Submitted:
24 November 2025
Posted:
25 November 2025
You are already at the latest version
Abstract
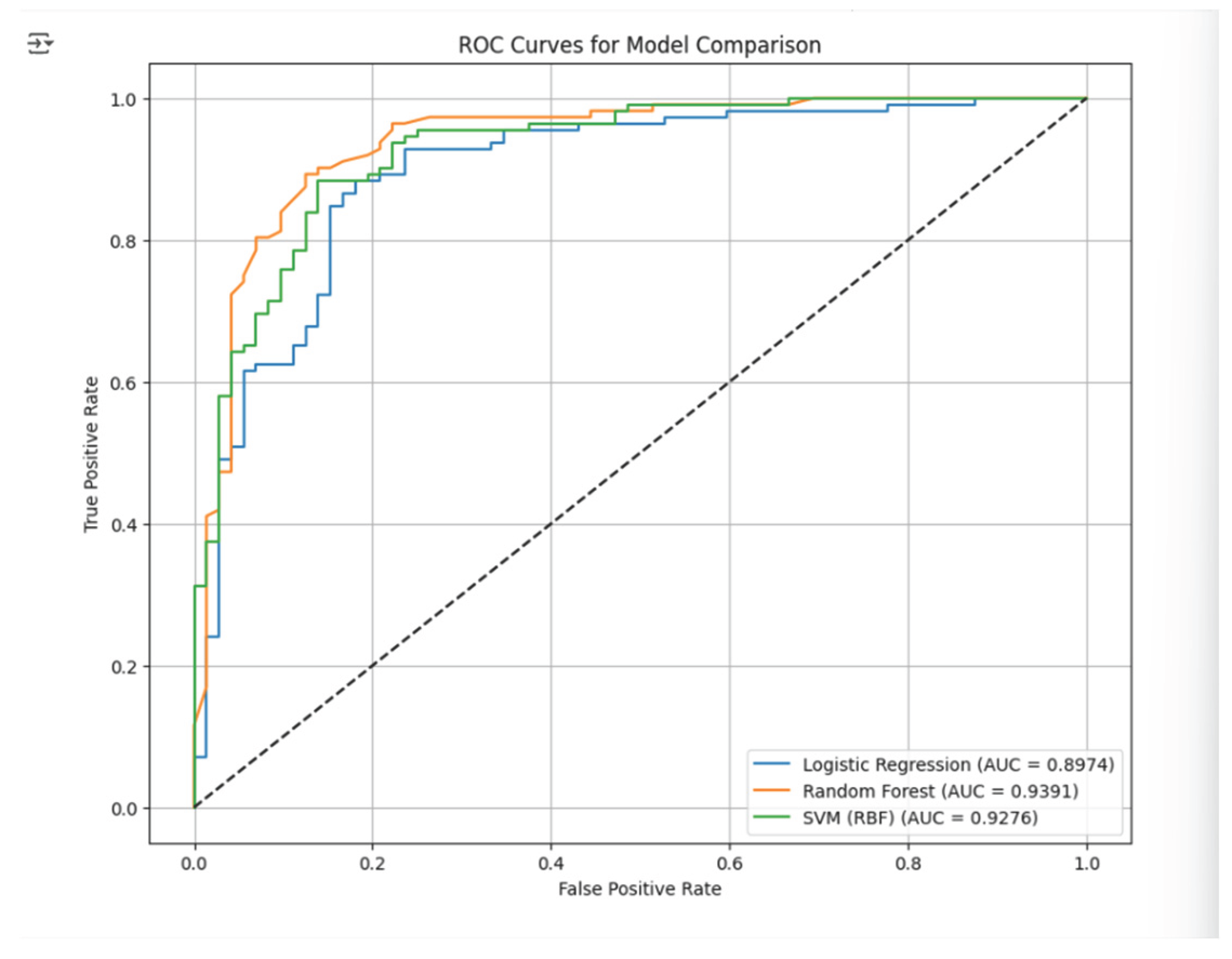
Heart disease is still at the top of the list of causes of deaths around the globe, which shows that there is a great need for early and accurate diagnostic methods that will aid clinical decision-making. A machine learning–based predictive system for heart disease will be developed and evaluated in this project using a real-world Heart Failure Prediction dataset that contains 918 anonymized patient records and 11 clinical attributes. As part of data preprocessing, medically impossible values were identified and treated, invalid cholesterol readings were replaced with the median, non-sensical entries were removed, categorical variables were encoded, and feature standardization was done to ready the dataset for model training. Accordingly, Logistic Regression, Support Vector Machine (SVM) with an RBF kernel, and Random Forest were three supervised learning algorithms implemented to evaluate their performances in binary classification. To guarantee data quality and model trustworthiness, Exploratory Data Analysis (EDA) and cross-validation were done. Model performance evaluation included the use of accuracy, precision, recall, F1-score, confusion matrices, and ROC–AUC metrics. The results indicate that the Random Forest classifier produced the best overall performance with an accuracy of 87.50%, precision of 91.59%, recall of 87.50%, F1-score of 89.50%, and an AUC of 0.9391, thus beating both SVM and Logistic Regression. Though Logistic Regression gave a comprehensible baseline, its greater false-negative rate made it less suitable for high-risk clinical applications. SVM displayed excellent non-linear classification power but needed more computational tuning. Taken together, these results show that Random Forest is the most dependable and robust model for heart disease prediction with this dataset. The next step should be incorporating wider lifestyle factors, using improved data collection methods, sophisticated outlier handling, additional machine learning models, and possibly deployment as a clinical decision-support tool through web or mobile applications.
Keywords:
1. Background of the Study
2. Introduction
Rationale
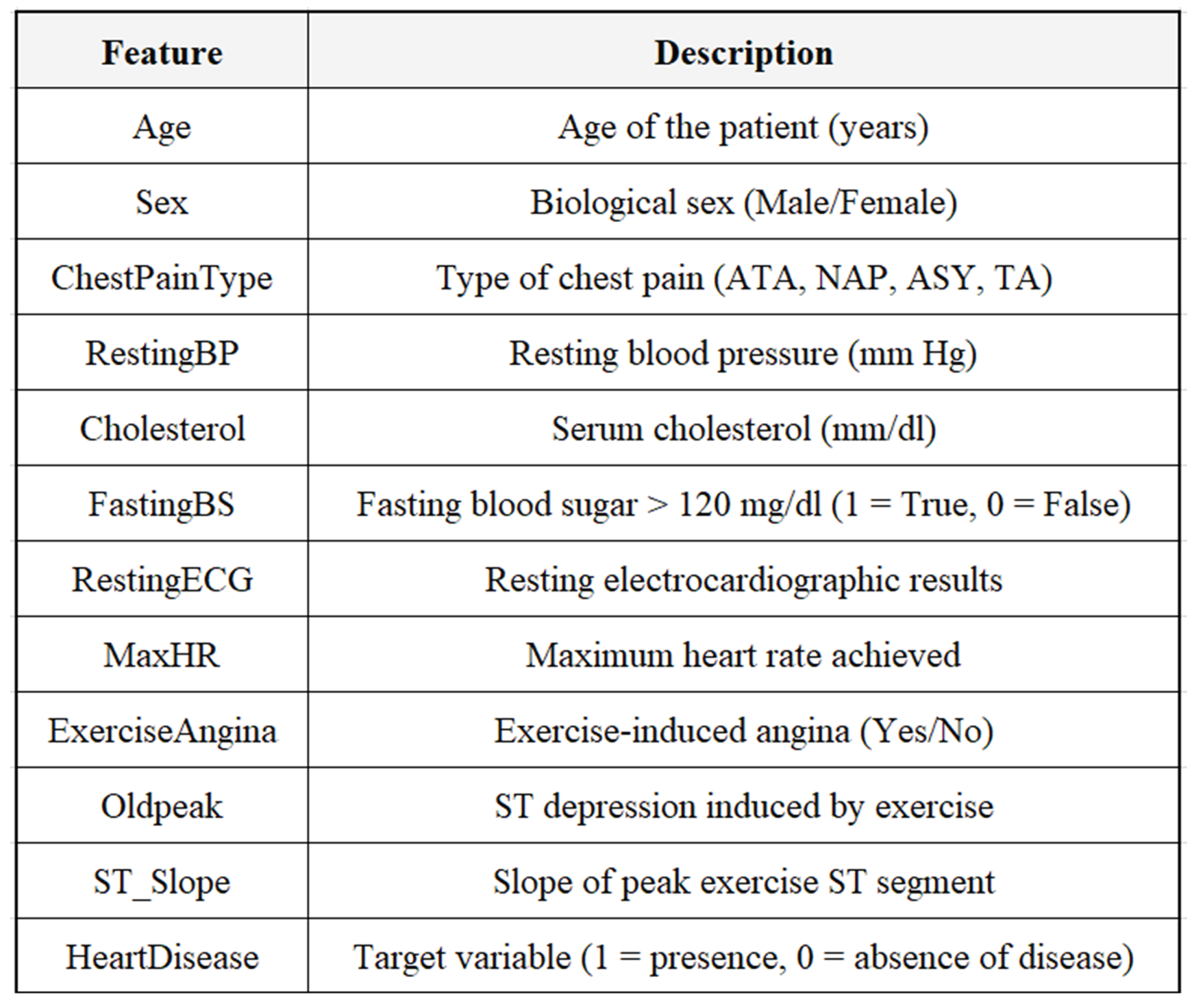
3. Data Set Description
4. Data-Related Issues and Pre-Processing
4.1. Data-Related Issues
4.2. Data Pre-Processing
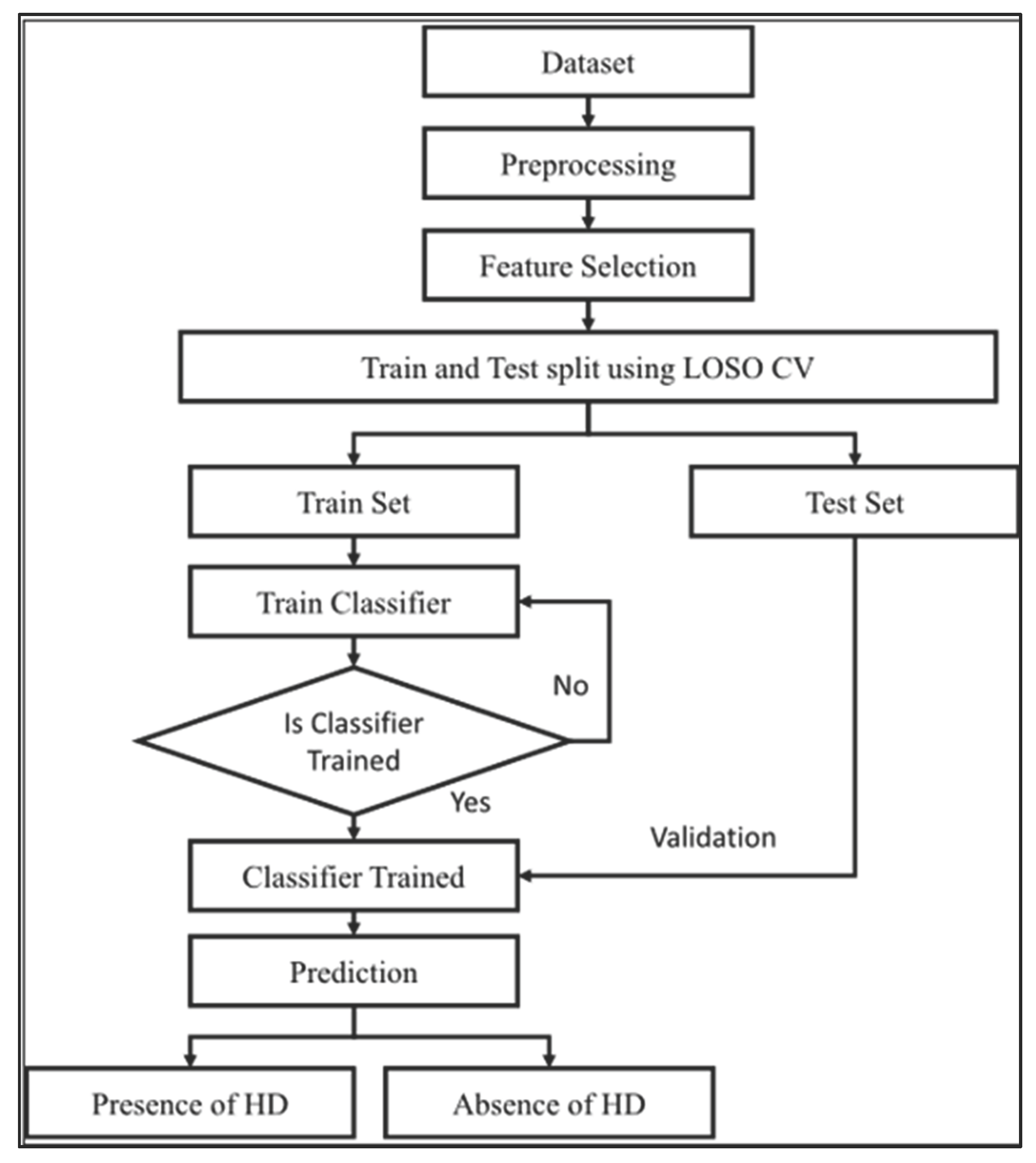
5. Methodology
5.1. Exploratory Data Analysis (EDA)
- The dataset has 918 observations and 11 clinical attributes.
- There were neither missing values nor duplicates in the dataset.
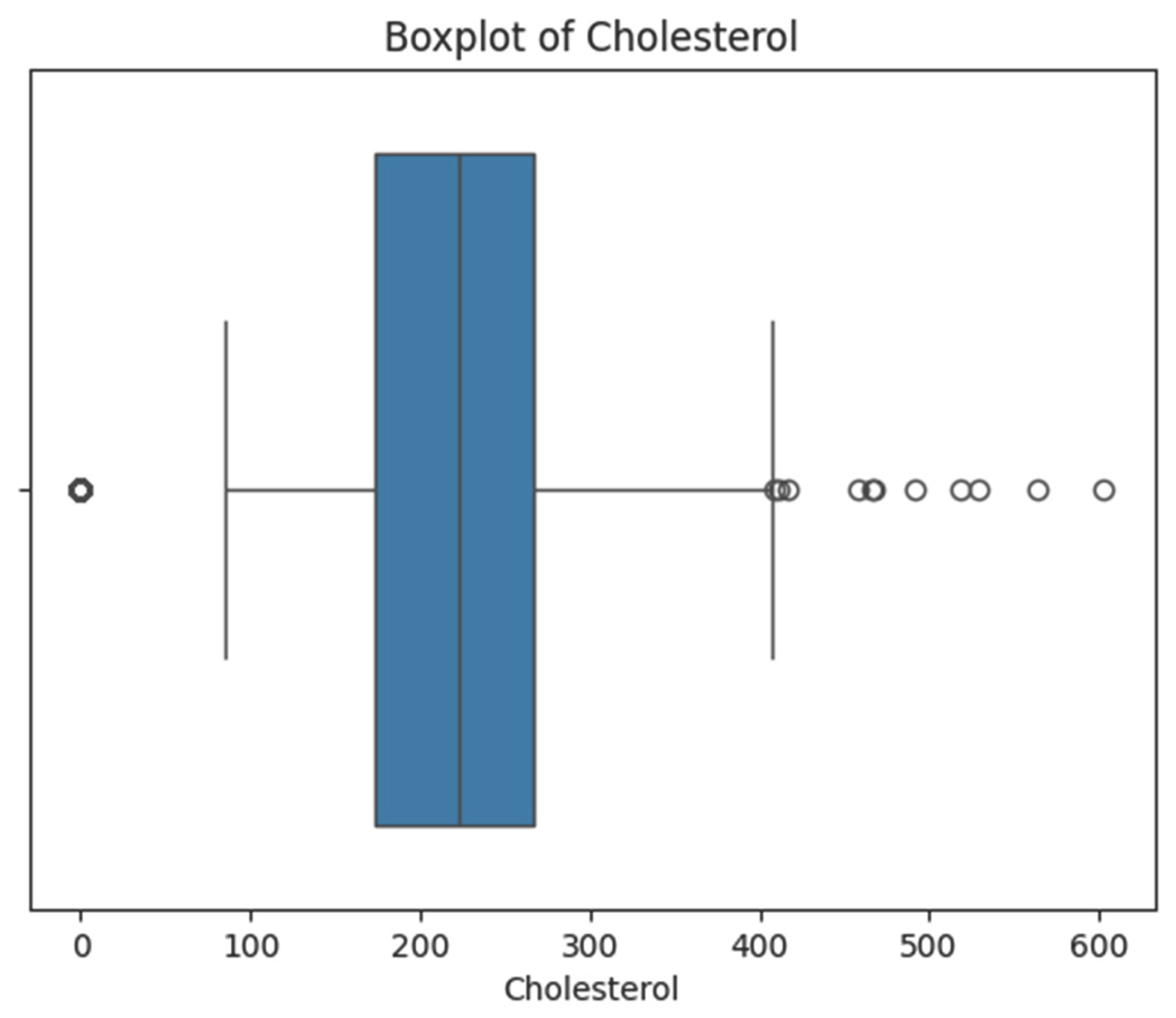
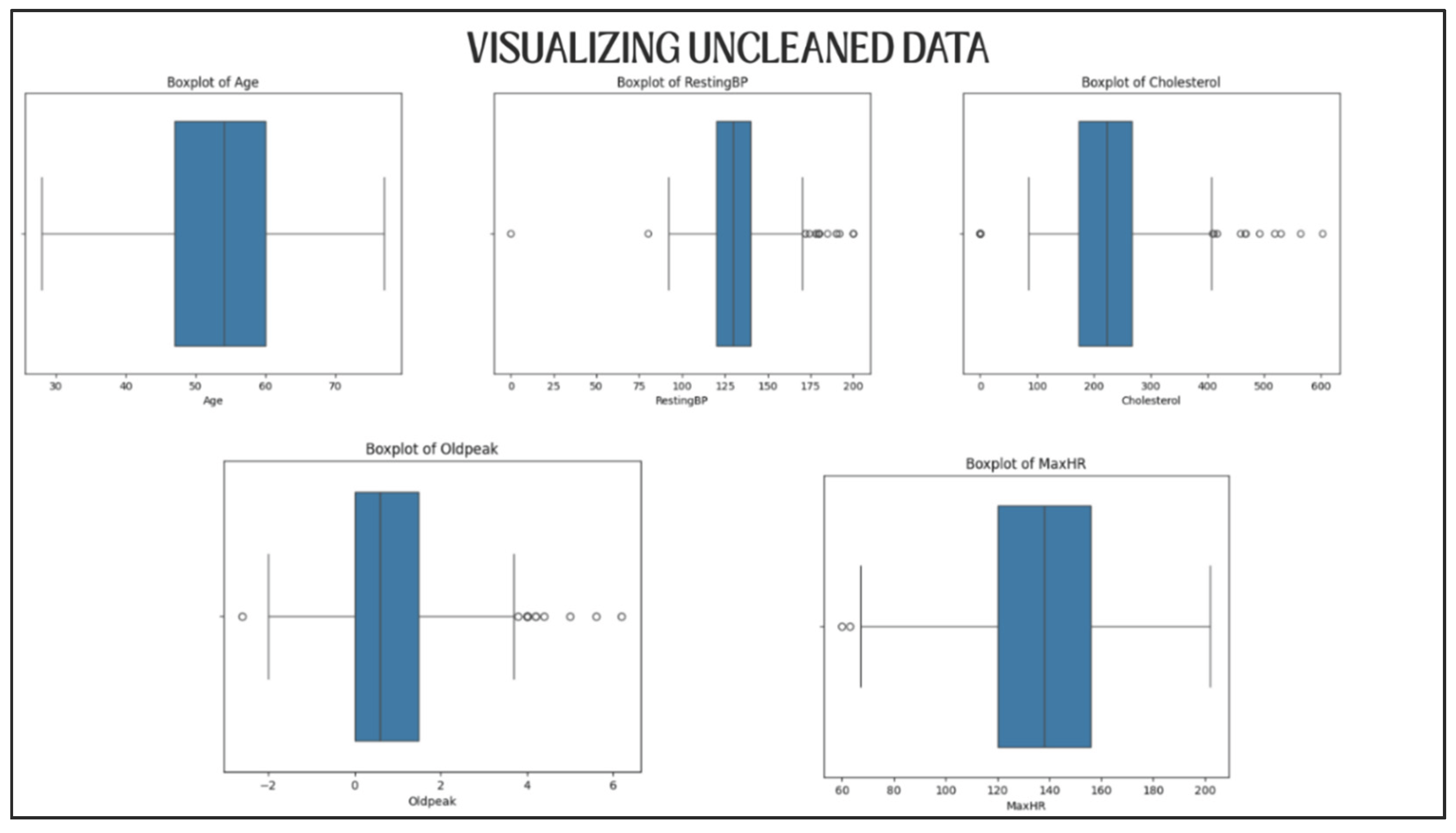
- Some features, such as Cholesterol, RestingBP, and MaxHR, had unrealistic values or very easily perceivable outliers.
5.2. Data Pre-Processing
5.2.1. Medically Impossible Values Handling
- RestingBP: A row with an invalid value was deleted.
- Cholesterol: 172 values were recognized as medically impossible. If all were removed, the dataset would be considerably reduced (i.e. only around 800 records left), so median imputation method was applied.
- Max_HR: No invalid values were found.
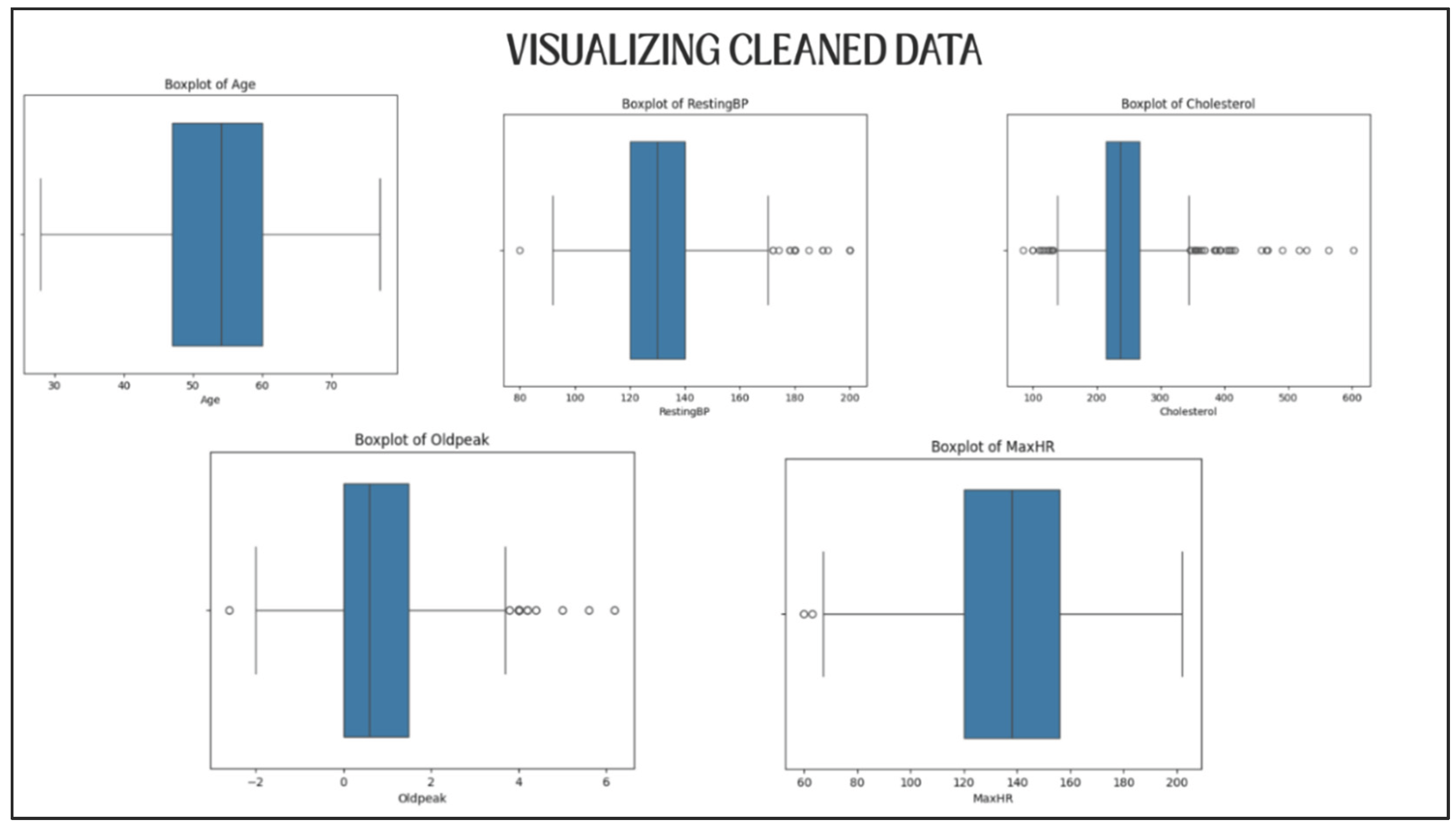
5.2.2. Data Visualization for Validation
- The medically implausible values had been properly replaced.
- Some of the statistically identified outliers had been removed but their presence was considered to be clinically valid.
5.2.3. Encoding of Categorical Variables
5.2.4. Train–Test Split
- 80% for training
- 20% for testing
5.2.5. Feature Scaling
5.3. Machine Learning Model and Evaluation
5.3.1. Logistic Regression
5.3.2. Random Forest Classifier
5.3.3. Support Vector Machine (SVM) with RBF Kernel
5.4. Model Validation and Evaluation

6. Conclusion and Future Recommendations
References
- Baxani, R., & Edinburgh, M. (2022). Heart disease prediction using machine learning algorithms logistic regression, support vector machine and random forest classification techniques. Support Vector Machine and Random Forest Classification Techniques (July 1, 2022).
- Rimal, Y., Sharma, N., Paudel, S., Alsadoon, A., Koirala, M. P., & Gill, S. (2025). Comparative analysis of heart disease prediction using logistic regression, SVM, KNN, and random forest with cross-validation for improved accuracy. Scientific Reports, 15(1), 13444. [CrossRef]
- Misra, P. K., Kumar, N., Misra, A., & Khang, A. (2023). Heart disease prediction using logistic regression and random forest classifier. In Data-Centric AI Solutions and Emerging Technologies in the Healthcare Ecosystem (pp. 83-112). CRC Press.
- Saeedbakhsh, S., Sattari, M., Mohammadi, M., Najafian, J., & Mohammadi, F. (2023). Diagnosis of coronary artery disease based on machine learning algorithms support vector machine, artificial neural network, and random forest. Advanced Biomedical Research, 12(1), 51. [CrossRef]
- Mythili, T., Mukherji, D., Padalia, N., & Naidu, A. (2013). A heart disease prediction model using SVM-decision trees-logistic regression (SDL). International Journal of Computer Applications, 68(16). [CrossRef]
- Nasution, N., Hasan, M. A., & Nasution, F. B. (2025). Predicting Heart Disease Using Machine Learning: An Evaluation of Logistic Regression, Random Forest, SVM, and KNN Models on the UCI Heart Disease Dataset. IT Journal Research and Development, 9(2), 140-150. [CrossRef]
- Rani, P., Kumar, R., Ahmed, N. M. S., & Jain, A. (2021). A decision support system for heart disease prediction based upon machine learning. Journal of Reliable Intelligent Environments, 7(3), 263-275. [CrossRef]
- Khan, A., Qureshi, M., Daniyal, M., & Tawiah, K. (2023). A novel study on machine learning algorithm-based cardiovascular disease prediction. Health & Social Care in the Community, 2023(1), 1406060. [CrossRef]
- Khanna, D., Sahu, R., Baths, V., & Deshpande, B. (2015). Comparative study of classification techniques (SVM, logistic regression and neural networks) to predict the prevalence of heart disease. International Journal of Machine Learning and Computing, 5(5), 414. [CrossRef]
- Munmun, Z. S., Akter, S., & Parvez, C. R. (2025). Machine Learning-Based Classification of Coronary Heart Disease: A Comparative Analysis of Logistic Regression, Random Forest, and Support Vector Machine Models. Open Access Library Journal, 12(3), 1-12. [CrossRef]
- Vijayashree, J., & Sultana, H. P. (2018). A machine learning framework for feature selection in heart disease classification using improved particle swarm optimization with support vector machine classifier. Programming and Computer Software, 44(6), 388-397. [CrossRef]
- Dinesh, P., Vickram, A. S., & Kalyanasundaram, P. (2024, May). Medical image prediction for diagnosis of breast cancer disease comparing the machine learning algorithms: SVM, KNN, logistic regression, random forest and decision tree to measure accuracy. In AIP Conference Proceedings (Vol. 2853, No. 1, p. 020140). AIP Publishing LLC.

 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



