Submitted:
09 June 2026
Posted:
10 June 2026
You are already at the latest version
Abstract
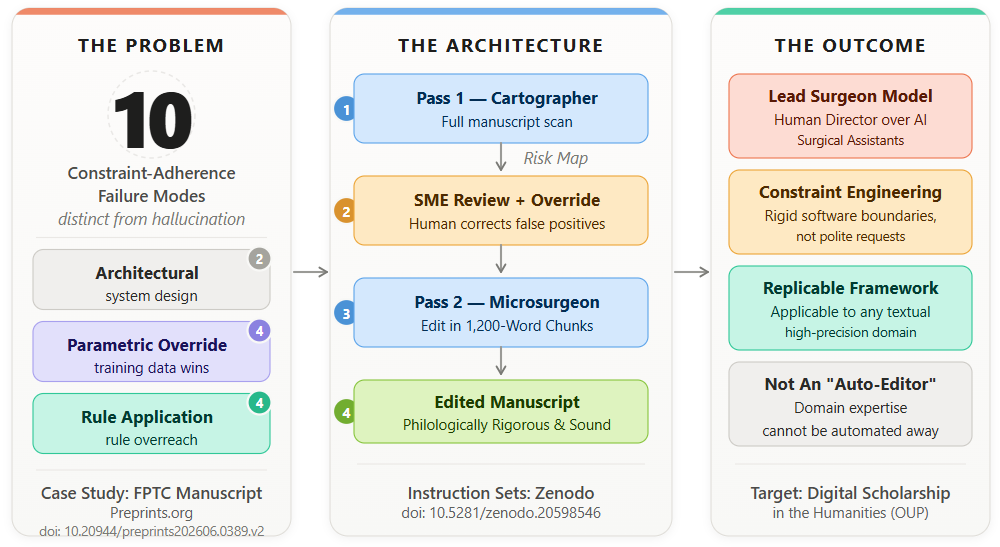
Large Language Models (LLMs) are increasingly deployed for editorial and text-processing tasks, yet their application to high-stakes domain editing exposes a class of failures distinct from hallucination. Where hallucination involves a model generating false information, constraint-adherence failure involves a model ignoring or overriding explicit user constraints in favour of its parametrically weighted training data — producing output that is fluent, stylistically polished, and wrong in precisely the ways that matter most. This paper documents the development, iterative testing, and deployment of a dual-pass HITL (Human-in-the-Loop) architecture designed to perform source-critical developmental editing on an 8,000-word academic manuscript analyzing the genealogy of nineteenth-century homeopathic materia medica. Through systematic prompt engineering conducted under a HITL framework, we identified and categorized ten distinct constraint-adherence failure modes, including Parametric Memory Override, Constraint Poisoning, Invented Math Anchors, and Source-Category Collapse. We demonstrate that effective mitigation of these failures requires not elaborated natural-language requests — the conventional understanding of prompt engineering — but the application of rigid, software-like constraints that directly counteract specific neural network behaviors at the token-generation level. Our findings reframe the role of LLMs in scholarly editorial work: not as autonomous “Auto-Editors” capable of independent philological judgment, but as “AI Surgical Assistants” operating under the continuous direction of a human Lead Surgeon whose domain expertise cannot be encoded in any prompt. The Subject Matter Expert Override Protocol documented here provides a replicable model for high-fidelity LLM-assisted editing in any domain where semantic precision is non-negotiable.
Keywords:
constraint engineering
; LLM
; constraint-adherence failure
; philological editing
; HITL
; Human-in-the-Loop
; parametric memory override
; digital humanities
; homeopathic materia medica
; prompt architecture
1. Introduction
The source-critical editing of historical texts is among the most demanding forms of scholarly work. It requires not fluency but precision: the ability to distinguish between a primary proving observation and a bibliographic compilation, to detect when a claimed “sixty years” of editorial separation is arithmetically fifty-one, to recognize that near-identical language across two nineteenth-century medical texts represents textual inheritance rather than independent clinical corroboration. These are not tasks that reward confident paraphrase. They reward rigorous constraint.
Large Language Models (LLMs) are increasingly adopted for editorial and text-processing tasks across academic disciplines, and the appeal is understandable. Contemporary frontier models demonstrate remarkable fluency, broad factual knowledge, and an ability to generate scholarly-sounding prose at speed. Recent studies have documented their deployment in academic research workflows, peer review assistance, and manuscript processing (Mishra et al., 2024; Drori and Te’eni, 2024). What has received less systematic attention is how these models behave when deployed for high-stakes domain editing — editing tasks in which the preservation of specific distinctions, taxonomic categories, and evidential standards is not merely desirable but constitutive of the work’s validity.
The dominant concern in LLM criticism has been hallucination: the generation of plausible-sounding but factually false content (Ji et al., 2023; Woesle et al., 2025; Abdullahi et al., 2026). Hallucination is a genuine and well-documented problem. But for philological editing it is not the primary failure mode. A model that invents a citation is wrong in a detectable way. Far more consequential for editorial work is what we term constraint-adherence failure: a model’s tendency to ignore or override explicit user constraints in favour of its parametrically weighted training data, producing output that is fluent, stylistically polished, and wrong in precisely the ways that matter most. When an LLM is instructed not to describe a nineteenth-century manuscript collection as a “dataset” and proceeds to do so anyway — not because it lacks the instruction, but because the statistical weight of the association in its training data overrides the constraint — the failure is not hallucination in the conventional sense. This failure class is consistent with findings on the dissociation between formal linguistic competence and functional understanding in large language models: a model may process and reproduce an instruction correctly at the formal level while failing to implement its semantic intent (Mahowald et al., 2024). It is structurally different, and it requires a structurally different class of intervention.
This paper documents the development, iterative testing, and deployment of a dual-pass HITL (Human-in-the-Loop) architecture designed to perform source-critical developmental editing on an 8,000-word academic manuscript analyzing the genealogy of nineteenth-century homeopathic materia medica. The domain was selected not for its familiarity but for its difficulty: homeopathic philology requires strict closed-world evidentiary standards, highly specific source taxonomies, chronological precision, and the preservation of intra-author structural distinctions that LLMs systematically eliminate in their default operating mode. The manuscript under analysis — From Proving to Canon: The Genealogy of Classical Homeopathic Materia Medica and What Computational Analysis Reveals About Its Epistemological Structure (Latif and Uddin, 2026a) — presented every failure mode we subsequently documented, making it an ideal case study for both the problem and the intervention.
Through systematic iterative testing under a HITL framework, we identified and categorized ten distinct constraint-adherence failure modes. These range from Parametric Memory Override — the model reverting to training-data-weighted outputs despite explicit prohibition — to Constraint Poisoning — the over-application of a correct rule beyond its defined scope — to Invented Math Anchors — the model generating a phantom intermediate date in order to make its own arithmetic internally consistent. For each failure mode, we developed and validated a targeted architectural intervention. Collectively, these interventions demonstrate a central finding: effective LLM constraint management requires not elaborated natural-language requests — the conventional understanding of prompt engineering — but the application of rigid, software-like constraints that directly counteract specific neural network behaviors at the token-generation level.
This finding reframes the role of LLMs in scholarly editorial work. We argue that the appropriate model is not the “Auto-Editor” — a system that autonomously refines texts according to inferred scholarly standards — but the “AI Surgical Assistant”: a tightly constrained instrument that executes specific, well-defined operations under the continuous direction of a human Lead Surgeon whose domain expertise cannot be encoded in any prompt. The Subject Matter Expert (SME) Override Protocol documented in this paper provides a replicable mechanism for this model of collaboration. The paper proceeds as follows. Section 2 describes the dual-pass HITL architecture and the iterative testing methodology. Section 3 presents the taxonomy of ten constraint-adherence failure modes with their targeted interventions. Section 4 applies the architecture to the HomeoAnalytics case study, presenting before-and-after evidence from the manuscript editing process. Section 5 documents the SME Override event. Section 6 concludes with implications for LLM-assisted editorial practice across the digital humanities.
2. Architecture and Methodology
2.1. Design Rationale
The development of the dual-pass HITL architecture was motivated by three limitations inherent to naive LLM deployment for long-form editorial tasks.
The first is the output token limit. Contemporary frontier LLMs have large input context windows — capable of reading 8,000 words without difficulty — but are constrained in how much text they can generate in a single response. Requesting a full editorial revision of an 8,000-word manuscript in a single prompt produces a compressed, ellipsis-filled output that summarizes rather than edits. The practical limit for reliable full-text output is approximately 1,200 words per prompt.
The second limitation is attention dilution. Even within manageable chunk sizes, LLMs apply editorial rules more rigorously to the opening paragraphs of a chunk than to later ones. Rule compliance degrades within a single generation pass, independent of context window constraints. This behavior is documented as the Attention Dilution failure mode in Section 3.
The third limitation is the loss of global context in sequential chunked editing. If a manuscript is divided into sequential chunks and edited in isolation, the model has no awareness of taxonomic inconsistencies that span chunks, or of the manuscript’s overarching argument. Blind chunking solves the output token problem while creating an equally serious coherence problem. The dual-pass architecture was designed to solve all three limitations simultaneously.
2.2. The Dual-Pass Architecture
Pass 1: The Philological Cartographer. Pass 1 reads the complete manuscript in a single prompt but produces no editorial revision. Its output is strictly restricted to a Philological Risk Map: a structured diagnostic document comprising five components: (1) a three-sentence summary of the manuscript’s overarching argument; (2) a list of taxonomic inconsistencies across sections; (3) an Echo Matrix cataloguing instances where later compilations are framed as independent confirmations of primary sources; (4) section-level anachronism and arithmetic flags; and (5) a list of historical claims lacking citations. By restricting the output to a diagnostic map rather than a revision, Pass 1 consistently produces approximately 500 words of output — well within generation limits — while processing the complete manuscript.
Pass 2: The Philological Microsurgeon. Pass 2 operates on chunks of approximately 1,000–1,200 words, but each chunk is not processed in isolation. Before the first chunk is submitted, a Calibration Prompt loads the Philological Risk Map from Pass 1 into the model’s active context window. Each chunk prompt produces a four-component output: (1) a Developmental Commentary; (2) Source-Critical Observations; (3) a Publication-Grade Revision of the complete chunk, output continuously without ellipsis; and (4) a Spartan Data Block cataloguing all dated sources against a controlled source taxonomy. The Calibration Prompt also contains Critical Map Overrides: explicit corrections to any errors in the Pass 1 Risk Map identified by the human editor before editing begins.
2.3. The Constraint Engineering Process
The editorial rules governing both passes were developed through an iterative process: deploying a draft instruction set against sample text, observing specific failure behaviors, diagnosing the neural network mechanism responsible, and designing a targeted constraint to counteract it. This process produced the ten failure modes documented in Section 3. For example, the Invented Math Anchor failure emerged when the model, tasked with correcting “sixty years” to “fifty-one years” between 1830 and 1881, generated the phantom date ‘1884’ to produce the internally consistent calculation 1884 − 1830 = 54. The Arithmetic Anchor Rule, which forbids the generation of date tokens not present in the source text, was then injected and the test repeated until compliance was verified. This iterative pattern — observe, diagnose, intervene, retest — is methodologically analogous to unit testing in software development. The complete instruction set, comprising approximately 2,500 tokens across eight numbered sections, is provided as Supplementary Appendix A.
2.4. The Human-in-the-Loop Framework
The HITL framework distributes editorial responsibility according to the principle of comparative advantage. The LLM performs operations that require speed, consistency, and exhaustive rule application: arithmetic verification, anachronism detection, source taxonomy classification, and citation flagging. The human expert performs operations that require domain knowledge, conceptual understanding, and the capacity to distinguish a valid intellectual contribution from a rule violation. This division of labor is operationalized through two mechanisms: the Map Override protocol (through which the human corrects false positives before editing begins) and the SME Override Protocol (a formal intervention mechanism documented in Section 5).
2.5. Materials
The manuscript edited in this study was From Proving to Canon (Latif and Uddin, 2026a), an 8,000-word academic manuscript analyzing the genealogy of classical homeopathic materia medica through computational analysis of nineteenth-century source texts. The dual-pass architecture was implemented as a custom conversational LLM configuration on Google’s Gemini 1.5 Pro platform. Testing and iterative constraint development were conducted through structured dialogue sessions in which draft outputs were systematically evaluated against the instruction set’s own Final Gatekeeper Questions — a self-audit protocol embedded in the instruction architecture requiring the model to verify its output against twelve explicit compliance criteria before finalizing any response.
3. A Taxonomy of Constraint-Adherence Failure Modes
The ten failure modes identified through iterative testing cluster into three mechanistically distinct categories, each requiring a different class of intervention. Architectural failures arise from system design limitations independent of the model’s behavior. Parametric override failures arise from the statistical weight of training data overriding explicit instructions. Rule application failures arise from the over-generalization or misapplication of correct rules. This three-part classification matters because the intervention strategy is different for each type. Architectural failures require system redesign. Parametric override failures require syntactic substitution mandates that bypass semantic processing. Rule application failures require explicit scope definitions that constrain where a rule applies and, critically, where it stops.
3.1. Architectural Failure Modes
Output Token Truncation occurs when the requested output volume exceeds the model’s generation ceiling. When the full 8,000-word manuscript was submitted with a request for the standard four-component editorial output, the model produced the first two or three sections in full and then began compressing: paragraphs were skipped, ellipses substituted for unrevised text. The intervention is the dual-pass architecture itself: by separating the diagnostic pass (≈500 words of output) from the editorial pass (≈1,200-word chunks), the system remains permanently below the generation ceiling.
Prompt Leakage occurs when instructional scaffolding included in the system prompt is reproduced verbatim in the model’s output. When a “Spartan Data Block Taxonomy Reminder” was placed in the Output Format section of the instruction set, the model printed it as a formal numbered heading in its response, treating it as a required output element rather than an internal directive. The intervention is positional: instructional reminders must be placed in internal protocol sections where the model treats them as self-auditing directives rather than output instructions.
3.2. Parametric Override Failure Modes
Parametric override failures are the most epistemologically significant class in this taxonomy. In each case, the model possesses accurate information from its training data, receives a conflicting explicit instruction, and — despite repeated instruction reformulation — defaults to its training-data-weighted output. The phenomenon of parametric knowledge conflicting with contextual instruction has been documented across multiple evaluation frameworks (Longpre et al., 2021; Xu et al., 2024), and benchmarking studies have confirmed that LLMs exhibit what Xie et al. (2023) term “stubborn sloth” behavior — defaulting to parametric associations with striking consistency even when contextual instructions explicitly prohibit the associated output. Wu et al. (2024) quantify this as a “tug-of-war” dynamic in which parametric confidence correlates inversely with susceptibility to instructional override. The technical mechanisms by which factual associations are encoded in transformer weight matrices and resist surface-level override are reviewed in Zhang N. et al. (2024). The practical consequence is that natural-language instructions, however precisely worded, are insufficient to override heavily weighted parametric associations. A different class of constraint is required.
Parametric Memory Override is the foundational failure mode from which this class takes its name. When the source text cited Hering’s Guiding Symptoms with the approximate date “c. 1881,” the model consistently expanded this to the full publication span “(1879–1891 [c. 1881])” — accurate in its training data but a direct violation of the closed-world evidentiary mandate. The failure was eliminated only when the constraint was reframed as a Literal String Mandate: “You are forbidden from outputting ‘1879–1891’. Your output must contain the exact character string: (c. 1881).” The shift from semantic instruction to syntactic substitution command bypasses the model’s semantic reasoning and triggers its token-matching behavior instead.
Invented Math Anchors represents a related but distinct failure. When instructed to correct “sixty years of editorial separation” between 1830 and c. 1881 to the arithmetically correct “fifty-one years,” the model generated the phantom year ‘1884’ in its observations — a date not present anywhere in the source text — to perform the calculation 1884 − 1830 = 54. The Arithmetic Anchor Rule explicitly forbids the generation of date tokens not present in the source text.
Footnote Hallucination demonstrates that parametric override operates on confident negative claims. When instructed to identify unsupported historical assertions, the model flagged the attribution of specific remedy examples to the footnotes of Aphorism 213 in the sixth edition of the Organon of Medicine. The model had checked the body text, found the examples absent, and inserted a [Source needed] flag. The flag was incorrect: the examples appear explicitly in the footnotes. The Footnote Inclusivity Mandate specifies that claims attributed to a named footnote are categorically exempt from [Source needed] flagging.
Source-Category Collapse arises when semantic similarity associations override an imposed categorical taxonomy. In the controlled vocabulary applied to homeopathic source texts, Hahnemann’s Fragmenta de Viribus Medicamentorum (1805) and his Materia Medica Pura (1830) occupy distinct categories: the former is a Materia Medica Synthesis and the latter is a Primary Proving Observation. The model consistently grouped them under the same category. The intervention is hardcoded taxonomic exception injection: “Fragmenta de Viribus is ALWAYS ‘Materia Medica Synthesis’” is expressed as an unconditional categorical constant.
3.3. Rule Application Failure Modes
Constraint Poisoning is the failure mode in which a correct rule is over-generalized beyond its defined scope. Having correctly learned that the interval between 1830 and c. 1881 is fifty-one years, the model began correcting all nearby fifty-year references to fifty-one, including Hering’s “fifty years of clinical practice.” The False Precision Prohibition explicitly scopes the rule: “Apply this correction only to the specific editorial separation between the Materia Medica Pura (1830) and the Guiding Symptoms (c. 1881).”
Attention Dilution manifests as rule compliance decay within a single generation pass. The model successfully replaced the phrase “pathological noise” in the first sentence of a paragraph and reintroduced it in the fourth. The intervention is trigger word banning: the word is placed on an unconditional prohibition list, eliminating the semantic pathway entirely.
Binary Model Imposition is the most analytically consequential failure mode. The manuscript’s theoretical framework rested on a three-part lineage model distinguishing Textual Transmission, Editorial Convergence, and Independent Experimental Replication. A rule prohibiting the description of Textual Transmission as “convergence” was processed as “never use ‘convergence,’” causing the model to replace all instances of “Editorial Convergence” — the paper’s central construct — with “textual transmission.” The intervention required both a structural expansion of the instruction set (the Dual Editorial Response Model) and a human SME Override. This failure mode is examined in detail in Section 5.
Computational Data Flagging occurs when the Closed-World Evidentiary Mandate is applied to the author’s own original research findings. When the manuscript cited specific metrics from the HomeoAnalytics computational pipeline — for example, “Allen’s citation record attributes 45.6% of proving citations to Hahnemann himself” — the model flagged these with [Source needed]. The Author’s Original Research Exemption specifies that metrics explicitly framed as the author’s own computational analysis are categorically exempt from citation demands.

Table 1.
Ten Constraint-Adherence Failure Modes — A Summary.
| No. | Failure Mode | Type | Core Behavior | Intervention |
| 1 | Output Token Truncation | Architectural | Requested output exceeds generation ceiling; model compresses and skips text | Dual-pass architecture; restrict output volume per prompt |
| 2 | Prompt Leakage | Architectural | Instructional scaffolding reproduced verbatim as output content | Relocate reminders from Output Format to internal protocol sections |
| 3 | Parametric Memory Override | Parametric Override | Model reverts to training-data output despite explicit prohibition | Literal String Mandate; reframe as syntactic substitution command |
| 4 | Invented Math Anchors | Parametric Override | Model generates phantom date tokens to produce internally consistent arithmetic | Arithmetic Anchor Rule; forbid generation of dates absent from source text |
| 5 | Footnote Hallucination | Parametric Override | Model makes confident negative claim from incomplete evidence | Footnote Inclusivity Mandate; categorical exemption for footnote-attributed claims |
| 6 | Source-Category Collapse | Parametric Override | Semantic similarity overrides imposed categorical distinctions | Hardcoded Taxonomic Exception Injection; categorical constants over reasoned rules |
| 7 | Constraint Poisoning | Rule Application | Correct rule over-generalized beyond its defined scope | False Precision Prohibition with explicit scope boundaries |
| 8 | Attention Dilution | Rule Application | Rule compliance decays within a single generation pass | Trigger Word Bans; unconditional prohibition over contextual instruction |
| 9 | Binary Model Imposition | Rule Application | Multi-part conceptual model reduced to binary by over-aggressive rule | Dual Editorial Response Model + SME Override Protocol |
| 10 | Computational Data Flagging | Rule Application | Closed-World Mandate applied to author’s own original research findings | Author’s Original Research Exemption; categorical scope definition |
4. Case Study Application — The HomeoAnalytics Corpus
4.1. The Case Study: Domain and Manuscript
The manuscript subjected to the dual-pass HITL architecture was From Proving to Canon (Latif and Uddin, 2026a), an academic manuscript presenting a computational analysis of approximately 400,000 computationally structured symptom records drawn from three foundational nineteenth-century homeopathic texts: Hahnemann’s Materia Medica Pura (1811–1833), Allen’s Encyclopedia of Pure Materia Medica (1874–79), and Hering’s Guiding Symptoms of Our Materia Medica (1879–91). No single failure mode from the taxonomy operates in isolation within this domain; all ten are active simultaneously across the manuscript.
4.2. The Pass 1 Output
The Pass 1 Philological Risk Map identified: three instances of source-category ambiguity (including the treatment of the Fragmenta de Viribus [1805] as equivalent to the Materia Medica Pura); one Echo Fallacy instance in the opening passage; six anachronism locations (“dataset,” “data points,” “structured encoding,” “salience signal”); one arithmetic error (“sixty years” between 1830 and 1881); and five historical claims lacking citations. Critically, the Risk Map also contained two errors requiring human SME correction: the author’s own computational metrics were flagged as missing citations (applying the Closed-World Mandate to original research findings), and the Editorial Convergence construct was flagged as an Echo Fallacy instance. Both errors were corrected via the Map Override protocol before Pass 2 editing began.
4.3. Evidence of Architectural Effectiveness
Example 1: Source-Category Collapse and Anachronism. The original manuscript read: “What emerges from a proving is not a theory, but a dataset.” The GEM’s revision produced “a structured record.” The published preprint reads “a structured record — a numbered account of symptoms.” The human author’s refinement (“a numbered account” rather than “a numbered list”) demonstrates the HITL model: the LLM’s correction is accepted and given its final wording by the domain expert.
Example 2: Constraint Poisoning and the HITL Override. The Arithmetic Anchor Rule was first applied correctly: “Three texts. Sixty years of editorial separation” (between 1830 and c. 1881) was correctly changed to “Fifty-one years.” The same rule’s application to Section 7 — “Three sources, three encoding systems, sixty years of editorial distance” — produced a false correction: the Section 7 reference spans 1830 to 1891, approximately sixty years. The published preprint retains “sixty years of editorial distance.” The three-column record — original “sixty years” → GEM “fifty-one years” → published preprint “sixty years” — documents Constraint Poisoning followed by a HITL override.
Example 3: Zero-Tolerance Citation Protocol. The original manuscript stated that Carroll Dunham and Adolph Lippe “reviewed the manuscript and entered their attestations before press” without citation. The GEM correctly flagged this with [Source needed]. The published preprint cites Allen’s own introduction with a fully attributed account of Dunham’s and Lippe’s distinct contributions. The flag did not insert a citation; it created the human action that produced one.
4.4. Scale and Human Override
The full manuscript was processed across seven Pass 2 chunks averaging approximately 1,200 words each. The architecture identified and corrected six instances of anachronistic vocabulary, one arithmetic error, five historical claims requiring citation, and three taxonomic misclassifications. Two categories of systematic hyper-correction required human override: the repeated application of the 51-year arithmetic correction to Hering’s career length, and the persistent misclassification of Hering’s Guiding Symptoms as “Clinical Synthesis” rather than “Bibliographic Compilation.” Both were corrected by the human editor. Version 2 of the preprint (Latif and Uddin, 2026a) incorporates the accepted editorial interventions documented in this paper.
As a secondary validation, the dual-pass architecture was subsequently applied to audit this methodology paper itself. Pass 1 generated five flags, of which four were false positives correctly handled by the SME Override protocol. One — an anachronism bleed risk where “structured symptom records” appeared without qualification — was a legitimate observation, resolved by inserting the qualifier “computationally structured.” This meta-application confirms that constraint-adherence failure modes are not domain-specific and that a false-positive rate of four out of five flags is consistent with the expectation that the SME Override is a structural component of every deployment.
5. The SME Override — The Limits of Automated Auditing
The most consequential intervention in the editing of this manuscript did not involve detecting an anachronism or correcting an arithmetic error. It involved preventing the architecture from deleting the manuscript’s central intellectual contribution.
During the Pass 1 Cartography phase, the Risk Map flagged several instances of “convergence” throughout the manuscript as potential Echo Fallacy violations. This flagging was partially correct: the manuscript’s opening passage used “convergence” in a way that implied independent corroboration between Hahnemann (1830) and Hering (1879–91) — a genuine Echo Fallacy. But the Risk Map also flagged the manuscript’s use of “Editorial Convergence” — the paper’s carefully defined analytical construct for the independent editorial selection of the same symptom by Allen and Hering from their shared primary source — as a further instance of the same error. Had this Risk Map been forwarded to the Pass 2 Microsurgeon without correction, the model would have replaced all instances of “convergence” with “textual transmission,” systematically deleting the paper’s central argument.
The mechanism underlying this failure is what we term Binary Model Imposition (Failure Mode 9). The constraint set contained the rule: “Never describe the similarity between a primary source and a later compilation as ‘convergence.’” The model internalized this as a lexical prohibition. It had no capacity to distinguish between “convergence” used as a proxy for the Echo Fallacy and “convergence” as the authors’ technical term for a categorically distinct phenomenon. Distinguishing them requires understanding the manuscript’s three-part lineage model and the specific conceptual work the term “Editorial Convergence” performs within it. No constraint statement can encode this. It is domain expertise.
The intervention was applied before Pass 2 editing began. Reviewing the Pass 1 Risk Map, the domain expert identified the false positive and injected a Critical Map Override: “Two independent editors selecting the same modality from a shared primary source is ‘Editorial Convergence’ — which is valid. Do NOT treat Editorial Convergence as Textual Transmission.” With the override in place, the Pass 2 Microsurgeon correctly preserved all instances of the Editorial Convergence construct while still eliminating the genuine Echo Fallacy instances. The intervention required less than three minutes of human review. The damage it prevented would have been structurally invisible to any reviewer unfamiliar with the manuscript’s framework.
This event furnishes the clearest available evidence for the Lead Surgeon / Surgical Assistant model. The dual-pass HITL architecture is capable of executing correct editorial operations with a consistency that unaided manual review cannot match at scale. But the architecture cannot evaluate the conceptual validity of a claim it encounters. It can only evaluate whether the surface features of a claim match the patterns encoded in its constraint set. The domain expert recognized the false positive immediately, because they understood the paper. The constraint architecture does not understand papers. It enforces rules about them.
The Subject Matter Expert Override Protocol is therefore not an optional enhancement to the system. It is the architectural component that prevents the system’s most powerful constraint from becoming its most destructive failure mode. Only the domain expert knows the boundary between a valid application and a false positive, because only the domain expert holds the theoretical model against which the word’s usage must be evaluated. That knowledge — irreplaceable, non-encodable, specific to the human Lead Surgeon — is the condition of possibility for the architecture’s reliability.
6. Conclusion
The ten failure modes documented in this paper are not a catalog of misbehaviors particular to a single domain or a single model. They are properties of transformer-based language generation operating under constraint: the tendency of parametric associations to override explicit instructions, the tendency of correct rules to be over-applied beyond their defined scope, the tendency of output format instructions to be reproduced verbatim as content. Each failure mode reflects a structural characteristic of how large language models generate text, and each targeted intervention addresses that characteristic at the level of token generation rather than semantic intent. The taxonomy is presented as a testable framework; its replication across additional high-stakes editing domains will determine which failure modes are universal properties of transformer-based generation and which are particular to the philological task.
The central finding — that effective LLM constraint management requires not elaborated natural-language requests but rigid, software-like specifications that directly counteract neural network behaviors — reconstitutes what is commonly understood as prompt engineering. Prompting is typically framed as a communication problem: how to ask a model clearly enough that it understands and complies — the foundational assumption underlying instruction-tuning methodology (Zhang S. et al., 2025). The evidence presented here requires a different framing. The models studied understood the instructions. They complied when the statistical weight of their parametric associations permitted it, and they overrode the instructions when that weight exceeded the instructional signal. The solution is not communicative but architectural: semantic appeals are replaced with syntactic substitution mandates, contextual prohibitions with unconditional trigger word bans, general rules with explicitly scoped categorical constants. This is not prompt engineering in the conventional sense. It is constraint engineering — and the distinction is not terminological but methodological.
The implications extend beyond philological editing to any domain where the difference between fluent-and-plausible and correct is consequential. Legal document analysis, archival transcription, clinical terminology review, technical standards editing — in each of these domains, an LLM that produces confident, well-structured, wrong output does not assist the expert. It misleads them. The constraint architecture documented here provides a replicable methodology for identifying domain-specific failure modes and designing targeted interventions wherever the cost of semantic smoothing exceeds the benefit of generative fluency.
The SME Override Protocol demonstrates that this architecture has a ceiling, and that the ceiling is precisely the right one. The system can be made mechanically rigorous within the domain defined by its constraints. It cannot be made to understand the document it is editing. That understanding belongs to the domain expert who designed the constraints, reviews the diagnostic map, and holds the conceptual model against which every editorial decision must ultimately be evaluated. The Lead Surgeon does not merely supervise the instrument. The Lead Surgeon is the condition of possibility for the instrument’s correct use.
Supplementary Materials
Appendix A — Complete GEM Instruction Sets: Pass 1 (Philological Cartographer) and Pass 2 (Philological Microsurgeon). Permanently deposited at Zenodo: Latif, M. S., and Uddin, J. (2026b). Dual-Pass HITL Constraint Architecture for LLM-Assisted Philological Editing (Version 1.0). Zenodo. https://doi.org/10.5281/zenodo.20598546. Full instruction sets reproduced below as supplementary material. Appendix B — Spartan Data Block: Complete Source Taxonomy for From Proving to Canon (Latif and Uddin, 2026a), as produced by the Pass 2 Philological Microsurgeon across the seven-chunk editing session. Eleven dated source entries are catalogued against the controlled source taxonomy (format: [Date] → [Source] → [Claim] → [Taxonomy Category]). Attached as a supplementary file. Note: the Kishore (1971) entry was reclassified from the GEM’s original “Clinical Synthesis” to “Bibliographic Compilation” by the human editor — a minor HITL taxonomy override of the kind documented in Section 4.4.
Author Contributions
Muhammad Sohail Latif: Conceptualization, Methodology, Data Curation, Formal Analysis, Investigation, Constraint Architecture Development, Writing — Original Draft, Writing — Review & Editing. Jamal Uddin: Methodology, Writing — Review & Editing, Supervision.
Funding
This research received no external funding.
Acknowledgments
Google Gemini 1.5 Pro — Philological Editing Architecture. The philological editing architecture described in this paper was developed and deployed using Google’s Gemini 1.5 Pro platform (custom GEM configuration) as a philological auditing tool, operating under a Closed-World Evidentiary Mandate that forbids the injection of external training data. A mandatory Human-in-the-Loop (HITL) protocol governed all editing sessions: all diagnostic flags were reviewed by the principal investigator, with specific Override Directives issued to prevent the deletion of valid methodological descriptions. In a secondary validation pass applied to this methodology paper itself, the architecture generated five diagnostic flags, of which one — an instance of Attention Dilution causing valid computational methodology vocabulary to be flagged as a historical anachronism — was a false positive, correctly overridden by the human author. The complete instruction sets are permanently deposited at Zenodo (https://doi.org/10.5281/zenodo.20598546). The AI acted as an editorial instrument, not a generative co-author. Claude (Anthropic) — Writing Assistance. The preparation of this manuscript was assisted by Claude (Anthropic) in a bounded writing-assistance capacity: Claude contributed to prose articulation, section organization, and the verbalization of content directed, supplied, and substantially drafted by the principal investigator, Dr. Muhammad Sohail Latif. Claude did not independently contribute conceptual, methodological, or analytical content. All intellectual contributions to this paper — including the conceptualization of the constraint-adherence failure taxonomy, the design and iterative development of the dual-pass HITL architecture, the identification, naming, and empirical grounding of the ten failure modes and their targeted interventions, and the Lead Surgeon / Surgical Assistant theoretical framework — originate exclusively with Dr. Muhammad Sohail Latif, Principal Investigator, HomeoAnalytics Project, Talagang, Punjab, Pakistan. The authors substantially revised all AI-assisted text and take full intellectual and editorial responsibility for the content of this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abdullahi, S.; Danyaro, K. U.; Chiroma, H. ‘The rise of hallucination in large language models: systematic reviews, performance analysis and challenges’. Cluster Computing 2026, 29(2), 124. [Google Scholar] [CrossRef]
- Drori, I.; Te’eni, D. ‘Human-in-the-loop AI reviewing: Feasibility, opportunities, and risks’. Journal of the Association for Information Systems 2024, 25(1), 98–109. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.; Madotto, A.; Fung, P. ‘Survey of Hallucination in Natural Language Generation’. ACM Computing Surveys 2023, 55(12), 248. [Google Scholar] [CrossRef]
- Latif, M. S.; Uddin, J. ‘From Proving to Canon: The Genealogy of Classical Homeopathic Materia Medica and What Computational Analysis Reveals About Its Epistemological Structure’. Preprints 2026a, 2026060389. [Google Scholar] [CrossRef]
- Latif, M. S.; Uddin, J. Dual-Pass HITL Constraint Architecture for LLM-Assisted Philological Editing: Pass 1 (Philological Cartographer) and Pass 2 (Philological Microsurgeon) Instruction Sets (Version 1.0). Zenodo 2026b. [Google Scholar] [CrossRef]
- Longpre, S.; Perisetla, K.; Chen, A.; Ramesh, N.; DuBois, C.; Singh, S. ‘Entity-Based Knowledge Conflicts in Question Answering’. In in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021); 2021. [Google Scholar] [CrossRef]
- Mahowald, K.; Ivanova, A. A.; Blank, I. A.; Kanwisher, N.; Tenenbaum, J. B.; Fedorenko, E. ‘Dissociating language and thought in large language models’. Trends in Cognitive Sciences 2024, 28(6), 517–540. [Google Scholar] [CrossRef] [PubMed]
- Mishra, T.; Sutanto, E.; Rossanti, R.; et al. ‘Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers’. Scientific Reports 2024, 14(1), 31672. [Google Scholar] [CrossRef] [PubMed]
- Woesle, C.; Fischer-Brandies, L.; Buettner, R. ‘A Systematic Literature Review of Hallucinations in Large Language Models’. IEEE Access 2025, 13. [Google Scholar] [CrossRef]
- Wu, K.; Wu, E.; Zou, J. ‘ClashEval: Quantifying the tug-of-war between an LLM’s internal prior and external evidence’. arXiv 10.48550/arXiv.2404.10198. 2024, arXiv:2404.10198. [Google Scholar]
- Xie, J.; Zhang, K.; Chen, J.; Lou, R.; Su, Y. ‘Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts’. In in Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024); 2023. [Google Scholar] [CrossRef]
- Xu, R.; Qi, Z.; Guo, Z.; Wang, C.; Wang, H.; Zhang, Y.; Xu, W. ‘Knowledge Conflicts for LLMs: A Survey’. arXiv 2024, arXiv:2403.08319. [Google Scholar] [CrossRef]
- Zhang, N.; et al. ‘A Comprehensive Study of Knowledge Editing for Large Language Models’. arXiv 2024, arXiv:2401.01286. [Google Scholar] [CrossRef]
- Zhang, S.; Dong, L.; Li, X.; Zhang, S.; Sun, X.; Wang, S.; Li, J.; Hu, R.; Zhang, T.; Wang, G.; Wu, F. ‘Instruction Tuning for Large Language Models: A Survey’. ACM Computing Surveys 2025, 58(7). [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



