Submitted:
01 March 2025
Posted:
03 March 2025
You are already at the latest version
Abstract
Due to the complexities of traditional database querying methods, accessing data can be a challenge for nontechnical users. CypherQuery addresses this issue by leveraging Natural Language Processing (NLP) and conversational large language models (LLMs) to facilitate intuitive database interactions. Users can pose natural language questions without understanding SQL or database schemas.The system utilizes Python for backend processing, LangChain for AI model orchestration, and Streamlit for an interactive user interface. CypherQuery ensures compatibility with a wide array of datasets by supporting both SQL databases (like MySQL and SQLite) and graph databases (such as Neo4j). It efficiently translates user inquiries into structured queries, providing accurate results in real-time.By democratizing data access, improving efficiency in data retrieval, and simplifying the user experience, CypherQuery enhances engagement with data across various sectors, including e-commerce, healthcare, and customer support. This innovative approach fosters datadriven decision-making and operational excellence, transforming how users interact with information.
Keywords:
1. Introduction
2. Objectives
3. Literature Review
4. Methodology
- a.
- Technology stack and Databases
- Frontend Module: Constructed utilizing Streamlit, providing a user-oriented interface for conversational interactions. Facilitates text input, file uploads (e.g., PDFs), and intuitive user engagement with the system.
- Backend Module: Powered by OpenAI LLMs, OpenAI Embeddings, and Groq APIs for high-performance natural language interpretation, query generation, and execution. Groq APIs enhance computational efficiency, ensuring expedited processing of queries and embedding-based operations.
- Database Layer: Supports multi-database integration for diverse data management. Operates with MySQL and SQLite for relational data and Neo4j for graph-based data, accommodating a wide range of database requirements.
- Technology Stack
- Frontend: Streamlit for interactive web interfaces.
- Backend: OpenAI APIs (LLMs and Embeddings) and Groq APIs for optimized query processing and execution.
- Databases: MySQL, SQLite (Relational Databases), and Neo4j (Graph Database).
- b.
- Modular Architecture
- Following is an outline of the Application Architecture:

- c.
- Query Execution Workflow
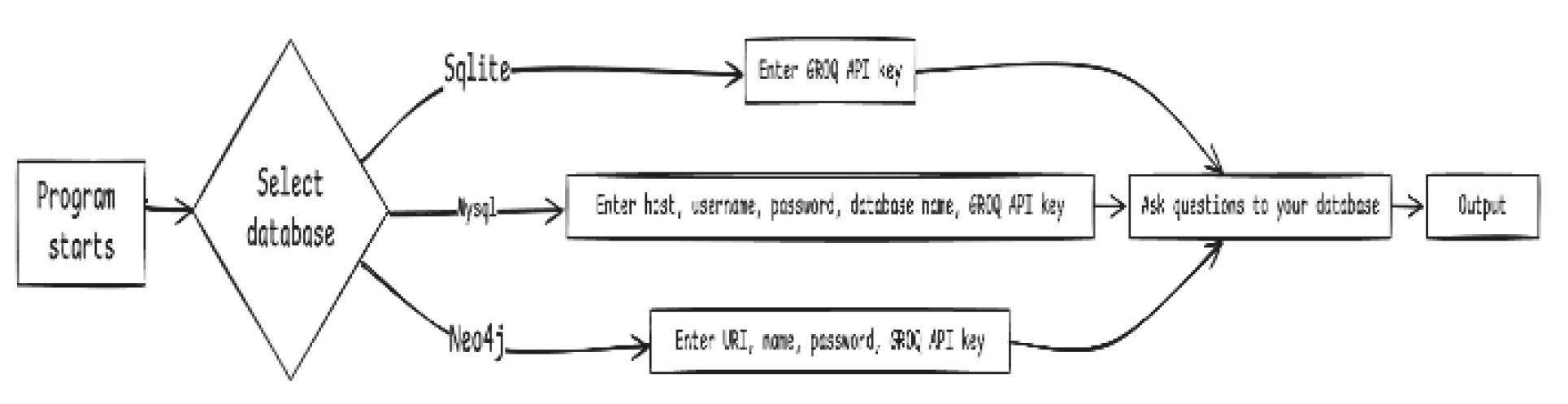
- 1.
-
To utilize the model, the user must adhere to the following procedure:
- Select the desired database;
- Provide the requisite specifications (Groq API key/Host/Username/Password, etc.) corresponding to the database type (SQLite/SQL/Neo4j);
- Submit a query to the model in natural language. The model assistant generates output accompanied by its reasoning process.
- 2.
- Processing Workflow
- Input: Users submit queries in natural language through the conversational interface.
- Processing: The backend system converts the input into a structured query format utilizing the NLP layer.
- Execution: The generated query is executed on the respective database, and results are retrieved.
- Output: The processed results are presented to the user in a comprehensible and actionable format.
5. Result and Discussion
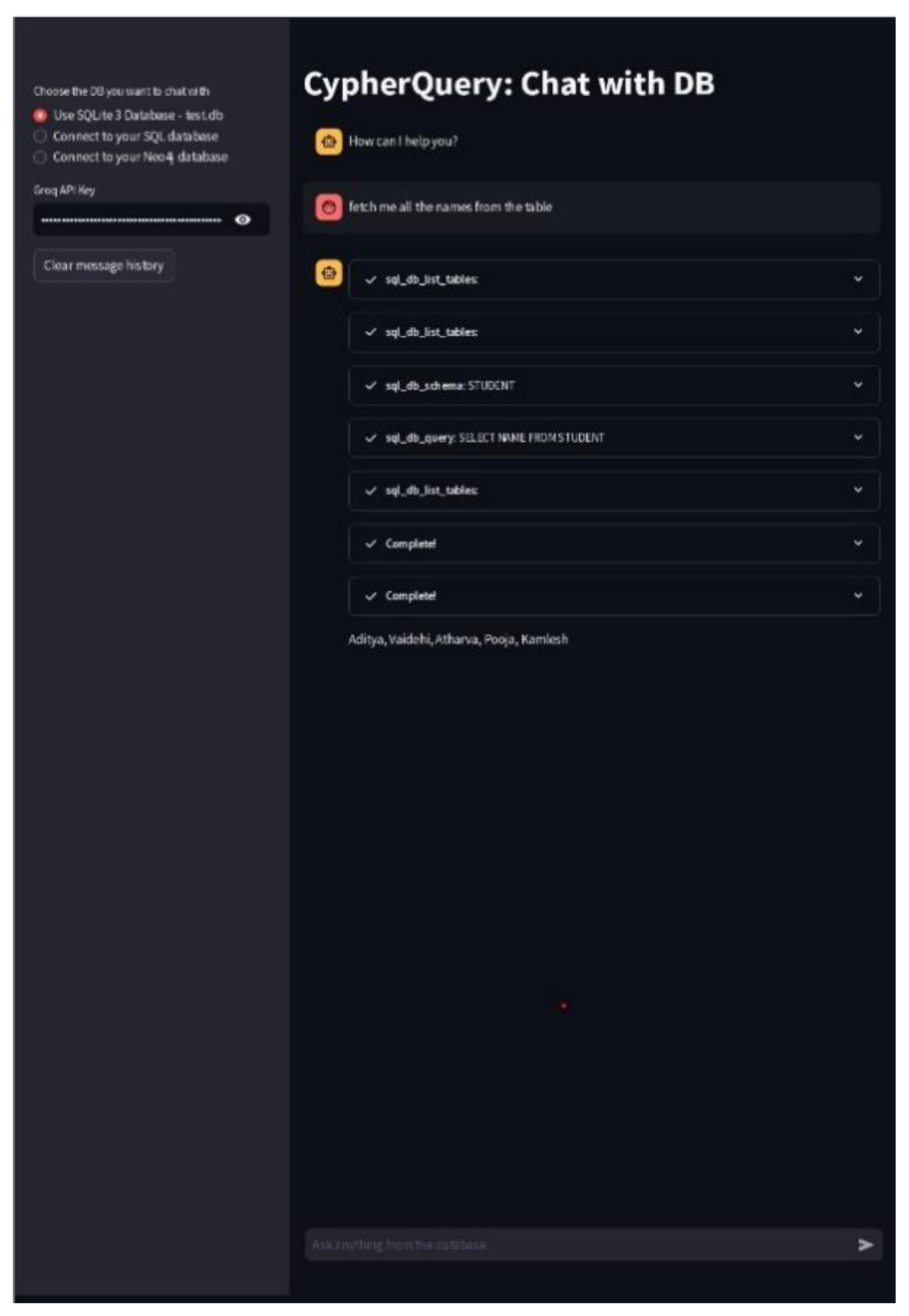
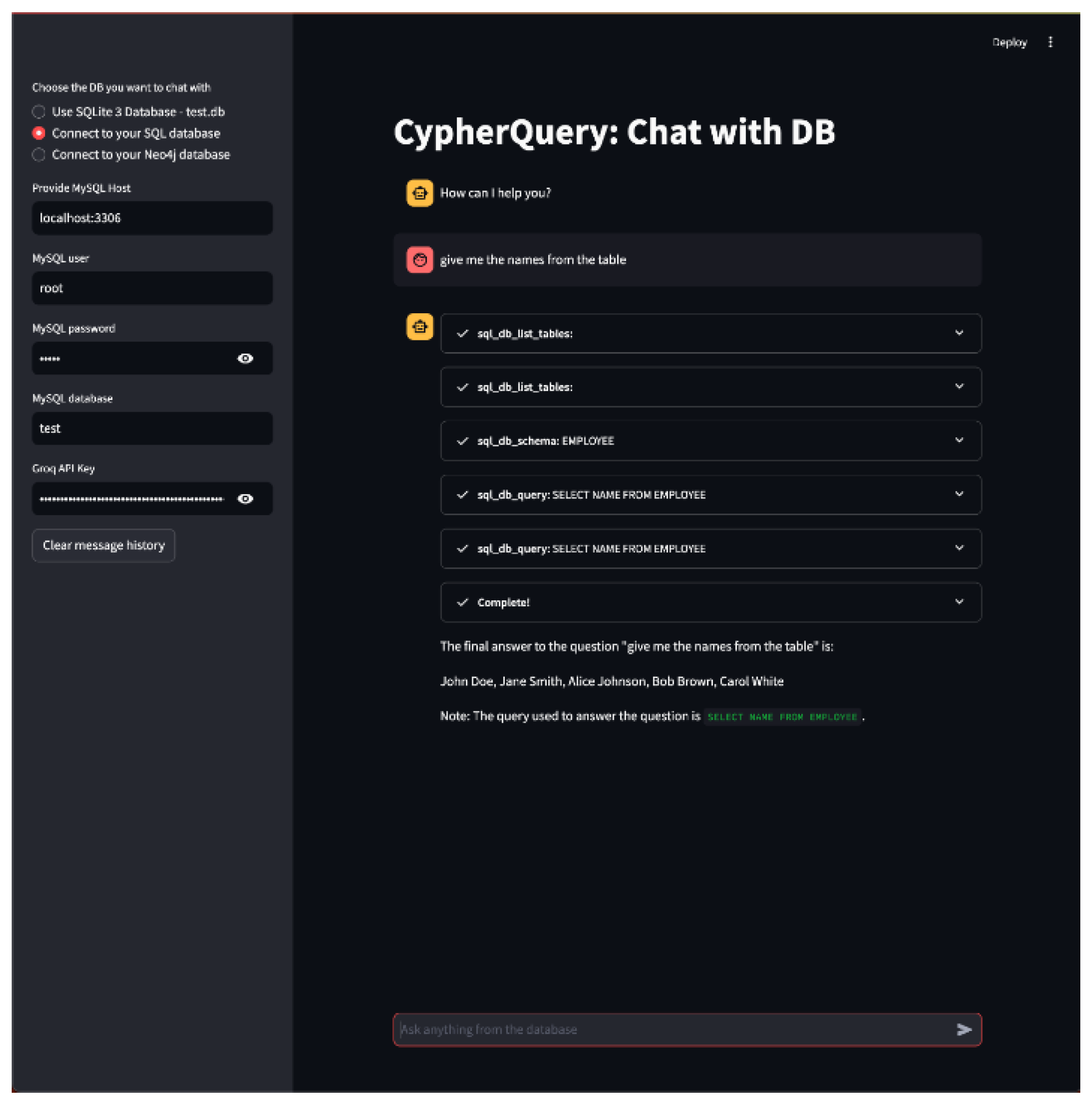
- B.
- Illustration with MY SQL database
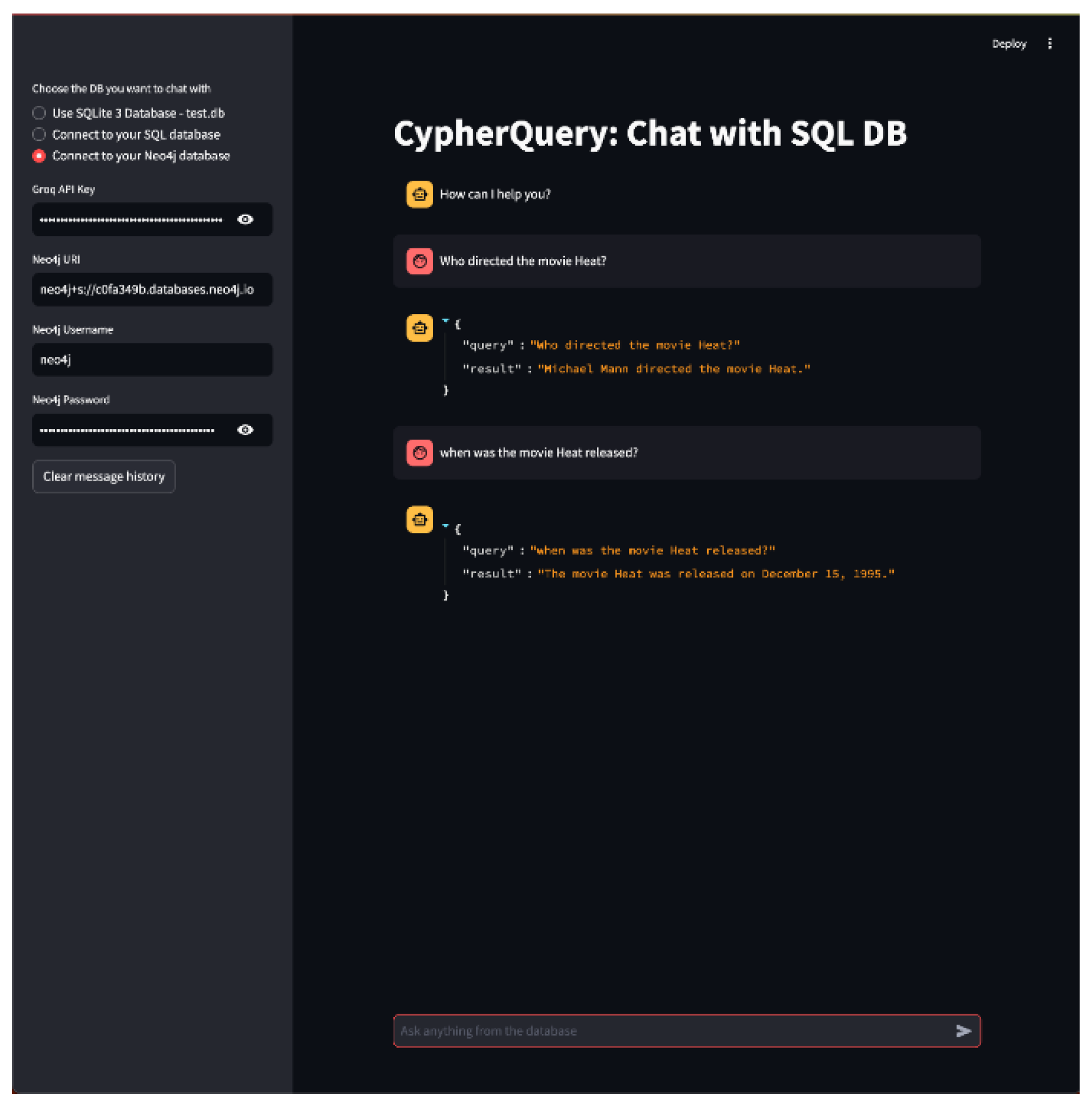
- C.
- Illustration with Neo4j (graph database)
6. Conclusion
Acknowledgment
References
- Brown, J.A.; Smith, L.T.; Clarke, R.M. Simplifying database interaction through natural language interfaces. Journal of Database Systems 2019, 35, 123–135. [Google Scholar]
- Smith, R.L.; Patel, K.R.; Zhao, H. Multi-database query generation and optimization. Proceedings of the International Conference on Database Technology 2020, 18, 200–210. [Google Scholar]
- Gupta, P.K.; Desai, M.J.; Thakur, A.R. Adapting conversational AI for database querying. Journal of AI and Data Science, 2021, 29, 45–60. [Google Scholar]
- Choi, L.Y.; Wang, S.; Lee, H.J. A unified approach to querying relational and graph databases. Journal of Database Innovation 2022, 42, 75–89. [Google Scholar]
- White, T.F.; Sanders, P.Q.; Moore, J.L. Improving data accessibility through streamlined user interfaces. Journal of Information Systems 2023, 48, 145–156. [Google Scholar]
- Tan, H.S.; Gupta, S.V.; Lin, T. Automating query optimization in multi-language databases. International Journal of Data Management 2023, 21, 310–325. [Google Scholar]
- Francis, A.; Walker, D.J. Graph databases and querying with Cypher. Database Systems Review 2018, 31, 98–110. [Google Scholar]
- Meharwade, A.; Patil, G. A. Efficient keyword search over encrypted cloud data. Procedia Computer Science 2016, 78, 139–145. [Google Scholar] [CrossRef]
- Nashipudimath, M.; Shinde, S.; Jain, J. An efficient integration and indexing method based on feature patterns and semantic analysis for big data. Array 2020, 7, 100033. [Google Scholar] [CrossRef]
- Zhu, M.; Cole, J. PDFDataExtractor: A tool for reading scientific text and interpreting metadata from the typeset literature in the portable document format. Journal of Chemical Information and Modeling 2022, 62. [Google Scholar] [CrossRef] [PubMed]
- https://streamlit.io/.
- https://python.langchain.com/.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



