Submitted:
04 September 2025
Posted:
05 September 2025
You are already at the latest version
Abstract
Recent years have seen the growth of hydrologic and hydraulic models operating at varying spatial resolutions at regional scales, which emphasizes the need for consistent naming methodologies to enhance model interoperability and integration across domains, sub-models, and modeling frameworks. This paper introduces HRI-HydroName, a high-resolution, interoperable, and human-friendly model naming system designed to complement to the Hydrologic Unit Code (HUC) watershed naming convention and support high spatial resolution model development and interoperability. HRI-HydroName establishes a convention for naming stream and river segments, forming the basis for naming associated physical hydrographic features and logical model elements. The system is particularly suited for naming regional models developed using the Hydrologic Engineering Center (HEC) software. HRI-HydroName addresses the constraints of identifier character limits in modeling software while ensuring comprehensibility and model composability. HRI-HydroName is illustrated through an application to HUC8-scale hydrologic and hydraulic models of the Amite River basin in southern Louisiana, though it is generalizable to other regions and models. The data and the software that support the implementation and adaptation of the HRI-HydroName system are shared in a publicly accessible repository. The paper discusses implementation challenges and suggests solutions for software utilities to support streamlined adoption and usability by different stakeholders.
Keywords:
stream network
; models
; watersheds
; naming system
1. Introduction
Recent years have witnessed growth in hydrologic and hydraulic models that operate at varying spatial resolutions at regional scales (e.g., HUC8 and HUC12 watershed scales; county and multi-county spatial domains). Examples of such efforts include the HUC12 flood models by the Harris County Flood Control District [1], the North Carolina Flood Risk Information System [2], and the HUC8 flood models of the Louisiana Watershed Initiative [3].
Although hydrologic models theoretically extend to watershed divides and hydraulic models either follow the hydrologic model domain or terminate at gauge stations where boundary conditions can be established, in practice, these models often overlap with neighboring basin models. This overlap or model handoff between different modeling teams can result in inconsistencies, ambiguity, or errors as there is no standardized naming convention to ensure that identical elements across different models retain uniform identifiers. Establishing a structured and consistent naming methodology is critical for improving model integration (i.e., hydrologic and hydraulic), interoperability, enabling seamless data exchange across basins, and facilitating the extraction and reintegration of model subsets. A standardized nomenclature enhances communication amongst modelers, simplifies model management, and strengthens documentation practices [4]. Additionally, a unified naming convention enhances reproducibility, ensuring that when different teams develop different models for the same basin, they generate modeling elements with consistent identifiers, preventing ambiguity and errors. A review of model integration processes [5] highlighted the use of naming conventions as part of establishing controlled vocabularies for data interoperability between coupled models (as HEC-RAS and -HMS are in this study). The Community Surface Dynamics Modeling System (CSDMS) framework [6,7] underscores how consistent naming conventions allow automated coupling of models and datasets from diverse contributors, enabling the development of integrated, multi-source models. Furthermore, a standardized naming system improves compatibility with various modeling platforms and computational tools, streamlining workflows and ensuring efficiency in model deployment and long-term usability.
The naming of hydrologic and hydraulic model components is often based on physical hydrographic features, namely river reaches and networks in the case of models of inland domains. Modern river network naming conventions can be traced back to Horton [8] and Strahler [9]. Horton [8] developed a depth-first stream order scheme that assigns order one to the smallest tributaries, with higher orders formed by the confluence of same-order tributaries. This sequence of an Nth order stream reach formed by flow from one or more N-1th order reaches, as well as flow from zero or more N-Mth order reaches, continues up to the highest-order stream in a particular network, which is deemed the mainstem. Horton’s scheme suffers from requiring constant subjective judgments (heuristics) to determine the order of a downstream reach when joined by an upstream reach. Strahler [9] modified Horton’s [8] scheme by declaring a downstream reach to be of order N+1 only at the union of two stream reaches of the same order N, thus removing the subjectivity from Horton’s ordering, opening the way to algorithmic, rather than heuristic, classification of all stream reaches in a network.
Strahler’s [9] stream ordering is primarily useful for studying runoff generation processes in watershed hydrology. However, it has limited utility in naming stream networks for numerical modeling because it does not provide unique identifiers for each stream reach, which are necessary for computer modeling, nor does it encode the network’s topology, which reduces human interpretability, or result in unique reach identifiers. Despite this, the Strahler algorithm is effective for automatically determining tributary order when traversing stream networks encoded in geodatabases.
Contemporaneous to the work of Horton [8] and Strahler [9], Otto Pfafstetter, in the 1950s, developed a hierarchical naming scheme for the stream reaches in a river network [10] that serves as the basis for assigning unique names to river basins drained by a river network [11]. The Pfafstetter coding system assigns unique identifiers to each stream reach in a network. Due to the system’s hierarchical nature, these unique identifiers also encode the topology of the stream reach network. The Pfafstetter coding system is similar, in that it is hierarchical and applicable to continental scales, to the Hydrologic Unit Code (HUC) system used in the United States [12]. HUC codes are used mainly for cataloging hydrologic units, which correspond to regions (HUC2), sub-regions (HUC4), basins (HUC6), sub-basins (HUC8), watersheds (HUC10), and sub-watersheds (HUC12).
This study proposes a standardized naming convention for hydrologic and hydraulic model elements (e.g., reaches, cross-sections, 2D flow areas) to enhance interoperability in regional flood models implemented with Hydrologic Engineering Center (HEC) software (https://www.hec.usace.army.mil). The convention is structured around a consistent naming framework for streams, rivers, and related physical hydrographic features (e.g., artificial channels, control structures, watersheds) to ensure uniformity across modeling efforts. This naming convention provides a high-resolution, interoperable, user-friendly hydrographic naming system that functions as a complement to the HUC watersheds naming convention to support high spatial resolution regional flood model development and interoperability across different geographies and modeling frameworks. Such flood models need to be constructed in such a way as to allow the modeling of local flooding and mitigation projects at adequate scales while enabling integration with neighboring models to simulate the upstream and downstream effects of mitigation projects. For such models to be composable, the constituent elements of a model and the physical hydrographic features they are based on need to be assigned unique identifiers that are guaranteed not to collide with unique identifiers assigned to elements of another model (possibly developed by another modeling team).
The following section describes HRI-HydroName (High-Resolution Interoperable Hydrographic Naming) a new naming convention, which represents the beginning of a new approach for the naming of hydrographic features and model elements. HRI-HydroName is then illustrated by an example application to the Amite River basin in southern Louisiana. The paper concludes with a discussion and summary, including possible future directions for research.
2. Materials and Methods
HRI-HydroName provides a high-resolution, user-friendly hydrographic naming system that functions as a complement to the HUC watershed naming convention to support model development and interoperability across different geographies and modeling frameworks. The HRI-HydroName methodology has two main components: naming of watersheds and streams, and naming of hydrologic and hydraulic model elements. The first component is developed to complement the Hydrologic Unit Code (HUC) system and can be implemented for any river network dataset, including those of the National Hydrography Dataset (NHD). The second component is developed for watershed-scale models (HUC8) and will be illustrated by naming hydrologic and hydraulic models for the Amite River HUC8 watershed in South Louisiana (Figure 1). While the methodology is illustrated for watersheds and models in south Louisiana, it is general and can be applied to other regions and models.
2.1. Assigning Watershed Codes
HRI-HydroName starts by assigning each HUC8 watershed a two-letter code encoded as Latin letters A-Z naming system. The watershed codes are designed to generally be mnemonics of watershed names. For example, the state of Louisiana is divided into 52 HUC8 watersheds and the code “BT” can be assigned to represent Bayou Teche watershed, and the code “RC” can be assigned to represent Red Chute watershed. These codes are used as the first component of the name of each stream within a particular watershed and form the beginning of the names of many model components within the HydroName system.
2.2. Naming of HUC8 Streams
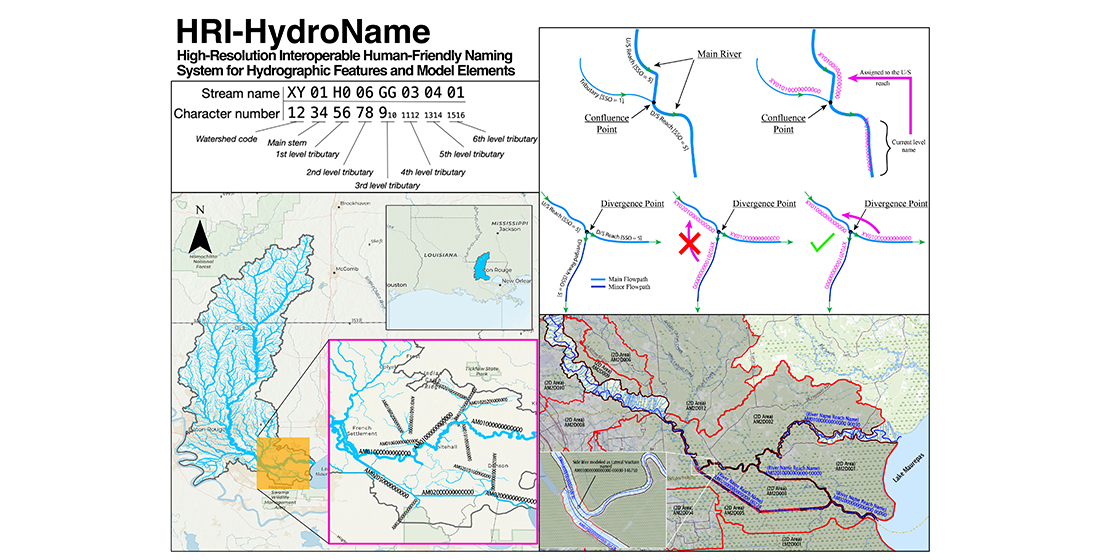
Following the naming of each watershed, HRI-HydroName identifies streams within HUC8 watersheds using unique hierarchical unit numbers, beginning with the two-letter watershed code, followed by a series of two-digit identifiers for each level of the stream hierarchy, starting with the main stem stream. Each outlet of a HUC8 watershed is assigned a unique main-stem stream identifier, ordered from downstream to upstream, with the main outlet typically receiving the first identifier. First-level tributaries are indicated by the first two-digit sequence after the main-stem identifier. The two-digit sequence indicates second-level tributaries after the 1st order tributary ID. Third through 6th level tributaries are indicated by additional two-digit sequences. Note that the first through 6th level identifiers are incremented in a downstream-to-upstream order. All remaining levels in the hierarchy above the level of a given named tributary must be padded with zeros so that the assigned identifier for any stream using the HRI-HydroName is always 16 characters long. A schematic for the stream naming convention is described in Figure 2.
2.2.1. Mainstem and Tributary Identifier Encoding
Identifiers for mainstems and all levels of tributary streams are encoded as two Crockford base-32 digits (https://en.wikipedia.org/wiki/Base32#Crockford’s_Base32). This system, convenient for humans and computers, uses Arabic numbers 0-9 and capital Latin letters A-Z, omitting I, L, O, and U to avoid conflation with numbers 1 and 0 (the letter U is also omitted to avoid unintentional obscenity). The choice of Base-32 encoding was driven by the need to balance compactness with capacity. With two digits, Base-32 can represent up to 1,023 unique values. In comparison, two digits in a decimal (Base-10) system allow only 99 values, and two digits in hexadecimal (Base-16) allow 255 values. This distinction is important as some watersheds are so complex that their stream representation might require far more than 99 or even 255 streams at a certain tributary level. Thus, a representation beyond base-10 was needed to limit tributary level identifiers to two digits, ensuring that full stream names remain within the 16-character limit required for backward compatibility with older versions of HEC-RAS.
2.2.2. Stream Naming Across Confluences and Divergences
The HRI-HydroName system is designed to propagate names from the most downstream stream reach and carry them consistently upstream through the network. When streams meet or split, the HRI-HydroName system applies a consistent set of rules to preserve clarity and hierarchy. At confluences, the system continues the name of the downstream mainstem across the merged segments into the upstream dominant flow path using Strahler’s hierarchical ordering of stream networks, while the other merging tributary is named using the higher-level tributary (Figure 3). In the case where both merging streams carry the same Strahler’s Order, same level tributary, the naming of the downstream stream reach doesn’t get carried over to any of the upstream reaches; instead, both upstream merging streams are being named using a higher-level tributary.
Similarly, at points of divergence, where a stream splits into multiple channels, the system distinguishes between the primary and secondary flow paths. Unfortunately, such distinguishing can’t be identified using Strahler’s stream ordering, as the common practice is to assign the same order for all streams (Figure 3), so a good knowledge of the stream is needed to provide an informed judgment. The dominant branch retains the identifier of the parent stream, maintaining continuity along the main channel. This rule ensures that each flow path is uniquely identified while still reflecting its relationship to the originating stream.
The HRI-HydroName algorithm works by carrying the name of a given mainstem or tributary upstream across stream segments at the same level of the hierarchy (as defined by Strahler ‘s order). Additionally, it ensures that primary flow paths of divergent flows maintain the same name of the mainstem or tributary that they diverged from; minor flow paths should receive a new unique identifier at the same level of the stream hierarchy as the major flow path.
2.3. Naming HEC Model Elements
The HEC models, particularly the HEC-River Analysis Software (HEC-RAS), allow for unique identification of model elements and underlying hydrographic features (namely reaches and rivers) using a pre-set number of characters. The number of characters varies with the different versions of the HEC models; for example, version HEC-RAS 6.0 allowed for a maximum of 16 characters, which is to increase to 256 characters in the latest version RAS2025. As such, a “flat” 16- or 256-character namespace, where each character can be [A-Z] or [0–9], would provide enough unique identifiers to represent watersheds of any computationally tractable size. However, such a flat namespace does not address the need for allowing for human interpretability. Fortunately, the dendritic structure of river networks lends itself naturally to hierarchical ways of thinking about and naming elements of these networks, as proposed by the HRI-HydroName system.
The HRI-HydroName system provides a unified framework for assigning names to hydrologic and hydraulic model elements across both HEC-HMS and HEC-RAS platforms. The method builds on the hierarchical stream identifiers established earlier and extends them to model components such as subbasins, routing reaches, junctions, diversions, detention basins, sources, sinks, cross-sections, and 2D flow areas. By embedding each element’s name within the context of its watershed and associated stream, the system ensures that model identifiers are not only unique but also intuitive to interpret.
The naming method follows a consistent pattern. Each identifier begins with the two-letter watershed code, followed by the full stream identifier. To this base, additional characters or suffixes are appended that specify the element type and, when necessary, its relative position along the stream (e.g., using station values or alphabetical ordering). This structure allows modelers to distinguish between different element types at a glance while preserving their hierarchical relationships within the river network.
For HEC-HMS models, elements such as subbasins, routing reaches, junctions, diversions, and detention basins use extended identifiers that balance detail and interpretability (Table 1). For HEC-RAS models, where strict character limits are imposed to insure backward compatibility with any HEC-RAS version, shorter identifiers are employed while still maintaining logical ties to the underlying hydrography (Table 1). This balance between compactness and interpretability ensures that even large, complex models remain manageable, interoperable, and easy to compose with neighboring basins. In short, the HRI-HydroName method provides a systematic approach that avoids ad hoc or inconsistent naming, reducing ambiguity and improving communication among modelers.
3. Results
The application of the HRI-HydroName is illustrated for hydrologic and hydraulic models developed for the Amite River Basin in south Louisiana. The models were developed and publicly available through the statewide modeling program conducted by the Louisiana Department of Transportation and Development under the Louisiana Watershed Initiative (LWI, n.d.). The hydrologic and hydraulic models are developed using the U.S. Army Corps of Engineers (USACE) Hydrologic Engineering Center (HEC) produces software, HEC-HMS and HEC-RAS, respectively. Both models contain a comprehensive representation of the geospatial characteristics of the Amite River watershed (e.g., basins and sub-basins, rivers, main streams, tributaries, diversions, stream divergences and confluences, detention basins, sources and sinks, cross sections, hydraulic structures, 2D and 1D model elements, and boundary conditions), thus allowing a complete illustration of the capabilities of the HRI-HydroName system in handling complex models and watersheds.
3.1. Naming of Streams and Tributaries
The HRI-HydroName system was applied to the Amite River Basin, which was assigned the watershed code “AM” as a mnemonic of its name. The watershed has only one outlet, where its stream was assigned the main stem level with value of 01, and then padded with zeros to fill a 16-character space making the whole ID of the stream according to the HRI-Hydroname “AM01000000000000” (Figure 4). Using this code as the foundation, identifiers were generated for the mainstem of the Amite River and systematically propagated upstream through its tributary network.
3.2. Naming of Hydrologic Model Elements
Hydrologic model elements that are part of HEC-HMS models are typically assigned unique identifiers based on an associated HUC8 watershed and stream. The specific requirements for each element type (subbasin, routing reach, junction, diversion, reservoir, source, etc.) are described in the following subsections. See Figure 5 and Figure 6 for examples of the named model elements.
3.2.1. Subbasins
Subbasin identifiers are typically eighteen characters long, consisting of the stream name the subbasin contributes to, followed by an underscore and a capital Latin letter (e.g., XY01H006GG030401_A). Assignment of the final letter begins with the letter A for the downstream-most subbasin along the main stem or tributary and increases alphabetically from downstream to upstream. If an existing subbasin were to be later subdivided, the new subbasins would retain the original eighteen-character identifier with a sequential decimal digit added (e.g., XY01H006GG030401_A1).
3.2.2. Routing Reaches
The identification of routing reaches (e.g., XY01H006GG030401_00570_R) starts with the watershed identifier (e.g., XY), followed by the name of the stream represented by the reach (e.g., 01H006GG030401), followed by five additional digits describing the stream station distance from the mouth of the stream in feet divided by 10 and rounded to remove decimals (e.g., 00570) at the downstream end of the reach, followed by the character “R”, indicates that the element is a routing reach, all separated by underscores (see example in Figure 5).
If it is necessary to subdivide an existing routing reach, the subdivided reaches should retain the original routing reach name with the station number changed to indicate the station downstream of the routing reach. The description field for the HEC-HMS reach element must contain the most upstream and downstream HEC-RAS cross sections that bound the hydrologic routing reach.
3.2.3. Junctions
Junctions in HMS models are identified (e.g., XY01H006GG030401_00030_J) by the full stream name of the highest-order tributary at the junction (e.g., 01H006GG030401), typically the outlet stream from the junction, followed by five additional digits (e.g., 00030) describing the nearest station distance from the mouth of the stream in feet divided by 10 and rounded to remove decimals, ending with the character “J” to indicate a junction.
3.2.4. Diversions
There are two primary naming conventions for diversion and side-weir elements in HEC-HMS models. Both should be based on the full name of the stream providing the flow followed by five additional digits describing the nearest stream station (stream distance from the mouth in feet divided by 10 and rounded to remove decimals) upstream of the diversion or side-weir. In the case of a regular diversion, the character “D” should be appended to the base name. while the characters “SW” should be appended in for a side-weir. Each element must be separated by the underscore character. In cases where the diversion is from one watershed to another, the name should be associated with the source of the diversion. Figure 6 shows an example from the Amite River basin model for the naming of diversions in HEC-HMS. An example of a regular diversion is XY01H006GG030401_00457_D, and an example of a side weir diversion is XY01H006GG030401_00457_SW.
3.2.5. Detention Basins
Detention basins (including reservoirs) are identified (e.g., XY01H006GG030401_00030_DET) by the name of the highest order tributary that they contribute flow to (e.g., 01H006GG030401), followed by five digits (e.g., 00030) describing the nearest downstream station (distance from the mouth of the stream in feet divided by 10, which represents the station of the detention basin using the nearest downstream HEC-RAS cross section station), followed by “DET”.
3.2.6. Sources
Sources used in HEC-HMS models represent flows from adjacent watersheds. The names for sources (e.g., XY01H006GG030401_A_SRC) will consist of the originating subbasin in the contributing watershed followed by the characters “SRC”. Each element must be separated by the underscore character.
3.2.7. Sinks
Sinks are identified (e.g., XY01H006GG030401_00030_S) by the watershed identifier (e.g., XY) followed by the name of the stream that directly contributes to them (e.g., 01H006GG030401), then by five digits (e.g., 00030) describing the nearest upstream station (distance from the mouth of the stream in feet divided by 10), followed by the character “S” to indicate a sink.
3.3. Naming of Hydraulic Model Elements
Hydraulic model elements that are part of HEC-RAS models are assigned unique identifiers based on some combination of the associated HUC8 watershed and stream or tributary identifiers. Unlike HEC-HMS, HEC-RAS, up to version 6.6, limits river and reach names to 16 characters, requiring truncated identifiers for some model elements. (see Figure 7 for some real-world features named in HEC-RAS). The HEC-RAS model domain excerpt depicted in Figure 7 can be compared with the corresponding HEC-HMS model domain shown in Figure 5 and Figure 6.
Requirements for naming each model element are described in the following subsections.
3.3.1. River
A “river” element in the HEC-RAS model is labeled following the HRI-HydroName of its corresponding stream. This name will take the form of XY01H006GG030401, where XY represents the watershed, and the remaining digits identify the stream as described earlier.
3.3.2. Reach
Reaches are identified by five digits describing the most downstream station (divided by 10 and rounded to remove decimals) of the reach. For example, 00500, where 00,500 is the station 5000 divided by 10, represents the station at the downstream end of the reach.
3.3.3. Cross Sections
The cross-section station is generally based on the cumulative stream length from the mouth of the modeled stream in feet. In the case of the addition of new cross-sections or the repositioning of existing cross-sections (i.e., if a new structure is added or if channel realignment necessitates a change in the cross-section location), new stations should be assigned based on the stream length from the mouth of the modeled stream in feet.
3.3.4. Junctions
According to the HRI-HydroName system, names of junctions within HEC-RAS models (e.g., XY01_0023_J) are identified by the HUC8 watershed code (e.g., XY), followed by the two-digit Crockford base-32 identifier of the mainstem where the junction is nested (e.g., 01) then a four-decimal-digit identifier unique to a particular HUC8 watershed (e.g., 0023, indicating this is the 23rd named junction in a particular HUC8 watershed), followed by the character “J”. Each element must be separated by the underscore character. Note that HEC-RAS junction identifiers are limited to 12 characters. Thus, only the mainstem portion of the stream identifier is used in the junction identifier.
3.3.5. Bridges and Other Hydraulic Structures
According to the HRI-HydroName system, bridges or other hydraulic structures (e.g., culverts, pumps, gates) within HEC-RAS models are identified with the station and street name or type of crossing (e.g., “18-in pipeline” or “10-foot-wide pedestrian bridge”) if the bridge does not have an associated street name. The name should be entered into the model geometry file using the HEC-RAS geometry editor.
3.3.6. Two-Dimensional Model Elements
HEC-RAS 2D flow area elements can be connected to other elements in the following ways: (1) directly to the downstream or upstream end of a river reach; (2) laterally to 1D river reaches using a Lateral Structure(s); or (3) directly to another 2D area or storage area using the SA/2D Area Connection. HRI-HydroName naming conventions for 2D flow areas, as well as these connection schemes, are described in the sections that follow.
- 2D Flow Areas. Names for two-dimensional flow areas (e.g., XY2D042) are identified by the HUC8 watershed code, e.g., XY, followed by the characters “2D” followed by a three-digit Crockford base-32 identifier unique to a particular HUC8 watershed, e.g., 042, indicating that this is the 130th named 2D flow area in a particular HUC8 watershed (see Figure 7 for an example showing 2D areas named according to this scheme).
- Storage Areas. Names of storage areas (e.g., XYSA023) are identified by the HUC8 watershed code (e.g., XY), followed by the characters “SA” then a three Crockford base-32 digit identifier unique to a particular HUC8 watershed, e.g., 023 indicating that this is the 67th named storage area in a particular HUC8 watershed. Note that there are no separators between elements to allow connections between storage areas and 2D areas to be identified by combining connection end-point identifiers (see next section on SA/2D connections).
- SA/2D Flow Area Connections. Hydraulic structures linking storage areas and 2D flow areas are named by combining the identifiers of the storage area and 2D flow area, separated by “_”. For example, XYSA023_XY2D042, where XYSA023 is the identifier of the storage area being connected, XY2D042 is the identifier of the 2D flow area being connected. Note that HEC-RAS limits the storage area-2D area connection name to 16 characters.
3.3.7. Boundary Conditions
Boundary conditions can originate from various sources (e.g., gauges, HMS models). Consequently, the HRI-HydroName system does not prescribe a naming convention for these elements. However, if an inflow boundary condition is derived from an HMS model component, it is recommended to use the HMS component name for the HEC-RAS inflow boundary condition.
4. Discussion
This paper describes HRI-HydroName, a high-resolution, interoperable, human-friendly naming system for hydrographic features and model elements. HRI-HydroName attempts to balance the needs of hydrographic map users and hydrologic and hydraulic model users with the constraints on model element name length imposed by popular hydrologic and hydraulic modeling software. These users have a need for comprehensible (i.e., non-random) element names that relate to observable real-world hydrographic features. Further, model users have an interest in the production of composable models developed by potentially disparate model developers to enable regional modeling and watershed-based management. HRI-HydroName provides for model composability and element and hydrographic feature name comprehensibility by using a hierarchical naming scheme for stream reaches that begins with a two-character watershed code associated with the common name of the HUC8 sub-basin the stream is nested within. In principle, this watershed code need not be associated with a HUC8 watershed, for example, when applied to geographies outside the U.S. NHD system. Therefore, the HRI-HydroName scheme is generalizable (assuming a digital representation of the underlying stream network is available). This paper further demonstrates the straightforward naming of hydrologic and hydraulic model elements given a collection of HRI-HydroName stream reaches. When model elements are named according to this scheme, the resulting models can easily be composed to enable regional analyses of flood risk and mitigation. Initially developed with HEC-RAS 6.0, HRI-HydroName has been revised and tested for later versions (up to 6.5), showing its adaptability to new software releases.
While the HRI-HydroName scheme can be applied over large regional to multi-region extents, its application is limited in several ways. First, as described in this paper, the two-character watershed code consists of Latin letters A-Z, which would limit the number of watersheds modeled to 676 (262). This could be trivially extended to support up to 832 watersheds if the second character were encoded using Crockford base-32; it is usually preferable to require that identifiers begin with alphabetic characters, disallowing identifiers that begin with numerals (adding this constraint makes automating parsers easier to implement by simplifying the parser grammar, reducing ambiguity with number recognition when parsing). If this constraint were relaxed and base-32 encoding were allowed for both the first and last characters of the watershed code, then 1,023 watersheds could be represented (excluding 00). Given the average area of 3,804 km2 for the 2,133 HUC8 watersheds in the U.S., a rough upper limit on the area that could be modeled using components named via HRI-HydroName would be 3,892,434-km2 (based on analysis of NHDPlus V2.1 data), which is roughly 43% of the land area of the United States, and 1.3-times the drainage area of the Mississippi basin (2,980,000-km2).
Another consideration at the continental scale is the presence of duplicate watershed names across different regions. For instance, multiple HUC8 subbasins may share the name “Vermilion River” in different states. Under the proposed mnemonic-based naming convention, this could lead to conflicts when assigning codes based solely on basin or river names. To resolve this, the naming convention could be modified by selecting any two distinct characters from the watershed name rather than strictly following a mnemonic approach. This adaptation would maintain uniqueness while preserving logical naming conventions.
Another limitation pertains to the spatial scale at which the models are developed. A river or stream may belong to different hydrologic units depending on the resolution of the model. For instance, if a subbasin is modeled at the HUC8 scale, its assigned watershed code will be based on that specific subbasin. However, if the same region is modeled at a HUC6 scale, it will be incorporated into a larger hydrologic unit, requiring a different watershed code. Consequently, a river segment may receive different identifiers depending on the spatial scale of the model, potentially compromising naming consistency, uniqueness, and reproducibility across multiple resolutions. Despite this theoretical inconsistency, the practical implications are minimal. The authors do not anticipate the need to develop large-scale high-resolution hydrologic or hydraulic models at the HUC6 level, as such large-scale models would be computationally intensive and difficult to manage. Most regional and sub-regional flood modeling efforts are conducted at the HUC8 or finer resolution, rendering this limitation largely a non-issue in practical applications.
Perhaps the greatest challenge of implementing the HRI-HydroName scheme is the imposition of an unfamiliar approach to naming model elements for model developers. This can be mitigated by developing software utilities integrating HRI-HydroName with GIS and other modeling systems familiar to model builders. An initial tool could use the HRI-HydroName pseudocode (see “Supporting Information”) to algorithmically assign names to stream reaches. This algorithm does require a representation of flow network characteristics (e.g., as provided by the NHDPlus PlusFlow table), so the preparation of similar network characteristics for non-NHDPlus/NHDPlus HR networks (or extensions of those networks) would be required; however, these data would likely be needed to construct hydrologic or hydraulic models of these systems regardless of naming scheme. Given a sufficiently detailed flow network with HRI-HydroName-named stream reaches, the subsequent naming of hydrologic and hydraulic model elements according to the scheme is straightforward, though labor-intensive. However, naming model elements is a standard part of model construction (i.e., work that would need to be anyway), and with experience, using HRI-HydroName should not take significantly more time than other schemes.
Ultimately, the successful adoption of a high-resolution interoperable human-friendly naming system for hydrographic features and model elements such as HRI-HydroName will depend on balancing the benefits of such a scheme accrued to data product and model users with the costs incurred by model builders when applying such a scheme. To increase this benefit-cost ratio, further research should explore novel approaches, such as Large Language Models, to automate the naming of model elements according to HRI-HydroName. This automation would require programmatic access to model data structures, which is becoming more common and available as model systems grow in sophistication [16]. It is important for model developers to incorporate features like Application Programming Interfaces (APIs) as first-class features of hydrologic and hydraulic modeling systems. Model system APIs will allow for greater use of automation (though always with humans in the loop) in model construction so that high-resolution interoperable models can be constructed more efficiently to help more communities mitigate and adapt to growing flood risks in a world with warming atmosphere and oceans with attendant hydrologic intensification.
Author Contributions
Conceptualization, B.M., H.S. and E.H.; software, B.M. and H.S.; validation, B.M., H.S. and E.H.; formal analysis, B.M. and H.S.; investigation, B.M. and H.S.; resources, B.M. and H.S.; data curation, B.M. and H.S.; writing—original draft preparation, B.M. and H.S.; writing— review and editing, B.M. and E.H., visualization, B.M. and H.S.; supervision, E.H.; project administration, Habib; funding acquisition, E.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was made possible by the funding support of the State of Louisiana Office of Community Development and the U.S. Department of Housing and Urban Development (CDFA 14.228 Grant B-18-DP-22-001).
Data Availability Statement
The data and the HRI_HydroName software that support the findings of this study are publicly available in HydroShare at https://doi.org/10.4211/hs.d3421b2099ee4e378e0005e2cfcb2338 [17] and GitHub at https://github.com/ulfloodcenter/lwi-model-naming-conventions. The National Hydrography Dataset is available at https://www.usgs.gov/national-hydrography/nhdplus-high-resolution. A GIS representation of NHDPlus Version 2 streams that were labeled using the HRI_HydroName system can be accessed at the following data service: https://services9.arcgis.com/SfvtKAxCn62UWpRg/arcgis/rest/services/LWI_LabeledNHDStreams_2021_03_29/FeatureServer.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| HEC | Hydrologic Engineering Center |
| HUC | Hydrologic Unit Code |
| NHD | National Hydrography Dataset |
| GIS | Geographic Information System |
| HEC-RAS | Hydrologic Engineering Center—River Analysis System |
| HEC-HMS | Hydrologic Engineering Center—Hydrologic Modeling System |
References
- HCFCD. n.d. Harris County Flood Control District’s Model and Map Management System. Available online: https://www.hcfcd.org/Resources/Interactive-Mapping-Tools/Model-and-Map-Management-M3-System (accessed on 8 May 2024).
- NCFMP. “Riverine Hydrologic & Hydraulic Modeling Guidelines and Standards.” NC Cooperating Technical State Mapping Program. 4 September 2014. Available online: https://flood.nc.gov/NCFLOOD_BUCKET/NFIP/Riverine%20HandH%20Engineer ing%20Guidelines%20and%20Standards-05212020.pdf (accessed on 1 December 2021).
- LWI. n.d. Louisiana Watershed Initiative. Available online: https://watershed.la.gov/modeling-program (accessed on 8 May 2024).
- Doe, S.R.K.; Duncan, C.T. Naming conventions and documentation for distribution system modeling. Journal—American Water Works Association 2008, 100, 132–138. [Google Scholar] [CrossRef]
- Belete, G.; Voinov, A.; Laniak, G. An overview of the model integration process: From pre-integration assessment to testing. Environmental Modelling & Software 2017, 87, 49–63. [Google Scholar] [CrossRef] [PubMed]
- Overeem, I.; Berlin, M.M.; Syvitski, J.P.M. Strategies for integrated modeling: The community surface dynamics modeling system example. Environmental Modelling & Software 2013, 39, 314–321. [Google Scholar] [CrossRef]
- Peckham, S.D. The CSDMS Standard Names: Cross-Domain Naming Conventions for Describing Process Models, Data Sets and Their Associated Variables. International Congress on Environmental Modelling and Software 2014, 12. [Google Scholar]
- Horton, R. E. Erosional development of streams and their drainage basins: hydro-physical approach to quantitative morphology. Geological Society of America Bulletin 1945, 56, 275–370. [Google Scholar] [CrossRef]
- Strahler, A. N. Hypsometric (area-altitude) analysis of erosional topology. Geological Society of America Bulletin 1952, 63, 1117–1142. [Google Scholar] [CrossRef]
- Jager, A. L. de; Vogt, J. V. Development and demonstration of a structured hydrological feature coding system for Europe. Hydrological Sciences Journal 2010, 55, 661–675. [Google Scholar] [CrossRef]
- Pfafstatter, O. Classificação de Bacias Hidrográficas—Metodologia de Codificação; Departamento Nacional de Obras de Saneamento (DNOCS): Rio de Janeiro, RJ, 1989; p. 19. [Google Scholar]
- Seaber, P.R.; Kapinos, F.P.; Knapp, G.L. Hydrologic unit maps: U.S. Geological Survey Water-Supply Paper 2294, 63 p. 1987. Available online: https://pubs.usgs.gov/wsp/wsp2294/.
- Jones, K.A.; Niknami, L.S.; Buto, S.G.; Decker, D. Federal standards and procedures for the national Watershed Boundary Dataset (WBD) (5 ed.): U.S. Geological Survey Techniques and Methods 11-A3, 54 p. [CrossRef]
- U.S. Geological Survey. National Hydrography Dataset. 2023a. Available online: https://www.usgs.gov/national-hydrography/national-hydrography-dataset (accessed on 20 December 2023).
- U.S. Geological Survey. National Hydrography Dataset (NHD) Data Dictionary Feature Classes. 2023b. Available online: https://www.usgs.gov/ngp-standards-and-specifications/national-hydrography-dataset-nhd-data-dictionary-feature-classes (accessed on 20 December 2023).
- Goodell, Christopher R., “Breaking the HEC-RAS Code: A User’s Guide to Automating HEC-RAS” (2014). h2ls. ISBN 0990891801.
- Habib, E. H.; Miles, B. LWI Model Naming Conventions: Stream naming algorithm, HydroShare. [CrossRef]
Figure 1.
Map depicting Amite River basin used as an example application of the HRI-HydroName naming system.
Figure 1.
Map depicting Amite River basin used as an example application of the HRI-HydroName naming system.

Figure 2.
Schematic for the stream naming convention, where an example stream name would be XY10H006GG030401.
Figure 2.
Schematic for the stream naming convention, where an example stream name would be XY10H006GG030401.
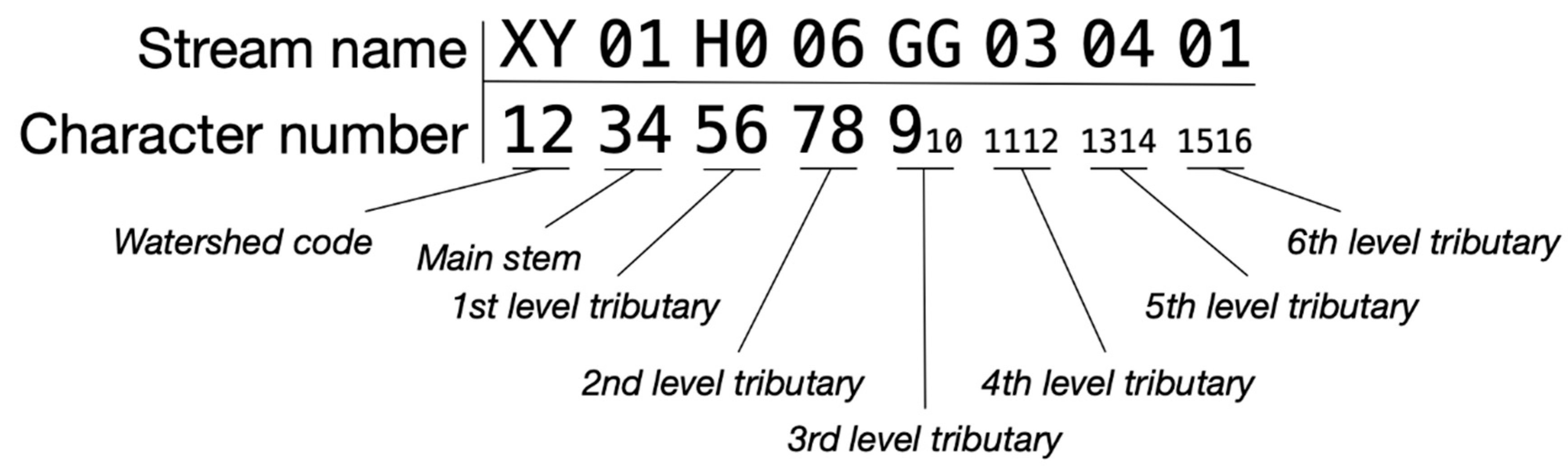
Figure 3.
Stream naming conventions at confluence points (top) and divergence points (bottom) illustrated using Strahler stream order. Green arrows show flow direction. At divergence points, both downstream streams are named first, with the naming convention continuing upstream along the major flow path. The right schematic in the bottom row demonstrates a correct naming progression, while the middle schematic shows an incorrect application.
Figure 3.
Stream naming conventions at confluence points (top) and divergence points (bottom) illustrated using Strahler stream order. Green arrows show flow direction. At divergence points, both downstream streams are named first, with the naming convention continuing upstream along the major flow path. The right schematic in the bottom row demonstrates a correct naming progression, while the middle schematic shows an incorrect application.
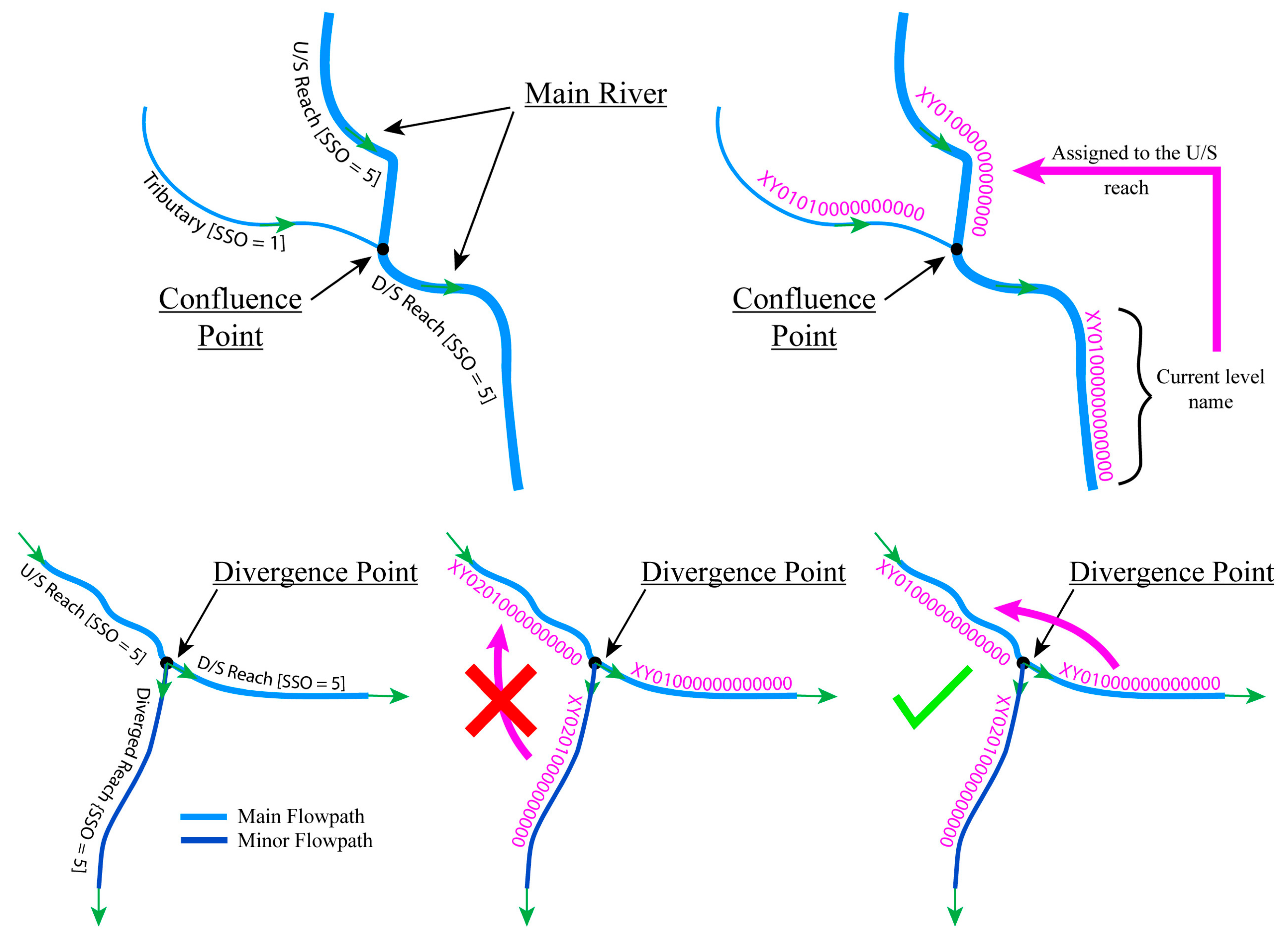
Figure 4.
Map depicting stream names for some NHD Flowlines. The map inset shows the region of the Amite River basin used to illustrate the model data naming.
Figure 4.
Map depicting stream names for some NHD Flowlines. The map inset shows the region of the Amite River basin used to illustrate the model data naming.
Figure 5.
Example from the Amite Basin HEC-HMS model showing naming convention for sub-basins and reaches.
Figure 5.
Example from the Amite Basin HEC-HMS model showing naming convention for sub-basins and reaches.
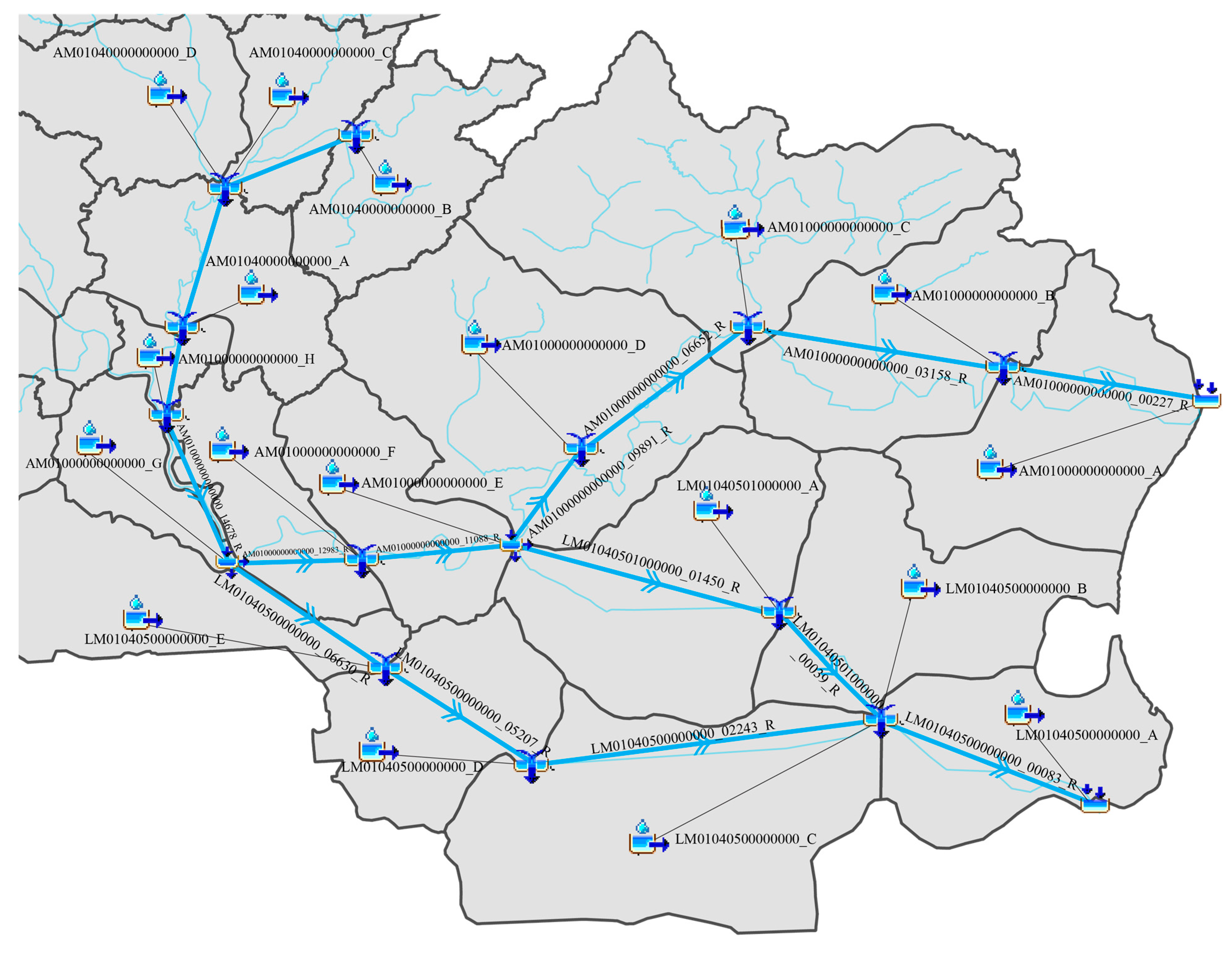
Figure 6.
Example from the Amite Basin HEC-HMS model showing naming convention for all type of junctions.
Figure 6.
Example from the Amite Basin HEC-HMS model showing naming convention for all type of junctions.
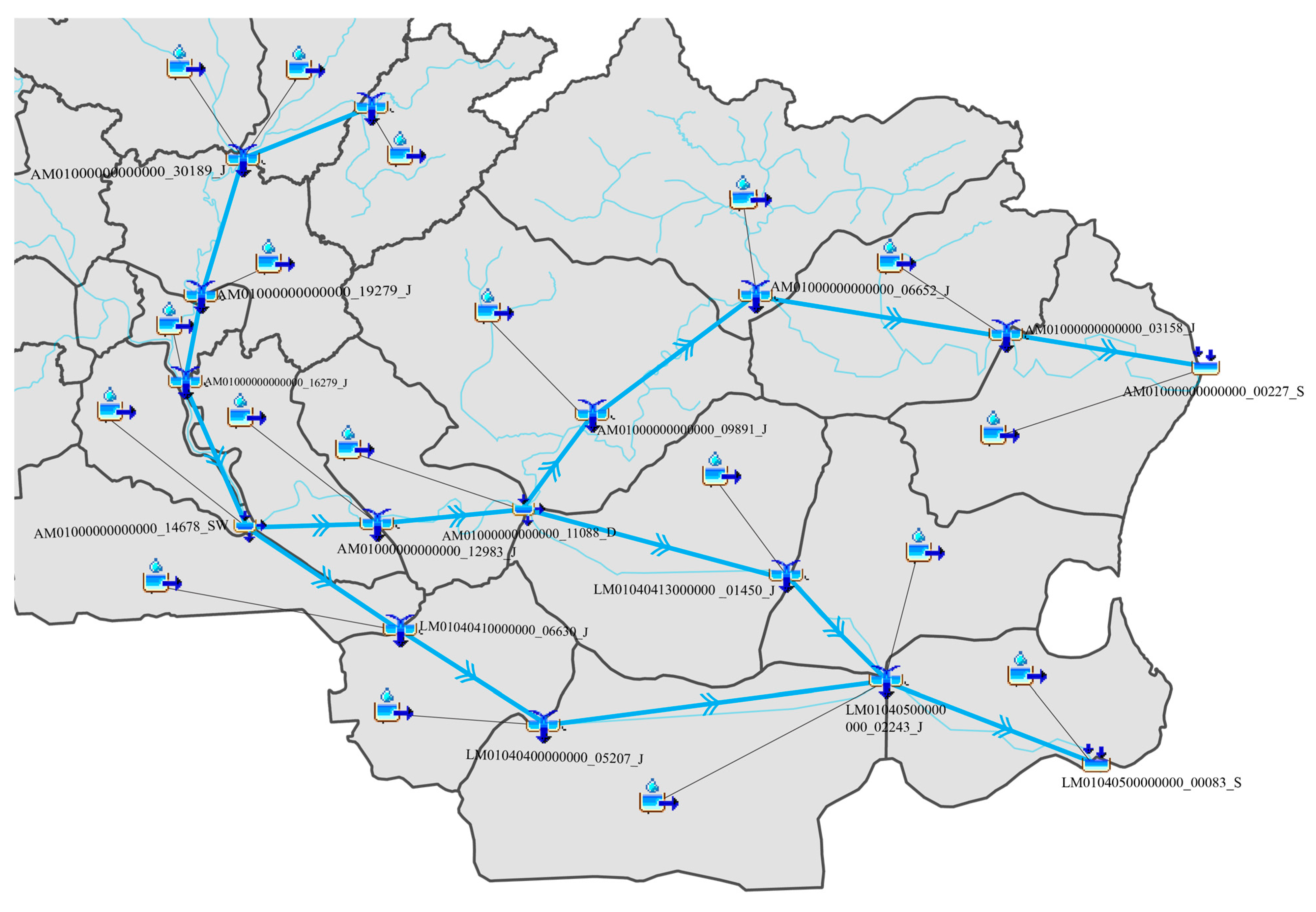
Figure 7.
Example from the Amite Basin HEC-RAS model showing HRI-HydroName system applied for river reaches and 2D areas.
Figure 7.
Example from the Amite Basin HEC-RAS model showing HRI-HydroName system applied for river reaches and 2D areas.

Table 1.
Naming convention structure and examples for HEC-HMS and HEC-RAS model elements under HRI-HydroName system.
Table 1.
Naming convention structure and examples for HEC-HMS and HEC-RAS model elements under HRI-HydroName system.
| Element Type | Identifier Structure | Example | Notes |
|---|---|---|---|
| Subbasins (HMS) | Receiving Stream ID + _ + letter (A, B, C…) | XY01H006GG030401_A | Letter progresses upstream; subdivisions add digits (e.g., _A1). |
| Routing Reaches (HMS) | Stream ID + _ + 5-digit station + _R | XY01H006GG030401_00570_R | Station based on distance from mouth (ft ÷ 10). |
| Junctions (HMS) | Stream ID + _ + 5-digit station + _J | XY01H006GG030401_00030_J | Station represents nearest downstream location. |
| Diversions (HMS) | Stream ID + _ + 5-digit station + _D or _SW | XY01H006GG030401_00457_D | _D for diversion, _SW for side-weir diversion. |
| Detention Basins (HMS) | Stream ID + _ + 5-digit station + _DET | XY01H006GG030401_00030_DET | Station taken from nearest downstream cross-section. |
| Sources (HMS) | Subbasin ID + _SRC | XY01H006GG030401_A_SRC | Represents inflow from adjacent watersheds. |
| Sinks (HMS) | Stream ID + _ + 5-digit station + _S | XY01H006GG030401_00030_S | Identifies outflows at downstream stations. |
| Rivers (RAS) | Stream ID | XY01H006GG030401 | Uses full stream identifier. |
| Reaches (RAS) | 5-digit station | 00500 | Based on downstream station (ft ÷ 10). |
| Cross Sections (RAS) | Station value (ft from mouth) | 12345 | Updated when new sections or structures are added. |
| Junctions (RAS) | Mainstem ID + _ + 4-digit sequence + _J | XY01_0023_J | Shortened due to 12-character limit. |
| 2D Flow Areas (RAS) | Watershed code + 2D + 3-digit Base-32 identifier | XY2D042 | Sequential numbering within HUC8 watershed. |
| Storage Areas (RAS) | Watershed code + SA + 3-digit Base-32 identifier | XYSA023 | Used for reservoirs or floodplains. |
| SA/2D Connections (RAS) | Storage Area ID + _ + 2D Flow Area ID | XYSA023_XY2D042 | Concatenated identifiers; limited to 16 characters. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



