Submitted:
20 November 2024
Posted:
21 November 2024
You are already at the latest version
Abstract
In recent years, significant progress has been achieved in understanding and processing tabular data. However, existing approaches often rely on task-specific features and model architectures, posing challenges in accurately extracting table structures amidst diverse layouts, styles, and noise contamination. This study introduces a comprehensive deep learning methodology that is tailored for precise identification and extraction of rows and columns from document images containing tables. The proposed model employs table detection and structure recognition to delineate table and column areas, followed by semantic rule- based approaches for row extraction within tabular sub-regions. The evaluation was performed on the publicly available Marmot data Table datasets demonstrates state-of-the-art performance. Additionally, transfer learning using VGG 19 is employed for fine-tuning the model, enhancing its capability further. Furthermore, this project fills a void in the Marmot dataset by providing it with extra annotations for table structure, expanding its scope to encompass column detection in addition to table identification.
Keywords:
Table Extraction Model
; Information Extraction
; Convolutional Neural Network
; Deep Neural Network
1. Introduction
Relational tables are abundant sources of valuable information. Each of these tables is characterized by labeled and typed columns, effectively functioning as a structured database. Over the past decade, the enormous amount of data has been represented through tables, that represents summarized information. These tables are not only abundant but also rich and highly useful, prompting significant advancements in the fields of table interpretation and augmentation in recent years. The tables include various types of text, including research articles, data analyses, newspapers, periodicals, invoices, and financial documents. Some times tables are considered as a prime source of displaying important data points for numerous items, facilitating analysis and interpretation.
Researchers have reported considerable attention to enhance the table recognition algorithms over the past decades, recognizing the critical importance of tables in various domains [1]. This collaborated effort has led to significant advancements in the field, enabling more accurate and efficient interpretation of tabular data across a wide range of applications [2].
The major challenge with tables is their designs, which represented in different form that makes it hard for traditional methods to understand them properly. These methods usually look for visual clues like grid lines, spacing between columns, the type of information in each cell, and the how cells are related to each other including when they overlap, or if certain areas are highlighted with colors. While these techniques might work fine for certain types of tables or in certain situations but not suitable for all kinds of data representation.
Convolutional Neural Networks (CNNs) are exceptionally well-suited for table extraction tasks due to their inherent capabilities in learning hierarchical features from input data. The tables within documents often exhibit complex structures, including various elements such as lines, borders, text regions, and cells. CNNs can automatically learn these intricate features from the input images, enabling them to effectively identify and extract tables. Furthermore, the spatial hierarchy present in tables, with rows and columns forming distinct patterns, aligns naturally with the hierarchical processing of information in CNNs. Through multiple layers of convolutional and pooling operations, CNNs can capture patterns at different spatial scales, facilitating the detection of table elements regardless of their size or position within the document. Another advantage of CNNs is their translation invariance property, allowing them to detect features irrespective of their location in the input image. This characteristic is particularly beneficial for table extraction, where tables can appear in various positions within documents. Additionally, CNNs manipulate shared parameters across different parts of the input data, enabling them to efficiently capture patterns and generalize well to unseen data. In this paper we proposed a model name as Table Extraction Model (TEM), which is a novel deep learning model that influence the natural interaction between table detection and table structure recognition tasks. The proposed model incorporates a pre-trained base network that incorporates VGG-19 characteristics, which are subsequently fine-tuned to improve overall performance.
This research proposed an idea of combining machine learning algorithms with advanced image processing techniques, so that we can accurately identify and outline tables in document images, leading to a significant improvement. Additionally, we’ve developed a specialized algorithm to minimize false positives when identifying table elements, which should significantly improve the precision of our table extraction system. T-Recs, which was one of the early successful attempts to tackle table extraction [2, 3, 4]. T-Recs works by using word bounding boxes as input, organizing them into rows and columns based on their vertical and horizontal overlaps. When compared to the T-Recs table structure recognition system using the widely-used Marmot dataset [29].
This study makes several important contributions to the field.
- We propose TEM model which is a new and advanced deep multi-task architecture specifically developed for detecting tables and columns, as well as recognizing structures. It has shown exceptional performance on the Marmot benchmark datasets [29], setting a new standard in the field.
- The proposed work demonstrates the efficacy of transfer learning through the process of fine-tuning a pre-trained TEM model using a novel dataset, leading to improved performance of the model.
This paper is organized into different sections. The literature review is discussed in Section II. The methodology is covered in Section III including the details about proposed classification model. Section IV of the paper delves into the assessment measures employed, as well as the process of benchmarking and evaluating the algorithm under consideration. Section V comprehensively discussed about benchmark work and evaluations of the algorithm under consideration. The conclusion is presented in Section VI.
2. Literature Review
The deep learning strategy for table recognition in document images was proposed by Schreiber et al. [1]. Their proposed system employs a semantic segmentation model that is based on FCN-Xs architectures. This model incorporates tailored modifications to hyper-features and skip pooling techniques in order to enhance the accuracy of segmentation. Nevertheless, a notable constraint of this approach is in the manner in which FCN handles tables. The stride of the FCN filter converts input image pixels into output pixels. However, it fails to consider the distinct recurring patterns found in row-column sequences commonly found in tables. These patterns involve precise constraints for spacing and data length across rows and columns.
The recent studies have extensively explored how to identify and extract tables from documents. Researchers have focused on detecting table structures using heuristic-based methods and deep learning techniques. For instance, Kieninger et al. [2] developed a system called T-Recs, which was one of the early successful attempts to tackle table extraction [2, 3, 4]. T-Recs works by using word bounding boxes as input, organizing them into rows and columns based on their vertical and horizontal overlaps. However, this method heavily relies on heuristic factors, leading to potential variations in results. Additionally, if the Optical Character Recognition (OCR) stage fails to accurately detect word boundaries, especially for numerical data with missing punctuation like dots and commas, the efficiency of the algorithm can be compromised.
Prior the deep learning popularity, table detection primarily relied on heuristics or metadata. For example, TINTIN [5] utilized structural clues to identify tables and their components. Another approach involved using hierarchical representations like the MXY tree to detect tables [6], marking the initial use of Machine Learning methods in this area. Additionally, T. Kasar et al. [7] conducted a study where they employed Support Vector Machine (SVM) classifiers to differentiate between areas that contain tables. Their focus was on identifying intersecting horizontal and vertical lines, along with other low-level characteristics.
Table detection methods have also incorporated probabilistic graphical models. In a study by Silva et al. [8], a Hidden Markov Model (HMM) was utilized to model the joint probability distribution between successive observations of visual page elements and the hidden state of a line. This approach effectively integrated potential table lines into tables, resulting in a considerable level of inclusiveness. Jing Fang et al. [9] detected the table area and decomposed its elements starting from the table header. Conversely, Raskovic et al. [10] focused on identifying borderless tables, using whitespace as a heuristic for detection rather than relying solely on text.
Wang et al. [11] introduced a data-driven approach inspired by the X-Y cut algorithm [12]. This strategy employed probability optimization techniques to address table structure extraction challenges. By considering probabilities derived from a vast training corpus and considering the distances between related terms, this statistical method efficiently handles three column layouts: single column, double column, and mixed column. Shigarov et al. [13] proposed an approach that considers metadata found in PDF files, which contains details about fonts and text bounding boxes. Their system employs ad-hoc heuristic principles to recover table cells from part of text and ruling lines. After integrating these text parts into text blocks using a text block recovery method, the algorithm then applies a threshold to organize the blocks either vertically or horizontally.
Recent developments have led to the introduction of DeepDeSRT [14], a system that employs deep learning strategies for the purpose of table identification as well as table structure recognition. Among these are the determination of the rows, columns, and cell locations within the tables that have been discovered. On the dataset used for the ICDAR 2013 table competition, DeepDeSRT attained performance that is now considered state-of-the-art. Immediately after this, [15] utilized a combination of deep convolutional neural networks, graphical models, and saliency ideas in order to locate tables and charts inside documented papers. An enhanced version of the dataset used for the ICDAR 2013 table competition was used to evaluate this strategy, and the results showed that it performed significantly better than other models that were already developed. It is also important to note that [16] concentrates on finding text components and extracting text chunks. As a consequence of this, the height of every text block is compared to the average height, and if it satisfies certain requirements, the Region of Interest (ROI) is taken into consideration as a table.
By grouping word segments and assessing text overlap inside the table, T-Recs [17] is one of the early attempts to extract tabular data. It was developed by Y. Wang and colleagues [18] using geometric measurements acquired from a variety of entities contained inside a document. Through the utilization of formatting signals that are available in semi-structured HTML tables, Ashwin et al. [19] are able to extract data from web pages. The process of extracting data from HTML tables is made easier by the fact that tags already demarcate separate cells. It appears that the text has been chopped off here, if you could just offer the full sentence, it would be greatly appreciated. The Object identification techniques are utilized by Singh et al. [20] in order to gain a knowledge of page layout.
An investigation of table recognition systems was carried out by Zainibbi et al.[21], with the primary focus being on the interactions that occur between table models, observations, transformations, and inferences. The results of their survey give insights into the datasets that are utilized for training and assessment, as well as answers to queries concerning decision-making processes in table structure recognition systems.
A generic technique was given by Jianying et al. [22] for the purpose of extracting table structures from table areas that have previously been recognized. The hierarchical clustering is used in their approach for column detection, and lexical and spatial criteria are utilized for the classification of table headers using this methodology. Utilizing a directed acyclic attribute graph (DAG) is the method that is utilized in order to evaluate the extraction of table structure.
3. Methodology
The proposed work is dissected into two parts. At first, we are delineating the process for table detection later, we explained about the process followed for table extraction.
3.1. TEM: VGG19 for Table and Column Detection
In earlier development of deep learning methods, table and column detection were viewed as separate challenges. However, when all columns within a document are predetermined, identifying the table region becomes simpler. The columns are of vertical arrangements of words or numbers, can be difficult to detect individually and may lead to false positives. Understanding the layout of the tabular region can significantly enhance column detection accuracy, as tables and columns often share common regions. Therefore, integrating column-detecting filters into convolutional filters used for table recognition is expected to enhance overall model performance. Our proposed approach draws from the encoder-decoder model for semantic segmentation developed by Long et al. [23] and builds upon this foundational concept.
The encoder of the model is applicable to both table and column detection tasks, however the decoder is divided into distinct paths for tables and columns. When doing training, the encoding layers are trained using ground truth data for both tables and columns. Nevertheless, the decoding layers exhibit unique characteristics when applied to the table and column, leading to the creation of two independent computational graphs throughout the training process.
The provided input image undergoes a conversion process to a RGB (Red, Green, Blue) image format, followed by resizing to a resolution of 1024 * 1024 pixels. The altered image is subjected to Tesseract OCR [24]. The generation of output masks for both table and column areas by a single model results in binary target pixel values. These values indicate whether a pixel region belongs to the table/column or background.
Detecting tables in text documents is akin to identifying items in real-world photographs. Similar to generic object detection, table detection relies on recognizing visual characteristics specific to tables. Unlike tasks involving object identification, table and column detection require a lower tolerance for noise. Our approach involves employing pixel-wise prediction to identify table and column areas, rather than solely predicting their borders. Recent advancements in semantic segmentation have highlighted the effectiveness of encoder-decoder network architectures, such as the Fully Convolutional Network (FCN) developed by Long et al. [25]. FCN architecture utilizes skip connections to merge low-resolution decoder feature maps with high-resolution encoder features, with VGG-19 serving as the base layer. Fractionally-strided convolution layers are then used to upscale the low-resolution semantic map, with additional high-resolution encoding layers integrated into the up sampled map. Fractionally strided Convolutional layers, also known as Transposed Convolution, are operations used in deep learning and convolutional neural networks (CNNs) for upsampling feature maps.
The method employed in our model is analogous to that of the encoder/decoder network observed in the FCN [25] design. The suggested model, as seen in Figure 1, employs a pre-trained VGG-19 layer as the foundational network. The VGG-19 model replaces its fully linked layers (layers after pool5) with two (1x1) convolution layers. In Figure 1, it can be observed that each convolution layer (conv6) is succeeded by a Rectified Linear Unit (ReLU) activation and a dropout layer with a dropout probability of 0.8 (conv6 + dropout). Following this, two distinct subsections of the decoder network are included. The underlying principle of this design is predicated on the notion that the column area is a subset of the table region. Hence, a solitary encoding network possesses the capability to effectively eliminate active areas by using attributes derived from both table and column regions. Convert the input image to grayscale by empirically selected values and apply a threshold to create a binary mask.
After thresholding:
Where,
, , are the red, green, and blue components of the original image, respectively.
T is the threshold value for binarization. Use morphological operations to detect horizontal and vertical lines corresponding to table rows and columns. Apply morphological operations (erosion followed by dilation) using a rectangular kernel that is wider than it is tall, mathematically this relation is defined in Equation (2),
Where is a kernel for detecting vertical lines (e.g., a rectangle of size h × 1, where h is the height of the expected vertical line). Combine horizontal and vertical masks to isolate the table structure:
This mask defines the regions corresponding to the table grid. For each detected vertical line in , calculate the bounding boxes that define individual table columns. Assuming i-th vertical line is located at as explained mathematically in Equation (4),
where and are consecutive vertical lines (column separator), and are the top and bottom of the table (as detected from ).
Both decoder branches get the output of the (conv6 + dropout) layer. The table branch utilizes an extra (1x1) convolution layer called conv7 table, which is then followed by a sequence of fractionally strided convolution layers to increase the resolution of the image. In addition to being upscaled using fractionally strided convolutions, the output of the conv7 table layer is additionally mixed with the pool4 pooling layer of the same dimension. Similarly, the feature map that has been merged is subjected to further upscaling and then combined with the pool3 pooling layer of the same dimension. This is followed by upscaled scaling to align with the original image dimension.
The column detection branch incorporates an additional convolution layer (conv7 column) that use a Rectified Linear Unit (ReLU) activation function. Additionally, a dropout layer is incorporated, with the same dropout probability. After a (1x1) convolution (conv8 column) layer, the feature maps are up-sampled using fractionally strided convolutions. The feature maps that have been up-sampled are combined with the pool4 pooling layer. Subsequently, the resulting combined feature map is further up-sampled and mixed with the pool3 pooling layer of the same dimension, until the original image size is achieved. Prior to the transposed layers, both branches utilize numerous (1x1) convolution layers. The utilization of (1x1) convolution is intended to decrease the size of feature maps (channels), which is essential for the prediction of pixel class. The channels of the output layers, also known as the encoder network output, should be equal to the number of classes. In this case, the channel with the highest probability is allocated to the relevant pixels. As a result, the computational graphs’ outputs provide masks for the table and column areas.
Figure 2.
TEM Architecture Flow Chart.
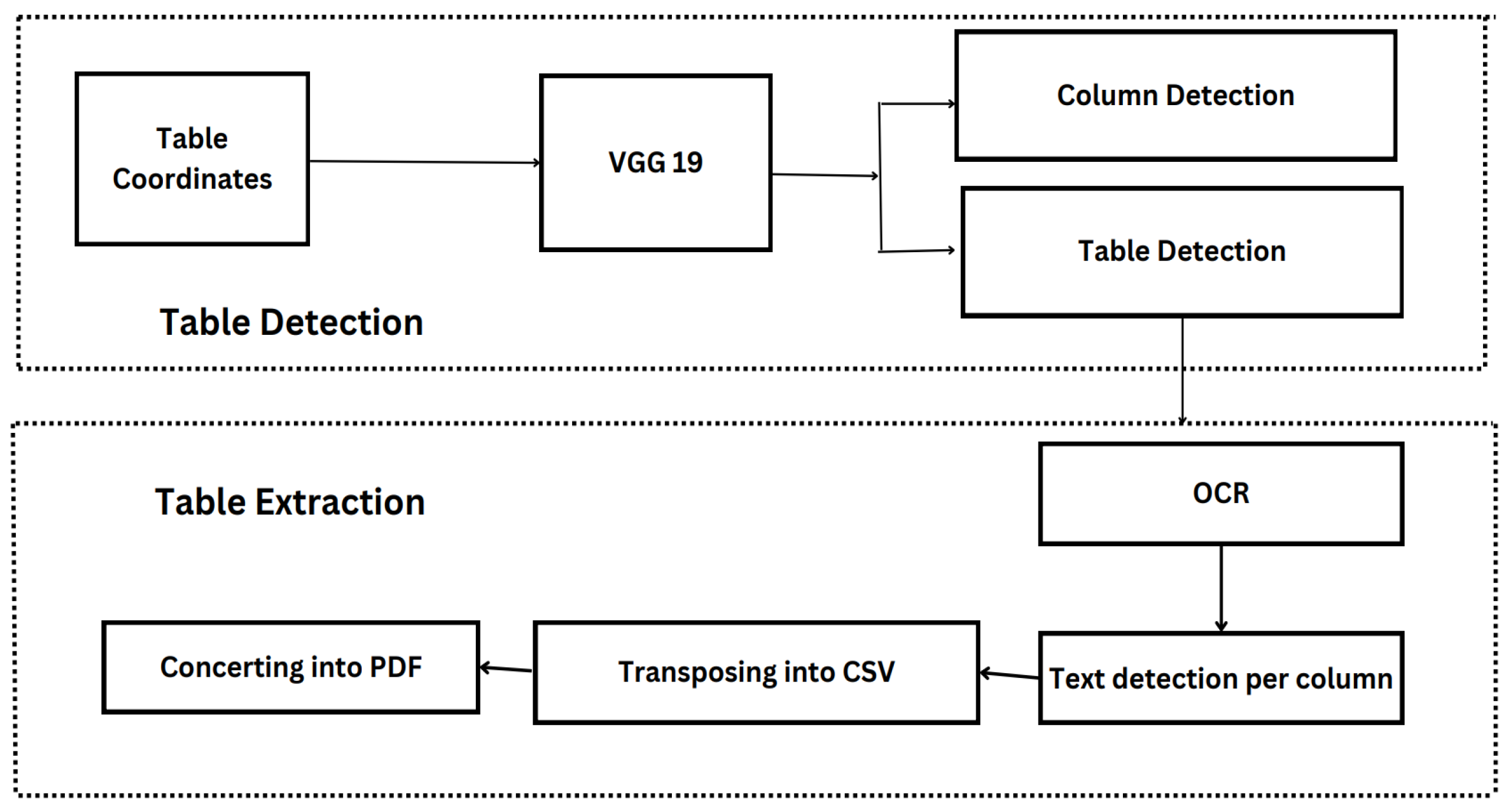
3.2. Table Data Extraction
Upon utilizing TEM for document processing, masks that depict the table and column areas are produced. The primary purpose of these masks is to effectively separate the table and its column sections from the overall image. Given the pre-existing knowledge of word placements in the document, as determined by Tesseract OCR, only word patches situated inside the table and column areas are retrieved. Within each detected column, apply an OCR (Optical Character Recognition) algorithm (such as Tesseract) to extract text as represented mathematically in Equation (5).
A row can be defined as a group of words from many columns that are at a comparable horizontal level, using the filtered words. It is noteworthy that a row is not inherently limited to a solitary line; rather, the extent to which a row extends over many lines is contingent upon the content of a column or the demarcations of the line. Consequently, in order to tackle these differences, we create three guidelines for dividing rows:
- In tables where line demarcations are visible, it is common for these lines to separate rows inside each column. In order to identify possible line boundaries for rows, we analyze each gap between two words that are vertically aligned in a column. This is done by applying a Radon transform [31] to see if there are any horizontal lines present. Horizontal line delineation facilitates the distinct separation of rows.
- In the case when a row extends across many lines, the initial position for a new row is determined by selecting the rows that contain the highest number of non-blank entries. In the context of a multi-column table, it is possible for certain columns to consist of items that span a single line, such as amount, while others may encompass data that span many lines, such as description. Consequently, every subsequent row begins after all columns have been populated with entries.
- In instances where all columns are completely populated and there are no line demarcations, it is possible to regard each line or level as an individual row.
3.3. Dataset Preparation
Deep learning methodologies are strongly dependent on data and often need substantial quantities of training data in order to acquire proficient representations. Nevertheless, there is a dearth of datasets that are explicitly tailored for the purpose of table identification, such as the Marmot dataset [29], which has about one thousand table images. Furthermore, there is a scarcity of datasets specifically designed for the purpose of identifying table structures. The only effort is by [29] which proposed the Marmot_data table competition dataset. The dataset contains images and xml files which the coordinates of table existing in the images. The limited availability of data is a significant obstacle for deep learning models that seek to address the tasks of table recognition and table structural analysis. In order to train our model, we employed the Marmot table recognition dataset, which was divided into a training set and a testing set, with a ratio of 90/10. Additionally, we normalized the value to fine tune the model by dividing it to 255. Then decode the image through tensor flow decoder for mask recognition.
3.4. Image Pre-Processing
Preprocessing table images to reduce its structure and make the table arrangement more visible is the first step in processing these images. Improving the classifier’s efficiency by removing extraneous image information relies heavily on this transformation. The first step is image cleaning, which entails erasing any foreground components other than text, such as ruling lines. After that, adaptive binarization is used to the cleaned images to make sure that the pixel intensities are consistent everywhere. The images are reduced in size to 1600 512 after binarization, because this is the input size that the neural network is specifically designed to process. The images are subjected to three rounds of dilation alteration using rectangular kernels after resizing. To identify columns, a vertical dilation filter with dimensions of 3 5 is utilized, whereas a horizontal dilation filter with dimensions of 5 3 is used for row recognition. The model is able to learn the patterns of row and column separators more successfully since these dilation operations connect nearby rows and columns. In order to get the changed images ready to be fed into the next recurrent neural network, they are normalized to a range 0 to 1.
3.5. Providing Semantics Information
Tables inherently possess data types that are constant within consecutive rows or columns, contingent upon whether the table adheres to a row-major or column-major structure. As an illustration, a column denoted as “Name” commonly comprises of textual data, but a column denoted as “Quantity” has numerical data. The semantic information is included into the deep learning model by color-coding text sections that have comparable data kinds. The network utilizes the color-coded representation of the text sections as input, leading to enhanced model performance. In addition, spatial semantic aspects have been included by emphasizing word patches according to their respective data kinds. After preprocessing, Tesseract OCR [32] is used to extract word blocks. The word patches are subsequently assigned colors based on their fundamental data type. The network receives the changed images with color-coded word patches as input. The TEM architecture is designed to analyze the input image and produce binary mask images for individual tables and columns. The result produced is subsequently enhanced by the use of predetermined rules that are derived from the identified table and column masks. An illustrative sample of the produced output is presented.
4. Evaluation
The initial step involves the utilization of Tesseract OCR to process the image, where as all word patches are extracted from the document image. Subsequently, regular expressions are employed to ascertain the data type of these words. The underlying justification for employing color-coding in word bounding boxes is to effectively communicate both semantic and spatial information to the neural network. A distinct color is allocated to each data type, and word bounding boxes with comparable data kinds are given same colors. This procedure facilitates the elimination of false detection within the word bounding boxes. In order to properly manage scenarios when noise is introduced during word identification and extraction from OCR, it is necessary to train the model accordingly. In order to replicate the process of partial word identification during training, a small number of word patches are intentionally excluded at random. This procedure facilitates the acquisition of resistance in the model towards missing or noisy data. In contrast to the original document image, the color-coded image exhibits a deficiency in visual elements such as line demarcations, corners, and color highlights, despite its use for training purposes. In order to preserve these significant visual characteristics in the training data, the image with highlighted words is merged with the original image on a pixel-by-pixel basis. The model is trained using modified document images that contain both semantic information and original visual attributes.
4.1. Training of Table Data
During the training of our models, we utilized the Adam optimizer in conjunction with the binary cross-entropy loss function. Table images often consist of a greater number of rows and columns compared to the empty spaces between them. A class imbalance issue was seen during the early training efforts, when the model consistently made predictions for row-column items but faced difficulties in detecting white space regions. In order to rectify this issue of imbalance, we implemented weighting into our loss function. The weighting technique employed in this study resulted in a penalty of just 66% for erroneously predicted row-column components compared to mistakenly predicted white space elements, thereby achieving a balanced learning process.
5. Experiment and Results
Page segmentation frequently employs two standard measures, namely precision and recall. When an area encompasses all the sub-objects that are present in the ground-truth, it is deemed to be complete. The sub-objects refers to the smaller elements or components within a table cell that are relevant for text recognition and extraction. An area is classified as pure when the elements within that area align perfectly with what is expected based on the manually annotated ground truth data. Subordinate entities are commonly established by partitioning the provided area into significant components, such as table heads, table contents, and so forth. The assessment process considers individual characters inside each zone as sub-objects. Subsequently, precision and recall metrics are generated by considering the sub-objects present inside each region. The average values are then computed for all regions within a particular text.
The adjacency connections are closest horizontal and vertical neighbors. The adjacency relations are denoted as a one-dimensional tuple that encompasses the textual data of the adjacent cells. In order to enhance the comparability with established data, the content within each cell underwent normalization procedures. These procedures involved the removal of white spaces, substitution of special characters with underscores, and conversion of lowercase letters to uppercase. TEM can’t learn about structures without annotated data, which is necessary for both table identification and training. The dataset includes 1016 images with tables in both Chinese and English. Out of them, 504 images in English have been annotated and utilized for training. This deep learning model was built using Tensorflow and executed on a machine that has a Intel(R) Core(TM) i5-8265U CPU @ 1.60GHz, 1.80 GHz, 8 GB of RAM, 64-bit operating system.
5.1. Experiments
The first experiment tested the model’s ability to recognize structures and tables on the Marmot_data table competition dataset after training it with all positive samples from the Marmot dataset. A computation graph for the table region and another for the column region are used in the training procedure. A document image, a table mask, and a column mask make up each training sample. There was a 2:1 ratio of table region to column region calculations during the first training period. Prior to its specialization in recognizing column areas, the model was trained to produce enormous active tabular regions. With a learning rate of 0.0001 and a batch size of 2, the training was adjusted to a 1:1 ratio for both branches until convergence after around 25 iterations. We used a validation set from the Marmot_data dataset to keep an eye on convergence and overfitting while we kept training for 25 iterations with the same training pattern and optimizer parameters. In order to reliably identify the table and column sections, pixel-wise prediction was employed during testing with a threshold probability of 0.99. Hence, we can then obtain a column mask and table mask using different batch sizes with an improved accuracy of 87% where a image from testing dataset is passed to the model and a mask is generated which is table mask after that additionally, the column mask is generated as shown in Figure 3.
To evaluate how well our model is learning from the data during training, we generated two types of curves: model accuracy and model loss. These curves show us how accurate our model’s predictions are and how much error or loss it experiences over time. We trained the model for 25 epochs, which means we ran the training process for 25 iterations or passes through the entire dataset. These curves can be seen in Figure 4 and Figure 5.
Our study compared various methods for image and PDF processing in terms of accuracy. Table 1 summarizes the results, showcasing the performance of different methods, including Khan, Saqib Ali et al. [33], Hsu et al. [27], Yildiz et al. [28], and our proposed method TEM. Our approach demonstrated superior accuracy compared to existing methods, particularly in handling image inputs, achieving an accuracy of 0.876.
6. Conclusion
This study presents TEM, a revolutionary deep learning model that has been trained to tackle the end-to-end tasks of structure identification and table detection simultaneously. The interesting thing about TEM is that it tackles both problems at once, unlike other approaches that do it in isolation. By utilizing the fundamental link between table detection and structure identification, TEM pioneers a unified strategy to solve these problems existed in table structure and data manipulation. In this research, we provide a new approach to deep learning table structure extraction using GRU-based sequential models. Due to sequence models’ high representation capabilities, which effectively capture the recurrent row/column patterns inherent in tables, this technique exhibits substantial improvement compared to heuristic approaches and DNN-based models. In the future, we want to build a complete framework for data extraction from table cells.
References
- S. Schreiber, S. Agne, I. Wolf, A. Dengel, and S. Ahmed, “Deepdesrt: Deep learning for detection and structure recognition of tables in document images,” in Fourteenth International Conference on Document Analysis and Recognition, vol. 1, pp. 1162–1167, 2017. [CrossRef]
- T. Kieninger and A. Dengel, “A paper-to-html table converting system,” in Proceedings of document analysis systems, pp. 356–365, 1998.
- T. Kieninger and A. Dengel, “Applying the T-RECS table recognition system to the business letter domain,” in International Conference on Document Analysis and Recognition, p. 0518, 2001. [CrossRef]
- T. Kieninger and A. Dengel, “The T-Recs table recognition and analysis system,” in Document Analysis Systems: Theory and Practice, pp. 255– 270, 1999. [CrossRef]
- P. Pyreddy and W. B. Croft, “Tintin: A system for retrieval in text tables,” in Proceedings of the second ACM international conference on Digital libraries. ACM, 1997, pp. 193–200.
- F. Cesarini, S. Marinai, L. Sarti, and G. Soda, “Trainable table location in document images,” in Pattern Recognition, 2002. Proceedings. 16th International Conference on, vol. 3. IEEE, 2002, pp. 236–240. [CrossRef]
- T. Kasar, P. Barlas, S. Adam, C. Chatelain, and T. Paquet, “Learning to detect tables in scanned document”.
- A. C. e Silva, “Learning rich hidden markov models in document analysis: Table location,” in Document Analysis and Recognition, 2009. ICDAR’09. 10th International Conference on. IEEE, 2009, pp. 843– 847. [CrossRef]
- J. Fang, P. Mitra, Z. Tang, and C. L. Giles, “Table header detection and classification.” in AAAI, 2012, pp. 599–605. [CrossRef]
- M. Raskovic, N. Bozidarevic, and M. Sesum, “Borderless table detection engine,” Jun. 5 2018, uS Patent 9,990,347.
- W. Yalin, I. T. Phillips, and R. M. Haralick, “Table structure understanding and its performance evaluation,” Pattern Recognition, vol. 37, pp. 1479–1497, 2004. [CrossRef]
- F. Shafait, D. Keysers, and T. M. Breuel, “Performance evaluation and benchmarking of six-page segmentation algorithms,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 30, no. 6, pp. 941– 954, 2008. [CrossRef]
- A. Shigarov, A. Mikhailov, and A. Altaev, “Configurable table structure recognition in untagged pdf documents,” in ACM Symposium on Document Engineering, 2016. [CrossRef]
- S. Schreiber, S. Agne, I. Wolf, A. Dengel, and S. Ahmed, “Deepdesrt: Deep learning for detection and structure recognition of tables in document images,” in Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, vol. 1. IEEE, 2017, pp. 1162–1167. [CrossRef]
- I. Kavasidis, S. Palazzo, C. Spampinato, C. Pino, D. Giordano, D. Giuffrida, and P. Messina, “A saliency-based convolutional neural network for table and chart detection in digitized documents,” arXiv preprint arXiv:1804.06236, 2018. [CrossRef]
- D. N. Tran, T. A. Tran, A. Oh, S. H. Kim, and I. S. Na, “Table detection from document image using vertical arrangement of text blocks,” International Journal of Contents, vol. 11, no. 4, pp. 77–85, 2015. [CrossRef]
- T. Kieninger and A. Dengel, “The t-recs table recognition and analysis system,” in International Workshop on Document Analysis Systems. Springer, 1998, pp. 255–270. [CrossRef]
- Y. Wang, I. T. Phillips, and R. M. Haralick, “Table structure understanding and its performance evaluation,” Pattern recognition, vol. 37, no. 7, pp. 1479–1497, 2004. [CrossRef]
- A. Tengli, Y. Yang, and N. L. Ma, “Learning table extraction from examples,” in Proceedings of the 20th international conference on Computational Linguistics. Association for Computational Linguistics, 2004, p. 987.
- P. Singh, S. Varadarajan, A. N. Singh, and M. M. Srivastava, “Multidomain document layout understanding using few shot object detection,” arXiv preprint arXiv:1808.07330, 2018. [CrossRef]
- R. Zanibbi, D. Blostein, and R. Cordy, “A survey of table recognition: Models, observations, transformations, and inferences,” International Journal on Document Analysis and Recognition, vol. 7, no. 1, pp. 1– 16, 2004. [CrossRef]
- J. Hu, R. S. Kashi, D. P. Lopresti, and G. Wilfong, “Table structure recognition and its evaluation,” in Document Recognition and Retrieval, pp. 44–55, 2001. [CrossRef]
- J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” CoRR, vol. abs/1411.4038, 2014.
- R. Smith, “An overview of the tesseract ocr engine,” in Document Analysis and Recognition, 2007. ICDAR 2007. Ninth International Conference on, vol. 2. IEEE, 2007, pp. 629–633. [CrossRef]
- J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” CoRR, vol. abs/1411.4038, 2014.
- “Parts that add up to a whole: a framework for the analysis of tables,” Ph.D. dissertation, University of Edinburgh, Edinburgh, Scotland, UK, 2010.
- M. C. Gobel, T. Hassan, E. Oro, and G. Orsi, “ICDAR 2013 Table ¨ Competition.” IEEE Computer Society, 2013, pp. 1449–1453. [CrossRef]
- B. Yildiz, K. Kaiser, and S. Miksch, “pdf2table: A Method to Extract Table Information from PDF Files,” in Proceedings of the 2nd Indian International Conference on Artificial Intelligence (IICAI) 2005, B. Prasad, Ed., 2005, pp. 1773–1785.
- https://www.icst.pku.edu.cn/cpdp/sjzy/.
- Khan, Saqib Ali, et al. “Table structure extraction with bi-directional gated recurrent unit networks.” 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019. [CrossRef]
- Toft, Peter. “The radon transform.” Theory and Implementation (Ph. D. Dissertation)(Copenhagen: Technical University of Denmark) (1996). [CrossRef]
- Smith, Ray. “An overview of the Tesseract OCR engine.” Ninth international conference on document analysis and recognition (ICDAR 2007). Vol. 2. IEEE, 2007. [CrossRef]
- Khan, Saqib Ali, et al. “Table structure extraction with bi-directional gated recurrent unit networks.” 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019. [CrossRef]
Figure 1.
Graphical representation of TEM architecture.
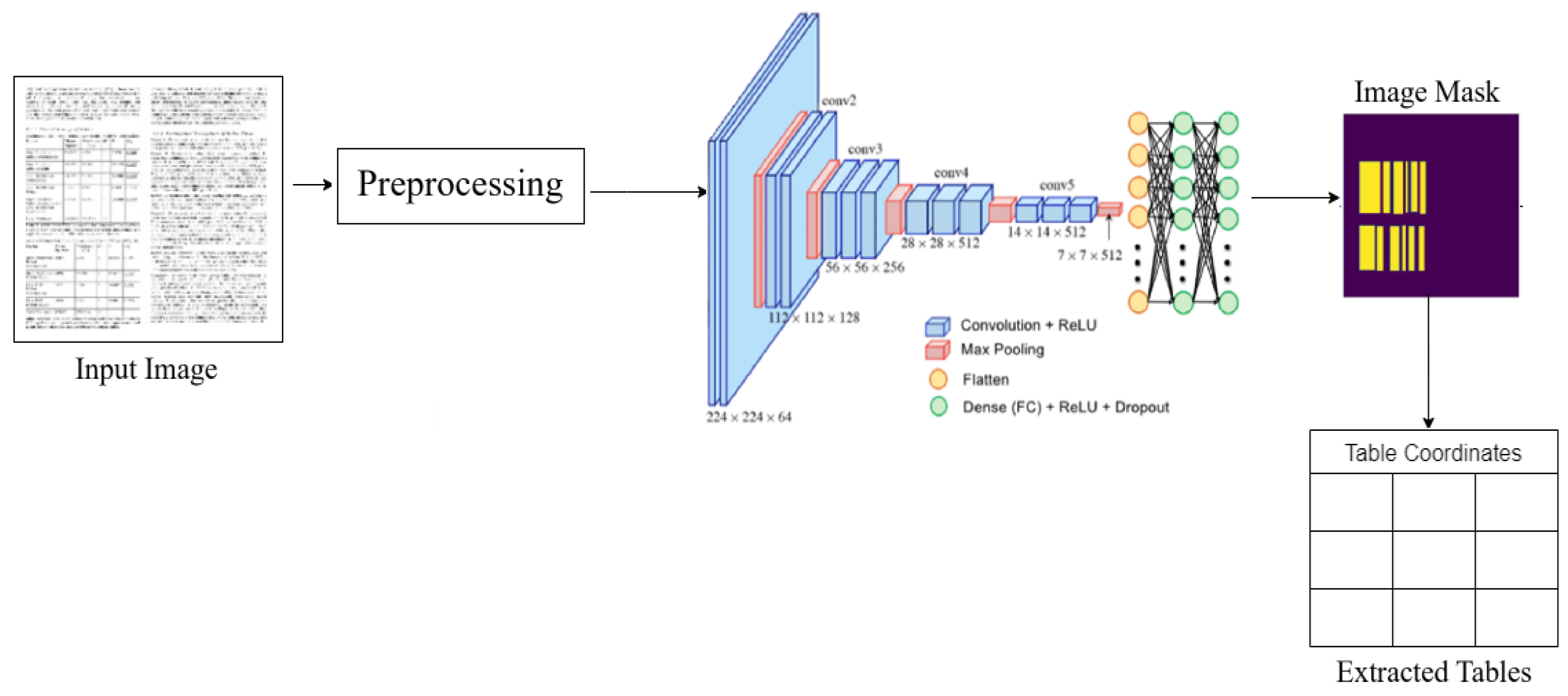
Figure 3.
Table mask and column mask.

Figure 4.
Table mask and column mask.
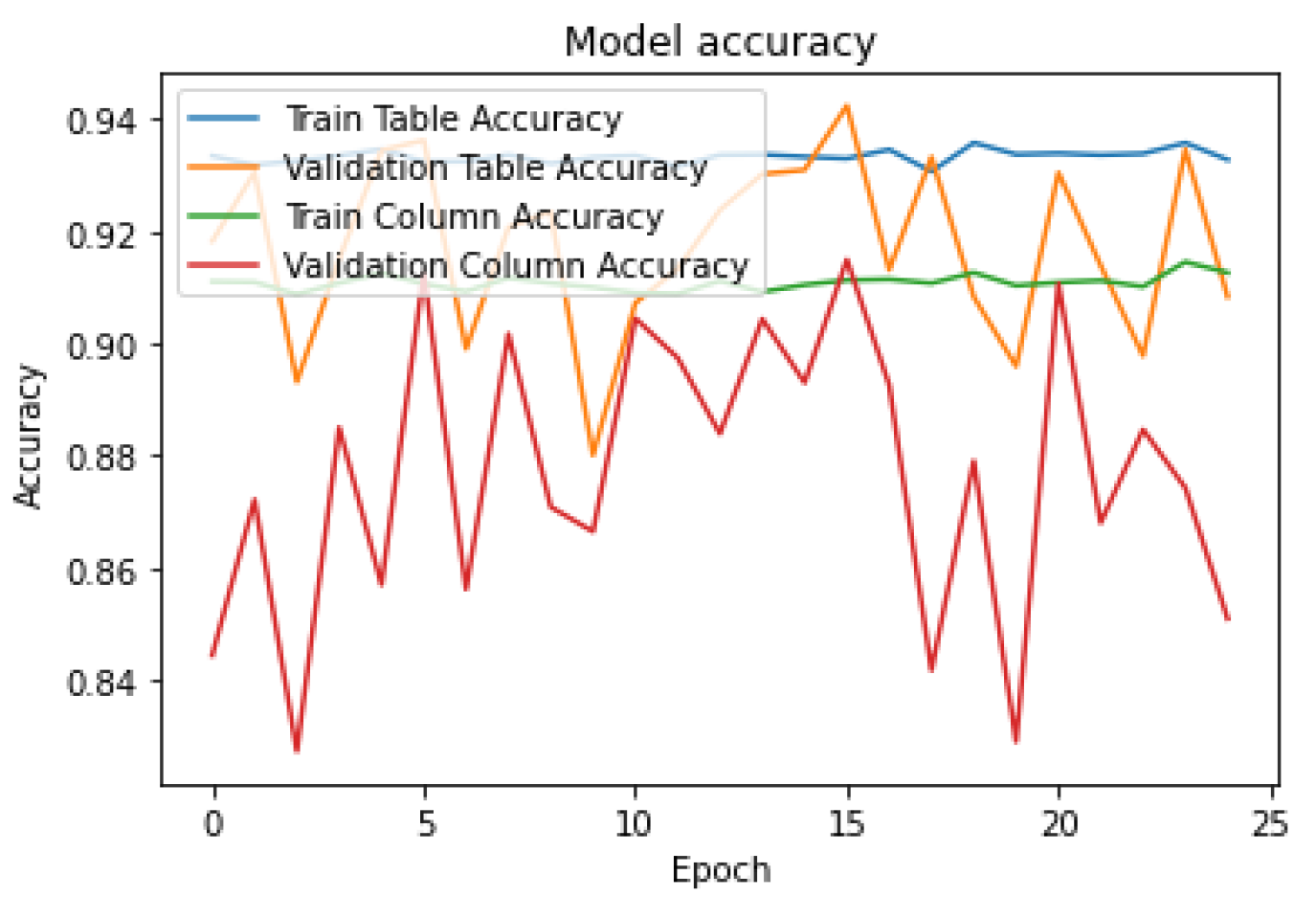
Figure 5.
Table mask and column mask.
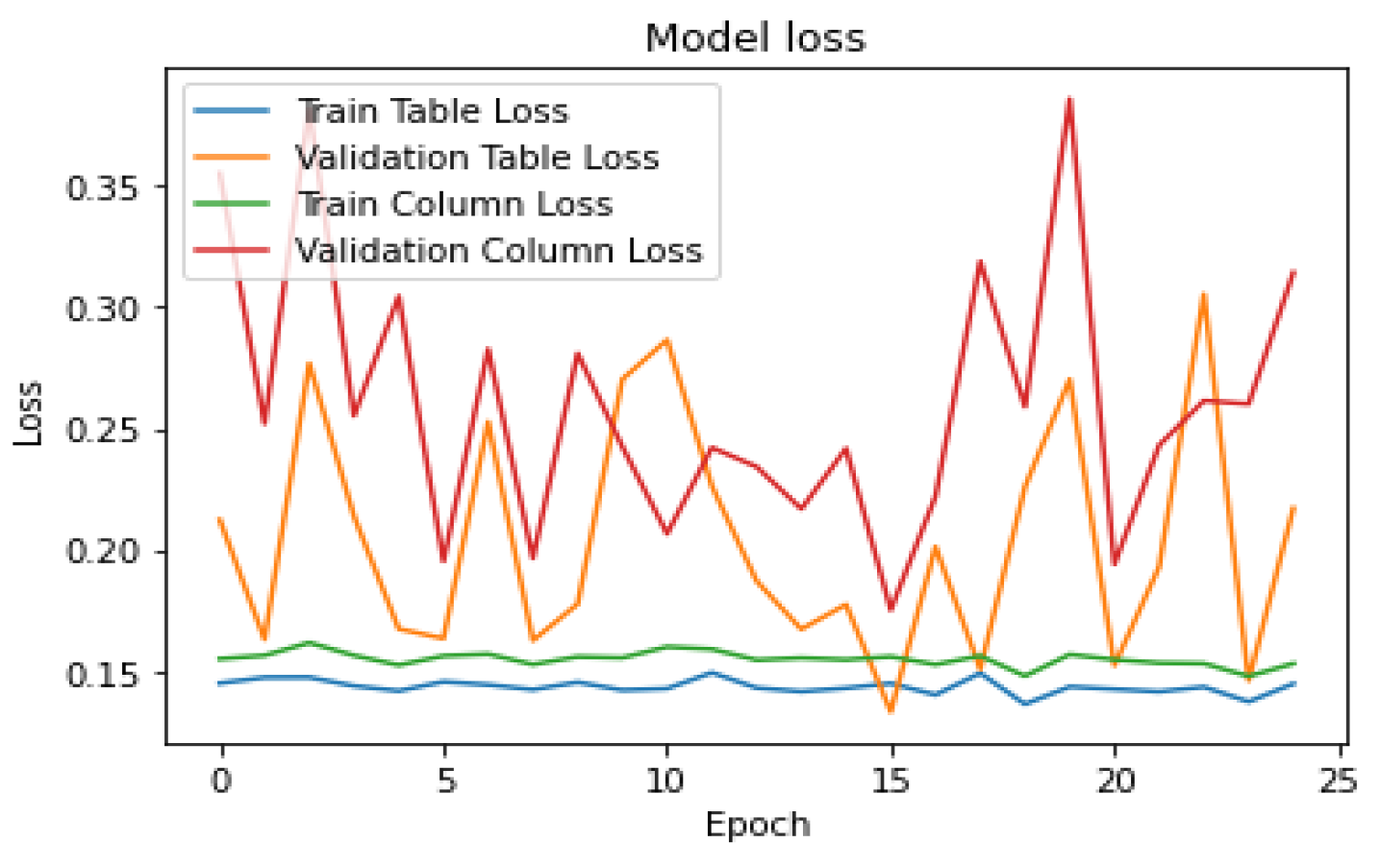

Table 1.
Comparison Table.
| Study | Method | Input | Accuracy |
|---|---|---|---|
| Table extraction using GRU | Khan, Saqib Ali, et al.[33] | Images | 0.55 |
| ICDAR Table comparison | Hsu et al.[27] | 0.5220 | |
| Extract Table Information from PDF Files | Yildiz[28] | 0.7313 | |
| Table detection and extraction with labels | TEM(Proposed) | Images | 0.876 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



