; Khan, R.; Ashakin, M. R.; Khou, T.; Nirzhor, S.; Haider, M. R. Quantum Variational Transformer Model for Enhanced Cancer Classification. In Proceedings of the 7th International conference on Industrial Engineering and Artificial Intelligence, Krabi, Thailand, 23–25 April 2026. [Google Scholar]
- Roosan, D.; Nirzhor, S.; Khan, R.; Hai, F. Quantum Gradient Optimized Drug Repurposing Prototype for Omics Data. In Proceedings of the 14th International Conference on Data Science, Technology and Applications, Bilbao, Spain, 10–12 June 2025. [Google Scholar]
- Acuña González, J.P.; Sánchez Adame, M.; Montiel Ross, O.H. Variational Quantum Eigensolver for Clinical Biomarker Classification: A Hybrid Quantum-Classical Approach to HIV/TB Co-Infection and Drug Resistance Prediction. In Proceedings of the Seminar of Artificial Intelligence and Quantum Computing, Tijuana, Mexico, 16 October 2025. [Google Scholar]
- Acuña González, J.P. qvirus: Quantum Computing for Analyzing CD4 Lymphocytes and Antiretroviral Therapy, version 0.0.4; CRAN, 2025.
- R Core Team, R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. 2025. Available online: https://www.R-project.org/ (accessed on 21 September 2025).
- Ozluer Baser, B. Analyzing the Competition of HIV-1 Phenotypes with Quantum Game Theory. GU J Sci 2022, 35, 1190–1198. [Google Scholar]
- Crawford, O.; Straaten, B.V.; Wang, D.; Parks, T.; Campbell, E.; Brierley, S. Efficient quantum measurement of pauli operators in the presence of finite sampling error. Quantum 2021, 5, 385. [Google Scholar] [CrossRef]

Table 1.
Clinical Hamiltonian Results, Latent Structural Risk and Hardware Analysis for the Stable Patient Scenario.
Table 1.
Clinical Hamiltonian Results, Latent Structural Risk and Hardware Analysis for the Stable Patient Scenario.
| Metric | Value | Search Parameter | Clinical Implication |
|---|---|---|---|
| Optimal Hamiltonian | 1 term | Defines the Intrinsic Base Energy of Health () | |
| Analytic Delta () | 0 | N/A | Exact Eigenspace Alignment |
| Min Delta (Comp.) | 100,000 shots | Minimal computational search error | |
| Qubit 1 Encoding | N/A | Active dynamics (non zero VL/CD4 differentials) | |
| Qubit 2 Encoding | N/A | Ideal outcome state () | |
| Latent Risk Coefficient C | Cor | Energy derived from the rejected risk term | |
| Feature | (Phenotypic Robustness) | System inertia embedded in the clinical cohort | |
| Feature | (Z gate strategy) | N/A | Most aggressive (high-risk) viral strategy |
| Prognostic Shots | 0 | Zero Measurement Cost (Eliminates Finite Sampling Error) | |
| Shots for Latent risk () | ≈ 47,710 | Budget required to measure the neutralized competing term |
Table 2.
Clinical Hamiltonian Results, Strategy Interaction, and Hardware Analysis for the TB Co-Infected Patient Scenario.
Table 2.
Clinical Hamiltonian Results, Strategy Interaction, and Hardware Analysis for the TB Co-Infected Patient Scenario.
| Metric | Value | Search Parameter | Clinical Implication |
|---|---|---|---|
| Optimal Hamiltonian | 1 term | Defines the Anti-Correlated Energy of Instability () | |
| Analytic Delta () | N/A | Good Approximate Eigenspace Alignment | |
| Min Delta (Comp.) | shots | High fidelity computational search convergence | |
| Qubit 1 Encoding | N/A | Active dynamics (non zero VL/CD4 changes) | |
| Qubit 2 Encoding | N/A | High risk, non ideal outcome state. | |
| Interaction Coefficient C | Cor | Inverse correlation (Suppression of strategic risk by dynamics) | |
| Feature | (low replication’s H strategy) | (low replication plays X) | Latent strategic risk factor |
| Feature | (viral load change) | Active biomarker coupled to the strategy | |
| Prognostic Shots | variance | Budget for high assurance clinical prognosis | |
| Prognostic Shots | Budget for cost-efficient NISQ tracking |
Table 3.
Clinical Hamiltonian Results, Strategy Interaction, and Hardware Analysis for the Drug Resistance (GR) Patient Scenario.
Table 3.
Clinical Hamiltonian Results, Strategy Interaction, and Hardware Analysis for the Drug Resistance (GR) Patient Scenario.
| Metric | Value | Search Parameter | Clinical Implication |
|---|---|---|---|
| Optimal Hamiltonian | 1 term | Defines the Conditional Payoff Energy of Instability () | |
| Analytic Delta () | N/A | High Approximate Eigenspace Alignment | |
| Min Delta (Comp.) | shots | Minimal computational search error | |
| Qubit 1 Encoding | N/A | Unstable, active dynamics | |
| Qubit 2 Encoding | N/A | Minimal outcome state shift | |
| Interaction Coefficient C | Cor(str2_5,payoffs) | Inverse Correlation (Strategy suppression vs. fitness) | |
| Feature | (high replication X strategy) | (high replication plays I) | Latent defensive strategic threat |
| Feature | payoffs (Viral Fitness) | Active biomarker proxy for reproductive capacity | |
| Prognostic Shots () | ZZ variance | Budget for high assurance clinical prognosis | |
| Prognostic Shots () | Budget for cost-efficient NISQ tracking |
Table 4.
Classification performance of the optimal single-term clinical Hamiltonian () when optimized for different loss functions for the status.
Table 4.
Classification performance of the optimal single-term clinical Hamiltonian () when optimized for different loss functions for the status.
| Loss Function | Accuracy | Sensitivity (TPR) | Specificity (TNR) | Balanced Accuracy |
|---|---|---|---|---|
| Simple Error | 0.960 | 0.125 | 1.000 | 0.563. |
| Balanced Error | 0.909 | 0.875 | 0.923 | 0.899 |
| Penalized Error | 0.955 | 0.375 | 0.982 | 0.679 |
Table 5.
Classification performance of the optimal single-term clinical Hamiltonian () when optimized for different loss functions for the status.
Table 5.
Classification performance of the optimal single-term clinical Hamiltonian () when optimized for different loss functions for the status.
| Loss Function | Accuracy | Sensitivity (TPR) | Specificity (TNR) | Balanced Accuracy |
|---|---|---|---|---|
| Simple Error | 0.972 | 0.167 | 1.000 | 0.583. |
| Balanced Error | 0.881 | 0.667 | 0.894 | 0.827 |
| Penalized Error | 0.977 | 0.333 | 1.000 | 0.667 |
Table 6.
Comparative performance of Weighted Classical Baselines (LogReg and MLP) for and statuses, against the optimal VQE (Balanced Error) model.
Table 6.
Comparative performance of Weighted Classical Baselines (LogReg and MLP) for and statuses, against the optimal VQE (Balanced Error) model.
| Target | Model | Accuracy | Sensitivity (TPR) | Specificity (TNR) | Balanced Accuracy |
|---|---|---|---|---|---|
| LogReg (Weighted) | 0.906 | 0.000 | 0.960 | 0.480 | |
| MLP (Weighted) | 0.925 | 0.000 | 0.980 | 0.490 | |
| VQE (Balanced Error) | 0.950 | 0.840 | 0.960 | 0.900 | |
| LogReg (Weighted) | 0.774 | 0.333 | 0.800 | 0.567 | |
| MLP (Weighted) | 0.623 | 0.667 | 0.620 | 0.644 | |
| VQE (Balanced Error) | 0.881 | 0.667 | 0.894 | 0.827 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



