Submitted:
13 August 2024
Posted:
20 August 2024
You are already at the latest version
Abstract
Human Pose Estimation (HPE) is a critical technology in computer vision with diverse applications ranging from healthcare to sports analysis. This project presents a method for detecting the 2D stance of multiple persons in an image using a nonparametric representation known as Part Affinity Fields (PAFs). By leveraging the first 10 layers of the VGG-19 convolutional neural network and training on the COCO dataset, our model effectively identifies and associates key points of the human body.The architecture employs a two-branch system that jointly learns part locations and their associations through sequential prediction. This enables the model to maintain real-time performance while achieving high accuracy, regardless of the number of persons in the image. To enhance accessibility, we developed a mobile application using Flutter and TensorFlow Lite, allowing real-time pose estimation via a mobile device’s front camera. The app provides immediate feedback on physical exercises and yoga poses, making it an invaluable tool for fitness enthusiasts and healthcare professionals. Visual outputs such as heatmaps and PAFs confirm the model’s capability to accurately localize and connect key points. Despite potential challenges such as data quality and hyperparameter tuning, the results indicate that our approach is both reliable and practical for real-world deployment. This project not only advances the state-of-the-art in HPE but also opens up possibilities for future enhancements, including integrating 3D pose estimation and applying the technology in augmented and virtual reality applications.
Keywords:
Human Pose Estimation (HPE)
; Convolutional Neural Network (CNN)
; VGG-19
; Part Affinity Fields (PAFs)
; COCO Dataset
; Real-Time Pose Detection
Introduction
Human Pose Estimation (HPE) is the process of identifying, tracking, predicting, and classifying the movement and orientation of the human body through input data from images or videos. It captures the coordinates of the joints, including the knees, shoulders, and head. The three primary approaches to modeling a human body are Skeleton-based, Contour-based, and Volume-based models [1]. HPE has been evolving with the advancement of artificial intelligence and has applications in human-computer interaction, augmented reality, virtual reality, training robots, and activity recognition [2].
HPE is critical in various fields such as healthcare, sports, and entertainment. In healthcare, it is used for monitoring and analyzing physical therapy exercises to ensure patients perform movements correctly, reducing the risk of injury. In sports, it aids in performance analysis, helping athletes improve their techniques. In entertainment, HPE enables the creation of more interactive and immersive experiences in video games and virtual reality.
There are several approaches to modeling a human body in pose estimation, which can be broadly categorized into three types:
- Skeleton-based Models: These models represent the human body as a collection of joints connected by bones. The coordinates of the joints are tracked over time to understand the movement and posture.
- Contour-based Models: These models focus on the outer contour of the body, capturing the silhouette to infer pose and movement.
- Volume-based Models: These models create a volumetric representation of the body, capturing the full 3D structure, which is useful for more detailed analysis.
HPE can be divided into two primary techniques:
- 2D Pose Estimation: This technique involves estimating key points in the joints of the human body in the 2D space with respect to the image or video. It serves as a foundation for more advanced computer vision tasks like 3D human pose estimation, motion prediction, and human parsing.
- 3D Pose Estimation: This technique involves estimating the actual spatial positioning of the body in the 3D space, introducing the z-dimension. It provides a more comprehensive understanding of the body’s posture and movement [3].
With the advancement of deep learning and computer vision, significant progress has been made in HPE. Convolutional Neural Networks (CNNs) have been widely used to improve
the accuracy and efficiency of pose estimation. Libraries such as OpenPose, DeepCut, and AlphaPose have been developed, offering robust solutions for real-time multi-person pose estimation.
VGG-19, a convolutional network that is 19 layers deep, is known for its performance in large-scale image recognition tasks. It has been used in this project for feature extraction in human pose estimation. By utilizing the first 10 layers of VGG-19, we extract features from input images, which are then processed through various stages to acquire key points and part affinity fields.
The use of Part Affinity Fields (PAFs) allows the model to capture the spatial relationships between different body parts, enabling accurate detection of poses even in complex scenarios. By integrating these features into a mobile application, we aim to make pose estimation accessible and easy to use for a wide range of applications, from exercise monitoring to interactive gaming.
Literature Review
Human Pose Estimation (HPE) has evolved significantly over the past decades with advancements in computer vision and deep learning techniques. Initially, HPE relied on simpler models and smaller datasets, which limited the accuracy and applicability of the methods.
- A.
-
Early Models and Approaches
- Pictorial Structures: The concept of pictorial structures was introduced by Fischler and Elschlager in the 1970s. This approach represented objects using a collection of parts and their spatial relationships [4]. Felzenszwalb and Huttenlocher later made this method practical and tractable using the distance transform trick, which significantly improved its efficiency and accuracy [5].
- Datasets: Earlier models used smaller datasets like Parse and Buffy for evaluation. However, these datasets were not suitable for training complex models due to their limited size and variability. The introduction of larger datasets, such as the Leeds Sports Pose (LSP) dataset containing 10,000 images, marked a significant milestone in the development of HPE models [6].
- B.
-
Advancements with Larger Datasets
- COCO Dataset: The COCO (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset that has become a standard benchmark for HPE. It provides a diverse set of images with annotated key points, making it ideal for training and evaluating HPE models [7].
- MPII Human Pose Dataset: The MPII dataset is another extensive dataset that includes around 25,000 images with annotated body joints. It covers a wide range of human activities and poses, providing a robust benchmark for HPE algorithms [8].
- C.
- Key Libraries and Frameworks
Several libraries and frameworks have been developed to facilitate HPE, offering robust and efficient solutions for both single-person and multi-person pose estimation.
-
- OpenPose: Developed by Zhe Cao and his team in 2019, OpenPose is a real-time multi-person key point detection library capable of detecting 135 key points. It uses a bottom-up approach, which is efficient for handling multiple persons in an image. OpenPose is trained on COCO and MPII datasets and has become one of the most popular tools in HPE [9].Figure 1. Overall pipeline of Real time 2D pose estimation.
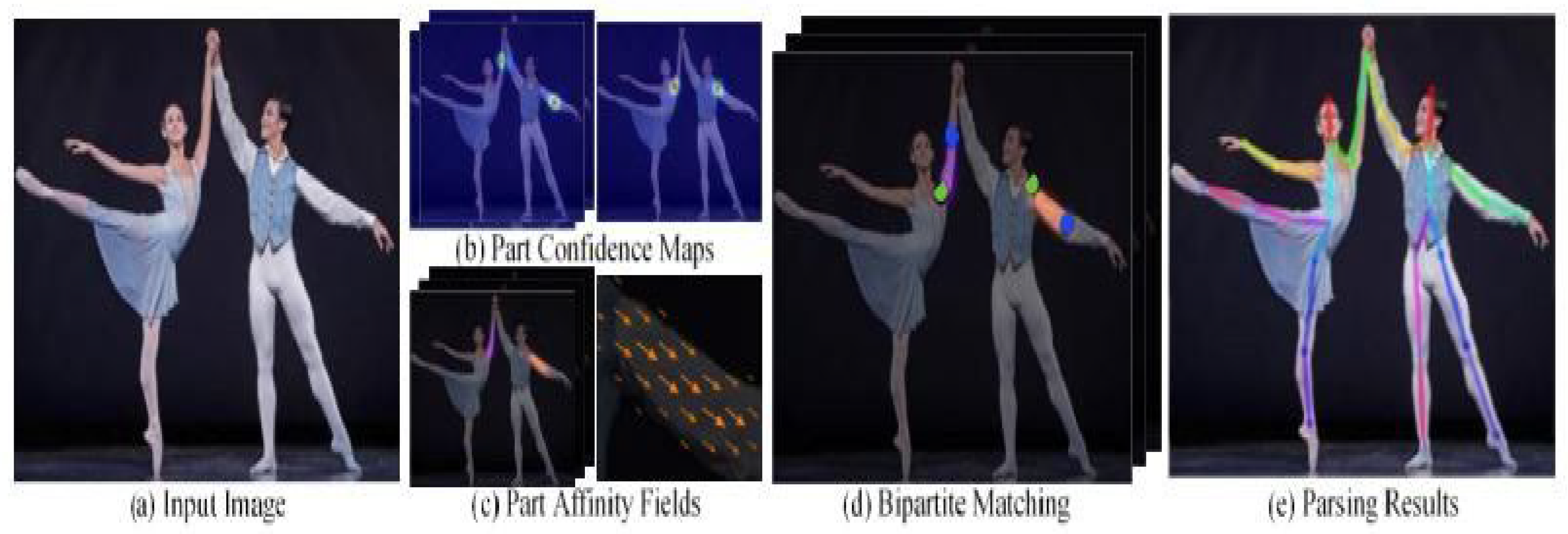
- DeepCut: Presented by Leonid Pishchulin in 2016, DeepCut uses a bottom-up approach with Integral Linear Programming to model detected key points and form a skeleton representation. It addresses the challenge of multi-person pose estimation by simultaneously detecting and associating body parts [10].
- AlphaPose: Developed in 2016, AlphaPose uses a topdown approach for human pose estimation. It detects human bodies first and then localizes key points within the detected regions. AlphaPose supports various operating systems and is known for its high accuracy and robustness [11].
- D.
- Convolutional Neural Networks (CNNs) in HPE
CNNs have revolutionized the field of HPE by providing powerful tools for feature extraction and pattern recognition.
-
- VGG-19: VGG-19 is a convolutional network that is 19 layers deep and was trained on the ImageNet database. It can classify more than 1,000 objects and is known for its performance in image recognition tasks. In this project, we use the first 10 layers of VGG-19 for feature extraction, which provides the basis for detecting key points in human poses [12].
- High-Resolution Net (HRNet): Introduced by Jingdong Wang, HRNet maintains high-resolution representations through the entire network. It has been used for semantic segmentation, object detection, and HPE, providing high accuracy and detailed pose estimations [13].
In this research project, we utilize the VGG-19 model for feature extraction. By using only the first 10 layers, we balance the need for detailed feature extraction with computational efficiency. The extracted features are processed through a series of CNN layers to generate Confidence Maps and Part Affinity Fields, which are used to determine the full-body pose. The final model is deployed in a mobile application, making it accessible for various use cases such as exercise monitoring.
- C.
- Model Training
I. Methodology
- A.
- Data collection and Preprocessing
The backbone of our Human Pose Estimation (HPE) model is the COCO (Common Objects in Context) dataset, which is a large-scale dataset containing over 2 million images with annotated key points. The diversity and extensive scale of this dataset make it ideal for training robust HPE models. The initial step involved filtering and annotating images using COCO’s annotation files, which include detailed information about each image’s size, bounding boxes, segmentation, and key point locations [14]. From this dataset, we selected approximately 65,000 images with crucial points necessary for our training purposes
To ensure consistency and improve the model's performance, we normalized the images. The normalization process involved scaling the pixel values using the formula , where x represents the pixel values. This transformation standardized the pixel values to fall within the range of −0.5 to 0.5, making the data more suitable for training the neural network. Furthermore, we converted each key point into a 32 × 32 × 17 matrix, which represents the probability function for the key points [15]. These matrices were essential for generating heatmaps that the model would use to learn the spatial distribution of key points.
- B.
- Model Architecture
The model architecture is built upon the VGG-19 convolutional neural network, specifically utilizing the first 10 layers for feature extraction [16]. VGG-19 is well-regarded for its performance in image recognition tasks due to its deep architecture and the use of small, 3 × 3 convolution filters, which effectively capture intricate details in the images. The output from these layers provided a robust set of features that served as the foundation for detecting key points and part affinity fields in the subsequent stages [16].
The extracted features were processed through a series of CNN layers, organized into stages. The first stage consisted of five convolutional layers designed to further refine the features extracted by VGG-19. The first three layers used 3 × 3 × 128 filters, the fourth layer used 3 × 3 × 512 filters, and the fifth layer employed 1 × 1 × 17 filters [17]. Each convolutional layer was followed by a ReLU activation function, introducing non-linearity and enabling the model to learn complex patterns [18].
In stages 2 through 6, the architecture branched into two separate paths: one path was responsible for generating heatmaps, while the other generated Part Affinity Fields (PAFs). These branches contained layers with 7 × 7 × 128 kernels, and the final layers had 1 × 1 × 128 and 1 × 1 × 34 kernels. The heatmaps represented the probability of key points in a two-dimensional space, while the PAFs depicted the location and orientation of limbs, forming pairs in the image domain [19].
- C.
- Model Training
The training and validation of the model were carried out using a split from the COCO dataset, where 50,000 images (90%) were used for training and 5,000 images (10%) for validation. This division ensured that the model had ample data to learn from while also providing a separate set of images to evaluate its performance. The training process spanned multiple epochs, during which the model’s parameters were optimized to minimize the loss functions for both branches (heatmaps and PAFs).
The loss function for the heatmaps was defined as
Where Sj(p) represents the predicted heatmap for the point j at the position p, S*j(p) represents the ground truth heatmap [20]. Similarly, the loss function of PAFs was defined as:
Where Lc(p) represents the predicted PAF for Limb c at position p, and L*c(p) represents ground truth PAF [20].
- D.
- Data Flow
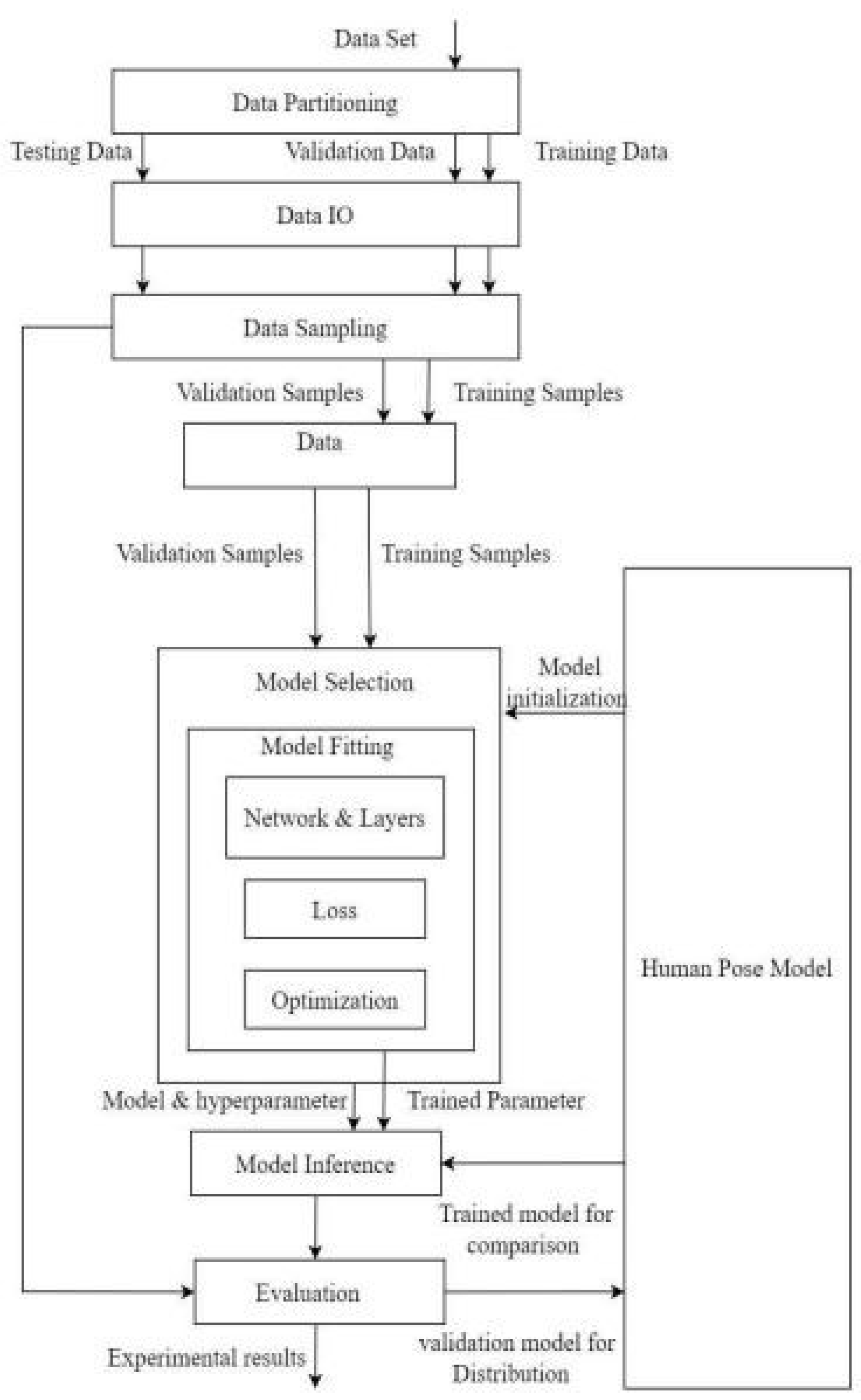
The data flow for the Human Pose Estimation project starts with collecting the COCO dataset, which is partitioned into training, validation, and testing subsets. Data IO processes ensure proper loading and saving of data during preprocessing, training, and evaluation. Samples are drawn for training and validation to refine the model.
Model selection involves choosing the architecture and hyperparameters, initializing the VGG-19 network for feature extraction, and defining loss functions for heatmaps and Part Affinity Fields (PAFs). The Adam optimizer is used to adjust model parameters, minimizing the loss functions.
The model undergoes fitting, with layers configured for extracting features and generating heatmaps and PAFs. Hyperparameters are fine-tuned to enhance performance. Model inference applies the trained model to validation samples, followed by evaluation using metrics like accuracy, precision, recall, F1 score, and Mean Squared Error (MSE).
Experimental results provide insights into model performance, with comparisons to benchmark its effectiveness. The validated model is then prepared for deployment in a mobile application, allowing real-time pose estimation using a mobile device’s front camera. This comprehensive data flow ensures the model is accurately trained and capable of effective human pose estimation.
Figure 2.
Data Flow diagram.
- E.
- Deployment in Mobile Application
To make the HPE model accessible and user-friendly, we deployed it as a mobile application using Google’s Flutter framework. Flutter is an open-source framework that allows developers to create natively compiled applications for mobile, web, and desktop from a single codebase. This choice ensured that our application could run efficiently on various devices.
We used TensorFlow Lite to deploy the trained model on mobile devices. TensorFlow Lite is a lightweight version of TensorFlow designed specifically for mobile and embedded devices, providing efficient performance and low latency. The application was equipped with features for real-time pose estimation, using the front camera of a mobile device to capture and analyze poses.
The user interface of the application was designed to be intuitive, allowing users to select different exercises or yoga poses and receive instant feedback on their performance. The feedback mechanism used visual indicators, such as green for correct poses and red for incorrect poses, to help users adjust their posture in real-time.
The model’s performance was evaluated using standard metrics such as precision, recall, F1-score, and Mean Squared Error (MSE). Precision measured the accuracy of key point detection, recall assessed the model’s ability to detect all relevant key points, and the F1-score provided a balanced measure of accuracy by combining precision and recall. MSE evaluated the difference between the predicted and actual key point locations, giving a quantitative measure of the model’s accuracy.
Result and Analysis
The Human Pose Estimation project achieved significant results through the implemented methodology. This section details the outcomes, including accuracy and loss analysis, heatmaps, part affinity fields, mobile application output, and error analysis.
- A.
- Accuracy and Loss Analysis
The training process involved monitoring the accuracy and loss metrics to evaluate the model’s performance over successive epochs. The metrics provided insights into the model’s learning progress and helped identify any potential issues.
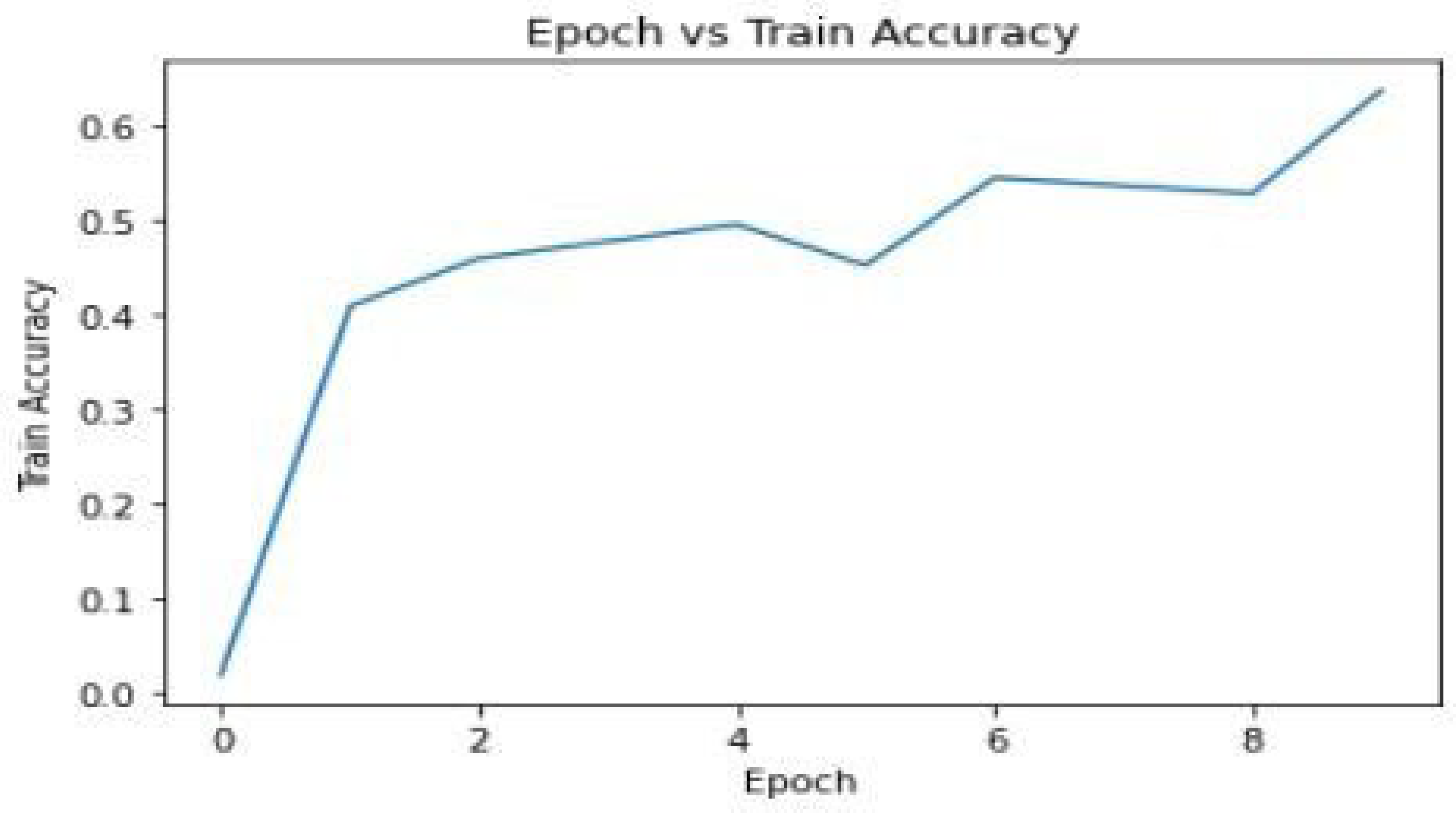
Epoch vs Training Accuracy: Training accuracy was tracked over each epoch to measure the model’s ability to correctly predict key points during the training phase. The training accuracy showed a steady improvement, indicating that the model was learning effectively from the training data.
Figure 3.
Epoch vs Training Accuracy.
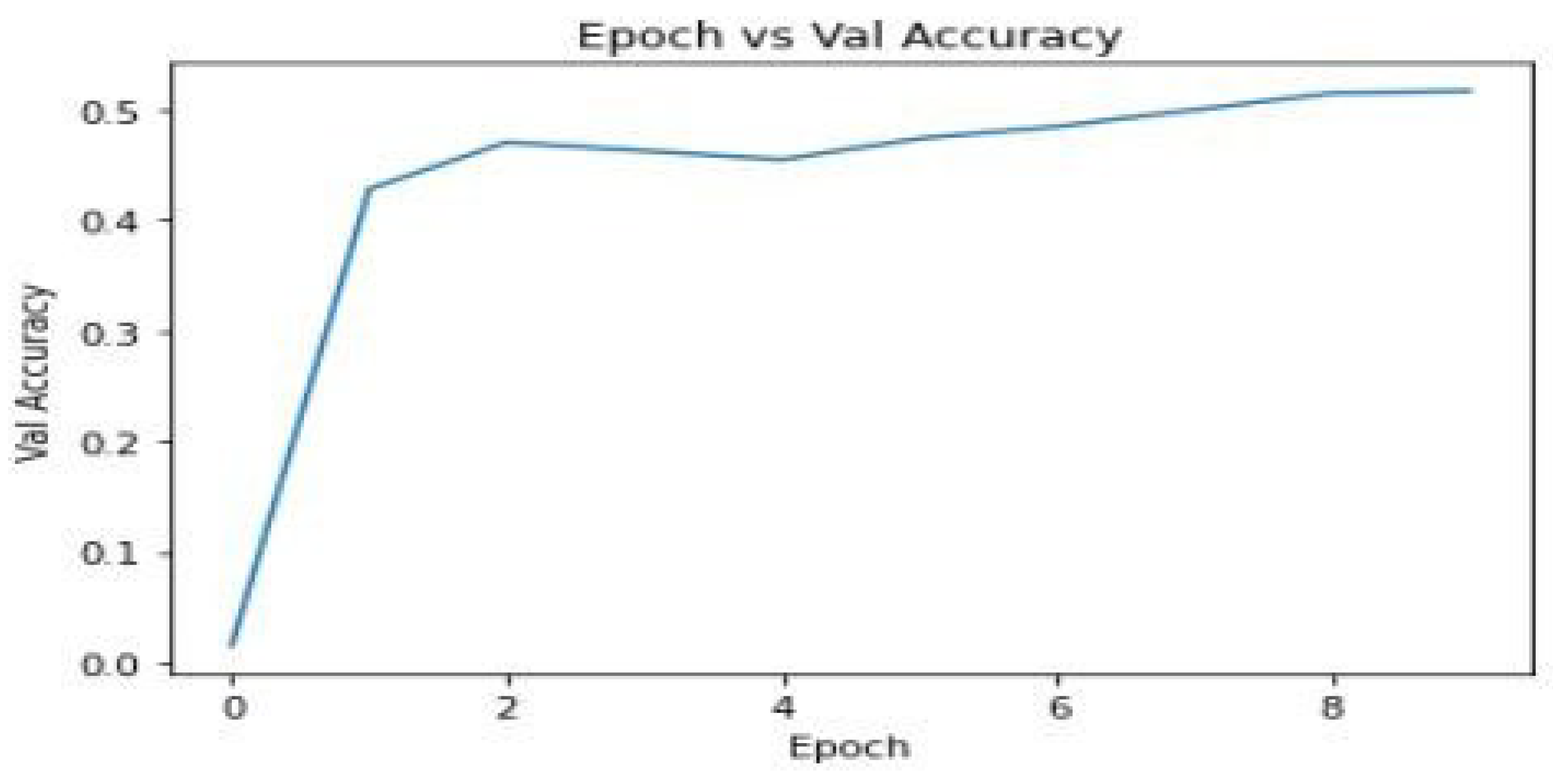
1) Epoch vs Validation Accuracy: Validation accuracy was tracked to measure the model’s performance on unseen data. This metric was crucial for assessing the model’s generalization ability. The validation accuracy also showed a consistent improvement, demonstrating that the model was not overfitting and could generalize well to new data.
Figure 4.
Epoch vs Validation Accuracy.
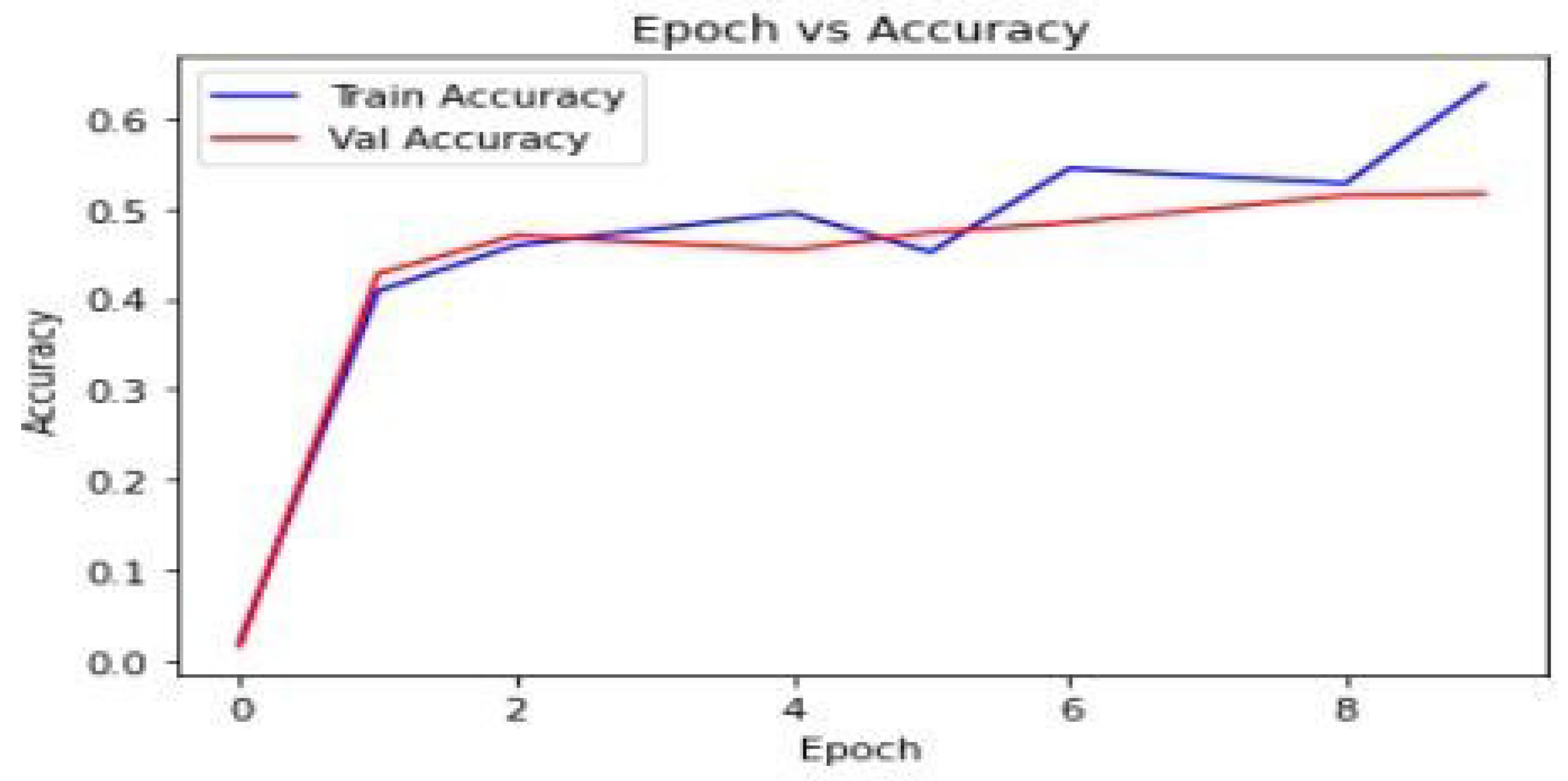
2) Epoch vs Training and Validation Accuracy: A combined plot of training and validation accuracy provided a comprehensive view of the model’s performance. Both metrics showed a similar trend, further confirming that the model was learning effectively without overfitting.
Figure 5.
Epoch vs Training and Validation Accuracy.
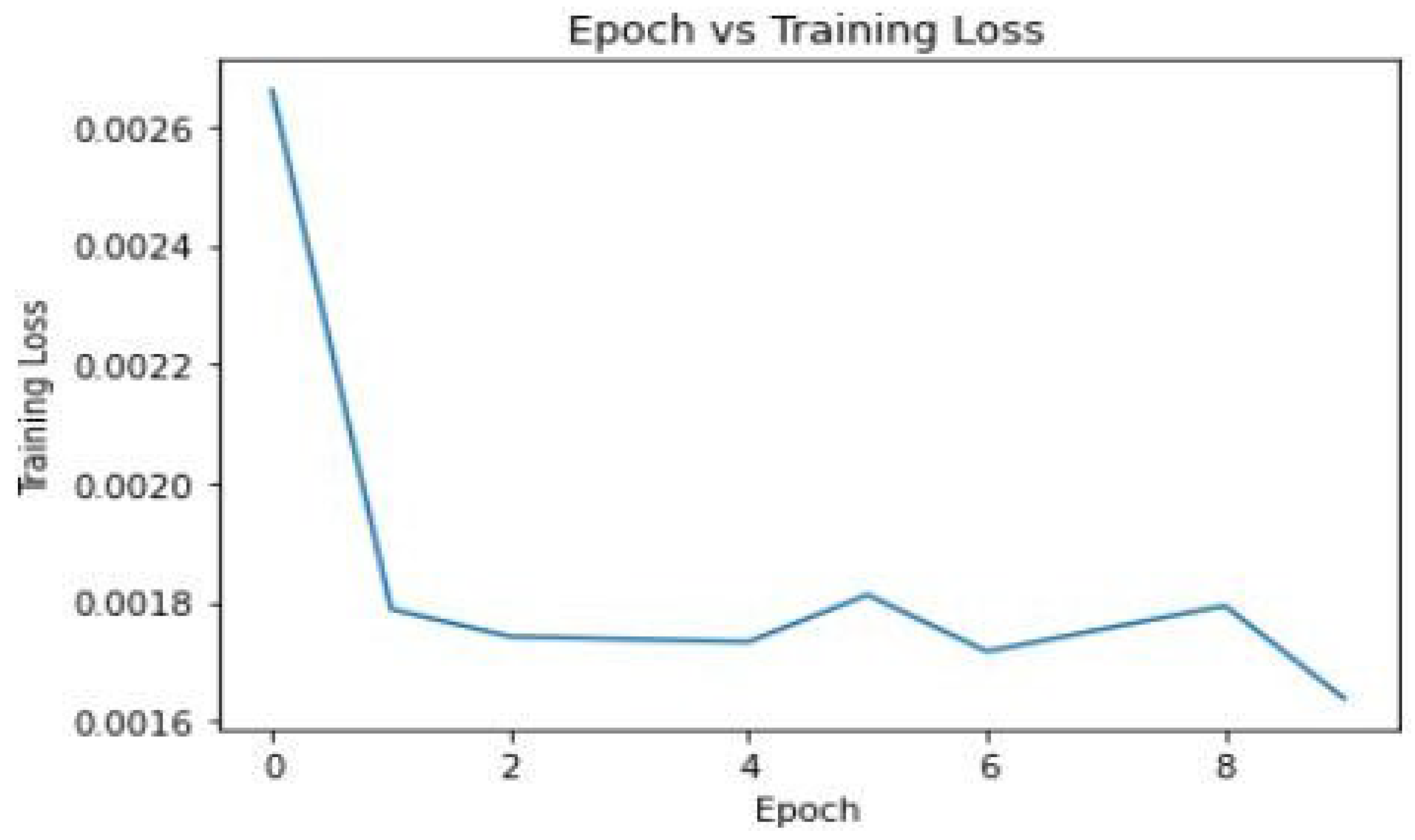
3) Epoch vs Training Loss: Training loss was monitored to evaluate the model’s error in predicting key points during the training phase. The loss showed a decreasing trend, indicating that the model’s predictions were becoming more accurate over time.
Figure 6.
Epoch vs Training Loss.
- B.
- Output
The project successfully visualized human poses by detecting 17 key points and joining them to form a skeletonlike structure. The key points included the nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
1) Heatmaps: Heatmaps were generated to visualize the probability of key point locations in a two-dimensional space. The heatmaps provided a clear representation of where the model predicted each key point to be. Each key point was represented by a separate heatmap, showing variations in color to indicate the probability of the key point’s occurrence [21].
Figure 7.
Heatmap of all keypoints.
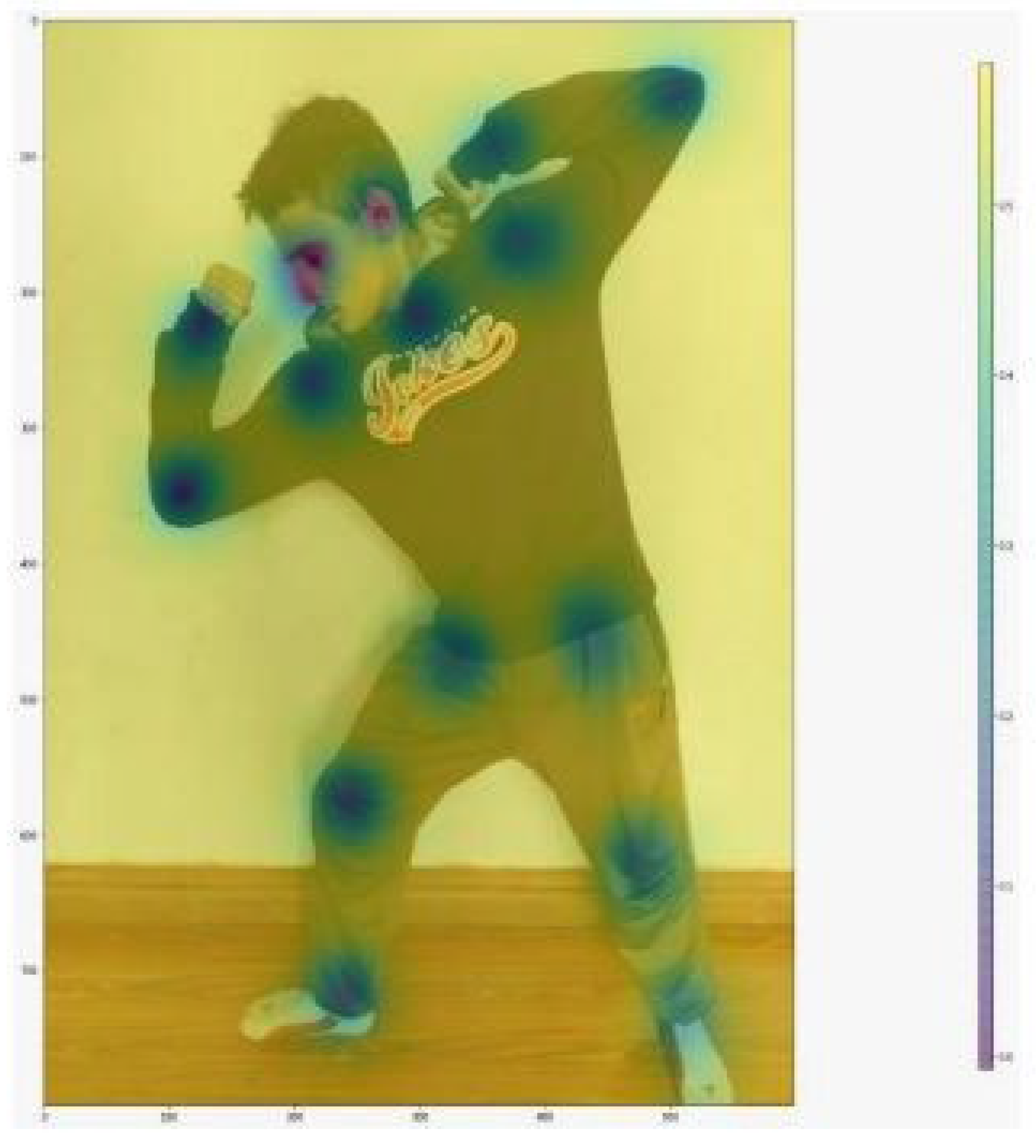
Figure 8.
Heatmaps of Part Affinity Field.

Part Affinity Fields (PAFs) were used to depict the location and orientation of limbs by forming pairs of key points. The PAFs were represented as 2D vector fields, providing direction vectors between key points that needed to be connected. The model generated a 32 × 32 × 34 matrix for PAFs, which was then processed using a greedy algorithm to identify the closest key points and connect them, forming a complete human skeleton.
Figure 9.
Part Affinity Field.

2) Joining Key Points and Final Output: The key points detected by the model were represented by different colors. These key points were then joined to form the final output, a skeleton-like structure that accurately represented the human pose.
Figure 10.
Key points represented by different colors.

Figure 11.
Joining keypoints and Final output.

- C.
- Output from Mobile Application
The model was deployed in a mobile application to provide real-time pose estimation using the front camera of a mobile device. The application could detect exercises such as squats and arm raises, providing visual feedback to the user on their performance.
Figure 12.
Output of squat in mobile app.

Figure 13.
Output of arm raise in mobile app.

Figure 14.
UI of Mobile app.

Conclusion
The Human Pose Estimation project successfully demonstrated the ability to detect and visualize human poses using deep learning techniques. The model achieved high accuracy in predicting key points and forming a skeleton-like structure, making it suitable for various applications such as exercise monitoring and interactive gaming. Despite the challenges and potential sources of error, the project provided reliable and consistent results, proving its feasibility for real-world deployment.
1) UI of Mobile App: The user interface of the mobile application was designed to be intuitive, allowing users to select exercises and receive instant feedback. The app displayed the detected key points and skeleton overlay on the camera feed, helping users adjust their posture in real-time.
Future Enhancement
The project demonstrated significant potential for future enhancements, including:
- Integrating face recognition and detection for defense applications.
- Enhancing the system to predict user movements, useful in defense and gaming.
- Applying pose estimation in CGI for movies and video games.
- Using 3D cameras for capturing three-dimensional human poses, providing better visualization and accuracy.
References
- N. Barla, ”V7Labs,” [Online]. Available:https://www.v7labs.com/blog/human-pose-estimation-guide.
- P. Ganesh, ”Towards Data Science,” 15 March 2019.[Online]. Available:https://towardsdatascience.com/human-pose-estimationsimplified-6cfd88542ab3.
- M. A. Fischler and R. A. Elschlager, ”The Representation and Matching of Pictorial Structures,” IEEE Transactions on Computers, vol. C-22, no. 1, pp. 67-92, 1973. [CrossRef]
- P. F. Felzenszwalb and D. P. Huttenlocher, ”Pictorial structures for object recognition,” International Journal of Computer Vision, vol. 61, no. 1,pp. 55-79, 2005. [CrossRef]
- L. Johnson and C. Everingham, ”Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation,” in Proceedings of the British Machine Vision Conference, 2010, pp. 1-11. [CrossRef]
- Y. Yorozu, M. Hirano, K. Oka, and Y. Tagawa, “Electron spectroscopy studies on magneto-optical media and plastic substrate interface,” IEEE Transl. J. Magn. Japan, vol. 2, pp. 740–741, August 1987 [Digests 9th Annual Conf. Magnetics Japan, p. 301, 1982]. [CrossRef]
- T.-Y. Lin et al., ”Microsoft COCO: Common Objects in Context,” in European Conference on Computer Vision (ECCV), 2014, pp. 740-755. [CrossRef]
- M. Andriluka et al., ”2D Human Pose Estimation: New Benchmark and State of the Art Analysis,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 3686-3693. [CrossRef]
- Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, ”OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, pp. 172-186, 2019. [CrossRef]
- L. Pishchulin et al., ”DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4929-4937. [CrossRef]
- H. Fang et al., ”RMPE: Regional Multi-person Pose Estimation,” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2334-2343. [CrossRef]
- K. Simonyan and A. Zisserman, ”Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv preprint arXiv:1409.1556, 2014.
- J. Wang et al., ”Deep High-Resolution Representation Learning for Visual Recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3349-3364, 2020. [CrossRef]
- T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dolla´r, ”Microsoft COCO: Common Objects in Context,” in European Conference on Computer Vision (ECCV), Zurich, Switzerland, 2014, pp. 740-755.
- K. Simonyan and A. Zisserman, ”Very Deep Convolutional Networks for Large-Scale Image Recognition,” in International Conference on Learning Representations (ICLR), San Diego, USA, 2015.
- Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, ”Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA, 2017, pp. 7291-7299.
- D. P. Kingma and J. Ba, ”Adam: A Method for Stochastic Optimization,” in International Conference on Learning Representations (ICLR), San Diego, USA, 2015.
- X. Peng and K. Saenko, ”Synthetic to Real Adaptation with Generative Correlation Alignment Networks,” in IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, USA, 2018, pp. 1982-1991.
- A. Newell, K. Yang, and J. Deng, ”Stacked Hourglass Networks for Human Pose Estimation,” in European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, 2016, pp. 483-499.
- S. Johnson and M. Everingham, ”Learning Effective Human Pose Estimation from Inaccurate Annotation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, 2011, pp. 14651472.
- D. Shrestha and D. Valles, “Evolving Autonomous Navigation: A NEAT Approach for Firefighting Rover Operations in Dynamic Environments,” 24th Annual IEEE International Conference on Electro Information Technology (EIT2024). [In Press].
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



