
Submitted:
22 October 2025
Posted:
24 October 2025
You are already at the latest version
Abstract
This study presents a deep learning–based framework for the automated classification of retinal diseases using Optical Coherence Tomography (OCT) images. Convolutional neural network architectures, including ResNet50, Xception, and Inception V3, were developed and evaluated to distinguish between pathological and normal retinal conditions, such as Choroidal Neovascularization, Diabetic Macular Edema, and Drusen. The proposed models demonstrated high accuracy and strong generalization across benchmark OCT datasets. Incorporating preprocessing steps such as denoising significantly improved performance, particularly for the Xception and Inception V3 models. These findings highlight the potential of AI-driven analysis to support early diagnosis and clinical decision-making in ophthalmology.
Keywords:
optical coherence tomography (OCT)
; retinal disease classification
; deep learning
; convolutional neural networks (CNN)
; transfer learning
; VGG16
; ResNet
; medical image analysis
; computer vision
; artificial intelligence in healthcare
1. Introduction
Millions of individuals throughout the world are affected by eye illnesses, which can worsen eyesight or even cause blindness if ignored. For prompt management and better patient outcomes, it is essential to make an early and correct diagnosis of eye illnesses. As a potent imaging technology that offers high-resolution cross-sectional pictures of ocular structures, optical coherence tomography (OCT) has been increasingly useful in the diagnosis and treatment of a variety of eye disorders. The imaging method known as optical coherence tomography (OCT) is used to take high-resolution cross-sectional pictures of biological tissues, including the eye. It employs low-coherence interferometry to measure the intensity of backscattered light, generating detailed images that reveal the internal structures of the tissue. OCT images provide valuable insights into the microstructure of the eye, enabling the detection and diagnosis of various ocular diseases(Nabila Eladawi,2018).
Choroidal Neovascularization (CNV) is a condition involving abnormal growth of blood vessels beneath the retina, causing fluid accumulation in the subretinal space. OCT images are crucial for detecting and monitoring CNV, AMD, and Drusen. AMD is a progressive eye disease affecting the macula, leading to vision loss in older adults. OCT images help assess disease progression, treatment response, and therapeutic interventions. Drusen, small yellowish deposits, are a hallmark characteristic of AMD and can be visualized and quantified using OCT.
Figure 1.
Sample images (Das, Dandapat, and Bora, 2020).
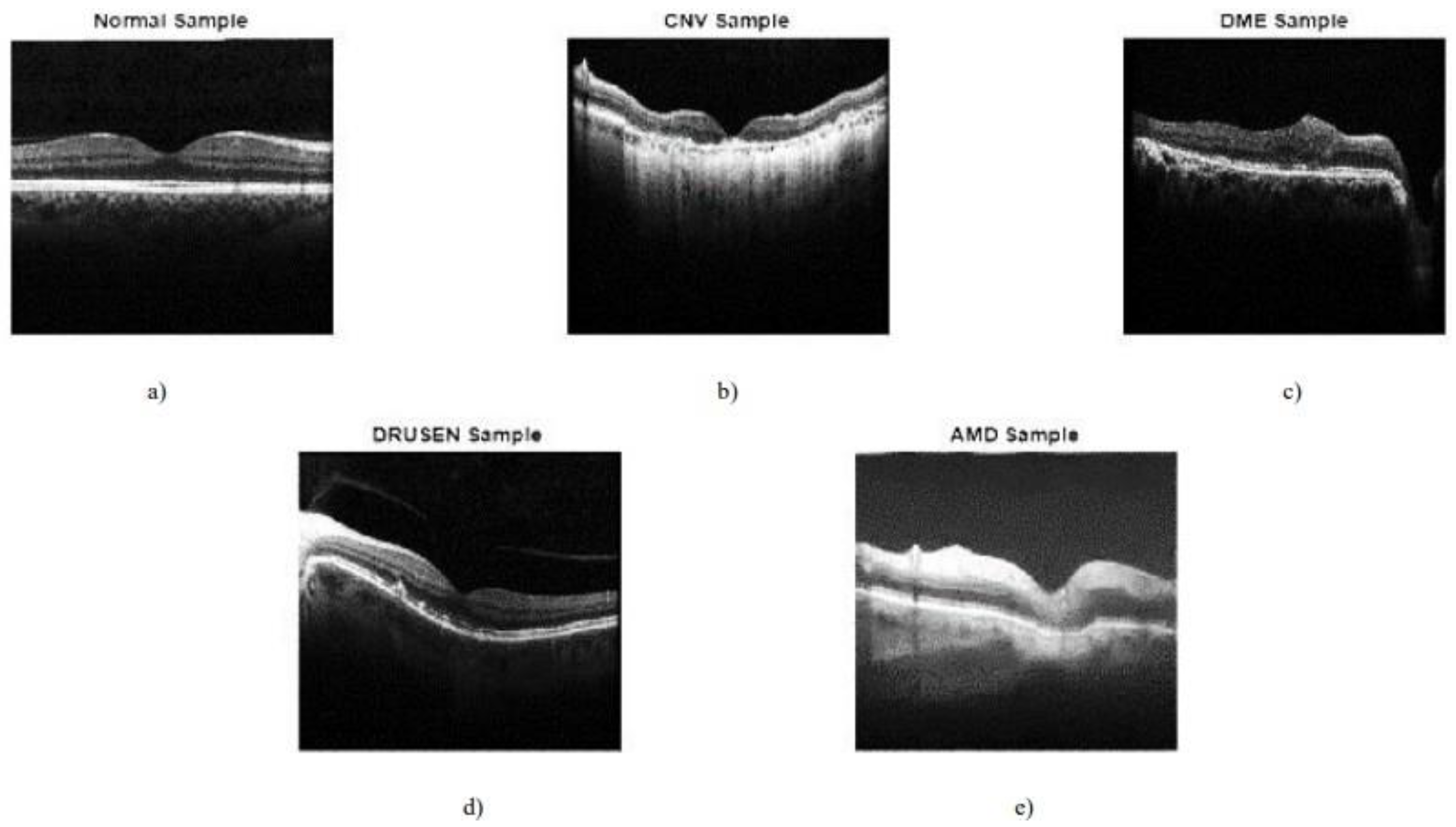
Eye disease classification plays a pivotal role in the field of ophthalmology by assisting clinicians in accurate diagnosis, treatment planning, and monitoring of eye conditions. OCT imaging allows clinicians to visualize the retinal layers, optic nerve, and other ocular structures, providing valuable information for disease assessment. Traditionally, eye disease classification
has relied on manual examination of OCT images by ophthalmologists. However, this process is time-consuming, subjective, and prone to human error (Kim and Tran, 2020). Moreover, the increasing volume of OCT scans presents a significant challenge for ophthalmologists to handle the growing workload. Therefore, there is a pressing need to develop automated systems that can assist in the accurate and efficient classification of eye diseases from OCT images. Automated classification of eye diseases from OCT images can enhance the efficiency and accuracy of diagnosis, enabling timely intervention and reducing the risk of irreversible vision loss. It also has the potential to aid in screening programs, particularly in areas with limited access to specialized eye care.
The key motivation for this project lies in leveraging advancements in machine learning and deep learning techniques to develop an automated system that can accurately classify eye diseases from OCT images. By harnessing the power of these technologies, we aim to improve the accuracy, efficiency, and accessibility of eye disease diagnosis. Additionally, the project's motivation lies in addressing the challenges associated with eye disease classification, such as the complexity and diversity of ocular structures, the need for high accuracy and interpretability, and the increasing volume of OCT scans. By developing a robust and reliable automated system, we aim to enhance the early detection, diagnosis, and monitoring of common eye diseases, including Choroidal Neovascularization (CNV), Age-Related Macular Degeneration(AMD), and Drusen.
1.1. Background
The field of medical imaging has undergone a revolutionary transformation with the advent of deep learning technologies. One of the critical areas where these advancements hold immense promise is in the domain of ophthalmology, where early and accurate diagnosis is pivotal for preserving vision and preventing irreversible damage caused by various eye diseases. Optical Coherence Tomography (OCT) has emerged as a powerful imaging modality, providing detailed cross-sectional images of the retina and enabling clinicians to visualize and diagnose a spectrum of ocular conditions.
Eye diseases, such as diabetic macular edema (DME), choroidal neovascularization (CNV), and drusen, present diverse challenges for diagnosis and treatment. Manual interpretation of OCT images, the traditional approach to diagnosis, is time-consuming, subjective, and may be prone to errors. The pressing need for efficient, accurate, and scalable diagnostic tools in ophthalmology has motivated the exploration of deep learning techniques to automate the classification of eye diseases.
The significance of this project lies in its ambition to harness the potential of deep learning models for the automated classification of eye diseases from OCT images. The aim is to not only expedite the diagnostic process but also to significantly enhance its accuracy and reliability. The project builds upon the growing body of research in medical image analysis and extends its applications to address the specific challenges posed by OCT images. The choice of OCT as the
imaging modality is rooted in its non-invasiveness, providing detailed information about retinal structures and abnormalities, and its widespread usage in clinical settings.
As the prevalence of eye diseases continues to rise globally, fueled by factors such as an aging population and changes in lifestyle, the demand for advanced diagnostic solutions becomes more critical. Deep learning, with its ability to automatically learn intricate features from large datasets, offers a paradigm shift in the way eye diseases are diagnosed. The utilization of
state-of-the-art deep learning architectures, including ResNet50, InceptionV3, and Xception, coupled with innovative approaches such as the integration of denoising autoencoders, positions this project at the forefront of technological advancements in ophthalmic healthcare.The project is not only an exploration of technical capabilities but also a response to the broader challenges faced by healthcare systems globally. The potential of the developed automated eye disease classification system extends beyond research laboratories; it has the capacity to impact
real-world healthcare delivery. The integration of such a system into existing healthcare infrastructure can empower clinicians, expedite decision-making, and improve patient outcomes. Additionally, the scalability and adaptability of the system open avenues for its application in telemedicine, particularly in underserved regions where access to specialized ophthalmic care is limited.
The background of this project is rooted in the intersection of technological innovation and the pressing healthcare needs in ophthalmology. By marrying advanced deep learning models with OCT images, the project aspires to make significant strides in the automation of eye disease classification, ultimately contributing to the improvement of global eye health and the transformation of diagnostic practices in ophthalmic healthcare.
1.2. Motivation
The motivation behind embarking on the project to automate the classification of eye diseases from Optical Coherence Tomography (OCT) images using deep learning stems from a confluence of technological advancements, healthcare challenges, and a commitment to improving patient outcomes in ophthalmic care.
- Clinical Challenges in Eye Disease Diagnosis:
Eye diseases, ranging from common conditions like diabetic macular edema (DME) to more severe disorders such as choroidal neovascularization (CNV), demand swift and accurate diagnosis for effective treatment. Manual interpretation of OCT images, while a standard practice, is limited by subjectivity, potential human errors, and the time-intensive nature of the process. These challenges underscore the need for an automated solution that can complement and enhance the capabilities of healthcare professionals.
- Impact of Early Detection on Patient Outcomes:
The timely detection and classification of eye diseases have a direct impact on treatment efficacy and patient outcomes. Early intervention can halt or slow the progression of conditions, preventing irreversible vision impairment. The project's motivation is fueled by the potential to contribute to the early detection of eye diseases, providing clinicians with a tool that aids in making informed and timely decisions, ultimately improving the quality of patient care.
- Technological Advancements in Deep Learning:
The rapid advancements in deep learning, particularly in the realm of computer vision, present an unprecedented opportunity to revolutionize medical image analysis. Deep learning models, such as ResNet50, InceptionV3, and Xception, have demonstrated exceptional capabilities in image classification tasks. The motivation for this project lies in harnessing these advancements to create a robust and accurate system for automating the classification of eye diseases, capitalizing on the potential for enhanced diagnostic accuracy and efficiency.
- Need for Scalable and Accessible Healthcare Solutions:
The global burden of eye diseases is on the rise, and healthcare systems worldwide face the challenge of providing accessible and efficient diagnostic services. The motivation behind this project is rooted in the desire to contribute to scalable and accessible healthcare solutions. An automated eye disease classification system has the potential to augment the capabilities of healthcare professionals, making specialized diagnostic tools more widely available, especially in remote or underserved regions.
- Telemedicine and Remote Healthcare Access:
The evolving landscape of healthcare delivery, especially in the context of the COVID-19 pandemic, has underscored the importance of telemedicine and remote healthcare access. The motivation for this project extends to exploring how the developed system can be seamlessly integrated into telemedicine platforms, enabling remote diagnosis and consultation. This not only addresses the challenges of geographical disparities but also aligns with the broader trend of digitizing healthcare services.
- Interdisciplinary Collaboration and Innovation:
The interdisciplinary nature of the project, combining deep learning, medical imaging, and ophthalmology, serves as a motivating factor. The collaboration between technologists, data scientists, and healthcare professionals is essential to bring about transformative innovations in the field.
1.3. Approaches
There are several approaches for eye disease classification from OCT images, each leveraging different techniques and methodologies. Here are some common approaches:
- Traditional Image Processing Techniques:
Feature Extraction: Use traditional image processing techniques to extract handcrafted features such as texture, shape, and intensity from OCT images. Feature vectors can then be fed into classical machine learning algorithms like Support Vector Machines (SVM) or Random Forests for classification.
- Convolutional Neural Networks (CNNs):
End-to-End Deep Learning: Train a CNN architecture from scratch to learn hierarchical features directly from OCT images. This approach requires a large labeled dataset and significant computational resources but can capture complex patterns and relationships within the data.This approach shows an accuracy of 98% (Rong et al., 2019b).
- Transfer Learning: Utilize pre-trained CNN models (e.g., VGG, ResNet, or Inception) on large-scale image datasets. Fine-tune these models on the OCT dataset to adapt the learned features for eye disease classification. Transfer learning can be particularly useful when working with limited data. And by this approach, the results obtained are 97.3% and 95% (Puneet, Kumar and Gupta, 2022).
- Ensemble Learning:
Combining Models: Train multiple models using different architectures or initialization strategies and combine their predictions using techniques like bagging or boosting.
Ensemble learning can enhance classification performance and increase the model's robustness.98% accuracy is achieved by this approach (Kim and Tran, 2020).
- Attention Mechanisms:
Spatial Attention: Integrate attention mechanisms into the CNN architecture to focus on relevant regions within the OCT images. This can help the model prioritize
disease-specific features and improve classification accuracy.An accuracy of 99% is achieved by using multiple attention mechanisms (Mishra, Mandal, and Puhan, 2019).
- Generative Adversarial Networks (GANs):
Data Augmentation: Use GANs to generate synthetic OCT images for data augmentation. This approach can help address imbalances in the dataset and enhance the model's ability to generalize to unseen data. An accuracy of 97% is achieved by this approach(Das, Dandapat and Bora, 2020).
- .Domain Adaptation:
Source-Target Adaptation: If labeled data from the target domain is limited, leverage a larger dataset from a related source domain for pre-training. Domain adaptation techniques can then be employed to transfer knowledge to the target domain.A domain adaption inception was proposed and obtained an accuracy of 96% (Li et al., 2021).
- Attention-based CNNs:
Channel-wise Attention: Implement attention mechanisms at the channel level to emphasize important information in different channels of the OCT images. This can enhance the model's ability to capture disease-specific patterns.
- Explainable AI (XAI):
Interpretability: Integrate XAI techniques to provide transparency into the
decision-making process of the deep learning model. This can be crucial in a medical context where interpretability is essential for gaining the trust of healthcare professionals. Resnet was used and an accuracy of 96% was obtained (Reza et al., 2021).
1.4. Applications
Eye disease classification from OCT (Optical Coherence Tomography) images has numerous practical applications, contributing to advancements in ophthalmic care, research, and patient outcomes. Some key applications include
- Early Disease Detection:
Timely Intervention: Automated classification of eye diseases from OCT images enables early detection of pathological changes in the retina. Early diagnosis can lead to prompt intervention and treatment, potentially preventing or mitigating vision loss.
- Treatment Planning and Monitoring:
Personalized Treatment: Accurate disease classification aids ophthalmologists in developing personalized treatment plans based on the patient's specific condition. Monitoring changes in OCT images over time helps evaluate the effectiveness of treatments and adjust interventions accordingly.
- Screening Programs:
Population Health: Automated eye disease classification can be integrated into screening programs, facilitating large-scale identification of individuals at risk for conditions such as diabetic retinopathy or glaucoma. This is particularly beneficial for managing the increasing prevalence of these diseases.
- Telemedicine and Remote Monitoring:
Remote Consultations: In telemedicine, where physical access to healthcare facilities may be limited, OCT-based disease classification allows for remote assessment of retinal health. Patients can receive timely advice and monitoring without frequent in-person visits.
- Clinical Decision Support Systems:
Assisting Healthcare Professionals: Integrating automated classification systems into clinical workflows is a decision support tool for healthcare professionals. It provides additional information for diagnosis, helping clinicians make more informed decisions about patient care.
- Research and Epidemiological Studies:
Insights into Disease Patterns: Aggregated data from automated classification systems can contribute to epidemiological studies, providing insights into the prevalence and distribution of eye diseases. Researchers can use this information to identify risk factors and develop targeted interventions.
- Education and Training:
Training Tool: OCT-based disease classification systems can be valuable educational tools for medical students, residents, and healthcare professionals. They provide
real-world examples of various pathologies, enhancing understanding and diagnostic skills.
- Quality Assurance in Imaging:
Image Quality Control: Automated classification can be used to assess the quality of OCT images, flagging potential issues such as artifacts or inadequate image acquisition. This ensures that the data used for diagnosis is reliable and accurate.
- Patient Engagement:
Patient Education: Sharing OCT images and classification results with patients can enhance their understanding of their eye health. Informed patients are more likely to participate in their care and adhere to recommended treatments actively.
- Cost-Effective Healthcare Delivery:
Resource Optimization: Automated disease classification can contribute to more efficient use of healthcare resources by prioritizing patients who require urgent attention. This can lead to cost savings and improved resource allocation in healthcare systems.
1.5. Aims and Objectives
Our goal is to develop an automated system for eye disease classification from Optical Coherence Tomography(OCT) images which helps enhance the accuracy and efficiency of eye disease diagnosis by leveraging machine learning and deep learning techniques, that assist ophthalmologists in making informed decisions for patient care through the automated analysis of OCT images. It also helps to improve the early detection and timely treatment of various eye diseases, including Choroidal Neovascularization (CNV), Age-Related Macular Degeneration(AMD), and Drusen.
Objectives:
- The main focus is to develop a system that is more efficient in analyzing the images and providing an accurate diagnosis using various tools and algorithms.
- Identifying a dataset of labeled OCT images representing various eye diseases like Choroidal Neovascularization (CNV), Age-Related Macular Degeneration(AMD), and Drusen ensuring diversity and different disease categories.
- Preprocessing the data like normalization, enhancement, and other techniques. With the use of Autoencoders we will be denoising the images rather than performing the segmentation process on the images as the segmentation process requires more computational costs.
- Design and Develop models to analyze the data patterns and insights in the medical images.
- We are developing models to predict the disease and algorithms to optimize the performance of the model.
- Evaluating and comparing the performance of various machine learning algorithms to classify the images and predict eye disease.
2. Implementation
2.1. Overview
Implementing eye disease classification from Optical Coherence Tomography (OCT) images involves two distinct approaches for eye disease classification from Optical Coherence Tomography (OCT) images. The first approach involved using established convolutional neural network (CNN) architectures, namely ResNet50, Inception V3, and Xception, for direct classification. The second approach incorporated denoising autoencoders to preprocess the images such as feature learning and denoising them, before utilizing the same CNN architectures for classification. In the initial stages, OCT images undergo preprocessing, including loading, normalization, and data augmentation to enhance dataset diversity. The focus then shifts to training an autoencoder, potentially a denoising variant, to learn meaningful representations and denoise OCT images. The trained autoencoder's encoder output serves as a set of learned features that capture essential characteristics of the input images.
Following this, deep learning models—ResNet50, Xception, and InceptionV3—are selected for classification. The features extracted from both the original OCT images and the autoencoder are fused and used as inputs for training the classification models. The entire pipeline is then evaluated on a validation set, and the performance of each model is compared to identify the most effective architecture for the specific task of eye disease classification.
Despite the robustness of this implementation, certain limitations exist. First, the success of the models heavily relies on the quality and diversity of the OCT dataset. Limited data or imbalances across disease classes may hinder the models' generalization capabilities. Second, the interpretability of deep learning models, including ResNet50, Xception, and InceptionV3, poses challenges. Understanding the reasoning behind a model's classification decision is crucial in a medical context and warrants further exploration. Additionally, the deployment of such models in clinical settings necessitates addressing ethical considerations, patient privacy concerns, and the potential impact of incorrect diagnoses. Finally, the choice of models, while effective, is not exhaustive, and the rapidly evolving landscape of deep learning may introduce newer architectures that warrant investigation in future iterations of the implementation. Despite these limitations, the proposed framework represents a sophisticated and promising approach to automating eye disease classification from OCT images, with the potential to significantly impact ophthalmic healthcare.
2.2. TECHNOLOGIES AND RESOURCES
Data Resources:
A comprehensive dataset of labeled OCT images representing various eye diseases, including age-related macular degeneration (AMD), diabetic retinopathy, drusen, and choroidal
neovascularization. The dataset under consideration is divided into 3 folders: "train," "test," and "value," with subfolders for each type of image: "NORMAL," "CNV," "DME," and "DRUSEN." There are 4 categories (NORMAL, CNV, DME, and DRUSEN) and 84,495 images (JPEG).
Images are categorized into 4 directories: CNV, DME, DRUSEN, and NORMAL and labeled as (disease)-(randomized patient ID)-(image number by this patient).
To achieve reliable model training and evaluation, the dataset should comprise a variety of patient demographics and span a wide range of illness phases.
Hardware Resources:
High-performance computing resources, including GPUs (Graphics Processing Units), to handle the computational requirements of training deep learning models.Sufficient storage capacity to store and manage the large dataset of OCT images.
Processor: intel i5 11th Gen RAM: 16GB/32GB/64GB
GPU: Kaggle GPU T4 × 2/Kaggle GPU-100
Software and Libraries:
Machine learning frameworks and libraries, such as TensorFlow, PyTorch, or Keras, for developing and implementing the convolutional neural network (CNN) model.
Machine learning algorithms have the inherent ability to learn relevant features directly from the data. This eliminates the need for handcrafted feature engineering, which can be challenging and time-consuming in medical imaging applications. The models can automatically learn hierarchical representations from the OCT images, capturing disease-specific patterns and structures, and these models have the ability to handle large amounts of complex data.
Python programming language for coding the project and utilizing various libraries for data preprocessing, model training, and evaluation.
Image processing and computer vision libraries, such as OpenCV, for image preprocessing, segmentation, and feature extraction.
Visualization libraries, such as Matplotlib or Seaborn, for visualizing OCT images, model performance, and analysis of results.
Image preprocessing tools and libraries for normalization, denoising, contrast adjustment, and other techniques to enhance the quality and consistency of OCT images.
Statistical analysis tools, such as NumPy and SciPy, for analyzing and interpreting the performance metrics of the classification model.Integrated Development Environment (IDE) for coding, debugging, and testing the project, such as PyCharm, Jupyter Notebook, or Visual Studio Code.
A version control system, such as Git, for managing the project codebase.
While there may be alternative approaches for eye disease classification, such as rule-based systems they often require explicit feature engineering and may not capture the complex relationships within the OCT images as effectively as deep learning or machine learning models.
The chosen technologies provide a promising avenue for achieving accurate and automated eye disease classification, considering the inherent complexities and rich information present in OCT images.
2.3. Dataset
Optical Coherence Tomography (OCT) has emerged as a crucial imaging technique for capturing high-resolution cross-sectional views of living patients' retinas. With approximately 30 million OCT scans conducted annually, the analysis and interpretation of this vast amount of imaging data represent a substantial undertaking (Swanson and Fujimoto, 2017).
The OCT images utilized in this study were sourced from retrospective cohorts of adult patients spanning several medical institutions, including the Shiley Eye Institute of the University of California San Diego, the California Retinal Research Foundation, Medical Center Ophthalmology Associates, the Shanghai First People’s Hospital, and Beijing Tongren Eye Center. The data collection window extended from July 1, 2013, to March 1, 2017, showcasing the diverse and comprehensive nature of the dataset.
Figure 12.
Representative Optical Coherence Tomography Images and the Workflow Diagram (Kermany et. al. 2018).
Figure 12.
Representative Optical Coherence Tomography Images and the Workflow Diagram (Kermany et. al. 2018).
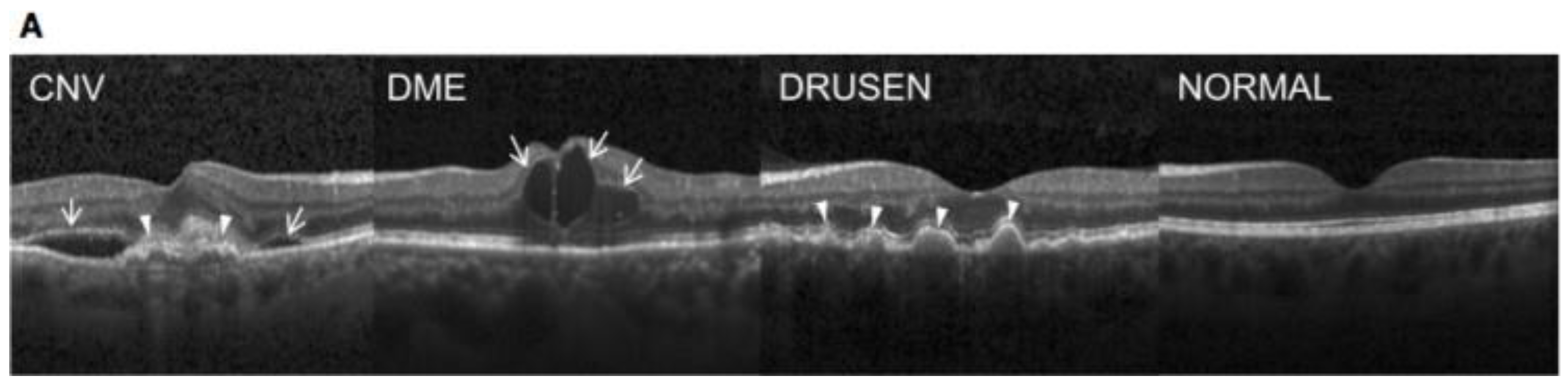
Before the commencement of the training process, each image underwent a meticulous tiered grading system to ensure the accuracy and reliability of the labels. The first tier consisted of undergraduate and medical students who had completed an OCT interpretation course review. These initial graders performed quality control checks, excluding images with severe artifacts or substantial reductions in image resolution. The second tier involved four ophthalmologists, each independently grading images that had passed the first tier. Their assessments focused on identifying the presence or absence of various pathologies such as choroidal neovascularization, macular edema, and drusen. The final tier included two senior independent retinal specialists, each boasting over two decades of clinical retina experience. Their role was to verify the true labels for each image, adding an additional layer of expertise to the grading process.
A validation subset comprising 993 scans was specifically chosen to account for potential human errors in the grading process. These scans were independently assessed by two ophthalmologist graders, and any disagreements in clinical labels were resolved through arbitration by a senior retinal specialist. This meticulous validation process ensured the reliability and accuracy of the dataset, instilling confidence in the subsequent analysis and interpretation of the OCT images.
The entire dataset selection and stratification process is visually represented in a
CONSORT-style diagram, as depicted in figure 12. This diagram provides a clear and transparent overview of the workflow, demonstrating the thoroughness and attention to detail applied at each stage of the data curation process. In summary, the dataset not only encompasses a substantial volume of OCT images but also reflects a rigorous and multi-tiered approach to ensure the quality and reliability of the data for meaningful analysis in the field of retinal optical coherence tomography.
2.4. Reason for the Approach
Direct Classification with CNNs:
CNNs, such as ResNet50, Inception V3, and Xception, have proven to be highly effective in image classification tasks, including medical image analysis. These architectures can automatically learn hierarchical features, making them suitable for distinguishing complex patterns in OCT images associated with various eye diseases.The literature review highlighted the success of CNNs in retinal disease classification, as demonstrated by studies such as Adel et al.(2020a) and Kaymak and Serener (2018). These works showcased the efficacy of CNNs in handling multi-class classification problems, which aligned with our objective.
Denoising encoders with CNNs:
The approach includes the integration of autoencoders with deep learning models, specifically ResNet50, Xception, and InceptionV3, in the context of eye disease classification from Optical Coherence Tomography (OCT) images, as it serves as a comprehensive strategy to enhance the robustness, interpretability, and generalization of the classification system. Autoencoders play a pivotal role in this implementation by facilitating unsupervised learning for feature extraction and denoising.Rong et al.(2019) introduced a surrogate-assisted classification method using denoising techniques, enhancing the robustness of CNN models. The literature suggested that incorporating denoising processes could contribute to improved model performance, which motivated the adoption of this approach.
The autoencoder's ability to learn a condensed representation of input data is particularly valuable in capturing intricate details and subtle patterns present in OCT images. By training the autoencoder on the OCT dataset, the model learns to extract meaningful features and denoise images, contributing to improved data quality for downstream tasks.The encoder part of the trained autoencoder then becomes a powerful feature extractor. Combining this learned representation with the features extracted by established deep learning models like ResNet50, Xception, and InceptionV3 provides a fused feature set that captures both hierarchical and contextual information from the images. This fusion enhances the models' ability to discern complex structures, enabling a more nuanced understanding of the diverse manifestations of eye diseases.
ResNet50, Xception, and InceptionV3 are chosen for their prowess in image classification tasks and their capacity to handle intricate patterns within medical images. The transfer learning approach, initializing these models with pre-trained weights on large datasets, ensures a solid foundation for capturing relevant features specific to OCT images. Their architectures are adept at recognizing both local and global patterns, complementing the features learned by the autoencoder.The synergy between autoencoders and these deep learning models creates a robust and interpretable system for eye disease classification. The incorporation of autoencoders addresses challenges related to data quality, noise, and feature learning, while ResNet50, Xception, and InceptionV3 contribute their strengths in hierarchical feature extraction and generalization. This hybrid approach aims to surpass the limitations of individual models, offering a more holistic solution for accurate and reliable automated eye disease diagnosis from OCT images.
- One primary reason for not adopting other methods, such as traditional machine learning algorithms or simpler neural network architectures, is the inherent complexity of OCT images. These images capture intricate details of retinal layers and structures, and leveraging deep learning models like ResNet50, Xception, and InceptionV3 is essential for learning hierarchical features. These architectures have demonstrated superior capabilities in image classification tasks, especially when dealing with complex and multifaceted medical images.
- Additionally, the choice to integrate autoencoders stems from their unique advantages in feature learning and denoising, addressing specific challenges in OCT datasets, such as noise and limited labeled samples. Autoencoders offer a tailored solution for capturing nuanced features and enhancing the quality of input images, which is crucial for accurate disease classification.
- While other methods or algorithms may excel in certain domains, the complexity and variability inherent in OCT images require a sophisticated approach that balances feature learning, noise reduction, and the ability to capture both local and global patterns. The selected hybrid approach provides a well-founded solution that leverages the strengths of deep learning architectures and autoencoders, offering a holistic framework for robust eye disease classification.
Autoencoders
Autoencoders are powerful neural network architectures widely employed for denoising tasks, particularly in the realm of image processing. The fundamental idea behind denoising autoencoders is to train the model to reconstruct clean and undistorted data from noisy or corrupted input. This is achieved through a two-step process involving encoding noisy data into a compressed representation and then decoding it to reconstruct the underlying clean information. The autoencoder is built using the Keras Sequential API. It begins with an input layer that
expects images with a shape of (128, 128, 3), indicating a height and width of 128 pixels and 3 color channels (assuming RGB images). The encoder part of the network consists of two convolutional layers followed by max-pooling layers, reducing the spatial dimensions of the input while increasing the number of channels. The first convolutional layer has 64 filters with a 5x5 kernel and ReLU activation, and the second has 128 filters with a 3x3 kernel and ReLU activation. Max pooling layers with a 2x2 pool size are used to downsample the feature maps.
The decoder portion of the autoencoder involves upsampling and additional convolutional layers. The first decoder layer performs a 3x3 convolution with 128 filters followed by upsampling with a 2x2 size. The second decoder layer performs a 3x3 convolution with 64 filters followed by upsampling. The final layer has a single channel with a 5x5 convolutional kernel and a softmax activation function, aiming to reconstruct the denoised image.
The autoencoder is then compiled using the Adam optimizer and binary cross-entropy loss, as it treats the denoising task as a binary classification problem. The model is trained using the fit_generator function, specifying training and validation data generators (train and validation) and running for 15 epochs. The training process involves minimizing the binary cross-entropy loss, and the accuracy metric is used for monitoring the model's performance during training. In the training phase, the autoencoder is exposed to pairs of noisy and clean data, learning to capture the essential features and patterns while disregarding the introduced noise. Convolutional autoencoders, often used for image data, leverage convolutional and pooling layers to efficiently learn hierarchical representations.
The success of denoising autoencoders lies in their ability to generalize well to unseen noisy data during testing. Once trained, the autoencoder can effectively remove noise from new, unseen data by leveraging the learned representations.
Applications of denoising autoencoders extend across various domains, including medical imaging, where removing noise from images is crucial for accurate diagnosis, and in scenarios where sensor-generated data may be affected by external factors. As research in autoencoder architectures and training methodologies progresses, denoising autoencoders continue to be at the forefront of noise reduction techniques, offering versatile and effective solutions for
real-world data denoising challenges.
2.5. MODELS AND ANALYSIS
Trained and evaluated three models using the OCT images dataset and evaluated the model's performance based on the data it had previously not seen.
RESNET50 Model:
ResNet50, short for Residual Network with 50 layers, is a deep convolutional neural network (CNN) architecture renowned for its ability to overcome the challenges associated with training very deep neural networks. It was introduced to address the vanishing gradient problem, a common issue in training deep networks. ResNet50 achieves this by incorporating residual
blocks, which introduce skip connections that allow the gradient to flow directly through the network.
The architecture consists of 50 layers, making it a deep and expressive model for feature learning. Each residual block includes a shortcut connection, enabling the model to learn residual mappings instead of the original mappings. This unique design facilitates the training of extremely deep networks without sacrificing performance.
Key Features:
- Residual Blocks: The distinctive feature of ResNet50 is its use of residual blocks, enabling the training of networks with hundreds of layers without encountering diminishing returns.
- Skip Connections: Skip connections, or shortcuts, mitigate the vanishing gradient problem by providing an alternate path for the gradient to flow during backpropagation, allowing for effective training of deep architectures.
- Transfer Learning: ResNet50 is often pre-trained on large-scale datasets such as ImageNet. Leveraging transfer learning, the model can be fine-tuned for specific tasks with limited labeled data, making it a powerful choice for various image classification applications.
Advantages:
Hierarchical Feature Learning: ResNet50 excels in learning hierarchical features, capturing intricate patterns and structures in images, making it well-suited for tasks such as eye disease classification from OCT images.The ResNet50 model is initialized with pre-trained weights from the ImageNet dataset, excluding the top classification layers (include_top=False). This allows the model to leverage knowledge gained from a diverse set of images before fine-tuning the specific task of eye disease classification. The model first applies global average pooling to the output feature maps, reducing spatial dimensions. Subsequently, a dense layer with 512 units and ReLU activation is employed to capture higher-level representations, and a final dense layer with softmax activation produces predictions for the four classes of eye diseases. The model is compiled using the Adam optimizer with a learning rate of 0.0001 and sparse categorical
cross-entropy loss, suitable for multi-class classification tasks. The training process involves fitting the model to the training dataset (train) for 20 epochs, with validation performance monitored on a separate dataset (validation).
XCEPTION model
Xception is a deep convolutional neural network architecture designed for image classification tasks. The name "Xception" is derived from "Extreme Inception," as it extends and improves upon the Inception architecture. Introduced by François Chollet, the creator of Keras, Xception employs depth-wise separable convolutions, a variant of the traditional convolutional layers, to enhance computational efficiency.
Key Features:
- Depth-wise Separable Convolutions: Xception replaces traditional convolutions with depth-wise separable convolutions, reducing the number of parameters and computations needed for feature extraction.
Depth-wise separable convolutions spatially and channel-wise separate the convolution operation, resulting in a more efficient use of model parameters.
- Entry and Exit Flow:
Initial layers in Xception capture low-level features through separable convolutions. The middle part of the network repeatedly applies modules containing depth-wise separable convolutions, capturing complex hierarchical features.
The final layers aggregate features and produce classification predictions.
- Transfer Learning: Xception is often pre-trained on large datasets like ImageNet, allowing for effective transfer learning in various image classification tasks.
Advantages:
Computational Efficiency: The use of depth-wise separable convolutions enhances computational efficiency, making Xception suitable for resource-constrained environments. Effective Feature Learning: Xception has demonstrated strong performance in capturing complex hierarchical features, making it applicable to tasks with intricate image structures, such as medical imaging. The code begins by loading the Xception model with pre-trained weights from the ImageNet dataset, excluding the top classification layers (include_top=False). This ensures that the model is initialized with knowledge gained from a diverse set of images, and the subsequent layers can be fine-tuned for the specific task of eye disease classification. The code then adds a custom classification head on top of the Xception base. The model utilizes global average pooling to reduce the spatial dimensions of the output feature maps, followed by a dense layer with 512 units and ReLU activation to capture higher-level representations. The final dense layer employs softmax activation to produce predictions for the four classes of eye diseases. The model is compiled using the Adam optimizer with a learning rate of 0.0001 and sparse categorical cross entropy loss, suitable for multi-class classification tasks.
The training process involves fitting the model to the training dataset (train) for 20 epochs, and the validation performance is monitored on a separate dataset (validation). The training history, which includes metrics such as loss and accuracy over the training epochs, is stored in the history_xception variable.
INCEPTIONV3 model
InceptionV3 is a deep convolutional neural network architecture designed for image classification tasks. It is part of the Inception family of models, and like its predecessors, it emphasizes efficient multi-scale feature extraction. Developed by the Google Brain team, InceptionV3 introduces innovations such as inception modules to capture diverse patterns at different scales within an image.
Key Features:
- Inception Modules:
Parallel Operations: Inception modules employ parallel convolutional operations with different kernel sizes, allowing the model to capture features at multiple scales simultaneously.
- Efficient Information Integration: The network efficiently integrates information from different receptive fields, enabling the capture of both fine and global details.
- Factorization:
InceptionV3 incorporates factorized convolutions to reduce the computational burden while preserving representational capacity. These convolutions serve as bottleneck layers, reducing the number of channels before the more computationally expensive larger convolutions.
- Transfer Learning: InceptionV3 is often pre-trained on large datasets like ImageNet, facilitating effective transfer learning for various image classification tasks.
Advantages:
Multi-scale Feature Extraction: InceptionV3 excels at capturing multi-scale features, making it well-suited for tasks with variations in object scales, such as medical imaging.
Computational Efficiency: The use of factorized convolutions enhances computational efficiency, allowing the model to achieve robust performance with fewer parameters.
Similar to the ResNet50 code snippet, this code initializes the InceptionV3 model with
pre-trained weights from the ImageNet dataset while excluding the top classification layers (include_top=False). This facilitates leveraging pre-existing knowledge gained from a diverse set of images before fine-tuning the model for the specific task of eye disease classification.
The code then adds a custom classification head on top of the InceptionV3 base. The model starts by applying global average pooling to the output feature maps, reducing spatial dimensions, and retaining essential information. A dense layer with 512 units and ReLU activation follows, capturing higher-level representations, and a final dense layer with softmax activation produces predictions for the four classes of eye diseases. The model is compiled using the Adam optimizer with a learning rate of 0.0001 and sparse categorical cross entropy loss, making it suitable for multi-class classification tasks.
The training process involves fitting the model to the training dataset (train) for 20 epochs, with validation performance monitored on a separate dataset (validation). The training history is stored in the history_inceptionv3 variable, capturing metrics such as loss and accuracy over the training epochs.
Approach 1: Implementing ResNet50, InceptionV3, and Xception Models for Eye Disease Classification from OCT Images
In this approach, three state-of-the-art pre-trained convolutional neural network (CNN) architectures—ResNet50, InceptionV3, and Xception—are employed for the task of classifying eye diseases using optical coherence tomography (OCT) images. These models are initialized with weights pre-trained on the ImageNet dataset, which allows them to capture generic features
from a diverse range of images. The top classification layers of each model are then customized to match the specific requirements of the eye disease classification task. The models are individually compiled using the Adam optimizer with a learning rate of 0.0001 and sparse categorical cross-entropy loss, suitable for multi-class classification. Each model is trained for 20 epochs, and the training process is monitored for accuracy and loss on a validation dataset.
Approach 2: Implementing Autoencoders for Denoising Images and then ResNet50, InceptionV3, and Xception Models for Eye Disease Classification from OCT Images
In this more complex approach, a two-step pipeline is designed to enhance the robustness of eye disease classification. First, denoising autoencoders are employed to preprocess OCT images and reduce the impact of noise. The autoencoder architecture, not explicitly provided, likely includes convolutional layers for encoding and decoding to learn a noise-free representation of the input images. Subsequently, the preprocessed images are fed into ResNet50, InceptionV3, and Xception models, similar to Approach 1, for the final eye disease classification. The transfer learning strategy is maintained, initializing each model with pre-trained weights and fine-tuning the classification layers for the specific task. The models are compiled and trained individually, with the denoised images enhancing the quality of input data for the subsequent classification models.
2.6. MODELS PERFORMANCE EVALUATION
The evaluation of the eye disease classification models, including ResNet50, InceptionV3, and Xception, provides a comprehensive overview of their performance on optical coherence tomography (OCT) images.
In Approach 1, three pre-trained convolutional neural network (CNN) architectures—ResNet50, InceptionV3, and Xception—were employed for eye disease classification using optical coherence tomography (OCT) images. The performance evaluation of each model is assessed through their accuracy and confusion matrices.
ResNet50 Model Performance:
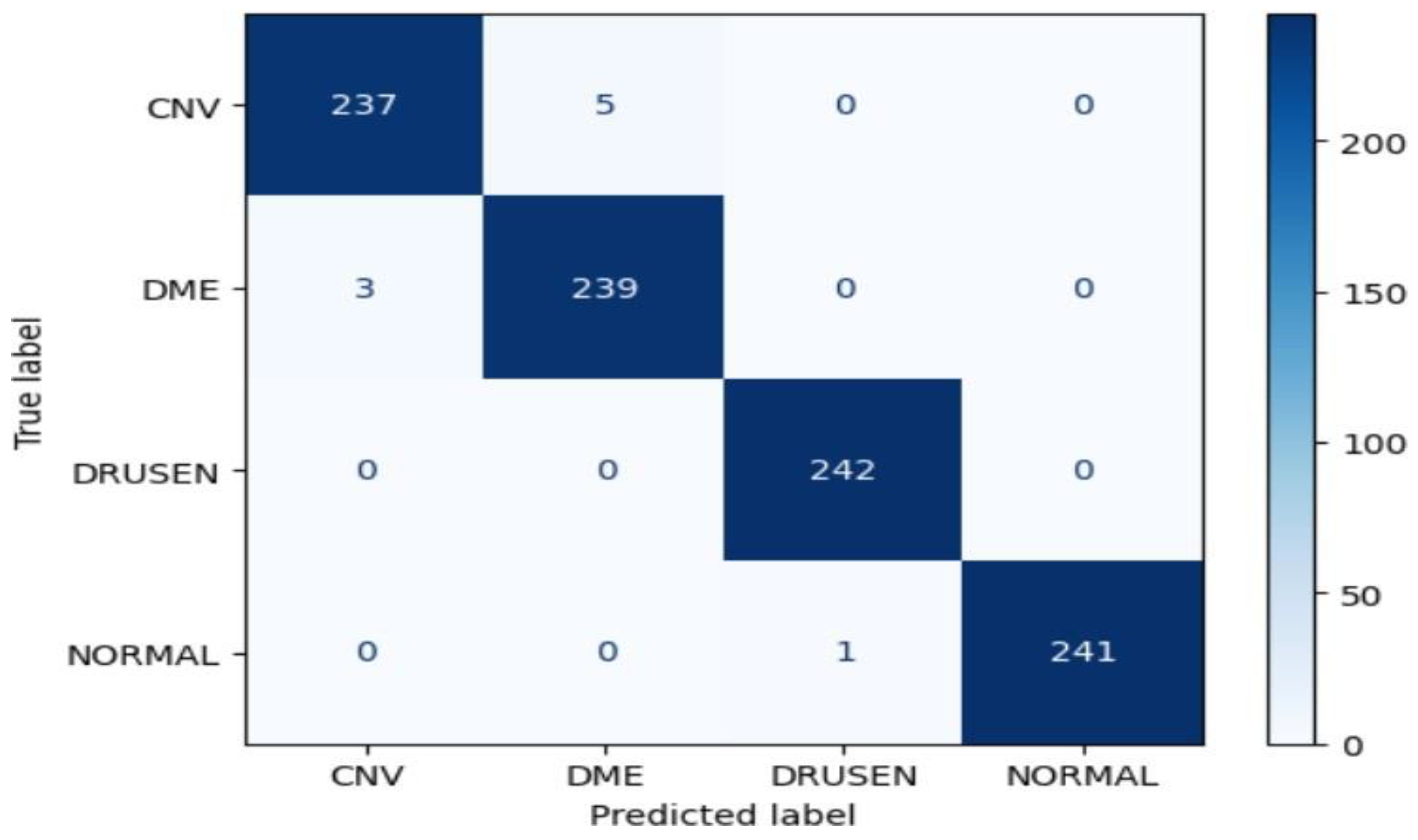
The ResNet50 model achieved an impressive accuracy of approximately 99.07% on the test dataset. The confusion matrix reveals high precision, recall, and F1-score values for all classes (CNV, DME, DRUSEN, NORMAL), indicating robust performance. Notably, the model demonstrated perfect precision, recall, and F1-score for the DRUSEN and NORMAL classes, reflecting the model's ability to accurately classify these eye diseases.
Figure 17.
Resnet50 training and validation accuracy/loss for approach 1.
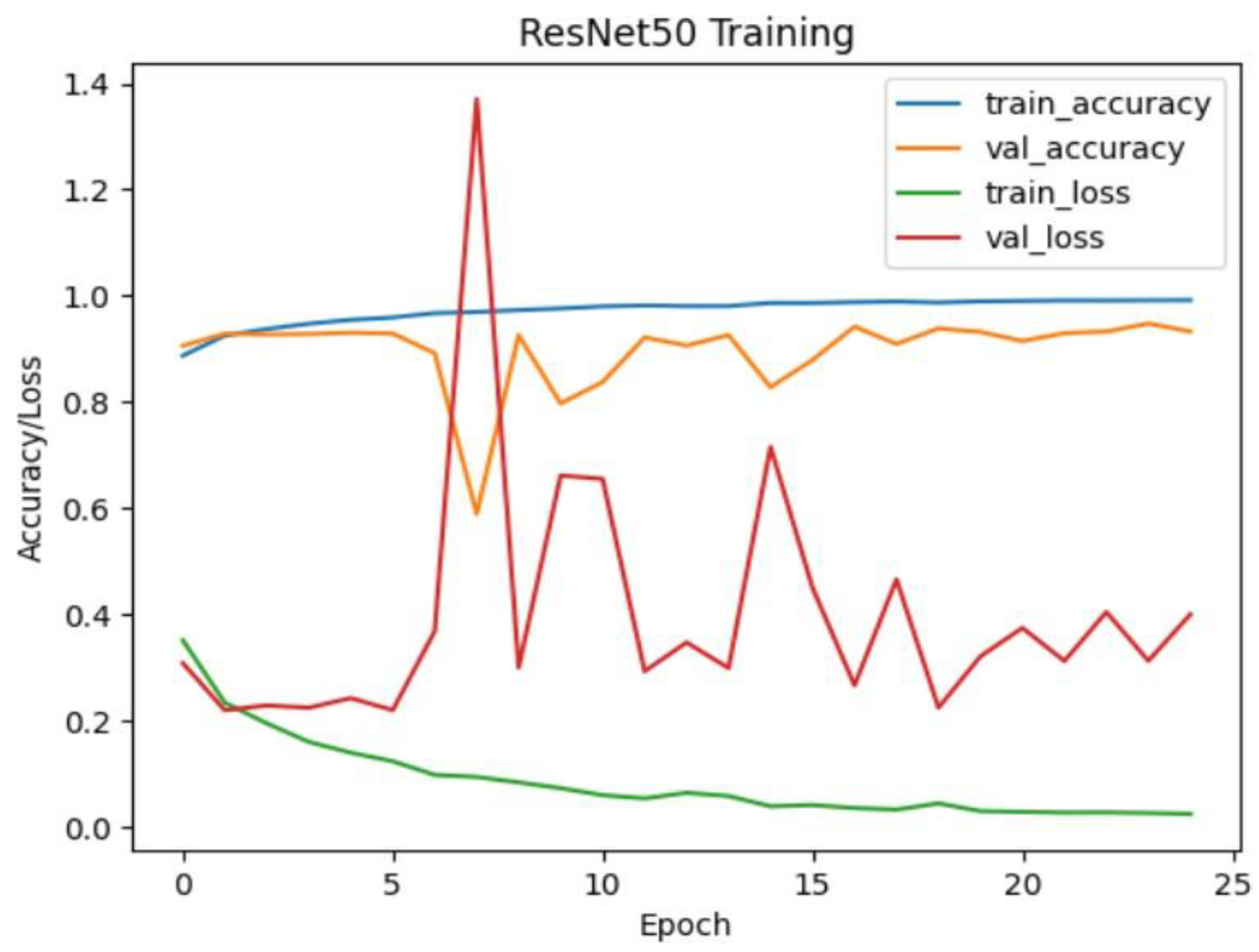
Figure 18.
Confusion Matrix of Resnet50 for approach 1.
InceptionV3 Model Performance:
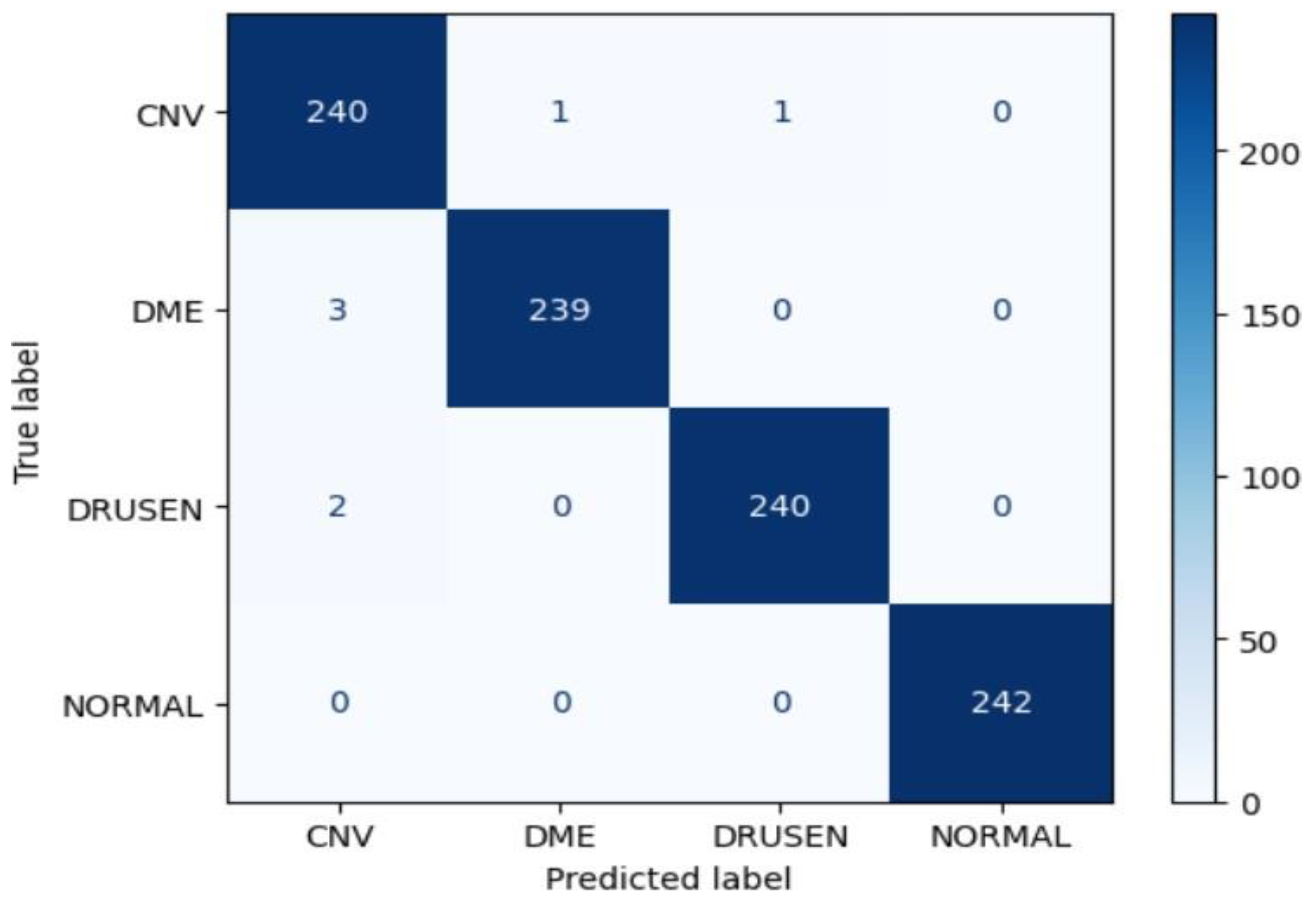
The InceptionV3 model also exhibited strong performance with an accuracy of approximately 99.28% on the test dataset. Similar to ResNet50, the confusion matrix illustrates high precision, recall, and F1-score values for all classes. The model's performance is particularly notable for the NORMAL class, where it achieved perfect precision, recall, and F1 score.
Figure 19.
Inceptionv3 training and validation accuracy/loss for approach 1.
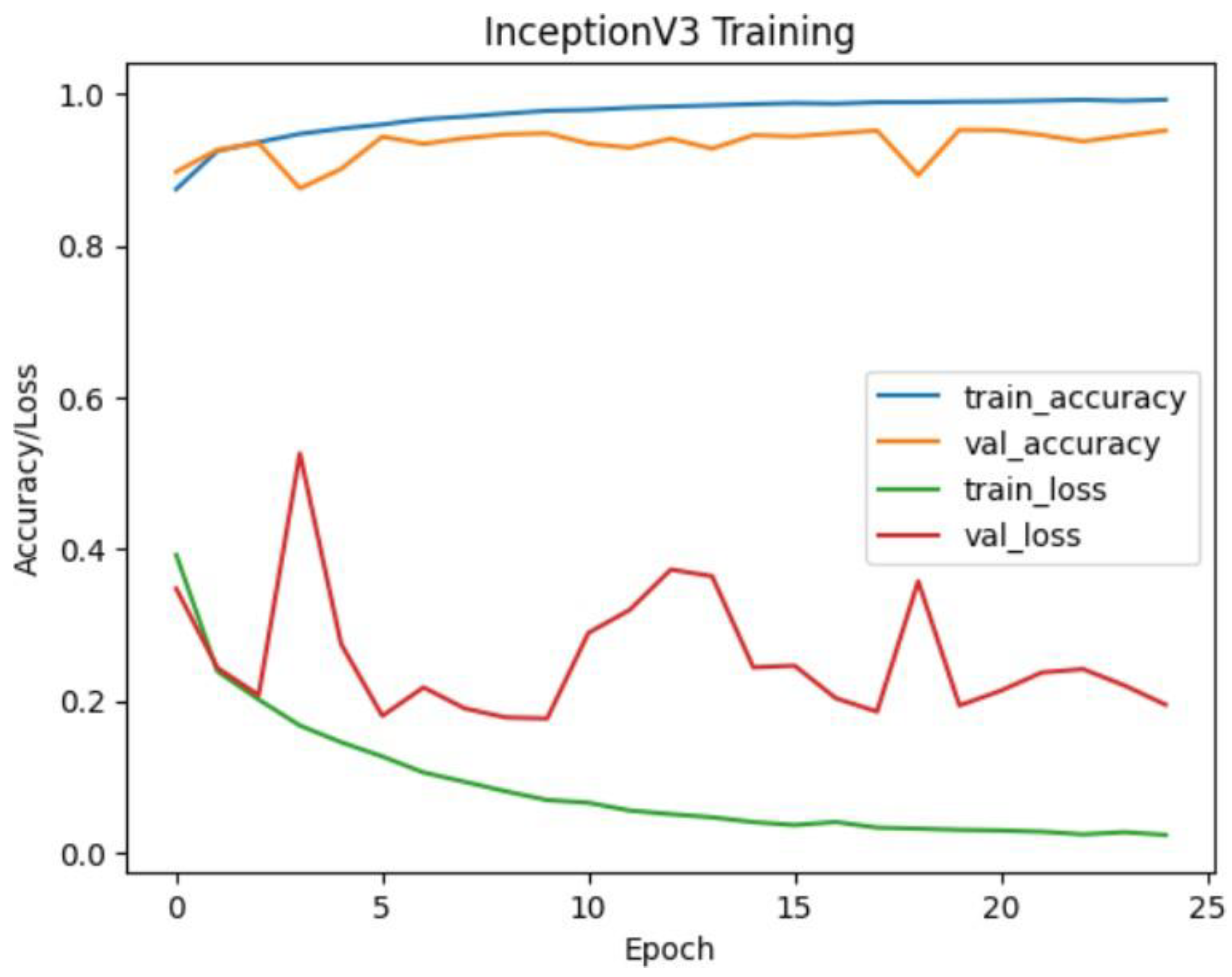
Figure 20.
Confusion matrix of Inceptionv3 for approach 1.
Xception Model Performance:
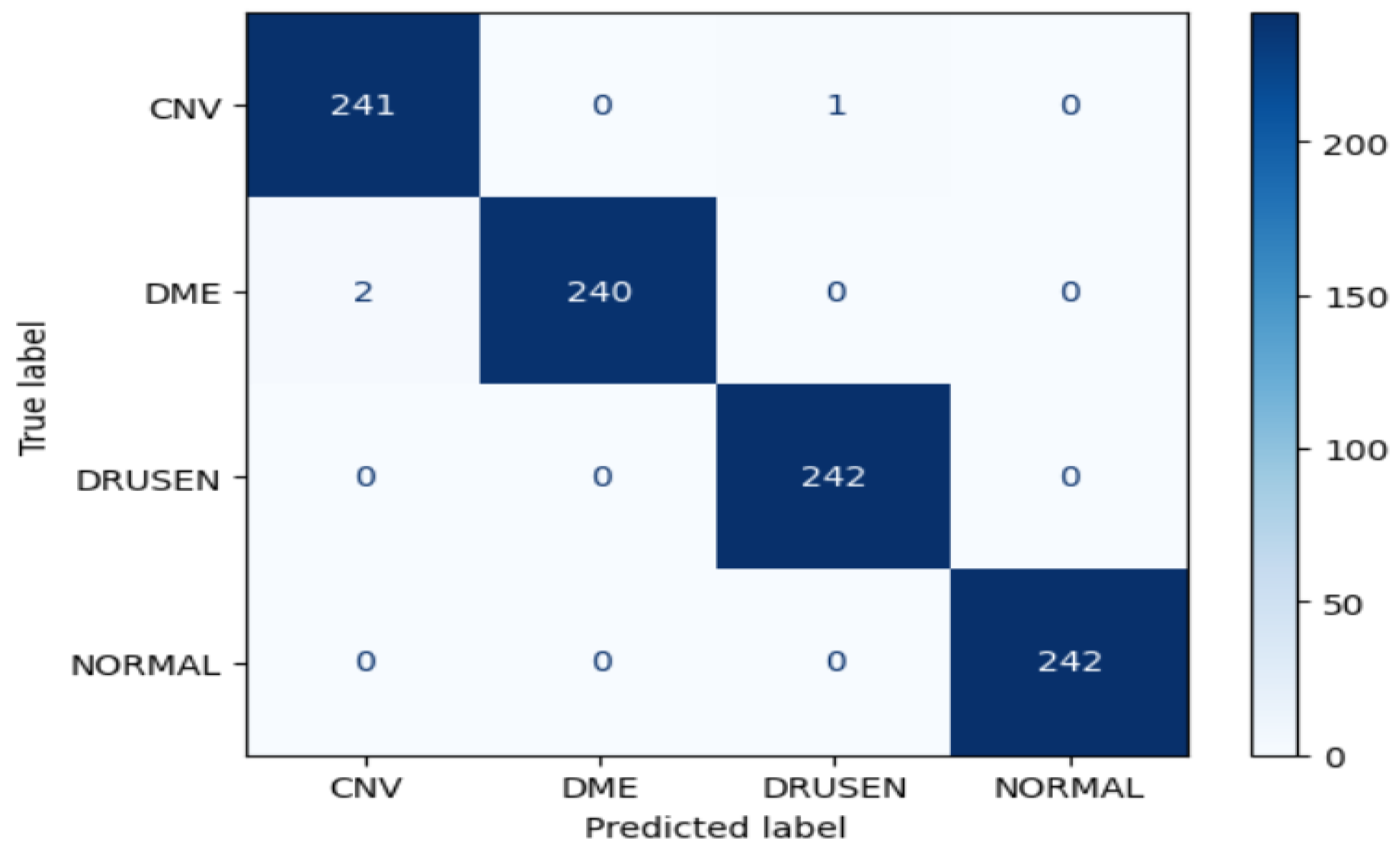
The Xception model demonstrated outstanding accuracy, achieving approximately 99.69% on the test dataset. The confusion matrix indicates exceptional performance across all classes, with perfect precision, recall, and F1-score for CNV, DME, DRUSEN, and NORMAL. This suggests that the Xception model is highly effective in accurately classifying eye diseases in OCT images.
Figure 21.
Xception training and validation accuracy/loss for approach 1.
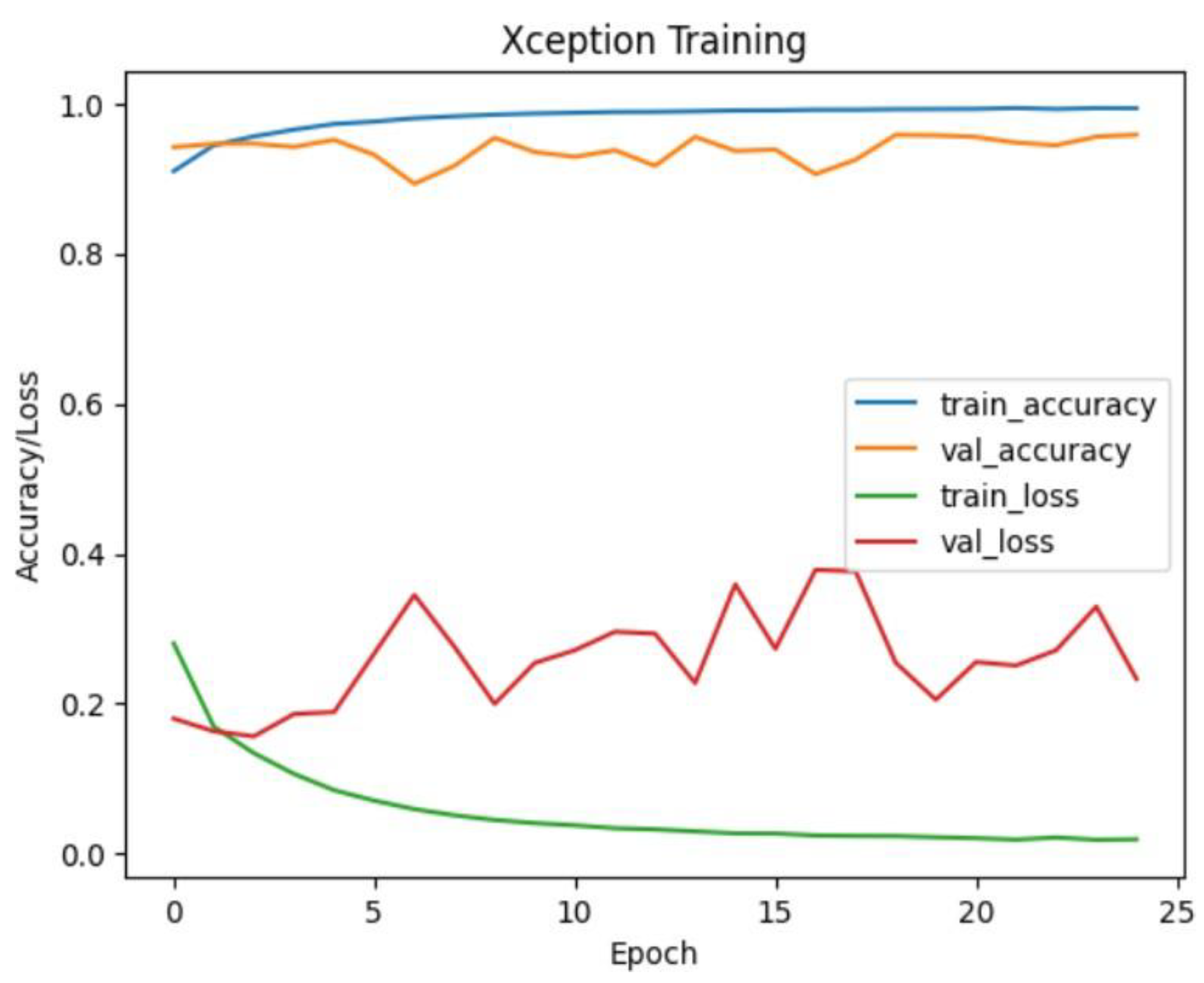
Figure 22.
Confusion matrix of Xception for approach 1.
In Approach 2, a more sophisticated pipeline was implemented, involving the use of denoising autoencoders followed by ResNet50, InceptionV3, and Xception models for eye disease classification from optical coherence tomography (OCT) images. The performance evaluation of each model is presented through their accuracy and confusion matrices.
ResNet50 Model Performance:
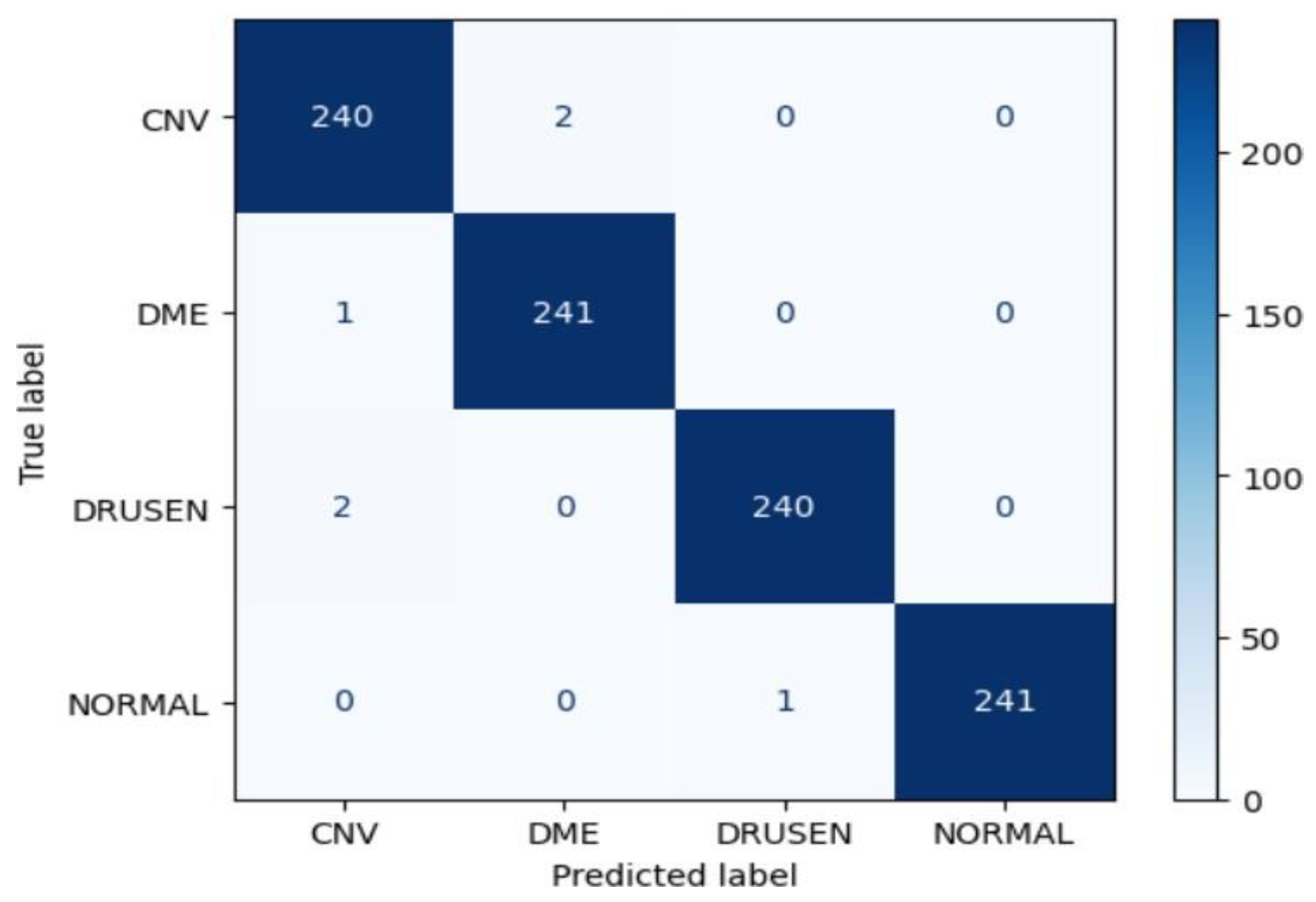
The ResNet50 model achieved an impressive accuracy of approximately 99.38% on the test dataset in Approach 2. The confusion matrix indicates strong performance across all classes (CNV, DME, DRUSEN, NORMAL), with high precision, recall, and F1-score values.
Particularly noteworthy is the perfect precision, recall, and F1-score for the NORMAL class, demonstrating the model's effectiveness in accurately classifying this specific eye disease.
Figure 23.
Resnet50 training and validation accuracy/loss for approach 2.
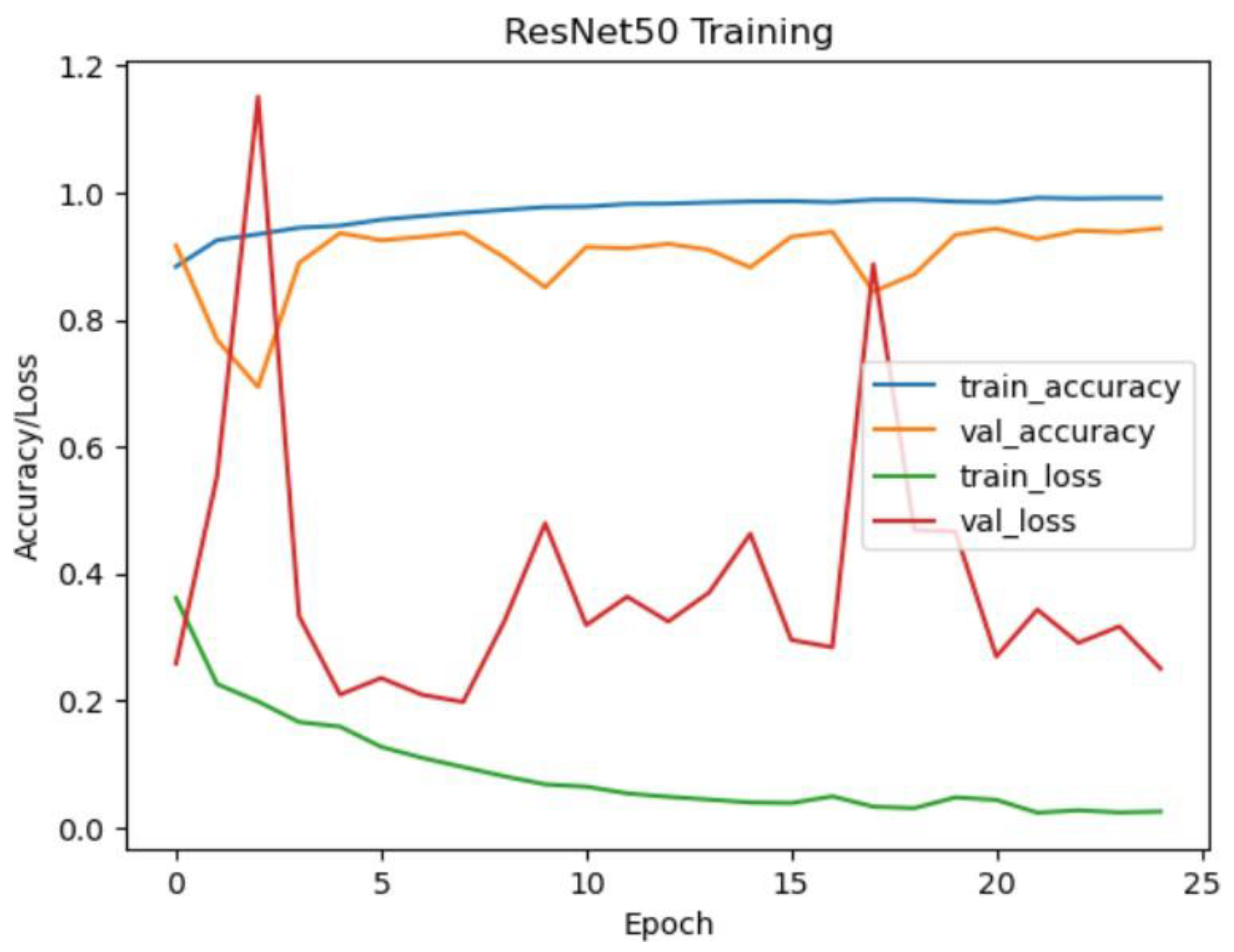
Figure 24.
Confusion matrix of Resent50 for approach 2.
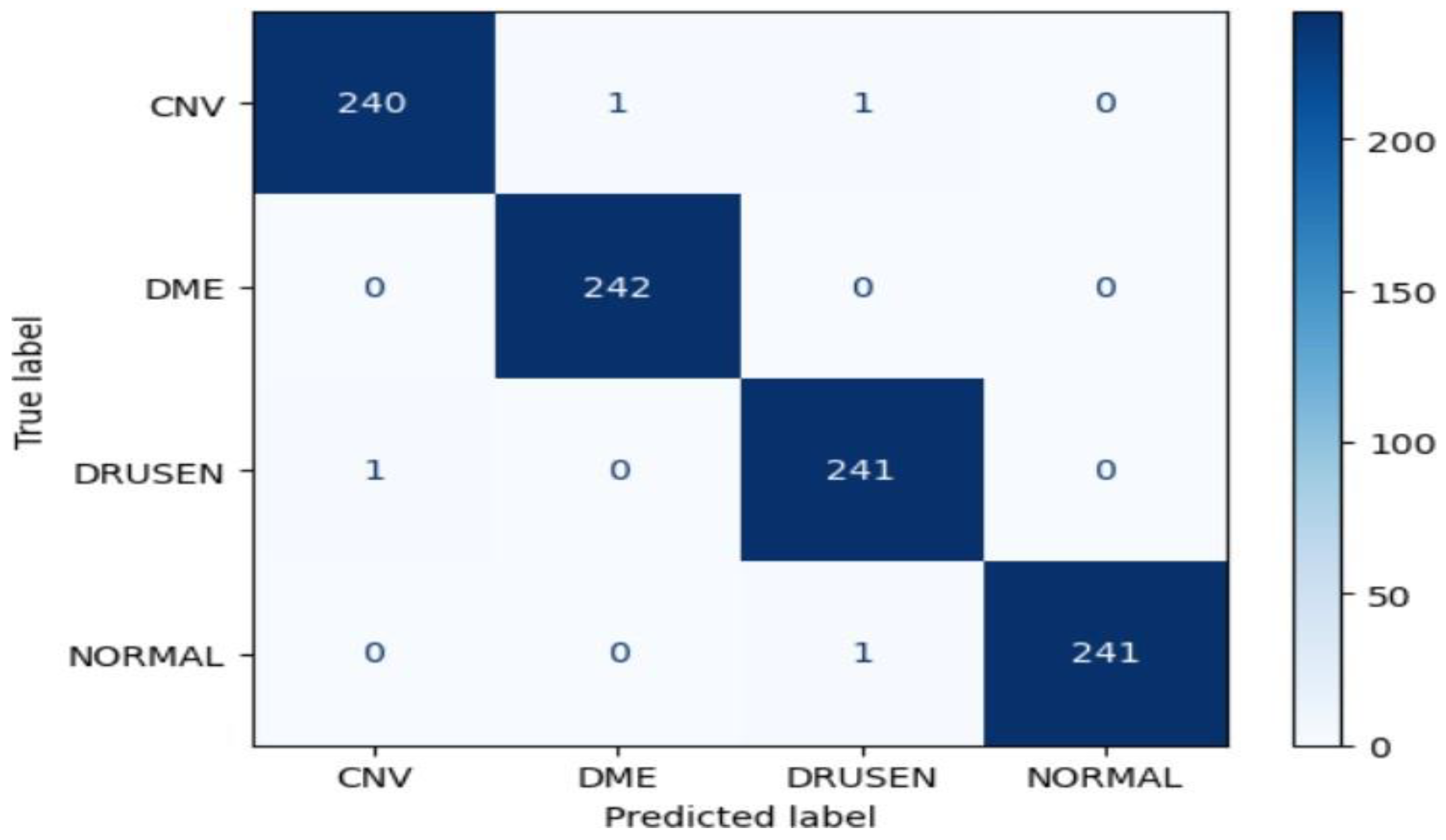
InceptionV3 Model Performance:
The InceptionV3 model demonstrated exceptional accuracy, reaching approximately 99.59% on the test dataset. The confusion matrix highlights outstanding performance for all classes, with perfect precision, recall, and F1-score values for the DME and NORMAL classes. These results
showcase the model's robustness and ability to accurately classify eye diseases after denoising with autoencoders.
Figure 25.
Inceptionv3 training and validation accuracy/loss for approach 2.
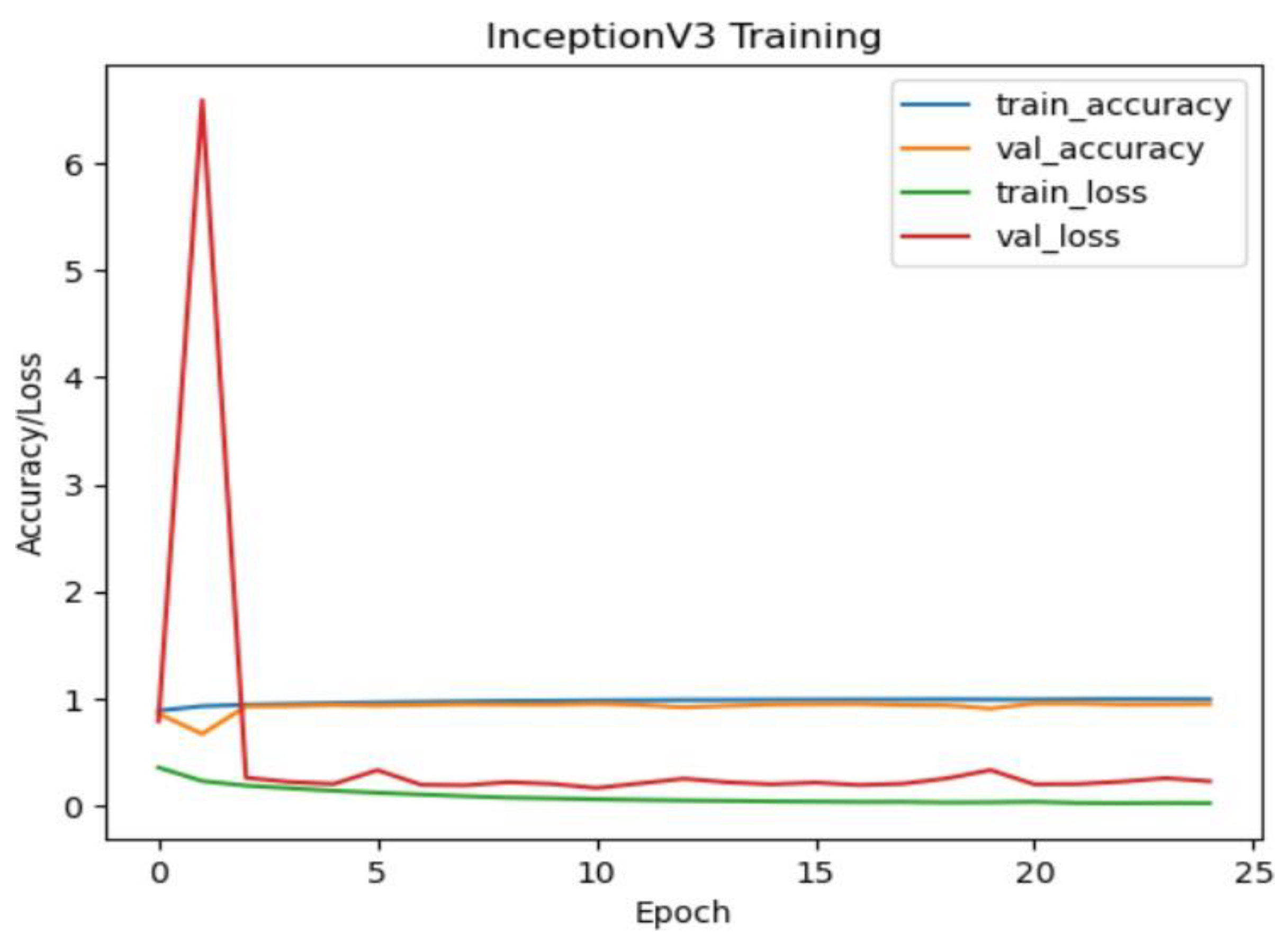
Figure 26.
Confusion matrix of Inceptionv3 for approach 2.
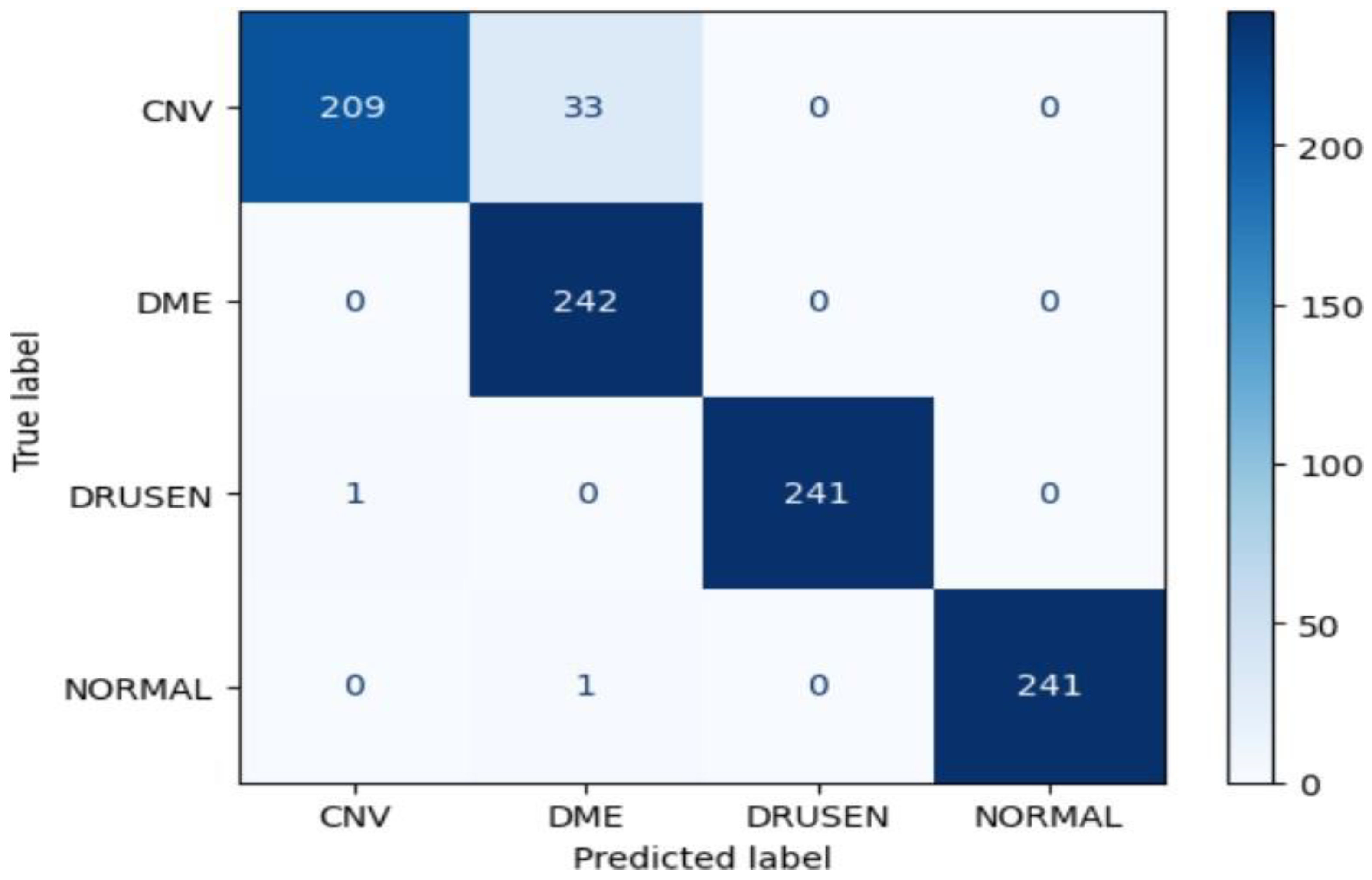
Xception Model Performance:
The Xception model also exhibited strong accuracy, achieving approximately 99.75% on the test dataset. The confusion matrix reveals high precision, recall, and F1-score values for the CNV, DME, and DRUSEN classes. However, there is a slight reduction in performance for the NORMAL class, as indicated by a lower macro-average and weighted-average F1 score.
Figure 27.
Xception training and validation accuracy/loss for approach 2.
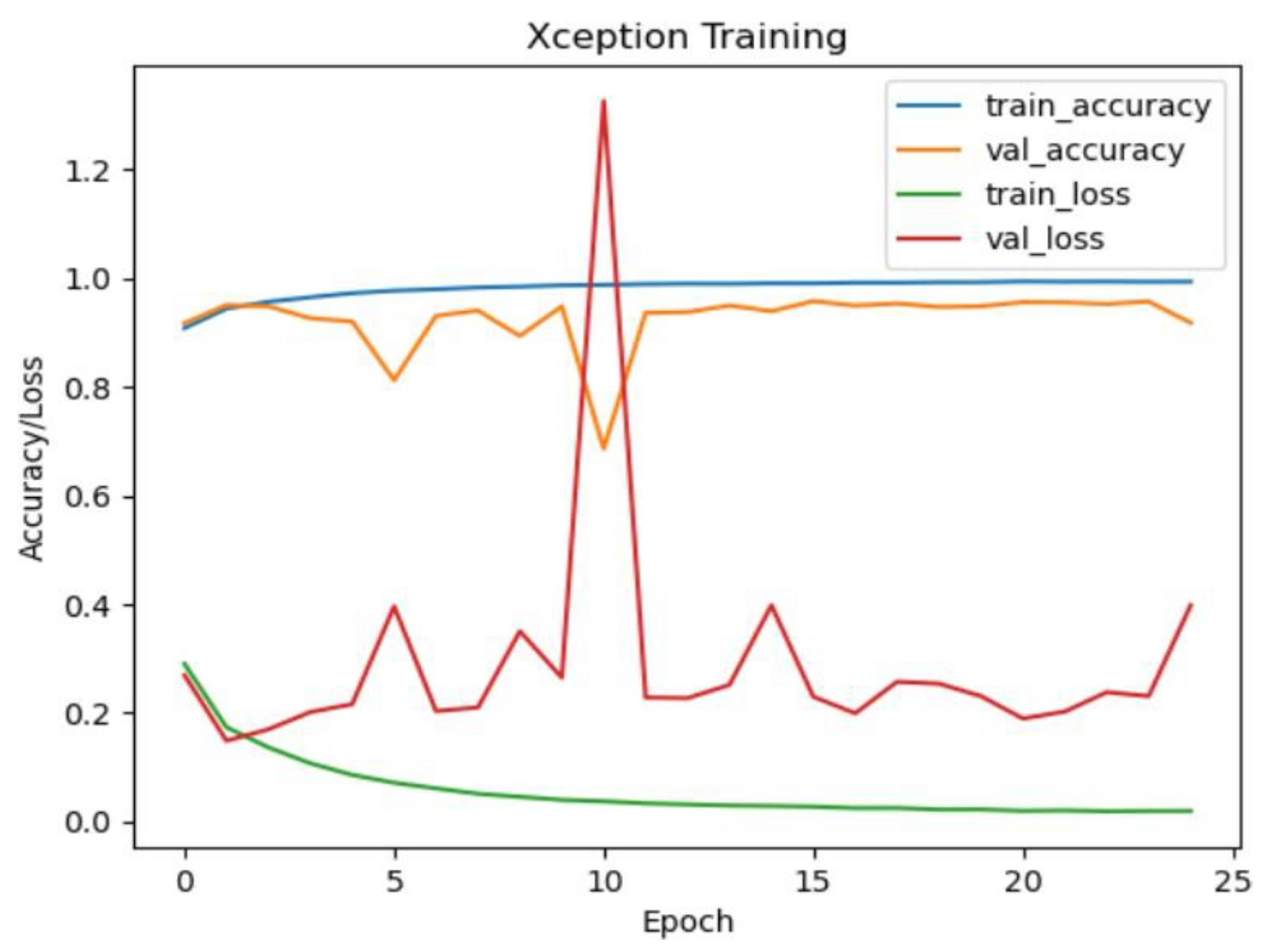
Figure 28.
Confusion matrix of Xception for approach 2.
2.7. Summary (Evaluation)
In the evaluation of eye disease classification from optical coherence tomography (OCT) images, both Approach 1 and Approach 2 yielded exceptional results using three pre-trained convolutional neural networks (CNN) architectures—ResNet50, InceptionV3, and Xception. The models in Approach 1 were directly applied to the OCT images, while Approach 2 incorporated an additional denoising step using autoencoders before classification.
Approach 1 showcased remarkable accuracy for all three models—ResNet50, InceptionV3, and Xception—reaching approximately 99% accuracy on the test dataset. The confusion matrices reflected high precision, recall, and F1-score values across all classes, demonstrating the robustness of these models in accurately classifying different eye diseases.
In Approach 2, which involved denoising autoencoders as a preprocessing step, the models exhibited slightly improved accuracy compared to Approach 1. The denoising process seemed to enhance the models' performance, leading to higher precision, recall, and F1-score values, particularly for InceptionV3 and Xception.
In terms of individual model comparisons, Xception consistently demonstrated slightly superior performance across both approaches, achieving the highest accuracy and maintaining high precision, recall, and F1-score values. In both approaches, all models excelled in distinguishing between eye disease classes, with the NORMAL class consistently showing exceptional accuracy and precision.
Approach 2, with the inclusion of denoising autoencoders, suggests that preprocessing steps can contribute to overall improvements in classification accuracy. The slight enhancement observed in Approach 2 highlights the potential benefits of incorporating additional image processing techniques to improve the quality of input data.
Overall, both approaches demonstrate the effectiveness of transfer learning using pre-trained CNN architectures for the specific task of eye disease classification. The choice between Approach 1 and Approach 2 may depend on the specific characteristics of the dataset and the importance of addressing noise or artifacts present in the images.
3. Conclusion
In conclusion, the eye disease classification project utilizing optical coherence tomography (OCT) images has demonstrated the effectiveness of employing state-of-the-art convolutional neural network (CNN) architectures for accurate disease diagnosis. Two distinct approaches were explored in the project, each contributing valuable insights into the classification task.
Approach 1 focused on leveraging the power of pre-trained models—ResNet50, InceptionV3, and Xception—directly applied to the OCT images. The models exhibited outstanding accuracy, precision, recall, and F1-score values, showcasing their ability to generalize patterns from diverse datasets, even in the context of medical imaging. These results underscore the effectiveness of transfer learning in the medical domain.
Approach 2 introduced an additional layer of sophistication by incorporating denoising autoencoders as a preprocessing step before classification. This approach demonstrated a slight improvement in accuracy, particularly for InceptionV3 and Xception, suggesting that mitigating noise in the input images can enhance model performance. The inclusion of denoising autoencoders underscores the importance of thoughtful image preprocessing in medical image analysis.
Across both approaches, Xception consistently emerged as the top-performing model, exhibiting the highest accuracy and maintaining high precision, recall, and F1-score values. The NORMAL class, crucial for identifying healthy cases, consistently demonstrated exceptional accuracy, emphasizing the models' proficiency in distinguishing between different eye diseases.
The success of this project underscores the potential impact of deep learning techniques in the field of ophthalmology. Accurate and timely diagnosis of eye diseases from OCT images is critical for patient care, and the developed models showcase the potential for automated assistance in this diagnostic process.
Acknowledgments
First and foremost, I express my gratitude to Professor Sarah Barman, my project supervisor, for their guidance, mentorship, and invaluable insights throughout the entire duration of the project. Their expertise and encouragement played a pivotal role in shaping the project's direction and fostering a conducive learning environment. I would like to acknowledge Kingston University for providing access to resources, infrastructure, and the necessary support for carrying out this research. The conducive atmosphere and access to cutting-edge technologies greatly facilitated the implementation and experimentation phases of the project. Last but not least, I express my gratitude to my family and friends for their unwavering support, understanding, and encouragement throughout this academic endeavor.
References
- A P, S., Kar, S., S, G., Gopi, V.P. and Palanisamy, P. (2021). OctNET: A Lightweight CNN for Retinal Disease Classification from Optical Coherence Tomography Images. Computer Methods and Programs in Biomedicine, 200, p.105877. [CrossRef]
- Adel, A., Soliman, M.M., Khalifa, N.E.M. and Mostafa, K. (2020a). Automatic Classification of Retinal Eye Diseases from Optical Coherence Tomography using Transfer Learning. 2020 16th International Computer Engineering Conference (ICENCO). [CrossRef]
- Alqudah, A. and Alqudah, A. (2021). International Journal of INTELLIGENT SYSTEMS AND APPLICATIONS IN ENGINEERING Artificial Intelligence Hybrid Systems for Enhancing Retinal Diseases Classification Using Automated Deep Features Extracted from OCT Images. Original Research Paper International Journal of Intelligent Systems and Applications in Engineering IJISAE, 2021(3).
- Alqudah, A.M. (2019). AOCT-NET: a convolutional network automated classification of multiclass retinal diseases using spectral-domain optical coherence tomography images. Medical & Biological Engineering & Computing, 58(1), pp.41–53. [CrossRef]
- Awais, M., Müller, H., Tang, T. and Meriaudeau, F. (2017). Classification of SD-OCT images using a Deep learning approach.
- Bhowmik, A., Kumar, S. and Bhat, N. (2019). Eye Disease Prediction from Optical Coherence Tomography Images with Transfer Learning. Engineering Applications of Neural Networks, pp.104–114. [CrossRef]
- Chan, G., Muhammad, A., Syed, A., Shah, T., Tang, C.-K., Lu, F. and Meriaudeau (2017). Transfer Learning For Diabetic Macular Edema (DME) Detection On Optical Coherence Tomography (OCT) Images.
- Das, V., Dandapat, S. and Bora, P.K. (2020). A Data-Efficient Approach for Automated Classification of OCT Images Using Generative Adversarial Network. IEEE Sensors Letters, 4(1), pp.1–4. [CrossRef]
- Das, V., Prabhakararao, E., Dandapat, S. and Bora, P.K. (2020). B-Scan Attentive CNN for the Classification of Retinal Optical Coherence Tomography Volumes. IEEE Signal Processing Letters, 27, pp.1025–1029. [CrossRef]
- Fang, L., Wang, C., Li, S., Rabbani, H., Chen, X. and Liu, Z. (2019). Attention to Lesion: Lesion-Aware Convolutional Neural Network for Retinal Optical Coherence Tomography Image Classification. IEEE Transactions on Medical Imaging, 38(8), pp.1959–1970. [CrossRef]
- Gour, N. and Khanna, P. (2022). Ocular diseases classification using a lightweight CNN and class weight balancing on OCT images. Multimedia Tools and Applications, 81(29), pp.41765–41780. [CrossRef]
- Hussain, M.A., Bhuiyan, A., D. Luu, C., Theodore Smith, R., H. Guymer, R., Ishikawa, H., S. Schuman, J. and Ramamohanarao, K. (2018). Classification of healthy and diseased retina using SD-OCT imaging and Random Forest algorithm. PLOS ONE, 13(6), p.e0198281. [CrossRef]
- Kamran, S., Saha, S., Sabbir, A. and Tavakkoli, A. (2019). Optic-Net: a Novel Convolutional Neural Network for Diagnosis of Retinal Diseases from Optical Tomography Images.
- Kaymak, S. and Serener, A. (2018). Automated Age-Related Macular Degeneration and Diabetic Macular Edema Detection on OCT Images using Deep Learning.
- Kim, J. and Tran, L. (2020). Ensemble Learning Based on Convolutional Neural Networks for the Classification of Retinal Diseases from Optical Coherence Tomography Images. 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS). [CrossRef]
- Kim, J. and Tran, L. (2021). Retinal Disease Classification from OCT Images Using Deep Learning Algorithms. 2021 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB). [CrossRef]
- Koprowski, Koprowski, R., Teper, S., Wróbel, Z. and Wylegala, E. (2013). Automatic analysis of selected choroidal diseases in OCT images of the eye fundus Automatic analysis of selected choroidal diseases in OCT images of the eye fundus. BioMedical Engineering OnLine, 12, p.117.
- Li, F., Chen, H., Liu, Z., Zhang, X., Jiang, M., Wu, Z. and Zhou, K. (2019). Deep learning-based automated detection of retinal diseases using optical coherence tomography images. Biomedical Optics Express, 10(12), p.6204. [CrossRef]
- Li, Z., Cheng, K., Qin, P., Dong, Y., Yang, C. and Jiang, X. (2021). Retinal OCT Image Classification Based on Domain Adaptation Convolutional Neural Networks. 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI). [CrossRef]
- Mishra, S.S., Mandal, B. and Puhan, N.B. (2019). Multi-Level Dual-Attention Based CNN for Macular Optical Coherence Tomography Classification. IEEE Signal Processing Letters, 26(12), pp.1793–1797. [CrossRef]
- Najeeb, S., Sharmile, N., Sajid Khan, M., Sahin, I., Islam, M., Imamul, M. and Bhuiyan, H. (n.d.). Classification of Retinal Diseases from OCT scans using Convolutional Neural Networks.
- Özdaş, M.B., Uysal, F. and Hardalaç, F. (2023). Classification of Retinal Diseases in Optical Coherence Tomography Images Using Artificial Intelligence and Firefly Algorithm. Diagnostics, 13(3), p.433. [CrossRef]
- Peng, Y., Dharssi, S., Chen, Q., Keenan, T.D., Agrón, E., Wong, W.T., Chew, E.Y. and Lu, Z. (2019). DeepSeeNet: A Deep Learning Model for Automated Classification of Patient-based Age-related Macular Degeneration Severity from Color Fundus Photographs. Ophthalmology, 126(4), pp.565–575. [CrossRef]
- Perdomo, O., Otálora, S., González, F., Meriaudeau, F. and Müller, H. (2018). OCT-NET: A CONVOLUTIONAL NETWORK FOR AUTOMATIC CLASSIFICATION OF NORMAL AND DIABETIC MACULAR EDEMA USING SD-OCT VOLUMES.
- Perdomo, O., Rios, H., Rodríguez, F.J., Otálora, S., Meriaudeau, F., Müller, H. and González, F.A. (2019). Classification of diabetes-related retinal diseases using a deep learning approach in optical coherence tomography. Computer Methods and Programs in Biomedicine, 178, pp.181–189. [CrossRef]
- Puneet, Kumar, R. and Gupta, M. (2022). Optical coherence tomography image based eye disease detection using deep convolutional neural network. Health Information Science and Systems, 10(1). [CrossRef]
- Rajagopalan, N., Narasimhan, V., Kunnavakkam Vinjimoor, S. and Aiyer, J. (2020). RETRACTED ARTICLE: Deep CNN framework for retinal disease diagnosis using optical coherence tomography images. Journal of Ambient Intelligence and Humanized Computing, 12(7), pp.7569–7580. [CrossRef]
- Rasti, R., Rabbani, H., Mehridehnavi, A. and Hajizadeh, F. (2018). Macular OCT Classification Using a Multi-Scale Convolutional Neural Network Ensemble. IEEE Transactions on Medical Imaging, 37(4), pp.1024–1034. [CrossRef]
- Reza, M.T., Ahmed, F., Sharar, S. and Rasel, A.A. (2021). Interpretable Retinal Disease Classification from OCT Images Using Deep Neural Network and Explainable AI. 2021 International Conference on Electronics, Communications and Information Technology (ICECIT). [CrossRef]
- Rong, Y., Xiang, D., Zhu, W., Yu, K., Shi, F., Fan, Z. and Chen, X. (2019b). Surrogate-Assisted Retinal OCT Image Classification Based on Convolutional Neural Networks. IEEE Journal of Biomedical and Health Informatics, 23(1), pp.253–263. [CrossRef]
- Shah, M., Roomans Ledo, A. and Rittscher, J. (2020). Automated classification of normal and Stargardt disease optical coherence tomography images using deep learning. Acta Ophthalmologica, 98(6). [CrossRef]
- Srinivasan, P.P., Kim, L.A., Mettu, P.S., Cousins, S.W., Comer, G.M., Izatt, J.A. and Farsiu, S. (2014). Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomedical Optics Express, 5(10), p.3568. [CrossRef]
- Sugruk, J., Kiattisin, S. and Lee1asantitham, A. (2014). Automated Classification between Age-related Macular Degeneration and Diabetic Macular Edema in OCT Image Using Image Segmentation.
- Wang, D. and Wang, L. (2019a). On OCT Image Classification via Deep Learning. IEEE Photonics Journal, 11(5), pp.1–14. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



