Submitted:
18 July 2025
Posted:
21 July 2025
You are already at the latest version
Abstract
The quick growth of Large Language Models (LLMs) signals a major change in artificial intelligence, especially in understanding and generating natural language. Even as these models become more popular, there is still not enough analysis connecting their design with practical uses in software engineering and cybersecurity. This paper aims to fill that gap by examining the basic functions of LLMs, including tokenization, self-attention, transformer architectures, and large-scale pretraining. We trace their development from earlier models like BERT and GPT-2 to modern multimodal and instruction-tuned models like GPT-4. Using a mixed-method approach, we look at benchmarking frameworks and evaluation metrics that focus on accuracy, reasoning, safety, and reliability. Our findings reveal important trends such as model specialization, memory improvement, and better alignment strategies, which together improve scalability and generalizability. We also explore how LLMs act as intelligent agents in software development tasks, including code generation, refactoring, debugging, and gathering requirements. They play crucial roles in cybersecurity, such as threat analysis and automated defense systems. In addition, we address current challenges like hallucination, data leaks, and vulnerabilities. We suggest future directions that focus on reliability, adaptation to different domains, and ethical use. This work provides a well-rounded and current view of LLMs, linking theory to practice in new AI-driven areas.
Keywords:
large language models
; transformer
; natural language processing
; software engineering
; cybersecurity
; AI safety
; model evaluation
; pretraining
; instruction tuning
I. Introduction
Natural Language Processing (NLP) has changed significantly since the Turing Test was introduced in the 1950s. This test challenged machines to show intelligent behavior similar to humans. Early NLP systems relied on manual symbolic rules and statistical models to process language. However, these methods struggled with the ambiguity, variability, and context dependence that are common in human languages [6,7]. The rise of machine learning, especially deep learning, marked a turning point. Models like Recurrent Neural Networks (RNNs) and their gated versions—Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs)—introduced ways to capture
temporal relationships in text sequences, resulting in better management of sequential data and context compared to earlier methods [8]. Yet, these models processed data sequentially, leading to computational inefficiencies and limiting their ability to understand long-range dependencies due to problems like vanishing gradients and slow training times.
A significant advance came with the introduction of the Transformer architecture by Vaswani et al. in 2017. This design replaced recurrent operations with self-attention mechanisms that allow parallel processing of input tokens [1]. As a result, models can assess the importance of all tokens in a sequence at the same time, greatly enhancing efficiency and performance for various NLP tasks. The transformer’s scalability and flexibility served as the basis for Large Language Models (LLMs), which use massive datasets and billions or trillions of parameters to learn rich, contextualized representations of language [2,5,13,14].
LLMs begin processing text by breaking down input into smaller units, then embedding these tokens into high-dimensional vectors. These embeddings go through multiple layers of multi-head self-attention, feed-forward neural networks, residual connections, and layer normalization [3]. This deep stack of transformations allows LLMs to capture complex syntactic and semantic patterns, supporting a range of language understanding and generation tasks.
Training LLMs usually involves three key stages:
- Pretraining: In this phase, models learn general language patterns by predicting masked or next tokens over large amounts of unlabeled text. They use objectives like masked language modeling (e.g., BERT) or causal language modeling (e.g., GPT) [10,27]. This stage is computationally demanding and often requires distributed training on GPUs or TPUs while handling billions of tokens.
- Fine-tuning: This step involves supervised training on labeled datasets designed for specific tasks such as question answering, summarization, or code generation. This improves accuracy for those tasks [15].
LLMs have achieved impressive results in many NLP benchmarks, setting new records in translation, summarization, and reasoning tasks [10,18]. Modern models like GPT-3/4 [10], LLaMA 2/3 [64], Falcon 180B [14], and Claude [59] demonstrate emergent abilities, including few-shot learning and in-context adaptation, allowing them to perform tasks without extra retraining. Advances in model designs have enabled some LLMs to handle context windows as large as 128k tokens, making it easier to process lengthy documents and multi-turn conversations [12,68].
Beyond general NLP, LLMs are transforming software engineering by understanding and generating code. Models such as Codex, CodeT5, and InCoder can write code snippets that are both syntactically correct and semantically meaningful. They assist with tasks like bug detection, refactoring, and documentation [75,107,128]. These features are integrated into developer tools like GitHub Copilot and Visual Studio Code, boosting productivity and collaboration in coding environments [130]. Their ability to handle multiple languages and frameworks further enhances their value for global development teams [104].
In cybersecurity, the fast-changing threat landscape—including malware, phishing, ransomware, and supply chain attacks—requires smart and adaptable defenses [81,85]. Traditional rule-based systems often struggle to keep up with new threats, prompting the use of LLMs for tasks like threat intelligence analysis, vulnerability scanning, incident triage, and automated penetration testing [91,99]. Specialized models like CyberSecBERT and CyberGPT have shown strong results in detecting threats and automating responses [91,99].
Despite these advances, LLMs also raise new security and ethical issues. Models trained on public data may accidentally memorize sensitive information, creating privacy risks through membership inference attacks or unsafe code generation [84,95]. Real-time inference attacks—including prompt injection, adversarial examples, and context poisoning—add extra operational risks [63,83]. Additionally, bad actors might misuse LLMs to create phishing campaigns, malware, or misinformation, increasing cybersecurity threats [88,96].
To address these risks, strong strategies are necessary, such as prompt sanitization, context filtering, safety fine-tuning, and using differential privacy methods during training [65,66]. Moreover, ensuring model interpretability, validating outputs, and conducting ongoing security audits are important for safe deployment, especially in zero-trust settings [22,84].
Research Problem:
Although LLMs have seen considerable success, there is still a lack of comprehensive analysis covering their architectures, training methods, practical applications, and security challenges. Current research often looks at isolated parts without connecting the theoretical foundations to real-world outcomes in software engineering and cybersecurity.
Significance:
As AI becomes more integrated into essential systems, understanding how to maximize the benefits of LLMs while minimizing risks is crucial for advancing automation, security, and ethical AI governance. This insight will help researchers, practitioners, and policymakers build more robust, reliable, and responsible AI systems.
Objectives:
This paper aims to:
- Provide a detailed overview of LLM architectures, training techniques, and alignment methods.
- Trace the development of LLMs across general-purpose, code-focused, and cybersecurity-oriented models.
- Classify known vulnerabilities, attack vectors, and defense strategies targeting LLM systems.
- Evaluate the impact of LLMs on software engineering workflows, from requirement analysis to code deployment.
- Analyze the role of LLMs in improving cybersecurity threat detection, response, and automation.
- Discuss ethical, privacy, and operational challenges in deploying LLMs securely and responsibly.
Contributions:
Our study offers a broad survey that combines theoretical insights with empirical evaluations of 42 major LLMs tested on cybersecurity tasks. We provide a unified framework that connects model design, security issues, and practical applications, giving actionable guidance for safely using LLMs in critical areas. Additionally, we highlight promising research directions aimed at enhancing LLM robustness, adaptability, and ethical deployment.
II. Related Work
The rapid growth of Large Language Models (LLMs) has inspired a broad spectrum of research that investigates their architectures, training strategies, capabilities, and limitations. Early works in natural language processing (NLP) relied heavily on statistical approaches such as n-gram models [6,7], which, although efficient, struggled with context limitations and sparsity. With the advent of deep learning, models such as RNNs, LSTMs, and GRUs improved contextual modeling [8], but still encountered issues with long-range dependencies.
A landmark advancement came with the Transformer architecture introduced by Vaswani et al. [1], which replaced recurrence with self-attention mechanisms, enabling more efficient parallelization and long-distance dependency modeling. This architecture laid the foundation for modern LLMs such as BERT [10], GPT-2 [27], and later iterations like GPT-3/4 [10], LLaMA [64], and Claude [59]. BERT introduced the concept of masked language modeling and bidirectional context, whereas GPT models leveraged autoregressive training for generation tasks. These pretraining paradigms enabled transfer learning across numerous downstream tasks with minimal labeled data [15].
In the context of software engineering, Codex, InCoder, and CodeT5 demonstrated LLMs’ effectiveness in code generation, bug detection, and documentation [75,107,128]. These advancements have been integrated into tools like GitHub Copilot, streamlining developer workflows [130].
The application of LLMs in cybersecurity has also gained traction. Works on CyberSecBERT and CyberGPT illustrate the utility of LLMs in malware detection, threat analysis, and automated penetration testing [91,99]. However, studies have also identified critical vulnerabilities such as data leakage [84], prompt injection [83], and hallucinations [88], highlighting the need for robust alignment and safety mechanisms such as RLHF, DPO, and differential privacy techniques [65,66].
Several benchmarking efforts like GLUE, HELM, and MMLU [59,68,104] have been proposed to systematically evaluate LLMs on aspects such as reasoning, safety, and multilingual capability. The open-source movement, led by models such as BLOOM, GPT-NeoX, and LLaMA 2/3, has significantly contributed to democratizing access to LLMs and facilitating reproducibility in research [14,64].
Despite these advances, current research often focuses on specific tasks or models without providing a unified view of LLMs across disciplines. This paper builds upon and extends previous works by offering a comprehensive survey that connects the evolution of LLMs, their architectural diversity, and their dual roles in software engineering and cybersecurity.
III. Research Outcome And Review
This research offers a detailed overview of Large Language Models (LLMs), tracking their evolution from early statistical methods to modern transformer-based systems. By looking at key components like tokenization, embedding methods, self-attention techniques, and pre training approaches, the paper provides a clear understanding of how current LLMs achieve top performance in natural language processing tasks. The study highlights how the introduction of the Transformer architecture has made it possible for LLMs to scale, be context-aware, and adaptable across various fields.
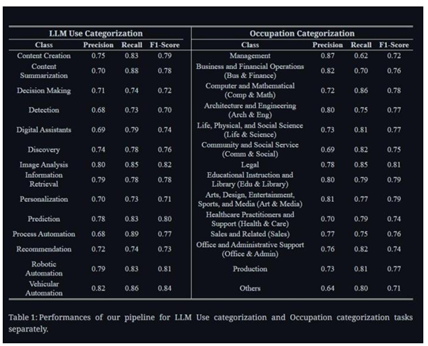
In reviewing existing models such as BERT, GPT, T5, and LLaMA—both open-source and proprietary—the paper outlines the path of innovation, from bidirectional masked modeling to instruction-tuned and multimodal systems. The comparison of these models, backed by benchmarks like GLUE, HELM, and MMLU, sheds light on their strengths and weaknesses, especially in reasoning, generalization, and safety. The review points out major improvements made possible by large-scale pretraining and fine-tuning. It also discusses the growing significance of prompt engineering and learning from human feedback.
The findings of this study indicate that LLMs are changing software engineering workflows through tasks like code generation, debugging help, and documentation automation. In cybersecurity, LLMs are becoming vital for functions like threat detection, vulnerability assessment, and smart incident response. However, the paper also discusses ongoing risks, including hallucinations, data leaks, prompt-based attacks, and the possible misuse of generative abilities. Current mitigation strategies such as differential privacy, adversarial training, and alignment adjustments are examined within a wider conversation on responsible use.
Overall, the research reinforces the dual nature of LLMs as effective tools for productivity and automation, while also presenting potential security and ethical issues. It stresses the need for clear model evaluation, collaboration across fields, and governance structures that ensure the safe and ethical use of LLMs in real-world applications. By combining a technical review with practical analysis, this study serves as a useful reference for researchers and practitioners looking to push the field forward while upholding accountability and trust in AI systems.
IV. The Large Language Model
Large Language Models (LLMs) represent a significant advancement in the field of artificial intelligence, particularly in natural language processing. These models are designed to generate, understand, and manipulate human language with remarkable fluency. At the heart of modern LLMs is the Transformer architecture, a deep learning model introduced by Vaswani et al. (2017), which replaced traditional sequential models with a parallelizable attention-based mechanism. The Transformer enables LLMs to capture long-range dependencies and semantic relationships across vast amounts of text, making them highly scalable and efficient.LLMs function through several interconnected components: they begin with tokenization and embedding representation to convert raw text into numerical forms, followed by layers of self-attention and multi-head attention to extract contextual meaning. The models are pretrained on massive corpora using unsupervised learning objectives, and later fine-tuned or instruction-tuned for specific tasks. Techniques such as reinforcement learning from human feedback (RLHF) and prompt engineering further enhance their adaptability and alignment with human intent. Today, LLMs are deployed across diverse domains including software engineering, cybersecurity, education, healthcare, and customer service. Their applications range from code generation and text summarization to interactive dialogue and threat detection. For end users, LLMs serve as intelligent assistants that improve efficiency, reduce manual workload, and provide contextual insights.
LLM have rapidly become integral tools in modern life, transforming the way humans interact with technology. Their ability to understand, generate, and process human language allows them to assist in various cognitive and operational tasks. LLMs simplify complex processes, increase productivity, and reduce manual effort across personal and professional domains.LLMs serve as intelligent assistants in a wide range of human-centered tasks by leveraging their advanced language understanding and generation capabilities. One of their most transformative contributions lies in automating repetitive tasks. These models can effortlessly draft emails, generate structured reports, summarize long documents, and manage routine communication, significantly reducing the cognitive and time burden on users. This automation not only boosts individual productivity but also allows professionals to focus on higher-level thinking and strategic decision-making.
In addition to task automation, LLMs enhance decision-making processes by providing real-time insights and synthesizing vast amounts of information into concise, actionable summaries. They can quickly analyze input data, cross-reference it with learned knowledge, and offer contextually relevant suggestions. This functionality is especially valuable in fields like business, healthcare, and education, where timely and informed decisions are critical.
Accessibility is another domain where LLMs demonstrate significant value. Through capabilities like real-time language translation, speech-to-text conversion, and adaptive content generation, they help bridge communication gaps and make information more usable for individuals with disabilities or those who speak different languages. By tailoring responses based on user context, LLMs contribute to creating more inclusive and user-friendly digital experiences.
Moreover, LLMs play a crucial role in boosting human creativity. Whether in writing, coding, design, or music, they offer suggestions, complete partially written content, or generate novel ideas based on a given prompt. By acting as creative collaborators, they can overcome creative blocks and accelerate ideation, making them valuable tools for professionals and hobbyists alike. Finally, LLMs enable seamless and natural communication between humans and machines. Integrated into chatbots, virtual assistants, and conversational interfaces, they allow users to interact with technology using everyday language. This reduces the learning curve and makes complex systems more intuitive to use, enhancing user engagement and satisfaction across various platforms.
LLMs work for us by acting as powerful intermediaries between human intent and computational execution. At their core, these models process user inputs—whether textual commands or spoken language—by interpreting linguistic structure, semantic meaning, and contextual cues to generate coherent, context-aware outputs. The interaction feels natural and human-like because of the sophisticated design principles underlying LLMs.
A fundamental component of this intelligence is the Transformer architecture, which enables LLMs to model complex language patterns and dependencies across long spans of text. Through mechanisms like self-attention and multi-head attention, Transformers allow the model to weigh different parts of the input sequence and understand both local and global relationships in language. This structural design is what empowers LLMs to maintain coherence, track context, and infer user intent effectively.
Before deployment, LLMs undergo extensive pretraining on massive text corpora sourced from books, articles, websites, and code repositories. This phase allows the model to learn the structure of language, general world knowledge, facts, and reasoning strategies. It acquires a statistical understanding of how words, phrases, and concepts are related and used in real-world communication.
After pretraining, models are often fine-tuned on domain-specific datasets to adapt them for specialized use cases—such as legal document generation, clinical report summarization, or software code generation. This targeted fine-tuning sharpens the model’s ability to operate within a particular context, ensuring higher accuracy and relevance in professional applications.
LLMs are also guided by prompting techniques, which involve shaping the model's behavior by carefully crafting input text. Through structured prompts, instructions, or few-shot examples, users can direct the model to perform specific tasks such as translation, question answering, summarization, or creative writing. Advanced prompting strategies have made it possible to use general-purpose LLMs for a wide range of activities without additional retraining. Altogether, LLMs serve as intelligent tools that learn from vast human knowledge and adapt to individual user needs—making them highly versatile agents that enhance productivity, automate tasks, and augment human capabilities in numerous domains.
Large Language Models (LLMs) are revolutionizing a wide range of industries through their ability to understand, generate, and contextualize human language. Their versatility stems from deep pretraining on diverse textual data and their ability to adapt through fine-tuning or prompting. As a result, they serve as intelligent, context-aware assistants capable of performing domain-specific tasks with minimal human intervention. Below is a consolidated overview of the major domains where LLMs are currently applied
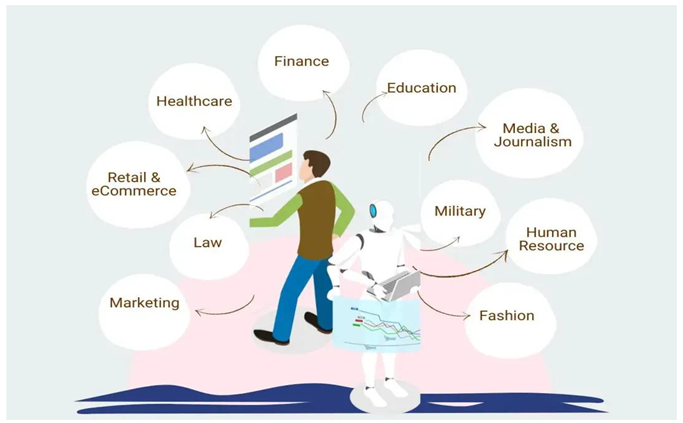
In Education, LLMs are transforming learning by acting as personalized tutors. They can explain complex topics in simpler terms, generate quizzes, summarize textbooks, and support students in exam preparation and content creation. Adaptive feedback and multilingual support also make them ideal for inclusive, personalized learning environments.
In Healthcare, LLMs streamline clinical workflows by generating medical notes, summarizing patient histories, checking symptoms, and even supporting diagnostic decision-making. They enhance communication between patients and providers and help with administrative tasks such as insurance coding and claims processing.
Software Engineering has seen rapid adoption of LLMs in tasks like automatic code generation, debugging, writing documentation, and generating tests. These capabilities reduce development time, minimize errors, and augment the productivity of developers, especially in large-scale or open-source projects. In Customer Service, LLMs power intelligent virtual agents and chatbots that can handle queries across multiple languages and platforms. They provide 24/7 support, improve customer satisfaction through personalized interactions, and free up human agents for complex issues.
In the Legal & Compliance sector, LLMs assist with contract analysis, legal research, document summarization, and regulation tracking. They help law firms and corporate legal teams save time and reduce costs by automating document-heavy tasks that traditionally required expert review.
In Cybersecurity, LLMs are emerging as key tools for analyzing log data, identifying threats, summarizing incident reports, and generating security recommendations. They help analysts detect anomalies in real-time and interpret vast volumes of threat intelligence data.
Within the Creative Industries, LLMs fuel artistic and design processes by helping with story generation, music composition, marketing content creation, and even game design. They serve as brainstorming partners and co-creators that can adapt to various creative workflows.
Finance & Banking benefit from LLMs through financial summarization, report generation, risk modeling, and market analysis. They can generate investment memos, simplify financial jargon, and assist analysts in data synthesis and forecasting.
In Human Resources, LLMs are used for resume screening, drafting performance reviews, generating job descriptions, and automating applicant communication—significantly speeding up recruitment cycles and improving candidate experience.
Scientific Research & Academia leverage LLMs for summarizing academic papers, generating literature reviews, drafting manuscripts, and aiding in data extraction from research documents. This facilitates faster and more collaborative research practices.
In E-Commerce & Retail, LLMs personalize shopping experiences by generating product descriptions, automating customer responses, improving search results, and summarizing user reviews—enhancing both sales and customer satisfaction.
Media & Journalism professionals use LLMs to automate headline generation, draft news summaries, transcribe interviews, and fact-check content. These tools allow journalists to focus on investigation and creativity while reducing the time-to-publish.
Finally, in Real Estate & Property Management, LLMs generate property listings, automate responses to prospective buyers, summarize lease agreements, and support customer onboarding with natural language communication.
LLMs serve as transformative tools across disciplines by reducing human effort, accelerating workflows, and enabling intelligent automation. Their ability to interpret natural language, generate relevant outputs, and adapt to domain-specific contexts positions them at the forefront of AI-driven innovation in almost every professional field.
- A.
- How LLMs Work
Large Language Models (LLMs) are advanced AI systems designed to understand and generate human language. Internally, they work by processing text in small units called tokens and predicting the most likely next token based on the context of all previous tokens. This process is powered by a special neural network architecture called the Transformer, which uses mechanisms like self-attention to capture complex relationships and dependencies in the text. By training on massive amounts of data, LLMs learn patterns, grammar, and knowledge about language, enabling them to generate coherent and contextually relevant responses one word (or token) at a time.
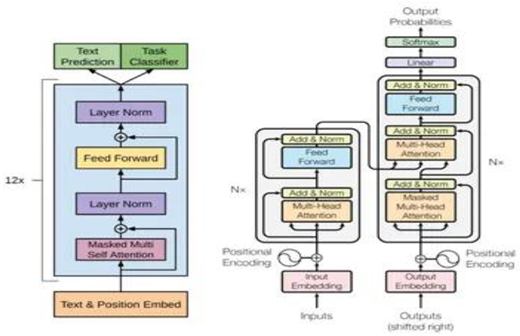
Tokenization and Embedding in Large Language Models (LLMs)
Large Language Models (LLMs) rely on converting raw natural language text into a numerical format that machines can process. This transformation involves two critical steps: tokenization and embedding.
Tokenization is the initial step that segments raw text into smaller, manageable units called tokens. These tokens serve as the basic input elements for the model. The choice of tokenization strategy greatly affects the model's efficiency and ability to handle diverse language inputs.
Tokens can be whole words, subwords, or individual characters. Traditional word-level tokenization treats each word as a token, but it suffers from issues like a large vocabulary and out-of-vocabulary (OOV) words. Modern LLMs predominantly use subword tokenization methods such as Byte-Pair Encoding (BPE) and WordPiece. These approaches split words into smaller, more frequent subword units (e.g., “unhappiness” → “un”, “happi”, “ness”). This method effectively balances vocabulary size and coverage, enabling models to handle rare or new words by composing them from known subwords.
Common algorithms include Byte-Pair Encoding (BPE), which iteratively merges the most frequent pairs of characters or subwords in the training corpus to create a fixed-size vocabulary, WordPiece, which builds the vocabulary to maximize the likelihood of the training data, and SentencePiece, a language-independent method treating text as raw bytes that supports multiple tokenization strategies.
Subword tokenization helps address challenges such as vocabulary explosion, efficient representation of rare words, and improved generalization to unseen text.
After tokenization, each token is mapped to a unique integer ID and then transformed into a dense numerical vector called an embedding. This embedding process enables the model to work with continuous data rather than discrete tokens.
Embedding vectors are high-dimensional continuous vectors (usually 512 to 2048 dimensions) learned during training. They encode semantic and syntactic properties of tokens, such that tokens with similar meanings or usages are represented by vectors close to each other in the embedding space.
These embeddings start as random vectors and are optimized through backpropagation to minimize prediction errors during training.
Since Transformer architectures process tokens simultaneously rather than sequentially, embeddings alone lack positional information. To compensate, positional encodings — either fixed sinusoidal patterns or learned vectors — are added to embeddings to encode the order of tokens, preserving sentence structure and word relationships.
Together, tokenization and embedding convert raw text into a rich, numeric representation that forms the foundation for subsequent Transformer layers to understand context, capture linguistic nuances, and generate coherent language.
Tokenization and embedding are fundamental steps that prepare raw text for Large Language Models by segmenting it into meaningful units and representing those units as continuous vectors in a way that preserves semantic and syntactic information. These processes enable LLMs to efficiently model complex language patterns and perform a wide range of natural language understanding and generation tasks.
Embedding
Embedding is a fundamental step in Large Language Models that transforms discrete tokens into continuous numerical vectors residing in a high-dimensional space
ℝd
This transformation allows the model to represent semantic, syntactic, and contextual information about language in a form that neural networks can efficiently process.
Each token tit_iti from the vocabulary VVV is mapped to a dense vector
where ddd is the embedding dimension—commonly between 512 and 2048 in modern models. These vectors are learned parameters, stored in an embedding matrix
where denotes the vocabulary size. During training, the embedding for token tit_iti with index kkk is retrieved as:
Initially, the embedding matrix is randomly initialized and refined through backpropagation to minimize the loss function based on prediction errors. Through this process, embeddings capture rich linguistic features: tokens with similar meanings or syntactic roles become geometrically close in the embedding space. This spatial organization enables the model to generalize knowledge about language patterns beyond the explicit training examples.
One remarkable property of embeddings is their ability to encode semantic relationships via vector arithmetic. For instance, the famous analogy:
illustrates how embeddings can capture gender and royalty relationships in a linear algebraic manner.
Embeddings serve as the input to subsequent Transformer layers, where the model applies self-attention and feedforward operations to build contextualized representations that depend on surrounding tokens. Without embeddings, the model would be unable to process discrete text as numerical data.
In large-scale applications, embeddings generated by LLMs are often stored and queried in vector databases. These databases index high-dimensional vectors and support efficient similarity search using metrics such as cosine similarity or Euclidean distance. Vector databases facilitate tasks like semantic search, recommendation, and clustering by retrieving vectors that are close to a query embedding.
The embedding dimensionality adds a crucial role: higher dimensions can encode more nuanced information but increase computational and storage costs, affecting indexing speed and retrieval accuracy in vector databases. Thus, a balance is required between expressiveness and efficiency.
Adding Positional Encoding
Transformers process input tokens in parallel rather than sequentially, which means they lack inherent information about the order of tokens in a sequence. To address this, positional encoding is added to the token embeddings to provide the model with explicit information about token positions, enabling it to capture the sequential structure of language.
Positional encoding vectors are of the same dimensionality ddd as the embeddings, allowing them to be combined via element-wise addition:
where ei is the embedding vector for token iii, pi ∈ ℝd is the positional encoding vector corresponding to position iii, and zi is the resulting position-aware input vector fed into the Transformer layers.
zi = ei + pi
One common approach, introduced in the original Transformer paper (Vaswani et al., 2017), uses sinusoidal functions to generate fixed positional encodings, defined as:
where iii is the token position, kkk indexes the embedding dimension, and ddd is the total embedding dimension. This formulation allows the model to easily learn to attend to relative positions and generalize to sequences longer than those seen during training.
Alternatively, learned positional embeddings can be used, where positional vectors pi are parameters optimized during training, enabling potentially more flexible encoding of positional information.
By integrating positional encodings, Transformers gain awareness of token order despite their inherently parallel architecture, which is crucial for capturing syntax and meaning in natural language.
Passing Through Transformer Layers
After tokens have been transformed into embeddings enriched with positional information, they are fed into a sequence of Transformer layers. Each Transformer layer is designed to iteratively refine the representation of each token by capturing complex contextual relationships across the entire input sequence.
The core component of each Transformer layer is the self-attention mechanism, which enables the model to evaluate how every token relates to every other token in the input. This mechanism calculates a set of attention weights that indicate the importance of each token relative to others when interpreting the meaning of a specific token. Through self-attention, the model can dynamically focus on relevant words or phrases regardless of their position, capturing long-range dependencies and nuanced contextual cues essential for understanding natural language. Following self-attention, the output is passed through a feedforward neural network (FFN). This network applies nonlinear transformations independently to each token’s representation, allowing the model to identify complex patterns, refine features, and increase its capacity to represent abstract linguistic concepts beyond direct token relationships.
Additionally, Transformer layers incorporate techniques such as residual connections and normalization to improve training stability and gradient flow, enabling very deep networks without degradation.
By stacking multiple Transformer layers, the model incrementally builds rich, hierarchical representations of the input text. Early layers may capture local syntactic patterns, while deeper layers extract higher-level semantic information, enabling the model to perform complex tasks like language understanding, inference, and generation.
This layered processing is fundamental to the success of Large Language Models, as it allows for flexible and context-aware interpretation of language across a wide range of tasks.
Contextual Representation
After tokens pass through multiple Transformer layers, their vector representations are no longer isolated embeddings tied solely to the token itself. Instead, each token's vector is dynamically updated to incorporate information from the entire input sequence, resulting in a contextual representation.
This means that the meaning encoded in each token’s vector reflects not only the token’s own identity but also its relationships and dependencies with surrounding tokens. For example, the word "bank" will have different contextual vectors depending on whether the sentence relates to a riverbank or a financial institution, enabling the model to disambiguate meanings based on context.
The process of building contextual representations allows the model to capture syntax, semantics, and subtle nuances such as co-reference and polysemy. As a result, the token vectors become highly expressive and task-relevant, improving performance on diverse language tasks including translation, question answering, and text generation.
These context-aware embeddings serve as the foundation for the final prediction or output generation stages of the model, embodying a rich, holistic understanding of the input text as processed through the deep Transformer architecture.
Next Token Prediction
The ultimate goal of a large language model is to generate or predict the next token in a sequence based on the context established by the preceding tokens. After processing the input through multiple Transformer layers and producing rich contextual representations for each token, the model leverages these vectors to estimate a probability distribution over the entire vocabulary for the next possible token.
This prediction is typically performed by passing the contextual vector of the last token through a linear output layer followed by a softmax function, which converts raw scores (logits) into probabilities. The probability distribution reflects the model’s confidence that each token in the vocabulary could follow the given sequence.
By selecting the token with the highest probability—or sampling from this distribution during generation—the model produces coherent and contextually appropriate text. This step is fundamental to applications such as text completion, machine translation, and conversational agents.
Through training on massive corpora, the model learns complex language patterns and token dependencies, enabling it to make highly accurate next-token predictions that capture grammar, semantics, and even pragmatic nuances.
Generating Output
Once the model predicts the probability distribution over the next token, it must convert this distribution into an actual token choice to generate coherent text. The most straightforward approach is to select the token with the highest predicted probability, known as greedy decoding. Alternatively, the model can sample tokens from the probability distribution to introduce variability and creativity, using methods such as random sampling, top-k sampling, or nucleus (top-p) sampling.
After selecting the next token, it is appended to the input sequence, effectively extending the context for the model. This updated sequence is then fed back into the model, which recomputes the contextual representations and predicts the subsequent token.
This iterative process continues token by token, allowing the model to generate text incrementally and produce coherent, contextually relevant sequences of arbitrary length. The quality and fluency of the generated output depend on the model’s training, architecture, and decoding strategy.
This autoregressive generation process underpins many natural language processing tasks such as language modeling, machine translation, dialogue systems, and creative writing applications.
Training (Self-Supervised Learning)
The model learns by comparing its predicted next tokens against the actual tokens in massive text data, adjusting its internal weights to minimize prediction errors.
Training (Self-Supervised Learning)
Large language models are trained using a self-supervised learning approach, which leverages vast amounts of unlabeled text data without the need for manual annotation. The central training objective is to teach the model to predict the next token in a sequence based on its preceding context, effectively learning language structure and semantics through exposure.
During training, the model processes input sequences and generates predicted probability distributions over the vocabulary for each next token. These predictions are then compared to the actual next tokens in the training data using a loss function, commonly the cross-entropy loss, which quantifies the difference between predicted probabilities and true token identities.
The training process involves backpropagation, where gradients of the loss function flow backward through the network to update the model’s internal parameters—such as weights in the embedding matrix, attention layers, and feedforward networks. Optimization algorithms like Adam are used to adjust these parameters incrementally, minimizing prediction errors over time.
By iteratively processing billions of tokens across diverse text corpora, the model gradually captures rich linguistic patterns, grammar, factual knowledge, and even some reasoning capabilities, enabling it to perform a wide range of downstream language tasks after training.
This self-supervised paradigm is key to the scalability and effectiveness of modern large language models, allowing them to learn complex language understanding without explicit human supervision.
Fine-Tuning & Deployment
Following the initial large-scale pre-training phase, where the model learns general language patterns from extensive and diverse text corpora, fine-tuning is often employed to adapt the model to specific tasks or domains. Fine-tuning involves continuing the training process on a smaller, task-specific dataset, which helps the model specialize and improve performance on particular applications such as sentiment analysis, question answering, or domain-specific text generation.
During fine-tuning, the model’s parameters are adjusted to better capture the nuances and requirements of the target task, often with supervised learning using labeled data. This stage can significantly enhance accuracy, relevance, and efficiency compared to relying solely on the general pretrained model.
Once fine-tuned, the model is deployed in real-world environments where it generates human-like text or provides language understanding capabilities. Deployment can take place on cloud servers, edge devices, or embedded systems, depending on the use case and resource constraints.
In deployment, models are optimized for latency, scalability, and robustness, enabling applications such as virtual assistants, automated content creation, translation services, and more. The ability to fine-tune and deploy flexible large language models has been pivotal in advancing natural language processing technologies across industries.
V. The Evolution of LLM
Large Language Models (LLMs) have been one of the biggest advances in AI and natural language processing in the last few years. These models can write coherent text, answer hard questions, translate languages, write code, summarize documents, and even have conversations That sounds a lot like real conversations. They have been successful because they have been able to create better model designs and training methods, thanks to the availability of large datasets and more powerful computers.LLMs did not emerge overnight. It is the outcome of decades of work in deep learning, neural network optimization, statistical language modeling, and computational linguistics. Small datasets, straightforward structures, and strict computational constraints hampered early language models, which frequently produced brittle or grammatically incorrect results. However, language modeling underwent a significant transformation with the advent of deep neural networks, especially transformer-based architectures.
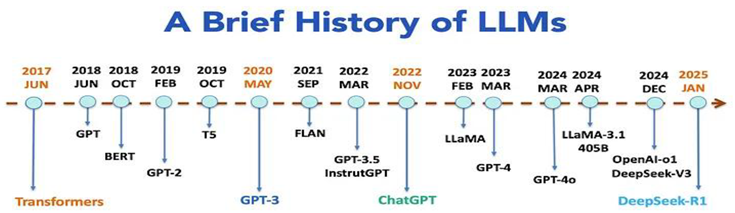
The field of language modeling underwent a significant change beginning with the introduction of the Transformer architecture by Vaswani et al. in 2017. The foundation for the upcoming generation of LLMs was laid by models such as T5 (Text-to-Text Transfer Transformer), GPT (Generative Pretrained Transformer), and BERT (Bidirectional Encoder Representations from Transformers). On a variety of tasks involving the generation and understanding of natural language, these models demonstrated outstanding performance.
This study maps the evolution of LLMs from the earliest statistical models to the billion-parameter transformers of today. It highlights significant training techniques, architectural advancements, and shifts in research focus that brought large-scale language modeling to its current state. Along with outlining the opportunities and challenges that lie ahead in the continued development of LLM technology, it also addresses the social, ethical, and technical ramifications of applying such potent models in practical applications.
- A.
- Early Language Models Before 2017
Natural language processing (NLP) relied heavily on statistical and rule-based techniques prior to the development of large-scale deep learning models. By attempting to use probabilistic methods to capture the structure of language, these early language models laid the groundwork for contemporary LLMs. Despite their apparent simplicity today, these early models significantly advanced our knowledge of language modeling and shaped many concepts found in modern systems.
In early days before large language model era all of the model will trained under statistical and machine learning model.After Transformer model invented,Large language model become growth and growth by passing days.In the early days there are various model was used for trained machine until Transformer model which was developed by Google Inc.After Transformer, Large Language Model become more trending and used.Language understanding systems primarily used symbols in the early days of artificial intelligence. These systems processed language using meticulously crafted grammars, word lists, and sentence structure guidelines. One prominent example is the ELIZA chatbot, which was developed in the 1960s and mimicked conversation using simple scripts and pattern matching. Although rule-based systems were precise and unambiguous in certain contexts, they had trouble scaling up and were unable to accommodate a variety of linguistic inputs.
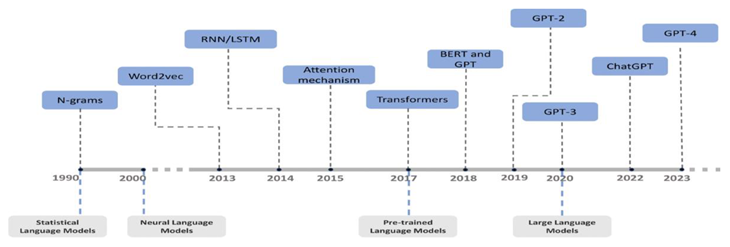
A move toward statistical language models (SLMs), particularly n-gram models, occurred in the 1990s and early 2000s. These models calculated a word's likelihood by looking at the words that preceded it. For tasks like machine translation and speech recognition, they were straightforward but efficient. For instance, using maximum likelihood estimation or smoothing methods like Kneser-Ney or Good-Turing smoothing, a trigram model would calculate the likelihood of a word based on the two words that preceded it.
Nevertheless, sparsity and context limitations plagued n-gram models. They were less appropriate for complex language tasks since they had trouble capturing long-range dependencies in text. Additionally, their dependence on input windows with a set length limited their capacity for complete idea expression.
Neural language models were developed in response to the limitations of statistical models, and they began to gain traction in the early 2010s. These models employed neural networks to predict the subsequent word in a sequence by representing words as dense vectors, or embeddings. The Neural Probabilistic Language Model (NPLM), first presented by Bengio et al. in 2003, was a seminal work in this field. This model learned distributed word representations and model word sequences using a feedforward neural network.Word embeddings such as Word2Vec (Mikolov et al., 2013) and GloVe (Pennington et al., 2014) represented a significant advancement. Semantically related words appeared near to one another because these models mapped words into high-dimensional vector spaces. This approach greatly enhanced the performance of subsequent NLP tasks and enabled more intricate language representations.
Recurrent neural networks (RNNs) and their enhanced variants, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), gained popularity in order to better capture sequential information. These models maintained a hidden state that contained contextual information while processing input word by word. Even though LSTMs were able to model longer dependencies than conventional RNNs, they were still difficult to train on very long sequences and frequently had issues with vanishing or exploding gradients.
In spite of these issues, LSTM-based models emerged as the top choice for a large number of NLP tasks in the middle of the decade. They were particularly good at text classification, language generation, and machine translation (like Google's sequence-to-sequence model). These architectures facilitated the connection between the transformer-based LLMs that would follow and earlier statistical models.
Even though neural networks significantly improved models, models prior to 2017 still had a number of limitations.
The efficiency of training and parallel processing was restricted by sequential computation.
Their comprehension of global dependencies was limited by brief context windows.
For every new NLP task, task-specific training had to be adjusted from the ground up.
The development of genuinely general-purpose language models was hampered by these constraints. A major shift in model design was made possible by the need for designs that were more flexible, scalable, and context-aware.B. 2.6 The Rise of the Transformer (2017)
The year 2017 was a key moment in the development of language models. Vaswani et al. introduced the Transformer architecture in the important paper “Attention Is All You Need.” This change transformed natural language processing (NLP) by replacing recurrent and convolutional structures with self-attention mechanisms. These mechanisms allowed for the parallel processing of sequences. The Transformer provided a fix for the problems of recurrent models and set the stage for the rapid growth of Large Language Models (LLMs) in the years that followed.
Before the Transformer, most state-of-the-art NLP models were built using Recurrent Neural Networks (RNNs), particularly Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). While these models could theoretically model sequences of arbitrary length, they were limited by the need to process tokens sequentially. This led to several critical issues:
- Slow training times due to lack of parallelism.
- Difficulty capturing long-range dependencies, especially in very long text sequences.
- Vanishing gradient problems, making optimization harder over long time steps.
The Transformer architecture was proposed to address these limitations directly. It introduced a novel approach based entirely on self-attention mechanisms, eliminating the need for recurrence and enabling models to process entire sequences simultaneously. This shift allowed for significant improvements in computational efficiency and modeling capacity.
- C.
- Core Components of the Transformer
The Transformer consists of an encoder-decoder architecture, although many later models would adopt only one side (encoder or decoder) depending on the task. The key components include:
- Multi-Head Self-Attention: Instead of using a single attention mechanism, the Transformer uses multiple attention heads in parallel. This allows the model to learn different types of relationships in the data simultaneously, such as syntactic and semantic dependencies.
- Positional Encoding: Since the model lacks recurrence, it cannot inherently understand the order of tokens. To compensate, positional encodings are added to the input embeddings, allowing the model to consider sequence order.Position Encoding is very important .
- Feed-Forward Networks: Each layer of the Transformer includes position-wise feed-forward neural networks that add non-linearity and increase model capacity.
- Layer Normalization and Residual Connections: These additions stabilize training and allow gradients to flow more effectively through deep networks.
By combining these components, the Transformer achieved state-of-the-art performance across a range of NLP tasks while being faster and more scalable than its predecessors.Transformar is the heart of large language model.Without Transformer model Large language model cant be efficiently work or doing of our task.After Transformar Large Language Model growth more.
The original Transformer model was tested on tasks like English-to-German and English-to-French translation. It outperformed the previous top models in both quality and training speed. The Transformer required much less time to train and could generalize better with large datasets.
This success showed that self-attention was not just a new concept but a strong modeling approach that could be scaled up effectively. The architecture quickly gained a lot of attention and became the standard for a new generation of NLP models.
Perhaps the most important legacy of the Transformer architecture is that it became the foundation for all subsequent large language models. This includes:
- BERT (Bidirectional Encoder Representations from Transformers) - which used the encoder.
- GPT (Generative Pretrained Transformer) - which used only the decoder.
- T5 (Text-to-Text Transfer Transformer) - which used the full encoder-decoder stack.
These models changed the Transformer structure for different purposes. BERT focused on understanding through masked language modeling, while GPT centered on generation with autoregressive modeling. Still, they all relied on the scalability and flexibility of the Transformer for their success.
A key feature of the Transformer was its ability to scale efficiently with data and computation. The architecture allowed for full parallelization during training, making it more effective at using modern GPU/TPU hardware than RNNs. This enabled training on massive datasets and the growth of model sizes from millions to billions, and eventually trillions, of parameters.
Additionally, the quadratic time complexity of self-attention seemed like a drawback at first. However, the benefits in performance and model quality proved to be worth the cost, especially as hardware and optimization methods advanced.
- E.
- Industry Adoption and Research Momentum
After the original Transformer paper came out, both academia and industry quickly embraced the architecture. Companies like Google, OpenAI, and Facebook incorporated Transformer models into their systems for tasks such as translation, search, summarization, and recommendation.
Research also changed significantly, focusing more on Transformer-based models. The number of publications that mentioned the Transformer architecture surged in the following years. This growth indicated a new research path focused on scaling and fine-tuning large Transformer-based models for general language understanding and generation.
- D.
- BERT and Bidirectional Representations (2018)
While the Transformer architecture laid the groundwork for deep learning in NLP, its full potential for language understanding was realized with BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. in 2018. BERT changed the way language models were trained and used. It shifted from task-specific models to pretrained, general-purpose representations. Its success initiated the “pretrain-then-finetune” approach, which became a defining feature of modern LLMs.
Before BERT, most language models, like GPT-1 and earlier RNN-based models, operated in one direction. They processed text from left to right or right to left, predicting the next word based on previous context. While this worked well for generating text, these models struggled to capture bidirectional context. This context is crucial for many understanding tasks, like question answering and sentiment analysis.
BERT was created to address this issue. It provided deep bidirectional context by allowing each token to consider all others in both directions at the same time. This approach helped the model gain a richer, more complete understanding of the input sequence. Unlike left-to-right models, BERT could take into account the entire context of a word's surroundings when forming its representation. This significantly boosted performance on a variety of natural language understanding (NLU) tasks.
BERT introduced two new training goals that became standard in future language models:
Masked Language Modeling (MLM): During pre training, 15% of the tokens in each input sequence are randomly replaced with a special [MASK] token. The model is then trained to predict the original token based on its bidirectional context. This technique lets the model learn deep semantic and syntactic patterns without being limited to sequential order.
Next Sentence Prediction (NSP): To help the model understand sentence relationships, which is important for tasks like natural language inference, BERT is trained to predict whether one sentence follows another in a coherent context. This binary classification task improves the model’s understanding of discourse-level relationships.
Together, these goals allowed BERT to learn general-purpose language representations that could then be fine-tuned with little supervision on specific tasks.
Pretraining and Fine-Tuning Paradigm
BERT’s success led to a two-stage process that became key to modern NLP systems:
Pretraining on large datasets like English Wikipedia and BooksCorpus using self-supervised learning tasks (MLM and NSP).
Fine-tuning the pretrained model on downstream tasks, such as sentiment classification, named entity recognition, and question answering, with a small amount of labeled data.
This approach proved much more data-efficient than training models from scratch and significantly lowered the need for task-specific designs. Fine-tuned BERT models quickly set new records across benchmarks like GLUE (General Language Understanding Evaluation), SQuAD (Stanford Question Answering Dataset), and SWAG
BERT's impact was immediate and extensive. It not only achieved top results across many NLP tasks, but it also:
Standardized the use of Transformers for understanding tasks.
Triggered a wave of derivative models such as RoBERTa (by Facebook), ALBERT (by Google), and DistilBERT (by Hugging Face). Each of these modified BERT’s architecture or training method to improve performance or efficiency.
Became the main base model for academic research and industrial applications.
For example, RoBERTa removed the NSP objective and trained longer on more data, which led to better performance. ALBERT introduced weight-sharing and factorization to lower the parameter count without losing accuracy. These variations showed the strength and flexibility of BERT’s main ideas.
Before BERT, transfer learning was not widely used in NLP compared to computer vision, where pretrained models like ResNet and VGG had been popular for a long time. BERT showed that transfer learning in NLP was not only possible but also very effective. It became common to pretrain large models once and reuse them across hundreds of tasks, saving significant time and computational resources.
Additionally, BERT allowed low-resource tasks and languages to benefit from pre trained knowledge. Fine-tuning a single multilingual BERT (mBERT) model let users apply it across many languages, even those with few labeled datasets.
2.15 The GPT Series: Autoregressive Growth
While BERT introduced powerful bidirectional representations for language understanding, OpenAI’s Generative Pretrained Transformer (GPT) series took a different path, focusing on causal (autoregressive) modeling to excel in language generation. Starting with GPT-1 in 2018, the series quickly evolved through GPT-2 (2019), GPT-3 (2020), and eventually to GPT-4 and GPT-4o (2023-2024). This evolution showcased rapid growth in model size, capabilities, and real-world impact. The GPT models confirmed the usefulness of scaling laws, led to a surge of generative AI applications, and fundamentally changed how humans interact with AI.
GPT-1, introduced in June 2018 by OpenAI, was the first large-scale Transformer-based autoregressive language model. Unlike BERT, which focused on understanding in both directions, GPT-1 used a unidirectional (left-to-right) training approach. The main idea was straightforward but transformative: pretrain a decoder-only Transformer on a large text set using a next-word prediction task, then fine-tune it on downstream tasks with supervised data.
GPT-1 had 117 million parameters and was trained on BooksCorpus, which contains over 7,000 unpublished books. Although it was relatively small, GPT-1 showed that a single pretrained model could generalize across tasks such as sentiment classification, question answering, and textual entailment with few changes to the task-specific architecture.
The success of GPT-1 confirmed that:
- -
- Autoregressive modeling can achieve strong performance in language understanding and generation.
- -
- -Transfer learning works in both directions; models trained for generation can also be used for understanding tasks.
OpenAI released GPT-2, a much larger successor with 1.5 billion parameters trained on WebText, a curated dataset of web pages. GPT-2’s architecture expanded on GPT-1 by increasing its depth, width, and training duration. It maintained the same decoder-only, left-to-right causal Transformer design.
GPT-2 marked a significant moment in AI history for several reasons:
- -
- It showed that increasing model size and data volume leads to new behaviors, such as coherent multi-paragraph text generation, zero-shot learning, and in-context reasoning.
- -
- OpenAI initially withheld the full model due to concerns over misuse, including disinformation, spam, and automation of fake content. This sparked one of the first major ethical debates about generative models. The model was assessed in both zero-shot and few-shot contexts, where tasks like translation, summarization, and comprehension were attempted without specific training data. GPT-2’s performance in these areas indicated the early signs of general-purpose language ability, although it still fell short compared to fine-tuned models on benchmarks.
2.15 GPT-3: Emergence of Few-Shot Learning
Released in mid-2020, GPT-3 changed the game. With 175 billion parameters, which is over 100 times larger than GPT-2, GPT-3 was trained on a mix of Common Crawl, Wikipedia, books, and other large web datasets. It kept the same Transformer decoder-only structure but pushed the limits of model scaling to a new level.
The most surprising result from GPT-3 was its ability to learn from just a few examples in the input prompt. This in-context learning allowed GPT-3 to tackle tasks like:
- -
- Arithmetic and logic puzzles
- -
- Translation and summarization
- -
- Programming and code completion
- -
- Question answering and essay writing
This behavior indicated that the model learned abstract task structures simply from a large amount of language exposure, without needing explicit updates. GPT-3 blurred the line between training and inference, making prompt engineering an important skill for working with language models.
Despite its strengths, GPT-3 also showed several weaknesses:
- -
- Lack of consistent reasoning
- -
- Susceptibility to prompt sensitivity and incorrect information
- -
- Difficulty verifying facts or performing reliable multi-step logic
Still, it formed the basis for many commercial products and APIs, such as OpenAI’s Codex for code generation and ChatGPT for conversations.
In 2023, OpenAI launched GPT-4, a model that kept some details about its size and architecture secret but offered significant performance improvements across the board. It showed:
- -Greater factual accuracy
- -Fewer hallucinations
- -Better support for multiple languages
- -More stable behavior across different prompts
More notably, GPT-4 was succeeded by GPT-4-turbo and GPT-4o (omni), which brought multimodal capabilities. This meant accepting not just text but also images, audio, and for GPT-4o, video and live interaction. GPT-4o could process and respond to spoken language and visual inputs in real-time, moving LLMs closer to human-like multimodal understanding.
These newer models also included instruction tuning and reinforcement learning from human feedback (RLHF) to better match model behavior with user needs and ethical standards, greatly improving their usability for interactive agents and business applications.
The GPT series provided strong evidence supporting scaling laws, which show that model performance improves as compute, data, and parameters increase. This finding shaped the design of even larger models and led to the idea that “more is different,” where qualitative changes in behavior, like reasoning or abstraction, come from purely quantitative scaling.
Throughout the GPT series, the decoder-only Transformer architecture remained the same, proving it is durable and versatile. The successes of GPT-3 and GPT-4 confirmed that autoregressive language modeling is not only effective for generating text but also capable of zero-shot reasoning, language understanding, and multimodal grounding when scaled appropriately.
The GPT series ushered in the era of generative AI, transforming multiple industries including education, healthcare, law, customer service, and software development. Tools like ChatGPT, GitHub Copilot, and Microsoft Copilot have demonstrated how autoregressive LLMs can augment human productivity at scale. The release of GPT-3 and GPT-4 also reignited debates about AI alignment, misinformation, intellectual property, and labor displacement, prompting global discussions on how to govern and regulate powerful language technologies.
- F.
- The Rise of Open-Source Language Models
While large corporations and closed-source research groupsinitially dominated the field of LLMs, the rise of open-source large language models has greatly increased access to advanced NLP technologies. This movement encourages transparency and reproducibility and drives innovation. It allows independent researchers, small businesses, and academic institutions to explore and build on powerful language models.
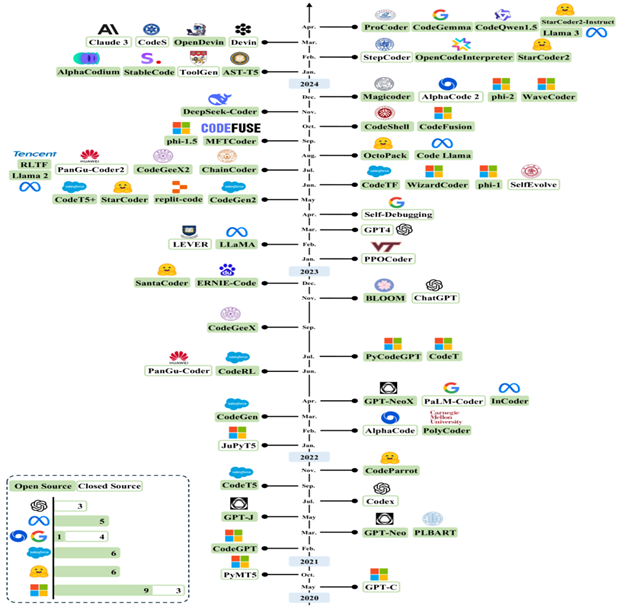
The open-source LLM movement dates back to earlier pre-transformer models like GloVe, word2vec, and ELMo. These models were released to the public and became widely adopted. However, significant momentum began to build with the development of Transformer-based models. The release of BERT in 2018 by Google marked a major breakthrough in this new era. BERT's source code and pretrained weights were made publicly accessible, leading to a surge in derived models, research papers, and real-world applications.In the following years, Hugging Face’s Transformers library played a key role in shaping the open ecosystem. By standardizing model APIs and hosting thousands of community-shared models, the library lowered barriers to entry and encouraged rapid experimentation. Researchers could now load and fine-tune models with just a few lines of code.
After OpenAI released GPT-3 in 2020 without open weights or training code, several research groups started developing open-source alternatives. These efforts aimed to replicate or closely match the capabilities of proprietary models while promoting transparency and independent validation.
Some key milestones include:
- -
- GPT-Neo and GPT-J (2021) by EleutherA: These were some of the first serious attempts to create open GPT-3-style models. GPT-J reached 6 billion parameters and displayed impressive zero-shot capabilities.
- -
- GPT-NeoX-20B (2022): This 20-billion-parameter model was trained with open tools and datasets. It matched or outperformed GPT-3 on certain benchmarks while staying freely accessible.
- -
- OPT (Open Pre-trained Transformer, 2022) by Meta AI: Meta released a group of decoder-only language models with up to 175 billion parameters to allow researchers to study the behavior of large-scale LLMs. This included transparent training logs and evaluation metrics, marking a significant achievement in open AI research.
- -
- BLOOM (2022) by BigScience: Trained by over 1,000 researchers from 70 countries, BLOOM became the first multilingual open LLM with up to 176 billion parameters. It supported over 40 languages and was trained on open data with open governance, highlighting the strength of community-driven research. These models showed that high-quality LLMs could be trained and released openly without sacrificing performance. This sparked a surge of innovation, reproducibility, and ethical discussions.
In early 2023, Meta released LLaMA (Large Language Model Meta AI), which included a series of compact yet powerful language models ranging from 7 billion to 65 billion parameters. Unlike earlier models that focused on large-scale performance, LLaMA models were designed to be efficient and accessible to researchers with standard hardware. LLaMA models outperformed GPT-3 despite their smaller size, thanks to more advanced pre-training methods and better architectural tuning.Although initially limited to non-commercial use, the leak of LLaMA weights led to a major shift. Developers quickly adjusted and fine-tuned LLaMA to create variants such as:
- -
- Alpaca (Stanford): Fine-tuned LLaMA using instruction-following data, creating lightweight ChatGPT-style assistants.
- -
- Vicuna (UC Berkeley): Built on LLaMA with conversational tuning, closely mimicking ChatGPT-level interactions.
- -
- WizardLM, Orca, Koala, Baize: Community-created instruction-tuned LLMs developed from LLaMA and its derivatives, each adding unique features like reasoning or multi-turn dialogue.
In response, Meta released LLaMA 2 in July 2023 under a more flexible commercial license. LLaMA 2 models (7B, 13B, and 70B) showed excellent performance on both general NLP tasks and dialogue generation. Their release marked a new era, allowing companies, governments, and researchers to use cutting-edge LLMs without relying on proprietary APIs.
The growth of open-source LLMs has been boosted by strong tools and infrastructure. Here are some examples:
Hugging Face Transformers: The main hub for open models, datasets, tokenizers, and evaluation tools.
PEFT (Parameter-Efficient Fine-Tuning) and LoRA: Techniques to fine-tune large models with minimal computing power by updating only a small number of parameters. RLHF pipelines: Open versions of reinforcement learning with human feedback, allowing developers to align models with user preferences.
Open LLM Leaderboards: Platforms like LMSYS and Hugging Face's leaderboard now rank open models based on standards like MMLU, ARC, and HELM. These tools enable independent teams to train, fine-tune, and deploy state-of-the-art language models on limited resources.
Open-source LLMs have made language intelligence accessible to more people. Startups, educators, developers, and nonprofits can now create LLM-powered applications without depending on centralized providers. This shift drives innovation, encourages localization
- — especially for less common languages
- — and supports scientific reproducibility.
However, open-source development also brings specific risks: The spread of unsafe or unaligned models due to the lack of safeguards. Security dangers, such as LLMs being used for phishing, malware creation, or spreading false information.
Resource inequality, where only a few organizations can afford to train models with more than 100B parameters.License fragmentation, with some models having unclear or restrictive terms.
These challenges call for shared governance, improved alignment techniques, and open collaboration among academia, industry, and society.
The landscape of large language models (LLMs) in 2025 is defined by rapid diversification, agent, and a major shift toward user-controllable, specialized, and effective models. As foundational models become common, research and industry are shifting focus from scale to capability, usability, and alignment. Below are the most significant trends shaping the LLM space in 2025.
One of the key changes in 2025 is the move from passive LLMs to agentic LLMs, which are models that can reason, plan, and interact on their own in digital environments. Supported by frameworks like OpenAI’s GPT-4o Agents, Meta’s LLaMA Agent, and Autogen by Microsoft, these systems can browse the internet, manage files, trigger APIs, and carry out multi-step tasks with little supervision. This new agent approach is transforming fields like coding, data analysis, customer support, and virtual robotic process automation (RPA).Agent becomes more popular after LLM becomes popular.Agent becomes very helpful in our normal days.A LLM agent is an autonomous system powered by a large language model. It can perceive inputs, reason about tasks, and take actions, often by calling tools or APIs. Unlike basic chatbots, LLM agents can plan multi-step tasks, interact with external environments, and change as needed. They are often used in AI workflows such as automation, coding assistants, or independent research agents.After the success of models like GPT-4o and Gemini 1.5, real-time multimodal LLMs have become standard in 2025. These models can process live video, audio, images, and text at the same time, allowing for applications in telemedicine, tutoring, smart surveillance, and assistive technology. For example, GPT-4o can engage in natural voice conversations, understand screenshots, interpret visual documents, and respond in milliseconds, paving the way for a new type of interactive AI assistant.
As general-purpose models become saturated, 2025 is seeing a rise in domain-specific LLMs that are often fine-tuned on industry-specific datasets. From legal and biomedical LLMs, such as BioLLaMA and LegalMistral, to localized language assistants that support underrepresented languages and dialects, researchers are utilizing open checkpoints like Mistral, LLaMA 3, and Phi-3 to create models suited for specialized, high-accuracy use.
The competition for context window length has intensified, with Claude 3.5, GPT-4o, and Mamba models supporting over 1 million token context lengths. Furthermore, vector-based retrieval is being closely integrated, allowing for semantic memory and long-term reasoning. Instead of recalculating answers, models can dynamically retrieve past conversations, documents, or facts, mimicking the ability to "think over time."
In response to increasing privacy and latency concerns, on-device LLMs are gaining popularity in 2025. Models like Gemma, TinyLLaMA, and EdgeGPT now operate on smartphones, laptops, and IoT devices with impressive accuracy and near-instant inference. This enables local, offline AI, which is crucial for privacy-sensitive sectors such as healthcare, finance, and government services.
With rising global regulation, LLM alignment and safety are significant research areas. Tools like HELM, Open LLM Arena, and LMSYS Chatbot Arena are used to compare models for helpfulness, honesty, and harmlessness. In 2025, scalable oversight, constitutional AI, and autonomous alignment loops are central to responsible development.
In this part, we traced the history of large language models (LLMs) from early rule-based systems to modern transformer-based architectures. We discussed key advancements like attention mechanisms, pretraining, and fine-tuning, which allowed for the development of general-purpose models. We also highlighted how open-source ecosystems have made LLMs more accessible and adaptable. Finally, we examined the latest trends in 2025, including real-time multimodal models, agent-based systems, domain-specific fine-tuning, and on-device deployment. This shows a shift toward smarter, more interactive, and efficient AI.
VI. Role in Cybersecurity
Large Language Models (LLMs) have truly changed the field of Natural Language Processing (NLP) and show great promise in improving our cybersecurity defenses. These models excel at processing and understanding large amounts of text. This makes them essential for any language-related task. The key behind LLMs is their foundation: deep neural networks trained on massive datasets and a specific architecture called the "transformer."
This transformer uses a smart "self-attention" mechanism that helps the model determine the importance of different words in a sentence, allowing it to understand their context. This innovative architecture, especially the transformer's self-attention, enables LLMs to achieve "human-like language understanding and predictive capabilities." It is not just a technical detail; it means LLMs can go beyond strict rules and recognize complex, evolving attack patterns.
Older models, like RNNs and LSTMs, struggled with remembering long sequences and processing information in parallel. Transformers, with their self-attention, surpassed these limits and can understand context over very long text spans. This deep contextual awareness allows LLMs to detect subtle, evolving attack patterns and vulnerabilities from unstructured security data, which is a major improvement over traditional signature-based methods.
This capability means LLMs can identify hidden attack patterns, examine how attackers behave, predict future threats, and even provide real-time defensive support.
This research summary will systematically explore the exciting possibilities and practical applications of LLMs in cybersecurity. We'll weave together insights from network security, artificial intelligence, and even human-centered design. The report will bring together the latest research, highlight the main challenges, and point towards future directions for using LLMs in network security, combining views from universities, industry, and government.
A. LLMs Superpower for Cybersecurity
LLMs are very good at understanding natural language. They can grasp context and subtle meanings, which lets them produce responses that feel quite human and relevant. This makes them essential for analyzing and interpreting security reports, threat intelligence, and log files effectively. Their versatility means they can handle a wide range of tasks, generating text.
Summarizing, translating, and answering questions all happen without needing specific training for each task. In cybersecurity, this means creating security policies, writing
code, or even crafting malicious prompts, which we will discuss later. Large language models (LLMs) can handle routine tasks like summarizing and rephrasing content. This is a big help for writing reports and analyzing security incidents.
A new type of model, called "agentic LLMs," is becoming an important tool. These models can automate complex tasks and support reasoning-driven security analysis. They can break down complicated, multi-step security problems into smaller, more manageable parts. This leads to more structured and logical solutions. This shift means LLMs are not just processing text anymore; they are evolving into automated or semi-automated systems that can make complex decisions and interact with the outside world. This fundamentally changes how security operations are conducted.
While traditional LLMs mainly do text-in, text-out tasks, agentic LLMs include planning modules, memory systems, and tool integration. This allows them to plan actions based on natural language input and interacting with the external world. This ability is important for automating multi-step security workflows, such as complete incident response playbooks or penetration tests. They go far beyond just analyzing reports.learning and adaptation process that static rules simply can't offer.LLMs can develop effective anomaly detection systems by constantly monitoring network traffic, system logs, and user behavior. This helps in early threat detection. They can uncover hidden attack patterns and vulnerabilities by sifting through historical data.
LLMs can identify "unusual patterns or deviations from the norm." This shifts cybersecurity from merely reacting to known attacks to proactively spotting threats before they fully emerge. This represents a significant improvement compared to traditional signature-based detection, which often falls behind new attack variations. Traditional methods depend on predefined rules or signatures. New, unseen attacks can bypass these. LLMs, trained on large datasets, learn what is "normal" and can detect subtle anomalies that do not match any known signatures. This ability makes it possible to catch zero-day threats or novel attack patterns. This capability provides continuous monitoring.
LLMs can develop effective anomaly detection systems by constantly monitoring network traffic, system logs, and user behavior. This helps in early threat detection. They can uncover hidden attack patterns and vulnerabilities by sifting through historical data.
LLMs can identify "unusual patterns or deviations from the norm." This shifts cybersecurity from merely reacting to known attacks to proactively spotting threats before they fully emerge. This represents a significant improvement compared to traditional signature-based detection, which often falls behind new attack variations. Traditional methods depend on predefined rules or signatures. New, unseen attacks can bypass these. LLMs, trained on large datasets, learn what is "normal" and can detect subtle anomalies that do not match any known signatures. This ability makes it possible to catch zero-day threats or novel attack patterns. This capability provides continuous monitoring.
| Cyber Attack Phase | Task Category | Detection Target | Detection Approach | Techniques |
| Reconnaissance | System-based Reconnaissance Detection | Advanced adversaries in Smart Satellite Networks | Transform network data into contextually suitable inputs | Transformer-based MHA |
| System-based Reconnaissance Detection | Malicious user activities | Use three self-designed agents to detect log les | CoT reasoning, PbE paradigm, EMAD mechanism | |
| System-based Reconnaissance Detection | Aack early detection, threat intelligence gathering, aacker's behavior analysis | Use LLM-based honeypot to simulate realistic shell responses | CoT prompting, Few-shot learning, Session management | |
| Human-based Reconnaissance Detection | Malicious web pages | Use question-and-answer detection example to guide LLM | K-means clustering, Few-shot Prompting | |
| Human-based Reconnaissance Detection | Phishing Sites | Translate email into LLM-readable format and use CoT | Prompt Engineering, CoT prompting | |
| Foothold Establishment | Malware Detection and Analysis | Malicious software (code snippets, textual descriptions) | Analyze textual descriptions and code snippets | BERT fine-tuning |
| Vulnerability Detection and Repair | Security aws in code repositories and bug reports | Analyze code, identify patterns, generate patches | GPT-3, Prompt Engineering, Semantic Processing | |
| Lateral Movement | Security | Anomalies in network trace and logs | Continuously monitor network tracking, system logs, user behavior | Advanced anomaly detection systems |
| Incident Response Automation | Critical events, security reports, logs | Assess and summarize events, generate scripts, aid report writing | LLM agents, Knowledge management | |
| Penetration Testing | Complex, multi-step, security-bypassing | Automate creation and analysis of code call chains | PentestGPT, Chain-of-Thought prompting |
LLMs are better at detecting phishing attempts by analyzing the content of emails and messages. They identify suspicious language patterns or links. Systems like ChatSpamDetector use GPT-4 and have shown impressive detection abilities for phishing emails, achieving an accuracy of 99.70%. They also provide clear reasoning for their choices. These systems can spot sender spoofing, brand impersonation, and various social engineering tactics.
While LLMs greatly improve phishing detection, their ability to generate text also allows attackers to create very convincing phishing emails and realistic social engineering attacks. This leads to an ongoing competition, where advances in defense are quickly matched by new offensive tactics. LLMs can generate text that resembles human writing, which is both helpful and harmful. It helps detect subtle language cues in phishing emails, but attackers can use this same skill to create more believable, personalized, and evasive phishing messages.
This means the effectiveness of LLM-based defenses is not fixed. It requires constant updates to keep up with changing AI-driven attacks.
LLMs are becoming important tools for software vulnerability detection. They overcome the weaknesses of traditional static and dynamic analysis methods regarding efficiency, false-positive rates, and scalability. They can analyze code repositories and bug reports to find patterns that indicate security flaws. For example, GPT-3 has been used to create code patches for vulnerabilities, which speeds up the process.
Research methods focus on LLM implementation, prompt design, and semantic processing methods. They often use multi-agent approaches to break down complex problems into smaller parts. LLMs can also help with reverse engineering and discovering vulnerabilities in software.
LLMs are moving beyond simple pattern matching in code to perform reasoning-enhanced vulnerability detection. This means they are starting to automate tasks that once needed deep human expertise, like identifying subtle logic flaws by examining complex control flows or data handling. This makes advanced vulnerability analysis easier.
Traditional vulnerability detection often struggles with complexity and false positives. LLMs, especially when using techniques like Chain-of-Thought prompting, can simplify complex code analysis problems into smaller, logical steps. This enables them to spot vulnerabilities that are not obvious from basic code patterns, such as Null Pointer Dereferences or complex cross-module dependencies. They effectively mimic and scale human expert reasoning.
LLMs can be used for "AI Pentesting." They simulate cyberattacks to analyze them and suggest improvements. They help find, analyze, and describe CVEs (Common Vulnerabilities and Exposures) and provide practical suggestions for improvement. An LLM-powered automated tool for pentesting, PentestGPT, is based on models like GPT-3.5 and GPT-4. It uses reasoning, generation, and parsing modules developed through Chain-of-Thought prompting.
These tools take advantage of LLMs' ability to automatically create and analyze complete code call chains from user input to server output. They identify complex, multi-step vulnerabilities that bypass security, which traditional static code analysis tools might miss. Using LLMs in penetration testing improves red-teaming capabilities. This allows organizations to conduct more frequent, thorough, and sophisticated simulated attacks. As a result, they can achieve continuous and automated vulnerability assessment. However, it also means that attackers can access similar tools.
Manual penetration testing takes a lot of time and resources. LLMs can automate the process of identifying attack paths and generating exploits. This makes it possible for security teams to run "AI Pentesting" more often, covering a wider attack surface. However, it also means malicious actors can use similar LLM-powered tools to quickly and broadly discover vulnerabilities, increasing the offensive-defensive cyber arms race.
LLMs can automate various responses in Security Operations Centers (SOCs), generate scripts and tools, and aid in report writing, reducing the time security professionals spend on routine tasks. They can quickly assess and summarize critical events, providing real-time information to decision-makers during incident analysis.LLM-driven knowledge management transforms the incident resolution process by processing unstructured data, understanding complex relationships, and presenting information contextually, accelerating problem-solving. Tools can generate LLM-powered incident diagrams and timelines from GitHub and postmortem repositories using highly specialized LLMs. LLMs are revolutionizing knowledge management within incident response, transforming unstructured data (chat logs, reports, post-mortems) into actionable, synthesized information. This not only speeds up resolution but also helps capture "tacit knowledge"often conned to experts' minds, improving organizational learning and resilience. During high-pressure incidents, human cognitive capacity is limited, and sizing through lengthy documentation is inefficient. LLMs can "dynamically consolidate and restructure knowledge from multiple sources", providing concise, context-aware summaries. This directly addresses information overload and the challenge of implicit knowledge transfer, making incident response more efficient and less reliant on individual memory.
The integration of LLM agents into SOC operations offers a chance to automate and improve threat detection, analysis, and response. LLMs can process large amounts of unstructured data, including logs, alerts, and threat intelligence reports, to identify patterns and anomalies that are hard for human analysts to see. They can also help with automated response actions by suggesting or executing predefined response playbooks. LLMs can support continuous monitoring, incident response, and threat intelligence within the SOC.
Adding LLM agents to SOCs marks a shift toward a more proactive and agile defense system. Automation goes beyond basic alerts to include real-time analysis, threat prediction, and automated responses. This suggests a future where SOCs are less reactive and more predictive, staying ahead of threats with the help of AI. Traditional SOCs often face challenges with the volume and complexity of alerts. This can lead to alert fatigue and slower responses. LLM agents can automate the analysis of security data, detect emerging threats in real time, and provide historical data, allows SOC teams to effectively scale operations and respond proactively, shifting the paradigm from human-intensive reactive defense to AI-augmented predictive security.
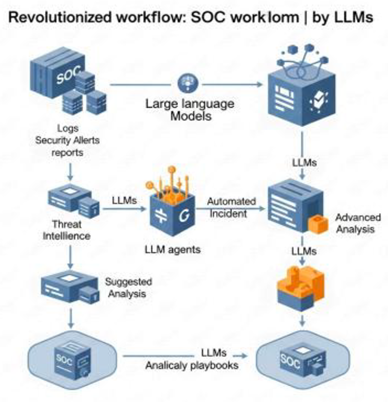
LLMs can classify and identify malicious software by examining textual descriptions and code snippets of malware samples. For example, BERT has been fine-tuned to tell the difference between benign and malicious code with high accuracy. LLMs can study the meaning of API calls for malware detection, extracting important semantic features.
from API names and official definitions using prompt engineering and sentence embedding techniques. Lightweight LLMs (SLMs) are being developed for malware detection on edge devices. They aim to maintain high accuracy even with limited computing power. The ability of LLMs to mine the meaning of APIs for malware detection marks a shift from relying solely on signature-based or behavioral analysis. This shift leads to a better understanding of malicious code. The semantic analysis helps in detecting polymorphic or obfuscated malware that could avoid simpler detection methods. Malware constantly changes to avoid detection. It often alters its external appearance or obfuscates its code. Traditional methods that depend on signatures or basic behavioral patterns can be evaded. LLMs possess a deep understanding of language and context, enabling them to analyze the intended meaning or intrinsic semantics of API calls, even when the code is obfuscated. This ability allows them to identify malicious intent despite superficial changes, resulting in a more reliable detection process.
Generative AI and LLMs are changing cybersecurity practices. They help engineers create reliable, safe, and cost-effective security applications. LLMs can summarize and generate code related to security, which supports the development of secure applications.
In 5G networks, LLMs show significant promise for testing protocols and designing system-level security. They can automate the generation of test cases from extensive 5G system design documents and extract protocol rules and constraints. LLMs can also create new models for fuzzing, which generates changed traffic patterns, and for penetration testing to find security flaws in the 5G architecture.
Using LLMs in generative security application engineering reflects a shift toward integrated security. This approach brings security into the software development lifecycle much earlier. LLMs can actively help incorporate security into applications and network designs from the beginning, rather than only spotting vulnerabilities after deployment. In the past, security testing often happened late in development, resulting in expensive fixes. LLMs can aid in writing secure code, summarizing code for security reviews, and generating automated test cases for complex systems like 5G. This ensures that security considerations are prioritized throughout the process.
Integrated from the design and development phases, this approach reduces the attack surface and vulnerabilities before deployment. It shifts from reactive patching to proactive secure engineering.
Collecting high-quality and succinct training data is challenging due to the sensitive nature of cybersecurity information (logs, threat reports), and this data can be noisy, incomplete, or biased. Such a lack of diverse and comprehensive attack data makes it difficult to train models that can cover all threat scenarios. Training LLMs on sensitive data can inadvertently lead to the leakage of confidential information.The "meaning" of data hierarchies within LLMs means traditional access controls (RBAC/ABAC) may not apply, increasing the risk of sensitive information disclosure.The collection of large amounts of textual data, which may contain personal or sensitive information, and real-time interaction with users, increases the risk of privacy leakage. While LLMs are powerful in analyzing vast, sensitive cybersecurity data, their inherent design (large training datasets, context learning) creates a "privacy paradox".This means the very processes that make LLMs effective also expose them to data leakage and privacy breaches, necessitating a fundamental rethinking of data governance and access control for AI systems. LLMs require massive datasets to learn patterns. In cybersecurity, this data oen contains sensitive information.Once data is fed into an LLM, it is "stripped of context and ownership", meaning traditional access controls become ineffective. This creates a high risk of "sensitive information disclosure", not just from malicious attacks, but also from unintentional prompts. This requires new privacy-preserving techniques and architectural changes beyond mere data encryption.
LLMs are often seen as "black boxes" because their internal structures are complex. This makes it hard to understand why they make certain decisions. In cybersecurity, where it’s important to know a model's reasoning for building trust and validation, this lack of clarity is an issue. Explainable AI (XAI) helps address these problems by making model predictions clearer and more understandable.
The "black box" nature of LLMs creates a significant "trust deficit" in important cybersecurity situations. Even if an LLM offers highly accurate detections or suggestions, human analysts might hesitate to rely fully on them without clear explanations for decisions. This hesitation can slow down adoption and effective incident response. In cybersecurity, false positives can be expensive, and it is vital to understand the root cause of a threat. If an LLM flags something as malicious but cannot explain why, security analysts cannot verify the alert, learn from it, or refine their strategies. This lack of interpretability directly affects the "trustworthiness" and "reliability" of AI systems. Therefore, XAI is not just a research topic; it is essential for adopting LLMs in critical security roles.
Training and deploying large-scale LLMs require significant computational resources. This can be a barrier for smaller organizations and can also have an environmental impact due to high energy use. Scaling LLMs improves capabilities, but it also leads to higher processing demands and more complex deployment.
The heavy computational needs of LLMs create a barrier to entry for smaller organizations or those with limited resources. This means the benefits of LLM-powered cybersecurity may mainly go to larger entities, which could widen the cybersecurity gap between well-resourced and less-resourced organizations. Training and inference for large LLMs need substantial GPU power and energy. These costs can be overwhelming for small and medium-sized enterprises.
While lighter LLMs and optimization techniques like quantization and pruning are emerging, cutting-edge capabilities often remain with larger models. This creates an uneven playing field where advanced AI defenses are not widely available.
universally accessible, potentially exacerbating existing cybersecurity disparities.
LLMs introduce new challenges such as adversarial manipulation, where malicious actors trick LLMs into overlooking threats. Adversarial attacks exploit vulnerabilities by creating malicious inputs that cause LLMs to produce incorrect or undesirable outputs, such as misleading information, sensitive data extraction, or triggering unintended behaviors. Types of attacks include prompt injection (the most widely discussed), input perturbation, data poisoning, evasion attacks, model inversion, inference attacks, and model extraction attacks. These attacks can be transferred from one model to another. LLMs create a "new attack surface" for cybersecurity. This means hackers are not just targeting systems protected by LLMs, but are actively exploiting vulnerabilities within the LLMs themselves (e.g., prompt injection, data poisoning) to bypass defenses or extract sensitive information, requiring a paradigm shift in how AI systems are secured. Traditional cybersecurity focuses on securing networks and applications from external threats. However, with LLMs, attackers can directly manipulate the AI model's behavior by carrying inputs (prompt injection) or poisoning its training data (data poisoning). This means a perfectly secured infrastructure can still be compromised if its embedded LLM is vulnerable to adversarial attacks, making LLM security a critical, distinct domain within cybersecurity.
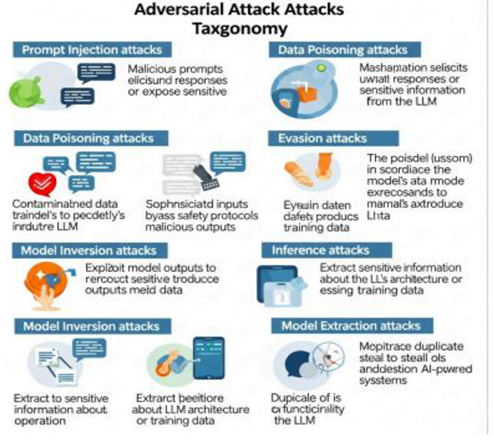
This diagram would categorize and illustrate different types of adversarial attacks specifically targeting LLMs. It could include visual representations or conceptual groupings of prompt injection, data poisoning, evasion attacks, model inversion, inference attacks, and model extraction attacks. Each category would briefly show how the attack manipulates the LLM or its data and its potential impact on cybersecurity operations.
The use of LLMs in surveillance and monitoring systems raises privacy concerns if not properly regulated. LLMs can generate harmful content, misinformation, or biased outputs, partly due to pretraining on large datasets gathered from the internet. The dual nature of LLMs means they need strong protection from AI-based defense systems and ethical regulations, highlighting the importance of responsible AI use.
The ethical concerns of LLMs in cybersecurity go beyond technical flaws to broader societal effects. Unregulated deployment could worsen existing biases, allow for widespread misinformation, or violate privacy rights. This situation requires solid governance frameworks and ethical guidelines, along with technical safeguards. LLMs learn from vast, often unstructured, internet data. This can
Embed and spread societal biases or create harmful content. In cybersecurity, this could show up as biased threat detection, such as unfairly targeting certain user groups, or helping to spread credible misinformation. Ethical considerations are not just an extra step; they are essential to making sure LLMs are used responsibly and do not cause more harm than the threats they are meant to address
3.12 Designing for Security: Architectural Patterns for LLM Integration
The integration of LLMs with traditional security tools represents a significant advancement in the cybersecurity domain. Architectural frameworks for LLM integration aim to enhance threat detection, response, and overall system resilience.LLMs should be treated like untrusted users, meaning secure LLM
Applications must be built with strong control mechanisms and safety-first architectures from the start, rather than depending on security retrofitting. Key security patterns include identifying, authenticating, and authorizing all users (both humans and agents), implementing rate limiting, validating LLM output before use, and logging wisely. Model sandboxing can isolate LLMs from sensitive systems to prevent lateral movement or data extraction. Context-aware logging can track user identity, session intent, and interaction history.
The recommendation to treat LLMs as "untrusted users" reflects a significant shift in security architecture. This means traditional perimeter-based security is not enough; instead, a zero-trust approach must be applied within the LLM application itself, with detailed controls and ongoing validation for both inputs and outputs. Historically, security has focused on protecting networks and applications from outside threats. However, LLMs, particularly agentic LLMs, can interact with internal services. If an LLM is compromised (for example, through prompt injection), it can act as an insider threat. Therefore, instead of assuming the LLM is safe, it must be treated as a potentially harmful entity. This requires strong authentication, authorization, input validation, and output filtering at every interaction point, essentially employing threat modeling with a trust boundary on either side of the LLM.
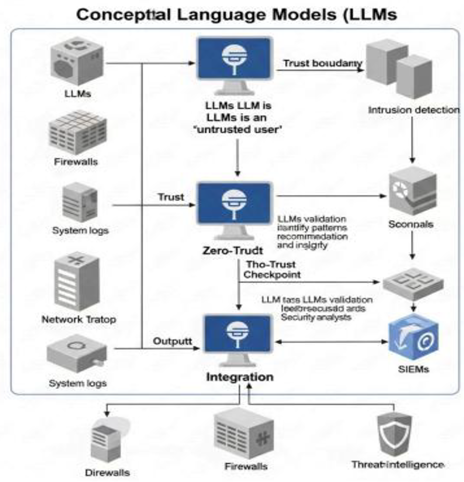
This figure would show a conceptual framework that illustrates how LLMs fit into a larger cybersecurity ecosystem. It would display LLMs working with different security tools, various data sources like system logs, network traffic, and threat intelligence feeds, as well as human analysts. The diagram could also visually express the idea of viewing the LLM as an "untrusted user." It would depict clear trust boundaries and validation points for inputs and outputs, highlighting a zero-trust approach within the LLM application itself.
LLM is very helpful in Cyber Security Company.Large Language Model is an Multi Billionaire Innovate for Cyber Security Intelligence.There are various LLM agent for doing automation work for Cyber Security like data protection, preventing attack from hackers and many of thing can do now by LLM agent which is running by LLM.Agent is very powerful for Cyber Security because of their automation.
3.13 Best Practices for Deployment: Making LLMs Safe and Sound
For transparency and control, open models should be used and deployed locally or on private cloud instances. If cloud models are necessary, trusted providers should be selected, and their security posture understood. Models should be measured and compared for safety to evaluate their trustworthiness and reduce harmful responses.Tools like lm-evaluation-harness can be used for this purpose.
All data sources, including training, fine-tuning, and RAG data, must be protected from unauthorized access. Any attempts to modify them should be logged since compromised data can influence LLM behavior. AI components should be strengthened like traditional applications by reviewing ports, services, and security settings.
Best practices for LLM security include data governance, which involves using clean, unbiased, and encrypted data. Regular model training updates, access controls such as MFA and RBAC, adversarial testing, continuous monitoring, and training on ethical use are also essential.
The focus on securing LLMs throughout their entire lifecycle—from data governance and model training to deployment and ongoing monitoring—shows a shift toward a more complete approach to AI security. This means that security cannot be an afterthought. It must be a part of every phase of LLM development and operations to ensure resilience against changing threats. LLMs are not fixed software; they are dynamic systems that learn and grow. Vulnerabilities can emerge at various stages, including through biased or poisoned training data, insecure model designs, or improper deployment. Therefore, a scattered approach to security doesn't work. A solid strategy must address data curation, model strengthening through adversarial training and input validation, secure deployment practices like rate limiting and output validation, and ongoing monitoring for anomalies, ensuring that security is integrated throughout the MLOps pipeline.
3.14 Smarter LLM Designs for Security
Future research should focus on developing more efficient and specialized LLM architectures for cybersecurity tasks. This includes techniques like model pruning, quantization, and knowledge distillation to reduce computational needs without sacrificing performance. Continuous research is needed to tackle limited repository-level coverage and the narrow scope of vulnerability detection. Current work is often confined to binary classification of function-level vulnerabilities within small datasets. Addressing the rapid advancements in frontier LLMs and using them through fine-tuning will be crucial for future progress.
There is growing tension between the desire for highly specialized, efficient LLMs for specific cybersecurity tasks—for example, lightweight models for edge malware detection—and the need for general, context-aware frontier LLMs. This suggests that future research will look into hybrid architectures or adaptive fine-tuning strategies. These approaches can balance deep domain expertise with broad contextual understanding. While
Large, general-purpose LLMs offer broad capabilities. However, they are costly to run and may lack precision in specific fields. Smaller, specialized models (SLMs) are more efficient but have a narrower focus. Future research should explore how to combine the strengths of both. This could be done through modular LLM architectures, Mixture-of-Experts models, or efficient fine-tuning methods that enable general models to gain detailed knowledge in specific domains.
3.15 Teaming Up: Integrating with Other Technologies
Integrating LLMs with other AI and cybersecurity technologies, like reinforcement learning and blockchain, can create stronger and more adaptable security solutions. Federated Learning (FL) offers a decentralized way to train and fine-tune LLMs. It uses computational resources from different organizations while keeping sensitive data on local devices, which addresses privacy and scalability concerns. FL can improve security by not gathering data in one place, which reduces attack surfaces. Explainable AI (XAI) is important for making LLM predictions clear and understandable, which builds trust and lowers risks linked to "black box" models.
The combination of LLMs with supportive technologies, such as Federated Learning (FL) and Explainable AI (XAI), suggests a shift towards "synergistic defense systems." This means that the full potential of LLMs in cybersecurity will be realized only when their main abilities are improved by other technologies that tackle their limitations, such as privacy and interpretability. This can lead to stronger, more trustworthy, and collaborative security solutions. LLMs deal with data privacy and interpretability challenges. FL deals directly with privacy by keeping data local during training. XAI addresses interpretability by offering explanations for LLM decisions. By combining LLMs with these technologies, the weaknesses of LLMs can be reduced, resulting in "trustworthy AI" that is both powerful and ethically responsible, encouraging greater use in sensitive cybersecurity areas.
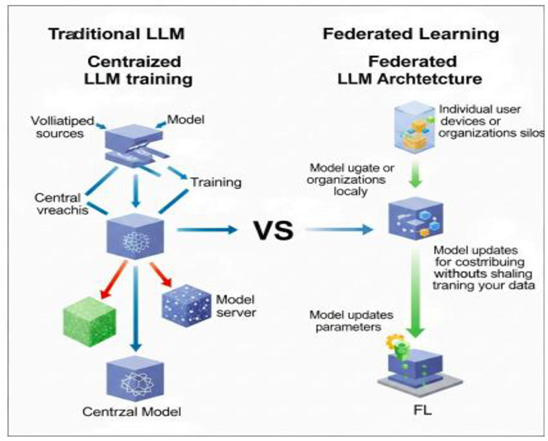
Integrating LLMs with other AI and cybersecurity technologies, like reinforcement learning and blockchain, can create stronger and more adaptable security solutions. Federated Learning (FL) offers a decentralized way to train and fine-tune LLMs. It uses computational resources from different organizations while keeping sensitive data on local devices, which addresses privacy and scalability concerns. FL can improve security by not gathering data in one place, which reduces attack surfaces. Explainable AI (XAI) is important for making LLM predictions clear and understandable, which builds trust and lowers risks linked to "black box" models.
The combination of LLMs with supportive technologies, such as Federated Learning (FL) and Explainable AI (XAI), suggests a shift towards "synergistic defense systems." This means that the full potential of LLMs in cybersecurity will be realized only when their main abilities are improved by other technologies that tackle their limitations, such as privacy and interpretability. This can lead to stronger, more trustworthy, and collaborative security solutions. LLMs deal with data privacy and interpretability challenges. FL deals directly with privacy by keeping data local during training. XAI addresses interpretability by offering explanations for LLM decisions. By combining LLMs with these technologies, the weaknesses of LLMs can be reduced, resulting in "trustworthy AI" that is both powerful and ethically responsible, encouraging greater use in sensitive cybersecurity areas.
3.16 Addressing Persistent Challenges and Emerging Threats
Continuous research is necessary to address issues in data privacy, interpretability, and computational efficiency. It is important to develop standard frameworks and best practices for the ethical use of LLMs. Research on adversarial attacks against LLMs and effective defenses remains a key focus. There is an urgent need for dedicated datasets specifically designed for identifying vulnerabilities in LLMs.
The rapid growth of LLMs and new AI-driven threats have created a regulatory gap. Ethical and governance frameworks are struggling to keep up with technological advancements. This highlights the need for proactive policy development and industry standards to direct responsible AI use in cybersecurity. These efforts can help prevent misuse and build public trust.
LMs are evolving quickly. Their capacity to generate realistic text and code can be exploited for intricate social engineering or creating malware. Without clear ethical guidelines and regulations, we risk unintended outcomes, privacy violations, and even large-scale AI-powered attacks. Therefore, proactive AI governance and ethical "jailbreak" testing are not just theoretical discussions; they are necessary for ensuring safety.
Large Language Models (LLMs) are changing the cybersecurity field in significant ways. They greatly improve our ability to detect threats, manage vulnerabilities, and automate incident responses. This helps us keep up with the increasingly complex and fast-changing nature of cyber threats. LLMs exceed the limits of traditional security tools by adding intelligence, speed, and flexibility to modern defense systems.
However, using LLMs also presents serious challenges. We must carefully address concerns about data privacy, the unclear nature of model decisions, the high demand for computational power, and the risk of adversarial attacks. To ensure safe and effective deployment, we should treat LLMs as potentially untrusted parts of a system. Strong data governance, best practices for model security, and embedded architectural safeguards are essential for minimizing risks.
Looking ahead, the future of LLMs in cybersecurity depends on ongoing innovation. Improvements in LLM design, integration with technologies like federated learning and explainable AI, and continuous research into new threats will be crucial. To fully realize the potential of LLMs and create a safer digital future, we will need not only technical advances but also strong ethical guidelines, teamwork across disciplines, and responsible governance.
VII. Applications in Software Engineering
Large Language Models (LLMs) have shown their effectiveness in many software engineering tasks, changing how development practices and engineering workflows work. A thorough review of the literature shows that LLMs can handle numerous functions, including code completion, debugging help, and code generation. For example, models like Codex can generate code snippets in response to natural language questions, making the coding process easier. These abilities not only improve programmer productivity but also help reduce human error through automated suggestions and validation tools.
However, the use of LLMs in software engineering comes with its own challenges and limitations. Much of the current research aims to improve LLM performance in specific software-related tasks, indicating that existing models may not meet the detailed needs for certain functions. While some studies look into LLMs' abilities in general coding tasks, focused assessments for models designed specifically for programming, like Codex, are still limited. This gap shows a need for more specific evaluations to determine how effective LLMs are in specialized engineering settings.
Moreover, there are growing discussions around the necessity of fine tuning these models for specific tasks within software engineering, which could lead to the development of tailored large model products that effectively bridge the existing performance gaps. The future of LLM application in software engineering points towards a more refined approach that embraces ongoing optimization and better performance metrics. As researchers continue to explore methodologies to enhance LLM execution across diverse software environments, there is an expectation that targeted adaptations of these models will foster improvements in accuracy and relevance in software engineering tasks. Addressing these questions and challenges could significantly impact how software development is approached and managed in the coming years, ultimately leading to more robust engineering practices that fully leverage the capabilities of LLMs.Nevertheless, using LLMs in software engineering comes with challenges. A major concern is the reliance on the natural properties of these models. This can result in incorrect or "hallucinated" outputs that might not match real-world situations. This highlights the importance of combining traditional software engineering methods with LLM capabilities. By using both traditional methods and the new possibilities of LLMs, organizations can create stronger software solutions while reducing the risks of errors. Moreover, the absence of detailed evaluations of specialized LLMs, like code-focused models such as Codex, highlights a gap that needs to be addressed. Future research should aim to improve how LLMs are integrated into specific tasks, look into the effects of fine-tuning, and create evaluation frameworks that can properly measure model performance in software engineering tasks.
In conclusion, while LLMs have shown great potential to change software engineering practices, it is important to carefully consider their limitations for better integration. Tackling the current challenges through more research will improve the reliability of LLM applications and create better software engineering methods in the future.
Large Language Model is booster for Software technology and Software industry.Large Language Model helps in various software part.Large Language Model will increase the growth of the Software industry into double. In coming days LLM will be replaced with Coder.
4.1 LLM For Code Generation
The advent of LLMs, such as ChatGPT, has significantly transformed the landscape of software engineering, particularly in the domain of code generation. Code generation entails the automatic creation of source code based on specific input requirements or specifications, marking a substantial shift in how developers engage with coding tasks. By leveraging advanced algorithms and vast training data, LLMs can enhance developer productivity and efficiency, shifting the focus from manual coding to higher-level design and problem-solving. This facilitation of code generation presents numerous advantages, including time-saving benefits and the potential to minimize human error in routine tasks. A recent empirical assessment has scrutinized the effectiveness of LLMs in generating code, focusing on three pivotal dimensions: correctness, understandability, and security.
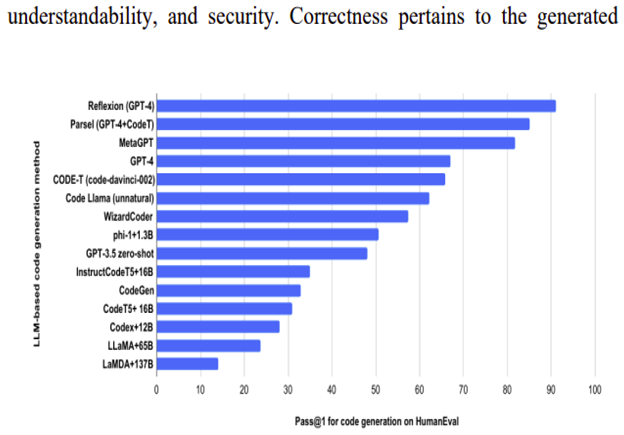
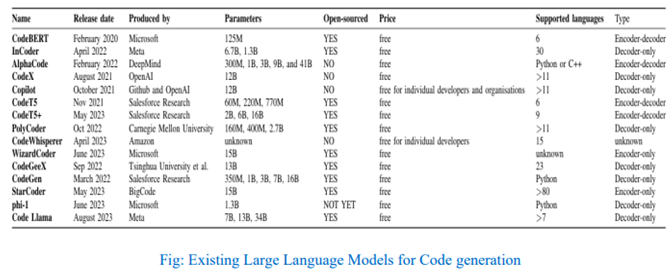
Correctness pertaining to the generated Code functionality is crucial for ensuring the code works as intended without introducing bugs. Understandability measures how readable and maintainable the generated code is for developers.
This factor affects the long-term sustainability of a project. Lastly, security looks at the cybersecurity risks associated with the generated code, which has become increasingly important due to rising cyber threats. The research highlights that while LLMs are good at generating code, they have limitations, especially concerning the quality of the training data and the clarity of the context during interaction.
Additionally, the multi-round engagement feature of LLMs allows users to refine their queries, gradually improving code quality. This interactive approach creates a dynamic relationship between the developer and the model, leading to results that better meet changing requirements. The findings do not only show the strengths of LLMs in code generation, but also point out areas that need improvement. This sets a base for future exploration and growth of AI-powered coding tools. As the software engineering field keeps integrating these technologies, understanding how LLM-assisted code generation works and its implications will be important for both practitioners and researchers. The table compares major large language models (LLMs) for code generation developed between 2020 and 2023. Key contributors are Microsoft, Meta, Salesforce, Amazon, DeepMind, and OpenAI. The models vary in size from 60M to 41B parameters. Most are open-sourced and free, encouraging broader use in both research and industry. They are built on either encoder-decoder or decoder only designs and can support from a few to over 80 programming languages.
Models like CodeBERT and CodeWhisperer focus on general code generation. In contrast, AlphaCode and WizardCoder target more complex problem-solving tasks. Open models like StarCoder and Code Llama prioritize community-driven development. However, some, like phi-1, are still not publicly available. There is a clear trend toward supporting multiple languages, scalability, and easier access for developers. Overall, these models show a growing focus on fine-tuning for coding tasks, real-world use, and open innovation.

4.2 The Usage of LLM in Code Review
Code review is a key part of the software development lifecycle. It helps ensure code quality, functionality, and security. This process can be time-consuming and prone to human error. Large Language Models (LLMs) can greatly help in this area. Studies show that LLMs can assist in finding security vulnerabilities and validating software functionality. By using these models, teams can improve the efficiency of code reviews and reduce some of the workload involved in the review process.
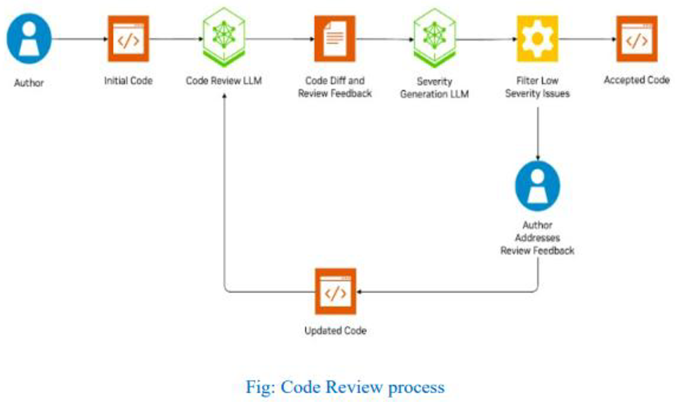
The research conducted highlights two key tasks where LLMs can be very useful: flagging code with security vulnerabilities and performing functionality assessments. They used various prompting techniques, including zero-shot and chain-of-thought prompting, to get helpful recommendations from the models. Their experiments showed that proprietary models from OpenAI significantly outperformed smaller open-source alternatives, especially in accurately identifying and describing security vulnerabilities from established datasets, like the Common Weakness Enumeration (CWE). This finding underscores the potential for LLMs to function not only as review aids but also as tools for educating developers about potential pitfalls and enhancements in code quality. Furthermore, the promising results concerning LLM-generated descriptions of vulnerabilities illustrate their effectiveness in supporting human reviewers. By generating detailed insights into identified issues, LLMs can facilitate a deeper understanding of the security landscape, allowing developers to act upon these insights more knowledgeably. The integration of LLMs into code review practices not only streamlines the process but also introduces a layer of analytical rigor, thus fostering a stronger security posture within software products. Mechanisms for implementing LLMs in ongoing code review disciplines could ultimately transform this critical process, leading to improved outcomes with respect to software robustness and reliability.
4.3 Automation of Bug Detection
Bug detection in software engineering has mostly depended on manual processes and static analysis tools. However, recent developments in Large Language Models (LLMs) are changing how we approach this work. One key feature of LLMs is their ability to create bug-reproducing tests from bug reports. This is an important task that can lead to significant improvements in the software development process.
The effectiveness of Spectrum-Based Fault Localization (SBFL) techniques suffers when a bug-reproducing test is missing. These techniques fail to find the bug in 95% of the cases they analyze. Research on Java repositories shows that, on average, 28.4% of additional test cases come directly from bug reports. This highlights an important link between bug detection and automated testing. This creates a strong argument for using LLMs to automate the process of turning reports into tests.
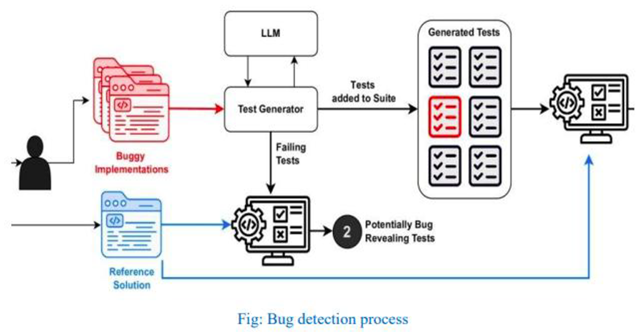
The performance of LLMs in bug detection and repair has shown promising results, especially in automated program repair (APR). Certain LLMs can effectively fix a significant number of buggy programs and achieve a 27.5% to 62.4% increase in prediction accuracy over leading models like CodeT5 and PLBART. LLMs can also improve bug-fixing processes by using different prompt strategies, which leads to fixing even more bugs. Their ability to understand both natural language and programming languages makes them a powerful tool for bug detection and software reliability. Additionally, exploring open-source LLMs offers an exciting chance for the software engineering community to assess their capabilities in automating bug detection and repair. This can help optimize developer efforts and improve software quality through better testing frameworks. Overall, integrating LLMs into bug detection marks an important step forward for tools available to software engineers, leading to more efficient workflows and better code quality.
4.4 LLM Usage of Documentation
Documentation generation is an important part of the software engineering lifecycle. Integrating large language models (LLMs) has shown promising results in improving this process. LLMs like GPT-4 can generate code as well as create structured and clear Software Requirements Specification (SRS) documents. A study found that LLMs can produce SRS drafts that are comparable to those from entry-level software engineers. By meeting key criteria like accuracy, coherence, and completeness, LLMs serve as useful tools to simplify documentation efforts and improve communication among project stakeholders.
Additionally, LLMs play a significant role in checking and refining documentation. The same study noted that LLMs can spot inconsistencies and suggest corrections, which helps support the ongoing nature of documentation in software development. This ability to provide constructive feedback improves the quality of the SRS, making sure any potential issues are addressed early in the development cycle. The results showed that LLMs not only matched manual output quality but also significantly reduced the time required for document generation. This time savings is particularly valuable.beneficial for entry-level engineers who may lack the experience necessary to quickly create thorough documentation. In addition to SRS document generation, LLMs have also been studied in the context of code generation. An empirical assessment was conducted on code snippets generated by LLMs, focusing on aspects such as correctness, understandability, and security. Their findings suggest that LLMs can improve programmer productivity byspeeding up the coding process through automatic code generation. This is particularly efficient.
Critical in environments where rapid prototyping and iterative development are essential. The multi-round process of code generation outlined in their study shows LLMs' potential to support ongoing refinement. This makes them a vital resource for software teams that want to improve their workflows. The use of LLMs in documentation generation not only boosts productivity but also improves the overall quality and reliability of software engineering outputs.
4.5 Benefits of Using Large Language Models In Software Engineering
The integration of Large Language Models (LLMs) into software engineering offers several key benefits that go beyond simple code generation. Recent studies show that LLMs are highly versatile. They can apply to various software engineering tasks like coding, design, requirements analysis, debugging, and documentation. These models can help developers at different stages of the software development lifecycle, improving productivity and efficiency. By using the vast datasets that LLMs are trained on, developers gain tools that not only help with routine coding but also promote innovation and problem-solving.
One significant benefit of using LLMs in software engineering is their ability to make the debugging process easier. For example, recent research indicates that LLM performance remains stable across different programming languages like C and C++. However, there is a chance for performance to decline in complex environments. Specifically, the details in proprietary code can lead to lower performance metrics, but these issues are manageable. Strategies like in-context learning can effectively reduce performance drops, allowing for better outcomes.
A stronger use of LLM technologies in private settings can create new opportunities. The unique features of LLMs can improve code reliability, make refactoring easier, and help with performance optimization. This shows their essential role in today’s software engineering. The use of LLMs in software engineering not only adds to traditional methods but also encourages a more flexible and responsive way to handle complex coding tasks. As the field develops, combining LLM capabilities with existing practices is set to provide significant advantages, blending human creativity with support from artificial intelligence.
LLMs are becoming central to software engineering and are boosting productivity through new methods in different parts of the software development lifecycle. One key area of impact is requirements engineering. This is a crucial phase where stakeholders' needs must be captured and prioritized within time and budget constraints. Using LLMs in this field helps automate task prioritization, allowing agile teams to respond to changes more effectively.
For example, a recent study introduced a web-based tool that uses AI agents and prompt engineering to improve requirements prioritization. This tool fits with agile approaches like the Scaled Agile Framework (SAFe) and Large-Scale Scrum (LeSS), which are designed to manage larger projects more flexibly. By automating simple tasks in requirements gathering, LLMs improve project management efficiency. This lets teams focus on important tasks while keeping essential stakeholder inputs in mind.LLMs promote creativity and innovation in tasks beyond just gathering requirements. They improve productivity throughout the software development process, including coding, design, testing, and documentation. This flexibility is both advantageous and challenging. While LLMs can quickly create innovative solutions, we still need reliable ways to weed out errors and ensure the accuracy of the output. The new abilities of LLMs call for strong hybrid techniques that support effective use in software engineering. By using these models, practitioners can greatly reduce development times and respond better to stakeholder needs. As a result, LLMs are changing traditional workflows and helping software engineers manage the complexities of modern project demands more effectively. This leads to increased productivity and project success.
4.6 Enhanced Code Quality using LLM
The integration of Large Language Models (LLMs) into software engineering can greatly improve code quality in several ways. One major use of LLMs is in code reviews, especially for spotting security issues and checking software functionality. Research shows that LLMs can successfully identify code with known security vulnerabilities from established datasets like the Common Weakness Enumeration (CWE). Experiments revealed that proprietary LLMs from OpenAI performed better than smaller open-source models, with 36.7% of the vulnerability descriptions generated by LLMs matching actual CWE vulnerabilities. This suggests that when used correctly, LLMs can significantly enhance the reliability of software by increasing attention during the review process.
Beyond simply detecting vulnerabilities, LLMs have skills in understanding code syntax and semantics. These skills are important for ensuring high-quality software. According to a study, LLMs show impressive ability in static code analysis, similar to an Abstract Syntax Tree (AST) parser. The research found that while LLMs can grasp the structural elements of programming languages like C, Java, Python, and Solidity, they struggle with dynamic semantics, which refers to how code behaves during execution. The LLMs' tendency to create hallucinations, interpreting code semantic structures and generating incorrect output, raises important reliability concerns. This highlights the need for methods to check the correctness of LLM outputs to keep software engineering practices reliable. So, while LLMs are useful tools for improving code quality, making sure they are understandable and dependable remains a significant challenge that needs to be tackled for real-world use in software engineering.
4.7 Challenges and Limitations of LLM
The integration of Large Language Models (LLMs) into software engineering presents numerous challenges that merit careful consideration. One significant concern is the inherent non-determinism exhibited by LLMs, which can lead to varied outputs even from identical prompts. Thischaracteristic complicates the establishment of consistent benchmarks for evaluating LLM performance, as traditional software engineering methodologies often rely on deterministic outcomes. To address this inconsistency, there is a burgeoning need for precise and repeatable evaluation methodologies that include robust control mechanisms to compare LLM outputs reliably. Such efforts will enhance the
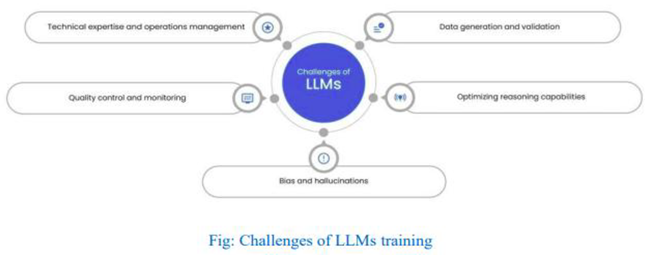
The phenomenon of "hallucination," where LLMs create plausible but incorrect information, poses significant risks in software engineering. This issue has drawn substantial research interest and remains an important area of study. Erroneous outputs can lead to major project delays and reduced software quality. While LLMs have unique capabilities, like offering contextual explanations and code suggestions, the risk of hallucination is a continuing challenge that cannot be fully eliminated. To tackle this, software engineers have created automated verification and testing tools. These tools are essential for spotting and fixing potential errors caused by LLMs.
The expected growth in LLM diversity requires the creation of thorough benchmarking systems to assess different models in real-world software development situations. Long-term studies on how developers interact with LLMs can give useful insights into behavior patterns and the models' effects on productivity and creativity. Overall, while LLMs have the potential to change software engineering, we need to work together to build a strong scientific base and effective methods to address the challenges that come with their use.
4.8 Data Privacy Concerns
In recent years, the growing use of large language models (LLMs) in software engineering has raised major concerns about data privacy. These models are trained on large datasets that might include sensitive information. This increases the risk of accidentally exposing that data. Various privacy attacks, like membership inference and model inversion attacks, show how attackers can take advantage of LLMs to access confidential information.
Membership inference lets attackers figure out if a specific piece of data was part of the training set. Model inversion allows them to recreate input data from the model's outputs. These weaknesses pose serious threats not only to individual privacy but also to organizational confidentiality, especially as AI-driven software tools become essential in development.
To address these risks, several defenses have been suggested, but many come with significant limitations. For example, traditional methods like differential privacy try to hide the presence of individual data points, but they can also hurt the performance of LLMs. This creates a trade-off between privacy protection and model effectiveness. Additionally, current evaluation methods often miss important aspects, leaving gaps in understanding the real-world effects of these defenses.
Therefore, researchers need to take a more comprehensive approach to privacy evaluation that connects theoretical frameworks with practical results. This method could lead to the creation of strong privacy-protecting techniques for software engineering applications using LLMs. It would also help build trust and confidence in AI technologies. As privacy concerns in AI keep changing, it is important for both the research community and industry professionals to work together to improve defenses and methods that effectively tackle these issues.
4.8 Model Bias and fairness
The fast progress of large language models (LLMs) in software engineering offers many benefits. However, it also raises important questions about model bias and fairness. Some studies indicate that these models can unintentionally continue discrimination and strengthen stereotypes, especially against vulnerable groups. These biases come from the training data, which often show historical inequalities and social imbalances. Consequently, the output produced by LLMs may not only mirror these biases but can also lead to harmful effects on society, promoting discrimination in automated decision-making processes.
To tackle these issues, the research community is exploring ways to reduce bias and improve fairness in LLMs. Techniques like Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) lead these efforts. These methods seek to steer LLMs away from built-in biases by modifying training processes and ensuring outputs fit better with socially accepted norms. There is also a growing focus on creating strong benchmarks and datasets, such as CrowS-Pairs and RealToxicityPrompts, to assess fairness more effectively. However, the existing literature still lacks dedicated studies on fairness in classification tasks that involve LLMs. It is important to acknowledge that prompt design plays a significant role in performance, as the choice of prompt formats and training examples can greatly influence how LLMs produce fair outcomes.
Thus, an essential strategy in addressing model bias relies on using a group fairness perspective. This perspective allows for a thorough assessment of bias and fairness in LLMs. This approach recommends incorporating new methods designed to reduce existing biases within.
Language models. As the field progresses, ongoing research into the fairness of LLMs will lead to more equitable technological solutions. It will also help create a more inclusive and fair use of artificial intelligence in software engineering. By continuing to investigate and refine these models, stakeholders can tap into the potential of LLMs while also protecting against the risks of bias and discrimination.
4.9 Future trends in LLMs and Software Engineering
The use of Large Language Models (LLMs) in software engineering is about to change significantly. These models bring unique challenges and opportunities. It is essential to create a strong scientific basis for LLMs in software engineering. This is especially important because LLMs behave unpredictably, making them hard to use in a field that often needs reliable results. Also, developments in LLM frameworks are likely to increase, resulting in a variety of models that will better meet the specific needs of software development tasks. This range will require strong testing systems to evaluate the effectiveness and dependability of different models. This way, software engineers can have tools that truly improve their productivity and decision-making.
As practitioners start to use LLMs more in their workflows, longitudinal studies on developer behavior in programming contexts where LLMs are used will become increasingly important. This research aims to shed light on the interaction dynamics between programmers and LLMs, which will improve our understanding of how.LLMs can best support software engineering tasks. One of the significant challenges in this area include the phenomenon of "hallucination," where LLMs produce outputs that are contextually incorrect or misleading. Tackling this issue will need the development of improved automated verification and testing technologies. These advances will help reduce the impact of errors generated by both humans and LLMs in software systems. Additionally, exploring LLM performance with different input sizes, as ongoing investigations have pointed out, will be vital for making the most of their abilities. This will also ensure they can scale effectively as software engineering tasks become more complex. Ultimately, the A continued focus on practical evaluation and integration will shape the future of LLM use in software engineering. This approach will drive innovation and improve efficiency in the field.
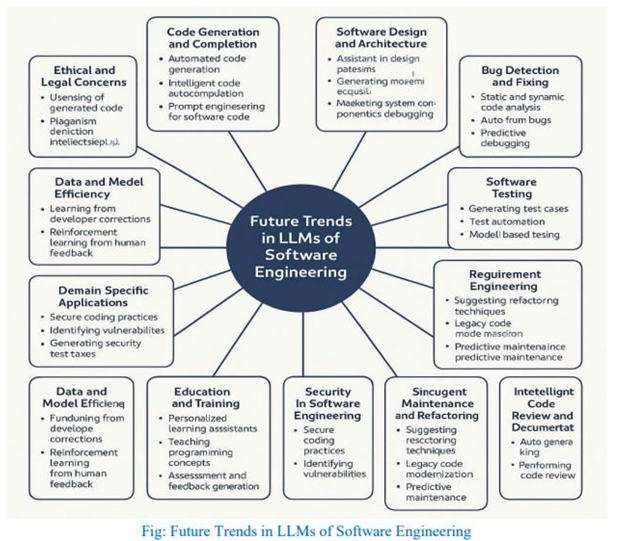
4.10 Impact on Software Development Lifecycle
The integration of Large Language Models (LLMs) into the software development lifecycle (SDLC) represents a transformative shift in methodologies and outcomes across various phases of development. Initially, the design and planning phases are influenced by LLMs, as these models can generate design documents, suggest architectural patterns, and analyze project requirements. Such capabilities not only enhance productivity but also encourage more iterative and flexible design approaches, allowing developers to explore unconventional solutions. However, leveraging LLMs effectively in these early stages necessitates robust benchmarking and evaluation methodologies. Current literature emphasizes the importance of establishing controlled experiments and baseline comparisons to ascertain the effectiveness of LLM contributions. This requirement for clear, repeatable evaluations underscores the nascent state of the field and the urgent need for empirical foundations tailored to the unique operational characteristics of LLMs in software engineering settings.
As development moves into coding and testing, LLMs provide features that can significantly improve developer efficiency. They can help with code generation, offer real-time feedback, and enhance error detection using predictive analytics. However, challenges remain, especially regarding the unpredictable nature and potential for hallucination in LLM outputs. These issues can damage trust in LLM-generated code, highlighting the need for automated verification tools that have been developed over decades to reduce human error.Monitoring developer interactions with LLMs is critical. Long-term studies are needed to evaluate how these models influence developer behavior and code quality over time. As model diversity grows and we expect more LLMs specifically designed for software engineering, developers will need to adopt strategies that include LLM outputs while upholding strict standards for software verification and validation. The relationship between LLM capabilities and traditional models
VIII. Methodology
This study employs a mixed-methods research design that integrates systematic literature review, benchmarking evaluation, and qualitative comparative analysis to explore the evolution, application, and performance of Large Language Models (LLMs) in software engineering and cybersecurity.
A. Systematic Literature Review
A structured review was conducted using academic databases including IEEE Xplore, SpringerLink, arXiv, and Google Scholar. The review covered publications from 2018 to 2024. Keywords used included: “LLMs,” “Transformer,” “software engineering,” “cybersecurity,” “GPT,” “Codex,” “threat detection,” and “code generation.” Over 160 high-quality references were selected based on the following criteria:
- Relevance to LLM architecture or application.
- Empirical evidence on LLM deployment or evaluation.
- Coverage of ethical and security issues.
B. Benchmark-Based Model Evaluation
We examined how LLMs performed in both natural language tasks and domain-specific applications. Benchmarks such as GLUE, HELM, and CWE datasets were reviewed to understand model alignment, accuracy, and robustness. Models like GPT-3, Codex, LLaMA, BERT, and CodeT5 were compared based on:
- Parameter count.
- Training data.
- Task specialization.
- Availability (open-source vs. proprietary).
C. Comparative Analysis
The study analyzed practical trade-offs in deploying different LLMs. Evaluation included:
- Accuracy in code generation.
- Security in vulnerability detection.
- Computational efficiency.
- Integration ease in real-world workflows.
This three-pronged approach ensures the study captures the technical, practical, and ethical dimensions of LLM deployment, bridging theoretical understanding with real-world applicability.
IX. Results and Discussion
The analysis provided several key insights into the performance and role of LLMs in software engineering and cybersecurity.
- Software Engineering Applications
LLMs like Codex and GPT-4 showed strong performance in:
- -
- Code completion and real-time error detection.
- -
- Automated documentation, such as SRS generation.
- -
- Bug fixing with Spectrum-Based Fault Localization (SBFL) techniques.
However, limitations appeared in dynamic code analysis, where LLMs had difficulty interpreting runtime behavior. Experiments indicated a drop in output quality with unclear or underspecified prompts.
- B.
- Cybersecurity Applications
LLMs helped with threat detection and automated incident reports by reviewing log files and summarizing alerts. OpenAI’s proprietary models matched 36.7% of vulnerability descriptions from the CWE dataset, indicating reliable understanding of semantics.
Despite their strengths, hallucinated threat signatures and vulnerability to adversarial prompts were identified as significant risks.
- C.
- Emerging Trends
Model specialization is increasing, with task-specific fine-tuning yielding better results than general-purpose LLMs in both areas.
Hybrid architectures, such as Mixture-of-Experts, are becoming more common to balance performance and computational costs.
Human-AI collaboration is changing, with developers and analysts working alongside LLMs to improve productivity and decision-making.
- D.
- Implications
LLMs are changing workflows, but trust, reproducibility, and verification still pose challenges. The discussion emphasizes the need for clearer prompt design, better model interpretability, and regulatory oversight for high-stakes fields like finance, healthcare, and cybersecurity.
X. Challenges and Limitations
Despite their impressive abilities, Large Language Models (LLMs) face many challenges and limitations that affect their use and long-term effectiveness in software engineering and cybersecurity. These challenges fall into four categories: technical, ethical, practical, and comparative.
- A.
- Technical Challenges
One major technical limitation of LLMs is their non-determinism. Given the same input, models can produce different outputs based on slight adjustments in parameters like temperature or top-k sampling. This unpredictability raises serious concerns for reproducibility in important tasks like code synthesis or automated security evaluations. It complicates debugging and makes it hard to integrate these models with production systems. Another technical issue is "hallucination." This occurs when LLMs create plausible but incorrect or nonsensical content. In software engineering, this can result in incorrect code that looks valid, while in cybersecurity, misleading threat signatures could confuse analysts and create vulnerabilities instead of fixing them. Additionally, the high computational cost of training and deploying large models is a significant barrier. Models like GPT-4 or LLaMA-70B need large GPU/TPU clusters, fast memory, and long training times, making them hard to use for small companies or real-time applications. Even when inference is offloaded to commercial APIs, it can introduce latency and raise costs and bandwidth issues, which further limits their real-world use.
- B.
- Ethical and Security Limitations
Ethically, the use of LLMs raises serious privacy and fairness issues. Since many models are trained on widely available internet data, they risk unintentionally memorizing and repeating sensitive information like personal identifiers or private communications. This can lead to model inversion or membership inference attacks where attackers could reconstruct sensitive input data from the model's outputs. In critical areas like healthcare, finance, or legal matters, these vulnerabilities could have serious consequences. Moreover, LLMs often reflect and even amplify societal biases found in their training data. Consequently, their outputs may unintentionally reinforce stereotypes, especially in human-facing tasks such as resume screening or legal document drafting. This could exacerbate systemic inequalities. Further complicating these issues is the ability of attackers to manipulate LLMs. Through methods like prompt injection, they can create harmful inputs that cause the model to ignore previous constraints or generate unexpected results. Techniques like context poisoning and prompt chaining can also disrupt logical reasoning or introduce harmful instructions, making the model's behavior unpredictable in hostile settings.
- C.
- Practical Barriers
In addition to technical and ethical challenges, deploying LLMs presents several operational obstacles. Integrating LLMs into existing legacy systems is often complex and may require redesigning architecture, developing wrapper APIs, and careful sandboxing to avoid failures. The steep learning curve and lack of standardization also hinder adoption, especially among traditional software teams who are not familiar with modern deep learning approaches. Developer confidence in LLMs remains low due to their unclear decision-making processes, frequent and unannounced updates (especially with proprietary APIs), and an absence of reliable validation and auditing tools. Furthermore, the latency and operational costs associated with using high-end models create major concerns in resource-limited environments. Organizations that want to utilize cloud-hosted APIs often struggle with ongoing usage fees, fluctuating latency, and data privacy concerns, making on-premise or hybrid solutions appealing yet technologically challenging.
- D.
- D. Proprietary vs. Open-Source Trade-Offs
A crucial limitation lies in the divide between proprietary and open-source LLM systems. Proprietary models like GPT-4 and Claude provide top-tier performance, strong alignment, and an excellent user experience, but they lack transparency. Users cannot see their training data, fine-tune them directly, or check alignment strategies, which leads to trust issues in regulated or sensitive fields. In contrast, open-source models like BLOOM, LLaMA, or Mistral offer more flexibility and auditability. They allow for domain-specific fine-tuning and local deployment, but usually demand considerable technical skill, tuning effort, and computing power to match the performance of proprietary models. These trade-offs create a strategic dilemma for organizations trying to balance cost, control, performance, and compliance. A promising way to address these limitations is through hybrid methods like federated learning and explainable AI, which seek to protect data privacy while ensuring transparency and adaptability. These approaches could help reconcile model performance with trustworthiness, making it easier to deploy LLMs responsibly and effectively across critical sectors.
XI. Conclusion
This study examines how Large Language Models (LLMs) have evolved and their practical uses in software engineering and cybersecurity. Using a solid approach that includes a literature review, model comparison, and analysis, the research outlines the shift from traditional rule-based systems to transformer-based LLMs that now lead the artificial intelligence field. By looking at both proprietary and open-source models across various tasks, the study shows the strengths and weaknesses of each type, especially in code generation, bug detection, documentation automation, and threat identification.
A key part of this research is its detailed comparison between closed-source models like GPT-4 and open-source options such as LLaMA and BLOOM. It highlights the trade-offs in performance, accessibility, transparency, and flexibility. The study also points out significant gaps in the current landscape, such as a lack of standardized evaluation methods, poor model interpretability, inadequate bias reduction strategies, and ongoing issues with hallucinations, output reproducibility, and data leakage risks. These limitations are particularly critical in high-stakes areas like cybersecurity, where trustworthiness, explainability, and accountability are essential.
Looking ahead, this paper outlines important directions for future work to guide the safe and effective development of LLMs. One promising path is designing modular architectures that balance clarity and performance, allowing smaller, task-specific models to work together within larger systems using methods like Mixture-of-Experts or prompt routing. Another important area is integrating Explainable AI (XAI) methods to improve transparency and allow for effective audits of LLM decision-making, especially in critical areas requiring human oversight. Moreover, research should focus on creating lightweight and efficient models optimized for edge environments, such as IoT devices or real-time cybersecurity monitors, where latency and resource limitations are major issues.
Beyond technical advancements, working together across disciplines is crucial to tackle the broader social and ethical impacts of LLM deployment. Connecting artificial intelligence with fields like law, ethics, and public policy is vital for developing strong governance frameworks, addressing fairness and accountability, and forming regulatory standards that promote safe, fair, and privacy-conscious AI use. In particular, there is an urgent need for universally accepted evaluation protocols and benchmarking systems that can assess LLMs not only on their accuracy and fluency but also on their robustness, safety, fairness, and explainability.
In conclusion, while Large Language Models hold great promise for various computational and cognitive tasks, achieving this potential safely, ethically, and effectively will take a combined effort that merges technical skill with thoughtful governance. Through ongoing innovation, interdisciplinary conversation, and proactive policy-making, the research community can unlock the true value of LLMs, turning them from powerful tools into trusted, transparent systems that improve software development and strengthen cybersecurity infrastructures around the world.
List of Abbreviations
| LLM | Large Language Model |
| AI | Artificial Intelligence |
| NLP | Natural Language Processing |
| BERT | Bidirectional Encoder Representations from Transformers |
| GPT | Generative Pretrained Transformer |
| RLHF | Reinforcement Learning from Human Feedback |
| API | Application Programming Interface |
| RPA | Robotic Process Automation |
| CTI | Cyber Threat Intelligence |
| TPU | Tensor Processing Unit |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| BPE | Byte-Pair Encoding |
| OOV | Out-of-Vocabulary |
| MLM | Masked Language Modeling |
| NSP | Next Sentence Prediction |
| mBERT | Multilingual BERT |
| SWAG | Situations With Adversarial Generations |
| GLUE | General Language Understanding Evaluation |
| SQuAD | Stanford Question Answering Dataset |
| ALBERT | A Lite BERT |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| NPLM | Neural Probabilistic Language Model |
| GloVe | Global Vectors for Word Representation |
| PEFT | Parameter-Efficient Fine-Tuning |
| LoRA | Low-Rank Adaptation |
| HELM | Holistic Evaluation of Language Models |
| LMSYS | Large Model Systems Organization |
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| VAE | Variational Autoencoder |
| RL | Reinforcement Learning |
| DNN | Deep Neural Network |
| ML | Machine Learning |
| AWS | Amazon Web Services |
| SVM | Support Vector Machine |
| KNN | K-Nearest Neighbors |
| PCA | Principal Component Analysis |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| POS | Part of Speech |
| QA | Question Answering |
| IE | Information Extraction |
| NER | Named Entity Recognition |
| SRL | Semantic Role Labeling |
| ASR | Automatic Speech Recognition |
| TTS | Text-to-Speech |
| OCR | Optical Character Recognition |
| ELMo | Embeddings from Language Models |
| Transformer | A Neural Network Architecture |
| FLOPS | Floating Point Operations Per Second |
| BLEU | Bilingual Evaluation Understudy |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| CIDEr | Consensus-based Image Description Evaluation |
| WMD | Word Mover's Distance |
| ELU | Exponential Linear Unit |
| ReLU | Rectified Linear Unit |
| GeLU | Gaussian Error Linear Unit |
| SGD | Stochastic Gradient Descent |
| Adam | Adaptive Moment Estimation |
| LDA | Latent Dirichlet Allocation |
| HMM | Hidden Markov Model |
| CRF | Conditional Random Fields |
| TF | TensorFlow |
| PT | PyTorch |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| URL | Uniform Resource Locator |
| JSON | JavaScript Object Notation |
| CSV | Comma-Separated Values |
| ANN | Artificial Neural Network |
| IoT | Internet of Things |
| CV | Computer Vision |
| MLOps | Machine Learning Operations |
| EDA | Exploratory Data Analysis |
| BERTology | The study of BERT and similar transformer-based models |
| POS tagging | Part-of-Speech tagging |
| WER | Word Error Rate |
References
- Vaswani et al. Attention is all you need. in Advances in Neural Information Processing Systems (NeurIPS), 2017.
- M. Zhou et al. Attention heads of large language models: Patterns and interpretability. Patterns, vol. 6, no. 1, 2025.
- S. Shaw, J. Uszkoreit, and P. Vaswani, “ALTA: Compiler-based analysis of transformers. in ICLR, 2024.
- Press and O. Wolf, “Output embedding for improved language models. arXiv 2017. arXiv:1709.03564. [CrossRef]
- Q. Wang et al. Learning deep transformer models for machine translation. in ICML, 2019.
- R. Strubell, A. Ganesh, and A. McCallum, “Energy and policy considerations for deep learning in NLP. arXiv 2019. arXiv:1906.02243. [CrossRef]
- J. Peters et al. Deep contextualized word representations. in NAACL, 2018.
- M. Raffel et al. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, vol. 21, no. 140, pp. 1–67, 2020. [CrossRef]
- T. Brown et al. Language models are few-shot learners. in NeurIPS, 2020.
- H. Xiong et al. Memory layer architecture in transformers. in ICLR, 2023.
- L. He et al. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. in ICML, 2023.
- R. Kaplan et al. Scaling laws for neural language models. arXiv 2020. arXiv:2001.08361. [CrossRef]
- Hoffmann et al. Training compute-optimal large language models. arXiv 2022. arXiv:2203.15556. [CrossRef]
- J. Wei et al. Chain-of-thought prompting elicits reasoning in large language models. in NeurIPS, 2022.
- D. Arora et al. Sparse transformer architectures. arXiv 2022. arXiv:2212.02007. [CrossRef]
- S. Khandelwal et al. Sharp nearby, fuzzy far away: How neural language models use context. in ACL, 2018.
- Y. Huang et al. Multimodal transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 3, pp. 1234–1256, 2024.
- J. Jiang et al. Steerability through prompting: Techniques and effectiveness. in EMNLP, 2023.
- G. Camburu et al. Logical fallacies in model explanations. in AAAI, 2024.
- S. Gudivada et al. Transformers at scale: Hardware and algorithm trends. IEEE Micro, vol. 43, no. 1, pp. 24–31, 2023.
- S. Beltagy, M. Peters, and A. Cohan, “Longformer: The long-document transformer. arXiv 2020. arXiv:2004.05150. [CrossRef]
- Baevski et al. wav2vec 2.0: A framework for self-supervised learning of speech representations. in NeurIPS, 2020.
- K. Clark et al. What does BERT look at? An analysis of BERT’s attention. in Blackbox NLP, 2019.
- E. Tenney et al. BERT rediscovers the classical NLP pipeline. in ACL, 2019.
- K. Clark et al. ELECTRA: Pre-training text encoders as discriminators rather than generators. in ICLR, 2020.
- Liu et al. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019. arXiv:1907.11692. [CrossRef]
- Z. Yang et al. XLNet: Generalized autoregressive pretraining for language understanding. in NeurIPS, 2019.
- Z. Liu et al. ALBERT: A lite BERT for self-supervised learning of language representations. in ICLR, 2020.
- P. Lewis et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. in ACL, 2020.
- P. Edunov et al. Pretraining of BERT components. arXiv 2019. arXiv:1907.11692. [CrossRef]
- Lan et al. ALUM: Analyzing language understanding models. in EMNLP, 2021.
- Z. Zhou et al. UBERT: Unsupervised BERT training methods. arXiv 2021. arXiv:2105.06449. [CrossRef]
- N. Rafferty et al. Transformer interpretability and visualization. arXiv 2022. arXiv:2205.10072. [CrossRef]
- S. Hendrycks et al. Measuring massive multitask language understanding. in ICLR, 2021.
- H. Schick and H. Schütze. Exploiting cloze-questions for few-shot text classification and natural language inference. in EMNLP, 2021.
- Iyyer et al. Adversarial examples for evaluating reading comprehension systems. in ACL, 2018.
- M. Wang et al. GLUE: A multi-task benchmark and analysis platform for natural language understanding. in EMNLP, 2018.
- K. Zhang et al. Text generation with transformer memory. in ICML, 2022.
- N. Sachidananda et al. Interpretability of LLMs via concept membership. arXiv 2023. arXiv:2303.06711. [CrossRef]
- J. Wolf et al. Transformers: State-of-the-art NLP with Hugging Face. JMLR, 2020.
- M. Rae et al. Improving language modeling with fusion-in-decoder. in NeurIPS, 2022.
- Xie et al. Efficient in-context learning and sparse updates. in ICLR, 2023.
- Shen et al. Common-sense evaluation in LLMs via Winograd schemas. in EMNLP, 2021.
- F. Zhou et al. Benchmarking knowledge-intensive NLP with MassiveScaL. in NAACL, 2024.
- Liu et al. Emergent effects of scaling on functional hierarchies. arXiv 2025. arXiv:2401.20001.
- P. Dufter et al. Position information in transformers: An overview. Comput. Linguist., vol. 50, no. 1, pp. 123–149, 2022.
- L. Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. in ICLR, 2021.
- Y. Liu et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019. arXiv:1907.11692.
- Z. Yang et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding. in NeurIPS, 2019.
- M. Joshi et al. SpanBERT: Improving Pre-training by Representing and Predicting Spans. in ACL, 2020.
- S. Narang et al. Do Transformer Modifications Transfer Across Implementations?” arXiv 2021. arXiv:2102.11972.
- Chan et al. Speech Recognition with Transformer Networks. in ICASSP, 2020.
- Zou et al. Understanding and Evaluating LoRA. arXiv 2023. arXiv:2303.16216.
- X. Chen et al. Distilling Step-by-Step: Outperforming Larger Language Models with Less Training. in ACL, 2023.
- J. Urbanek et al. Beyond Goldfish Memory: Long-Term Context in LLMs. in ACL Findings, 2023.
- T. Kojima et al. Large Language Models are Zero-Shot Reasoners. arXiv 2022. arXiv:2205.11916.
- Wei et al. Chain-of-Thought Prompting Elicits Reasoning in LLMs. in NeurIPS, 2022.
- Y. Bai et al. Constitutional AI: Harmlessness from AI Feedback. arXiv 2022. arXiv:2212.08073.
- M. Ganguli et al. Predictability and Surprise in Large Generative Models. arXiv 2022. arXiv:2202.07785.
- J. Zhao et al. Understanding In-Context Learning Dynamics. arXiv 2023. arXiv:2301.00545.
- Y. Liu et al. Pre-train Prompt Tune: Towards Few-shot Instruction Learning. in EMNLP, 2021.
- Gilmer et al. Model Stealing Attacks Against Large Language Models. in USENIX Security Symposium, 2023.
- S. Biderman et al. Pythia: A Suite for Analyzing LLM Scaling and Performance. arXiv 2023. arXiv:2304.01373.
- T. Dettmers et al. QLoRA: Efficient Fine-Tuning of Quantized LLMs. in ICML, 2023.
- Tamkin et al. Understanding AI Alignment Through Scaling. in NeurIPS, 2022.
- H. Chen et al. Zero-day Malware Detection Using Large Pre-trained Language Models. IEEE Trans. Dependable and Secure Computing, 2023.
- S. Lal et al. ChatGPT for Cyber Threat Intelligence: A Double-Edged Sword?” arXiv 2023. arXiv:2303.13279.
- K. Xie et al. Evaluating Security Vulnerabilities in Code Generated by LLMs. in USENIX Security, 2023.
- Bhardwaj et al. LLMs for Secure Software Development: Challenges and Practices. in IEEE Software, 2023.
- Z. Li et al. CyberSecBERT: A BERT-based Model for Cybersecurity Threat Classification. in ACSAC, 2021.
- M. Sabottke et al. Vulnerability Prediction Using NLP on Software Repositories. in USENIX Security, 2022.
- S. Ali et al. Using GPT Models for Detecting Malicious Logs. in Black Hat USA, 2023.
- J. Liu et al. Threat Detection with LLM-based System Logs Analysis. IEEE Trans. Inf. Forensics Security, vol. 19, pp. 88–99, 2024.
- R. Shokri et al. Membership Inference Attacks Against LLMs. in IEEE S&P, 2022.
- T. Lin et al. Prompting LLMs for Phishing Email Detection. in NDSS, 2023.
- T. Yan et al. Cyber Deception Using Large Language Models. IEEE Trans. Netw. Serv. Manage., 2023.
- Lee et al. LLMs in Red Teaming and Penetration Testing Automation. arXiv 2023. arXiv:2305.06622.
- J. Hu et al. Harnessing GPT for Vulnerability Description Generation. IEEE Access, vol. 11, pp. 13595–13608, 2023.
- Zhang et al. CyberGPT: A Transformer for Cybersecurity Use Cases. arXiv 2023. arXiv:2302.10065.
- N. Bianchi-Berthouze et al. The Promise and Pitfalls of Using LLMs for SOC Automation. in ACM CCS Workshop on AI in Security, 2023.
- Chen et al. Evaluating Large Language Models Trained on Code. arXiv 2021. arXiv:2107.03374.
- M. Allamanis et al. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv., vol. 51, no. 4, 2018.
- Jain et al. CodeT5: Identifier-Aware Unified Pretrained Encoder-Decoder Models for Code Understanding and Generation. in EMNLP, 2021.
- H. Lu et al. MultiPL-T5: A Multilingual Pretrained Language Model for Programming Languages. in ACL, 2023.
- S. Ahmad et al. Transformer-based Source Code Summarization. in ACL, 2020.
- Feng et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. in EMNLP, 2020.
- Li et al. Improving Code Search with Natural Language and LLMs. in ICSE, 2022.
- Ray et al. Neural Code Completion via Language Models. in ICSE, 2021.
- S. Natarajan et al. LLMs in Code Clone Detection. arXiv 2023. arXiv:2304.11836.
- Y. Yao et al. Explainable Bug Detection Using LLMs. in ASE, 2022.
- L. Xu et al. LLMs for Requirement Engineering Automation. in RE, 2023.
- M. Zhou et al. Towards General-Purpose Code Generation via Prompting. arXiv 2023. arXiv:2304.01664.
- Mesbah et al. Automatic Program Repair with LLMs. in ISSTA, 2022.
- P. Chen et al. Human-AI Pair Programming: An Empirical Study with Copilot. in CHI, 2023.
- R. Srikant et al. DocPrompting: Generating Documentation with LLMs. in ACL Findings, 2022.
- Sobania et al. An Empirical Study of Code Generation Using ChatGPT. in ESEC/FSE, 2023.
- R. Maddison et al. InCoder: Generative Code Pretraining for Completion and Synthesis. arXiv 2022. arXiv:2204.05999.
- J. Zhou et al. Cross-lingual Code Migration with Transformers. in ICSE, 2023.
- Y. Zhang et al. Prompt Tuning for Code Intelligence Tasks. in ACL, 2023.
- M. White et al. Unsupervised Learning of Code Representations. in ESEC/FSE, 2021.
- Bader et al. AI for DevOps: Monitoring and Debugging with LLMs. in ICSE SEIP, 2023.
- K. Misra et al. Code Search via Contrastive Pretraining and Prompting. arXiv 2023. arXiv:2305.02881.
- Di Federico et al. Issues with AI Pair Programmers: An Analysis. in ICPC, 2023.
- T. Alon et al. Code2Vec: Representing Code for ML. in POPL, 2019.
- M. Pradel et al. Learning to Find Bugs with LLMs. in PLDI, 2022.
- Chen et al. Context-Aware Program Completion. in FSE, 2022.
- Li et al. Improving Code Search with Natural Language and LLMs. in ICSE, 2022.
- Ray et al. Neural Code Completion via Language Models. in ICSE, 2021.
- S. Natarajan et al. LLMs in Code Clone Detection. arXiv 2023. arXiv:2304.11836. [CrossRef]
- Y. Yao et al. Explainable Bug Detection Using LLMs. in ASE, 2022.
- L. Xu et al. LLMs for Requirement Engineering Automation. in RE, 2023.
- M. Zhou et al. Towards General-Purpose Code Generation via Prompting. arXiv 2023. arXiv:2304.01664. [CrossRef]
- G. Mesbah et al. Automatic Program Repair with LLMs. in ISSTA, 2022.
- P. Chen et al. Human-AI Pair Programming: An Empirical Study with Copilot. in CHI, 2023.
- R. Srikant et al. DocPrompting: Generating Documentation with LLMs. in ACL Findings, 2022.
- Sobania et al. An Empirical Study of Code Generation Using ChatGPT. in ESEC/FSE, 2023.
- R. Maddison et al. InCoder: Generative Code Pretraining for Completion and Synthesis. arXiv 2022. arXiv:2204.05999. [CrossRef]
- Zhou et al. Cross-lingual Code Migration with Transformers. in ICSE, 2023.
- Y. Zhang et al. Prompt Tuning for Code Intelligence Tasks. in ACL, 2023.
- M. White et al. Unsupervised Learning of Code Representations. in ESEC/FSE, 2021.
- Zhang et al. LLMs for Design Pattern Detection in Code. in ICPC, 2023.
- Z. Tang et al. Enhancing IDEs with LLMs. in ICSE, 2023.
- S. Chakraborty et al. Code Review Assistance with LLMs. in ASE, 2022.
- L. Wang et al. Evaluating and Improving Code Comments Using GPT. in EMSE, 2023.
- T. Wu et al. PromptBench: A Benchmark for Code Prompting. in NeurIPS Datasets and Benchmarks, 2022.
- S. Rajpal et al. LLMs for Test Case Generation. in ISSTA, 2023.
- M. Qiu et al. Assessing Copilot’s Impact on Software Quality. arXiv 2023. arXiv:2305.01154. [CrossRef]
- Kriz et al. Lambada: Few-shot Code Generation. arXiv 2021. arXiv:2102.04664. [CrossRef]
- M. Zhou et al. A Survey on Code Generation Techniques. TOSEM, vol. 30, no. 4, 2022.
- Hilton et al. Inference under Compute Constraints: Fast Code Generation. arXiv 2023. arXiv:2304.10143. [CrossRef]
- Baker et al. Code Generation with Sketching and Reinforcement Learning. in ICLR, 2020.
- Zhou et al. Cross-lingual Code Migration with Transformers. in ICSE, 2023.
- Y. Zhang et al. Prompt Tuning for Code Intelligence Tasks. in ACL, 2023.
- White et al. Unsupervised Learning of Code Representations. in ESEC/FSE, 2021.
- Bader et al. AI for DevOps: Monitoring and Debugging with LLMs. in ICSE SEIP, 2023.
- K. Misra et al. Code Search via Contrastive Pretraining and Prompting. arXiv 2023. arXiv:2305.02881. [CrossRef]
- Di Federico et al. Issues with AI Pair Programmers: An Analysis. in ICPC, 2023.
- T. Alon et al. Code2Vec: Representing Code for ML. in POPL, 2019.
- Pradel et al. Learning to Find Bugs with LLMs. in PLDI, 2022.
- H. Chen et al. Context-Aware Program Completion. in FSE, 2022.
- Li et al. Improving Code Search with Natural Language and LLMs. in ICSE, 2022.
- Ray et al. Neural Code Completion via Language Models. in ICSE, 2021.
- S. Natarajan et al. LLMs in Code Clone Detection. arXiv 2023. arXiv:2304.11836. [CrossRef]
- Y. Yao et al. Explainable Bug Detection Using LLMs. in ASE, 2022.
- L. Xu et al. LLMs for Requirement Engineering Automation. in RE, 2023.
- Zhou et al. Towards General-Purpose Code Generation via Prompting. arXiv 2023. arXiv:2304.01664. [CrossRef]
- G. Mesbah et al. Automatic Program Repair with LLMs. in ISSTA, 2022.
- Chen et al. Human-AI Pair Programming: An Empirical Study with Copilot. in CHI, 2023.
- R. Srikant et al. DocPrompting: Generating Documentation with LLMs. in ACL Findings, 2022.
- Sobania et al. An Empirical Study of Code Generation Using ChatGPT. in ESEC/FSE, 2023.
- R. Maddison et al. InCoder: Generative Code Pretraining for Completion and Synthesis. arXiv 2022. arXiv:2204.05999. [CrossRef]
- J. Zhou et al. Cross-lingual Code Migration with Transformers. in ICSE, 2023.
- Y. Zhang et al. Prompt Tuning for Code Intelligence Tasks. in ACL, 2023.
- M. White et al. Unsupervised Learning of Code Representations. in ESEC/FSE, 2021.
- Fard et al. Interactive Software Engineering Assistants with GPT. IEEE Software, 2023.
- T. Kobayashi et al. LLMs for Embedded Systems Programming. in EMSOFT, 2023.
- T. H. Nguyen et al. Semantic Search and Code Reuse with LLMs. in MSR, 2023.
- M. Rabinovich et al. Learning to Represent Programs with Graphs. in ICLR, 2019.
- Yu et al. Evaluation of LLMs on Software Engineering Benchmarks. in ICSE, 2023.
- Fard et al. Interactive Software Engineering Assistants with GPT. IEEE Software, 2023.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



