Submitted:
05 January 2025
Posted:
07 January 2025
Read the latest preprint version here
Abstract
Windows represents the most common platform found in seized computers due to its widespread presence. This disparity has become worse due to the introduction of Microsoft’s Windows. Post Cyber Incident analysis of Microsoft Windows machines has become increasingly challenging due to the ever-evolving nature of digital threats. Traditional digital forensics methods often struggle to keep pace with modern cybercrime activities’ volume, sophistication, and complexity, which either target or originate from Windows machines. In response to these challenges, this research introduces WinRegRL, a framework that combines Reinforcement Learning (RL) and Rule-Based Artificial Intelligence (RB-AI) to enhance the efficiency, effectiveness and accuracy of digital investigations in the context of Windows Operating Systems. WinRegRL fully captures key information, elaborates the MDP environment, solves the RL problem and extracts expertise for later use. Implementation and testing of WinRegRL validated the research hypothesis by enabling optimised analysis and correlation of Registry forensics. Results prove that the proposed RL model outperforms all previous approaches including bling automation and human expert performance in terms of time, the number of artefacts explored, and the accuracy of results. Another advantage of the proposed framework is the ease of repetition, especially in this context, where more than one machine of the same configuration is under investigation, a context often faced in real DFIR practice.
Keywords:
1. Introduction
1.1. Challenges and Motivation
- Volume of Data: The Registry contains vast amounts of data reflecting system activities and user interactions.
- Lack of Automation: Many traditional tools require manual, repetitive tasks, consuming significant time and resources.
- Dynamic Nature: Registry entries frequently change during system operation or software installations.
- Limited Contextual Information: Registry entries often lack explicit context, necessitating expert interpretation.
- Data Fragmentation: Registry data may be fragmented across hives and keys.
- Evolution of Windows Versions: Different Windows versions introduce variations in Registry structures.
- Limited Advanced Analysis: Traditional tools often lack features like anomaly detection or pattern recognition.
1.2. Research Questions
1.3. Novelty and Contribution
1.4. Article Organization
2. Literature Review
2.1. Windows Registry
2.2. Window Cyber Incident Response and Analysis
2.3. Windows Registry Hives and Volatile Data Acquisition

| Windows Artefacts | Scope & Description |
| Operating Systems fingerprinting | Windows 7, Windows 8/8.1, Windows 10, Windows 11, and Server 2008/2012/2016/2019/2022 |
| File Systems | NTFS, FAT, exFAT |
| Registry Forensics | Shell Items, Shortcut Files (LNK)-File Opening, ShellBags-Folder Opening |
| Jump Lists | File Opening and Program Execution |
| Users’ Activities | Browser, Webmail, MS Office Documents, System Resource Usage DB |
| Search Index, Recycle Bin, Files Metadata, Myriad Execution, Electron/WebView2 | |
| Cloud Files and Metadata | OneDrive, Dropbox, Google Drive, and Box |
| Timeline and Journaling | Microsoft Unified Audit Logging, Event Log Analysis, Deleted Registry Key, File Recovery |
| ESE Database, .log Files, Data Recovery, String Searching, File Carving | |
| Peripheral Profiling and Analysis | Removable Device, Suspect Executed Program, Remote Logging (Console, RDP, or Network) |
| Anti-Forensics | Auto-Deleted Browse (Private Browsing), File Wiping, Time Manipulation, and Application Removal |
2.4. Manual Events Timeline Analysis
2.5. Related Works
| Reference | Tool - Framework | Technique and Approach | Output & Description |
| [8] | TREDE & VMPOP | (1) Practical methodology to develop synthetic reference datasets in security and digital forensics. (2) Dataset automated generation feasibility and effectiveness through practical deployment and values assessment. | Generating a synthetic corpus into two different classes: user-generated and system-generated reference data. |
| [18] | ReLOAD | (1) A digital forensic tool used to generate and analyse data. (2) It utilises hardware resources and highlights deleted files | has the ability to analyse a broad range of data. |
| [25] | AXREL | (1) Interactive GUI for Windows registry analysis (2) Extracts data from Eo1 image using NTFSDUMP, and outputs results in a table format. | Filters system info, Program execution, and Installed Software. It is time efficient, although it requires manual verification. |
| [36] | MADIK | (1) MultiAgent digital investigation toolkit that utilises intelligent software agents (ISA) to analyse OSs forensics extracted Data. (2) Contains six agents: HashSetAgent, TimelineAgent, FileSignatureAgent, FilePathAgent, KeywordAgent, and WindowsRegistryAgent. | Processes and Analyses Time Zone info, installed software, removable media info, and OS events. |
| [44] | RaDaR | (1) multi-perspective data collection and labelling of malware activity. (2) Contains 7 million network packets, 11.3 million OS system call traces, and 3.3 million events related to 10,434 malware samples. | Open real-world datasets for run-time behavioural analysis of Windows malware. Dataset offers a comparison of different solutions and fosters multiple verticals in malware research. |
| [46] | Kroll KAPE | Kroll artefact Parser And Extractor automates the extraction of key forensic artefacts and supports rapid analysis. | Identification module to identify and collect specific forensic artefacts from systems. Parsing module targets specify what to collect (e.g., registry keys, logs), and the processing module to analyse and collects relevant artefacts. |
3. Research Methodology
- Current Methods Review for Windows Registry Analysis Automation and study the mechanisms, limitations, and challenges of existing methods in light of the requirements set by Windows Registry forensics for efficiency and accuracy.
- Investigating Techniques and Approaches used in Windows Registry Forensics. we particularly focused on machine learning approaches and rule-based reasoning systems that can extend or replace human intervention in the sequential decision-making processes involved in Windows Registry forensics. Find the best ways through which expert systems can be integrated into the forensics process in order to gain better investigative results.
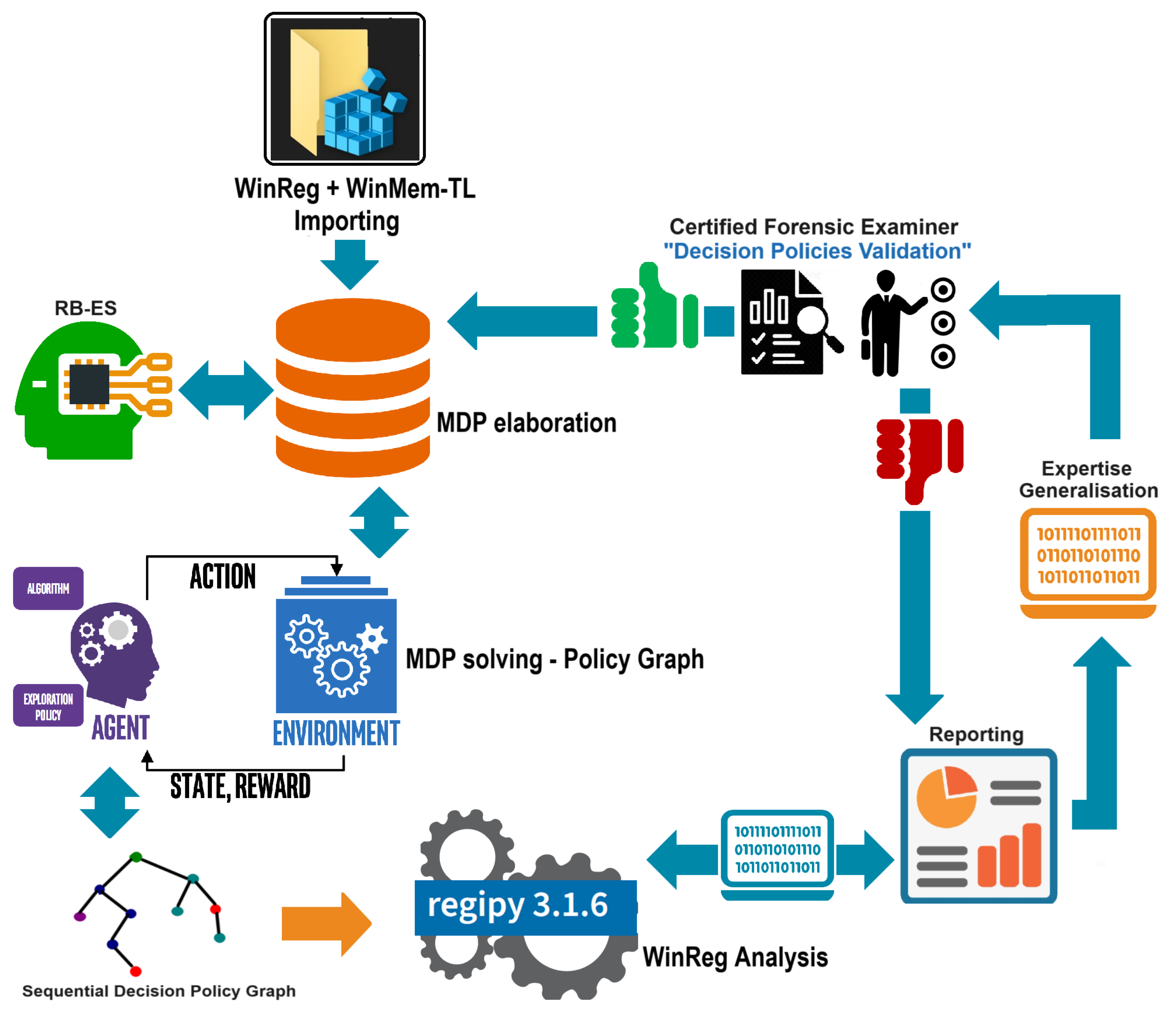
- WinRegEL Framework Developmentas we progress with the design and implemention of diffirenet modules making the WinRegRL framework, we first focus on the WinRegRL-Core which introduce a new MDP model and Reinforcement Learning to optimize and enhance Windows Registry investigations. Also, add a module to capture, process, generalize, and feed human expertise into the RL environment using a Rule-Based Expert System (RBES) via Pyke Python Knowledge Engine.
- Testing and Validation of WinRegRL on the latest research and industry standards datasets made to mimic real-world DFIR scenarios and covering different size evidences especially in large-scale Windows Registry forensics. The performance of the framework should be evaluated against traditional methods and human experts in terms of efficiency, accuracy, time reduction, and artefact exploration. Refine the framework iteratively based on feedback testing for robust and adaptive performance in diverse investigative contexts.
- Finalisation of the WinRegRL Framework through unifying reinforcement learning and rule-based reasoning to support efficient Windows Registry and volatile data investigations. the final testing will demonstrate how it reduces reliance on human expertise while increasing efficiency, accuracy, and repeatability significantly, especially in cases with multiple machines of similar configurations.
3.1. Windows Registry and Volatile Data Markov Decision Process
3.2. Overall Windows Registry and Timeline MDP Modelling
- State Space: In Windows Registry and volatile memory forensics, the state space refers to the status of a system at some time points. Such states include the structure and values of Registry keys, the presence of volatile artefacts, and other forensic evidence. The state space captures a finite and plausible set of such abstractions, allowing the modeling of the investigative process as an MDP. For example, states could be "Registry key exists with specific value" or "Volatile memory contains a given process artefact."
- Actions Space: Actions denote forensic steps that move the system from one state to another. Examples of these are Registry investigation, memory dump analysis, or timeline artefact correlation. Every action can probabilistically progress to one of many possible states. The latter reflect inherent uncertainties of forensic methods: for example, querying a given Registry key might show some value with some probability and guide the investigator with future actions.
- Transition Function: The transition function models the probability of moving from one state another after performing an action. For example, examining a process in memory might lead to identifying associated Registry keys or other volatile artefacts with a given likelihood. The transition probabilities capture the dynamics of the forensic investigation, reflecting how evidence unfolds as actions are performed.
- Reward Function: The reward function assigns a numerical value to state-action pairs, representing the immediate benefit obtained by taking a specific action in a given state. In the forensics context, rewards can quantify the importance of discovering critical evidence or reducing uncertainty in the investigation process. For example, finding a timestamp in the Registry that corresponds to one of the known events can be assigned a large reward for solving the case.
3.3. Reinforcement Learning
- Value Iteration
- Policy Iteration
- Linear Programming
3.3.1. Value Iteration and Action-Value (Q) Function
3.3.2. Optimal Decision Policy
Algorithm 1 WinRegRL Value Iteration |
|
3.3.3. Bellman Equation
3.3.4. Value Function
3.3.5. Policy Iteration
Algorithm 2 WinRegRL Policy Iteration |
|
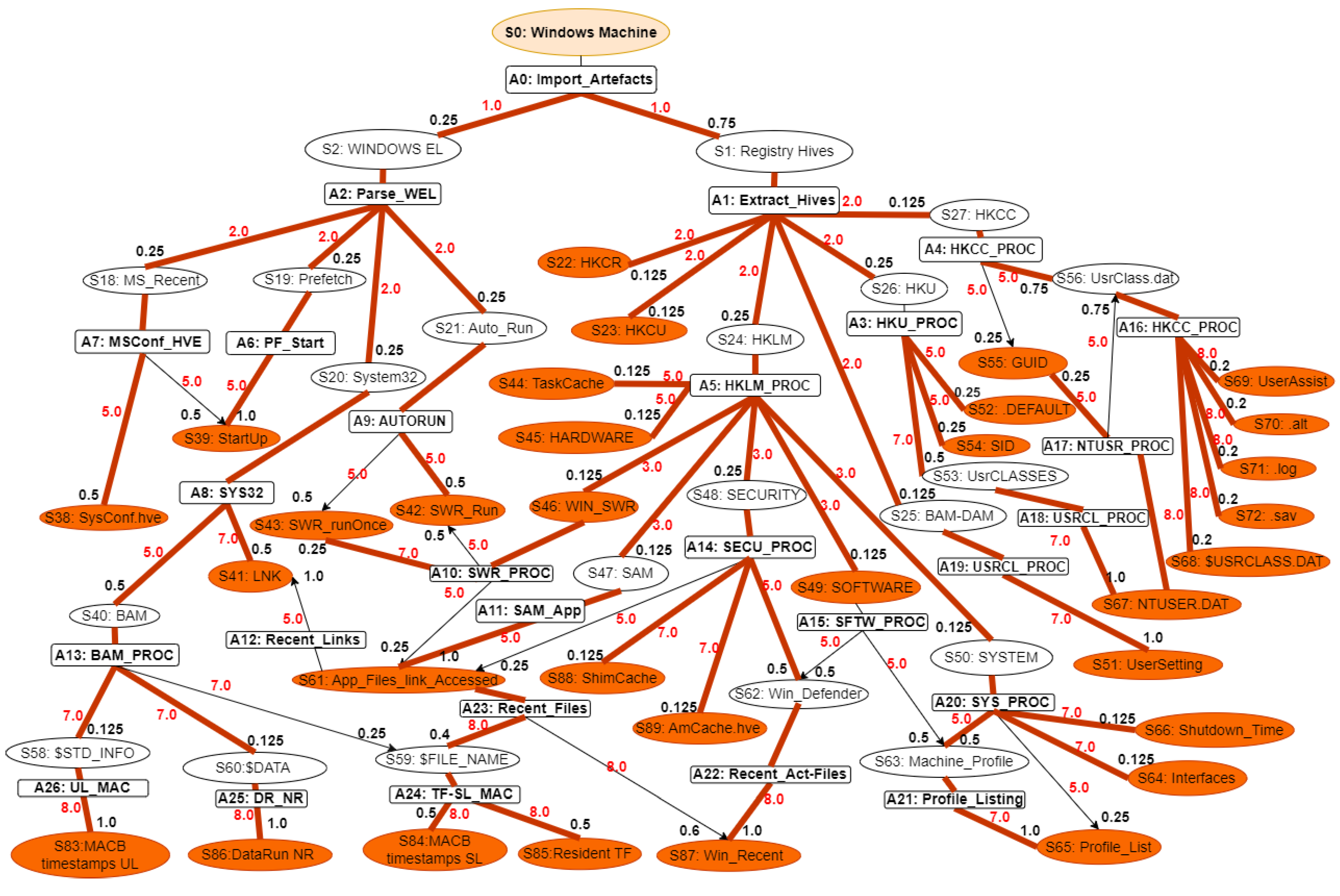
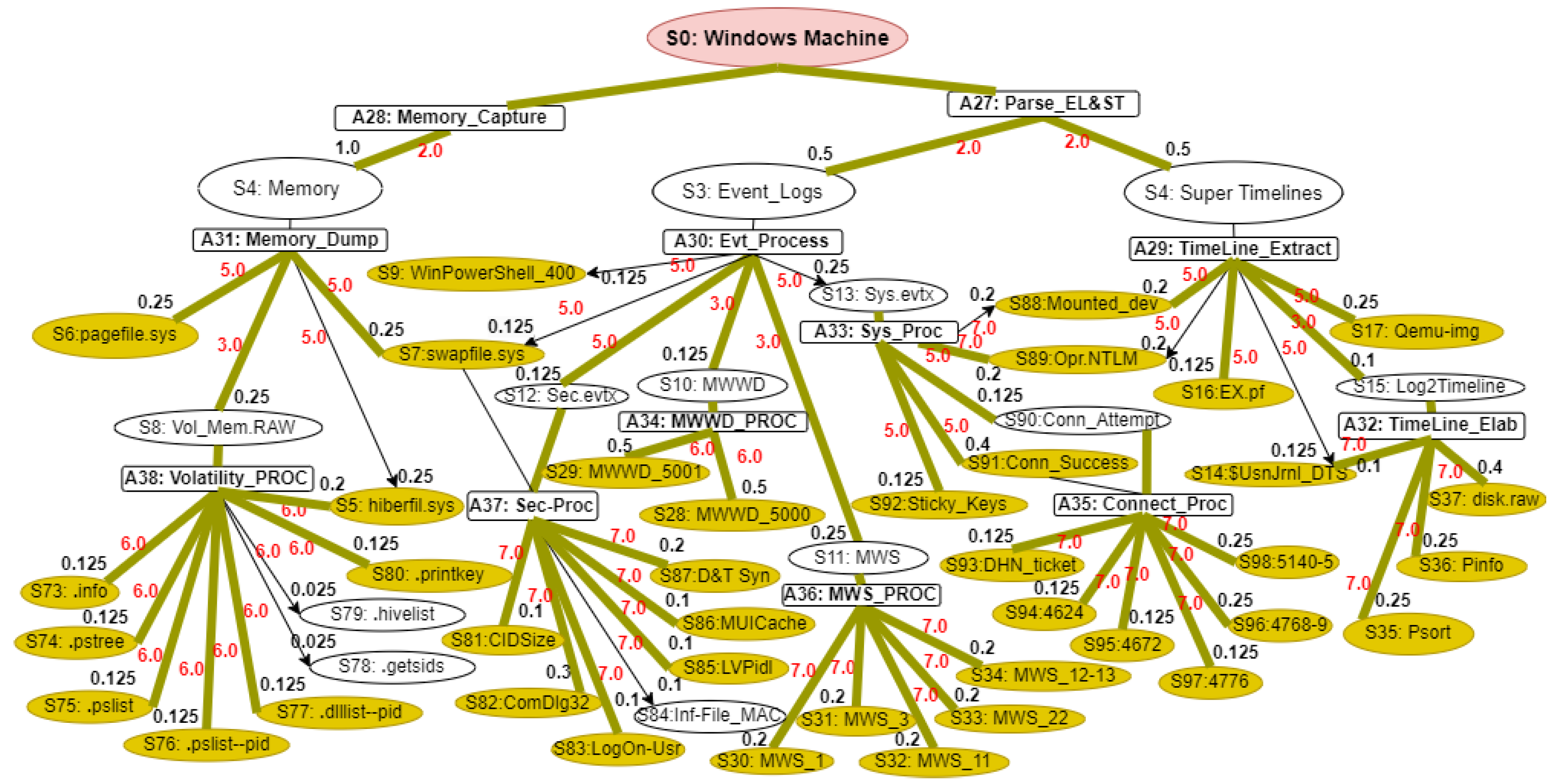
3.4. WinRegRL Framework Design and Implementation
3.5. Expertise Capturing and Generalisation
3.5.1. Expertise Generalisation
3.5.2. Reporting and Analysis
3.6. Human Expert Validation module
3.7. WinRegRL-Core
| Algorithm 3 WinRegRL-Core |
|
3.8. PGGenExpert-Core
| Algorithm 4 GenExpert: Policy Graph Expertise Extraction, Assessment and Generalisation Algorithm |
|
4. Testing, Results and Discussion
4.1. Testing Datasets
4.2. Reinforcement Learning Parameters and Variables
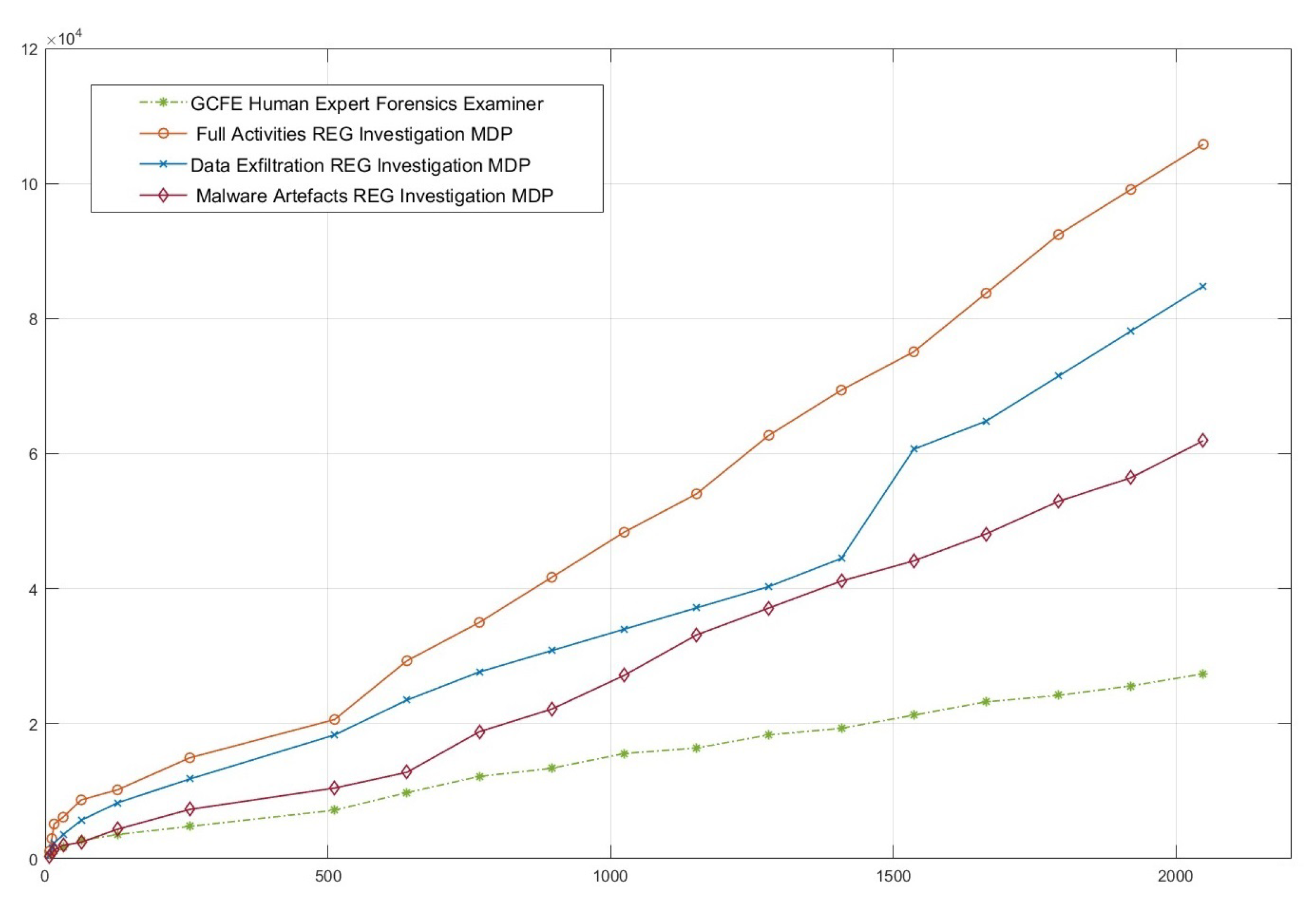
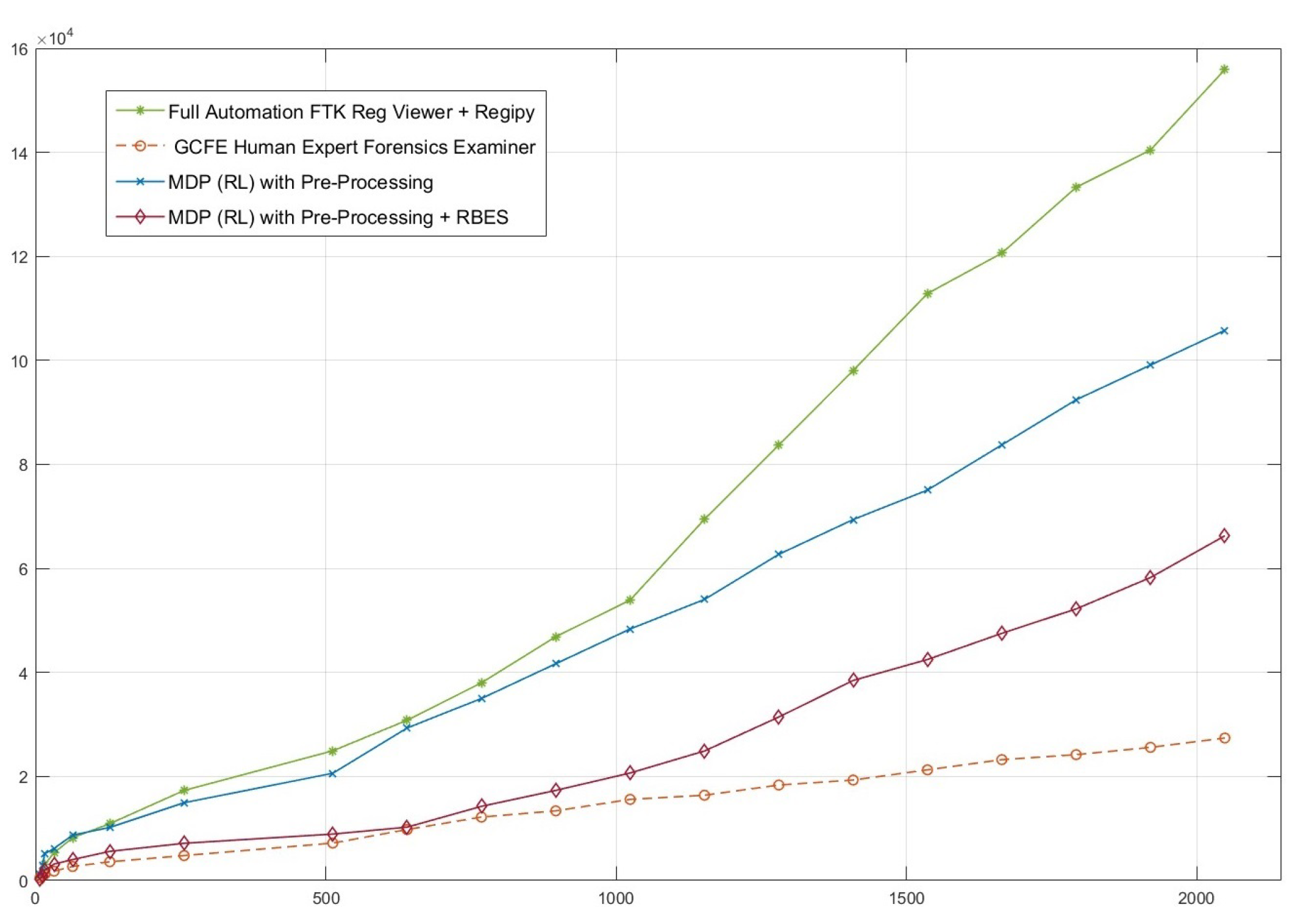
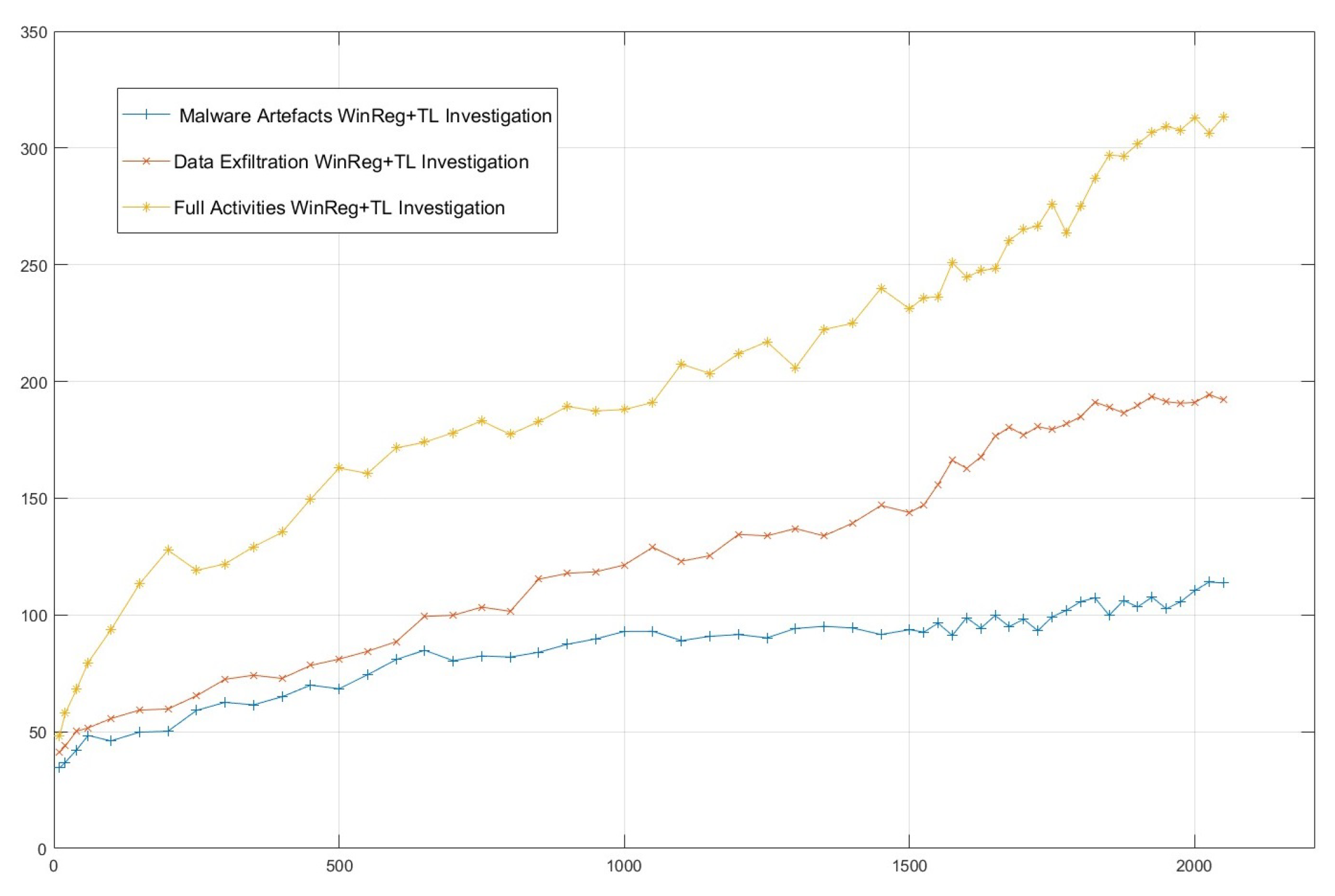
4.3. WinRegRL Results
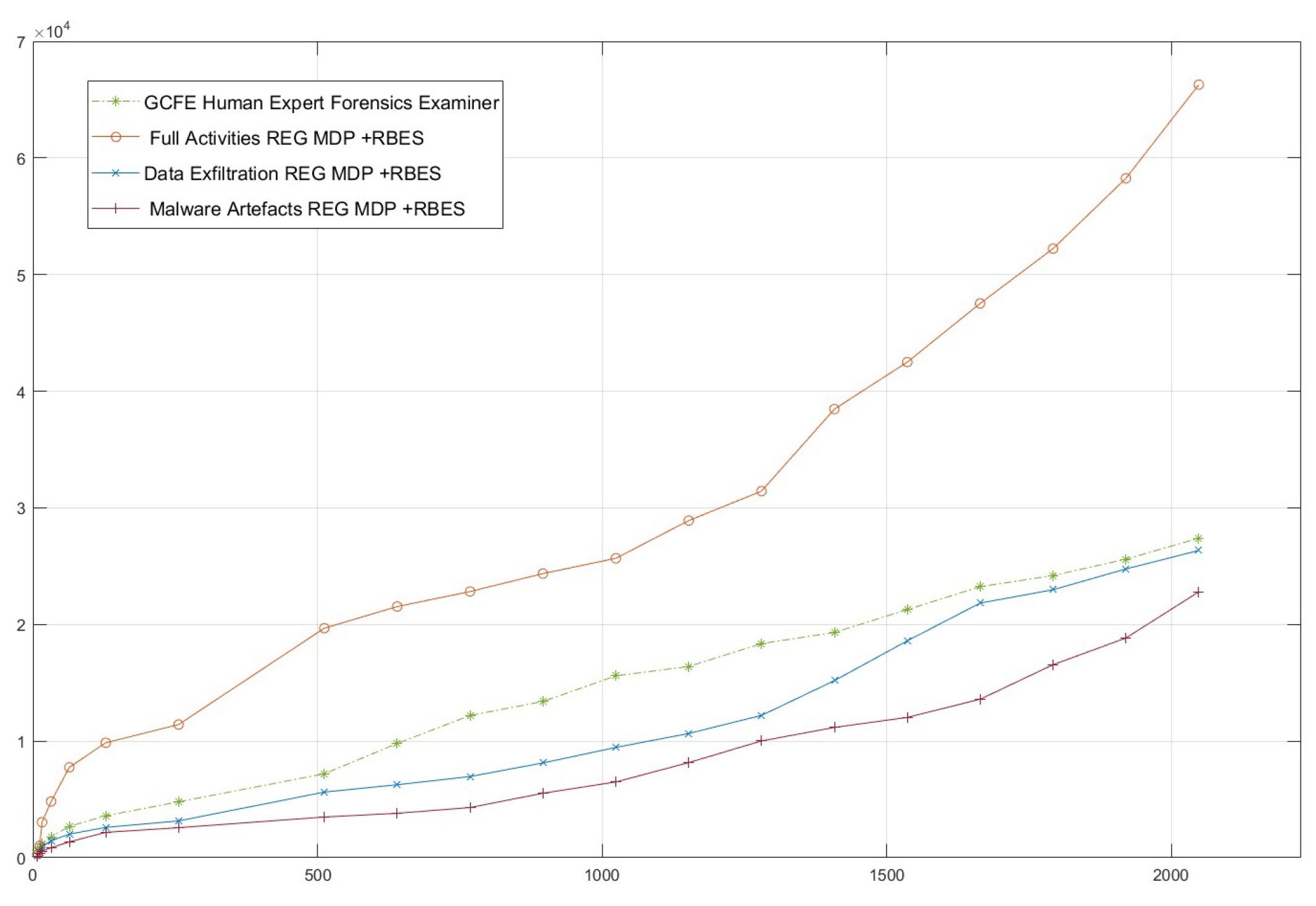
4.4. WinRegRL Performances Validation
4.5. Discussion
5. Conclusion and Future Works
References
- StatCounter. 2024. Desktop Windows Version Market Share Worldwide for the period Oct 2023 - Oct 2024. Statcounter GlobalStats Report. https://gs.statcounter.com/os-version-market-share/windows/desktop/worldwide.Microsoft2024rathee2021design.
- Microsoft Inc. 2024. Microsoft Digital Defense Report 2024 The foundations and new frontiers of cybersecurity. https://www.microsoft.com/en-us/security/security-insider/intelligence-reports/microsoft-digital-defense-report-2024.CDSAG2022rathee2021design.
- Casino, F. , Dasaklis, T.K., Spathoulas, G.P., Anagnostopoulos, M., Ghosal, A., Borocz, I., Solanas, A., Conti, M. and Patsakis, C., 2022. Research trends, challenges, and emerging topics in digital forensics: A review of reviews. IEEE Access, 10, pp.25464-25493. [CrossRef]
- Yosifovich, P., Solomon, D.A., Russinovich, M.E. and Ionescu, A., 2017. Windows Internals: System architecture, processes, threads, memory management, and more, Part 1. Microsoft Press.https://dl.acm.org/doi/abs/10.5555/3158930 SVI2020Arathee2021design.
- Singh, A. , Venter, H.S. and Ikuesan, A.R., 2020. Windows registry harnesser for incident response and digital forensic analysis. Australian Journal of Forensic Sciences, 52(3), pp.337-353. [CrossRef]
- Lee, J.H. and Kwon, H.Y., 2022. Large-scale digital forensic investigation for Windows registry on Apache Spark. Plos one, 17(12), p.e0267411. [CrossRef]
- Ghanem, M.C. , Mulvihill, P., Ouazzane, K., Djemai, R. and Dunsin, D., 2023. D2WFP: a novel protocol for forensically identifying, extracting, and analysing deep and dark web browsing activities. Journal of Cybersecurity and Privacy, 3(4), pp.808-829. [CrossRef]
- Park, J. , 2018. TREDE and VMPOP: Cultivating multi-purpose datasets for digital forensics–A Windows registry corpus as an example. Digital Investigation, 26, pp.3-18. [CrossRef]
- Dunsin, D. , Ghanem, M.C., Ouazzane, K., Vassilev, V., 2024. A comprehensive analysis of the role of artificial intelligence and machine learning in modern digital forensics and incident response. Forensic Science International. Digital Investigation 48, 301675. [CrossRef]
- Marková, Eva; Sokol, Pavol; Krišáková, Sophia Petra; Kováčová, Kristína. 2024. Dataset of Windows operating system forensics artefacts, Mendeley Data, V1. [CrossRef]
- Farzaan, M.A., Ghanem, M.C. and El-Hajjar, A., 2024. AI-Enabled System for Efficient and Effective Cyber Incident Detection and Response in Cloud Environments. https://arxiv.org/abs/2404.05602.
- Park, J., Lyle, J.R. and Guttman, B., 2016. Introduction to CFTT and CFReDS projects at NIST. https://cfreds.nist.gov/https://doi.org/10.1080/00450618.2018.1551421. [CrossRef]
- Dunsin, D. , Ghanem, M.C., Ouazzane, K. and Vassilev, V., 2024. Reinforcement Learning for an Efficient and Effective Malware Investigation during Cyber Incident Response. High-Confidence Computing Journal. [CrossRef]
- Lee, Jun-Ha, and Hyuk-Yoon Kwon. 2020.Redundancy analysis and elimination on access patterns of the Windows applications based on I/O log data. IEEE Access 8 (2020): 40640-40655. [CrossRef]
- X. Wang, Z. X. Wang, Z.Yang, G. Chen, Y. Liu. (2023). A Reinforcement Learning Method of Solving Markov Decision Processes: An Adaptive Exploration Model Based on Temporal Difference Error. Electronics. 12. 4176. [CrossRef]
- T. Zhang, C. Xu, J. Shen, X. Kuang and L. A. Grieco, How to Disturb Network Reconnaissance: A Moving Target Defense Approach Based on Deep Reinforcement Learning,in IEEE Transactions on Information Forensics and Security, vol. 18, pp. 5735-5748, 2023. [CrossRef]
- A. Bashar, S. Muhammad, N. Mohammad and M. Khan, "Modeling and Analysis of MDP-based Security Risk Assessment System for Smart Grids", 2020 Fourth International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 2020, pp. 25-30. [CrossRef]
- X. Mo, S. Tan, W. Tang, B. Li and J. Huang, ReLOAD: Using Reinforcement Learning to Optimize Asymmetric Distortion for Additive Steganography. IEEE Transactions on Information Forensics and Security, vol. 18, pp. 1524-1538, 2023. [CrossRef]
- Borkar, V. and Jain, R., 2014. Risk-constrained Markov decision processes. IEEE Transactions on Automatic Control, 59(9), pp.2574-2579. [CrossRef]
- Dunsin, D. , Ghanem, M.C., Ouazzane, K. and Vassilev, V., 2024. A comprehensive analysis of the role of artificial intelligence and machine learning in modern digital forensics and incident response. Forensic Science International: Digital Investigation, 48, p.301675. [CrossRef]
- Wang, C. , Ju, P., Lei, S., Wang, Z., Wu, F. and Hou, Y., 2019. Markov decision process-based resilience enhancement for distribution systems: An approximate dynamic programming approach. IEEE Transactions on Smart Grid, 11(3), pp.2498-2510. [CrossRef]
- Kwon, Hyuk-Yoon (2022). Windows Registry Data Sets, Mendeley Data, V1. [CrossRef]
- MChadès, I., Cros, M.J., Garcia, F. and Sabbadin, R., 2009. Markov decision processes (MDP) toolbox. http://www.inra.fr/mia/T/MDPtoolbox.
- Hore, S. , Shah, A. and Bastian, N.D., 2023. Deep VULMAN: A deep reinforcement learning-enabled cyber vulnerability management framework. Expert Systems with Applications, 221, p.119734. [CrossRef]
- Ganesan, R. , Jajodia, S., Shah, A. and Cam, H., 2016. Dynamic scheduling of cybersecurity analysts for minimising risk using reinforcement learning. ACM Transactions on Intelligent Systems and Technology (TIST), 8(1), pp.1-21. [CrossRef]
- Huang, C. , Zhang, Z., Mao, B. and Yao, X., 2022. An overview of artificial intelligence ethics. IEEE Transactions on Artificial Intelligence, 4(4), pp.799-819. [CrossRef]
- Puterman, M.L. , 1990. Markov decision processes. Handbooks in operations research and management science, 2, pp.331-434. [CrossRef]
- Littman, M.L., Dean, T.L. and Kaelbling, L.P., 1995, August. On the complexity of solving Markov decision problems. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence (pp. 394-402). https://dl.acm.org/doi/abs/10.5555/2074158.2074203.
- Lapso, J.A. , Peterson, G.L. and Okolica, J.S., 2017. Whitelisting system state in Windows forensic memory visualizations. Digital Investigation, 20, pp. [CrossRef]
- Choi, J. , Park, J. and Lee, S., 2021. Forensic exploration on Windows File History. Forensic Science International: Digital Investigation, 36, p.301134. [CrossRef]
- Berlin, K., Slater, D. and Saxe, J., 2015, October. Malicious behaviour detection using Windows audit logs. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security (pp. 35-44). [CrossRef]
- Visoottiviseth, V. , Noonkhan, A., Phonpanit, R., Wanichayagosol, P. and Jitpukdebodin, S., 2023, September. AXREL: Automated Extracting Registry and Event Logs for Windows Forensics. In 2023 27th International Computer Science and Engineering Conference (ICSEC) (pp. 74-78). IEEE. [CrossRef]
- Bhatt, S. and Garg, G., 2021, July. Comparative analysis of acquisition methods in digital forensics. In 2021 Fourth International Conference on Computational Intelligence and Communication Technologies (CCICT) (pp. 129-134). IEEE. [CrossRef]
- Studiawan, H. , Ahmad, T., Santoso, B.J. and Pratomo, B.A., 2022, October. Forensic timeline analysis of iOS devices. In 2022 International Conference on Engineering and Emerging Technologies (ICEET) (pp. 1-5). IEEE. [CrossRef]
- Ionita, M.G. and Patriciu, V.V., 2015, May. Cyber incident response aided by neural networks and visual analytics. In 2015 20th International Conference on Control Systems and Computer Science (pp. 229-233). IEEE. [CrossRef]
- Hoelz, B.W., Ralha, C.G., Geeverghese, R. and Junior, H.C., 2008. Madik: A collaborative multi-agent toolkit to computer forensics. OTM Confederated International Workshops and Posters, Monterrey, Mexico, November 9-14, 2008. Proceedings (pp. 20-21). [CrossRef]
- Ghanem, M.C., Chen, T.M., Ferrag, M.A. and Kettouche, M.E., 2023. ESASCF: expertise extraction, generalization and reply framework for optimized automation of network security compliance. IEEE Access.
- Horsman, G. and Lyle, J.R., 2021. Dataset construction challenges for digital forensics. Forensic Science International: Digital Investigation, 38, p.301264. [CrossRef]
- Dunsin, D., Ghanem, M.C., Ouazzane, K. and Vassilev, V., 2024. Reinforcement learning for an efficient and effective malware investigation during cyber Incident response. High-Confidence Computing. https://arxiv.org/abs/2408.01999.
- Du, J. , Raza, S.H., Ahmad, M., Alam, I., Dar, S.H. and Habib, M.A., 2022. Digital Forensics as Advanced Ransomware Pre-Attack Detection Algorithm for Endpoint Data Protection. Security and Communication Networks, 2022(1), p.1424638. [CrossRef]
- Moore C., Detecting ransomware with honeypot techniques, Proceedings of the 2016 Cybersecurity and Cyberforensics Conference (CCC), August 2016, Amman, Jordan, IEEE, 77–81, https://doi.org/10.1109/CCC.2016.14. [CrossRef]
- Du, J. , Raza, S.H., Ahmad, M., Alam, I., Dar, S.H. and Habib, M.A., 2022. Digital Forensics as Advanced Ransomware Pre-Attack Detection Algorithm for Endpoint Data Protection. Security and Communication Networks, 2022(1), p.1424638. [CrossRef]
- Lapso, J.A. , Peterson, G.L. and Okolica, J.S., 2017. Whitelisting system state in Windows forensic memory visualizations. Digital Investigation, 20, pp.2-15. [CrossRef]
- Karapoola, S., Singh, N., Rebeiro, C., 2022, October. RaDaR: A Real-Word Dataset for AI-powered Run-time Detection of Cyber-Attacks. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (pp. 3222-3232). [CrossRef]
- Zhu, M., Hu, Z. and Liu, P., 2014, November. Reinforcement learning algorithms for adaptive cyber defense against heartbleed. In Proceedings of the first ACM workshop on moving target defense (pp. 51-58).https://dl.acm.org/doi/abs/10.1145/2663474.2663481.
- Zimmerman, E. 2019. I KAPE - Kroll artefact Parser and Extractor, Cyber Incident Division- Kroll LLC, https://ericzimmerman.github.io/KapeDocs/ (Accessed July 21, 2024).
- Hore, S. , Shah, A. and Bastian, N.D., 2023. Deep VULMAN: A deep reinforcement learning-enabled cyber vulnerability management framework. Expert Systems with Applications, 221, p.119734. [CrossRef]
- Yao, Y. , Duan, J., Xu, K., Cai, Y., Sun, Z. and Zhang, Y., 2024. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confidence Computing, p.100211. [CrossRef]
- Khalid J. Rozner E. Felter W. Xu C. Rajamani K. Ferreira A. Akella A. Seshan S. Banerjee S(2018) Iron. Proceedings of the 15th USENIX Conference on Networked Systems Design and Implementation. https://dl.acm.org/doi/10.5555/3307441.3307468.
- Guestrin, C. , Koller, D., Parr, R. and Venkataraman, S., 2003. Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research, 19, pp.399-468. [CrossRef]
- Littman, M.L., Dean, T.L. and Kaelbling, L.P., 1995, August. On the complexity of solving Markov decision problems. In Proceedings of the Eleventh conference on Uncertainty in artificial intelligence (pp. 394-402). https://dl.acm.org/doi/abs/10.5555/2074158.2074203.
- Sanner, S. and Boutilier, C., 2009. Practical solution techniques for first-order MDPs. Artificial Intelligence, 173(5-6), pp.748-788. [CrossRef]
- Hahn, E.M., Perez, M., Schewe, S., Somenzi, F., Trivedi, A. and Wojtczak, D., 2020, April. Good-for-MDPs automata for probabilistic analysis and reinforcement learning. In International Conference on Tools and Algorithms for the Construction and Analysis of Systems (pp. 306-323). Cham: Springer International Publishing. [CrossRef]
- Kimball, J., Navarro, D., Froio, H., Cash, A. and Hyde,J. 2022. Magnet Forenisics Inc. CTF 2022 dataset. https://cfreds.nist.gov/all/MagnetForensics/2022WindowsMagnetCTF.(Accessed 08/12/2024).
- Demir, M. 2024. IGU-CTF24: İstanbul Gelişim Üniversitesi Siber Güvenlik Uygulamaları Kulübü bünyesinde düzenlenen İGÜCTF 24’. https://cfreds.nist.gov/all/GCTF24Forensics. (Accessed 08/12/2024).
- Givan, R. , Dean, T. and Greig, M., 2003. Equivalence notions and model minimization in Markov decision processes. Artificial intelligence, 147(1-2), pp.163-223. [CrossRef]
- Patiballa, A.K. 2019. MemLabs Windows Forensics Dataset. https://cfreds.nist.gov/all/AbhiramKumarPatiballa/MemLabs.(Accessed 08/12/2024).
- Digital Corpora. 2009. NPS-Domexusers 2009 Windows XP Registry and RAM Dataset. https://corp.digitalcorpora.org/corpora/drives/nps-2009-domexusers.
- Loumachi, F.Y. and Ghanem, M.C., 2024. GenDFIR:Advancing Cyber Incident Timeline Analysis Through Rule Based AI and Large Language Models. arXiv preprint arXiv:2409.02572. https://arxiv.org/abs/2409.02572.
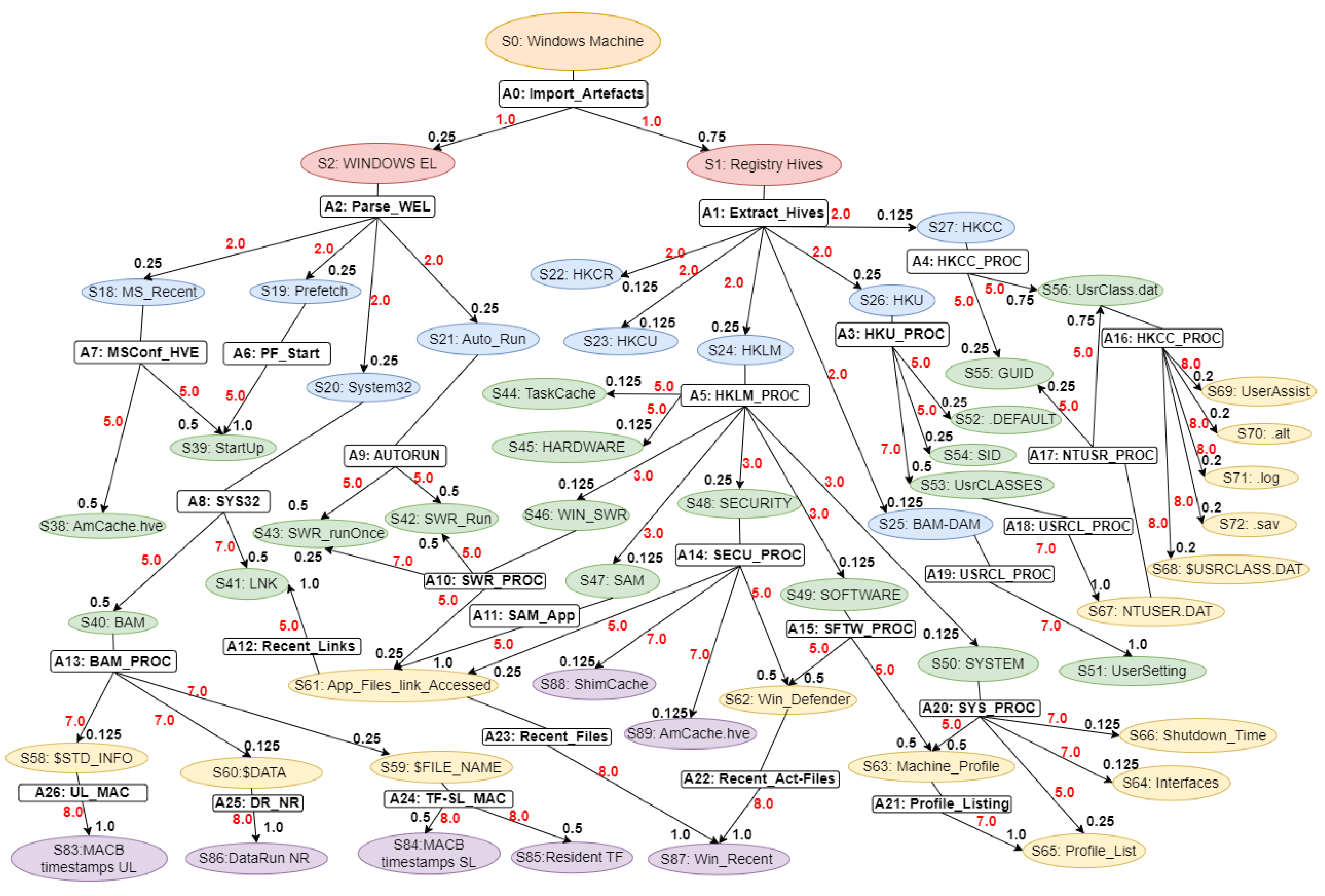
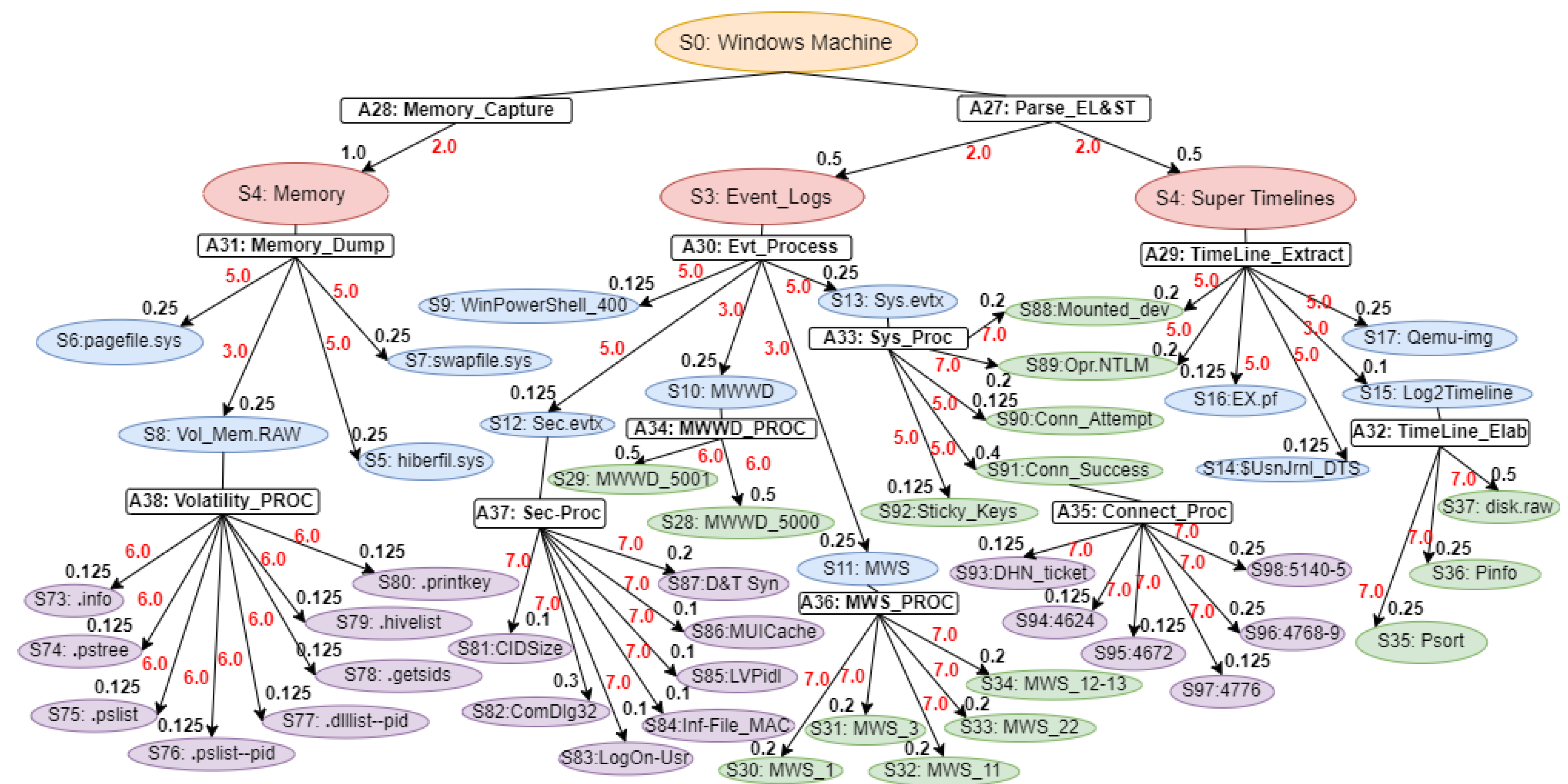
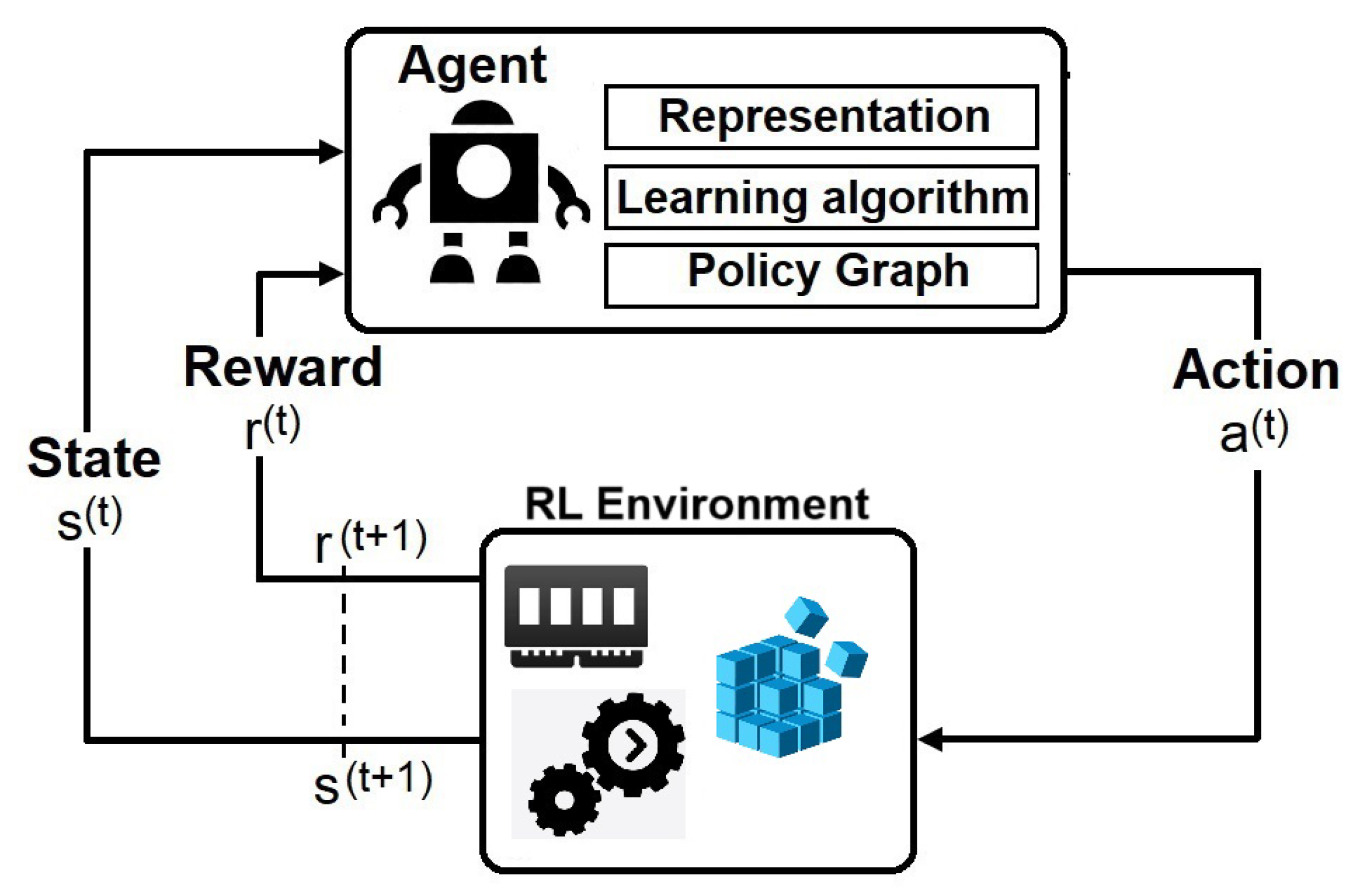
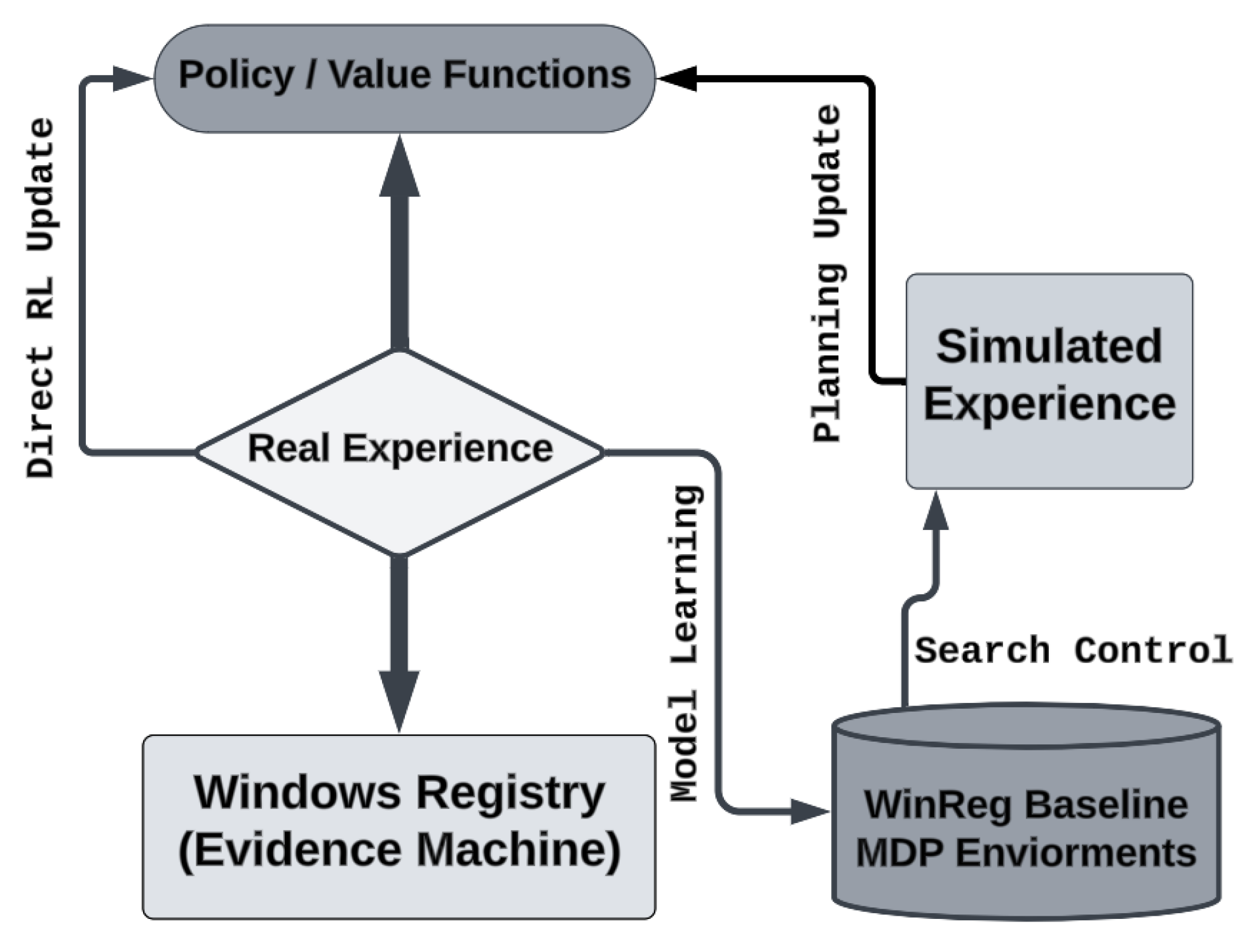
| Registry hive | Supporting files |
|---|---|
| HKEY_LOCAL_MACHINE_SAM | SAM, SAM.log, SAM.sav |
| HKEY_LOCAL_MACHINE_Security | Security, Security.log, Security.sav |
| HKEY_LOCAL_MACHINE_Software | Software, Software.log, Software.sav |
| HKEY_LOCAL_MACHINE_System | System, System.alt, System.log, System.sav |
| HKEY_CURRENT_CONFIG | System, System.alt, System.log, System.sav, Ntuser.dat, Ntuser.dat.log |
| HKEY_USERS_DEFAULT | Default, Default.log, Default.sav |
| Ref. | Datasets | Description |
|---|---|---|
| [54] | Magnet-CTF 2022 | Dataset developed by Magnet Forensics including several forensic image as a public service part of Magnet CTF-2022. Datasets made of Registry and Memory of different Windows Machines (10, 8, 7 and XP). |
| [55] | IGU-CTF 2024 | Dataset was taken from IGUCTF-24 which include CVE-2023-38831 Lockbit 3.0 Ransomware. Dataset is made of Registry and Memory of infected Windows machine capturing Powershell2exe and Persistence tactics. |
| [57] | MemLabs-CTF 2019 | Dataset developed by MemLabs with CTF Registry and Memory Forensics. All the labs are of Windows 7. Datasets made of Registry and Memory of Six (06) different Windows 7 Machines. |
| [58] | NPS-Domexusers 2009 | Digital-Corpora, Two disk images including full system Registry of Widows XP executables redacted so that they cannot be executed. |
| Parameter | Value | Description |
| Discount Factor value is determined by testing - adopted is 0.99) | ||
| H | 200 | Decision Epochs; Maximum number of steps allowed per episode |
| 0.001 | Value Function Tolerance where the algorithm will if two successive iterations are smaller | |
| 0.00001 | Vectors are only added if the value improvement exceeds Epsilon | |
| [0 - 99%] | Learning Generator rate | |
| Reward and Penalty Function | ||
| [0 - 99%] | Expertise Extractor Thresholds | |
| 0.01 | Interpolated sample | |
| Expertise Generalization Loss | ||
| Buffer Size | 100,000 | The size of a replay buffer (Learning from older samples) including Memory usage |
| Batch Size | [1024, 512, 256] | The number of samples trained in neural work |
| Gradient Steps | 3 | Parameter based on the change in weights in relation to a change in error Number of steps to update a policy |
| Exploration Fraction | 0.1 | How much of the training time does the algorithm spend exploring |
| Exploration Final Eps | 0.02 | Updating after an episode will take longer to converge but offers more exploration |
| Artefacts Relevance Accuracy | Artefacts Attribution Performance | |||||
| Tool or Framework | WinRegRL | FTK + Register Viewer | KAPE | WinRegRL | FTK + Register Viewer | KAPE |
| Magnet-CTF 2022 [54] | 98.7% | 76.4% | 81.4% | 100.0% | 63.9% | 41.6% |
| IGU-CTF 2024 [55] | 98.5% | 77.2% | 80.9% | 100.0% | 53.5% | 46.8% |
| MemLabs-CTF 2019 [57] | 99.5% | 82.1% | 88.7% | 100.0% | 66.7% | 50.1% |
| NPS-Domexusers 2009 [58] | 100.0% | 90.7% | 93.2% | 100.0% | 71.2% | 52.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



