
Submitted:
18 July 2023
Posted:
19 July 2023
You are already at the latest version
Abstract
Intelligent transportation systems (ITS) are at the forefront of advancements in transportation, offering enhanced efficiency, safety, and environmental friendliness. To enable ITS, autonomous systems play a pivotal role, leveraging breakthroughs in autonomous driving, data-driven modeling, and multiagent control strategies to establish sustainable and coordinated traffic management. The integration of connected and automated vehicles has garnered significant attention as a potential solution for alleviating traffic congestion and improving fuel economy, achieved through global route optimization and cooperative driving. This study focuses on a predictive control perspective to address the cooperative cruise control problem. Online decision-making is employed during the driving process, utilizing information gathered from the network. By employing bargaining games to establish an operating agreement among vehicles, we formalize a synchronization approach based on predictive control theory. Ultimately, these findings are put to the test in an emulation environment within a hardware-in-the-loop system.
Keywords:
emulation systems
; cooperative cruise control
; bargaining games
; predictive control
1. Introduction
As the vehicular industry continues to experience exponential growth, it is accompanied by a surge in challenges and issues, particularly concerning environmental impacts [1]. The proliferation of vehicles has led to escalating concerns such as air pollution, carbon emissions, and traffic congestion [2,3]. In response to these pressing issues, the emergence of electrical vehicles and the development of cooperative networks among vehicles have gained significant traction. Electrical vehicles offer a greener alternative by reducing greenhouse gas emissions and dependence on fossil fuels, while the concept of cooperative networks fosters synchronized and efficient traffic management, further minimizing environmental impacts [4]. These innovative solutions hold tremendous promise for mitigating the adverse effects of the expanding vehicular industry and steering transportation towards a more sustainable and environmentally conscious future [5].
In this way, Intelligent Transportation Systems (ITS) have emerged as the leading transportation technology to advance toward more efficient, safer, and greener future transportation [6]. Autonomous systems have been recognized as a cornerstone for enabling ITS through technological advances such as autonomous driving, data-driven modeling, and multiagent control strategies to achieve sustainable, coordinated traffic management. Connected and Automated Vehicles (CAVs) have received great attention as a potential way to improve traffic congestion and fuel economy through global route optimization and cooperative driving [7]. It is analyzed the challenges of cooperative, connected decision-making in multi-vehicle networks, and it is suggested that theoretical control methods should be developed in the future deployment of autonomous systems in ITS, in particular, control of multiple distributed heterogeneous vehicles. For this reason, using cooperative control strategies may help as a ITS strategy [8].
Several cooperative control approaches have recently been proposed for networked vehicles [9]. The first works focused on cruise control without employing inter-vehicle communications to improve highway comfort and energy expenditure. The rise of wireless communications allows a network of vehicles to be seen as a cooperative study case [3]. The Cooperative Adaptive Cruise Control (CCAC) concept has been developed using synchronization laws based on a reference acceleration profile [10]. The CCAC technique is based on string stability, where vehicles maintain a predefined distance at a constant speed, but it might not result in an optimal response [11]. Likewsie, in [12], a recent survey of some experimental results on cooperative control in an intelligent connected vehicle environment is presented, where the importance of cooperative control for urban mobility is emphasized. Active control methods of intelligent connected vehicles and indirect control of regular vehicles through intelligent vehicles are studied for multi-intersection coordinated heterogeneous vehicle traffic flow.
Within the active control strategies to be used with ITS, predictive control mehodologies can find the optimal values in terms of energy or performance [13]. In [14,15], distributed predictive control strategies for agent synchronization have been developed using inter-agent communication and constructing cost functions involving network information. A Model Predictive Control (MPC) problem involving different agents where decisions depend on others can be considered as a game [16]. In the same way, if these agents manage a common goal, the problem can be described as a bargaining game, with a target that modify their actions based on a disagreement between them [17,18,19]. Theoretically, the point of disagreement is defined as the minimum satisfaction expected for the negotiation. In practical implementation, cooperative cruise strategies can present several drawbacks, and only a few authors have validated these developments in highway vehicle platoons [20]. The main practical tests of the theories explained are usually validated in dynamic emulation models or robot networks [21,22].
For initial test of vehicular applications, The emulation of dynamic systems in hardware-in-the-loop (HIL) enables the validation of real-time methods in situations where the models are unavailable (e.g., autonomous vehicle network). Emulation hardware based on embedded systems is used as a dynamic environment simulation with predefined interaction models and a visualization interface for validating desired signals [23]. The validation of these systems is mainly given by the need to prove the algorithm’s correct operation in harsh application environments [24,25,26].
In recent works, only some results have been based on the theory of bargaining games as a problem of cooperative control in distributed systems without considering vehicle platoon emulation [27]. Other works have emulated multiagent systems without considering the application of predictive control techniques or game theory in vehicles [28]. Identifying the research gap falls at the application level in the case of cooperative cruise control, where the control strategy must solve a distributed optimization problem according to the states of the agents, the point of disagreement, and the predefined cost functions for energy expenditure presets for simulation and emulation. A distributed bargaining methodology is a technique that allows managing control algorithms efficiently without increasing computational expense in the presence of the network. The main contribution of this paper is threefold: 1) First, the appropriation of a networked vehicle control problem is to be developed from a predictive perspective using bargaining methodology as far as we know, it has not been used. 2) Second, the inclusion of bargaining game theory for the cooperative control problem in simulation. This development allows it to be compared with centralized and decentralized predictive control algorithms for symmetric and non-symmetric cases. It allows observing the response in comparison with conventional methods and validate its efficiency. 3) Finally, a validation of the procedures developed in emulation with a HIL system for application.
The rest of the paper is organized as follows: Section 2 presents the cooperative cruise control and bargaining games as a tool for the background of Distributed Model Predictive Control (DMPC). Section 3 contextualizes the bargaining problem to solve the cooperative cruise problem. In Section 4, we show the study case application and its simulation. Section 5 shows the emulation of the system in HIL, and finally, Section 6 sets out the conclusions of the work.
2. Background
This section presents the basic foundations of the cooperative cruise control theory and DMPC as a bargaining game.
2.1. Cooperative Cruise Control
The cooperative cruise control problem has been extensively studied in the latest years. Recent developments have focused on wireless Vehicle-to-Vehicle (V2V) communication that has grown commercially. The wireless communication led to the definition of the Grand Cooperative Driving Challenge (GCDC) to manage a platoon of vehicles that have this technology. The main objective of cooperative cruise control is synchronizing the vehicles on the road with the traffic profile considered by an established reference. The traffic profile is commonly constituted by the inter-vehicle distance and the speed on a highway, reducing the time to transit in a highway and the fuel consumption. Communication is usually considered by the predecessor vehicle as a string stability case.
A simple description of the CACC setting (for longitudinal dynamics) is considered. In this case, each vehicle is modeled through its physical and mechanical parameters. The dynamics proposed in this case are linear as
where variables are speed v and position p, respectively. The parameters and are transmission parameters, b is related to transmission efficiency, and has the dimension of acceleration, or the force when it is multiplied by the vehicle mass. The term is associated with an input uncertainty. These parameters can be included in the dynamics due to the approximation by an invertible steady-stable time-invariant model without the presence of uncertainties [29]. This approach considerably reduces the complexity of the model without losing performance, and it has been used as an approximation in previous theories to validate this type of problem [30].
The controller must be able to regulate the speed of each vehicle and maintain a distance from its neighbors. The graphic representation of the vehicle’s platoon is shown in Figure 1, where the distance between each vehicle is defined as , that is, the difference of the position of vehicles 1 and 2 with its respective subscripts and .
Let the states of the system be , where the distance is position minus a predefined distance, and the control input with a possibly input matched uncertainty . It is possible to write the system as a linear affine continuous model of the form
with
This model considers the acceleration of neighboring vehicles in a instant. For implementation control prediction, it is necessary to use the discrete dynamics of the system. Therefore, (3) is modified as
with and .
Note that onboard sensors for controller action measure distance and speed, and the parameters of each vehicle can be different for a heterogeneous case. In the same way, it is important to consider that for the managed approximations of the cooperative cruise control theory, the considered model relates the position, inter-vehicular distance, and the speed of the vehicles in the network. In this particular application, a constant acceleration in an instant of time for each agent is the input for the developments.
2.2. Distributed Model Predictive Control with Bargaining Games
This section introduces the basic concepts of MPC from a bargaining game perspective. The control problem is contextualized as the negotiation method for solving a distributed optimization problem. The block diagram representing the framework is presented in Figure 2, where it is observed that each vehicle, through its dynamics, enters a bargaining algorithm along a prediction horizon. This algorithm generates the optimal control action and the disagreement point . This block diagram is used for non-symmetric bargaining cases. For symmetric cases, the characteristics of each vehicle are the same. All cases are regulated by regulatory aspects or physical restrictions of the vehicles to be considered.
Definition 1.
Bargaining Game A bargaining game is mathematically defined as the tuple .
In this case, N is the number of vehicles involved in the process, is the decision space of the control law, and is defined as the local cost function of each vehicle. It is assumed that the vehicles are in a negotiating position to achieve a common objective, such as Nash’s notions [31]. In the game, if it is impossible to reach an agreement, the term disagreement point is used for the bargain between vehicles [32].
Assuming the dynamics of each vehicle as in (3) and with its discrete representation (5), the particular objective is to achieve energy-level optimization in each vehicle’s operation. For this optimization problem, a distributed locally cost function is defined as
with as the representation of vehicle i states built along the prediction horizon , likewise considering the control horizon with . Each cost function is defined as
which is positive defined, convex, and where and are weighted positive definite matrices, i.e., . This cost function, by taking a conventional quadratic form, does not become the main contribution of the paper, which focuses on the application of this application in the predictive control algorithm.
For the control problem formulation, defining a decision space for the whole system according to the physical operating conditions is important. An MPC problem with communication between agents is interpreted as a bargain so that it can be a bargaining game. For the analysis and solution of this type of game, Nash proposes an axiomatic methodology [33], which was used in continuous and static systems [32].
A continuous representation for a bargaining game is with the tuple , where S is the game decision space, which is a non-empty closed subset of and is the interaction disagreement point. For implementation purposes, it is important to consider the discrete dynamics of the game, so it is then defined as with , a closed non-empty subset that contains the profit functions values of each vehicle. The values of the states , the set , and the point of disagreement vary dynamically.
The evolution value of the disagreement point varies as
with as an adjustment constant according to the definition of the axioms of the negotiation processes raised from the work of John Nash [34]. In this case, if a vehicle decides to cooperate on the road, the disagreement point is reduced with a factor, otherwise, it is increased by a factor.
Definition 2.
Utopia point is defined as the utopia point available for the vehicle i as ,
In this case, is defined as the union of the cost functions of the game, where then the discrete game can be interpreted as . Notice that the analysis of a bargaining game can be carried out symmetrical for a game with similar characteristics between its players or non-symmetrical for a game where these characteristics differ, i.e., synchronization of oscillator systems with homogeneous characteristics or control of mechanical systems with heterogeneous physical characteristics. For the solution of a bargaining game, a non-symmetrical centralized scenario is proposed based on [35] as
with as a weight variable usually defined as , with N as the number of vehicles involved in the process. However, for a distributed control analysis, the solution to the optimization problem is proposed as
with a distributed cost function usually defined quadratic and the set of the remaining vehicles control actions except for the agent i.
The optimization problem (12) differs from problem (9) in the sense that it considers fixed and only optimizes as a function of , this means that optimization does not involve the decisions of the entire network cooperatively. The solution to this problem then arises as a negotiation model that depends on the context given by the cooperative cruise control theory. This methodology does not use iterative solutions as others commonly used in distributed optimization problems [36], which reduces the computational cost in operation with great benefits in high-impact applications such as vehicle platoon. Bargaining methodology allows the solution to a distributed control problem by solving only one local optimization with the information collected by its neighbors and achieving an agreement based on the Nash equilibrium concept of bargaining through the defined disagreement point. In summary, the objective is to apply a distributed control methodology for vehicles network on a highway. Based on the communication of their states, a negotiation can be interpreted as the solution to an optimization problem (12). It is important to note that the communication and the parameters sent need to be available at any time. The lack of information can hinder the ability to reach an optimal or efficient agreement.
3. Cooperative Cruise Control as a Bargaining Game
Considering the definition of a DMPC as a bargaining game presented in Section 2, the cooperative cruise control problem is contextualized. In this scenario, the vehicles on a highway synchronize their dynamics from a reference model in vehicle distance and speed. The global cost function of the DMPC must be made up of two terms: one term associated with the tracking error in the distance between vehicles and the other term with the speed of each one during its transit on the road.
The cooperative cruise control model is taken from (5), where matrices are obtained from dynamic models and (4). In this case, The output is defined as each vehicle’s speed. The vehicle’s acceleration gives the control action . An operative constraint is defined according to comfort parameters of m/s [37].
Initially considering each vehicle independently, the local MPC problem is formulated as
with , is the decision space of the control law, and are the state matrix and vector resulting from the prediction along . The characteristics of the software and hardware determine any possible delay that may be found in the communication for control operations.
Let be the global cost function of each vehicle defined as
with and as matrices obtained from and , respectively. The input restrictions and states are time-independent and may differ for each vehicle. Therefore, the bargaining game for cooperative cruise control is defined as , . Each vehicle at the control level has the same objective: minimize the synchronization error to maintain the distance between vehicles and the speed in a stable state. The solution of this game with discrete characteristics of the form is solved by Algorithm 1.
| Algorithm 1:Distributed bargaining algorithm |
 |
Algorithm 1 methodologically explains that each vehicle sends its dynamics information to its neighbors as long as the synchronization error is greater than a given constant . With this information, it is possible to solve the optimization problem (12) in each agent, to subsequently modify the values of the disagreement point until achieving convergence in the network synchronization. Finally, the modification to the point of disagreement is sent back to the neighbors. That process is one of the main contributions of this work since it summarizes the control methodology used in simulation and beyond with implementation for a cooperative cruise control problem.
The bargaining game result is mathematically defined as the tuple composed of the profit of each vehicle. If there is no cooperation on the highway, the disagreement point replaces its value in the tuple.
Proposition 1.
The proposed solution of a discrete bargaining game in k steptime is unique and depends on optimization problem (15) and Θ, that must be convex.
Proof.
It follows by [27]. □
Notice that we consider two cases, one with similar characteristics of vehicles assimilating a symmetric game and another one with vehicles with non-similar characteristics assimilating a non-symmetrical game. It is important to note that non-symmetric bargaining games are the most commonly found in real-life applications. For the solution of a bargaining game, the following lemma is proposed, based on Algorithm 1.
Lemma 1.
Consider a cooperative cruise control problem as a bargaining game , then solution is the Nash bargaining solution at time k computed by Algorithm 1.
Proof.
Explicitly, if required, this theory allows a complete structuring of the network through the transmission of the utility functions or system inputs to benefit the solution of each local optimization problem. These algorithms can make decisions separately, so their implementation does not need an iterative process. That decision-making process considerably reduces the computational burden that Lagrange multiplier-based solution methods can present.
4. Simulation Results
For the mentioned methodology, an application field is proposed based on the problem of an autonomous network of vehicles that is increasing nowadays, where each vehicle must follow the same patterns (position and speed). The most well-known technique for this problem is cooperative adaptive cruise control, an extension of adaptive cruise control; a problem worked at a platoon level with onboard sensors. In this case, each agent is modeled as a linear second-order system such as in (5). For the experiment, the leading vehicle defines an acceleration profile that all agents must follow through a fixed distance between each one. That profile means in terms of synchronization . It is important to highlight four aspects of this methodology: The vehicle dynamics, the distributed controller, the transmitted information, and the graph communication topology [38].
A numerical simulation is performed to validate the proposed control laws. Figure 3 shows the simulation digraph, with agent 0 acting as the leader node. The formation control idea in the platoon starts from the graph representing the communications, intercommunicated vehicles handle a speed and inter-vehicular distance contemplated by the reference vehicle.
Table 1 presents the simulation parameters used, highlighting that these are used only for simulation, not for control design. Both simulation and implementation show the results of symmetric and non-symmetric games. MATLAB software and the fmincon optimization problem-solving command are used for the optimization problems. The cost functions and decision variables are packed along the prediction horizon using Kronecker-like structures for all the procedures. External parameters of communication or interaction between the agents are not considered for simulation purposes.
4.1. Symmetric Game
For the simulation of the system, symmetric and non-symmetric cases are presented. In the symmetric case, the cost function is defined as (20), making a grouping according to the theory, and the local cost function is defined as (7).
The following figures show the agents’ response when the solution to the distributed optimization problem is obtained. For simulation purposes, the reference agents’ dynamic is defined with the parameters and . Figure 4 shows the network response with the bargaining model performed, with a convergence time of 60s approximately, a lower rate for synchronization in this type of application.
We compare a centralized with a decentralized model in a predictive control problem, reflected in Figure 4Figure 4. Generally, a centralized problem is solved for each agent without any information sent. In a decentralized way, the information is sent, and with it, a single optimization problem per agent is solved. The figures demonstrate that both centralized and decentralized systems exhibit faster response times. Additionally, synchronization is achieved through distributed communication of information, thereby optimizing the processes within the network. It is important to highlight that the distributed controller achieves a synchronization in 40 seconds, unlike the decentralized and centralized controllers with a time of 50 seconds, this is justified based on the complexity of the system. These factors may require additional time for data analysis, secure decision-making to ensure optimal performance.
Similarly, Figure 5Figure 6 shows the cost function and control action values evolution, respectively, where it is evident that they achieve synchronization based on Nash equilibrium, even when the value is increasing.Although a variation in the control signal is observed, derived from the analysis at each instant of the time horizon, these variations are very short, given the magnitude at the application level, they tend to be imperceptible.
4.2. Non-Symmetric Game
The same case of cooperative cruise control is used for the game with non-symmetric characteristics. However, the parameters of each agent are taken from Table 1. The cost function used is the same as in the symmetric case (7). Figure 7Figure 7 shows the output response of each system under the negotiation model compared with a centralized and decentralized predictive control methodology, where convergence is observed equally handling the information in a distributed way, with a similar qualitative response in comparison with symmetric cases, validating the behavior in both cases.
In this case, the point of disagreement is shown, since there may be a variation in that value under the concept of symmetric and non-symmetric games (even considering symmetric cases with different initial conditions). Then, the response of the disagreement point is observed in Figure 8, where the Nash agreement achieved from the consensus of this value is evidenced with a regulation of its value.
Finally, the cost function response is presented in Figure 9, where it is possible to validate the Nash equilibrium through the convergence of these values in all agents, as well as the application of the control action for each one in Figure 10. An oscillatory response is observed due to the fact that when working with a network of vehicles, the interaction between them can be complex. Among the strategies to combat this complexity is the simplification of the models, as in (1). The actions of one vehicle can affect other nearby vehicles, which can lead to non-linear effects and complicate the predictive control response.
5. Implementation Results
Basic experiments are performed to apply the developed algorithms with real-time simulation in HIL. Validation is made through a temporal response of the developed algorithms and physical considerations. We use the National Instruments CompactRio controllers connected through an Ethernet network. Four controllers of two types are used for development, a NI9045 CompactRio controller and three NI9063 CompactRio controllers. The photo of the modules inside the DESYNC laboratory at Universidad Nacional de Colombia is shown in Figure 11. Similarly, as seen in Figure 12, the inclusion of each controller within each rack is shown. Two NI9063 controllers and their two power supplies are observed. In the other cabinet, the remaining NI9063 and NI9045 controllers are shown next to their power supplies and the Ethernet communication switch. The communications graph is defined in Figure 13.
Similarly, for the dynamic models implemented, the same dynamic (1) is used with a Tustin discretization for system matrices with a sample time of 0.1s. The simulation parameters are observed in Table 2.
For the implementation, communication is made between Labview and Simulink, where the dynamics of the controllers are emulated. For the response of the symmetric game, the same parameters of the simulation case are used ( and ). Figure 14 shows the controller’s response implemented in a symmetric game. In emulation, the system presents some fluctuations initially, but their response also achieves an adequate bargain. In all those cases, the fluctuations are derived from the fact that by embedding the dynamics and control in each module separately and requiring communication between them, the response does not handle the same synchronization interval as in simulation, where the communication does not have delays.
Similarly, the response of the agents’ cost function is observed in Figure 15, which maintains similarity with the response of the simulation case and also reaches a correct bargain, as well as the application of the control action in Figure 16. The response of the signals take a high value while synchronizing the communication, and after this, they synchronize their value.
The response of the controller for non-symmetric cases is also validated, according to the parameters of Table 2, Figure 17 shows the response of the agents’ output in this case, where it is evidenced that as in the previous cases, the system achieves correct bargaining in a distributed scenario. It is possible to see in the same way an oscillation in the response, especially in some agents, derived from being the agent with the furthest communication from the reference, however with the passage of the transient a synchronization is achieved.
Figure 18, Figure 19 and Figure 20 show the response of the point of disagreement, the cost function, and the control action in the non-symmetrical case of emulation, the response, as in the previous cases, shows a fluctuation in their behavior at the first iterations, followed by a correct bargain in both cases.
In the same way, it is important to validate cases where a correct bargain is not achieved. Considering that, a scenario of multiple agents in the context of mechanical systems based on [39], presents a non-linearity in its systemic base that makes it difficult for the bargain algorithm, as is observed in Figure 21. It is validated that in those scenarios, synchronization of all the systems is not completely achieved when the value of the point of disagreement diverges.
6. Conclusions
In conclusion, this paper investigated the application of Distributed Model Predictive Control (DMPC) with Bargaining games for a vehicular network, considering both symmetric and non-symmetric cases in simulation and emulation. The results demonstrated that the proposed approach achieved convergence, albeit with slightly slower dynamics and occasional fluctuations observed in the non-symmetric cases during implementation. Nevertheless, despite these challenges, the system still managed to converge towards the desired reference signal. These findings highlight the efficacy and potential of DMPC with Bargaining games for coordinating and optimizing vehicular networks, paving the way for future research and development in this area. Further refinements and optimizations can address the observed limitations, ultimately leading to more robust and efficient cooperative driving solutions for enhanced traffic management, reduced environmental impacts, and improved overall transportation system performance.
Author Contributions
Conceptualization, M.F.A.C., E.M.N., and D.T.C; methodology, M.F.A.C. and D.T.C; software, M.F.A.C. and J.P.; validation, D.T.C. and E.M.N; formal analysis, M.F.A.C.; investigation, M.F.A.C., D.T.C; resources, E.M.N; data curation, J.P; writing—original draft preparation, M.F.A.C., J.P., and E.M.N; writing—review and editing, D.T.C, E.M.N; visualization, M.F.A.C.; supervision, D.T.C and E.M.N; project administration, E.M.N; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CAV | Connected and Autonomous Vehicle |
| CCAC | Cooperative Cruise Adaptive Control |
| DMPC | Distributed Model Predictive Control |
| HIL | Hardware-in-the-Loop |
| ITS | Intelligent Transportation Systems |
| MPC | Model Predictive Control |
| V2V | Vehicle to Vehicle |
References
- Ballinger, B.; Stringer, M.; Schmeda-Lopez, D.R.; Kefford, B.; Parkinson, B.; Greig, C.; Smart, S. The vulnerability of electric vehicle deployment to critical mineral supply. Applied Energy 2019, 255, 113844. [Google Scholar] [CrossRef]
- Jia, D.; Lu, K.; Wang, J.; Zhang, X.; Shen, X. A Survey on Platoon-Based Vehicular Cyber-Physical Systems. IEEE Communications Surveys Tutorials 2016, 18, 263–284. [Google Scholar] [CrossRef]
- van Arem, B.; van Driel, C.J.G.; Visser, R. The Impact of Cooperative Adaptive Cruise Control on Traffic Flow Characteristics. IEEE Transactions on Intelligent Transportation Systems 2006, 7, 429–436. [Google Scholar] [CrossRef]
- Lee, J.; Park, B.B.; Malakorn, K.; So, J.J. Sustainability assessments of cooperative vehicle intersection control at an urban corridor. Transportation Research Part C: Emerging Technologies 2013, 32, 193–206. [Google Scholar] [CrossRef]
- Kovačić, M.; Mutavdžija, M.; Buntak, K. New Paradigm of Sustainable Urban Mobility: Electric and Autonomous Vehicles: A Review and Bibliometric Analysis. Sustainability 2022, 14. [Google Scholar] [CrossRef]
- Kaffash, S.; Nguyen, A.T.; Zhu, J. Big data algorithms and applications in intelligent transportation system: A review and bibliometric analysis. International Journal of Production Economics 2021, 231, 107868. [Google Scholar] [CrossRef]
- Eskandarian, A.; Wu, C.; Sun, C. Research Advances and Challenges of Autonomous and Connected Ground Vehicles. IEEE Transactions on Intelligent Transportation Systems 2021, 22, 683–711. [Google Scholar] [CrossRef]
- Mcdonald, A.; McGehee, D.; Chrysler, S.; Angell, L.; Askelson, N.; Seppelt, B. National Survey Identifying Gaps in Consumer Knowledge of Advanced Vehicle Safety Systems. Transportation Research Record Journal of the Transportation Research Board 2016, 2559. [Google Scholar] [CrossRef]
- Li, Z.; Duan, Z. Cooperative control of multi-agent systems: a consensus region approach; CRC Press, 2017.
- Shladover, S.E.; Su, D.; Lu, X.Y. Impacts of cooperative adaptive cruise control on freeway traffic flow. Transportation Research Record 2012, 2324, 63–70. [Google Scholar] [CrossRef]
- Zohdy, I.H.; Rakha, H.A. Intersection management via vehicle connectivity: The intersection cooperative adaptive cruise control system concept. Journal of Intelligent Transportation Systems 2016, 20, 17–32. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Zhu, H. Theory and Experiment of Cooperative Control at Multi-Intersections in Intelligent Connected Vehicle Environment: Review and Perspectives. Sustainability 2022, 14. [Google Scholar] [CrossRef]
- Yang, H.; Rakha, H.; Ala, M.V. Eco-cooperative adaptive cruise control at signalized intersections considering queue effects. IEEE Transactions on Intelligent Transportation Systems 2016, 18, 1575–1585. [Google Scholar] [CrossRef]
- Farina, M.; Scattolini, R. Distributed predictive control: A non-cooperative algorithm with neighbor-to-neighbor communication for linear systems. Automatica 2012, 48, 1088–1096. [Google Scholar] [CrossRef]
- Trodden, P.A.; Maestre, J.M. Distributed predictive control with minimization of mutual disturbances. Automatica 2017, 77, 31–43. [Google Scholar] [CrossRef]
- Grammatico, S. Proximal Dynamics in Multiagent Network Games. IEEE Transactions on Control of Network Systems 2018, 5, 1707–1716. [Google Scholar] [CrossRef]
- Valencia, F.; López, J.D.; Patino, J.A.; Espinosa, J.J. Bargaining game based distributed MPC. In Distributed Model Predictive Control Made Easy; Springer, 2014; pp. 41–56.
- Oszczypała, M.; Ziółkowski, J.; Małachowski, J.; Lęgas, A. Nash Equilibrium and Stackelberg Approach for Traffic Flow Optimization in Road Transportation Networks—A Case Study of Warsaw. Applied Sciences 2023, 13, 3085. [Google Scholar] [CrossRef]
- Dixit, V.V.; Denant-Boemont, L. Is equilibrium in transport pure Nash, mixed or Stochastic? Transportation Research Part C: Emerging Technologies 2014, 48, 301–310. [Google Scholar] [CrossRef]
- Chu, H.; Guo, L.; Gao, B.; Chen, H.; Bian, N.; Zhou, J. Predictive cruise control using high-definition map and real vehicle implementation. IEEE Transactions on Vehicular Technology 2018, 67, 11377–11389. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, C.; Eskandarian, A. Integrating odometry and inter-vehicular communication for adaptive cruise control with target detection loss. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE; 2018; pp. 1848–1853. [Google Scholar] [CrossRef]
- Rayamajhi, A.; Biron, Z.A.; Merco, R.; Pisu, P.; Westall, J.M.; Martin, J. The impact of dedicated short range communication on cooperative adaptive cruise control. In Proceedings of the 2018 IEEE International Conference on Communications (ICC). IEEE; 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Isermann, R.; Schaffnit, J.; Sinsel, S. Hardware-in-the-loop simulation for the design and testing of engine-control systems. Control Engineering Practice 1999, 7, 643–653. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Shen, W. Lithium-ion battery pack state of charge and state of energy estimation algorithms using a hardware-in-the-loop validation. IEEE Transactions on Power Electronics 2016, 32, 4421–4431. [Google Scholar] [CrossRef]
- Maniatopoulos, M.; Lagos, D.; Kotsampopoulos, P.; Hatziargyriou, N. Combined control and power hardware in-the-loop simulation for testing smart grid control algorithms. IET Generation, Transmission & Distribution 2017, 11, 3009–3018. [Google Scholar]
- Wei, W.; Wu, Q.; Wu, J.; Du, B.; Shen, J.; Li, T. Multi-agent deep reinforcement learning for traffic signal control with Nash Equilibrium. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing &, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys). IEEE, 2021, Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor; pp. 1435–1442.
- Valencia, F.; Patiño, J.; López, J.D.; Espinosa, J. Game Theory Based Distributed Model Predictive Control for a Hydro-Power Valley Control. IFAC Proceedings Volumes 2013, 46, 538–544. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Guillo-Sansano, E.; Syed, M.H.; Nguyen, V.H.; Blair, S.M.; Reguera, L.; Tran, Q.T.; Caire, R.; Burt, G.M.; Gavriluta, C.; et al. Multi-agent system with plug and play feature for distributed secondary control in microgrid—Controller and power hardware-in-the-loop Implementation. Energies 2018, 11, 3253. [Google Scholar] [CrossRef]
- Filho, C.M.; Wolf, D.F.; Grassi, V.; Osório, F.S. Longitudinal and lateral control for autonomous ground vehicles. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings; 2014; pp. 588–593. [Google Scholar] [CrossRef]
- Baldi, S.; Frasca, P. Adaptive synchronization of unknown heterogeneous agents: An adaptive virtual model reference approach. Journal of the Franklin Institute 2019, 356, 935–955. [Google Scholar] [CrossRef]
- Nash Jr, J.F. The Bargaining Problem. Econometrica 1950, 18, 155–162. [Google Scholar] [CrossRef]
- Peters, H. Axiomatic bargaining game theory. In Proceedings of the Theory and decision library C; 1992. [Google Scholar]
- Nash, J.F. Equilibrium points in n-person games. Proceedings of the National Academy of Sciences 1950, 36, 48–49. [Google Scholar] [CrossRef]
- Peters, H.; Van Damme, E. Characterizing the Nash and Raiffa bargaining solutions by disagreement point axioms. Mathematics of Operations Research 1991, 16, 447–461. [Google Scholar] [CrossRef]
- Börgers, T.; Sarin, R. Learning through reinforcement and replicator dynamics. Journal of Economic Theory 1997, 77, 1–14. [Google Scholar] [CrossRef]
- Zou, Y.; Su, X.; Li, S.; Niu, Y.; Li, D. Event-triggered distributed predictive control for asynchronous coordination of multi-agent systems. Automatica 2019, 99, 92–98. [Google Scholar] [CrossRef]
- Zoccali, P.; Loprencipe, G.; Lupascu, R.C. Acceleration measurements inside vehicles: passengers’ comfort mapping on railways. Measurement 2018, 129, 489–498. [Google Scholar] [CrossRef]
- Baldi, S.; Rosa, M.R.; Frasca, P.; Kosmatopoulos, E.B. Platooning merging maneuvers in the presence of parametric uncertainty. IFAC-PapersOnLine 2018, 51, 148–153. [Google Scholar] [CrossRef]
- Arevalo-Castiblanco, M.F.; Tellez-Castro, D.; Sofrony, J.; Mojica-Nava, E. Adaptive synchronization of heterogeneous multi-agent systems: A free observer approach. Systems & Control Letters 2020, 146, 104804. [Google Scholar] [CrossRef]
Figure 1.
Vehicle Platoon Approach Diagram.
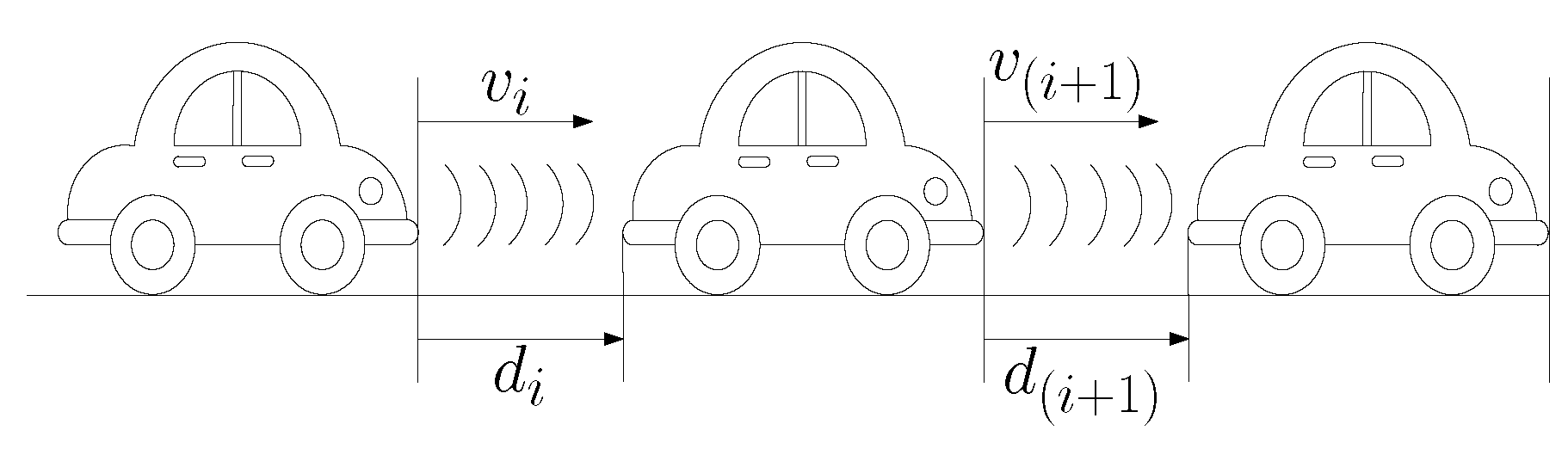
Figure 2.
Model predictive control with bargaining games.
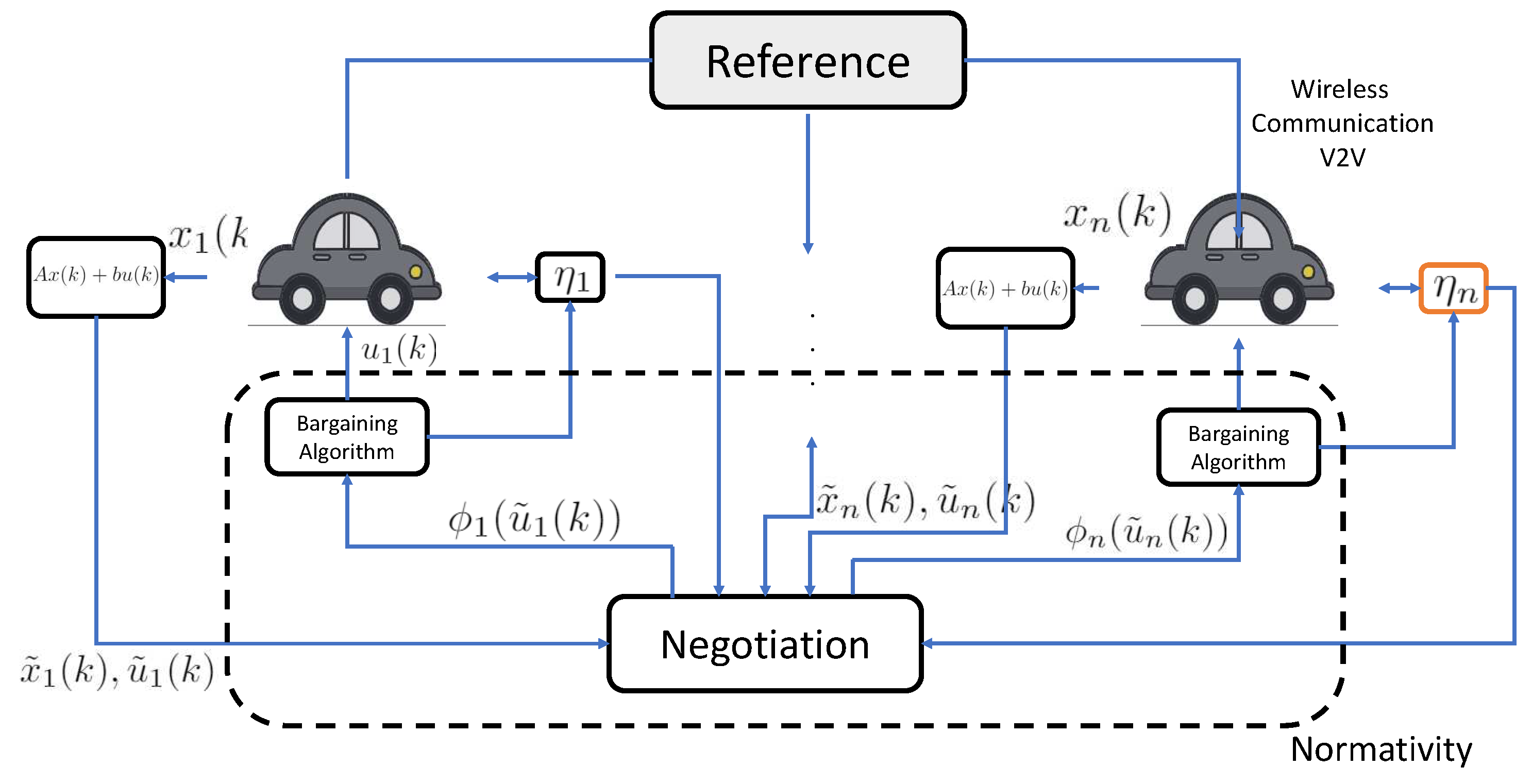
Figure 3.
Study case communication graph.
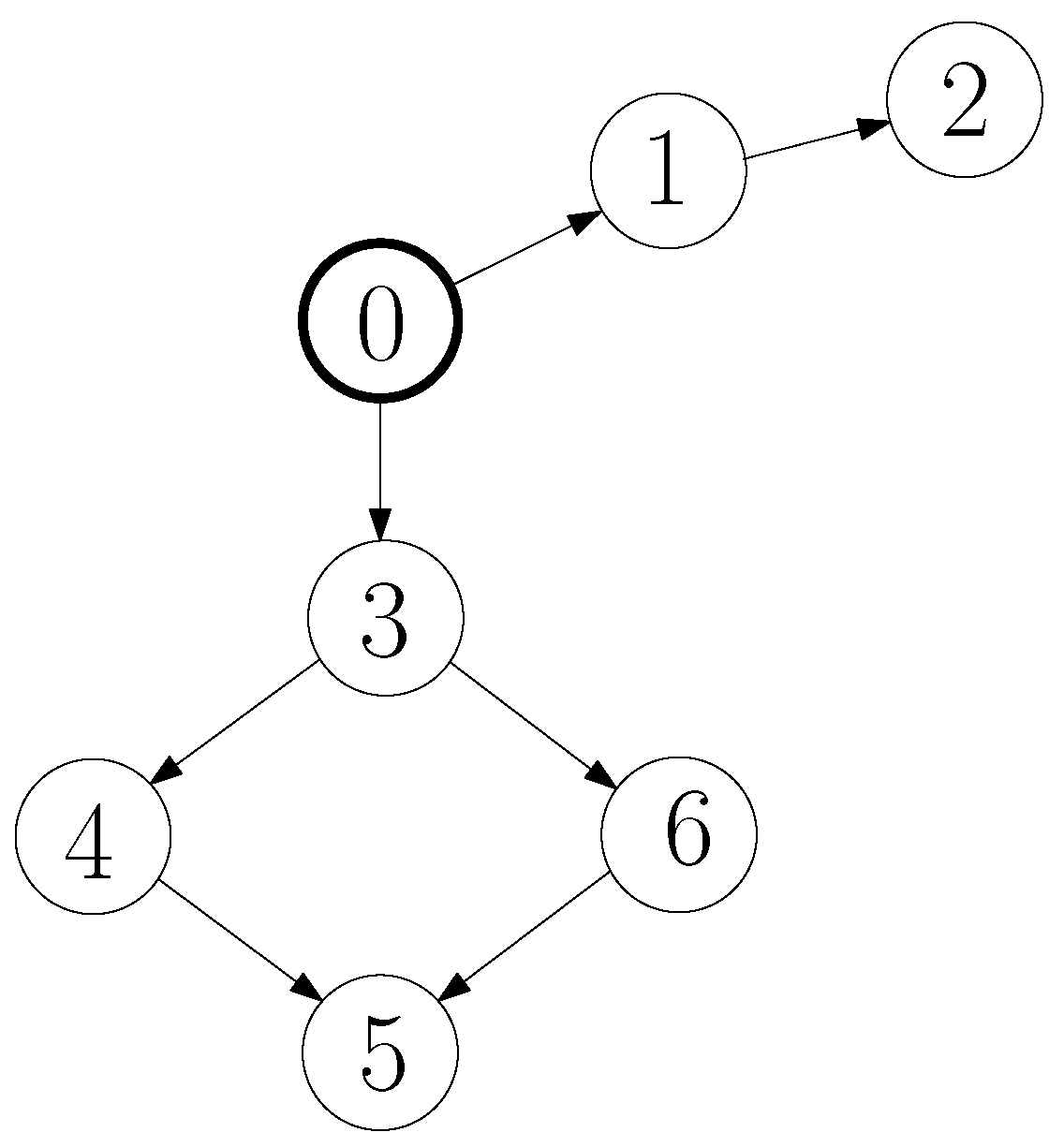
Figure 4.
Symmetric bargaining simulation results.
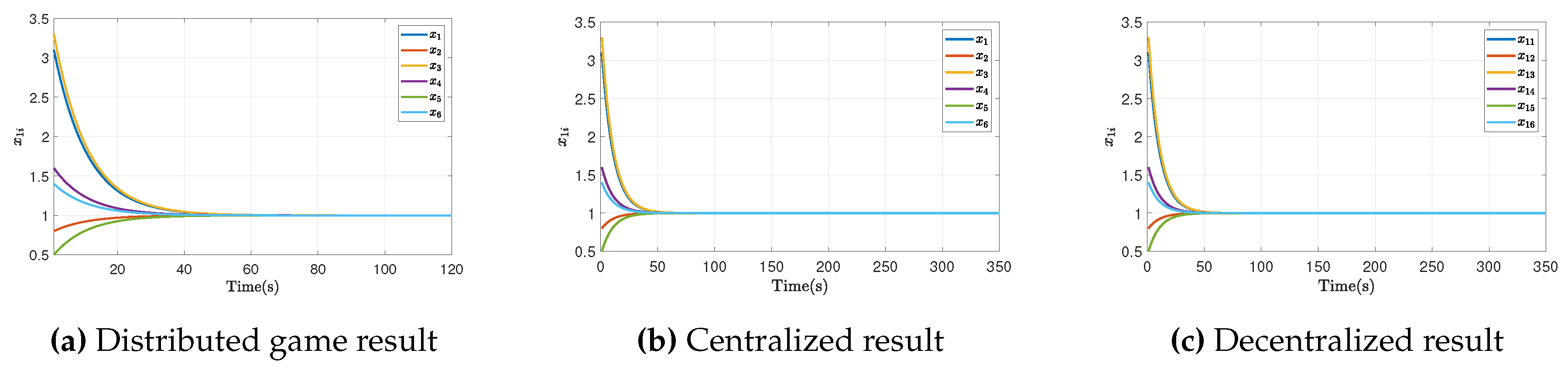
Figure 5.
Symmetric bargaining Cost Function.
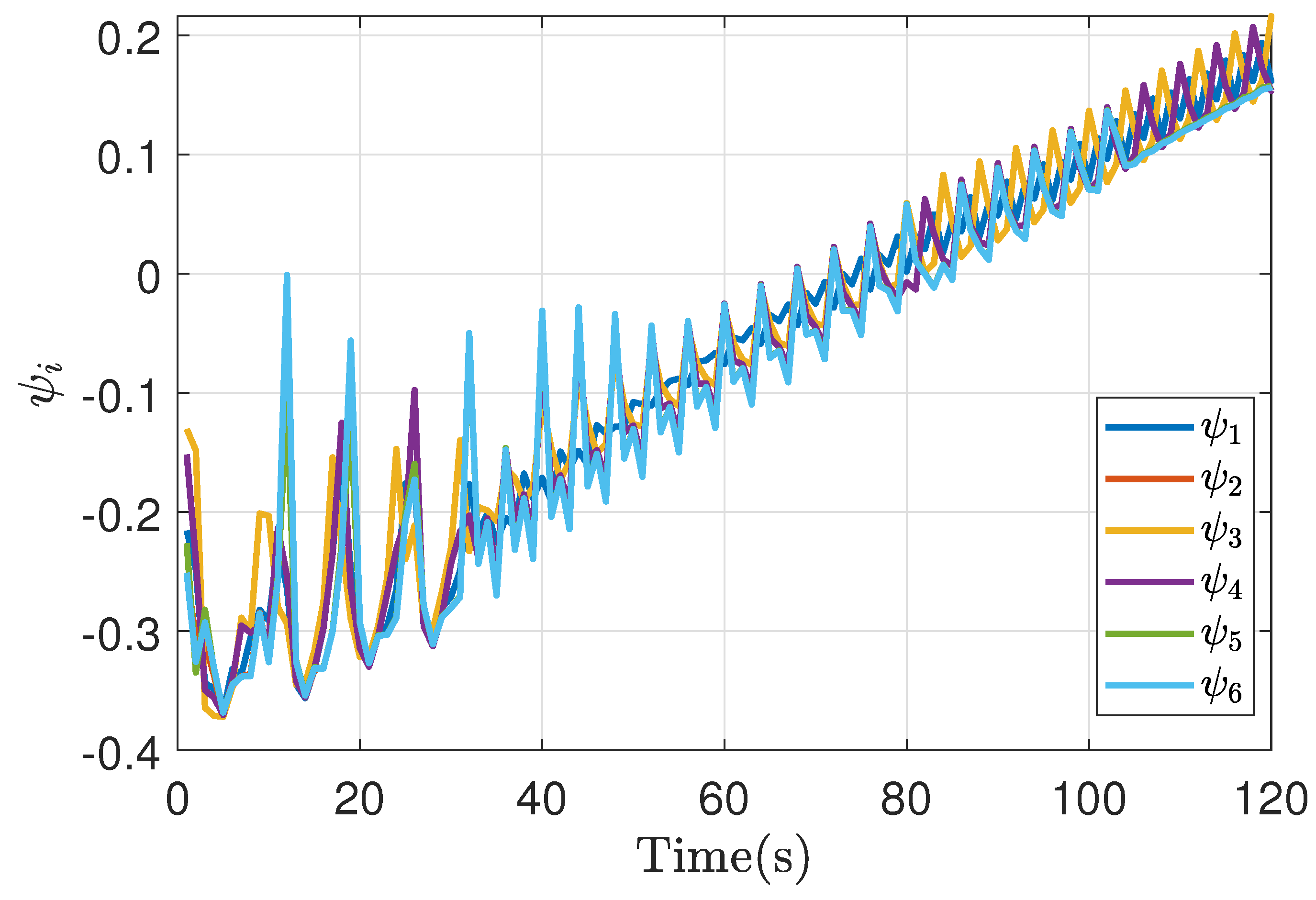
Figure 6.
Symmetric bargaining Control action.
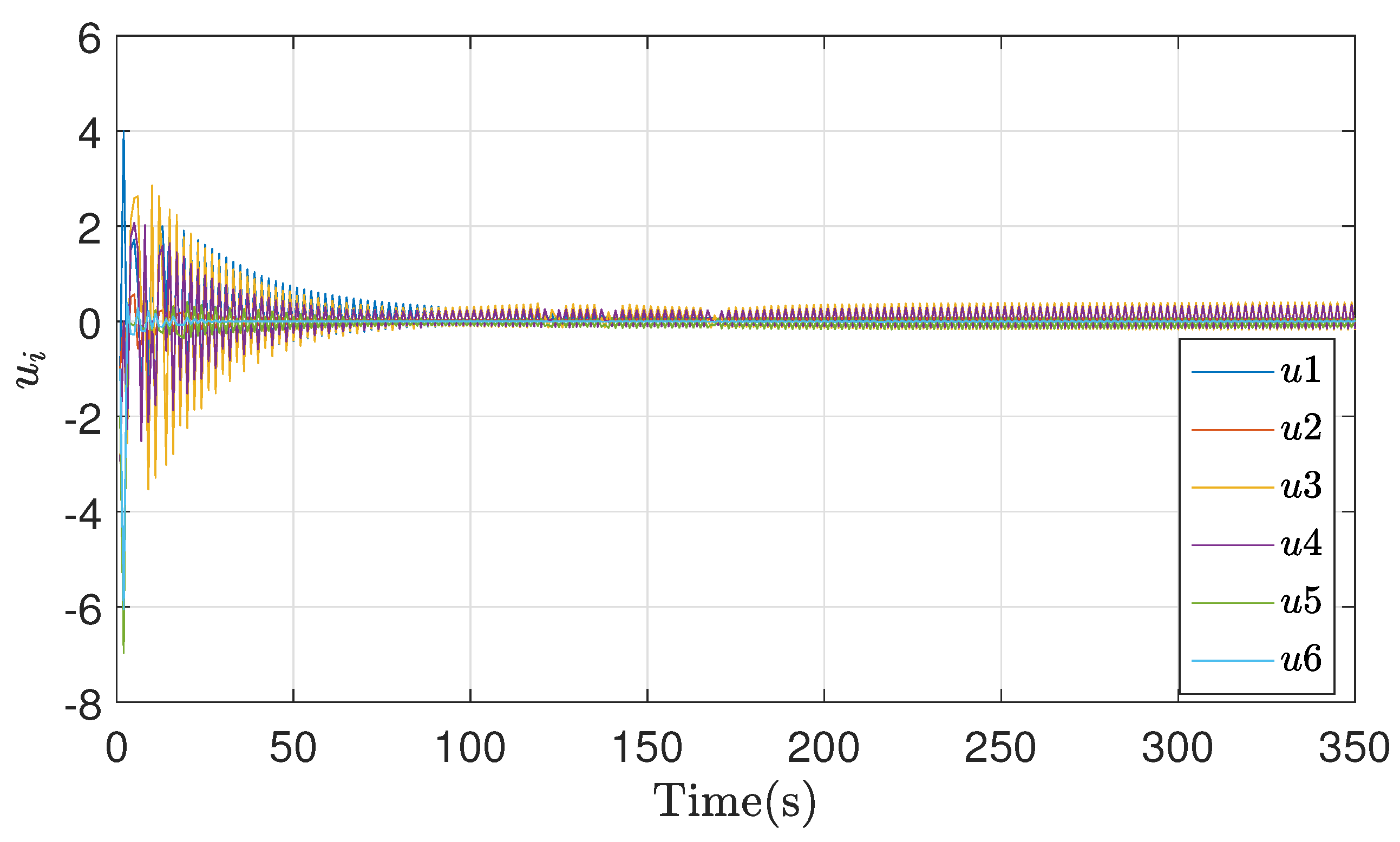
Figure 7.
Symmetric bargaining simulation results.
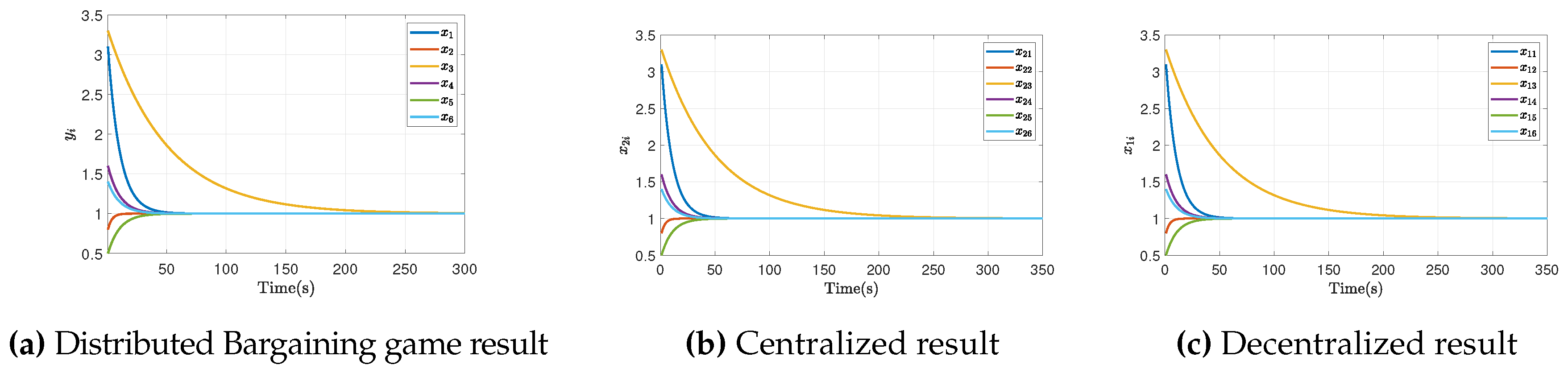
Figure 8.
Disagreement point Non-symmetric bargaining simulation result.
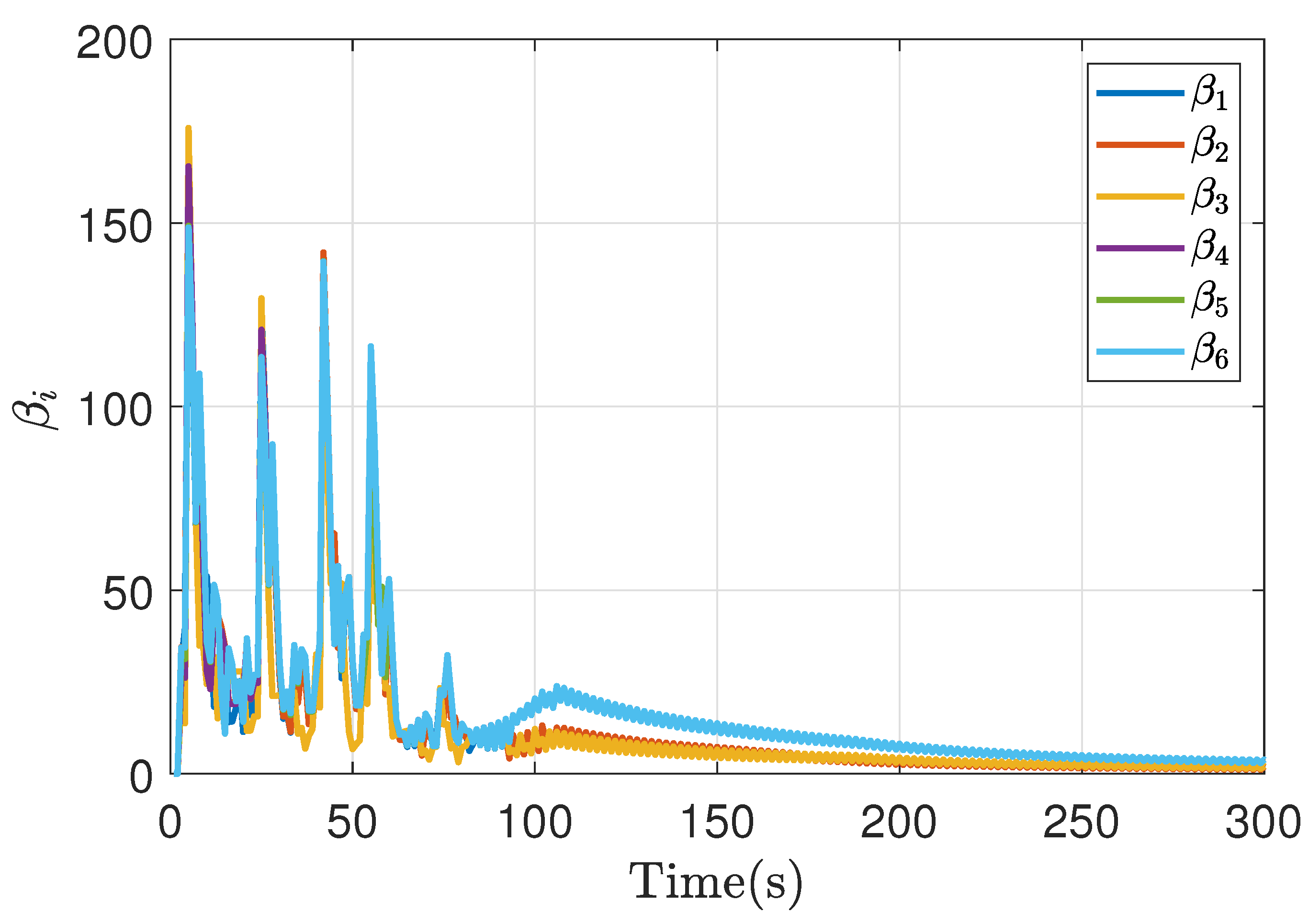
Figure 9.
Cost Function Non-symmetric bargaining simulation result.
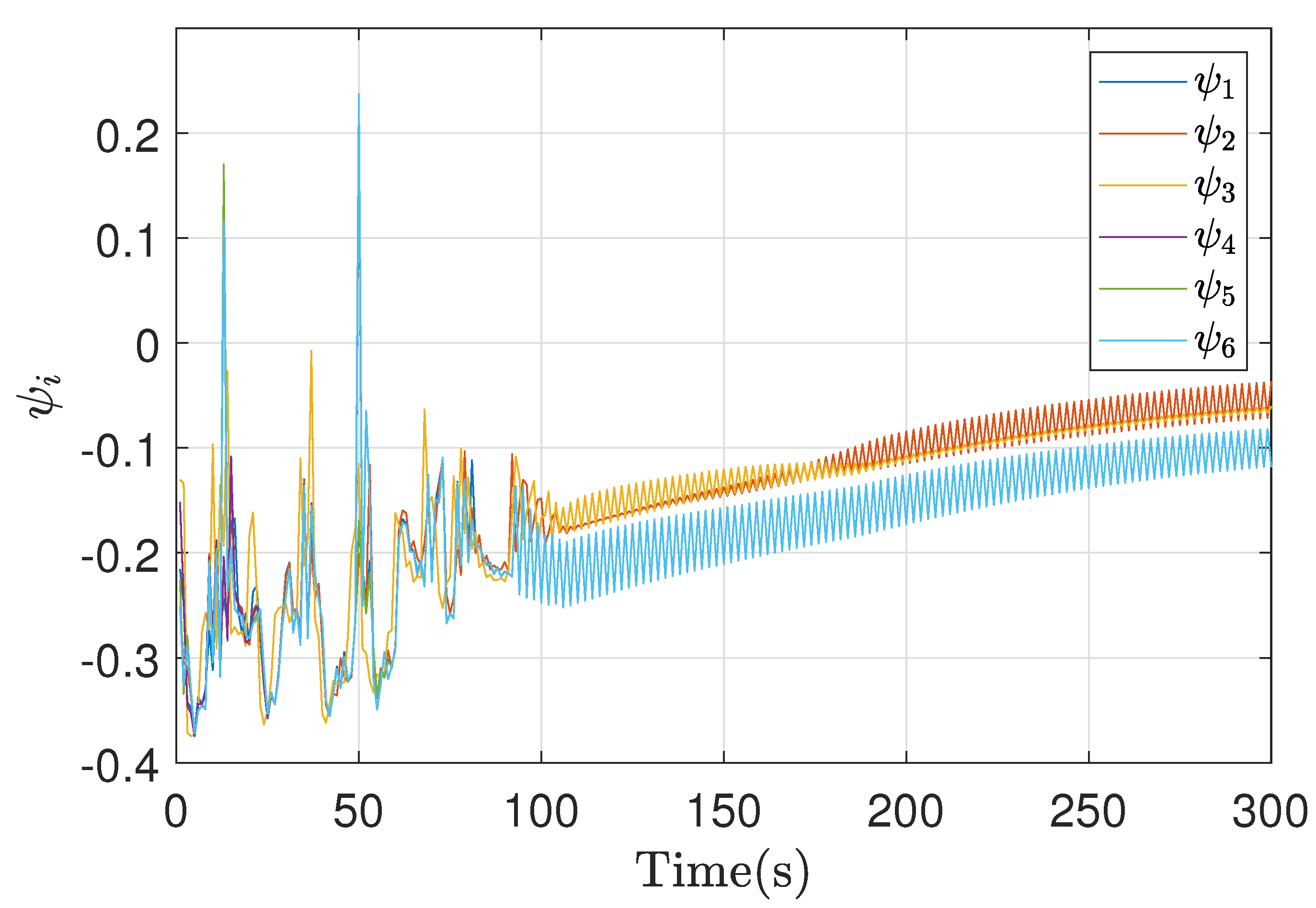
Figure 10.
Control action Non-symmetric bargaining simulation result.
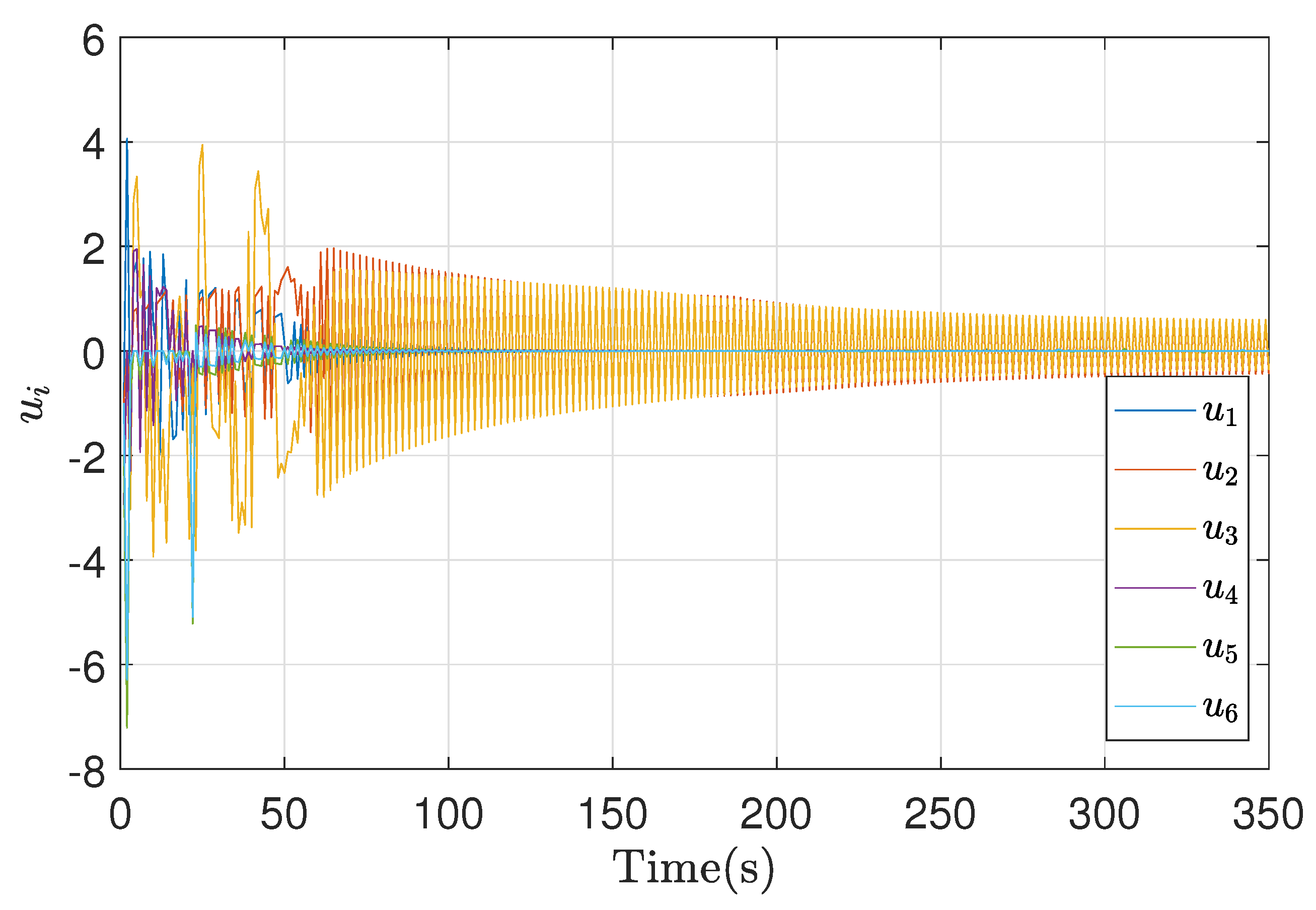
Figure 11.
DESYNC laboratory implementation modules.
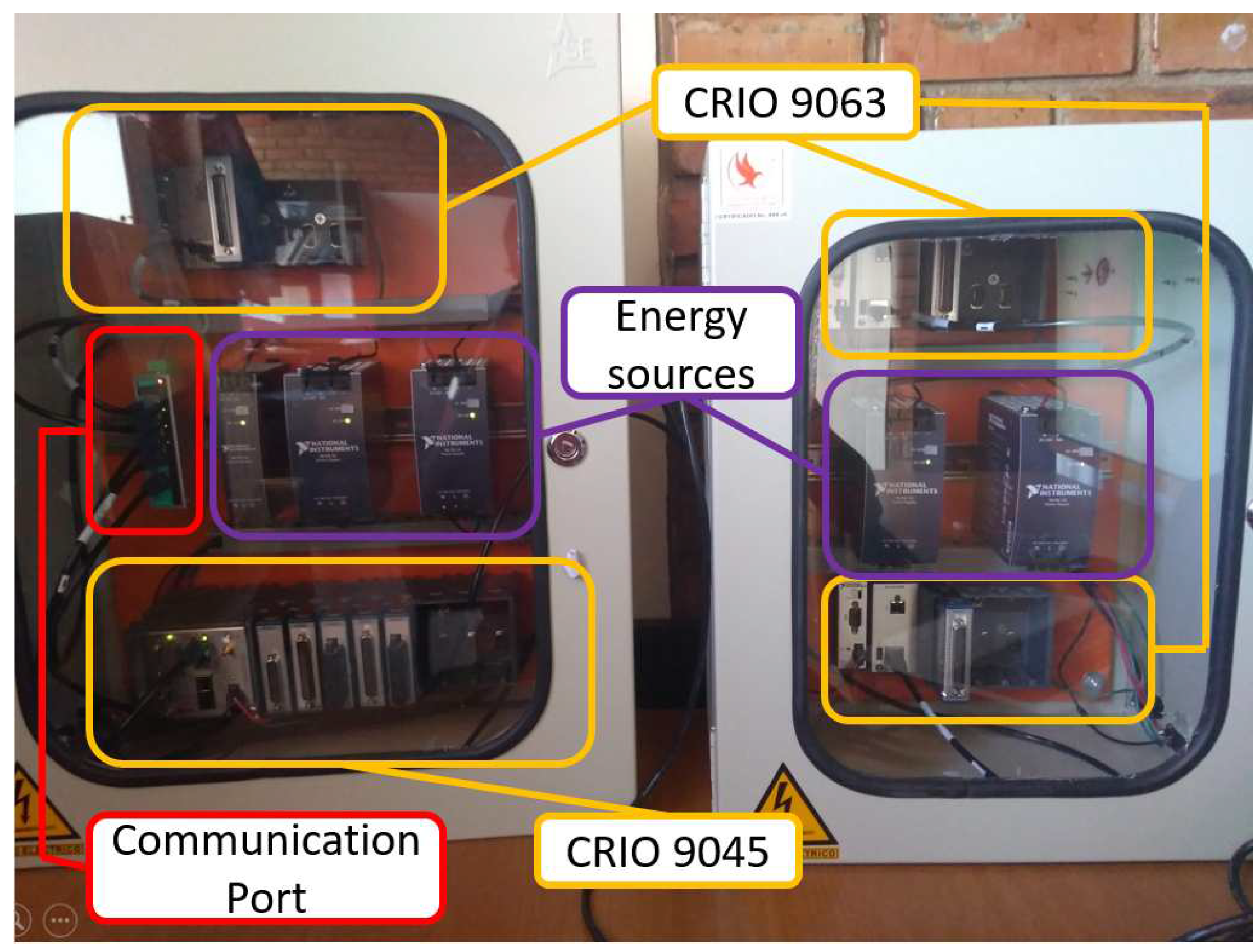
Figure 12.
Block diagram for HIL implementation.
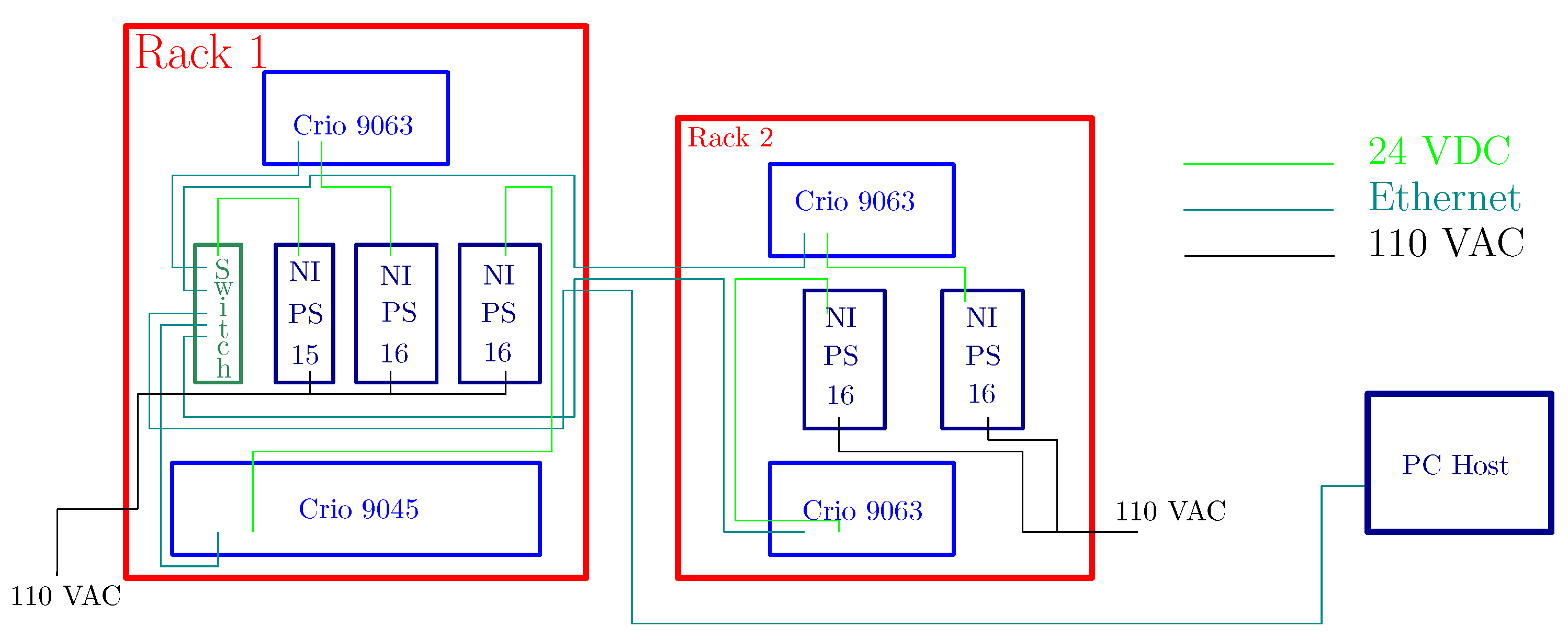
Figure 13.
Communication graph used in emulation case.
Figure 14.
Output synchronization of bargaining game theory implementation in the symmetric case.
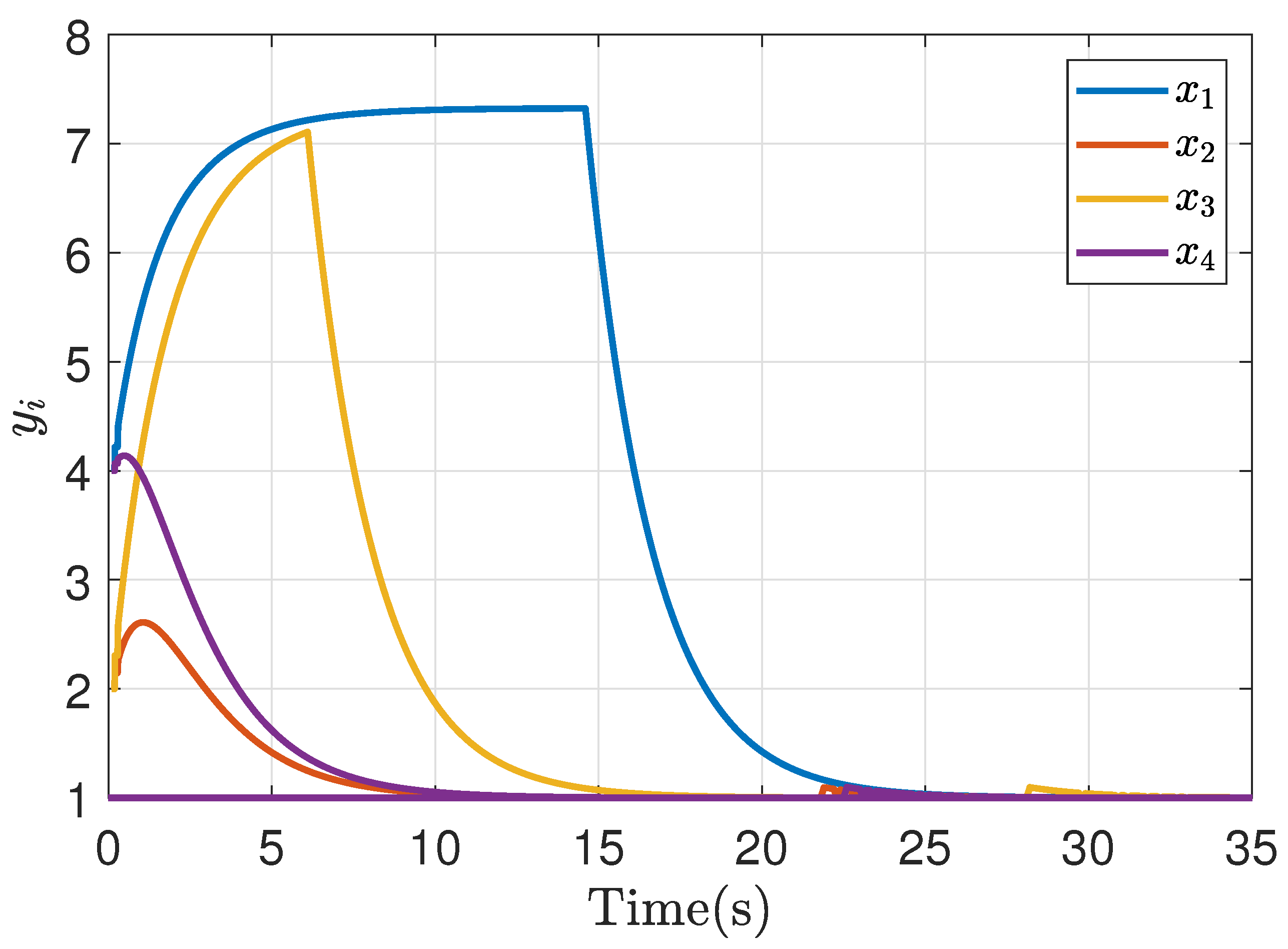
Figure 15.
Cost function of bargaining game theory implementation in a symmetric case.
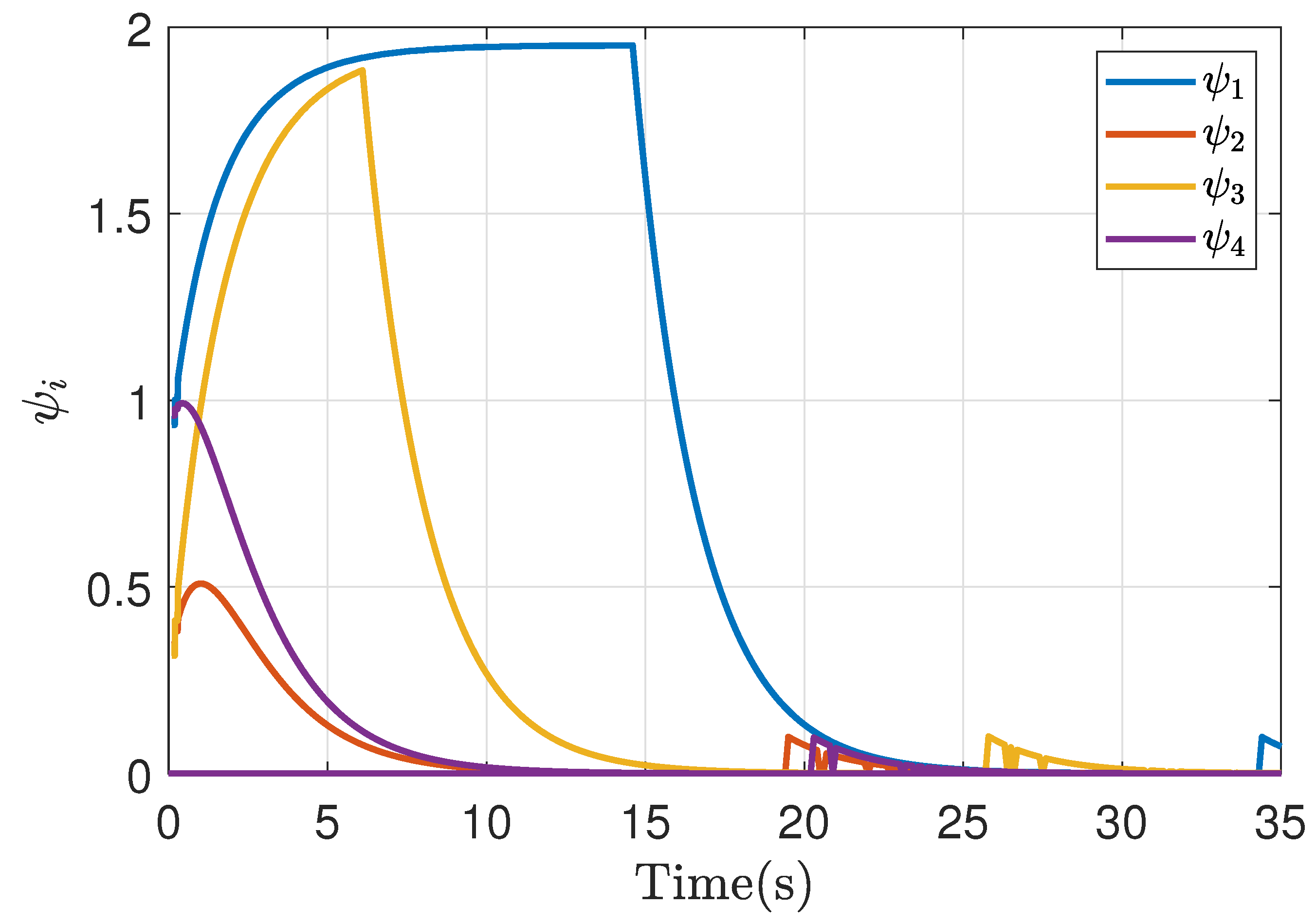
Figure 16.
Control action of bargaining game theory implementation in a symmetric case.
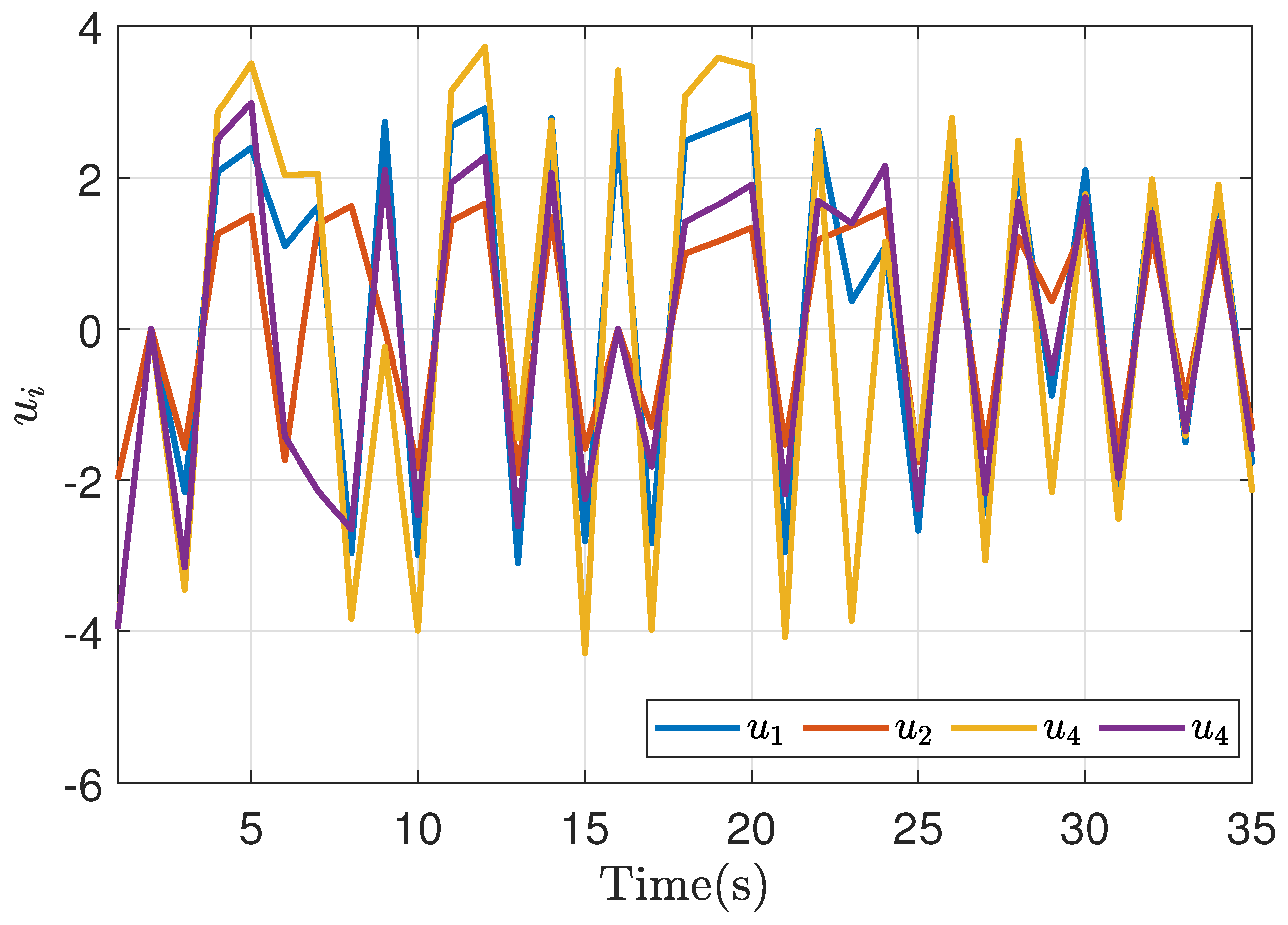
Figure 17.
Output synchronization of bargaining game theory implementation in a Non-symmetric case.
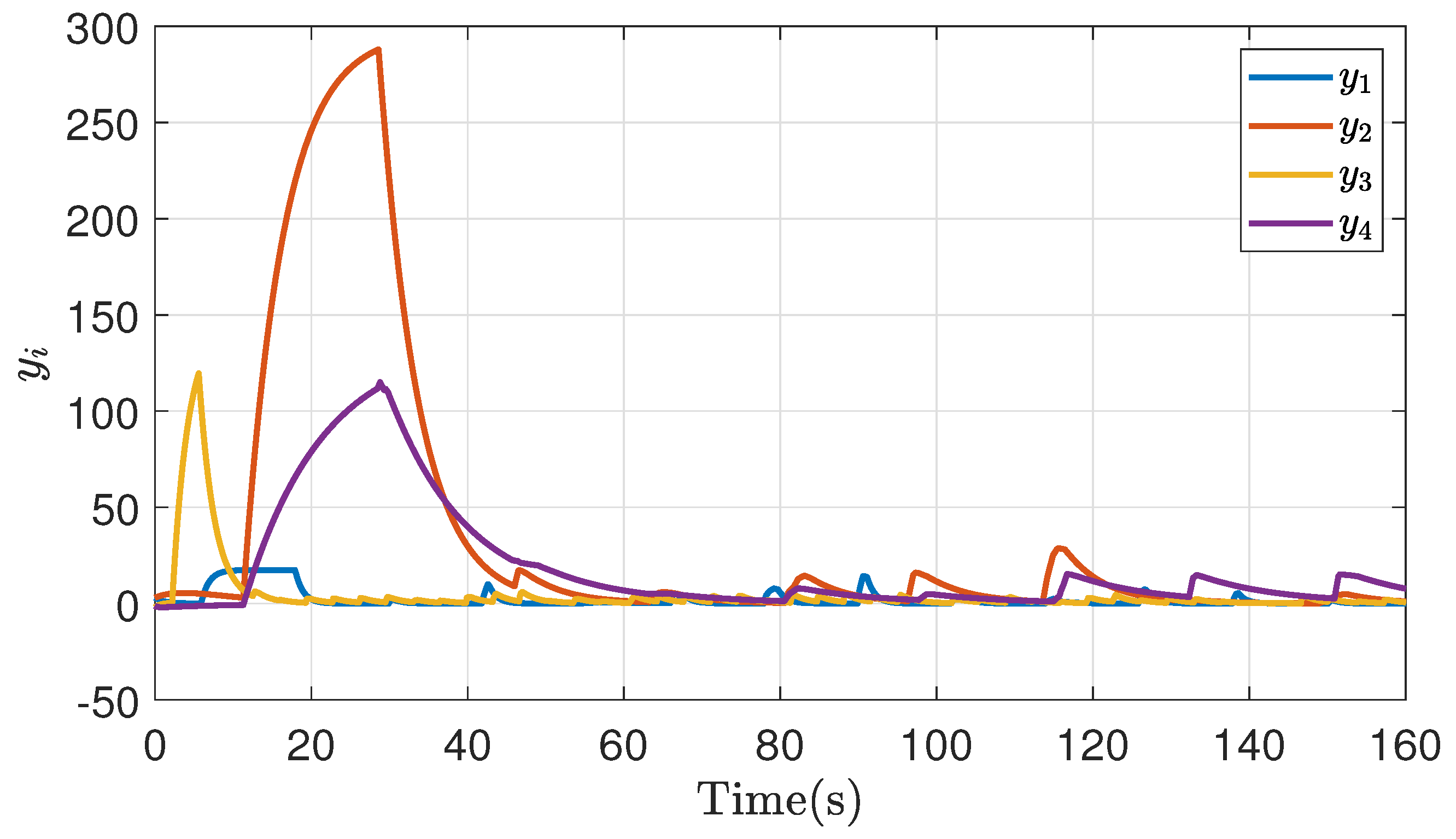
Figure 18.
Disagreement point of bargaining game theory implementation in a non-symmetric case.
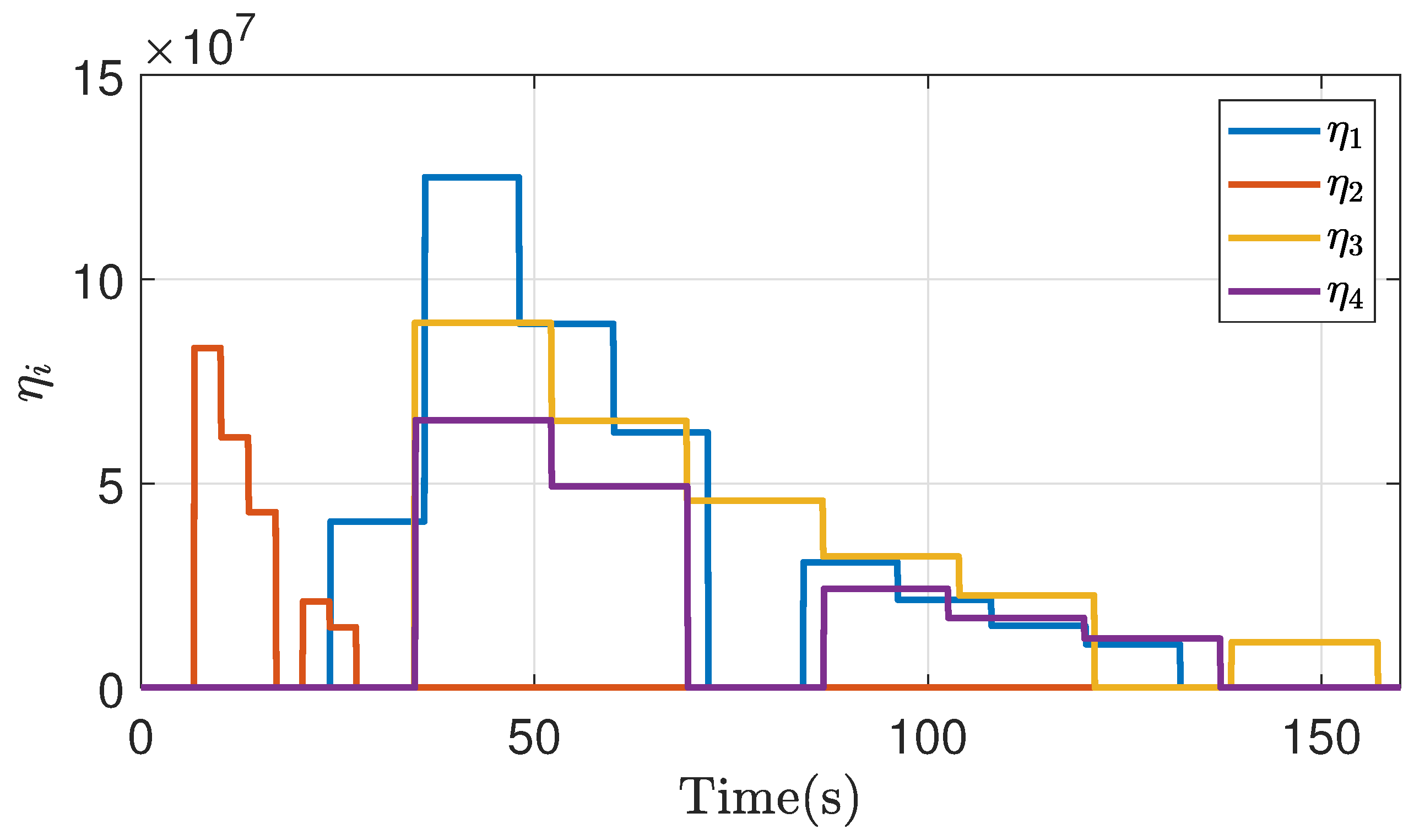
Figure 19.
Cost function of bargaining game theory implementation in a non-symmetric case.
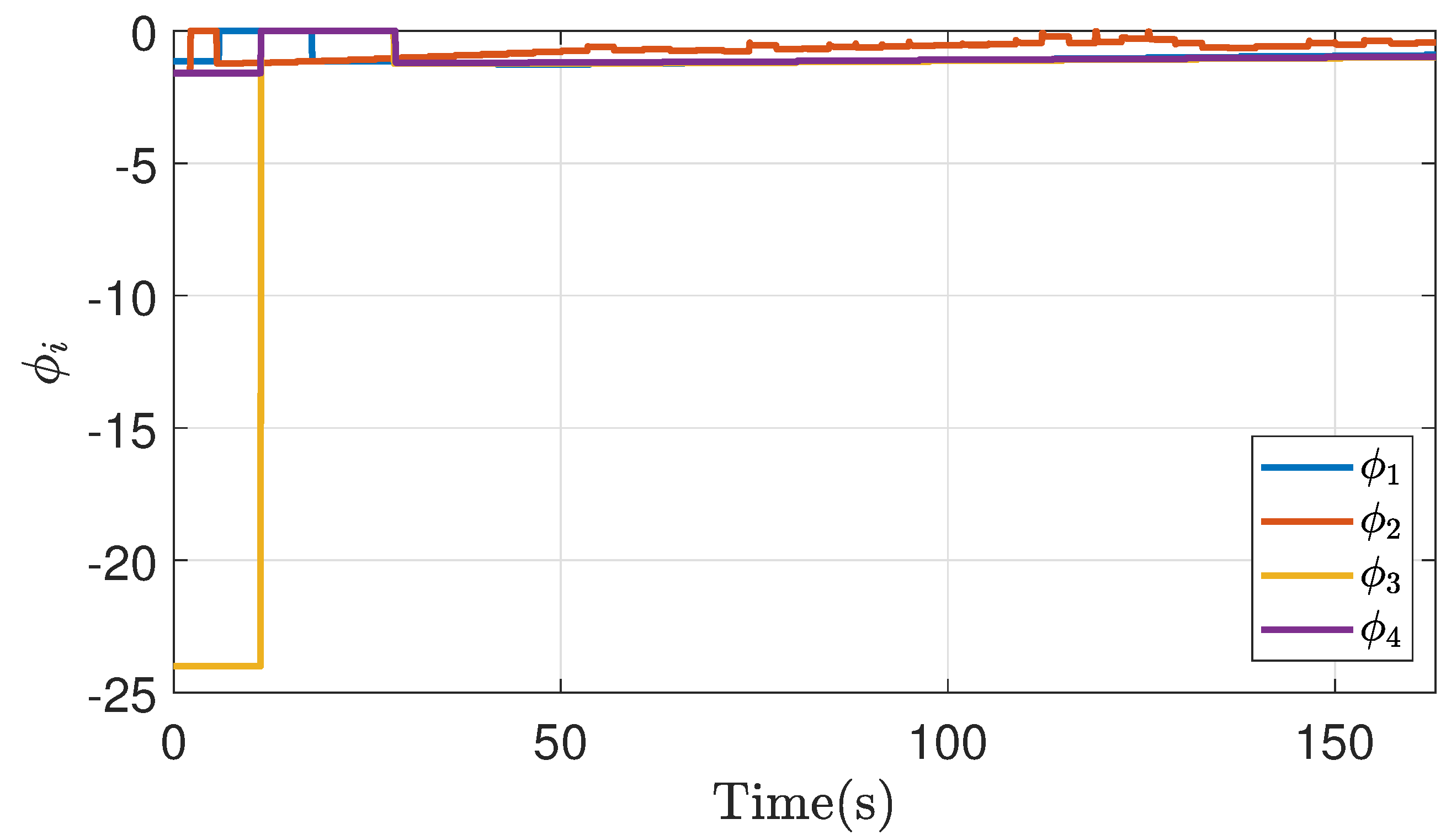
Figure 20.
Control action of bargaining game theory implementation in a non-symmetric case.
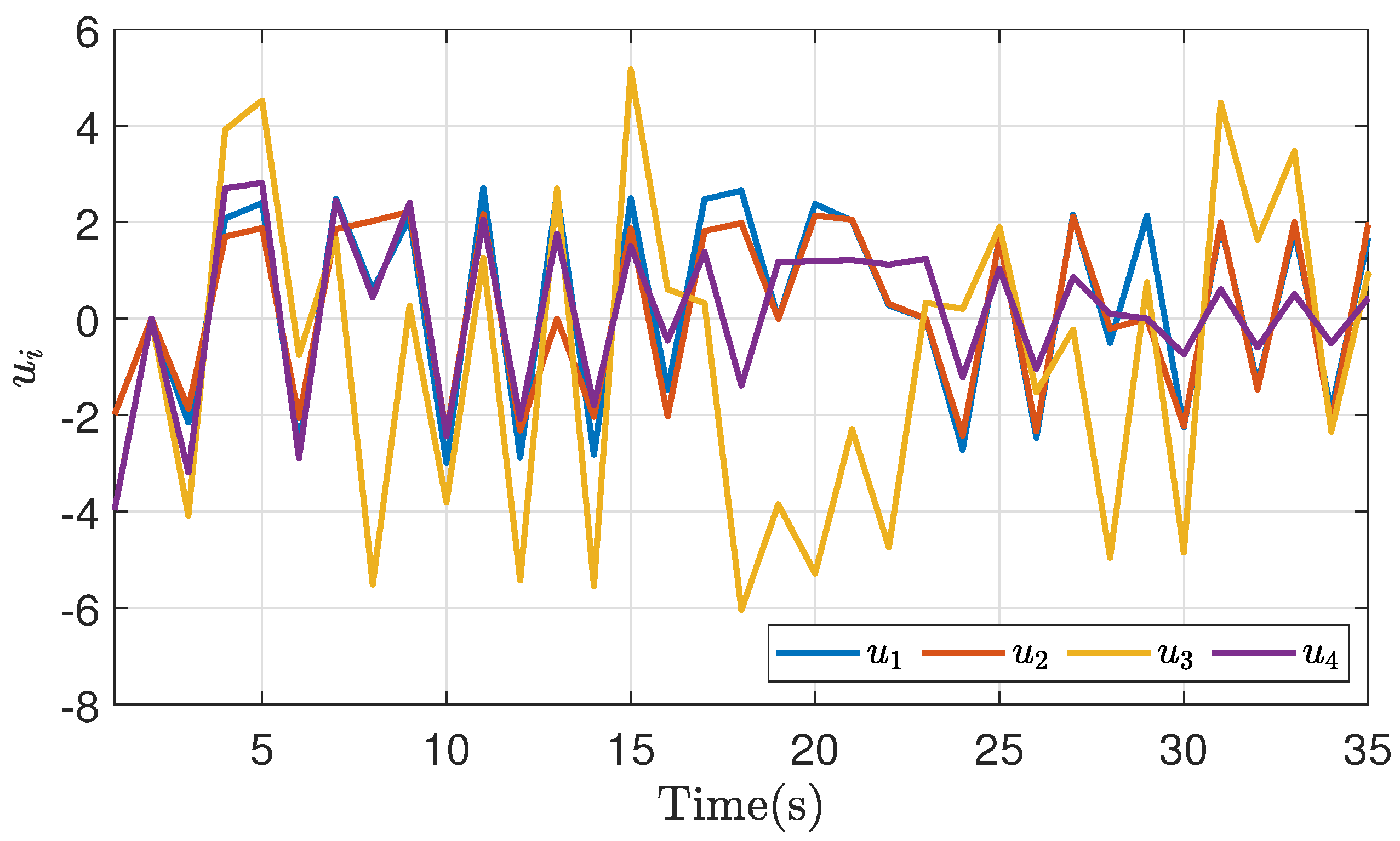
Figure 21.
Output synchronization of bargaining game theory implementation in a non-bargaining case.
Figure 21.
Output synchronization of bargaining game theory implementation in a non-bargaining case.
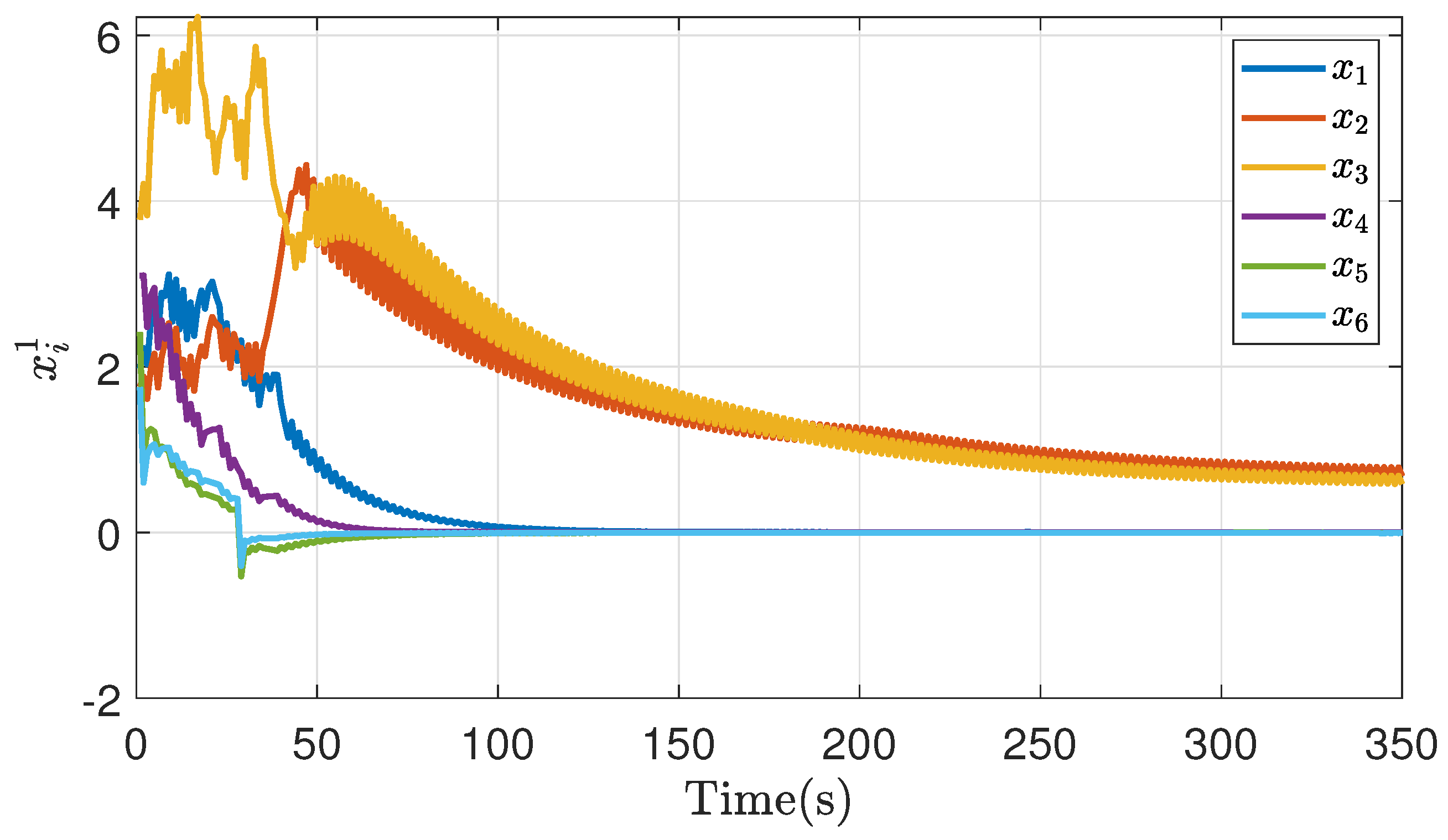

Table 1.
Players Coefficients and Initial Conditions.
| -0.25 | -0.5 | 1 | ||
| -1.25 | 1 | 0.5 | ||
| -0.5 | 2.5 | 0.75 | ||
| -0.75 | 2 | 1.5 | ||
| -1.5 | 2.5 | 1 | ||
| -1 | 2 | 1 | ||
| -0.75 | 1 | 0.5 |
Table 2.
Agent’s Coefficients and Initial Conditions for emulation case.
| -0.25 | -0.5 | 1 | ||
| -1.25 | 1 | 0.5 | ||
| -0.5 | 2.5 | 0.75 | ||
| -0.75 | 2 | 1.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



