Submitted:
02 July 2025
Posted:
02 July 2025
You are already at the latest version
Abstract
Infrared dim and small target detection aims to accurately localize targets within complex backgrounds or clutters. However, under extremely low signal-to-noise ratio (SNR) conditions, single-frame detection methods often fail to effectively detect such targets. In contrast, multi-frame detection can exploit temporal cues to significantly improve Pd (probability of detection) and reduce Fa (false alarms). Existing multi-frame approaches typically rely on 3D convolutions/RNNs to implicitly extract temporal features, yet they typically neglect the explicit modeling of target motion. In this paper, we propose a Dual-Encoder-Decoder Multi-Frame Infrared Small Target Detection Network with Motion Encoding (DEMNet) that explicitly incorporates motion information into the detection process. The first multi-level encoder-decoder module applies spatial and channel attention mechanisms to fuse hierarchical features across multiple scales, enabling robust spatial feature extraction from each frame of the temporally aligned input sequence. The second encoder-decoder module encodes both inter-frame target motion and intra-frame target position information, followed by 3D convolution to achieve effective motion information fusion. Extensive experiments demonstrate that DEMNet achieves state-of-the-art performance, outperforming recent advanced methods such as DTUM and SSTNet. On DAUB dataset, compared to the second-best model, DEMNet improves Pd by 2.42 percentage points and reduces Fa by 4.13×10⁻⁶ (reduced by 68.72%). On the NUDT dataset, it improves Pd by 1.68 percentage points, reduces Fa by 0.67×10⁻⁶ (reduced by 7.26%) compared to the next-best model. Notably, on the test sequences with SNR≤ 3, DEMNet’s advantages are even more pronounced.
Keywords:
infrared small target detection
; motion encoding
; multi-frame detection
; spatial-temporal fusion
1. Introduction
Infrared thermal imaging systems passively receive infrared radiation from scenes, offering advantages such as good concealment, high angular resolution, and strong anti-interference capabilities. Unlike visible light imaging systems, infrared systems can operate in all weather conditions, making them widely used in fields such as maritime rescue, military reconnaissance, and missile guidance. Among its related technologies, infrared small target detection has attracted widespread attention due to its ability to accurately locate targets of interest within an image. However, infrared targets are typically small in size, lack well-defined texture, possess limited shape and contour information, and are often embedded in low signal-to-noise ratio (SNR) environments. These challenges make it difficult to distinguish such targets from background clutter and noise, significantly complicating the detection task.
1.1. Related Works
1.1.1. Single-Frame Methods
Early methods for infrared small target detection were based on the assumption that the background of the image remained static or exhibited only minor variations, with background pixels showing strong correlation and similarity. Under this assumption, filter-based techniques were widely adopted [1]. However, the presence of prominent edges in the background can disrupt this correlation. To address such issues, some researchers proposed transforming the image from the spatial domain to various transform domains [2], such as the Fourier transform and gradient vector fields.
With the rise of saliency detection techniques in computer vision, infrared small target detection methods inspired by the human visual attention mechanism have also emerged. In 2012, Shao et al. proposed an approach based on the contrast mechanism of the human visual system (HVS), where a Laplacian of Gaussian (LoG) filter was used to suppress noise and enhance target intensity, thereby improving detection performance [3]. Also in 2012, Qi et al. introduced a saliency-based region detection method incorporating attention mechanisms to detect small infrared targets in complex backgrounds [4]. In 2013, Gao et al. developed an adaptive infrared patch-image model constructed from local patches, which was used to segment targets and suppress various types of clutter interference [5].
In addition, in 2013, Chen et al. proposed an algorithm based on the contrast mechanism of the HVS and a derived kernel model, in which local contrast and adaptive thresholding were employed to segment targets [6]. In 2014, Han et al. introduced a thresholding and rapid traversal method based on the attention shift mechanism of the HVS for fast target acquisition [7]. In 2018, Zhang et al. calculated a local intensity and gradient (LIG) map from the original infrared image to enhance targets while suppressing clutter [8]. In the same year, Moradia et al. modeled point targets using multi-scale average absolute gray difference (AAGD) and a Laplacian of point spread function (LoPSF) to reduce false alarm rates [9]. Although these methods significantly improve detection performance, they still struggle to handle complex and dynamically changing background scenarios.
In recent years, deep learning methods have been widely applied to various visual tasks. Dai et al. proposed asymmetric context modulation (ACM), which integrates high-level semantic information and low-level positional details through a comprehensive top-down and bottom-up attention modulation pathway [10]. In their subsequent work, they introduced the attention local contrast network (ALCNet), which refines features based on the idea of local contrast, particularly targeting small targets [11]. Furthermore, the internal attention-aware network (IAANet) first adopts a the region proposal network (RPN) to generate coarse target regions, and then pixel-level self-attention computation is applied to these proposed regions to obtain attention-aware features [12]. Wu et al. designed UIUNet, in which micro-UNet modules are embedded within a UNet architecture to learn multi-level and multi-scale features of infrared images [13]. The dense nested attention network (DNANet) extracts spatial features at multiple scales through a feature pyramid structure and effectively fuses them via densely connected skip pathways, achieving outstanding detection performance [14]. Liu et al. incorporated the Transformer architecture into infrared small target detection, yielding promising results [15]. He et al. employed discrete wavelet transform (DWT) and inverse DWT (IDWT) to extract and fuse frequency-domain and spatial-domain features, enhancing detection accuracy on public datasets [16]. Liu et al. also proposed MSHNet, a network capable of capturing multi-scale spatial location information. Combined with a novel scale and location sensitive loss function, their method achieved superior detection results [17].
To summarize, single-frame detection methods, whether model-driven traditional approaches or data-driven deep learning techniques, often fail to deliver satisfactory results in scenarios involving strong interfering targets or adverse imaging conditions characterized by low signal-to-noise ratios, heavy clutter, and significant noise. In such challenging environments, the detection of infrared small targets typically requires richer feature information for accurate identification. Therefore, multi-frame detection algorithms that are capable of capturing temporal contextual information are better suited for handling the aforementioned complex scenarios
1.1.2. Multi-Frame Methods
In the early stages, traditional multi-frame infrared small target detection algorithms primarily relied on target motion characteristics [18] or differences between adjacent frames to facilitate detection [19]. Subsequently, some methods attempted to extend single-frame detection algorithms into the multi-frame domain, achieving notable improvements. For example, the spatio-temporal local contrast filter (STLCF) [20] and the spatio-temporal local difference measure (STLDM) [21] expanded 2D operators into 3D spatio-temporal operators to compute information across the current and historical frames. These outputs were then fused with temporal saliency features to extract target locations. In 2021, the multi-subspace learning and spatio-temporal patch tensor model (MSLSTIPT) was proposed [22], which similarly extends 2D spatial low-rank decomposition into the 3D spatio-temporal domain for small target detection in multi-frame infrared image sequences. In more recent studies, Wu et al. proposed a 4-D tensor model that processes a sequence of infrared images and utilizes tensor train and its extension, tensor ring, to decompose them into 4-D tensors [23]. Li et al. introduced a twist tensor model based on sparse regularization, which enhances the contrast between targets and background for more effective small target detection [24].However, such approaches often rely heavily on scene-specific prior knowledge and make relatively narrow assumptions about the target types, leading to limited robustness. As a result, detection performance tends to degrade significantly when there are scene changes or variations in target characteristics.
In recent years, with the continuous advancement of deep learning algorithms and the release of infrared sequence image datasets [25,26], deep learning-based multi-frame infrared small target detection methods have gradually become mainstream. The earliest approaches simply extended single-frame detection methods to sequential images by applying single-frame detection to each frame independently [27,28]. Although this strategy enabled processing of consecutive frames, it failed to leverage temporal contextual information and could not fully exploit the advantages of multi-frame analysis. Subsequent research explored the use of motion cues from preceding and succeeding frames to perform super-resolution enhancement on the current frame, thereby improving the detail and visibility of dim infrared targets [29,30]. While this technique can enhance detection performance, it typically results in significant computational overhead due to the resolution upscaling process, which poses challenges for real-time applications. Later, Wang et al. proposed a network incorporating a spatio-temporal multi-scale feature extractor module, which captures multi-scale spatial information across frames in the temporal dimension. This approach significantly improved detection accuracy and fully exploited the advantages of multi-frame detection [31]. As a result, most subsequent studies have adopted similar strategies.
In 2023, Li et al. proposed an effective direction-coded temporal U-shape module in multi-frame detection [26]. In 2024, Chen et al. extended the use of ConvLSTM-based cross-spatiotemporal slice node feature processing to the field of infrared small target detection [32]. Duan et al. introduced frequency information by applying Fourier and inverse Fourier transforms to infrared images, achieving excellent detection performance [33]. Ying et al. enhanced target features by emphasizing specific frequency-domain components and incorporated a feature recurrence framework, yielding promising results on a self-constructed satellite dataset [34]. In 2025, Liu et al. proposed a long-term optical flow-based motion pattern extractor module that improves upon traditional optical flow methods by leveraging motion information for target detection [35]. Peng et al. adapted a dual-branch parallel feature extraction approach from the video domain to infrared small target detection, where one branch extracts global features while the other focuses on key frame features; the fusion of these features achieved competitive performance with low computational cost [36]. Zhu et al. incorporated a Transformer-based attention mechanism to encode and fuse spatiotemporal and channel-wise features for target detection [37]. Zhang et al. utilized the consistent motion direction and strong inter-frame correlation of infrared small targets by designing a spatial saliency feature generation module, which was fused across the temporal dimension for final detection [38]. Similarly, Zhu et al. adopted a parallel dual-branch feature extraction strategy, where spatial features assist in enhancing temporal motion cues, and proposed a complementary symmetric weighting module to fuse spatiotemporal features, resulting in outstanding detection performance [39].
1.2. Motivation
When detecting dim infrared targets in complex environments, the low contrast between the target and the background often renders single-frame infrared small target detection algorithms ineffective, either missing the target or generating a large number of false alarms. In such scenarios, multi-frame infrared small target detection algorithms can leverage temporal contextual information by perceiving differences across consecutive frames, thereby achieving better detection performance. However, despite the improvements over single-frame methods, existing multi-frame detection approaches still suffer from several limitations:
(1) Although these methods adopt various spatiotemporal feature fusion strategies, most rely on implicit extraction via 3D convolutions or attention mechanisms, and they often overlook the motion consistency of the target. Li et al. [26] proposed an explicit encoding method that maps the target’s position within each frame to model its motion features. However, the motion encoding strategy is insufficiently developed and fails to capture the relative positional relationships of the target across frames, leaving substantial room for refinement in motion representation.
(2) Current methods usually integrate spatiotemporal feature extraction into one encode-decode architecture, which may impede the performance for the tight coupling of the spatial and temporal feature extraction process.
(3) The commonly used false alarm rate (Fa) metric presents limitations. Fa is defined as the ratio of non-target pixels incorrectly predicted as targets to the total number of pixels in the image, which fails to intuitively reflect the model’s ability to suppress target level false positive ratio. In practical applications, detection results are typically processed on a per-target basis rather than per-pixel.
This paper proposes a novel Dual-Encoder-decoder Multi-frame infrared small target detection Network with motion encoding, termed DEMNet. The proposed method first employs a Spatial Feature Extractor module, which uses an encoder-decoder structure to extract multi-scale spatial features from input images. Then, a motion information encoder-decoder module is used to map and reconstruct the motion characteristics of the target, thereby capturing rich temporal contextual information. A multi-stage decoder and prediction head are used to generate the target prediction map for the last frame. This process effectively enhances the representation of dim targets embedded in complex backgrounds.
The main contributions of this paper are summarized as follows:
(1) A dual encoder-decoder multi-frame infrared small target detection network, DEMNet, was proposed. The network integrates spatial and temporal contextual features, and employs end-to-end learning to enhance the representation of dim and small targets under complex backgrounds.
(2) Based on the motion consistency of infrared targets, a motion encoding strategy was introduced. It consists of inter-frame motion encoding and intra-frame location encoding to explicitly capture spatiotemporal motion characteristics and improve temporal feature utilization.
(3) A target level false alarm evaluation metric, FaT, was proposed to address the limitations of pixel-level metrics. FaT evaluates false alarms at the object level, providing a more intuitive and accurate assessment of the model's false alarm suppression ability in practical scenarios.
2. Methods
In this section, the implementation and application of DEMNet are presented. The main components of the proposed model are introduced in detail, including the design of the spatial feature extractor module and the motion information encoding. Furthermore, the specific implementation of the proposed algorithm on input image sequences is described.
2.1. Overall Architecture
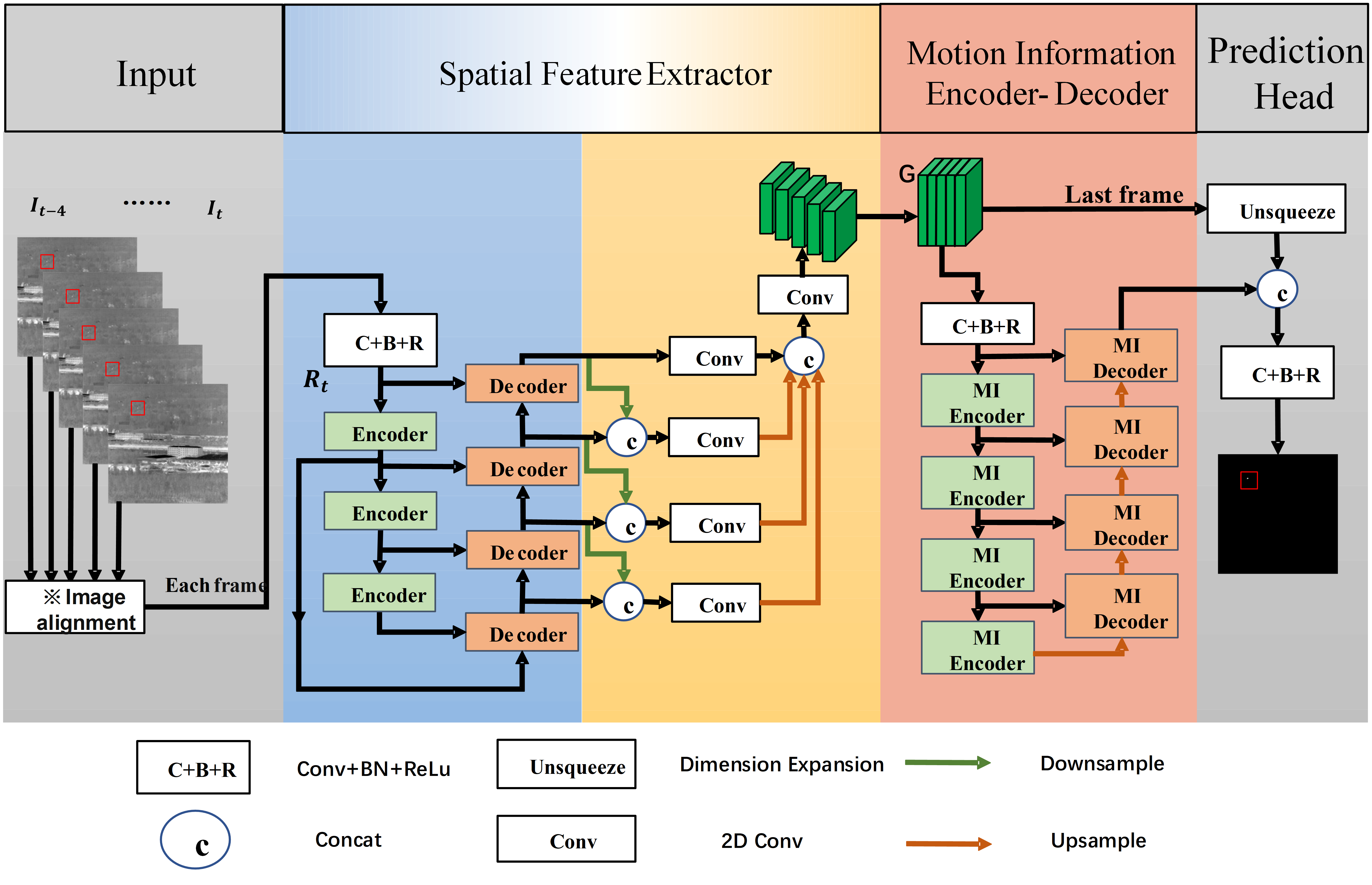
The overall architecture of DEMNet is illustrated in Figure 1. It consists of three major components: Spatial Feature Extractor, the motion information encoder-decoder structure, and a prediction head composed of convolution, normalization, and activation functions.
The input to the network is a sequence of consecutive infrared frames denoted as , where T denotes the length of the input sequence (5 frames are used in this work). Firstly, all previous frames in the input sequence are aligned with the last frame individually. The image alignment operation consists of four steps: detecting feature points, matching feature points, computing the homography matrix, and performing image transformation. Each aligned frame is sequentially fed into the Spatial Feature Extractor module. The resulting feature maps are then concatenated along the temporal dimension to produce a feature map .
Subsequently, is passed into the multi-stage Motion Information Encoder (MI Encoder) to extract motion features across the multiple frames. These features are then progressively decoded through a multi-stage decoder, where they are fused with shallow features at each stage.
Finally, the output feature map from the highest-level decoder is concatenated with the last frame of , and this fused representation is passed through the prediction head to generate the final detection map of infrared small targets for the last frame.
2.2. Spatial Feature Extractor
First, the input image sequence is processed frame by frame through channel expansion to obtain T feature maps . Each frame is then fed into multi-level encoders to extract feature maps that contain multi-scale spatial information. These features are subsequently passed through a multi-level decoder for feature fusion and decoding. Finally, the decoded features from all T frames are concatenated to form the output feature map .
2.2.1. Encoder
The encoder uses 2×2 average pooling to obtain the global low-frequency information of the feature map, and its structure is shown in Figure 2.
At the encoder at level m, the output feature map of the average pooling layer has a size of . It is subsequently processed by two convolutional layers, each convolution is followed with batch normalization and activation, resulting in a refined feature map P whose size is . This output is forwarded to the encoder at the next level and also to the decoder at level (m+1) for further processing. The final level of the encoder is slightly different, where the feature map P is only transmitted laterally, without being passed down to the next encoder level.
2.2.2. Decoder
The decoder employs channel attention and pixel attention mechanisms to highlight critical features. The output features from different decoding levels are resized and undergo complex top-down and bottom-up information propagation and fusion. Ultimately, a single-frame feature map enriched with multiscale spatial information is obtained, as illustrated in Figure 3.
The pixel attention and channel attention of the received feature maps and are calculated and cross multiplied to get the high-level semantic feature map output containing rich context information. The whole process is shown in Equation (1) - (8) as follows:
2.3. Motion Information Encoder
2.3.1. Inter-Frame Motion Encoding Module
Based on the assumption of motion consistency of targets, an inter-frame motion encoding module and an intra-frame position encoding module are proposed. On this basis, a motion information encoder (MI Encoder) is constructed. The feature maps obtained from the spatial feature extractor are concatenated along the temporal dimension and fed into the MI Encoder. This encoder module comprises the inter-frame motion encoding module, intra-frame positional encoding module, as well as 3D maxpooling layer, 3D convolutional layers, batch normalization (BN) layer, and ReLU activation layer. It effectively encodes the motion information of the target and fuses it with multiscale spatial features, yielding feature maps that contain both motion and spatial information of the target, as illustrated in Figure 4.
The inter-frame motion encoding module encodes the directional relationship of the maximum value in each 2×2 pooling region of past frames relative to the current frame, capturing the target’s motion characteristics through variations in directional relationships. As illustrated in Figure 6, in a sequence of consecutive frames, it is assumed that both targets and clutter appear as the brightest regions within their local neighborhoods. However, the motion patterns of targets and clutter differ significantly. Typically, targets move along specific, regular trajectories, while clutter tends to move randomly. Let denotes the directional mapping between the maximum pixel in each pooling region of the past frame and the corresponding position in the current frame . The average of the mapping values across all past frames is defined as P, as expressed in Equation (9):
where is determined by the horizontal positional mapping and the vertical positional mapping . and are derived based on the relative directional relationship between the location of the maximum pixel in the pooling region of the past frame and its corresponding position in the current frame. If the maximum pixel in the past frame is located to the left or above its position in the current frame, and are set to 1, respectively. If the horizontal or vertical position remains unchanged, the values are set to 0. If the direction is to the right or below, and are set to -1, respectively. The definition of is then given in Equation (10):
has the following properties:
Figure 5.
Motion characteristics of clutter and targets: (a)clutter; (b) target.
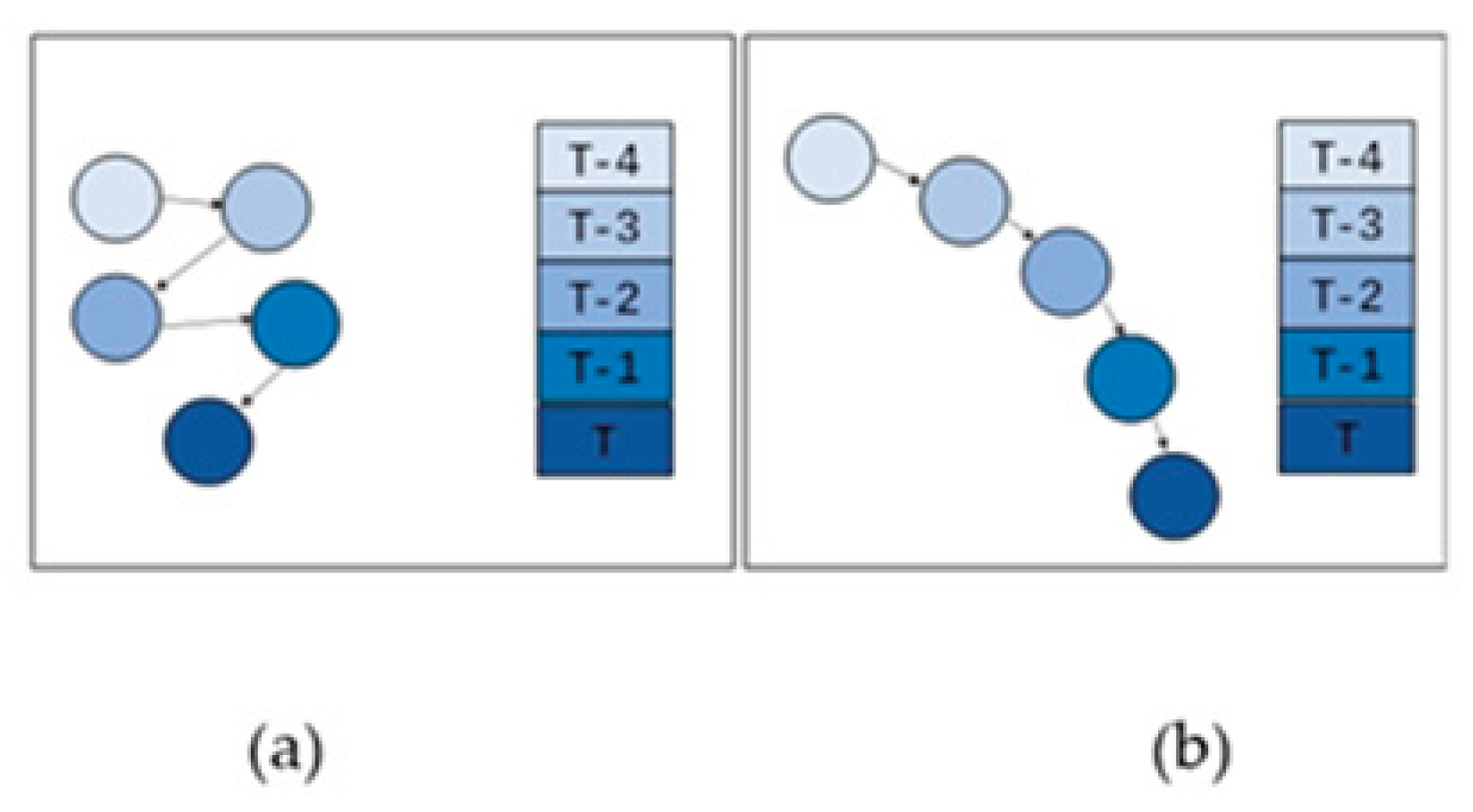
1) When the position of the maximum pixel within the pooling region remains in the same direction across frames, the sign remains unchanged; when the direction changes, the sign is reversed.
2) By setting α=0.8, it ensures that the mapping values are unique under all nine possible directional relationships between the positions of the maximum pixel in the past and current frames.
3) A square root operation is applied to to avoid conflicts where the summation of are the same across different previous frames, but the motion trajectories differ. For example, in one pooling region, the directional encoding for two previous frames may both be 1. In another region, the encodings for the same two frames may be 0 and 2, respectively. So without the square root operation, the summation cannot differ different motion trajectories.
The specific computation process of is shown in the pseudo code of Algorithm 1.
| Algorithm 1: Inter-Frame Motion Encoding |
|
Input: Feature map F Output: Mapping value vector V |
| 1.(F_pool,index)=3DMaxpooling(F) 2: index_x(i)=index(i)%W // index_x [0,W) 3. index_y(i)=index(i)//W // index_y [0,H) 4. for i in range(T-1): if index_x(i)< index_x(t): = -1 if index_x(i)= index_x(t): = 0 if index_x(i)> index_x(t): = 1 // Horizontal direction encoding 5.for i in range(T-1): if index_y(i)< index_y (t): = -1 if index_y (i)= index_y (t): = 0 if index_y (i)> index_y (t): = 1 // Vertical direction encoding 6. for i in range(T-1): // V+= v(i) 7.V=V/(t-1) 8: return V |
2.3.2. Intra-Frame Position Encoding
The intra-frame position encoding module encodes the position of the maximum value within each pooling regions of a single frame, capturing the motion characteristics of the target based on the positional patterns of maximum values across consecutive frames. As shown in Figure 6, for the four pooling regions within the 4×4 area enclosed by the red dashed box in the feature map, when a target passes through this window over several consecutive frames, both the maximum value and its location within each pooling region change in each frame. The variations in the maximum value and its index position caused by target motion exhibit more regular patterns, whereas those induced by clutter signals or background regions tend to be more random.
Figure 6.
The process of the target crossing through four 2×2 pooling windows.
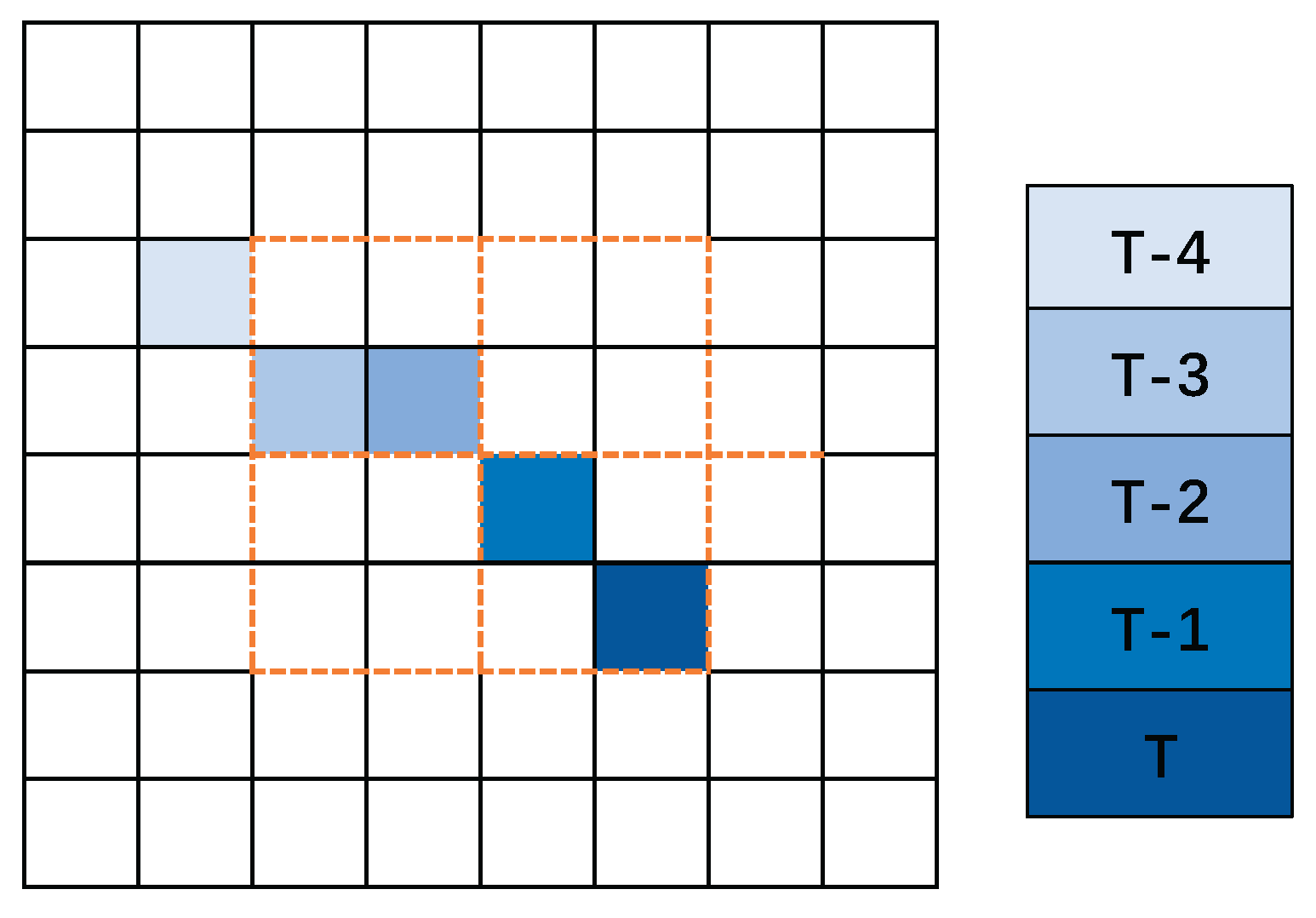
Therefore, by encoding the index positions of the maximum values during pooling in each frame, the model can perceive the intra-frame variations caused by target motion, distinguish them from the irregular patterns of clutter or background, and thus improve detection performance. Specifically, the encoding process of the intra-frame location information encoding module is presented in Algorithm 2.
| Algorithm 2: Intra-Frame Position Encoding Module |
|
Input: Feature map F Output: Mapping value vector D |
| 1: (F_pool,index)=3DMaxpooling(F) 2: index_x(i)=index(i)%2 //The result is 0 or 1, which means on the left or right 3. index_y(i)=(index(i)//W)%2 // The result is 0 or 1, which means in the upper or lower area 4. for i in range(T): D(i)=1.25+ // The codes of the four positions are 5: return D |
2.4. Motion Information Decoder
The motion information decoder performs simple decoding on the received features, as shown in Figure 7.
In the decoder module, the decoder at level n receives deep features passed upward from the decoder at the lower level (the lowest-level decoder receives features from the corresponding encoder at the same level). After upsampling, these features are concatenated with the shallow features from the encoder at level n–1 along the channel dimension, followed by 3D convolution, BN, and a ReLU activation layer. The output is then passed to the upper-level decoder. The top-level decoder is slightly different in its 3D convolution module, the temporal padding is set to 0, and the output feature map has the shape .
3. Experiments and Results
3.1. Dataset
The DAUB dataset [25] was created by B. Hui et al. from the National University of Defense Technology. It consists of 22 video sequences with a total of 16,177 frames, each with a resolution of 256×256 pixels and corresponding annotations. The dataset focuses on detecting fixed-wing UAV targets and includes various backgrounds such as sky and ground across diverse scenes. As a real-world dataset, its annotations include frame index, target index, and the target's center point. Following the work of Yuan et al. [40], binary mask labels were generated from the center point annotations. The training set and test set split follows the protocol provided at https://github.com/UESTC-nnLab/SSTNet.
However, in the test set, sequence 21 contains severe blind pixels, nearly no inter-frame motion of the target, and extremely dim targets, as illustrated in Figure 8, where the red box indicates the target and the blue box marks the blind pixel region. Therefore, this noisy sequence was excluded from evaluation.
The NUDT-MIRST dataset was developed by Li et al. from the National University of Defense Technology [26]. It was generated by embedding targets into real-world captured infrared images, followed by jitter and noise augmentation. The dataset consists of 100 sequences with a total of 10,000 frames, covering diverse scenarios including sky, ocean, and land. Designed to highlight the advantages of multi-frame detection methods under complex backgrounds, the dataset is split based on the signal-to-noise ratio between the target and its surrounding background. The images are categorized into two groups: SNR≤3 and 3<SNR<10. In the training set, the first 10 frames of each sequence are composed of images with SNR≤3, while the remaining 90 frames contain images with 3<SNR<10. The test set includes 8 sequences entirely consisting of images with SNR≤3 and 12 sequences entirely composed of images with 3<SNR<10. The training and testing split follows the protocol available at https://github.com/TinaLRJ/Multi-frame-infrared-small-target-detection-DTUM.
3.2. Performance Evaluation Indices
Pd(Probability of Detection), used to evaluate the detection performance of the model, is calculated as shown in Equation (11):
where TTP is the number of correctly predicted targets and TAll is the number of all targets in labels. A predicted target is deemed correctly detected if the Euclidean distance between its center and the nearest ground-truth target center is less than or equal to 3 pixels.
Fa (False alarm rate), used to evaluate the model's anti-false-alarm performance, and its calculation method is presented as follows:
where PFP represents the number of all pixels falsely predicted as targets, is the size of the i-th input image, and N is the number of test images. If the distance between the center of a predicted target and the nearest annotated target center exceeds 3 pixels, or no matching target exists, the pixels contained in the predicted target are considered as false alarms.
In infrared small target detection tasks, the proportion of target pixels in the entire image is extremely small, typically on the order of . This proportion varies significantly across different datasets and therefore cannot intuitively reflect the performance of the model. Specifically, in some cases, it becomes difficult to distinguish between models based on commonly used metrics. As shown in Figure 9, black pixels represent the ground-truth targets, while red and orange pixels denote false alarms detected by two different models. For this particular image prediction, both models yield the same false alarm Fa score. However, the red model predicts only one false target, whereas the orange model generates three. These two scenarios have distinctly different negative impacts. In general, the model represented by red causes less interference and thus has a relatively smaller impact. Nevertheless, this advantage is not reflected in the Fa metric, highlighting its limitation.
In such scenarios, a new metric, False Alarms of Target (FaT), is proposed to address this limitation. The definition of FaT is given as follows:
where represents the number of correctly predicted targets and represents the number of all targets in labels. A prediction target is considered a false alarm if the distance between the center of the predicted target and the nearest annotated target center exceeds 3 pixels, or if no corresponding ground truth target exists. This metric counts the number of false alarm targets, providing a closer alignment with real-world usage scenarios. The numerical value can more intuitively reflect the model's false alarm performance.
Params: Refers to the number of model parameters, which is used to measure the size and complexity of the model. It represents the total sum of all parameters in the model.
FLOPs: Stands for Floating-Point Operations per Second, a metric used to assess the computational complexity of the model. It indicates the number of floating-point operations required for one forward pass through the model. In this study, tests were conducted using images with a resolution of 256×256.
FPS: Represents the model's running speed, defined as the number of frames processed per second.
ROC curve (Receiver Operating Characteristic curve): It is used to evaluate the performance of a model across varying detection thresholds. The Pd and Fa are metrics used to assess model performance at fixed detection thresholds, whereas the ROC curve provides an overview of model performance across a range of sliding thresholds. In the ROC curve, Fa is plotted on the x-axis and Pd on the y-axis. The closer the ROC curve approaches the top-left corner, the better the model's performance.
3.3. Network Training
The model was trained on an Intel(R) Core(TM) i9-10920X @ 3.50GHz CPU and an NVIDIA GeForce RTX 3090 with 24GB of VRAM. The primary software versions used were Python 3.8 and PyTorch 1.8. The optimizer employed was the adam optimizer [41], with an initial learning rate of 0.001. Testing was conducted after 20 epochs of training. The learning strategy adopted was Cosine Annealing LR [42], where the learning rate gradually decreases to its minimum value over the course of 20 epochs. Unless otherwise specified, the loss function used in the following experiments is soft-IoU loss, as shown in Equation (14):
where i and j represent the row and column coordinates of the image, respectively; background pixels are labeled as 0, and target pixels are labeled as 1. ti,j denotes the ground truth pixel value at the corresponding coordinate, and pi,j represents the predicted pixel value. a is a small constant added to prevent division by zero.
3.4. Ablation Study
3.4.1. Effectiveness of the MI Encoder
The study constructed four different models to evaluate the effectiveness of the motion information encoding modules:
- Model A: An encoder that uses neither the inter-frame nor intra-frame encoding modules.
- Model B: An encoder that uses only the intra-frame position encoding module.
- Model C: An encoder that uses only the inter-frame motion encoding module.
- Model D: The complete encoder with both inter-frame and intra-frame motion encoding modules.
These models were trained and tested on the DAUB and NUDT-MIRST datasets, and the results are shown in Table 1. The best results are shown in boldface and the second best results are shown in underlined.
On the DAUB dataset, the baseline model A, which uses a conventional encoder without any motion encoding module, achieved a Pd of 94.71%. Using only the intra-frame encoding module (model B) improved Pd by 1.66 percentage points, while using only the inter-frame encoding module (model C) improved Pd by 0.85 percentage points. The complete encoder module (model D) achieved a detection rate of 98.28%, an increase of 3.57 percentage points, outperforming both models B and C.
Regarding false alarm suppression performance, compared to baseline model A, the Fa metric of models B, C, and D improved by 3.14×10⁻⁶, 5.05×10⁻⁶, and 6.25×10⁻⁶, corresponding to improvements of 38.54%, 60.10%, and 76.88%, respectively. In terms of the FaT metric, compared to model A, the values decreased by 8.987, 13.993, and 14.19 percentage points, respectively.
On the NUDT dataset, model A achieved a Pd of 96.01% as the baseline. Compared to this, models B, C, and D improved Pd by 1.66, 0.85, and 2.2 percentage points, respectively.
In terms of false alarm suppression performance, the Fa metric of models B, C, and D increased by 9.01×10⁻⁶, 16.83×10⁻⁶, and 18.61×10⁻⁶ compared to baseline model A, corresponding to improvements of 33.16%, 61.94%, and 68.49%, respectively. For the FaT metric, compared to model A, the values decreased by 4.61, 6.27, and 7.43 percentage points, respectively.
Overall, the experimental results demonstrate that the two motion encoding modules indeed enhance the model's target detection capability, resulting in higher detection rates and lower false alarms, thereby improving the overall performance of the model.
3.4.2. Effectiveness of the Spatial Feature Extractor
This section constructs and evaluates three models:
Model A: an encoder module using spatial downsampling and a ResBlock-like [43] residual connection structure for encoding, combined with a decoder module that performs decoding only through concatenation and upsampling.
Model B: an encoder-decoder module without integrating a global attention mechanism during decoding.
Model C: the complete spatial feature extractor module.
These models were trained and tested on the DAUB and NUDT datasets. The results are presented in Table 2.
On the DAUB dataset, Model A achieved a Pd of 94.62% as the baseline. Model B improved Pd by 2.44 percentage points, while Model C, which consists of the complete spatial feature extractor module, improved Pd by 3.66 percentage points. Regarding false alarm performance, the Fa metric for Models B and C increased by 1.08×10⁻⁶ and 7.40×10⁻⁶ compared to baseline Model A, representing improvements of 11.64% and 79.74%, respectively. In terms of FaT, Models B and C reduced the false alarm rate by 0.41 and 1.47 percentage points compared to Model A.
On the NUDT dataset, Model A had a Pd of 94.39% as baseline. Model B improved Pd by 1.65 percentage points, and Model C improved by 3.82 percentage points. For false alarm performance, the Fa metric of Models B and C decreased by 1.09×10⁻⁶ and 0.72×10⁻⁶ compared to Model A, representing improvements of 11.7% and 7.76%, respectively. In FaT, Models B and C reduced false alarms by 0.46 and 0.28 percentage points compared to Model A.
Overall, the spatial feature extractor of the encoding-decoding structure can better extract the spatial features of the image, so that the model has a higher detection rate and lower false alarm rate, and the overall performance of the model has been improved.
3.5. Comparative Experiments
This paper conducted comparative experiments by evaluating DEMNet against classic single-frame algorithms such as ResUNet [43], DNANet [14], UIUNet [13], MSHNet [17], as well as multi-frame models including RFR [34], DTUM [26], and SST [32] on the DAUB and NUDT datasets. Table 3 and Table 4 present the comparative results on the DAUB and NUDT datasets, respectively.
Note that for the DTUM model trained on the NUDT-MIRST dataset, the hybrid training scheme combining the authors’ proposed HPM loss and soft-IoU loss achieved better performance, and these results are reported here. However, on the DAUB dataset, the hybrid loss scheme underperformed compared to using only soft-IoU loss, so the results shown are based solely on the soft-IoU loss training.
The SST model’s test results were obtained using the original authors’ best model weights and evaluated with the same metrics. However, since SST model’s predictions are bounding boxes, the pixel-level Fa could not be calculated and thus only other metrics besides Fa are presented.
On the DAUB dataset, DEMNet achieved Pd of 98.28%, Fa of 1.88×10⁻⁶, and FaT of 5.01%, outperforming all other compared models and reaching the best overall performance. Among these, Pd improved by 2.42 percentage points over the second-best model, Fa decreased by 4.13×10⁻⁶ (a reduction of 68.72%), and FaT improved by 5.3 percentage points compared to the second best.
On the NUDT dataset, DEMNet also demonstrated excellent performance. Across the entire test set, Pd was 98.21%, Fa was 8.56×10⁻⁶, and FaT was 6.19%, all better than the other compared models and achieving the top performance. Compared to the second-best model, Pd increased by 1.68 percentage points, Fa decreased by 0.67×10⁻⁶ (a reduction of 7.26%), and FaT improved by 0.46 percentage points. Notably, on the test sequences with SNR≤ 3, DEMNet’s advantages were even more pronounced, with a Pd of 96.41%, Fa of 6.77×10⁻⁶, and FaT of 11.72%. Here, Pd outperformed the second-best by 5.67 percentage points, Fa decreased by 2.45×10⁻⁶ (a reduction of 26.57%), and FaT led by 2.46 percentage points.
Overall, DEMNet demonstrates excellent performance on both datasets, with a particularly significant advantage in detection rate, while also leading to false alarm suppression.
To more clearly showcase the detection capability of DEMNet and the comparison models for dim and small targets under complex environments, two sets of images were randomly selected from the NUDT test sequences with SNR ≤ 3 and from the DAUB test sequences. The visualized prediction results are shown in Figure 10. Images 1 and 2 are from NUDT, while Images 3 and 4 are from DAUB. Targets are highlighted and zoomed in with red boxes, while false alarm targets are highlighted and zoomed in with green boxes.
For images 1 and 2, the prediction maps from different models show that single-frame methods either fail to detect the target, resulting in blank prediction maps, or detect a large number of false alarm pixels and false targets. Only a few single-frame models manage to detect the target, but their predicted shapes deviate significantly from the real target. In contrast, most multi-frame models can locate the target, although the predicted shapes may vary somewhat, and occasionally some false alarms appear. Among them, DEMNet not only detects the target but also predicts the target’s contour most closely matching the real one.
For image 3, the target is relatively small in the frame, with weak infrared features and interference from other bright spots, making detection challenging. Most single-frame methods fail to identify the true target and instead detect interference targets. While multi-frame methods (except DEMNet) detect the true target, they still produce many false alarms.
For image 4, the target has a good signal-to-noise ratio and high contrast against the background, so all models successfully detect the correct target. However, some models’ prediction results contain false alarms. Among the models without false alarms, DEMNet and DTUM provide the most accurate target contour predictions, demonstrating their performance advantages consistent with the comparative experimental results.
Figure 11 shows the ROC curves of DEMNet and the comparison models on the DAUB dataset. In the figure, the ROC curve of DEMNet envelops those of the other models, meaning that at various Fa levels, DEMNet consistently achieves higher Pd values than the comparison models. This demonstrates that DEMNet’s detection performance under varying threshold settings is also superior to all the other models.
4. Conclusions
For detecting dim and weak targets in complex environments, this paper proposes DEMNet, a multi-frame infrared small target detection algorithm featuring a dual-encoder-decoder architecture with well-designed motion encoding. In the feature extraction phase, the model extracts and fuses features through average pooling and attention mechanism, and obtains multi-scale spatial features. Additionally, based on the motion consistency principle, a frame-to-frame motion information encoding module and an intra-frame position information encoding module are designed. These form the basis of the motion information encoder, which further extracts temporal contextual information of features, especially the inter-frame motion of targets, enabling full utilization of temporal cues. Compared with existing algorithms, DEMNet achieves outstanding detection performance.
Specifically, on the DAUB dataset, compared to the second-best model, DEMNet improves Pd by 2.42 percentage points, reduces Fa by 4.13×10⁻⁶ (reduced by 68.72%), and decreases FaT by 5.3 percentage points. On the NUDT dataset, it improves Pd by 1.68 percentage points, reduces Fa by 0.67×10⁻⁶ (reduced by 7.26%), and lowers FaT by 0.46 percentage points compared to the next-best model. Particularly on the low signal-to-noise ratio (SNR≤3) test sequences, DEMNet achieves a Pd of 96.41%, Fa of 6.77×10⁻⁶, and FaT of 11.72%, outperforming the second-best model by increasing Pd by 5.67 percentage points, reducing Fa by 2.45×10⁻⁶ (26.57% decrease), and lowering FaT by 2.46 percentage points.
Author Contributions
Conceptualization, Q.Z. and F.H.; methodology, Q.Z. and F.H.; software, Q.Z.; validation, Q.Z., F.H. and Y.L.; formal analysis, Q.Z. and F.H.; data curation, Q.Z. and T. W.; writing—original draft preparation, Q.Z. and F.H.; writing—review and editing, F.H.; visualization, T.W.; supervision, F.H.; funding acquisition, F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Deshpande, S.D.; Er, M.H.; Ronda, V.; Chan, P. Max-Mean and Max-Median Filters for Detection of Small-Targets [C]. Proceedings of SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, Denver, CO 1999, 74–83. [CrossRef]
- Zhou, A.; Xie, W.; Pei, J. Background Modeling in the Fourier Domain for Maritime Infrared Target Detection. IEEE Transactions on Circuits and Systems for Video Technology 2020, 30, 2634–2649. [CrossRef]
- Shao, X.; Fan, H.; Lu, G.; Xu, J. An Improved Infrared Dim and Small Target Detection Algorithm Based on the Contrast Mechanism of Human Visual System. Infrared Physics & Technology 2012, 55, 403–408. [CrossRef]
- Shengxiang Qi; Jie Ma; Chao Tao; Changcai Yang; Jinwen Tian A Robust Directional Saliency-Based Method for Infrared Small-Target Detection Under Various Complex Backgrounds. IEEE Geosci. Remote Sensing Lett. 2013, 10, 495–499. [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. on Image Process. 2013, 22, 4996–5009. [CrossRef]
- Chen, C.L.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Transactions on Geoscience and Remote Sensing 2014, 52, 574–581. [CrossRef]
- Jinhui Han; Yong Ma; Bo Zhou; Fan Fan; Kun Liang; Yu Fang A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sensing Lett. 2014, 11, 2168–2172. [CrossRef]
- Zhang, H.; Zhang, L.; Yuan, D.; Chen, H. Infrared Small Target Detection Based on Local Intensity and Gradient Properties. Infrared Physics & Technology 2018, 89, 88–96. [CrossRef]
- Moradi, S.; Moallem, P.; Sabahi, M.F. A False-Alarm Aware Methodology to Develop Robust and Efficient Multi-Scale Infrared Small Target Detection Algorithm. Infrared Physics & Technology 2018, 89, 387–397. [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV); 2021; pp. 949–958.
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Transactions on Geoscience and Remote Sensing 2021, 59, 9813–9824. [CrossRef]
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sensing 2022, 60, 1–13. [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. on Image Process. 2023, 32, 364–376. [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. on Image Process. 2023, 32, 1745–1758. [CrossRef]
- Liu, F.; Gao, C.; Chen, F.; Meng, D.; Zuo, W.; Gao, X. Infrared Small and Dim Target Detection With Transformer Under Complex Backgrounds. IEEE Trans. on Image Process. 2023, 32, 5921–5932. [CrossRef]
- He, H.; Wan, M.; Xu, Y.; Kong, X.; Liu, Z.; Chen, Q.; Gu, G. WTAPNet: Wavelet Transform-Based Augmented Perception Network for Infrared Small-Target Detection. IEEE Trans. Instrum. Meas. 2024, 73, 1–17. [CrossRef]
- Liu, Q.; Liu, R.; Zheng, B.; Wang, H.; Fu, Y. Infrared Small Target Detection with Scale and Location Sensitivity. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Seattle, WA, USA, June 16 2024; pp. 17490–17499.
- Zhang, F.; Li, C.; Shi, L. Detecting and Tracking Dim Moving Point Target in IR Image Sequence. Infrared Physics & Technology 2005, 46, 323–328. [CrossRef]
- Kim, S.; Sun, S.-G.; Kim, K.-T. Highly Efficient Supersonic Small Infrared Target Detection Using Temporal Contrast Filter. Electronics Letters 2014, 50, 81–83. [CrossRef]
- Deng, L.; Zhu, H.; Tao, C.; Wei, Y. Infrared Moving Point Target Detection Based on Spatial–Temporal Local Contrast Filter. Infrared Physics & Technology 2016, 76, 168–173. [CrossRef]
- Zhu, H.; Guan, Y.; Deng, L.; Li, Y.; Li, Y. Infrared Moving Point Target Detection Based on an Anisotropic Spatial-Temporal Fourth-Order Diffusion Filter. Computers & Electrical Engineering 2018, 68, 550–556. [CrossRef]
- Sun, Y.; Yang, J.; An, W. Infrared Dim and Small Target Detection via Multiple Subspace Learning and Spatial-Temporal Patch-Tensor Model. IEEE Trans. Geosci. Remote Sensing 2021, 59, 3737–3752. [CrossRef]
- Wu, F.; Yu, H.; Liu, A.; Luo, J.; Peng, Z. Infrared Small Target Detection Using Spatiotemporal 4-D Tensor Train and Ring Unfolding. IEEE Transactions on Geoscience and Remote Sensing 2023, 61, 1–22. [CrossRef]
- Li, J.; Zhang, P.; Zhang, L.; Zhang, Z. Sparse Regularization-Based Spatial–Temporal Twist Tensor Model for Infrared Small Target Detection. IEEE Transactions on Geoscience and Remote Sensing 2023, 61, 1–17. [CrossRef]
- Hui, B.; Song, Z.; Fan, H.; Zhong, P.; Hu, W.; Zhang, X.; Ling, J.; Su, H.; Jin, W.; Zhang, Y; Bai, Y. A Dataset for Infrared Detection and Tracking of Dim-Small Aircraft Targets under Ground / Air Background. China Scientific Data 2020, 5(3).
- Li, R.; An, W.; Xiao, C.; Li, B.; Wang, Y.; Li, M.; Guo, Y. Direction-Coded Temporal U-Shape Module for Multiframe Infrared Small Target Detection. IEEE Trans Neural Netw Learn Syst 2025, 36, 555–568. [CrossRef]
- Yao, S.; Zhu, Q.; Zhang, T.; Cui, W.; Yan, P. Infrared Image Small-Target Detection Based on Improved FCOS and Spatio-Temporal Features. Electronics 2022, 11, 933. [CrossRef]
- Kwan, C.; Gribben, D. Practical Approaches to Target Detection in Long Range and Low Quality Infrared Videos. Signal & Image Processing An International Journal 2021, 12, 01–16.
- Kwan, C.; Gribben, D.; Budavari, B. Target Detection and Classification Performance Enhancement Using Super-Resolution Infrared Videos. Signal & Image Processing : An International Journal 2021, 12, 33–45. [CrossRef]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; Liu, L.; Lin, Z.; Zhou, S. Local Motion and Contrast Priors Driven Deep Network for Infrared Small Target Super-Resolution. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2022, 15, 1–16. [CrossRef]
- Yan, P.; Hou, R.; Duan, X.; Yue, C.; Wang, X.; Cao, X. STDMANet: Spatio-Temporal Differential Multiscale Attention Network for Small Moving Infrared Target Detection. IEEE Trans. Geosci. Remote Sensing 2023, 61, 1–16. [CrossRef]
- Chen, S.; Ji, L.; Zhu, J.; Ye, M.; Yao, X. SSTNet: Sliced Spatio-Temporal Network With Cross-Slice ConvLSTM for Moving Infrared Dim-Small Target Detection. IEEE Trans. Geosci. Remote Sensing 2024, 62, 1–12. [CrossRef]
- Duan, W.; Ji, L.; Chen, S.; Zhu, S.; Ye, M. Triple-Domain Feature Learning with Frequency-Aware Memory Enhancement for Moving Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sensing 2024, 62, 1–14. [CrossRef]
- Ying, X.; Liu, L.; Lin, Z.; Shi, Y.; Wang, Y.; Li, R.; Cao, X.; Li, B.; Zhou, S.; An, W. Infrared Small Target Detection in Satellite Videos: A New Dataset and A Novel Recurrent Feature Refinement Framework. IEEE Trans. Geosci. Remote Sensing 2025, 1–1.
- Liu, X.; Zhu, W.; Yan, P.; Tan, Y. IR-MPE: A Long-Term Optical Flow-Based Motion Pattern Extractor for Infrared Small Dim Targets. IEEE Trans. Instrum. Meas. 2025, 74, 1–15. [CrossRef]
- Peng, S.; Ji, L.; Chen, S.; Duan, W.; Zhu, S. Moving Infrared Dim and Small Target Detection by Mixed Spatio-Temporal Encoding. Engineering Applications of Artificial Intelligence 2025, 144, 110100.
- Zhu, S.; Ji, L.; Chen, S.; Duan, W. Spatial–Temporal-Channel Collaborative Feature Learning with Transformers for Infrared Small Target Detection. Image and Vision Computing 2025, 154, 105435. [CrossRef]
- Zhang, L.; Zhou, Z.; Xi, Y.; Tan, F.; Hou, Q. STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets. Remote Sensing 2025, 17, 250. [CrossRef]
- Zhu, S.; Ji, L.; Zhu, J.; Chen, S.; Duan, W. TMP: Temporal Motion Perception with Spatial Auxiliary Enhancement for Moving Infrared Dim-Small Target Detection. Expert Systems with Applications 2024, 255, 124731. [CrossRef]
- Yuan, S.; Qin, H.; Kou, R.; Yan, X.; Li, Z.; Peng, C.; Wu, D.; Zhou, H. Beyond Full Labels: Energy-Double-Guided Single-Point Prompt for Infrared Small Target Label Generation. IEEE J. Sel. Top. Appl. Earth Observations Remote Sensing 2025, 1–14. [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. International Conference on Learning Representations 2014.
- Xu, G.; Cao, H.; Dong, Y.; Yue, C.; Zou, Y. Stochastic Gradient Descent with Step Cosine Warm Restarts for Pathological Lymph Node Image Classification via PET/CT Images. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP); 2020; pp. 490–493.
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A Deep Learning Framework for Semantic Segmentation of Remotely Sensed Data. ISPRS Journal of Photogrammetry and Remote Sensing 2020, 162, 94–114. [CrossRef]
Figure 1.
Network architecture of DEMNet.
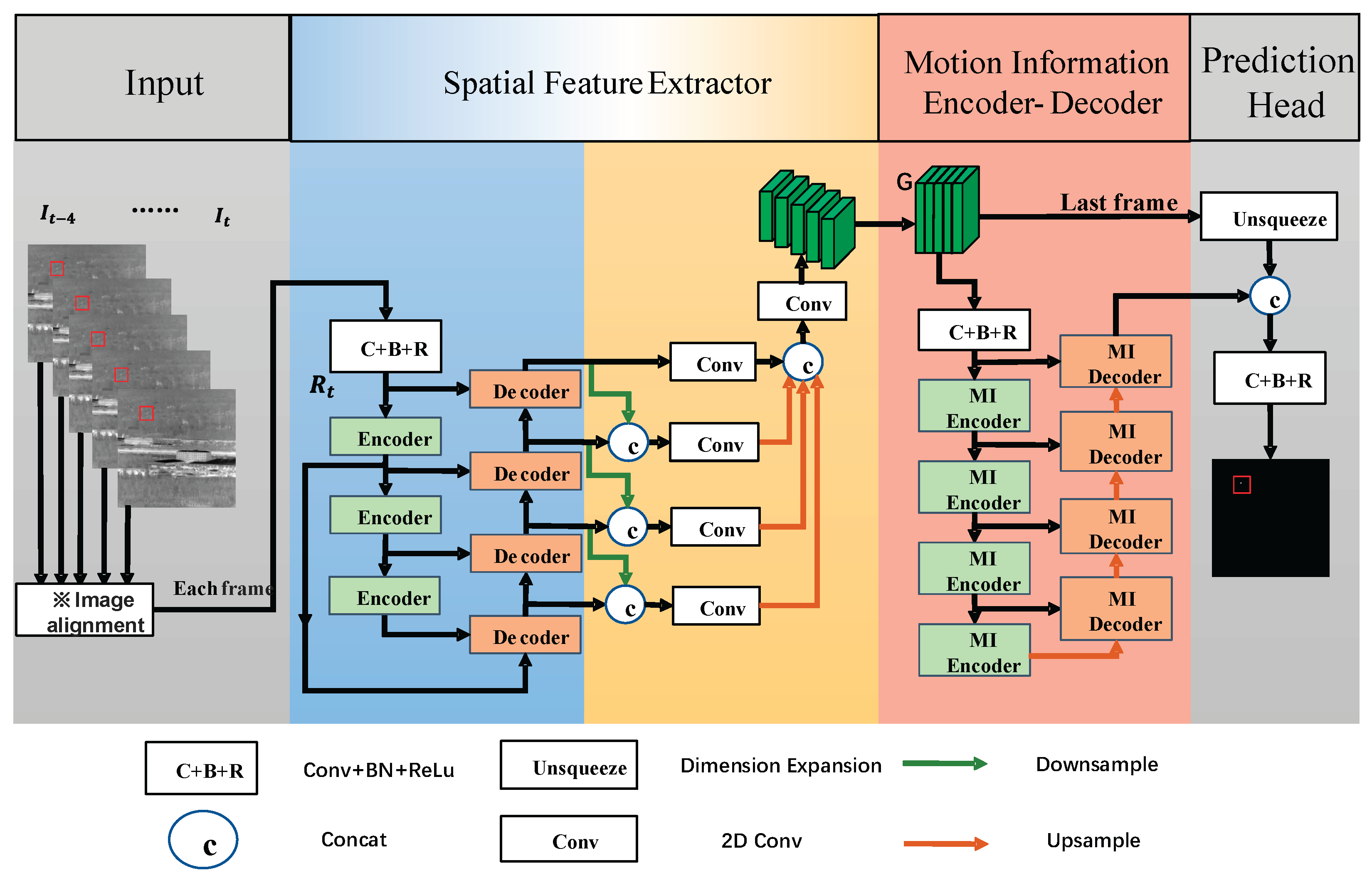
Figure 2.
Illustration of encoder.
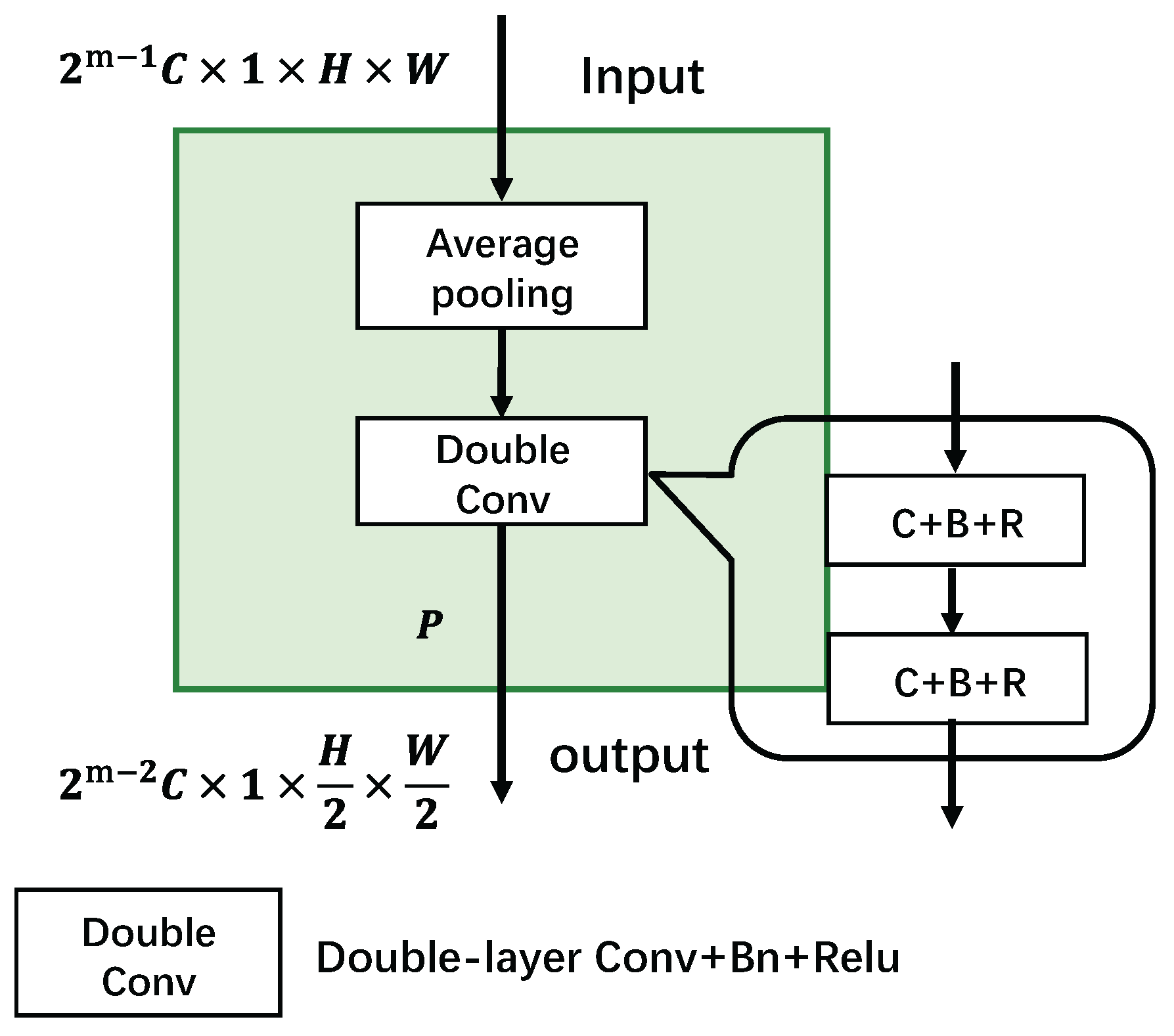
Figure 3.
Illustration of decoder.
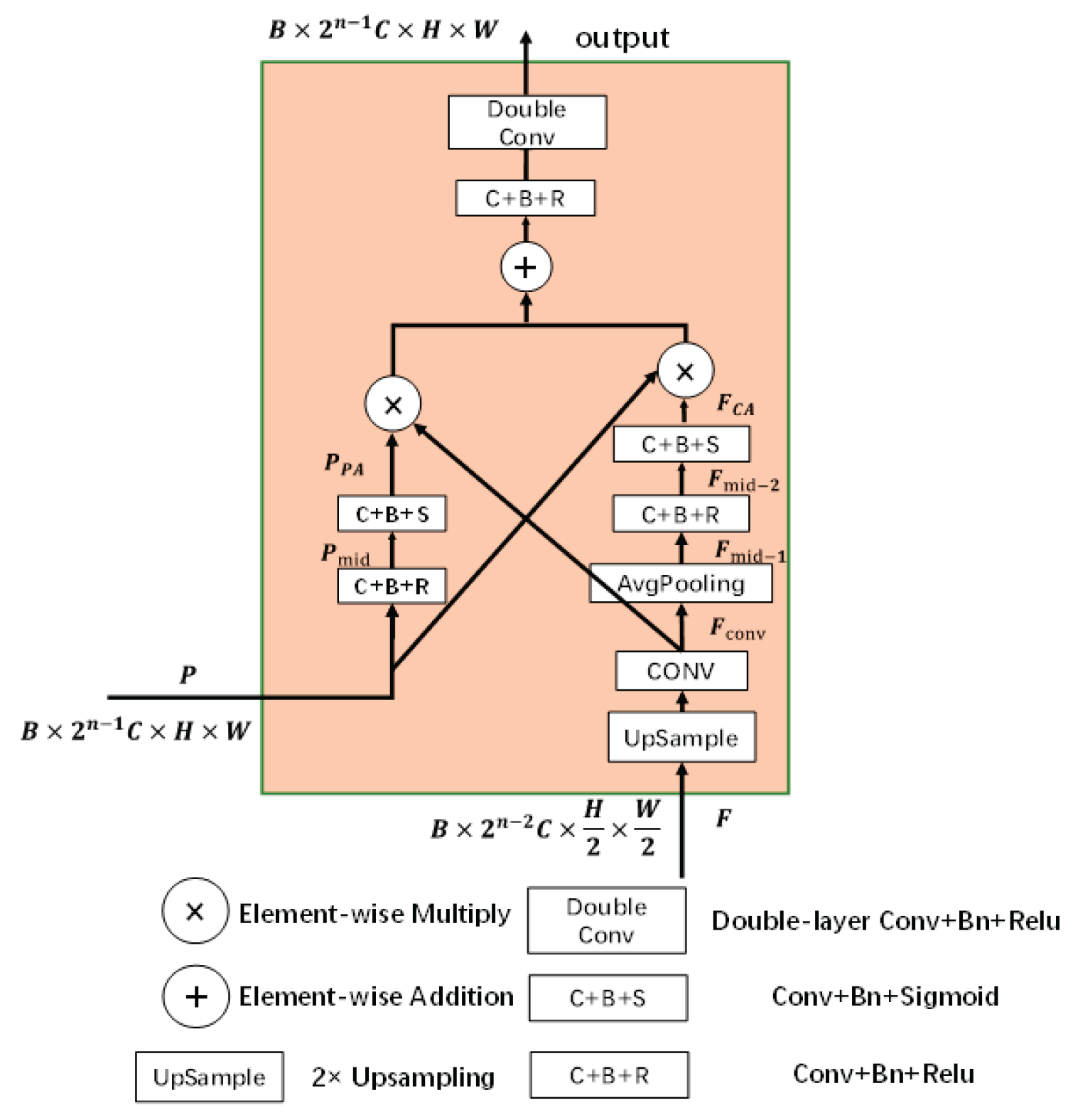
Figure 4.
Illustration of MI encoder.
Figure 7.
Illustration of MI Decoder.
Figure 8.
An example image in sequence 21 of DAUB dataset

Figure 9.
Illustration of the limitations of the Fa metric.
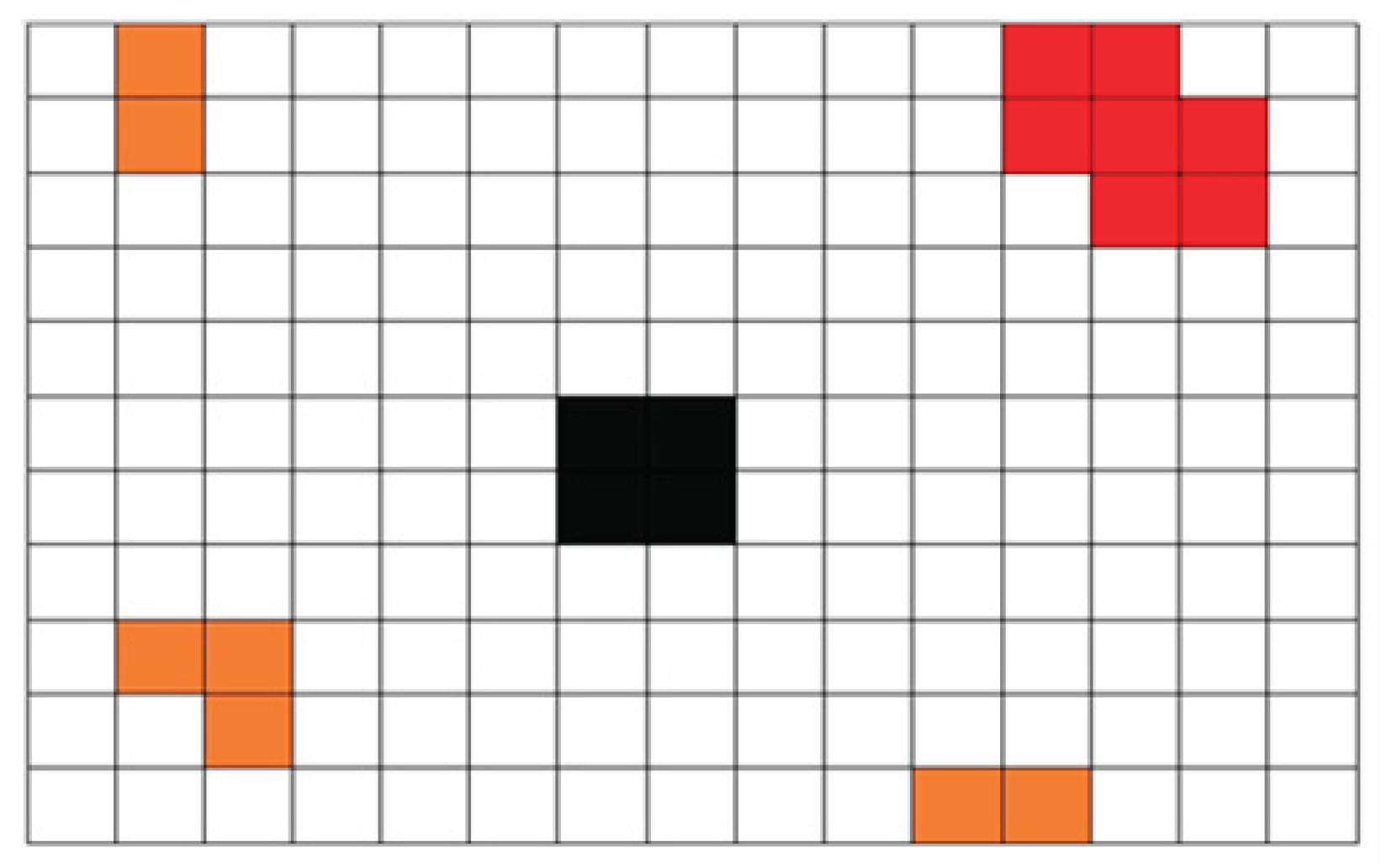
Figure 10.
Visualized results of different methods. Images 1 and 2 are from NUDT, images 3 and 4 are from DAUB.
Figure 10.
Visualized results of different methods. Images 1 and 2 are from NUDT, images 3 and 4 are from DAUB.


Figure 11.
Comparison of ROC curves for different networks on the DAUB dataset
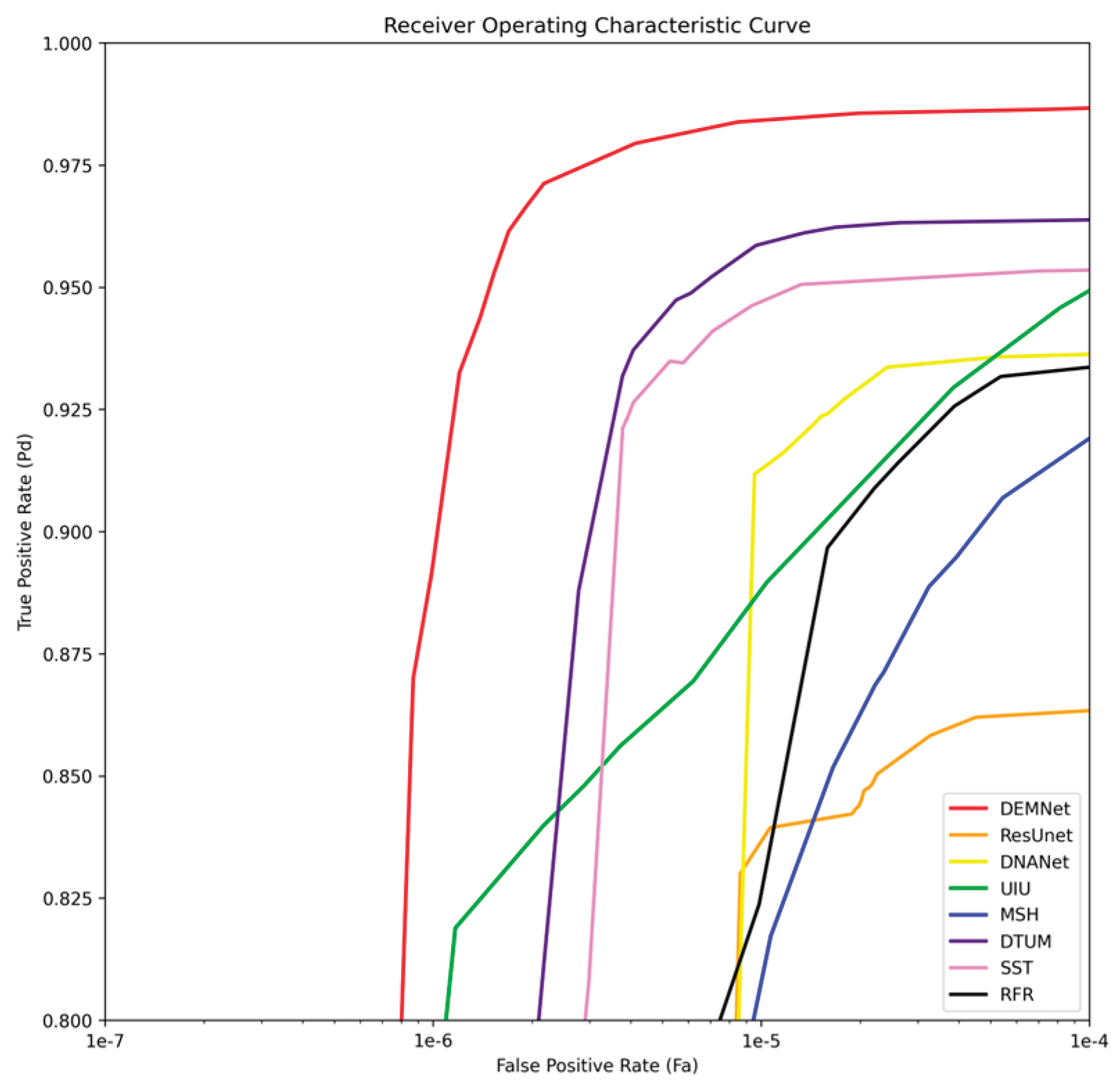

Table 1.
Ablation Study of the MI Encoder
| Model | Module | DAUB | NUDT(All) | ||||||
| 3D Max-pooling |
Intra-frame encoding |
Inter-frame encoding |
Pd/% | Fa/10-6 | FaT/% | Pd/% | Fa/10-6 | FaT/% | |
| A | √ | 94.71 | 8.13 | 19.20 | 96.01 | 27.17 | 13.62 | ||
| B | √ | √ | 96.37 | 4.99 | 10.22 | 97.39 | 18.16 | 9.01 | |
| C | √ | √ | 95.56 | 3.08 | 5.21 | 96.82 | 10.34 | 7.35 | |
| D | √ | √ | √ | 98.28 | 1.88 | 5.01 | 98.21 | 8.56 | 6.19 |
Table 2.
Ablation study of the spatial feature extractor
| Model | Module | DAUB | NUDT(All) | ||||
| Pd/% | Fa/10-6 | FaT/% | Pd/% | Fa/10-6 | FaT/% | ||
| A | ResBlock & Upsample | 94.62 | 9.28 | 6.48 | 94.39 | 9.28 | 6.48 |
| B | w/o Attention Fusion | 97.06 | 8.20 | 6.07 | 96.04 | 8.19 | 6.02 |
| C | Complete module | 98.28 | 1.88 | 5.01 | 98.21 | 8.56 | 6.19 |
Table 3.
Experimental results and resource overhead of different models on the DAUB dataset
| DAUB | Resource and Speed | ||||||
| Pd/% | Fa/10-6 | FaT/% | Params/M | Flops/G | FPS | ||
| Single Frame |
ResUNet [43] | 85.70 | 25.48 | 20.45 | 0.914 | 2.589 | 79.9 |
| DNANet [14] | 92.15 | 14.35 | 21.63 | 1.134 | 7.795 | 37.6 | |
| UIUNet [13] | 86.54 | 7.85 | 16.18 | 50.541 | 54.501 | 32.7 | |
| MSHNet [17] | 87.29 | 24.77 | 32.74 | 4.065 | 6.065 | 45.1 | |
| Multi Frame |
DTUM [26] | 95.86 | 6.01 | 10.31 | 0.298 | 15.351 | 24.4 |
| SST [32] | 89.76 | \ | 5.05 | 11.418 | 43.242 | 21.8 | |
| RFR [34] | 92.16 | 8.79 | 19.43 | 1.206 | 14.719 | 40.2 | |
| DEMNet | 98.28 | 1.88 | 5.01 | 4.458 | 64.131* | 14.8 | |
(*Note: When feature extraction is performed on every single frame, the computation cost is 64.131G. However, when the background remains nearly unchanged, features from the latest 4 frames can be reused, reducing the computation cost to 18.299G.).
Table 4.
Experimental results of different models on NUDT dataset.
| NUDT(SNR≤3) | NUDT(3<SNR<10) | NUDT(All) | ||||||||
| Pd/% | Fa/10-6 | FaT/% | Pd/% | Fa/10-6 | FaT/% | Pd/% | Fa/10-6 | FaT/% | ||
| Single Frame |
ResUNet [43] | 17.58 | 506.95 | 246.13 | 81.33 | 472.12 | 116.67 | 61.48 | 485.97 | 155.87 |
| DNANet [14] | 19.28 | 441.42 | 227.60 | 89.83 | 123.56 | 35.83 | 68.25 | 249.91 | 94.51 | |
| UIUNet [13] | 28.36 | 195.82 | 106.62 | 82.67 | 62.81 | 28.47 | 66.05 | 115.69 | 52.17 | |
| MSHNet [17] | 4.537 | 441.44 | 175.61 | 86.00 | 66.63 | 29.75 | 61.08 | 215.65 | 74.38 | |
| Multi Frame |
DTUM [26] | 90.74 | 9.22 | 14.18 | 99.08 | 9.23 | 3.33 | 96.53 | 9.23 | 6.65 |
| SST [32] | 51.04 | \ | 32.9 | 80.75 | \ | 26.33 | 71.66 | \ | 28.34 | |
| RFR [34] | 39.41 | 60.907 | 39.779 | 90.42 | 106.28 | 41.50 | 74.527 | 88.240 | 40.96 | |
| DEMNet | 96.41 | 6.77 | 11.72 | 99.00 | 9.74 | 3.75 | 98.21 | 8.56 | 6.19 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



