
Submitted:
28 December 2023
Posted:
29 December 2023
Read the latest preprint version here
Abstract
Suppose for n∈ ℕ, set A⊆ℝⁿ and function f∶A→ℝⁿ. If set A is Borel; we want to find an unique and “natural” extension of the expected value, w.r.t the Hausdorff measure, that's finite for all f in a non-shy subset of ℝᴬ. The issue is current extensions of the expected value are finite for all functions in only a shy subset of ℝᴬ. The reason this issue wasn't resolved is mathematicians have not thought of the problem, focusing on application rather than generalization. Despite the lack of potential use, we'll attempt to solve the problem by defining a choice function---this shall choose a unique set of equivalent sequences of sets (Fₖ***) , where the set-theoretic limit of Fₖ*** is the graph of f; the measure Hʰ is the ℎ-Hausdorff measure, such for each k∈ℕ, 0 < Hʰ(Fₖ***) < +∞; and (fₖ*) is a sequence of functions where {(x₁,...,xₙ,fₖ*(x₁,...,xₙ))∶x∈ dom(Fₖ***)}=Fₖ***. Thus, if (Fₖ***) converges to A at a rate linear or super-linear to the rate non-equivelant sequences of sets converge, the extended expected value of or E**[f,Fₖ***] is: ∀(ε>0)∃(N∈ℕ)∀(k∈N)(k≥N⇒1/Hʰ(dom(Fₖ***))∫dom(Fₖ*** )fₖ* dHʰ - E**[f,Fₖ***]<ε ) which should be unique and “natural” extension (defined on §2.3 & §2.4) for all f in a non-shy subset of ℝᴬ. Note we guessed the choice function using computer programming but we don’t use mathematical proofs due to the lack of expertise in the subject matter. Despite this, the biggest use of this research is the extension of the expected value is finite for "almost all" functions: this is easier to use in application when finding the "average" of functions covering an infinite expanse of space.
Keywords:
expected value
; hausdorff measure
; (Exact) dimension function
; function space
; prevalent and shy sets
; entropy
; choice function
1. Introduction
According to an article in Quanta Magazine [2] Wood writes, "No known mathematical procedure can meaningfully average an infinite number of objects covering an infinite expanse of space in general. The path integral is more of a physics philosophy than an exact mathematical recipe." The cited paper [3] presents a constructive approach to Wood’s statement using filters over families of finite set; however, the average in the approach is not unique: the method determines the average value of functions with a range that lies in any algebraic structure for which the finite averages make sense. In this paper, we will explore a more constructive approach where the average is unique, finite, and "natural" (defined in 3.3 & 3.4) for a non-shy subset [4] of the set of measurable functions. (Note the functions must be measurable for application purposes).
We begin by describing "the infinite objects" which cover "an infinite expanse of space" as unbounded functions, since these functions are approachable from a mathematical standpoint. Moreover, if we define , where set and function ; suppose a prevalent subset of a function-space means "almost all" functions are in that space, a shy subset of a function-space means "almost no" functions are in that space and is the set of all Borel measurable functions in . We then get the set of unbounded f where the expected value is infinite or undefined, forms a non-shy (i.e., prevalent nor shy or prevelant) subset of . Furthermore, the set of all f with a finite expected value forms only a shy subset of , meaning only a "negligible" amount of measurable functions have finite expected values.
Therefore, when defining prevalent and shy sets using mathematics in 2.1; we’ll define four attempts to answer the thesis 1 of the first paragraph of 2.2. Note neither attempts give complete answers: they extend the Hausdorff measure of A to be positive and finite for "most" subsets of but don’t guarantee that unbounded functions in a non-shy subset of measurable functions have finite expected values. Infact, the expected value from all attempts might be positive and finite for only a shy subset of .
Hence, we define a sequence of sets called ★-sequence of sets (def. 8) whose properties allow for finite expected values for a non-shy subset of . Note these ★-sequences of sets converge to the graph of f i.e. rather than A; otherwise, the generalized expected value of f w.r.t to a ★-sequence (def. 9) cannot, in general, be finite for unbounded functions. Moreover, since there are functions with multiple ★-sequences of sets, where generalized expected values of f w.r.t each ★-sequence are different and non-unique—we must have a choice function which chooses a unique set of equivalent ★-sequences with the same, unique expected value.
For defining the choice function, we ask a question in 3.4 where with previous sections; we define equivalent & non-equivalent ★-sequences of sets for 3.1, as well as "natural" expected values for 3.3. We attempt to answer the question in 3.4 by redefining linear/super-linear convergence (def. 16) in terms of entropy, samples and "pathways" where the samples are derived by taking a point from each partition of a ★-sequence of sets, such the partitions have equal Hausdorff measure. Since all samples have finite points; we take a "pathway" of line segments between the nearest point to each start-point of all segments in the pathway (i.e., the pathway should intersect every point once), where in def. 19 we exclude segments with lengths which are anomalies [5]. The procedure is similar to the ones used in computers to graph functions [6]. We also take the length of each of the line segments in the "pathway", multiplying all lengths by a constant so they add up to one (i.e. a discrete probability distribution). We take the supremum of the Entropy of the distribution [7] w.r.t all "pathways" to redefine def. 16 as def. 20, where the redefined definition is used to create a choice function in 5.1.
2. Preliminary Definitons/Motivation
Other than integration with filters [3], there are few other constructive approaches to finding a unique and "natural" extension of the average that takes a finite value for additional functions. Before beginning, consider the following mathematical definitions:
2.1. Preliminary Definitions
Let X be a completely metrizable topological vector space.
Definition 1
(Prevalent Subset of X). A Borel set is said to be prevalent if there exists a Borel measure μ on X such that:
- for some compact subset C of X, and
- the set has full μ-measure (that is, the complement of has measure zero) for all .
More generally, a subset F of X is prevalent if F contains a prevalent Borel Set. Also note:
Definition 2
(Shy Subset of X). The complement of a prevalent set is called a shy set.
such that we define:
Definition 3
(Non-Shy Subset of X). A subset of X that is prevalent or neither prevalent nor shy.
Furthermore, suppose we define:
Definition 4
(Hausdorff Measure). Let be a metric space, . For every , define the diameter of C as:
We define:
The Hausdorff Outer Measure is defined by
If and such that , where the Euler’s Gamma function is Γ and constant is:
when and E is a Borel set we have that
such that is related to the α-dimensional Lebesgue Measure.
Definition 5
(Hausdorff Dimension). The Hausdorff Dimension of E is defined by where:
Therefore, we can use definitions 1, 2, 4 to prove or disprove:
Theorem 1.
The set of unbounded functions forms a prevalent subset of the set of all measurable functions.
Note 2
(Notes on Theorem 1). By measurable function, we mean the pre-image of any subset of (under a measurable function) is in the sigma-algebra of the Hausdorff measure. (Note function f on set A is unbounded when there is no such that for all ):
however, we’re unsure if theorem 1 is correct. Despite this, we could prove or disprove theorem 1 using the paper on prevalence in [4].
We, therefore, define the expected value w.r.t the Hausdorff measure to be the following:
Definition 6
(Expected Value off). If , where set , the expected value of function (using def. 4 and 5) is
where we can see there are cases where is undefined or infinite (e.g. is zero, or f is unbounded). In this case, if topological vector space X is (see 2.1) where we define such that:
Definition 7
(The set of all measurable functions). is the set of all Borel measurable functions in .
Then, we must prove:
Theorem 3.
The expected value is finite for all f in only a shy subset of .
Note 4
(Note on Theorem 3). We’re not sure how to prove theorem 3; however, we refer to an answer from @Mathe at the last page of this citation [8],
"We can follow the argument presented in example 3.6 of [4]:
Because a function can always be represented as we only consider whether positive functions have a mean value. We consider the case of a set A with finite positive measure. In this context having a mean means having a finite integral, and not being integrable means having an infinite integral.
Take (measurable functions over A) let P denote the one-dimensional subspace of consisting of constant functions (assuming the Hausdorff measure on A) and let (measurable functions over A with no finite integral)
If denotes the Lebesgue measure over P, for any fixed
Meaning P is a 1-dimensional probe of F, so F is a 1-prevalent set. (In other terms, the set of measurable functions over A with no finite integral or mean, forms a prevalent subset of the set of all measurable functions in . Therefore, using def. 2, the set of measurable functions with a finite integral or mean forms a shy subset of all Borel measurable functions in .)
2.2. Extended Expected Values
Four solutions to getting a finite expected value for "larger" subset of is:
-
Defining a dimension function; i.e., , that’s monotonically increasing, strictly positive and right continuous, such that when R denotes the radius of a ball in a covering for the definition of the Hausdorff Measure, we replace with so : the h-Hausdorff measure, is positive and finite. This leads to the extended expected value , where:Note, however, not all A has dimension function h which leads to:
- If A is fractal but has no gauge function, we could use this paper [9] which is an extension of the Lebesgue density theorem and this paper [10] which is an extension of the Hausdorff measure using Hyperbolic Cantor sets. Note, however, when A is non-fractal (e.g. countably infinite) or f is unbounded, there is a possibility that the expected value is infinite or undefined. Hence,
- In the case f is unbounded and fractal, we could use [11] [ p.19-47], which applies a Henstock-Kurzweil type integral (i.e., -HK integral) on a measure Metric Space. This coincides with unbounded functions with finite improper Riemman integrals, including bounded functions with finite Lebesgue integrals, bounded function with finite integrals w.r.t the Hausdorff measure, or function with finite Henstock-Kurzweil integrals.
2.3. Examples
If , set and function , we want to apply the definitions of the next section for the following examples:
- (a)
- and . This function is unbounded and has an undefined expected value since the average of , using the improper Riemann integral on :is (when , , and ) or (when , , and ), making the average undefined.
- (b)
-
, gcd is the greatest common divisor, and where:For instance, point is a point in the graph of f (since and , making ). Also, point is a point in the graph of f (since and , making ); however, point is not in the graph of f (since ).Note the function in eq. 8 is bounded; however, the expected value & extensions are undefined. (Using def. 6, we know but , which makes :undefined by division of .) Further, we assume using 2.2, crit. 1, there is no (exact) dimension function of A nor could A be "fractal" enough for extensions of the Lebesgue Density Theorem [9], extensions of the Hausdorff measure using Hyperbolic Cantor Sets [10], or extension of the Henstock-Kurzweil integral on the Metric Space [11, p.19-47].
3. Attempt to Answer Thesis
Suppose for , set and function . Moreover, is the h-Hausdorff measure (2.2, crit. 1) where h is the dimension function, and is the set of all Borel measurable functions in .
Definition 8
(★-Sequence of Sets). If we define a sequence of sets , where h is the dimension function, then when:
- (a)
- The set theoretic limit of is the graph of f (i.e., converges to the graph of f) wherewith the graph of f as:the set-theoretic limit should be:
- (b)
- For all , where is the h-Hausdorff measure (2.2, crit. 1),
- (c)
- we define sequence of functions where such that:we have is a ★-sequence of sets or starred-sequence of sets.
Example 1.
One ★-sequence of sets of on (2.3, crit. 3a) is:
Example 2.
Another example of a ★-sequence of sets of where:
using (2.3, crit. 3b) is the following:
another example is:
Note this leads to a new extension of the expected value where when there’s at least one starred-sequence of sets where the extension is finite, the extension could be finite for all f in a non-shy subset of all Borel measurable functions in .
Definition 9
(Generalized Expected Value).
If is a ★-sequence of sets (def. 8), the generalized expected value of f w.r.t is (when it exists) where:
Example 3.
Using example 1, we find that when :
- (a)
- (b)
- for
and the generalized expected value is:
We can see from example 1, the average was once undefined but now we’ve "chosen" a ★-sequence which gives a finite expected value.
3.1. Equivalent and Non-Equivalent ★-sequences of Sets
Suppose we define the following:
Definition 10
(Set ).
Set is the set of all f, where the generalized expected value, w.r.t at least one sequence, exists.
The following are definitions of equivelant and non-equivelant starred-sequences of sets:
Definition 11
(Non-Equivalent Starred-Sequences of Sets).
All starred-sequences of sets (in a set of ★-sequences of sets) are non-equivalent, if there exists an , where the generalized expected values of f w.r.t each starred-sequence of sets has two or more different values (e.g., defined and undefined values are different).
Figure 1.
Below , , are non-equivalent starred sequences of sets, where is all circles and is the generalized expected value of f w.r.t either ★-sequence of sets (def. 8)
Figure 1.
Below , , are non-equivalent starred sequences of sets, where is all circles and is the generalized expected value of f w.r.t either ★-sequence of sets (def. 8)
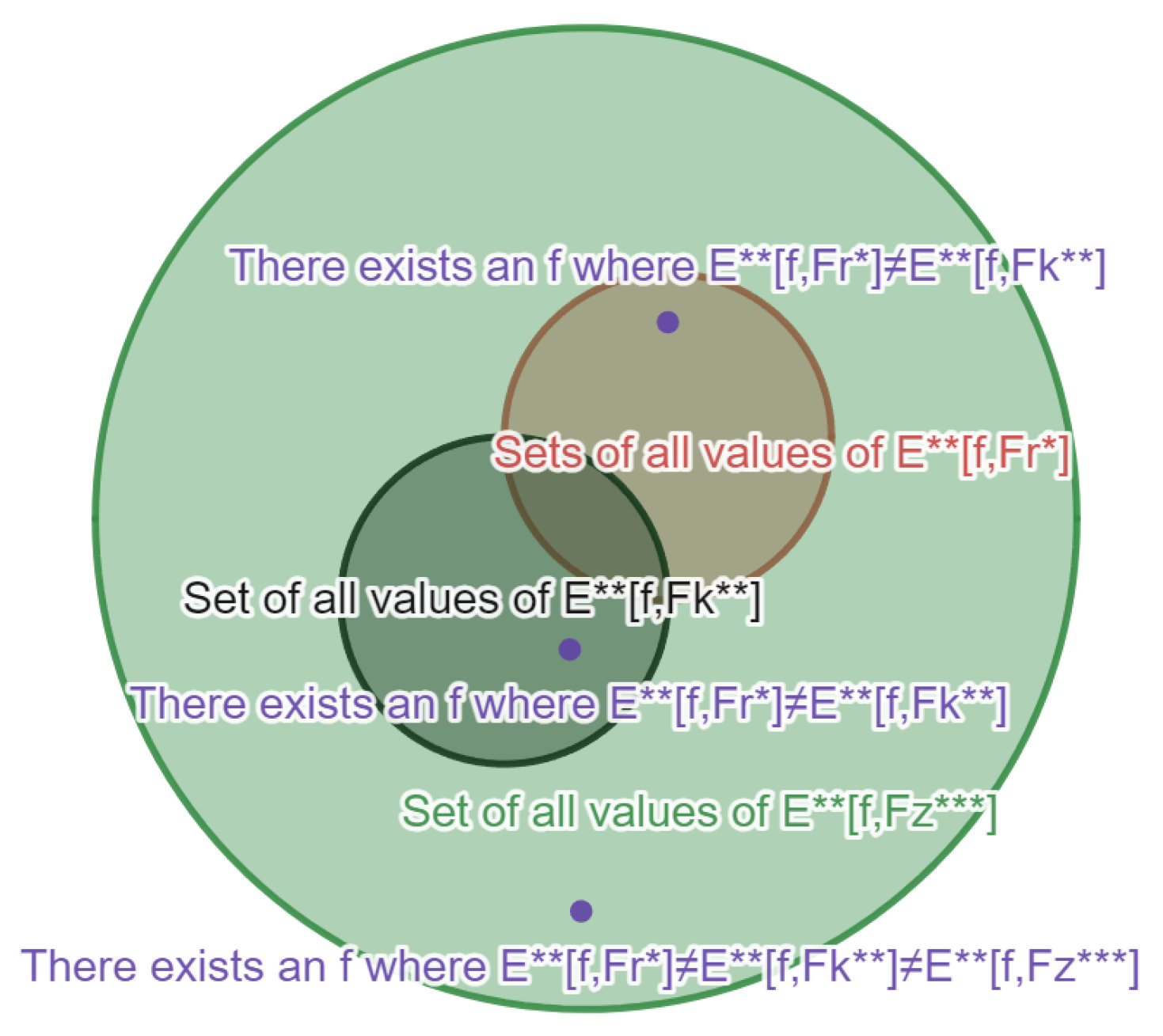
Definition 12
(Equivalent Starred-Sequences of Sets).
All starred-sequences of sets (in the set of ★-sequences of sets) are equivalent, if we get for all ; the generalized expected value of f (def. 9) w.r.t each starred-sequence of sets has the same value.
Figure 2.
Below , , are equivalent starred sequences of sets, where is the entire circle and is the generalized expected value of f w.r.t either ★-sequence of sets (def. 8)
Figure 2.
Below , , are equivalent starred sequences of sets, where is the entire circle and is the generalized expected value of f w.r.t either ★-sequence of sets (def. 8)
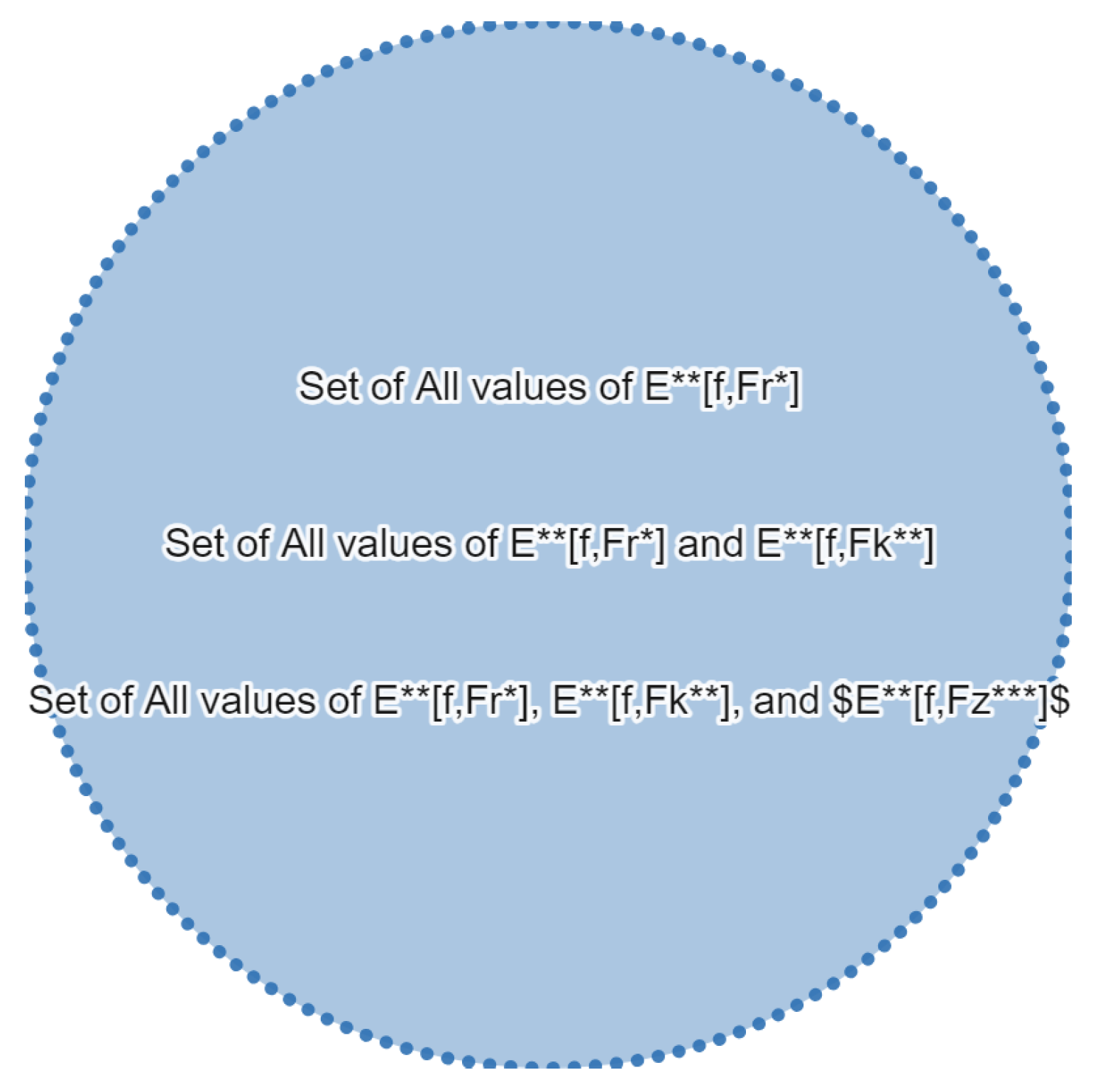
However, proving that two or more starred-sequences of sets are non-equivalent or equivalent (using def. 12 or 11) is tedious. Therefore, we ask the following:
3.1.1. Question 1
Is there are a simpler definition of equivalent and non-equivalent ★-sequences of sets.
3.1.2. Possible Answer
For the sake of brevity, suppose starred-sequences , such that , , and
Definition 13
(Equivalent Starred-Sequences of Sets).
Starred-sequence of sets and are equivalent, if there exists a , where for all , there exists a , where if is the dimension function (2.2, crit. 1) of ,
and also for all , there exists a , where if is the dimension function of then:
Note we denote these equivalent starred-sequence of sets as
Definition 14
(Multiple Equivalent Starred-Sequences of Sets).
All starred-sequences of sets in:
are equivalent, if for all where , and are equivelant (def. 13). We also state the former as:
Theorem 5.
If starred-sequences of sets in:
are equivalent (def. 12), then for all where , the generalized means of A w.r.t the ★-sequences (def. 9) have the same mean value. In other words:
Definition 15
(Non-Equivalent Starred-Sequences of Sets).
All starred-sequences of sets in are non-equivalent, if def. 12 is false.
3.2. Motivation For Sec. 3.4
For all f in a non-shy subset of (def. 7), we may choose a ★-sequence of sets where the generalized expected value of f w.r.t least one starred-sequence is finite. However, consider the following problem:
Theorem 6.
The set of all f, where the generalized expected values of f w.r.t two or more non-equivalent ★-sequences of sets has different values, form a non-shy subset of all Borel measurable functions in .
This means "almost all" measurable functions have several generalized expected values depending on the starred-sequence chosen. Therefore, we need to choose a unique ★-sequence of sets where the new extended expected value is an "natural" extension of the original expected value.
3.3. Essential Definitions for a "Natural" Expected Value
Suppose and are non-equivelant starred-sequences of sets (def. 8 & 15): we have the following is essential for a "natural" expected value.
Definition 16
(Linear & Super-linear Convergence of a ★-Sequence of Sets To That Of Another ★-Sequence of Sets).
If we define function , where and for any linear , where such that:
where we have as the Big-O notation and , then converges to the graph of f: i.e.,
at a linear or super-linear rate compared to that of .
Now we may combine the previous definitions into a main question with an answer that solves the thesis 2.
3.4. Main Question
Does there exist a choice function that chooses a unique set (of equivalent ★-sequences of sets) such that:
- (a)
- The chosen starred-sequences of sets converge to at a rate linear or super-linear (def. 16) to the rate non-equivalent ★-sequences of sets converge to
- (b)
- The generalized expected value (def. 9) of f w.r.t the chosen (and equivalent) starred-sequences of sets is finite.
- (c)
- The choice function chooses a unique set of equivalent ★-sequences of sets which satisfy (1) and (2), for all such that Q is a non-shy subset (def. 5) of (i.e., the set of all Borel measurable functions in ).
- (d)
- Out of all the choice functions which satisfy (1), (2) and (3), we choose the one with the simplest form, meaning for each choice function fully expanded, we take the one with the fewest variables/numbers (excluding those with quantifiers)?
Note 7
(Notes On Question).
Note, the unique set of equivalent and chosen starred-sequences of sets is defined using notation , where is a starred-sequence in . Therefore, after we define the choice function, the answer should be —using def. 9 (when it exists):
Also, consider the following: if the solution to the main question is extraneous, what other criteria can be included to get a unique choice function? (Note if the solution is always extraneous, we want to replace “equivelant starred-sequences of sets” with the following: ”the set of all ★-sequences of sets, where the generalized expected values of f w.r.t each starred-sequence is the same”.)
4. Solution To The Main Question Of Section 2.4
Suppose h is the dimension function, is the h-Hausdorff measure (2.2, crit. 1), and is the starred-sequence of sets (def. 8). We will use an alternative approach to definition 16 or def. 20 so we can define a choice function which solves the main question. Read from the second sentence of the last paragraph of the intro of 1 for a summary. Also, refer to sec. 3 and 4 of [1] for examples: (the cited paper uses sets instead of functions).
4.1. Preliminary Definitions
Definition 17
(Uniform coverings of each term of a ★-sequence of sets).
We define uniform ε coverings of each term of as a group of pair-wise disjoint sets which cover (for some ), such when taking dimension function h of , we want of each pair-wise disjoint set to have the same value , where and the total sum of of the coverings is minimized. In shorter notation, if
- The element
- The set is arbitrary and uncountable.
and set Ω is defined as:
then for every , the set of uniform ε coverings is defined using where ω “enumerates" all possible uniform ε coverings of for every .
Definition 18
(Sample of the uniform coverings of each term of a ★-sequence of sets).
The sample of uniform ε coverings of each term of is the set of points where for every and , we take a point from each pair-wise disjoint set in the uniform ε coverings of (def. 17). In shorter notation, if
- The element
- The set is arbitrary and uncountable.
and set is defined as:
then for every , the set of all samples of the set of uniform ε coverings is defined using , such that ψ “enumerates" all possible samples of .
Definition 19
(Entropy on the sample of uniform coverings of each term of ★-sequence of sets).
Since there are finitely many points in the sample of the uniform ε coverings of each term of (def. 18), we:
- (a)
-
Take a "pathway" of line segments between all points in each sample (def. 18), such that if we define the following:
- is the ceiling function
- is the Euclidean-distance between points and
-
The sequence:contains all points in the "original" sample where we define a "pathway" for which we:
- Choose a point
- Take a point from (excluding ) with smallest euclidean distance from point . We denote this point where we take . (If more than one point has the smallest Euclidean distance from , we take either point).
- Take a point in (excluding and ) with smallest euclidean distance from . We denote this point , where we take . (If more than one point has the smallest Euclidean distance from , we take either point).
- Take a point in (excluding , , and ) with smallest euclidean distance from . We denote this point then take . (If more than one point has the smallest Euclidean distance from , we take either point).
- Repeat the process excluding points etc. until all points in the sample are "denoted". (This should occur times.)
-
is a subset of with the largest cardinality, where that we take the subset of i-values where has the -th smallest Euclidean distance from (compared to every point in ) such that is not an anomaly [5] ofIn other words:
- For all , we want to be the largest subset of for which w-values are all i-values satisfying criteria 3(a)iv.
- Combining everything in (3a), we ultimately want all lengths between every point in the "pathway" (def. 18) satisfying crit. 3(a)iv. We call this:
- (b)
- Using def. 19, crit. 3(a)v, normalize into a discrete probability distribution. This is defined as:
- (c)
- Take the entropy of (2), (for further reading, see [7, p.61-95]). This is defined as:
- (d)
- Take where is maximized. Call this, where:with eq. 24 the entropy of the sample of uniform ε coverings of .
Definition 20
(Starred-Sequence of sets converging Sublinearly, Linearly, or Superlinearly to A compared to that of another ★-Sequence).
Suppose we define starred-sequences of sets and , where for aconstant greater than zero and variable , we say:
- (a)
-
Using def. 18 and 19, suppose we have:then (using ) we get
- (b)
- From def. 18 and 19, suppose we have:then (using ) we have:
- If using and we have that:we say converges to A at a rate superlinear to that of .
- If using equations and (where we swap in and with ) we have that:we then say converges to A at a rate sublinear to that of .
-
If using equations , , , and (such for the two latter, we swapin and with ) we have both:
- (a)
- or does not equal zero
- (b)
- or does not equal zero
and say converges to A at a rate linear to that of .
5. Attempt to Answer Main Question Of Section 2.4
5.1. Choice Function
Suppose we define the following:
- is a starred-sequence of sets (def. 8) which satisfies (1), (2), and (3) of the main question in 3.4
-
, where G is the graph of f; i.e.,is the set of the starred-sequences of sets that have finite generalized mean (def. 9).
- is an element but not an element in the set of equivalent starred-sequences of sets (def. 14) of where using note 7, we can represent this criteria as:
Further note, from def. 20, if we take:
and from def. 20, we take:
the choice function (which we’ll later define on pg., thm. 8) should immediately choose when:
-
For all when defining the set of all values of the m-th coordinate of (i.e., —where, unlike cit. [1, §4], we focus on the domain of to get "" instead of "n"), then when , we either want:
- (a)
- and .
- (b)
- and .
- (c)
- and .
- (d)
- and .
-
If the center of the universe is a chosen point , where:then for all , there exists , s.t.for all , when set is a collection of all the values of the m-th co-ordinate of , such that (again, unlike cit. [1, §4], we focus on the domain of to get "" instead of "n"), we must get:where, using absolute value function and , when set is a collection of all the values of the m-th co-ordinate of , for , when we define:andcriteria (1) is achieved, using eq. 37, when:such that, for all :and criteria (2) is achieved, using eq. 35 and 38, when:such that, for all :where we consider the following:
5.2.Question:
How do we create a choice function which solves the question in sec. 3.4 using , , , , and or equations 32, 33, 34, 39 and 41 resp.?
5.3."Attempt" to answer the Question
(Note the attempt might be wrong but could offer hints to how the solution would appear).
Suppose and the chosen coordinate for the center of the universe (i.e., eq. 35) is the origin, where for all :
Using equations , , , , and (i.e., eq. 32, 33, 34, 39 and 41) with the absolute value function and the nearest integer function , we define:
where using , the choice function should be the following:
Theorem 8.
If we define:
where for , we define to be the same as when swapping "" with "" (for eq. 33 & 34) and sets with (for eq. 32–44), then for constant and variable , if:
and:
then for all (5.1, crit. 3), if:
we choose satisfying eq. 47. (Note, we want , , and to answer the main question of 3.4) where the answer to the focus3 is in eq. 48—using def. 9 (when it exists):
Note 9
(Explanation of Theorem 8). The theorem 8 is similar to the methods used in def. 20 crit. 0a and 0b orandand def. 20 crit. 1, where:
such that we replace:
note the changes to def. 20, crit. 1 were made, so is "large enough" compared to , with non-equivalent to (e.g. when , should be and never give smaller than "small" , e.g.:
or larger than "large" ; e.g., )
Moreover, in and of thm. 8, we add constant and variable so if either
the limit in eq. 47 still exists.
5.4.Question:
How do we use mathematica code to illustrate §4 and 5?
References
- Krishnan, B. Mean of Unbounded Sets Using Method Similar To Conditional Expectation. ResearchGate, https://www.researchgate.net/publication/376597571_Mean_Of_Unbounded_Sets_Using_Conditional_Expectation_No_Programming_Just_Condensed_Version.
- C., W. Mathematicians Prove 2D Version of Quantum Gravity Really Works. Quanta Magazine. https://www.quantamagazine.org/mathematicians-prove-2d-version-of-quantum-gravity-really-works-20210617/.
- E., B.; M., E. Integration with Filters. https://arxiv.org/pdf/2004.09103.pdf.
- Ott, W.; Yorke, J.A. Prevelance. Bulletin of the American Mathematical Society 2005, 42, 263–290, https: //www.ams.org/journals/bull/2005-42-03/S0273-0979-05-01060-8/S0273-0979-05-01060-8.pdf. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41. [Google Scholar] [CrossRef]
- Emily. How do computers draw function graphs? Mathematics Stack Exchange, [https://math.stackexchange.com/q/634338]. https://math.stackexchange.com/q/634338.
- M., G. 2 ed.; Springer New York: New York [America];, 2011; pp. 61–95. https://ee.stanford.edu/~gray/it.pdf. [CrossRef]
- Mathe. Mean of a function in Rn. Matchmaticians, [https://matchmaticians.com/storage/answer/101942/matchmaticians-7gatrd-file-1.pdf]. https://matchmaticians.com/storage/answer/101942/matchmaticians-7gatrd-file-1.pdf.
- B., B.; A., F. Analogues Of The Lebesgue Density Theorem For Fractal Sets Of Reals And Integers. https://www.ime.usp.br/~afisher/ps/Analogues.pdf.
- B., B.; A., F. Ratio Geometry, Rigidity And The Scenery Process For Hyperbolic Cantor Sets. https://arxiv.org/pdf/math/9405217.pdf.
- Corrao, G. AN HENSTOCK-KURZWEIL TYPE INTEGRAL ON A MEASURE METRIC SPACE. https://core.ac.uk/download/pdf/53287889.pdf.
| 1 | We want to find an unique and "natural" extension of the expected value, w.r.t the Hausdorff measure, that takes finite values for all f in a non-shy subset of all Borel measurable functions in
|
| 2 | We want to find unique and "natural" extension of the expected value, w.r.t the Hausdorff measure, that takes finite values for all f in a non-shy subset of all Borel measurable functions in
|
| 3 | We want to find an unique and "natural" extension of the expected value, w.r.t the Hausdorff measure, that takes finite values for all f in a non-shy subset of all Borel measurable functions in
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



