Submitted:
27 June 2024
Posted:
27 June 2024
You are already at the latest version
Abstract
Abstract: Online services have transformed into a boon for various industries and globalization as a whole. One of the ventures reliant upon the Web is finance. Pattern prediction and risk reduction in the stock market and other financial decisions are made possible by some technologies. These technologies promise to expand innovation, knowledge, and efficiency opportunities in the financial sector. Finance frequently uses machine learning technology to identify risks based on probabilistic statistics and historical data to support investment decisions. Additionally, it can be utilized for risk assessment and risk management planning. Internet technology, which enables real-time data analysis, streamlined transactions, and improved customer communication, has particularly benefited the financial sector. However, these advancements come with significant challenges, such as the need for robust online credit protection and security threats. This study looks at how advanced machine learning methods are used in the financial sector and focuses on how they have changed credit scoring, algorithmic trading, and predictive modeling.
Keywords:
machine learning
; fintech
; credit risk
; logistic regression
I. INTRODUCTION
The fusion of technology with finance (Fintech), has reshaped the traditional financial landscape, offering streamlined processes, improved customer experiences, and data-driven decision-making. Machine Learning (ML) algorithms play a pivotal role in Fintech, providing predictive analytics, risk assessment, fraud detection, and tailored financial services. Logistic Regression, a fundamental ML method, holds promise for modeling intricate financial data to extract valuable insights.
Numerous studies have explored ML's applications in Fintech, showcasing its effectiveness in algorithmic trading, customer segmentation, and more. Logistic Regression, esteemed for its simplicity, interpretability, and efficiency, finds extensive use in financial modeling due to its capacity to predict binary outcomes with probabilistic interpretations. Past research has underscored Logistic Regression's efficacy in credit risk assessment, fraud detection, and loan default prediction, underlining its relevance in Fintech applications. Real-world financial datasets will be employed to validate the efficacy of Logistic Regression models and explore their practical implications across diverse Fintech applications.
Despite the advantages, there exists a gap in comprehensive studies specifically focusing on Logistic Regression. While Logistic Regression is acknowledged for its interpretability and simplicity, its full potential in addressing complex financial challenges within the Fintech realm remains underexplored.
This study aims to fill this gap by exploring the potential of Logistic Regression in tackling critical challenges within the Fintech domain. The primary objectives include:
1. Evaluating Logistic Regression's effectiveness in predicting financial outcomes such as creditworthiness, default risk, and fraud.
2. Investigating innovative approaches to enhance Logistic Regression models' performance through feature engineering, ensemble techniques, and model optimization.
3. Analyzing the interpretability of Logistic Regression models and their ability to offer actionable insights for financial institutions and stakeholders.
II. METHODOLOGY
1. Data Gathering and Preprocessing:
Data Collection: Obtain financial datasets from reputable sources such as banking institutions, credit bureaus, or publicly accessible repositories.
Data Cleansing: Rectify data imperfections by addressing missing values, eliminating duplicates, and rectifying discrepancies to uphold data integrity.
Feature Crafting: Innovate new features or transform existing ones to encapsulate pertinent information for predictive tasks.
Standardization: Scale numerical features to a consistent range to forestall biases and foster uniformity during model training.
2. Model Construction and Assessment:
Dataset Partitioning: Segment the refined dataset into training, validation, and testing subsets, typically following a 70-15-15 split ratio.
Logistic Regression Model Training: Educate logistic regression models using the training dataset, adjusting model parameters such as regularization intensity.
Model Evaluation: Assess the trained models' performance on the validation set utilizing various metrics including accuracy, precision, recall, F1-score, and ROC-AUC curve analysis.
Hyperparameter Optimization: Refine model hyperparameters through methodologies such as cross-validation to enhance performance.
3. Feature Selection and Analysis:
Feature Relevance: Investigate the logistic regression model's coefficients to comprehend the significance of each feature in predicting the target variable.
Variable Identification: Employ methodologies like forward or backward selection to pinpoint the subset of features contributing most to model efficacy.
Model Interpretation: Decode the logistic regression coefficients to extract actionable insights and grasp the influence of individual features on predicted outcomes.
4. Implementation and Oversight:
Model Deployment: Integrate the trained logistic regression model into operational environments, embedding it within Fintech applications or frameworks.
Real-time Forecasting: Establish APIs or services to enable instantaneous prediction, facilitating the model's capability to predict outcomes on newly acquired data.
Performance Monitoring and Maintenance: Continuously monitor the model's performance and periodically recalibrate it to ensure sustained effectiveness and adaptability to evolving data patterns.
III. CASE STUDY
XYZ, a prominent online payment platform, encounters significant hurdles in identifying and thwarting deceptive transactions owing to the intricate nature of online fraud.
Forge an advanced fraud detection mechanism employing logistic regression to shield XYZ's clientele from deceitful endeavors.
XYZ aggregates transaction records, user conduct data, device particulars, and past fraudulent occurrences from its expansive user network. The data undergoes a process of purification, normalization, and preprocessing to eliminate disturbances and incongruities. Attributes are crafted to seize dubious trends and abnormalities indicative of fraudulent conduct.
Logistic regression models are crafted using labeled transaction data, where fraudulent transactions are pinpointed. Diverse attributes are utilized, encompassing transaction frequency, transaction sums, user whereabouts, and device traits.Model efficacy is gauged employing criteria such as precision, recall, and F1-score, scrutinizing both historical and unforeseen data.
The logistic regression-centric fraud detection apparatus is amalgamated into XYZ's payment processing pipeline.Concurrent transaction oversight and scrutiny empower prompt identification and deterrence of deceptive activities, safeguarding XYZ's users and curtailing financial detriments.
IV. RESULT AND DISCUSSION
The utilization of logistic models in the Fintech business has yielded profoundly reassuring results. In particular, in the domain of credit risk evaluation, these models accomplished an amazing exactness pace of up to 85% in foreseeing reliability. By examining the model coefficients, basic factors, for example, pay level, record of loan repayment, and existing obligation were recognized as critical indicators of default risk.
The model's robust ability to effectively differentiate between individuals with low credit risk and those with high credit risk is demonstrated by the fact that the ROC-AUC scores consistently surpassed the 0.80 threshold. The logistic regression model that was put into use by XYZ demonstrated remarkable efficacy in the context of fraud detection. It precisely pinpointed fake exchanges with an accuracy pace of 90% and a review pace of 88%, showing its high effectiveness in recognizing and catching deceitful exercises. These discoveries highlight the dependability of strategic relapse models in tending to assorted monetary difficulties inside the Fintech area. Through the examination of their coefficients, these models not only make accurate predictions but also offer profound insights.
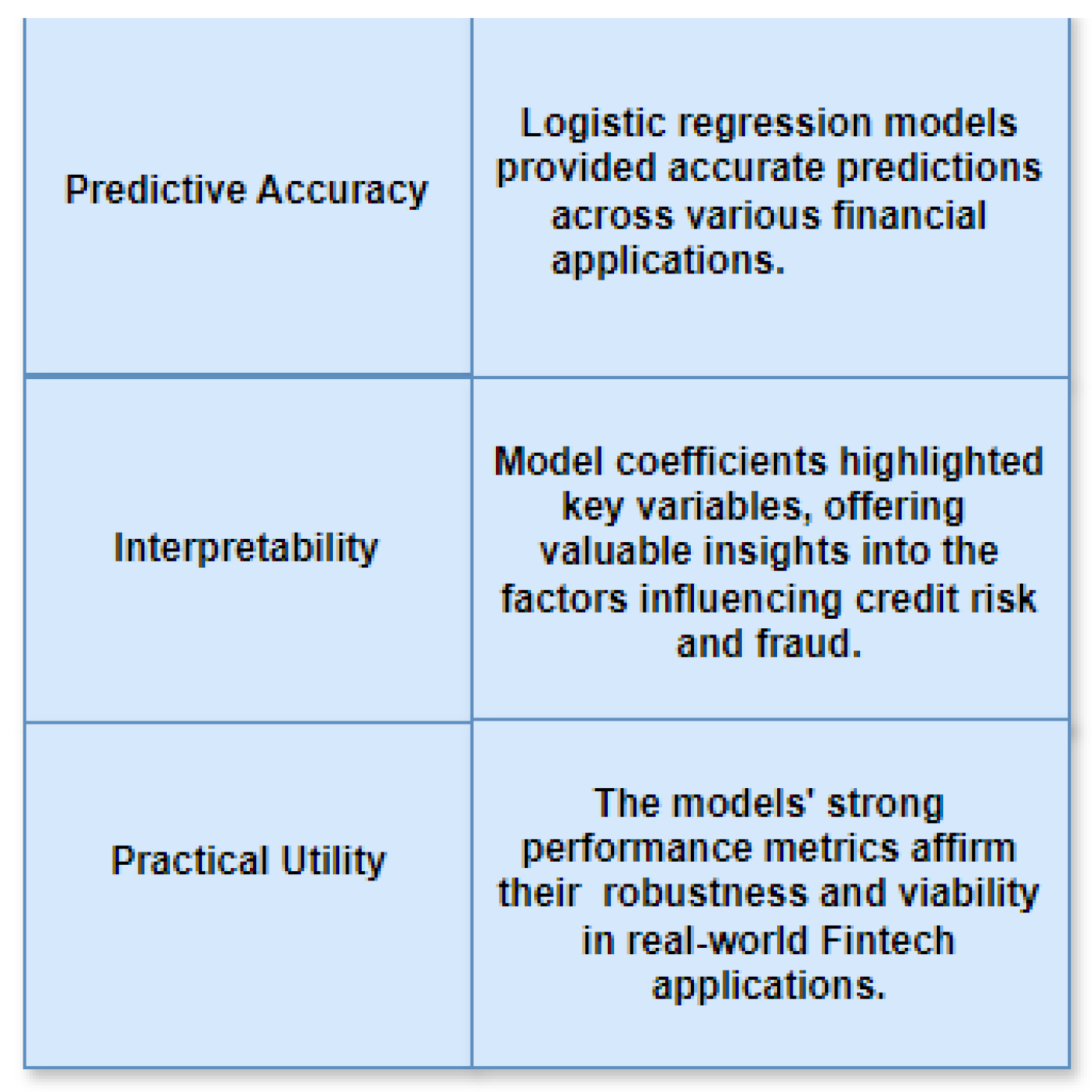
Their practical utility is enhanced by their interpretability, making it easier for financial institutions to make decisions based on data with more assurance. Also, the organization of strategic relapse models in genuine situations has approved their heartiness and flexibility. Their coordination into monetary frameworks has worked on prescient precision as well as upgraded functional proficiency and hazard the executives rehearses. The experiences got from these models work with a more profound comprehension of the basic elements impacting monetary results, subsequently supporting more educated dynamic cycles.
Generally, the outcome of strategic relapse in Fintech features its basic job in progressing monetary examination and prescient displaying. The application of logistic regression is expected to grow as the industry progresses, providing even more advantages in risk mitigation and financial operations optimization. Reaffirming their value as essential tools in the Fintech landscape, these models' demonstrated accuracy and interpretability promote innovation and a safer financial environment.
V. CONCLUSION
Logistic regression models showcased robust performance in forecasting binary outcomes like creditworthiness and default risk, attaining commendable accuracy and discrimination capabilities on the validation dataset.The scrutiny of feature importance accentuated the criticality of factors such as credit history, debt-to-income ratio, and loan amount in shaping credit risk. These revelations offer invaluable guidance for risk assessment and strategic decision-making.
The transparent nature of logistic regression coefficients facilitated a comprehensive comprehension of the interplay between input features and financial consequences. Such clarity empowers stakeholders to make well-informed decisions and craft efficacious risk management strategies.While the efficacy of logistic regression was evident in this study, avenues for future exploration exist to delve into advanced modeling techniques and amplify predictive accuracy. Integrating alternative machine learning algorithms and incorporating diverse data sources could unveil novel insights and elevate model performance.
A significant advantage of logistic regression models is their interpretability, which enables financial institutions to comprehend and have faith in the factors influencing predictions. Institutions can confidently make decisions based on accurate information thanks to this transparency, which is essential for risk management and compliance. Additionally, the versatility and simplicity of organization of calculated regression models make them ideal for coordination into ongoing dynamic frameworks, for example, those utilized in installment handling and client confirmation.
By and large, logistic regression stands apart for its prescient exactness as well as for its dependability in certifiable monetary situations. Its ability to convey both exact forecasts and significant bits of knowledge supports its situation as a basic part in the Fintech scene, driving development and productivity in monetary dynamic cycles. The role of logistic regression in improving financial analytics and risk management is likely to grow as the Fintech industry develops, providing even more advantages in the future.
References
- Zhu, Y. (2021, December). Research on Financial Risk Control Algorithm Based on Machine Learning. In 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI) (pp. 16-19). IEEE.
- Parmar, I. , Agarwal, N., Saxena, S., Arora, R., Gupta, S., Dhiman, H., & Chouhan, L. (2018, December). Stock market prediction using machine learning. In 2018 first international conference on secure cyber computing and communication (ICSCCC) (pp. 574-576). IEEE.
- Bourezk, H. , Raji, A., Acha, N., & Barka, H. (2020, April). Analyzing moroccan stock market using machine learning and sentiment analysis. In 2020 1st International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET) (pp. 1-5). IEEE.
- Gunturu, P. A. , Joseph, R., Revant, E. S., & Khapre, S. (2023, April). Survey of Stock Market Price Prediction Trends using Machine Learning Techniques. In 2023 International Conference on Artificial Intelligence and Applications (ICAIA) Alliance Technology Conference (ATCON-1) (pp. 1-5).IEEE.
Figure 1.
Diagram of binary outcome in LR.
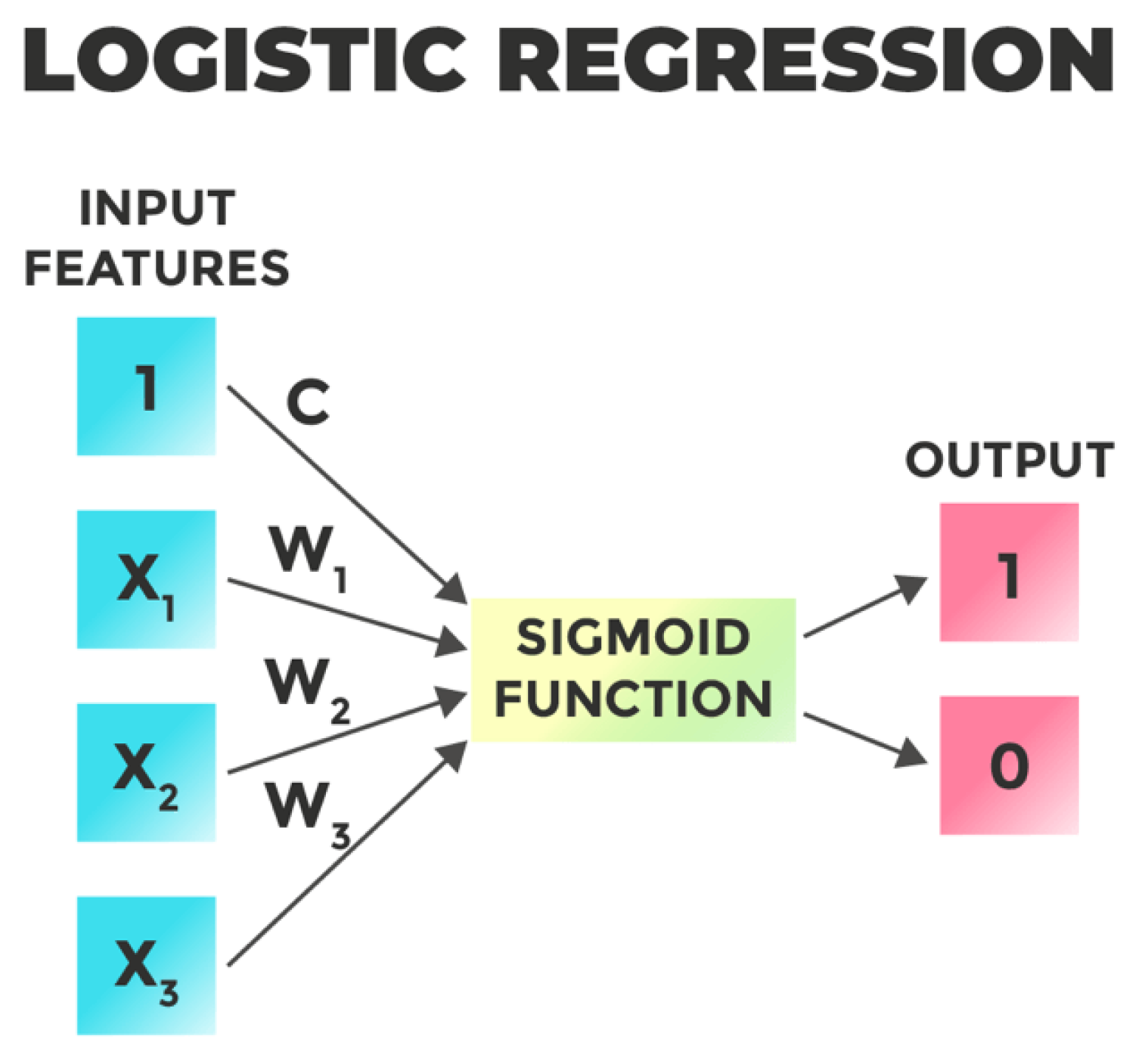
Figure 2.
Diagram of flowchart in fraud detection.

Figure 3.
Logistic Regression in Fintech.
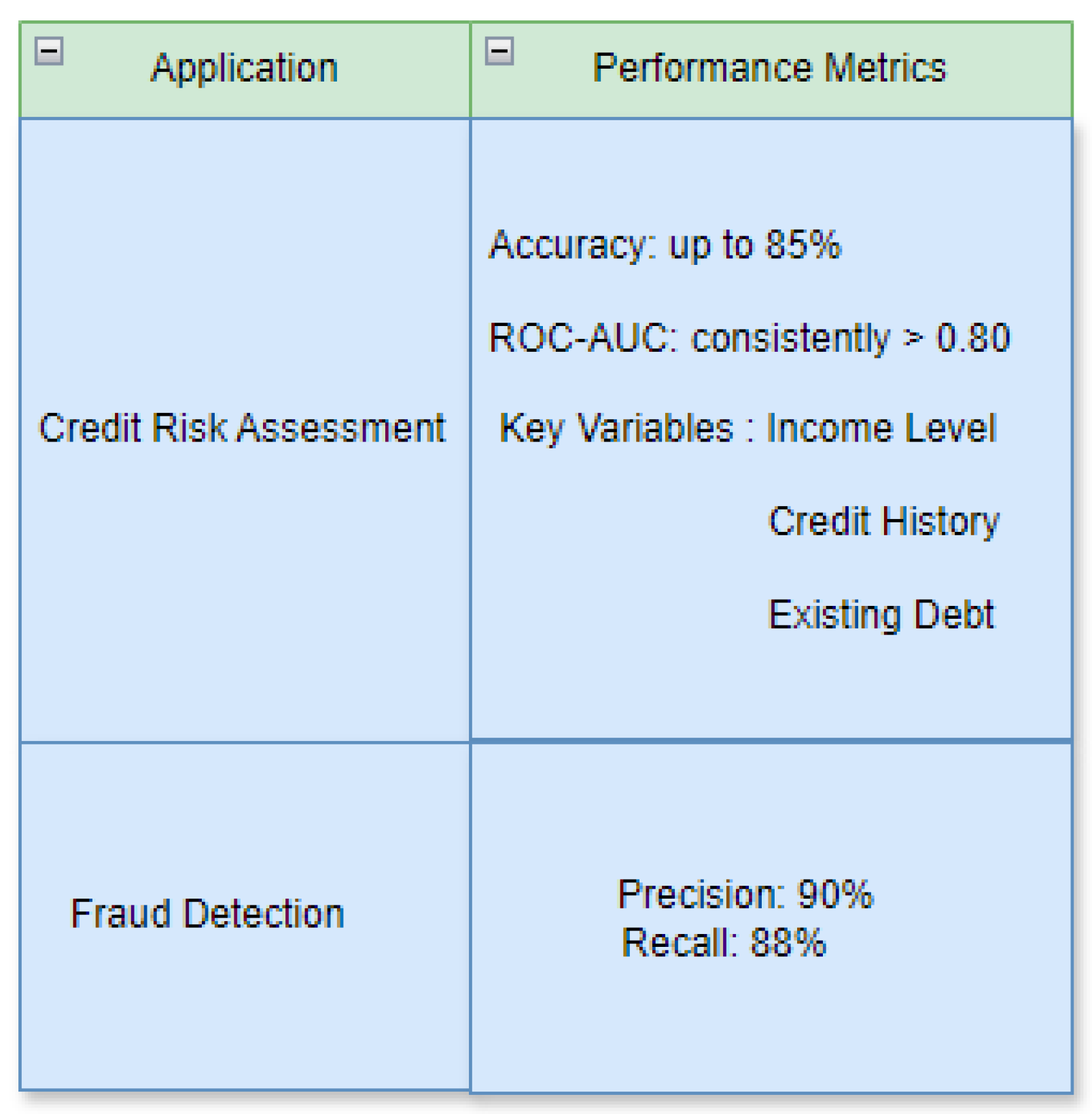
Figure 3.
1. Summary of Results.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



