Submitted:
30 October 2025
Posted:
31 October 2025
You are already at the latest version
Abstract
Machine learning (ML) models deployed in production face inevitable challenges such as concept drift, data distribution shifts, and pipeline failures, which can erode performance and reliability. Traditional monitoring systems identify anomalies but require manual intervention, leading to delays in remediation and increased operational costs. This paper explores the paradigm of self-healing ML pipelines, which integrate automated drift detection with remediation mechanisms to sustain performance in dynamic environments. We examine architectural patterns, frameworks, and practical implementations that enable continuous monitoring, adaptive retraining, and pipeline recovery with minimal human input. Case studies from diverse sectors highlight how production-grade ML systems can evolve toward resilience, scalability, and long-term trustworthiness through automation. This work contributes a comprehensive survey of drift detection techniques, remediation strategies, and self-healing frameworks, offering insights for researchers and practitioners designing reliable production ML systems.
Keywords:
self-healing systems
; machine learning pipelines
; drift detection
; remediation
; automation
; model monitoring
; adaptive retraining
; production ML
; resilience
1. Introduction
Machine learning has rapidly transitioned from research prototypes to mission-critical systems in finance, healthcare, e-commerce, and other industries. As organizations integrate ML models into decision-making pipelines, ensuring sustained performance becomes a pressing concern. However, real-world production environments are inherently dynamic: user behaviors evolve, sensor conditions fluctuate, and external market trends shift unpredictably. These changes can introduce drift, where the statistical properties of input data or relationships between features and labels differ from those seen during training. Left unchecked, drift can degrade prediction quality, reduce trust in AI systems, and generate costly failures.
Traditional monitoring and maintenance approaches rely heavily on human oversight. Data scientists or ML engineers set up dashboards, track key metrics, and manually intervene when performance drops. While this approach can identify problems, it scales poorly in environments where multiple models are deployed simultaneously, each consuming heterogeneous data streams. The rise of self-healing ML pipelines addresses this challenge by embedding automation into both detection and remediation processes. Instead of merely flagging anomalies, such systems proactively respond—triggering retraining workflows, adjusting feature engineering steps, or rolling back to safe models with minimal downtime.
The notion of self-healing pipelines is rooted in principles from distributed systems and autonomic computing. Just as modern cloud infrastructure employs self-healing mechanisms (such as restarting failed containers or rescheduling workloads), ML pipelines can incorporate similar resilience strategies. For instance, a pipeline detecting label drift in a fraud detection system could automatically initiate incremental retraining using the latest labeled transactions, ensuring the model remains aligned with evolving fraud patterns.
Another driver for self-healing ML systems is the growing importance of compliance and reliability. Regulatory frameworks in sectors like healthcare and finance demand robust model governance. Automated remediation provides not only efficiency but also a documented audit trail of system responses to drift. This capability aligns operational ML practices with the accountability requirements emerging worldwide.
The diagram in Figure 1 illustrates the layered structure of a self-healing ML pipeline. Each stage is tightly integrated, with feedback loops ensuring that drift detection directly informs retraining or rollback operations. The inclusion of automated healing actions differentiates these pipelines from traditional ML workflows, aligning them with the demands of production resilience.
Moreover, organizations increasingly expect ML pipelines to be cost-efficient. Manual interventions extend recovery times and increase reliance on specialized expertise. Automated solutions reduce mean time to repair (MTTR), improve return on investment, and free up ML teams to focus on innovation rather than firefighting production issues. Self-healing pipelines thus sit at the intersection of operational efficiency, trustworthiness, and regulatory compliance.
In this paper, we conduct a structured survey and review of frameworks, techniques, and case studies that support self-healing ML pipelines. Section II surveys drift detection methods, spanning statistical hypothesis testing, distance-based metrics, and ML-based detectors. Section III examines remediation strategies, including incremental learning, pipeline rollback, and active learning-driven retraining. Section IV highlights real-world frameworks and platforms that enable automated healing, while Section V discusses sectoral case studies from finance, healthcare, and e-commerce. Section VI addresses challenges, including explainability, fairness, and engineering complexity. Finally, Section VII offers conclusions and future directions for resilient ML systems.
2. Drift Detection Techniques
Drift in machine learning pipelines occurs when the statistical distribution of incoming data or its relationship with the target variable changes over time. Detecting such drift early is crucial to prevent model degradation and ensure reliability in production systems. Various categories of drift detection methods have been proposed, each with strengths and limitations depending on application context, data availability, and computational constraints.
A fundamental class of methods involves statistical hypothesis testing. These approaches compare the distributions of recent data with historical or training distributions. Techniques such as the Kolmogorov–Smirnov test, Chi-square test, and Jensen–Shannon divergence are frequently applied to numerical and categorical features. Their strength lies in simplicity and interpretability, but they may struggle with high-dimensional data where multiple comparisons complicate decision-making [1].
Another prominent approach leverages distance-based metrics. By quantifying divergence between feature distributions or embeddings, methods such as Kullback–Leibler divergence or Wasserstein distance provide fine-grained drift measurement. These metrics are well-suited for detecting gradual shifts in input space, particularly in applications like image recognition or natural language processing, where latent space representations are available from deep models.
A third class consists of ML-based detectors, where a secondary model is trained to discriminate between past and present data. If this discriminator achieves high accuracy, it indicates drift between the two distributions. Examples include adversarial validation, where a classifier distinguishes training versus production samples. Such methods are powerful in capturing complex, non-linear shifts but require careful calibration to avoid false positives in dynamic environments.
Table 1 summarizes the comparative strengths and weaknesses of major drift detection techniques across different criteria. The table highlights how method selection is influenced by trade-offs between accuracy, interpretability, and computational cost. Meanwhile, Figure 2 illustrates adoption patterns of these methods across practical use cases.
The comparison in Table 1 shows that no single technique is universally optimal. Instead, production systems often combine multiple detectors, using lightweight statistical tests for real-time signals and more complex detectors for periodic validation. This layered approach maximizes both responsiveness and robustness.
Figure 2 visualizes how statistical and distance-based methods dominate due to their simplicity and computational tractability, while ML-based and streaming algorithms are emerging for complex, dynamic pipelines. This trend underscores the gradual evolution of drift detection from traditional statistical tools toward more adaptive, AI-driven solutions.
More advanced frameworks integrate streaming drift detection, allowing continuous monitoring of incoming data with bounded memory and low latency. Algorithms like DDM (Drift Detection Method) and EDDM (Early Drift Detection Method) are widely used in streaming contexts such as online recommendation systems and IoT analytics. These methods balance sensitivity with computational efficiency, ensuring timely responses without overwhelming resources [2].
Beyond input data distributions, pipelines must also consider concept drift, where the relationship between inputs and outputs changes. This scenario is particularly challenging, as label availability may lag in production. Techniques such as performance monitoring, delayed feedback loops, and active learning strategies can provide indirect signals for concept drift, enabling retraining decisions even in partially supervised contexts.
3. Remediation Strategies
While drift detection alerts practitioners to changes in data or model behavior, the true strength of a self-healing ML pipeline lies in its ability to remediate issues with minimal manual intervention. Remediation strategies ensure that once drift is detected, the pipeline adapts by retraining models, adjusting preprocessing steps, or rolling back to safer configurations. The following subsections highlight key remediation techniques and their operational considerations.
A widely adopted remediation strategy is incremental learning, where models are continuously updated with newly arriving data. Instead of retraining from scratch, incremental updates reduce training time and allow models to adapt smoothly to changing distributions. This method is particularly useful in domains such as fraud detection or recommender systems, where new patterns emerge frequently and models must stay current without excessive downtime[3].
Another important approach involves pipeline rollback. In this method, if a newly deployed model exhibits degraded performance due to unforeseen drift, the system automatically reverts to a previous stable version. Rollbacks provide safety nets for production environments by ensuring that service continuity is maintained, even while newer models are re-evaluated. Although rollbacks may not always provide optimal accuracy, they preserve user trust by preventing catastrophic errors.
Active learning has also emerged as a remediation strategy, particularly in scenarios with delayed or limited label availability. In this setup, the pipeline actively queries for labels on uncertain or representative samples and incorporates them into retraining processes. By focusing annotation efforts where they matter most, active learning reduces labeling costs while still addressing concept drift effectively.
Some organizations employ automated retraining schedules, where models are periodically retrained regardless of explicit drift detection. This strategy simplifies pipeline design but may waste resources if drift is absent or minor. Hybrid strategies, combining drift-triggered retraining with scheduled updates, often strike the best balance between efficiency and responsiveness.
Self-healing pipelines also leverage ensemble strategies. For example, multiple models can be maintained simultaneously, with a monitoring layer dynamically selecting the best-performing one. This approach enables graceful degradation, where even if one model deteriorates due to drift, alternatives sustain accuracy until a retraining cycle completes [4] .
Table 2 summarizes these remediation strategies, highlighting their trade-offs in terms of latency, cost, and operational complexity. Figure 3 illustrates the remediation flow in a self-healing pipeline. Finally, Listing provides an example of an automated retraining loop in Python.
The comparison in Table 2 shows how organizations often mix and match strategies based on their production constraints. While rollback guarantees immediate stability, incremental learning and ensembles maximize adaptability. The right choice depends on balancing latency, accuracy, and resource efficiency.
Figure 3 demonstrates how multiple remediation strategies can be orchestrated. Depending on severity and context, the pipeline may trigger rollbacks, incremental updates, or ensemble switches, ensuring resilience while minimizing downtime.
Listing 3 provides a simplified code snippet for automating retraining. When drift exceeds a defined threshold, the pipeline retrains on the latest data and redeploys the model automatically. In real-world deployments, this loop would be integrated with orchestration systems such as Kubernetes, Airflow, or MLflow to ensure robustness and scalability [5].
| Listing 1. Automated retraining loop triggered by drift detection. |
 |
4. Frameworks and Platforms for Self-Healing ML
The implementation of self-healing ML pipelines depends heavily on orchestration platforms and monitoring frameworks that provide automation, scalability, and reliability. Over the past few years, open-source and commercial solutions have evolved to support automated drift detection, retraining workflows, and lifecycle management. This section reviews key platforms that enable production-grade self-healing pipelines[6].
Kubeflow is a leading open-source project that provides end-to-end ML lifecycle management on Kubernetes. Its modular architecture includes pipelines for workflow orchestration, KFServing for model serving, and integrations for continuous monitoring. Kubeflow’s containerized design makes it especially suited for large-scale deployments, where automated healing is achieved through Kubernetes-native features like pod restarts and job rescheduling.
MLflow, on the other hand, emphasizes experiment tracking, model registry, and reproducibility. While not designed specifically for self-healing, MLflow integrates seamlessly with monitoring tools to trigger retraining workflows. Organizations often combine MLflow with orchestration engines such as Apache Airflow or Prefect to create automated retraining loops when drift is detected [7] .
Cloud-native services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI provide built-in features for monitoring, retraining, and deployment. These platforms simplify self-healing implementations by abstracting infrastructure concerns. For example, SageMaker Model Monitor can detect data drift and initiate retraining pipelines, while Azure ML integrates alert-driven retraining through its event-based architecture[8] .
Workflow orchestrators such as Apache Airflow, Prefect, and Dagster play a complementary role. They allow engineers to design DAGs (Directed Acyclic Graphs) that define remediation steps triggered by drift detection. These orchestrators ensure that retraining jobs, rollbacks, and ensemble switches occur in a reliable, fault-tolerant manner [9].
Another important trend is the emergence of MLOps observability platforms. Tools like Evidently AI, Fiddler, and Arize AI provide detailed monitoring dashboards, alerting systems, and performance tracking. While these tools do not directly perform remediation, they feed actionable insights into self-healing workflows, ensuring that remediation actions are context-aware and well-targeted.
Table 3 compares key frameworks and platforms on dimensions such as automation, monitoring, and scalability. Figure 4 presents a layered architecture for integrating self-healing capabilities, while Figure 5 shows adoption trends among organizations.
Table 3 highlights how framework choice depends on organizational priorities. Enterprises seeking scale may prefer Kubeflow, while cloud-first firms rely on SageMaker or Azure ML. In contrast, teams emphasizing modularity may combine MLflow with Airflow to assemble lightweight healing pipelines.
Figure 4 illustrates how platforms combine multiple layers into a cohesive self-healing system. Each layer is responsible for a different dimension, from infrastructure to monitoring to active remediation.
Figure 5 shows adoption trends, where Kubeflow and MLflow + Airflow dominate due to their flexibility and strong open-source ecosystems. Cloud-native solutions such as SageMaker and Azure ML hold significant shares in enterprise settings, especially where compliance and vendor integration are priorities.
5. Case Studies: Applying Self-Healing ML Pipelines
The true value of self-healing ML pipelines emerges when applied to real-world domains with high stakes and dynamic data environments. Finance, healthcare, and e-commerce represent industries where drift is frequent and costly, making automated remediation strategies indispensable. This section surveys case studies that highlight the effectiveness of self-healing pipelines in production [10].
5.1. Finance: Fraud Detection
In financial services, fraud detection systems must adapt to ever-changing fraud patterns. Traditional supervised models degrade quickly as adversaries develop new tactics. A leading bank implemented a self-healing ML pipeline where drift detectors monitored transaction features in real time. Upon drift detection, the pipeline triggered incremental retraining with the latest labeled fraud cases. This approach reduced false positives while maintaining high recall. Figure 6 illustrates the fraud detection workflow.
Figure 6 shows how finance pipelines automate retraining upon drift detection, ensuring fraud models remain adaptive against evolving threats.
5.2. Healthcare: Predictive Analytics
In healthcare, predictive models for patient outcomes face drift as medical practices evolve or patient demographics change. For example, a hospital system deployed a pipeline predicting readmission risk. Over time, input data shifted as new diagnostic codes and treatment patterns emerged. The pipeline’s drift detectors identified distributional changes, and remediation was performed using ensemble switching—deploying alternative models trained on more recent cohorts. This strategy ensured continuity of accurate risk predictions while complying with regulatory demands for transparency and accountability [11] .
5.3. E-Commerce: Recommendation Engines
E-commerce recommendation systems must react to seasonal trends, promotions, and sudden popularity shifts. A retail platform integrated a self-healing recommendation engine where concept drift detection flagged misaligned purchase predictions. Remediation strategies included active learning and periodic retraining on streaming clickstream data. This adaptive pipeline improved user engagement metrics, leading to measurable increases in sales and customer satisfaction. Figure 7 compares key performance improvements across domains.
Figure 7 illustrates performance gains: financial fraud detection pipelines achieved a 30% improvement in recall stability, healthcare models reduced error rates by 25%, and e-commerce recommendations boosted engagement by 35%.
5.4. Key Lessons Learned
Table 4 distills the lessons across industries, demonstrating common benefits such as reduced downtime, improved trust, and regulatory alignment. However, it also highlights challenges such as annotation bottlenecks and infrastructure overhead.
Table 4 reinforces that while benefits are domain-specific, self-healing pipelines consistently enhance resilience and trustworthiness. Organizations must carefully tailor strategies to domain requirements while managing the engineering trade-offs.
6. Challenges and Ethical Considerations
While self-healing ML pipelines promise resilience and automation, they introduce a host of challenges and ethical considerations that must be carefully addressed. Without thoughtful design, automation can lead to unintended consequences such as bias reinforcement, explainability gaps, or compliance violations. This section explores the major barriers and ethical issues in deploying production-ready self-healing pipelines [12].
A primary challenge is explainability. Automated remediation actions—such as retraining or switching models—may improve performance but obscure the reasoning behind system behavior. In regulated industries like finance or healthcare, black-box healing actions can create mistrust among stakeholders. Designing pipelines with built-in audit trails and interpretable monitoring outputs is critical for accountability.
Another important issue involves fairness and bias. Drift detection may reveal changes in population distributions, but if retraining is performed on skewed or incomplete data, pipelines risk amplifying unfair outcomes. For example, an automated retraining cycle in healthcare could unintentionally prioritize certain demographics if recent samples are imbalanced. Ethical remediation requires fairness audits and representative sampling strategies [13].
Compliance with regulations such as GDPR, HIPAA, and emerging AI governance laws adds complexity. Automated remediation must align with requirements for transparency, data privacy, and explainability. This includes documenting when retraining occurred, what data was used, and how performance was validated. Ensuring that pipelines meet these standards is non-trivial, particularly when multiple jurisdictions are involved.
Resource management poses another operational challenge. Automated retraining consumes computational resources, and frequent healing cycles may increase costs. This raises questions about sustainability and efficiency, especially in large-scale deployments. Organizations must weigh the trade-off between accuracy gains and resource expenditure, optimizing for both performance and cost [14].
Additionally, self-healing introduces engineering complexity. Integrating drift detectors, orchestrators, and remediation modules requires coordination across teams. Debugging automated responses can be difficult when multiple layers interact in real time. Clear observability and alerting mechanisms are therefore essential to ensure engineers remain in control even when pipelines act autonomously [15].
Finally, ethical considerations extend to the broader societal impact. As automation reduces human oversight, there is a risk of delegating too much decision-making power to algorithms. A responsible balance must be struck between efficiency and human-in-the-loop governance. Figure 8 and Figure 9 illustrate these trade-offs, while Table 5 summarizes challenges and mitigation strategies.
Figure 8 shows that organizations must carefully balance competing priorities. Optimizing solely for accuracy may increase costs, while prioritizing transparency without automation may slow responsiveness.
Figure 9 illustrates how explainability and fairness dominate the challenge landscape, while compliance and resource costs remain persistent barriers. Engineering complexity, though less frequently cited, can become a critical bottleneck in large deployments.
Table 5 reinforces that successful adoption requires proactive mitigation strategies. By combining governance, observability, and fairness-aware design, organizations can navigate both technical and ethical challenges effectively.
7. Conclusions and Future Directions
The emergence of self-healing ML pipelines represents a transformative step in the evolution of machine learning operations. Unlike traditional approaches that rely on manual monitoring and reactive troubleshooting, self-healing systems offer proactive resilience by integrating drift detection with automated remediation strategies. This paradigm enables production pipelines to remain robust, adaptive, and trustworthy in the face of continuous environmental change. Throughout this paper, we have reviewed detection methods, remediation strategies, frameworks, and real-world case studies that highlight the practicality of these approaches across industries.
The introduction of automated drift detection methods has redefined how organizations view data reliability. Rather than treating drift as a post-hoc concern, pipelines now incorporate detection modules as first-class citizens of the architecture. This change ensures that system behavior is continually assessed against evolving data conditions. From statistical tests to ML-based discriminators, the breadth of detection techniques shows how the field has matured toward layered, adaptive monitoring.
Equally critical are the remediation strategies that follow detection. Incremental retraining, rollback procedures, ensemble switching, and active learning all provide complementary mechanisms to address different drift scenarios. These strategies highlight the importance of flexibility: no single remediation approach is universally sufficient, and practical pipelines combine multiple methods to achieve resilience. The use of orchestration tools and code automation further demonstrates how self-healing pipelines integrate seamlessly with modern infrastructure.
The review of frameworks and platforms revealed that both open-source and commercial ecosystems are converging toward supporting self-healing features. Kubeflow and MLflow exemplify modular, open-source designs, while cloud-native platforms such as SageMaker and Azure ML offer integrated monitoring and remediation pipelines. These options empower organizations to tailor implementations to their specific operational and regulatory contexts, balancing control with scalability.
Case studies in finance, healthcare, and e-commerce illustrated how self-healing pipelines are already delivering tangible benefits. Fraud detection systems maintained resilience against adversarial strategies, healthcare pipelines improved predictive accuracy while adhering to compliance, and retail recommendation engines adapted to dynamic consumer behaviors. These examples emphasize that self-healing is not just a theoretical construct but a practical necessity in real-world production environments.
At the same time, challenges and ethical considerations remind us that automation cannot replace responsible governance. Issues of explainability, fairness, compliance, and resource management remain central to the debate. Ensuring that pipelines not only heal themselves but also act responsibly requires continued research, particularly in fairness-aware retraining, transparent auditing, and regulatory alignment. The trade-offs between accuracy, transparency, and resource efficiency must remain at the heart of system design.
Looking forward, future research will likely focus on developing hybrid frameworks that combine real-time monitoring with predictive remediation. Instead of reacting after drift occurs, pipelines may forecast drift likelihood and prepare countermeasures in advance. Integration with reinforcement learning, adaptive sampling, and human-in-the-loop mechanisms will further enrich resilience. Another frontier lies in extending self-healing principles beyond ML to encompass broader AI ecosystems, where multi-agent systems and foundation models require equally robust healing mechanisms.
In conclusion, self-healing ML pipelines represent a paradigm shift in production ML operations. By blending automation with governance, they ensure that machine learning remains both effective and trustworthy at scale. As industries increasingly depend on AI-driven decision-making, the ability of systems to detect, adapt, and heal autonomously will define the future of reliable and ethical artificial intelligence.
References
- T. Zhang, Y. Li, and Q. Zhao, “A comprehensive survey on concept drift and feature dynamics,” Information Sciences, vol. 642, pp. 1–28, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0952197624013010.
- S. P. Veluguri, “Convattrecurnet: An attention-based hybrid model for suicidal thoughts detection,” in Proceedings of the 2025 3rd International Conference on Cognitive Computing and Applications (ICCCA). IEEE, 2025. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/10986603.
- A. L. S. Cetrulo, D. Quintana, and A. Cervantes, “A survey on machine learning for recurring concept drifting data streams,” Elsevier, pp. 1–32, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0957417422019522. [CrossRef]
- S. Devarapalli, V. G. Vathsavai, V. Katkam, and R. K. Kanji, “Cloud-native llmops meets dataops: A unified framework for high-volume analytical systems,” in Proceedings of the 2025 International Conference on Advanced Computing and Data Engineering (ICACDE). IEEE, 2025. [Online]. Available: https://ieeexplore.ieee.org/document/11158069.
- Hao Yu, Nezir Aydin, Selcuk Alp, K.Y. Kizgin, “Machine learning-based sales forecasting during crises: Evidence from a turkish women’s clothing retailer,” NCBI Articles, 2025. [Online]. Available: https://pmc.ncbi.nlm.nih.gov/articles/PMC11752178/. [CrossRef]
- F. Hinder, V. Vaquet, and B. Hammer, “One or two things we know about concept drift — a survey on monitoring evolving environments,” Frontiers in Artificial Intelligence, vol. 7, p. 1330258, 2024. [Online]. Available: https://www.frontiersin.org/articles/10.3389/frai.2024.1330258. [CrossRef]
- Intelegain Technologies, “Ethical considerations in ai and machine learning,” Intelegain Blog, 2024. [Online]. Available: https://www.intelegain.com/ethical-considerations-in-ai-machine-learning/.
- A. Mallick and K. Hsieh, “Data drift mitigation in machine learning for large-scale systems,” Proceedings of MLSys, pp. 1–18, 2022. [Online]. Available: https://proceedings.mlsys.org/paper_files/paper/2022/file/069a002768bcb31509d4901961f23b3c-Paper.pdf.
- S. Lu, D. Guo, S. Ren, J. Huang, and A. Svyatkovskiy, “Codexglue: A machine learning benchmark dataset for code understanding and generation,” 2021. [Online]. Available: https://arxiv.org/abs/2102.04664.
- A. Shirdi, S. B. Peta, N. Sajanraj, and S. Acharya, “Federated learning for privacy-preserving big data analytics in cloud environments,” in Proceedings of the 2025 Global Conference in Emerging Technologies (GCET). IEEE, 2025. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/11076984.
- Niral Sutaria, “Bias and ethical concerns in machine learning,” ISACA Journal, 2023. [Online]. Available: https://www.isaca.org/resources/isaca-journal/issues/2022/volume-4/bias-and-ethical-concerns-in-machine-learning.
- P. Devaraju, S. Devarapalli, R. R. Tuniki, and S. Kamatala, “Secure and adaptive federated learning pipelines: A framework for multi-tenant enterprise data systems,” in Proceedings of the 2025 International Conference on Intelligent Cloud and Federated Systems (ICICFS). IEEE, 2025. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/11118425.
- SixtySixTen, “Machine learning sales forecasting: Predict growth,” SixtySixTen Blog, 2025. [Online]. Available: https://sixtysixten.com/machine-learning-sales-forecasting-predict-growth/.
- Prescience Decision Solutions, “Transforming sales forecasting with adaptive machine learning models and data integration,” Prescience Decision Solutions Blog, 2025. [Online]. Available: https://prescienceds.com/transforming-sales-forecasting-with-adaptive-machine-learning-models-and-data-integration/.
- R. Shahane and S. Prakash, “Quantum machine learning opportunities for scalable ai,” Journal of Validation Technology, vol. 28, no. 1, pp. 75–89, 2025. [Online]. Available: https://jvtnetwork.com/index.php/journals/article/view/131.
Figure 1.
High-level flow of a self-healing ML pipeline, showing integration of monitoring and automated remediation loops.
Figure 1.
High-level flow of a self-healing ML pipeline, showing integration of monitoring and automated remediation loops.
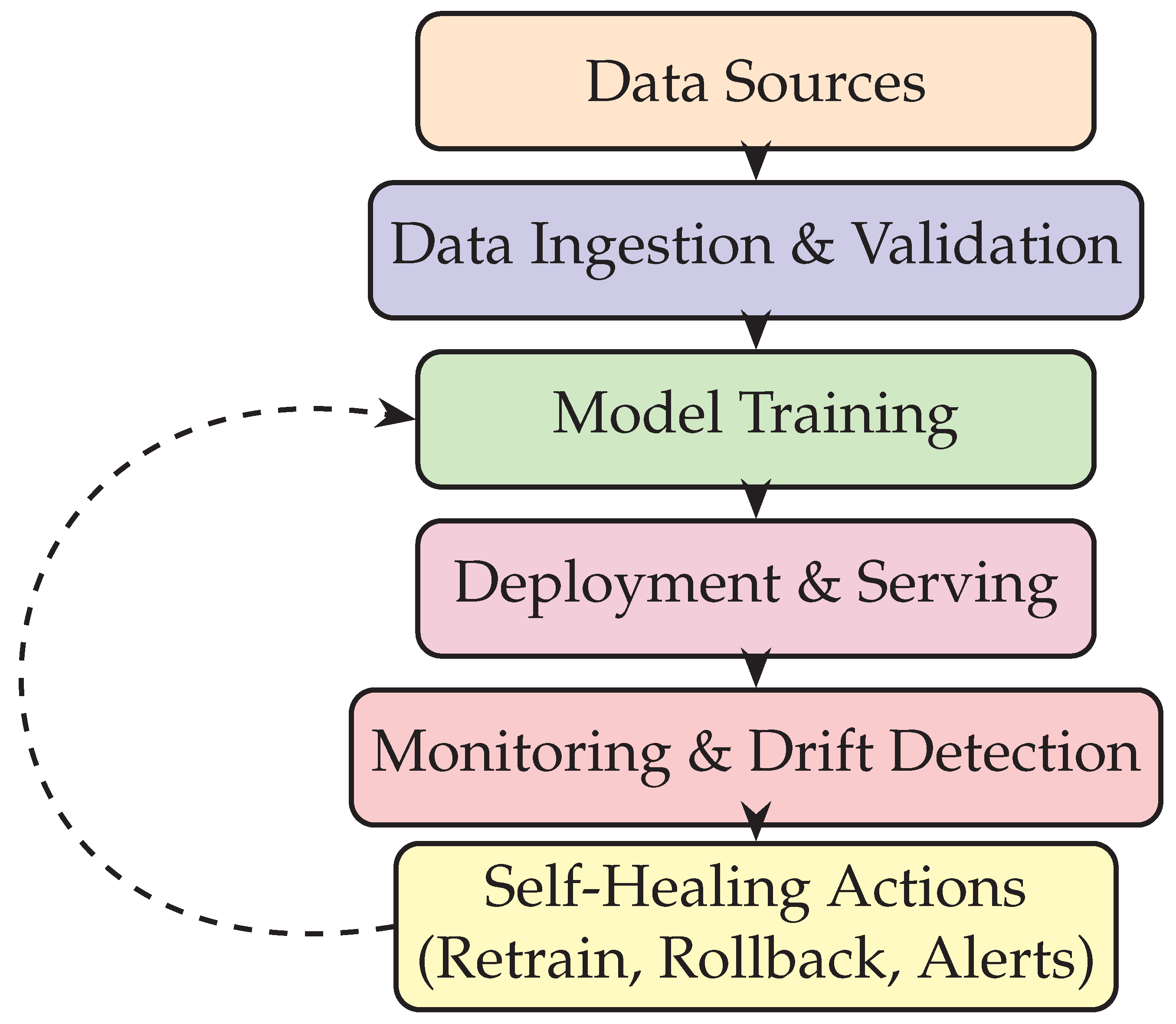
Figure 2.
Illustration of practical adoption rates of different drift detection methods in production ML systems.
Figure 2.
Illustration of practical adoption rates of different drift detection methods in production ML systems.

Figure 3.
Flow of remediation strategies following drift detection in a self-healing ML pipeline.
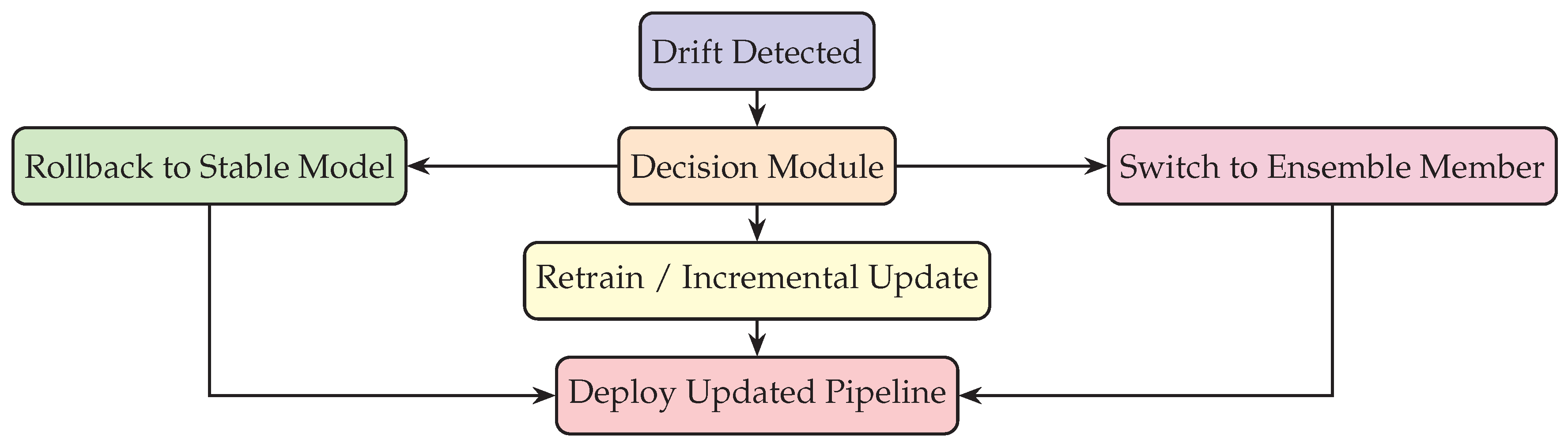
Figure 4.
Layered architecture of self-healing ML pipelines, integrating orchestration, monitoring, and remediation.
Figure 4.
Layered architecture of self-healing ML pipelines, integrating orchestration, monitoring, and remediation.
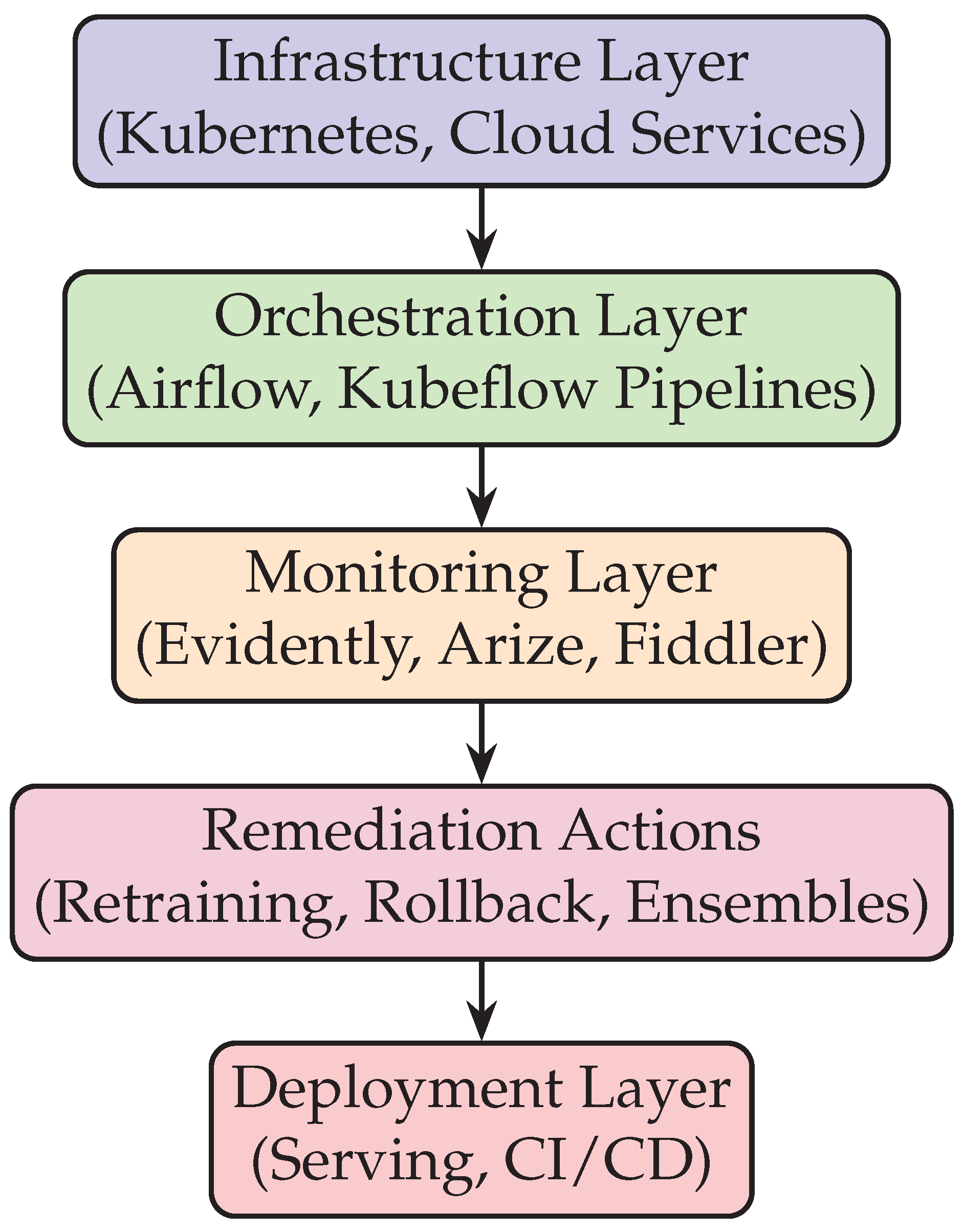
Figure 5.
Adoption distribution of frameworks for self-healing ML pipelines across enterprises.
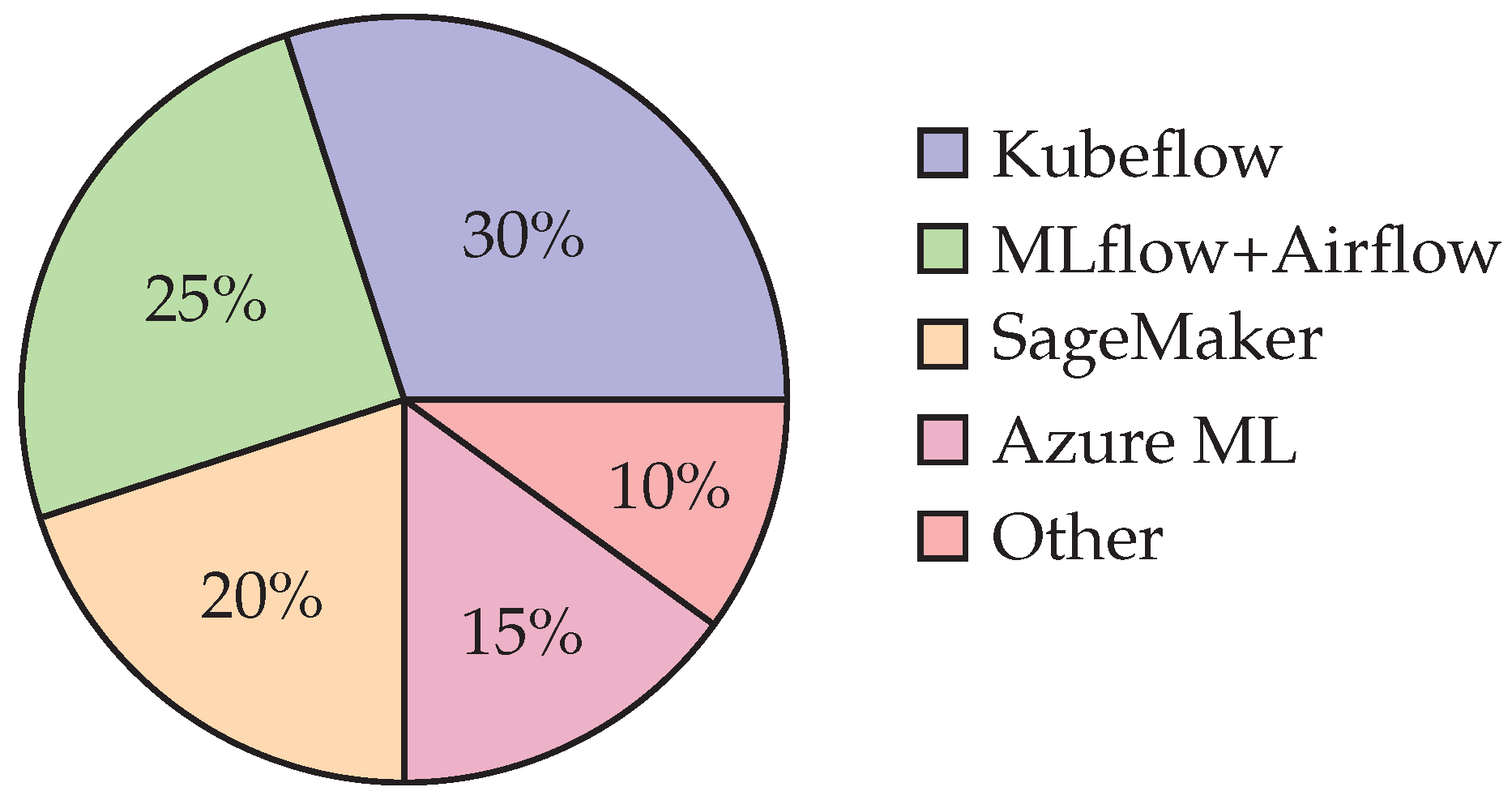
Figure 6.
Fraud detection self-healing pipeline: transaction drift triggers retraining workflows.
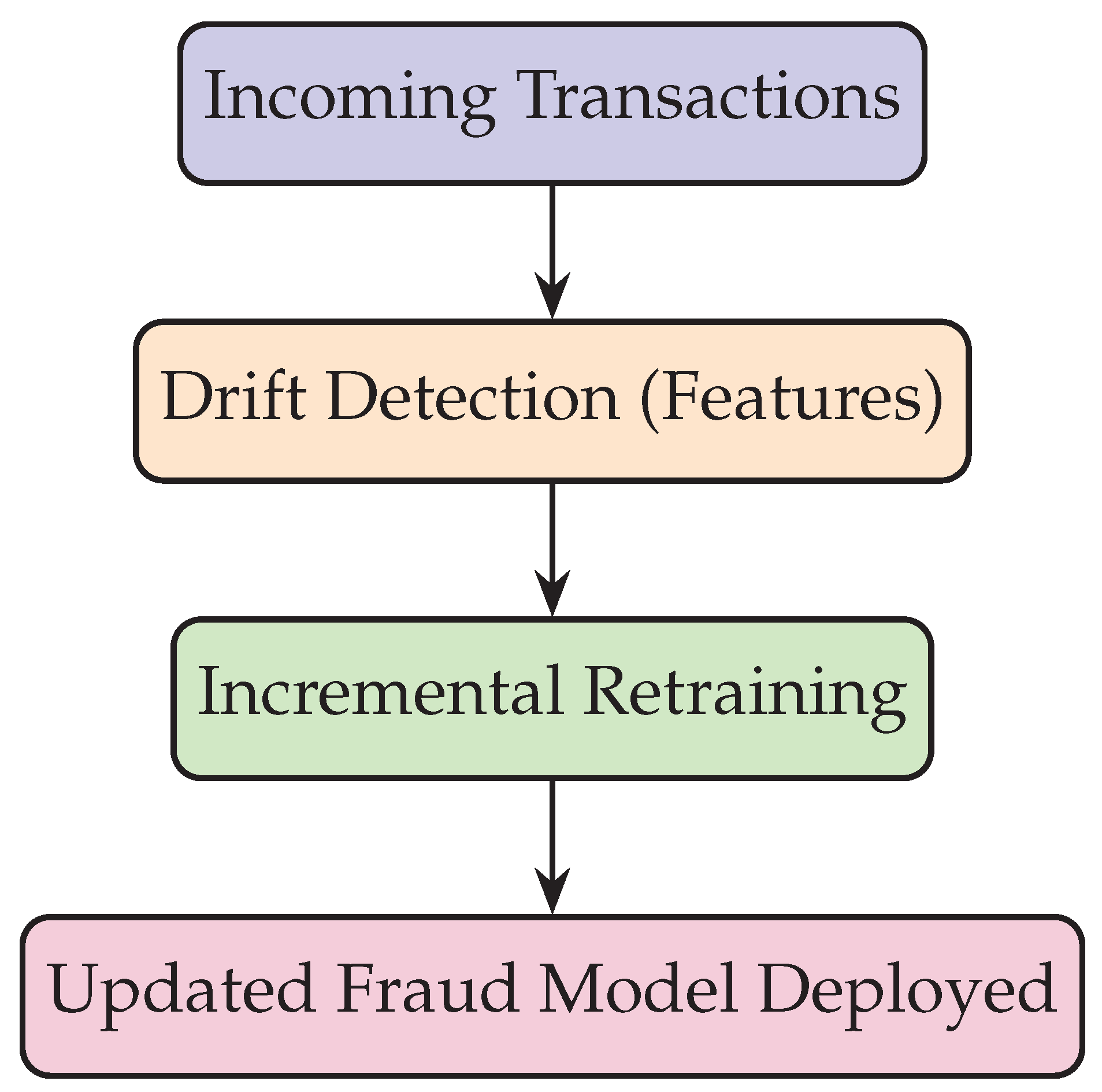
Figure 7.
Performance improvements from self-healing pipelines in different domains.
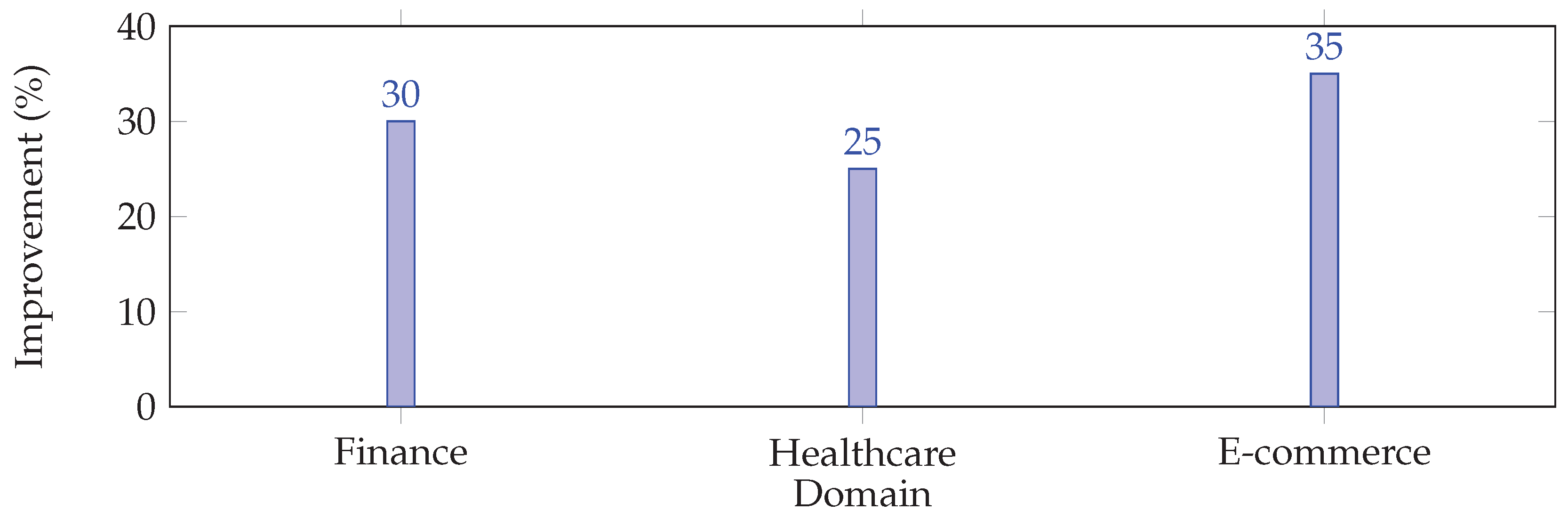
Figure 8.
Trade-off considerations in self-healing ML pipelines between accuracy, cost, transparency, and compliance.
Figure 8.
Trade-off considerations in self-healing ML pipelines between accuracy, cost, transparency, and compliance.
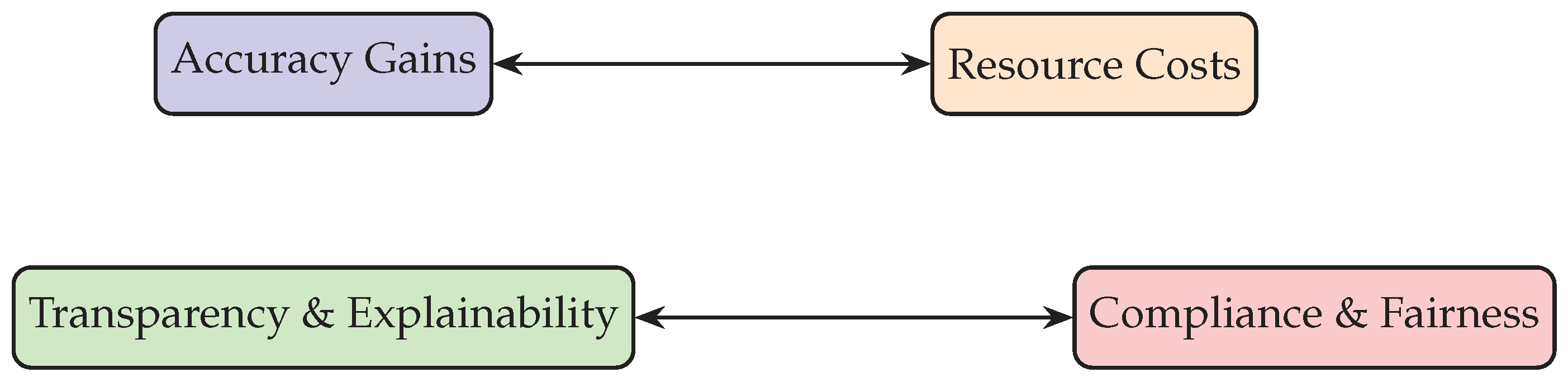
Figure 9.
Distribution of key challenges in deploying self-healing ML pipelines.
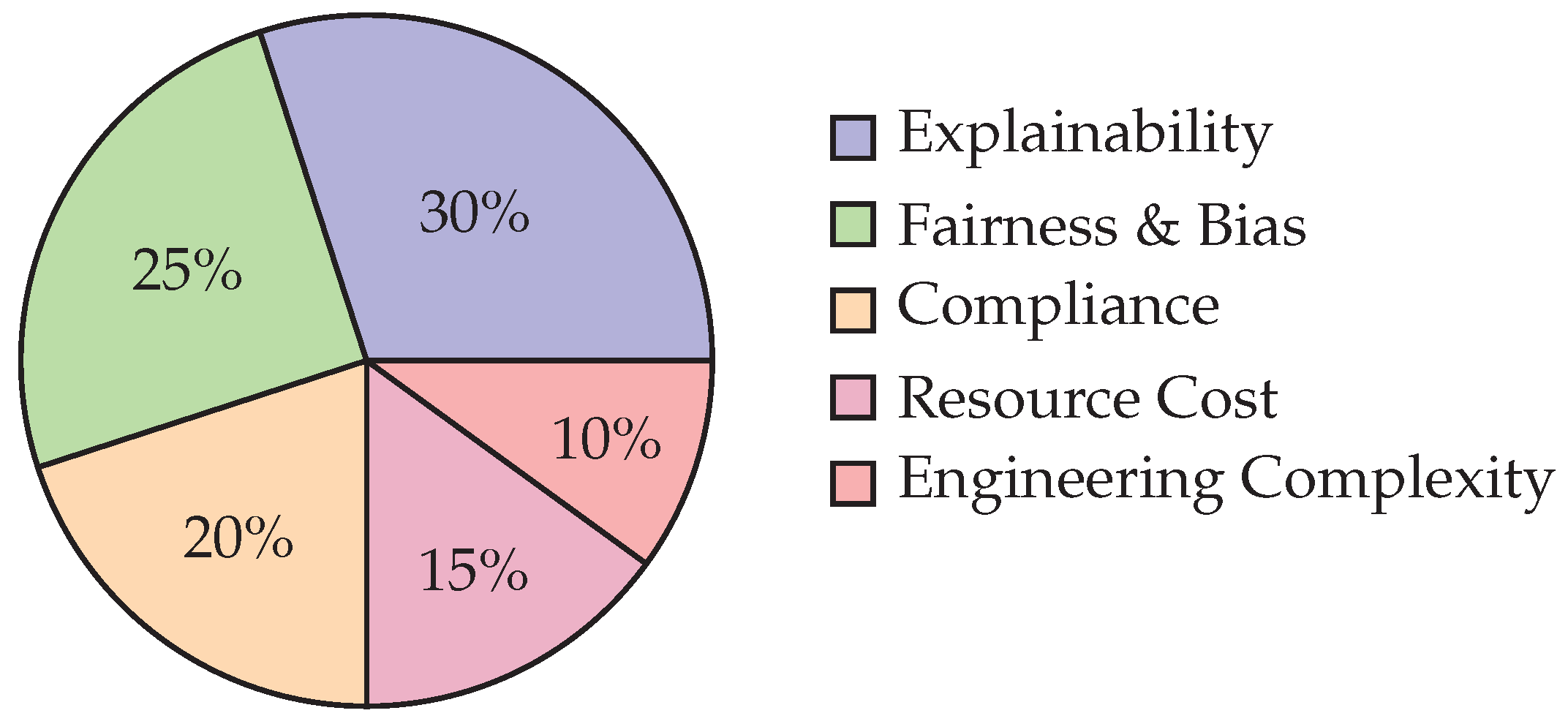

Table 1.
Comparison of Drift Detection Techniques.
| Method | Strengths | Limitations | Use Cases |
|---|---|---|---|
| Statistical Tests | Simple, interpretable | Struggles with high-dimensional data | Tabular features, monitoring dashboards |
| Distance Metrics | Sensitive to gradual shifts | Requires embeddings or distributions | NLP embeddings, image features |
| ML-based Detectors | Captures complex drift | Risk of false positives | Adversarial validation, fraud detection |
| Streaming Algorithms | Low-latency, memory-efficient | Limited flexibility in concept drift | Online recommendations, IoT data streams |
Table 2.
Comparison of Remediation Strategies.
| Strategy | Advantages | Limitations |
|---|---|---|
| Incremental Learning | Fast, adaptive | May accumulate noise |
| Rollback | Ensures stability | Reverts to suboptimal model |
| Active Learning | Reduces labeling cost | Relies on annotation pipeline |
| Scheduled Retraining | Simple to implement | Wastes compute if drift absent |
| Ensemble Switching | High resilience | Increased resource usage |
Table 3.
Comparison of Frameworks for Self-Healing ML.
| Framework | Strengths | Limitations | Best Use Cases |
|---|---|---|---|
| Kubeflow | Kubernetes-native, scalable | Steep learning curve | Large-scale enterprise ML |
| MLflow | Tracking, model registry | Needs orchestration integration | Experiment mgmt, retraining triggers |
| SageMaker | Built-in monitoring | Cloud vendor lock-in | Retail, finance cloud ML |
| Azure ML | Event-driven automation | Limited OSS portability | Enterprise AI compliance |
| Airflow / Prefect | Flexible DAG orchestration | External monitoring needed | Workflow-driven remediation |
Table 4.
Key Lessons from Self-Healing Case Studies.
| Domain | Benefits | Challenges |
|---|---|---|
| Finance | Adaptive fraud detection, lower false positives | Need for real-time labeling |
| Healthcare | Improved predictive accuracy, compliance support | Complex model governance |
| E-commerce | Higher engagement, faster trend adaptation | Resource-intensive retraining |
Table 5.
Challenges and Mitigation Strategies in Self-Healing Pipelines.
| Challenge | Risk | Mitigation Strategy |
|---|---|---|
| Explainability | Loss of stakeholder trust | Audit trails, interpretable dashboards |
| Fairness & Bias | Amplified inequities | Fairness audits, representative sampling |
| Compliance | Regulatory violations | Governance frameworks, documentation |
| Resource Cost | High compute expenditure | Hybrid retraining, resource scaling |
| Engineering Complexity | Difficult debugging | Strong observability, layered monitoring |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



