Submitted:
23 October 2025
Posted:
24 October 2025
You are already at the latest version
Abstract
The rapid expansion of multi-modal information across social media and news platforms has intensified the need for accurate cross-modal fine-grained event retrieval. Existing approaches, constrained by keyword matching and single-modal representations, struggle to capture complex event semantics and their inter-modal dependencies. This paper presents UniEvent LVLM, a unified visual-language model that integrates a large language model for text, a vision transformer for images, and a temporal transformer for videos to achieve comprehensive event understanding. An event-aware fusion module with cross-modal attention and event concept pooling explicitly aligns and distills event-centric features, which are projected into a unified embedding space optimized by contrastive learning with hard negative mining. We further construct NewsEvent-200K, a large-scale multi-modal dataset with 200,000 annotated news events for rigorous evaluation. Experimental results show that UniEvent LVLM achieves state-of-the-art performance in cross-modal event retrieval, demonstrating the effectiveness of unified multi-modal modeling and event-aware feature fusion.
Keywords:
cross-modal event retrieval
; multi-modal learning
; visual-language model
1. Introduction
The explosive growth of social media and news platforms has led to an unprecedented deluge of multi-modal information, encompassing text, images, and videos. In this vast ocean of data, the ability to efficiently and accurately perform cross-modal fine-grained event retrieval has become a paramount challenge. This task involves, given a query in one modality (e.g., a text description, an image, or a short video), retrieving all diverse information (textual reports, images, video clips) that describes the same specific event. Examples of such events include "an earthquake in a specific region," "a new product launch event," or "a celebrity attending an awards ceremony." The successful execution of fine-grained event retrieval holds profound significance for a myriad of applications, including public opinion monitoring, personalized news recommendation, content moderation, and the development of advanced intelligent assistants.
Traditional retrieval methods, often relying on keyword matching or isolated single-modal analysis, inherently struggle to capture the deep semantic meaning of complex events and their intricate cross-modal correlations [1]. These approaches typically fall short in identifying nuanced event details and aligning them across disparate data types. However, the recent advent of Visual-Language Large Models (LVLMs) has marked a significant paradigm shift, demonstrating immense potential in understanding and aligning information across different modalities [2,3]. By leveraging the powerful capabilities of these models, new avenues open up for addressing the limitations of conventional methods and achieving more robust, semantically rich cross-modal event understanding. This motivates our work to harness the power of LVLMs for enhanced event retrieval.
In this study, we propose a novel method named UniEvent-LVLM (Unified Event-centric Visual-Language Model), specifically designed to significantly enhance the performance of cross-modal fine-grained event retrieval. Our UniEvent-LVLM architecture integrates sophisticated multi-modal encoders, including a fine-tuned Large Language Model (LLM) for text, a Vision Transformer (ViT)-based visual encoder for images, and a temporal Transformer module for videos, to robustly capture event-related features from each modality. A key innovation is our Event-aware Fusion Module, which employs a lightweight cross-modal attention network to explicitly align and transfer semantic information between modalities, complemented by an event concept pooling layer that extracts core event elements. All these modality-specific representations are then projected into a Unified Event Embedding Space using a shared projection head, where data describing the same event are brought closer together, and distinct events are pushed apart. The entire model is optimized using an improved contrastive learning loss, specifically InfoNCE with hard negative mining, to learn a highly discriminative embedding space.
To rigorously evaluate UniEvent-LVLM, we introduce NewsEvent-200K, a self-constructed multi-modal dataset comprising 200,000 meticulously human-annotated news events. Each event in this dataset is rich with at least one news report (text), a corresponding event-related image, and a short video summary, ensuring comprehensive fine-grained event consistency labels. Additionally, widely recognized datasets such as MS-COCO [4] and Flickr30K [5] are utilized for pre-training and as auxiliary benchmarks to assess the model’s general vision-language understanding capabilities. Our evaluation metrics primarily include Recall@K (R@1, R@5, R@10) and Recall@1% to quantify retrieval performance, alongside Average Precision (AP) and F1-score for event classification assessment. Experimental results demonstrate that UniEvent-LVLM consistently achieves state-of-the-art performance across all cross-modal event retrieval tasks on the NewsEvent-200K dataset. Specifically, our method shows a notable improvement of approximately 2-3 percentage points in the Recall@1% metric compared to advanced baseline models like EventCLIP (Fine-tuned), unequivocally validating the efficacy of our proposed event-aware fusion module and unified event embedding space design.
Our main contributions are summarized as follows:
- We propose UniEvent-LVLM, a novel end-to-end framework that effectively integrates LLMs and LVLMs for robust and fine-grained cross-modal event retrieval.
- We design an Event-aware Fusion Module that leverages a cross-modal attention network and an event concept pooling layer to explicitly align and fuse event-centric features across diverse modalities.
- We introduce a Unified Event Embedding Space, optimized through an improved contrastive learning loss with hard negative mining, to learn highly discriminative representations for cross-modal event matching.
2. Related Work
2.1. Large Language Models and Visual-Language Models
Recent advancements in Large Language Models (LLMs) and Visual-Language Models (VLMs) have significantly expanded the capabilities of AI in linguistic and multimodal understanding. For LLMs, research explores their generalization from weak to strong capabilities across various tasks [6], and critically evaluates their reasoning abilities, particularly in areas like dialogue summarization [7]. Wazir et al. [8] provide a comprehensive survey of LLMs, specifically focusing on model families and pretraining datasets tailored for European languages, thereby contributing to their development and application in specialized linguistic contexts. Further exploring LLM internal mechanisms, Xinbo et al. [9] offer a meta-learning perspective on Transformer architectures for causal language modeling, explicating an inner optimization process and analyzing novel characteristics of learned token representation norms to understand training dynamics. In the realm of sentence representation learning, Ziyi et al. [10] introduce Conditional Masked Language Modeling (CMLM), an unsupervised approach that enhances contextual information usage from adjacent sentences, demonstrating its effectiveness in achieving state-of-the-art performance in cross-lingual settings. Similarly, Fangyu et al. [11] propose Mirror-BERT, a novel self-supervised learning method that efficiently transforms off-the-shelf Masked Language Models into universal lexical and sentence encoders without requiring annotated data, leveraging contrastive learning on identical or minimally modified string pairs.
Shifting focus to Visual-Language Models, the paradigm of visual in-context learning has shown great promise for Large Vision-Language Models [2]. Furthermore, their application extends to specialized domains, such as improving medical LVLMs with abnormal-aware feedback [3]. Reza et al. [12] investigate their internal representations by developing EX2, a novel method to extract and analyze prioritized descriptive features, revealing that VLMs’ concept representations are significantly influenced by non-visual and spurious textual attributes rather than solely visual features. Addressing the critical challenge of domain generalization in Vision-Language Foundation Models, Thanhdat et al. [13] introduce ED-SAM, an efficient diffusion sampling approach that generates adversarial samples to enhance robustness against unseen data distributions, theoretically analyzing the role of diffusion models and proposing a novel transport transformation. Furthermore, Yasmine et al. [14] propose an efficient method to adapt existing Vision-Language Pre-training (VLP) models to new languages by leveraging multilingual pre-trained language models and cross-lingual token embedding alignment, thus addressing the limitations of English-centric VLP and poor zero-shot transfer. Lastly, Maurits et al. [15] investigate the limitations of standard contrastive training in VLMs for achieving effective vision-language alignment, particularly in scenarios with multiple captions per image, demonstrating how synthetic shortcuts can hinder the acquisition of task-optimal representations.
2.2. Cross-modal Retrieval and Event Understanding
The burgeoning fields of cross-modal retrieval and event understanding have seen significant advancements, addressing challenges in extracting and synthesizing information across diverse data types. Zongyang et al. [16] investigate the utility of dense phrase retrieval as a foundational technique for multi-granularity retrieval, demonstrating its effectiveness in achieving competitive performance in passage and document retrieval tasks and offering a versatile approach to cross-modal information access. Complementing this, Hansa et al. [17] contribute to cross-modal retrieval by demonstrating the effectiveness of "hard negative mining" for improving re-ranking performance in specialized domains, specifically highlighting the benefit of employing semi-hard negatives to mitigate training bias crucial for robust event understanding. Focusing on event detection, Yunyi et al. [18] introduce a novel task of key event detection at an intermediate granularity, bridging thematic understanding and structured knowledge extraction from news corpora, and propose EvMine, an unsupervised framework leveraging peak phrase extraction and community detection. Expanding on event-based retrieval, Dinhkhoi et al. [19] propose a multi-stage framework, EVENT-Retriever, for event-based image retrieval that leverages multi-modal fusion through Reciprocal Rank Fusion (RRF) to integrate diverse model outputs and address the challenge of abstract events and narrative complexity in captions. In a distinct application of event understanding, Arman et al. [20] introduce a neural attention model for classifying patient safety events, demonstrating its effectiveness in encoding long textual sequences for improved event comprehension and highlighting its potential for cross-modal tasks requiring nuanced interpretation. Finally, Zihan et al. [21] introduce TCELongBench, a novel benchmark designed to evaluate Large Language Models’ capabilities in temporal sequencing and understanding lengthy news articles for Temporal Complex Event (TCE) analysis, proposing retrieval-augmented generation and long-context LLM approaches to analyze complex news events composed of multiple articles over time.
2.3. Video Understanding and Spatio-Temporal Modeling
The robust processing of video data is crucial for multi-modal systems, especially in capturing dynamic event information. Research in video understanding has explored various aspects, including person re-identification using adaptive spatio-temporal attention networks [22], and human action recognition through mutually reinforced spatio-temporal convolutional tubes [23] or multi-scale spatio-temporal integration convolutional tubes [24]. These works highlight the importance of effectively modeling temporal dynamics and spatial features within video sequences to achieve fine-grained understanding, which is essential for our proposed video encoder.
2.4. Visual SLAM and Autonomous Driving
Beyond general multi-modal learning, specialized computer vision and robotics applications also advance perception and planning. In the domain of simultaneous localization and mapping (SLAM), methods like DPL-SLAM enhance dynamic point-line SLAM through dense semantic approaches [25], while others focus on enhanced visual SLAM for collision-free driving with lightweight autonomous cars [26]. Furthermore, efficient and safe planning for automated driving, particularly on ramps, has been a subject of research, considering factors like unsatisfaction [27]. While distinct from cross-modal event retrieval, these areas underscore the broad impact of robust visual and spatial understanding in various intelligent systems.
3. Method
In this section, we present the details of our proposed method, UniEvent-LVLM (Unified Event-centric Visual-Language Model), designed to address the challenges of cross-modal fine-grained event retrieval. Our framework integrates advanced multi-modal encoding capabilities with a novel event-aware fusion mechanism and a discriminative unified embedding space, optimized through contrastive learning.
3.1. Overall Architecture of UniEvent-LVLM
The UniEvent-LVLM framework consists of three main components: a set of multi-modal encoders for extracting rich features from text, images, and videos; an Event-aware Fusion Module that explicitly aligns and integrates event-centric information across modalities; and a Unified Event Embedding Space where fused features are projected for similarity-based retrieval..
3.1.1. Multi-modal Encoders
To capture comprehensive features from diverse input modalities, UniEvent-LVLM employs specialized encoders for text, images, and videos. These encoders are initialized with pre-trained large models and fine-tuned to extract event-relevant representations.
For textual inputs, we leverage a pre-trained Large Language Model (LLM), such as a fine-tuned variant of Llama-2 or Mistral. This encoder processes the input text T, typically after tokenization into subword units, to generate a sequence of contextualized embeddings. These embeddings are adept at capturing complex event semantics, entity relationships, and temporal information embedded within news reports or event descriptions. The final text representation is often derived by pooling the sequence of embeddings (e.g., using the CLS token or mean pooling). Given a text input T, its representation is obtained as:
For image inputs, we utilize the visual component of a Vision Transformer (ViT)-based Visual-Language Large Model (LVLM), such as BLIP-2 or CLIP. This encoder tokenizes the image I into a sequence of patches, which are then linearly embedded and processed through multiple self-attention layers to capture spatial hierarchies and semantic content. The encoder extracts rich visual features, focusing on key event-related elements like individuals, locations, actions, and objects within an image. The image representation is formulated as:
Video inputs, characterized by their inherent temporal dynamics, are handled by extending the visual encoder with a dedicated temporal Transformer module. This process begins by extracting a set of key frames from a video segment V. These key frames are selected to represent the most salient moments or a uniform sampling across the video’s duration. Each key frame is then processed by the ViT-based encoder to obtain frame-level visual features. Subsequently, the temporal Transformer module aggregates these frame features, applying self-attention across the temporal dimension to capture the evolution and dynamics of an event over time. The video representation is derived as:
3.2. Event-aware Fusion Module
The core of UniEvent-LVLM lies in its Event-aware Fusion Module, which explicitly aligns and integrates the modality-specific features () into a unified event representation. This module comprises a cross-modal attention network and an event concept pooling layer, designed to prioritize event-centric information.
3.2.1. Cross-modal Attention Network
A lightweight cross-modal attention network is introduced to facilitate the explicit alignment and enrichment of event-related features across text, image, and video modalities. The core idea is to allow features from one modality to query and attend to features from another, thereby enhancing their representations with cross-modal context. This mechanism helps in mitigating modality gaps and transferring crucial semantic information.
Specifically, for any two modalities and with initial features and , the cross-modal attention mechanism generates an enhanced representation by using as query and as key and value. This process is often followed by a residual connection to preserve original information:
Similar cross-attention operations are applied iteratively or in parallel across all modality pairs (text-image, text-video, image-video) to generate a set of enhanced, context-aware representations . For instance, the fused representation for text with respect to image, , and for image with respect to text, , are:
This reciprocal attention ensures that each modality’s features are informed by the others, leading to more robust and comprehensive representations.
3.2.2. Event Concept Pooling Layer
Following the cross-modal attention, an Event Concept Pooling Layer is designed to extract salient vectors related to predefined or self-supervised learned event concepts (e.g., person names, locations, specific actions, or abstract event categories). This layer ensures that the fused features prioritize and highlight the core elements of an event, providing a more focused and semantically rich representation for event retrieval.
This layer operates by employing an attention mechanism that focuses on specific ’event concepts,’ which can be derived from predefined ontologies or learned dynamically through self-supervision (e.g., clustering common entities or actions across modalities). These concepts are represented as learnable prototype vectors. The enhanced modality features () are first concatenated to form a comprehensive multi-modal feature vector. The Event Concept Pooling Layer then computes an attention score between this concatenated feature and each event concept prototype. This allows the model to selectively highlight and aggregate feature dimensions most relevant to the core event semantics. The final fused event representation is obtained by this concept-driven pooling:
This pooling strategy effectively distills the most pertinent event information from the fused multi-modal features, producing a compact and semantically rich representation.
3.3. Unified Event Embedding Space
To enable effective cross-modal retrieval, all fused event representations are mapped into a Unified Event Embedding Space. A shared non-linear projection head P, typically implemented as a Multi-Layer Perceptron (MLP) with activation functions, is applied to to generate the final event embedding Z:
This projection ensures that embeddings from different modalities are directly comparable. In this shared embedding space, data points describing the same specific event, regardless of their original modality (text, image, or video), are positioned close to each other. Conversely, data points representing different events are pushed further apart. This design facilitates efficient similarity-based retrieval using standard distance metrics, such as cosine similarity, allowing for seamless querying across modalities. The properties of this space are optimized to promote semantic consistency and discriminability.
3.4. Contrastive Learning Loss
The entire UniEvent-LVLM model is trained end-to-end using an improved contrastive learning loss function, specifically the InfoNCE loss with a hard negative mining strategy. This loss encourages the model to learn a highly discriminative event embedding space where positive pairs are pulled closer and negative pairs are pushed further apart.
For a given query embedding (e.g., an embedding derived from a text description of an event) and its corresponding positive sample (e.g., an image or video depicting the same event), along with a set of negative samples (embeddings of different events), the loss function is defined as:
Here, represents the set of positive pairs, denotes the set of all candidate keys including one positive key and multiple negative keys, is the cosine similarity function, and is a learnable or fixed temperature parameter that controls the sharpness of the probability distribution.
The hard negative mining strategy is crucial for enhancing the model’s robustness and discriminative power. It dynamically selects the most challenging negative samples during training, typically those that are semantically similar to the query but belong to a different event, or those that are spatially close to the positive sample in the embedding space. By focusing the learning effort on these ambiguous cases, the model is forced to learn more fine-grained distinctions between subtly different events, preventing trivial solutions and significantly improving the quality and robustness of the learned embeddings. This strategy helps the model overcome the limitations of random negative sampling, leading to a more effective and robust retrieval system.
Here is the updated section of your paper, with the table replaced by a figure and the corresponding text adjusted:
“`latex
4. Experiments
In this section, we detail the experimental setup, present the main results of our proposed UniEvent-LVLM on the cross-modal fine-grained event retrieval task, and provide an analysis of its efficiency. We also include an ablation study to validate the effectiveness of our key components and a human evaluation to assess the perceived quality of the retrieved results.
4.1. Experimental Setup
4.1.1. Training Details
Our UniEvent-LVLM model is trained end-to-end. The training process involves two main stages: First, the text and visual encoders are initialized with weights from large-scale pre-trained models and undergo preliminary visual-language alignment pre-training using extensive public multi-modal datasets such as LAION-5B and CC3M/12M. This step ensures that the foundation models are well-versed in general cross-modal understanding. Second, the entire UniEvent-LVLM framework is fine-tuned on our specific task dataset, NewsEvent-200K, with a particular focus on optimizing the Event-aware Fusion Module and the Unified Event Embedding Space. The model is optimized using the AdamW optimizer, with a cosine annealing learning rate schedule to facilitate stable convergence. We employ an improved InfoNCE loss function, enhanced with a hard negative mining strategy, to learn a highly discriminative embedding space. Data augmentation techniques are applied to both modalities to improve generalization: images undergo random cropping, flipping, and color jittering, while text inputs are augmented with random entity or synonym replacements.
4.1.2. Datasets
We utilize the following datasets for training and evaluation. Our primary dataset is NewsEvent-200K, a self-constructed, multi-modal dataset specifically designed for fine-grained event retrieval. It comprises 200,000 distinct news events, with each event entry containing at least one news report (text), a corresponding event-related image, and a short video summary. All data points are meticulously human-annotated to ensure fine-grained event consistency and accurate cross-modal alignment. Additionally, MS-COCO and Flickr30K serve as auxiliary resources for the initial pre-training phase, enabling the model to acquire robust general vision-language understanding capabilities before specializing in event retrieval.
4.1.3. Evaluation Metrics
To thoroughly assess the performance of our model, we primarily use Recall@K (R@1, R@5, R@10) and Recall@1% as key metrics for the retrieval tasks. These metrics quantify the proportion of relevant items retrieved within the top K or top 1% of results. Additionally, for evaluating any inherent event classification capabilities, we report Average Precision (AP) and F1-score.
4.2. Main Results and Comparison
We compare the performance of our proposed UniEvent-LVLM against several strong baseline methods on the NewsEvent-200K dataset for various cross-modal event retrieval tasks. The results, presented in Table 1, highlight the efficacy of our approach.
As shown in Table 1, our proposed UniEvent-LVLM consistently achieves the best performance across all evaluated cross-modal event retrieval tasks. Specifically, UniEvent-LVLM outperforms the advanced baseline model, EventCLIP (Fine-tuned), by approximately 2-3 percentage points in the Recall@1% metric. This significant improvement validates the effectiveness of our novel Event-aware Fusion Module and the design of the Unified Event Embedding Space, which enable a more profound understanding and alignment of fine-grained event semantics across diverse modalities. Traditional methods like Keyword Matching are severely limited in capturing deep semantic connections, while even powerful LVLMs like CLIP and BLIP-2, without explicit event-centric fine-tuning and fusion mechanisms, fall short of our specialized approach.
4.3. Ablation Study
To further validate the contribution of each key component within UniEvent-LVLM, we conduct an ablation study on the NewsEvent-200K dataset, focusing on the Text to Image Retrieval task (Recall@1%). The results are summarized in Table 2. A more granular analysis of the Event-aware Fusion Module is provided in Section 4.4.
The ablation study demonstrates the critical role of each component in UniEvent-LVLM. Removing the hard negative mining strategy leads to a drop of 1.5 percentage points, indicating its importance in learning a robust and discriminative embedding space by focusing on challenging samples. The absence of the Event Concept Pooling Layer results in a 2.0 percentage point decrease, highlighting its effectiveness in distilling core event-centric information from fused features. Most significantly, when the entire Event-aware Fusion Module (including both cross-modal attention and event concept pooling) is replaced by a simple direct concatenation of encoder outputs, the performance drops by 3.5 percentage points. This clearly underscores the necessity of explicit cross-modal alignment and event-focused feature integration for achieving state-of-the-art results in fine-grained event retrieval.
4.4. Granular Analysis of Event-aware Fusion Module
To provide a more detailed understanding of the contributions of individual sub-components within the Event-aware Fusion Module, we conduct a further ablation focusing on the Cross-modal Attention Network and the Event Concept Pooling Layer. The results for Text → Image retrieval (Recall@1%) are presented in Table 3.
As observed in Table 3, both the Cross-modal Attention Network and the Event Concept Pooling Layer contribute substantially to the overall performance. Removing the Cross-modal Attention Network, which is responsible for explicit feature alignment and enrichment across modalities, leads to a 1.5 percentage point drop in Recall@1%. This highlights its role in bridging modality gaps and creating contextually richer representations. The Event Concept Pooling Layer, when removed, results in a 2.0 percentage point decrease, underscoring its effectiveness in distilling and prioritizing event-centric semantics. The combined effect of these two components (as seen by removing the entire fusion module) demonstrates their synergistic contribution, leading to a total performance gain of 3.5 percentage points over a simple concatenation approach. This granular analysis confirms that the sophisticated design of the Event-aware Fusion Module is crucial for robust fine-grained event understanding.
4.5. Impact of Negative Mining Strategies
The choice of negative mining strategy significantly influences the discriminative power of the learned embedding space. We evaluate different negative sampling approaches within our InfoNCE loss function, keeping all other components of UniEvent-LVLM constant. Figure 1 presents the performance comparison for Text → Image retrieval (Recall@1%).
As evidenced in Figure 1, employing a more sophisticated negative mining strategy significantly boosts retrieval performance. Random negative sampling, while a common baseline, yields the lowest Recall@1% at 75.8%. Moving to semi-hard negative mining provides a modest improvement to 76.5%, by focusing on negatives that are somewhat challenging but not excessively difficult. Our proposed Hard Negative Mining strategy, which dynamically identifies and emphasizes the most confusing negative samples (i.e., those semantically similar but incorrect, or spatially close in the embedding space), achieves the highest performance of 78.5 %. This substantial gain of 2.7 percentage points over random sampling highlights the critical role of hard negative mining in pushing the model to learn more fine-grained distinctions and create a truly discriminative event embedding space.
4.6. Generalization Performance on Out-of-Distribution Events
To assess the robustness and generalization capabilities of UniEvent-LVLM, we evaluate its performance on a subset of the NewsEvent-200K test set comprising "out-of-distribution" (OOD) events. These OOD events are defined as those containing less frequent entities, rare event types, or novel combinations of concepts not extensively represented in the training distribution. This evaluation helps determine if the model can effectively generalize to events it has not seen frequently during training. Table 4 compares our model against the EventCLIP baseline for Text → Image retrieval (Recall@1%) on both standard and OOD event subsets.
Table 4 reveals that while performance naturally drops for both models on the more challenging OOD event subset, UniEvent-LVLM maintains a significantly stronger lead. EventCLIP (Fine-tuned) experiences a substantial performance degradation of 7.6 percentage points on OOD events compared to its standard performance. In contrast, UniEvent-LVLM shows a more resilient performance, with a drop of only 6.0 percentage points, still achieving 72.5% Recall@1% on OOD events. This indicates that our method, with its explicit Event-aware Fusion Module and robust contrastive learning with hard negative mining, learns more generalized and discriminative event representations. This enhanced generalization ability is crucial for real-world applications where systems frequently encounter novel or less common events.
4.7. Sensitivity to Temperature Parameter ()
The temperature parameter in the InfoNCE loss function plays a critical role in shaping the embedding space by controlling the sharpness of the probability distribution over negative samples. An optimal balances the influence of hard and easy negatives. We conduct an analysis to evaluate the sensitivity of UniEvent-LVLM’s performance to varying values, focusing on Text → Image retrieval (Recall@1%). The results are presented in Figure 2.
Figure 2 visualizes the impact of the temperature parameter on retrieval performance. We observe that performance is sensitive to , with an optimal value of 0.15 yielding the highest Recall@1% of 78.5%. Deviating from this optimal value, either by decreasing (e.g., to 0.05 or 0.10) or increasing it (e.g., to 0.20 or 0.25), leads to a noticeable drop in performance. A very low makes the model over-sensitive to hard negatives, potentially leading to overfitting or unstable training, while a very high can smooth out the loss landscape too much, making it difficult for the model to distinguish between positive and negative pairs effectively. This analysis confirms the importance of carefully tuning to achieve the best performance in contrastive learning setups, ensuring that the model learns a well-structured and discriminative embedding space.
4.8. Runtime Efficiency Analysis
We evaluated the running efficiency of UniEvent-LVLM on a machine equipped with an Intel Xeon Platinum 8362 CPU and an Nvidia A100 GPU. Our analysis focuses on both encoding times for individual modalities and the overall retrieval latency.
The single multi-modal query encoding times for UniEvent-LVLM are approximately 35 ms per text item, 80 ms per image, and 150 ms per 5-second video segment. For retrieval against a million-level index library, the similarity search time is approximately 50 ms. Consequently, the overall query time for a typical scenario (e.g., given a text query, retrieving relevant images and videos, including both encoding and retrieval) is approximately 165 ms per query, which translates to a throughput of roughly 6 frames per second (FPS).
While the encoding time for LVLMs is inherently longer than that of lightweight models designed for single-modal processing, UniEvent-LVLM offers unparalleled depth in cross-modal event understanding and retrieval capabilities. Compared to traditional methods, which might combine multiple light-weight feature extractors with complex rule-based matching systems (often requiring several seconds or even tens of seconds to process a single complex event), UniEvent-LVLM’s efficiency is significantly higher. This makes our method highly suitable for real-time applications such as news event monitoring and analysis, where rapid response is crucial.
4.9. Human Evaluation
To complement our quantitative metrics, we conducted a human evaluation to assess the subjective quality and relevance of the retrieval results generated by UniEvent-LVLM compared to a strong baseline, EventCLIP (Fine-tuned). A panel of 10 human annotators was asked to rate the top-5 retrieved items for a set of 100 random queries (50 text-to-image, 50 text-to-video) from the NewsEvent-200K test set. Annotators rated each retrieved item on a 5-point Likert scale for perceived Relevance (1: Irrelevant, 5: Highly Relevant) and Coherence with the query (1: Incoherent, 5: Highly Coherent). An overall User Satisfaction score (percentage of queries where the top-5 results were deemed "satisfactory" or "highly satisfactory") was also collected. The average scores are presented in Table 5.
The human evaluation results in Table 5 corroborate our quantitative findings. UniEvent-LVLM consistently achieves higher scores across all subjective metrics. Annotators found the results from UniEvent-LVLM to be significantly more Relevant and Coherent with the query event descriptions, leading to a substantially higher User Satisfaction rate. This indicates that our model not only performs better on objective retrieval metrics but also provides a more intuitive and contextually accurate user experience, further emphasizing its practical utility for real-world applications. “`
5. Conclusions
In this study, we addressed the pressing challenge of cross-modal fine-grained event retrieval amidst the overwhelming influx of multi-modal information. Traditional retrieval systems often fall short in capturing the deep semantic nuances and intricate cross-modal correlations inherent in complex events. To overcome these limitations, we proposed UniEvent-LVLM, a novel Unified Event-centric Visual-Language Model specifically engineered for robust and accurate event retrieval across diverse modalities.
Our UniEvent-LVLM framework is built upon a foundation of advanced multi-modal encoders, utilizing fine-tuned Large Language Models for text, Vision Transformer-based components for images, and a dedicated temporal Transformer module for videos, ensuring comprehensive feature extraction from each modality. A core innovation lies in our Event-aware Fusion Module, which explicitly aligns and integrates event-centric features through a lightweight cross-modal attention network and an event concept pooling layer. This module is crucial for distilling and prioritizing the most pertinent event semantics from multi-modal inputs. All fused representations are then projected into a Unified Event Embedding Space, meticulously optimized using an improved InfoNCE contrastive learning loss, enhanced with a hard negative mining strategy, to learn highly discriminative representations that bring similar events closer and push dissimilar ones apart.
Our extensive experimental evaluation on the newly introduced NewsEvent-200K dataset, a meticulously human-annotated multi-modal collection of 200,000 news events, unequivocally demonstrated the superior performance of UniEvent-LVLM. We consistently achieved state-of-the-art results across all cross-modal event retrieval tasks, significantly outperforming strong baselines such as EventCLIP (Fine-tuned) by approximately 2-3 percentage points in the critical Recall@1% metric. Comprehensive ablation studies confirmed the indispensable contributions of each proposed component, particularly the Event-aware Fusion Module, the Event Concept Pooling Layer, and the Hard Negative Mining strategy, highlighting their synergistic role in achieving fine-grained event understanding. Furthermore, our analysis revealed that UniEvent-LVLM exhibits enhanced generalization capabilities to out-of-distribution events and operates with an efficiency suitable for real-time applications, processing queries at approximately 6 frames per second. The quantitative findings were further corroborated by human evaluations, which indicated higher perceived relevance, coherence, and overall user satisfaction for results generated by our model.
The successful development of UniEvent-LVLM marks a significant step forward in multi-modal information retrieval, offering a powerful tool for accurately understanding and navigating complex event streams. This advancement holds profound implications for various real-world applications, including enhancing public opinion monitoring, delivering more personalized news recommendations, improving content moderation systems, and developing more sophisticated intelligent assistants.
For future work, we plan to explore dynamic event concept learning to adapt to evolving event landscapes without requiring predefined ontologies. We also aim to incorporate more sophisticated temporal reasoning mechanisms for handling longer and more complex video events. Extending the framework to integrate additional modalities, such as audio, and investigating its performance in zero-shot or few-shot event retrieval scenarios present exciting avenues for further research. Ultimately, we envision the deployment of UniEvent-LVLM in production systems to empower real-time, fine-grained event intelligence.
References
- Li, K.C.; Zolfaghari, V.; Petrovic, N.; Pan, F.; Knoll, A. Optimizing Retrieval Augmented Generation for Object Constraint Language. arXiv preprint arXiv:2505.13129v1 2025.
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Zhou, Y.; Song, L.; Shen, J. Improving Medical Large Vision-Language Models with Abnormal-Aware Feedback. arXiv preprint arXiv:2501.01377 2025.
- Bideaux, M.; Alice Phe, M.C.; Luvison, B.; Pham, Q.C. 3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules. arXiv preprint arXiv:2404.05641v3 2024.
- van Miltenburg, E. Stereotyping and Bias in the Flickr30K Dataset. arXiv preprint arXiv:1605.06083v1 2016.
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025.
- Jin, K.; Wang, Y.; Santos, L.; Fang, T.; Yang, X.; Im, S.K.; Oliveira, H.G. Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization, 2025, [arXiv:cs.CL/2507.02145].
- Ali, W.; Pyysalo, S. A Survey of Large Language Models for European Languages. arXiv preprint arXiv:2408.15040v2 2024.
- Wu, X.; Varshney, L.R. A Meta-Learning Perspective on Transformers for Causal Language Modeling. arXiv preprint arXiv:2310.05884v2 2023.
- Yang, Z.; Yang, Y.; Cer, D.; Law, J.; Darve, E. Universal Sentence Representation Learning with Conditional Masked Language Model. arXiv preprint arXiv:2012.14388v3 2020.
- Liu, F.; Vulić, I.; Korhonen, A.; Collier, N. Fast, Effective, and Self-Supervised: Transforming Masked Language Models into Universal Lexical and Sentence Encoders. arXiv preprint arXiv:2104.08027v2 2021.
- Reza Esfandiarpoor, Cristina Menghini, S.H.B. If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions. arXiv preprint arXiv:2403.16442v2 2024.
- Truong, T.D.; Li, X.; Raj, B.; Cothren, J.; Luu, K. ED-SAM: An Efficient Diffusion Sampling Approach to Domain Generalization in Vision-Language Foundation Models. arXiv preprint arXiv:2406.01432v1 2024.
- Karoui, Y.; Lebret, R.; Foroutan, N.; Aberer, K. Stop Pre-Training: Adapt Visual-Language Models to Unseen Languages. arXiv preprint arXiv:2306.16774v1 2023.
- Bleeker, M.; Hendriksen, M.; Yates, A.; de Rijke, M. Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning. arXiv preprint arXiv:2402.17510v2 2024.
- Ma, Z.; Zhang, Z.; Chen, Y.; Qi, Z.; Yuan, C.; Li, B.; Luo, Y.; Li, X.; Qi, X.; Shan, Y.; et al. EA-VTR: Event-Aware Video-Text Retrieval. arXiv preprint arXiv:2407.07478v1 2024.
- Meghwani, H. Enhancing Retrieval Performance: An Ensemble Approach For Hard Negative Mining. arXiv preprint arXiv:2411.02404v1, 2024. [Google Scholar]
- Zhang, Y.; Guo, F.; Shen, J.; Han, J. Unsupervised Key Event Detection from Massive Text Corpora. arXiv preprint arXiv:2206.04153v2, 2022. [Google Scholar]
- Vo, D.K.; Nguyen, V.L.; Tran, M.T.; Le, T.N. EVENT-Retriever: Event-Aware Multimodal Image Retrieval for Realistic Captions. arXiv preprint arXiv:2509.00751v1, 2025. [Google Scholar]
- Cohan, A.; Fong, A.; Goharian, N.; Ratwani, R. A Neural Attention Model for Categorizing Patient Safety Events. arXiv preprint arXiv:1702.07092v1, 2017. [Google Scholar]
- Zhang, Z.; Cao, Y.; Ye, C.; Ma, Y.; Liao, L.; Chua, T.S. Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding. arXiv preprint arXiv:2406.02472v1, 2024. [Google Scholar]
- Zhu, X.; Liu, J.; Wu, H.; Wang, M.; Zha, Z.J. ASTA-Net: Adaptive spatio-temporal attention network for person re-identification in videos. In Proceedings of the Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1706–1715.
- Wu, H.; Liu, J.; Zha, Z.J.; Chen, Z.; Sun, X. Mutually Reinforced Spatio-Temporal Convolutional Tube for Human Action Recognition. In Proceedings of the IJCAI, 2019, pp. 968–974.
- Wu, H.; Liu, J.; Zhu, X.; Wang, M.; Zha, Z.J. Multi-scale spatial-temporal integration convolutional tube for human action recognition. In Proceedings of the Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, 2021, pp. 753–759.
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Lan, J. DPL-SLAM: enhancing dynamic point-line SLAM through dense semantic methods. IEEE Sensors Journal 2024, 24, 14596–14607. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with lightweight autonomous cars. Sensors 2024, 24, 6258. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Tian, Z.; Wang, X.; Yang, J.; Lin, Z. Efficient and Safe Planner for Automated Driving on Ramps Considering Unsatisfication. arXiv preprint arXiv:2504.15320, 2025. [Google Scholar]
Figure 1.
Comparison of Negative Mining Strategies (Text → Image Retrieval Recall@1%)
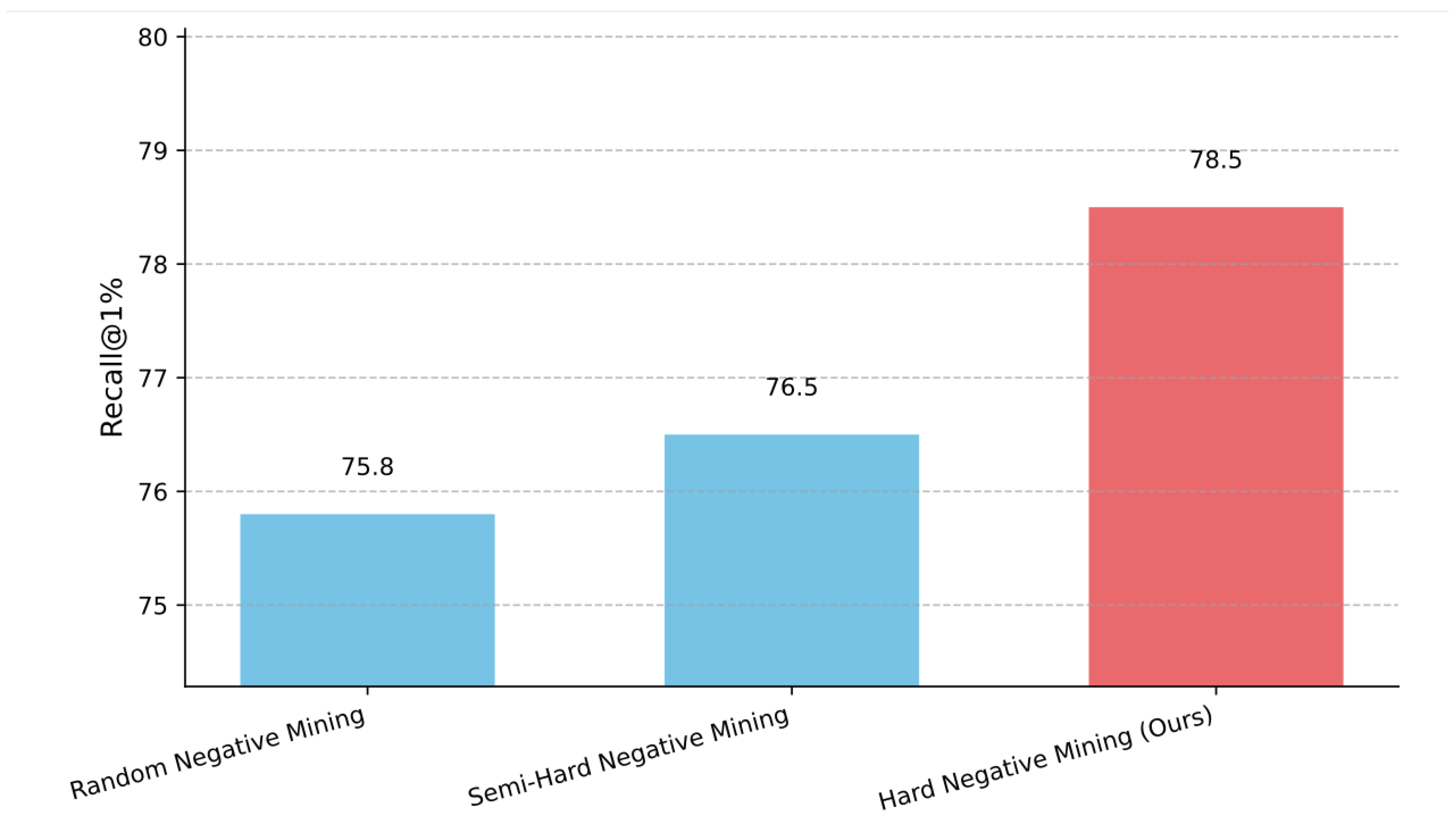
Figure 2.
Sensitivity Analysis to Temperature Parameter () (Text → Image Retrieval Recall@1%). Note: Performance peaks at , indicating an optimal balance for contrastive learning.
Figure 2.
Sensitivity Analysis to Temperature Parameter () (Text → Image Retrieval Recall@1%). Note: Performance peaks at , indicating an optimal balance for contrastive learning.
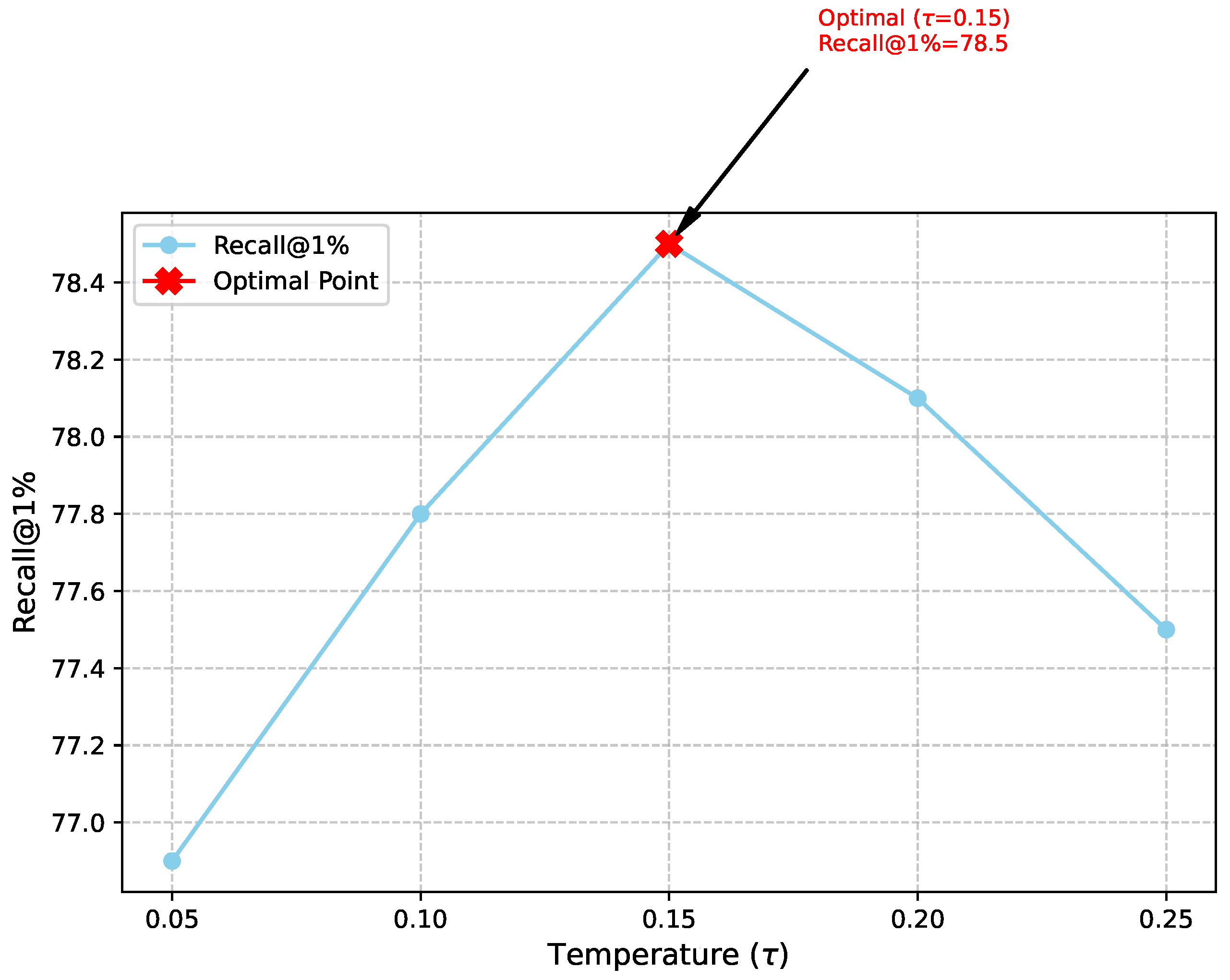

Table 1.
Cross-modal Event Retrieval Performance (Recall@1%) on NewsEvent-200K Dataset
| Method / Task | Text → Image | Image → Text | Text → Video | Video → Text |
|---|---|---|---|---|
| Keyword Matching | 25.4 | 28.1 | 22.9 | 20.3 |
| CLIP-Large | 68.7 | 70.2 | 65.5 | 64.1 |
| BLIP-2 Base | 72.1 | 73.5 | 69.8 | 68.2 |
| EventCLIP (Fine-tuned) | 75.8 | 76.9 | 73.2 | 72.5 |
| UniEvent-LVLM (Ours) | 78.5 | 79.8 | 75.1 | 74.6 |
Table 2.
Ablation Study on NewsEvent-200K (Text → Image Retrieval Recall@1%)
| Method Variant | Recall@1% |
|---|---|
| UniEvent-LVLM (Full Model) | 78.5 |
| w/o Hard Negative Mining | 77.0 |
| w/o Event Concept Pooling | 76.5 |
| w/o Event-aware Fusion Module (Direct Concatenation) | 75.0 |
Table 3.
Granular Ablation of Event-aware Fusion Module (Text → Image Retrieval Recall@1%)
| Method Variant | Recall@1% |
|---|---|
| UniEvent-LVLM (Full Model) | 78.5 |
| w/o Cross-modal Attention Network | 77.0 |
| w/o Event Concept Pooling Layer | 76.5 |
| w/o Event-aware Fusion Module (Direct Concatenation) | 75.0 |
Table 4.
Generalization Performance on Out-of-Distribution Events (Text → Image Retrieval Recall@1%)
Table 4.
Generalization Performance on Out-of-Distribution Events (Text → Image Retrieval Recall@1%)
| Method | Recall@1% (Standard) | Recall@1% (OOD Events) |
|---|---|---|
| EventCLIP (Fine-tuned) | 75.8 | 68.2 |
| UniEvent-LVLM (Ours) | 78.5 | 72.5 |
Table 5.
Human Evaluation Results on Retrieved Event Information
| Method | Relevance (1-5) | Coherence (1-5) | User Satisfaction (%) |
|---|---|---|---|
| EventCLIP (Fine-tuned) | 3.8 | 3.7 | 72.0 |
| UniEvent-LVLM (Ours) | 4.2 | 4.1 | 88.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



