
Submitted:
22 January 2024
Posted:
22 January 2024
You are already at the latest version
Abstract
When it comes to financial transactions and counterfeit detection systems, banknote classification is crucial. In this paper, we propose an approach for the classification of Kazakhstan banknote images integrating Learning Vector Quantization (LVQ) with Statistical Texture Feature Extraction using the Gray Level Co-occurrence matrix (GLCM). Our methodology demonstrates effectiveness in accurately classifying banknote images, as evidenced by experimental results. The comprehensive testing scenarios show promising outcomes, with the combination of GLCM and Color Histogram under the LVQ algorithm achieving a high accuracy of 94.87 percent at distance 1 and 90°. These findings indicate the robustness and practical viability of the proposed method for authenticating banknotes.
Keywords:
Kazakhstan Banknotes
; Image Classification
; Gray Level Co-occurrence matrix
; Learning Vector Quantization
1. Introduction
Verifying banknotes is an essential part of financial security. The goal of this work is to improve the classification of banknote images from Kazakhstan through the combination of learning vector quantization with statistical feature extraction using the Gray Level Co-occurrence Matrix (GLCM).
The project is divided into three phases, each of which is designed to address important aspects of banknote classification. Phase 1 establishes the framework by highlighting the special capacity of GLCM to extract data from banknotes. This stage acts as the foundation, providing the framework on which further stages can be built.
Phase 2 investigates the fundamental color-based features contained in Kazakhstan banknote pictures in an effort to improve banknote classification. This stage departs from feature based analysis and explores the RGB color space with the goal of using these color characteristics to improve classification accuracy. The use of color histograms in the extraction and analysis of color information is essential to this stage. These histograms are very useful tools that help us identify the frequency and distribution of different RGB values in banknote images. Our goal is to identify unique color patterns that can be integrated into a classification model by analyzing the frequency and distribution of colors. Furthermore, this stage particularly highlights the use of average values from the Red, Green, and Blue channels within the RGB color space. The average intensity of each color channel shown in the banknote images is captured by the mean values. To extract useful color-related characteristics, we reduce the complex RGB color space to simple mean values. These mean values serve as basic descriptors, capturing the predominant color tones present in banknote images from Kazakhstan. These qualities are intended to improve the overall framework and aid in the more thorough and accurate classification of banknotes by means of careful analysis and inclusion into our classification model. In phase 2 findings from color-based RGB feature extraction and GLCM analysis are meticulously combined. The combination of these different but complementary characteristics seeks to create a robust and complete classification model. This stage aims to develop a comprehensive method that optimizes banknote categorization accuracy by combining GLCM and color characteristics.
The purpose of this work is to evaluate and compare how well these stages perform in correctly classifying images of Kazakhstan banknotes. The ultimate objective is to aid in the creation of an extensive system for verifying banknotes, which will improve both the safety and reliability of financial transactions by accurately differentiating banknotes.
2. Materials and Methods
2.1. Dataset
For this research, a custom dataset of Kazakhstan banknote images was carefully collected to facilitate the study’s objectives. The dataset was purposefully focused on paper currency images, excluding images of Kazakhstan coins. The dataset includes banknotes in the following denominations from Kazakhstan: 500 tenge, 1000 tenge, 2000 tenge, 5000 tenge, 10000 tenge, and 20000 tenge notes. The wide range of denominations provides a thorough portrayal of the nation’s paper money.
The Kazakhstan Banknote dataset consists of .jpg pictures with a standard dimension of 1024 × 1024 pixels for paper currency and 3024 × 4032 for coins, offering an opportunity for full analysis and processing. Using an Apple iPhone 11 mobile device’s high-resolution back camera, pictures of banknotes were taken in order to get the dataset. In order to provide structured data management, images of paper banknotes were carefully arranged into folders according to their different denomination values. The Figure 1 illustrates the step-by-step workflow followed for the acquisition of banknote images.
Banknotes from Kazakhstan valued at 500, 1000, 2000, 5000, 10000, and 20000 Tenge are displayed in Figure 2, which provides visual samples of the dataset. The images display both the front and back sides of the paper currency, providing a comprehensive visual representation of the dataset’s diversity.
2.2. Image Pre-Processing
One of the most important steps in getting the raw dataset ready for further analysis and feature extraction is image pre-processing. To maintain consistency, improve feature extraction, and minimize the effects of noise or environmental changes, the obtained banknote images frequently go through a number of changes and improvements.The image pre-processing part consists of three major steps, namely:
- (1)
- Image Resizing: The first step involves resizing the image dimensions to a uniform size in order to maximize computational efficiency in later processing stages. In order to maintain image integrity, all acquired images in this study were reduced to 200 × 200 pixels.
- (2)
- Noise Reduction: To minimize the effects of picture noise and flaws, Gaussian blur, a popular noise reduction method, was used. A 5x5 kernel size Gaussian filter was used to smooth the images without losing important features.
- (3)
- Gray-scale Conversion: The images were converted from RGB to gray-scale in order to simplify and improve the following feature extraction procedures. By lowering the dimension of the data, this modification reduces the computing load while maintaining the structural and textural details that are crucial for classifying banknotes.
The multi-step procedure used on the original banknote image is shown in Figure 3. The original image (5.a), which was taken at 1024 × 1024 and 3024 × 4032 pixels, was resized to 200 × 200 pixels (5.b) in order to maintain consistency and improve computational performance. The image was then transformed to gray-scale (5.c) in order to reduce the dimension of the data and maintain important structural and textural information, which would otherwise complicate later feature extraction stages. Lastly, a Gaussian blur approach was used for noise reduction (5.d), which successfully reduced picture noise and flaws while maintaining important details of the banknote images.
2.3. GLCM Features
The Grey Level Co-Occurrence Matrix, or GLCM, is an essential tool for obtaining texture features and image data. This technique, which was first presented in 1973 by Haralick and others in analyzes the frequency of pixel pairs with particular gray-level values in order to define the textures of images.
The extraction of textural information using the Gray Level Co-Occurrence Matrix (GLCM) is important for the classification of banknotes in Kazakhstan using images of the currencies. Through the characterization of the interactions between pixel pairs in images with particular gray-level values, GLCM sheds light on the textural features of the banknotes.
A second-order statistical feature, the Gray Level Co-occurrence Matrix (GLCM) calculates the likelihood of pixel adjacency inside an image at a given distance (d) and angle orientation (). This technique comprises building an image-based Co-occurrence matrix, evaluating the correlation between pixel pairings, and characterizing them. The square matrix known as the Co-occurrence matrix represents the sum of the elements, or the squared sum of the intensity levels. It contains the instances of particular pairings of pixels at a given distance (d) and angle (). This usually consists of four angular orientations (0°, 45°, 90°, and 135°), each of which specifies a pixel-by-pixel distance that indicates how close together pixels are in the image.
In GLCM, the features in this study consist of contrast, correlation, energy, homogeneity,dissimilarity, and entropy.
1. Contrast: Measures the local intensity variation between a pixel and its neighbor over the entire image.
2. Correlation: Indicates the degree of correlation between a pixel and its neighbor in the image.
3. Energy (Uniformity or ASM - Angular Second Moment): Represents the sum of squared elements in the GLCM.
4. Homogeneity: Measures the closeness of the distribution of elements in the GLCM.
5. Dissimilarity: Measures the distance between pairs of objects in pixels in the expected region.
6. Entropy:
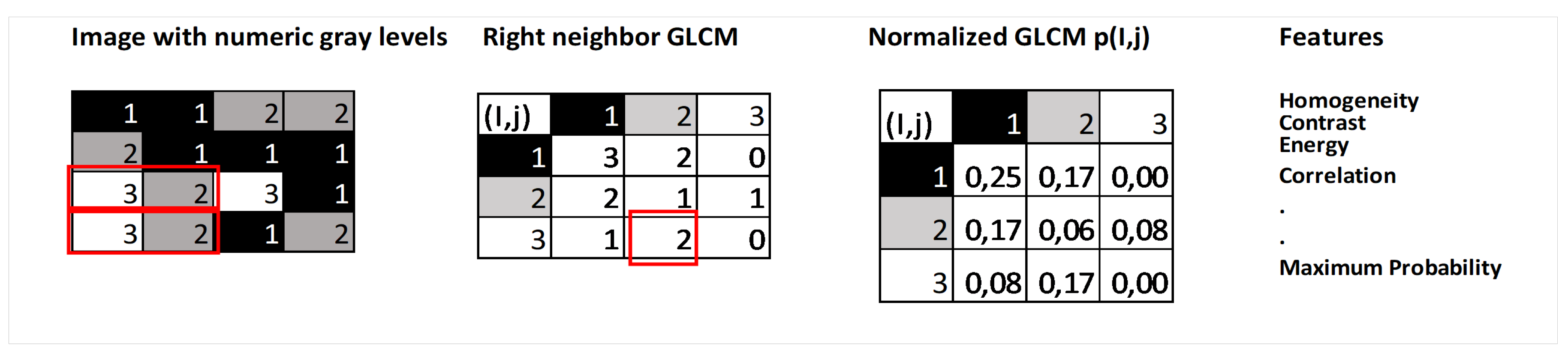
The steps involved in determining GLCM texture features are shown in Figure 5. Each gray level in a 4 x 4 image region of interest (ROI) is represented by a number between 1 and 3. Each voxel’s link to its neighboring voxel is examined to create the Gray Level Co-occurrence Matrix (GLCM), which in this case is the neighbor to the right. In essence, the GLCM records instances of gray level pair combinations in the image, serving as a counter. Every voxel’s value, along with that of its neighbors, contributes to a particular GLCM element.
Figure 4.
GLCM Angle.
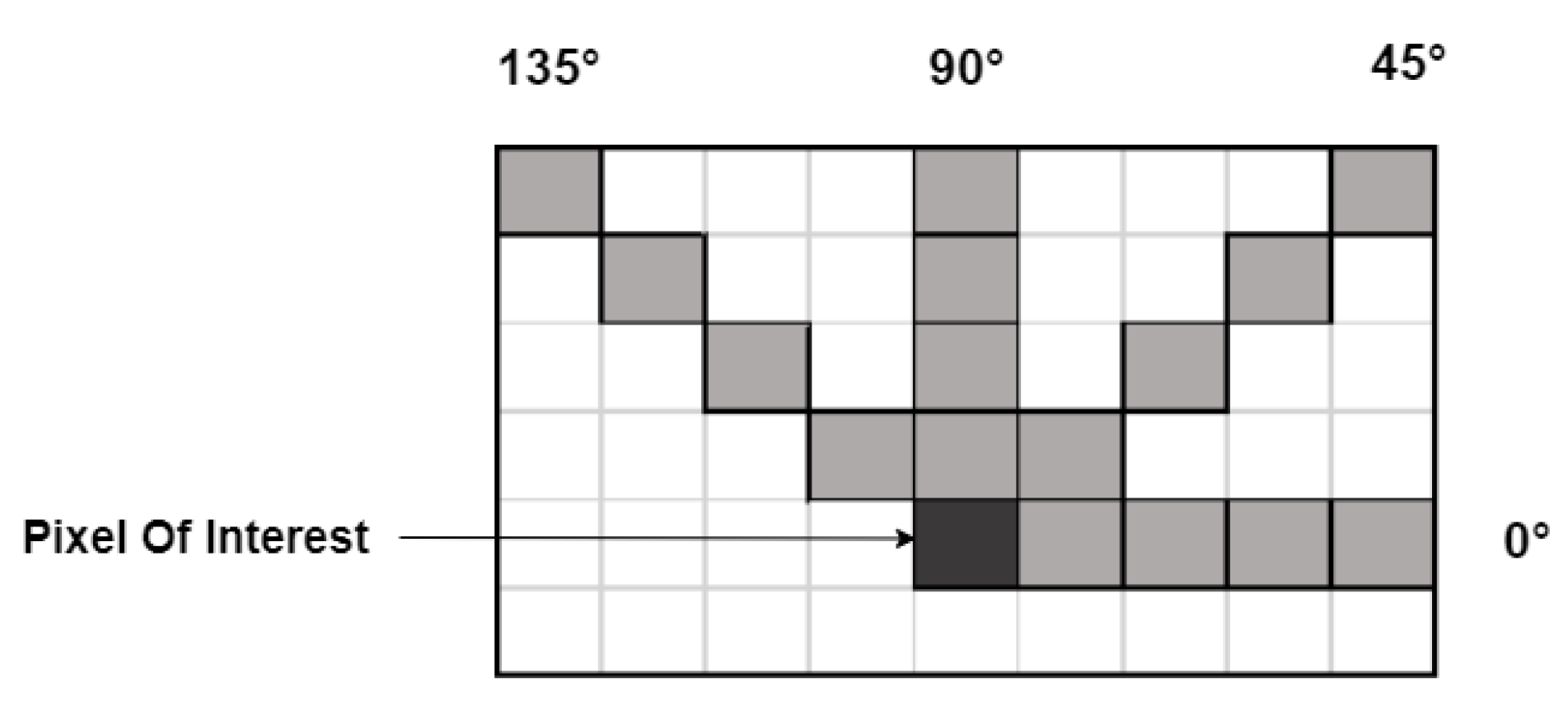
In the given ROI example, solid red indicates the times when a neighbor voxel of 2 "co-occurs" with a reference voxel of 3.The frequency or chance of any combination happening in the image is then represented by the normalized GLCM.
The normalized GLCM is the source of Haralick’s features, which capture different facets of the ROI’s gray level distribution. In the GLCM, for example, diagonal elements stand for pairs of voxels with the same gray level. Elements with identical gray level values are given a low weight by the "contrast" texture feature, whereas elements with different gray levels are given a high weight. Prior to normalization, it is customary to add GLCMs from neighboring opposites, producing symmetric GLCMs that represent the "horizontal" or "vertical" aspects of the picture. When GLCM construction is done with all neighbors taken into account, the texture features become direction invariant.
Figure 5.
An explanation of the GLCM feature calculation process
2.4. Color Histogram
In Phase 2, the investigation extends to the analysis of color histograms to capture color distribution characteristics within the banknote images.
Color histograms are essential tools in image processing, allowing a comprehensive analysis of the distribution of color intensities within an image. Knowing the color distribution in the context of classifying banknote images can provide important insights into the unique characteristics of various denominations of money. In order to provide robust banknote classification, this section examines the computation and importance of color histograms as additional characteristics in along with Gray Level Co-occurrence Matrix (GLCM) data.
A color histogram is a statistical representation that quantifies the frequency of various color intensities in an image. The process of calculating the color histogram involves splitting an image into its individual RGB color channels and counting the frequency of each intensity level within each channel. The general color composition and distribution of the image can be understood by examining the histograms.
The Use of Mean Color Values Mean values obtained from color histograms provide a brief description of the average color intensity in an image, in addition to the histogram representation. Through the calculation of the average for each color channel—that is, Red (R), Green (G), and Blue (B)—a representative value representing the image’s predominant color intensity is obtained.
The color histogram is essentially a distribution function that counts the frequency of intensity levels for each color channel. The color histogram for a single channel (e.g., Red) can be represented mathematically as:
Where is the intensity value of pixel j in channel c.
Normalization (optional):
Mean Calculation (for normalized histogram):
This mean represents the average intensity level for that color channel.These formulas are applied to each color channel separately to compute individual histograms and mean color values. Color histograms can enhance standard texture-based GLCM features in the field of banknote image classification. The histograms capture distinct color patterns associated with different denominations of banknotes. These histograms could be used to capture, for example, the diverse color distributions, colors, or dominant color tones that different denominations can display. Additionally, a visual representation of a computed color histogram for a banknote image provided in Figure 6. This figure showcases the distribution of color intensities across different channels, highlighting distinctive color patterns and their significance in characterizing banknote features.
2.5. Learning Vector Quantization
Learning Vector Quantization (LVQ) serves as a fundamental technique employed in the classification phase of the banknote images. LVQ is an artificial neural network method used for pattern recognition and classification tasks.
LVQ is a supervised learning algorithm that operates by defining a set of reference vectors or prototypes, each associated with a specific class. These reference vectors evolve during the learning process to represent different classes within the input data space. The LVQ network determines the closest reference vector to an input sample, thereby assigning it to the class represented by that reference vector. The LVQ method involves the following key steps:
- Initialization of Reference Vectors: Initially, the reference vectors are initialized, often randomly or based on specific criteria, to represent different classes in the input space.
- Training Process: The training process involves iteratively presenting input samples to the LVQ network. During training, the network adjusts the reference vectors based on a learning rate and a competitive learning mechanism. The reference vectors that are closer to the input samples get adjusted more, aligning themselves to better represent the input data distribution.
- Classification: After training, the LVQ network can classify new, unseen samples by assigning them to the class represented by the closest reference vector.
3. Results
3.1. Testing Scenarios
Testing Scenarios for "Applying Gray Level Co-occurrence Matrix features and Learning Vector Quantization for Kazakhstan Banknote Classification":
1st Scenario: GLCM Feature - Learning Vector Quantization (LVQ) Algorithm
In this scenario, the GLCM feature extraction is applied, and the classification is performed using the Learning Vector Quantization (LVQ) algorithm. The parameters in GLCM are analyzed, and the experiment involves using a maximum distance of 2 while considering all degrees (0°, 45°, 90°, 135°).
2nd Scenario: GLCM + Color Histogram - Learning Vector Quantization Algorithm
The second scenario focuses on the Color Histogram for feature extraction, and the classification is carried out using the Learning Vector Quantization (LVQ) algorithm. Similar to the 1st scenario, testing is performed with the LVQ classification system. The parameters are set with a maximum distance of 2, considering all degrees (0°, 45°, 90°, 135°). The experiment aims to analyze the differences in accuracy between using only GLCM and combining GLCM with a color histogram.
3.2. Analysis of Testing Results
The evaluation of the proposed method involved two test scenarios, each providing insights into the system’s performance under varied conditions.
1st Scenario: GLCM Feature - Learning Vector Quantization (LVQ) Algorithm
In this case, the Learning Vector Quantization (LVQ) technique was used for classification, and GLCM feature extraction was used. The testing included a range of distances (1, 2) and angles (0°, 45°, 90°, and 135°). Table 1 provides a summary of the accuracy results.
Table 1: GLCM Feature - LVQ Algorithm Accuracy
The system’s performance with GLCM feature extraction under various orientations and distances is shown by the study of the first scenario. Interestingly, accuracy at distance 2 continuously outperformed accuracy at distance 1, suggesting that a bigger neighborhood for GLCM calculations had a beneficial effect on classification accuracy.
2nd Scenario: GLCM + Color Histogram - LVQ Algorithm
In the second case, the LVQ algorithm was used for classification after GLCM and Color Histogram were integrated for feature extraction. Testing was done at different distances and angles, and Table 2 displays the accuracy findings.
Table 2: GLCM + Color Histogram - LVQ Algorithm Accuracy
The impact of integrating GLCM and Color Histogram features on classification accuracy is investigated in the analysis of the second case. In comparison to the first case, this hybrid technique shows better accuracy, suggesting that the addition of color information enriches the feature set and improves classification performance. According to the analysis, distance 2 generally performs better than distance 1, which is consistent with the results from the first case. Furthermore, greater accuracy is obtained when GLCM and Color Histogram features are combined. The maximum accuracy was attained at distance 1 and angle 90°, where it was 94.87 percent.
The importance of feature combination and selection in the context of banknote categorization is highlighted by these thorough evaluations. The findings offer insightful information for improving the suggested approach, highlight the possible advantages of various feature combinations, and establish the framework for more research into the best feature sets and algorithmic arrangements.
4. Discussion
The experimental evaluation’s findings provide insight into the efficacy of the suggested approach for classifying banknotes, which combines the Learning Vector Quantization (LVQ) algorithm with Gray Level Co-occurrence Matrix (GLCM) characteristics in various settings.
In the first case, where the LVQ method was used to apply GLCM feature extraction, the findings demonstrate promising levels of accuracy at different angles and distances. When distance 2 was used instead of distance 1 in GLCM computations, the results were consistently more accurate. This is consistent with the idea that classification accuracy is positively impacted by a wider neighborhood for GLCM computations. The best accuracy, which was attained at distances of 2 and 0° and reached 85.4 percent , highlights how reliable the suggested method is at obtaining textural data for accurate banknote classification.
The results of this situation are consistent with earlier research highlighting the usefulness of GLCM features in texture analysis. The capacity of GLCM to record spatial correlations between pixel intensities offers useful discriminative data for identifying various banknote classes. Furthermore, the system’s overall performance is aided by the LVQ algorithm’s use of these features for classification.
When using the LVQ method in the second situation, the combination of GLCM and Color Histogram data improved classification accuracy even further. The system’s overall performance was greatly enhanced with the addition of color information. Distance 2 continuously performed better than distance 1, as the data showed, highlighting the significance of a broader neighborhood for precise feature extraction.
The accuracy boost that was seen—up to 94.87 percent at distances of 1 and 90°—highlights the beneficial impact of combining color and textural data. With a richer feature set from this combination, the system can distinguish between different banknote classes more effectively. The results imply that a more reliable and accurate classification model is produced when the extra data from color histograms is combined with the textural characteristics that GLCM was able to gather.
The suggested banknote classification approach, which combines the Learning Vector Quantization (LVQ) algorithm with features from the Color Histogram and Gray Level Co-occurrence Matrix (GLCM), has intriguing applications beyond real banknote recognition. The method has proven to be highly accurate in identifying real currency, but it also has potential in the vital area of counterfeit identification.
This method’s adaptability makes it a useful tool for both successfully recognizing counterfeit currency and differentiating real banknotes. Through the use of textural and color information, the algorithm learns to identify minute patterns that point to fake sounds. To strengthen the discriminatory power of the system, future research paths could investigate additional texture and color features unique to faked banknotes.
The suggested methodology shows up as a complete answer when it comes to dealing with more general issues related to money security, guaranteeing the integrity of financial transactions. It will be crucial to continuously enhance and validate the system against various datasets, including counterfeit banknotes, in order to prove its robustness and dependability in practical situations.
5. Conclusions
This work concludes by introducing a strong banknote classification system for Kazakhstan based on LVQ algorithms and GLCM characteristics. The first step showed how well GLCM extracted useful textural information, and the second phase improved the accuracy of the model even more by adding color-based features. The final integrated model represents a breakthrough in banknote classification by incorporating both GLCM and color information. This work establishes the foundation for the advancement of banknote authentication at the nexus of financial security and computer vision.
Author Contributions
Conceptualization, Ualikhan Sadyk, Rashid Baimukashev, Akgul Bozshina, and Cemil Turan; methodology, Rashid Baimukashev; software, Ualikhan Sadyk and Cemil Turan; validation, Ualikhan Sadyk and Rashid Baimukashev ; formal analysis, Ualikhan Sadyk; resources, Cemil Turan; data curation, Akgul Bozshina; visualization, Akgul Bozshina and Cemil Turan; supervision, Cemil Turan; project administration, Ualikhan Sadyk; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding
Informed Consent Statement
Not applicable
Data Availability Statement
We acknowledge the importance of data sharing and transparency in research. The dataset is publicly available. Researchers and interested parties can access the dataset through the following link to Mendeley Data: Sadyk, Ualikhan; Bozshina, Akgul (2023), "Dataset Of Kazakhstan Banknotes with Annotations", Mendeley Data, V1, doi: 10.17632/dny3dgvvw8.1
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sadyk, Ualikhan; Bozshina, Akgul (2023), “Dataset Of Kazakhstan Banknotes with Annotations”, Mendeley Data, V1, doi: 10.17632/dny3dgvvw8.1. [CrossRef]
- Mall, Pawan & Singh, Pradeep & Yadav, Divakar. (2019). GLCM Based Feature Extraction and Medical X-RAY Image Classification using Machine Learning Techniques. 1-6. 10.1109/CICT48419.2019.9066263. [CrossRef]
- Er. Kanchan Sharma, Er. Priyanka , Er. Aditi Kalsh, Er.Kulbeer Saini (2015). "GLCM and its Features". International Journal of Advanced Research in Electronics and Communication Engineering (IJARECE) Volume 4, Issue 8, August 2015. [CrossRef]
- Radi, & Rivai, Muhammad & Hery Purnomo, Mauridhi. (2015). Combination of first and second order statistical features of bulk grain image for quality grade estimation of green coffee bean. 10. 8165-8174.
- García-Lamont, Farid & Cervantes, Jair & Lopez-Chau, Asdrubal & Rodríguez, Lisbeth. (2013). Classification of Mexican Paper Currency Denomination by Extracting Their Discriminative Colors. 8266. 403-412. [CrossRef]
- Sukiman, T. & Suwilo, Saib & Zarlis, Muhammad. (2019). Feature Extraction Method GLCM and LVQ in Digital Image-Based Face Recognition. SinkrOn. 4. 1. [CrossRef]
- Purwanti, Endah & Hariono, Lellen & Astuti, Suryani. (2022). Identification of Stroke with MRI Images Using the Learning Vector Quantization (LVQ) Method Based on Texture Features. Indonesian Applied Physics Letters. 3. 62-69. [CrossRef]
- Satria, E & Arnia, Fitri & Muchtar, Kahlil. (2021). Identification of male and female nutmeg seeds based on the shape and texture features of leaf images using the learning vector quantization (LVQ). Journal of Physics: Conference Series. 1807. 012001. [CrossRef]
- Kavin Kumar, K.; Devi, M.; Maheswaran, S. An efficient method for brain tumor detection using texture features and SVM classifier in MR images. Asian Pac. J. Cancer Prev. APJCP 2018, 19, 2789. [CrossRef]
- Soh, L.-K.; Tsatsoulis, C. Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote. Sens. 1999, 37, 780–795. [CrossRef]
Figure 1.
Banknote Data Acquisition Process

Figure 2.
Visual Samples of a dataset

Figure 3.
Pre-processed image of banknote
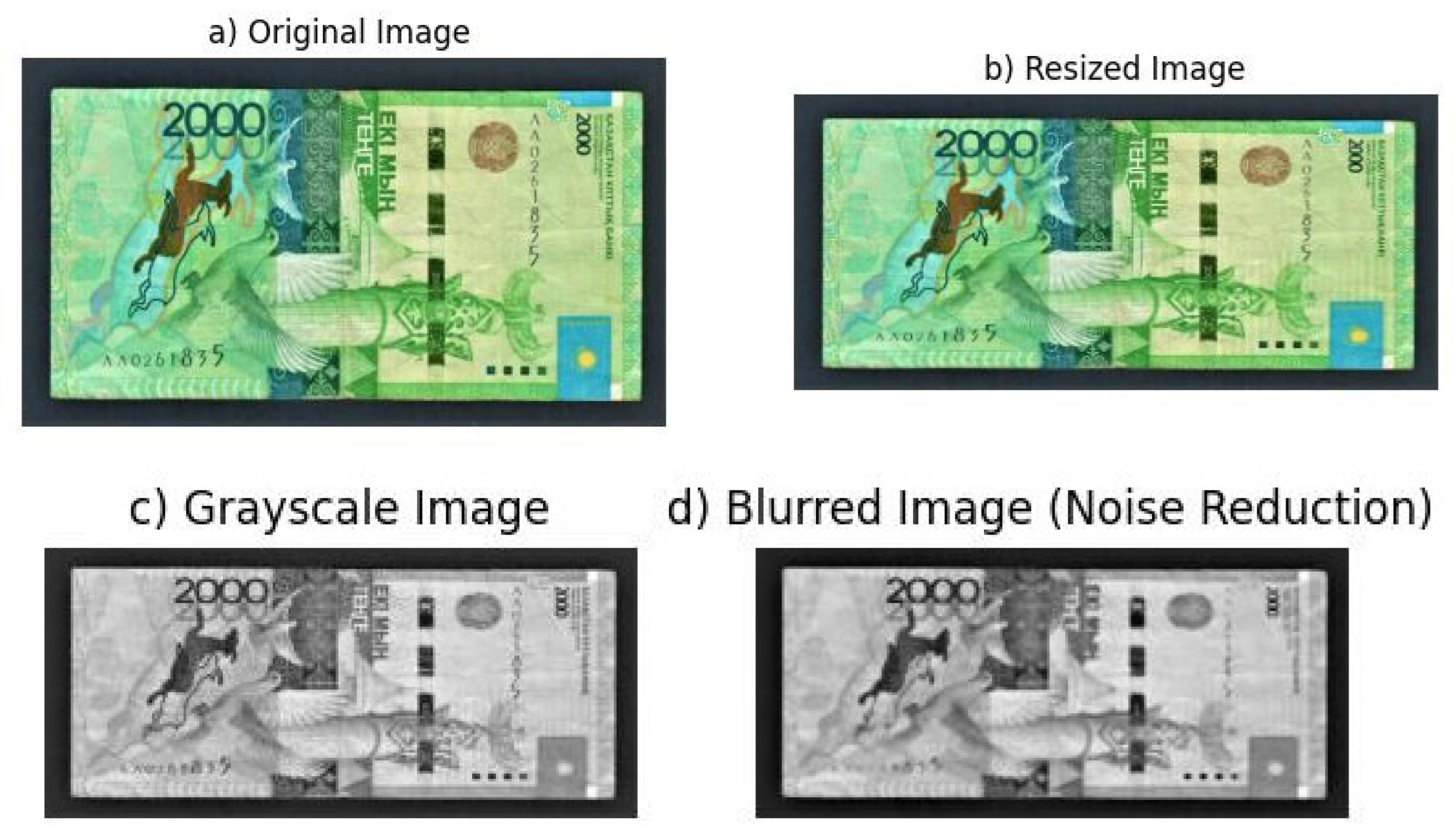
Figure 6.
Visual Samples of a dataset
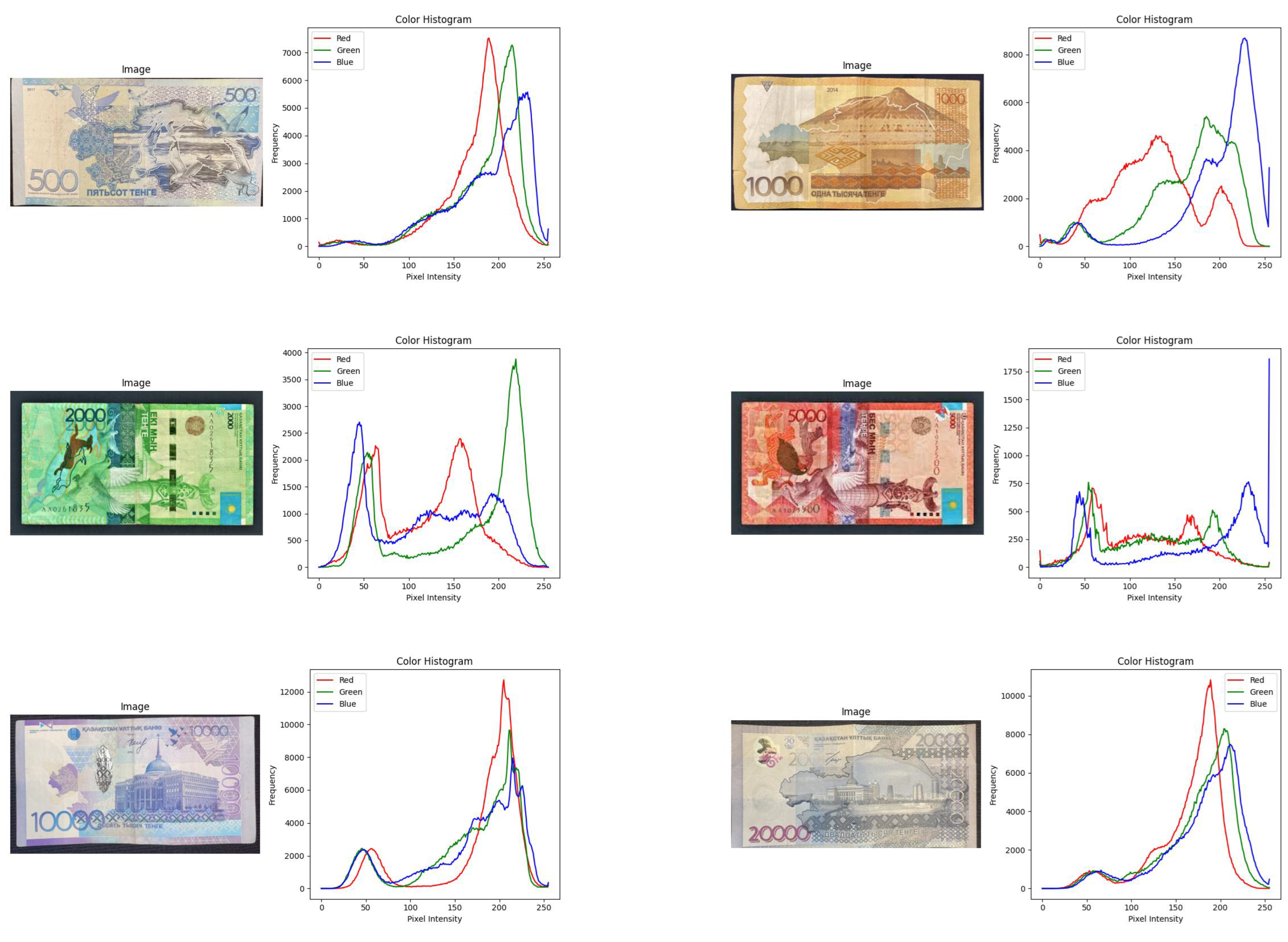

Table 1.
GLCM Feature - LVQ Algorithm Accuracy
| Distance/Degree | 0° | 45° | 90° | 135° |
|---|---|---|---|---|
| 1 | 83.20% | 84.00% | 82.44% | 84.30% |
| 2 | 85.4% | 84.30% | 82% | 84% |
Table 2.
GLCM + Color Histogram - LVQ Algorithm Accuracy
| Distance/Degree | 0° | 45° | 90° | 135° |
|---|---|---|---|---|
| 1 | 93% | 93.42% | 94.87% | 94% |
| 2 | 94.83% | 94% | 94.67% | 94.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



