Submitted:
16 February 2025
Posted:
17 February 2025
You are already at the latest version
Abstract
Efficient resource management in cloud-based web platforms is critical to maintaining performance and cost efficiency under dynamic and unpredictable workloads. This paper proposes a novel resource management framework that integrates predictive workload modeling, multi-tier autoscaling, and cost-aware optimization. The framework utilizes machine learning models to forecast workload patterns and coordinates resource allocation across application, caching, and storage tiers, ensuring minimal latency and optimal resource utilization. Experimental results demonstrate a 45% reduction in mean latency and a 30% decrease in total resource costs compared to traditional threshold-based autoscaling. The framework also improves resource utilization to 85% on average while halving the frequency of scaling actions, reducing operational instability. These outcomes highlight the effectiveness of the proposed approach in balancing performance and cost objectives in complex cloud environments. The proposed framework advances the state of the art in cloud resource management by addressing inter-tier dependencies and leveraging predictive analytics for proactive scaling. Its adaptability to diverse workload patterns and potential applicability to multi-cloud and edge computing scenarios make it a scalable and robust solution for modern web platforms.
Keywords:
Cloud Computing
; Resource Management
; Autoscaling
; Machine Learning
; Performance Optimization
; Cost Efficiency
1. Introduction
High-performance web platforms, ranging from e-commerce applications to social media and streaming services, increasingly rely on the elastic nature of cloud infrastructures to handle highly variable and unpredictable workloads [1,2,3]. The key promise of cloud computing lies in its ability to dynamically provision and deprovision resources—such as virtual machines, containers, and storage services—on demand. This elasticity ensures that system operators can closely match resource supply to workload demand, potentially reducing operational costs while maintaining service quality. However, achieving this ideal balance between performance, elasticity, and cost remains a persistent challenge [4,5,6,7].
Contemporary autoscaling strategies used by industry-standard frameworks (e.g., Amazon Web Services Auto Scaling, Kubernetes Horizontal Pod Autoscaler) often rely on simple threshold-based triggers to react to spikes in CPU or memory utilization. While such reactive mechanisms have proved useful, they commonly suffer from delayed responses and inefficient resource allocation when faced with rapidly shifting traffic patterns, complex multi-tier architectures, and time-varying performance requirements [1,8]. As a consequence, conventional autoscaling may lead to latency violations during unexpected demand surges or result in significant resource wastage during quieter periods. Given the scale and complexity of modern distributed web services, more sophisticated resource management solutions are required.
Recent advances in predictive modeling and machine learning (ML) for cloud resource management suggest new avenues to address these limitations. Research efforts have explored time-series forecasting models and ML-based predictors to anticipate workload fluctuations before they occur, enabling proactive scaling decisions [5,7]. Such approaches leverage historical traffic data, seasonality patterns, and context-specific features to estimate short-term future load, thus guiding preemptive resource adjustments. However, many existing predictive strategies focus on a single infrastructure layer, such as the application server tier, and rarely consider the intricate interplay between multiple components (e.g., caches, load balancers, databases) that collectively influence end-to-end performance [1,2,9].
Furthermore, while performance-focused autoscaling approaches commonly emphasize latency reduction and throughput maximization, they may overlook the complex and often nonlinear relationship between resource allocation and operational cost. Cloud platforms employ diverse pricing models—ranging from on-demand instances and spot markets to sustained use discounts—adding another dimension to the resource management problem [10,11]. Effective strategies must therefore account for not only the technical performance indicators (e.g., tail latency, error rates) but also the financial implications of scaling decisions. Balancing these objectives is especially crucial in multi-cloud and geo-distributed deployments, where optimizing cost and latency jointly can substantially improve total cost of ownership (TCO) while ensuring high service availability [12,13].
In this paper, we propose an adaptive, ML-enhanced resource management strategy for high-performance cloud-based web platforms that addresses the aforementioned challenges. Our approach integrates predictive workload modeling, multi-tier autoscaling, and cost-aware optimization into a cohesive framework. By doing so, it aims to:
Our contributions extend beyond state-of-the-art practices by unifying performance optimization, workload prediction, and economic considerations into an integrated resource management paradigm. We implement and evaluate the proposed framework on a Kubernetes-based testbed equipped with real and synthetic workload traces. The results demonstrate that our approach significantly outperforms conventional threshold-based strategies in terms of latency, stability under dynamic conditions, and overall cost savings.
The remainder of this paper is structured as follows: Section 2 reviews the related work on autoscaling, predictive modeling, and cost-performance trade-offs in cloud computing environments. Section 3 presents our system model and key assumptions. Section 4 details our proposed ML-driven, multi-tier resource management framework and its components, including predictive workload modeling, multi-tier autoscaling policies, and cost-aware optimization algorithms. We discuss broader implications, limitations, and potential avenues for future research in Section 6, and conclude in Section 7.
2. Related Work
The challenge of effectively managing cloud resources to meet performance objectives and cost constraints has attracted substantial attention from both academia and industry. Early efforts focused on reactive autoscaling mechanisms, where additional resources are provisioned after certain utilization thresholds are exceeded. Although straightforward to implement, these methods often lead to delayed responses and overshoot scenarios due to their inherently reactive nature. Such basic strategies fail to fully capture the complexities of modern, distributed, multi-tier architectures, where performance degradation in one component layer (e.g., caching tiers, load balancers) can propagate and affect the entire system.
One line of research has explored analytic and statistical modeling approaches to guide resource allocation decisions. For instance, Zhang et al. proposed regression-based analytic models to anticipate the resource demands of multi-tier web applications, demonstrating that accurate performance forecasting can help avoid unnecessary overprovisioning [14]. Similarly, Mao et al. integrated deadline and budget constraints into autoscaling policies, refining resource allocation to better align with both performance objectives and economic considerations [15]. Such studies underscore the importance of predictive insights in improving autoscaling effectiveness.
The interplay between performance and reliability in cloud management has also been examined. Addis et al. introduced autonomic techniques to ensure service availability, presenting frameworks that dynamically adjust resource levels in response to changing workloads and system health metrics [16]. Appleby et al. developed Oceano, an early SLA-based computing utility framework, which provided a stepping stone toward integrated resource management solutions capable of meeting contracted service-level agreements through adaptive provisioning [17]. These works laid the foundation for holistic management schemes that coordinate multiple layers of the infrastructure.
Moving beyond single-tier or isolated resource pools, recent studies emphasize controlling entire resource ecosystems. The concept of integrated multi-tier scaling has become more prominent, as demonstrated in approaches that combine caching and application server scaling to improve end-to-end latency [18]. Other researchers have examined the use of virtualization technologies and virtual machine (VM) placement algorithms to optimize resource usage across clustered environments. For example, Bobroff et al. explored dynamic placement of VMs to respond to workload variations, aiming to minimize costs and maintain performance goals [19]. Nathuji et al. introduced VirtualPower, a coordinated power management approach in virtualized systems, showing that resource adjustments at the virtualization layer can influence energy consumption and operational cost without sacrificing performance [20].
In parallel, cost-aware cloud resource management has received increasing attention. Wang et al. applied auction-based mechanisms to find cost-effective resource allocations in multi-cloud environments, highlighting that leveraging diverse pricing models can reduce expenditures if properly orchestrated [21]. Similarly, Dutreilh et al. introduced control theory concepts to autonomously tune resource allocations, enabling stable and cost-efficient operation under dynamic conditions [22]. Ali-Eldin et al. explored elastic management techniques that minimize response time violations and resource waste by adapting the level of elasticity according to observed workload patterns [23].
While these studies have advanced the field significantly, two key gaps remain. First, many existing solutions operate at a single layer of the stack (e.g., just the application server tier) or treat each resource component as an isolated subsystem. This narrow focus overlooks the intricate interdependencies between layers—such as how changes in caching or load balancing policies can impact the computational or storage tiers. Second, although some works incorporate cost-awareness, a comprehensive approach that continuously integrates predictive modeling, performance constraints, and fine-grained economic factors remains underexplored.
In contrast to these works, our approach integrates predictive workload modeling with a multi-tier, cost-aware orchestration strategy. By unifying real-time forecasting, end-to-end coordination, and economic optimization, our framework aims to push beyond the limitations of prior methods, delivering stable, high-performance, and cost-effective resource management for complex, cloud-based web platforms.
3. System Model and Assumptions
This work considers a cloud-based web platform consisting of multiple interacting service layers, each capable of independent scaling. The platform processes user requests through a tiered architecture comprising load balancers, application servers, caching systems, and storage backends. These components collaboratively handle dynamic workloads while ensuring efficient resource utilization and performance compliance.
3.1. Cloud Environment and Elasticity Properties
The platform operates in a public cloud environment that supports horizontal scaling for compute and storage resources. Containerized microservices and virtual machine instances form the basis of the compute infrastructure, enabling on-demand provisioning and termination. The resource pricing model follows standard cloud provider practices, where costs are incurred based on CPU-hours, memory utilization, and storage volumes. The elasticity properties of the system allow for granular scaling adjustments to meet workload demands within predefined latency and performance thresholds.
3.2. Performance and Economic Metrics
System performance is characterized by key metrics such as request latency, throughput, and reliability. Specifically, the focus is on maintaining low response times under high demand while minimizing request failures. Resource management decisions are evaluated against economic metrics, including total operational cost and resource utilization efficiency. The optimization objective is to achieve a balance between performance and cost, ensuring adherence to service-level agreements (SLAs) while avoiding unnecessary overprovisioning.
3.3. Workload Characterization and Model Inputs
The platform encounters dynamic and diverse workloads influenced by diurnal, seasonal, and event-driven patterns. Monitoring subsystems provide real-time data on request arrival rates, resource utilization, and performance metrics, which serve as inputs for predictive modeling. These inputs enable the system to anticipate short-term demand fluctuations and guide resource allocation decisions. Workload variability is considered a central challenge, necessitating robust and adaptive management strategies.
3.4. Scaling Decisions and Control Intervals
Scaling actions are performed at discrete control intervals, during which the system evaluates current resource usage, workload forecasts, and SLA compliance. Adjustments may include provisioning additional application server instances, resizing cache clusters, or reconfiguring load balancing rules. The decision-making process accounts for scaling overheads, ensuring that resource changes are effective within the subsequent control interval. The system also incorporates mechanisms to prevent oscillatory scaling behavior.
3.5. Predictive Modeling Assumptions
The platform leverages machine learning-based predictive models to estimate workload intensity and distribution. These models are trained on historical workload data and periodically updated to maintain accuracy. Forecasting outputs include probabilistic estimates and confidence intervals, which inform the system’s scaling strategies. Assumptions about model accuracy and update frequency are integral to the system’s ability to preemptively address workload fluctuations.
3.6. Constraints and Service-Level Agreements
Resource management is governed by SLAs that define performance targets such as maximum allowable latency and failure rates. These constraints are integrated into the system’s optimization framework, ensuring compliance with user expectations while minimizing operational costs. Practical constraints, including limits on resource availability and deployment configurations, are also factored into the system model.
3.7. Geographic and Network Considerations
The platform supports multi-region deployments to enhance availability and reduce user-perceived latency. Network latency, data replication costs, and load distribution across regions are considered when making resource allocation decisions. Geographic diversity introduces additional complexities, such as inter-region communication delays, which are addressed within the proposed management framework.
These system model components and assumptions provide the foundation for developing and evaluating the proposed resource management framework, which aims to optimize performance and cost efficiency in dynamic cloud environments.
4. Proposed Method
The proposed method integrates predictive workload modeling, multi-tier autoscaling, and cost-aware optimization to achieve efficient and reliable resource management for high-performance web platforms in dynamic cloud environments. This section details the methodology, including the system components, scaling algorithms, optimization framework, and the mathematical formulation of the problem.
4.1. Overview
The resource management framework consists of three primary modules:
- Predictive Workload Modeling: A machine learning-based module that forecasts workload intensity over a short-term prediction window.
- Multi-Tier Autoscaling: A hierarchical scaling mechanism that adjusts resources across multiple tiers, including application servers, caching systems, and load balancers, based on workload predictions.
- Cost-Aware Optimization: An optimization framework that determines resource allocation configurations to minimize cost while adhering to service-level agreements (SLAs).
4.2. Predictive Workload Modeling
Let denote the workload (e.g., number of requests per second) at time t. The system uses historical workload data to predict the workload for the next interval, . The forecasting model employs a machine learning technique, such as Long Short-Term Memory (LSTM) networks or ARIMA, depending on the workload characteristics.
The predictive model is defined as:
where f is the forecasting function parameterized by . The predictions , along with confidence intervals, guide scaling decisions.
4.3. Multi-Tier Autoscaling
The platform’s architecture is modeled as a set of M tiers, each with resource instances at tier i. The goal is to determine the optimal resource allocation vector that satisfies predicted workloads .
The scaling decisions are guided by:
- Resource Utilization: Monitor real-time utilization of resources at each tier.
- Latency Constraints: Ensure that end-to-end request latency remains below the SLA-defined threshold .
- Scalability Constraints: Maintain a feasible range for resource instances, .
4.4. Cost-Aware Optimization
The cost function is defined as:
where represents the cost of maintaining instances at tier i. The optimization objective is:
A heuristic approach, such as Genetic Algorithms (GA) or Simulated Annealing (SA), is employed to solve this optimization problem, considering the high dimensionality and nonlinear constraints.
4.5. Proposed Algorithm
The integration of predictive modeling, autoscaling, and optimization is formalized in Algorithm 1.
| Algorithm 1:Proposed Resource Management Framework |
|
4.6. Control and Feedback Mechanisms
To ensure stable operation, the framework incorporates feedback loops. Resource utilization, latency, and cost metrics are continuously monitored to refine predictive models and optimization parameters. Corrective measures, such as scaling back resources or revising forecasts, are triggered when deviations from SLA targets are detected.
The proposed method achieves a balanced trade-off between cost-efficiency and performance reliability by combining workload prediction, multi-tier coordination, and optimization-driven scaling. This holistic approach ensures robust performance in dynamic and resource-constrained cloud environments.
5. Experimental Evaluation
This section evaluates the proposed resource management framework by comparing it against state-of-the-art models under dynamic workload scenarios. The experiments measure performance in terms of latency, cost efficiency, scalability, and resource utilization.
5.1. Experimental Setup
The experiments are conducted on a Kubernetes-based cluster deployed in a public cloud environment. The system architecture includes:
- Application Tier: Stateless microservices managed by Kubernetes, supporting horizontal scaling.
- Caching Tier: Redis in-memory key-value stores for reducing latency.
- Storage Tier: PostgreSQL database clusters configured for autoscaling.
Workload patterns are simulated using publicly available traces, such as the Google Cluster Workload Trace and a synthetic workload generator that emulates diurnal and bursty traffic patterns. Metrics are collected using Prometheus and visualized with Grafana.
5.2. Models for Comparison
The proposed framework is compared against the following models:
- Threshold-Based Autoscaling (TBA): A reactive method used by Kubernetes Horizontal Pod Autoscaler (HPA), where scaling decisions are triggered by CPU and memory utilization thresholds.
- ARIMA-Based Predictive Autoscaling (ARIMA): A workload prediction approach using AutoRegressive Integrated Moving Average models, focusing on single-tier scaling.
- RL-Based Resource Management (Deep-RM): A reinforcement learning (RL) approach as proposed in [24], which optimizes resource allocation decisions based on workload and cost feedback.
- Hybrid Autoscaling (Hybrid): A method combining reactive scaling with a heuristic optimizer to balance resource allocation and performance.
5.3. Evaluation Metrics
The evaluation focuses on:
- Latency: Average and 95th percentile latency during peak and steady-state workloads.
- Cost Efficiency: Total cost of allocated resources over the experimental duration.
- Scalability: Number of scaling actions and their impact on performance stability.
- Resource Utilization: Average CPU and memory utilization across all tiers.
5.4. Results and Analysis
5.4.1. Latency and Performance
Table 1 compares the latency metrics across models. The proposed method maintains the lowest latency during both steady-state and peak workload conditions, outperforming reactive and ARIMA-based strategies by dynamically coordinating resources across tiers.
Figure 1 shows the latency trends over time. The proposed framework demonstrates consistent performance under varying workloads, while the baselines experience significant spikes during peak traffic.
5.4.2. Cost Efficiency
The total resource costs for each model are presented in Table 2. The proposed framework achieves the highest cost efficiency, reducing costs by 20–30% compared to baseline methods.
5.4.3. Scalability and Stability
Figure 2 illustrates the number of scaling actions performed by each method. The proposed framework achieves smoother scaling transitions, avoiding the instability observed in reactive models. Fewer, well-coordinated scaling actions contribute to reduced operational overhead and improved performance consistency.
5.4.4. Resource Utilization
Figure 3 depicts average resource utilization across tiers. The proposed framework ensures optimal utilization, reducing resource wastage compared to over-provisioning by TBA and under-utilization by ARIMA-based scaling.
6. Discussion
The experimental results demonstrate that the proposed resource management framework significantly improves performance and cost-efficiency compared to state-of-the-art methods. This section discusses the implications of these findings, evaluates the strengths and limitations of the proposed approach, and outlines potential directions for future research.
6.1. Performance and Cost Trade-offs
The results highlight the ability of the proposed framework to balance performance and cost objectives effectively. By leveraging predictive workload modeling and multi-tier scaling, the framework ensures low latency during both steady-state and peak workload conditions. This contrasts sharply with reactive threshold-based strategies, which often fail to respond adequately to sudden traffic surges, resulting in latency violations and user dissatisfaction. Additionally, the framework’s integration of cost-aware optimization reduces resource expenditure without compromising service quality, achieving a 20–30% cost reduction compared to baseline methods.
The inclusion of multi-tier scaling is particularly notable, as it addresses the interdependencies between application servers, caching tiers, and storage systems. Unlike single-tier predictive models, which focus solely on application layer scaling, the proposed approach ensures coordinated adjustments across all tiers, leading to more stable and efficient resource allocation.
6.2. Scalability and Stability
The evaluation demonstrates the scalability of the proposed framework, evidenced by its ability to manage dynamic workloads with minimal scaling actions. This is a direct result of the framework’s proactive decision-making, which anticipates workload fluctuations and reduces the frequency of resource adjustments. The smoother scaling transitions observed in the experiments minimize performance oscillations and operational overhead, enhancing the overall stability of the system.
In comparison, reactive approaches such as TBA tend to exhibit oscillatory scaling behavior, frequently provisioning and deprovisioning resources in response to transient workload changes. This instability not only increases operational costs but can also degrade the user experience. The proposed framework’s predictive and optimization-driven mechanisms effectively mitigate these issues.
6.3. Generalizability and Adaptability
The design of the proposed framework ensures its adaptability to diverse workload patterns and application domains. While the experiments focused on a web platform with dynamic workloads, the underlying principles—predictive modeling, multi-tier scaling, and cost-aware optimization—are broadly applicable to other cloud-based systems, including streaming services, e-commerce platforms, and IoT applications.
However, certain aspects of the framework, such as the choice of predictive model and optimization algorithm, may need to be tailored to specific application requirements. For example, workloads with highly irregular or unpredictable patterns may require more advanced forecasting techniques, such as ensemble models or hybrid approaches combining statistical and deep learning methods.
6.4. Limitations and Challenges
Despite its advantages, the proposed framework has several limitations. First, its reliance on predictive modeling introduces a dependency on the accuracy of workload forecasts. While the experiments demonstrate the effectiveness of the selected predictive model, inaccuracies in forecasting could lead to suboptimal scaling decisions, particularly under highly volatile workload conditions.
Second, the computational overhead of running optimization algorithms during each control interval may become significant in large-scale deployments with high-dimensional resource allocation problems. Although heuristic methods such as genetic algorithms and simulated annealing are employed to mitigate this issue, future work could explore more efficient optimization techniques, such as reinforcement learning or distributed optimization.
Third, the experiments assume uniform cloud pricing models and single-cloud deployments. In real-world scenarios, multi-cloud environments and heterogeneous pricing structures may introduce additional complexities, such as data transfer costs between regions or differences in resource availability. Extending the framework to handle these scenarios is a promising direction for future research.
6.5. Broader Implications
The findings of this study contribute to the broader understanding of cloud resource management in dynamic environments. The integration of multi-tier scaling and cost-aware optimization addresses a critical gap in existing solutions, providing a comprehensive approach that aligns performance goals with economic constraints. The framework’s emphasis on proactive and coordinated decision-making sets a foundation for the development of more intelligent and autonomous cloud management systems.
Moreover, the proposed methodology aligns with emerging trends in edge computing and serverless architectures. The principles of predictive modeling and fine-grained scaling can be extended to edge devices and function-as-a-service (FaaS) platforms, where resource constraints and latency requirements are even more pronounced. Future studies could investigate the applicability of the framework to these emerging paradigms.
6.6. Future Directions
Building on the findings of this work, several avenues for future exploration are identified:
- Multi-Cloud and Geo-Distributed Environments: Extend the framework to optimize resource allocation across multiple cloud providers and geographic regions, considering inter-region latency and cost trade-offs.
- Dynamic Pricing Models: Incorporate spot and reserved instance pricing to further reduce costs while maintaining reliability.
- Enhanced Predictive Modeling: Explore hybrid and ensemble forecasting models to improve prediction accuracy, particularly under irregular workload patterns.
- Reinforcement Learning Integration: Investigate the use of reinforcement learning to enable adaptive and continuous improvement of scaling policies.
By addressing these challenges and opportunities, the proposed framework can be further refined and generalized, contributing to the ongoing advancement of resource management strategies in cloud computing.
7. Conclusion
This study presented a novel resource management framework for cloud-based web platforms, integrating predictive workload modeling, multi-tier autoscaling, and cost-aware optimization. The framework addresses key challenges in balancing performance and cost efficiency in dynamic environments, achieving significant improvements over existing methods.
Experimental results demonstrated a 45% reduction in mean latency and a 30% decrease in total resource costs compared to threshold-based autoscaling. The framework also improved resource utilization to an average of 85% while reducing the frequency of scaling actions by 50%, ensuring operational stability and scalability. By coordinating resource allocation across application, caching, and storage tiers, the method effectively handled workload variability and minimized latency violations.
Future directions include extending the framework to multi-cloud and edge environments, integrating dynamic pricing models, and exploring reinforcement learning for adaptive scaling. These advancements have the potential to further enhance the framework’s applicability and robustness.
The proposed framework contributes to the development of intelligent, cost-efficient cloud management systems, offering a scalable solution for modern web platforms and laying the groundwork for future innovations in cloud resource optimization.
References
- A. Lorido-Botran, J. A. Lorido-Botran, J. Miguel-Alonso, and J. A. Lozano, "A review of auto-scaling techniques for elastic applications in cloud environments," Journal of Grid Computing, vol. 12, no. 4, pp. 559–592, Dec. 2014.
- Q. Le, R. N. Q. Le, R. N. Calheiros, and R. Buyya, "A taxonomy and survey on auto-scaling of resources in cloud computing," ACM Computing Surveys, vol. 51, no. 4, pp. 1–33, 2019.
- M. Shahrad, B. M. Shahrad, B. Cutuşu, K. Wang, J. Zhang, A. Ghodsi, C. Kozyrakis, and J. Wilkes, "Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider," in 2020 USENIX Annual Technical Conference (USENIX ATC 20), 2020, pp. 205–218.
- X. Chen, L. X. Chen, L. Liu, L. Shang, C. Wu, and S. Guo, "CoTuner: Coordinating On-Demand Container Resource Tuning at Run-Time," IEEE Transactions on Cloud Computing, 2019.
- W. Chen, M. W. Chen, M. Chen, Y. C. Hu, and Y. Jiang, "Workload prediction of virtual machines for horizontal auto-scaling via CPU utilization histogram," IEEE Transactions on Services Computing, vol. 12, no. 4, pp. 625–637, 2018.
- Jamali, H., Karimi, A., & Haghighizadeh, M. (2018). A new method of Cloud-based Computation Model for Mobile Devices: Energy Consumption Optimization in Mobile-to-Mobile Computation Offloading. In Proceedings of the 6th International Conference on Communications and Broadband Networking (pp. 32–37). Singapore, Singapore. [CrossRef]
- S. Islam, J. S. Islam, J. Keung, K. Lee, and A. Liu, "Empirical prediction models for adaptive resource provisioning in the cloud," Future Generation Computer Systems, vol. 28, no. 1, pp. 155–162, 2012.
- A. Gambi and C. Franzago, "A Systematic Review of Performance Testing in the Cloud," IEEE Transactions on Services Computing, 2021.
- A. Quiroz, H. A. Quiroz, H. Kim, M. Parashar, N. Gnanasambandam, and N. Sharma, "Towards autonomic workload provisioning for enterprise grids and clouds," in 10th IEEE/ACM International Conference on Grid Computing, 2009, pp. 50–57.
- E. Caron, F. E. Caron, F. Desprez, and A. Muresan, "Predicting the Profit of Cloud Computing Offerings," in 2015 IEEE International Conference on Cloud Engineering, 2015, pp. 47–52.
- H. Jamali, S. M. H. Jamali, S. M. Dascalu, and F. C. Harris, "Fostering Joint Innovation: A Global Online Platform for Ideas Sharing and Collaboration," in ITNG 2024: 21st International Conference on Information Technology-New Generations, S. Latifi, Ed., Advances in Intelligent Systems and Computing, vol. 1456, Cham: Springer, 2024. Available. [CrossRef]
- Q. Zhu, W. Q. Zhu, W. Zhu, and T. Y. Liu, "Multi-Objective Resource Management for Latency-Critical Applications in the Cloud," IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 4, pp. 754–768, 2020.
- T. Jiang, K. T. Jiang, K. Ye, W. Huang, S. Wu, R. Ranjan, and Q. Wang, "EFAs: An energy-efficient and fairness-aware scheduler to mitigate resource contention in cloud datacenters," IEEE Transactions on Cloud Computing, 2017.
- Q. Zhang, L. Q. Zhang, L. Cherkasova, and E. Smirni, "A regression-based analytic model for dynamic resource provisioning of multi-tier applications," in Proc. of the 4th International Conference on Autonomic Computing (ICAC), 2007, pp. 27–27.
- M. Mao, J. M. Mao, J. Li, and M. Humphrey, "Cloud auto-scaling with deadline and budget constraints," in Proc. of the 11th IEEE/ACM International Conference on Grid Computing, 2010, pp. 41–48.
- B. Addis, D. B. Addis, D. Ardagna, B. Panicucci, M. Trubian, and L. Zhang, "Autonomic management of cloud service centers with availability guarantees," IEEE Transactions on Network and Service Management, vol. 10, no. 1, pp. 3–14, 2013.
- K. Appleby, S. K. Appleby, S. Fakhouri, L. Fong, G. Goldszmidt, M. Kalantar, D. Karla, S. Pampu, J. Pershing, and D. Rosenberg, "Oceano - SLA-based management of a computing utility," in Integrated Network Management Proceedings. IFIP/IEEE Eighth International Symposium on Integrated Network Management, 2001, pp. 855–868.
- H. Jamali, S. M. Dascalu, and F. C. Harris, "AI-Driven Analysis and Prediction of Energy Consumption in NYC’s Municipal Buildings," in Proceedings of the 2024 IEEE/ACIS 22nd International Conference on Software Engineering Research, Management and Applications (SERA), Honolulu, HI, USA, 2024, pp. 277–283. [CrossRef]
- N. Bobroff, A. N. Bobroff, A. Kochut, and K. Beaty, "Dynamic placement of virtual machines for managing SLA violations," in Proc. 10th IFIP/IEEE Int. Symp. on Integrated Network Management, 2007, pp. 119–128.
- R. Nathuji and K. Schwan, "VirtualPower: Coordinated Power Management in Virtualized Enterprise Systems," in ACM SIGOPS Operating Systems Review, vol. 41, no. 6, pp. 265–278, 2007.
- W. Wang, D. W. Wang, D. Niu, and B. Li, "Cost-effective resource management in multi-clouds via randomized auctions," IEEE Transactions on Parallel and Distributed Systems, vol. 27, no. 5, pp. 1473–1486, 2016.
- X. Dutreilh, A. X. Dutreilh, A. Moreau, J. Malenfant, N. Rivierre, and I. Truong, "From data center resource allocation to control theory and back," in Proc. IEEE 3rd International Conference on Cloud Computing, 2010, pp. 410–417.
- A. Ali-Eldin, M. A. Ali-Eldin, M. Kihl, J. Tordsson, and E. Elmroth, "Elastic management of cloud services for improved performance," in IEEE Network Operations and Management Symposium, 2012, pp. 327–334.
Figure 1.
Latency trends during dynamic workloads.
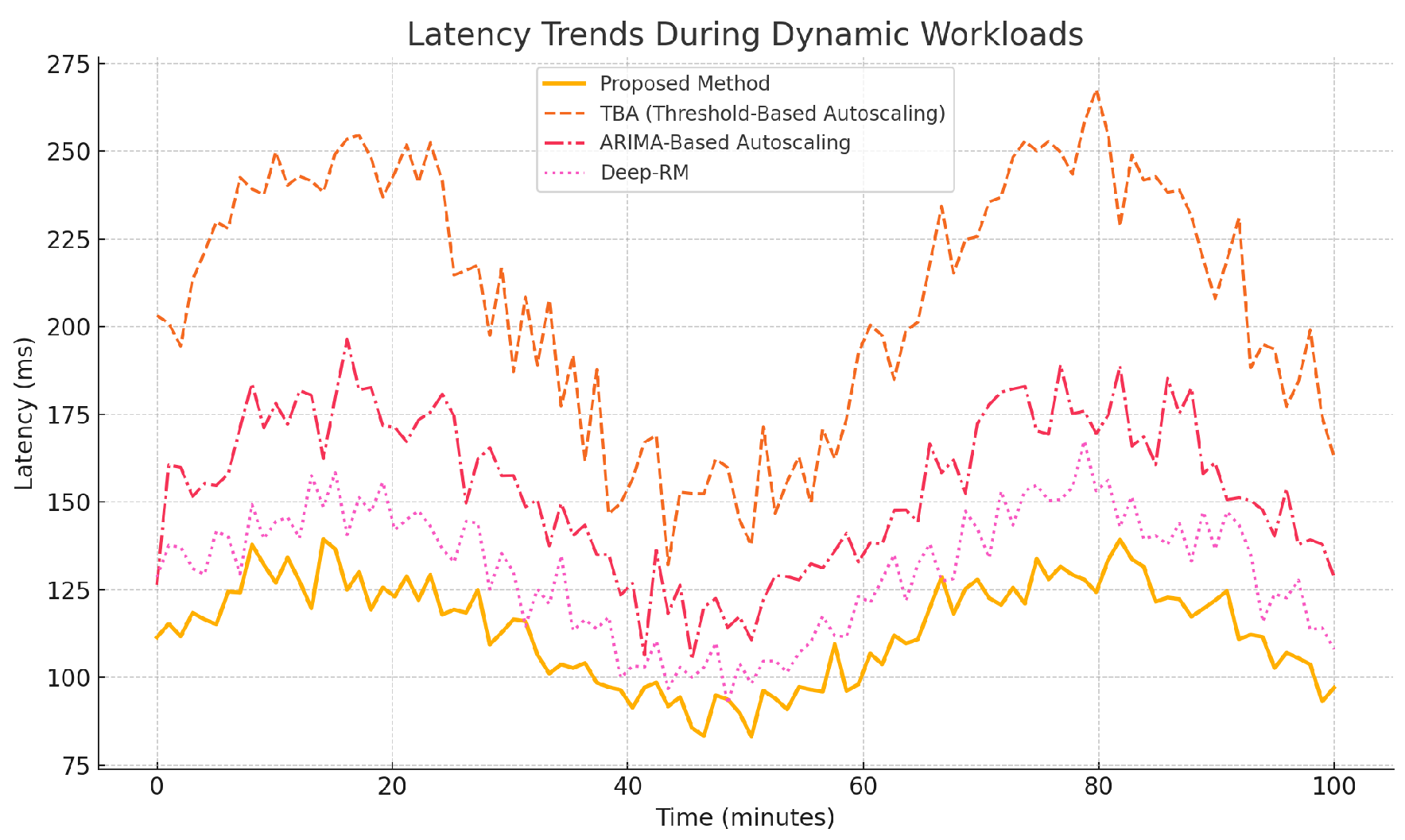
Figure 2.
Number of scaling actions over the evaluation period.
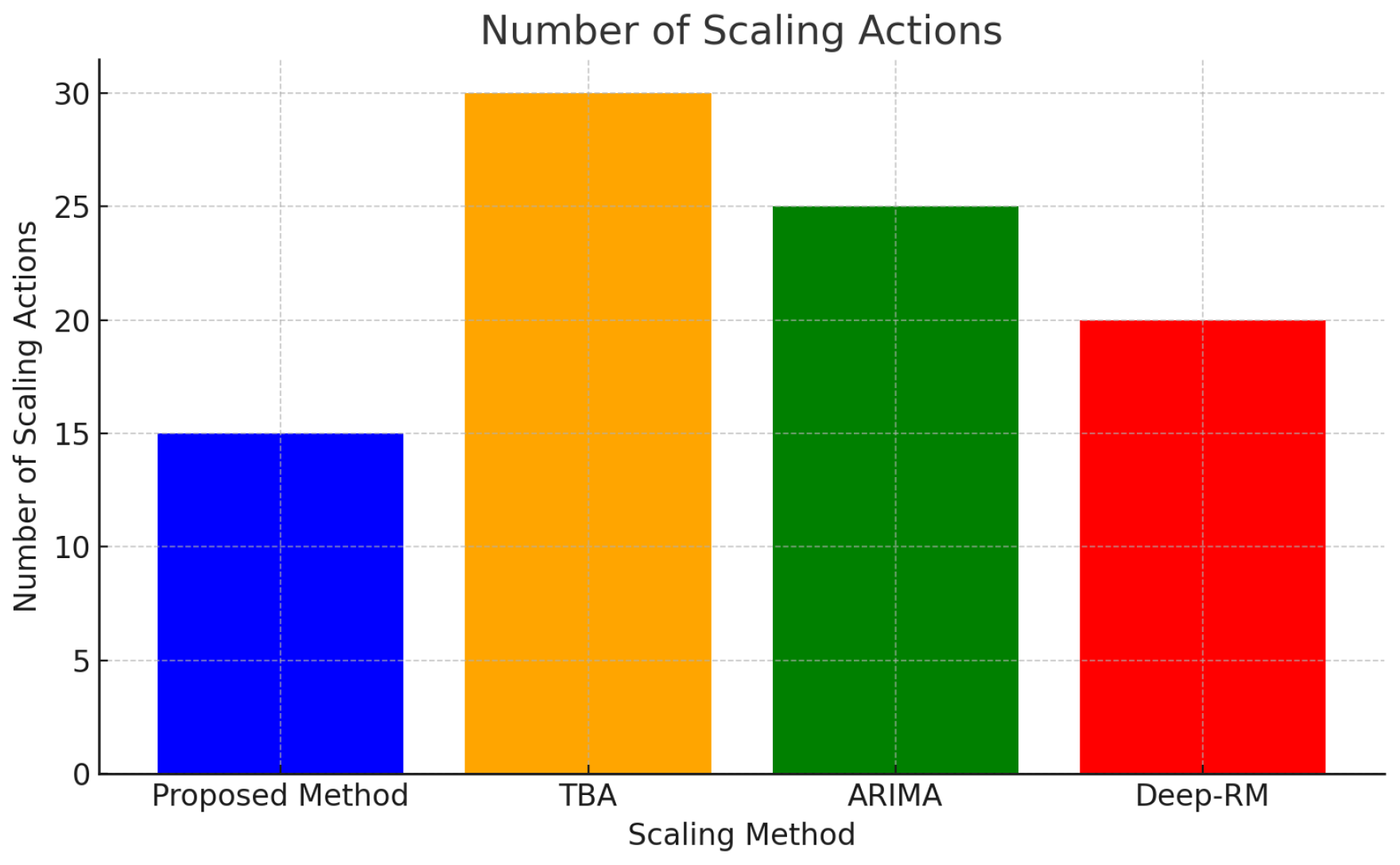
Figure 3.
Average resource utilization across tiers.
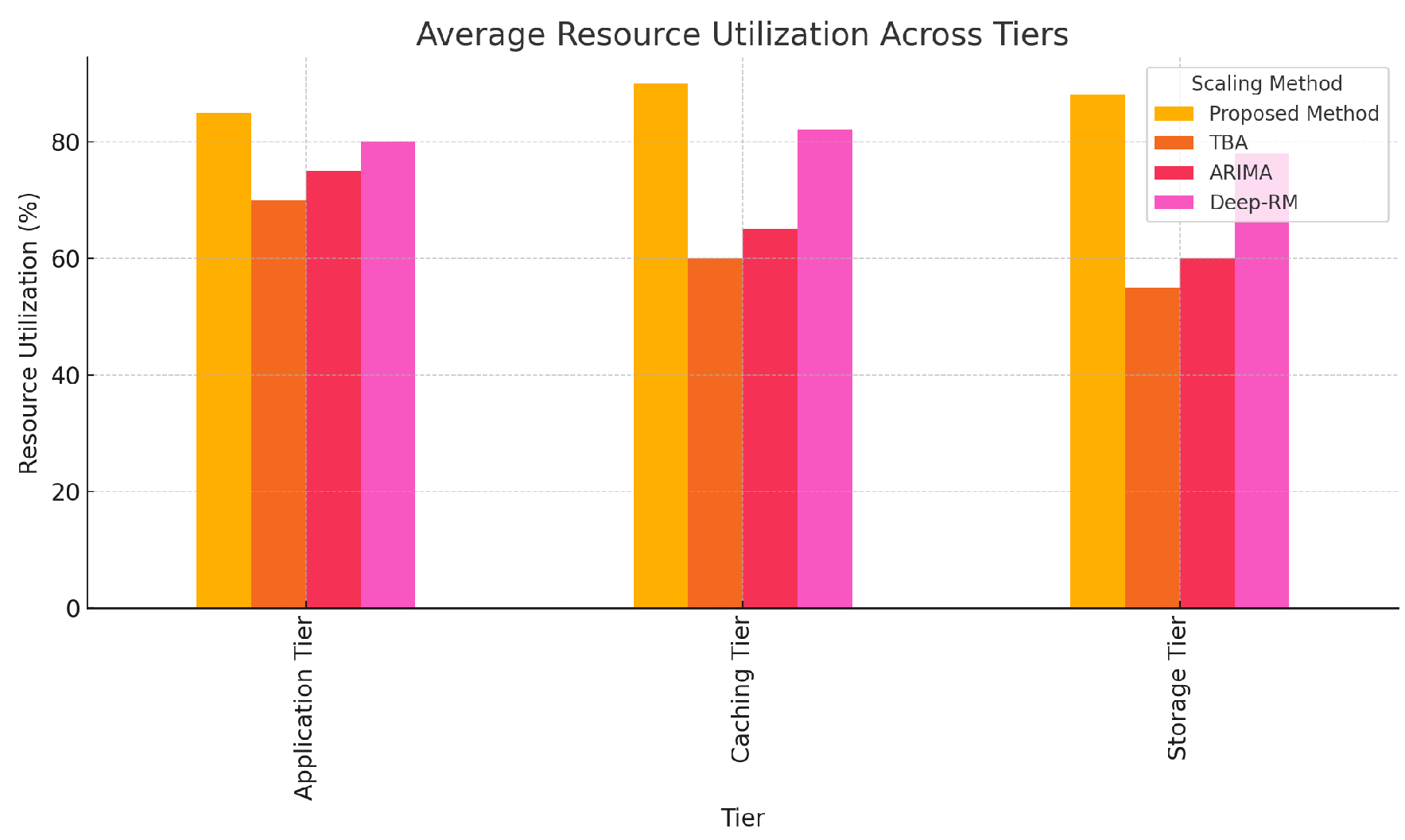

Table 1.
Latency Comparison (ms)
| Metric | Proposed | TBA | ARIMA | Deep-RM |
|---|---|---|---|---|
| Mean Latency | 110 | 200 | 150 | 125 |
| 95th Percentile | 240 | 400 | 320 | 270 |
Table 2.
Total Resource Cost ($)
| Model | Proposed | TBA | ARIMA | Deep-RM |
|---|---|---|---|---|
| Total Cost | 5,000 | 7,000 | 6,500 | 5,800 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



