Submitted:
31 August 2025
Posted:
02 September 2025
You are already at the latest version
Abstract
As AI systems become increasingly embedded in multi-tenant platforms, ensuring regulatory compliance and accountability requires more than ad hoc rule encoding. In the absence of a formal mathematical foundation, compliance logic cannot be guaranteed to remain consistent under evolving legal norms. This paper introduces a decision-theoretic semantic compliance framework that integrates a rigorous probabilistic reasoning model with ontology- and rule-based representations. Legal obligations are encoded in OWL ontologies and SWRL rules, while compliance judgments are derived through a mathematically grounded chain that includes prior probability estimation, Bayesian updating, likelihood ratio testing, and log-likelihood ratio decomposition. The architecture is modular and extensible, encapsulating compliance logic in a semantic layer that can be updated independently of the core platform. A prototype implementation in a healthcare scenario demonstrates the framework’s ability to detect policy violations, provide interpretable reasoning traces, and adapt to jurisdiction-specific regulations. The approach offers a verifiable and reusable compliance model applicable to a wide range of high-stakes, regulation-intensive domains, enhancing both transparency and trust in AI-enabled decision-making.
Keywords:
I. Introduction
II. Methodology
A. Theoretical Framework
1). Prior Violation Probability via the Law of Total Probability
2). Posterior Violation Probability via Bayes’ Theorem
3). Neyman–Pearson Likelihood Ratio Test for Compliance Decision
4). Log-Likelihood Ratio Decomposition for Rule-Based Evidence
5). Minimal Numerical Example
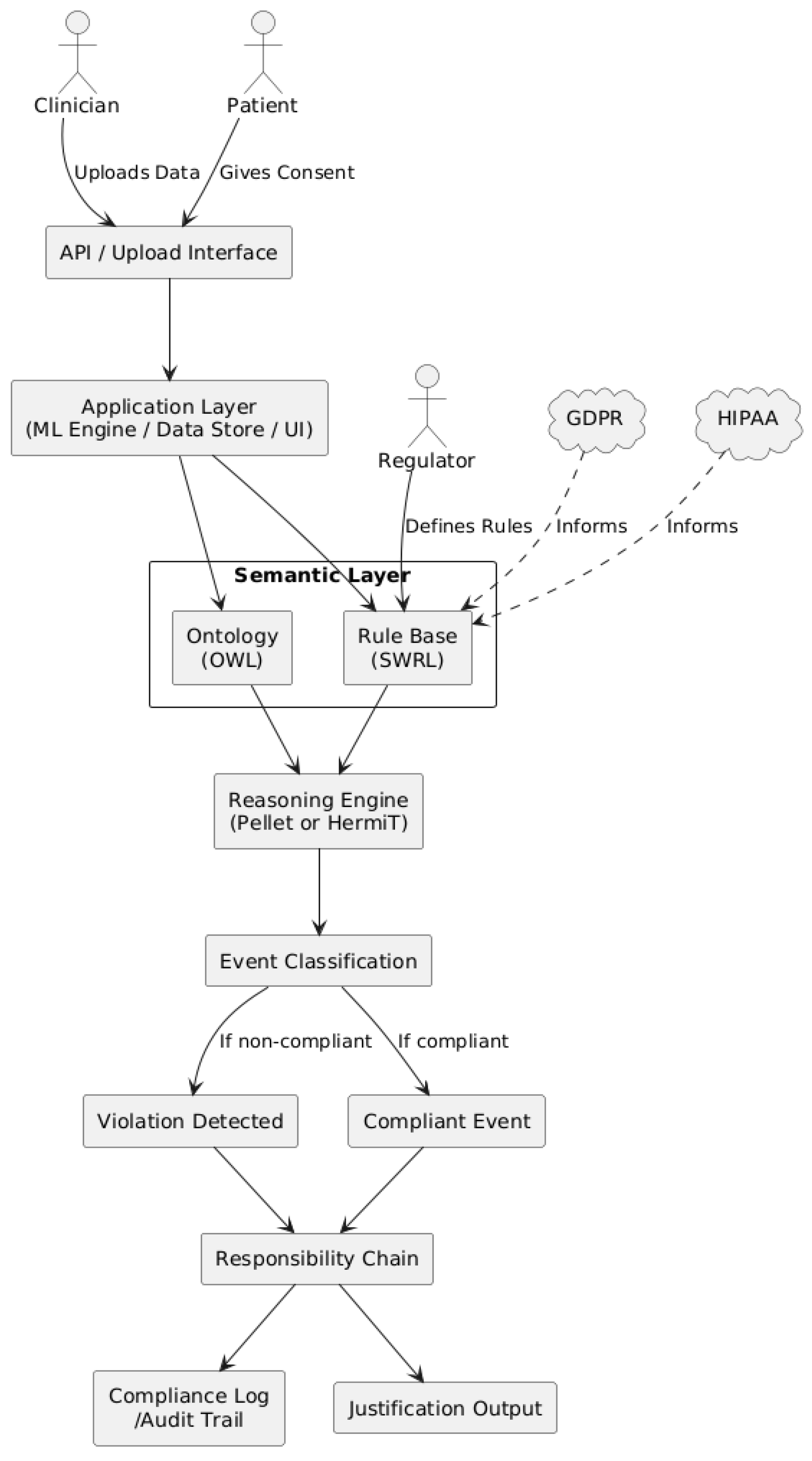
B. Semantic Compliance Architecture for Multi-Tenant Platforms
1). Three-layer Governance Model
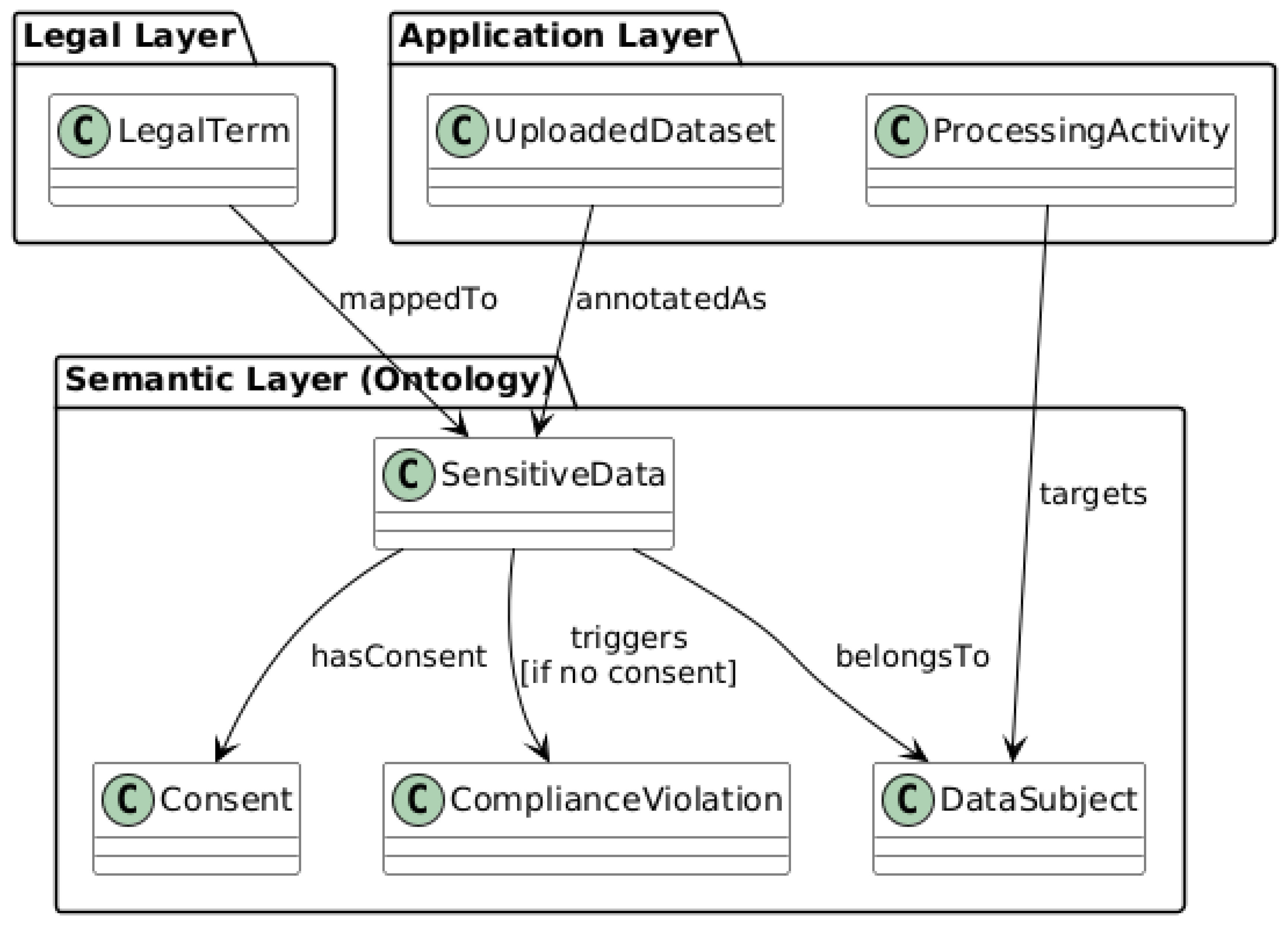
2). Ontology and Rule Encoding
3). Semantic Tenant Isolation
4). Runtime Policy Engine
5). Responsibility-Chain Model
C. Explainable AI for Role-Specific Compliance
D. Legal and Application Layers
E. Semantic Layer: Ontology and Rule Formalization
F. Semantic Mapping and Rule-Based Compliance Reasoning
G. Obligation Embedding and Responsibility Chain Modeling
H. Role-Based Responsibility and Reasoning Paths
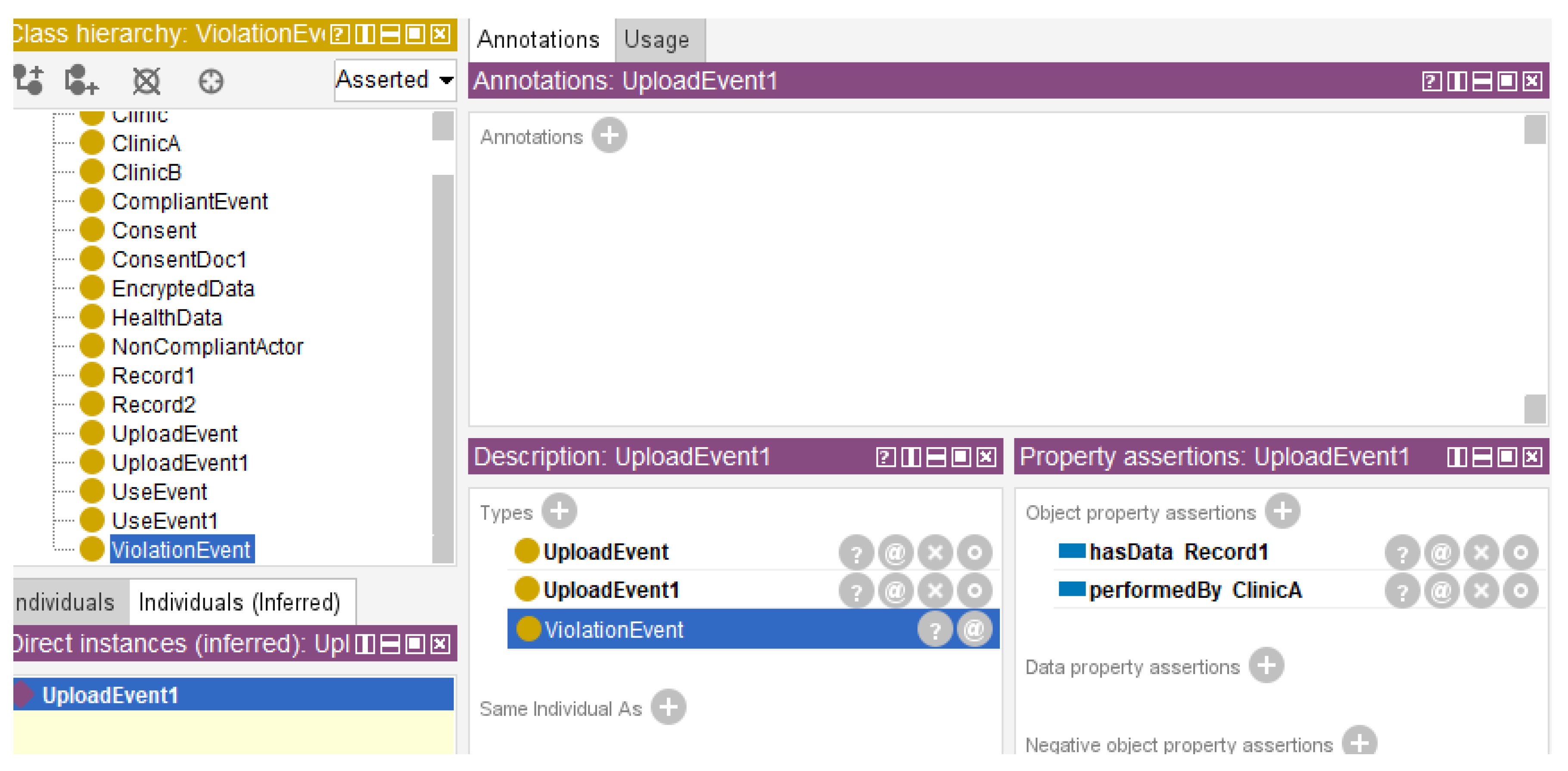
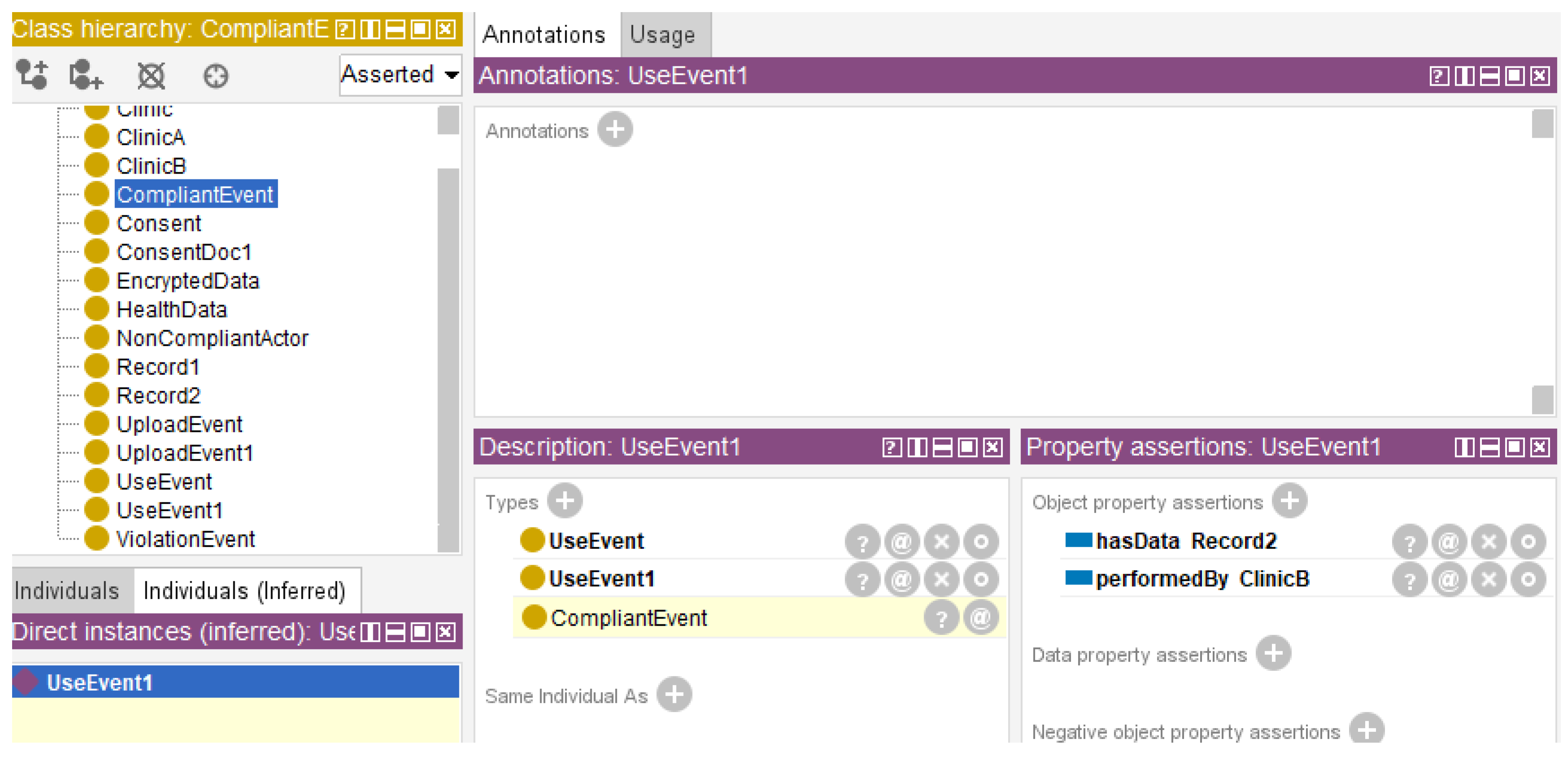
III. Semantic Explainability and Experimental Validation
IV. Discussion
V. Conclusion
VI. Future Work
References
- L. Xu, C. Zhao, W. Jiang, J. Ye, Y. Zhao and Z. Zhang, “Secure Encryption Scheme for Medical Data based on Homomorphic Encryption,” 2023 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 2023, pp. 01-09. [CrossRef]
- L. Wang, D. T. Liu, and P. Li, “Policy-driven security management for multi-tenant cloud applications,” IEEE Transactions on Cloud Computing, vol. 9, no. 4, pp. 1294–1307, Oct.–Dec. 2021. [CrossRef]
- J. Xu, “Building a Structured Reasoning AI Model for Legal Judgment in Telehealth Systems,” Preprints, Jul. 2025, preprint of paper presented at the 41st Int. RAIS Conf. on Social Sciences and Humanities, Washington, DC, USA, Aug. 2025. [Online]. [CrossRef]
- J. Xu, H. Wang, and H. Trimbach, “An OWL ontology representation for machine-learned functions using linked data,” 2016 IEEE International Congress on Big Data (BigData Congress), pp. 319–322, Jun. 2016. [CrossRef]
- H. Pandit, D. O’Sullivan, and D. Lewis, “GConsent: a consent ontology based on the GDPR,” Semantic Web, vol. 10, no. 1, pp. 27–52, 2019.
- S. Batsakis et al., “A scalable reasoning engine for OWL 2 DL ontologies,” J. Web Semantics, vol. 43, pp. 55–74, 2017.
- Gyrard, S. Zimmermann, and I. Z. Álvarez, “Semantic Web technologies for the internet of things,” IEEE Internet Computing, vol. 23, no. 4, pp. 54–63, Jul. 2019.
- S. Villata and F. Gandon, “Licentia: A linked data platform for licensing data,” Proc. International Semantic Web Conf., 2014, pp. 312–327.

| Theoretical Meaning | Corresponding SWRL Rule | Experimental Scenario | |
|---|---|---|---|
| Eq. (1) | Prior violation probability via the law of total probability across tenants and jurisdictions. | Jurisdiction-specific policy modules loaded per tenant. | All scenarios (modular vs static rule sets). |
| Eq. (2) | Posterior violation probability update using Bayesian inference. | Evidence vector E from consent, encryption, and data category. | Scenario 1: No consent + no encryption. Scenario 2: Consent + encryption. |
| Eq. (3) | Neyman–Pearson likelihood ratio test. | Runtime evaluation of | All scenarios with decision classification. |
| Eq. (4) | Log-likelihood ratio decomposition under conditional independence. | Binary rule triggers for all rules in | Any scenario with active rule firing. |
| Type | Name |
|---|---|
| Class | DataSubject |
| Class | SensitiveData |
| ObjectProperty | hasConsent |
| Domain | SensitiveData |
| Range | Consent |
| Class | Consent |
| Class | ComplianceViolation |
| Aspect | Static Architecture | Modular Architecture |
|---|---|---|
| Rule Storage | All rules combined in one shared ontology | Rules stored in separate modules per tenant |
| Policy Switching | Requires manual editing of shared rule set | Automatic via context-based module loading |
| Tenant Separation | None; all rules active globally | Full; each tenant’s rules applied independently |
| Conflict Risk | High – overlapping rules may interfere | Low – rules isolated per tenant context |
| Ontology Structure | Single combined ontology | Base ontology + imported tenant policies |
| Maintenance | Hard to manage and update | Easy to extend and adapt |
| Reasoning Flow | Applies all rules in one global pass | Loads and reasons over relevant rules only |
| Adaptability | Limited to single-policy context | Designed for dynamic, multi-policy support |
| Scenario / Tenant | Static SWRL Components Outcome | Semantic Architecture Outcome |
|---|---|---|
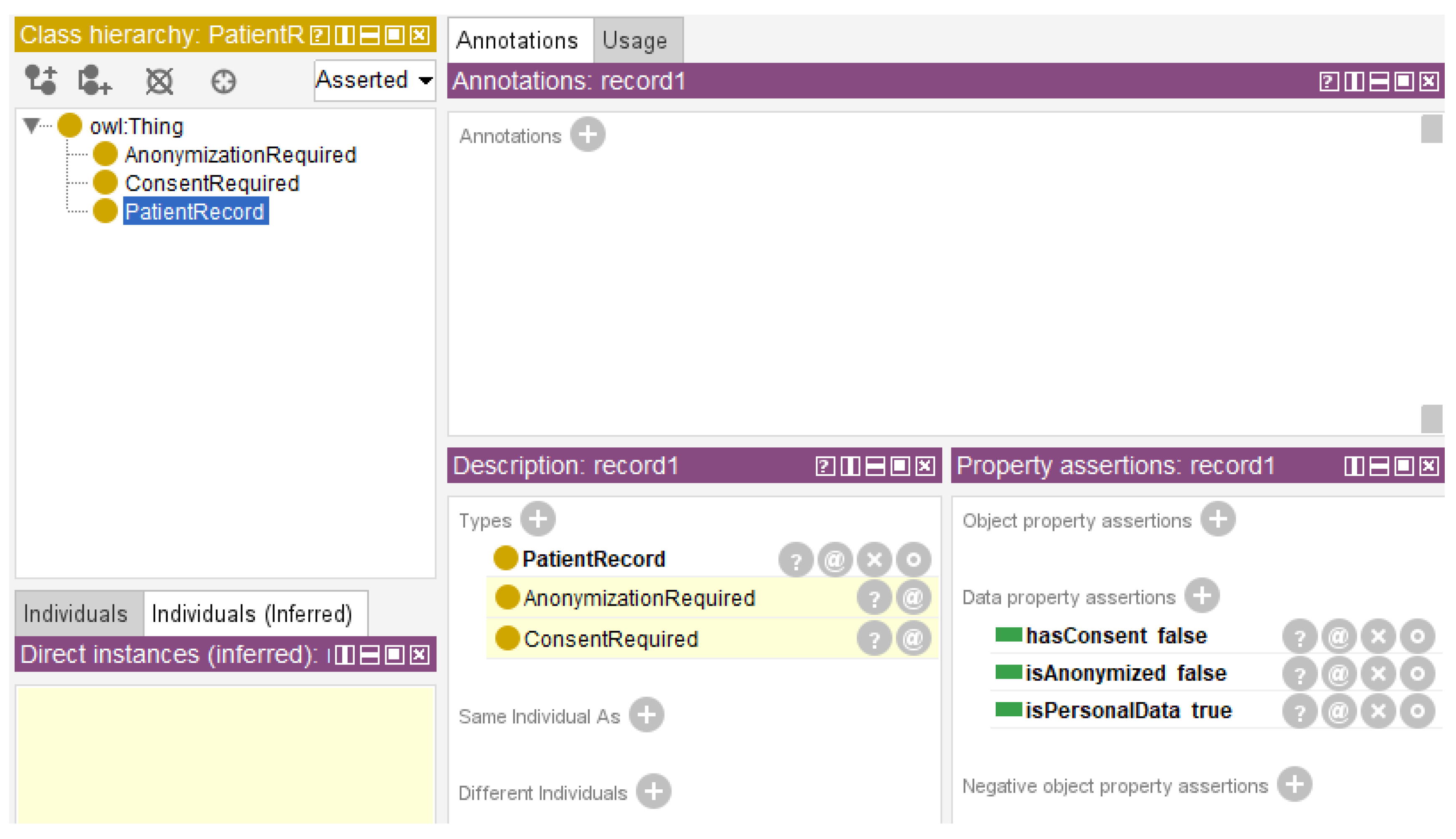
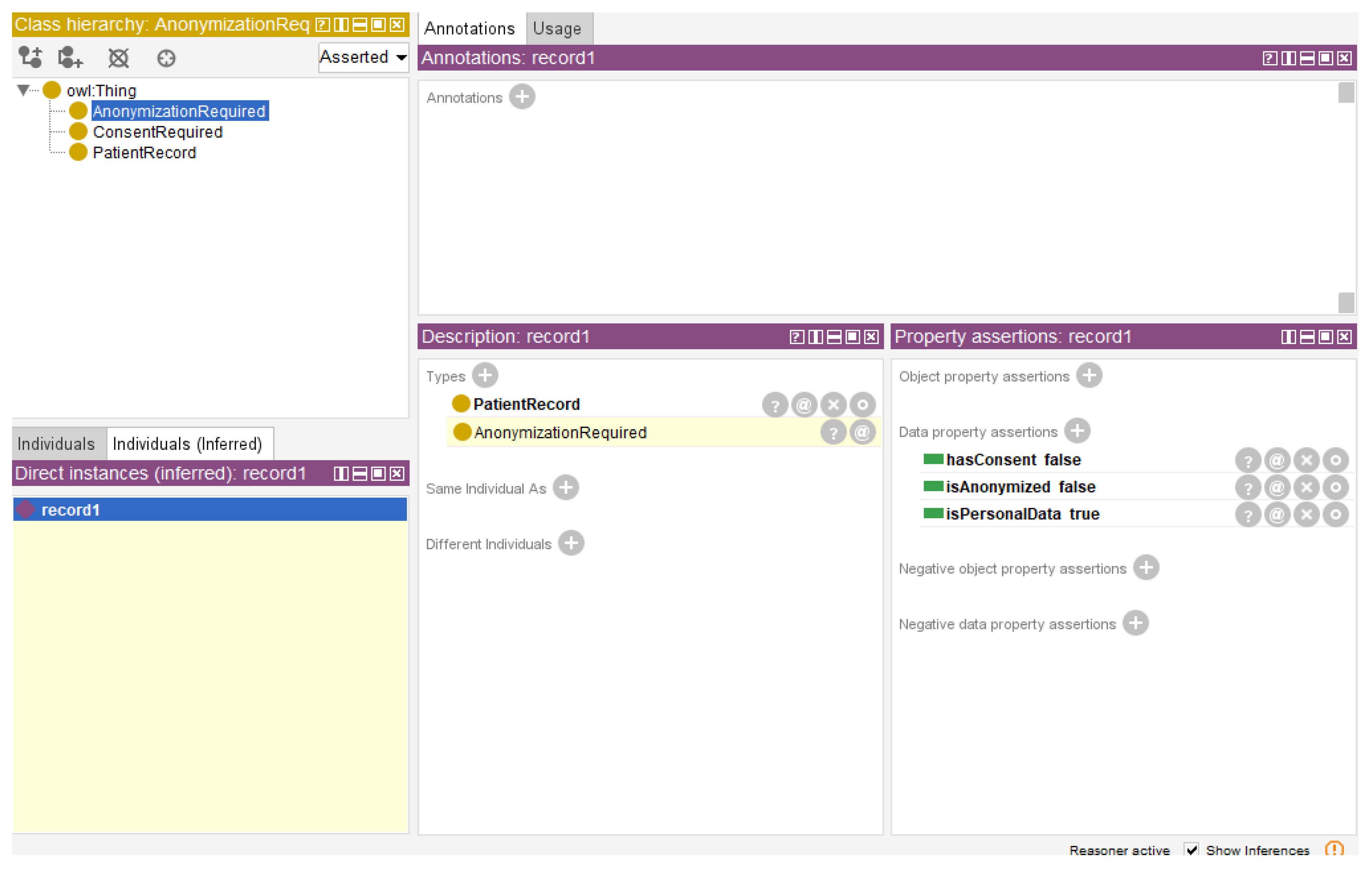
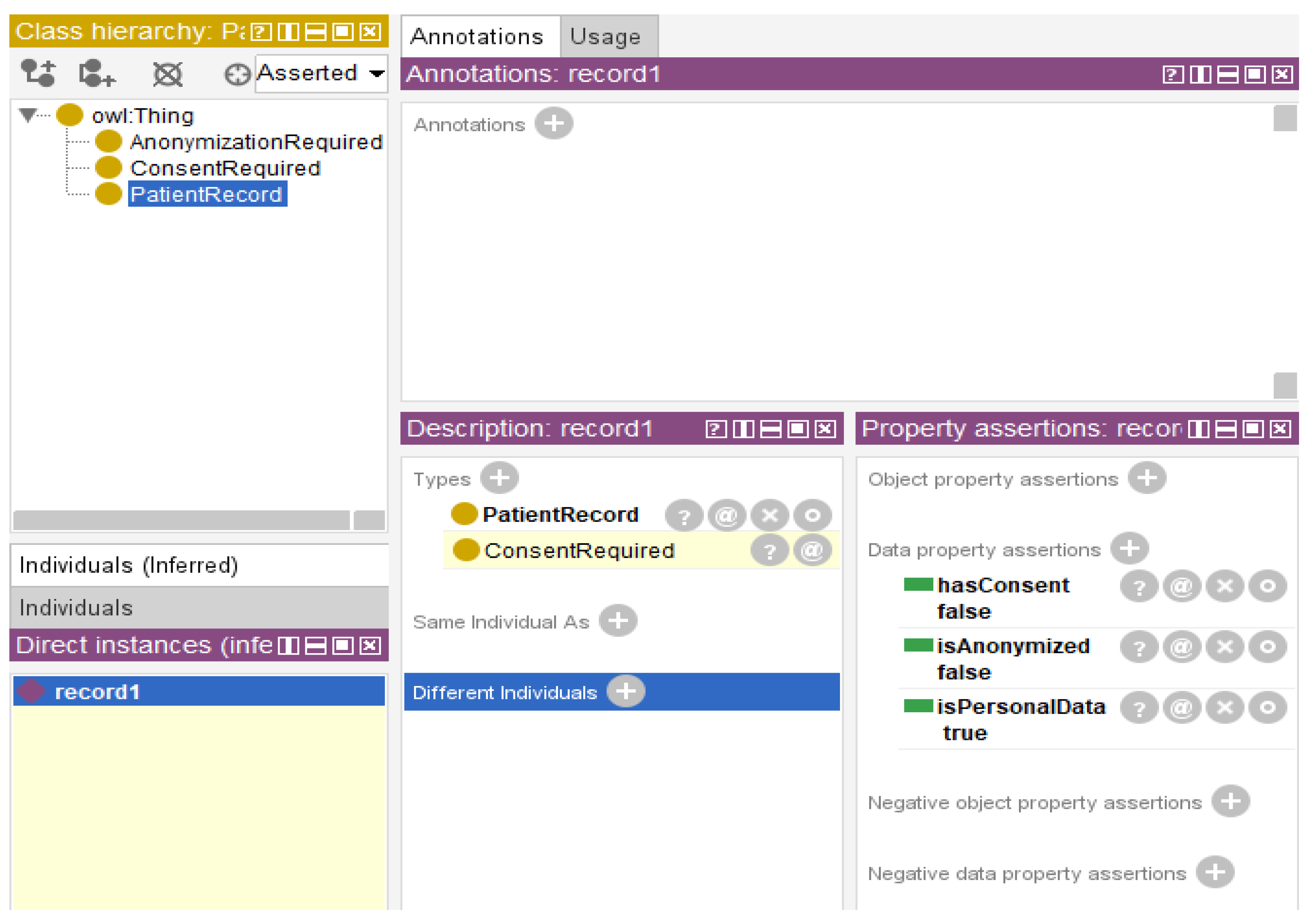
| HIPAA-only rules | record1 is inferred as ConsentRequired (sharing disallowed without consent). All HIPAA conditions applied globally. | Same inference: ConsentRequired(record1) is true. Achieved by importing the HIPAA module for Tenant A. |
| GDPR-only rules | record1 is inferred as AnonymizationRequired (must anonymize before sharing). GDPR rule applied globally. | Same inference: AnonymizationRequired(record1) is true. Achieved by importing the GDPR module for Tenant B. |
| Mixed (HIPAA+GDPR) | Not tested together. In a naive global rule set, contradictory requirements could clash. For example one rule says “must anonymize” while another says “must obtain consent”. | Not applicable, since each tenant loads only one module. Policy sets remain isolated. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



