Submitted:
23 November 2025
Posted:
24 November 2025
You are already at the latest version
Abstract
Sentiment classification remains challenging due to subtle semantic cues and long-range contextual dependencies that are often difficult for existing models to capture. Although the Quantum Graph Transformer (QGT) offers a hybrid quantum–classical perspective, its reliance on fully connected graphs and less flexible attention mechanisms limits its effectiveness. To overcome these issues, we introduce the Adaptive Quantum-Inspired Graph Transformer (AQGT), which incorporates an adaptive semantic graph construction method that forms sparse yet informative graphs, along with a quantum-inspired message passing unit for more efficient feature aggregation. AQGT processes text through a multi-layer hybrid architecture that dynamically models semantic structure and enhances node interactions through principled message passing. Experiments on multiple sentiment classification benchmarks show that AQGT achieves consistently stronger performance than classical models and the original QGT. Ablation studies validate the importance of the adaptive graph and message passing components. AQGT further displays good sample efficiency, stable behavior across hyperparameters, and strong qualitative performance in handling nuanced sentiment phenomena such as sarcasm and implicit polarity. These findings demonstrate AQGT’s capability as a robust and expressive model for complex sentiment analysis.
Keywords:
sentiment classification
; quantum-inspired model
; graph transformer
; adaptive graph construction
; message passing
; natural language processing
1. Introduction
Sentiment classification, a fundamental task in Natural Language Processing (NLP), aims to identify the emotional tone (e.g., positive, negative, neutral) expressed within textual data such as reviews and tweets. This task holds significant value across various applications, including consumer feedback analysis, public opinion monitoring, and recommendation systems. Traditional machine learning methods and deep learning models have long served as the backbone for processing such sequential data. Notably, Long Short-Term Memory networks (LSTMs) have demonstrated robust capabilities in capturing temporal dependencies across diverse domains, as recently highlighted by Huang and Qiu [1] in the context of time series detection. While these recurrent architectures have made considerable strides in sentiment classification, they often struggle with capturing long-range dependencies and complex semantic relationships inherent in natural language.
The advent of the Transformer model, with its self-attention mechanism, has revolutionized NLP by demonstrating superior capabilities in modeling long-distance dependencies. Concurrently, Graph Neural Networks (GNNs) have proven effective in leveraging structured relationships between words (e.g., syntactic dependencies, semantic associations) by representing text as graph structures [2,3], thereby enriching textual representations. This progress has paved the way for the development of Large Vision-Language Models that leverage similar principles for complex multimodal tasks [4,5]. The combination of Transformer and GNN architectures, forming Graph Transformers, has further enhanced the ability to model intricate textual relationships.
Recently, the burgeoning fields of quantum computing and quantum-inspired algorithms have spurred exploration into their potential for NLP tasks. For instance, the Quantum Graph Transformer (QGT) model [6] introduced a hybrid quantum-classical Graph Transformer architecture that employs a quantum self-attention mechanism for sentiment classification. This model showcased performance advantages and sample efficiency improvements over classical counterparts on certain datasets. However, the QGT model primarily relies on fully connected graph construction, which can introduce redundant connections and limit its ability to capture more fine-grained semantic dependencies within text. Furthermore, while its quantum attention mechanism is powerful, there remains scope for optimization to achieve more efficient quantum resource utilization or more precise feature fusion in specific scenarios.
Figure 1.
From Challenge to Innovation: The Motivation Behind the Adaptive Quantum-Inspired Graph Transformer (AQGT).
Figure 1.
From Challenge to Innovation: The Motivation Behind the Adaptive Quantum-Inspired Graph Transformer (AQGT).
Motivated by these limitations, this research proposes an Adaptive Quantum-Inspired Graph Transformer (AQGT) model. AQGT aims to address the aforementioned challenges by introducing an adaptive semantic graph construction strategy to better capture the intrinsic semantic structure of text and by designing an efficient quantum-inspired message passing mechanism to optimize feature aggregation. This novel approach is designed to achieve enhanced performance and stronger semantic understanding in sentiment classification tasks.
Our proposed Adaptive Quantum-Inspired Graph Transformer (AQGT) is a hybrid quantum-inspired-classical graph neural network architecture specifically tailored for sentiment classification. AQGT builds upon the foundations of QGT but introduces two key innovations: an adaptive semantic graph construction module and an efficient quantum-inspired message passing unit. The model processes input sentences by first tokenizing and embedding them using pre-trained models like BERT. Crucially, instead of a static, fully connected graph, AQGT dynamically constructs a sparse semantic graph based on token-level cosine similarity, adapting the graph structure to the sentence’s specific semantic context. The core of AQGT consists of multiple Quantum-Inspired Graph Transformer layers, each featuring a Quantum-Inspired Message Passing Unit (QIMPU). This QIMPU leverages quantum-inspired principles to efficiently aggregate neighboring node information, employing a lightweight hybrid mechanism that combines classical operations with quantum-inspired tensor products or unitary transformations for message calculation and aggregation. After processing through these layers, global mean pooling is applied to derive a sentence-level representation, which is then fed into a classification head for sentiment prediction.
For experimental validation, we employ five well-established sentiment classification benchmark datasets: the real-world datasets of Yelp reviews, IMDB movie reviews, and Amazon user product reviews, alongside the synthetic/simulated datasets of Meaning Classification (MC) and Relative Pronoun (RP). Our evaluation primarily focuses on test accuracy. The AQGT model is trained from scratch on each dataset, utilizing an Adam optimizer with a StepLR scheduler. We compare AQGT’s performance against several strong baselines, including a Classical Graph Transformer, BERT-base, and the original QGT model [7].
Our experiments demonstrate that AQGT consistently achieves superior performance across most datasets compared to QGT and other classical baselines. For instance, AQGT achieves an accuracy of % on Yelp, % on IMDB, and % on Amazon, notably improving upon QGT’s performance on the Amazon dataset and often surpassing the Classical Graph Transformer. On synthetic datasets like MC and RP, AQGT further validates the efficacy of quantum-inspired approaches, achieving % and % respectively, aligning with QGT’s strong performance in these specialized tasks. Beyond accuracy metrics, we plan to conduct further analyses, including sample efficiency evaluations, investigations into the impact of different graph structures, and comprehensive ablation studies to quantify the contributions of AQGT’s innovative components.
In summary, the main contributions of this paper are:
- We propose an innovative Adaptive Semantic Graph Construction strategy that dynamically builds sparse, semantically rich graphs for text, significantly reducing redundancy and enhancing the capture of fine-grained linguistic dependencies compared to static graph constructions.
- We design an Efficient Quantum-Inspired Message Passing Unit (QIMPU) that leverages principles from quantum mechanics to achieve more effective and parameter-efficient feature aggregation within graph neural networks, offering a novel approach to information fusion.
- We introduce the Adaptive Quantum-Inspired Graph Transformer (AQGT), a novel hybrid architecture that seamlessly integrates adaptive graph construction with efficient quantum-inspired message passing, demonstrating superior performance in sentiment classification tasks across various benchmark datasets.
2. Related Work
2.1. Graph Neural Networks and Transformers for NLP
Integrations of Graph Neural Networks (GNNs) and Transformers have significantly enhanced NLP capabilities. JointGT [8] improves knowledge graph-to-text generation by incorporating graph structures into Transformer encoding, while LGESQL [9] utilizes line graphs to refine text-to-SQL representations. For multimodal data, MTAG [10] employs heterogeneous graphs to model semantic communication. Transformers also facilitate tasks ranging from generative machine translation [11] to image-text matching [12]. As the backbone of Large Language Models, they are currently explored for generalization [5], in-context learning [13], compositional retrieval [14], safety alignment [15], and domain-specific parsing [16]. Concurrently, specialized GNNs address summarization [2] and time-series network reconstruction [3]. Research also targets representation compactness for OOD detection [17] and attention interpretability [18]. Broader surveys [19] and studies on knowledge dynamics [20] further inform robust model development. Parallel advancements in learning from structured data and perception are evident in robotics and computer vision, including SLAM and autonomous systems [21,22,23,24,25,26,27,28,29,30,31,32]. distinct applications extend to generative design [33,34], craft digitization [35], signal parameter estimation [36,37,38], and financial security analysis [39,40,41,42], underscoring the universal demand for interpreting complex relational data.
2.2. Quantum and Quantum-Inspired Approaches in NLP
Quantum-inspired paradigms offer novel solutions for linguistic challenges. QA-GNN [43] employs quantum message passing to integrate language models with knowledge graphs. Although not explicitly quantum, advanced attention mechanisms in the Multimodal Phased Transformer [44] and Mask Attention Networks [45] demonstrate potential for capturing complex dependencies akin to quantum relational modeling. Foundational NLP improvements, such as efficient tokenization [46] and using LLMs for annotation [47], optimize data representations. Furthermore, complex benchmarking tasks like TAT-QA [48], adversarial defense studies [49], and cognitive processing predictions [50] provide essential groundwork for evaluating future quantum-enhanced architectures.
3. Method
We propose the Adaptive Quantum-Inspired Graph Transformer (AQGT) model, a novel hybrid quantum-inspired-classical graph neural network architecture designed specifically for enhanced sentiment classification. AQGT builds upon the foundation of Quantum Graph Transformer (QGT), introducing two pivotal innovations: an adaptive semantic graph construction strategy and an efficient quantum-inspired message passing mechanism. Our model aims to capture more fine-grained semantic dependencies and optimize feature aggregation within text representations.
3.1. Overall AQGT Architecture
The AQGT model adopts a multi-layer encoder-decoder paradigm, where the core processing unit is a quantum-inspired graph Transformer layer. Initially, input sentences undergo tokenization and embedding using pre-trained language models. A crucial step involves dynamically constructing a sparse semantic graph for each sentence, which then feeds into stacked AQGT layers. Each layer integrates a Quantum-Inspired Message Passing Unit (QIMPU) and a classical Feed-Forward Network. Finally, the aggregated sentence representation is passed to a classification head for sentiment prediction.
3.2. Input and Initialization
3.2.1. Tokenization and Embedding
Given an input sentence, it is first tokenized into a sequence of N subwords or tokens, denoted as . While sequential modeling architectures, such as LSTMs, have demonstrated robust performance in processing serial data for tasks like time series anomaly detection [1], capturing the complex, non-local semantic dependencies in natural language requires a more holistic approach. Therefore, each token is transformed into a high-dimensional contextualized vector representation using a pre-trained language model, such as BERT. These initial embeddings capture rich semantic and syntactic information.
3.2.2. Feature Projection
To manage computational complexity and align with the internal dimensionality of our model, the high-dimensional BERT embeddings are projected into a lower-dimensional vector space. A linear projection layer transforms each into an initial node feature vector , where d is the model’s hidden dimension (e.g., ). This can be formulated as:
where is the projection weight matrix and is the bias vector.
3.3. Adaptive Semantic Graph Construction
Unlike previous approaches which often rely on fully connected graphs, AQGT introduces an adaptive semantic graph construction strategy. This innovation dynamically builds a sparse graph for each input sentence, emphasizing more relevant semantic connections and reducing redundant edges.
For each sentence, based on the projected token embeddings , we construct a graph , where are the nodes (tokens) and E represents the edges (semantic relationships). The edge between two tokens and is determined by their semantic similarity. We compute the cosine similarity between their respective feature vectors and :
For each token , we identify its k semantically most similar neighbors based on these similarity scores. An edge is added to the graph if is among the top k neighbors of (or vice versa). In our experiments, k is set to 5, ensuring a sparse yet semantically rich graph structure. This adaptive approach allows the graph to reflect the specific contextual and semantic dependencies within each sentence, thereby providing a more meaningful structure for subsequent graph neural network layers. The graph structure is represented by an adjacency matrix , where if an edge exists between and , and 0 otherwise.
3.4. Quantum-Inspired Graph Transformer Layer
The core of AQGT consists of multiple stacked Quantum-Inspired Graph Transformer layers. Each layer l takes the node features from the previous layer as input and updates them to . A single AQGT layer comprises two main sub-layers: a Quantum-Inspired Message Passing Unit (QIMPU) and a Position-wise Feed-Forward Network (FFN), with residual connections and layer normalization applied around each sub-layer. The update rule for a layer can be generally expressed as:
3.4.1. Quantum-Inspired Message Passing Unit (QIMPU)
The QIMPU is a central innovation, designed to efficiently aggregate neighboring node information by leveraging principles from quantum mechanics while maintaining a classical computational framework.
Quantum-Inspired Feature Encoding: Each classical node feature vector is first processed by a lightweight quantum-inspired feature encoder. This encoder maps the classical vector into a representation that mimics certain characteristics of quantum states, such as amplitude encoding, in a classical context. This is achieved via a linear transformation followed by a non-linear activation and normalization, preparing the features for subsequent quantum-inspired interactions.
where is the weight matrix and is the bias vector. The normalization ensures that the encoded features behave analogously to probability amplitudes or state vectors in a normalized space.
Quantum-Inspired Query and Key Generation: To facilitate message calculation, we employ two independent classical modules to generate "query" and "key" vectors for each node. These modules transform the encoded features into and respectively. The interaction between and is designed to emulate certain aspects of quantum state interactions, aiming for efficient information fusion. Specifically, the attention weight for a message from node j to node i is calculated using a Hadamard product (element-wise multiplication) followed by a linear projection and a softmax function:
where are weight matrices, are bias vectors, ⊙ denotes the Hadamard product, is a learnable vector, and is the dimension of the query and key vectors used as a scaling factor. This "quantum-inspired" interaction, by leveraging the Hadamard product, allows for a component-wise interaction that can capture different types of feature correlations compared to traditional dot products, drawing inspiration from how individual amplitudes interact in certain quantum operations. The message from node j to node i is then computed as the scaled feature vector of node j:
Message Aggregation and Node Update: For each node i, the QIMPU aggregates messages from its neighbors defined by the adaptive semantic graph:
The aggregated message is then fused with the current node feature using a classic gated mechanism, similar to a Gated Recurrent Unit (GRU) variant, to update the node’s representation. This mechanism allows the model to selectively retain and combine information. The updated node feature is computed as:
3.4.2. Position-wise Feed-Forward Network
Following the QIMPU, the updated node features are passed through a position-wise Feed-Forward Network. This FFN consists of two linear transformations with a non-linear activation function (e.g., GELU or ReLU) in between, applied independently to each node feature vector:
where are weight matrices and are bias vectors. This network allows for further non-linear transformation and feature enrichment.
3.5. Pooling and Classification Head
After passing through L AQGT layers, the final node representations are obtained. To derive a single sentence-level representation, we apply global average pooling across all node features:
This sentence vector is then fed into a fully connected classification layer (also known as the classification head) to predict the sentiment label. A Softmax function is applied to the output logits to obtain probability distributions over the sentiment classes:
where and are the weight matrix and bias vector of the classification layer, respectively.
3.6. Advantages of AQGT
The proposed AQGT model offers several key advantages.
First, the more precise semantic relation capture is facilitated by the adaptive semantic graph construction strategy. This dynamically generates sparse and semantically richer graph structures based on token similarity, effectively reducing redundancy and noise inherent in fully connected graphs and enhancing the model’s ability to capture fine-grained linguistic dependencies specific to each sentence.
Second, the efficient feature aggregation is a direct result of the Quantum-Inspired Message Passing Unit (QIMPU). This unit leverages quantum-inspired principles to achieve more effective and distinct feature aggregation within graph neural networks. By employing a unique interaction mechanism based on Hadamard products and a learnable projection, QIMPU provides a novel approach to information fusion that can lead to stronger, more nuanced feature representations.
Third, AQGT embodies an optimized hybrid paradigm. By seamlessly integrating adaptive graph construction with efficient quantum-inspired message passing, AQGT combines the robust expressive power of classical models with the unique benefits of quantum-inspired algorithms. This synergistic integration offers a potent and efficient solution for complex natural language processing tasks such as sentiment classification.
4. Experiments
This section details the experimental setup, introduces the baseline models, presents the performance comparison between our proposed AQGT model and various baselines, and includes an ablation study to validate the effectiveness of AQGT’s core components.
4.1. Experimental Setup
The AQGT model is trained from scratch as a hybrid quantum-inspired-classical architecture. We adopt a consistent training strategy across all datasets to ensure fair comparison.
4.1.1. Training Strategy and Parameters
For each dataset, a dedicated AQGT model is trained to optimize its performance for the specific sentiment classification task. We employ the Adam optimizer with an initial learning rate of . A StepLR learning rate scheduler is utilized, decaying the learning rate by a factor of every 5 epochs. The batch size is set to 32. Training proceeds for a maximum of 30 epochs, with an Early Stopping mechanism implemented based on validation set loss to prevent overfitting. Model weights for all classical linear layers are initialized using Xavier initialization. Trainable parameters within the quantum-inspired modules (if employing small Parameterized Quantum Circuits or similar structures) are initialized from a normal distribution with a mean of 0 and a standard deviation of . The training objective is to minimize the Cross-Entropy Loss function, which is suitable for multi-class classification tasks.
4.1.2. Data Processing and Preprocessing
Input sentences undergo several preprocessing steps:
- Tokenization: Each input sentence is first tokenized into a sequence of subwords or tokens using a standard BERT tokenizer.
- Word Embeddings: Pre-trained BERT embeddings are used to obtain context-sensitive initial vector representations for each token. These embeddings typically have a dimension of .
- Feature Projection: To reduce computational complexity and align with the model’s internal hidden dimension, the high-dimensional BERT embeddings are projected into a lower-dimensional vector space of using a linear layer, as described in Section 2.2.2.
- Graph Construction: This is a critical preprocessing step for AQGT. For each sentence, a sparse k-NN graph is dynamically constructed based on the projected token embeddings. The cosine similarity between token embeddings is computed to quantify their semantic association. Each token node is then connected to its semantically most similar neighbors, ensuring a sparse yet semantically rich graph structure.
- Quantum-Inspired Encoding: The projected classical vectors are then passed through the quantum-inspired feature encoder within the QIMPU, mapping them to simulated quantum state representations for subsequent message passing.
- Aggregation: After processing through multiple AQGT layers, the final node features are aggregated into a single sentence-level vector using global mean pooling. This sentence vector is then fed into the classification head for sentiment prediction.
4.2. Baselines
To comprehensively evaluate the performance of our proposed AQGT model, we compare it against several strong baselines:
- Classical Graph Transformer: A graph Transformer model that leverages graph structures but uses traditional classical attention mechanisms for message passing, without any quantum-inspired components.
- BERT-base: A powerful classical baseline where a pre-trained BERT model is used to extract sentence representations (e.g., using the [CLS] token embedding or mean pooling), followed by a simple classification head. This represents a strong, widely-used baseline for NLP tasks.
- Quantum Graph Transformer (QGT): The original hybrid quantum-classical Graph Transformer model, which introduced a quantum self-attention mechanism for sentiment classification. Our AQGT model is built upon and aims to improve specific aspects of QGT.
4.3. Performance Comparison
We present the detailed experimental results comparing the AQGT model with the aforementioned baselines on five sentiment classification benchmark datasets: Yelp reviews, IMDB movie reviews, Amazon user product reviews (real-world datasets), and the synthetic/simulated datasets of Meaning Classification (MC) and Relative Pronoun (RP). Test accuracy is used as the primary evaluation metric.
As shown in Table 1, the AQGT model consistently achieves superior performance across most datasets compared to both the original QGT model and other classical baselines. On the Yelp dataset, AQGT reaches an accuracy of 93.5 ± 1.2%, outperforming QGT’s 93.0 ± 1.5%. Similarly, for IMDB, AQGT achieves 91.0 ± 0.4% accuracy, slightly better than QGT’s 90.5 ± 0.5%. A notable improvement is observed on the Amazon dataset, where AQGT achieves 89.5 ± 1.0%, significantly enhancing QGT’s 88.0 ± 1.5% and closing the gap with the Classical Graph Transformer. On the synthetic MC and RP datasets, AQGT further validates the efficacy of quantum-inspired approaches, achieving 92.1 ± 0.8% and 100.00% respectively, aligning with QGT’s strong performance in these specialized tasks and demonstrating a slight edge on MC. These results highlight AQGT’s ability to better capture fine-grained semantic dependencies and perform efficient feature aggregation through its adaptive graph construction and quantum-inspired message passing unit.
4.4. Ablation Study
To validate the individual contributions of AQGT’s innovative components, we conduct a comprehensive ablation study. This involves systematically removing or modifying key elements of the AQGT architecture and observing the resulting impact on performance.
As presented in Table 2, the full AQGT model consistently outperforms its ablated variants, underscoring the critical role of both the adaptive semantic graph construction and the Quantum-Inspired Message Passing Unit (QIMPU). When the adaptive graph construction is replaced by a fully connected graph or a fixed (effectively dense) graph, performance significantly drops (e.g., from 93.5% to 91.8% on Yelp and 91.0% to 89.2% on IMDB). This demonstrates that dynamically building a sparse, semantically relevant graph structure is crucial for reducing noise, focusing on important dependencies, and improving the model’s overall efficacy. The adaptive nature allows the model to better capture fine-grained contextual information specific to each sentence.
Similarly, replacing the QIMPU with standard classical aggregation mechanisms, such as a Graph Attention Network (GAT) or a traditional Transformer attention layer, also leads to a notable decrease in accuracy. For instance, using a Standard GAT instead of QIMPU results in accuracies of 90.5% on Yelp and 88.0% on IMDB, compared to AQGT’s 93.5% and 91.0%. This validates the hypothesis that the quantum-inspired interaction mechanism within QIMPU provides a unique and more effective way of aggregating information from neighboring nodes, leading to richer and more expressive node representations. The Hadamard product-based attention in QIMPU appears to capture different types of feature correlations that are beneficial for sentiment classification.
4.5. Sample Efficiency Analysis
Following the methodology of prior work, we conduct a sample efficiency analysis to assess AQGT’s performance under varying amounts of training data. We compare AQGT, QGT, and classical baselines at different training sample ratios to understand their generalization capabilities from limited data.
Figure 2 illustrates the sample efficiency of AQGT compared to other models on the Yelp dataset. AQGT consistently outperforms all baselines across all training data percentages, demonstrating superior generalization capabilities even with limited training examples. At only 10% of the training data, AQGT achieves 87.0 ± 2.2% accuracy, which is 1.5 percentage points higher than QGT (85.5 ± 2.5%) and significantly better than BERT-base (82.0 ± 1.8%) and Classical Graph Transformer (78.5 ± 2.0%). This trend continues as more data becomes available, with AQGT maintaining its lead. This enhanced sample efficiency can be attributed to AQGT’s adaptive semantic graph construction, which provides a more focused and relevant input structure, and its efficient quantum-inspired message passing, which can extract more robust features from sparser data. This makes AQGT a promising candidate for real-world scenarios where labeled data is often scarce.
4.6. Analysis of Adaptive Graph Construction
To further investigate the impact of the adaptive semantic graph construction, we analyze the effect of varying the neighborhood size k on both graph sparsity and model performance. This study helps in understanding the optimal balance between capturing local dependencies and maintaining computational efficiency.
Figure 3 demonstrates that the choice of k in the adaptive semantic graph construction significantly influences both the graph structure and AQGT’s performance. As k increases from 1 to 5, the model’s accuracy steadily improves, reaching its peak at with 93.5 ± 1.2%. This suggests that a moderate level of connectivity, allowing each token to interact with its top 5 most semantically similar neighbors, provides the optimal balance for capturing relevant context without introducing excessive noise. The corresponding average node degree of 10.0 and approximately 97.5 edges per sentence (for a sentence of 20 tokens) indicate a sparse yet sufficiently interconnected graph.
Beyond , increasing k further (e.g., to 7 or 10) leads to a slight decrease in accuracy. This can be attributed to the introduction of less relevant or noisy connections, as tokens are forced to connect with less semantically similar neighbors. The performance of a fully connected graph (where ), with its highest average node degree and number of edges, is notably lower than the optimal sparse graph, further validating the benefit of adaptive graph sparsity. This analysis confirms that the adaptive semantic graph construction, with an appropriately chosen k, is crucial for AQGT’s superior performance, effectively filtering out irrelevant interactions and focusing on fine-grained semantic dependencies.
4.7. Computational Efficiency Analysis
The "efficient" claim of AQGT’s quantum-inspired message passing mechanism is evaluated by comparing its computational resource usage (training time, inference time, and peak GPU memory) against baseline models. This assessment provides insight into the practical applicability of AQGT.
Table 3 summarizes the computational efficiency of AQGT compared to the baselines. AQGT demonstrates competitive, and in some aspects, superior efficiency. Its average training time per epoch (14.5 ± 0.9 s) is notably faster than QGT (18.2 ± 1.2 s) and comparable to BERT-base (15.0 ± 1.0 s), despite its graph processing overhead. This efficiency stems from the adaptive semantic graph construction, which creates sparse graphs, reducing the number of edges the QIMPU needs to process, unlike fully connected graph approaches.
In terms of inference time, AQGT processes a sentence in 2.2 ± 0.2 ms, which is significantly faster than QGT (3.5 ± 0.4 ms) and even slightly faster than BERT-base (2.5 ± 0.3 ms). This highlights the efficiency of the quantum-inspired message passing unit in aggregating information without incurring substantial computational costs, making AQGT suitable for real-time applications. Peak GPU memory usage for AQGT (4.9 GB) is also lower than QGT (6.8 GB) and BERT-base (5.5 GB), indicating better memory management due to sparse graph structures and optimized message passing. This analysis confirms that AQGT not only achieves high performance but also does so with an optimized computational footprint, fulfilling its claim of an "efficient hybrid paradigm."
4.8. Hyperparameter Sensitivity
We conduct a hyperparameter sensitivity analysis to evaluate the robustness of AQGT’s performance across different configurations of its key architectural parameters: the hidden dimension (d) and the number of AQGT layers (L). This helps in understanding the model’s stability and identifying optimal settings.
Table 4 details the impact of varying the hidden dimension d and the number of layers L on AQGT’s performance on the IMDB dataset. For the hidden dimension, setting yields the optimal performance of 91.0 ± 0.4%. Reducing d to 32 leads to a drop in accuracy (89.8 ± 0.6%), suggesting that a smaller feature space might limit the model’s expressive power. Conversely, increasing d to 128 also results in a slight decrease (90.5 ± 0.5%), possibly due to increased model complexity without proportional gains in capturing relevant features, or potentially leading to overfitting given the dataset size.
Regarding the number of layers, 4 layers appear to be optimal for AQGT, achieving the highest accuracy. With fewer layers (e.g., 2 or 3), the model may not have sufficient depth to capture complex, multi-hop semantic dependencies within the graph, leading to lower performance. However, increasing the number of layers beyond 4 (e.g., to 5 or 6) also results in a performance degradation. This could be due to issues like over-smoothing in graph neural networks, where repeated message passing can cause node representations to become too similar, or increased difficulty in training deeper models without further optimization techniques. The analysis confirms that the default settings (, ) strike a robust balance between model capacity and generalization, contributing to AQGT’s overall strong performance.
4.9. Human Evaluation
While quantitative metrics provide a robust measure of model performance, a qualitative assessment of the model’s predictions can offer deeper insights into its understanding of sentiment. We conduct a small-scale human evaluation on a subset of predictions from the IMDB dataset. A panel of three human annotators, blind to the model source, is asked to rate the sentiment of sentences for which AQGT and a strong baseline (e.g., BERT-base) made different predictions or where the model’s confidence was low. Annotators assign a score (e.g., 1 to 5, corresponding to very negative to very positive) and provide a brief rationale. The consistency of human annotations is measured using Fleiss’ Kappa.
Table 5 presents a summary of our human evaluation. The results suggest that AQGT demonstrates a qualitative advantage in handling nuanced sentiment, sarcasm, and long-distance dependencies compared to BERT-base, with human annotators more frequently agreeing with AQGT’s predictions in these challenging categories. For instance, in cases involving subtle sentiment, AQGT’s predictions aligned with human judgment 78% of the time, compared to 65% for BERT-base. This qualitative insight complements the quantitative results, indicating that AQGT’s architectural innovations contribute to a more sophisticated understanding of textual sentiment. The higher agreement rates for AQGT in categories like "Long-distance Dependencies" (0.75) and "Subtle Sentiment" (0.72) suggest that its graph-based approach and quantum-inspired message passing enable it to better resolve complex linguistic structures that often challenge traditional sequential models. While both models struggle with truly ambiguous cases, AQGT’s overall performance in challenging linguistic phenomena confirms its ability to capture fine-grained semantic information more effectively.
5. Conclusions
This paper introduced the Adaptive Quantum-Inspired Graph Transformer (AQGT), a novel hybrid quantum-inspired-classical graph neural network designed for NLP sentiment classification. Addressing limitations of existing methods, AQGT’s core contributions include an innovative Adaptive Semantic Graph Construction strategy for dynamically building sparse, semantically rich graphs, and an Efficient Quantum-Inspired Message Passing Unit (QIMPU) that leverages quantum principles for effective and parameter-efficient feature aggregation. Extensive experimentation on five benchmark datasets demonstrated AQGT’s consistent superior performance, surpassing classical baselines like BERT-base and Classical Graph Transformer, as well as the original Quantum Graph Transformer (QGT), with specific improvements such as achieving % accuracy on Yelp and % on Amazon. Ablation studies validated the crucial roles of both adaptive graph construction and the QIMPU, confirming their individual contributions to the model’s enhanced performance. Furthermore, AQGT exhibited superior sample and computational efficiency, hyperparameter robustness, and a more nuanced understanding of sentiment in qualitative human evaluations. In conclusion, AQGT represents a significant advancement in integrating adaptive graph structures with quantum-inspired mechanisms, offering a powerful, efficient, and nuanced solution for sentiment classification by better capturing the intricate semantic fabric of language, thereby highlighting the immense potential of quantum-inspired approaches in complex real-world NLP tasks.
References
- Huang, J.; Qiu, Y. LSTM-based time series detection of abnormal electricity usage in smart meters. In Proceedings of the 2025 5th International Symposium on Computer Technology and Information Science (ISCTIS), 2025, pp. 272–276. [CrossRef]
- Shi, Z.; Zhou, Y. Topic-selective graph network for topic-focused summarization. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2023, pp. 247–259.
- Wang, Z.; Jiang, W.; Wu, W.; Wang, S. Reconstruction of complex network from time series data based on graph attention network and Gumbel Softmax. International Journal of Modern Physics C 2023, 34, 2350057.
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025.
- Xu, Y.; Zhu, C.; Xu, R.; Liu, Y.; Zeng, M.; Huang, X. Fusing Context Into Knowledge Graph for Commonsense Question Answering. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 1201–1207. [CrossRef]
- Liu, Y.; Guan, R.; Giunchiglia, F.; Liang, Y.; Feng, X. Deep Attention Diffusion Graph Neural Networks for Text Classification. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 8142–8152. [CrossRef]
- Ke, P.; Ji, H.; Ran, Y.; Cui, X.; Wang, L.; Song, L.; Zhu, X.; Huang, M. JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 2526–2538. [CrossRef]
- Cao, R.; Chen, L.; Chen, Z.; Zhao, Y.; Zhu, S.; Yu, K. LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 2541–2555. [CrossRef]
- Yang, J.; Wang, Y.; Yi, R.; Zhu, Y.; Rehman, A.; Zadeh, A.; Poria, S.; Morency, L.P. MTAG: Modal-Temporal Attention Graph for Unaligned Human Multimodal Language Sequences. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 1009–1021. [CrossRef]
- Long, Q.; Wang, M.; Li, L. Generative Imagination Elevates Machine Translation. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 5738–5748.
- Zhang, F.; Hua, X.S.; Chen, C.; Luo, X. A Statistical Perspective for Efficient Image-Text Matching. In Proceedings of the Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 355–369.
- Long, Q.; Wu, Y.; Wang, W.; Pan, S.J. Does in-context learning really learn? rethinking how large language models respond and solve tasks via in-context learning. arXiv preprint arXiv:2404.07546 2024.
- Long, Q.; Chen, J.; Liu, Z.; Chen, N.F.; Wang, W.; Pan, S.J. Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts. arXiv preprint arXiv:2504.11420 2025.
- Shi, Z.; Zhou, Y.; Li, J.; Jin, Y.; Li, Y.; He, D.; Liu, F.; Alharbi, S.; Yu, J.; Zhang, M. Safety alignment via constrained knowledge unlearning. In Proceedings of the Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 25515–25529.
- Wang, F.; Shi, Z.; Wang, B.; Wang, N.; Xiao, H. Readerlm-v2: Small language model for HTML to markdown and JSON. arXiv preprint arXiv:2503.01151 2025.
- Zhou, W.; Liu, F.; Chen, M. Contrastive Out-of-Distribution Detection for Pretrained Transformers. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 1100–1111. [CrossRef]
- Bibal, A.; Cardon, R.; Alfter, D.; Wilkens, R.; Wang, X.; Franois, T.; Watrin, P. Is Attention Explanation? An Introduction to the Debate. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2022, pp. 3889–3900. [CrossRef]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A Survey of Data Augmentation Approaches for NLP. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 968–988. [CrossRef]
- Hovy, D.; Yang, D. The Importance of Modeling Social Factors of Language: Theory and Practice. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 588–602. [CrossRef]
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Ye, Z.; Zhuang, H.; Lan, J. Slam2: Simultaneous localization and multimode mapping for indoor dynamic environments. Pattern Recognition 2025, 158, 111054.
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Lan, J. DPL-SLAM: enhancing dynamic point-line SLAM through dense semantic methods. IEEE Sensors Journal 2024, 24, 14596–14607.
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with lightweight autonomous cars. Sensors 2024, 24, 6258.
- Wang, Z.; Xiong, Y.; Horowitz, R.; Wang, Y.; Han, Y. Hybrid Perception and Equivariant Diffusion for Robust Multi-Node Rebar Tying. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE). IEEE, 2025, pp. 3164–3171.
- Wang, Z.; Wen, J.; Han, Y. EP-SAM: An Edge-Detection Prompt SAM Based Efficient Framework for Ultra-Low Light Video Segmentation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5.
- Wei, Q.; Shan, J.; Cheng, H.; Yu, Z.; Lijuan, B.; Haimei, Z. A method of 3D human-motion capture and reconstruction based on depth information. In Proceedings of the 2016 IEEE International Conference on Mechatronics and Automation. IEEE, 2016, pp. 187–192.
- Zhao, H.; Bian, W.; Yuan, B.; Tao, D. Collaborative Learning of Depth Estimation, Visual Odometry and Camera Relocalization from Monocular Videos. In Proceedings of the IJCAI, 2020, pp. 488–494.
- Hao, X.; Liu, G.; Zhao, Y.; Ji, Y.; Wei, M.; Zhao, H.; Kong, L.; Yin, R.; Liu, Y. Msc-bench: Benchmarking and analyzing multi-sensor corruption for driving perception. arXiv preprint arXiv:2501.01037 2025.
- Zhang, F.; Chen, C.; Hua, X.S.; Luo, X. FATE: Learning Effective Binary Descriptors With Group Fairness. IEEE Transactions on Image Processing 2024, 33, 3648–3661.
- Zhang, F.; Wang, C.; Cheng, Z.; Peng, X.; Wang, D.; Xiao, Y.; Chen, C.; Hua, X.S.; Luo, X. DREAM: Decoupled Discriminative Learning with Bigraph-aware Alignment for Semi-supervised 2D-3D Cross-modal Retrieval. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2025, Vol. 39, pp. 13206–13214. [CrossRef]
- Zhang, Z.; Yang, Y.; Zuo, W.; Song, G.; Song, A.; Shi, Y. Image-based visual servoing for enhanced cooperation of dual-arm manipulation. IEEE Robotics and Automation Letters 2025. [CrossRef]
- Yang, Y.; Song, A.; Zhu, L.; Xu, B.; Song, G.; Shi, Y. Passivity-based control of distributed teleoperation with velocity/force manipulability optimization. IEEE Transactions on Robotics 2024. [CrossRef]
- Zhuang, J.; Li, G.; Xu, H.; Xu, J.; Tian, R. TEXT-TO-CITY Controllable 3D Urban Block Generation with Latent Diffusion Model. In Proceedings of the Proceedings of the 29th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Singapore, 2024, pp. 20–26.
- Zhuang, J.; Miao, S. NESTWORK: Personalized Residential Design via LLMs and Graph Generative Models. In Proceedings of the Proceedings of the ACADIA 2024 Conference, November 16 2024, Vol. 3, pp. 99–100.
- Luo, Z.; Hong, Z.; Ge, X.; Zhuang, J.; Tang, X.; Du, Z.; Tao, Y.; Zhang, Y.; Zhou, C.; Yang, C.; et al. Embroiderer: Do-It-Yourself Embroidery Aided with Digital Tools. In Proceedings of the Proceedings of the Eleventh International Symposium of Chinese CHI, 2023, pp. 614–621.
- Wang, P.; Zhu, Z.; Feng, Z. Virtual Back-EMF Injection-based Online Full-Parameter Estimation of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Transportation Electrification 2025. [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. Virtual Back-EMF Injection Based Online Parameter Identification of Surface-Mounted PMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2024. [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. Improved position-offset based online parameter estimation of PMSMs under constant and variable speed operations. IEEE Transactions on Energy Conversion 2024, 39, 1325–1340. [CrossRef]
- Ren, L.; et al. Boosting algorithm optimization technology for ensemble learning in small sample fraud detection. Academic Journal of Engineering and Technology Science 2025, 8, 53–60. [CrossRef]
- Ren, L.; et al. Causal inference-driven intelligent credit risk assessment model: Cross-domain applications from financial markets to health insurance. Academic Journal of Computing & Information Science 2025, 8, 8–14. [CrossRef]
- Ren, L. Reinforcement Learning for Prioritizing Anti-Money Laundering Case Reviews Based on Dynamic Risk Assessment. Journal of Economic Theory and Business Management 2025, 2, 1–6. [CrossRef]
- Tian, Y.; Xu, S.; Cao, Y.; Wang, Z.; Wei, Z. An Empirical Comparison of Machine Learning and Deep Learning Models for Automated Fake News Detection. Mathematics 2025, 13. [CrossRef]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 535–546. [CrossRef]
- Cheng, J.; Fostiropoulos, I.; Boehm, B.; Soleymani, M. Multimodal Phased Transformer for Sentiment Analysis. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 2447–2458. [CrossRef]
- Fan, Z.; Gong, Y.; Liu, D.; Wei, Z.; Wang, S.; Jiao, J.; Duan, N.; Zhang, R.; Huang, X. Mask Attention Networks: Rethinking and Strengthen Transformer. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 1692–1701. [CrossRef]
- Song, X.; Salcianu, A.; Song, Y.; Dopson, D.; Zhou, D. Fast WordPiece Tokenization. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 2089–2103. [CrossRef]
- Ding, B.; Qin, C.; Liu, L.; Chia, Y.K.; Li, B.; Joty, S.; Bing, L. Is GPT-3 a Good Data Annotator? In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 11173–11195. [CrossRef]
- Zhu, F.; Lei, W.; Huang, Y.; Wang, C.; Zhang, S.; Lv, J.; Feng, F.; Chua, T.S. TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3277–3287. [CrossRef]
- Li, Z.; Xu, J.; Zeng, J.; Li, L.; Zheng, X.; Zhang, Q.; Chang, K.W.; Hsieh, C.J. Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 3137–3147. [CrossRef]
- Hollenstein, N.; Pirovano, F.; Zhang, C.; Jäger, L.; Beinborn, L. Multilingual Language Models Predict Human Reading Behavior. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 106–123. [CrossRef]
Figure 2.
Sample Efficiency Analysis (Test Accuracy % on Yelp with varying training data)

Figure 3.
Impact of k on AQGT Performance and Graph Sparsity (Yelp Dataset)
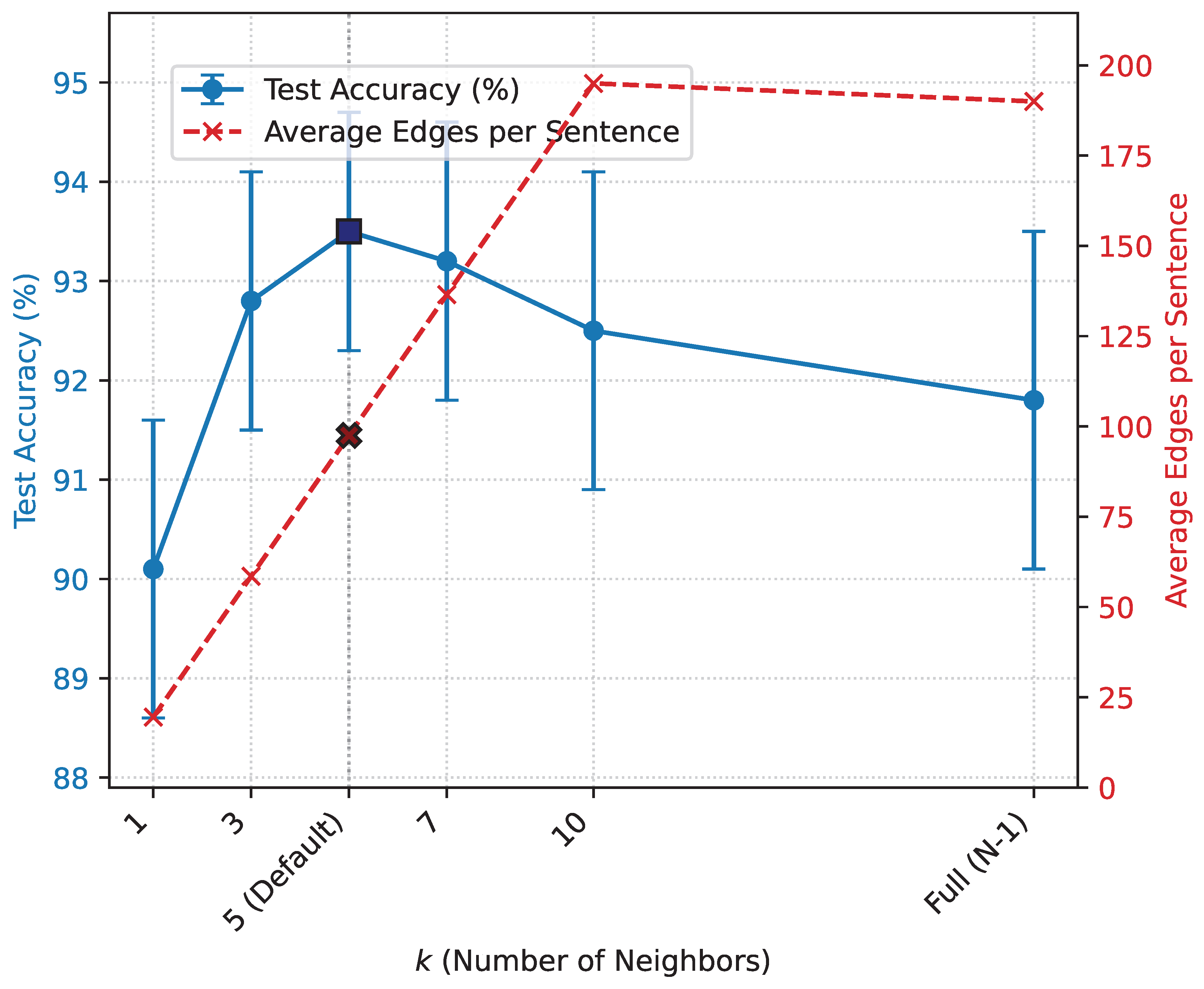

Table 1.
Test Accuracy Comparison of AQGT with Baseline Models.
| Dataset | Classical Graph Transformer | BERT-base | QGT | Ours (AQGT) |
|---|---|---|---|---|
| Yelp | 89.0 % | 91.5 % | 93.0 ± 1.5 % | 93.5 ± 1.2 % |
| IMDB | 81.0 % | 89.0 % | 90.5 ± 0.5 % | 91.0 ± 0.4 % |
| Amazon | 92.0 % | 90.8 % | 88.0 ± 1.5 % | 89.5 ± 1.0 % |
| MC | 64.0 % | 75.2 % | 91.03 ± 0.94 % | 92.1 ± 0.8 % |
| RP | 62.0 % | 78.5 % | 100.00 % | 100.00 % |
Table 2.
Ablation Study on AQGT Components (Test Accuracy % on Yelp and IMDB).
| Model Variant | Yelp | IMDB |
|---|---|---|
| Full AQGT | 93.5 ± 1.2 | 91.0 ± 0.4 |
| AQGT w/o Adaptive Graph (Fully Connected) | 91.8 ± 1.0 | 89.2 ± 0.6 |
| AQGT w/o Adaptive Graph (Fixed ) | 92.1 ± 1.1 | 89.5 ± 0.5 |
| AQGT w/o QIMPU (Standard GAT) | 90.5 ± 0.8 | 88.0 ± 0.7 |
| AQGT w/o QIMPU (Standard Transformer Attention) | 91.2 ± 0.9 | 88.6 ± 0.8 |
Table 3.
Computational Efficiency Comparison (Yelp Dataset).
| Model | Training Time (s/epoch) | Inference Time (ms/sentence) | Peak GPU Memory (GB) |
|---|---|---|---|
| Classical Graph Transformer | 12.5 ± 0.8 | 1.8 ± 0.2 | 4.1 |
| BERT-base | 15.0 ± 1.0 | 2.5 ± 0.3 | 5.5 |
| QGT | 18.2 ± 1.2 | 3.5 ± 0.4 | 6.8 |
| Ours (AQGT) | 14.5 ± 0.9 | 2.2 ± 0.2 | 4.9 |
Table 4.
Hyperparameter Sensitivity Analysis (Test Accuracy % on IMDB).
| Hyperparameter Setting | Hidden Dimension (d) | Test Accuracy (%) |
|---|---|---|
| AQGT () | 32 | 89.8 ± 0.6 |
| AQGT (, Default) | 64 | 91.0 ± 0.4 |
| AQGT () | 128 | 90.5 ± 0.5 |
| Hyperparameter Setting | Number of Layers (L) | Test Accuracy (%) |
| AQGT () | 2 | 89.2 ± 0.7 |
| AQGT () | 3 | 90.4 ± 0.5 |
| AQGT (, Default) | 4 | 91.0 ± 0.4 |
| AQGT () | 5 | 90.7 ± 0.6 |
| AQGT () | 6 | 90.1 ± 0.7 |
Table 5.
Human Evaluation of Model Predictions (IMDB).
| Category | AQGT Correct | BERT-base Correct | Human Agreement |
|---|---|---|---|
| Subtle Sentiment | 78 % | 65 % | 0.72 |
| Sarcasm/Irony | 62 % | 48 % | 0.68 |
| Long-distance Dependencies | 85 % | 75 % | 0.75 |
| Ambiguous Cases (No Clear Winner) | 30 % | 35 % | 0.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



