Submitted:
18 January 2025
Posted:
20 January 2025
You are already at the latest version
Abstract
The proliferation of unauthorized Unmanned Aerial Vehicles (UAVs) has heightened security concerns, driving the need for advanced detection systems. YOLO-based algorithms show promise but struggle with detecting tiny UAVs (5x5 to 400x400 pixels) in complex backgrounds. To address these challenges, we introduce the Enhanced Tiny UAV-target YOLOv6n network (ET-YOLOv6n). Our contributions are threefold: Firstly, we enhance the backbone by introducing a C2f-Star Module, which replaces conventional blocks with Star Operation Blocks to improve feature extraction for tiny targets while reducing computational overhead. Secondly, in the neck, we propose a Cross-Two-Layer BiFPN that integrates features across both vertical and horizontal directions within the network graph, ensuring robust multi-scale feature fusion. Lastly, we augment the head with an additional P2 layer, leveraging detailed geometric information from the p2 feature map to predict extremely small objects more accurately. Empirical evaluations on the DUT Anti-UAV dataset demonstrate that our proposed ET-YOLOv6n achieves competitive and often superior performance in detecting tiny UAV targets compared to existing YOLO-based approaches, including both smaller and medium-sized models. Specifically, it outperforms the YOLOv6n baseline on mAP@0.5, increasing from 0.857 to 0.906, and on mAP@0.5:0.95, from 0.549 to 0.588. Notably, these improvements are achieved with over 30% fewer parameters and reduced computation flops, making ET-YOLOv6n not only more efficient but also highly effective for real-world applications.
Keywords:
1. Introduction
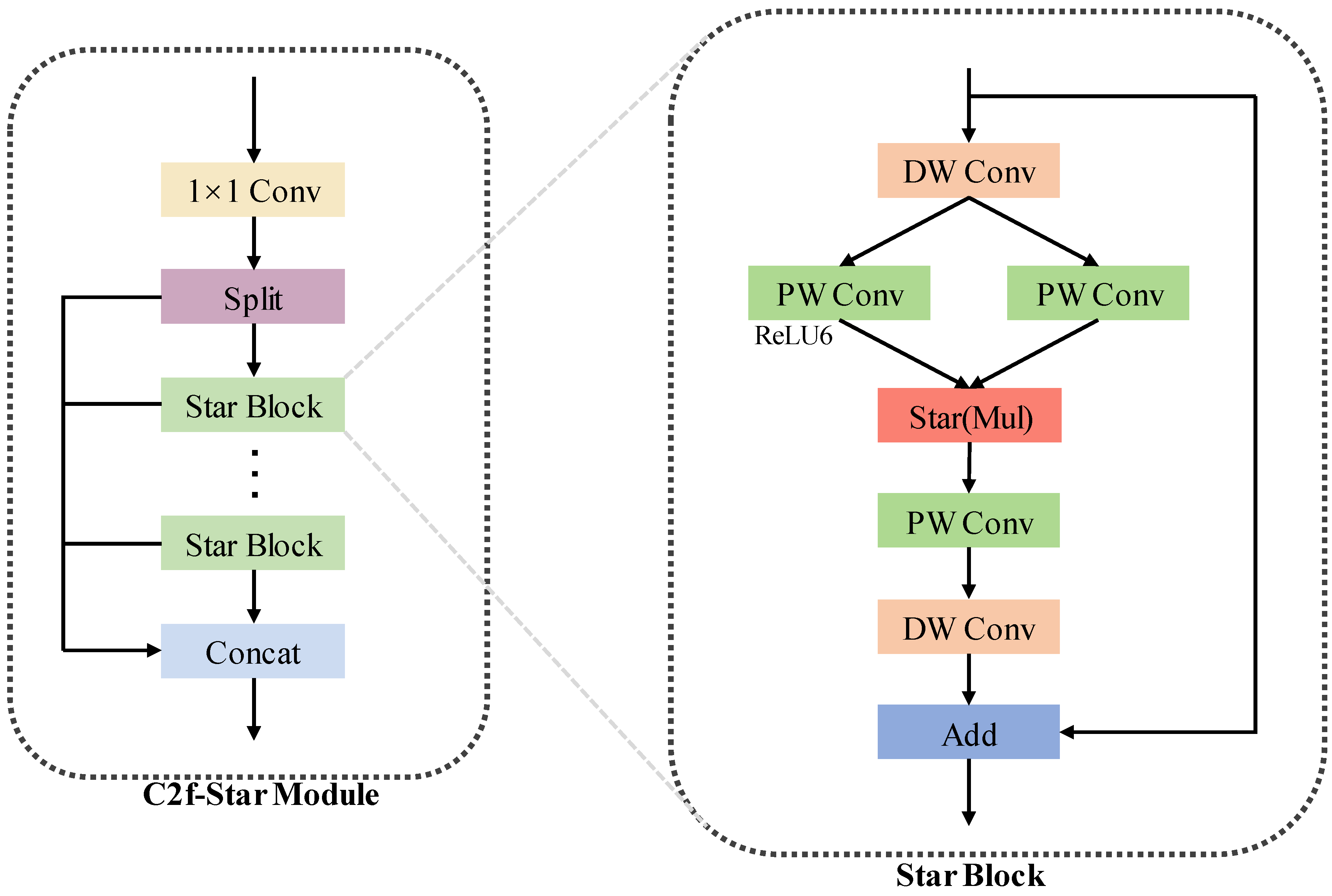
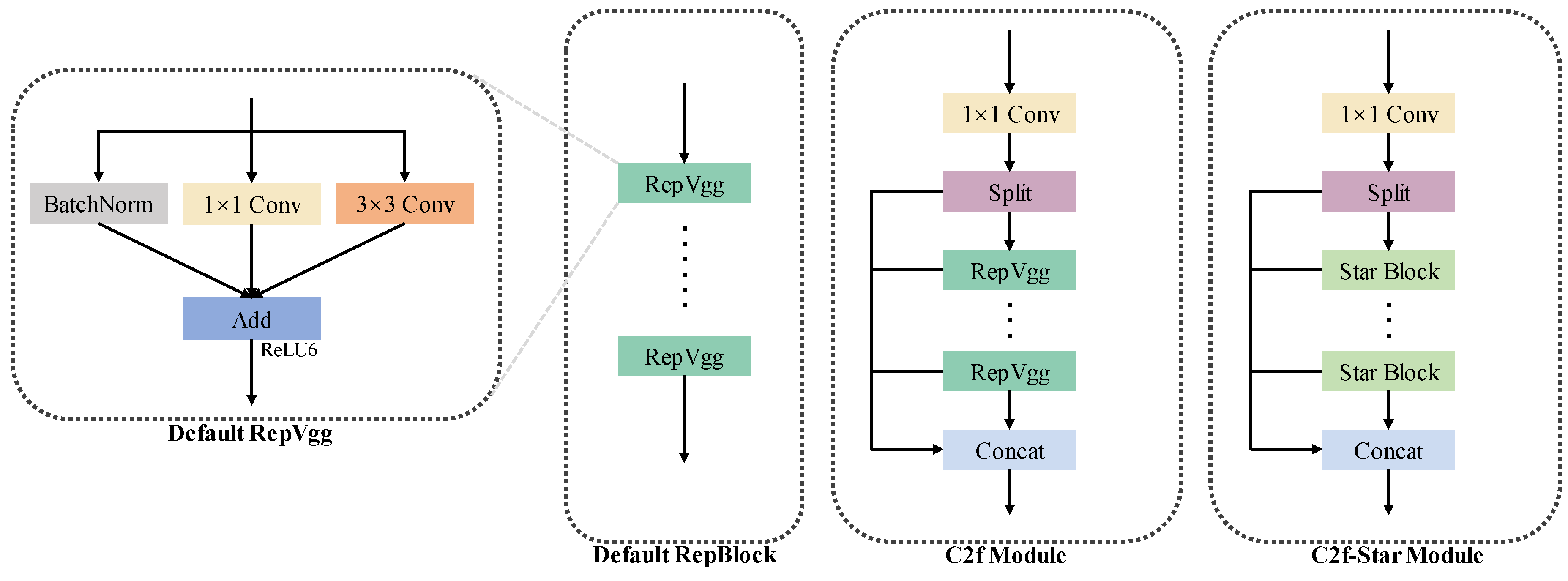
- We propose a novel C2f-Star Module in the Backbone, employing Star Operation to increase feature dimensions while reducing the number of parameters.
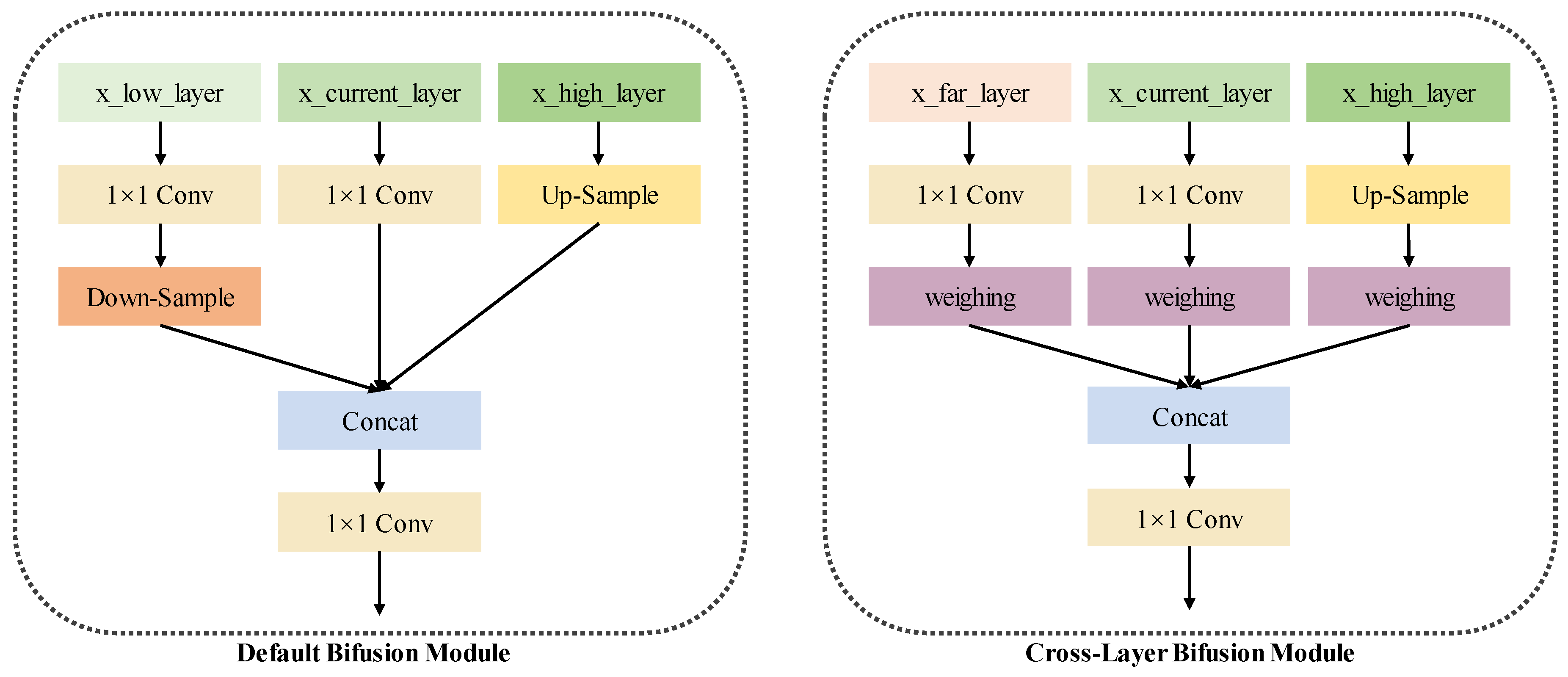
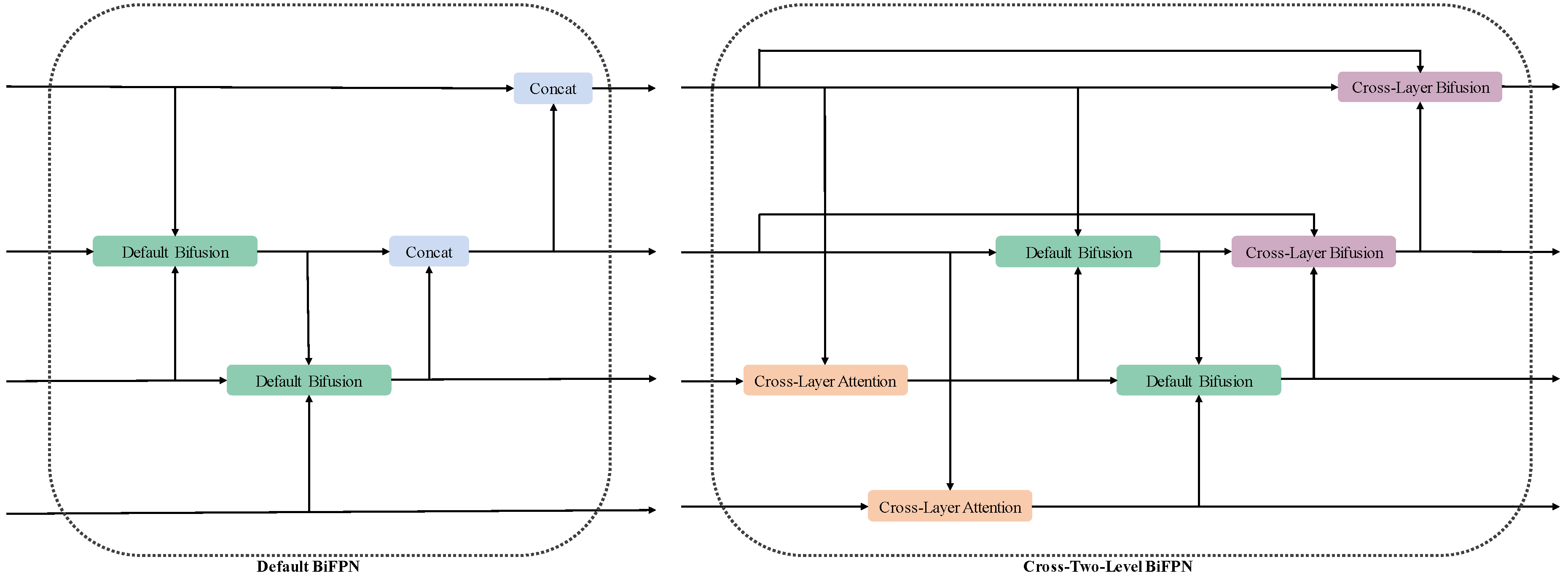
- We introduce Cross-Two-Layer BiFPN for feature fusion in both vertical and horizontal directions, effectively incorporating semantic and geometric features and preventing information loss.
- We add a P2 layer to improve the detection of minuscule UAV instances, enhancing the model’s ability to detect tiny UAV objects.
2. Related Work
2.1. Feature Pyramid Networks (FPN)
2.2. Attention Mechanism
2.2.1. Enhancing Feature Representation
2.2.2. Improving Small Object Detection Performance
2.3. StarNet
3. Methodology
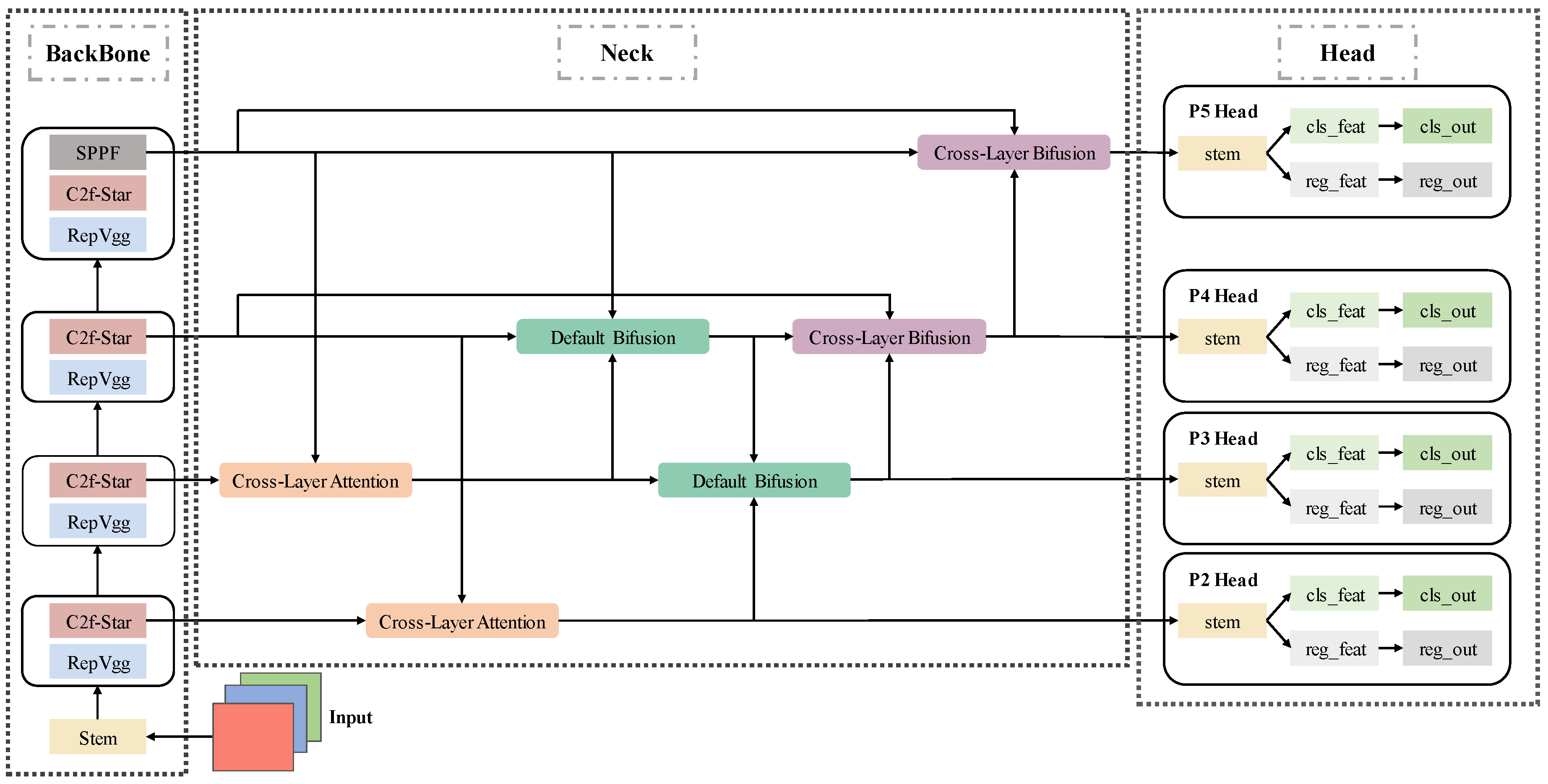
3.1. Overall Architecture
3.2. Enhancements to Backbone
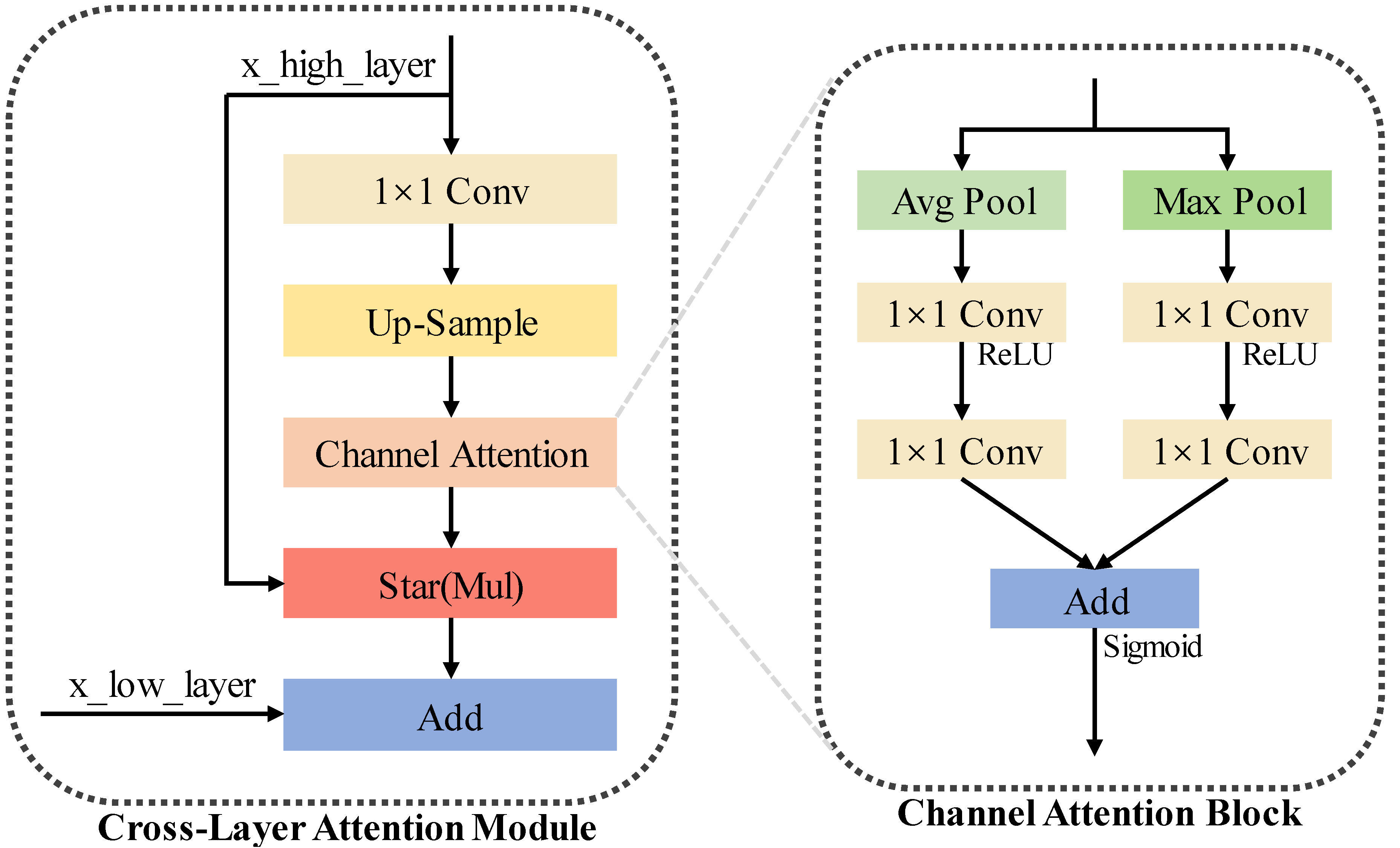
3.3. Enhancements to Neck
3.4. Enhancements to Head
4. Experiment
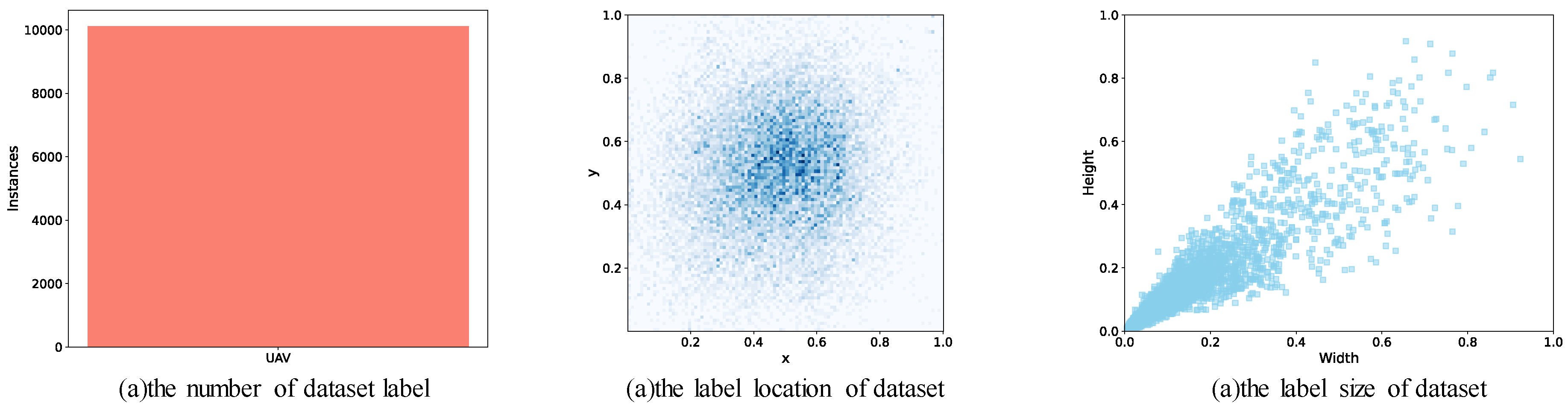
4.1. Dataset
4.2. Experiment Environment
4.3. Evaluation Metrics
4.4. Ablation Experiments
4.5. Comparison with Other YOLO Algorithms
5. Conclusion
References
- Li, Y.; Fu, M.; Sun, H.; Deng, Z.; Zhang, Y. Radar-based UAV swarm surveillance based on a two-stage wave path difference estimation method. IEEE Sensors Journal 2022, 22, 4268–4280. [Google Scholar] [CrossRef]
- Xiao, J.; Chee, J.H.; Feroskhan, M. Real-time multi-drone detection and tracking for pursuit-evasion with parameter search. IEEE Transactions on Intelligent Vehicles 2024. [Google Scholar] [CrossRef]
- Svanström, F.; Englund, C.; Alonso-Fernandez, F. Real-time drone detection and tracking with visible, thermal and acoustic sensors. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR). IEEE; 2021; pp. 7265–7272. [Google Scholar]
- Fang, H.; Wang, X.; Liao, Z.; Chang, Y.; Yan, L. A real-time anti-distractor infrared UAV tracker with channel feature refinement module. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.1240–1248.
- Xu, B.; Hou, R.; Bei, J.; Ren, T.; Wu, G. Jointly modeling association and motion cues for robust infrared UAV tracking. The Visual Computer, 2024, pp. 1–12.
- Fang, H.; Wu, C.; Wang, X.; Zhou, F.; Chang, Y.; Yan, L. Online infrared UAV target tracking with enhanced context-awareness and pixel-wise attention modulation. IEEE Transactions on Geoscience and Remote Sensing 2024. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR; 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the CVPR; 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the CVPR; 2018; pp. 8759–8768. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the CVPR; 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the ICCV; 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the CVPR; 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the CVPR; 2016; pp. 779–788. [Google Scholar]
- Zhao, H.; Shi, J.; Wang, X.; Qi, J.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the CVPR; 2019; pp. 2881–2890. [Google Scholar]
- Chen, L.J.L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation With Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the ECCV; 2017; pp. 630–645. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the NeurIPS; 2017; pp. 5998–6008. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; Krähenbühl, P. Non-local Neural Networks. In Proceedings of the CVPR; 2020; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the CVPR; 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the ECCV; 2018; pp. 3–19. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the NeurIPS; 2014; pp. 2204–2212. [Google Scholar]
- Zhang, H.; Goodfellow, I.J.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the ICML; 2019; pp. 7354–7363. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the ECCV; 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR; 2021. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Wu, Y.; Yao, Y. Dual Attention Network for Scene Segmentation. In Proceedings of the CVPR; 2019; pp. 3146–3154. [Google Scholar]
- Wang, Q.; Zhou, B.; Li, P.; Chen, Y. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the CVPR; 2020; pp. 11531–11539. [Google Scholar]
- Zhang, S.; Peng, Z.; Li, W.; Cui, L.; Xiao, T.; Wei, F.; Wen, S.; Li, H.; Luo, J. Transformer-based Feature Pyramid Network for Object Detection. In Proceedings of the ICCV; 2021; pp. 3575–3584. [Google Scholar]
- Kisantal, M.; Riess, C.; Wirkert, S.; Denzler, J. Augmentation for Small Object Detection. In Proceedings of the CVPR Workshops; 2019; pp. 1–8. [Google Scholar]
- Chen, C.; Lu, X.; Shen, H.; Zhang, L. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Applied Sciences 2020, 10, 829. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV; 2020; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the ICCV; 2017; pp. 2980–2988. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press, 2004.
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the ICCV; 2019. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martinez, B. EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers. In Proceedings of the ECCV; 2022. [Google Scholar]
- Chen, J.; hong Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the CVPR; 2023. [Google Scholar]


| Methods | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|
| YOLOv6n | 85.7 | 54.9 | 4.6 | 11.3 |
| Head Enhancement | 88.1 | 57.2 | 4.7 | 12.3 |
| Neck Enhancement | 86.9 | 55.6 | 4.9 | 11.7 |
| Backbone Enhancement | 84.2 | 53.8 | 3.0 | 6.6 |
| Head+Neck Enhancement | 89.9 | 58.2 | 4.9 | 12.7 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| Methods | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|
| YOLOv6n | 85.7 | 54.9 | 4.6 | 11.3 |
| YOLOv6s | 87.3 | 57.3 | 18.5 | 45.2 |
| YOLOv6m | 85.7 | 56.9 | 34.8 | 85.6 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| YOLOv7-tiny | 80.9 | 51.2 | 6.0 | 13.2 |
| YOLOv7 | 82.8 | 54.2 | 36.5 | 103.2 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| YOLOv8n | 84.6 | 54.0 | 3.0 | 8.2 |
| YOLOv8s | 86.0 | 56.3 | 11.1 | 28.4 |
| YOLOv8m | 87.7 | 58.3 | 25.8 | 78.7 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| YOLOv9t | 82.2 | 52.6 | 2.7 | 11.0 |
| YOLOv9s | 85.8 | 56.4 | 7.2 | 26.7 |
| YOLOv9m | 87.3 | 59.3 | 20.0 | 76.5 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| YOLOv10n | 83.1 | 52.8 | 2.7 | 8.4 |
| YOLOv10s | 86.8 | 57.2 | 8.1 | 24.8 |
| YOLOv10m | 87.2 | 57.4 | 16.5 | 64.0 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
| YOLOv11n | 84.1 | 53.7 | 2.6 | 6.4 |
| YOLOv11s | 86.9 | 57.4 | 9.4 | 21.5 |
| YOLOv11m | 88.4 | 58.9 | 20.1 | 68.2 |
| ET-YOLOv6n | 90.6 | 58.8 | 3.2 | 7.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



