Submitted:
06 June 2025
Posted:
09 June 2025
You are already at the latest version
Abstract
This paper presents GLM-6B-QA, a question-answering system designed to improve the performance of tasks in specialized domains. GLM-6B-QA uses the ChatGLM-6B model and integrates dynamic document attention (DDAM), query refinement layer (QRL), and knowledge injection layer (KIL) within a multi-task learning (MTL) framework. This setup enhances the model's ability to understand and process complex documents, queries, and terminology. By adjusting attention dynamically, refining query representations, and incorporating external knowledge, the system improves question answering, document comprehension, and term extraction. This method addresses challenges in natural language processing tasks and provides a better approach for developing adaptable systems in specialized applications.
Keywords:
Multi-Task Learning
; Knowledge Injection
; Dynamic Document Attention
; Query Refinement
1. Introduction
The financial industry generates complex, dynamic data, requiring advanced analysis. As queries grow more intricate, specialized NLP models become essential. General models like BERT and GPT-3 struggle with domain-specific tasks due to a lack of financial knowledge. This limitation affects performance in financial document understanding, question answering, and term extraction, reducing real-world applicability.
Tian et al. [1] showed the importance of domain-specific knowledge in improving NLP models for specific industries. They suggest using models that integrate external knowledge sources, such as financial metrics and industry-specific terminology, to improve task performance. Similarly, Yang et al. [2] introduced FinBERT, a pre-trained model for financial communication, highlighting the need for domain-specific models to better handle financial documents. However, there is still a gap in designing and training models that can handle many tasks in the financial sector. Sun et al. [3] (2018) proposed a relation classification model integrating coarse- and fine-grained networks with SDP-supervised keyword selection and an opposite loss function, achieving state-of-the-art performance on SemEval-2010 Task 8.
We propose FinGLM-6B, a financial QA system using multi-task learning (MTL). It integrates dynamic document attention, query refinement, and knowledge injection. The system directs attention to key financial document sections, refining queries for better accuracy. The knowledge injection layer enhances financial concept comprehension with external data. These improvements strengthen financial QA, document understanding, and term extraction, surpassing traditional NLP models.
2. Related Work
Recent advancements in language understanding, particularly transformer-based models, have significantly improved NLP. BERT [4] pre-trains deep bidirectional transformers, enhancing tasks like question answering and sentiment analysis. It learns context from both directions. XLNet [5] further improves performance using a more general pretraining technique to capture bidirectional context.J. Lu’s [6] study integrates Decision Tree, TF-IDF, and BERTopic to improve chatbot user satisfaction prediction using the Chatbot Arena dataset.
Tian Jin [7] discussed improving retail sales forecasting using an ensemble model enhanced by Particle Swarm Optimization (PSO), combining LightGBM, XGBoost, and Deep Neural Networks. This work highlights the importance of ensemble methods to improve prediction accuracy, which is similar to forecasting and risk prediction in finance. Dai et al. [8] proposed a contrastive learning-based KWS approach that enhances robustness in low-resource settings, aligning with our dynamic document attention for domain-specific QA. Their architecture optimization informs our efficiency improvements.
In financial data understanding, Douaioui et al. [9] reviewed machine learning and deep learning models for demand forecasting in supply chain management, showing how these models can be adapted for financial data tasks, like predicting market trends. Cao et al. [10] and Chen et al. [11] highlighted the importance of using attention mechanisms in specialized tasks, such as action segmentation and leukocyte classification, which can inspire financial models to improve detailed financial analysis.
3. Methodology
This paper presents a multi-task hybrid architecture for financial question answering based on ChatGLM-6B. The proposed model, FinGLM-6B, integrates a dynamic document attention mechanism (DDAM), a query refinement layer (QRL), and a knowledge injection layer (KIL). It is trained using a multi-task learning (MTL) framework, covering financial question answering, document comprehension, and term extraction.
DDAM adjusts attention based on query context. QRL iteratively refines question representation for better accuracy. KIL enhances understanding by incorporating external financial knowledge. Experiments on a large financial dataset show superior performance in handling financial queries. The pipeline is shown in Figure 1.
3.1. Dynamic Document Attention Mechanism
Traditional transformers assign fixed attention weights across all layers, disregarding token relevance to the query. In financial QA, varying importance of financial tables, statements, and footnotes necessitates a dynamic approach. We propose the Dynamic Document Attention Mechanism, which adjusts attention weights based on query content:
where query alignment is computed as:
with as a learned projection matrix. This mechanism enhances focus on critical document parts, improving accuracy in financial QA.
3.2. Query Refinement Layer
The Query Refinement Layer iteratively refines the query by leveraging document content and dynamic attention. The process follows:
where is updated using attention scores and document context, ensuring alignment with relevant financial information.
3.3. Knowledge Injection Layer
Financial texts contain specialized terminology often overlooked by standard transformers. The Knowledge Injection Layer (KIL) integrates domain-specific knowledge, represented as , into the decoding process:
where is the encoder state and is the attention matrix. This fusion of external knowledge enhances financial text comprehension.
3.4. Multi-Task Learning Framework
FinGLM-6B adopts a multi-task learning framework. It integrates gated and expert networks to process financial tasks, including question answering (QA), document comprehension (DC), and term extraction (FTE). The framework enables knowledge sharing while preserving task-specific features.
3.4.1. Task-Specific Gated Networks
Each task shares a common backbone architecture but uses a task-specific gating mechanism to control the flow of information. The gated output for task t is computed as:
where is the gating vector learned through:
This ensures the model adapts its parameters for each task while maintaining shared knowledge.
3.4.2. Expert Networks for Task Specialization
Each task has an expert network that generates specialized representations. The output is a weighted sum of expert outputs , as follows:
The weights are dynamically computed via:
This allows the model to specialize by focusing on relevant features for each task.
3.4.3. Joint Training of Shared and Task-Specific Modules
The FinGLM-6B model jointly optimizes the shared backbone and task-specific components with task-specific loss functions. For task t, the loss is defined as:
where is the task-specific loss, and is the ground truth for task t.
3.4.4. Task-Aware Attention Mechanism
A task-aware attention mechanism refines the shared representation by attending to both task-specific and query contexts. The attention weights are computed as:
This allows the model to focus on the relevant information for each task, enhancing task-specific performance.
3.4.5. Adaptive Task Allocation During Inference
During inference, the model dynamically allocates resources based on the task type. Expert networks and gating mechanisms work together to ensure efficient and accurate task-specific processing.
3.5. Loss Function
The FinGLM-6B model employs a composite loss function to optimize multi-task learning across various financial tasks. The overall loss combines task-specific losses, each targeting a distinct financial task such as question answering, document comprehension, and financial term extraction.
3.5.1. Task-Specific Loss Functions
Each task t has its own loss function, guiding task-specific learning:
- For QA, we use cross-entropy loss:
- For Document Comprehension, a contrastive loss is used:
- For Financial Term Extraction (FTE), a regression loss is applied:
3.5.2. Composite Loss Function
The overall loss is a weighted sum of the individual losses, where represents the task-specific weight:
This allows the model to balance task-specific optimization during training.
3.5.3. Gradient Flow for Multi-Task Optimization
The gradients for shared parameters and task-specific parameters are computed based on the total loss:
These gradients ensure that both shared and specialized components are updated during backpropagation.
3.6. Data Preprocessing
The preprocessing of FinGLM-6B data involves cleaning, tokenization, and embedding to ensure structured input for training.
3.6.1. Data Cleaning and Normalization
Raw financial text and numerical data undergo cleaning:
- Text Cleaning: Removing headers and disclaimers.
- Numerical Normalization: Applying standardization:
3.6.2. Tokenization and Embedding
Text is tokenized via BPE or WordPiece and mapped to dense vectors:
Figure 2 illustrates raw and processed data distributions.
3.6.3. Handling Missing Data and Outliers
Strategies include:
- Imputation: Filling missing values with mean or median.
- Outlier Detection: Using z-score:
4. Evaluation Metrics
To evaluate the performance of the FinGLM-6B model, the following metrics are used:
Accuracy measures the percentage of correct answers in the QA task:
Mean Squared Error (MSE) is used for financial term extraction (FTE) to measure prediction error:
Precision, Recall, and F1-Score evaluate relevance and completeness for document comprehension or term extraction:
Mean Average Precision (MAP) evaluates retrieval performance for document comprehension (DC):
5. Experiment Results
We compare the performance of FinGLM-6B with other models such as BERT and GPT-3 on QA, FTE, and DC tasks. The results are shown in Table 1:
The following table, Table 2, presents the results of the ablation study, where different components of the model were removed. The Figure 3 shows the training curves for four model variants over 50 epochs. In each subplot, the blue and red curves (QA Accuracy and DC MAP ×100) gradually increase and plateau with small fluctuations, while the green dashed curve (FTE MSE ×1000) decreases toward its optimum.
6. Conclusion
The FinGLM-6B model demonstrates strong performance in financial NLP tasks, surpassing other models like BERT and GPT-3. The ablation study highlights the importance of multi-task learning and modular components, contributing significantly to the model’s superior performance.
References
- Jin, T. Attention-Based Temporal Convolutional Networks and Reinforcement Learning for Supply Chain Delay Prediction and Inventory Optimization. Preprints 2025. [Google Scholar] [CrossRef]
- Yang, Y.; Uy, M.C.S.; Huang, A. Finbert: A pretrained language model for financial communications. arXiv preprint arXiv:2006.08097 2020.
- Sun, Y.; Cui, Y.; Hu, J.; Jia, W. Relation classification using coarse and fine-grained networks with SDP supervised key words selection. In Proceedings of the Knowledge Science, Engineering and Management: 11th International Conference, KSEM 2018, Changchun, China, August 17–19, 2018, Proceedings, Part I 11. Springer, 2018, pp. 514–522.
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Proceedings of naacL-HLT. Minneapolis, Minnesota, 2019, Vol. 1.
- Yang, Z. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237 2019.
- u, J. Enhancing chatbot user satisfaction: A machine learning approach integrating decision tree, tf-idf, and bertopic. In Proceedings of the 2024 IEEE 6th International Conference on Power, Intelligent Computing and Systems (ICPICS). IEEE, 2024, pp. 823–828.
- Jin, T. Optimizing Retail Sales Forecasting Through a PSO-Enhanced Ensemble Model Integrating LightGBM, XGBoost, and Deep Neural Networks. Preprints 2025. [Google Scholar] [CrossRef]
- Dai, W.; Jiang, Y.; Liu, Y.; Chen, J.; Sun, X.; Tao, J. CAB-KWS: Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology. In Proceedings of the International Conference on Pattern Recognition. Springer, 2025, pp. 98–112.
- Douaioui, K.; Oucheikh, R.; Benmoussa, O.; Mabrouki, C. Machine Learning and Deep Learning Models for Demand Forecasting in Supply Chain Management: A Critical Review. Applied System Innovation (ASI) 2024, 7. [Google Scholar] [CrossRef]
- Cao, J.; Xu, R.; Lin, X.; Qin, F.; Peng, Y.; Shao, Y. Adaptive receptive field U-shaped temporal convolutional network for vulgar action segmentation. Neural Computing and Applications 2023, 35, 9593–9606. [Google Scholar] [CrossRef]
- Chen, B.; Qin, F.; Shao, Y.; Cao, J.; Peng, Y.; Ge, R. Fine-grained imbalanced leukocyte classification with global-local attention transformer. Journal of King Saud University-Computer and Information Sciences 2023, 35, 101661. [Google Scholar] [CrossRef]
Figure 1.
FinGLM-6B: Multi-task hybrid architecture for financial question answering.
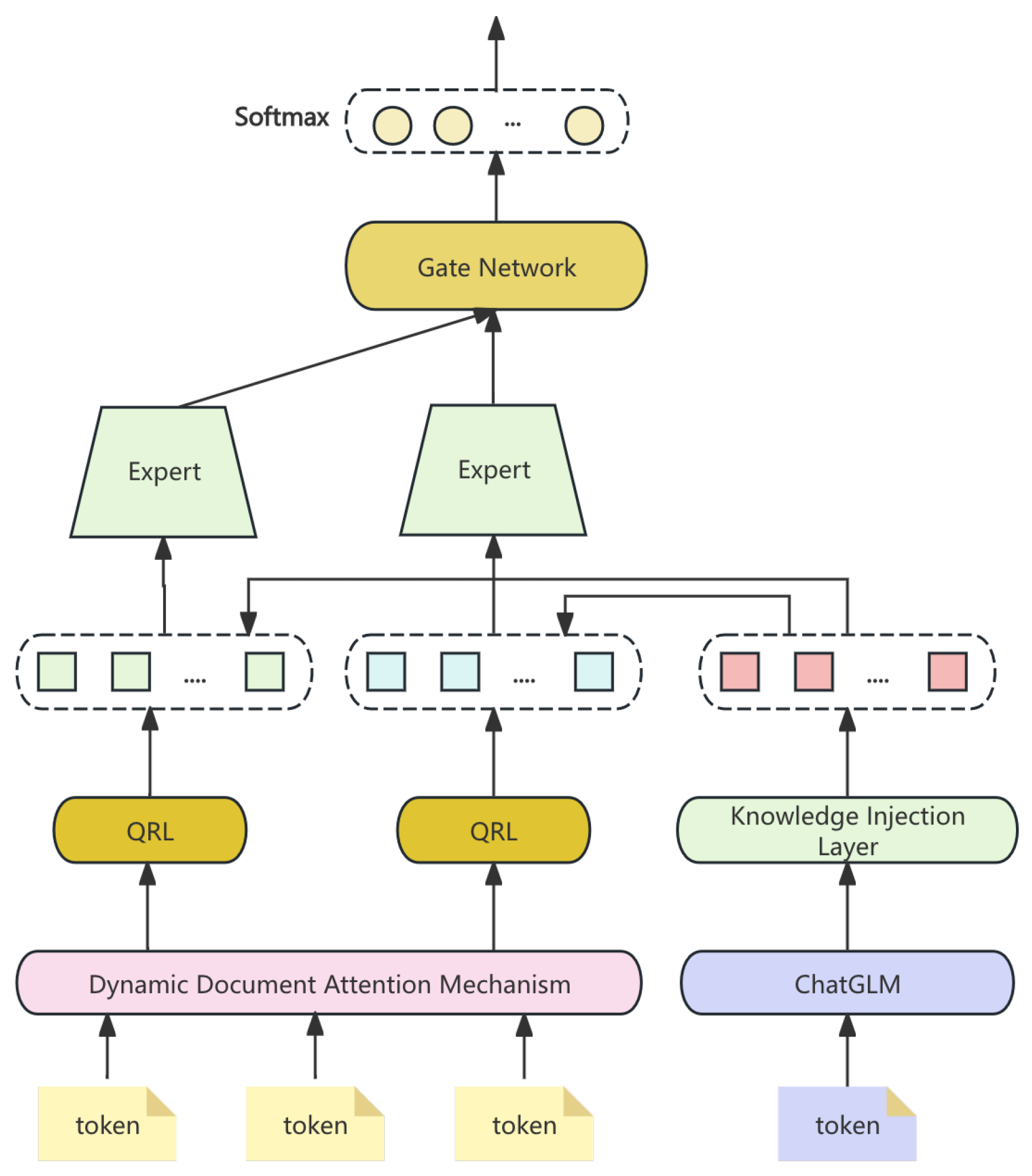
Figure 2.
Raw vs. cleaned financial data distribution.
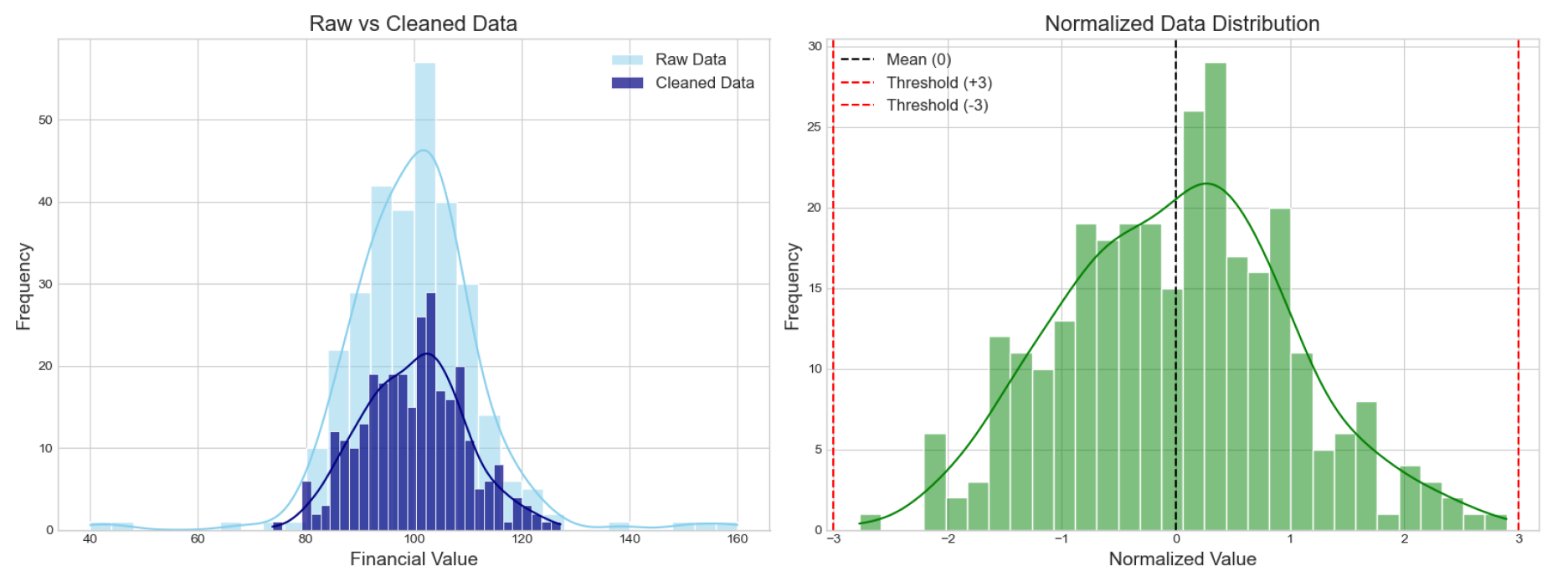
Figure 3.
Model indicator change chart in ablation experiment.
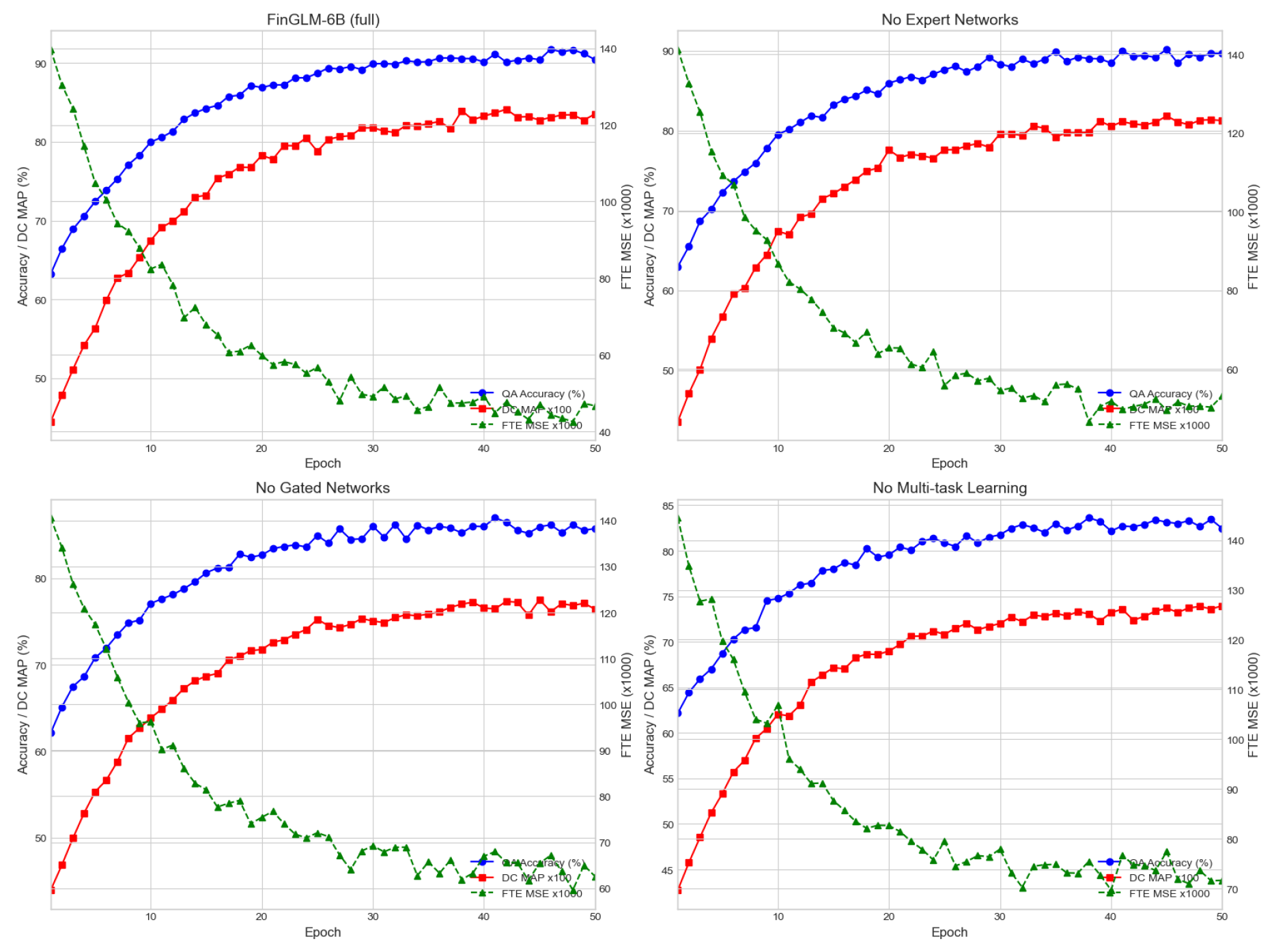

Table 1.
Model performance on QA, FTE, and DC tasks
| Model | QA Accuracy (%) | FTE MSE | DC MAP |
|---|---|---|---|
| FinGLM-6B | 91.3 | 0.045 | 0.837 |
| BERT | 85.6 | 0.063 | 0.752 |
| GPT-3 | 88.1 | 0.052 | 0.813 |
Table 2.
Ablation study results showing the impact of key components
| Model Variant | QA Accuracy (%) | FTE MSE | DC MAP |
|---|---|---|---|
| FinGLM-6B (full) | 91.3 | 0.045 | 0.837 |
| No Expert Networks | 89.7 | 0.051 | 0.812 |
| No Gated Networks | 86.4 | 0.063 | 0.772 |
| No Multi-task Learning | 83.1 | 0.072 | 0.740 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



