
Submitted:
27 September 2023
Posted:
28 September 2023
You are already at the latest version
Abstract
Background:
Although electronic health records (EHR) provide useful insights into disease patterns and patient treatment optimisation, their reliance on unstructured data presents a difficulty. Because of their narrative structure, echocardiography reports, which provide extensive pathology information for cardiovascular patients, are particularly challenging to extract and analyse. Although natural language processing (NLP) has been utilised successfully in a variety of medical fields, it is not commonly used in echocardiography analysis.
Objectives:
To develop an NLP-based approach for extracting and categorizing data from echocardiography reports by accurately converting continuous (e.g. LVOT VTI, AV VTI, and TR Vmax) and discrete (e.g. Regurgitation severity) outcomes in semi-structured narrative format into structured and categorized format, allowing for future research or clinical use.
Methods:
135,062 Trans-Thoracic Echocardiogram (TTE) reports were derived from 146967 baseline Echocardiogram reports and split into three cohorts: Training and Validation (n = 1075), Test Dataset (n = 98) and Application Dataset (n = 133,889). The NLP system was developed and iteratively refined using medical expert knowledge. The system was used to curate a moderate-fidelity database from extractions of 133,889 reports. A hold-out validation set of 98 reports was blindly annotated and extracted by two clinicians for comparison with the NLP extraction. Agreement, discrimination, accuracy and calibration of outcome measure extractions were evaluated.
Results:
Continuous outcomes including LVOT VTI, AV VTI, and TR Vmax exhibited perfect inter-rater reliability using intra-class correlation scores (ICC=1.00, P< 0.05) alongside high R2 values, demonstrating an ideal alignment between the NLP system and clinicians. Good level (ICC =0.75-0.9, P<0.05) of inter-rater reliability were observed for outcomes such as LVOT Diam, Lateral MAPSE, Peak E Velocity, Lateral E' Velocity, PV Vmax, Sinuses of Valsalva, and Ascending Aorta diameters. Furthermore, the accuracy rate for discrete outcome measures was 91.38% in the confusion matrix analysis, indicating effective performance.
Conclusions:
The NLP-based technique yielded good results when it came to extracting and categorising data from echocardiography reports. The system demonstrated a high degree of agreement and concordance with clinician extractions. This study contributes to the effective use of semi-structured data by providing a useful tool for converting semi-structured text to structured echo report that can be used for data management. Additional validation and implementation in healthcare settings can improve data availability and support research and clinical decision-making.
Keywords:
electronic health records
; big Data
; unstructured data
; echo report
; echocardiography analysis
; natural language processing
; data extraction
; validation
Introduction
Electronic health records (EHR) have become increasingly important as they generate more and more data leading to “Big Data” that hold key insights into disease patterns and opportunities to optimise patient treatment. However, the reliance on semi-structured data is a major barrier in using EHR. These types of data do not have a fixed structure but have some type of organisation, generally through the use of tags, labels, or metadata. While semi-structured data enables flexibility in data representation, they are limited in terms of the lack of standardisation, irregular organisation, ambiguity, and interpretation issues. Extracting useful information and integrating semi-structured data can be difficult, necessitating the use of advanced techniques such as natural language processing and data mapping. When interacting with patients, healthcare workers frequently use freeform notes to record vital details.[1]
The echo report based on echo imaging is the fundamental record of evidence for the diagnosis of a cardiovascular patient. The structure (e.g. valves, cardiac chambers and blood vessels dimensions) and functionalities (e.g. ejection fraction, global longitudinal strain) of the heart are examined and described in the echo report by the echocardiographer with a mix of semi-structured numerical data and free text descriptions. However, the extraction and generation of research data from the original document are challenging mainly due to the narrative nature of the echo report, different reporting styles of echocardiographers, differences in echo devices (reporting platforms and vendor software) and hospital specific protocol differences. As such, the extraction of structured data from semi-structured echo reports especially for statistical analyses tends to be excessively time consuming and requires tremendous effort and cost owing to its presentation as a narrative document.
While NPL models and tools were used to process data from psychiatry, X-ray radiography[2] and pathology[3] to distinguish healthy from diseased patients,[4,5] it is not frequently used in echocardiography analysis.
Whilst the retrieval of categorised data from clinical data repositories is relatively simple, not all data are available in this format. Large organisations such as the NHS typically store large amounts of information in the form of free text, within which specific categories of data (e.g. Aortic or Mitral Valve haemodynamics) cannot be easily retrieved for analysis. To enable the data contained within free text to be used for statistical analyses, it is necessary to both extract and convert that information into a structured format. However, there are significant challenges to the extraction process; summarised as a) variability of language which is often ambiguous and complex; B) lack of standardization and c) incomplete information and privacy concerns. This paper presents an approach that employs a natural language processing (NLP) system to handle variations in echocardiographic data to construct a comprehensive data repository by accurately categorising, extracting, and organising semi-structured echocardiographic data. Our study had two main aims. Firstly, we sought to create a moderate-fidelity echocardiography report database through automated data extraction and curation that has the potential to be integrated with high-fidelity datasets such as EHRs in future work, as detailed in [6] to support multimodality learning approaches.[7]
Secondly, we aimed to identify outcomes with consistently high extraction performance. This identification of robust variables is pivotal in enabling future clinical applications and the development of predictive risk scores. Through these aims, we sought to improve data management and analysis, allowing for more effective use of echocardiographic data for research and clinical applications. We validated the proposed method by comparison of the NLP extraction with clinician’s annotations on a sample of the most common Echocardiography examination type, Trans-Thoracic Echocardiogram (TTE). Finally, the approach is scaled to extract all available Echocardiogram free text reports within the local hospital. In the next section we report some related work.
Related Work
In [8], NLP algorithms were created and verified to identify Aortic stenosis (AS) cases from echocardiography reports and compare their precision to diagnosis codes. The promise of NLP for enhancing case identification in population health was demonstrated by the NLP algorithms' greater accuracy in detecting AS cases than diagnostic codes. An approach for obtaining numerical test results and associated descriptions from free-text echocardiogram reports was proposed in another study.[9] The system efficiently handled typos, synonyms, and abbreviations by using corpus-independent algorithms and fuzzy matching to detect and pair expressions with measurement results. It was useful for processing large numbers of echocardiographic findings and showed potential for assisting medical research or clinical trial verification. In a different study, a method for turning heterogeneous echocardiographic medical notes into structured data based on NLP was provided.[10] The researchers developed a unique NLP-based extraction and processing programme, EchoInfer, to automate the extraction and organisation of the 80 frequently evaluated echocardiogram data items. By converting unstructured, semi-structured, and structured data from echocardiograms into a format compatible with traditional analytical techniques, EchoInfer's effectiveness and consistency were established. Another study evaluated the generalizability of Left Ventricular Ejection Fraction (LVEF) extraction modules using a data set known as the TUCP EF year 3 corpus (including Echocardiography and Radiology data reports).[11] The features for detecting LVEF information were examined, and NLP techniques based on a machine learning sequential tagger were deployed. The work made contributions by assessing how well previous LVEF extraction modules performed on the new corpus and by examining how the amount of training data influenced the accuracy of the new NLP modules. Another study showed that NLP may be used to reliably to categorise Stress echocardiography (SE) data and extracted variables that were frequently utilised in stress testing score models.[12] By synthesising data elements from the reports, the NLP system produced a valid summary and demonstrated high accuracy in criteria validity when compared to the reference standard. Construct validity was also evaluated,[12] and the results demonstrated that, in line with prior findings, NLP-derived SE results effectively distinguished patients at short-term cardiac risk.
Previous research has mostly concentrated on extracting predefined outcomes from echocardiographic records. There have only been two published studies that integrated corpus-specific knowledge for complete extraction of measurement outcomes.[9,10] Few studies have applied automated conversion of units to a standardised dictionary-specified format. In addition, few studies have clinically applied the data extraction approach within the National Health Service (NHS) settings utilising efficient EHR database extraction and data loading processes for maximising the availability of structured echo report results.
Materials and methods
The register-based cohort study using de-identified patient data is part of a research approved by the Bristol Heart Institute and a need for patients’ consent was waived. Reporting of results follows the TRIPOD statement.
Dataset
The study was performed using the University Hospitals Bristol and Weston NHS Foundation Trust (UHBW) Echocardiogram dataset, which comprises UHBW Echocardiogram reports prospectively stored by UHBW following patient examinations. Cardiac resynchronisation optimisation echo, 3D TTE, TTE with contrast agents, Stress Echocardiogram with and without dobutamine and contrast agents and Trans-Oesophageal Echocardiogram (TOE) cases were excluded, resulting in a total of 135062 TTE reports for analysis. This study was performed using data from all TTE echocardiogram examinations across the UHBW from January 2009 to November 2020. 200 routinely reported Echocardiography outcomes measurements were extracted by the system at baseline. All names and demographics were removed from the echocardiography reports and corresponding metadata.
Although obtaining true labels for examination results through manual annotation can be a laborious process, two cardiologists undertook the task of blindly labelling of 98 reports from this TTE cohort to extract examination results for 43 of the most clinically relevant (35 continuous and 8 discrete) outcomes as the gold standard for the test dataset (Table 1). Differences in extraction were resolved by the lead cardiologists. Variables extracted by the cardiologists was on the same unit scale as that within the original echocardiography report.
The dataset was split into three cohorts: Training and Validation (n = 1075), Test Dataset (n = 98) and Application Dataset (n = 133,889). The primary evaluation criteria were discrimination, calibration, and overall accuracy of the NLP system in the extraction of TTE echocardiogram variables into the structured format.
Data Exploration
A list of common occurring words, but which are not specifically Echocardiogram variable related, in the Echocardiogram examination reports was curated (see supplementary materials Figure S 1). This list was entered into the high dimensionality Cluto clustering toolkit as exclusion criteria algorithm along with the training/validation dataset to identify important variables within the current context.[13] Hierarchical Clustering was utilised to cluster variables that showed a high degree of similarity across documents.
The clustering was analysed using i) automatic clustering (Figure S 2), allowing the algorithm to determine the appropriate detailed level clustering structure and ii) using a clustering size of 3 to show higher level similarities across variables (Figure S 3). Due to the high dimensionality of the heatmap, Ghostscript interpreter was used to visualise the heatmap. This exploratory analysis, along with echocardiography expertise was used to guide the categorisation of system extraction components including the JAPE rules (as discussed later).
An analysis of variations across Echocardiogram variables was then conducted for all 200 outcome variables (Table 2). The underlined textual elements show features that are taken into account during the text annotation and extraction process.
Model Development
The model was developed with the Java and GATE NLP framework using the Eclipse development environment. The JAPE Transducer was included to enable mapping of input text to output text to enable other components to be integrated as part of the processing pipeline. We used the GATE tokenizer, which separates the input text into discrete tokens that represent individual meaningful language components, such words or punctuation. The sentence splitter was then used to separate the text into individual sentences based on sentence boundaries identified by the output of the tokenizer (Figure 1).
We then used the Java Annotation Patterns Engine (JAPE, as explained further later on) to establish unique annotation rules over the text. We were able to define and match particular token patterns (combinations) using JAPE rules, applying new annotations based on the patterns discovered.
In addition, we used gazetteers,[14] referred to herewithin as dictionaries, which are standardised groupings of terms or phrases associated with a specific topic. Gazetteers contributed to improving the tokenization process by ensuring proper treatment of Echocardiography terms, levels of severity and exclusion topics that could not have been adequately captured in the general language corpora or Tokeniser. The JAPE rules and dictionaries were developed for 200 Echocardiography examination outcomes.
Furthermore, our technique is cross data repository compatible, enabling direct extraction to any specified data repository within the same distributed NHS network.
JAPE (Java Annotation Patterns Engine) is a rule-based language that is used in GATE to extract information from text. JAPE rules provide patterns and actions for detecting linguistic patterns in text and creating or modifying annotations.[14] These rules are carried out in a sequential manner, specified by their priority to resolve overlapping annotations. GATE JAPE rules were further used to extract the corresponding numerical (integer or float) or qualitative categorisation values of each variable. Some examples are provided in Table S 1.
For example, Aortic regurgitation (AR) level was defined quantitatively as integers with the following criteria: 0 – no regurgitation; 1 – Trivial regurgitation; 2 – Mild regurgitation (Or Trivial-mild); 3 – Moderate regurgitation (Or Mild-Moderate); 4 – Severe regurgitation (Or Moderate-Severe), while Left Ventricular (LV) Systolic Function were defined qualitatively with the following criteria: Hyperdynamic, Normal, Borderline, Mild, Mild-Moderate, Moderate, Moderate-Severe, Severe. For continuous values that have a range scale, e.g. Ejection Fraction (EF) 45-50%, the system extracted the average of the range values (47.5%).
Apart from the ability to pattern match data variations, the JAPE rules were designed to extract numerical clinical measurement values (Table S 1). During this process, our technique automatically converts any measurement values into pre-defined scales and units, standardising to a common unit scale where appropriate. For example, an outcome reported in cm in one examination but in m in another would have been standardised to cm by multiplication of 100 in the second report if cm was the most commonly reported unit type.
A graphical user interface (GUI) option can be turned on in the system to enable real-time tracking of the extraction process and to provide explainability of the extraction process (Figure 2). Red highlighted sections of the report show the relationship annotations generated through the JAPE rules for associating outcomes with their measurements.
The JAVA interface then enables the extraction of these annotations for matching and inserting into the corresponding table columns in the Microsoft SQL server database. The NLP model was iteratively refined using the training and validation dataset using echocardiography expert knowledge to drive human in the loop reinforcement-based improvements. Microsoft SQL server database was used for storing and loading raw and extracted reports through an interface with the main Java application.
Statistical analysis and Validation
The results for the aggregated mean and standard deviation of each continuous variable for both the doctor and NLP extractions were reported in the exploratory and calibration analysis. Additionally, Coefficients of determination (R2) and intraclass correlation coefficients (ICC)[12,16,17,18] with p-value for continuous variables were calculated. ICC is a measure of interrater reliability and was categorised as poor: < 0.5; moderate: 0.5-0.75; good: 0.75-0.9 and excellent: >0.9.[19]
The magnitude calibration of the variable values in the dataset was visualised using bubble plots. The x and y positions in these plots were determined by the total (combined) magnitude of the values across all test dataset reports for each outcome, and the size of the circles indicated how frequently the variable values occurred.
For the performance evaluation of discrete variables, we adopted the confusion matrix, precision-recall and the F1 score. The confusion matrix was determined to evaluate the system’s overall accuracy, while precision and recall values were applied to evaluate how accurately the system identified positive cases (presence of measurements) while avoiding false positives (measurement extracted where not actually present) and false negatives (measurement missed in the extraction process), respectively. Rare outcomes were aggregated to prevent undefined (NaN) values that would otherwise prevent calculation of precision and recall values. F1 score was utilised for evaluation of the overall performance of positive case extraction.
Practical System Application
Once development was complete, the system was installed onto the central hospital server and utilised to process the automated extraction for 133962 separate TTE reports (Application Dataset).
Results
Demographics
A total 146967 Echocardiogram examinations were conducted on 78536 patients within UHBW during the study period at baseline. Cardiac resynchronisation optimisation echo, 3D TTE, TTE with contrast agents, Stress Echocardiogram with and without dobutamine and contrast agents and Trans-Oesophageal Echocardiogram (TOE) cases were excluded, resulting in 135062 reports. The pre-processing of data has been described previously in the methods section. A patient flow consort diagram is shown in Supplementary Materials, Figure S 4. Baseline differences in Echocardiogram variables between clinician and algorithm extractions are shown in Table 3.
Using coefficients of determination (R2) and intraclass correlation coefficients (ICC) for continuous outcomes, the effectiveness of the system for outcome measures extraction was assessed (Table 4). Variables including LVOT VTI, LVOT Vmax, AV VTI, and TR Vmax showed R2 values of 1, demonstrating a perfect fit between the predictions of the system and the clinicians’ extractions. Of these outcomes, LVOT VTI, AV VTI, and TR Vmax exhibited perfect ICC scores (1.00, P< 0.05) alongside high R2 values, demonstrating ideal agreement between the system and clinicians.
The ICC results demonstrated a good level of inter-rater reliability for numerous outcomes. ICC values of 0.75-0.9 were observed for variables such LVOT Diam, Lateral MAPSE, Peak E Velocity, Lateral E' Velocity, PV Vmax, Sinuses of Valsalva, and Ascending Aorta diameters. Furthermore, with excellent ICC scores (0.97b, 0.99b, 0.92b, and 0.90b, respectively) and high R2 values, the outcomes LA Area, LA Volume, RA Area, and Peak A Velocity demonstrated excellent inter-rater reliability across the system and clinicians’ extractions.
For outcomes with very low R and ICC values e.g. Aortic Valve max Pressure Gradient (AV max PG), we analysed the reports in detail and discovered that the reason for low observed performance was due to the following factors: i) the system extracted the correct values, but the clinicians missed such values (Figure 3, green annotations) possibly due to incorrect recording by the echocardiographer. In this case the “38 9” should likely be recorded as “38.9” instead when considering the correct scale required; ii) the echocardiographer used the wrong terminology (e.g. incorrectly using Peak transvalvular velocity to describe AV max PG, Figure 3, purple annotations);
iii) due to low number of cases – there were only 7 AV max PG positive cases recorded by the clinician out of 98 documents in the test dataset. Hence, non-system induced errors (e.g. from i) and ii)) can inflate the perceived underperformance of the system.
In the bubble plot, larger bubbles represent frequently occurring outcomes across all reports in the test dataset, while smaller bubbles represent less frequent outcomes (Figure 4). The bubble plot demonstrates that the LA area, located close to the plot's centre, is represented by the largest circle. This shows that the LA area is the variable that is most frequently extracted. Other variables with substantial circle sizes include LA volume, Lateral E' velocity, and RA area, indicating that they are also frequently extracted by the NLP system.
The centres of circles of the bubbles in the bubble plot are closely aligned to the diagonal line from the origin, indicating that the system and clinician extractions are well calibrated overall. However, certain variables, including EF, AR PHT, and TR max PG were below the diagonal line, suggesting under-extraction by the system compared to the clinician.

Table 5.
Precision Recall results for discrete variables sets in the test dataset.
| Outcome | TP | FN | FP | TN | precision | recall | F1 Score |
|---|---|---|---|---|---|---|---|
| AR level | 24 | 3 | 4 | 67 | 0.86 | 0.89 | 0.87 |
| LV Systolic Function | 12 | 17 | 3 | 66 | 0.80 | 0.41 | 0.55 |
| MV Regurgitation Level | 59 | 2 | 1 | 36 | 0.98 | 0.97 | 0.98 |
| AV+MV+PV+TV Stenosis | 5 | 4 | 8 | 375 | 0.38 | 0.56 | 0.45 |
| TR Level | 57 | 32 | 2 | 105 | 0.97 | 0.64 | 0.77 |
Using precision, recall, and F1 score metrics, we assessed the effectiveness of the system for extracting discrete outcome measures.
Aortic Regurgitation (AR) Level
The system showed a precision of 0.86 and a recall of 0.89 for the identification of AR levels. Only 3 occurrences (false negatives) were missed while accurately identifying 24 true positive situations. The system generated 4 instances of false positives. The final F1 score was 0.87, demonstrating a performance that was balanced across recall and precision.
LV Systolic Function
The NLP algorithm achieved a precision of 0.80 and a recall of 0.41 for the classification of Left Ventricular (LV) Systolic Function. While missing 17 occurrences (false negatives), it accurately recognised 12 true positive cases. Three false positive cases were produced by the algorithm. In this situation, there was a trade-off between precision and recall, as indicated by the F1 score of 0.55.
MV Regurgitation Level
The NLP algorithm performed exceptionally in the detection of Mitral Valve (MV) Regurgitation levels. With a precision and recall of 0.98 and 0.97, respectively, it was able to correctly identify 59 true positive cases while producing only 2 false negatives. One false positive case was obtained by the algorithm. The final F1 score was 0.98, which represents a strong overall performance.
AV+MV+PV+TV Stenosis
The Aortic Valve (AV), Mitral Valve (MV), Pulmonic Valve (PV), and Tricuspid Valve (TV) Stenosis levels extractions were aggregated since occurrences were rare and were classified with moderate precision and recall by the system. The precision and recall were 0.38 and 0.56, respectively. 5 true positive cases were accurately recognised by the algorithm, whereas 4 false negative cases were missed. It produced 8 instances of false positives. The F1 score for this result was 0.45, indicating a performance that was reasonably balanced between recall and precision.
TR Level
The system displayed high precision and moderate recall for classifying extractions of Tricuspid Regurgitation (TR) levels. It achieved a precision of 0.97 and a recall of 0.64. 32 instances (false negatives) were missed by the system, while 57 true positive cases were successfully identified. It obtained 2 false positive cases. The F1 score for this result was 0.77, indicating a favourable balance of precision over recall.
Figure 5.
Confusion matrix analysis of classification performance for discrete variable sets. system (Predicted) is shown on the y-axis while the clinicians (Actual) is shown on the x-axis. Accuracies are shown in green and errors in red. % represent percentage of total.
Figure 5.
Confusion matrix analysis of classification performance for discrete variable sets. system (Predicted) is shown on the y-axis while the clinicians (Actual) is shown on the x-axis. Accuracies are shown in green and errors in red. % represent percentage of total.
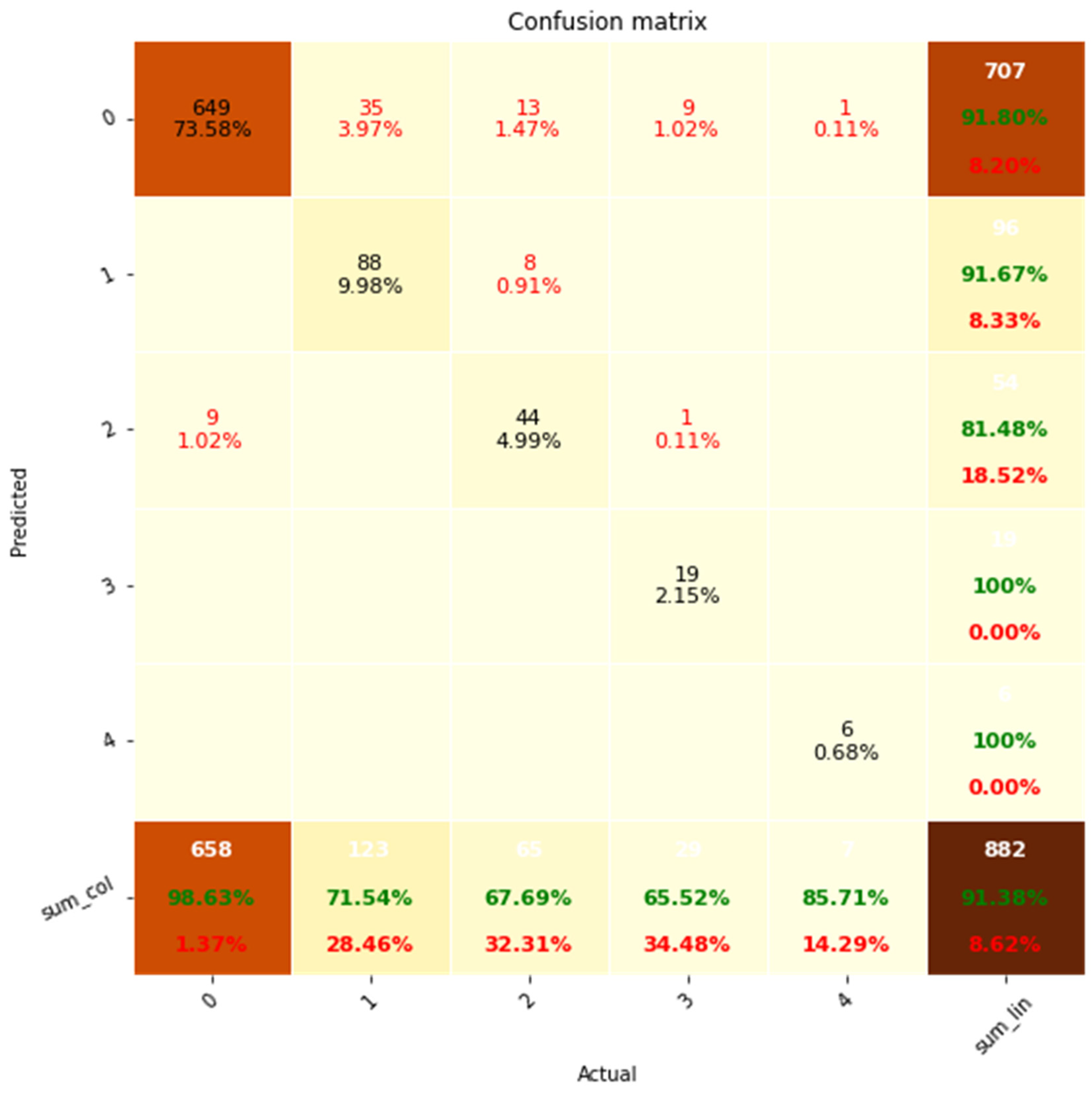
The confusion matrix exhibits a predominant pattern where the extractions align diagonally from the top left to the bottom right, indicating a high degree of correct classification. Out of the 882 instances evaluated, the NLP system achieved an accuracy rate of 91.38%. The remaining 8.62% of errors primarily consisted of false negatives, accounting for 7.6% of the total. Conversely, false positives constituted only 1.02% of the errors.
Discussion
This study presents the use of a GATE-based system for extracting outcomes from TTE echocardiogram reports, with a special emphasis on capturing both discrete and continuous variables. Most of the rule-based research in the field of NLP in healthcare have focused on general clinical text, methodology or specific medical domains, with limited exploration in the context of echocardiography reports or the use of GUI based interface to interpret extraction.[15,16,17,18,18,20,21,22,23,24] To the best of our knowledge, this is one of the first studies to use a GATE-based NLP system for TTE echocardiogram extraction, adding to the understanding of natural language processing (NLP) in this area.
Our study set out to achieve two separate aims that aligned to increase the management and utility of echocardiographic data. First, we attempted to create a moderate-fidelity echocardiography report database by utilising automated data extraction and curation. The intention to integrate this with high-fidelity datasets, exemplified in [6], highlights the potential of multimodality learning strategies.[7]
Our analysis also included identifying outcomes with consistently high extraction performance. The selection of robust variables is paramount since it provides the foundation for potential clinical applications and the development of predicted risk scores. These two initiatives are aligned, aiming to improve data utilisation, ultimately enabling more efficient use of echocardiographic data in both research and clinical contexts.
Technical Perspective
While studies have generally evaluated outcomes irrespective of the data type, this study presents an evaluation pipeline for considering discrete and continuous outcomes using their own respective sets of evaluation metrics. A recent study demonstrates that, for both discrete and sequential datasets, discrete-feature approaches outperformed sequential time-series (continuous variable) methods.[25] This finding contrasted with conventional assumptions and emphasised the importance of integrating discrete data, which is consistent with our exploration of diverse variable types in echocardiography reports. Another study highlighted the advantages of translating datasets into appropriate formats, by comparing continuous (Visual analogue scales) against discrete (Verbal Descriptor Scales) rating scales.[26] It was found that both continuous and discrete rating scales gave similar performances in terms of inter-rater reliability. However, raters were found to prefer the continuous scale. This is consistent with our work to efficiently classify and handle data from echocardiogram reports using either continuous or qualitative rating scales, where appropriate.
In relation to our NLP-system study, applying insights from the broader deep learning domain's debate on merging discrete and continuous processing has important implications as indicated in [27]. The inherent role played by discrete symbols in human communication coincides nicely with the language of medical reports and allows for nuanced comprehension of discrete outcome rating scales. The idea that discrete symbols need context-expansion by incorporating continuous scale outcomes resonates with the explanative nature of the latter type of data. This data framework of integrating discrete and continuous data parallels the structured data generated from the NLP system in this study.
There are numerous methods to mix continuous and discrete processing in ways that support gradient-based learning in addition to attention mechanisms. It is common practise to use policy gradients,[28] a technique for backpropagation through discrete decisions.[29] A differentiable method for choosing distinct categories in a sampling setting is provided by reparameterization techniques such as the Gumbel-Softmax distribution.[30] Modelling a categorical probability distribution over the discrete elements, determined by the continuous input, is also a popular technique for converting continuous representations into discrete outputs (Bengio et al., 2003).[25,31] On the other hand, discrete elements (such as word tokens or actions) can be transformed into continuous representations by locating the appropriate token (feature) vector from its matrix embeddings using the corresponding token index.
It has also been suggested that composable neural module networks (NMN) might be advantageous for combining continuous and discrete information.[32,33] These modules can be combined into intricate networks according to the computations required to respond to natural language queries. They are specialised for specific subtasks. By concentrating on training component modules and learning how to combine them, this method minimises the need to relearn for every type of issue. The JAPE rules as part of the JAVA interfacing NLP system in this study have similarities in principle to the methodology for composing NMNs modules,[34] and may provide the basis for integrating neural based approaches to TTE Echocardiogram extraction systems in an interpretable manner. For studies have generally focusing on image based problems, the attention module generally prefer the use of attention extracted from Convolution Neural Networks.[35,36] Recurrent and Transformer Neural Networks may be more suitable to model text and non-text based sequential interactions,[37] with latter able to excel in modelling long term dependencies, through parallel processing and self-attention to capture relationships across input all input features simultaneously.
Relevance to clinical practice
Cardiac surgery perspective
In addition to its applications within the context of echocardiography reports, the NLP system may have potential for broader clinical implications and research opportunities. Preoperatively, the algorithm offers the possibility of identifying critical parameters from echo data that could act as “red flags,” prompting surgeons to prioritize surgery for patients with specific aortic diameters or valve hemodynamics. This functionality may assist surgeons in managing surgery waiting lists more efficiently.
Following surgical interventions, the system’s functionalities may extend to the post-operative phase, assisting clinicians to promptly identify issues related to structural valve degeneration and adjust the frequency of monitoring accordingly. Furthermore, the algorithm may play a potential role in addressing challenges like patient-prosthesis mismatch, enabling clinicians to make informed decisions for clinical interventions and facilitating audits for quality control purposes.
The System’s applicability includes not only echocardiography report analysis but also other types of investigative modalities. For instance, the system’s capabilities might be increased to examine computer tomography (CT) results and aid aortic surveillance initiatives. Additionally, the system’s potential to integrate with risk modelling approaches to automate text extraction and identify risks holds potential for advancing research projects in cardiac care.
Cardiologist Perspective
Ability to extract echo data for reports using NLP would have significant benefits to managing a range of patients including those with valvular heart disease, heart failure and ischaemic heart disease. As workflows in clinical practice become more automated it is crucial to be able to prioritise and manage referrals and outpatient waiting lists. Being able to identify patients who have had a significant worsening of their valvular heart disease or cardiac function in a way that doesn’t increase the administrative burden of reviewing every echo report would be extremely appealing to cardiologists. This tool also has great potential for research and audit. For instance, to be able to track rates of change of aortic stenosis over time or monitoring aortic root dimensions.
This tool can integrate both the quantitative and qualitative data from an echo report which is crucial in optimal management of these patients.
Limitations and future work
Future work shall investigate the comparison of ICD-10 diagnostic codes against NLP for detecting cardiac diseases in the evaluation of this patient cohort.[8] Due to the cost in terms of time and effort required for clinicians to manually annotate and extract the validation labels, limited number of evaluation samples were available. Thus, future work should seek to obtain a larger sample of labelled validation samples from the entire hospital extracted set. It would also be interesting to refine the categorization process to capture more nuanced information from echocardiography reports. This could involve identifying and extracting specific details related to different cardiac conditions e.g. Heart Failure. Future work should also further improve the NLP system compatibility with existing electronic health record systems to seamlessly integrate with healthcare IT infrastructure for wider adoption, possibly with a web-based view of the extracted data to enable echocardiographers or clinicians to perform quality inspections and manually modify the extracted data. Application of Cluto based clustering using graph representations are possible but were not investigated. This and similar approaches would be interesting to analyse in future studies.[13,38] While the approach has also been developed for extracting Magnetic resonance imaging (MRI) unstructured data, future work should identify clinicians with expertise for curating the validation labels in this type of device. Certain variables such as LVOT Vmax showed high R2 correlation but low ICC scores, suggesting that the scalar value of the NLP system extraction is correct but potentially on a different unit scale to that extracted by the clinician. Future work should aim to develop a plugin to the existing system to convert the clinician extraction to the NLP system unit scale. The mean values for some continuous outcomes extracted by the system were lower than those by the cardiologists, suggesting that any differences are more likely due to false negative than false positive findings. Although any improvements in extraction process would still be limited by the accuracy of the initial report, standardising the reporting of Echocardiography across different vendors, national and international societies would be beneficial. Future work should also aim to further develop the approach using hybrid (machine learning plus rule-based) approaches to enhance existing variables with relatively lower extraction performance. For example, the combination with NMN-based approaches through reinforcement learning to select modules may encapsulate greater variations in outcome terminologies across different hospital locations. It would also be interesting to incorporate fuzzy[9], foundation learning and reinforcement based approaches on a larger local validation cohort to further improve the modelling performance. Future work should also consider analysing data extracted from echocardiography reports over time to track disease progression and treatment outcomes. One should also aim to validate the NLP system’s performance in diverse patient populations to ensure that it can effectively handle variations in language and medical terminology.
Conclusions
In summary, this study offers a novel application of the GATE-based system in the extraction of echocardiogram report data to curate a moderate fidelity TTE Echocardiogram database that could be used for multi-fidelity data fusion. The study contributes to the understanding of NLP in the context of echocardiography by addressing both approaches for discrete and continuous outcomes. These findings emphasize the valuable contribution of NLP in automating data extraction and improving clinical decision-making processes. By bridging the gap between structured and semi-structured healthcare data, our approach holds promise for advancing research, risk prediction, and patient care in the realm of echocardiography and beyond.
Contributorship
T.D., and U.B. contributed to experimental design. T.D., N.S. and M.W. acquired data. T.D. performed the data preprocessing. T.D. wrote the source code to perform the experiments, and are accountable for all aspects of the work. T.D., N.S, A.N, D.P.F, J.C, B.Z, A.F, M.C, A.D, M.W, U.B. and G.D.A analyzed the results. T.D. wrote the first version of the paper. All authors revised the paper and approve the submission.
Funding
No funding was received to carry out this work.
Data availability
All data used in this study are from the UHBW and can be provided upon on reasonable request subject to regulatory approval.
Acknowledgements
We are grateful to Philip Harfield and Tom Johnson for initial meetings on the project.
Competing Interests
All authors declare that there are no competing interests.
Ethics statement
This study used de-identified data and so the requirement for Research Ethics Committee approval and participant informed consent were waived by the University Hospitals Bristol and Weston NHS Foundation Trust (UHBW).
Guarantor TD.
Code availability
Code for the system is available on GitHub: https://github.com/s0810110/neoImage/tree/neoImage_v-1.1 and validation: https://github.com/s0810110/neoImageClinicalValidation; access can be provided upon reasonable request with the main author. Analyses were performed using JAVA.
References
- Thompson J, Hu J, Mudaranthakam DP, et al. Relevant Word Order Vectorization for Improved Natural Language Processing in Electronic Health Records. Sci Rep 2019;9:9253. [CrossRef]
- Zhang Y, Liu M, Hu S, et al. Development and multicenter validation of chest X-ray radiography interpretations based on natural language processing. Commun Med 2021;1:1–12. [CrossRef]
- Kim Y, Lee JH, Choi S, et al. Validation of deep learning natural language processing algorithm for keyword extraction from pathology reports in electronic health records. Sci Rep 2020;10:20265. [CrossRef]
- Morgan SE, Diederen K, Vértes PE, et al. Natural Language Processing markers in first episode psychosis and people at clinical high-risk. Transl Psychiatry 2021;11:1–9. [CrossRef]
- Dickerson LK, Rouhizadeh M, Korotkaya Y, et al. Language impairment in adults with end-stage liver disease: application of natural language processing towards patient-generated health records. npj Digit Med 2019;2:1–7. [CrossRef]
- Liu L, Zhang C, Tao D. GAN-MDF: A Method for Multi-fidelity Data Fusion in Digital Twins. 2021.http://arxiv.org/abs/2106.14655 (accessed 13 Apr 2023).
- Liu Z, Yin H, Chai Y, et al. A novel approach for multimodal medical image fusion. Expert Systems with Applications 2014;41:7425–35. [CrossRef]
- Large-scale identification of aortic stenosis and its severity using natural language processing on electronic health records - ScienceDirect. https://www.sciencedirect.com/science/article/pii/S2666693621000256 (accessed 20 Jun 2023).
- Szekér S, Fogarassy G, Vathy-Fogarassy Á. A general text mining method to extract echocardiography measurement results from echocardiography documents. Artificial Intelligence in Medicine 2023;143:102584. [CrossRef]
- Nath C, Albaghdadi MS, Jonnalagadda SR. A Natural Language Processing Tool for Large-Scale Data Extraction from Echocardiography Reports. PLOS ONE 2016;11:e0153749. [CrossRef]
- Kim Y, Garvin JH, Goldstein MK, et al. Extraction of left ventricular ejection fraction information from various types of clinical reports. J Biomed Inform 2017;67:42–8. [CrossRef]
- Zheng C, Sun BC, Wu Y-L, et al. Automated interpretation of stress echocardiography reports using natural language processing. European Heart Journal - Digital Health 2022;3:626–37. [CrossRef]
- Kim Y, Riloff E, Meystre SM. Exploiting Unlabeled Texts with Clustering-based Instance Selection for Medical Relation Classification. AMIA Annu Symp Proc 2018;2017:1060–9.
- Cunningham H, Tablan V, Roberts A, et al. Getting More Out of Biomedical Documents with GATE’s Full Lifecycle Open Source Text Analytics. PLoS Comput Biol 2013;9:e1002854. [CrossRef]
- Khalifa A, Meystre S. Adapting existing natural language processing resources for cardiovascular risk factors identification in clinical notes. Journal of Biomedical Informatics 2015;58:S128–32. [CrossRef]
- Yeung A, Iaboni A, Rochon E, et al. Correlating natural language processing and automated speech analysis with clinician assessment to quantify speech-language changes in mild cognitive impairment and Alzheimer’s dementia. Alz Res Therapy 2021;13:109. [CrossRef]
- Rahman M, Nowakowski S, Agrawal R, et al. Validation of a Natural Language Processing Algorithm for the Extraction of the Sleep Parameters from the Polysomnography Reports. Healthcare 2022;10:1837. [CrossRef]
- Cohen AS, Rodriguez Z, Warren KK, et al. Natural Language Processing and Psychosis: On the Need for Comprehensive Psychometric Evaluation. Schizophrenia Bulletin 2022;48:939–48. [CrossRef]
- Koo TK, Li MY. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J Chiropr Med 2016;15:155–63. [CrossRef]
- Yang H, Spasic I, Keane JA, et al. A Text Mining Approach to the Prediction of Disease Status from Clinical Discharge Summaries. J Am Med Inform Assoc 2009;16:596–600. [CrossRef]
- Cunliffe D, Vlachidis A, Williams D, et al. Natural language processing for under-resourced languages: Developing a Welsh natural language toolkit. Computer Speech & Language 2022;72:101311. [CrossRef]
- Blandón Andrade JC, Zapata Jaramillo CM, Blandón Andrade JC, et al. Gate-based Rules for Extracting Attribute Values. Computación y Sistemas 2021;25:851–62. [CrossRef]
- Digan W, Névéol A, Neuraz A, et al. Can reproducibility be improved in clinical natural language processing? A study of 7 clinical NLP suites. Journal of the American Medical Informatics Association 2021;28:504–15. [CrossRef]
- Amato F, Cozzolino G, Moscato V, et al. Analyse digital forensic evidences through a semantic-based methodology and NLP techniques. Future Generation Computer Systems 2019;98:297–307. [CrossRef]
- Drousiotis E, Pentaliotis P, Shi L, et al. Balancing Fined-Tuned Machine Learning Models Between Continuous and Discrete Variables - A Comprehensive Analysis Using Educational Data. 2022. 256–68. [CrossRef]
- Belz A, Kow E. Discrete vs. continuous rating scales for language evaluation in NLP. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers - Volume 2. USA: : Association for Computational Linguistics 2011. 230–5.
- Cartuyvels R, Spinks G, Moens M-F. Discrete and continuous representations and processing in deep learning: Looking forward. AI Open 2021;2:143–59. [CrossRef]
- Sutton RS, McAllester D, Singh S, et al. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In: Advances in Neural Information Processing Systems. MIT Press 1999. https://papers.nips.cc/paper_files/paper/1999/hash/464d828b85b0bed98e80ade0a5c43b0f-Abstract.html (accessed 7 Aug 2023).
- Hu R, Andreas J, Rohrbach M, et al. Learning to Reason: End-to-End Module Networks for Visual Question Answering. 2017. [CrossRef]
- Maddison CJ, Mnih A, Teh YW. The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net 2017. https://openreview.net/forum?id=S1jE5L5gl (accessed 7 Aug 2023).
- Bengio Y, Ducharme R, Vincent P, et al. A Neural Probabilistic Language Model.
- Johnson J, Hariharan B, Van Der Maaten L, et al. Inferring and Executing Programs for Visual Reasoning. In: 2017 IEEE International Conference on Computer Vision (ICCV). Venice: : IEEE 2017. 3008–17. [CrossRef]
- Andreas J, Rohrbach M, Darrell T, et al. Learning to Compose Neural Networks for Question Answering. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, California: : Association for Computational Linguistics 2016. 1545–54. [CrossRef]
- Hu R, Andreas J, Darrell T, et al. Explainable Neural Computation via Stack Neural Module Networks.
- Mascharka D, Tran P, Soklaski R, et al. Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: : IEEE 2018. 4942–50. [CrossRef]
- Yi K, Wu J, Gan C, et al. Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding. In: Advances in Neural Information Processing Systems. Curran Associates, Inc. 2018. https://proceedings.neurips.cc/paper_files/paper/2018/hash/5e388103a391daabe3de1d76a6739ccd-Abstract.html (accessed 8 Aug 2023).
- Peng B, Alcaide E, Anthony Q, et al. RWKV: Reinventing RNNs for the Transformer Era. 2023.http://arxiv.org/abs/2305.13048 (accessed 8 Aug 2023).
- Karypis G. CLUTO - A Clustering Toolkit. 2002. http://conservancy.umn.edu/handle/11299/215521 (accessed 2 Aug 2023).
Figure 1.
Design of the NLP Echo extraction system.
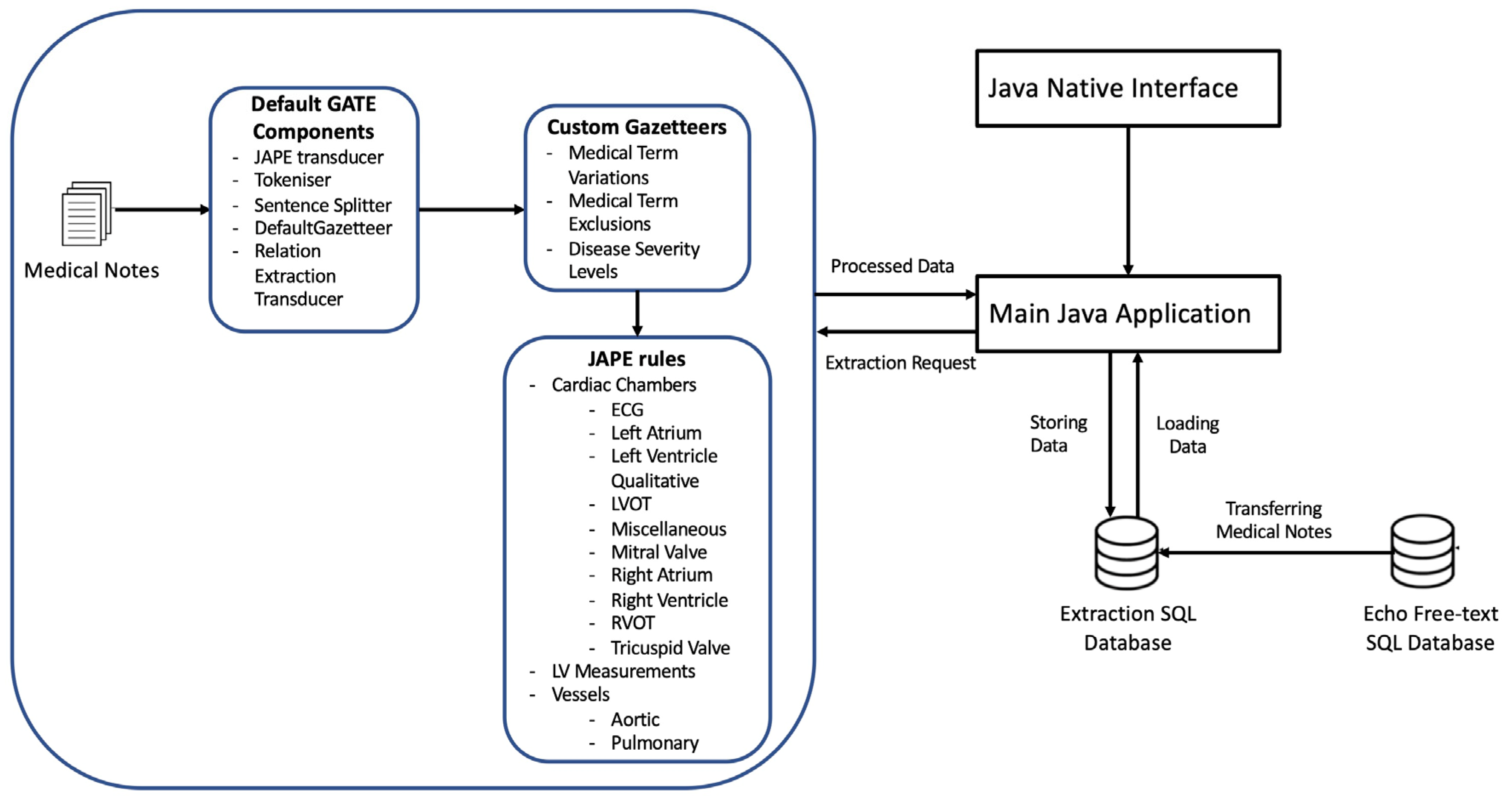
Figure 2.
Graphical user interface of system to explainability of extraction for the continuous variable, EF. varValue1 shows the lower range value if this exists; varValue2 shows the upper range value; varValue shows the average of lower and upper range values if these exist.
Figure 2.
Graphical user interface of system to explainability of extraction for the continuous variable, EF. varValue1 shows the lower range value if this exists; varValue2 shows the upper range value; varValue shows the average of lower and upper range values if these exist.
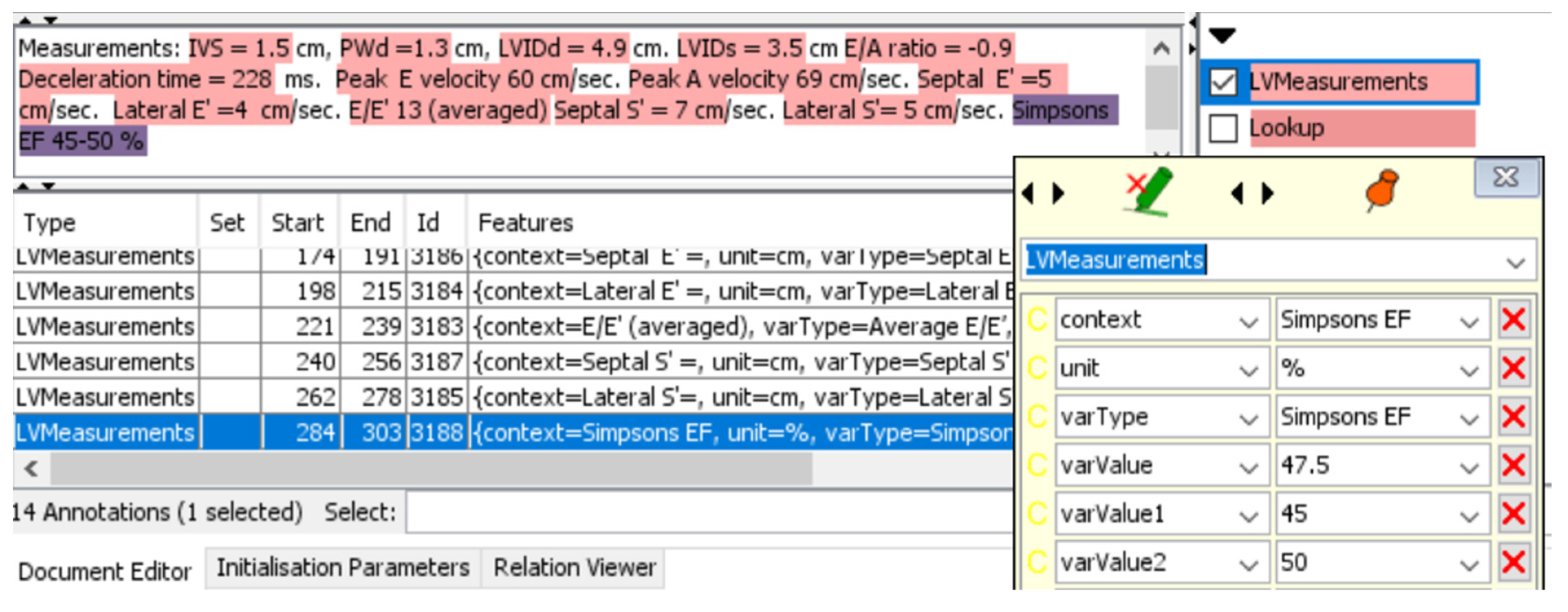
Figure 3.
In depth analysis of clinician and system extractions for AV max PG; green and pink region indicates region of features involved in the annotation process.
Figure 3.
In depth analysis of clinician and system extractions for AV max PG; green and pink region indicates region of features involved in the annotation process.

Figure 4.
Bubble plot analysis of magnitude and calibration for continuous variable sets. X-axis and y-axis show the total magnitude of extracted outcome measures for clinician and NLP, respectively. The size of circles represents the frequency of each variable extracted by the NLP system.
Figure 4.
Bubble plot analysis of magnitude and calibration for continuous variable sets. X-axis and y-axis show the total magnitude of extracted outcome measures for clinician and NLP, respectively. The size of circles represents the frequency of each variable extracted by the NLP system.
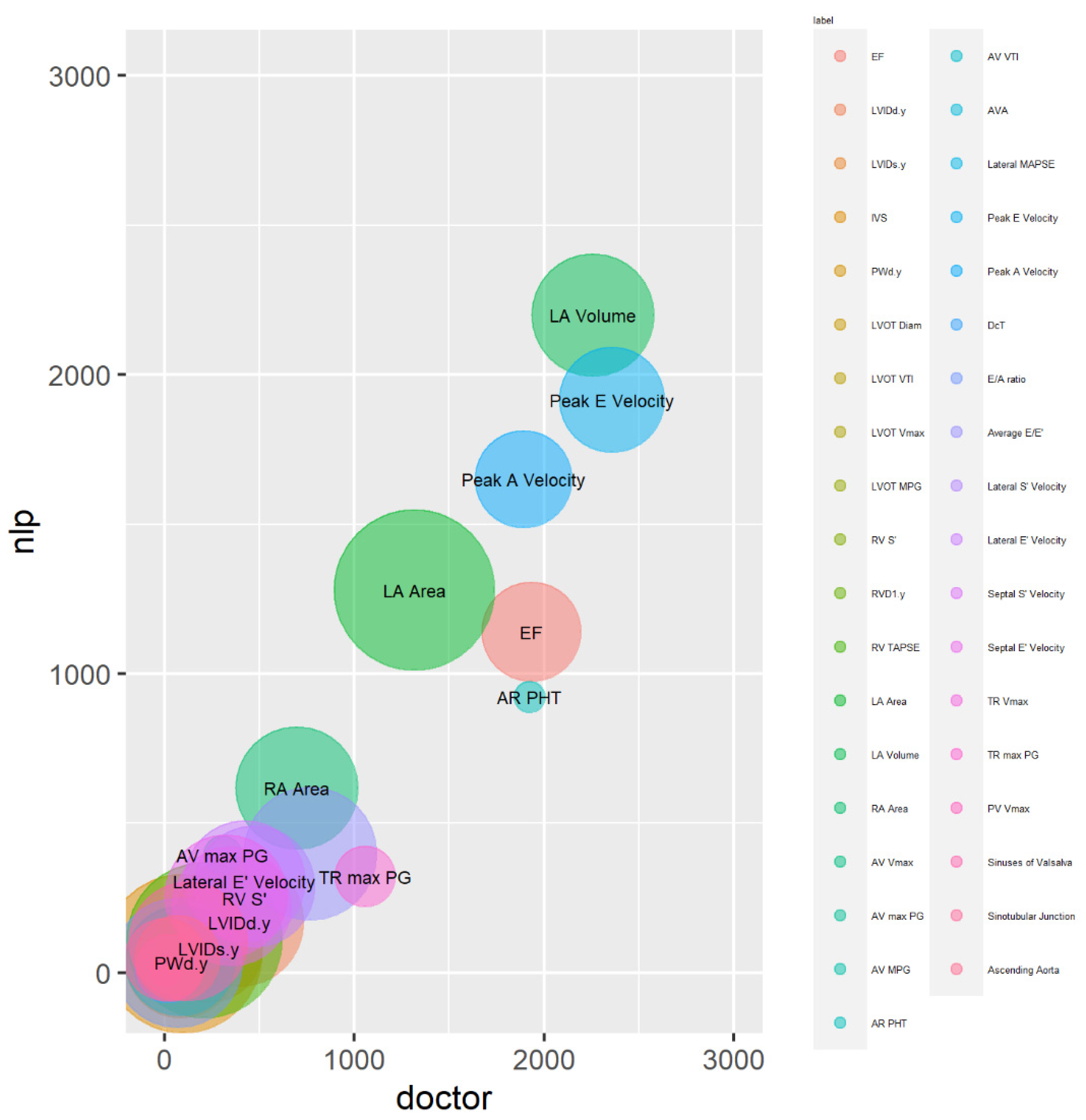
Table 1.
Abbreviations and Definitions for 43 of the most clinically relevant outcomes labelled by the two clinicians. Heart category and data type are also shown.
Table 1.
Abbreviations and Definitions for 43 of the most clinically relevant outcomes labelled by the two clinicians. Heart category and data type are also shown.
| Abbreviation Clinician | Abbreviation NLP | Definition | Category | Data Type |
|---|---|---|---|---|
| LVEF | EF | Left Ventricular Ejection Fraction | Left ventricle | Continuous |
| LVIDd | LVIDd | Left Ventricular Internal Diameter in Diastole | Continuous | |
| LVIDs | LVIDs | Left Ventricular Internal Diameter in Systole | Continuous | |
| LVSF | LV Systolic Function | Left Ventricular Shortening Fraction | Discrete | |
| IVSd | IVS | Interventricular Septum Thickness in Diastole | Continuous | |
| PWd | PWd | Posterior Wall Thickness in Diastole | Continuous | |
| LVOTd | LVOT Diam | Left Ventricular Outflow Tract Diameter | Continuous | |
| LVOTvti | LVOT VTI | Left Ventricular Outflow Tract Velocity-Time Integral | Continuous | |
| LVOTpv | LVOT Vmax | Left Ventricular Outflow Tract Peak Velocity | Continuous | |
| RV_TDI_S | RV S' | Right Ventricle Tissue Doppler Imaging S Wave | Right ventricle | Continuous |
| RVD1 | RVD1 | Right Ventricle Diameter at Basal Level | Continuous | |
| TAPSE | RV TAPSE | Tricuspid Annular Plane Systolic Excursion | Continuous | |
| LA_area | LA Area | Left Atrial Area | Left atrium | Continuous |
| LA_vol | LA Volume | Left Atrial Volume | Continuous | |
| RA_area | RA Area | Right Atrial Area | Right atrium | Continuous |
| AS_sev | AV Stenosis | Aortic Stenosis Severity | Aortic valve | Discrete |
| AR_sev | AR level | Aortic Regurgitation Severity | Discrete | |
| AVpv | AV Vmax | Aortic Valve Peak Velocity | Continuous | |
| AVpg | AV max PG | Aortic Valve Peak Gradient | Continuous | |
| AVmg | AV MPG | Aortic Valve Mean Gradient | Continuous | |
| AVpht | AR PHT | Aortic Valve Pressure Half-Time | Continuous | |
| AVvti | AV VTI | Aortic Valve Velocity-Time Integral | Continuous | |
| MS_sev | MV Stenosis | Mitral Stenosis Severity | Mitral valve | Discrete |
| MR_sev | MV Regurgitation Level | Mitral Regurgitation Severity | Discrete | |
| MAPSE | Lateral MAPSE | Lateral Mitral Annular Plane Systolic Excursion | Continuous | |
| MV_E_vel | Peak E Velocity | Mitral Valve E Wave Velocity | Continuous | |
| MV_A_vel | Peak A Velocity | Mitral Valve A Wave Velocity | Continuous | |
| MV_decT | DcT | Mitral Valve Deceleration Time | Continuous | |
| MV_Earatio | E/A ratio | Mitral Valve E/A Ratio | Continuous | |
| MV_EE_avg | Average E/E' | Mitral Valve E/E' Average | Continuous | |
| TDI_lat_S | Lateral S' Velocity | Tissue Doppler Imaging Lateral S Wave | Continuous | |
| TDI_lat_E | Lateral E' Velocity | Tissue Doppler Imaging Lateral E Wave | Continuous | |
| TDI_sep_S | Septal S' Velocity | Tissue Doppler Imaging Septal S Wave | Continuous | |
| TDI_sep_E | Septal E' Velocity | Tissue Doppler Imaging Septal E Wave | Continuous | |
| TS_sev | TV Stenosis | Tricuspid Stenosis Severity | Tricuspid valve | Discrete |
| TR_sev | TR level | Tricuspid Regurgitation Severity | Discrete | |
| TR_pv | TR Vmax | Tricuspid Regurgitation Peak Velocity | Continuous | |
| TR_pg | TR max PG | Tricuspid Regurgitation Peak Gradient | Continuous | |
| PS_sev | PV Stenosis | Pulmonary Stenosis Severity | Pulmonary valve | Discrete |
| PV_Vmax | PV Vmax | Pulmonary Valve Maximum Velocity | Continuous | |
| AO_SOV | Sinuses of Valsalva | Sinus of Valsalva | Aorta | Continuous |
| AO_STJ | Sinotubular Junction | Aortic Outflow Sinotubular Junction | Continuous | |
| AO_ASC | Ascending Aorta | Aortic Outflow Ascending Aorta | Continuous |
Table 2.
Showing example of outcome measure variations for continuous and qualitative (discrete) measurements.
Table 2.
Showing example of outcome measure variations for continuous and qualitative (discrete) measurements.
| Aortic Valve (AV) Velocity Time Integral (VTI) | AV Regurgitation Level |
|---|---|
| AV Vmax 4.2m/s MPD 46mmHg VTI 103cm | Aortic Valve (Biological AVR): AVR in situ, well seated. … No significant regurgitation. … Aorta: |
| AV Vmax 4m/s MPD 42mmHg VTI 87.9cm | Aortic Valve (Unclear imaging of AVR): … AVR seen in situ with a mild paraprosthetic regurgitation. … Aorta: |
| Ao VTI 36cm ; AVA (VTI) 1.8cm2 | Aortic Valve: … with valve type/size in situ No aortic regurgitation Right Ventricle: |
| Ao VTI 36cm ; | Aortic Valve: … No aortic stenosis. Trivial aortic regurgitation. AV Vmax: 1.6m/s. Aorta: |
| Aortic Valve: Appears Trileaflet. Thickening of LCC/ NCC with reduced mobility of these cusps. V max 2.8m/s, PPD:32mmHg, MPD:19 mmHg, VTI: 62.3 cm. | Aortic Valve (TAVI): …. No aortic stenosis/obstruction indicated. Trivial-mild paravalvular aortic regurgitation. … Aorta: |
| AV Vmax 4m/s MPD 42mmHg VTI 87.9cm LVOT 2.7cm Peak V= 0.7m/s, MPD 1.2mmHg, VTI 16.2cm | Aortic Valve: AVR in situ. …No significant obstruction/stenosis indicated. No obvious aortic regurgitation. … Aorta: |
| AV Vmax:4.8m/s, PPD: 91mmHg, MPD: 57mmHg, VTI: 107cm | Aortic Valve: … Mild eccentric paravalvular aortic regurgitation seen. Aorta: |
| AV mean PG: 54mmHg. AV VTI: 78cm. AVA VTI: 0.88cm2. AVAi VTI: 0.45cm/m2 | Aortic Valve: …. Mild transvalvular aortic regurgitation. … |
| AV VTI 61.3 cm | Aorta: Aortic Valve: … Aortic regurgitation present …Overall assessment is of mild aortic regurgitation. AV Vmax: 1.5 m/s. Aorta: |
| Ao VTI 106cm; | Aortic Valve: … ? BAV. Moderate AS. Trivial AR …. Aorta: |
| AV VTI: 78cm. | Aortic Valve: …. Overall assessment is of severe aortic regurgitation. … Aorta: |
Table 3.
Baseline patient demographics.
| Baseline Patient Total=78536 | |
|---|---|
| Age (years), mean (SD) | 59.4 (33.0) |
| Female gender, n (%) | 36959 (47.1%) |
| Mortalities, n (%) | 25048 (31.9%) |
| number of repeat Echocardiograms | |
| 1 | 53508 (68.1%) |
| 2 | 13031 (16.6%) |
| 3 | 5064 (6.4%) |
| 4 | 2675 (3.4%) |
| 5 | 1632 (2.1%) |
| 6 | 933 (1.2%) |
| 7 | 531 (0.7%) |
| 8 | 356 (0.5%) |
| 9 | 233 (0.3%) |
| >10 | 573 (0.7%) |
Table 4.
Coefficients of determination (R2) and intraclass correlation coefficients (ICC) with p-value for continuous variables; a represents Good interrater reliability 0.75-0.9; b Indicate Excellent interrater reliability 0.9-1.0.[19].
Table 4.
Coefficients of determination (R2) and intraclass correlation coefficients (ICC) with p-value for continuous variables; a represents Good interrater reliability 0.75-0.9; b Indicate Excellent interrater reliability 0.9-1.0.[19].
| Variable Name | R Squared | ICC | ICC p-value |
|---|---|---|---|
| EF | 0.47 | 0.64 | 0.00 |
| LVIDd | 0.10 | 0.18 | 0.07 |
| LVIDs | 0.14 | 0.25 | 0.04 |
| IVS | 0.31 | 0.47 | 0.00 |
| PWd | 0.39 | 0.43 | 0.04 |
| LVOT Diam | 0.70 | 0.83a | 0.00 |
| LVOT VTI | 1.00 | 1.00b | 0.00 |
| LVOT Vmax | 1.00 | 0.02 | 0.42 |
| RV S' | 0.10 | 0.29 | 0.00 |
| RVD1 | 0.07 | 0.16 | 0.05 |
| RV TAPSE | 0.11 | 0.16 | 0.05 |
| LA Area | 0.95 | 0.97b | 0.00 |
| LA Volume | 0.98 | 0.99b | 0.00 |
| RA Area | 0.86 | 0.92b | 0.00 |
| AV Vmax | 0.13 | 0.29 | 0.00 |
| AV max PG | 0.00 | 0.03 | 0.39 |
| AV MPG | 0.20 | 0.35 | 0.00 |
| AR PHT | 0.46 | 0.63 | 0.00 |
| AV VTI | 1.00 | 1.00b | 0.00 |
| Lateral MAPSE | 0.60 | 0.76a | 0.00 |
| Peak E Velocity | 0.59 | 0.76a | 0.00 |
| Peak A Velocity | 0.81 | 0.90b | 0.00 |
| DcT | 0.05 | 0.15 | 0.06 |
| E/A ratio | 0.18 | 0.36 | 0.00 |
| Average E/E' | 0.03 | 0.13 | 0.08 |
| Lateral S' Velocity | 0.49 | 0.65 | 0.00 |
| Lateral E' Velocity | 0.62 | 0.77a | 0.00 |
| Septal S' Velocity | 0.45 | 0.62 | 0.00 |
| Septal E' Velocity | 0.49 | 0.69 | 0.00 |
| TR Vmax | 1.00 | 1.00b | 0.00 |
| TR max PG | 0.30 | 0.45 | 0.00 |
| PV Vmax | 0.62 | 0.77a | 0.00 |
| Sinuses of Valsalva | 0.73 | 0.85a | 0.00 |
| Sinotubular Junction | 0.82 | 0.17 | 0.03 |
| Ascending Aorta | 0.64 | 0.78a | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



