Submitted:
21 February 2025
Posted:
25 February 2025
You are already at the latest version
Abstract
Text-to-music generation integrates natural language processing and music generation, enabling artificial intelligence (AI) to compose music from textual descriptions. While AI enabled music generation has advanced, challenges in aligning text with musical structures remain under explored. This paper systematically reviews text-to-music generation across symbolic and audio domains, covering melody composition, polyphony, instrumental synthesis, and singing voice generation. It categorizes existing methods into traditional, hybrid, and LLM-centric frameworks according to the usage of large language model (LLM), highlighting the growing role of LLMs in improving controllability and expressiveness. Despite progress, challenges such as data scarcity, representation limitations, and long-term coherence persist. Future work should enhance multi-modal integration, improve model generalization, and develop more user-controllable frameworks to advance AI-enabled music composition.
Keywords:
Introduction
1.1. Background
1.2. Motivation
1.3. Objectives
- To systematically classify and analyze text-to-music generation tasks: By categorizing tasks into symbolic and audio domains, the paper examines subtasks such as melody generation, polyphony generation, singing voice synthesis, and complete song composition. This taxonomy offers a clear aspect for understanding the distinct challenges and opportunities within each domain. This framework supports modular method development by providing researchers with a structured reference for locating domain-specific innovations.
- To emphasize the potential of LLMs through framework comparison: The study focuses on the traditional methods, hybrid approaches, and end-to-end LLM systems, providing a detailed analysis of their strengths, limitations, and applicability. The analysis highlights the progressive improvements introduced by LLMs, demonstrating their ability to enhance user controllability, generalization capability, etc., offering a clearer perspective on the role of LLMs in advancing AI-enabled music composition.
- To identify challenges and propose future directions: This objective is crucial because addressing unresolved challenges—such as data scarcity, model generalization, emotion modeling, and user interactivity—is the foundation for advancing text-to-music generation. By systematically analyzing these barriers, the paper provides a roadmap for overcoming limitations that currently hinder the effectiveness and creativity of such systems. This exploration advances text-to-music generation, establishing it as a key direction for creative industries.
2. Evolution
2.1. Early Rule-Based Systems
2.2. Emergence of Machine Learning
2.3. The Rise of Deep Learning and Cross-Modal Approaches
2.4. The Integration of LLMs
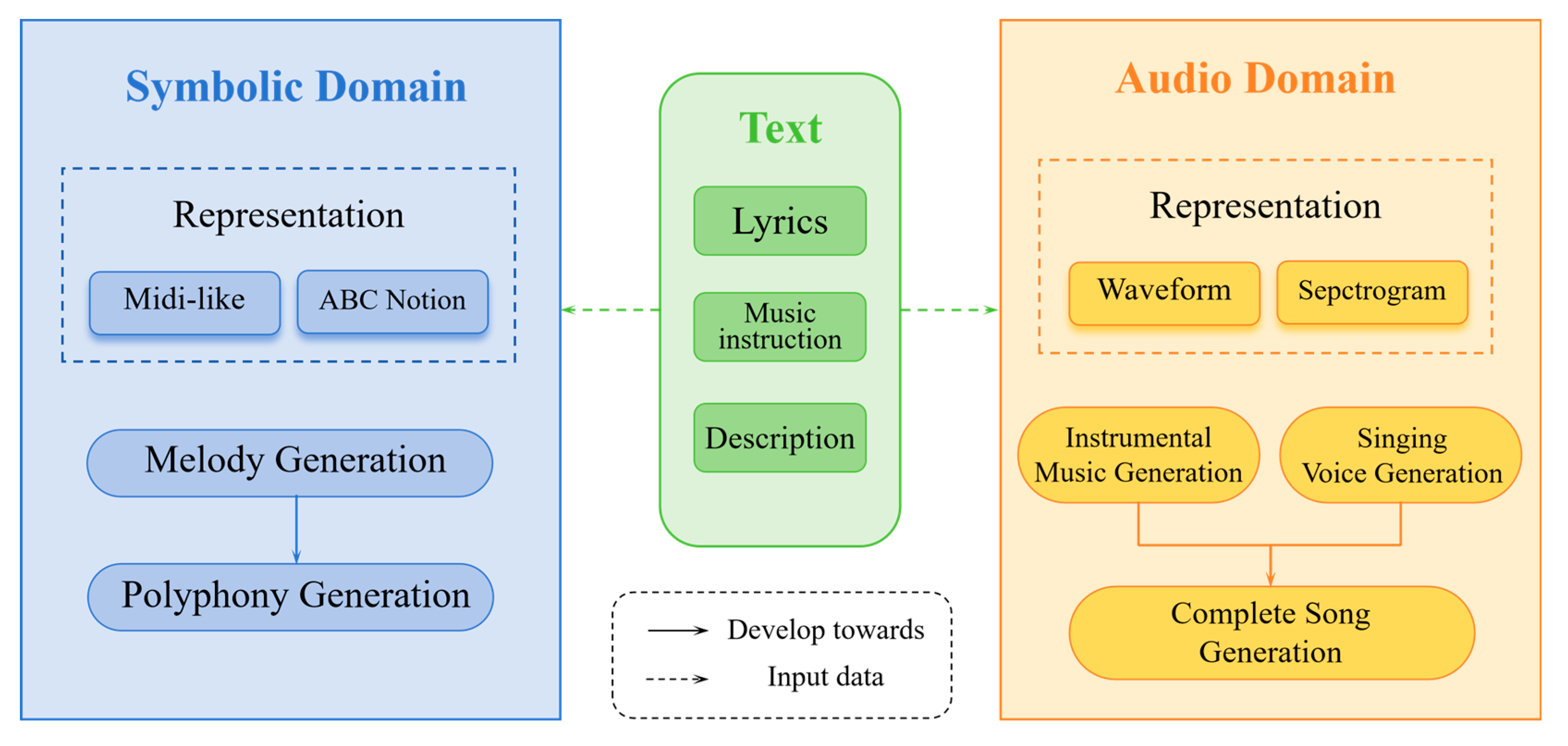
3. Representation Forms of Text and Music
3.1. Text Types
3.2. Musical Representation
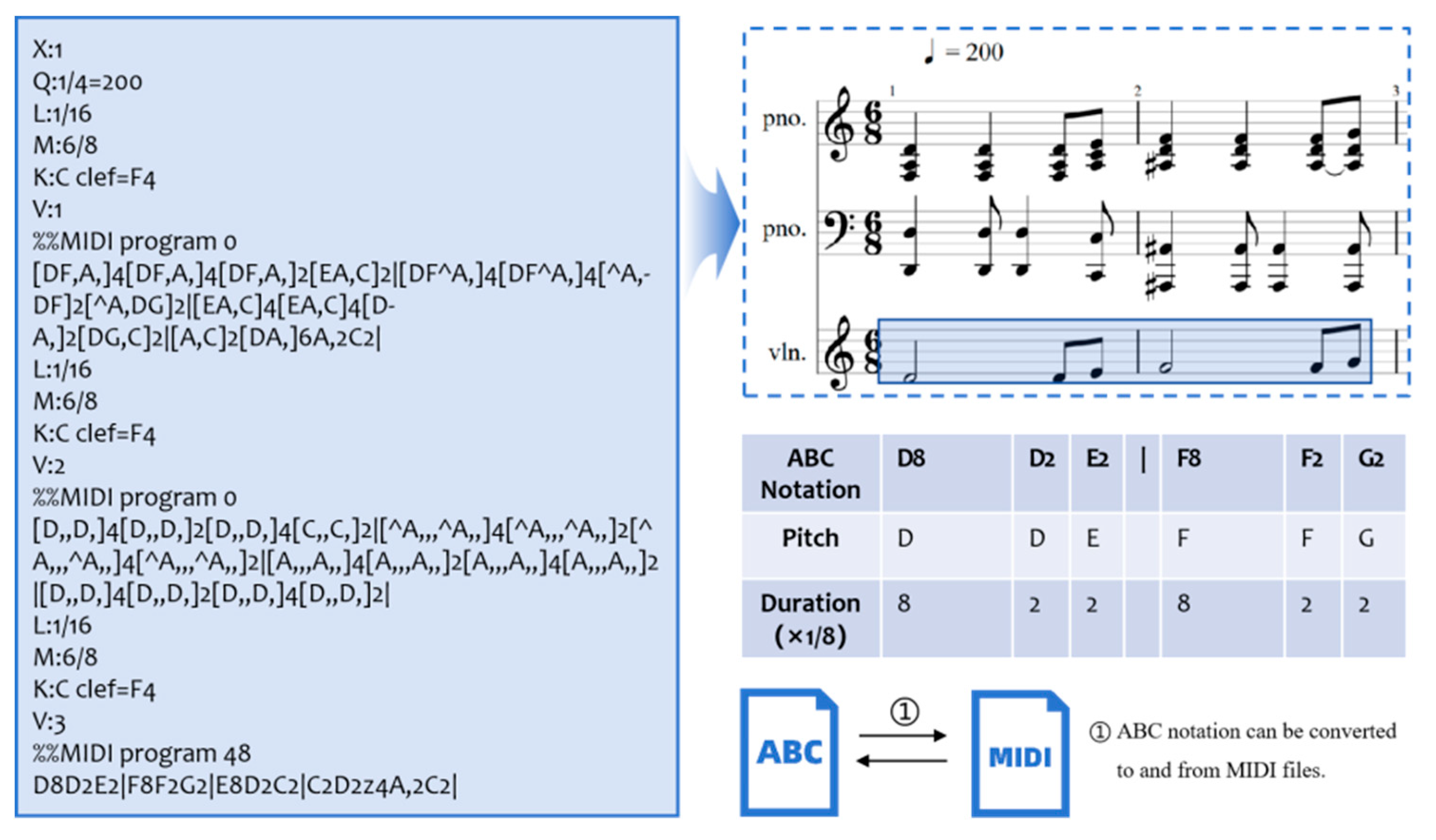
3.2.1. Event Representation: Midi-like
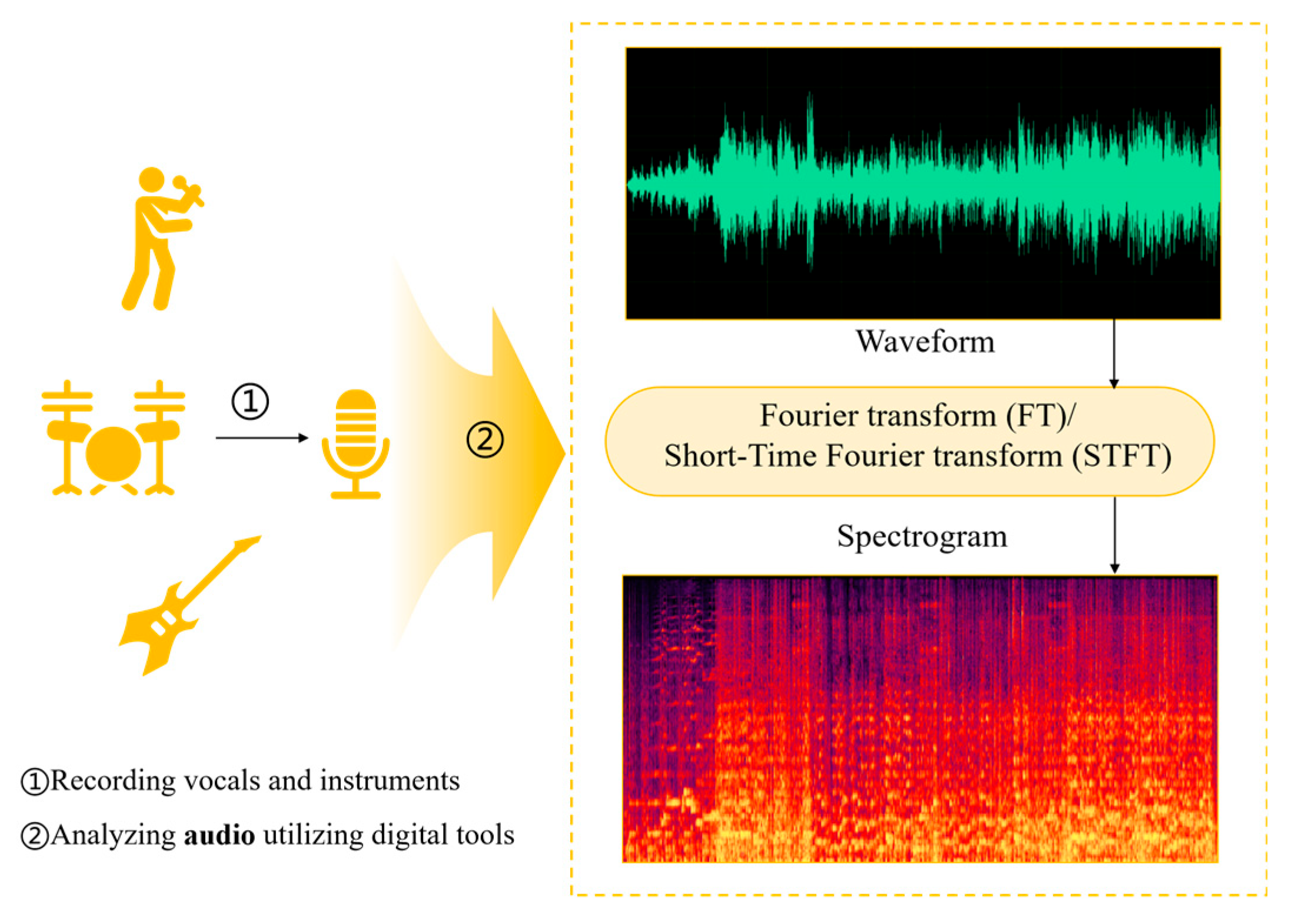
3.2.2. Audio Representation: Waveform and Spectrogram
3.2.3. Text Representation: ABC Notation
4. Methods
4.1. Symbolic Domain Methods
4.1.1. Melody Generation
- Lyric-based Melody Generation
- 2.
- Musical attribute-based Melody Generation
- 3.
- Description-based Melody Generation
4.1.2. Polyphony Generation
- Musical Attribute-based Polyphony Generation
- 2.
- Description-based Polyphony Generation
4.2. Audio Domain Methods
4.2.1. Instrumental Music Generation
4.2.2. Singing Voice Synthesis
- Splicing Synthesis
- 2.
- Statistical Parameter Synthesis
- 3.
- Neural Network Synthesis
4.2.3. Complete Song Generation
4.3. Comments on Existing Techniques
- Rule-Based and Template Methods
- 2.
- Statistical Models
- 3.
- Generative Models
- 4.
- Transformer-Based Architectures
- 5.
- Large Language Models
5. Frameworks
5.1. Traditional Learning-Based Frameworks
- Text Encoding: The input text (e.g., lyrics) is converted into numerical representations using embedding layers, capturing semantic and rhythmic information.
- Sequence Generation: Deep learning models (e.g. LSTM, RNN) generate musical sequences (e.g., melody, chords, or rhythm) based on the encoded text.
- Output Synthesis: The generated musical sequences are converted into symbolic music formats (e.g., MIDI) or synthesized into audio.
5.2. Hybrid LLM-Augmented Frameworks
- Text Encoding: With traditional methods.
- LLM Module: Extracts key semantic features and contextual information from the input text and generates new content, such as lyrics or expanded descriptions, based on the input.
- Sequence Generation: With traditional methods.
- Output Synthesis: With traditional methods. Sometimes LLM is used to give feedback.
5.3. End-to-End LLM-Centric Frameworks
- Text Encoding: With traditional methods.
- LLM Processing: The encoded text is processed by the language model, which treats music as a sequence similar to text. The model predicts the next musical element (e.g., note, rhythm, or harmony) based on the current context, generating a complete musical sequence in an iterative manner. In this stage, the LLM is able to use its extensive pre-trained knowledge of language and patterns to generate musically coherent sequences that align with the input description.
- Output Synthesis: Extract symbol information from textual music sequences and synthesize them.
5.4. Comparative Analysis and Limitations
- Creativity: The ability to generate unique and diverse outputs.
- Control over Output: The level of control a user has over specific aspects of the generated music (e.g., tempo, harmony).
- Data Dependency: The reliance on high-quality labeled datasets for training the model. (More stars mean low dependency.)
- Generalization: The ability to adapt across different genres and tasks.
- Training Complexity: The computational cost and difficulty of training the model. (More stars mean low Complexity.)
- Output Quality: The coherence, relevance, and alignment of generated music with the text input.
6. Challenges and Future Directions
6.1. Challenges
6.1.1. Technical Level
- Dataset Scarcity and Representation Limitations
- 2.
- Model Training and Generalization
- 3.
- Evaluation Metrics for Creativity
- 4.
- Song Structure and Long-Term Coherence
- 5.
- Emotion Representation and Modeling
- 6.
- Interactivity between Human and Computer
6.1.2. Social Level
- Copyright Issues
- 2.
- Privacy Concerns
- 3.
- Music Industry Impact
6.2. Future Directions
- Enhancing Data Quality and Diversity
- 2.
- Optimizing Training Efficiency
- 3.
- Improving the Quality and Personalization
- 4.
- Deepening Understanding of Musical Structures
- 5.
- Bridging Music and Emotion
- 6.
- Advancing Cross-Modal Music Generation
- 7.
- Establishing Clear Copyright Ownership
- 8.
- Strengthening Privacy Protection
- 9.
- Fostering Collaboration Between Technology and Artists
7. Conclusion
Author Contributions
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | F0: The fundamental frequency of pitch, commonly used to describe the pitch of a sound. |
| 7 | |
| 8 | Relevant content referenced from the podcast: https://www.latent.space/p/suno
|
| 9 | |
| 10 |
References
- Ji, S.; Luo, J.; Yang, X. A Comprehensive Survey on Deep Music Generation: Multi-Level Representations, Algorithms, Evaluations, and Future Directions 2020.
- Ma, Y.; Øland, A.; Ragni, A.; Sette, B.M.D.; Saitis, C.; Donahue, C.; Lin, C.; Plachouras, C.; Benetos, E.; Shatri, E.; et al. Foundation Models for Music: A Survey 2024.
- Briot, J.-P.; Pachet, F. Music Generation by Deep Learning - Challenges and Directions. Neural Computing and Applications 2020, 32, 981–993. [Google Scholar] [CrossRef]
- Ji, S.; Yang, X.; Luo, J. A Survey on Deep Learning for Symbolic Music Generation: Representations, Algorithms, Evaluations, and Challenges. ACM Computing Surveys 2023, 56. [Google Scholar] [CrossRef]
- Hernandez-Olivan, C.; Beltran, J.R. Music Composition with Deep Learning: A Review 2021.
- Civit, M.; Civit-Masot, J.; Cuadrado, F.; Escalona, M.J. A Systematic Review of Artificial Intelligence-Based Music Generation: Scope, Applications, and Future Trends. Expert Systems with Applications 2022, 209, 118190. [Google Scholar] [CrossRef]
- Herremans, D.; Chuan, C.-H.; Chew, E. A Functional Taxonomy of Music Generation Systems. ACM Comput. Surv. 2017, 50, 69:1–69:30. [Google Scholar] [CrossRef]
- Zhu, Y.; Baca, J.; Rekabdar, B.; Rawassizadeh, R. A Survey of AI Music Generation Tools and Models. 2023. [CrossRef]
- Wen, Y.-W.; Ting, C.-K. Recent Advances of Computational Intelligence Techniques for Composing Music. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 578–597. [Google Scholar] [CrossRef]
- Xenakis, I. Formalized Music: Thought and Mathematics in Composition; Pendragon Press, 1992.
- Schot, J.W.; Hiller, L.; Isaacson, L.M. Experimental Music Composition with an Electronic Computer. In Proceedings of the Mathematics of Computation; October 1962; Vol. 16, p. 507.
- Fukayama, S.; Nakatsuma, K.; Sako, S.; Nishimoto, T.; Sagayama, S. Automatic Song Composition From The Lyrics Exploiting Prosody Of Japanese Language.; Zenodo, July 21 2010.
- Scirea, M.; Barros, G.A.B.; Shaker, N.; Togelius, J. SMUG: Scientific Music Generator.; 2015.
- Rütte, D. von; Biggio, L.; Kilcher, Y.; Hofmann, T. FIGARO: Controllable Music Generation Using Learned and Expert Features.; September 29 2022.
- Lu, P.; Xu, X.; Kang, C.; Yu, B.; Xing, C.; Tan, X.; Bian, J. MuseCoco: Generating Symbolic Music from Text. 2023. [CrossRef]
- Herremans, D.; Weisser, S.; Sörensen, K.; Conklin, D. Generating Structured Music for Bagana Using Quality Metrics Based on Markov Models. Expert Syst. Appl. 2015, 42, 7424–7435. [Google Scholar] [CrossRef]
- Wu, J.; Hu, C.; Wang, Y.; Hu, X.; Zhu, J. A Hierarchical Recurrent Neural Network for Symbolic Melody Generation. IEEE Transactions on Cybernetics 2020, 50, 2749–2757. [Google Scholar] [CrossRef]
- Guo, Z.; Dimos, M.; Dorien, H. Hierarchical Recurrent Neural Networks for Conditional Melody Generation with Long-Term Structure 2021.
- Choi, K.; Fazekas, G.; Sandler, M. Text-Based LSTM Networks for Automatic Music Composition. arXiv preprint, 2016; arXiv:1604.05358 2016. [Google Scholar]
- Dong, H.-W.; Hsiao, W.-Y.; Yang, L.-C.; Yang, Y.-H. MuseGAN: Multi-Track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment. Proceedings of the AAAI Conference on Artificial Intelligence 2018, 32. [Google Scholar] [CrossRef]
- Huang, C.-Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.M.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.; Dinculescu, M.; Eck, D. Music Transformer: Generating Music with Long-Term Structure.; September 12 2018.
- Borsos, Z.; Marinier, R.; Vincent, D.; Kharitonov, E.; Pietquin, O.; Sharifi, M.; Roblek, D.; Teboul, O.; Grangier, D.; Tagliasacchi, M.; et al. AudioLM: A Language Modeling Approach to Audio Generation 2023.
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models 2022.
- Forsgren, S. Riffusion Stable Diffusion for Real-Time Music Generation. 2022.
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report 2024.
- Huang, Y.-S.; Yang, Y.-H. Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions. Proceedings of the 28th ACM International Conference on Multimedia 2020, 1180–1188. [Google Scholar] [CrossRef]
- Monteith, K.; Martinez, T.; Ventura, D. Automatic Generation of Melodic Accompaniments for Lyrics.; 2012.
- Ackerman, M.; Loker, D. Algorithmic Songwriting with ALYSIA. In Proceedings of the Computational Intelligence in Music, Sound, Art and Design; Correia, J., Ciesielski, V., Liapis, A., Eds.; Springer International Publishing: Cham, 2017; pp. 1–16. [Google Scholar]
- Bao, H.; Huang, S.; Wei, F.; Cui, L.; Wu, Y.; Tan, C.; Piao, S.; Zhou, M. Neural Melody Composition from Lyrics. 2019, 11838, 499–511. [Google Scholar] [CrossRef]
- Yu, Y.; Srivastava, A.; Canales, S. Conditional LSTM-GAN for Melody Generation from Lyrics. ACM Trans. Multimedia Comput. Commun. Appl. 2021, 17, 1–20. [Google Scholar] [CrossRef]
- Srivastava, A.; Duan, W.; Shah, R.R.; Wu, J.; Tang, S.; Li, W.; Yu, Y. Melody Generation from Lyrics Using Three Branch Conditional LSTM-GAN. In Proceedings of the MultiMedia Modeling; Þór Jónsson, B., Gurrin, C., Tran, M.-T., Dang-Nguyen, D.-T., Hu, A.M.-C., Huynh Thi Thanh, B., Huet, B., Eds.; Springer International Publishing: Cham, 2022; pp. 569–581. [Google Scholar]
- Yu, Y.; Zhang, Z.; Duan, W.; Srivastava, A.; Shah, R.; Ren, Y. Conditional Hybrid GAN for Melody Generation from Lyrics. Neural Comput & Applic 2023, 35, 3191–3202. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, Y.; Takasu, A. Controllable Lyrics-to-Melody Generation. Neural Comput & Applic 2023, 35, 19805–19819. [Google Scholar] [CrossRef]
- Sheng, Z.; Song, K.; Tan, X.; Ren, Y.; Ye, W.; Zhang, S.; Qin, T. SongMASS: Automatic Song Writing with Pre-Training and Alignment Constraint. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence; May 18 2021; Vol. 35, pp. 13798–13805.
- Ju, Z.; Lu, P.; Tan, X.; Wang, R.; Zhang, C.; Wu, S.; Zhang, K.; Li, X.-Y.; Qin, T.; Liu, T.-Y. TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing 2022, 5426–5437. [Google Scholar] [CrossRef]
- Ding, S.; Liu, Z.; Dong, X.; Zhang, P.; Qian, R.; He, C.; Lin, D.; Wang, J. SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation. 2024. [Google Scholar] [CrossRef]
- Davis, H.; Mohammad, S. Generating Music from Literature. In Proceedings of the Proceedings of the 3rd Workshop on Computational Linguistics for Literature (CLFL); Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 1–10. [Google Scholar]
- Rangarajan, R. Generating Music from Natural Language Text. 2015 Tenth International Conference on Digital Information Management (ICDIM) 2015, 85–88. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.; Wang, D.; Xia, G. BUTTER: A Representation Learning Framework for Bi-Directional Music-Sentence Retrieval and Generation. In Proceedings of the Proceedings of the 1st Workshop on NLP for Music and Audio (NLP4MusA); Oramas, S., Espinosa-Anke, L., Epure, E., Jones, R., Sordo, M., Quadrana, M., Watanabe, K., Eds.; Association for Computational Linguistics: Online, 2020; pp. 54–58. [Google Scholar]
- Wu, S.; Sun, M. Exploring the Efficacy of Pre-Trained Checkpoints in Text-to-Music Generation Task 2023.
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models 2023.
- Yuan, R.; Lin, H.; Wang, Y.; Tian, Z.; Wu, S.; Shen, T.; Zhang, G.; Wu, Y.; Liu, C.; Zhou, Z.; et al. ChatMusician: Understanding and Generating Music Intrinsically with LLM. 2024. [CrossRef]
- Liang, X.; Du, X.; Lin, J.; Zou, P.; Wan, Y.; Zhu, B. ByteComposer: A Human-like Melody Composition Method Based on Language Model Agent 2024.
- Deng, Q.; Yang, Q.; Yuan, R.; Huang, Y.; Wang, Y.; Liu, X.; Tian, Z.; Pan, J.; Zhang, G.; Lin, H.; et al. ComposerX: Multi-Agent Symbolic Music Composition with LLMs 2024.
- Liu, H.; Chen, Z.; Yuan, Y.; Mei, X.; Liu, X.; Mandic, D.; Wang, W.; Plumbley, M.D. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models 2023.
- Ghosal, D.; Majumder, N.; Mehrish, A.; Poria, S. Text-to-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model 2023.
- Majumder, N.; Hung, C.-Y.; Ghosal, D.; Hsu, W.-N.; Mihalcea, R.; Poria, S. Tango 2: Aligning Diffusion-Based Text-to-Audio Generations through Direct Preference Optimization. In Proceedings of the Proceedings of the 32nd ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, October 28, 2024; pp. 564–572. [Google Scholar]
- Huang, Q.; Park, D.S.; Wang, T.; Denk, T.I.; Ly, A.; Chen, N.; Zhang, Z.; Zhang, Z.; Yu, J.; Frank, C.; et al. Noise2Music: Text-Conditioned Music Generation with Diffusion Models 2023.
- Schneider, F.; Kamal, O.; Jin, Z.; Schölkopf, B. Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion. 2023. [Google Scholar] [CrossRef]
- Li, P.P.; Chen, B.; Yao, Y.; Wang, Y.; Wang, A.; Wang, A. JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models. 2024 IEEE Conference on Artificial Intelligence (CAI) 2024, 762–769. [Google Scholar] [CrossRef]
- Agostinelli, A.; Denk, T.I.; Borsos, Z.; Engel, J.; Verzetti, M.; Caillon, A.; Huang, Q.; Jansen, A.; Roberts, A.; Tagliasacchi, M.; et al. MusicLM: Generating Music From Text 2023.
- Huang, Q.; Jansen, A.; Lee, J.; Ganti, R.; Li, J.Y.; Ellis, D.P.W. MuLan: A Joint Embedding of Music Audio and Natural Language 2022.
- Lam, M.W.Y.; Tian, Q.; Li, T.; Yin, Z.; Feng, S.; Tu, M.; Ji, Y.; Xia, R.; Ma, M.; Song, X.; et al. Efficient Neural Music Generation. Advances in Neural Information Processing Systems 2023, 36, 17450–17463. [Google Scholar]
- Chen, K.; Wu, Y.; Liu, H.; Nezhurina, M.; Berg-Kirkpatrick, T.; Dubnov, S. MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies. In Proceedings of the ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); April 2024; pp. 1206–1210. [Google Scholar]
- Copet, J.; Kreuk, F.; Gat, I.; Remez, T.; Kant, D.; Synnaeve, G.; Adi, Y.; Defossez, A. Simple and Controllable Music Generation. Advances in Neural Information Processing Systems 2023, 36, 47704–47720. [Google Scholar]
- Macon, M.W.; Jensen-Link, L.; George, E.; Oliverio, J.C.; Clements, M. Concatenation-Based MIDI-to-Singing Voice Synthesis. Journal of The Audio Engineering Society 1997. [Google Scholar]
- Kenmochi, H.; Ohshita, H. VOCALOID-Commercial Singing Synthesizer Based on Sample Concatenation. In Proceedings of the Interspeech; 2007; Vol. 2007; pp. 4009–4010. [Google Scholar]
- Saino, K.; Zen, H.; Nankaku, Y.; Lee, A.; Tokuda, K. An HMM-Based Singing Voice Synthesis System. In Proceedings of the Interspeech 2006; ISCA, September 17 2006; p. paper 2077-Thu1BuP.7-0.
- Nishimura, M.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Deep Neural Networks. In Proceedings of the Interspeech 2016; ISCA, September 8 2016; pp. 2478–2482. [Google Scholar]
- Nakamura, K.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Convolutional Neural Networks 2019.
- Kim, J.; Choi, H.; Park, J.; Kim, S.; Kim, J.; Hahn, M. Korean Singing Voice Synthesis System Based on an LSTM Recurrent Neural Network. In Proceedings of the Proc. Interspeech; 2018; pp. 1551–1555. [Google Scholar]
- Hono, Y.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Generative Adversarial Networks. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019; 6955–6959. [Google Scholar] [CrossRef]
- Lu, P.; Wu, J.; Luan, J.; Tan, X.; Zhou, L. XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System 2020.
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. FastSpeech: Fast, Robust and Controllable Text to Speech 2019.
- Morise, M.; Yokomori, F.; Ozawa, K. World: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications. IEICE TRANSACTIONS on Information and Systems 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Blaauw, M.; Bonada, J. Sequence-to-Sequence Singing Synthesis Using the Feed-Forward Transformer. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020; 7229–7233. [Google Scholar] [CrossRef]
- Zhuang, X.; Jiang, T.; Chou, S.-Y.; Wu, B.; Hu, P.; Lui, S. Litesing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis; 2021; p. 7082.
- Lee, G.-H.; Kim, T.-W.; Bae, H.; Lee, M.-J.; Kim, Y.-I.; Cho, H.-Y. N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement 2022.
- Chen, J.; Tan, X.; Luan, J.; Qin, T.; Liu, T.-Y. HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis 2020.
- Yamamoto, R.; Song, E.; Kim, J.-M. Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram 2020.
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis 2017.
- Gu, Y.; Yin, X.; Rao, Y.; Wan, Y.; Tang, B.; Zhang, Y.; Chen, J.; Wang, Y.; Ma, Z. ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders.; January 24 2021; pp. 1–5.
- Liu, J.; Li, C.; Ren, Y.; Chen, F.; Zhao, Z. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism 2022.
- Hono, Y.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Sinsy: A Deep Neural Network-Based Singing Voice Synthesis System. IEEE/ACM Transactions on Audio, Speech, and Language Processing 2021, PP, 1–1. [CrossRef]
- Zhang, Y.; Cong, J.; Xue, H.; Xie, L.; Zhu, P.; Bi, M. VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis 2022.
- Zhang, Y.; Xue, H.; Li, H.; Xie, L.; Guo, T.; Zhang, R.; Gong, C. VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer 2022.
- Kim, J.; Kong, J.; Son, J. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning; PMLR, July 1 2021; pp. 5530–5540.
- Dhariwal, P.; Jun, H.; Payne, C.; Kim, J.W.; Radford, A.; Sutskever, I. Jukebox: A Generative Model for Music. arXiv preprint, arXiv:2005.00341 2020.
- Hong, Z.; Huang, R.; Cheng, X.; Wang, Y.; Li, R.; You, F.; Zhao, Z.; Zhang, Z. Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment 2024.
- Bai, Y.; Chen, H.; Chen, J.; Chen, Z.; Deng, Y.; Dong, X.; Hantrakul, L.; Hao, W.; Huang, Q.; Huang, Z.; et al. Seed-Music: A Unified Framework for High Quality and Controlled Music Generation 2024.
- Chen, G.; Liu, Y.; Zhong, S.; Zhang, X. Musicality-Novelty Generative Adversarial Nets for Algorithmic Composition. Proceedings of the 26th ACM international conference on Multimedia 2018, 1607–1615. [Google Scholar] [CrossRef]
- Hakimi, S.H.; Bhonker, N.; El-Yaniv, R. BebopNet: Deep Neural Models for Personalized Jazz Improvisations. In Proceedings of the ISMIR; 2020; pp. 828–836. [Google Scholar]
- Martinez, T.R.; Monteith, K.; Ventura, D.A. Automatic Generation of Music for Inducing Emotive Response. 2010.
- Hung, H.-T.; Ching, J.; Doh, S.; Kim, N.; Nam, J.; Yang, Y.-H. EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-Based Music Generation 2021.
- Zheng, K.; Meng, R.; Zheng, C.; Li, X.; Sang, J.; Cai, J.; Wang, J.; Wang, X. EmotionBox: A Music-Element-Driven Emotional Music Generation System Based on Music Psychology. Front. Psychol. 2022, 13. [Google Scholar] [CrossRef] [PubMed]
- Neves, P.; Fornari, J.; Florindo, J. Generating Music with Sentiment Using Transformer-GANs 2022.
- Dash, A.; Agres, K.R. AI-Based Affective Music Generation Systems: A Review of Methods, and Challenges 2023.
- Ji, S.; Yang, X. EmoMusicTV: Emotion-Conditioned Symbolic Music Generation With Hierarchical Transformer VAE. IEEE Trans. Multimedia 2024, 26, 1076–1088. [Google Scholar] [CrossRef]
- Jiang, N.; Jin, S.; Duan, Z.; Zhang, C. RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence; April 3 2020; Vol. 34, pp. 710–718.
- Louie, R.; Coenen, A.; Huang, C.Z.; Terry, M.; Cai, C.J. Novice-AI Music Co-Creation via AI-Steering Tools for Deep Generative Models. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems 2020, 1–13. [Google Scholar] [CrossRef]
- Surbhi, A.; Roy, D. Tunes of Tomorrow: Copyright and AI-Generated Music in the Digital Age. AIP Conference Proceedings 2024, 3220, 050003. [Google Scholar] [CrossRef]
- Bulayenko, O.; Quintais, J.P.; Gervais, D.J.; Poort, J. AI Music Outputs: Challenges to the Copyright Legal Framework 2022.
- Hsiao, W.-Y.; Liu, J.-Y.; Yeh, Y.-C.; Yang, Y.-H. Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs. Proceedings of the AAAI Conference on Artificial Intelligence 2021, 35, 178–186. [Google Scholar] [CrossRef]
- Josan, H.H.S. AI and Deepfake Voice Cloning: Innovation, Copyright and Artists’ Rights. Artificial Intelligence 2024. [Google Scholar]
- Zhang, Z.; Ning, H.; Shi, F.; Farha, F.; Xu, Y.; Xu, J.; Zhang, F.; Choo, K.-K.R. Artificial Intelligence in Cyber Security: Research Advances, Challenges, and Opportunities. Artif Intell Rev 2022, 55, 1029–1053. [Google Scholar] [CrossRef]
- Fox, M.; Vaidyanathan, G.; Breese, J.L. The Impact of Artificial Intelligence on Musicians. Issues in Information Systems 2024, 25. [Google Scholar]


| Category | Description | Application Example |
Generation Characteristics | Challenges |
|---|---|---|---|---|
| Lyrics | The singing words of songs. | "Let it be, let it be..." |
|
|
| Musical Attributes |
Describes musical rules like chords. | I-IV-V-I, 120 bpm |
|
|
| Natural Language Description |
Describes emotion or scene. | "Create a melody filled with hope..." |
|
|
| Event Type | Description | Example Format |
|---|---|---|
| Note On | Starts a note | Note On, Channel 1, Pitch 60, Velocity 100 |
| Note Off | Ends a note | Note Off, Channel 1, Pitch 60, Velocity 0 |
| Program Change | Changes in instrument or sound | Program Change, Channel 1, Program 32 |
| Control Change | Adjusts control parameters (e.g., volume, sustain pedal) | Control Change, Channel 1, Controller 64, Value 127 |
| Pitch Bend | Bends pitch slightly or continuously | Pitch Bend, Channel 1, Value 8192 |
| Aftertouch | Pressure applied after pressing a note | Aftertouch, Channel 1, Pressure 60 |
| Tempo Change | Sets playback speed in beats per minute (BPM) | Tempo Change, 120 BPM |
| Time Signature | Defines beat structure (e.g., 4/4, 3/4 time) | Time Signature, 4/4 |
| Key Signature | Sets the song’s key (e.g., C Major, G Minor) | Key Signature, C Major |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Description | Large Model Relevance | Dataset Name | Generated Music Length | Accessed Link |
|---|---|---|---|---|---|---|---|---|---|
| Lyric-based Melody Generation | SongComposer [36] | 2024 | MIDI | Transformer | LLM, Instruction Following, Next Token Prediction | A LLM designed for composing songs | SongCompose-PT | Multiple minutes | https://pjlab-songcomposer.github.io/ |
| TeleMelody [35] | 2022 | MIDI | Transformer | Transformer-based Encoder-Decoder, Template-Based Two-Stage Method | / | lyric-rhythm data (9,761 samples in English and 74,328 samples in Chinese) | Not mentioned | https://ai-muzic.github.io/telemelody/ | |
| SongMass [34] | 2021 | MIDI | Transformer | Pre-training, the sentence-level and token-level alignment constraints. | / | 380,000+ lyrics from MetroLyrics; The Lakh MIDI Dataset | Not mentioned | https://musicgeneration.github.io/SongMASS/ | |
| [30] | 2021 | MIDI | LSTM-GAN | Conditional LSTM-GAN, Synchronized Lyrics - Note Alignment | / | 12,197 MIDI songs | Not mentioned | https://drive.google.com/file/d/1ugOwfBsURax1VQ4jHmI8P3ldE5xdDj0l/view?usp=sharing | |
| SongWriter [29] | 2019 | MIDI | RNN | Seq-to-Seq, Lyric-Melody Alignment | / | 18,451 Chinese pop songs | Not mentioned | / | |
| ALYSIA [28] | 2017 | MusicXML&MIDI | Random Forests | Co-creative Songwriting Partner, Rhythm Model, Melody Model | / | / | Not mentioned | http://bit.ly/2eQHado | |
| Orpheus [12] | 2010 | MIDI | / | Dynamic Programming | / | Japanese prosody dataset | Not mentioned | http://orpheus.hil.t.u-tokyo.ac.jp | |
| Musical attribute-based Melody Generation | BUTTER [39] | 2020 | MIDI, ABC Notation | VAE | Representation Learning, Bi-directional Music-Text Retrieval | / | 16,257 Chinese folk songs | Short Music Fragment | https://github.com/ldzhangyx/BUTTER |
| [38] | 2015 | MIDI | / | Full parse tree, POS Tag | / | / | Not mentioned | / | |
| TransProse [37] | 2014 | MIDI | Markov Chains | Generate music from Literature, Emotion Density | / | Emotional words from literature | Not mentioned | http://transprose.weebly.com/final-pieces.html | |
| Description-based Melody Generation | ChatMusician [42] | 2024 | ABC Notation | Transformer | Music Reasoning, Repetition Structure | An LLM of symbolic music understanding and generation | MusicPile (4B tokens) | Full Score of ABC Notation | https://shanghaicannon.github.io/ChatMusician/ |
| [40] | 2023 | ABC Notation | Transformer | Exploring the Efficacy of Pre-trained Checkpoints. | Using pre-trained checkpoints | Textune (282,870 text-tune pairs) | Full Score of ABC Notation | / |
| Agent Name | Task Description |
|---|---|
| Group Leader Agent | Responsible for analyzing user input and breaking it down into specific tasks to be assigned to other agents. |
| Melody Agent | Generates a monophonic melody under the guidance of the Group Leader. |
| Harmony Agent | Adds harmony and counterpoint elements to the composition to enrich its structure. |
| Instrument Agent | Selects appropriate instruments for each voice part. |
| Reviewer Agent | Evaluates and provides feedback on the melody, harmony, and instrument choices. |
| Arrangement Agent | Standardizes the final output into ABC notation format. |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Description | Large Model Relevance | Dataset Name | Generated Music Length | Accessed Link |
|---|---|---|---|---|---|---|---|---|---|
| Musical Attribute-based Polyphony Generation | FIGARO [14] | 2023 | REMI+ | Transformer | Human- interpretable, Expert Description, Multi-Track |
/ | LakhMIDI Dataset | Not mentioned | https://tinyurl.com/28etxz27 |
| MuseCoco [15] | 2023 | MIDI | Transformer | Text-to-attribute understanding and attribute-to-music generation | Textual synthesis and template refinement | MMD, EMOPIA, MetaMidi, POP909, Symphony, Emotion-gen |
<= 16 bars | https://ai-muzic.github.io/musecoco/ | |
| Description- based Polyphony Generation |
ByteComposer [43] |
2024 | MIDI | Transformer | Imitate the human creative process, Multi-step Reasoning, Procedural Control | A melody composition LLM agent | the Irish Massive ABC Notation dataset | Not mentioned | / |
| ComposerX [44] | 2024 | ABC Notation | Transformer | Significantly improve the music generation quality of GPT-4 through a multi-agent approach | Multi-agent LLM-based framework | the Irish Massive ABC Notation dataset, KernScores |
Varied Lengths | https://lllindsey0615.github.io/ComposerX_demo/ |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Description | Large Model Relevance | Dataset Name | Generated Music Length | Accessed Link |
|---|---|---|---|---|---|---|---|---|---|
| Commercial instrumental music Generation | Mubert | / | Waveform | / | Tag-based control, Music segment combination | / | / | Varied lengths | https://mubert.com/ |
| Description-based instrumental music Generation | JEN-1 [50] | 2024 | Waveform | Diffusion | Omnidirectional Diffusion Models,Hybrid AR and NAR Architecture, Masked Noise Robust Autoencoder | / | Pond5, MusicCaps |
Varied lengths | https://jenmusic.ai/audio-demos |
| MusicLDM [54] | 2024 | Mel-Spectrogram | Diffusion | Beat-synchronous mixup,Latent Diffusion,CLAP,AudioLDM | Trained on Broad Data at Scale | Audiostock dataset, 2.8 Million text-audio pairs | Varied lengths | https://musicldm.github.io/ | |
| Moûsai [49] | 2023 | Waveform (48kHz@2) | Diffusion | Latent Diffusion, 64x compression | / | TEXT2MUSIC Dataset | Multiple minutes | https://bit.ly/audio-diffusion | |
| MusicGen [55] | 2023 | Discrete tokens (32kHz) | Transformer | Transformer LM,Codebook Interleaving Strategy | Trained on Broad Data at Scale | Internal Dataset,ShutterStock,Pond5,MusicCaps | <= 5 minutes | https://github.com/facebookresearch/audiocraft | |
| MeLoDy [53] | 2023 | Waveform (32kHz) | Diffusion& VAE-GAN |
Dual-path diffusion, language model,Audio VAE-GAN | Trained LLaMA for semantic modeling | 257k hours of music | 10s - 30s | https://efficient-melody.github.io/ | |
| MusicLM [51] | 2023 | Waveform (24kHz) | Transformer | Based on AudioLM,multi-stage modeling, MuLan | Optimize using pre-trained models Mulan and w2v-BERT | MusicCaps (280k hours) | Multiple minutes | https://google-research.github.io/seanet/musiclm/examples/ | |
| Noise2Music [48] | 2023 | Spectrogram and Waveform(better) | Diffusion | Cascading diffusion,1D Efficient U-Net | Using for Description for Training Generation and Text Embedding Extraction | MuLaMCap (150k hours) | 30 seconds | https://google-research.github.io/noise2music | |
| Riffusion [24] | 2022 | Spectrogram | Diffusion | Tag-based control, Music segment combination | / | / | ≈10 seconds | https://www.riffusion.com/ |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Keywords | Dataset Name | Accessed Link |
|---|---|---|---|---|---|---|---|
| Commercial Singing Voice Engine | ACE Studio | 2021 | / | / | AI synthesis,Auto pitch | / | https://acestudio.ai/ |
| Synthesizer V Studio | 2018 | / | / | WaveNet vocoder,DNN,AI synthesis | / | https://dreamtonics.com/synthesizerv/ | |
| Vocaloid | 2004 | Waveform&Spectrum | / | sample concatenation | / | https://www.vocaloid.com/ | |
| Singing Voice Synthesis | VISinger 2 [76] | 2022 | Mel-Spectrogram | VAE+DSP | conditional VAE,Improved Decoder, Parameter Optimization, Higher Sampling Rate(Considering to VISinger) | OpenCpop | https://zhangyongmao.github.io/VISinger2/ |
| VISinger [75] | 2022 | Mel-Spectrogram | VAE | end-to-end solution, F0 predictor, normalizing flow based prior encoder and adversarial decoder | 4.7 hours singing dataset with 100 songs | https://zhangyongmao.github.io/VISinger/ | |
| DiffSinger [73] | 2021 | Mel-Spectrogram | Diffusion+Neural Vocoder | Shallow diffusion mechanism, parameterized Markov chain, Denoising Diffusion Probabilistic Model, FastSpeech | PopCS | https://diffsinger.github.io | |
| HiFiSinger [69] | 2020 | Mel-Spectrogram | Transformer + Neural Vocoder | Parallel WaveGAN (sub-frequency GAN+multi-length GAN), FastSpeech | Chinese Mandarin pop songs | https://speechresearch.github.io/hifisinger/ | |
| ByteSing [72] | 2020 | Mel-Spectrogram | Transformer+Neural Vocoder | WaveRNN, Auxiliary Phoneme Duration Prediction model, Tacotron | 90 Chinese songs (MusicXML1) | https://ByteSings.github.io | |
| XiaoiceSing [63] | 2020 | Acoustic parameters | Transformer + WORLD | integrated network, Residual F0, syllable duration modeling, FastSpeech | Mandarin pop songs | https://xiaoicesing.github.io/ | |
| [59] | 2016 | Acoustic parameters | DNN | musical-note-level pitch normalization, linear-interpolation | 70 Japanese children’s songs (female) | / | |
| [58] | 2006 | Acoustic parameters | HMM | Context-dependent HMMs, duration models, and time-lag models | 60 Japanese children’s songs (male) | https://www.sp.nitech.ac.jp/~k-saino/music/ | |
| Lyricos [56] | 1997 | Waveform | Sinusoidal model | ABS/OLA sinusoidal model, vibrato, phonetic modeling | ten minutes of continuous singing data | / |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Keywords | Large Model Relevance | Dataset Name | Generated Music Length | Accessed Link |
|---|---|---|---|---|---|---|---|---|---|
| Text-to- Song Generation |
Seed-Music [80] |
2024 | Waveform & MIDI | Transformer& Diffusion |
Multi-modal Inputs, Auto-regressive Language Modeling,Vocoder Latents,Zero-shot Singing Voice Conversion | Large multi-modal language models for understanding and generation | Not mentioned | Varied Length | https://team.doubao.com/en/special/seed-music |
| Melodist [79] | 2024 | Waveform | Transformer | Tri-Tower Contrastive Pre-training, Cross-Modality Information Matching, Lyrics and Prompt-based | Using LLM to generate natural language prompts | Chinese song datasets and Open-Source Datasets | Not mentioned | https://text2songMelodist.github.io/Sample/ | |
| Jukebox [78] | 2020 | Waveform | VQ-VAE+ Transformer |
Multiscale VQ-VAE, Autoregressive Transformer, Conditional Generation, Hierarchical Modeling |
Trained on Broad Data at Scale | 1.2 million songs with lyrics | Multiple minutes | https://jukebox.openai.com/ | |
| Commercial Complete Song Generation | Suno AI | 2023 | Waveform | Transformer | Heuristic method, Audio Tokenization, Zero threshold for use |
/ | Singing audio and non-singing audio | <= 4 minutes | https://alpha.suno.ai/ |
| Creativity | Control over Output | Data Dependency | Generalization | Training Complexity | Output Quality | |
|---|---|---|---|---|---|---|
| Traditional Methods | ★★ | ★★★ | ★★ | ★★ | ★★★★★ | ★★★ |
| Hybrid Approaches | ★★★★ | ★★★★ | ★★★ | ★★★ | ★★★ | ★★★★ |
| End-to-End LLM Systems | ★★★★★ | ★★★★★ | ★★★★ | ★★★★★ | ★★ | ★★★★★ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



