Submitted:
13 September 2021
Posted:
14 September 2021
You are already at the latest version
Abstract
Recently, spam emails have become a significant problem with the expanding usage of the Internet. It is to some extend obvious to filter emails. A spam filter is a system that detects undesired and malicious emails and blocks them from getting into the users' inboxes. Spam filters check emails for something "suspicious" in terms of text, email address, header, attachments, and language. However, we have used different features such as word2vec, word n-grams, character n-grams, and a combination of variable length n-grams for comparative analysis in our proposed approach. Different machine learning models such as support vector machine (SVM), decision tree (DT), logistic regression (LR), and multinomial naïve bayes (MNB) are applied to train the extracted features. We use different evaluation metrics such as precision, recall, f1-score, and accuracy to evaluate the experimental results. Among them, SVM provides 97.6 \% of accuracy, 98.8\% of precision, and 94.9\% of f1-score using a combination of n-gram features.
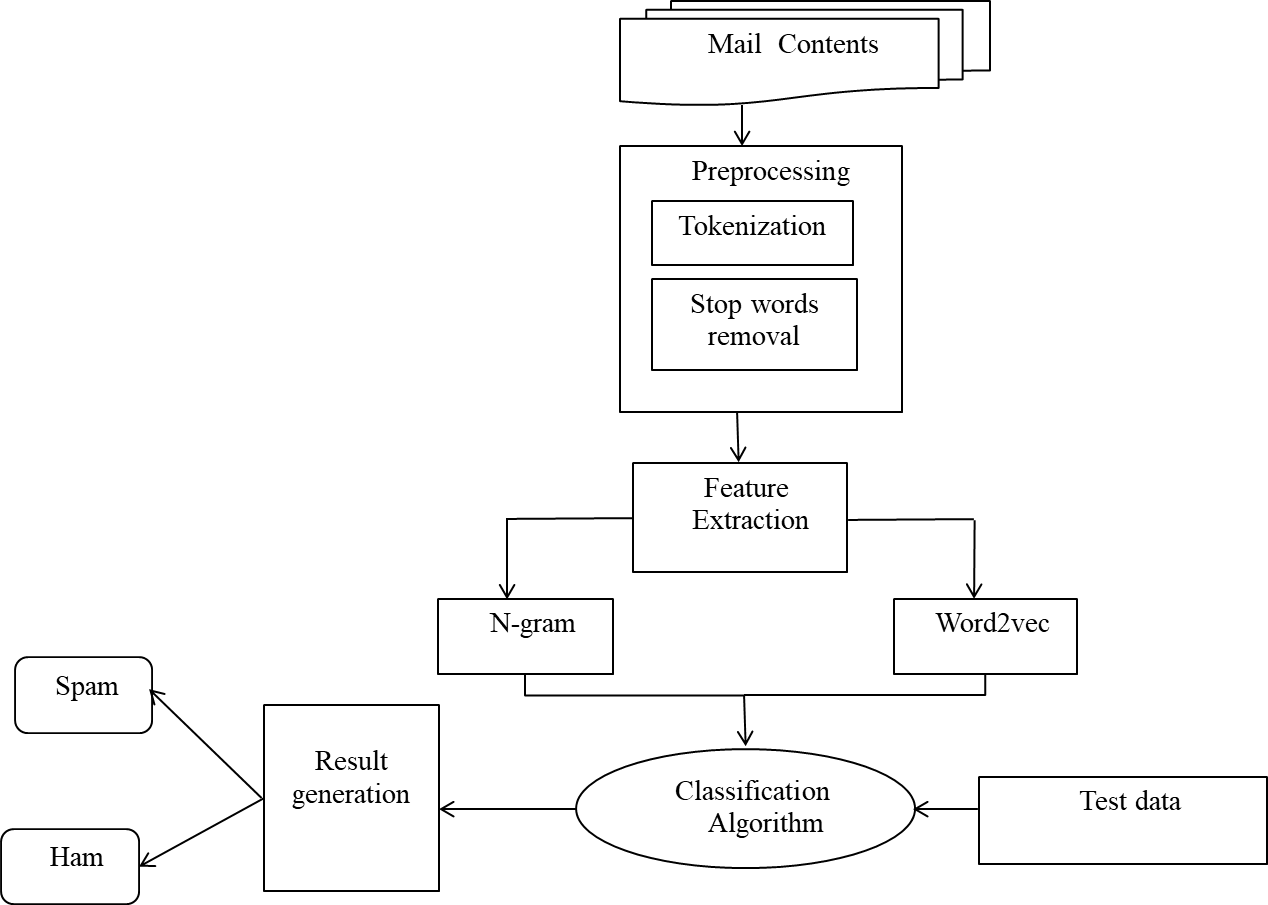
Keywords:
Spam Detection
; Feature extraction
; N-grams
; Machine Learning
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



