
Submitted:
03 October 2025
Posted:
08 October 2025
You are already at the latest version
Abstract
Safety and security are major priorities in modern society. Especially for vulnerable groups of individuals, such as the elderly and patients with disabilities, providing a safe environment and adequate alerting for debilitating events and situations can be critical. Wearable devices can be effective but require frequent maintenance and can be obstructive or stigmatizing. Video monitoring by trained operators solves those issues but requires human resources, time and attention and may present certain privacy issues. We propose optical flow-based automated approaches for a multitude of situation awareness and event alerting challenges. The core of our method is an algorithm providing the reconstruction of global movement parameters from video sequences. This way the computationally most intensive task is performed once and the output is dispatched to a variety of modules dedicated to detect adverse events such as convulsive seizures, falls, apnea and signs of possible post-seizure arrests. The software modules can operate separately or in parallel as required. Our results show that the optical flow-based detectors provide robust performance and are suitable for real-time alerting systems. In addition, the optical flow reconstruction is applicable to real-time tracking and stabilizing video sequences. The proposed system is already functional and undergoes field trials for cases of epileptic patients.
Keywords:
1. Introduction
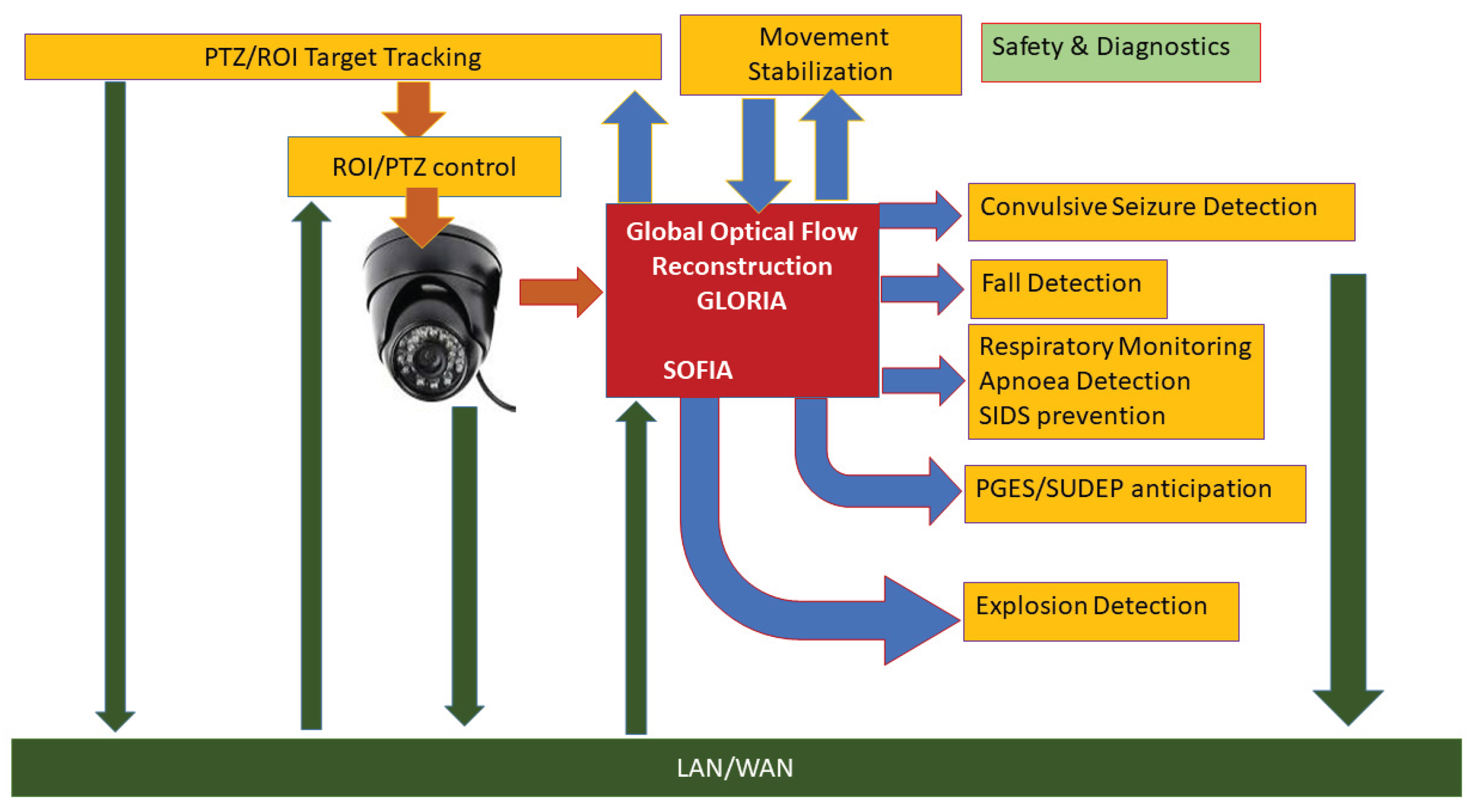
2. Materials and Methods
2.1. Spectral Optical Flow Iterative Algorithm (SOFIA)
2.2. Global Lie-Algebra Optical Flow Reconstruction Algorithm (GLORIA)
2.3. Detection of Convulsive Epileptic Seizures
2.4. Forecasting Postictal Generalized Electrographis Suppression (PGES)
2.5. Detection of Falls
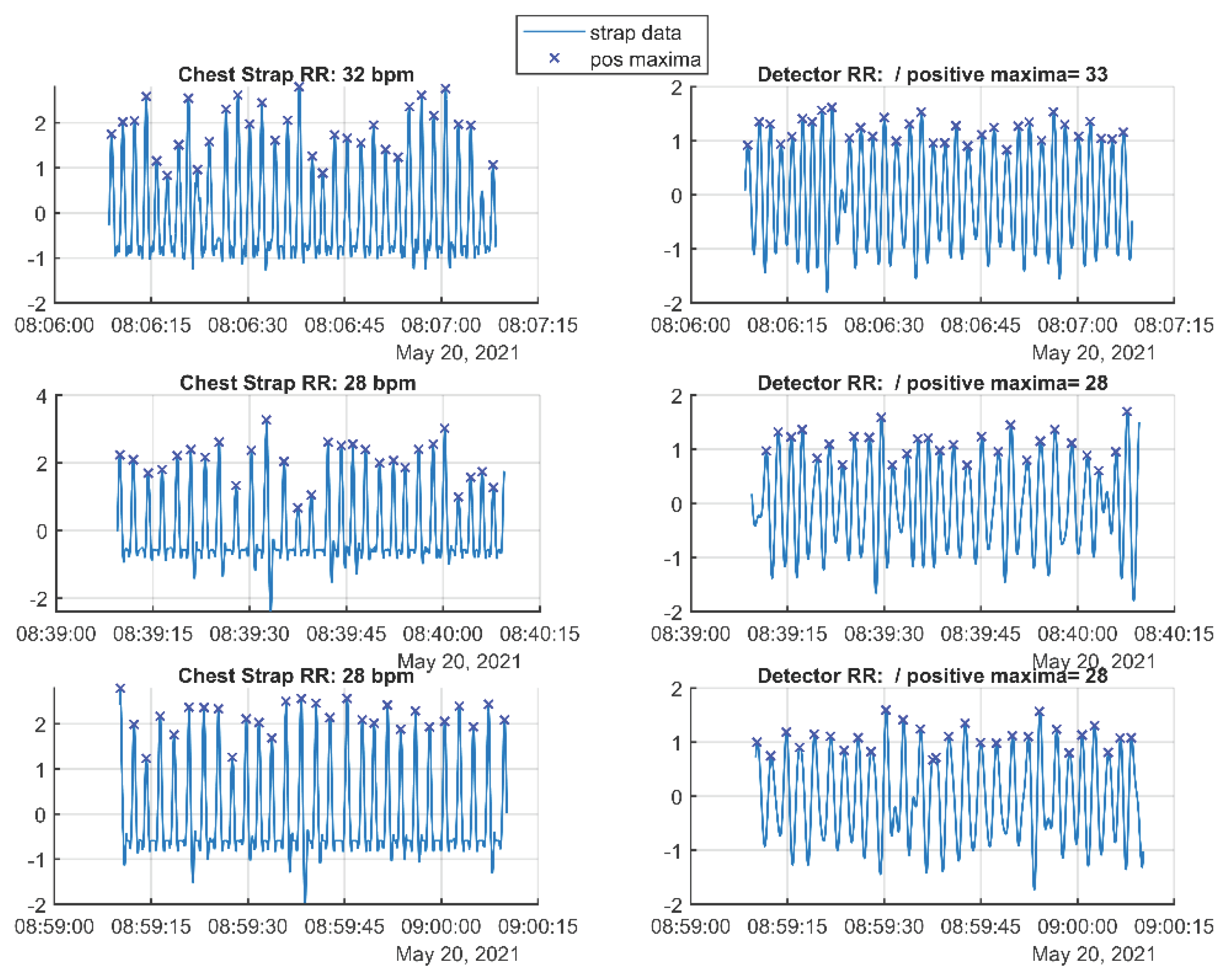
2.6. Detection of Respiratory Arrests, Apnea
2.7. Detection and Charge Estimation of Explosions
2.8. Object Tracking
2.9. Image Stabilizing
3. Results
3.1. Spectral Optical Flow Iterative Algorithm (SOFIA)
3.2. Global Lie-Algebra Optical Flow Reconstruction Algorithm (GLORIA)
3.3. Detection of Convulsive Epileptic Seizures
3.4. Forecasting (PGES)
3.5. Detection of Falls
3.6. Detection of Respiratory Arrests, Apnea
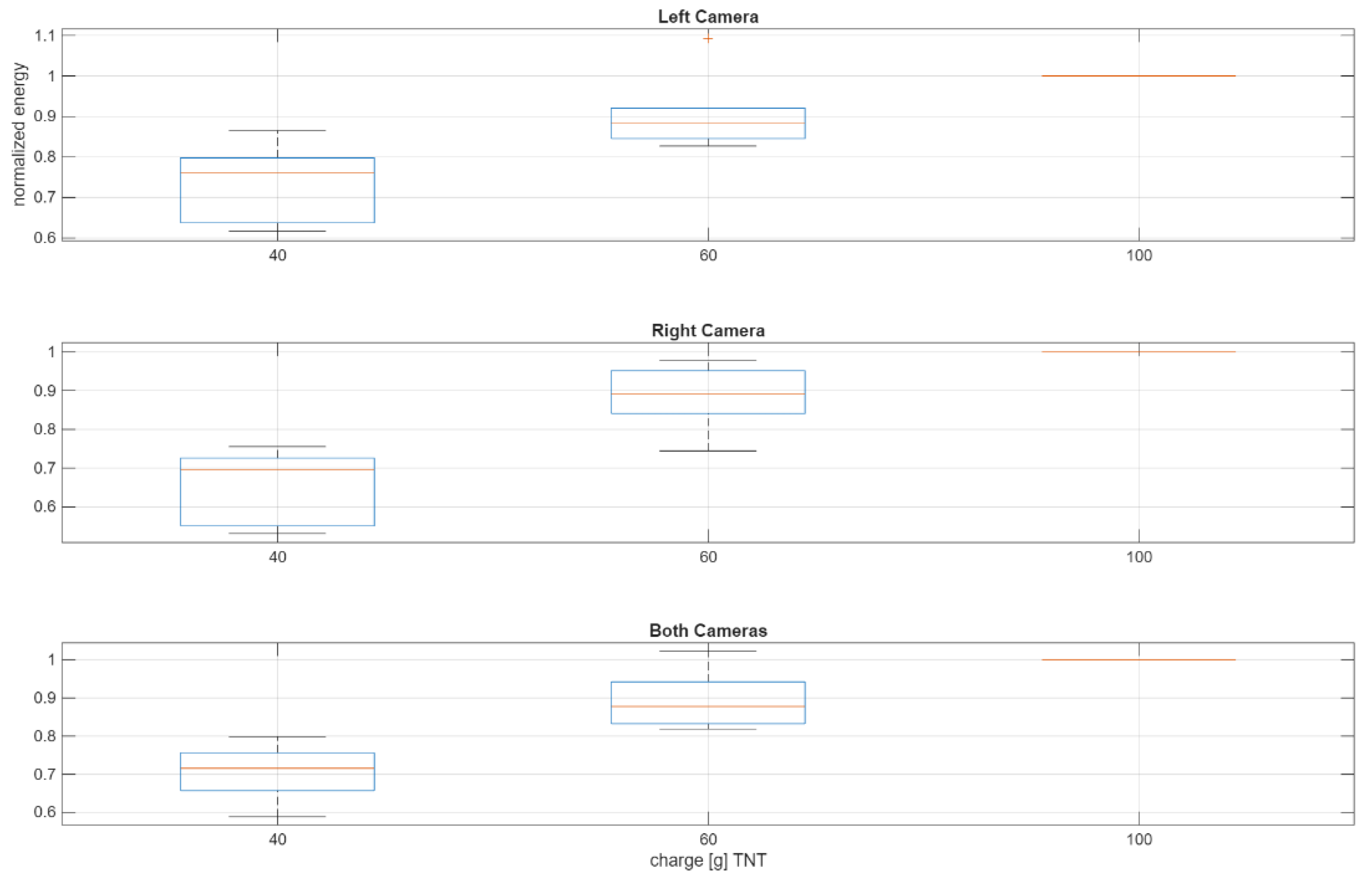
3.7. Detection and Charge Estimation of Explosions
3.8. Object Tracking
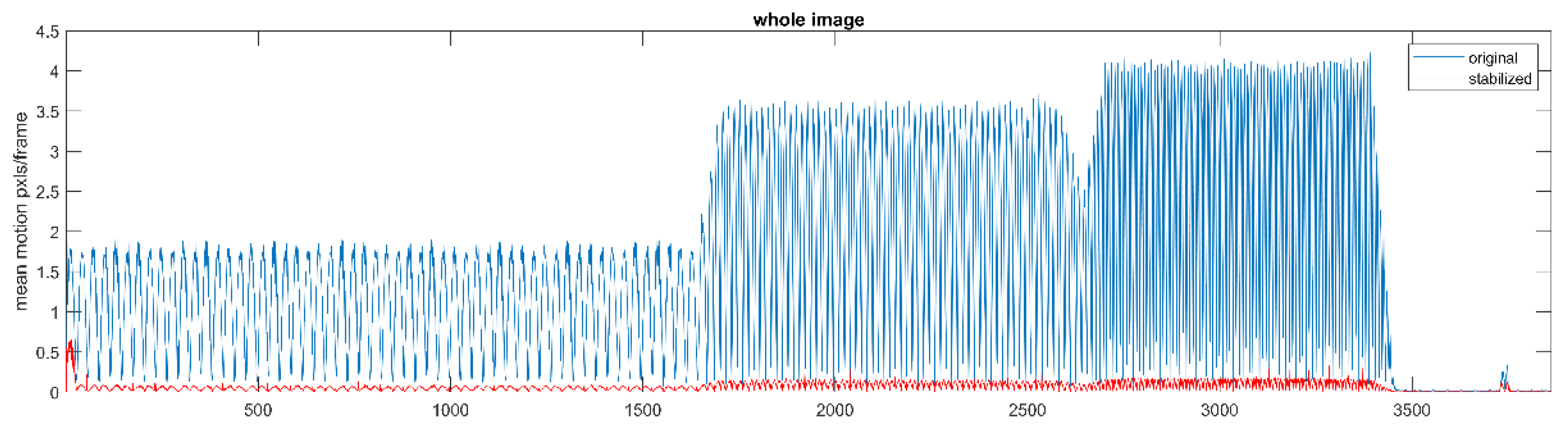
3.9. Image Stabilizing
4. Discussion
5. Conclusions
6. Patents
- Karpuzov S, Kalitzin S., Petkov A, Ilieva S, Petkov G, METHOD AND SYSTEM FOR OBJECTS TRACKING IN VIDEO SEQUENCES https://patentscope.wipo.int/search/en/WO2025085981
- Petkov, G., Fornell, P., Ristic, B. and Trujillo, I., HB Innovations Inc, 2023. System and method for video detection of breathing rates. U.S. Patent Application 17/682,645. https://patents.google.com/patent/US20230270337A1/en
- Petkov G, Kalitzin S, Fornell P. Global movement image stabilisation systems and methods [US PATENT US20220207657A1/US11494881B2 citations (17)/(5)]. Available from: https://patents.google.com/patent/US11494881B2
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| OF | Optical Flow |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| ROI | Region Of Interest |
| PTZ | Pen, Tilt, Zoom |
| SUDEP | Sudden Unexpected Death in Epilepsy |
| PGES | Post-ictal Generalized Electrographic Suppression |
| FP | False Positive |
| ICI | Inter-Clonic Interval |
| TNT | Tri Nitro Toluene |
References
- Beauchemin, S.S.; Barron, J.L. The computation of optical flow. ACM Computing Surveys (CSUR) 1995, 27(3), 433–466. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining optical flow. Artif Intell 1981, vol. 17, 1–3, 185–203. [CrossRef]
- Niessen, W.J.; Duncan, J.S.; Florack, L.M.J.; ter Haar Romeny, B.M.; Viergever, M.A. Spatiotemporal operators and optic flow. Physics-Based Modeling in Computer Vision, IEEE Computer Society Press 1995, 7. [Google Scholar]
- Niessen, W.J.; Maas, R. Multiscale optic flow and stereo. In: Computational Imaging and Vision. Sporring, J., Nielsen, M., Florack, L., Johansen, P., Eds.; Kluwer Academic Publishers, 1997, 31-42.
- Maas, R.; ter Haar Romeny, B.M.; Viergever, M.A. A multiscale Taylor series approach to optic flow and stereo: a generalization of optic flow under the aperture. In: Scale-Space Theories in Computer Vision. Nielsen, M., Johansen, P., Fogh Olsen, O., Weickert, J., Eds.; Springer, 1999, vol. 1682, 519-524.
- Kalitzin, S.; Geertsema, E.; Petkov, G. (2018), Scale-iterative optical flow reconstruction from multi-channel image sequences. In: Frontiers of Artificial Intelligence and Applications. Petkov, N., Strisciuglio, N., Travieso-Gonzalez, C., Eds.; IOS Press, Amsterdam, 2018, Vol 310, Application of Intelligent Systems, 302-314. [CrossRef]
- Florack, L.M.J.; Nielsen, M.; Niessen, W.J. The intrinsic structure of optic flow incorporating measurement duality. International Journal of Computer Vision 1998, 27(3), 24. [Google Scholar] [CrossRef]
- Kalitzin, S.; Geertsema, E.; Petkov, G. (2018), Optical flow group-parameter reconstruction from multi-channel image sequences. In: Frontiers of Artificial Intelligence and Applications, Petkov, N., Strisciuglio, N., Travieso-Gonzalez, C., Eds.; IOS Press, Amsterdam, 2018, vol 310, Application of Intelligent Systems, 290 – 301. [CrossRef]
- Sander, J.W. Some aspects of prognosis in the epilepsies: a review. Epilepsia. 1993, 34(6), 1007–1016. [Google Scholar] [CrossRef]
- Blume, W.T.; Luders, H.O.; Mizrahi, E.; Tassinari, C.; van Emde Boas, C.W. ; J. Engel Jr., J. Glossary of descriptive terminology for ictal semiology: Report of the ILAE task force on classification and terminology, Epilepsia, 2001, vol. 42, 1212–1218.
- Karayiannis, N.B.; Mukherjee, A.; Glover, J.R.; Ktonas, P.Y.; Frost, J.D.; Hrachovy Jr., R. A.; Mizrahi, E.M. Detection of pseudosinusoidal epileptic seizure segments in the neonatal EEG by cascading a rule-based algorithm with a neural network, IEEE Trans. Biomed. Eng., 2006, vol. 53, no. 4, 633–641.
- Becq, G.; Bonnet, S.; Minotti, L.; Antonakios, M.; Guillemaud, R.; Kahane, P. Classification of epileptic motor manifestations using inertial and magnetic sensors, Comput. Biol. Med., 2011, vol. 41, 46–55.
- Surges, R.; Sander, J.W. Sudden unexpected death in epilepsy: mechanisms, prevalence, and prevention. Curr Opin Neurol 2012, 25, 201–7. [Google Scholar] [CrossRef]
- Ryvlin, P.; Nashef, L.; Lhatoo, S.D.; Bateman, L.M.; Bird, J.; Bleasel, A.; et al. Incidence and mechanisms of cardiorespiratory arrests in epilepsy monitoring units (MORTEMUS): a retrospective study. Lancet Neurol 2013, 12, 966–77. [Google Scholar] [CrossRef]
- an de Vel, A.; Cuppens, K.; Bonroy, B.; Milosevic, M.; Jansen, K.; Van Huffel, S.; Vanrumste, B.; Lagae, L.; Ceulemans, B. Non-EEG seizure-detection systems and potential SUDEP prevention: state of the art, Seizure, 2013, 22, 345–355. [CrossRef]
- Saab, M.E.; Gotman, J. A system to detect the onset of epileptic seizures in scalp EEG, Clin. Neurophysiol., 2005, vol. 116, 427–442.
- Pauri, F.; Pierelli, F.; Chatrian,G. E.; Erdly,W.W. Long-term EEG video- audio monitoring: computer detection of focal EEG seizure patterns. Electroencephalogr. Clin. Neurophysiol. 1992, vol. 82, 1–9. [Google Scholar] [CrossRef]
- Gotman, J. Automatic recognition of epileptic seizures in the EEG. Electroencephalogr. Clin. Neurophysiol. 1982, vol. 54, 530–540. [Google Scholar] [CrossRef]
- Salinsky, M.C. A practical analysis of computer based seizure detection during continuous video-EEG monitoring, Electroencephalogr. Clin. Neurophysiol. 1997, vol. 103, 445–449. [Google Scholar] [CrossRef]
- Schulc, E.; Unterberger, I.; Saboor, S.; Hilbe, J.; Ertl, M.; Ammenwerth, E.; Trinka, E.; Them, C. Measurement and quantification of generalized tonic–clonic seizures in epilepsy patients by means of accelerometry—An explorative study, Epilepsy Res. 2011, vol. 95, 173–183.
- Kramer, U.; Kipervasser,S.; Shlitner, A.; Kuzniecky, R. A novel portable seizure detection alarm system: preliminary results, J. Clin. Neurophysiol. 2011, vol. 28, 36–38.
- Lockman, J.; Fisher, R.S.; Olson, D.M. Detection of seizurelike movements using a wrist accelerometer. Epilepsy Behav. 2011, vol. 20, 638–641. [Google Scholar] [CrossRef] [PubMed]
- van Andel, J.; Thijs, R.D.; de Weerd, A.; et al. Non-EEG based ambulatory seizure detection designed for home use: what is available and how will it influence epilepsy care? Epilepsy Behav. 2016, 57, 82–9. [Google Scholar] [CrossRef] [PubMed]
- Arends, J.; Thijs, R.D.; Gutter, T.; et al. Multimodal nocturnal seizure detection in a residential care setting: a long-term prospective trial. Neurology. 2018, 91, e2010–9. [Google Scholar] [CrossRef]
- Narechania, A.P.; Garic, I.I.; Sen-Gupta, I.; et al. Assessment of a quasi-piezoelectric mattress monitor as a detection system for generalized convulsions. Epilepsy Behav. 2013, 28, 172–6. [Google Scholar] [CrossRef]
- Van Poppel, K.; Fulton, S.P.; McGregor, A.; et al. Prospective study of the Emfit movement monitor. J Child Neurol. 2013, 28, 1434–6. [Google Scholar] [CrossRef]
- Cuppens, K.; Lagae, L.; Ceulemans, B.; Van Huffel, S.; Vanrumste, B. Automatic video detection of body movement during sleep based on optical flow in pediatric patients with epilepsy, Med. Biol. Eng. Comput. 2010, vol. 48, 923–931. [Google Scholar] [CrossRef]
- Karayiannis, N.B.; Tao, G.; Frost Jr., J. D.; Wise, M.S.; Hrachovy, R.A.; Mizrahi, E.M. Automated detection of videotaped neonatal seizures based on motion segmentation methods, Clin. Neurophysiol. 2006, vol. 117, 1585–1594.
- Karayiannis, N.B.; Xiong, Y.; Tao, G.; Frost Jr., J.D.; Wise, M.S.; Hrachovy, R.A.; Mizrahi, E.M. Automated detection of videotaped neonatal seizures of epileptic origin. Epilepsia, 2006, vol. 47, 966–980.
- Karayiannis, N.B.; Tao, G.; Varughese, B.; Frost Jr., J. D.; Wise, M.S.; Mizrahi, E.M. Discrete optical flow estimation methods and their application in the extraction of motion strength signals from video recordings of neonatal seizures. in Proc. 26th Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2004, vol. 3, 1718–1721. [Google Scholar]
- Karayiannis, N.B.; Tao, G.; Xiong, Y.; Sami, A.; Varughese, B.; Frost Jr., J. D.; Wise, M.S.; Mizrahi, E.M. Computerized motion analysis of videotaped neonatal seizures of epileptic origin. Epilepsia 2005, vol. 46, 901–917. [Google Scholar] [CrossRef]
- Chen, L.; Yang, X.; Liu, Y.; Zeng, D.; Tang, Y.; Yan, B.; Lin, X.; Liu, L.; Xu, H.; Zhou, D. Quantitative and trajectory analysis of movement trajectories in supplementary motor area seizures of frontal lobe epilepsy. Epilepsy Behav. 2009, vol. 14, 344–353. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Martins da Silva, A.; Cunha, J.P. Movement quantification in epileptic seizures: a new approach to video-EEG analysis. IEEE Trans. Biomed. Eng. 2002, vol. 49, no. 6, 565–573.
- van Westrhenen, A.; Petkov,G.; Kalitzin, S.N.; Lazeron, R.H.C.; Thijs, R.D. Automated video-based detection of nocturnal motor seizures in children. Epilepsia 2020, 61(S1),S36–S40. [CrossRef]
- Geertsema, E.; Thijs, R.D.; Gutter,T.; Vledder, B.; Arends, J.B.; Leijten, F.S.; Visser, G.H.; Kalitzin S.N. Automated video-based detection of nocturnal convulsive seizures in a residential care setting. Epilepsia 2018, vol. 59, (S1), 53-60. [CrossRef]
- Kalitzin, S..; Petkov, G.; Velis, D.; Vledder B.; Lopes da Silva, F. Automatic Segmentation of Episodes Containing Epileptic Clonic Seizures in Video Sequences. in IEEE Transactions on Biomedical Engineering, 2012, vol. 59, no. 12, 3379-3385. [CrossRef]
- Kalitzin, S. Adaptive Remote Sensing Paradigm for Real-Time Alerting of Convulsive Epileptic Seizures. Sensors 2023, 23, 968. [Google Scholar] [CrossRef]
- Kalitzin, S. Topological Reinforcement Adaptive Algorithm (TOREADA) Application to the Alerting of Convulsive Seizures and Validation with Monte Carlo Numerical Simulations. Algorithms 2024, 17, 516. [Google Scholar] [CrossRef]
- Surges, R.; Strzelczyk, A.; Scott, C.A.; Walker, M.C.; Sander, J.W. Postictal generalized electroencephalographic suppression is associated with generalized seizures. Epilepsy Behav 2011, 21, 271–4. [Google Scholar] [CrossRef]
- Kalitzin, S.N.; Bauer, P.R.; Lamberts, R.J.; Velis, D.N.; Thijs, R.D.; Lopes Da Silva, F.H. Automated Video Detection Of Epileptic Convulsion Slowing As A Precursor For Post-Seizure Neuronal Collapse. International Journal of Neural Systems 2016, 26(8), 1650027. [Google Scholar] [CrossRef] [PubMed]
- Bauer, P.R.; Thijs, R.D.; Lamberts, R.J.; Velis, D.N.; Visser, G.H.; Tolner, E.A.; Sander, J.W; Lopes da Silva, F.H.; Kalitzin, S.N. Dynamics of convulsive seizure termination and postictal generalized EEG suppression. Brain 2017, Volume 140, Issue 3, 655–668. [Google Scholar] [CrossRef]
- van Beurden, A.W.; Petkov, G.H. ; N. In Kalitzin, S.N. Remote-sensor automated system for SUDEP (sudden unexplained death in epilepsy) forecast and alerting: analytic concepts and support from clinical data. In Proceedings of the 2nd International Conference on Applications of Intelligent Systems (APPIS ‘19). ACM, New York, NY, USA, 1-6, Article 2. [CrossRef]
- Rubenstein, L.Z. Falls in older people: epidemiology, risk factors and strategies for prevention. Age Ageing 2006, 35, ii37–ii41. [Google Scholar] [CrossRef]
- Davis J.C. et al., Cost-effectiveness of falls prevention strategies for older adults: protocol for a living systematic review BMJ Open, 2024, vol. 14, no. 11, e088536. [CrossRef]
- European Public Health Association, “Falls in Older Adults in the EU: Factsheet.” [Online]. Available on site: https://eupha.org/repository/sections/ipsp/Factsheet_falls_in_older_adults_in_EU.pdf (Accessed: Jun. 04, 2025).
- Davis, J.C.; Robertson, M.C.; Ashe, M.C.; Liu-Ambrose, T.; Khan, K.M. Marra, C.A. International comparison of cost of falls in older adults living in the community: a systematic review. Osteoporosis International 2010, 21:8, vol. 21, no. 8, 1295–1306. [CrossRef]
- Krumholz, A.; Hopp, J. ; Falls give another reason for taking seizures to heart. Neurology 2008, 70, 1874–1875. [Google Scholar] [CrossRef] [PubMed]
- Russell-Jones, D.L.; Shorvon, S.D. The frequency and consequences of head injury in epileptic seizures. J. Neurol. Neurosurg. Psychiatry 1989, 52, 659–662. [Google Scholar] [CrossRef] [PubMed]
- Nait-Charif, H.; McKenna, S. 2004. Activity summarization and fall detection in a supportive home environment. IEEE International Conference on Pattern Recognition, 26-26 Aug, 2004, 20–23. [CrossRef]
- Wang, X.; Ellul, J.; Azzopardi, G. Elderly Fall Detection Systems: A Literature Survey. Frontiers Robots AI. 2020, vol 7,. [CrossRef]
- WO2025082457 FALL DETECTION AND PREVENTION SYSTEM AND METHOD. Available online: https://patentscope.wipo.int/search/en/detail.jsf?docId=WO2025082457 (Accessed: Jun. 16, 2025).
- “US8217795B2 - Method and system for fall detection - Google Patents.” Available online: https://patents.google.com/patent/US8217795B2/en (Accessed: Jun. 16, 2025).
- Soaz González, C. “DEVICE, SYSTEM AND METHOD FOR FALL DETECTION,” EP 3 796 282 A2, Mar. 21, 2021. Available online: https://patentimages.storage.goo leapis.com/e9/e8/a1/fc9d181803c231/EP3796282A2.pdf#page=19.77 (Accessed: Jun. 16,2025).
- Khawandi, S.; Daya, B.; Chauvet, P. Implementation of a monitoring system for fall detection in elderly healthcare. Proc. Comput. Sci. 2011, 3, 216–220. [CrossRef]
- Liao, Y.T.; Huang, C.L.; Hsu, S.C. Slip and fall event detection using Bayesian Belief Network. Pattern Recognit. 2012, 45, 24–32. [Google Scholar] [CrossRef]
- Liu, C.L.; Lee, C.H.; Lin, P.M. A fall detection system using k-nearest neighbor classifier. Expert Syst. 2010, Appl. 37, 7174–7181. [Google Scholar] [CrossRef]
- Vikman, I.; Nyberg, L.; Korpelainen, R.; Lindblom, J.; Jämsä, T. Comparison of real-life accidental falls in older people with experimental falls in middle-aged test subjects. Gait Posture 2012, 35, 500–505. [Google Scholar] [CrossRef]
- Zerrouki, N.; Harrou, F.; Sun, Y.; Houacine, A. A data-driven monitoring technique for enhanced fall events detection. IFAC-PapersOnLine 2016, 49, 333–338. [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach, Sensors 2019, Vol. 19, 1988. [CrossRef]
- Charfi, I.; Miteran, J.; Dubois, J.; Atri, M.; Tourki, R. Optimized spatio-temporal descriptors for real-time fall detection: comparison of support vector machine and Ada boost-based classification. J Electron Imaging 2013, vol. 22, no. 4, 041106. [CrossRef]
- Belshaw, M.; Taati, B.; Snoek, J.; Mihailidis, A. Towards a single sensor passive solution for automated fall detection. In: Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society. EMBS, 2011, 1773–1776. [CrossRef]
- Charfi, I.; Miteran, J.; Dubois, J.; Atri, M.; Tourki, R. Optimized spatio-temporal descriptors for real-time fall detection: comparison of support vector machine and Adaboost-based classification. J. Electron. Imaging 2013, 22. [Google Scholar] [CrossRef]
- Fan, Y.; Levine, M.D.; Wen, G.; Qiu, S. A deep neural network for real-time detection of falling humans in naturally occurring scenes. Neurocomputing 2017, 260, 43–58. [Google Scholar] [CrossRef]
- Goudelis, G.; Tsatiris, G.; Karpouzis, K.; Kollias, S. Fall detection using history triple features. In: Proceedings of the 8th ACM International Conference on PErvasive Technologies Related to Assistive Environments, 1-3 July, 2015, Corfu Greece, Article No.: 81, Pages 1 – 7. [CrossRef]
- Yu, M.; Yu, Y.; Rhuma, A.; Naqvi, S.M.R.; Wang, L.; Chambers, J.A. 2013. An online one class support vector machine-based person-specific fall detection system for monitoring an elderly individual in a room environment. IEEE J. Biomed. Heal. Inform. 2013, 17, 1002–1014. [CrossRef]
- Debard, G.; Karsmakers, P.; Deschodt, M.; Vlaeyen, E.; Dejaeger, E.; Milisen, K.; Goedemé, T.; Vanrumste, B.; Tuytelaars, T. 2012. Camera-based fall detection on real world data. In: Outdoor and Large-Scale Real-World Scene Analysis. Lecture Notes in Computer Science. Dellaert, F., Frahm, J.-M., Pollefeys, M., Leal-Taixé, L., Rosenhahn, B., Eds.; Springer, Berlin, Heidelberg, 2012, 356–375. [CrossRef]
- Debard, G.; Mertens, M.; Deschodt, M.; Vlaeyen, E.; Devriendt, E.; Dejaeger, E.; Milisen, K.; Tournoy, J.; Croonenborghs, T.; Goedemé, T.; Tuytelaars, T.; Vanrumste, B. 2016. Camera-based fall detection using real-world versus simulated data: How far are we from the solution? J. Ambient Intell. Smart Environ 2016, 8, 149–168. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput Methods Programs Biomed 2014, 117(3):489-501. [CrossRef]
- Vargas, V.; Ramos, P.; Orbe, E.A.; Zapata, M.; Valencia-Aragón, K. Low-Cost Non-Wearable Fall Detection System Implemented on a Single Board Computer for People in Need of Care. Sensors 2024, Vol. 24, 5592. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ho, K.C.; Popescu. A microphone array system for automatic falldetection. IEEE Trans. 2012, Biomed. Eng. 59, 1291–1301. [Google Scholar] [CrossRef]
- Popescu, M.; Li, Y.; Skubic, M.; Rantz, M. An acoustic fall detector system that uses sound height information to reduce the false alarm rate. In: 30th Annual International IEEE EMBS Conference, 20-23 Aug. 2008, 4628–4631.
- Salman Khan, M.; Yu, M.; Feng, P.; Wang, L.; Chambers, J. An unsupervised acoustic fall detection system using source separation for sound interference suppression. Signal Process. 2015, 110, 199–210. [Google Scholar] [CrossRef]
- Tao, J.; Turjo, M.; Wong, M.-F.; Wang, M.; Tan, Y.-P. Fall incidents detection for intelligent video surveillance. In: 5th International Conference on Information Communications & Signal Processing, 6-9 Dec, 2005, 1590–1594. [CrossRef]
- Vishwakarma, V.; Mandal, C. ; Sural. Automatic detection of human fall in video. International Conference on Pattern Recognition and Machine Intelligence,2007, 616–623. [CrossRef]
- Wang, S.; Chen, L.; Zhou, Z.; Sun, X.; Dong, J. Human fall detection in surveillance video based on PCANet. Multimed. Tools Appl. 2016, 75, 11603–11613. [Google Scholar] [CrossRef]
- Zhang, Z.; Tong, L.G.; Wang, L. Experiments with computer vision methods for fall detection. In: Proceedings of the 3rd International Conference on Pervasive Technologies Related to Assistive Environments (PETRA ’10), 2010. [CrossRef]
- Zweng, A.; Zambanini, S.; Kampel, M. 2010. Introducing a statistical behavior model into camera-based fall detection. In: Advances in Visual Computing. ISVC 2010. Lecture Notes inComputer Science. Bebis, G., Boyle, R., Parvin, B., Koracin, D., Chung, R., Hammoud, R., Hussain, M., Kar-Han, T., Crawfis, R., Thalmann, D., Kao, D., Avila, L., Eds.; 2010, Springer, Berlin, Heidelberg, 163–172. [CrossRef]
- Senouci, B.; Charfi, I.; Heyrman, B.; Dubois, J.; Miteran, J. Fast prototyping of a SoC-based smart-camera: a real-time fall detection case study. J. Real-Time Image Process. 2016, 12, 649–662. [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; E. Gambao. Home camera-based fall detection system for the elderly. Sensors 2017, vol. 17, no. 12. [CrossRef]
- Hazelhoff, L.; Han, J.; de With, P.H.N. 2008. Video-based fall detection in the home using principal component analysis. In: Advanced Concepts for Intelligent Vision Systems. ACIVS 2008. Lecture Notes in Computer Science. Blanc-Talon, J., Bourennane, S., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer, Berlin, Heidelberg, 2008, 298–309. [CrossRef]
- Feng, W.; Liu, R.; Zhu, M. Fall detection for elderly person care in a vision based home surveillance environment using a monocular camera. Signal, Image Video Process 2014, 8, 1129–1138. [CrossRef]
- Foroughi, H.; Aski, B.S.; Pourreza, H. Intelligent video surveillance for monitoring fall detection of elderly in home environments. In: Proceedings of 11th International Conference on Computer and Information Technology, ICCIT 2008, 219–224. [CrossRef]
- Horaud, R.; Hansard, M.; Evangelidis; G., Clément, M. An overview of depth cameras and range scanners based on time-of-flight technologies. Mach. Vis. Appl. 2016, 27, 1005–1020. [CrossRef]
- Stone, E.E.; Skubic, M. Fall detection in homes of older adults using the microsoft kinect. IEEE J. Biomed. Heal. Inform. 2015, 19, 290–301. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, E.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach, Sensors 2019, Vol. 19, no. 9, 1988. [CrossRef]
- Toreyin, B.U.; Dedeoglu, Y.; Cetin, A.E. HMM based falling person detection using both audio and video. In: Computer Vision in Human-Computer Interaction. HCI, Lecture Notes in Computer Science. Sebe, N., Lew, M., Huang, T., Eds.; Springer, Berlin, Heidelberg, 2005, 211–220. [CrossRef]
- Geertsema, E.; Visser, G.H.; Viergever M.A.; Kalitzin S.N. Automated remote fall detection using impact features from video and audio, Journal of Biomechanics, 2018, 88, 25-32. [CrossRef]
- Wu L.; et al., Robust fall detection in video surveillance based on weakly supervised learning. Neural Networks 2023, vol. 163, 286–297. [CrossRef]
- Chhetri, S.; Alsadoon, A.; Al-Dala’In, T.; Prasad, P.W.C.; Rashid, T.A.; Maag, A. Deep Learning for Vision-Based Fall Detection System: Enhanced Optical Dynamic Flow. Comput Intell, 2021, vol. 37, no. 1, 578–595. [CrossRef]
- Gaya-Morey, F.X.; Manresa-Yee, C.; Buades-Rubio, J.M. Deep learning for computer vision based activity recognition and fall detection of the elderly: a systematic review. Applied Intelligence 2024, vol. 54, no. 19, 8982–9007. [Google Scholar] [CrossRef]
- Alhimale, L.; Zedan, H.; Al-Bayatti, A. The implementation of an intelligent and video-based fall detection system using a neural network. Appl. Soft Comput. 2014, 18, 59–69. [Google Scholar] [CrossRef]
- Fan, Y.; Levine, M.D.; Wen, G.; Qiu, S. A deep neural network for real-time detection of falling humans in naturally occurring scenes. Neurocomputing 2017, 260, 43–58. [Google Scholar] [CrossRef]
- Karpuzov, S.; Kalitzin, S.; Georgieva, O.; Trifonov, A.; Stoyanov T.; Petkov G. Automated remote detection of falls using direct reconstruction of optical flow principal motion parameters. Sensors 2025, Under Review; [CrossRef]
- Hsieh, Y.Z.; Jeng, Y.L. Development of Home Intelligent Fall Detection IoT System Based on Feedback Optical Flow Convolutional Neural Network. IEEE Access 2017, vol. 6, 6048–6057. [Google Scholar] [CrossRef]
- Huang, C.; Chen, E.; Chung, P. Fall detection using modular neural networks with back-projected optical flow. Biomed. Eng. Appl. Basis Commun. 2007, 19, 415–424. [Google Scholar] [CrossRef]
- Lacuey, N.; Zonjy, B.; Hampson, J.P.; Rani, M.R.S.; Devinsky, O.; Nei, M.; et al. The incidence and significance of periictal apnea in epileptic seizures, Epilepsia 2018, 59, 573–582. [CrossRef]
- Van de Vel, A.; Cuppens, K.; Bonroy, B.; Milosevic, M.; Jansen, K.; Van Huffel, S.; Vanrumste, B.; Lagae, L.; Ceuleman B. Non-EEG seizure-detection systems and potential SUDEP prevention: state of the art, Seizure 2013, 22, 345–355. [CrossRef]
- Baillieul, S.; Revol, B.; Jullian-Desayes, L.; Joyeux-Faure, M.; Tamisier, R.; Pépin, J.-L. Diagnosis and management of sleep apnea syndrome, Expert Rev. Respir.Med. 2019, 13, 445–557. [Google Scholar] [CrossRef]
- Senaratna, CV.; Perret, J.L.; Lodge, C.J.; Lowe, A.J.; Campbell, B.E.; Matheson, M.C; Hamilton, G.S.; Dharmage, S.C. Prevalence of obstructive sleep apnea in the general population: a systematic review, Sleep Med. Rev. 2017, 34, 70–81. [Google Scholar] [CrossRef]
- Zaffaroni, A.; Kent, B.; O’Hare, E.; Heneghan, C.; Boyle, P.; O’Connell, G.; Pallin,P. M.; De Chazal, W.T. Mcnicholas, Assessment of sleep-disordered breathing using a non-contact bio-motion sensor, J. Sleep Res. 2013, 22, 231–236. [CrossRef]
- Castro, I.D.; Varon, C.; Torfs, T.; van Huffel, S.; Puers, R.; van Hoof, C. Evaluation of a multichannel non-contact ECG system and signal quality algorithms for sleep apnea detection and monitoring, Sensors 2018, 18 1–20. [CrossRef]
- Hers, V.; Corbugy, D.; Joslet, I.; Hermant, P.; Demarteau, J.; Delhougne, B.; Vandermoten,G.; Hermanne, J.P. New concept using Passive Infrared (PIR)technology for a contactless detection of breathing movement: a pilot study involving a cohort of 169 adult patients. J. Clin. Monit. Comput. 2013, 27, 521–529. [CrossRef]
- Garn, H. Kohn, B.; Wiesmeyr, C.; Dittrich, K.; Wimmer, M.; Mandl, M.; Kloesch, G.; Boeck, M.; Stefanic, A.; Seidel, S. 3D detection of the central sleep apnoea syndrome, Curr. Dir. Biomed. Eng. 3017, 3, 829–833. [CrossRef]
- Nandakumar, R.; Gollakota, S.; Watson, N. Contactless sleep apnea detection on smart phones, Proc. 13th Annu. Int. Conf. Mob. Syst. Appl. Serv. - MobiSys’ 15, Florence Italy, May 18-22, 2015, 45–57. [CrossRef]
- Al-Naji, A.; Gibson, K.; Lee, S.-H.; Chahl, J. Real time apnoea monitoring of children using the microsoft kinect sensoa pilot study. Sensors 2017, 17, 286. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Cheung, G.; Stankovic, V.; Chan, K.; Ono, N. Sleep apnea detection via depth video and audio feature learning, IEEE Trans. Multimed. 2017, 19, 822–835. [Google Scholar] [CrossRef]
- Wang, C.W. Hunter, A.; Gravill, N.; Matusiewicz, S. Unconstrained video monitoring of breathing behavior and application to diagnosis of sleep apnea, IEEE Trans. Biomed. Eng. 2014, 61, 396–404. [CrossRef]
- Sharma, S.; Bhattacharyya, S.; Mukherjee, J.; Purkait, P.K.; Biswas, A.; Deb, A.K. Automated detection of newborn sleep apnea using video monitoring system, proceedings: Eighth Int. Conf. Adv. Pattern Recognit. 4-7 January, 2015, England, 1–6. [CrossRef]
- Jorge, J.; Villarroel, M.; Chaichulee, S.; Guazzi, A.; Davis, S.; Green, G.; McCormick, K.; Tarassenko, L. Non-contact monitoring of respiration in the neonatal intensive care unit, Proc. - 12th IEEE Int. Conf. Autom. Face Gesture Recognit , 2017, 286–293. [CrossRef]
- Cattani, L.; Alinovi, D.; Ferrari, G.; Raheli, R.; Pavlidis, E.; Spagnoli, C.; Pisani, F.; Monitoring, F. fants by automatic video processing: a unified approach to motion analysis, Comput. Biol. Med. 2017, 80, 158–165. [Google Scholar] [CrossRef]
- Koolen, N.; Decroupet, O.; Dereymaeker, A.; Jansen, K.; Vervisch, J.; Matic, V.; Vanrumste, B.; Naulaers, G.; Van Huffel, S.; De Vos, M. Automated respiration detection from neonatal video data, Proc. 4th Int. Conf. Pattern Recognit. Appl.Methods 2015, vol. 2, 164–169. [Google Scholar] [CrossRef]
- Li, M.H.; Yadollahi, A.; Taati, B. Noncontact vision-based cardiopulmonary monitoring in different sleeping positions. IEEE J. Biomed. Heal. Inf. 2017, 21, 1367–1375. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining optical flow, Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Groote,A.; Wantier, M.; Cheron, G.; Estenne, M.; Paiva, M. Chest wall motion during tidal breathing, J. Appl. Physiol. 1997, 83, 1531–1537. [CrossRef]
- Geertsema, E.E.; Visser, G.H.; Sander, J.W.; Kalitzin, S.N. Automated non-contact detection of central apneas using video. Biomedical Signal Processing and Control 2020, 55, 101658. [Google Scholar] [CrossRef]
- Petkov, G.; Mladenov N.; Kalitzin S. Integral scene reconstruction from general over-complete sets of measurements with application to explosions localization and charge estimation. Int. Journal of Computer Aided Engineering, 2013, 20, 95-110.
- Higham J.E.; Isaac, O.S.; Rigby, S.E. Optical flow tracking velocimetry of near-field explosion Meas. Sci. Technol. 2022, 33 047001. [CrossRef]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38, 13–es. [Google Scholar] [CrossRef]
- Li, X.; Hu, W.; Shen, C.; Zhang, Z.; Dick, A.; Hengel, A.V.D. A survey of appearance models in visual object tracking. ACM Trans. Intell. Syst. Technol. 2013, 4, 1–48. [Google Scholar] [CrossRef]
- Chen, F.; Wang, X.; Zhao, Y.; Lv, S.; Niu, X. Visual object tracking: A survey. Comput. Vis. Image Underst. 2022, 222, 103508. [Google Scholar] [CrossRef]
- Ondrašoviˇc, M.; Tarábek, P. Siamese visual object tracking: A survey. IEEE Access 2021, 9, 110149–110172. [Google Scholar] [CrossRef]
- Farag,W.; Saleh, Z. An advanced vehicle detection and tracking scheme for self-driving cars. In Proceedings of the 2nd Smart Cities Symposium (SCS 2019), Bahrain, 24–26 March 2019; IET: Stevenage, UK, 2019.
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Lipton, A.J.; Reartwell, C.; Haering, N.; Madden, D. Automated video protection, monitoring & detection. IEEE Aerosp. Electron. Syst. Mag. 2003, 18, 3–18. [Google Scholar]
- Wang, W.; Gee, T.; Price, J.; Qi, H. Real time multi-vehicle tracking and counting at intersections from a fisheye camera. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Kim, H. Multiple vehicle tracking and classification system with a convolutional neural network. J. Ambient Intell. Humaniz. Comput. 2022, 13, 1603–1614. [Google Scholar] [CrossRef]
- Deori, B.; Thounaojam, D.M. A survey on moving object tracking in video. Int. J. Inf. Theory 2014, 3, 31–46. [Google Scholar] [CrossRef]
- Mangawati, A.; Leesan, M.; Aradhya, H.R. Object Tracking Algorithms for video surveillance applications. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 3–5 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Gilbert, A.; Bowden, R. Incremental, scalable tracking of objects inter camera. Comput. Vis. Image Underst. 2008, 111, 43–58. [Google Scholar] [CrossRef]
- Yeo, H.-S.; Lee, B.-G.; Lim, H. Hand tracking and gesture recognition system for human-computer interaction using low-cost hardware. Multimed. Tools Appl. 2015, 74, 2687–2715. [Google Scholar] [CrossRef]
- Fagiani, C.; Betke, M.; Gips, J. Evaluation of Tracking Methods for Human-Computer Interaction. In Proceedings of theWACV, Orlando, FL, USA, 3–4 December 2002. [Google Scholar]
- Hunke, M.; Waibel, A. Face locating and tracking for human-computer interaction. In Proceedings of the 1994 28th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 31 October–2 November 1994; IEEE: Piscataway, NJ, USA, 1994. [Google Scholar]
- Karpuzov S,; Petkov, G.; Ilieva, S.; Petkov A.; Kalitzin S. Object Tracking Based on Optical Flow Reconstruction of Motion-Group Parameters. Information 2024, 15, 296. [CrossRef]
- Doyle, D.D.; Jennings, A.L.; Black, J.T. Optical flow background estimation for real-time pan/tilt camera object tracking. Measurement 2014, 48, 195–207. [Google Scholar] [CrossRef]
- Husseini, S. A Survey of Optical Flow Techniques for Object Tracking. Bachelor’s Thesis, Tampere University, Tampere, Finland, 2017. [Google Scholar]
- Zhang, P.; Tao, Z.; Yang,W.; Chen, M.; Ding, S.; Liu, X.; Yang, R.; Zhang, H. Unveiling personnel movement in a larger indoor area with a non-overlapping multi-camera system. arXiv 2021, arXiv:2104.04662.
- Porikli, F.; Divakaran, A. Multi-camera calibration, object tracking and query generation. In Proceedings of the 2003 International Conference on Multimedia and Expo. ICME’03, Baltimore, MD, USA, 6–9 July 2003; Proceedings (Cat. No. 03TH8698); IEEE: Piscataway, NJ, USA, 2003. [Google Scholar]
- Dick, A.R.; Brooks, M.J. A stochastic approach to tracking objects across multiple cameras. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Cairns, Australia, 4–6 December 2004; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Yang, F.; Odashima, S.; Masui, S.; Kusajima, I.; Yamao, S.; Jiang, S. Enhancing Multi-Camera Gymnast Tracking Through Domain Knowledge Integration. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 13386–13400. [Google Scholar] [CrossRef]
- Amosa, T.I.; Sebastian, P.; Izhar, L.I.; Ibrahim, O.; Ayinla, L.S.; Bahashwan, A.A.; Bala, A.; Samaila, Y.A. Multi-camera multi-object tracking: A review of current trends and future advances. Neurocomputing 2023, 552, 126558. [Google Scholar] [CrossRef]
- Cherian, R.; Jothimani, K.; Reeja, S. A Review on Object Tracking Across Real-World Multi Camera Environment. Int. J. Comput. Appl. 2021, 174, 32–37. [Google Scholar] [CrossRef]
- Yang, F.; Odashima, S.; Yamao, S.; Fujimoto, H.; Masui, S.; Jiang, S. A unified multi-view multi-person tracking framework. Comput. Vis. Media 2024, 10, 137–160. [Google Scholar] [CrossRef]
- Karpuzov, S.; Petkov, G.; Kalitzin, S. Multiple-Camera Patient Tracking Method Based on Motion-Group Parameter Reconstruction. Information 2025, 16, 4. [Google Scholar] [CrossRef]
- Fei, L.; Han, B. Multi-object multi-camera tracking based on deep learning for intelligent transportation: A review. Sensors 2023, 23, 3852. [Google Scholar] [CrossRef] [PubMed]
- Elmenreich, W. An introduction to sensor fusion. Vienna Univ. Technol. Austria 2002, 502, 1–28. [Google Scholar]
- Fung, M.L.; Chen, M.Z.; Chen, Y.H. Sensor fusion: A review of methods and applications. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017. [Google Scholar]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.;Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140.
- Yu, L.; Ramamoorthi, R. Learning Video Stabilization Using Optical Flow, In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seatle WA, June 13-19, 2020, 8159-8167.
- Chang, I.-Y.; Hu, W.-F.; Cheng, M.-H.; Chang, B.-S. Digital image translational and rotational motion stabilization using optical flow technique. IEEE Transactions on Consumer Electronics, 2002, vol. 48, no. 1, 108-115, Feb. 2002. [CrossRef]
- Deng, D.; Yang, D.; Zhang, X.; Dong, Y.; Liu C.; Shen, Q. Real-Time Image Stabilization Method Based on Optical Flow and Binary Point Feature Matching, Electronics 2020, 9, 198. [CrossRef]

| Scales [pixels] | Error % |
|---|---|
| [16] | 30 |
| [8, 16] | 10 |
| [8,1] | 5 |
| [16, 8, 4, 2] | 3 |
| [16, 8, 4, 2, 1] | 2.5 |
| Magnitude [pxls]/Transformation | 1 | 2 | 3 | 4 | 5 | 6 |
| Reconstruction error [%] | 2 | 5 | 6 | 7 | 7 | 8 |
| RES | ROC AUC | SPEC @ 100% SENS |
SPEC @ 90% SENS |
SPEC @ 80% SENS |
|
|---|---|---|---|---|---|
| DATA | |||||
| Video & audio | 0.957 | 0.818 | 0.919 | 0.945 | |
| Video only | 0.947 | 0.799 | 0.896 | 0.923 | |
| Video file index (.mp4) | A = Detector RR | B = Chest Strap RR | (A-B) |
| 01 | 45 | 43 | 2 |
| 02 | 39 | 37 | 2 |
| 54 | 47 | 46 | 1 |
| 55 | 38 | 37 | 1 |
| 56 | 48 | 47 | 1 |
| 58 | 48 | 45 | 3 |
| 59 | 45 | 44 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



