Submitted:
28 July 2025
Posted:
29 July 2025
You are already at the latest version
Abstract
Accurate extraction of airways from computed tomography (CT) images of the lungs is essential for assessing pulmonary ventilation function and diagnosing respiratory diseases. Traditional airway segmentation methods rely heavily on manual interaction, limiting segmentation accuracy. Deep learning has been widely applied in medical image processing, especially in lung nodule detection and benign/malignant diagnosis. However, its application to airway segmentation in lung CT images faces challenges due to image noise and varying tissue densities, making it difficult to segment fine airways. Original CT images contain non-relevant regions such as bones and beds, increasing processing overhead and error rates. To address these issues, this paper proposes an Attention-Unet-based airway segmentation method using a stepwise processing strategy to enhance structural representation. Experimental results demonstrate that applying the Attention-Unet network to airway segmentation in lung CT images significantly improves segmentation speed and accuracy while effectively reducing leakage.
Keywords:
deep learning
; lung tissue segmentation
; airway segmentation
; Attention-Unet network
1. Introduction
The airway is an essential anatomical structure. Although many approaches have been explored, there is still no universally effective solution for airway segmentation in lung CT images. Accurate segmentation of the airway’s 3D structure is vital not only for diagnostic analysis but also for determining lesion locations and guiding clinical procedures, helping to avoid unnecessary invasive operations.
While large airways are relatively easy to segment due to their clear anatomical boundaries, the increasingly thinner walls of small airways, together with the variability in diameter and tissue quality, result in a high risk of segmentation leakage [1,2]. Region growing is one of the classical methods in airway segmentation, which connects pixels with similar intensity to form a continuous region. Fabijanska [4] proposed a region growing technique to track airway branches by controlling growth thresholds. Ginneken [5] introduced length constraints for branch segmentation, applicable to multi-generation branches.
Zhang et al. [6] improved the classical region growing with fuzzy logic for better boundary detection. Aykac [8] proposed shape-based level set methods for robust airway boundary evolution. Other methods include model-based, shape-based, and graph-based approaches. Aykac [9] also used distance transform for 3D shape modeling, segmenting airways with strong connectivity while filtering noise and irrelevant tissues.
Deep learning-based methods, especially convolutional neural networks (CNN), have become dominant in medical image segmentation. They have been widely adopted in lung CT airway segmentation research due to their strong feature extraction capabilities. Jin [3] used a 3D CNN to extract airway structure directly from CT data. Zhao [10] trained a 3D CNN on multi-orientation slices for central airway segmentation. Zhang [11] combined rule-based pre-processing with CNN for terminal bronchiole segmentation.
Additionally, GAN-based methods have been applied to enhance segmentation results through adversarial learning. Li [12] proposed a GAN-based approach to reconstruct 3D airway structures, while Cheng [13] used Unet to segment lung CT images. Despite promising results, these approaches may still suffer from leakage and low segmentation precision in small airways.
This study explores deep learning-based segmentation of airways in lung CT, using the U-net and its improved variant Attention-Unet. Experimental results demonstrate that Attention-Unet offers better segmentation speed and accuracy while effectively reducing leakage, thus supporting clinical diagnosis of pulmonary diseases.
2. Related Work
Recent progress in medical image segmentation has demonstrated the effectiveness of domain-adaptive architectures. For instance, transformer-based frameworks designed for clinical imaging tasks have shown strong cross-domain generalization, which is particularly relevant for organ segmentation in CT images where anatomical variability is high [14]. Transferable modeling strategies, such as prompt tuning and semantic alignment, provide lightweight mechanisms for adapting deep models to low-resource medical scenarios, offering scalable solutions for tasks like airway detection [15]. Efficient deployment methods, including collaborative distillation, have also been introduced to reduce the overhead of large models while maintaining high segmentation fidelity [16].
Reinforcement learning has been applied to elastic resource scaling, demonstrating adaptive control in dynamic environments. These techniques provide conceptual parallels to multi-phase segmentation processes in medical imaging where structural complexity varies across image regions [17]. Furthermore, attention-based deep learning models have achieved strong performance in clinical NLP for multi-label disease prediction, suggesting that multi-focus attention mechanisms can be extended to spatial domain tasks such as segmenting airways of varying sizes in CT scans [18]. Policy-guided reasoning frameworks have been explored in multi-step language modeling, demonstrating effective path selection under uncertainty. This principle translates well into multi-stage image segmentation pipelines, where intermediate decisions impact downstream segmentation quality [19]. In distributed systems, contrastive learning has been leveraged for behavioral anomaly detection, employing federated training mechanisms to preserve privacy and improve generalization—an approach aligned with decentralized segmentation tasks across heterogeneous medical imaging datasets [20].
Semantic intent modeling using capsule networks enhances part-whole representation learning, supporting accurate identification of complex anatomical regions. This structural sensitivity is especially valuable in airway segmentation, where branching patterns must be preserved [21]. Recent advancements in modular adaptation techniques, such as selective knowledge injection, allow large models to incorporate domain-specific priors efficiently. This enables robust learning without full retraining, a necessity when fine-tuning for airway extraction across diverse patient populations [22]. Additionally, low-rank adaptation schemes guided by semantic cues offer further compression benefits while preserving segmentation precision, balancing computational efficiency and model capacity [23]. Distilling semantic knowledge across multiple alignment levels has proven effective for compressing and adapting transformer-based architectures, which is beneficial for lightweight deployment of segmentation models in real-time clinical environments [24]. Methods focusing on hallucination detection in model outputs emphasize the importance of contextual consistency and evidence alignment, offering frameworks for ensuring prediction reliability—a critical factor when delineating intricate airway structures [25]. Graph-based collaborative perception systems, powered by neural networks, have also been utilized for adaptive task scheduling. These systems model inter-entity dependencies and can inform spatial coordination in medical image segmentation, particularly when tracking connectivity between airway branches [26].
Feature integration across multiple spatial resolutions, combined with attention-based mechanisms, has shown to significantly improve segmentation accuracy in medical imaging tasks. This approach directly addresses the challenges of detecting small or obscured anatomical features, such as fine bronchioles in noisy CT scans [27]. Furthermore, noise injection and feature scoring strategies have enhanced robustness in unsupervised anomaly detection. These techniques may be extended to improve segmentation resilience against imaging artifacts or irregular tissue patterns [28]. Sequence modeling frameworks that integrate bidirectional LSTM with multi-scale attention mechanisms have shown strong performance in temporal pattern discovery. These approaches are relevant for modeling complex spatial structures in 3D medical images, where contextual dependencies extend across multiple anatomical layers [29]. Transformer-based architectures with dual-loss optimization have also been employed for few-shot classification, offering robustness in low-data environments—a property valuable for medical segmentation tasks involving rare structural variations or incomplete annotations [30].
Visual tracking methods such as DeepSORT have enhanced gesture recognition by maintaining consistent localization over time, illustrating the effectiveness of spatial continuity in dynamic scene interpretation. This principle is transferable to airway segmentation, where contiguous segmentation across slices is essential for accurate 3D reconstruction [31]. In recommendation systems, time-aware convolutional models have captured multi-channel dependencies, highlighting the importance of combining temporal and semantic cues—a dual attention strategy that can guide segmentation refinement [32]. Moreover, hybrid graph convolution and sequential learning models have achieved scalability in network prediction tasks, offering insights into integrating global context and local patterns in airway delineation [33]. Adaptive scheduling strategies using deep reinforcement learning have enabled state-aware decision-making in Internet-of-Things systems. These frameworks manage real-time environmental dynamics, analogous to how segmentation models adapt to spatial variability in CT scans [34]. To address data imbalance in structured domains, probabilistic graphical models combined with variational inference have been applied, allowing better uncertainty modeling—a critical capability when segmenting underrepresented or subtle airway structures [35].
Attention-driven transformer models have proven effective in anomaly detection for video data, capturing global temporal correlations. The underlying mechanism can be extended to volumetric medical imaging, supporting holistic interpretation across sequential slices [36]. Efficient fine-tuning techniques such as low-rank adaptation have emerged as viable solutions for adapting large models to new domains with minimal overhead, ensuring both scalability and performance when applied to CT-based segmentation [37]. Additionally, dynamic fine-tuning strategies that incorporate semantic structure constraints have demonstrated improvements in few-shot tasks, enabling fast adaptation to novel anatomical configurations [38]. Behavioral detection frameworks, particularly those built on real-time object detection models like YOLO, have shown how behavior-specific features can be extracted and aggregated for precise identification. This strategy can inspire feature selection and region-of-interest prioritization in airway segmentation models, ensuring attention is directed to clinically relevant structures [39]. Lastly, attention-based architectures using multi-head mechanisms have been employed to model service access patterns in microservice environments, revealing the potential of distributed attention for capturing complex interdependencies—an approach that can enrich feature modeling in multiscale airway segmentation tasks [40].
3. Model Introduction
3.1. U-net Network Architecture
Since 2015, the U-net architecture has achieved remarkable success in the field of image segmentation. U-net is built upon the fully convolutional network (FCN) and addresses FCN’s inability to retain and recognize spatial positional information. Originally proposed by Hinton in 2006, U-net adopts an encoder-decoder architecture, which compresses input images through down-sampling to extract high-level features, then reconstructs the original image via up-sampling.
Its main innovation lies in the fusion of low-level features from the encoder with high-level features from the decoder through skip connections, enabling more detailed reconstruction. Down-sampling layers preserve object-level localization, while up-sampling layers refine boundaries by filling in contextual features.
3.2. Improved U-net Architectures
3.2.1. Unet++ Segmentation Algorithm
Unet++ enhances the original U-net by redesigning skip connections to reduce the semantic gap between encoder and decoder features. As illustrated in Figure 1, Unet++ integrates intermediate decoder nodes for deeper supervision and efficient learning across layers of different depths.
This approach allows each layer to share a decoder and incorporate deep supervision, improving learning efficiency and reducing segmentation complexity. Furthermore, Unet++ supports parallel training and avoids rigid layer matching constraints, optimizing information flow and network flexibility.
3.2.2. Attention-Unet Segmentation Algorithm
Attention-Unet introduces attention mechanisms into U-net, applying an attention module before concatenating features at each resolution level of the decoder. As shown in Figure 2, the Attention Gate (AG) selectively adjusts decoder outputs to emphasize relevant spatial features and suppress irrelevant background noise.
Compared to conventional CNN layers, AG improves learning efficiency by reducing the number of parameters and increasing feature focus. It also minimizes interference from unrelated regions and suppresses redundant skip connections. Integrating AG into U-net improves robustness and segmentation precision, especially in detecting fine structures like airways.
4. Overall Segmentation Process
Based on the characteristics of the bronchial tree, this paper optimizes the Attention-Unet architecture and proposes a segmentation network model specifically for pulmonary CT images, as shown in Figure 3.
For preprocessing, a simple and efficient approach is applied to lung CT images. Morphological operations and smoothing are used to reduce noise and extract complete bronchial textures, laying the foundation for accurate pulmonary parenchyma segmentation. The preprocessed result is then fed into the Attention-Unet model, where the Attention Gate suppresses task-irrelevant features while enhancing task-relevant ones to ensure accurate tracheal extraction.
4.1. Lung CT Image Preprocessing
Original lung CT images may contain motion artifacts or environmental interference during the scan, leading to substantial noise. To mitigate this and enhance lung tissue clarity and boundary reliability, the image is preprocessed using smoothing and morphological operations.
Morphological processing extracts image regions of interest by applying predefined structural elements and filtering unwanted components, ensuring better segmentation precision. Smoothing further removes irregularities at the image edges, facilitating more robust region matching.
4.2. Parenchyma Extraction and Trachea Segmentation
Since lung parenchyma regions exhibit clear CT value differences from surrounding tissues, we first extract these regions to reduce downstream processing complexity, as illustrated in Figure 4.
The extracted data is fed into the Attention-Unet model for trachea segmentation. The internal structure of the Attention Gate is shown in Figure 5. In this figure, g represents the gating signal matrix from the decoder, is the encoder matrix. The Attention Gate calculates the attention coefficient using the following formula:
5. Experimental Results and Analysis
To train the model, Adam optimizer is used with a learning rate of 1e-4, and the models U-net, Unet++ and Attention-Unet are trained with 100 epochs. The neural network training environment includes Python 3.6, PyCharm Community Edition 2020.2, running on a 64-bit Windows 10 operating system, with an Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz.
5.1. Dataset and Evaluation Metrics
The dataset used is from the EXACT09 public dataset (http://image.diku.dk/), which contains CT scans of lungs collected from various hospitals and scanned using different equipment. The file format is DICOM, with a single image slice thickness ranging from 0.6 to 1.25 mm and a resolution of 512 × 512 pixels.
Evaluation metrics include Miou, Dice, and Aver_hd:
- Miou: Mean intersection over union, evaluating the overlap between predicted and ground-truth regions.
- Dice: Dice similarity coefficient, evaluating the overlap accuracy.
- Aver_hd: Average Hausdorff distance, evaluating boundary accuracy.
5.2. Lung Parenchyma Segmentation Results
To compare segmentation effectiveness, the performance of U-net, Unet++, and Attention-Unet is visually compared in Figure 6, Figure 7 and Figure 8.
From Table 1, it is evident that both U-net and Attention-Unet perform well in segmenting lung parenchyma. However, Unet++ struggles without preprocessing, yielding poor segmentation.
5.3. Pulmonary Trachea Segmentation Results
6. Conclusions
This paper focuses on image segmentation techniques and proposes an improved Attention-Unet-based method for pulmonary trachea segmentation in CT images. The segmentation results of Attention-Unet are compared with those of U-net and Unet++.
The trained model can directly perform automatic segmentation on original CT images. Due to its optimized structure and integrated attention mechanism, the Attention-Unet network exhibits better adaptability to data and performs better on the same dataset compared to U-net and Unet++.
This method is simple yet effective, accurately extracting complete bronchial structures and effectively solving the issue of segmentation leakage in the airway, showing strong robustness.
References
- Lo, P.; Sporring, J.; Ashraf, H.; Pedersen, J. H.; de Bruijne, M. Vessel-guided airway tree segmentation: A voxel classification approach. Medical Image Analysis 2010, 14(4), 527–538. [Google Scholar] [CrossRef]
- Garcia-Uceda Juarez, A.; Summers, R. M. Airway segmentation and analysis in computed tomography: A review. Medical Image Analysis 2018, 49, 45–68. [Google Scholar]
- Pu, J.; Leader, J. K.; et al. A computational geometry approach to automated pulmonary fissure segmentation in CT. Medical Image Analysis 2011, 15(4), 530–542. [Google Scholar]
- Fabijanska, A. Results of applying two-pass region growing algorithm for airway tree segmentation on MDCT chest scans from EXACT database. In Proc. 2nd Int. Workshop on Pulmonary Image Analysis; USA: CreateSpace, 2009; pp. 251–260. [Google Scholar]
- Ginneken, B.; Baggerman, W.; Ritsoqort, E. M. Robust segmentation and anatomical labeling of the airway tree from thoracic CT scans. In Medical Image Computing and Computer-Assisted Intervention; Springer, 2008; pp. 219–226. [Google Scholar]
- Meng, Y.; Zhang, J.; Xu, Y. Airway segmentation using attention-based 3D convolutional networks. Computer Methods and Programs in Biomedicine 2021, 200, 105836. [Google Scholar]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P. A. Automated airway segmentation using cascaded 3D fully convolutional networks. Medical Physics 2017, 44(5), 1835–1847. [Google Scholar]
- Aykac, D.; Hoffman, E. A.; McLennan, G. Segmentation and analysis of the human airway tree from three-dimensional X-ray CT images. IEEE Trans. Med. Imaging 2003, 22(8), 940–950. [Google Scholar] [CrossRef] [PubMed]
- Jin, D.; Xu, Z.; Harrison, A. P.; et al. 3D convolutional neural networks with graph refinement for airway segmentation using incomplete data labels. In Machine Learning in Medical Imaging; Springer, 2017; pp. 141–149. [Google Scholar]
- Zhao, T.; Yin, Z.; Wang, J.; et al. Bronchus segmentation and classification by neural networks and linear programming. In Medical Image Computing and Computer-Assisted Intervention; Springer, 2019; pp. 230–239. [Google Scholar]
- Charbonnier, J.-P.; van Rikxoort, E. M.; et al. Improving airway segmentation using a hybrid approach with supervised learning and topological refinement. Medical Physics 2015, 42(4), 1961–1973. [Google Scholar]
- Wang, J.; Gao, J.; Wang, X. A hybrid 3D U-Net for airway segmentation in CT images. Biomedical Signal Processing and Control 2020, 60, 101977. [Google Scholar]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A mutual bootstrapping model for automated skin lesion segmentation and classification. IEEE Trans. Med. Imaging 2020, 39(7), 2482–2493. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X. Domain-Adaptive Organ Segmentation through SegFormer Architecture in Clinical Imaging. Transactions on Computational and Scientific Methods 2025, 5(7). [Google Scholar]
- Lyu, S.; Deng, Y.; Liu, G.; Qi, Z.; Wang, R. Transferable Modeling Strategies for Low-Resource LLM Tasks: A Prompt and Alignment-Based. arXiv 2025. [Google Scholar] [CrossRef]
- Meng, X.; Wu, Y.; Tian, Y.; Hu, X.; Kang, T.; Du, J. Collaborative Distillation Strategies for Parameter-Efficient Language Model Deployment. arXiv 2025. [Google Scholar] [CrossRef]
- Fang, B.; Gao, D. Collaborative Multi-Agent Reinforcement Learning Approach for Elastic Cloud Resource Scaling. arXiv 2025. [Google Scholar] [CrossRef]
- Xu, T.; Deng, X.; Meng, X.; Yang, H.; Wu, Y. Clinical NLP with Attention-Based Deep Learning for Multi-Disease Prediction. arXiv 2025, arXiv:2507.01437. [Google Scholar]
- Pan, R. Policy-Guided Path Selection and Evaluation in Multi-Step Reasoning with Large Language Models. Transactions on Computational and Scientific Methods 2024, 4(8). [Google Scholar]
- Meng, R.; Wang, H.; Sun, Y.; Wu, Q.; Lian, L.; Zhang, R. Behavioral Anomaly Detection in Distributed Systems via Federated Contrastive Learning. arXiv 2025. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, Y.; Zhang, R.; Song, Z. Capsule Network-Based Semantic Intent Modeling for Human-Computer Interaction. arXiv 2025, arXiv:2507.00540. [Google Scholar]
- Zheng, H.; Zhu, L.; Cui, W.; Pan, R.; Yan, X.; Xing, Y. Selective Knowledge Injection via Adapter Modules in Large-Scale Language Models, 2025.
- Zheng, H.; Ma, Y.; Wang, Y.; Liu, G.; Qi, Z.; Yan, X. Structuring Low-Rank Adaptation with Semantic Guidance for Model Fine-Tuning, 2025.
- Yang, T.; Cheng, Y.; Qi, Y.; Wei, M. Distilling Semantic Knowledge via Multi-Level Alignment in TinyBERT-Based Language Models. Journal of Computer Technology and Software 2025, 4(5). [Google Scholar]
- Peng, Y. Context-Aligned and Evidence-Based Detection of Hallucinations in Large Language Model Outputs. Transactions on Computational and Scientific Methods 2025, 5(6). [Google Scholar]
- Zhu, W.; Wu, Q.; Tang, T.; Meng, R.; Chai, S.; Quan, X. Graph Neural Network-Based Collaborative Perception for Adaptive Scheduling in Distributed Systems. arXiv 2025. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, Y.; Xu, T.; Meng, X.; Liu, H.; Kang, T. Multi-Scale Feature Integration and Spatial Attention for Accurate Lesion Segmentation, 2025.
- Cheng, Y. Selective Noise Injection and Feature Scoring for Unsupervised Request Anomaly Detection. Journal of Computer Technology and Software 2024, 3(9). [Google Scholar]
- Yang, T.; Cheng, Y.; Ren, Y.; Lou, Y.; Wei, M.; Xin, H. A Deep Learning Framework for Sequence Mining with Bidirectional LSTM and Multi-Scale Attention. arXiv 2025. [Google Scholar] [CrossRef]
- Han, X.; Sun, Y.; Huang, W.; Zheng, H.; Du, J. Towards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies. arXiv 2025. [Google Scholar] [CrossRef]
- Zhang, T.; Shao, F.; Zhang, R.; Zhuang, Y.; Yang, L. DeepSORT-Driven Visual Tracking Approach for Gesture Recognition in Interactive Systems. arXiv 2025, arXiv:2505.07110. [Google Scholar]
- Xing, Y.; Wang, Y.; Zhu, L. Sequential Recommendation via Time-Aware and Multi-Channel Convolutional User Modeling. Transactions on Computational and Scientific Methods 2025, 5(5). [Google Scholar]
- Jiang, N.; Zhu, W.; Han, X.; Huang, W.; Sun, Y. Joint Graph Convolution and Sequential Modeling for Scalable Network Traffic Estimation. arXiv 2025. [Google Scholar] [CrossRef]
- He, Q.; Liu, C.; Zhan, J.; Huang, W.; Hao, R. State-Aware IoT Scheduling Using Deep Q-Networks and Edge-Based Coordination. arXiv 2025, arXiv:2504.15577. [Google Scholar]
- Lou, Y.; Liu, J.; Sheng, Y.; Wang, J.; Zhang, Y.; Ren, Y. Addressing Class Imbalance with Probabilistic Graphical Models and Variational Inference. In Proc. 5th Int. Conf. on Artificial Intelligence and Industrial Technology Applications (AIITA); IEEE, March 2025; pp. 1238–1242. [Google Scholar]
- Liu, J. Global Temporal Attention-Driven Transformer Model for Video Anomaly Detection. In Proc. 5th Int. Conf. on Artificial Intelligence and Industrial Technology Applications (AIITA); IEEE, March 2025; pp. 1909–1913. [Google Scholar]
- Peng, Y.; Wang, Y.; Fang, Z.; Zhu, L.; Deng, Y.; Duan, Y. Revisiting LoRA: A Smarter Low-Rank Approach for Efficient Model Adaptation. In Proc. 5th Int. Conf. on Artificial Intelligence and Industrial Technology Applications (AIITA); IEEE, March 2025; pp. 1248–1252. [Google Scholar]
- Cai, G.; Kai, A.; Guo, F. Dynamic and Low-Rank Fine-Tuning of Large Language Models for Robust Few-Shot Learning. Transactions on Computational and Scientific Methods 2025, 5(4). [Google Scholar]
- Peng, S.; Zhang, X.; Zhou, L.; Wang, P. YOLO-CBD: Classroom Behavior Detection Method Based on Behavior Feature Extraction and Aggregation. Sensors 2025, 25(10), 3073. [Google Scholar] [CrossRef]
- Gong, M. Modeling Microservice Access Patterns with Multi-Head Attention and Service Semantics. Journal of Computer Technology and Software 2025, 4(6). [Google Scholar]
Figure 1.
Unet++ architecture.
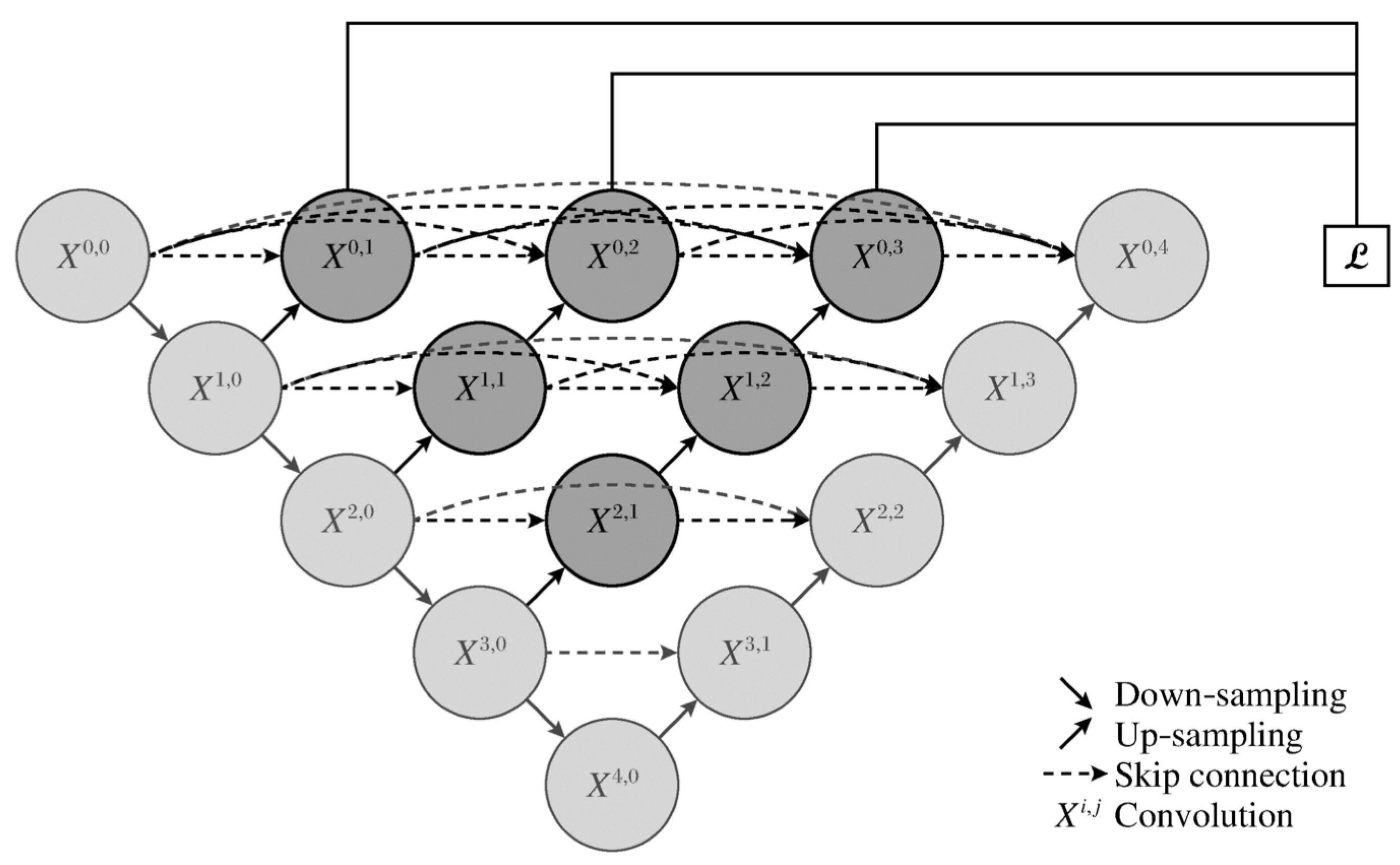
Figure 2.
Attention-Unet architecture.
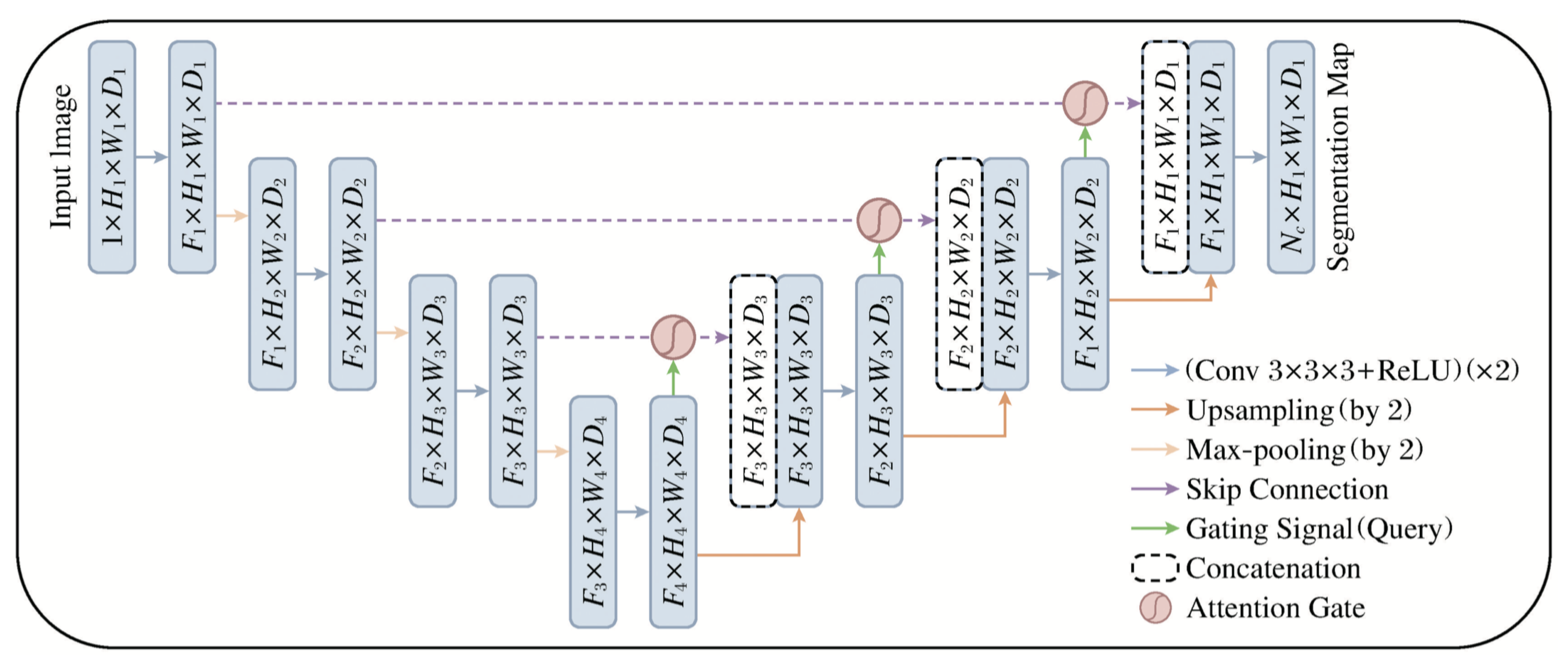
Figure 3.
Flow chart of pulmonary trachea segmentation.
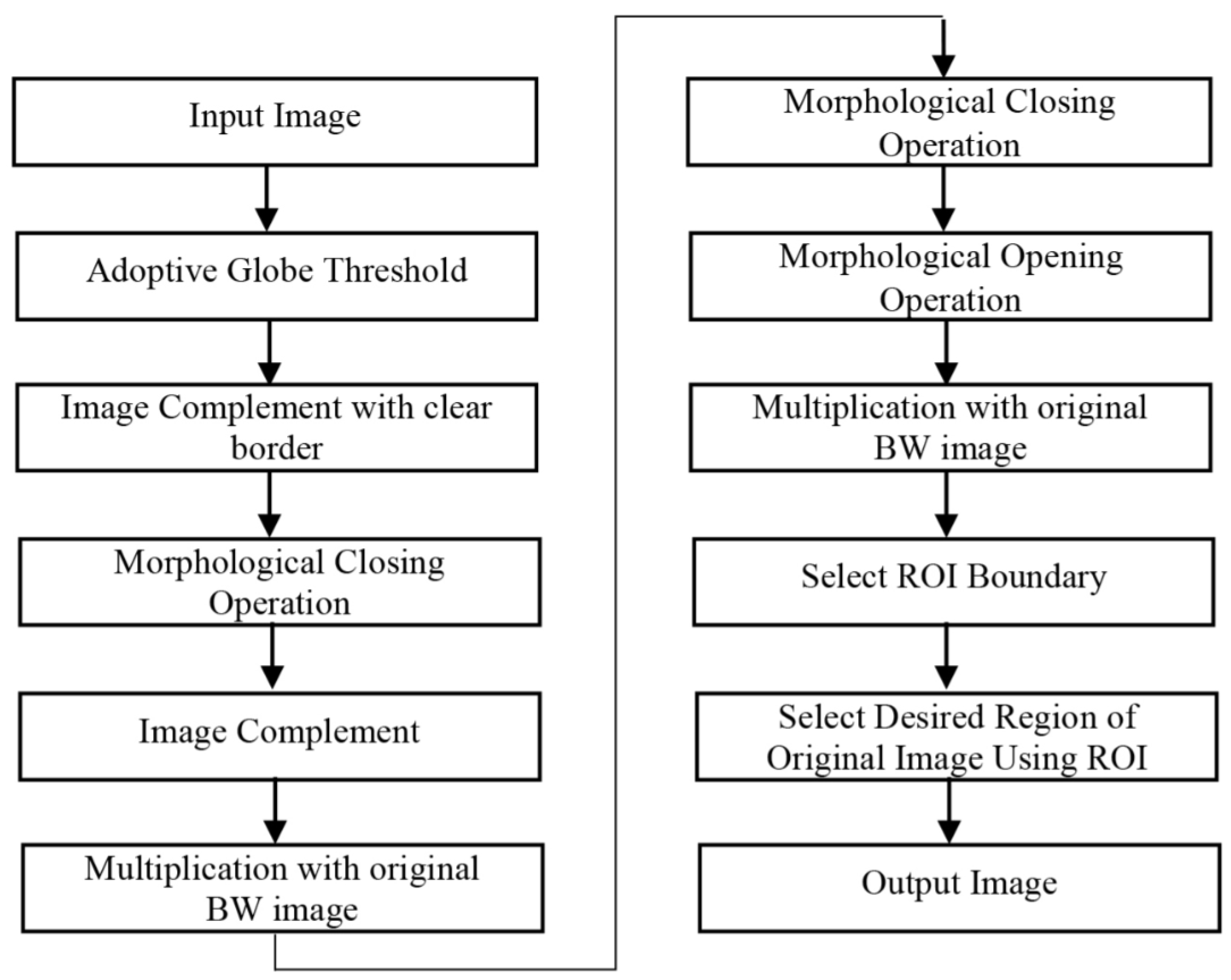
Figure 4.
Flow chart of pulmonary parenchymal segmentation based on U-net.
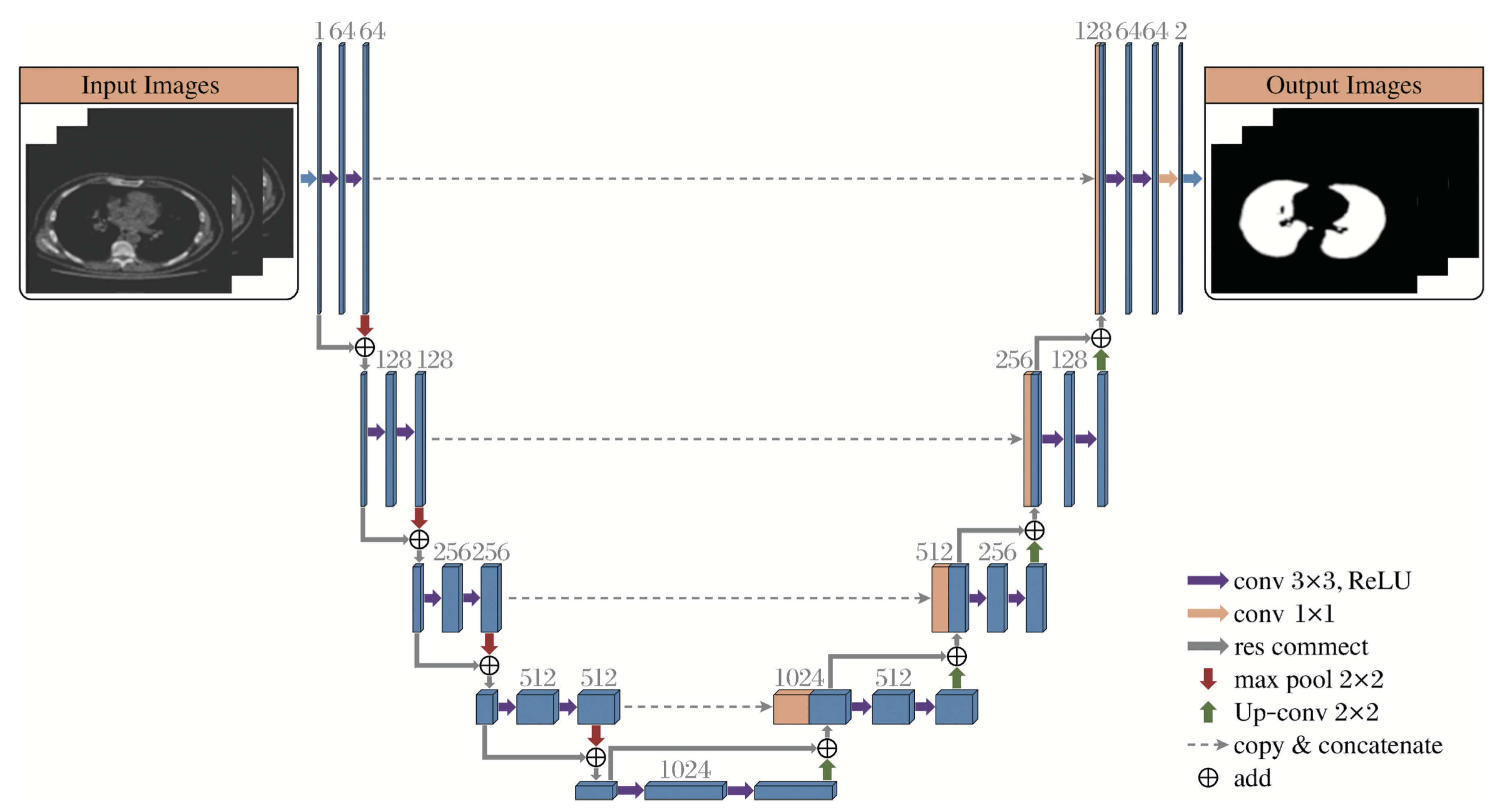
Figure 5.
Attention Gate internal structure diagram.
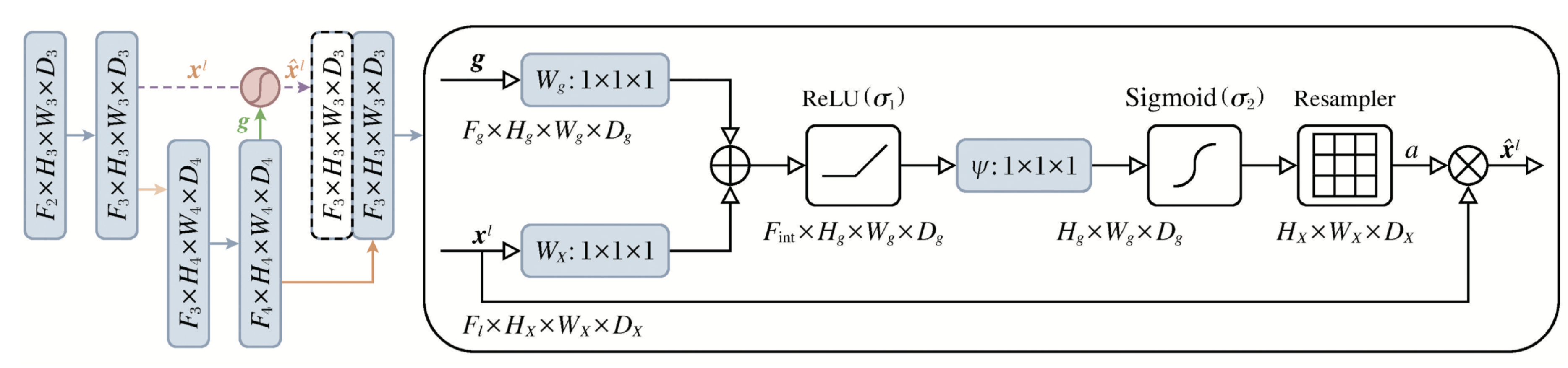
Figure 6.
U-net segmentation of lung parenchyma
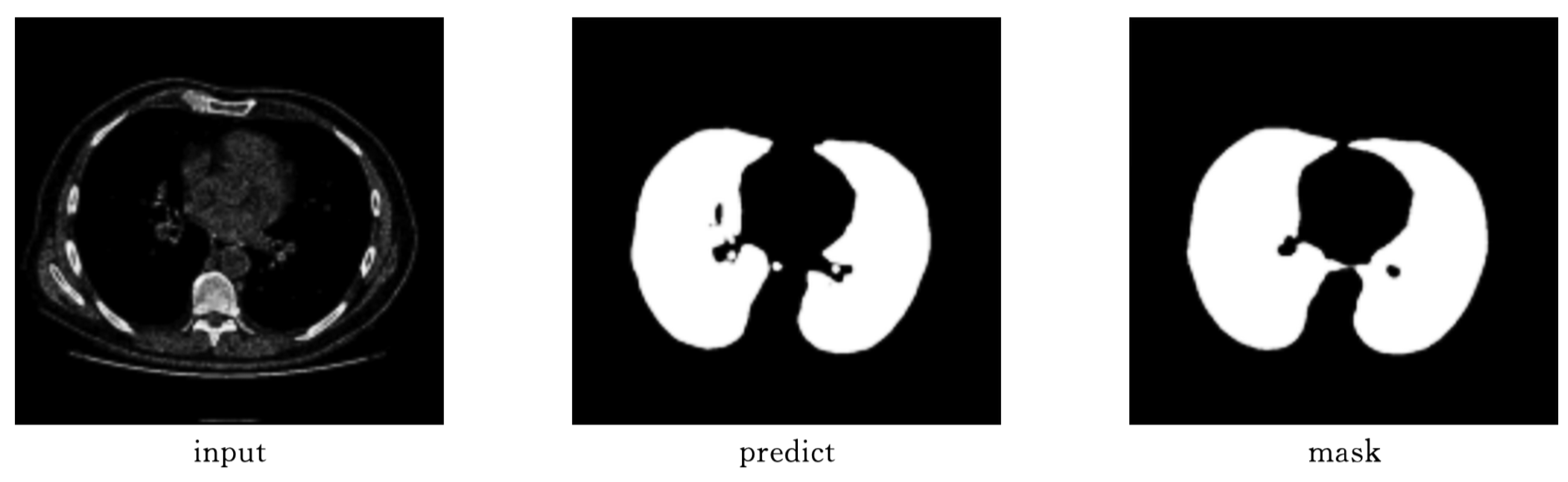
Figure 7.
Unet++ segmentation of lung parenchyma

Figure 8.
Attention-Unet segmentation of lung parenchyma.
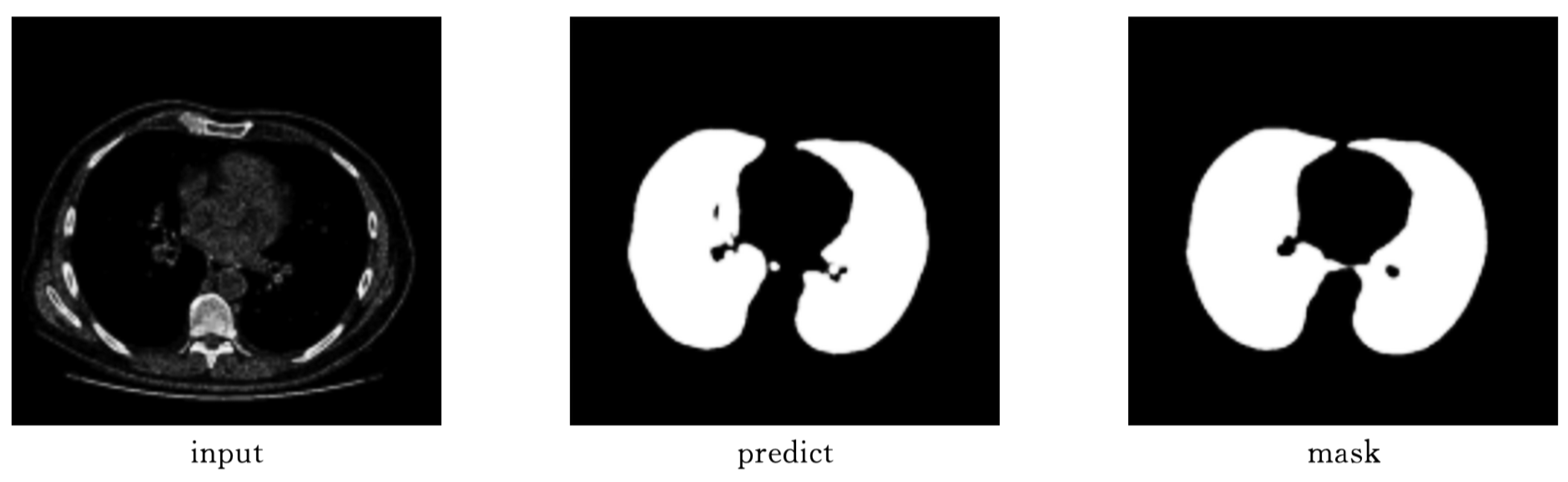
Figure 9.
Unet++ segmentation effect of pulmonary trachea.

Figure 10.
ttention-Unet segmentation effect of pulmonary trachea.


Table 1.
Evaluation table of pulmonary parenchymal segmentation results
| Model | Miou | Dice | Aver_hd |
|---|---|---|---|
| U-net | 0.930155 | 0.963422 | 7.564403 |
| Attention-Unet | 0.934628 | 0.965216 | 7.310714 |
| Unet++ | 0.459279 | 0.350791 | 14.755168 |
Table 2.
Evaluation table of pulmonary tracheal segmentation results.
| Model | Miou | Dice | Aver_hd |
|---|---|---|---|
| Unet++ | 0.367870 | 0.471136 | 3.936441 |
| Attention-Unet | 0.653436 | 0.721396 | 3.453898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



