Submitted:
05 January 2025
Posted:
06 January 2025
You are already at the latest version
Abstract
With the rapid rise of large language models (LLMs), phone automation has undergone transformative changes. This paper systematically reviews LLM-driven phone GUI agents, highlighting their evolution from script-based automation to intelligent, adaptive systems. We first contextualize key challenges, (i) limited generality, (ii) high maintenance overhead, and (iii) weak intent comprehension, and show how LLMs address these issues through advanced language understanding, multimodal perception, and robust decision-making. We then propose a taxonomy covering fundamental agent frameworks (single-agent, multi-agent, plan-then-act), modeling approaches (prompt engineering, training-based), and essential datasets and benchmarks. Furthermore, we detail task-specific architectures, supervised fine-tuning, and reinforcement learning strategies that bridge user intent and GUI operations. Finally, we discuss open challenges such as dataset diversity, on-device deployment efficiency, user-centric adaptation, and security concerns, offering forward-looking insights into this rapidly evolving field. By providing a structured overview and identifying pressing research gaps, this paper serves as a definitive reference for researchers and practitioners seeking to harness LLMs in designing scalable, user-friendly phone GUI agents. Project Homepage: github.com/PhoneLLM/Awesome-LLM-Powered-Phone-GUI-Agents
Keywords:
1. Introduction
- A Comprehensive and Systematic Survey of LLM-Powered Phone GUI Agents. We provide an in-depth and structured overview of recent literature on LLM-powered phone automation, examining its developmental trajectory, core technologies, and real-world application scenarios. By comparing LLM-driven methods to traditional phone automation approaches, this survey clarifies how large models transform GUI-based tasks and enable more intelligent, adaptive interaction paradigms.
- Methodological Framework from Multiple Perspectives. Leveraging insights from existing studies, we propose a unified methodology for designing LLM-driven phone GUI agents. This encompasses framework design (e.g., single-agent vs. multi-agent vs. plan-then-act frameworks), LLM model selection and training (prompt engineering vs. training-based methods), data collection and preparation strategies (GUI-specific datasets and annotations), and evaluation protocols (benchmarks and metrics). Our systematic taxonomy and method-oriented discussion serve as practical guidelines for both academic and industrial practitioners.
- In-Depth Analysis of Why LLMs Empower Phone Automation. We delve into the fundamental reasons behind LLMs’ capacity to enhance phone automation. By detailing their advancements in natural language comprehension, multimodal grounding, reasoning, and decision-making, we illustrate how LLMs bridge the gap between user intent and GUI actions. This analysis elucidates the critical role of large models in tackling issues of scalability, adaptability, and human-like interaction in real-world mobile environment.
- Insights into Latest Developments, Datasets, and Benchmarks. We introduce and evaluate the most recent progress in the field, highlighting innovative datasets that capture the complexity of modern GUIs and benchmarks that allow reliable performance assessment. These resources form the backbone of LLM-based phone automation, enabling systematic training, fair evaluation, and transparent comparisons across different agent designs.
- Identification of Key Challenges and Novel Perspectives for Future Research. Beyond discussing mainstream hurdles (e.g., dataset coverage, on-device constraints, reliability), we propose forward-looking viewpoints on user-centric adaptations, security and privacy considerations, long-horizon planning, and multi-agent coordination. These novel perspectives shed light on how researchers and developers might advance the current state of the art toward more robust, secure, and personalized phone GUI agents.
2. Development of Phone Automation
2.1. Phone Automation Before the LLM Era
2.1.1. Automation Testing
2.1.2. Shortcuts
2.1.3. Robotic Process Automation
2.2. Challenges of Traditional Methods
2.2.1. Limited Generality
2.2.2. High Maintenance Costs
2.2.3. Poor Intent Comprehension
2.2.4. Weak Screen GUI Perception
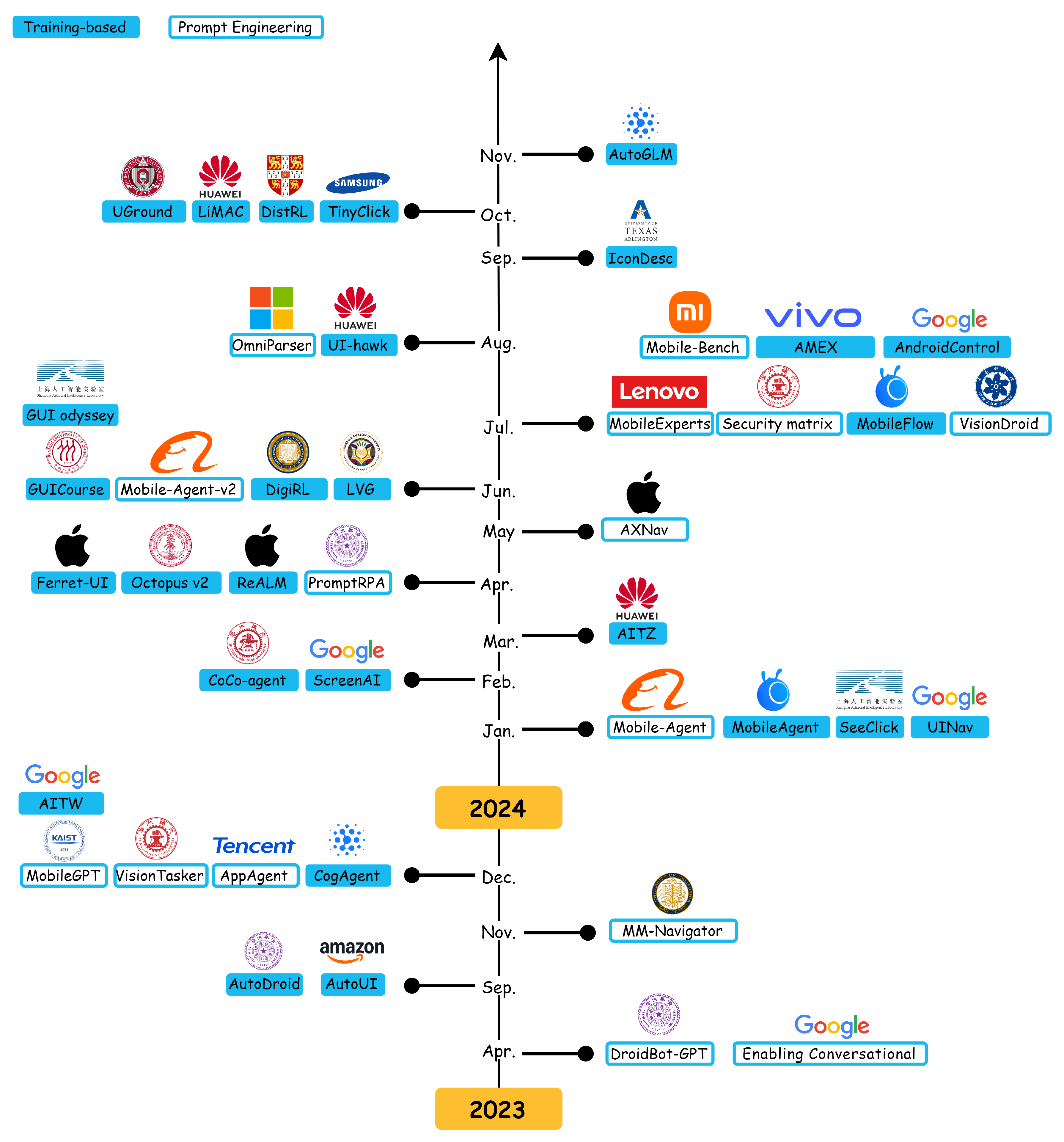
2.3. LLMs Boost Phone Automation
2.4. Emerging Commercial Applications
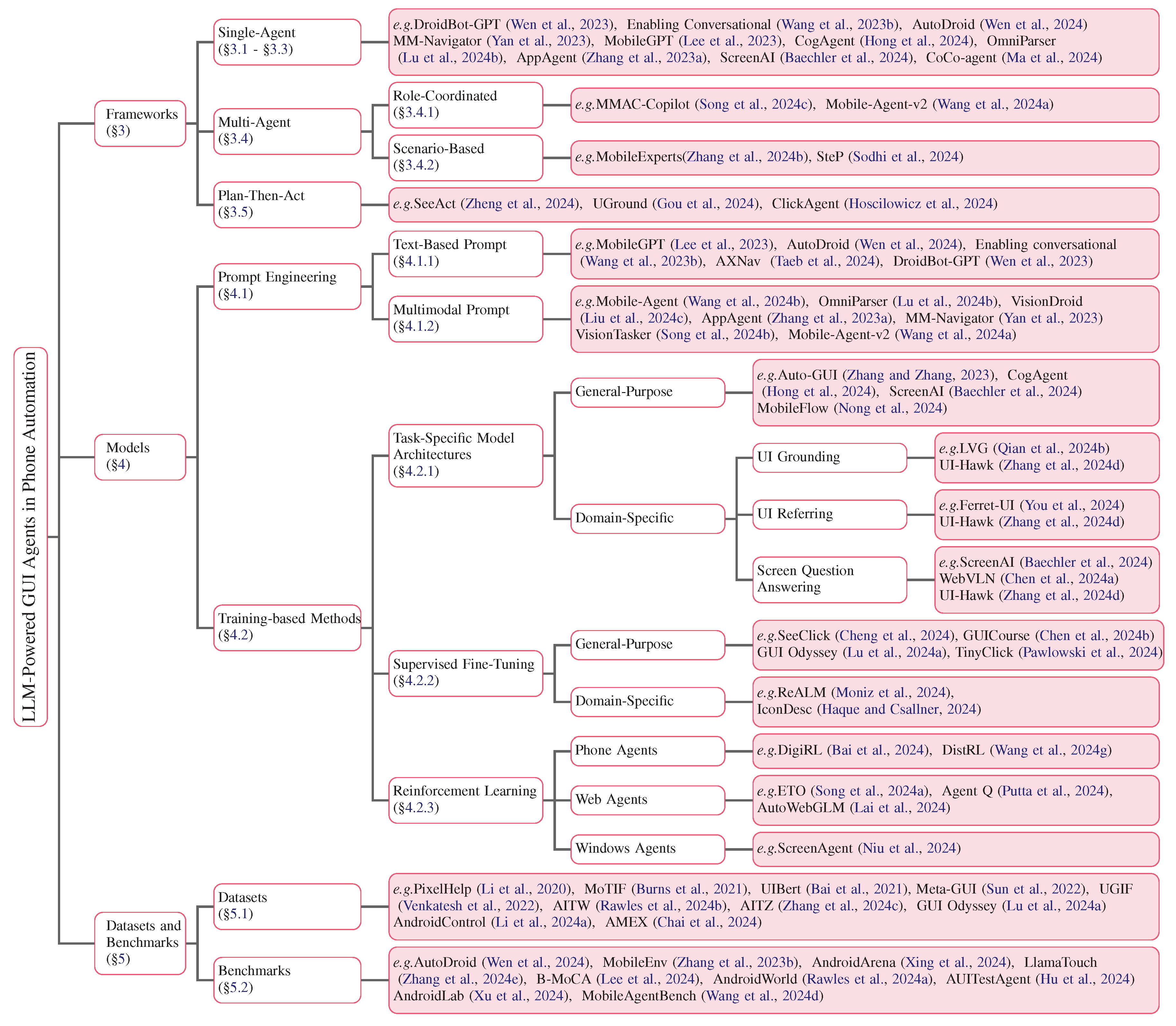
3. Frameworks and Components of Phone GUI Agents
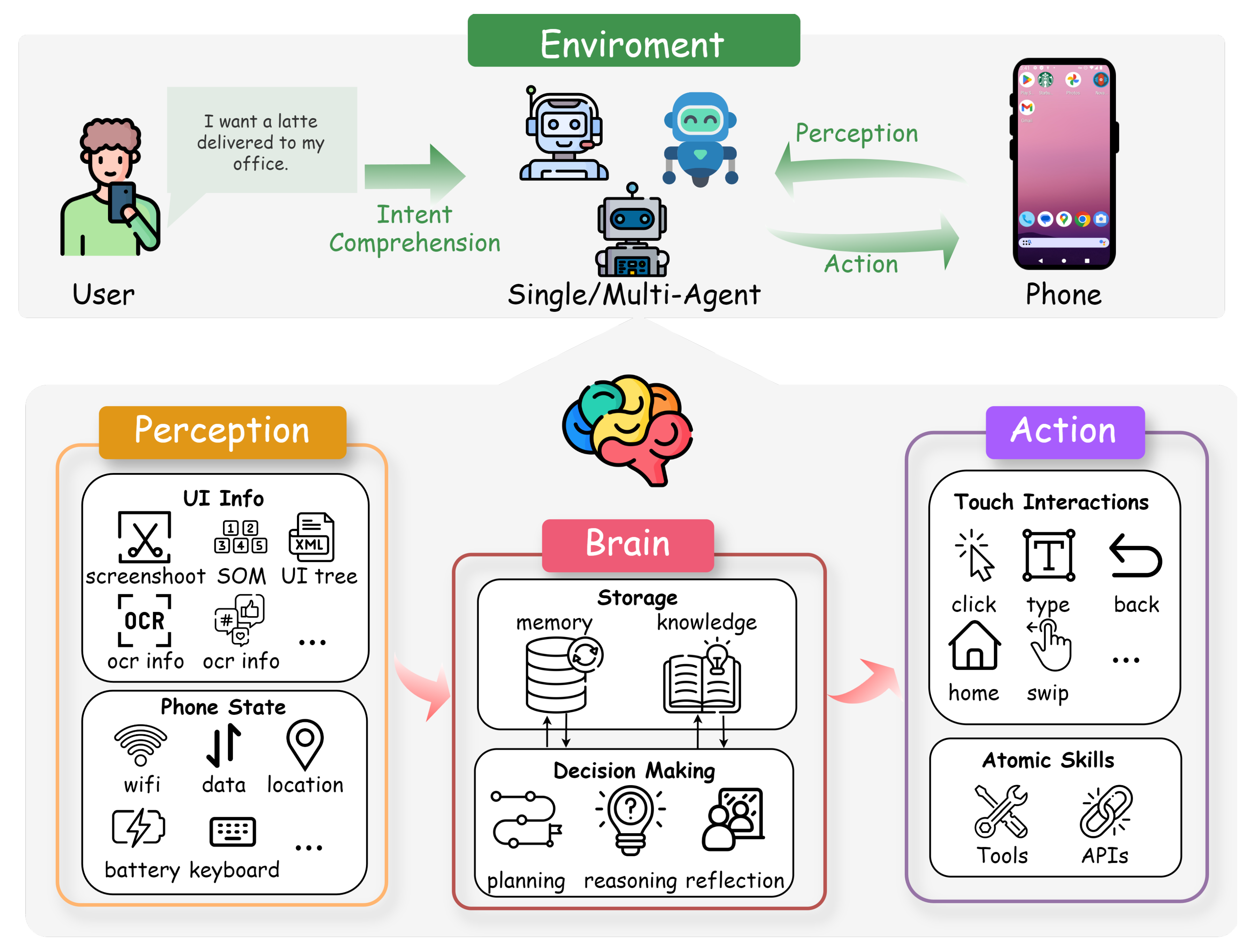
3.1. Perception in Phone GUI Agents
3.1.1. UI Information Perception
3.1.2. Phone State Perception
3.2. Brain in Phone GUI Agents
3.2.1. Storage
- Pre-trained Knowledge. LLMs are inherently equipped with a vast amount of general knowledge, including common-sense reasoning and familiarity with programming and markup languages such as HTML. This pre-existing knowledge allows the agent to interpret and generate meaningful actions based on the UI representations.
- Domain-Specific Training. Some agents enhance their knowledge by training on phone automation-specific datasets. Works such as AutoUI Zhang and Zhang (2023), CogAgent Hong et al. (2024), ScreenAI Baechler et al. (2024), CoCo-agent Ma et al. (2024), and Ferret-UI You et al. (2024) have trained LLMs on datasets tailored for mobile UI interactions, thereby improving their capability to understand and manipulate mobile interfaces effectively. For a more detailed discussion of knowledge acquisition through model training, see § 4.2.
- Knowledge Injection. Agents can enhance their decision-making by incorporating knowledge derived from exploratory interactions and stored contextual information. This involves utilizing data collected during offline exploration phases or from observed human demonstrations to inform the LLM’s reasoning process. For instance, AutoDroid Wen et al. (2024) explores app functionalities and records UI transitions in a UI Transition Graph (UTG) memory, which are then used to generate task-specific prompts for the LLM. Similarly, AppAgent Zhang et al. (2023a) compiles knowledge from autonomous interactions and human demonstrations into structured documents, enabling the LLM to make informed decisions based on comprehensive UI state information and task requirements.
3.2.2. Decision Making
3.3. Action in Phone GUI Agents
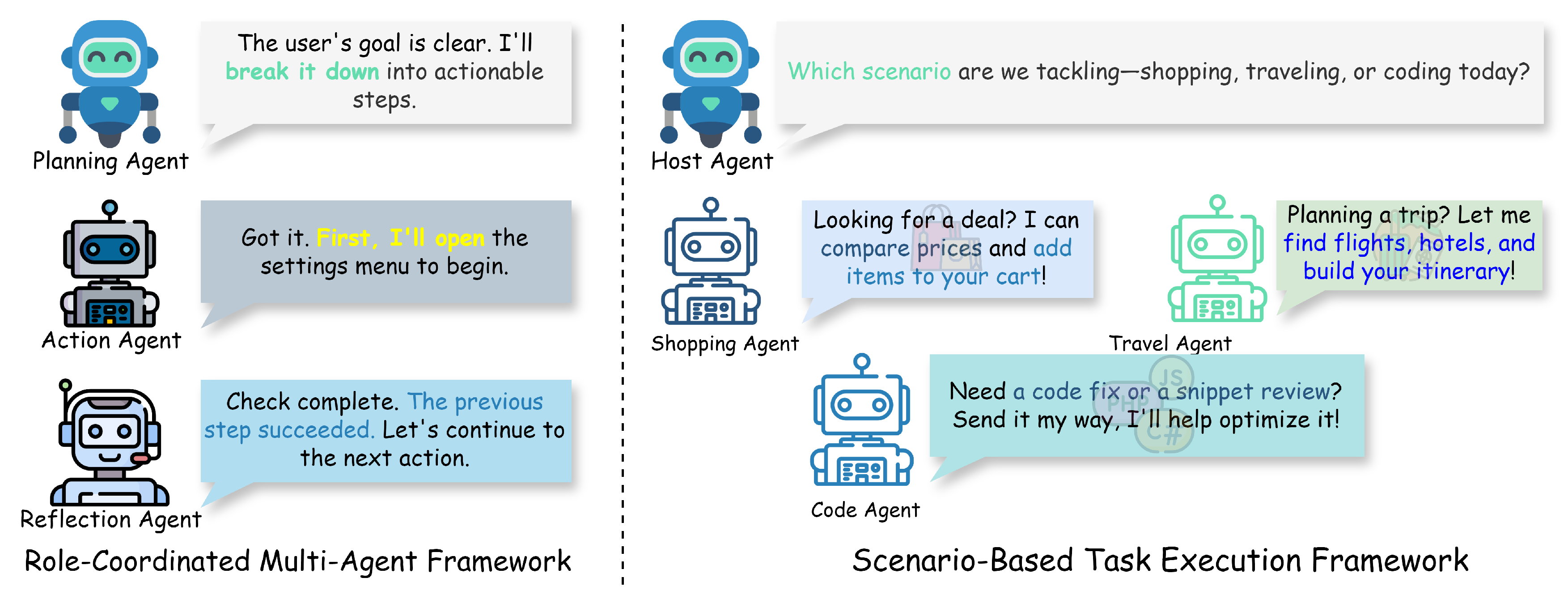
3.4. Multi-Agent Framework
3.4.1. Role-Coordinated Multi-Agent
3.4.2. Scenario-Based Task Execution
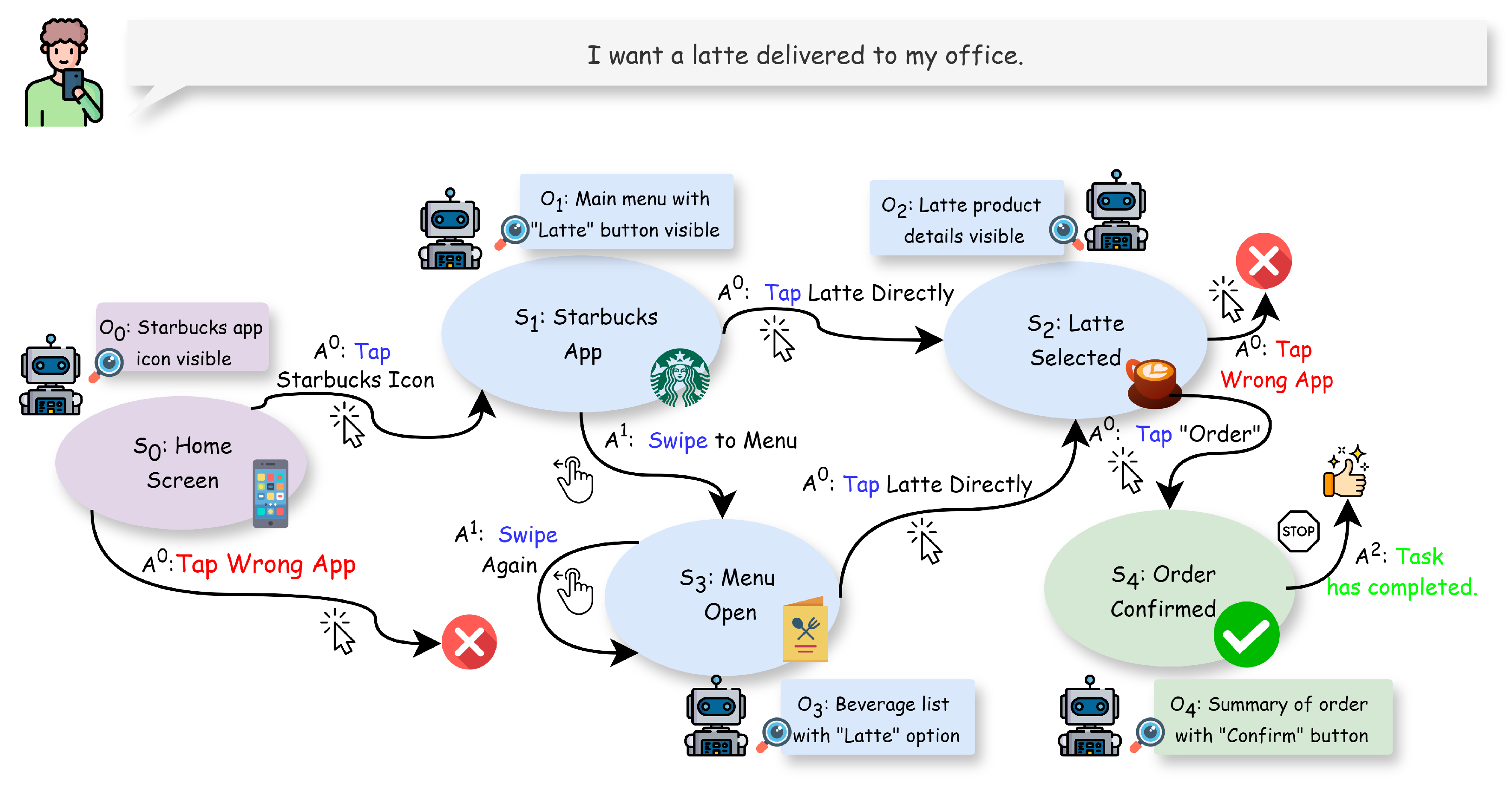
3.5. Plan-Then-Act Framework
4. LLMs for Phone Automation
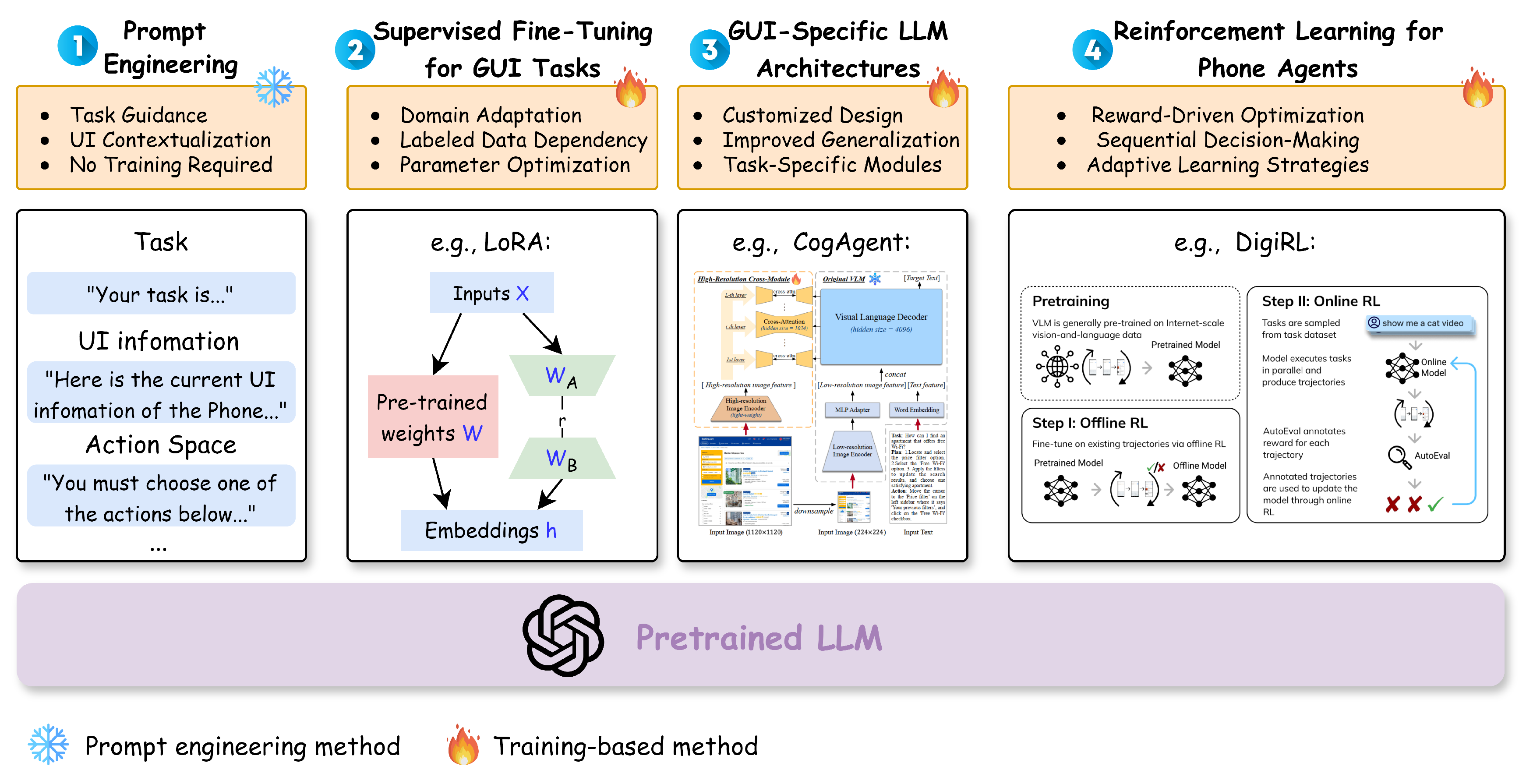
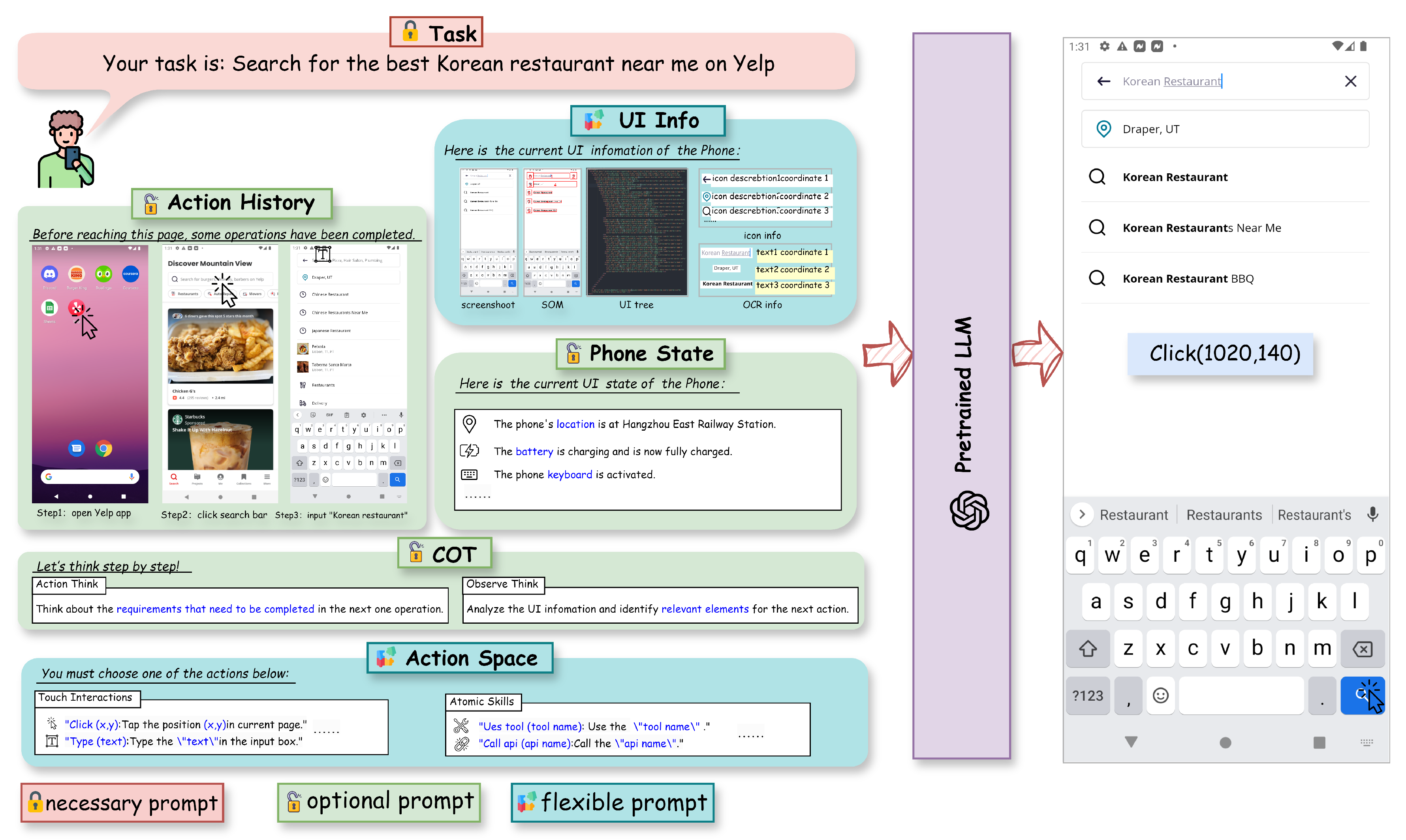
4.1. Prompt Engineering
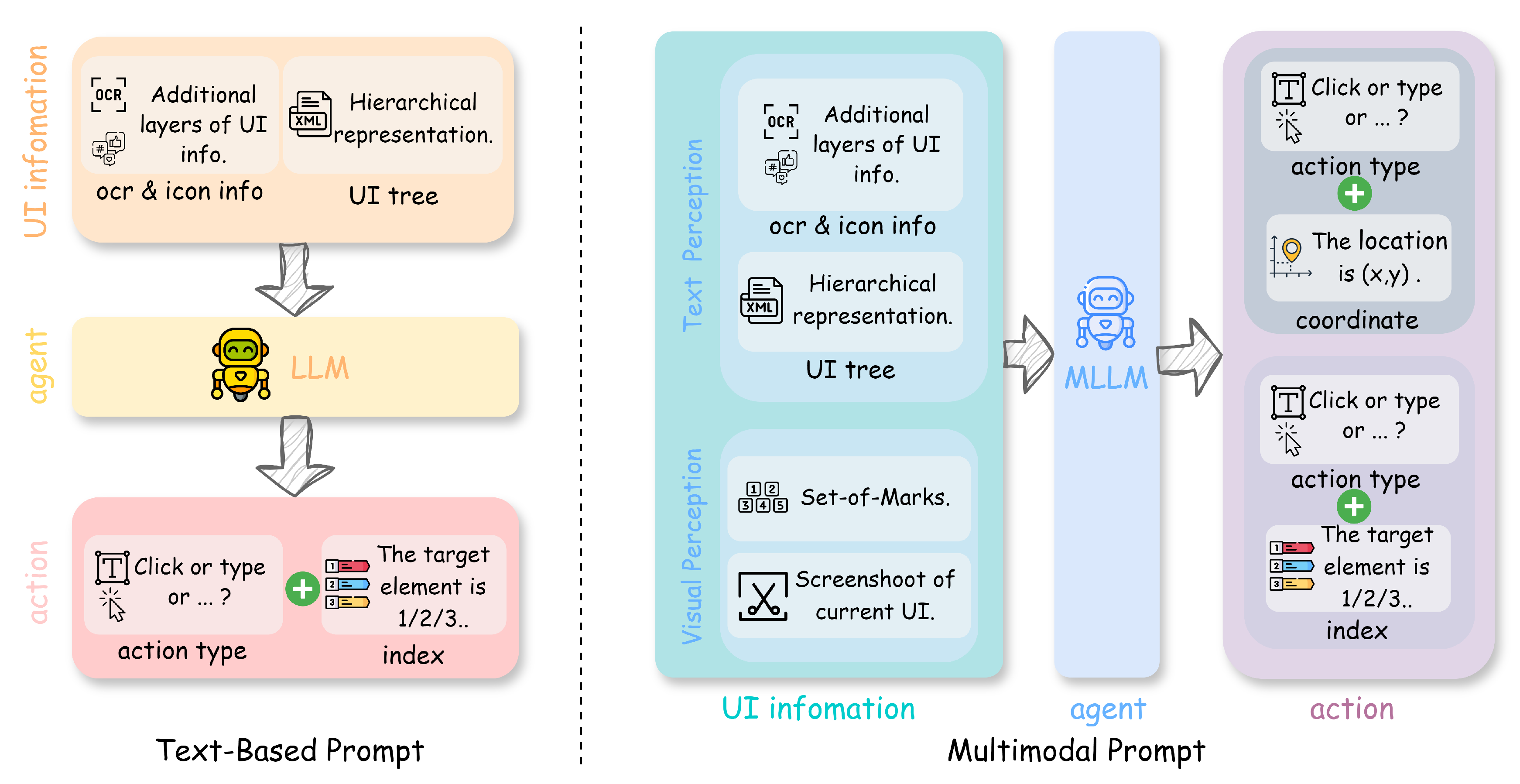
4.1.1. Text-Based Prompt
4.1.2. Multimodal Prompt
4.2. Training-Based Methods
4.2.1. Task-Specific LLM-based Agents

| Method | Date | Task Type | Backbone | Size | Contributions |
|---|---|---|---|---|---|
Auto-GUI Zhang and Zhang (2023) 
|
2023.09 | General | N/A | 60M / 200M / 700M | Direct screen interaction; Chain-of-action; Uses action histories and future plans |
|
CogAgent Hong et al. (2024)
|
2023.12 | General | CogVLM | 18B | High-res input (); Specialized in GUI understanding |
|
WebVLN-Net Chen et al. (2024a)
|
2023.12 | Screen Understanding, QA | N/A | N/A | Web navigation with visual and HTML content; WebVLN-v1 dataset |
|
ScreenAI Baechler et al. (2024)
|
2024.02 | Screen Understanding, QA | N/A | 4.6B | UI and infographic understanding; Flexible patching; Three datasets released |
|
CoCo-Agent Ma et al. (2024)
|
2024.02 | General | LLaVA (LLaMA-2-chat-7B, CLIP) | N/A | Comprehensive perception; Conditional action prediction; Enhanced automation |
| Ferret-UI You et al. (2024) | 2024.04 | Screen Understanding, Grounding | Ferret | N/A | "Any resolution" techniques; Precise referring and grounding |
| LVG Qian et al. (2024b) | 2024.06 | Screen Understanding, Grounding | SWIN Transformer, BERT | N/A | Visual UI grounding; Layout-guided contrastive learning |
| MobileFlow Nong et al. (2024) | 2024.07 | General | Qwen-VL-Chat | 21B | Hybrid visual encoders; Variable resolutions; Multilingual support |
| UI-Hawk Zhang et al. (2024d) | 2024.08 | Screen Understanding, Grounding | N/A | N/A | History-aware encoder; Screen stream processing; FunUI benchmark |
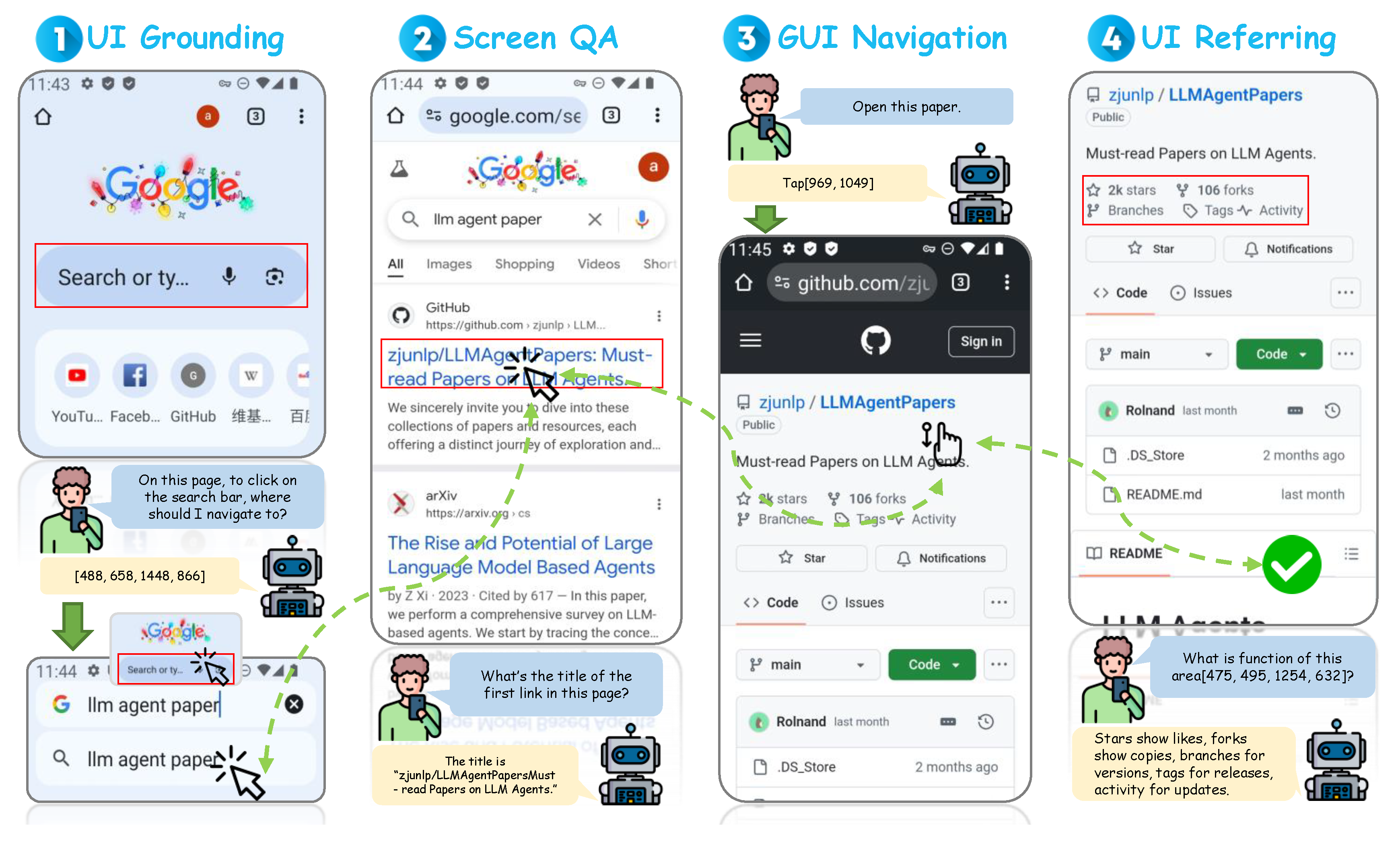
- UI Grounding involves identifying and localizing UI elements on a screen that correspond to a given natural language description. This task is critical for agents to perform precise interactions with GUIs based on user instructions. LVG (Layout-guided Visual Grounding) Qian et al. (2024b) addresses UI grounding by unifying detection and grounding of UI elements within application interfaces. LVG tackles challenges such as application sensitivity, where UI elements with similar appearances have different functions across applications, and context sensitivity, where the functionality of UI elements depends on their context within the interface. By introducing layout-guided contrastive learning, LVG learns the semantics of UI objects from their visual organization and spatial relationships, improving grounding accuracy. UI-Hawk Zhang et al. (2024d) enhances UI grounding by incorporating a history-aware visual encoder and an efficient resampler to process screen sequences during GUI navigation. By understanding historical screens, UI-Hawk improves the agent’s ability to ground UI elements accurately over time. An automated data curation method generates training data for UI grounding, contributing to the creation of the FunUI benchmark for evaluating screen understanding capabilities.
- UI Referring focuses on generating natural language descriptions for specified UI elements on a screen. This task enables agents to explain UI components to users or other agents, facilitating better communication and interaction. Ferret-UI You et al. (2024) is a multimodal LLM designed for enhanced understanding of mobile UI screens, emphasizing precise referring and grounding tasks. By incorporating any resolution techniques to handle various screen aspect ratios and dividing screens into sub-images for detailed analysis, Ferret-UI generates accurate descriptions of UI elements. Training on a curated dataset of elementary UI tasks, Ferret-UI demonstrates strong performance in UI referring tasks. UI-Hawk Zhang et al. (2024d) also contributes to UI referring by defining tasks that require the agent to generate descriptions for UI elements based on their role and context within the interface. By processing screen sequences and understanding the temporal relationships between screens, UI-Hawk improves the agent’s ability to refer to UI elements accurately.
- Screen Question Answering involves answering questions about the content and functionality of a screen based on visual and textual information. This task requires agents to comprehend complex screen layouts and extract relevant information to provide accurate answers. ScreenAI Baechler et al. (2024) specializes in understanding screen UIs and infographics, leveraging the common visual language and design principles shared between them. By introducing a flexible patching strategy and a novel textual representation for UIs, ScreenAI pre-trains models to interpret UI elements effectively. Using large language models to automatically generate training data, ScreenAI covers tasks such as screen annotation and screen QA. WebVLN Chen et al. (2024a) extends vision-and-language navigation to websites, where agents navigate based on question-based instructions and answer questions using information extracted from target web pages. By integrating visual inputs, linguistic instructions, and web-specific content like HTML, WebVLN enables agents to understand both the visual layout and underlying structure of web pages, enhancing screen QA capabilities. UI-Hawk Zhang et al. (2024d) further enhances screen QA by enabling agents to process screen sequences and answer questions based on historical interactions. By incorporating screen question answering as one of its fundamental tasks, UI-Hawk improves the agent’s ability to comprehend and reason about screen content over time.
4.2.2. Supervised Fine-Tuning
4.2.3. Reinforcement Learning
| Method | Date | Platform | RL Type | Backbone | Size |
|---|---|---|---|---|---|
|
DigiRL Bai et al. (2024)
|
2024.06 | Phone | Online RL | AutoUI-Base | 200M |
| DistRL Wang et al. (2024g) | 2024.10 | Phone | Online RL | T5-based | 1.3B |
|
AutoGLM Liu et al. (2024b)
|
2024.11 | Phone, Web | Online RL | GLM-4-9B-Base | 9B |
|
ScreenAgent Niu et al. (2024)
|
2024.02 | PC OS | N/A | CogAgent | 18B |
|
ETO Song et al. (2024a)
|
2024.03 | Web | Offline-to-Online RL | LLaMA-2-7B-Chat | 7B |
|
AutoWebGLM Lai et al. (2024)
|
2024.04 | Web | RL (Curriculum Learning, Bootstrapped RL) | ChatGLM3-6B | 6B |
| Agent Q Putta et al. (2024) | 2024.08 | Web | Offline RL with MCTS | LLaMA-3-70B | 70B |
5. Datasets and Benchmarks
5.1. Datasets
5.2. Benchmarks
5.2.1. Evaluation Pipelines
5.2.2. Evaluation Metrics
6. Challenges and Future Directions
7. Conclusion
References
- Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Simone Agostinelli, Marco Lupia, Andrea Marrella, and Massimo Mecella. 2022. Reactive synthesis of software robots in rpa from user interface logs. Computers in Industry, 142:103721. [CrossRef]
- Simone Agostinelli, Andrea Marrella, and Massimo Mecella. 2019. Research challenges for intelligent robotic process automation. In Business Process Management Workshops: BPM 2019 International Workshops, Vienna, Austria, September 1–6, 2019, Revised Selected Papers 17, pages 12–18. Springer.
- Stefano V Albrecht and Peter Stone. 2018. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artificial Intelligence, 258:66–95. [CrossRef]
- Domenico Amalfitano, Anna Rita Fasolino, Porfirio Tramontana, Salvatore De Carmine, and Atif M Memon. 2012. Using gui ripping for automated testing of android applications. In Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering, pages 258–261.
- Domenico Amalfitano, Anna Rita Fasolino, Porfirio Tramontana, Bryan Dzung Ta, and Atif M Memon. 2014. Mobiguitar: Automated model-based testing of mobile apps. IEEE software, 32(5):53–59. [CrossRef]
- Saleema Amershi, Maya Cakmak, William Bradley Knox, and Todd Kulesza. 2014. Power to the people: The role of humans in interactive machine learning. AI magazine, 35(4):105–120. [CrossRef]
- Darko Anicic, Paul Fodor, Sebastian Rudolph, Roland Stühmer, Nenad Stojanovic, and Rudi Studer. 2010. A rule-based language for complex event processing and reasoning. In Web Reasoning and Rule Systems: Fourth International Conference, RR 2010, Bressanone/Brixen, Italy, September 22-24, 2010. Proceedings 4, pages 42–57. Springer.
- GEM Anscombe. 2000. Intention.
- Yauhen Leanidavich Arnatovich and Lipo Wang. 2018. A systematic literature review of automated techniques for functional gui testing of mobile applications. arXiv preprint arXiv:1812.11470.
- Muhammad Asadullah and Ahsan Raza. 2016. An overview of home automation systems. In 2016 2nd international conference on robotics and artificial intelligence (ICRAI), pages 27–31. IEEE.
- Tanzirul Azim and Iulian Neamtiu. 2013. Targeted and depth-first exploration for systematic testing of android apps. In Proceedings of the 2013 ACM SIGPLAN international conference on Object oriented programming systems languages & applications, pages 641–660.
- Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Cărbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. 2024. Screenai: A vision-language model for ui and infographics understanding. arXiv preprint arXiv:2402.04615.
- Chongyang Bai, Xiaoxue Zang, Ying Xu, Srinivas Sunkara, Abhinav Rastogi, Jindong Chen, et al. 2021. Uibert: Learning generic multimodal representations for ui understanding. arXiv preprint arXiv:2107.13731.
- Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. 2024. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. arXiv preprint arXiv:2406.11896.
- Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966.
- Ishan Banerjee, Bao Nguyen, Vahid Garousi, and Atif Memon. 2013. Graphical user interface (gui) testing: Systematic mapping and repository. Information and Software Technology, 55(10):1679–1694. [CrossRef]
- Daniil A Boiko, Robert MacKnight, and Gabe Gomes. 2023. Emergent autonomous scientific research capabilities of large language models. arXiv preprint arXiv:2304.05332.
- Julia Brich, Marcel Walch, Michael Rietzler, Michael Weber, and Florian Schaub. 2017. Exploring end user programming needs in home automation. ACM Transactions on Computer-Human Interaction (TOCHI), 24(2):1–35. [CrossRef]
- Robert Bridle and Eric McCreath. 2006. Inducing shortcuts on a mobile phone interface. In Proceedings of the 11th international conference on Intelligent user interfaces, pages 327–329.
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, and Bryan A Plummer. 2021. Mobile app tasks with iterative feedback (motif): Addressing task feasibility in interactive visual environments. arXiv preprint arXiv:2104.08560.
- Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. 2024. Amex: Android multi-annotation expo dataset for mobile gui agents. arXiv preprint arXiv:2407.17490.
- Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45.
- Chunyang Chen, Ting Su, Guozhu Meng, Zhenchang Xing, and Yang Liu. 2018. From ui design image to gui skeleton: a neural machine translator to bootstrap mobile gui implementation. In Proceedings of the 40th International Conference on Software Engineering, pages 665–676.
- Fei Chen, Wei Ren, et al. 2019. On the control of multi-agent systems: A survey. Foundations and Trends® in Systems and Control, 6(4):339–499. [CrossRef]
- Qi Chen, Dileepa Pitawela, Chongyang Zhao, Gengze Zhou, Hsiang-Ting Chen, and Qi Wu. 2024a. Webvln: Vision-and-language navigation on websites. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1165–1173.
- Wei Chen and Zhiyuan Li. 2024. Octopus v2: On-device language model for super agent. arXiv preprint arXiv:2404.01744.
- Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588.
- Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. 2024b. Guicourse: From general vision language models to versatile gui agents. arXiv preprint arXiv:2406.11317.
- Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. 2024c. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821. [CrossRef]
- Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. 2024d. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198.
- Zhiyuan Chen, Yaning Li, and Kairui Wang. 2024e. Optimizing reasoning abilities in large language models: A step-by-step approach. Authorea Preprints.
- Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935.
- Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- Filippos Christianos, Georgios Papoudakis, Thomas Coste, Jianye Hao, Jun Wang, and Kun Shao. 2024. Lightweight neural app control. arXiv preprint arXiv:2410.17883.
- Janine Clarke, Judith Proudfoot, Alexis Whitton, Mary-Rose Birch, Megan Boyd, Gordon Parker, Vijaya Manicavasagar, Dusan Hadzi-Pavlovic, Andrea Fogarty, et al. 2016. Therapeutic alliance with a fully automated mobile phone and web-based intervention: secondary analysis of a randomized controlled trial. JMIR mental health, 3(1):e4656. [CrossRef]
- Benjamin R Cowan, Nadia Pantidi, David Coyle, Kellie Morrissey, Peter Clarke, Sara Al-Shehri, David Earley, and Natasha Bandeira. 2017. " what can i help you with?" infrequent users’ experiences of intelligent personal assistants. In Proceedings of the 19th international conference on human-computer interaction with mobile devices and services, pages 1–12.
- Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Arun Ahuja, Sheila Babayan, Felix Hill, and Rob Fergus. 2023. Collaborating with language models for embodied reasoning. arXiv preprint arXiv:2302.00763.
- Christian Degott, Nataniel P Borges Jr, and Andreas Zeller. 2019. Learning user interface element interactions. In Proceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, pages 296–306.
- Daniel C Dennett. 1988. Précis of the intentional stance. Behavioral and brain sciences, 11(3):495–505.
- Parth S Deshmukh, Saroj S Date, Parikshit N Mahalle, and Janki Barot. 2023. Automated gui testing for enhancing user experience (ux): A survey of the state of the art. In International Conference on ICT for Sustainable Development, pages 619–628. Springer.
- Jacob Devlin. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Tinghe Ding. 2024. Mobileagent: enhancing mobile control via human-machine interaction and sop integration. arXiv preprint arXiv:2401.04124.
- Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2024. Self-collaboration code generation via chatgpt. ACM Transactions on Software Engineering and Methodology, 33(7):1–38.
- Ali Dorri, Salil S Kanhere, and Raja Jurdak. 2018. Multi-agent systems: A survey. Ieee Access, 6:28573–28593. [CrossRef]
- Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, et al. 2020. Pp-ocr: A practical ultra lightweight ocr system. arXiv preprint arXiv:2009.09941.
- Jianqing Fan, Zhaoran Wang, Yuchen Xie, and Zhuoran Yang. 2020. A theoretical analysis of deep q-learning. In Learning for dynamics and control, pages 486–489. PMLR.
- Jingwen Fu, Xiaoyi Zhang, Yuwang Wang, Wenjun Zeng, and Nanning Zheng. 2024. Understanding mobile gui: From pixel-words to screen-sentences. Neurocomputing, 601:128200. [CrossRef]
- Kanishk Gandhi, Jan-Philipp Fränken, Tobias Gerstenberg, and Noah Goodman. 2024. Understanding social reasoning in language models with language models. Advances in Neural Information Processing Systems, 36.
- Jianfeng Gao, Michel Galley, and Lihong Li. 2018. Neural approaches to conversational ai. In The 41st international ACM SIGIR conference on research & development in information retrieval, pages 1371–1374.
- Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 2024. Navigating the digital world as humans do: Universal visual grounding for gui agents. arXiv preprint arXiv:2410.05243.
- Tiago Guerreiro, Ricardo Gamboa, and Joaquim Jorge. 2008. Mnemonical body shortcuts: improving mobile interaction. In Proceedings of the 15th European conference on Cognitive ergonomics: the ergonomics of cool interaction, pages 1–8.
- Unmesh Gundecha. 2015. Selenium Testing Tools Cookbook. Packt Publishing Ltd.
- Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680.
- Thilo Hagendorff. 2023. Machine psychology: Investigating emergent capabilities and behavior in large language models using psychological methods. arXiv preprint arXiv:2303.13988, 1.
- Sabrina Haque and Christoph Csallner. 2024. Infering alt-text for ui icons with large language models during app development. arXiv preprint arXiv:2409.18060.
- Geoffrey Hecht, Omar Benomar, Romain Rouvoy, Naouel Moha, and Laurence Duchien. 2015. Tracking the software quality of android applications along their evolution (t). In 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 236–247. IEEE.
- Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. 2023. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352.
- Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281–14290.
- Jakub Hoscilowicz, Bartosz Maj, Bartosz Kozakiewicz, Oleksii Tymoshchuk, and Artur Janicki. 2024. Clickagent: Enhancing ui location capabilities of autonomous agents. arXiv preprint arXiv:2410.11872.
- Yongxiang Hu, Xuan Wang, Yingchuan Wang, Yu Zhang, Shiyu Guo, Chaoyi Chen, Xin Wang, and Yangfan Zhou. 2024. Auitestagent: Automatic requirements oriented gui function testing. arXiv preprint arXiv:2407.09018.
- Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of llm agents: A survey. arXiv preprint arXiv:2402.02716.
- Becky Inkster, Shubhankar Sarda, Vinod Subramanian, et al. 2018. An empathy-driven, conversational artificial intelligence agent (wysa) for digital mental well-being: real-world data evaluation mixed-methods study. JMIR mHealth and uHealth, 6(11):e12106. [CrossRef]
- Casper S Jensen, Mukul R Prasad, and Anders Møller. 2013. Automated testing with targeted event sequence generation. In Proceedings of the 2013 International Symposium on Software Testing and Analysis, pages 67–77.
- Haolin Jin, Linghan Huang, Haipeng Cai, Jun Yan, Bo Li, and Huaming Chen. 2024. From llms to llm-based agents for software engineering: A survey of current, challenges and future. arXiv preprint arXiv:2408.02479.
- Ning Kang, Bharat Singh, Zubair Afzal, Erik M van Mulligen, and Jan A Kors. 2013. Using rule-based natural language processing to improve disease normalization in biomedical text. Journal of the American Medical Informatics Association, 20(5):876–881. [CrossRef]
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Nikitas Karanikolas, Eirini Manga, Nikoletta Samaridi, Eleni Tousidou, and Michael Vassilakopoulos. 2023. Large language models versus natural language understanding and generation. In Proceedings of the 27th Pan-Hellenic Conference on Progress in Computing and Informatics, pages 278–290.
- Courtney Kennedy and Stephen E Everett. 2011. Use of cognitive shortcuts in landline and cell phone surveys. Public Opinion Quarterly, 75(2):336–348.
- Veton Kepuska and Gamal Bohouta. 2018. Next-generation of virtual personal assistants (microsoft cortana, apple siri, amazon alexa and google home). In 2018 IEEE 8th annual computing and communication workshop and conference (CCWC), pages 99–103. IEEE.
- B Kirubakaran and V Karthikeyani. 2013. Mobile application testing—challenges and solution approach through automation. In 2013 International Conference on Pattern Recognition, Informatics and Mobile Engineering, pages 79–84. IEEE.
- Ravi Kishore Kodali and Kopulwar Shishir Mahesh. 2017. Low cost implementation of smart home automation. In 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), pages 461–466. IEEE.
- Ravi Kishore Kodali, Sasweth C Rajanarayanan, Lakshmi Boppana, Samradh Sharma, and Ankit Kumar. 2019. Low cost smart home automation system using smart phone. In 2019 IEEE R10 humanitarian technology conference (R10-HTC)(47129), pages 120–125. IEEE.
- Jürgen Köhl, Rogier Kolnaar, and Willem J Ravensberg. 2019. Mode of action of microbial biological control agents against plant diseases: relevance beyond efficacy. Frontiers in plant science, 10:845. [CrossRef]
- Ryuto Koike, Masahiro Kaneko, and Naoaki Okazaki. 2024. Outfox: Llm-generated essay detection through in-context learning with adversarially generated examples. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21258–21266. [CrossRef]
- Pingfan Kong, Li Li, Jun Gao, Kui Liu, Tegawendé F Bissyandé, and Jacques Klein. 2018. Automated testing of android apps: A systematic literature review. IEEE Transactions on Reliability, 68(1):45–66. [CrossRef]
- Yavuz Koroglu, Alper Sen, Ozlem Muslu, Yunus Mete, Ceyda Ulker, Tolga Tanriverdi, and Yunus Donmez. 2018. Qbe: Qlearning-based exploration of android applications. In 2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST), pages 105–115. IEEE.
- Pawel Ladosz, Lilian Weng, Minwoo Kim, and Hyondong Oh. 2022. Exploration in deep reinforcement learning: A survey. Information Fusion, 85:1–22. [CrossRef]
- Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, et al. 2024. Autowebglm: A large language model-based web navigating agent. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5295–5306.
- Chris Lamberton, Damiano Brigo, and Dave Hoy. 2017. Impact of robotics, rpa and ai on the insurance industry: challenges and opportunities. Journal of Financial Perspectives, 4(1).
- Huy Viet Le, Sven Mayer, Maximilian Weiß, Jonas Vogelsang, Henrike Weingärtner, and Niels Henze. 2020. Shortcut gestures for mobile text editing on fully touch sensitive smartphones. ACM Transactions on Computer-Human Interaction (TOCHI), 27(5):1–38. [CrossRef]
- Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. 2024. Benchmarking mobile device control agents across diverse configurations. arXiv preprint arXiv:2404.16660.
- Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Hojun Choi, Steven Y Ko, Sangeun Oh, and Insik Shin. 2023. Explore, select, derive, and recall: Augmenting llm with human-like memory for mobile task automation. arXiv preprint arXiv:2312.03003.
- Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023a. Camel: Communicative agents for" mind" exploration of large language model society. Advances in Neural Information Processing Systems, 36:51991–52008.
- Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023b. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR.
- Toby Jia-Jun Li, Amos Azaria, and Brad A Myers. 2017. Sugilite: creating multimodal smartphone automation by demonstration. In Proceedings of the 2017 CHI conference on human factors in computing systems, pages 6038–6049.
- Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. 2024a. On the effects of data scale on computer control agents. arXiv preprint arXiv:2406.03679.
- Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. 2024b. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges. Vicinagearth, 1(1):9. [CrossRef]
- Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, and Jason Baldridge. 2020. Mapping natural language instructions to mobile ui action sequences. arXiv preprint arXiv:2005.03776.
- Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, et al. 2024c. Personal llm agents: Insights and survey about the capability, efficiency and security. arXiv preprint arXiv:2401.05459.
- Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2019. Humanoid: A deep learning-based approach to automated black-box android app testing. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 1070–1073. IEEE.
- Mario Linares-Vásquez, Kevin Moran, and Denys Poshyvanyk. 2017. Continuous, evolutionary and large-scale: A new perspective for automated mobile app testing. In 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 399–410. IEEE.
- Xufeng Ling, Ming Gao, and Dong Wang. 2020. Intelligent document processing based on rpa and machine learning. In 2020 Chinese Automation Congress (CAC), pages 1349–1353. IEEE.
- Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024a. Visual instruction tuning. Advances in neural information processing systems, 36.
- Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, et al. 2024b. Autoglm: Autonomous foundation agents for guis. arXiv preprint arXiv:2411.00820.
- Xiaoyi Liu, Yingtian Shi, Chun Yu, Cheng Gao, Tianao Yang, Chen Liang, and Yuanchun Shi. 2023. Understanding in-situ programming for smart home automation. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7(2):1–31. [CrossRef]
- Zhe Liu, Cheng Li, Chunyang Chen, Junjie Wang, Boyu Wu, Yawen Wang, Jun Hu, and Qing Wang. 2024c. Vision-driven automated mobile gui testing via multimodal large language model. arXiv preprint arXiv:2407.03037.
- Gio Lodi. 2021. Xctest introduction. In Test-Driven Development in Swift: Compile Better Code with XCTest and TDD, pages 13–25. Springer.
- Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. 2024a. Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. arXiv preprint arXiv:2406.08451.
- Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. 2024b. Omniparser for pure vision based gui agent. arXiv preprint arXiv:2408.00203.
- Ewa Luger and Abigail Sellen. 2016. " like having a really bad pa" the gulf between user expectation and experience of conversational agents. In Proceedings of the 2016 CHI conference on human factors in computing systems, pages 5286–5297.
- Fan-Ming Luo, Tian Xu, Hang Lai, Xiong-Hui Chen, Weinan Zhang, and Yang Yu. 2024. A survey on model-based reinforcement learning. Science China Information Sciences, 67(2):121101. [CrossRef]
- Xinbei Ma, Zhuosheng Zhang, and Hai Zhao. 2024. Coco-agent: A comprehensive cognitive mllm agent for smartphone gui automation. In Findings of the Association for Computational Linguistics ACL 2024, pages 9097–9110.
- Aravind Machiry, Rohan Tahiliani, and Mayur Naik. 2013. Dynodroid: An input generation system for android apps. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, pages 224–234.
- Rizwan Majeed, Nurul Azma Abdullah, Imran Ashraf, Yousaf Bin Zikria, Muhammad Faheem Mushtaq, and Muhammad Umer. 2020. An intelligent, secure, and smart home automation system. Scientific Programming, 2020(1):4579291.
- Indrani Medhi, Kentaro Toyama, Anirudha Joshi, Uday Athavankar, and Edward Cutrell. 2013. A comparison of list vs. hierarchical uis on mobile phones for non-literate users. In Human-Computer Interaction–INTERACT 2013: 14th IFIP TC 13 International Conference, Cape Town, South Africa, September 2-6, 2013, Proceedings, Part II 14, pages 497–504. Springer.
- Anja Meironke and Stephan Kuehnel. 2022. How to measure rpa’s benefits? a review on metrics, indicators, and evaluation methods of rpa benefit assessment.
- Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey. arXiv preprint arXiv:2402.06196.
- George E Monahan. 1982. State of the art—a survey of partially observable markov decision processes: theory, models, and algorithms. Management science, 28(1):1–16.
- Joel Ruben Antony Moniz, Soundarya Krishnan, Melis Ozyildirim, Prathamesh Saraf, Halim Cagri Ates, Yuan Zhang, Hong Yu, and Nidhi Rajshree. 2024. Realm: Reference resolution as language modeling. arXiv preprint arXiv:2403.20329.
- Sílvia Moreira, Henrique S Mamede, and Arnaldo Santos. 2023. Process automation using rpa–a literature review. Procedia Computer Science, 219:244–254.
- Michel Nass. 2024. On overcoming challenges with GUI-based test automation. Ph.D. thesis, Blekinge Tekniska Högskola.
- Michel Nass, Emil Alégroth, and Robert Feldt. 2021. Why many challenges with gui test automation (will) remain. Information and Software Technology, 138:106625. [CrossRef]
- Runliang Niu, Jindong Li, Shiqi Wang, Yali Fu, Xiyu Hu, Xueyuan Leng, He Kong, Yi Chang, and Qi Wang. 2024. Screenagent: A vision language model-driven computer control agent. arXiv preprint arXiv:2402.07945.
- Songqin Nong, Jiali Zhu, Rui Wu, Jiongchao Jin, Shuo Shan, Xiutian Huang, and Wenhao Xu. 2024. Mobileflow: A multimodal llm for mobile gui agent. arXiv preprint arXiv:2407.04346.
- Minxue Pan, An Huang, Guoxin Wang, Tian Zhang, and Xuandong Li. 2020. Reinforcement learning based curiosity-driven testing of android applications. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 153–164.
- Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22.
- Syeh Mujeeb Patel and Syed Jilani Pasha. 2015. Home automation system (has) using android for mobile phone. International Journal Of Scientific Engeneering and Technology Research,, ISSN, pages 2319–8885.
- Neha Patil, Dhananjay Bhole, and Prasanna Shete. 2016. Enhanced ui automator viewer with improved android accessibility evaluation features. In 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), pages 977–983. IEEE.
- Pawel Pawlowski, Krystian Zawistowski, Wojciech Lapacz, Marcin Skorupa, Adam Wiacek, Sebastien Postansque, and Jakub Hoscilowicz. 2024. Tinyclick: Single-turn agent for empowering gui automation. arXiv preprint arXiv:2410.11871.
- Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thomas Back. 2024. Reasoning with large language models, a survey. arXiv preprint arXiv:2407.11511.
- David L Poole and Alan K Mackworth. 2010. Artificial Intelligence: foundations of computational agents. Cambridge University Press.
- Dhanya Pramod. 2022. Robotic process automation for industry: adoption status, benefits, challenges and research agenda. Benchmarking: an international journal, 29(5):1562–1586. [CrossRef]
- Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. 2024. Agent q: Advanced reasoning and learning for autonomous ai agents. arXiv preprint arXiv:2408.07199.
- Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. arXiv preprint arXiv:2307.07924, 6(3).
- Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. 2024a. Chatdev: Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15174–15186.
- Yijun Qian, Yujie Lu, Alexander G Hauptmann, and Oriana Riva. 2024b. Visual grounding for user interfaces. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), pages 97–107.
- Alec Radford. 2018a. Improving language understanding by generative pre-training.
- Alec Radford. 2018b. Improving language understanding by generative pre-training.
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Okko J Räsänen and Jukka P Saarinen. 2015. Sequence prediction with sparse distributed hyperdimensional coding applied to the analysis of mobile phone use patterns. IEEE transactions on neural networks and learning systems, 27(9):1878–1889. [CrossRef]
- Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. 2024a. Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573.
- Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. 2024b. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems, 36.
- Alberto Monge Roffarello, Aditya Kumar Purohit, and Satyam V Purohit. 2024. Trigger-action programming for wellbeing: Insights from 6590 ios shortcuts. IEEE Pervasive Computing. [CrossRef]
- Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2024. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
- Yoav Shoham. 1993. Agent-oriented programming. Artificial intelligence, 60(1):51–92. [CrossRef]
- Chloe Sinclair. The role of selenium in mobile application testing.
- Shiwangi Singh, Rucha Gadgil, and Ayushi Chudgor. 2014. Automated testing of mobile applications using scripting technique: A study on appium. International Journal of Current Engineering and Technology (IJCET), 4(5):3627–3630.
- Paloma Sodhi, SRK Branavan, Yoav Artzi, and Ryan McDonald. 2024. Step: Stacked llm policies for web actions. In First Conference on Language Modeling.
- Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. 2023a. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2998–3009.
- Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. 2024a. Trial and error: Exploration-based trajectory optimization for llm agents. arXiv preprint arXiv:2403.02502.
- Yunpeng Song, Yiheng Bian, Yongtao Tang, and Zhongmin Cai. 2023b. Navigating interfaces with ai for enhanced user interaction. arXiv preprint arXiv:2312.11190.
- Yunpeng Song, Yiheng Bian, Yongtao Tang, Guiyu Ma, and Zhongmin Cai. 2024b. Visiontasker: Mobile task automation using vision based ui understanding and llm task planning. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pages 1–17.
- Zirui Song, Yaohang Li, Meng Fang, Zhenhao Chen, Zecheng Shi, and Yuan Huang. 2024c. Mmac-copilot: Multi-modal agent collaboration operating system copilot. arXiv preprint arXiv:2404.18074.
- Matthijs TJ Spaan. 2012. Partially observable markov decision processes. In Reinforcement learning: State-of-the-art, pages 387–414. Springer.
- Liangtai Sun, Xingyu Chen, Lu Chen, Tianle Dai, Zichen Zhu, and Kai Yu. 2022. Meta-gui: Towards multi-modal conversational agents on mobile gui. arXiv preprint arXiv:2205.11029.
- Rehan Syed, Suriadi Suriadi, Michael Adams, Wasana Bandara, Sander JJ Leemans, Chun Ouyang, Arthur HM Ter Hofstede, Inge Van De Weerd, Moe Thandar Wynn, and Hajo A Reijers. 2020. Robotic process automation: contemporary themes and challenges. Computers in Industry, 115:103162.
- Maryam Taeb, Amanda Swearngin, Eldon Schoop, Ruijia Cheng, Yue Jiang, and Jeffrey Nichols. 2024. Axnav: Replaying accessibility tests from natural language. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pages 1–16.
- Wrick Talukdar and Anjanava Biswas. 2024. Improving large language model (llm) fidelity through context-aware grounding: A systematic approach to reliability and veracity. arXiv preprint arXiv:2408.04023. [CrossRef]
- Weihao Tan, Wentao Zhang, Xinrun Xu, Haochong Xia, Ziluo Ding, Boyu Li, Bohan Zhou, Junpeng Yue, Jiechuan Jiang, Yewen Li, et al. Cradle: Empowering foundation agents towards general computer control. In NeurIPS 2024 Workshop on Open-World Agents.
- Alejandro Torreno, Eva Onaindia, Antonín Komenda, and Michal Štolba. 2017. Cooperative multi-agent planning: A survey. ACM Computing Surveys (CSUR), 50(6):1–32.
- Porfirio Tramontana, Domenico Amalfitano, Nicola Amatucci, and Anna Rita Fasolino. 2019. Automated functional testing of mobile applications: a systematic mapping study. Software Quality Journal, 27:149–201.
- Alok Mani Tripathi. 2018. Learning Robotic Process Automation: Create Software robots and automate business processes with the leading RPA tool–UiPath. Packt Publishing Ltd.
- Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. 2023. On the planning abilities of large language models-a critical investigation. Advances in Neural Information Processing Systems, 36:75993–76005.
- Rejin Varghese and M Sambath. 2024. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), pages 1–6. IEEE.
- A Vaswani. 2017. Attention is all you need. Advances in Neural Information Processing Systems.
- Sagar Gubbi Venkatesh, Partha Talukdar, and Srini Narayanan. 2022. Ugif: Ui grounded instruction following. arXiv preprint arXiv:2211.07615.
- Boshi Wang, Xiang Yue, and Huan Sun. 2023a. Can chatgpt defend its belief in truth? evaluating llm reasoning via debate. arXiv preprint arXiv:2305.13160.
- Bryan Wang, Gang Li, and Yang Li. 2023b. Enabling conversational interaction with mobile ui using large language models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–17.
- Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023c. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291.
- Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024a. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration. arXiv preprint arXiv:2406.01014.
- Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024b. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158.
- Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024c. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345. [CrossRef]
- Luyuan Wang, Yongyu Deng, Yiwei Zha, Guodong Mao, Qinmin Wang, Tianchen Min, Wei Chen, and Shoufa Chen. 2024d. Mobileagentbench: An efficient and user-friendly benchmark for mobile llm agents. arXiv preprint arXiv:2406.08184.
- Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024e. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191.
- Shuai Wang, Weiwen Liu, Jingxuan Chen, Weinan Gan, Xingshan Zeng, Shuai Yu, Xinlong Hao, Kun Shao, Yasheng Wang, and Ruiming Tang. 2024f. Gui agents with foundation models: A comprehensive survey. arXiv preprint arXiv:2411.04890.
- Taiyi Wang, Zhihao Wu, Jianheng Liu, Jianye Hao, Jun Wang, and Kun Shao. 2024g. Distrl: An asynchronous distributed reinforcement learning framework for on-device control agents. arXiv preprint arXiv:2410.14803.
- Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. 2023d. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. Autodroid: Llm-powered task automation in android. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pages 543–557.
- Hao Wen, Hongming Wang, Jiaxuan Liu, and Yuanchun Li. 2023. Droidbot-gpt: Gpt-powered ui automation for android. arXiv preprint arXiv:2304.07061.
- Biao Wu, Yanda Li, Meng Fang, Zirui Song, Zhiwei Zhang, Yunchao Wei, and Ling Chen. 2024. Foundations and recent trends in multimodal mobile agents: A survey. arXiv preprint arXiv:2411.02006.
- Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2023. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864. [CrossRef]
- Yuchen Xia, Manthan Shenoy, Nasser Jazdi, and Michael Weyrich. 2023. Towards autonomous system: flexible modular production system enhanced with large language model agents. In 2023 IEEE 28th International Conference on Emerging Technologies and Factory Automation (ETFA), pages 1–8. IEEE.
- Mingzhe Xing, Rongkai Zhang, Hui Xue, Qi Chen, Fan Yang, and Zhen Xiao. 2024. Understanding the weakness of large language model agents within a complex android environment. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6061–6072.
- Yifan Xu, Xiao Liu, Xueqiao Sun, Siyi Cheng, Hao Yu, Hanyu Lai, Shudan Zhang, Dan Zhang, Jie Tang, and Yuxiao Dong. 2024. Androidlab: Training and systematic benchmarking of android autonomous agents. arXiv preprint arXiv:2410.24024.
- An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, et al. 2023. Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation. arXiv preprint arXiv:2311.07562.
- Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.
- Yulong Yang, Xinshan Yang, Shuaidong Li, Chenhao Lin, Zhengyu Zhao, Chao Shen, and Tianwei Zhang. 2024. Security matrix for multimodal agents on mobile devices: A systematic and proof of concept study. arXiv preprint arXiv:2407.09295.
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
- Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. 2023. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178.
- Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. 2024. Ferret-ui: Grounded mobile ui understanding with multimodal llms. arXiv preprint arXiv:2404.05719.
- Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan, Huimin Chen, Ruobing Xie, Yankai Lin, et al. 2024. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078.
- Samer Zein, Norsaremah Salleh, and John Grundy. 2016. A systematic mapping study of mobile application testing techniques. Journal of Systems and Software, 117:334–356. [CrossRef]
- Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Qingwei Lin, Saravan Rajmohan, et al. 2024a. Large language model-brained gui agents: A survey. arXiv preprint arXiv:2411.18279.
- Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2023a. Appagent: Multimodal agents as smartphone users. arXiv preprint arXiv:2312.13771.
- Danyang Zhang, Lu Chen, and Kai Yu. 2023b. Mobile-env: A universal platform for training and evaluation of mobile interaction. arXiv preprint arXiv:2305.08144.
- Jiayi Zhang, Chuang Zhao, Yihan Zhao, Zhaoyang Yu, Ming He, and Jianping Fan. 2024b. Mobileexperts: A dynamic tool-enabled agent team in mobile devices. arXiv preprint arXiv:2407.03913.
- Jiwen Zhang, Jihao Wu, Yihua Teng, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. 2024c. Android in the zoo: Chain-of-action-thought for gui agents. arXiv preprint arXiv:2403.02713.
- Jiwen Zhang, Yaqi Yu, Minghui Liao, Wentao Li, Jihao Wu, and Zhongyu Wei. 2024d. Ui-hawk: Unleashing the screen stream understanding for gui agents.
- Li Zhang, Shihe Wang, Xianqing Jia, Zhihan Zheng, Yunhe Yan, Longxi Gao, Yuanchun Li, and Mengwei Xu. 2024e. Llamatouch: A faithful and scalable testbed for mobile ui automation task evaluation. arXiv preprint arXiv:2404.16054.
- Shaoqing Zhang, Zhuosheng Zhang, Kehai Chen, Xinbe Ma, Muyun Yang, Tiejun Zhao, and Min Zhang. 2024f. Dynamic planning for llm-based graphical user interface automation. arXiv preprint arXiv:2410.00467.
- Zhuosheng Zhang and Aston Zhang. 2023. You only look at screens: Multimodal chain-of-action agents. arXiv preprint arXiv:2309.11436.
- Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223.
- Yu Zhao, Brent Harrison, and Tingting Yu. 2024. Dinodroid: Testing android apps using deep q-networks. ACM Transactions on Software Engineering and Methodology, 33(5):1–24.
- Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. 2024. Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614.
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |

| Action Type | Description |
|---|---|
| Touch Interactions |
Tap: Select a specific UI element. Double Tap: Quickly tap twice to trigger an action. Long Press: Hold a touch for extended interaction, triggering contextual options or menus. |
| Gesture-Based Actions |
Swipe: Move a finger in a direction (left, right, up, down). Pinch: Zoom in/out by bringing fingers together/apart. Drag: Move UI elements to a new location. |
| Typing and Input |
Type Text: Enter text into input fields. Select Text: Highlight text for editing or copying. |
| System Operations |
Launch Application: Open a specific app. Change Settings: Modify system settings (e.g., Wi-Fi, brightness). Navigate Menus: Access app sections or system menus. |
| Media Control |
Play/Pause: Control media playback. Adjust Volume: Increase or decrease device volume. |
| Method | Date | Task Type | Model | Screenshot | SoM | UI tree | Icon & OCR | Grounding |
|---|---|---|---|---|---|---|---|---|
|
DroidBot-GPT Wen et al. (2023)
|
2023.04 | General | ChatGPT |  |
|
 |
|
Index |
| Enabling conversational Wang et al. (2023b) | 2023.04 | Screen Understanding, QA | PaLM | |
|
|
|
Index |
|
AutoDroid Wen et al. (2024)
|
2023.09 | General | GPT-4, GPT-3.5 | |
|
|
|
Index |
| MM-Navigator Yan et al. (2023) | 2023.11 | General | GPT-4V | |
|
|
|
Index |
| AppAgent Zhang et al. (2023a) | 2023.12 | General | GPT-4 | |
|
|
|
Index |
| VisionTasker Song et al. (2024b) | 2023.12 | Manual Teaching | GPT-4 | |
|
|
|
Index |
| MobileGPT Lee et al. (2023) | 2023.12 | General | GPT-3.5, GPT-4 | |
|
|
|
Index |
|
Mobile-Agent Wang et al. (2024b)
|
2024.01 | General | GPT-4V | |
|
|
|
Coordinate |
| AXNav Taeb et al. (2024) | 2024.05 | Bug Testing | GPT-4 | |
|
|
|
Index |
|
Mobile-Agent-v2 Wang et al. (2024a)
|
2024.06 | General | GPT-4V | |
|
|
|
Coordinate |
| MobileExpert Zhang et al. (2024b) | 2024.07 | General | GPT-4V | |
|
|
|
Coordinate |
|
VisionDroid Liu et al. (2024c)
|
2024.07 | Non-Crash Functional Bug Detection | GPT-4 | |
|
|
|
Index |
| OmniParser Lu et al. (2024b) | 2024.08 | General | GPT-4V | |
|
|
|
Index |
| Method | Date | Task Type | Backbone | Size | Contributions |
|---|---|---|---|---|---|
|
Auto-GUI Zhang and Zhang (2023)
|
2024.01 | General | Qwen-VL | 9.6B | GUI grounding pre-training; ScreenSpot benchmark |
| ReALM Moniz et al. (2024) | 2024.04 | Reference Resolution | FLAN-T5 | 80M–3B | Formulated reference resolution as language modeling; Improved performance on resolving references |
|
GUICourse Chen et al. (2024b)
|
2024.06 | General | Qwen-VL, Fuyu-8B, MiniCPM-V | N/A | Suite of datasets (GUIEnv, GUIAct, GUIChat); Enhanced OCR and grounding |
|
GUI Odyssey Lu et al. (2024a)
|
2024.06 | General | Qwen-VL | N/A | Cross-app navigation dataset; OdysseyAgent with history resampling |
| IconDesc Haque and Csallner (2024) | 2024.09 | Alt-Text Generation | GPT-3.5 | N/A | Generated alt-text for UI icons using partial UI data; Improved accessibility |
| TinyClick Pawlowski et al. (2024) | 2024.10 | General | Florence-2 | 0.27B | Single-turn agent; Multitask training; MLLM-based data augmentation |
| Dataset | Date | Screenshots | UI Trees | Actions | Demos | Apps | Instr. | Avg. Steps | Contributions |
|---|---|---|---|---|---|---|---|---|---|
|
PixelHelpLi et al. (2020)
|
2020.05 | |
|
4 | 187 | 4 | 187 | 4.2 | Grounding instructions to actions |
|
MoTIF Burns et al. (2021)
|
2021.04 | |
|
6 | 4,707 | 125 | 276 | 4.5 | Interactive visual environment |
|
UIBert Bai et al. (2021)
|
2021.07 | |
|
N/A | N/A | N/A | 16,660 | 1 | Pre-training task |
|
Meta-GUI Sun et al. (2022)
|
2022.05 | |
|
7 | 4,684 | 11 | 1,125 | 5.3 | Multi-turn dialogues |
|
UGIF Venkatesh et al. (2022)
|
2022.11 | |
|
8 | 523 | 12 | 523 | 5.3 | Multilingual UI-grounded instructions |
|
AITW Rawles et al. (2024b)
|
2023.12 | |
|
7 | 715,142 | 357 | 30,378 | 6.5 | Large-scale interactions |
|
AITZ Zhang et al. (2024c)
|
2024.03 | |
|
7 | 18,643 | 70 | 2,504 | 7.5 | Chain-of-Action-Thought annotations |
|
GUI Odyssey Lu et al. (2024a)
|
2024.06 | |
|
9 | 7,735 | 201 | 7,735 | 15.4 | Cross-app navigation |
|
AndroidControl Li et al. (2024a)
|
2024.07 | |
|
8 | 15,283 | 833 | 15,283 | 4.8 | UI task scaling law |
|
AMEX Chai et al. (2024)
|
2024.07 | |
|
8 | 2,946 | 110 | 2,946 | 12.8 | Multi-level detailed annotations |
| Benchmark | Date | Tasks | Task Completion | Action Quality | Resource Efficiency | Task Understanding | Format Compliance | Completion Awareness | Reward | Eval Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|
|
AutoDroid Wen et al. (2024)
|
2023.09 | N/A | |
|
|
|
|
|
|
|
|
MobileEnv Zhang et al. (2023b)
|
2023.05 | 74 | |
|
|
|
|
|
|
|
|
AndroidArena Xing et al. (2024)
|
2024.02 | N/A | |
|
|
|
|
|
|
|
|
LlamaTouch Zhang et al. (2024e)
|
2024.04 | 496 | |
|
|
|
|
|
|
|
|
B-MoCA Lee et al. (2024)
|
2024.04 | 131 | |
|
|
|
|
|
|
|
|
AndroidWorld Rawles et al. (2024a)
|
2024.05 | 116 | |
|
|
|
|
|
|
|
|
MobileAgentBench Wang et al. (2024d)
|
2024.06 | 100 | |
|
|
|
|
|
|
|
|
AUITestAgent Hu et al. (2024)
|
2024.07 | N/A | |
|
|
|
|
|
|
|
|
AndroidLab Xu et al. (2024)
|
2024.10 | 138 | |
|
|
|
|
|
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



