Submitted:
10 November 2025
Posted:
11 November 2025
You are already at the latest version
Abstract
This study focuses on analyzing students' educational performance and their behavior in relation to their grade point average (GPA), using a dataset that includes socio-behavioral and educational attributes. Machine learning techniques were applied to predict GPA and to develop a predictive model. Exploratory data analysis identified key correlations, and various algorithms were used for GPA prediction. The aim of this study is to assist policymakers in designing strategies to enhance educational outcomes and support student development. It highlights the importance for universities to identify students at risk of low GPA and to improve future predictions to help boost student performance.
Keywords:
student performance
; GPA prediction
; machine learning
; behavioral factor
1. Introduction
This dataset is a comprehensive educational dataset that contains a detailed analysis of 2,392 students’ academic performance and other curricular activities. It includes 15 columns that cover various metrics such as demographic, behavioral, and educational (or academic) attributes [11].
Demographic features include Student ID, Age, Gender, and Ethnicity. The dataset also includes variables like Parental Education, Weekly Study Time, and Absences, which highlight study habits and parental background [12].
The core objective of this dataset is to evaluate and predict students’ educational performance, particularly focusing on GPA (Grade Point Average) and grade class as outcome variables. It provides valuable insights into student performance and allows for multiple types of analysis, especially those involving demographic and behavioral factors [13,14,15].
The dataset also addresses key challenges in predicting student performance, such as determining their grade class. This problem is approached using various machine learning algorithms, including Random Forest, SVM, ANN, Naïve Bayes, AutoML, KNN, and Decision Tree [16,17,18,19]. By applying these algorithms using RapidMiner, their predictive accuracies were compared. The structure of this study follows a systematic research flow, as illustrated in Figure 1. The workflow begins with the Introduction, which sets the foundation by outlining the research problem and objectives [20,21]. This is followed by the Literature Review, which explores existing work and identifies gaps in prior research. The Proposed Methodology section details the techniques and models employed to address the research problem. The Results section presents the findings derived from experimentation and analysis. Finally, the paper concludes with the Conclusion, summarizing key insights and future research directions.
2. Literature Review
This paper focuses on analyzing student educational performance using machine learning techniques. Ghorbani and Ghousi [2] compared different resampling methods for handling class imbalance in predicting student performance using Support Vector Machines (SVM) and SMOTE, achieving the highest accuracy of 73% on an Iranian dataset. Their study enhances understanding in educational data mining and improves predictive modeling.
Mengash [1] applied Artificial Neural Networks (ANN) to analyze data from a Saudi university. Despite fixed admission criteria, only first-year students’ performance was used to refine university decision-making using data mining techniques. Albreiki et al. [3] proposed a six-step framework data collection, statistical analysis, preparation, preprocessing, implementation, and evaluation for predicting academic success indicators such as GPA, persistence, and engagement without requiring advanced technical skills.
Yağcı [4] analyzed Chinese university data using trained ANN models and recommended future refinements to improve prediction accuracy. The model identified critical factors such as exam results, gender, and institutional support, although it also highlighted challenges related to gender classification imbalances.
A study on 1,854 undergraduate students from a Turkish university [5] predicted final term grades using midterm grades, department, and faculty. It found midterm grades to be strong predictors of final outcomes, even without demographic data. Algorithms such as Random Forest, Neural Networks, and SVM achieved accuracies between 70–75%.
Namoun and Alshanqiti [6] surveyed machine learning approaches from 2009 to 2021, focusing on university databases and online learning platforms to predict student performance. Their findings emphasized the importance of incorporating both static and dynamic data to improve educational outcomes and reduce dropout rates.
Zhang et al. [8] explored how higher education institutions could use video learning and data mining techniques across student information systems and learning management systems, applying eight classification algorithms to predict performance.
A study focusing on Nigerian engineering students [7] calculated final CGPA based on performance in the first three years using data mining techniques. By applying k-Nearest Neighbors (kNN) and regression analysis, it achieved 89% prediction accuracy. This approach proved useful for identifying weak students and reducing failure and dropout rates.
Rehman et al. [9] conducted a study on 124 students, showing that those more active in model learning systems tended to achieve better final grades. The study also revealed that female students outperformed males. The results helped identify students’ weaknesses and improve the teaching–learning process.
Allensworth and Clark [10] found that high school GPAs were a stronger and more consistent predictor of college graduation than ACT scores, which were shown to be influenced more by school effects. Their study suggested that educational systems should place less reliance on standardized tests and focus more on GPA-based assessments..
3. Proposed Methodology
This research proposes a machine learning-based methodology for predicting student GPA using various classification algorithms. The workflow was implemented in RapidMiner, with a dataset sourced from Kaggle. Figure 2 shows the detailed steps of machine learning workflow.
The methodology follows these major steps:
- Data Preprocessing: Cleaning missing values, removing irrelevant columns, and normalizing features.
- Exploratory Data Analysis (EDA): Identifying relationships between key attributes.
- Feature Engineering: Creating new attributes such as total activity count and transforming categorical variables into numerical ones.
- Model Training: Four classifiers were trained—KNN, Naïve Bayes, Artificial Neural Network (ANN), and AutoMLP. The dataset was split into training and testing subsets.
- Model Evaluation: Accuracy was used as the primary metric to compare model performance.
- Recommendation: Insights were drawn from the analysis to assist educational institutions in identifying at-risk students and enhancing learning strategies [16].
Table 1 shows the different selected ML models with their parameter descriptions.
3.1. Dataset Description
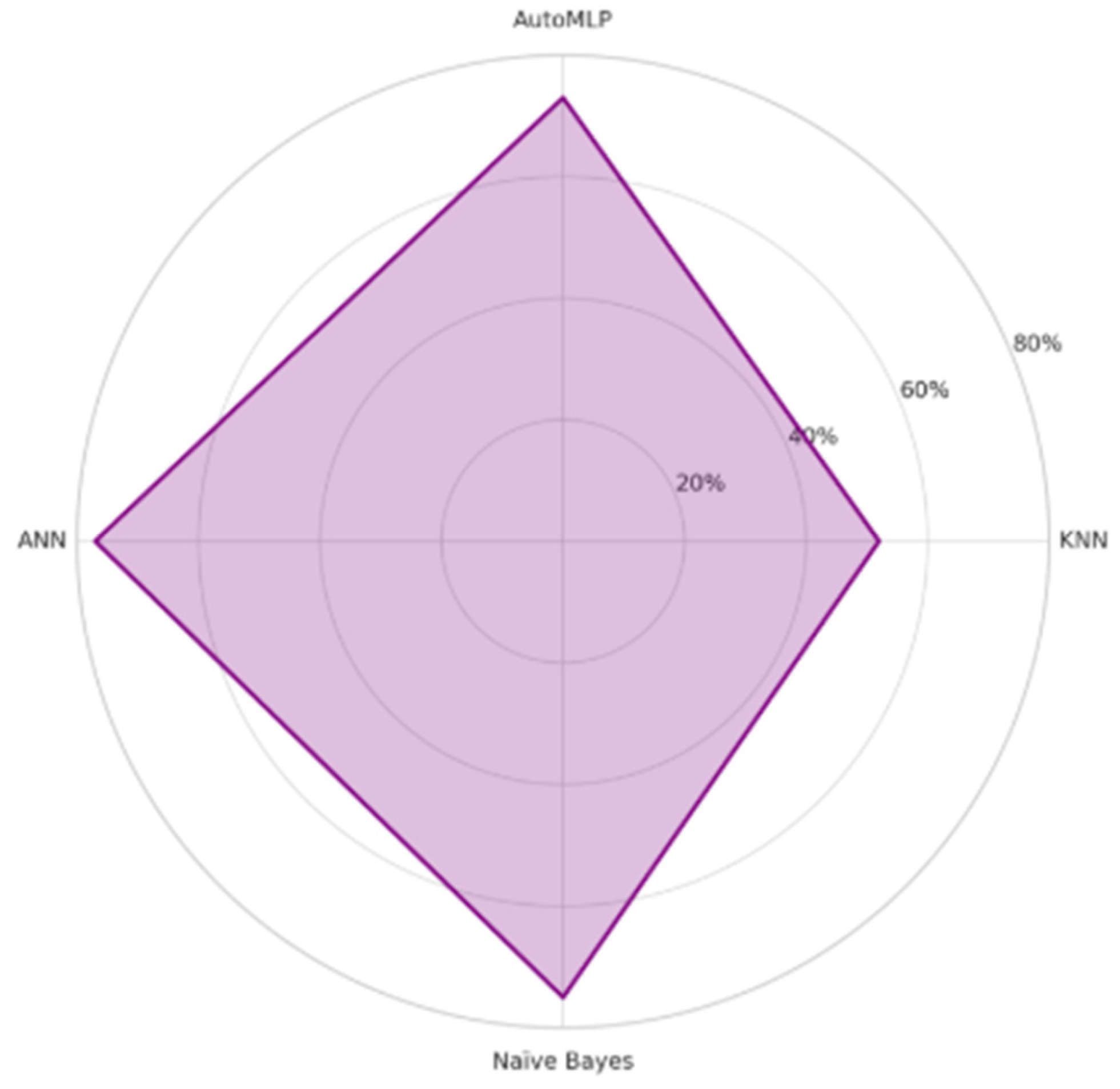
The dataset consists of 2,392 high school students and includes variables such as study habits, parental involvement, and extracurricular activities. The target variable is the Grade Class. After applying all algorithms, ANN achieved the highest accuracy of 77%, making it the best-performing model for predicting student academic outcomes. Table 2 shows dataset description.
Figure 3 shows a sample rapid miner workflow.
4. Results
The primary objective of this study was to predict student GPA and understand the factors influencing academic performance using machine learning. The analysis revealed key influencers such as study time, parental support, and extracurricular involvement. These social and behavioral factors play a significant role in shaping educational outcomes.
We used predictive modeling, the system identifies students with lower expected performance, enabling targeted interventions to improve learning outcomes and reduce dropout rates. The study demonstrates that data-driven approaches can significantly enhance educational strategy and student success.

Table 3.
Accuracy Comparison of ML Algorithms.
| Algorithm | Accuracy |
| KNN | 52% |
| AutoMLP | 73% |
| ANN | 77% |
| Naïve Bayes | 75% |
Figure 4.
Polar Bar Chart Visualization of Results.
5. Conclusions
The main goal of this research paper is to understand student performance and identify the factors that affect GPA. By applying machine learning techniques, we not only predict students’ GPA but also gain insights into their potential for educational and professional success. This study emphasizes the importance of data-driven approaches to enhance the educational system, particularly for supporting underperforming students. Among the tested models, the Artificial Neural Network (ANN) achieved the highest accuracy at 77%, making it the most effective in predicting student GPA. For future work, this model can be further refined to adapt to different educational systems and grading structures. Incorporating a more diverse dataset that includes social, cultural, and economic factors will enhance the model’s robustness.
References
- Mengash, H.A. Using data mining techniques to predict student performance to support decision making in university admission systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Ghorbani, R.; Ghousi, R. Comparing different resampling methods in predicting students’ performance using machine learning techniques. IEEE Access 2020, 8, 67899–67911. [Google Scholar] [CrossRef]
- Albreiki, B.; Zaki, N.; Alashwal, H. Systematic literature review of predicting student performance using machine learning techniques. Education Sciences 2021, 11. [Google Scholar] [CrossRef]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learning Environments 2022, 9. [Google Scholar] [CrossRef]
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Applied Sciences 2021, 11, 237. [Google Scholar] [CrossRef]
- Allensworth, E.M.; Clark, K. High school GPAs and ACT scores as predictors of college completion: Examining assumptions about consistency across high schools. Educational Researcher 2020, 49, 198–211. [Google Scholar] [CrossRef]
- Zhang, Y.; Ghandour, A.; Shestak, V. Using learning analytics to predict students’ performance in Moodle LMS. International Journal of Emerging Technologies in Learning 2020, 15, 102–114. [Google Scholar] [CrossRef]
- Rehman, A.U.; et al. A machine learning--based framework for accurate and early diagnosis of liver diseases: A comprehensive study on feature selection, data imbalance, and algorithmic performance. International Journal of Intelligent Systems 2024. [Google Scholar] [CrossRef]
- Ali, T.M.; et al. A sequential machine learning-cum-attention mechanism for effective segmentation of brain tumor. Frontiers in Oncology 2022, 12, 873268. [Google Scholar] [CrossRef] [PubMed]
- Mir, H.; et al. A novel approach for the effective prediction of cardiovascular disease using applied artificial intelligence techniques. ESC Heart Failure 2024. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, Q.W.; Garg, S.; Rai, A.; Ramachandran, M.; Jhanjhi, N.Z.; Masud, M.; Baz, M. Ai-based resource allocation techniques in wireless sensor internet of things networks in energy efficiency with data optimization. Electronics 2022, 11, 2071. [Google Scholar] [CrossRef]
- Khan, N.A.; Jhanjhi, N.Z.; Brohi, S.N.; Almazroi, A.A.; Almazroi, A.A. A secure communication protocol for unmanned aerial vehicles. CMC-Computers Materials & Continua 2020, 70, 601–618. [Google Scholar]
- Muzafar, S.; Jhanjhi, N.Z. Success stories of ICT implementation in Saudi Arabia. In Employing Recent Technologies for Improved Digital Governance; IGI Global Scientific Publishing, 2020; pp. 151–163. [Google Scholar]
- Jabeen, T.; Jabeen, I.; Ashraf, H.; Jhanjhi, N.Z.; Yassine, A.; Hossain, M.S. An intelligent healthcare system using IoT in wireless sensor network. Sensors 2023, 23, 5055. [Google Scholar] [CrossRef] [PubMed]
- Shah, I.A.; Jhanjhi, N.Z.; Laraib, A. Cybersecurity and blockchain usage in contemporary business. In Handbook of Research on Cybersecurity Issues and Challenges for Business and FinTech Applications; IGI Global, 2023; pp. 49–64. [Google Scholar]
- Hanif, M.; Ashraf, H.; Jalil, Z.; Jhanjhi, N.Z.; Humayun, M.; Saeed, S.; Almuhaideb, A.M. AI-based wormhole attack detection techniques in wireless sensor networks. Electronics 2022, 11, 2324. [Google Scholar] [CrossRef]
- Shah, I.A.; Jhanjhi, N.Z.; Amsaad, F.; Razaque, A. The role of cutting-edge technologies in industry 4.0. In Cyber Security Applications for Industry 4.0; Chapman and Hall/CRC, 2022; pp. 97–109. [Google Scholar]
- Humayun, M.; Almufareh, M.F.; Jhanjhi, N.Z. Autonomous traffic system for emergency vehicles. Electronics 2022, 11, 510. [Google Scholar] [CrossRef]
- Muzammal, S.M.; Murugesan, R.K.; Jhanjhi, N.Z.; Jung, L.T. SMTrust: Proposing trust-based secure routing protocol for RPL attacks for IoT applications. In 2020 International Conference on Computational Intelligence (ICCI); IEEE, 2020; pp. 305–310. [Google Scholar]
- Brohi, S.N.; Jhanjhi, N.Z.; Brohi, N.N.; Brohi, M.N. Key applications of state-of-the-art technologies to mitigate and eliminate COVID-19. Authorea Preprints 2023.
- Khalil, M.I.; Humayun, M.; Jhanjhi, N.Z.; Talib, M.N.; Tabbakh, T.A. Multi-class segmentation of organ at risk from abdominal ct images: A deep learning approach. In Intelligent Computing and Innovation on Data Science: Proceedings of ICTIDS 2021.; Singapore: Springer Nature Singapore, 2021; pp. 425–434. [Google Scholar]
- Humayun, M.; Jhanjhi, N.Z.; Niazi, M.; Amsaad, F.; Masood, I. Securing drug distribution systems from tampering using blockchain. Electronics 2022, 11, 1195. [Google Scholar] [CrossRef]
Figure 1.
Workflow diagram representing the structure of the research paper.
Figure 2.
ML Workflow.
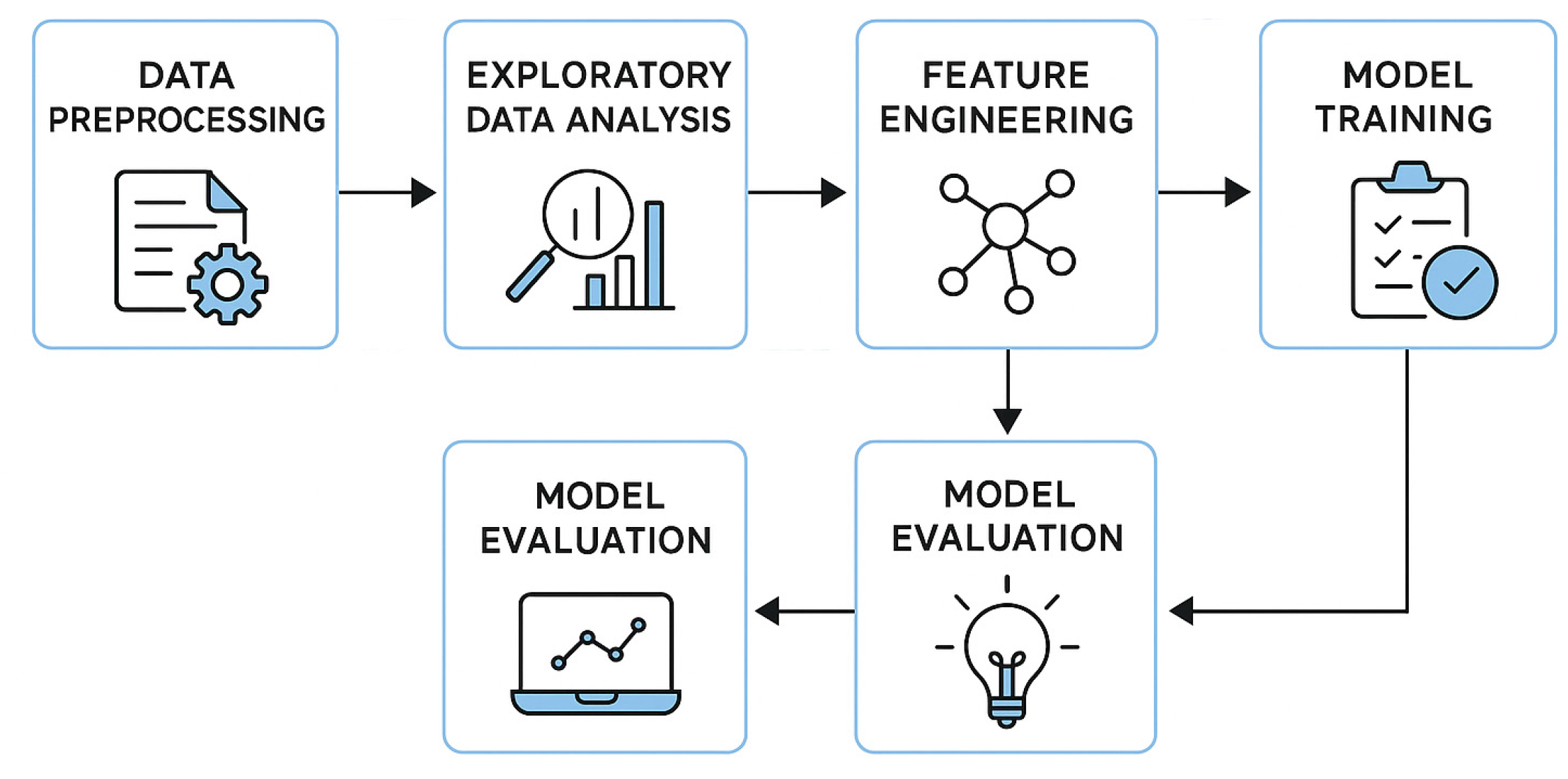
Figure 3.
Rapid Miner Workflow.
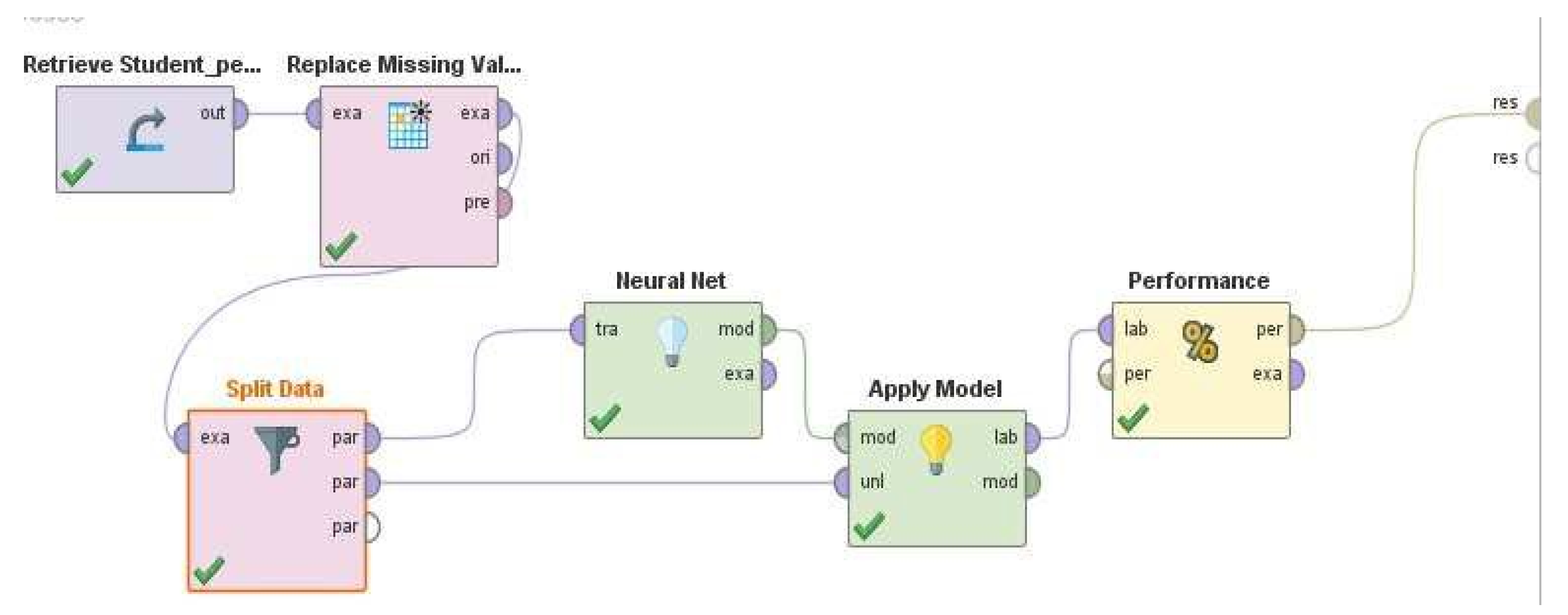
Table 1.
ML Algorithms and Parameters.
| Algorithm | Key Parameters Used |
| KNN | k=5, Distance: Euclidean |
| Naïve Bayes | Assumes independent features, Gaussian distribution |
| ANN | 3 hidden layers, ReLU activation, 100 epochs |
| AutoMLP | Random/Grid Search, Auto-optimized architecture |
Table 2.
Dataset Description of Parameters.
| Attribute | Description |
| StudentID | Unique identifier for each student |
| Age | Age of the student |
| Gender | Gender of the student (Male = 1, Female = 0) |
| Ethnicity | Ethnic background of the student |
| ParentalEducation | Educational level of the parents |
| GPA | Grade Point Average |
| GradeClass | Grade category (1, 2, 3, 4) |
| ParentalSupport | Level of support from parents |
| StudyTimeWeekly | Number of hours studied per week |
| Absences | Total number of absences |
| Tutoring | Whether the student receives tutoring (Yes/No) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



