Submitted:
14 January 2025
Posted:
15 January 2025
You are already at the latest version
Abstract
Given that Machine Learning algorithms are data-driven, the way datasets are collected significantly impacts their performance. Data must be gathered methodically to avoid missing values or class imbalance, but sometimes the inherent nature of the data tends to lead to such imbalances. An unbalanced dataset can lead to biased models whose predictions are influenced by the majority class. To avoid this problem, balancing strategies can be used to equalize the instances of each class. In this paper, we propose a methodology to evaluate which balancing strategies, depending on the dataset, yield the best results. We leverage Self-Organizing Maps, an unsupervised neural network model, to identify which strategy generates the most suitable balanced synthetic data. By considering their topological structure, we also propose a metric that uses the trained map to measure changes between the original dataset and the same dataset after applying the different strategies.
Keywords:
1. Introduction
2. Related Work
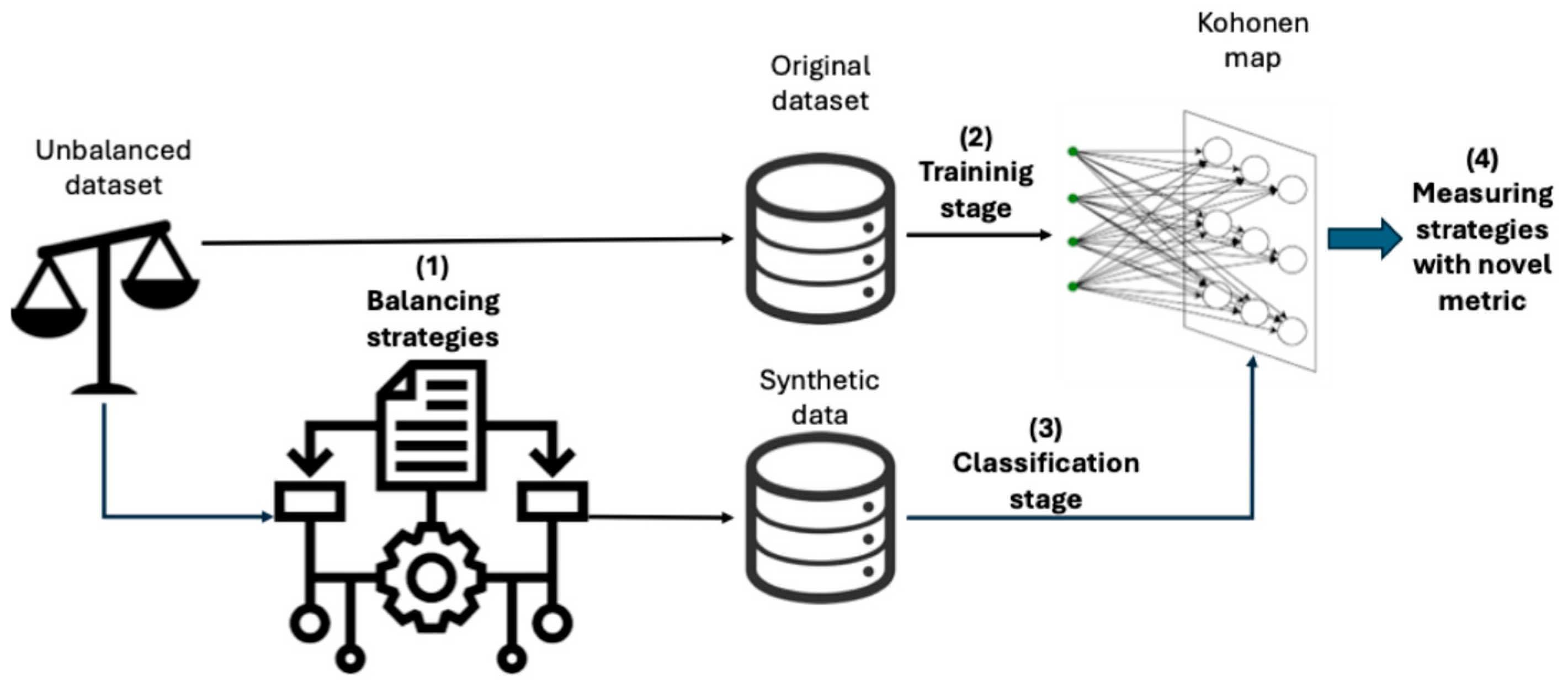
3. Materials and Methods
3.1. Unbalanced Datasets

| Dataset | Number of features | Missing values | Classification type | Imbalance | |
| Breast cancer | 3 | 0 | Binary numerical | 225/81 | |
| Oil spills | 49 | 0 | Binary numerical | 896/41 | |
| German credits | 20 | 0 | Binary numerical | 700/300 | |
| Phonemes | 5 | 0 | Binary numerical | 3,818/1,586 | |
| Microcalcifications | 6 | 0 | Binary numerical | 10,923/260 | |
| Credit card fraud | 6 | 0 | Binary numerical | 284,315/492 | |
3.2. Balancing Strategies
4. Results
| Dataset | Training | Validation | Test |
| Bank loans | 90.4% ± 1.8% | 86.2% ± 2.5% | 82.7% |
| Phonemes | 81.3% ± 5% | 80.6% ± 4.5% | 78% |
| Breast cancer | 97.3% ± 0.8% | 89.0% ± 6.0% | 87.3% |
| Credit frauds | 99.7% ± 0.2% | 99.6% ± 0.3% | 99.8% |
| Oil spills | 93.9% ± 0.8% | 93.6% ± 0.7% | 93.4% |
| Microcalcifications | 93.9% ± 0.8% | 93.6% ± 0.7% | 93.4% |
5. Conclusions and Future Works
References
- Belkin, Mikhail, Daniel Hsu, Siyuan Ma, and Soumik Mandal. 2019. “Reconciling Modern Machine-Learning Practice and the Classical Bias--Variance Trade-Off.” Proceedings of the National Academy of Sciences 116(32): 15849–54. [CrossRef]
- Bergstra, James, and Yoshua Bengio. 2012. “Random Search for Hyper-Parameter Optimization.” Journal of machine learning research 13(2).
- Chawla, Nitesh V, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. 2002. “SMOTE: Synthetic Minority over-Sampling Technique.” Journal of artificial intelligence research 16: 321–57.
- Chawla, Nitesh V, Aleksandar Lazarevic, Lawrence O Hall, and Kevin W Bowyer. 2003. “SMOTEBoost: Improving Prediction of the Minority Class in Boosting.” In Knowledge Discovery in Databases: PKDD 2003: 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Cavtat-Dubrovnik, Croatia, September 22-26, 2003. Proceedings 7, , 107–19.
- Choirunnisa, Shabrina, and Joko Lianto. 2018. “Hybrid Method of Undersampling and Oversampling for Handling Imbalanced Data.” In 2018 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), , 276–80.
- Costa, Afonso José, Miriam Seoane Santos, Carlos Soares, and Pedro Henriques Abreu. 2020. “Analysis of Imbalance Strategies Recommendation Using a Meta-Learning Approach.” In 7th ICML Workshop on Automated Machine Learning (AutoML-ICML2020), , 1–10.
- Dong, Qi, Shaogang Gong, and Xiatian Zhu. 2018. “Imbalanced Deep Learning by Minority Class Incremental Rectification.” IEEE transactions on pattern analysis and machine intelligence 41(6): 1367–81.
- García-Tejedor, Álvaro José, and Alberto Nogales. 2022. “An Open-Source Python Library for Self-Organizing-Maps.” Software Impacts 12. [CrossRef]
- Goel, Garima, Liam Maguire, Yuhua Li, and Sean McLoone. 2013. “Evaluation of Sampling Methods for Learning from Imbalanced Data.” In International Conference on Intelligent Computing, , 392–401.
- Gosain, Anjana, and Saanchi Sardana. 2017. “Handling Class Imbalance Problem Using Oversampling Techniques: A Review.” In 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), , 79–85.
- Han, Hui, Wen-Yuan Wang, and Bing-Huan Mao. 2005. “Borderline-SMOTE: A New over-Sampling Method in Imbalanced Data Sets Learning.” In International Conference on Intelligent Computing, , 878–87.
- Hart, Peter. 1968. “The Condensed Nearest Neighbor Rule (Corresp.).” IEEE transactions on information theory 14(3): 515–16.
- He, Haibo, Yang Bai, Edwardo A Garcia, and Shutao Li. 2008. “ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning.” In 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), , 1322–28.
- Jaccard, Paul. 1912. “The Distribution of the Flora in the Alpine Zone. 1.” New phytologist 11(2): 37–50.
- Johnson, Justin M, and Taghi M Khoshgoftaar. 2019. “Survey on Deep Learning with Class Imbalance.” Journal of Big Data 6(1): 1–54. [CrossRef]
- Junsomboon, Nutthaporn, and Tanasanee Phienthrakul. 2017. “Combining Over-Sampling and under-Sampling Techniques for Imbalance Dataset.” In Proceedings of the 9th International Conference on Machine Learning and Computing, , 243–47.
- Khalilia, Mohammed, and Mihail Popescu. 2014. “Topology Preservation in Fuzzy Self-Organizing Maps.”. [CrossRef]
- Kohonen, Teuvo. 1982. “Self-Organized Formation of Topologically Correct Feature Maps.” Biological Cybernetics 43(1): 59–69. [CrossRef]
- Kohonen, Teuvo. 1998. “The Self-Organizing Map.” Neurocomputing 21(1): 1–6. [CrossRef]
- Kraiem, Mohamed S., Fernando Sánchez-Hernández, and María N. Moreno-García. 2021. “Selecting the Suitable Resampling Strategy for Imbalanced Data Classification Regarding Dataset Properties. An Approach Based on Association Models.” Applied Sciences (Switzerland) 11(18). [CrossRef]
- Kubat, Miroslav, Robert C Holte, and Stan Matwin. 1998. “Machine Learning for the Detection of Oil Spills in Satellite Radar Images.” Machine learning 30(2): 195–215. [CrossRef]
- Kubat, Miroslav, Stan Matwin, and others. 1997. “Addressing the Curse of Imbalanced Training Sets: One-Sided Selection.” In Icml, , 179.
- Last, Felix, Georgios Douzas, and Fernando Bacao. 2017. “Oversampling for Imbalanced Learning Based on K-Means and Smote.” arXiv preprint arXiv:1711.00837.
- Laurikkala, Jorma. 2001. “Improving Identification of Difficult Small Classes by Balancing Class Distribution.” In Conference on Artificial Intelligence in Medicine in Europe, , 63–66.
- Liu, Tong, Yongquan Liang, and Weijian Ni. 2011. “A Hybrid Strategy for Imbalanced Classification.” In 2011 3rd Symposium on Web Society, , 105–10.
- Mujahid, Muhammad, E. R.O.L. Kına, Furqan Rustam, Monica Gracia Villar, Eduardo Silva Alvarado, Isabel De La Torre Diez, and Imran Ashraf. 2024. “Data Oversampling and Imbalanced Datasets: An Investigation of Performance for Machine Learning and Feature Engineering.” Journal of Big Data 11(1). [CrossRef]
- Nguyen, Hien M, Eric W Cooper, and Katsuari Kamei. 2009. “Borderline Over-Sampling for Imbalanced Data Classification.” In Proceedings: Fifth International Workshop on Computational Intelligence \& Applications, , 24–29.
- Pérez, Joaqu\’\in, Emmanuel Iturbide, V\’\ictor Olivares, Miguel Hidalgo, Nelva Almanza, and Alicia Mart\’\inez. 2015. “A Data Preparation Methodology in Data Mining Applied to Mortality Population Databases.” In New Contributions in Information Systems and Technologies, Springer, 1173–82. [CrossRef]
- Raeder, Troy, George Forman, and Nitesh V Chawla. 2012. “Learning from Imbalanced Data: Evaluation Matters.” In Data Mining: Foundations and Intelligent Paradigms, Springer, 315–31.
- Rumelhart, David E, Geoffrey E Hinton, and Ronald J Williams. 1986. “Learning Representations by Back-Propagating Errors.” nature 323(6088): 533–36.
- Santoso, B, H Wijayanto, K A Notodiputro, and B Sartono. 2017. “Synthetic over Sampling Methods for Handling Class Imbalanced Problems: A Review.” In IOP Conference Series: Earth and Environmental Science, , 12031. [CrossRef]
- Shamsudin, Haziqah, Umi Kalsom Yusof, Andal Jayalakshmi, and Mohd Nor Akmal Khalid. 2020. “Combining Oversampling and Undersampling Techniques for Imbalanced Classification: A Comparative Study Using Credit Card Fraudulent Transaction Dataset.” In 2020 IEEE 16th International Conference on Control \& Automation (ICCA), , 803–8.
- Sun, Aixin, Ee-Peng Lim, and Ying Liu. 2009. “On Strategies for Imbalanced Text Classification Using SVM: A Comparative Study.” Decision Support Systems 48(1): 191–201. [CrossRef]
- Tomek, Ivan. 1976. “AN EXPERIMENT WITH THE EDITED NEAREST-NIEGHBOR RULE.”.
- Wainer, Jacques, and Rodrigo A Franceschinell. 2018. “An Empirical Evaluation of Imbalanced Data Strategies from a Practitioner’s Point of View.” arXiv preprint arXiv:1810.07168.
- Wilson, Dennis L. 1972. “Asymptotic Properties of Nearest Neighbor Rules Using Edited Data.” IEEE Transactions on Systems, Man, and Cybernetics (3): 408–21. [CrossRef]
- Winston, J. Jenkin, Gul Fatma Turker, Utku Kose, and D. Jude Hemanth. 2020. “Novel Optimization Based Hybrid Self-Organizing Map Classifiers for Iris Image Recognition.” International Journal of Computational Intelligence Systems 13(1): 1048–58. [CrossRef]
- Wongvorachan, Tarid, Surina He, and Okan Bulut. 2023. “A Comparison of Undersampling, Oversampling, and SMOTE Methods for Dealing with Imbalanced Classification in Educational Data Mining.” Information (Switzerland) 14(1). [CrossRef]
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 |

| Hyperparameter | Values |
| Side map | [5 – 25] |
| Epochs | 500, 1000, 2500, 5000, 7500, 10000 |
| Learning rate | 0.01, 0.05, 0.1, 0.2, 0.3 |
| Quantization error |
Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.926 | 0.176 |
| Edited Nearest Neighbours |
0.916 | 0.174 | |
| Condensed Nearest Neighbours | 0.912 | 0.172 | |
| Neighbourhood Cleaning Rule |
0.914 | 0.179 | |
| One Side Selection | 0.920 | 0.190 | |
| ADASYN | Tomek Links | 0.923 | 0.177 |
| Edited Nearest Neighbours |
0.924 | 0.183 | |
| Condensed Nearest Neighbours | 0.912 | 0.172 | |
| Neighbourhood Cleaning Rule |
0.914 | 0.179 | |
| One Side Selection | 0.920 | 0.190 | |
| Borderline SMOTE | Tomek Links | 0.926 | 0.175 |
| Edited Nearest Neighbours |
0.915 | 0.167 | |
| Condensed Nearest Neighbours | 0.919 | 0.163 | |
| Neighbourhood Cleaning Rule |
0.923 | 0.175 | |
| One Side Selection | 0.924 | 0.170 | |
| SVM SMOTE | Tomek Links | 0.954 | 0.175 |
| Edited Nearest Neighbours |
0.974 | 0.200 | |
| Condensed Nearest Neighbours | 0.968 | 0.170 | |
| Neighbourhood Cleaning Rule |
0.960 | 0.184 | |
| One Side Selection | 0.978 | 0.170 | |
| K-Means SMOTE | Tomek Links | 0.940 | 0.163 |
| Edited Nearest Neighbours | 0.933 | 0.174 | |
| Condensed Nearest Neighbours | 0.936 | 0.163 | |
| Neighbourhood Cleaning Rule | 0.964 | 0.171 | |
| One Side Selection | 0.939 | 0.162 | |
| Quantization error |
Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.143 | 0.226 |
| Edited Nearest Neighbours |
0.142 | 0.215 | |
| Condensed Nearest Neighbours | 0.143 | 0.216 | |
| Neighbourhood Cleaning Rule | 0.143 | 0.217 | |
| One Side Selection | 0.145 | 0.221 | |
| ADASYN | Tomek Links | 0.142 | 0.212 |
| Edited Nearest Neighbours |
0.141 | 0.207 | |
| Condensed Nearest Neighbours | 0.143 | 0.216 | |
| Neighbourhood Cleaning Rule | 0.143 | 0.217 | |
| One Side Selection | 0.145 | 0.221 | |
| Borderline SMOTE | Tomek Links | 0.145 | 0.206 |
| Edited Nearest Neighbours |
0.143 | 0.213 | |
| Condensed Nearest Neighbours | 0.144 | 0.206 | |
| Neighbourhood Cleaning Rule | 0.141 | 0.208 | |
| One Side Selection | 0.146 | 0.219 | |
| SVM SMOTE | Tomek Links | 0.145 | 0.217 |
| Edited Nearest Neighbours |
0.143 | 0.211 | |
| Condensed Nearest Neighbours | 0.145 | 0.215 | |
| Neighbourhood Cleaning Rule | 0.145 | 0.220 | |
| One Side Selection | 0.146 | 0.215 | |
| K-Means SMOTE | Tomek Links | 0.165 | 0.240 |
| Edited Nearest Neighbours |
0.150 | 0.248 | |
| Condensed Nearest Neighbours | 0.151 | 0.246 | |
| Neighbourhood Cleaning Rule | 0.157 | 0.239 | |
| One Side Selection | 0.218 | 0.152 | |
| Quantization error | Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.081 | 0.118 |
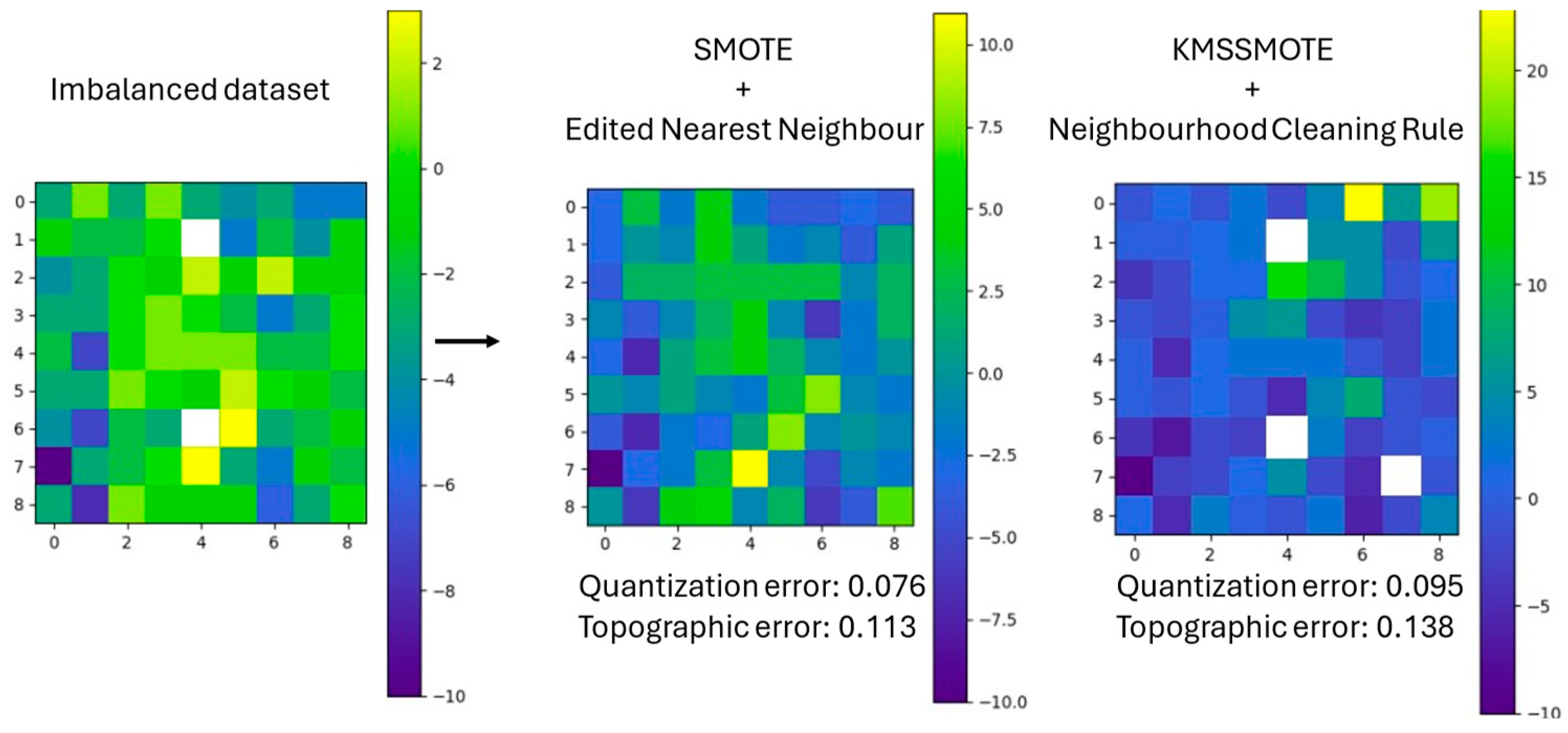
| Edited Nearest Neighbours | 0.076 | 0.113 | |
| Condensed Nearest Neighbours | 0.080 | 0.163 | |
| Neighbourhood Cleaning Rule | 0.080 | 0.128 | |
| One Side Selection | 0.076 | 0.105 | |
| ADASYN | Tomek Links | 0.081 | 0.114 |
| Edited Nearest Neighbours | 0.077 | 0.118 | |
| Condensed Nearest Neighbours | 0.080 | 0.086 | |
| Neighbourhood Cleaning Rule | 0.080 | 0.128 | |
| One Side Selection | 0.076 | 0.105 | |
| Borderline SMOTE | Tomek Links | 0.079 | 0.126 |
| Edited Nearest Neighbours | 0.081 | 0.117 | |
| Condensed Nearest Neighbours | 0.078 | 0.120 | |
| Neighbourhood Cleaning Rule | 0.077 | 0.134 | |
| One Side Selection | 0.085 | 0.121 | |
| SVM SMOTE | Tomek Links | 0.100 | 0.121 |
| Edited Nearest Neighbours | 0.097 | 0.128 | |
| Condensed Nearest Neighbours | 0.083 | 0.109 | |
| Neighbourhood Cleaning Rule | 0.092 | 0.116 | |
| One Side Selection | 0.097 | 0.102 | |
| K-Means SMOTE | Tomek Links | 0.084 | 0.118 |
| Edited Nearest Neighbours | 0.140 | 0.125 | |
| Condensed Nearest Neighbours | 0.094 | 0.106 | |
| Neighbourhood Cleaning Rule | 0.095 | 0.138 | |
| One Side Selection | 0.079 | 0.103 | |
| Quantization error | Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.406 | 0.074 |
| Edited Nearest Neighbours | 0.407 | 0.074 | |
| Condensed Nearest Neighbours | 0.408 | 0.075 | |
| Neighbourhood Cleaning Rule | 0.407 | 0.073 | |
| One Side Selection | 0.405 | 0.075 | |
| ADASYN | Tomek Links | 0.221 | 0.156 |
| Edited Nearest Neighbours | 0.221 | 0.158 | |
| Condensed Nearest Neighbours | 0.225 | 0.157 | |
| Neighbourhood Cleaning Rule | 0.221 | 0.157 | |
| One Side Selection | 0.223 | 0.158 | |
| Borderline SMOTE | Tomek Links | 0.243 | 0.144 |
| Edited Nearest Neighbours | 0.242 | 0.149 | |
| Condensed Nearest Neighbours | 0.243 | 0.145 | |
| Neighbourhood Cleaning Rule | 0.242 | 0.148 | |
| One Side Selection | 0.243 | 0.149 | |
| SVM SMOTE | Tomek Links | 0.282 | 0.149 |
| Edited Nearest Neighbours | 0.292 | 0.149 | |
| Condensed Nearest Neighbours | 0.277 | 0.148 | |
| Neighbourhood Cleaning Rule | 0.269 | 0.149 | |
| One Side Selection | 0.289 | 0.156 | |
| K-Means SMOTE | Tomek Links | 0.313 | 0.230 |
| Edited Nearest Neighbours | 0.295 | 0.133 | |
| Condensed Nearest Neighbours | 0.231 | 0.174 | |
| Neighbourhood Cleaning Rule | 0.239 | 0.112 | |
| One Side Selection | 0.196 | 0.152 | |
| Quantization error |
Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.563 | 0.112 |
| Edited Nearest Neighbours |
0.566 | 0.114 | |
| Condensed Nearest Neighbours | 0.566 | 0.119 | |
| Neighbourhood Cleaning Rule |
0.556 | 0.116 | |
| One Side Selection | 0.555 | 0.120 | |
| ADASYN | Tomek Links | 0.529 | 0.184 |
| Edited Nearest Neighbours |
0.528 | 0.192 | |
| Condensed Nearest Neighbours | 0.541 | 0.161 | |
| Neighbourhood Cleaning Rule |
0.530 | 0.175 | |
| One Side Selection | 0.538 | 0.157 | |
| Borderline SMOTE | Tomek Links | 0.554 | 0.179 |
| Edited Nearest Neighbours |
0.555 | 0.178 | |
| Condensed Nearest Neighbours | 0.561 | 0.171 | |
| Neighbourhood Cleaning Rule |
0.556 | 0.177 | |
| One Side Selection | 0.558 | 0.174 | |
| SVM SMOTE | Tomek Links | 0.579 | 0.145 |
| Edited Nearest Neighbours |
0.601 | 0.102 | |
| Condensed Nearest Neighbours | 0.592 | 0.09 | |
| Neighbourhood Cleaning Rule |
0.597 | 0.105 | |
| One Side Selection | 0.593 | 0.114 | |
| K-Means SMOTE | Tomek Links | 0.537 | 0.154 |
| Edited Nearest Neighbours |
0.513 | 0.146 | |
| Condensed Nearest Neighbours | 0.538 | 0.138 | |
| Neighbourhood Cleaning Rule |
0.525 | 0.133 | |
| One Side Selection | 0.538 | 0.145 | |
| Quantization error | Topographic error | ||
|---|---|---|---|
| SMOTE | Tomek Links | 0.095 | 0.208 |
| Edited Nearest Neighbours | 0.096 | 0.213 | |
| Condensed Nearest Neighbours | 0.092 | 0.202 | |
| Neighbourhood Cleaning Rule | 0.096 | 0.218 | |
| One Side Selection | 0.093 | 0.205 | |
| ADASYN | Tomek Links | 0.073 | 0.194 |
| Edited Nearest Neighbours | 0.075 | 0.203 | |
| Condensed Nearest Neighbours | 0.076 | 0.202 | |
| Neighbourhood Cleaning Rule | 0.075 | 0.199 | |
| One Side Selection | 0.073 | 0.196 | |
| Borderline SMOTE | Tomek Links | 0.078 | 0.252 |
| Edited Nearest Neighbours | 0.077 | 0.244 | |
| Condensed Nearest Neighbours | 0.077 | 0.248 | |
| Neighbourhood Cleaning Rule | 0.077 | 0.245 | |
| One Side Selection | 0.078 | 0.243 | |
| SVM SMOTE | Tomek Links | 0.088 | 0.107 |
| Edited Nearest Neighbours | 0.092 | 0.101 | |
| Condensed Nearest Neighbours | 0.093 | 0.098 | |
| Neighbourhood Cleaning Rule | 0.088 | 0.108 | |
| One Side Selection | 0.091 | 0.109 | |
| K-Means SMOTE | Tomek Links | 0.193 | 0.056 |
| Edited Nearest Neighbours | 0.154 | 0.177 | |
| Condensed Nearest Neighbours | 0.194 | 0.057 | |
| Neighbourhood Cleaning Rule | 0.187 | 0.108 | |
| One Side Selection | 0.145 | 0.172 | |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| KMSSMOTE + CNN | 69.1% | 69.8% | 68.6% | 69.1% ± 0.54 |
| SMOTE + ENN | 69.7% | 67.3% | 68.1% | 68.3% ± 1.38 |
| KMSSMOTE + OSS | 66.5% | 65.4% | 65.7% | 65.8% ± 0.57 |
| Mean total (N=25) | 63.5% ± 5.50 | 63.3 ± 3.3 0 | 62.8% ± 3.05 |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| SMOTE + ENN | 76.7% | 76.1% | 74.9% | 75.9% ± 0.81 |
| BSMOTE + CNN | 74.5% | 72.1% | 73.0% | 73.8% ± 1.25 |
| SMOTE + OSS | 68.6% | 66.7% | 68.0% | 67.7% ± 0.92 |
| Mean total (N=25) | 66.4% ± 5.49 | 63.1% ± 5.72 | 65.5% ± 6.00 |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| SMOTE + ENN | 81.1% | 71.4% | 71.9% | 74.8%± 4.70 |
| SMOTE + NCR | 75.6% | 71.7% | 70.5% | 72.6% ± 2.81 |
| BSMOTE + OSS | 73.6% | 71.7% | 70.5% | 71.9% ± 1.61 |
| Mean total (N=25) | 66.4% ± 6.15 | 63.8% ± 5.10 | 63.4% ± 5.30 |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| KMSSMOTE + NCR | 71.6% | 70.4% | 70.7% | 70.9% ± 0.61 |
| ADASYN + ENN | 67.4% | 66.5% | 66.8% | 66.9% ± 0.40 |
| SMOTE + ENN | 66.9% | 66.1% | 65.9% | 66.3% ± 0.41 |
| Mean total (N=25) | 64.2% ± 4.70 | 63.8% ± 4.10 | 65.6% ± 3.80 |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| KMSSMOTE + NCR | 79.2% | 73% | 73.3% | 75.1% ± 3.20 |
| SMOTE + ENN | 74.5% | 73.1% | 71.5% | 73.0% ± 1.46 |
| KMSSMOTE + CNN | 70.1% | 68.8% | 69.0% | 69.6% ± 0.68 |
| Mean total (N=25) | 66.3% ± 6.20 | 64.9% ± 5.40 | 63.8% ± 5.30 |
| Imbalanced Strategy | Threshold=80% | Threshold=75% | Threshold=70% | Mean per strategy |
| ADASYN + TL | 72.5% | 71.4% | 71.8% | 71.9% ± 0.55 |
| KMSSMOTE + TL | 70.1% | 69.4% | 69.2% | 69.5% ± 0.41 |
| SVMSMOTE + TL | 69.8% | 68.7% | 65.3% | 68.0% ± 2.46% |
| Mean total (N=25) | 64.4% ± 5.40 | 63.8% ± 5.10 | 63.3% ± 5.80 |
| Dataset (Unbalanced %) | Threshold=80% |
| Bank loans (40%) | 63.54% ± 5.5% |
| Phonemes (41%) | 66.4% ± 5.49% |
| Breast cancer (47%) | 66.4% ± 6.15% |
| Credit fraud (90%) | 64.2% ± 4.7% |
| Oil spills (91%) | 66.3% ± 6.2% |
| Microcalcifications (91%) | 64.4% ± 5.4% |
| Strategy | Times in the top 3 |
| SMOTE + ENN | 14 |
| KMSSMOTE + NCR | 6 |
| KMSSMOTE + CNN | 5 |
| SMOTE + OSS | 4 |
| SMOTE + NCR | 3 |
| ADASYN + TL | 3 |
| ADASYN + ENN | 3 |
| BSMOTE + CNN | 3 |
| SVMSMOTE + TL | 3 |
| KMSSMOTE + TL | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



