Submitted:
23 January 2025
Posted:
26 January 2025
You are already at the latest version
Abstract
The poultry industry plays a pivotal role in global agriculture, serving as a major source of protein and contributing significantly to economic growth. However, the sector faces challenges associated with labor-intensive tasks that are repetitive and physically demanding. Automation has emerged as a critical solution to enhance operational efficiency and improve working conditions. Specifically, robot manipulation and handling of objects is becoming ubiquitous in factories. However, challenges exist to precisely identify and guide the robot to handle a pile of objects with similar textures and colors. This paper focuses on the development of a vision system for a robotic solution aimed at automating the chicken rehanging process, a fundamental yet physically strenuous activity in poultry processing. To address the limitation of the generic instance segmentation model in identifying overlapped objects, a cost-effective dual-active laser scanning system was developed to generate precise depth data of objects. The generated well-registered depth data integrated with the RGB images were sent into the instance segmentation model for individual chicken detection and identification. This enhanced approach significantly improved the model’s performance in handling complex scenarios involving overlapping chickens. Specifically, the integration of RGB-D data increased the model’s mean Average Precision (mAP) detection accuracy by 4.9% and significantly improved the center offset—a customized metric introduced in this study to quantify the distance between the ground truth mask center and the predicted mask center. Precise center detection is crucial for the development of future robotic control solutions, as it ensures accurate grasping during the chicken rehanging process. The center offset was reduced from 22.09 pixels (7.30 mm) to 8.09 pixels (2.65 mm), demonstrating the approach’s effectiveness in mitigating occlusion challenges and enhancing the reliability of the vision system.
Keywords:
poultry
; precision food manufacturing
; meat processing
; instance segmentation
; active laser scanning
1. Introduction
The poultry industry remains the largest meat sector globally. In 2025, global poultry meat production is forecast to reach approximately 104.93 million tons, continuing its role as the leading sector in global meat production [1]. In 2025, the United States is projected to produce approximately 21.72 billion pounds of broiler meat, maintaining its position as the leading global producer. Compared to other meat products such as beef and pork, chicken is recognized for its superior sustainability and environmentally friendly properties [2]. The demand for chicken products has consistently increased in recent decades, a trend that is expected to continue in the foreseeable future [3].
In recent years, the general meat industry, and more specifically the poultry industry, has employed significant advances in automation and robotics to improve process efficiency, reduce labor costs, and improve product quality. This transition is driven by the need to address labor shortages and global protein production demands. For instance, collaborative robots have been explored for their potential to work alongside human operators, improving safety and productivity in meat processing tasks [17]. Robotic technology has been effectively integrated into various stages of meat processing, including butchery, evisceration, and carcass cutting [21,22]. The development of these specialized robotic systems highlights the potential for tailored automation solutions in response to specific industry needs [18,26]. In addition, technologies such as three dimensional (3D) vision and advanced vision systems are essential to ensure precision in cutting and de-boning tasks, allowing real-time adaptability to variations in each individual carcass [19]. AI and image processing technologies have been effectively employed to improve meat quality assessment and inspection processes, ensuring product safety and minimizing reliance on human labor [8,9]. As the meat industry continues to evolve, despite the challenges of high initial investments and the lack of skilled labor to operate sophisticated machinery [23,24], the application of Industry 4.0 technologies, including robotics and the Internet of Things (IoT), is anticipated to revolutionize current labor-intensive operations, leading to more sustainable practices, improving food quality, and reducing food waste [20,25].
More specifically, within the poultry supply chain, the processing industry plays a vital role in preparing value-added products. Many steps in poultry processing have been transitioning from manual to autonomous operations, such as slaughtering, evisceration, and chilling [4]. However, certain processing steps, including the chicken rehanging step, still heavily rely on human labor. This step, which occurs after the chilling operation and USDA inspections, involves hanging chickens from the evisceration line onto an additional line for subsequent deboning, wing cutting, and packaging processes. As shown in Figure 1, the chicken rehanging process is performed manually by workers, who are required to work closely together and carry out repetitive, monotonous tasks on a daily basis. To automate the chicken rehanging process, some early studies have explored the feasibility of utilizing robotic rehanging solutions [27]. However, in the real poultry processing plant settings, chickens are not separated as individual carcasses as desired in the laboratory settings, and most chicken carcasses are typically piled together [4]. Considering the similar color and texture of chicken skin (as shown in Figure 1), the vision identification of individual carcasses, the initial step of the robotic operation, is extremely challenging. In recent years, advances in deep learning have achieved great success in object segmentation and detection in the agricultural engineering field, particularly in meat processing. For example, studies have demonstrated the efficacy of various deep learning models for tasks such as detecting and segmenting animal carcasses and meat parts, enhancing both efficiency and accuracy [47]. The applications of computer vision systems have been highlighted in research focused on detecting foreign objects in meat products [28], assessing meat quality and safety [29,48], and even estimating the meat content in products such as meatballs using advanced imaging techniques [30]. Moreover, methods like the Mask R-CNN and SSD have been effectively utilized for beef carcasses segmentation [31,32]. The implementation of attention mechanisms in YOLO models has further improved detection capabilities in livestock management [33]. Together, these advancements underscore the critical role of effective vision system algorithms in enabling vision-guided agriculture and food automation, which are essential for successful automation in the meat industry, ultimately enhancing operational efficiency and ensuring product quality. However, very few existing studies have considered the instance segmentation of products with similar visual traits and extensive overlapping [52] which is a common scenario in practice. To overcome this challenge, in this study, we aim to integrate the depth information into the deep learning-based instance segmentation model to achieve a more accurate segmentation mask to guide the robotic operations. However, the commonly used commercialized RGB-D cameras, such as Intel RealSense D435i, can only achieve depth accuracy of 2% at a range of 1 meter, and cannot meet the requirements needed for high-accuracy robotic operations. To fill the gap, an active laser scanning system was developed recently that enables the generation of high-resolution depth maps [15,36]. Different from prior work using a costly hardware configuration, such as a National Instruments Data Acquisition Board 6003 )($900), to control the laser scanning system, this study develops a cost-effective laser scanning hardware system to achieve accurate depth scanning, which is composed of a Raspberry Pi ($35), an Arduino ($25), and a low-cost PWM-to-voltage converter ($10), with a total cost of approximately $70 for the control system.
The following sections, provide an outline of the methodology and results in detail. Section 2 describes the experimental material and methods, including the development of the cost-effective Dual-line Laser Active Scanning system, incorporating both hardware and software components, the use of optical triangulation for object height estimation, and depth information infused chicken instance segmentation. Section 3 provides the experimental results, which include a detailed performance evaluation of the Active Laser Scanning System and an analysis of the chicken instance segmentation performance across different backbones, with a focus on key metrics such as mean Average Precision (mAP) and a customized metric Center Offset. Section 4 presents the broader implications of these findings, highlighting the benefits of integrating depth sensing, as well as addressing the challenges associated with real-time depth sensing and computational efficiency. The paper concludes by emphasizing the scalability and practical applications of the proposed system, along with directions for future research.
2. Material and Methods
2.1. Dual-Line Laser Active Scanning: A Hardware and Software System for Height Estimation
In recent years, the integration of 3D vision systems has significantly advanced various applications in robotics and automation, particularly in the meat industry [41]. A popular choice for measuring depth perception is the use of stereo cameras, such as Intel’s real-sense series, which employ dual-camera setups to capture stereo images, and to use the stereo matching technique to calculate the depth information, enabling the identification of distances and spatial relationships within a scene [42]. Although these systems are known for their rapid depth acquisition capabilities, they often struggle with depth reconstruction accuracy, especially when depth accuracy is critical. In the context of poultry processing, particularly during the chicken rehanging stage, accurate acquisition of depth data is critical to guide the robot performing the rehang operation [53]. Given that chickens are typically piled together after leaving the chiller, as shown in Figure 1, relying solely on color and stereo cameras does not provide the precise depth information needed for effective robotic manipulation. As shown in Figure 2, the depth accuracy with stereo Intel Realsense cameras is low and the boundary between chickens is not well defined. To overcome this limitation, we implemented a novel active laser scanning-based depth vision reconstruction system. The traditional laser scanning system in the automation industry needs a conveyor belt to carry the target object to create the relative movement between the laser scanner and the object. Considering the stationary nature of the chickens in poultry operations and the absence of a conveyor belt during the rehang stage, the active laser scanning system developed aims to effectively capture depth data in this fixed environment. With the setup, we can achieve significantly higher accuracy in depth perception, which is crucial for distinguishing individual chicken carcasses piled together. This enhanced capability supports the automation of the rehanging process, ultimately improving operational efficiency and ensuring better handling of poultry products.
In this experimental setup (as shown in Figure 3), two one-axis controllable galvanometers (GVS011, Thorlabs, Inc, Newton, New Jersey) were utilized alongside a camera (Basler acA1920-40gc, 1920x1200 pixels, 40 fps, GigE interface) for image captures, two green lasers (520 nm ± 10 nm, 50 mW, linewidth <3 mm at 1 m, divergence angle 88° producing a 2 m line at 1 m distance; NaKu Technology Co., Ltd, Hangzhou, China), a Raspberry Pi3B for image acquisition and 3D reconstruction, and an Arduino Uno REV3 for laser control. The lasers and two galvanometers are affixed to an 80/20 slot structure. Two low-cost enclosures have been manufactured using 3D printing techniques to secure the laser and galvanometer, as illustrated in Figure 3. The angle projection positions of two lasers were adjusted through a controllable analog voltage fed to the motors which can be generated from Arduino via a Pulse Width Modulation(PWM)-to-voltage converter, allowing for programmable laser manipulation with a scale of 0.5V per degree of movement. The PWM-to-Analog voltage converter translates a PWM range of 0% to 100% into an analog voltage range of 0V to 10V, that is within the working range of the galvanometer. An increase of 1% in the PWM results in a 0.1V increment in the output voltage of the module that controls the galvanometer. The laser will scan across the entire field of view, covering approximately 61 cm horizontally and 40 cm vertically at a 1-meter distance. Each time the Arduino increases the PWM output duty cycle by 1%, a signal is sent to the Raspberry Pi to activate the camera to capture the image of the green laser and to process the resulting image to acquire the depth information at a specific location. The exposure time of the camera has been set to 2 milliseconds to minimize background noise and enhance the visualization of the laser line. Synchronization of the vision and control code was implemented through serial communication between the Arduino and Raspberry Pi via the Universal Asynchronous Receiver Transmitter (UART) ports. The flowchart of this procedure is depicted in Figure 4. The Raspberry Pi is connected to the Basler camera via an Ethernet cable. Upon completion of the image processing required for depth calculation, the Raspberry Pi sends a signal to the Arduino to advance the laser by one step. Compared to the previous study using a National Instrument (NI) data acquisition board for mirror control [15,36], this experimental hardware setup is more cost-effective while still maintaining the necessary functionality for 3D vision reconstruction in poultry processing applications.
As shown in Figure 5, the image processing for depth reconstruction involves multiple steps. One of the key step is to capture the pixel coordinates (u,v) of the laser line, where u represents the x-coordinate and v represents the y-coordinate of a pixel in the image. Specifically, these coordinates are pixel coordinates of both the baseline and object pixels. To obtain the (u,v) of the laser pixels, a binary image is created using manually defined RGB thresholds under the preset exposure time. The morphological closing method is applied to the binary image to fill any gaps present in the laser line. Once the binary line segmentation image is accurately generated, the central pixels of the laser line are captured as the (u,v) coordinates of the laser line.
2.2. Optical Triangulation for Object Height Estimation
The developed 3D range scanning imaging system was founded on the principles of optical triangulation. As shown in Figure 6, the height of an object can be calculated by the geometry equations, as shown in Eq. 1. When an object obstructs the path of the laser line, a displacement occurs in the projected laser line compared to its position in the absence of the object. When no object is present, the position of the laser is referred as (baseline), while the position when an object is present is designated as (object pixel). By determining the shift between the baseline and object pixels () and knowing the laser angle (the angle between the laser line and the ground, where (), it is able to calculate the height of the object using the following equation. In the experiment, can be calculated during the calibration stage by scanning objects of known height.
and are world coordinates of the pixels which are found from (u,v) of the laser pixels and utilizing the camera calibration formulas [15,36]. Details of the camera calibration process are provided in the supplementary materials.
After calculating and using pixel locations, could be calculated based on Eq. 1.
In which, represents the x-coordinate of the baseline pixel, and represents the y-coordinate of the baseline pixel in the image. Similarly, denotes the x-coordinate of the object pixel, while represents the y-coordinate of the laser pixel when an object is present under the laser.
Laser depth resolution can be derived by Eq. 2.
2.2.1. Baseline Position Collection of Laser Line
In this experimental laser scanning system, the PWM duty cycle was utilized to adjust the laser position, allowing precise modifications to the baseline. With every change of the PWM duty cycle, the Arduino sends a signal to the Raspberry Pi to capture an image to record the current position of the laser using the aforementioned image processing method. Subsequently, the Raspberry Pi transmits a serial signal back to the Arduino, instructing it to reposition the laser to the next baseline. This cycle is repeated continuously until all designated baselines are established. This approach made our hardware setup significantly more cost-effective than currently available laser active scanning machine vision systems. Figure 5 shows an example of laser projection images of a specific PWM output.
2.2.2. Laser Angle Calibration
In the laser scanning system, each PWM duty cycle corresponds to a specific laser angle relative to the ground. To calibrate the angle, a manufactured calibration phantom with a known height ranging from 50 mm to 150 mm with the step of 50 mm was utilized for the calibration process to establish the relationship between and PWM. By the known height of the calibration phantom and the baseline coordinates associated with the PWM duty cycle, the laser projection angle for each laser position was estimated using Eq. 4. This procedure was conducted for all PWM duty cycles. A linear regression model using the ordinary least squares (OLS) method was applied to remove angle estimation noise.
2.3. Instance Segmentation of Chicken Carcass
Instance segmentation is a critical task in computer vision that involves precisely identifying and segmenting individual objects in an image by assigning a unique pixel-level mask to each instance [44]. Instance segmentation focuses on delineating the exact boundaries of each object, making it invaluable for applications requiring detailed spatial understanding. This approach enables models to detect multiple instances of the same category, each with its distinct mask.
The process of instance segmentation typically involves advanced algorithms that leverage deep learning techniques to achieve high levels of accuracy and efficiency. Modern methods are designed to identify and classify objects while simultaneously generating detailed masks that outline their shapes. These masks help extract intricate details about object size, position, and orientation, which will be critical in directing robots in the poultry rehang operation [43]. Mask R-CNN is an advanced deep learning model that has made significant strides in the field of instance segmentation [44]. What sets it apart is its ability to not only detect objects in images, but also to precisely outline their shapes.
For this study, we created a dataset consisting of 160 images of whole chicken carcasses, with the RGB data labeled for segmentation and the depth data collected using our custom dual-line laser scanning system. The data was collected over the span of a month to increase the dataset variety, and whole chicken carcasses were purchased from local grocery stores and used for image acquisition. For each image, three to five different chicken were randomly stacked together, arranged by their legs, wings, and chest to mimic the different stacking patterns observed in the real poultry industry. Efforts were made to maximize overlap between carcasses to better represent real-world conditions. To ensure a robust training process, the dataset was split into 70% for training, 20% for validation, and 10% for testing. Data augmentation techniques, including rotation and vertical and horizontal flips, were applied to expand the dataset five times, effectively increasing the variety of training samples. This augmentation ensured that the model could be generalized well to diverse scenarios. The network architecture consists of a backbone network, such as ResNet [45], which extracts feature maps from the input image. This is followed by a Region Proposal Network (RPN) that generates candidate object proposals. For each proposal, the network predicts a bounding box and a mask for the object class. The mask prediction uses a Fully Convolutional Network (FCN) that outputs a binary mask for each object instance, allowing for pixel-level segmentation.
The training process of mask R-CNN involves multiple loss functions, including the classification loss, which measures the accuracy of object classification, and the bounding box regression loss, which evaluates the accuracy of the predicted bounding box locations. Additionally, a mask loss is computed to assess the quality of the predicted masks against the ground truth, which is manually labeled using the LabelMe application. The combination of these losses enables Mask R-CNN to learn effectively, balancing the need for accurate object detection with precise segmentation capabilities. As shown in Figure 7, depth information was added to the RGB data to create RGB-D inputs. Both RGB and depth data were resized to 1024 × 1024 dimensions prior to the training process, and concatenated to form an input with dimensions 1024 × 1024 × 4. The first layer of the backbone network was modified to accommodate the four-channel input.
In Mask R-CNN, the backbone network is crucial for extracting high-level features from the input images, which are essential for both object detection and instance segmentation tasks. The backbone typically consists of established convolutional neural network (CNN) architectures such as ResNet, VGG [49], or more efficient alternatives such as MobileNet [51] and EfficientNet [50]. Each of these architectures is designed to capture and learn hierarchical patterns in images, providing a robust set of features that can be utilized in downstream tasks. For example, deeper networks such as ResNet-101 can capture complex patterns and finer details due to their increased depth, while lightweight models like MobileNet are optimized for speed and efficiency, making them suitable for deployment in resource-constrained environments [39,40,45].
In our study, data from both the laser scanning system (depth map) and RGB camera (RGB image) are incorporated into the network for feature extraction. Compared to limited information offered by sole RGB images, the additional depth information can offer more comprehensive 3D representations of the objects within the scene, and lead to improved accuracy in detection and segmentation tasks.
3. Results
The initial results begin with the calibration and accuracy assessment of the laser system. In the laser calibration process, where the relationship between the mirror input voltage and the corresponding angular displacement (theta) was established. Following the calibration, the accuracy of the depth maps generated by the right and left lasers were evaluated independently, quantifying their precision in capturing depth information. The individual heatmaps were merged from the right and left lasers to create a single combined depth map that accounts for all occlusions. Using a standardized phantom, this final heatmap was compared with the depth map generated using a real-sense camera to validate its accuracy and completeness.
In the second part of this section, the performance of the Mask R-CNN model with RGB and RGB-D inputs using various backbone architectures was assessed. To evaluate segmentation quality, a new metric called the Center Offset was utilized, which measures the distance between the predicted mask center and the ground truth mask center. This metric is particularly relevant for our application, as precise center alignment ensures that the robot can accurately grasp chicken carcasses from their middle point. The results demonstrated the superior performance of RGB-D data compared to RGB data alone as input to the instance segmentation model, as well as the impact of different backbones on segmentation accuracy and center alignment. The following subsections provide detailed analyses of these findings.
3.1. The Performance Evaluation of Active Laser Scanning System
The performance evaluation of the active laser scanning system is essential to validate its precision and reliability for applications such as object detection using RGB-D data [46]. This evaluation focuses on two critical aspects: laser calibration, which determines the relationship between the input voltage applied to the mirror and the resulting laser angle () and system accuracy, which assesses the laser’s capability to measure predefined physical features accurately. Laser calibration involved analyzing and defining the relationship between the input voltage of the laser-scanning mirror and the laser angle relative to the horizon. This relationship is crucial for ensuring correct laser alignment, enabling consistent and precise scanning results. A series of experiments were conducted to map this relationship and optimize the system’s operational parameters. The accuracy of the system is pivotal in determining how effectively the laser scanning system measures the physical dimensions of target objects. To evaluate the accuracy, a standard height step with dimensions of 50, 100, and 150 mm was used as a reference. The measured heights were compared to the actual dimensions of the step and validated against measurements from a commercial Interl Realsense camera.
The following subsections explore the evaluation of system calibration and accuracy. These analyses provide a detailed understanding of the active laser scanning system’s performance and highlight its capabilities in real-world applications.
3.1.1. Laser Calibration Performance
The laser calibration process aimed to establish a precise relationship between the PWM duty cycle and the laser projection angle (). The laser angle was initially approximately 90°, decreasing to 58° at the maximum PWM duty cycle, resulting in an angular range of 32 °. Figure 8 illustrates this strong linear relationship, characterized by a coefficient of determination () of 0.9835.
In our setup, the mirrors controlling the laser scanning system are actuated through a PWM-to-voltage converter. The converter outputs a voltage ranging from 0 to 10 V, corresponding to PWM duty cycles from 0% to 100%. The mirrors exhibit a movement response of 0.5 V per degree, translating the voltage to angular displacement.
To determine the laser projection angle () in the actual experiment setup for further height estimation, we utilized Eq. 3 with an object with known height, which requires the baseline, object pixel positions, and their differences. This process was repeated systematically for each PWM duty cycle across the range between 0% and 100%. For every PWM value, the converter generated a corresponding voltage, and the laser angle was calculated. The object used for calibration was a 50 mm cube that was 3D printed to ensure precise and consistent dimensions. By placing this object within the scanning range, the known height provided a reliable reference for calculating the laser angle during the calibration process.
3.1.2. System Depth Estimation Accuracy
To evaluate the accuracy of the lasers, we fabricated a multi-step object using 3D printing, with heights ranging from 50 mm to 150 mm in increments of 50 mm. The height of each step was measured using our active laser scanning based depth imaging system. The table below presents the actual and measured heights of each step in one meter imaging distance. Additionally, the same process has been done by Intel Real-sense D435 camera to compare the accuracy of our laser setup with the Real-sense camera.
Figure 9 illustrates the color image depth reconstruction for the left laser and the right laser, together with their final integrated depth map. During the preliminary data collection, data losses occurred using a single laser because the laser beam sensed obstructions, which led to the decision to incorporate data from two lasers. By combining the 3D depth maps from both lasers, the impact of obstructions on data loss was minimized.
3.2. Performance of Chicken Instance Segmentation
In the experiment, the RGB and corresponding depth data obtained from the customized active laser scanning system were concatenated and used to train the instance segmentation model. The performance was benchmarked by Mask R-CNN model [44]. As shown in Figure 7, initially the model was trained on RGB data alone for 400 epochs, yielding optimal model weights. These weights were then subsequently used to initialize the Mask R-CNN model for RGB-D data training, where various backbones were evaluated. For the backbone architectures, ResNet-50, ResNet-101, VGG16, and EfficientNet-B0 were selected. ResNet-50 and ResNet-101 were included due to their widespread use in Mask R-CNN and their robust performance on object detection and segmentation tasks. VGG16 was chosen to analyze the performance of an older, simpler architecture and provide a baseline for comparison against more advanced models. EfficientNet-B0 was selected for its promising performance in balancing accuracy and computational efficiency, particularly for RGB-D data.
The implementation was conducted using Python 3.9, with PyTorch as the deep learning framework. CUDA version 11.4 was employed for GPU acceleration, and the experiments were executed on the High-Performance Computing (HPC) cluster at the University of Arkansas, equipped with NVIDIA A100 GPUs, and 64 CPU cores for preprocessing and data augmentation. Results indicate that incorporating depth data improved the mean Average Precision (mAP) and Intersection over Union thresholds (IoU). mAP is a commonly used metric in object detection and instance segmentation tasks that calculates the average precision across all classes. IoU thresholds (0.5:0.95) is a measure of overlap between the predicted mask and the ground truth mask, defined as:
where the area of overlap is the intersection of the predicted and ground truth masks, and the area of union is their combined region. IoU thresholds specify the minimum required overlap for a prediction to be considered correct. The range 0.5:0.95 denotes that mAP is averaged over multiple IoU thresholds from 0.5 to 0.95 in increments of 0.05, providing a comprehensive evaluation of model performance across varying levels of overlap tolerance. In this study, the inclusion of depth data resulted in enhanced segmentation accuracy, with ResNet-50 achieving the highest mAP among the evaluated backbones, highlighting its effectiveness in leveraging RGB-D data for chicken instance segmentation. Additionally, a customized metric was introduced to assess the accuracy of mask center predictions, which is crucial for the downstream robotics-based chicken re-hanging process. This metric calculates the offset distance between the ground truth mask center and the predicted mask center, providing a quantitative measure of alignment accuracy. The offset distance is defined as:
where represents the coordinates of the ground truth mask center and represents the coordinates of the predicted mask center. A lower value of D indicates better alignment between the prediction and the ground truth. Table 2 presents a comparison of mAP and center offset metrics for Mask R-CNN with RGB and RGB-D inputs across different backbones.
The ResNet50 backbone demonstrated superior performance in generating accurate segmentation maps and minimizing the offset in mask centers. This performance highlights its capability to effectively learn and segment overlapping chickens within the dataset, especially when augmented with the depth channel data provided by the laser system. As shown in Figure 10, the RGB image, ground truth, Mask R-CNN output with RGB data, and Mask R-CNN output with RGB-D data using the ResNet50 backbone are compared. The results indicate that segmentation using RGB data alone is significantly less accurate, whereas the incorporation of RGB-D data achieves notably improved segmentation performance especailly when extensive overlapping happens.
4. Discussion
The automation of the chicken rehanging process offers significant potential to improve efficiency and reduce health risks for laborers exposed to repetitive manual work in poultry processing facilities. This research focused on solving the critical vision problem required for automating this process, demonstrating the value of integrating depth sensing and advanced segmentation techniques to address the inherent challenges.
Initial experiments using instance segmentation model on RGB data, which achieves promising results when chickens were well separated. However, the performance of the model decreased significantly in scenarios where chickens overlapped, a more practical scenario, leading to errors in segmentation and object detection. To address this, we incorporated depth data from a customize cost-effective dual-line laser scanning system into the generic instance segmentation Mask R-CNN framework. This modification resulted in a substantial improvement in object detection accuracy. To further evaluate the performance of the segmentation models, we introduced a novel metric, Center Offset, which quantifies the distance between the mask center in the Ground Truth (GT) and the predicted mask center. This metric is critical for assessing the precision of object localization, especially for reliable and consistent robotic handling of chicken carcasses.
The impact of various backbone architectures on the performance of the Mask R-CNN model was also explored. Among the tested backbones, ResNet50 RGB-D achieved the best results, delivering a 4.9% increase in mAP and reducing the Center Offset from 22.09 pixels to 8.09 pixels compared to sole RGB input. These results highlight the importance of selecting an appropriate backbone to achieve robust segmentation and precise mask center predictions, which are crucial for guiding future robotic operations. The incorporation of depth data further underscores its value in enhancing both segmentation accuracy and object localization precision, enabling more effective robotic handling in complex scenarios.
Despite these advancements, several challenges still remain. While the RGB-D model significantly outperformed the RGB-only model, its reliance on depth data introduces practical limitations. Collecting depth data using the dual-line laser scanning system is a time-consuming process due to the limited movement speed of the lasers. This limitation arises from the time-consuming communication process between the control system and the vision system, which restricts the overall scanning rate. This limitation affects both dataset creation and real-world applications. The time required to scan and gather depth information could delay mask predictions and reduce the efficiency of the system. Future work could focus on optimizing the laser system to enable faster data acquisition and real-time depth sensing. Additionally, while ResNet50 provided excellent segmentation performance, its computational demands may pose challenges for real-time applications on resource-constrained hardware. Future experiments exploring lightweight architectures or applying model compression techniques could further enhance the feasibility of real-time deployment.
In conclusion, this study demonstrates that integrating depth data into vision systems can significantly enhance egmentation and localization challenges in automating chicken rehanging process. The dual-line laser scanning system played a pivotal role by providing accurate and reliable depth data at a lower cost compared to previously developed systems [15]. The laser system’s superior depth accuracy not only improved the Mask R-CNN model’s ability to handle complex scenarios, but also proved critical for future robotic arm control. By leveraging the cost-effective dual-line laser system and optimizing the Mask R-CNN framework, this research offers a scalable and practical solution for potential poultry processing automation. However, further advancements in depth sensing, real-time processing, and adaptive algorithms will be essential to fully realize the goal.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Conceptualization, P.S. and D.W.; methodology, P.S and D.W; software, P.S.; validation, P.S., D.W. and S.M.; formal analysis, P.S. and D.W; investigation, P.S.; resources, P.S. and D.W.; data curation,S.M., C.P, A.D; writing—original draft preparation, P.S., D.W.; writing—review and editing, W.S., P.C.; visualization, P.S.; supervision, W.S., Y.S., D.W.; project administration, W.S., Y.S., D.W.; funding acquisition, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the award no. 2023-67021-39072, 2023-67022-39074, 2023-67022-39075, from the U.S. Department of Agriculture (USDA)’s National Institute of Food and Agriculture (NIFA) in collaboration with National Science Foundation (NSF) through National Robotics Initiative (NRI) 3.0
Institutional Review Board Statement
Not applicable
Informed Consent Statement
Not applicable
Acknowledgments
Not applicable
Conflicts of Interest
The authors declare no conflicts of interest
References
- United States Department of Agriculture (USDA), 2025. Livestock and Poultry: World Markets and Trade. Available online: https://www.fas.usda.gov/sites/default/files/2024-10/Livestock_poultry.pdf (accessed on 16 January 2025).
- Kalhor, T.; Rajabipour, A.; Akram, A.; Sharifi, M. Environmental impact assessment of chicken meat production using life cycle assessment. Information Processing in Agriculture 2016, 3(4), 262–271. [Google Scholar] [CrossRef]
- Derya, Y. Global Poultry Industry and Trends. 2021. Available online: https://www.feedandadditive.com/global-poultry-industry-and-trends/.
- Barbut, S. Automation and meat quality-global challenges. Meat Science 2014, 96(1), 335–345. [Google Scholar] [CrossRef] [PubMed]
- Austin, A. (2019). How to get a processing line speed waiver. WATTPoultry. https://www.wattagnet.com/articles/38224-how-to-get-a-processing-line-speed-waiver?
- Christopher, Q. Ga. poultry producers scratch for workers amid rising demand, prices. The Atlanta Journal-Constitution. https://www.ajc.com/news/ga-poultry-producers-scratch-for-workers-amid-risingdemand-prices/AOBN7F6ZRZC2PPBDWDYUOECSY4/ 2021. [Google Scholar]
- Matthews, D.; Pabiou, T.; Evans, R. D.; Beder, C.; Daly, A. Predicting carcass cut yields in cattle from digital images using artificial intelligence. Meat Science 2021, 181, 108671. [Google Scholar] [CrossRef]
- Chowdhury, E. U.; Morey, A. Application of optical technologies in the US poultry slaughter facilities for the detection of poultry carcass condemnation. Journal of the Science of Food and Agriculture 2020, 100(10), 3736–3744. [Google Scholar] [CrossRef]
- Kang, R.; Yang, K.; Zhang, X. X.; Chen, K. Development of Online Detection and Processing System for Contaminants on Chicken Carcass Surface. Applied Engineering in Agriculture 2016, 32(1), 133–139. [Google Scholar] [CrossRef]
- De La Iglesia, D. H.; Villarrubia González, G.; Vallejo García, M.; López Rivero, A. J.; De Paz, J. F. Non-invasive automatic beef carcass classification based on sensor network and image analysis. Future Generation Computer Systems 2020, 113, 168–176. [Google Scholar] [CrossRef]
- Barbon, S. B. J.; Ayub da Costa Barbon, A. P.; Mantovani, R. G.; Barbin, D. F. Prediction of pork loin quality using online computer vision system and artificial intelligence model. Meat Science 2018, 140, 155–163. [Google Scholar] [CrossRef]
- Vajdi, M.; Varidi, M. J.; Varidi, M.; Mohebbi, M. Using electronic nose to recognize fish spoilage with an optimum classifier. Journal of Food Measurement and Characterization 2019, 13, 1205–1217. [Google Scholar] [CrossRef]
- Joutou, T.; Yanai, K. A food image recognition system with Multiple Kernel Learning. In Proceedings of the 16th IEEE International Conference on Image Processing; pp. 285–288. [CrossRef]
- Tanno, R.; Okamoto, K.; Yanai, K. DeepFoodCam: ADCNN-based Real-time Mobile Food Recognition System; ACM Digital Library, 2016. [Google Scholar] [CrossRef]
- Wang, D.; Ali, M.; Cobau, J.; Tao, Y. Designs of a customized active 3D scanning system for food processing applications. In Proceedings of the 2021 ASABE Annual International Virtual Meeting; p. 2100388. [CrossRef]
- Misimi, E.; Øye, E. R.; Eilertsen, A.; Mathiassen, J. R. B.; Åsebø Berg, O.; Gjerstad, T. B.; Buljo, J. O.; Skotheim, Ø. GRIBBOT - Robotic 3D vision-guided harvesting of chicken fillets. Computers and Electronics in Agriculture 2016, 121, 84–100. [Google Scholar] [CrossRef]
- Wright, R.; Parekh, S.; White, R.; Losey, D. P. Safely and autonomously cutting meat with a collaborative robot arm. Scientific Reports 2024, 14, 299. [Google Scholar] [CrossRef] [PubMed]
- Aly, B. A.; Low, T.; Long, D.; Baillie, C.; Brett, P. Robotics and sensing technologies in red meat processing: A review. Trends in Food Science Technology 2023, 132, 264–276. [Google Scholar] [CrossRef]
- Choi, S., Zhang, G., Fuhlbrigge, T., Watson, T., and Tallian, R. (2023). Applications and requirements of industrial robots in meat processing. IEEE (Year). [DOI/Link if available].
- Echegaray, N.; Hassoun, A.; Jagtap, S.; Tetteh-Caesar, M.; Kumar, M.; Tomasevic, I.; Goksen, G.; Lorenzo, J. M. Meat 4.0: Principles and Applications of Industry 4.0 Technologies in the Meat Industry. Applied Sciences 2022, 12(14), 6986. [Google Scholar] [CrossRef]
- Templer, R. G.; Nicholls, H. R.; Nicolle, T. Robotics for meat processing – from research to commercialisation. Industrial Robot 1999, 26(3), 247–252. [Google Scholar] [CrossRef]
- Purnell, G. Robots for the meat industry. Industrial Robot 1995, 22(5), 31–35. [Google Scholar] [CrossRef]
- Joshi, K., Norton, T., Frías, J. M., and Tiwari, B. K. (2017). Robotics in meat processing. In Emerging Technologies in Meat Processing (eds E.J. Cummins and J.G. Lyng). [CrossRef]
- Khodabandehloo, K. Achieving robotic meat cutting. Animal Frontiers 2022, 12(2), 3–4. [Google Scholar] [CrossRef] [PubMed]
- Nayik, G. A.; Muzaffar, K.; Gull, A. Robotics and Food Technology: A Mini Review. Food Engineering 2023, 148, 103623. [Google Scholar]
- Kim, J.; Kwon, Y.; Kim, H.-W.; Seol, K.-H.; Cho, B.-K. Robot Technology for Pork and Beef Meat Slaughtering Process: A Review. Animals 2023, 13(4), 651. [Google Scholar] [CrossRef]
- Walker, T.; Ahlin, K.; Joffe, B. P. Robotic Rehang with Machine Vision. In Proceedings of the 2021 ASABE Annual International Virtual Meeting; p. 202100519. [CrossRef]
- Xiong, Z.; Sun, D. W.; Pu, H.; Gao, W.; Dai, Q. Applications of emerging imaging techniques for meat quality and safety detection and evaluation: A review. Journal of Food Engineering 2017, 104, 755–768. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Hao, G.; Zhang, Y.; Wang, S. A real-time classification and detection method for mutton parts based on single shot multi-box detector. Journal of Food Processing and Preservation 2021, 45(10). [Google Scholar] [CrossRef]
- Ulum, M. F., Maryani, Min Rahminiwati, L. C., Hendra Setyawan, N., Ain, K., Mukhaiyar, U., Pamungkas, F. A., Jakaria, & Garnadi, A. D. (2024). Assessment of Meat Content and Foreign Object Detection in Cattle Meatballs Using Ultrasonography, Radiography, and Electrical Impedance Tomography Imaging. Advances in Mechanical Engineering, 2024. [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Wang, Y.; Zhang, W.; Li, Y. Evaluation of Deep Learning for Automatic Multi-View Face Detection in Cattle. Agriculture 2021, 11(11), 1062. [Google Scholar] [CrossRef]
- Qiao, Y., Truman, M., & Sukkarieh, S. (2019). Cattle segmentation and contour extraction based on Mask R-CNN for precision livestock farming. Computers and Electronics in Agriculture, 164, 104958. [CrossRef]
- Jiang, K., Xie, T., Yan, R., Wen, X., Li, D., Jiang, H., Jiang, N., Feng, L., Duan, X. (2022). An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture, 12(10), 1659. [CrossRef]
- Li, J., Su, H., Zheng, X., Liu, Y., Zhou, R., Xu, L., Liu, Q., Liu, D., Wang, Z., & Duan, X. (2022). Study of a QueryPNet Model for Accurate Detection and Segmentation of Goose Body Edge Contours. Animals, 12(19), 2653. [CrossRef]
- Modzelewska-Kapituła, M., & Jun, S. (2022). The application of computer vision systems in meat science and industry – A review. Meat Science, 182, 108904. [CrossRef]
- Ali, M. A., Wang, D., & Tao, Y. (2024). Active Dual Line-Laser Scanning for Depth Imaging of Piled Agricultural Commodities for Itemized Processing Lines. Sensors, 24(8), 2385. [CrossRef]
- Sun, X., Li, J., Liu, C., & Liu, G. (2018). Prediction of pork loin quality using online computer vision system and artificial intelligence model. Meat Science, 140, 155-163. [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2016, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Wang, Z. (2023). Challenges and Opportunities in Robotic Food Handling: A Review.
- An, G., et al. (2024). Deep spatial and discriminative feature enhancement network for stereo matching. The Visual Computer, 40, 1–16. Springer.
- Zhao, Z.; Cao, Q.; Zhang, X. Segmentation and Tracking of Vegetable Plants by Exploiting Vegetable Shape Feature for Precision Spray of Agricultural Robots. arXiv 2023, arXiv:2306.13518. [Google Scholar]
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2961-2969. [CrossRef]
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778. 2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. [CrossRef]
- Ai Chen, Xin Li, Tianxiang He, Junlin Zhou, and Duanbing Chen, Advancing in RGB-D Salient Object Detection: A Survey, Applied Sciences, vol. 14, no. 17, pp. 8078, 2024. [CrossRef]
- Tran, M. Tran, M., Truong, S., Fernandes, A. F. A., Kidd, M. T., & Le, N. CarcassFormer: An End-to-end Transformer-based Framework for Simultaneous Localization, Segmentation and Classification of Poultry Carcass Defects. arXiv 2024, arXiv:2404.11429. [Google Scholar]
- Chaitanya Pallerla, Yihong Feng, Casey M. Owens, Ramesh Bahadur Bist, Siavash Mahmoudi, Pouya Sohrabipour, Amirreza Davar, and Dongyi Wang, Neural network architecture search enabled wide-deep learning (NAS-WD) for spatially heterogenous property aware chicken woody breast classification and hardness regression, available at ScienceDirect, 2024.
- K. Simonyan and A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition," in *Proceedings of the International Conference on Learning Representations (ICLR)*, 2015. [Online]. Available online: https://arxiv.org/abs/1409.1556.
- M. Tan and Q. Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks," in *Proceedings of the 36th International Conference on Machine Learning (ICML)*, vol. 97, 2019, pp. 6105–6114. [Online]. Available online: https://arxiv.org/abs/1905.11946.
- A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications," 2017. [Online]. Available: https://arxiv.org/abs/1704.04861.
- A. Author, B. Author, and C. Author, “MultiStar: Instance Segmentation of Overlapping Objects with Star-Convex Polygons,” arXiv, 2020. [Online]. Available: https://arxiv.org/abs/2011.13228.
- Teledyne Vision Solutions, 2023. Accuracy of Stereo Vision Camera Disparity Depth Calculations. Available online: https://www.teledynevisionsolutions.com/support/support-center/technical-guidance/iis/accuracy-of-stereo-vision-camera-disparity-depth-calculations/ (accessed on 16 January 2025).
Figure 1.
Images of chicken rehanging lines [5,6], where chickens are piled together, with each pile consisting of chickens exhibiting similar color and texture. In large-scale processing plants, line speeds can reach up to 175 birds per minute.

Figure 2.
RGB image (left) of a chicken and the corresponding depth heatmap (right) from Intel real-sense camera. The depth heatmap generated by the Intel real-sense camera shows a lack of clarity in the boundary between chickens, indicating that the camera lacks sufficient accuracy in distinguishing fine details between the objects
Figure 2.
RGB image (left) of a chicken and the corresponding depth heatmap (right) from Intel real-sense camera. The depth heatmap generated by the Intel real-sense camera shows a lack of clarity in the boundary between chickens, indicating that the camera lacks sufficient accuracy in distinguishing fine details between the objects

Figure 3.
The overall diagram of the low cost active dual line-laser scanning system.
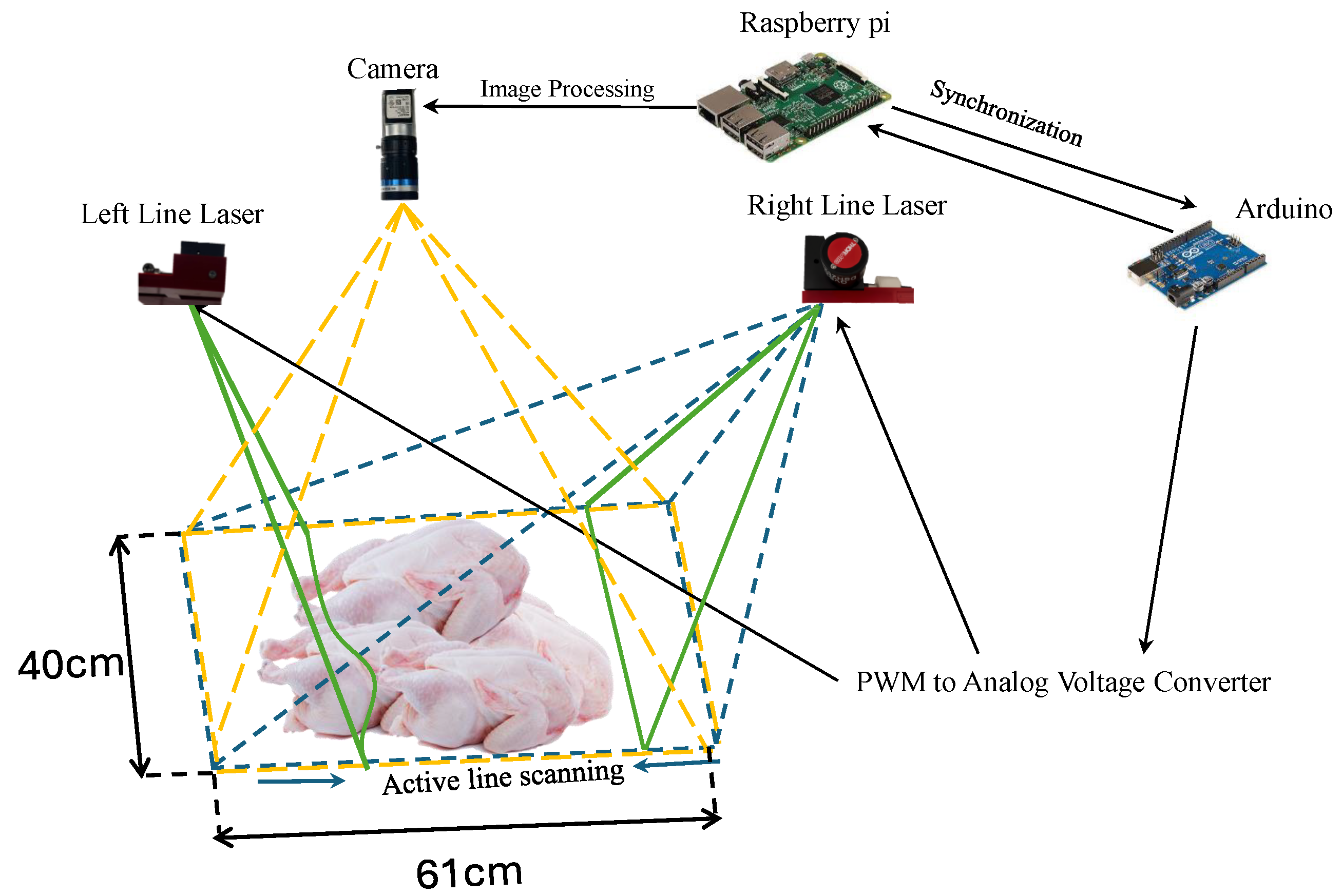
Figure 4.
The flowchart of the cost-effective communication framework implemented between the vision and control systems.
Figure 4.
The flowchart of the cost-effective communication framework implemented between the vision and control systems.
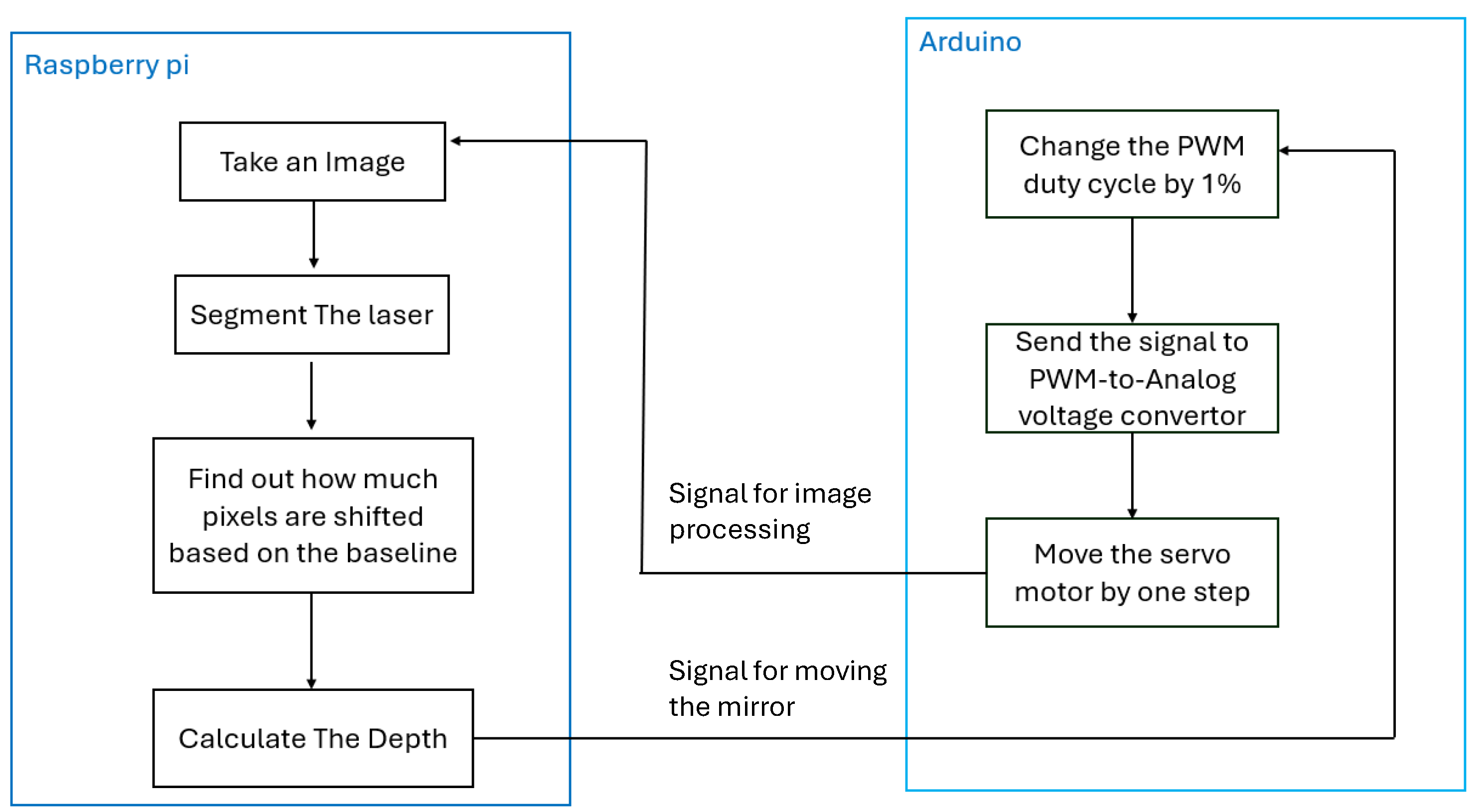
Figure 5.
Image processing procedures of depth heatmap generation.
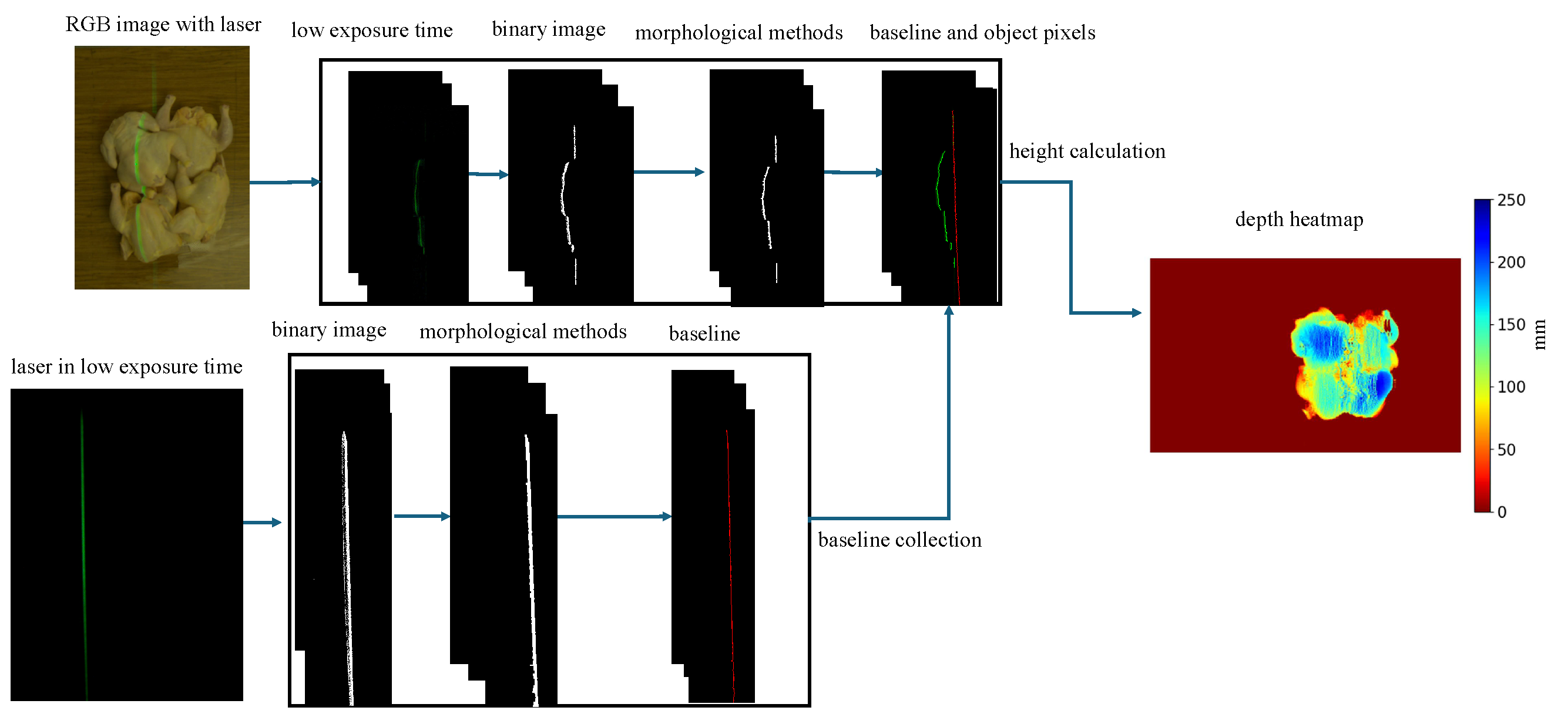
Figure 6.
Optical triangulation diagram for object height estimation.
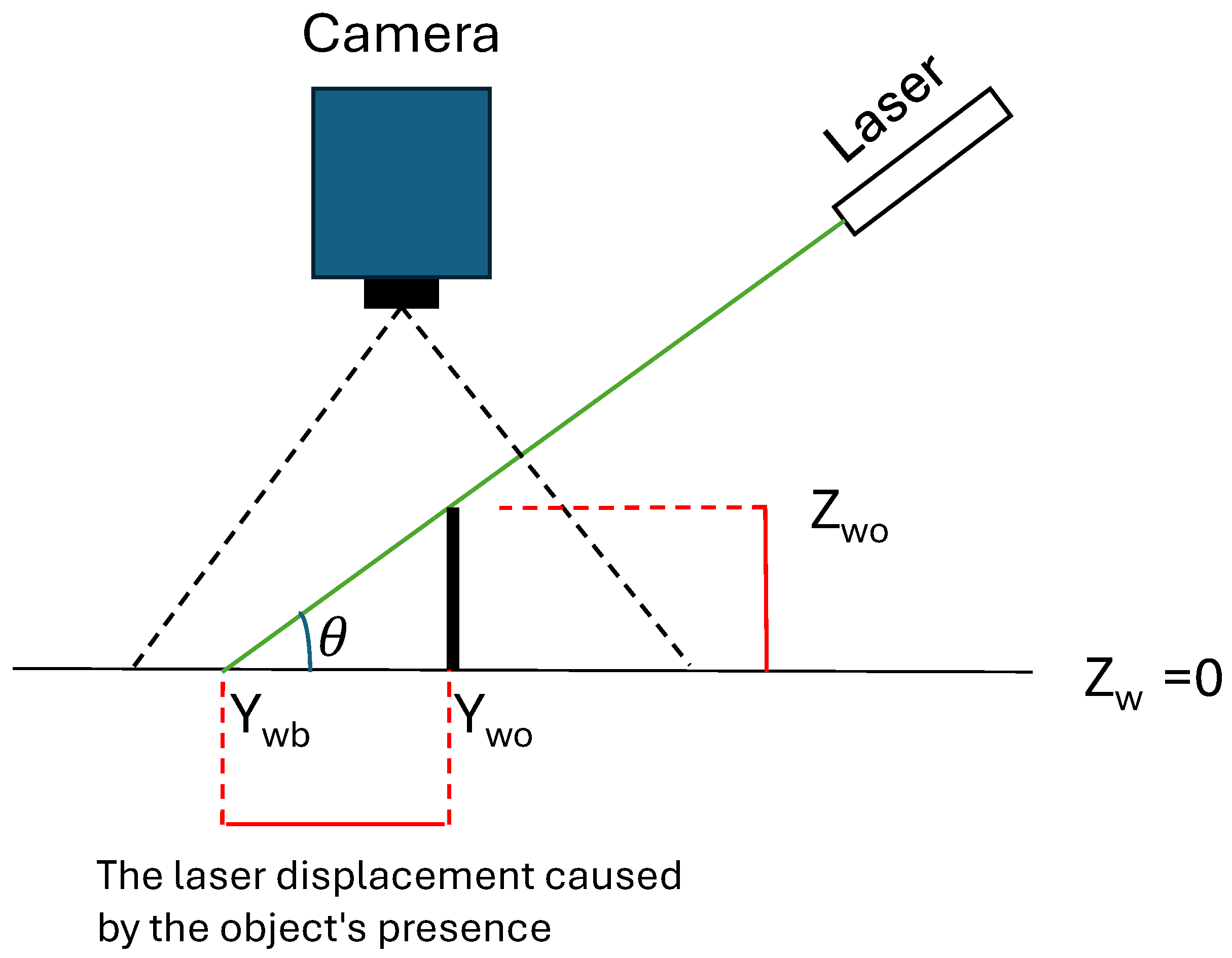
Figure 7.
Illustration of the Mask R-CNN architecture, adapted for RGB-D input. The RGB and depth (D) data are concatenated to form a 4-channel input, and the first layer of the backbone network is to accommodate the additional depth channel.
Figure 7.
Illustration of the Mask R-CNN architecture, adapted for RGB-D input. The RGB and depth (D) data are concatenated to form a 4-channel input, and the first layer of the backbone network is to accommodate the additional depth channel.
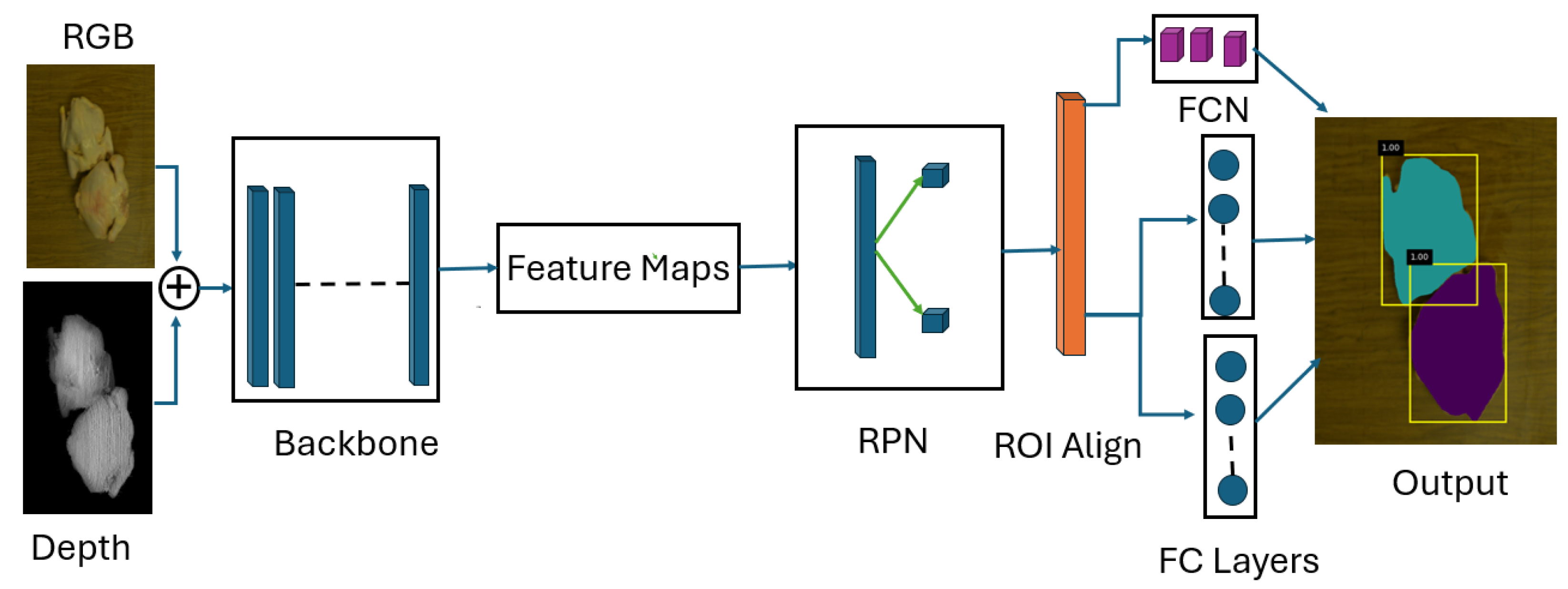
Figure 8.
Laser Calibration Analysis: The relationship between Arduino PWM output and line-laser projected angle.
Figure 8.
Laser Calibration Analysis: The relationship between Arduino PWM output and line-laser projected angle.
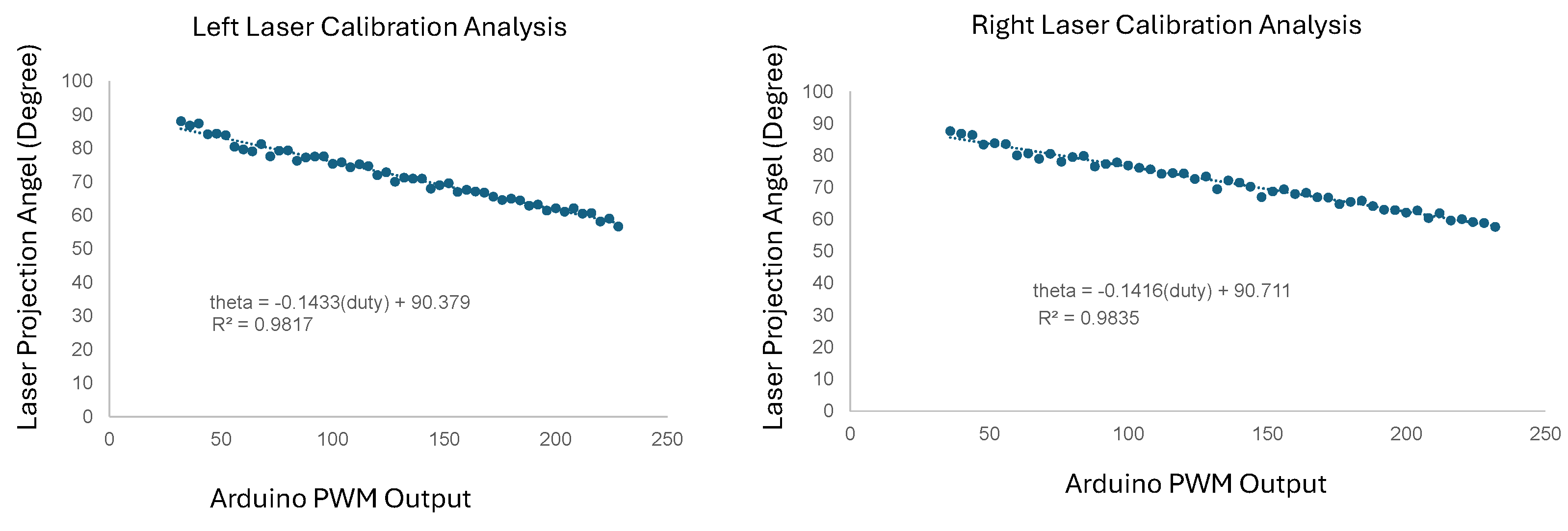
Figure 9.
Illustration of the RGB image and corresponding depth map generation process using dual lasers. The left image shows the raw RGB input, while the middle images display the heat maps derived from the right and left green lasers, respectively. White pixels in the heat maps indicate occluded areas where the laser could not be detected by the camera.
Figure 9.
Illustration of the RGB image and corresponding depth map generation process using dual lasers. The left image shows the raw RGB input, while the middle images display the heat maps derived from the right and left green lasers, respectively. White pixels in the heat maps indicate occluded areas where the laser could not be detected by the camera.
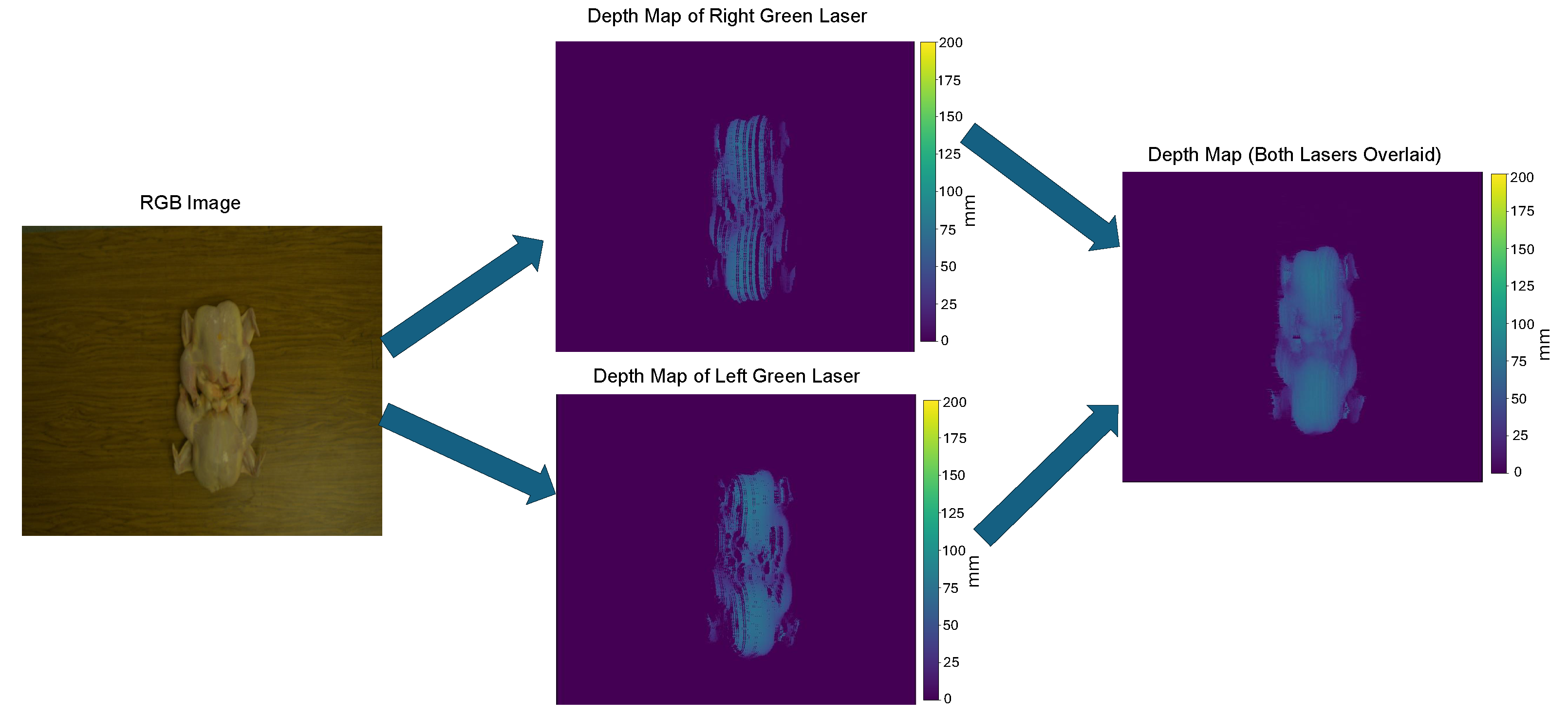
Figure 10.
Comparison of Mask R-CNN results on RGB and RGB-D inputs, alongside the corresponding RGB image and ground truth (GT) masks. The RGB image illustrates the input data, while the GT masks serve as the reference for evaluating segmentation accuracy. Moreover, the blue circles represent the centers of the ground truth masks, while the red circles indicate the centers of the predicted masks.
Figure 10.
Comparison of Mask R-CNN results on RGB and RGB-D inputs, alongside the corresponding RGB image and ground truth (GT) masks. The RGB image illustrates the input data, while the GT masks serve as the reference for evaluating segmentation accuracy. Moreover, the blue circles represent the centers of the ground truth masks, while the red circles indicate the centers of the predicted masks.
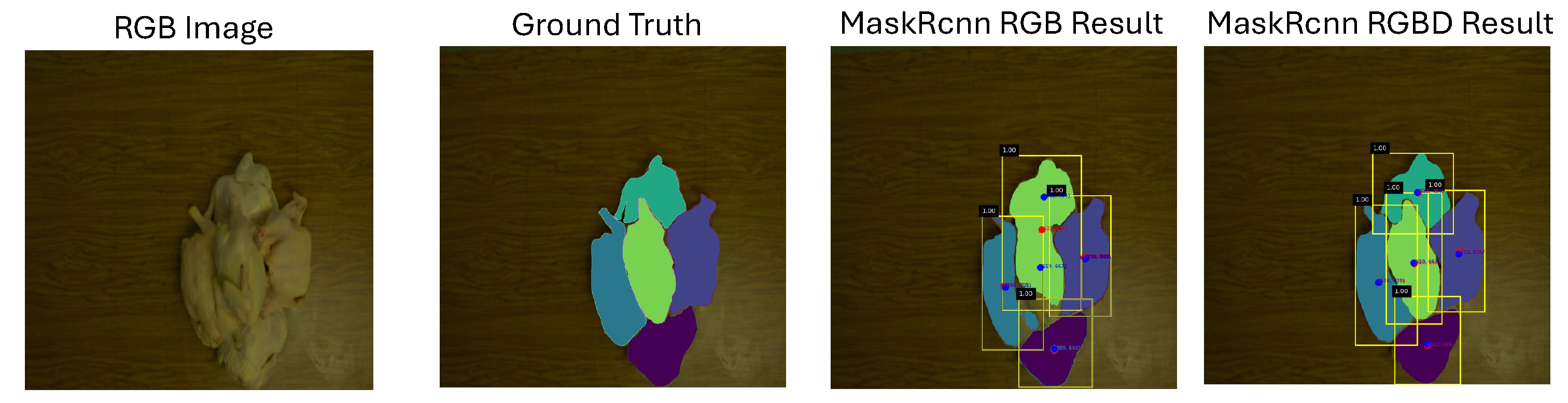

Table 1.
Accuracy evaluation of the right laser, left laser, and their final integration at different step sizes (50 mm, 100 mm, 150mm). The table compares the calculated heights for each step by the individual lasers, the integrated depth map, and the real-sense camera.
Table 1.
Accuracy evaluation of the right laser, left laser, and their final integration at different step sizes (50 mm, 100 mm, 150mm). The table compares the calculated heights for each step by the individual lasers, the integrated depth map, and the real-sense camera.
| Step Height (mm) | Height Value (mm) from Right Laser | Height Value (mm) from Left Laser | Final Height Value Using Both Lasers (mm) | Height Value from Real-Sense (mm) |
|---|---|---|---|---|
| 50 | 43.09 | 46.15 | 45.89 | 27.13 |
| 100 | 97.00 | 99.85 | 98.37 | 83.58 |
| 150 | 143.91 | 147.92 | 145.85 | 202.00 |
Table 2.
Comparison of Mask R-CNN performance on RGB and RGB-D inputs across various backbone architectures. The table reports the mAP (IoU 50:95) and Center Offset metrics, highlighting the impact of depth information (D) on segmentation accuracy and center alignment.
Table 2.
Comparison of Mask R-CNN performance on RGB and RGB-D inputs across various backbone architectures. The table reports the mAP (IoU 50:95) and Center Offset metrics, highlighting the impact of depth information (D) on segmentation accuracy and center alignment.
| Mask R-CNN RGB Backbones | mAP IoU=0.50:0.95 | Center Offset (pixels) | ||
|---|---|---|---|---|
| RGB | RGBD | RGB | RGBD | |
| ResNet50 | 0.631 | 0.680 | 22.09 | 8.99 |
| ResNet101 | 0.508 | 0.638 | 22.18 | 13.34 |
| VGG16 | 0.132 | 0.466 | 19.57 | 21.19 |
| EfficientNetB0 | 0.132 | 0.565 | 22.58 | 16.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



