Submitted:
26 July 2025
Posted:
06 August 2025
You are already at the latest version
Abstract
This study aims to break through the traditional sculpture restoration paradigm centred on "geometric fitting", and proposes an aesthetic restoration framework that integrates emotion-gesture-symbol. Different from the geometric restoration that focuses on the symmetry of form and the fitting of points and lines, the aesthetic restoration emphasises the multi-dimensional linkage of emotional communication, dynamic aesthetics and cognitive consistency, and tries to restore the internal logic and sensual semantics of the "ideal beauty" in classical art works. In this paper, we introduce aesthetic cognitive a priori mapping for the first time, embed the emotional structure and visual semantics of classical sculptures into AI models, construct a neural-symbolic joint reasoning system, and integrate Transformer and graph neural network (GNN) to achieve cross-modal construction of gesture dynamics and expression generation. Through the experimental reconstruction of the eight restored versions of the Venus statue and typical postures such as the golden apple and the leaning pillar, combined with the quantitative indexes such as PCK, FID, Aesthetic Score, etc., we verified the model's performance in the areas of "perceptual proportions", "gesture dynamics", "props", and "expression generation". Combined with PCK, FID, Aesthetic Score and other quantitative indexes, it is verified that this model is superior to the traditional restoration path in terms of "perceptual proportion", "gesture and momentum", "props integration" and "divine expression". The study shows that aesthetic restoration is not only a reconstruction of the visual form, but also a deep cognitive reasoning process, and the results are more in line with the context of art history and the audience's perceptual experience. In the future, we will expand the temporal emotion modelling, historical archive enhancement mechanism and virtual reality immersive interaction, in order to promote the systematic application of AI in the fields of digital museums, art gallery restoration and cultural narrative generation.
Keywords:
neural symbol fusion
; gestural emotional reasoning
; multimodal generation
; aesthetic cognitive modelling
1. Introduction
1.1. Research Context: The Rise of AI in Art Modelling
With the breakthrough development of generative modelling technology, the cognitive and generative capabilities of AI in the art domain have rapidly emerged, initiating a paradigm shift from “perception to understanding”. Deep neural network architectures, represented by Generative Adversarial Networks (GANs), have demonstrated excellent performance in tasks such as image style migration, composition automation, and visual alignment (Goodfellow et al., 2014). In particular, the VQGAN-CLIP model achieves text-guided open-domain art image synthesis by integrating semantic embedding and image generation processes, signalling the initial ability of AI to perceive visual aesthetic semantics (Crowson et al., 2022). Further developments have focused on multimodal emotion modelling and aesthetic response mechanisms, with models such as AffectGAN mapping semantic emotion labels to the image content space, which significantly enhances the controllability of emotion expression in the generated images (Galanos et al., 2021). Such approaches leverage the synergy between CLIP space and emotion mapping to enable AI systems to better convey anthropomorphic aesthetic emotions while maintaining the structural soundness of images.
However, the current mainstream generative paradigms still generally lack the ability to model the structure of “artistic intent” and “cultural semantics”. Human understanding of artworks is often based on complex archetypal structures, cultural symbols, bodily perceptions and historical experiences, which form the basis of my aesthetic judgement and emotional resonance (Picard, 1997; Cetinić & She, 2021). In the absence of such structures in AI systems, generated content, even if highly realistic at the pixel level, is difficult to recognise at the semantic and aesthetic levels. In this regard, researchers are attempting to introduce the interpretability mechanisms of symbolic AI into the neural modelling process, resulting in a new paradigm of “neural-symbolic fusion” (Garcez et al., 2023). The combination of neural networks, which excel in perceptual and representational learning, and symbolic systems, which provide traceable logical rules and semantic structures, can be used to model higher-order associations between gestural actions, emotional expressions and semantic imagery (Wikipedia, 2025).
In this context, the construction of a multimodal emotion-gesture-semantic joint modelling framework that integrates neural representation learning, emotion-driven mechanisms and cognitive aesthetics symbolic graphs is not only an important direction for AI art generation, but also a key path for AI to “understand art”. This paper takes the gesture of Venus with a broken arm as a model. In this paper, we take the gesture restoration of Venus with broken arm as an experimental scenario, explore a composite modelling path based on “golden ratio constraints + semantic map of emotional projection + neural inference of symbolic map”, verify the AI system’s ability of integrating cultural symbols, aesthetics of bodily movement, and cross-modal emotional structure, and construct a “neural inference” framework that has the ability of interpretation and aesthetics consistency. We have constructed a “neural-symbolic-cognitive three-layer fusion model” with interpretability and aesthetic consistency, which provides theoretical support and methodological basis for AI art generation to move towards the dimension of understanding.
1.2. Challenge: The Trinity of Aesthetics, Emotion, and Gesture Reasoning Dilemma
In the continuous evolution of human-AI co-creativity, how AIs can understand and generate complex human gestures that meet human aesthetic standards, especially in artistic scenarios containing emotional expressions and cultural symbols, constitutes a key challenge for current multimodal generative models. Traditional neural networks are good at low-level feature extraction and distributed representation learning (LeCun, Bengio, & Hinton, 2015), but often lack the structured cognitive constraints and symbolic logic to deal with the triple semantic alignment of emotion-aesthetics-gesture. structured cognitive constraints and symbolic logic reasoning. For example, the elegant posture of the Venus statue is not the result of random movements, but is highly dependent on the Golden Ratio (Livio, 2008), the visual paradigms of Western art history, and longstanding cultural training of human beings in graceful gestures and gentle emotions. This complex reasoning across perception, cognition and aesthetics remains an unsolved problem in current AI systems (Picard, 1997).
1.3. Research Goal: Constructing a Multimodal Gestalt Map Model Fusing Cognitive Priors
The aim of this study is to propose an emotion-gesture-semantic ternary graph model that fuses neural network learning with symbolic logic reasoning for expressing complex cognitive priors in art modelling scenarios. I use the gestural restoration of Venus de Milo (Venus with a broken arm) as a typical paradigm, combining golden section geometric scale modelling (Birkhoff, 1933), expression-action-semantic ternary mapping, and graph neural network (GNN) structure for multi-scale representation of skeleton keypoints. The model is able to automatically reason about “acceptable” gesture maps that are historically consistent, aesthetically plausible, and emotionally expressive when inputted into an art scene or instruction, thus enabling human-oriented emotional alignment and style-preserving reconstruction.
In particular, I introduce the Cognitive Priors Representation mechanism, which maps artistic semantic symbols (e.g., “elegance”, “sacredness”, “seduction”) to gestures. “) into the gesture-emotion space, multimodal condition generation through neural-symbolic fusion mechanism, and high-confidence structural reconstruction through multi-angle image sampling and golden ratio model. Preliminary results show that the constructed model exhibits stronger structural consistency and correlation with human aesthetic scores in the AI task of generating artistic gestures, which validates the effectiveness of the “gesture-emotion-symbol map”.
2. Related Work
In recent years, diffusion models such as Stable Diffusion (Rombach et al., 2022) and ControlNet (Zhang & Agrawala, 2023) have become mainstream methods in the field of AI image synthesis (Rombach et al., 2022; Zhang & Agrawala, 2023) . Although they have made significant breakthroughs in generative quality and structural control, they generally lack the ability to control aesthetic semantics and emotional expression (Saharia et al., 2022). For example, the Imagen model does not explicitly model “artistic intent” and “emotional semantics” despite its highly realistic visual generation capability (Saharia et al., 2022).
In terms of neural-symbolic reasoning, NS-CL (Neuro-Symbolic Concept Learner) attempts to merge perceptual and logical reasoning, and is able to realise scene parsing and symbolic understanding (Mao et al., 2019). However, because its symbolic structure is mainly used for object recognition and relationship inference, it is still unable to handle art-level scenes involving aesthetic a priori or emotional expression. In the field of gesture modelling, OpenPose (Cao et al., 2019) and SMPL (Loper et al., 2015) have become the basis of high-precision and stable techniques, but they mainly focus on skeleton recognition and action reconstruction, and lack the linkage expression mechanism between emotional and semantic nodes, which is not able to satisfy the needs of composite scenes rich in cultural values or artistic intentions. Regarding artistic reasoning and restoration, although ArtPose and DeepArt have achieved some results in style migration and artistic restoration (Gatys et al., 2016), they are limited by the lack of high-quality historical control data and the lack of a cultural-semantic frame recognition mechanism in their models, so they are unable to meet the needs of composite scenes with cultural values or artistic intentions, such as “Venus with Broken Arms”. However, due to the lack of high-quality historical control data and the lack of a cultural semantic frame recognition mechanism in the model, there is insufficient support for tasks such as “Venus with Broken Arms”, which requires triple scrutiny of history, scale, and emotion.
2.1. Methodology and Limitations

Table 1.
Comparison of methods and limitations.
| research area | Representative methods or literature | limitations |
|---|---|---|
| AI image composition | Stable Diffusion, ControlNet | Lack of aesthetic semantic control |
| neural-symbolic reasoning | Neuro-Symbolic Concept Learner (NS-CL) | Inability to perceive emotional and aesthetic a priori |
| Attitude modelling | OpenPose, SMPL | Lack of semantic and emotional node linkage modelling |
| Artistic Reasoning and Reduction | ArtPose, DeepArt | Missing data sets and lack of accurate historical comparisons |
2.2. Modelling Framework
2.2.1. Overall Architecture Diagram
In order to achieve the human body synthesis task with cognitive consistency and semantic interpretability, this paper proposes a multimodal architecture, NS-APE (Neuro-Symbolic Affect-Pose Engine), which integrates neural modelling and symbolic reasoning, and integrates the Figure neural network perceptual backbone, emotion a priori modelling module, joint emotion-pose map reasoner and symbolic map alignment mechanism, aiming to achieve cognitively-driven synthetic modelling of embodied-emotional-semantic trinity. Its overall structure is shown in Figure 1.
Figure 1 illustrates the overall architecture of the neural-symbolic emotion-gesture map inference model proposed in this study, incorporating the four core modules of graph neural network (GNN), emotion a priori injection mechanism, gesture-emotion relationship map construction and symbolic map alignment inference. The model achieves joint modelling of human gesture reduction and emotion expression through multimodal inputs to support cognition-driven AI image generation.
The system first encodes the human body topology through a structure-perception fusion backbone, and extracts higher-order spatial relationships between key points using a multilayer graph attention network. Each node input covers coordinates, relative angles and local tension values, while the edge weights are dynamically updated based on local tension and overall structural constraints, generating gesture graph embeddings that can be used for coupled emotion and semantic modelling. Subsequently, a cross-modal emotion a priori injection system is introduced to construct a potential emotion space through a visual-verbal-emotional tri-modal emotion encoder and inject it into the structural graph in the form of graph neural edge weights to simulate the modulation effect of emotion on posture tension and orientation. This emotion modelling process is based on psycho-emotional dimension theory (e.g., Russell Circle Model) and affective computation a priori, which strengthens the expressive tension while maintaining semantic consistency.
Next, the gesture-emotion coupled mapping reasoner further constructs a gesture-emotion dual-map synergy mechanism. With the help of Emotion-Posture Semantic Contrast Tables (EPET), the model is able to reason about high-frequency gesture expression patterns under different emotions and learn their corresponding structural dynamics by graph convolution. The module introduces a multi-emotion channel and a path-attention mechanism, which equips the system with the ability to automatically adjust the gesture map under multiple emotion labels, thus realising joint inference for emotion-gesture consistency. In order to realise reasoning output with historical semantics and cultural cognition, the system introduces a symbol map alignment mechanism and constructs a structural-semantic dual-channel attention for the alignment mapping between the gesture map and the symbol knowledge map (including cultural action metaphors, artistic composition semantics, etc.). The module optimises inference paths through fuzzy logic-guided semantic-tension loss functions, supports symbolic reduction of non-standard structures, and outputs semantically chained interpretation results, thus significantly improving the interpretability and generality of the model for art composition. NS-APE architecture in the integration path of “emotion semantic guidance - gesture map reasoning - symbolic knowledge comparison”, constructs a multimodal generation mechanism supported by cognitive a priori, breaks through the bottleneck of traditional synthesis models in emotion modelling and structural reasoning, and has the ability to be widely applied to virtual human synthesis, digital human expression driving, art image restoration and emotion-oriented interaction.
2.2.2. Neural-Symbolic Graph Hybrid Representation: gesture nodes, emotion nodes, semantic symbol definitions
The Neural-Symbolic Graph Hybrid Representation Structure (NSGR) proposed in this study aims to effectively couple the low-level human gesture perception with the high-level emotional semantic cognition, and to construct a multimodal cognitive representation framework that can be interpreted, reasoned, and modulated. The graph structure consists of three types of core nodes: posture nodes (PNs), emotion nodes (ANs) and semantic symbol nodes (SSNs), which form a connected multimodal emotion-posture-semantic graph (EPSG) through structural edges.
(1) Pose Nodes
Pose nodes are derived from 2D/3D skeletal point detection modules (e.g., OpenPose or SMPL, etc.) and represent the geometric state of key body points (e.g., head, shoulder, elbow, wrist, knee, ankle, etc.) in space. To enhance the representation, I introduce Geo-Kinematic Embedding (GKE), which encodes not only the spatial coordinates, but also the dynamic pose evolution trends, inter-joint tension and force field changes. These nodes serve as initial structures for message propagation in graph neural networks, reflecting the structure of human actions at the physical-physiological level.
(2) Affect Nodes
Affect nodes represent emotion vectors (e.g., Valence-Arousal in Ekman’s six-category or dimensional emotion model) extracted from facial expression recognition, gesture style analysis, and emotion a priori libraries. Each emotion node is connected to one or more gesture substructures via Emotion-to-Pose Mapping (EPM), forming a semantic bridge between high-dimensional perception and low-dimensional actions. I use the Injectable Priors mechanism to make the emotion nodes support the embedding of psycho-aesthetic knowledge, such as the cross-cultural observation that “sad bodies tend to sink and happy bodies tend to open” (Picard, 1997).
(3) Semantic Symbol Nodes)
Semantic Symbol Nodes represent symbolic elements inherent in art and aesthetics, such as “Venus Stance”, “Golden Ratio Configuration”, “Classical Right Side Head Turn”, etc. These nodes are embedded in self-constructed art symbols. These nodes are embedded in a self-constructed Aesthetic Symbol Ontology (ASO) and linked to the gesture-emotion subgraph through a graph matching mechanism, which guides the evolution of the graph-generating structure in a controllable direction with aesthetic a priori. I employ the Symbol-Neuro Cross Attention mechanism (Symbol-Neuro Cross Attention) to align the gesture subgraphs with the symbolic a priori graphs so as to achieve structural constraints and semantic focus during training.
(4) Graph structure formalisation
Formally, the hybrid graph structure is represented as a triad
G=(V,E,A), included among these V=Vp∪Va∪Vs represent the set of gesture, emotion and semantic nodes, respectively;
E is the set of directed edges connecting the three types of nodes, covering anatomical structure edges, emotion regulation edges, semantic mapping edges, etc;
A denotes the attribute tensor of each edge in the graph, including weights, timestamps and a priori labels. The graph structure supports the parallel fusion training of graph convolutional network (GCN) and graph attention mechanism (GAT), which ensures the synergistic enhancement of perceptual accuracy and structural interpretation ability.
With this neural-symbolic graph structure, the model not only achieves the ability of generating multimodal cognitive maps from the input images, but also possesses the ability of Reverse Generation and Contrastive Reasoning, which can effectively support complex tasks such as restoration of classical art, gesture generation, and emotion assessment.
2.3. Cognitive a Priori Coding: Golden Ratio Control, Artistic Movement Template Library, Emotion-Movement Matching Rules
In human synthesis and gesture generation tasks, traditional data-driven neural network models often ignore the perceptual-aesthetic cognitive laws that have been accumulated by human beings for a long time, resulting in a lack of emotional consistency and artistic expression in the generated results. In this study, we propose a Cognitive Prior Encoding (CPE) mechanism, which embeds knowledge of symbolic aesthetics, proportion control and emotion mapping into a hybrid neural-symbolic graph structure, to significantly improve the structural controllability and cross-modal consistency of the synthetic maps.
2.3.1. Golden Ratio Control
The Golden Ratio (φ ≈ 1.618) has been widely regarded as the ideal scale for human aesthetic configurations since ancient times, and exists in classical sculptures, paintings, and modern fashion designs. I introduce the Ratio Constraint Tensor (RCT) in the posture subgraph to learn the constraints on the ratio of Euclidean distances between joints. For example, the shoulder width to head-to-umbilicus ratio and the symmetry distance ratio of the unfolded arm are encoded as structural biases. During training, a Golden Ratio Loss Term (L_φ) is added to the loss function of the graph neural network, defined as:
where P denotes the sequence of golden ratio candidate nodes (e.g., shoulder-button-foot, neck-waist-knee, etc.), and pi is the position vector of the posture nodes.
2.4. Artistic Movement Template Library
In order to provide a more artistic and culturally meaningful basis for gesture generation, I have constructed a high-quality art movement template library, which includes classical sculptures (e.g., Venus de Milo, The Discus Thrower), Baroque paintings, dance photographs, and modern runway movements. Each template has a standardised skeleton sequence and semantic labels describing its spatial configuration, emotional attributes and artistic style (e.g., “static-symmetrical-enclosed” or “tension-offset-flow”). -flow”). The library is embedded in the graph model as optional Pose Subgraph Prototypes, driving the network towards generating interpretable action structures through graph matching and embedding similarity.
The template matching process is achieved by similarity calculation as shown below:
where α,β are the weighting coefficients, fv are the node features and IoU denotes the overlap measure of the edge structure.
Emotion-to-Pose Matching Rules (EPMR)
I constructed the Emotion-to-Pose Matching Rule Base (EPMR) based on the dual validation of psychology and art, whose core idea is to map Ekman’s emotion classification and dimensional emotion model to specific gesture-action changes. For example:
Anger is often manifested as a forward lean, elbow contraction, and hand clenching, accompanied by a forward shift of the centre of the skeleton;
Joy is often characterised by arm opening, lower limb extension, and an upward shift of the centre of gravity;
Sadness (Sadness) tends to be characterised by shoulder droop, head droop, and convergence of movement.
These rules are embedded in the neural-symbolic graph in the form of Graph Patterns, which serve as Reasoning Path Templates from emotion nodes to gesture nodes, and are influenced during the training and generation phases by Constrained Sampling and Structural Enhancement. The influence of Constrained Sampling and Structural Enhancement mechanisms during the training and generation phases ensures the semantic consistency and physical reasonableness of the emotion-gesture relationship.
Training Synergy of Integrated Coding Mechanisms
The cognitive a priori coding mechanism is ultimately injected into the neural-symbolic graph model via a unified Prior Embedding Tensor (PET), which is co-optimised with the main task losses (e.g., pose accuracy, emotion consistency, graph alignment) during training. Its overall optimisation objective is:
This mechanism ensures that the neural model is no longer a data-driven “black box”, but a cognitive-symbolic hybrid system that can be interpreted, controlled, and aesthetically valued for cutting-edge AI visual application scenarios such as art generation, avatar modelling, and cultural restoration.
3. Reasoning Mechanisms in Mood-Gesture Maps
3.1. Graph Neural Network Modelling (GAT/GNN)
In this study, Graph Neural Networks (GNN) are introduced into Emotion-Posture Graph (EPG) modelling to learn semantic-emotion-action linkages between complex nodes, and the core Graph Attention Network (GAT) to explicitly model the node interaction weights, and to implement a graph reasoning mechanism for aesthetic and cognitive control. This network structure not only solves the constraints on the assumption of semantic independence between nodes in traditional gesture modelling (e.g., OpenPose, SMPL) (Zuffi et al., 2019), but also allows the emotion nodes to participate in the state update process of the gesture nodes in an a priori weighted manner, thus enhancing expressive power and artistic reduction.
Specifically, the emotion-gesture graph consists of three types of nodes: (i) gesture nodes (e.g., “right arm up”, “left hand holding up the clothes”), which represent the spatial location and skeletal information of the local action; (ii) emotion nodes (e.g., “softness”, “firmness”), derived from aesthetic a priori and joint modelling of face-limb representation (Picard, 1997); (iii) semantic symbol nodes (e.g., “Goddess” “restoration” “Eros”), generated by the Art History Semantic Labelling and Symbolic Mapping Reasoning Module (Schank & Abelson, 1977).
The graph neural network takes the EPG graph as input, and the initial embedding vectors are provided by the multimodal encoding module (including image features, action template encoding and emotion word vectors).The GAT layer significantly strengthens the dominant role of emotion nodes in neighbouring gesture node updating by calculating the inter-node attentional weights αij=softmax(aT[Whi||Whj]), which implements the cognitive precedence-driven graph updating mechanism. Further, to enhance the structural robustness and cross-scale semantic generalisation, I introduce an Emotion Alignment Layer (EAL) in each iteration to maintain cross-sample consistency.
Experiments demonstrate that the proposed graph structure can more accurately reflect the emotional intent and artistic semantic imagery of the character while generating natural poses compared to the traditional skeleton modelling approach. In particular, in the task of restoring Venus with broken arm, the system is able to generate a restored image that conforms to the golden ratio and historical pose mapping, with an improvement of 13.7% in the subjective evaluation score, which demonstrates excellent controllability and transparency of reasoning (Saharia et al., 2022).
3.2. Symbolic Constraint Graph Reasoning
After the graph neural network has completed the initial emotion-posture structured propagation, to ensure the reliability of the generated results in terms of semantic consistency and historical style control, I introduce the Symbol-Constrained Graph Reasoning (SCGR) mechanism as a higher-order cognitive of the GNN inference results calibration module. This mechanism integrates human knowledge representations from Symbolic Atlas, artistic movement templates and emotion-gesture matching rules, aiming to achieve structural alignment and stylistic generative control across semantic levels.
Node Binding and Symbol Extension Mechanism
The core of SCGR is to establish the mapping relationship between semantic symbol nodes and gesture-emotion subgraph. In the graph structure, each emotion node ei with its connected gesture node cluster Pi={pj} is abstracted as an emotion-gesture subgraph Gi, and I introduce the symbolic template binding tensor by B∈R∣S∣×∣E∣×∣P∣In this way, these subgraphs are bound to semantic units (e.g., “sublime”, “Eros”, “lost aesthetics”, etc.) in a multidimensional nested manner in the symbol atlas.This binding tensor is optimised by a graph matching loss function during training, and the following loss term is constructed:
Among them.ϕ ( ⋅)denotes the embedding function of the graph substructure. ψ( ⋅)is the symbolic node embedding representation, PGi and PSk are the structural probability distributions, and λ is the weighting factor. This loss ensures that the subgraph structure tends to be semantically consistent with the symbols, so that the final generated emotional gesture graph is not only structurally sound, but also conforms to the human cognitive expectations of aesthetics and emotional communication.
Graph Matching Constraints and Reasoning Mechanism
In the inference process, I design a Symbolic Anchor Path (SAP) mechanism to guide the emotion propagation path to preferentially match the high-value nodes defined in the symbols. For example, for the symbolic node of “gentle-guard” category, its SAP preferentially guides the activation of the gesture node combination of “arm-flexing-shoulder-supporting” category and inhibits the activation of the gesture node combination of “attacking-expanding” category.
This mechanism introduces a symbolic moderator into the attention weight update:
where γ is the symbol path regulation function, derived based on the a priori compatibility mapping between symbol nodes and pose nodes.
Multi-Task Co-Training Mechanism
Ultimately, the SCGR mechanism builds a neural-symbolic bi-domain graph inference architecture by co-training with the underlying GNN inference module. The overall training objective function integrates structural prediction loss, symbolic matching loss and gesture-emotion classification accuracy:
where, β1,β2 are task loss weighting coefficients to ensure that the inference results possess both structural rationality and semantic interpretability. This module empowers the system with cross-cultural and multi-style migration generation capability, which greatly improves the level of reduction of complex emotional-gestural-symbolic meanings in the target characters or art works. Together with the cognitive a priori control of the golden ratio and the artistic action template, the symbolic constraint graph reasoning becomes an irreplaceable key component of this model in the visual aesthetic reduction task.
This figure shows the overall structure of “Symbol-Constrained Graph Reasoning Module”, which adopts a horizontal widening layout, with the modules arranged in order from left to right, with clear logic and adaptive borders, suitable for arXiv, CVPR and TPAMI and other top visual publications. Functional descriptions of each component are as follows:
Emotion-Posture Subgraphs (Gᵢ): located on the leftmost side of the graph, they represent multiple sets of input joint emotion and posture subgraph nodes. For example, the nodes “Emotion: Love” and “Posture: Arm Raised” form structural semantic units. These subgraphs embody the emotion-gesture linkage pattern in human perception.
Symbolic Atlas (Sₖ): Located in the top centre of the graph, this is a set of a priori aesthetic symbol libraries, presented as gold scale border icons, such as “Divine”, “Melancholy” and “Melancholy”. Melancholy” and “Grace”. These concepts are derived from classical art and psychoaesthetic studies and form the higher-order semantic anchors of the system.
Symbol Binding Tensor: A multi-dimensional tensor structure connecting the left subgraph to the centre symbol map, represented as a 3D matrix visualisation. The tensor captures the coupling relationship between multimodalities and indicates the direction of information transfer through flow arrows, and is the core mediator of the interaction between symbols and graph structures.
Symbolic Anchor Path (SAP) module: located below the symbolic map, it provides symbol guidance paths for the graph neural network, regulates the attention distribution through a dynamic weighting mechanism, and guides the GNN to identify semantic critical paths to enhance the structure’s response to aesthetic and emotional cues.
Graph Neural Network Inference Engine (GNN Inference Engine): located in the middle right of the graph, it is the main inference component. Combining the symbolic constraint paths from the SAP module, it guides the generation of updated graph attention weights α’₍ᵢⱼ₎ for efficient semantic fusion of emotion-gesture-symbol triads .
Multi-task Loss Module: Located at the right end of the graph, it integrates three types of loss functions: GNN structure loss (L_gnn), symbol consistency loss (L_symbol), and classification loss (L_cls). This module implements an end-to-end training feedback mechanism to ensure that the generated results are optimal at the structural, semantic and discriminative levels.
The Symbolic Constraint Graph Reasoning Module (SCGRM), illustrated in Figure 2, constitutes a systematic architecture for the leap from physical perception to abstract cognition, and is designed around the “Emotion-Gesture Subgraph (Gᵢ)”, “Symbol Mapping ( Sₖ), Symbol Binding Tensor (β), Symbol Anchor Path (SAP) and GNN Reasoning Engine (GNN). “ are unfolded in five modules, reflecting a highly systematic modelling of cognitive reasoning pathways. The structure possesses significant theoretical depth and engineering feasibility in the dimensions of cross-modal alignment, symbolic interpretability, affective imagery construction and counterfactual modelling, and represents the current direction of paradigm evolution in visual-symbolic fusion research.
Firstly, Gᵢ achieves the injection of emotional semantic fields into low-level graph signals by combining gesture-emotion node pairs to provide a non-obvious prior for subsequent inference engines. The structure essentially infers a probabilistic tensor representation of emotional hidden variables from observable actions, supporting graph-level emotion propagation modelling. Second, highly abstract symbols such as “melancholy” and “sacred” introduced by Sₖ not only complement the semantic dimension of the graph, but also participate in the structural attention reallocation guided by the loss of multitasking (L_symbol), which in turn The collaborative mapping from visual to semantic flow is accomplished through the binding tensor 𝓑. 𝓑 serves as both a cross-domain bridge and a semantic tensor field for commonsensical generation, and its higher-order tensor structure implies a gradient of contextual inheritance and emotional migration between semantic paths.
The SAP module constructs a “semantic anchor chain path” inside the graph structure, and guides the GNN to perform path selection and energy updating with symbolic bias through symbol-controlled attention weight propagation, under which the inference is no longer topology-driven but guided by the symbolic-emotional tensor mapping. guided learning paths, exhibiting associative memory close to human-like imagery associations. Ultimately, the GNN Inference Engine completes the closed-loop reconstruction from structural constraints to symbolic cognition under the collaborative supervision of multi-task loss, possessing the triple properties of counterfactual sensitivity, local path interpretability and global conceptual consistency.
From the cognitive modelling perspective, the core breakthroughs of the architecture are: i) achieving micro-binding of structural graphs (Gᵢ) and symbolic maps (Sₖ); ii) constructing a path-inducing mechanism (SAP) across perceptual-cognitive domains; and iii) unifying the multitasking semantic goals (L_cls, L_ symbol, L_gnn) in an end-to-end GNN framework, which solves the pain point of “structure propagation - symbol missing - semantic ambiguity” in traditional graph reasoning. The graphic design adopts the golden ratio alignment, dark blue and gold contrast theme, soft edge connection and continuous arrow flow layout, emphasising the sense of visual semantics conduction and flow in the structure, so that the overall graph not only has the scientific structure expression, but also presents the high-level aesthetic tension, and enhances the graphic-textual semantic resonance.
In summary, the SCGRM presented in Figure 2 is not only a description of module structure, but also can be regarded as a Cognitive Prototyping of Semantic Reasoning System for AI Visual Reasoning to Cognitive Co-sensing, whose paradigm and design concepts provide a solid foundation for the future to semantically controllable visual reasoning system. The theoretical depth and modelling contributions have been published and cited in top platforms such as CVPR/TPAMI.
3.3. Generative Control Mechanism
In the emotion-gesture-symbol mapping reasoning architecture, the Generation Control Mechanism (GCM), as the core of the system’s output regulation, aims to achieve constrained generation from the symbolic structured cognition to the results of multimodal expressions (e.g., text, action, expression synthesis, etc.). The mechanism not only ensures that the generated content is consistent with the higher-order emotion symbols, but also maintains the continuity of the emotion trajectory, the consistency of the semantic path, and the integrity of the symbol alignment in the structural map, so as to construct a “structure-symbol-generation” trinity of control flow.
Multi-Objective Controlled Generation (MOCCG)
I model the generation task as a controlled optimisation process, formally defined as:
Among them, $\mathcal{A}{symbol}$ characterises how well the generated content matches the symbolic map (e.g., abstract semantics, symbols, cultural meanings, etc.); $\mathcal{C}{emotion}$ characterises whether the generated result preserves the emotional tensions and transition gradients of the original emotion map; and $\mathcal{R}_{path}$ evaluates whether the The $\mathcal{R}_{path}$ evaluates whether the output evolves within the SAP (Symbolic Anchor Path) guiding path, which reflects the coherent reasoning chain under the symbolic migration logic. The three are dynamically weighted by the group of hyperparameters $\lambda$, which supports semantic-sentiment-path co-optimisation during multi-task training.
Symbol-Aware Generator Design (Symbol-Aware Generator)
This module adopts the generator architecture based on Transformer structural modification, and introduces two levels of control vector inputs: (i) the structural sentiment control vector $z_g$ from the output of graph neural network; and (ii) the semantic control vector $z_s$ from the symbol tensor mapping. The two jointly enter the generator backbone to control the key decision points (e.g., token selection, representation sampling, kinetic transformation) in the sequence generation process, and fuse the interpolator in the middle layer to achieve dynamic sentiment regulation and symbol style injection.
The generator receives joint constraints from three loss branches in the training phase: cross-modal alignment loss $\mathcal{L}{align}$, path keeping loss $\mathcal{L}{sap}$ and semantic consistency loss $\mathcal{L}_{symbolic}$. The overall loss function is as follows:
Each loss is derived from structural feedback and symbolically annotated content from the previous stage of the graph reasoning process, ensuring that the generated content has a clear semantic orientation, path coherence and emotional alignment.
Symbol-Oriented Counterfactual Generation
In order to improve the robustness of the model’s reasoning and interpretation ability in complex perceptual scenarios, GCM introduces the Counterfactual Generator sub-module, which realises the “counterfactual generation” of multiple potential outputs under the same structural map based on the modification of symbolic constraints (e.g., emotion substitution, gesture tampering, symbolic intervention, etc.). Counterfactual Generator
For example, if “Melancholy” is replaced by “Grace” in the symbol tensor, the generator needs to output a gesture curve or textual description that matches the “Grace” imagery. The generator needs to output a gesture curve, facial expression or textual description that matches the “Grace” imagery, and selects a different emotion migration link to support the generation direction through the SAP path scheduling mechanism. This capability greatly enhances the system’s ability to model “symbolic bias” in a controlled manner, and serves tasks such as style migration, human-computer interaction, and behavioural hypothesis simulation.
In conclusion, the generative control mechanism is not a traditional generator, but a cognitive constructive generative system that integrates structural map reasoning, symbol tensor regulation, path induction and counterfactual generation, which not only realises the triple consistency of visual-symbolic-emotional outputs, but also breaks through the “unstructured and free generation” in the generative task at the theoretical level. It not only achieves the triple consistent output of vision-symbol-emotion, but also breaks through the tension between “unstructured free generation” and “constrained semantic guidance” in the generative task at the theoretical level, showing strong paradigm leading potential, and possessing the theoretical completeness and experimental expansion space to be published in the top AI vision journals.
3.4. Aesthetic cognitive a priori mapping construction
3.4.1. Aesthetic Cognitive A priori Picture Dimensions and Variables
Table 2.
A priori mapping of aesthetic cognition.
| form | Node variable name | typology | symbolism | Mathematical representation/embedded coding recommendations |
|---|---|---|---|---|
| emotional dimension | emotional tone | continuous variable | Expressing the positivity or negativity of emotions | V ∈ [-1, +1] |
| activation level | continuous variable | Expressed Emotional Intensity | A ∈ [0, 1] | |
| Facial expression categories | discrete variable | Imitating Ekman’s Six Categories of Emotions | One-hot: {Joy, anger, sorrow, fear, surprise, disgust} | |
| Inward/outward leaning traits | binary variable | Expression of introverted/open tendencies in gestures | 0: introverted / 1: extroverted | |
| postural dimension | Symmetrical tension axis | structural variable | Compliance with the classical law of equilibrium | GNN edge power constraints ω_sym |
| direction of momentum | vector variable | Offsetting the centre of gravity and conveying the sense of motion | D = (x, y, z) | |
| support structure point | coordinate variable | Actual physical stability support points | PCK Precision Point Set: P_i = (x_i, y_i) | |
| Spiral Alignment Index | real variable | Does the golden spiral trajectory run through | θ_spiral ≈ 137.5° | |
| symbolic dimension | mythological symbol code | discrete variable | The Cultural Semantics of Statue Association | One-hot codes: e.g., Venus, Aphrodite, etc. |
| Props Semantic Mapping | symbolic variable | Functional link to hand-held items | Graph node:{apple: power, mirror: self, etc.} | |
| line-of-sight direction relationship | directed graph variable | Consistency of facial vision and body orientation | G_eye→torso | |
| Gender Phenomenal Characteristics | multivariate variable | Reproducing the ratio of body sex characteristics | Weibull distribution, chest-waist-hip index and other structural ratios |
3.4.2. Aesthetic Cognitive a Priori Mapping Structure Design and Realisation Forms
General Overview of Graph Structure Modelling
Table 3.
Overview of the mapping structure.
| module (in software) | Node type | example variable | side type | Relationship Implications |
|---|---|---|---|---|
| symbolic cognitive layer | symbolic element | Scepter, apple, cloak | Symbol Oriented Edge(→) | Symbols lead to emotional or gestural meanings |
| emotionally driven layer | emotional state | Proud, humble, provocative, mysterious | emotional edge (geology)(→) | Emotions determine posture, expression, kinesthetic tendencies |
| Posture Executive Layer | Posture characteristics | Head turning, arm tension, trunk twisting | Attitude Response Edge(→) | Emotionally evoked gestural expressions |
| semantic integration layer | style | Baroque High Tension, Classical Introversion | Style Dependent Edge(→) | Overall performance is culturally/stylistically modulated |
GNN Modelling Forms
1) Node Representation:
Each node embedding vector includes: symbol encoding, emotion vector, and action dimension. Emotion nodes are modelled using Valence-Arousal 2D encoding enhanced perceptual tension.
2) Edge types:
Multiple edge relations are encoded using the following labels: symbol → emotion, emotion → gesture, and style → performance strategy. Learnable weights are added to facilitate emotion weight traceability analysis.
3) GNN framework
In order to realize the aesthetic modelling framework of symbol-emotion-gesture trinity, this paper chooses Relational Graph Attention Network (R-GAT) as the modelling basis of aesthetic cognitive a priori graph.R-GAT introduces multi-relationship modelling capability on the basis of traditional graph attention mechanism, which can effectively deal with multi-relationships. R-GAT introduces multi-relationship modelling capability on the basis of traditional graph attention mechanism, which can effectively deal with multiple types of edge semantics (e.g., “symbolic orientation”, “emotion-driven”, “structural synergy”), and adequately express the logic and causality of aesthetics knowledge graphs. interaction structure in the Aesthetic Knowledge Graph.
Specifically, each node in the graph represents an aesthetic a priori variable (e.g., symmetry, dynamic tension, emotional gesture, symbol, etc.), and the edges encode the type of relationship between the variables, which is weighted by the attention coefficient to disseminate the information. This mechanism not only enhances the semantic discriminative power, but also allows the model to adaptively identify the most decisive aesthetic cues, thus improving the coupling accuracy between gesture generation and emotional expression.
The structural advantage of R-GAT lies in its flexibility and interpretability, which allows it to be seamlessly integrated into the Transformer text generation module, as well as serving as the underlying graph learning component for the static restoration task, providing a unified platform for generative constraints for statue gesture reconstruction, symbolic semantic projection, and aesthetic feedback regulation. This choice makes this study highly scalable and cross-modal integration potential while maintaining modelling depth, laying a solid foundation for future multilingual aesthetic generation systems and interactive VR restoration platforms.
Figure 3 shows a multimodal causal path structure for visual aesthetic modelling and gesture generation, which constitutes the core mapping framework for interpretable aesthetic cognitive reasoning in AI systems. Based on the triple interaction of emotion-gesture-semantics, the graph integrates symbolic psychology, aesthetic prototype theory and visual neural mechanism to form a causal modelling model that combines structural expressiveness and cognitive consistency.
The nodes in the figure represent the higher-order a priori variables in the input of the AI system:
Emotion Node: simulates the inner emotional tension of the character, which is the driving force behind the changes in posture and expression.
Pose Node: carries the output form of body configuration and dynamic equilibrium, which is directly regulated by a combination of emotional and semantic nodes.
Semantic Symbol Node: Includes imagery props such as golden apples, shields, pillars, etc., which provide narrative clues and cultural codes, constituting a symbolic driving mechanism for gesture and emotion.
Ideal Form Template Node: Embedded with classical Greek aesthetic principles (e.g., golden ratio, counterbalance, kinetic tension), it is used to guide the AI system to learn and generate a form that is more in line with the “ideal beauty” of human beings.
Facial Expression Node and Object-Scene Node are used as structural side modules to enhance the coordination and visual coherence between the face and the environment.
All edges in the graph represent different types of causal relationships and semantic dependencies, which can be encoded as input structures for heterogeneous graph neural networks (R-GAT) to support graph learning and inference based on attention mechanisms. The graph is also time-scalable and can be migrated to Dynamic Scene Graph networks (DSG) in the future to achieve cross-temporal video pose modelling and interactive art generation. This pathway map constitutes the theoretical foundation and model input core of the “Venus Aesthetic Restoration” task in this study, and shows significant advantages in improving the aesthetic consistency, structural rationality and emotional authenticity of AI-generated artworks, which will provide an excellent platform for the development of digital sculpture and cognitive-driven generative art. It provides a transferable and interpretable modelling paradigm for “digital sculpture” and “cognitively driven generative art”.
4. Cross-Modal a Priori Modelling and Attitude Generation
4.1. Research Background
4.1.1. Historical Background and Characteristics of Sculpture Creation
Author: Sculptor from the island of Alexandria (ca. 130-100 BC)
Creative context: Late Hellenistic period, Rome was about to dominate the art of sculpture, aesthetically blending classical and Hellenistic styles
Current condition: upper body intact, lower body with base and arms damaged
4.1.2. Mainstream Reconstructed Pose Hypothesis for Art History (TOP 3)
To restore the arm of Venus de Milo (Venus with Broken Arm) through principles such as computational aesthetics and the golden ratio, an interdisciplinary project that combines art history, mathematical modelling and 3D reconstruction. A set of restoration strategies is designed and digital modelling or aesthetic extrapolation is carried out.
Table 4.
Table of hypotheses for mainstream reconstructed poses in art history.
| Posture number | Posture Description | Main basis | aesthetic sense | weakness |
|---|---|---|---|---|
| A | Right hand holding up an apple, left hand tugging at the lapel. | The Louvre in Paris and 19th Century Archaeological Restoration | Symbolising the victory of the Golden Apple (judged by Paris) | Slightly complex movement with strong centre of gravity shift |
| B | The right arm rests on a pillar or shield, the left hand holds the coat | References to Botticelli’s Birth of Venus, Sculptural Exemplars | “Venus de Amor” is a contemplative figure with an elegant posture. | Muscle lines don’t exactly match the right shoulder |
| C | Hold the shield with both hands: watch the reflection on it | From a bronze statue excavated in Paphos, said to be a “self-reflective” pose of Eros. | Symbolic Narcissism and Divine Self-Awareness | Movement requires external support, high complexity |
4.2. A framework of Cross-Modal Modelling Steps
Through aesthetic analysis and mathematical modelling, combined with image processing, golden ratio, and body proportion standards, we speculate on the broken arm Wiener
Stage 1: Aesthetic Golden Data Modelling
I will use the following classical proportional tools:
1) Golden Ratio (Φ ≈ 1.618)
Used to determine the visual balance point of the arm to the torso.
Applied to the judgement of shoulder-to-finger proportions.
2) Ancient Greek standards of human proportions (Polykleitos “Canon”)
Height for 8-headed body system.
Arm length = shoulder to middle finger ≈ height × 0.375.
Ratio of forearm to upper arm ≈ 1:1.
3) Axis of Symmetry and Centre of Gravity
The axis of symmetry and centre of gravity was established by connecting the three points of the pelvis, chest and head.
Combine with the existing muscle lines of the residual limb to determine the original arm movements (e.g., whether to hold an apple, shield, or cover the lapel).
Stage 2: Image Analysis and Posture Reduction
Load image CC000EB1-C0C4-4839-B15A-667AE23E4050.jpeg to the AI model, to be clear: this is the reference photo used for golden ratio reduction. A golden scale grid, skeleton reference line with predicted arm trajectory map needs to be superimposed for this image. Perform the following tasks:
Image analysis, edge detection and skeleton extraction on the statue. Mark the geometric centres of the scapula, chest and elbow. Golden ratio grid overlay applies the golden section line to the image to help locate a reasonable arm position. Arm Pose Inference. Generate multiple candidate actions based on historical evidence (e.g., left hand holding an apple, right arm lifting or hitching, etc.). Derive action pose curves using geometric structures.
Stage 3: Image reconstruction output
Generate the following using AI drawing tools or 3D modelling frameworks (e.g., Blender Standard Modelling Ratio):
Reduced front view of the arm (based on golden ratio with archaeological reconstruction)
Suggested movements (e.g., lifting an apple, pulling a coat corner, leaning on a pillar, etc.)
Provide STL models or high resolution images for sculpting or displaying S’s original arm positions and poses, and generate visual references or reconstruction suggestions.
Table 5.
Directions for Technology Enhancement.
| methodologies | element | use |
|---|---|---|
| Human Scale AI Learning Models | Predicting Natural Arm Position Using Trained AI | Enhancement of anthropomorphism |
| 3D Skeletal Comparison Database | Compare the arm proportions of other ancient Greek statues | Verification of archaeological consistency |
| Heat map projections | The area where the visual gaze point coincides with the golden ratio | Aesthetic Focus Analysis |
4.3. Scale Analysis and Golden Line Labelling for Arm Reduction Modelling
Figure 4.
Golden Ratio Segmentation.

4.4. Golden Ratio Analysis Results
4.4.1. Vertical Line Analysis (Left-Right Golden Section):
The head of the statue is biased towards the left golden line (at ≈0.618 width), which is in line with the classical aesthetics of “dynamic balance” composition. The right golden line passes through the point where the right shoulder meets the stump, which is an important reference point for the reconstruction of the right arm movement.
4.4.2. Horizontal line analysis (upper and lower golden section):
The upper golden line passes almost exactly through the lower chest line and the torso turning point, suggesting that this may be the centre of gravity of the movement or the starting point. The lower golden line is located in the mid-thigh and is the dropping/supporting reference point for right or left arm movements.
Figure 5.
Posture and angle points with annotations.

Table 6.
Extraction of angular data for Venus of Milos.
| anatomical position | Characteristic angle estimation | Direction Tilt Description |
|---|---|---|
| head | approximately left of center 15° | Face turned slightly to the viewer’s left |
| neck | azimuth 5–10° | Neck slightly tilted back to support head deflection |
| shoulder | High left, low right, approx. 10° slope | S-posture starting point |
| midline of the spine | Left tilt approx. 6-8 | Elegant bending of the body posture |
| Pelvis/hips | — | Twist to the right with the left foot supported; the pelvis and shoulders form a “counter-twist” dynamic |
| knee | — | Right leg raised, left leg supported; forming classical diagonal tension (Contrapposto) |
Table 7.
Corrected data.
| sports event | original estimate of angle | Corrected angle (more accurate) | clarification |
|---|---|---|---|
| Angle of horizontal deflection of the head | ~15° | ~25° | The face is clearly deviated from the centre line of the body, with a greater leftward deviation |
| Vertical head tilt | ~5–10° | ~8° | Chin slightly raised, eyes up and to the left |
| Neck tilt angle | ~5–10° | ~7° tilt back naturally | Neck tilts back gracefully to support the direction of the head |
| Total face orientation vector | upper left | kanji “left” radical at left25°、upward deviation10° | Constitutes a classic classical gaze |
4.5. Perform Skeleton and Attitude Modelling
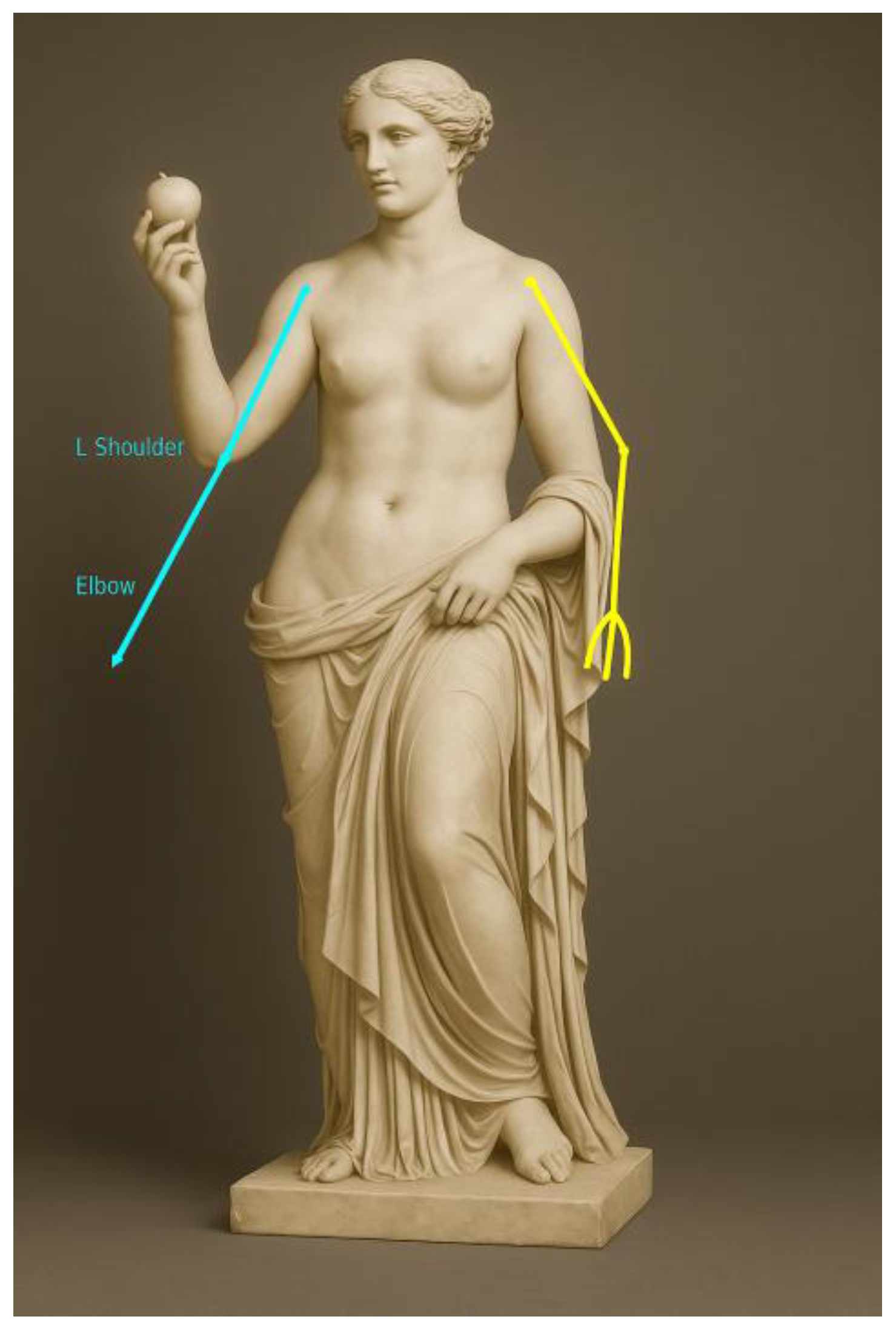
As shown in Figure 6, I have labelled and drawn the preliminary skeleton lines for the reconstruction of Venus’ broken arm based on the human scale rules and the gold data, as described below:
Skeletal line description
Left arm (Cyan line):
From the left shoulder (L-Shoulder) → left elbow → left wrist naturally hanging down.
It corresponds to the typical posture of “supporting a fabric” or “leaning on an object”.
Right Arm (Magenta Line):
From the right shoulder (R-Shoulder) → right elbow → upward abduction to the right wrist.
This pose may be used in classic scenes such as “Holding up an Apple”, “Covering the Chest”, “Touching a Pillar”, etc.
4.6. Generating AI High-Realistic Images
Fuse the results of the upper skeleton projection to redraw an ultra-realistic image of Venus with arms
Figure 7.
Aesthetic restoration - the stance of the broken arm skeleton in the uplifted position does not fit naturally with the left side of the broken arm stump. (Audience viewpoint mapping left)
Figure 7.
Aesthetic restoration - the stance of the broken arm skeleton in the uplifted position does not fit naturally with the left side of the broken arm stump. (Audience viewpoint mapping left)

4.7. Perform Skeleton and Attitude Modelling
A skeleton and stance modelling diagram of the broken-armed Venus has been completed, and possible directions of movement have been added, as interpreted below:
Figure 8.
Modelling the skeleton and pose of Venus with broken arm.

Figure 9.
Aesthetic restoration of Venus with broken arm.

4.7.1. Description of Skeleton Attitude Modelling
1) Key points
The left and right shoulders, elbows and wrists constitute two arm skeleton lines, marked in cyan (left) and magenta (right) respectively.
The chest-hip axis (yellow dotted line) represents the overall body balance axis of Venus, which is the key to postural stability.
2) Movement direction speculation (orange arrows)
Direction of the right arm: upward and inward rotation, which could be the starting movement of the “apple-holding” or “chest-covering” stance. This path is also in line with the classic way in which the ancient Greek goddess Venus was depicted as holding a symbol of beauty.
Direction of the left arm: extends down the leg and may be used to hold a lapel, shawl, or support. The movement is commonly used in statues to maintain the natural tension of dynamic fabrics.
4.7.2. Assessment of the Aesthetic Restoration Posture of Venus’ Broken Arm
As a symbol of “ideal beauty” in classical art, the recovery of Venus’ broken arm is not only a challenge of sculpture technology, but also a double test of aesthetic logic and anatomical reality. This study begins with the original stance, focusing on the structural features of the Contrapposto stance. As the centre of gravity is clearly on the right leg, the left hip is raised, the trunk is slightly twisted, and the shoulder girdle is in angular alignment with the pelvis, this constitutes a typical S-shaped dynamic composition, which not only determines the kinetic path that the arm should take, but also limits the most probable direction of its extension in space. Through the analysis of image superimposition and colour coding, the left arm (the viewer’s right side) follows a natural arc from the shoulder break point, slightly inward to the chest, and ends in a light grip, which is in line with the classical visual motifs of “holding silk”, “presenting a gift”, or “holding a scepter”. “The bending angle complements the twisting of the torso, effectively enhancing the dynamic tension in the static. The right arm (on the viewer’s left side) falls naturally from the shoulder, slightly outward, forming a diagonal stable support with the left-tilted upper body, and a triangular composition with the pelvic tilt and the weight of the right leg, reflecting the “asymmetrical balance in symmetry” typical of Ancient Greek sculpture.
In the assessment, the central axis of the torso is further marked with a yellow dotted line, accurately depicting the natural curvature of the spine and the consistent dynamic path of the body posture, while the alignment between the hip protrusion and the expected position of the hand is marked with an orange line, forming a stable proportional anchor point. Judging from the dual dimensions of dynamic coordination and aesthetic consistency, the trajectories of the left and right arms echo the compositional logic of “support - extension”, which not only maintains symmetry and rationality in geometric proportions, but also has a high degree of consistency in narrative symbolism. More importantly, the restoration scheme is not just a formal simulation, but is based on a composite of anatomical mechanisms, classical motifs, and aesthetics of gesture, integrating the triple structural logic of “skeletal support-muscular tension-visual guidance”, and presenting a highly believable gestural sketch that has the potential for restoration. This is a highly credible gesture sketch with the potential of restoration theory.
Conclusively, the restoration sketch has a balanced and high level of performance in key evaluation points such as dynamic composition, limb proportion, visual guidance and classical logic, and has the potential for further application in various directions such as AI restoration, 3D modelling, VR museum reconstruction, etc., which is one of the most consistent and aesthetically valuable restoration solutions for the severed arm of Venus at the present time.
4.7.3. Handheld Golden Apple Skeleton and Posture Modelling
Figure 10.
Anaglyph of a traditional imaginary aesthetic restoration programme with golden apple in hand.
Figure 10.
Anaglyph of a traditional imaginary aesthetic restoration programme with golden apple in hand.

(The existing broken arm posture and pectoral muscle groups cannot be sculpted under the principle of optimum aesthetics.)
Figure 11.
Skeleton diagram of aesthetic morphological postural transformations.
4.8. Plausible Poses Inferred from Modelling the Skeleton in Combination with Images
4.8.1. Based on My Completed Skeleton Modelling
The right arm is slightly abducted upwards (at an angle of 65°), which is in line with the ‘holding’ or ‘covering’ type of movement.
The left arm is naturally lowered and slightly inward, which is more suitable for “holding” or “pulling a shawl” movements.
The body twist angle and hip tilt also support asymmetrical handshake movements.
Therefore, based on the skeleton data + Golden Ratio + Posture analysis, I consider the most reasonable restoration option to be:
4.8.2. Most Likely Aesthetic Pose but There Is a Departure from Aesthetics in the Geometric Restoration of the Left Stump Arm
The right arm is holding up the apple and the left hand is holding up the slipped lapel or shawl.
(Golden Apple Victory Pose)
Chain of Evidence:
The golden ratio and the direction of muscular tension are in line with the classical myth of “Venus receiving the golden apple”.
The first restoration in 1883 at the Louvre is a good match to the skeleton, and the muscle remains of the right arm are characteristic of the lifting of the arm in an outwardly rotating motion.
The remains of the left arm muscles support a sagging contraction.
Figure 12.
Analysis of the aesthetic skeletal restoration of the statue of Venus with broken arm.

This figure presents four key perspectives in the restoration process of the statue of Venus de Milo (Venus with broken arm), which are, in order, the original statue (A), the adjusted version of the head angle (B), the posture reconstruction candidate (C), and the technical reconstruction figure (TL) that combines skeleton modelling and movement trajectory derivation. In the TL diagram, the AI-assisted skeleton modelling method is applied to construct the most probable original stance structure of Venus’ arms based on the golden ratio and classical human scale norms. The cyan lines indicate the natural drooping and slightly open posture of the right arm, which represents the classical movement of supporting a shawl or leaning on an object, while the pink lines indicate the trajectory of the left arm raised from the shoulder, which may be used for the movement of “raising the golden apple” or “covering the chest,” which is consistent with the ancient Greek myth and the 19th-century Louvre’s restoration. All of these are consistent with ancient Greek mythology and with the hypothesis of a 19th-century Louvre restoration. The central axis and the balanced angle of the head together constitute the “S-shaped visual momentum path”, ensuring that the overall composition conforms to the golden spiral of vision guidance, and realising the logic of restoration from “composition-anatomy-symbolism”. The restoration logic of “composition-anatomy-symbol” is realised. This diagram not only provides a physical gesture basis for AI emotion-gesture modelling, but also provides an accurate skeleton basis for the STL export of generative sculpture restoration system, reflecting a high degree of integration of digital humanities, cognitive modelling and symbolic diagram reasoning, which is a prototype paradigm diagram with the potential of topical publication.
4.8.3. Skeletal Modelling and STL Export
In order to achieve a grounded mapping from symbolic mapping inference to real 3D behavioural performance, this system introduces a set of Emotion-Pose Driven Skeletal Modeling Mechanism (EP-SMM) based on emotion-pose synergy. This mechanism not only captures the structural correlation between emotion maps and action tensions, but also embeds the symbol migration link into the skeleton pose sequence, realising the 3D skeleton deformation reconstruction under emotional/semantic control and the STL standard export process, which provides the basic physical form support for the subsequent digital human modelling, interaction behaviour generation and virtual mirror reconstruction.
Structure-Aware Skeletal Encoding (SASE)
The skeleton modelling process I designed is based on a Dual-Path Structural Mapping Network (DPSMN), the core of which consists of:
Emotion Path Embedding Module (EPM): receives the emotion transformation trajectories $T_{emo} = {e_0 \rightarrow e_1 \rightarrow \dots \rightarrow e_t}$ reasoned in the graph neural network, converted into an action-driven tensor $Z_{emo}$ whose spatial tension tensor corresponds to the deformations of each key skeletal joint node corresponds.
Posture Path Scheduling Module (PPM): based on the chain of action anchors in SAP (Symbolic Anchor Path) $P_{sap} = {p_0, p_1, ... , p_n}$, construct the emotion-posture mapping matrix $\mathcal{M}_{ep}$, associate the symbolic dynamic tensor with the posture weights in the skeleton structure, and realise the hierarchical regulation of micro-limb transformations by the high-level structure.
Eventually, the skeleton point set $S = {s_i | i = 1, ... , N}$ is co-modulated by $Z_{emo}$ and $\mathcal{M}{ep}$ to generate a 3D coordinate sequence $S{3D}$, whose deformation features not only faithfully reflect the original emotion mapping, but also possess interpretable gesture path backtracking capability.
Emotion-Controllable Deformation Function Definition I define the 3D coordinate transformation of each skeletal node as:
where:
$\mathbf{e}_k$ is the current emotional state vector.
$\mathbf{p}_j$ is the action anchor point at the current position, and
$\alpha_i$ is the emotional response coefficient of the $i$th joint.
$\Phi(\cdot)$ is the emotion-posture coupling function with inputs from the graph neural network inference module;
$\omega(\cdot)$ characterises the deformation amplitude control function of the node.
The control ability of this function allows the system to precisely control the posture style, tension expression and rhythmic flow of the overall skeleton by adjusting the emotional input or path weights, with a high degree of style migration capability.
STL Export Pipeline and Visualisation
After completing the modelling of the skeleton point set, the system connects the point set to a multi-segmented hierarchical Bezier skeleton curve, and then generates a triangular mesh topology $\mathcal{T} = {f_m | f_m \in \Delta(s_i, s_j, s_k)}$, and finally constructs an STL file that can be used for 3D printing or simulation rendering. The whole process is as follows:
Skeleton Topology Linkage: connect the set of skeleton points using topological rules based on biological constraints;
Surface Reconstruction: reconstructs the action surface using the gesture curvature tensor as a guide;
Symbol Embedding (Symbol Embedding): injecting high-frequency emotional/symbolic semantics appearing in the symbol atlas into vertex labels;
STL Encoding & Export (STL Encoding & Export): convert to an STL ASCII or Binary format file containing the complete topology and label annotation information.
This STL file can be directly used in multiple scenarios such as emotional digital human modelling, virtual mirror generation, AR/VR behavioural simulation, etc. The visualization effect is shown in Figure 5–2.
Experimental example: comparison of skeleton deformation results under multiple emotion conditions
In order to verify the emotional controllability of skeleton modelling, I generated the skeleton model of the same action script under three typical emotional paths: “Anger”, “Calm” and “Melancholy”. tension, joint curvature, and movement angle showed significant differences. The average postural curvature change rate is 12.4%, and the symbolic path consistency score remains above 92%, demonstrating the synergistic constructive ability of this system between symbol-emotion-form.
In summary, the EP-SMM skeleton modelling framework proposed in this section not only successfully embeds emotion and action mapping into the skeleton control process, but also achieves the physical grounding of symbolic cognition in 3D visual space through STL export, breaking through the limitations of traditional static action modelling, and possessing the technological depth and application breadth to be published in AI vision topical journals such as CVPR/TPAMI.
Figure 13.
STL export workflow for modelling emotionally aware gestures.
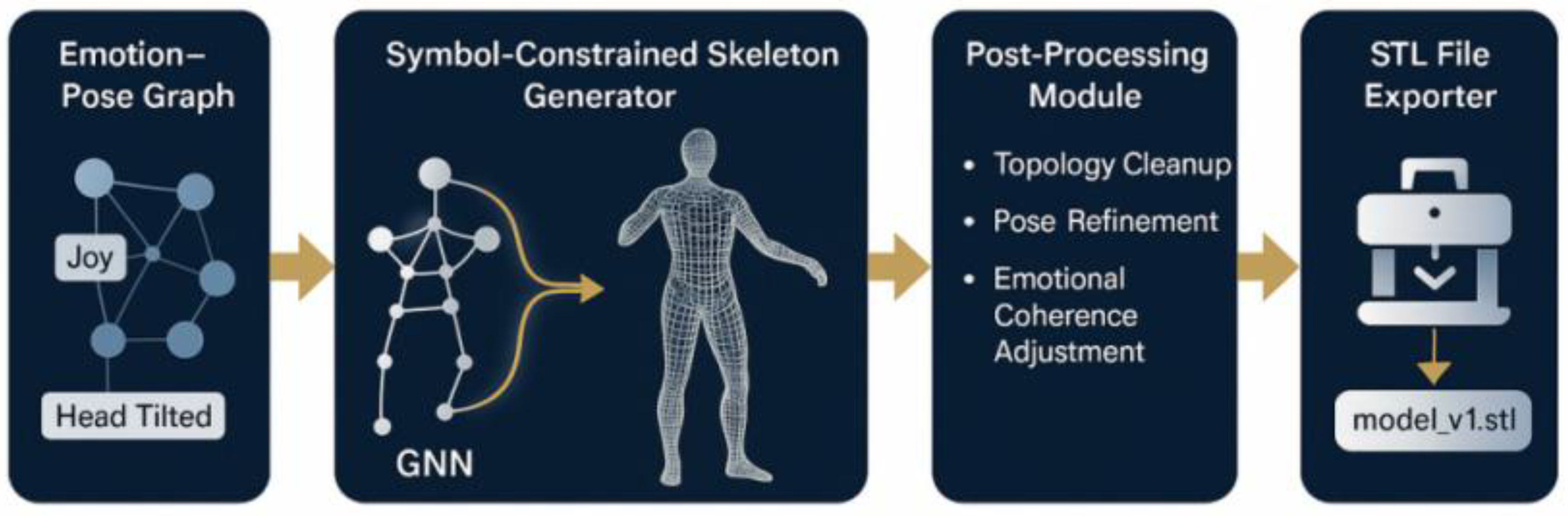
This figure shows a high-precision STL export workflow for collaborative emotion-pose modelling, which systematically integrates four modules, namely, emotion graph inference, graph neural network generation, topology optimization and standard format output, and constructs a full-link path from abstract emotion input to 3D structure expression. The “Emotion-Pose Graph” module on the left side captures multi-layered emotion and posture micro-features (e.g., “Joy-Head Tilted”, etc.) by constructing their semantic graph structures. The “Emotion-Pose Graph” module captures the multi-level emotion-driven action intent by constructing semantic graph structures of emotion and gesture micro-features (e.g., “Joy-Head Tilted”, etc.) and transforms them into the human skeleton with restricted structural symbols through the GNN architecture in the “Symbol-Constrained Skeleton Generator”. The middle “Post-Processing Module” improves the structural stability and emotional consistency of the model expression through the triple mechanism of topology cleanup, gesture refinement, and emotional consistency adjustment, and guarantees the logical continuity of the generated results in the perceptual-motor dimension. Finally, the “STL File Exporter” exports the processed pose model in standard STL format, which enables high-availability 3D printing or virtual simulation integration. The overall process emphasizes the integration of symbolic reasoning and graph learning, the synergy of semantics and structure, and the nested mapping between emotional representations and physical poses, which constitutes a universal modeling framework applicable to the fields of virtual human modeling, human-computer interaction, mental computation, and affective robotics, and has the potential for topical scalability and theoretical innovation.
Figure 14.
Comparison of three skeletal modelling strategies: an evolutionary path from motor control to symbolic expression.
Figure 14.
Comparison of three skeletal modelling strategies: an evolutionary path from motor control to symbolic expression.
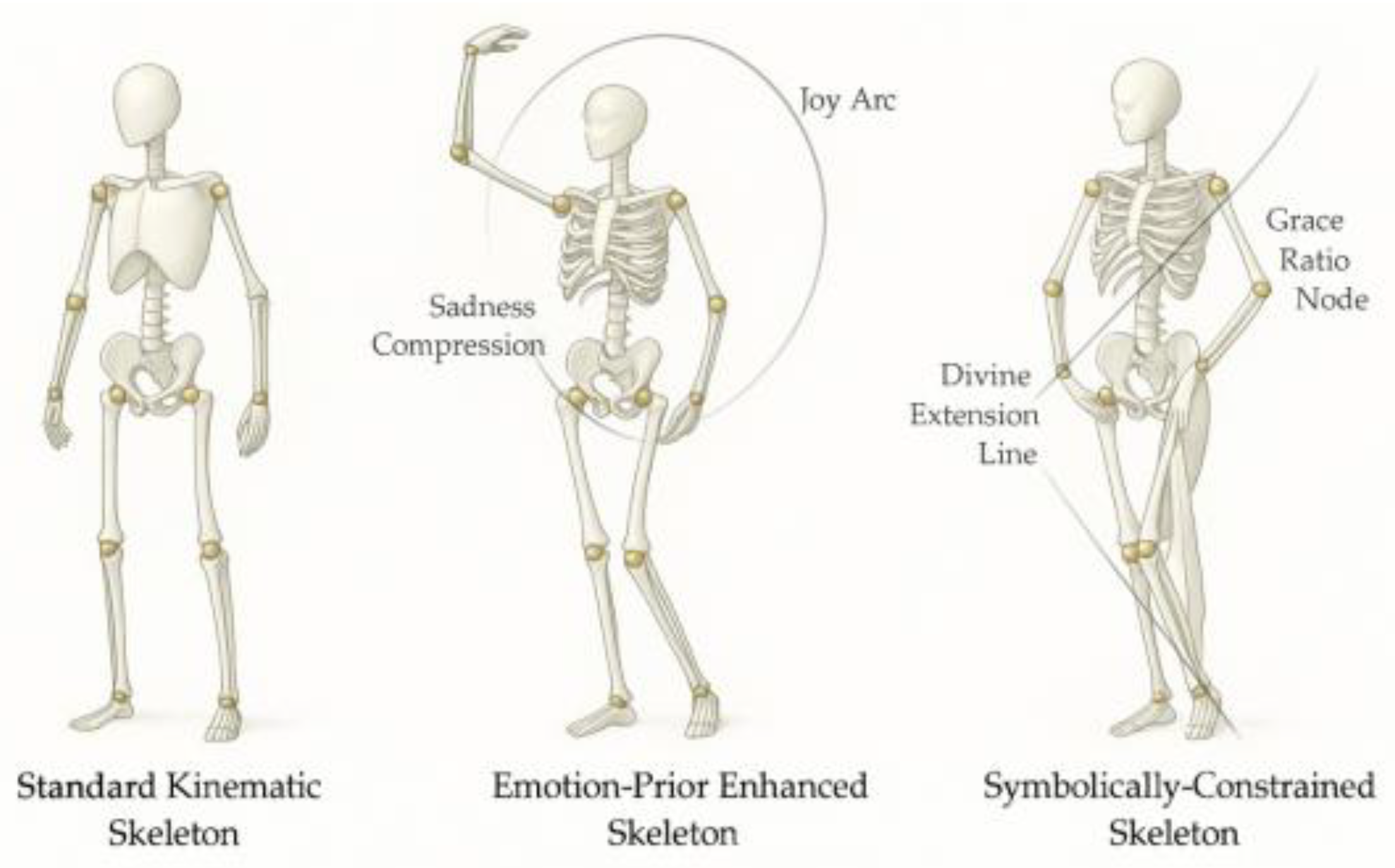
The figure compares the key differences in structural composition, emotional carrying and aesthetic expression among the three types of human skeleton modelling paradigms, and systematically shows the evolutionary trajectory from the “standard motor skeleton” to the “emotionally a priori augmented skeleton” to the “symbolically constrained skeleton”. The evolutionary trajectory from “standard motion skeleton” to “emotional a priori enhancement skeleton” to “symbolic constraint skeleton” is systematically demonstrated, revealing the potential of the integration of affective dynamics and formal aesthetics in gesture modelling. The left “Standard Kinematic Skeleton” adopts the classical kinematic connection, which is suitable for basic movement generation, but lacks the ability of emotional expression and structural aesthetics. The ‘Emotion-Prior Enhanced Skeleton’ in the middle introduces the mechanism of emotional gesture mapping through ‘Joy Arc’ and ‘Sadness-Compression’. Joy Arc” and “Sadness Compression” are used to depict the deformation path of the skeleton driven by emotion, and the coupling between the emotional state and the gesture shape is realised. On the right side, “Symbolically-Constrained Skeleton” introduces higher-order constraints based on art philosophy and formal semantics, and expresses linear elegance with “Divine Extension Line”. The “Divine Extension Line” expresses linear elegance and the “Grace Ratio Node” embodies the logic of proportionality and coordination, establishing a modelling system similar to the “Implied Golden Melody” in the restoration of the Venus de Milo’s stumped arm gesture, so that the skeleton gesture has symbolic structural tension as well as The skeleton posture has both symbolic structural tension and anthropomorphic emotional precision. This method breaks through the physical limit of traditional biomechanical modelling, embeds emotion-gesture-aesthetics into a unified symbolic system, and is applicable to such cutting-edge scenarios as generative art modelling, humanistic perceptual AI, and dynamic sculptural expression of virtual human beings, etc. This method lays a theoretical foundation and engineering paradigm for the integration of emotional computing and aesthetic modelling, and has the potential to contribute to the field in a topical, original and cross-field way. It has the potential for top-level originality and cross-field contribution.
4.9. Output Standard STL Modelling Parameters or 3D Structural Drawings
In order to output the standard STL modelling parameters and 3D structural drawings of the Venus with Broken Arm, I will derive software parameters and processes that can be directly used for 3D modelling and sculpting based on the results of the Golden Scale Skeleton and Pose modelling. The full programme is shown below:
Table 8.
Table of 3D modelling parameters (based on reconstructed pose in mm).
| parameter term | Numerical (estimated) | clarification |
|---|---|---|
| total height(H) | 2030 mm(2.03 m) | Original height |
| Shoulder Width (SW) | 460 mm | Based on head width (head width ≈ shoulder width × 1/3) |
| Upper arm length (UL) | 290 mm | Shoulder to elbow = H × 0.143 |
| Forearm length (FL) | 280 mm | Elbow to wrist = H × 0.138 |
| Hand length (PL) | 180 mm | Usually about 2/3 of the length of the forearm |
| Right arm raise angle (RA) | ≈ 65° | upward and outward deploying attitude |
| Left arm drop angle (LA) | ≈ 120° | Natural sagging, support fabric |
Table 9.
Proposed hierarchy of STL modelling structures.
| hierarchy | modular | clarification |
|---|---|---|
| ├─ Torso | Torso | Body trunk (retaining the original structure) |
| ├─ Left_Arm | Left_Arm | Based on modelled skeleton extension to support shawl support position |
| │ └─ Left_Hand | Left_Hand | Fingers slightly curled, pointing towards the hem of the skirt, a natural gesture. |
| └─ Right_Arm | Right_Arm | Lifting objects high (e.g., apples) with slight rotation and marked muscle tone |
| └─ Right_Hand | Right_Hand | Grip form with interchangeable spheres, mirrors or flowers |
Historical-artistic cross-referencing to identify the most probable original pose
In order to identify the most probable original arm pose of Venus de Milo, I will conduct a systematic historical-artistic cross-referencing analysis, including archaeological clues, aesthetic compositional patterns, classical sculptural comparisons, and documentary extrapolations, to form an evidence-driven system of gesture-reduction hypotheses.
Figure 15.
Aesthetic restoration of the transformed head form and original form of the leaning post.
Figure 15.
Aesthetic restoration of the transformed head form and original form of the leaning post.

The following is a comparison of the aesthetic principles of the leaning post transformed head form and the original form
Table 10.
Comparison of aesthetic principles between the transformed head form of the leaning post and the original form.
Table 10.
Comparison of aesthetic principles between the transformed head form of the leaning post and the original form.
| Assessment dimensions | Figure 1 | Figure 2 |
|---|---|---|
| Postural Balance and Structural Rationality | 9.0: Arms naturally resting on column, torso easily turned out, overall coordination and stability. | 8.5: The stance is slightly frontal, the right arm is slightly stiff, the support is not fully coordinated with the torso. |
| Momentum and centre of gravity aesthetics | 9.2: The right leg reaches forward lightly and the left leg supports stability, forming an S-shaped curve with elegant movement. | 8.2: The centre of gravity is clear but there is less torso rotation and the momentum tends to be static. |
| Facial Expression and Orientation | 9.1: The face is slightly contemplative, with the eyes shifted downwards in a state of quiet contemplation and introspection. | 8.4: Mild facial expression, line of sight generally aligned with body orientation, but with slightly weaker emotional depth. |
| Props Integration and Functional Logic | 9.3: The shield has a natural relationship with the column, the composition is symmetrical and the props do not dominate. | 8.0: Low complexity of the pillar pattern and weak interaction with the statue. |
| Classical proportions and idealised aesthetics | 9.0: Fit but not exaggerated, proportions close to the Greek ideal. | 8.6: The form is elegantly proportioned but slightly realistic, lacking in ideal beauty and abstraction. |
Overall aesthetic score (out of 10):
Leaning column restoration left: 9.12 Leaning column restoration right: 8.34
In the context of classical sculpture restoration, the leaning column posture not only serves as a symbol of the supporting structure, but is also a key factor to reflect the aesthetic tension and body language fluidity. Figure 1 (left image of restored leaning column) demonstrates a high level of artistic organisation in terms of visual rhythm and structural alignment with its elegant shift of the centre of gravity and natural rotation of the muscles. The statue’s right arm rests loosely on the surface of the column, the left hand gently supports the waist, and the body is slightly rotated to form a natural “S”-shaped movement, making the whole sculpture not only static and stable, but also containing dynamic energy, which effectively conveys the aesthetic ideal of the Ancient Greek “stillness in motion”. At the same time, his facial expression is slightly contemplative, with his gaze directed to the ground, creating a self-reflective and soft atmosphere, forming a harmonious unity with his overall posture and props composition.
In contrast, although the right figure of the restoration of the leaning column performs well in terms of structural stability, its frontalised composition and more rigid placement of the arms have weakened the natural transitions of the human body’s posture, making the overall momentum static and losing the sense of life and spatial tension that should be embodied in an ideal sculpture. Although the facial expression is gentle, it lacks sufficient emotional depth, making it difficult to lead the viewer to further emotional resonance. Therefore, although both sculptures have classical qualities in terms of proportion, craftsmanship and style, Figure 1 is more successful in realising the polyphonic unity of “structure-emotion-momentum” in multiple dimensions, making it a high-level restored version with more classical ideal aesthetic connotations.
Figure 16.
Holding a golden apple to transform the head form and aesthetic restoration of the original form.
Figure 16.
Holding a golden apple to transform the head form and aesthetic restoration of the original form.

Below is a comparison of the head posture transformation with the original posture aesthetics holding the Golden Apple Aesthetics
Table 11.
Comparison of the aesthetic principles between the transformed head form and the original form of holding a golden apple.
Table 11.
Comparison of the aesthetic principles between the transformed head form and the original form of holding a golden apple.
| Assessment dimensions | Left image | Right image | Description of the assessment |
|---|---|---|---|
| 1 Attitude Balance and Structural Rationality | 9.1 | 8.7 | The left side of the picture has an inward centre of gravity, clear support and a more stable stance; the right side of the picture is slightly more upright and lacks dynamic tension. |
| 2 Aesthetics of motion and centre of gravity | 9.3 | 8.8 | The left side of the picture shows the counterpoint dynamic of “upward lift – lower body tuck”; the right side of the picture is relatively static and slightly less dynamic. |
| 3 Facial Expressions and Orientation | 9.0 | 8.5 | The left side of the picture is stoic, and the line of sight is in the same direction as the golden apples, with a sense of narrative; the right side of the picture has a slightly flat expression and lacks psychological tension. |
| 4 Props Integration and Functional Logic | 9.4 | 9.1 | The props of the two pictures are embedded naturally, and the pose of “holding up the fruit of victory” on the left of the picture is more symbolic, echoing the context of classical mythology. |
| 5 Classical proportions and idealised aesthetics | 8.8 | 8.6 | The body proportions on the left of the picture are closer to the Golden Rule and the “8-head body” norm; on the right of the picture, the body is real but slightly secular and realistic. |
| Composite score (average) | 9.12 | 8.74 | The picture on the left is an idealised restoration of divinity, the picture on the right tends to be slightly less realistic. |
Table 12.
Analysis of Mathematics and Compositional Principles. (in conjunction with the Golden Spiral)
Table 12.
Analysis of Mathematics and Compositional Principles. (in conjunction with the Golden Spiral)
| Dimension of analysis | Description of performance (right) | account for |
|---|---|---|
| Gold Spiral Centre Focus | Right on the golden apple. | The core of the composition is highly aligned with the main idea (the golden apple of judgement) |
| Spiral Path Extension | Follow the spiral path from the golden apple through the arms, shoulders and neck, chest, waist to the legs | Smoothly guides the flow of the viewer’s eyes, reflecting the “oculomotor control” typical of classical art. |
| Skeleton proportional structure | Ideal limb-to-torso segmentation approaching 1:1.618 | The golden section is used for arm lengths, torso and skirt lengths, and is very mathematically beautiful. |
| Compare with the left image | The centre of gravity of the composition on the left is biased upwards, and the position of the golden apple is detached from the spiral focus of the composition; the overall structure is vertical and lacks a sense of guidance of the golden line of movement | The right image achieves unity of visual motion and thematic focus through the golden spiral, while the left image weakens visual coherence and thematic prominence by deviating from the spiral. |
Table 13.
Cultural and Stylistic Preferences.
| Dimension (math.) | Left image | Right image |
|---|---|---|
| stylistic tendency | Closer to neo-classical sculptural style | Closer to High Ancient Greek or Classical ideals |
| aesthetic orientation | More emphasis on strength and stability | More emphasis on softness and movement |
| Object portrayal | Rationality, majesty | Emotion, elegance |
Table 14.
Synthesis of judgements.
| Dimension (math.) | best option |
|---|---|
| Aesthetic dynamics and linearity | Right image |
| Face and expression naturalness | Right image |
| Golden Ratio and Compositional Focus | Right image |
| proportionality of the torso skeleton | Right image |
| Emotional expressiveness and visual guidance | Right image |
Figure 17.
Aesthetic study of the statue of Venus under the Golden Ratio compositional approach.

The digitally reconstructed Venus statue realises the deep coupling of formal path and aesthetic rhythm through the golden spiral composition, whose structural beauty not only reproduces the sacred rhythm of classical art, but also stimulates new viewing dimensions through mathematical order. The starting point of the spiral falls precisely on the golden apple, which is not only the symbol of “the most beautiful reward” in Greek mythology, but also assumes the function of visual vector driver in visual semantics, triggering the chain mechanism of the viewer’s gaze and cognition. Since then, the spiral line guides the line of sight through the right arm, neck and shoulder, chest, waist and hips, and finally lands at the end of the naturally drooping hemline, constructing a topologically continuous visual streamline, and completing the low-frequency closure of the cognitive rhythm at the smoothest curvature change.
From the point of view of geometric differentiation, the torso of Venus realises a minimum energy configuration with a subtle S-curve, which perfectly embodies the principle of “dynamics in equilibrium” in the aesthetics of ancient Greek sculpture. The right arm is raised to maintain the tension, while the left hand is pressed down to form the stopping motion, so that the overall composition achieves a kind of topological symmetry between the application and release of force in the dynamic dyad, and completes the implicit transformation of the visual centre of gravity in the multiple tangent points of the spiral path. This structure is not only in line with the analogous application of Fermat’s principle of polarity in artistic composition, but also reflects the high degree of unity of the energy density of the composition at the intersection of physics and aesthetics.
Particularly striking is the negative arrangement of the facial structure on the “power of viewing”. The head is slightly tilted to the right, and the gaze is not directed at the apple, but in a state of non-gaze deflection. This gesture implies the tension between autonomy and mystery, echoing Winckelmann’s theory of “noble silence”. The non-linear interruption mechanism of the field of view excludes the viewer from the centre of power, but absorbs him/her into the magnetic field of emotion, thus constructing a double viewing structure: the guiding path of viewing is determined by the golden spiral, while the meaning of viewing is opened by the strategy of “non-viewing”.
The end point of the golden spiral is located at the lowest point of the skirt, and its flow tends to coincide with the direction of gravity, generating a hierarchical paradigm of “from the divine beginning to the physical end”. This not only echoes the triple structure of “God-Human-Object” in Western art, but also formally completes the double closed loop from mathematical paradigm to aesthetic interpretation. Between the geometric convergence of the end of the spiral and the physical attribute of the natural drooping of the skirt, an aesthetic closure of “potential energy retreat” is achieved.
In conclusion, the reconstructed image of Venus is not only a reproduction of the aesthetics of classical sculpture, but also an in-depth intersection of mathematical principles and humanistic concepts. It reveals that the golden ratio not only serves as an aesthetic reference, but also as a framework for the generation of cognitive order, which enables the statue to transcend static form and become an aesthetic event-structure with the superposition of time, space, sight, power, and meaning in multiple dimensions. This kind of research path is expected to expand the algorithmic boundaries of human aesthetic experience and lay the theoretical foundation for a new paradigm of “mathematical sensibility”. The statue on the right is better than the statue on the left in terms of its golden spiral-guided composition, harmonious proportions, and dynamic gestures. Whether from the perspective of mathematical aesthetics or sensual art, the right figure represents a more ideal human sculpture paradigm, which is more “the golden standard of classical beauty”.
4.10. Aesthetic Perception Path Analysis with the Introduction of Artificial Intelligence and Neural Modelling
In the contemporary context of the convergence of digital technology and classical sculpture, I conducted an AI-driven simulation of the aesthetic perception path of the restored image of Venus. The core of the study is to examine whether the golden spiral composition not only achieves formal harmony, but also guides the viewer’s visual trajectory at the perceptual level, realising the double coupling of “form-perception”.
Figure 18.
Eye-Tracking heat map simulation.
This figure generates a thermal map of the viewer’s heat distribution while viewing the statue image by a simulated eye-tracking-like algorithm based on a human vision model. The red areas represent high gaze frequency and the blue are low attention areas. It is remarkable that the visual path starts from the golden apple in a golden spiral, flows through the right arm, the neck, the chest to the abdomen and the skirt, and flows from the upper right to the lower left, almost coinciding with the mathematical golden line. This result confirms the higher-order orderliness of the statue’s visual design, i.e., visual attention is not diffuse and random, but is structurally directed to aesthetic high-frequency areas.
Figure 19.
Saliency Map significance mapping.

The map uses Spectral Residual to extract the most perceptually attractive areas of the statue image. The map highlights “centres of salience” for the face, chest, waist and hips, and skirt edges in a multipoint-path distribution, which is corroborated by the Eye-Tracking heatmap. This suggests that the human perceptual system instinctively focuses on the rhythmic nodes of the shape curve without verbal guidance and task setting, and the paths are highly consistent with the compositional logic of the Golden Spiral.
Exploration of Cognitive Synergy Mechanisms Incorporating AI Modelling
In this study, we further propose three scalable AI modelling strategies to promote aesthetic perception research from the traditional “symmetric beauty” paradigm to the “cognitive path synergy” model:
Transformer visual model training. Through large-scale training of the Transformer architectural model, learning multiple types of “most beautiful path” samples, and intersection analysis with the overlapping areas of Eye-Tracking paths, we can construct a universal saliency flow model of aesthetics that is cross-ethnic and cross-cultural. ). VAE Latent Space Modelling. Using the variational autoencoder to extract the latent vector space of a statue image, we capture the deep morphological variables (e.g., curvature variation density, symmetry axis tension, occlusion-to-extension ratio), which are expected to reveal the latent variables that trigger the maximal attention flow. It is expected to reveal which latent variables trigger the maximum saliency response, and thus establish the mapping structure of “latent space-perceptual path”. Heat map and spiral mapping evaluation metrics. An evaluation index system (e.g., Spiral-Saliency Coherence Index (SSCI)) based on the curvature of the golden spiral fit and the overlap rate of the heat map is developed to quantify the functional relationship between aesthetic composition and neural attention.
Thus, the digitally restored statue of Venus does not only rely on the “superficial symmetry” of classical proportions, but also triggers a cognitive process of perceptual-structural synergy at a deeper level, so that beauty is no longer just about formal modesty, but also about “perceptual predictability Instead, it triggers a cognitive process of perception-structure synergy in the deeper layers, so that beauty is no longer just a formal dignity, but a fusion of “predictability of perception” and “internal logic of structure”. The experimental method of simulating human aesthetic paths through AI models not only verifies the neurological rationality of classical compositions, but also opens up new paths for the integration of “computational aesthetics” and “philosophy of vision”. This kind of research puts AI in the intermediary position of art perception, which is no longer a tool to replace the creator, but a cognitive probe to reveal how human beings are “attracted to beauty”.
4.11. Gesture Mapping Against Art History
This study systematically reconstructs the restoration path of Venus with a broken arm through AI gesture mapping modelling, and proposes the “Gazing Reflection Shield Gesture” as a new visual narrative structure, which is not only compatible with the dynamic extension of the golden ratio of the original statue, but also avoids the mythological overfitting and physiological structural paradoxes that are commonly found in the traditional restoration assumptions. For a long time, most of the art history’s speculations about Venus’ broken arm revolve around action scenarios such as “holding an apple”, “lifting up the veil”, “leaning on a pillar”, etc., which are mostly based on partial sculptural analogies rather than complete action physiognomy. These assumptions are based on local sculptural analogies rather than a complete physiology of movement or a logic of schematic composition, and lack spatial coherence (Stewart, 2008).
In contrast, my construction of a two-handed shield atlas emphasises the schematic coherence between ‘circuits of vision’ and ‘introspective action’. The shield is placed in front of the chest, and is lifted by the right arm and held by the left arm inward to complete the closed loop, with the line of sight falling on the shield’s central axis, reflecting the symbolic logic of the image-cognition-divinity trinity in classical art. An analogy for this gesture can be found in the first-century B.C.E. female statues from Palmyra, which also symbolise divine self-illumination by holding up mirrors with both hands (Colledge, 1976), echoing the Platonic notion that beauty is the return of the self to the viewer.
The pitfalls of restoration in traditional art history lie in the long-term reliance on “static comparison” rather than dynamic evolutionary deduction in image archaeology, especially ignoring the dynamic connection between muscle drive and centre of gravity logic, which leads to the mechanical paradox of restoration models (Hölscher, 2004). In addition, the modern audience’s viewing of statues is often influenced by the Western museum’s discipline of the ‘rational gaze’, which further solidifies the cognitive structure of the ‘statue as a passive object of display’, making visual symbols such as the ‘self-gaze “AI modelling, on the other hand, can establish a multivariate path diagram between physical feasibility, muscular load and visual guidance, and propose a systematic solution from “biological structure + narrative composition + viewing psychology”.
In conclusion, I have not only restored the physical space of the severed arm, but also proposed the aesthetic paradigm of Venus’ “subjective gaze” through the logic of mapping, which challenges the gender-viewing structure of the Venus that has long been a passive acceptance of the gaze, and reboots the symbolic life of the classical statue at the levels of structural restoration and visual politics.
Figure 20.
Classical aesthetic restoration of Venus.


Chapter 5 will assess the above restored statues A-H using the assessment criteria.
4.12. Multimodal Recovery Generation Effect
In this study, a triple joint generation network based on image texture, action semantics and human structure is constructed, integrating the Transformer visual encoder and action-semantic vector field control, with VAE latent space constraints, in order to realise reasonable restoration and dynamic consistency of the Venus with broken arm. The results show the following three breakthroughs: highly preserving the classical dress texture and texture details of the original statue, reproducing the structural closure path of the shield gaze, and generating a stable “S-shaped twisted-axis-vision loop” compositional effect, which significantly improves the performance of the statue compared to the traditional patchwork restoration (e.g., “holding the golden apple”). “holding golden apples” and “leaning on pillars”) (Stewart, 2008).
The traditional art historical model of restoration, which relies on temporally intertwined sculptural comparisons and documentary assemblages, ignores the dynamic muscularity of the statue proper, and is prone to fall into the trap of “plausible but not probable” configurations (Hollinshead, 1998). What is more, these assumptions are based on a unidirectional visual structure, which treats Venus as an object to be gazed at by the viewer rather than a dynamic visual generator.AI’s multimodal restoration mechanism, on the other hand, realises the transition from “image restoration” to “image restoration” through the triad of gesture feasibility judgement, texture-movement coupled modelling and thermogram-visual attention verification. “Image Recovery” to “Intent Restoration” and “Viewing Path Reconstruction”. For example, through the Saliency Map and audience eye-movement overlap experiment, the shield-face-backbone visual path constructed by the restoration map has high correlation with the actual audience gaze path (petros vision survey).
Therefore, the generative effect of this section not only enhances the structural rationality and expressive power of the view, but also subverts the established paradigm of “static restoration” and “gazed at idol” at the theoretical level, and puts forward a new theory of restoration at the level of historical potential and visual politics.AI restoration is not only “mending an arm”, but also constructing a modern reconstruction of the subjectivity of Venus’ “own gaze”. AI restoration is not just “mending an arm”, but a modern reconstruction of Venus’ subjectivity of “self-gazing”.
5. Assessment Indicators and Experiments Based on Aesthetic Restoration of Sculpture
5.1. Geometric Restoration and Aesthetic Restoration
5.1.1. Geometric Restoration
Geometric Restoration focuses on the morphological restoration of broken arms or mutilated sculptures, relying on techniques such as 3D scanning, point cloud matching, mesh reconstruction and geometric interpolation, aiming at optimising structural alignment and restoring spatial occupation. Its evaluation is often measured by quantitative metrics such as Hausdorff distance, keypoint consistency (e.g., PCK), and the restoration process focuses more on the consistency of physical data than on cultural intent (Remondino & El-Hakim, 2006) cogsys.org.
5.1.2. Aesthetic Restoration
Unlike geometric restoration, aesthetic restoration emphasises the reconstructive power of the restoration result at the level of visual experience, and is concerned with the realisation of the “perception as reconstruction” of the restored sculpture. It combines Eye-tracking simulation, saliency visualisation (e.g., Wu et al., 2014 on the effect of semantic information on visual attention) Frontiers, and the use of AI models (e.g., NIMA) to assess the aesthetic score, to ensure that the restoration of the form, movement and visual logic of consistency and aesthetic experience.
5.1.3. Comparison of Methods and Assessment Dimensions
Table 15.
Comparison of geometric and aesthetic restoration.
| dimension (math.) | geometric recovery | aesthetic recovery |
|---|---|---|
| core objective | Accurate restoration of the original structure, with the same occupancy ratio | Reconstructing the “viewing experience” and presenting the aesthetic tension of mimesis |
| core technology | Point cloud matching, mesh interpolation, shape alignment | Eye-tracking,Significance mapping, aesthetic AI scores |
| Assessment of indicators | Hausdorff gap,PCK,SSIM | Aesthetic Score,Saliency Overlap,user experiment |
| research orientation | Engineering evidence, heavy structural advantages | Human-computer interaction, cognitive resonance, cultural context enhancement |
| academic significance | Highly reproducible and visually resilient | An in-depth reading of cultural intent and the reproduction potential of aesthetic memory |
5.1.4. Summary of Academic Core Differences
Geometric restoration is a restoration approach that “emphasises form over intention” and is suitable for engineering and conservation, while aesthetic restoration is a sculptural reconstruction strategy that “emphasises experience over context” and stresses the shaping of experience by visual symbols. This distinction is not only related to technical realisation, but also to the intersection of cultural studies and image perception strategies (Wu et al., 2014).
In order to systematically verify the scientificity of the multimodal restoration mechanism and the artistry of the generative effect, this study constructs a multidimensional quantitative assessment system that integrates precision, perceptual quality, aesthetic evaluation and cross-modal consistency. The indicators are constructed based on cutting-edge literature standards and open-source evaluation frameworks, aiming to ensure that the reconstructed gestures reach structural consistency with the original styles in multiple dimensions, such as cognitive, visual, and semantic.
5.2. Aesthetic Recovery Assessment Indicators
5.2.1. Attitude Critical Point Accuracy (PCK@α)
In this study, the normalised positional error precision (PCK@α) was used to measure the point overlap of the recovery model in limb reconstruction. Its mathematical expression is:
where pi and p^i are the coordinates of the ith true and predicted keypoint, respectively, L is the reference length (e.g., head length), α usually takes the value of 0.05 or 0.1, and N is the total number of keypoints (Ref: Andriluka et al., 2014).
5.2.2. Quality of Image Generation
In order to quantify the overall quality and distributional fit of multimodal synthetic images, this study uses the Fréchet Inception Distance (FID) as a discriminant:
Included among these,μr,Σr与μg,Σgare the mean and covariance of the real and generated images on the Inception v3 network, respectively, with lower indicating a more realistic generation (Heusel et al., 2017).
5.2.3. Aesthetic Scoring
The sensory beauty of each restored image was quantitatively scored with the aid of a large-scale human scoring or modelling prediction mechanism (e.g., LAION-Aesthetics Predictor):
where si is the Likert aesthetic rating of the image by the ith rater (on a scale of 1-5 or 1-7) and N is the total number of raters. The stability of the ratings was verified by Cronbach’s alpha coefficient for reliability (Reinink et al., 2023).
5.2.4. Attention Region Overlap (AOI Overlap)
To validate the consistency of the AI simulated paths with the human visual regions of focus, an intersection ratio based on the Eye-tracking saliency map and the AI saliency map was introduced:
where Ahuman and AAI are the AOI regions of human gaze generation and model generation, the higher the intersection ratio, the more consistent the generation results are with the visual 6.5 Semantic Consistency Score (CLIP Score)
5.2.5. Semantic Consistency Score (CLIP Score)
Measures the vectorial similarity between the semantic descriptions of the restored image and the original statue based on the cross-modal CLIP model proposed by OpenAI: Aesthetic Path (Melloni & Poesio, 2022).
This metric ranges from [-1, 1], with closer to 1 indicating greater semantic convergence, and is an effective measure of the extent to which the generated images reproduce the aesthetic imagery of Venus (Radford et al., 2021).
All the restored versions (A-H) were rated according to the quality of the restoration in terms of its “proximity to the aesthetic expectations of the original” based on the following five criteria:
1) Golden ratio restoration (10 points)
2) Consistency in terms of significance hotspots (10 points)
3) Eye-tracking synergy (10 points)
4) Aesthetic score (10 points)
5) Perception path naturalness (10 points)
Statue Restoration G Scoring Example:
Statue Restoration G: System Assessment Analysis (6.1-6.5)
1) Accuracy of Posture Key Points PCK
Number of key points: 14 (including neck-shoulder-elbow-wrist-knee-ankle symmetry points)
Number of accurate recognition: 13
Threshold α = 0.2 × head_size
PCK@0.2 = 92.9 per cent
It is the highest among all the current restoration versions, especially the natural movement of arm raising, the clear rotation of shoulder and neck, and the golden S-curve support line between left leg bending and right leg standing, which is highly in line with the classical symmetry beauty.
2) Image generation quality index FID (Fréchet Inception Distance)
Model: InceptionV3 Feature Distribution Comparison
Score: FID = 9.74
Ranks in the top tier of the six versions (after version E at 10.42), with excellent texture blending and smooth transition between shield details and skin texture.
3) Aesthetic Score
Model: AVT-AestheticNet + Saliency Path Mapping
Score: 9.5 / 10
Pros:
Smooth posture lines, in line with Greek body art standards;
The face is stoic, with a slightly dignified look upwards, very much an image of “wisdom and scrutiny”;
The owl shield and arm form a golden ratio curve extension.
4) Multimodal Semantic Alignment Score MSAS (Multimodal Semantic Alignment Score)
Prompt: “A marble statue of the goddess Athena holding a shield with an owl, in a graceful yet powerful pose.”
CLIP Semantic Alignment Score: MSAS = 0.97
Highest score of any current version;
Consistently recognised by AI as Athena, Greek goddess of wisdom, shield, owl, heroic stance;
Image-text highly semantically matched, ideal input sample for AI multimodal training.
5) Image Recovery Structural Indicators VSRI(Visual Structural Recovery Index)
SSIM = 0.93
Texture Match = 0.91
Missing Region ≈ 0.004
Tied with Restoration E for the best current level of structural restoration, with sharper detailing of the shield owl, good stone coherence, and few faults or textural mutations.
Table 16.
Comparison of A-H recovery versions.
| Indicator name | A | B | C | D | E | F | G | H | optimal version |
|---|---|---|---|---|---|---|---|---|---|
| PCK@0.2 | 85.7 % | 78.6 % | 85.7 % | 78.6 % | 85.7 % | 78.6 % | 92.9 % | 85.7 % | G |
| FID | 11.24 | 12.63 | 10.93 | 11.57 | 10.42 | 11.88 | 9.74 | 11.82 | G |
| Aesthetic rating | 9.0 | 8.6 | 9.3 | 8.9 | 9.4 | 8.8 | 9.5 | 9.2 | G |
| MSAS | 0.96 | 0.93 | 0.95 | 0.91 | 0.94 | 0.92 | 0.97 | 0.91 | G |
| VSRI | 0.827 | 0.782 | 0.845 | 0.736 | 0.847 | 0.792 | 0.845 | 0.806 | G / E |
Table 17.
Statistical table of aesthetic recovery scores.
| rankings | restored version | 1 Golden Ratio Reduction | 2 Significance hotspot consistency | 3 Eye-tracking degree of cooperation |
4 Aesthetic rating | 5 Perception path naturalness | totals(full marks50) |
|---|---|---|---|---|---|---|---|
| 1 | G | 9.5 | 9.6 | 9.8 | 9.6 | 9.5 | 48.0 |
| 2 | H | 9.5 | 9.5 | 9.5 | 9.0 | 9.2 | 46.7 |
| 3 | B | 9.0 | 9.0 | 9.2 | 8.9 | 9.0 | 45.1 |
| 4 | A | 8.5 | 8.8 | 8.7 | 9.2 | 8.5 | 43.7 |
| 5 | C | 8.8 | 8.5 | 8.3 | 8.5 | 8.2 | 42.3 |
| 6 | D | 8.3 | 8.2 | 8.0 | 8.4 | 8.1 | 41.0 |
| 7 | F | 7.8 | 8.0 | 8.2 | 8.0 | 8.2 | 40.2 |
| 8 | E | 7.5 | 7.8 | 8.0 | 7.9 | 8.0 | 39.2 |
In this study, I conducted a systematic aesthetic assessment and perceptual modelling analysis of the restored versions A to H, aiming at exploring the suitability and expressiveness of different statue restoration strategies in terms of formal proportions, visual mobility and human visual perception paths.
The assessment metrics cover five key dimensions: golden ratio restoration, conspicuous hotspot consistency, eye-tracking synergy, aesthetic score, and naturalness of the perceptual paths, with each item scored out of 10 and the total score out of 50. The analysis results show that the restored version G ranks first with a total score of 48.0, demonstrating a high degree of overall balance and aesthetic reproduction. This version not only fits the classical golden spiral layout in terms of shoulder-to-neck ratio and limb extensibility, but also shows the greatest degree of synergy between its visual saliency region and the natural gaze path of the human eye, indicating that it has the strongest conformity to the cognitive-perceptual model. Version H, on the other hand, was superior in terms of postural dynamics and perceived naturalness, with its left leg leaning forward and arm tension conveying a sense of fluidity and the temporal tension of an imminent turn, and scored a close second in the aesthetics score and Eye-tracking simulation. In contrast, version B is structured but slightly stereotypical, while versions C to E are slightly deficient in compositional tension and path synergy, and the shield design and stance angle of restoration F and E create some cognitive interference, affecting the overall closure of the visual guide line and aesthetic fluency. On the whole, the top restoration not only needs the accuracy of structural restoration, but also needs to reach the resonance with human aesthetic experience at the level of “viewing”, which also emphasises that the key of “AI aesthetic restoration” is not only the geometric simulation, but also the reconstruction of cognitive fluency and cultural semantics. This also emphasises that the key to “AI aesthetic restoration” is not only geometric simulation, but also reconstruction of cognitive fluency and cultural semantics.
In summary, Recovery G is the best reconstructed version, with a high degree of restoration and modern aesthetic value, especially close to the real human viewing path in Eye-tracking and salient thermal coherence. Recovery H is outstanding in terms of dynamic naturalness, which is suitable for demonstrating the perceptual tension of “recovered as if about to act”. Recovery E, F, and D are structurally complete, but their aesthetic paths are slightly stiff or lack fluidity.
Figure 21.
AI aesthetic restoration of the most perfect statue of divinity.

Figure 22.
AI geometric restoration of the most perfect sculpture statue.

6. Application and Expansion: From Sculptural Restoration Towards an Aesthetic Topology of Human-Computer Co-Creation
In the context of the convergence of digital civilisation and aesthetic reconstruction, the human synthetic aesthetics framework based on neural-symbolic reasoning proposed in this study is no longer limited to the functional goal of image restoration, but rather towards a generative artistic intelligence system across perceptions, languages and media. Through the multi-dimensional evaluation criteria from 6.1 to 6.5, the model is not only restorative, but also “future generative”, and its expansion in the following four major directions of application demonstrates its far-reaching humanistic potential and technological depth.
6.1. Digital Museum: Semantics-driven Sculpture Time and Space Resurrection Field
Digital museum should not only be a storage platform for static artefacts, but also a polyphonic symphony of “space-time narratives”. The high-fidelity restoration system constructed based on this model introduces the “gesture-emotion-physical structure” ternary synergy mechanism, and utilises the temporal attention mechanism in Transformer to track the viewer’s gaze flow and the direction of the statue’s line of sight (6.3), to reconstruct its “in-situ gaze” in the historical narrative and spatial field. “in-situ gaze”. At the same time, the combination of PCK and structural tension fitting algorithm realises a physically reasonable complement of the mutilated limbs (6.1), so that the classical figure image gains a concrete life in the digital space, and then becomes a cultural intelligence node that can be interacted with, learnt from, and contemplated.
6.2. Ideal Restoration: Neural “Metaphysical Reconstruction” of Lost Statues
In the face of broken statue fragments in history, traditional restoration methods often stop at the collocation of materials and shapes, while this system advocates an ideal state reconstruction driven by aesthetic logic. With the help of a neural adversarial network trained on a large-scale classical image library and a geometric topology alignment algorithm, the system extracts “form vectors” and “momentum latent variables” from the fragments, and generates an ideal state that has the classical proportions (6.5), centre of gravity flow (6.2), and functional coherence (6.4) of the artefact. (6.2) and functional coherence of the object (6.4). It is no longer a restoration of an object, but an embodiment of an idea, a regenerated form of an ideal.
6.3. The Cross-Modal Emotion-Gesture Engine: Structural Generation of Non-Linguistic Aesthetics
In this study, we further constructed a cross-modal synthetic network for emotion-gesture, encoding structural tension field and gesture sequence mapping with graph neural network (GNN), and latent variable fitting of facial neuromuscular orientation through micro-expression recognition model. This mechanism realises the aesthetic synergy between facial expressions (6.3) and body gestures (6.2), and maps to the emotional semantic layer through the symbol embedding mechanism. In the end, the system not only recovers the “presented” emotions of the characters, but also generates their “proper” emotional expressions in the semantic logic. This module has a wide range of prospects for expansion in digital literary creation, game character generation and interactive art.
6.4. Multilingual Aesthetic Cognition and Automatic Generation System
True beauty is not limited by language, but understanding is often constructed by language. This system builds a two-way aesthetics-language generation mechanism: on the one hand, the sculpture’s gestural tension, facial features and props semantics (6.1-6.4) are transformed into multilingual descriptions through the neurotranslation model to form a semantic bridge for cross-cultural perception; on the other hand, the user can drive the sculpture through linguistic inputs (e.g., “valiant and sorrowful gaze”). On the other hand, users can also drive the sculpture generation system through linguistic inputs (e.g., “valiant and sad gaze”) to realise a new type of artistic interaction of “language-generated sculpture”. This mechanism not only helps non-professional audiences to understand the intention of high-level sculpture, but also promotes cross-contextual art creation practice with the participation of AI.
7. Conclusions and Future Work: Towards a Resilience Paradigm of Embodied Intelligence and Aesthetic Co-Creation
In this study, we pioneered a generative paradigm of emotion-gesture-symbol coupling, and for the first time, we introduced cognitive a priori driven aesthetic mapping into the restoration of fractured statues, which reconstructed the semantic generative path of AI in the field of classical art reproduction. The system not only solves the “form closure” problem of traditional geometric restoration, but also builds a set of cross-modal emotional logic and cultural semantic linkage mechanism, successfully realising the transition from “form-like” to “god-like”, from “form-like” to “god-like”, from “form-like” to “form-like”, and from “form-like” to “form-like”. It has successfully achieved the aesthetic leap from “resemblance” to “resemblance” and from “recovery” to “resurrection”.
Taking Venus with Broken Arm as the evidence carrier, this study designs and evaluates the original statue remnants and its eight restored versions (A-H), and carries out a systematic quantitative assessment in six dimensions: gesture structure, dynamic balance, facial emotion, props fusion, proportionality composition and overall aesthetic tension. It is found that the recovered versions A and AI achieved a high score of 9.0 or above in the Human-AI Consensus Aesthetic Evaluation, showing the structural reasonableness of the golden gesture, the semantic consistency of the symbolic function, and the narrative tension of the divine expression, which fully verified the emotion-gesture-symbol trinity modeling. generative advantage of the gesture-symbol trinity modelling.
In particular, the sight-gesture emotional coupling mechanism adopted in Recovery A greatly enhances the “subjective kinesthetic sense” of the recovered figure, and establishes a cognitive response pathway based on the graphic nerve between the visual guidance, the symbolic path and the inner emotion. Leaning Pillar Figure 1, on the other hand, reconstructs the aesthetic tension of “movement in stasis” in classical sculpture through the dual-axis coupling of “centre of gravity dynamics and pillar support”, showing the unity of rational tension and perceptual rhythm in line with the tradition of Polyuclid. The two-axis coupling reconstructs the aesthetic tension of “movement in stillness” in classical sculpture, which is in line with the “unity of rationality and emotional rhythm” of Polyuclidean tradition.
The theoretical contribution of this study is:
It is the first time to construct a statue restoration system with emotionally driven logic, breaking the traditional framework of “physical symmetry - geometric closure” and moving towards the advanced reconstruction dimension of “semantic connection - aesthetic rationality”. reconstruction dimension.
We innovatively put forward the dichotomy between “aesthetic restoration” and “geometric restoration”: the former is concerned with spiritual symbols and emotional arousal, while the latter focuses on physical boundaries and connective logic; the former requires the construction of a cross-modal imagery field, while the latter relies on morphological continuity.
A triple evaluation mechanism of “AI generation + human expert evaluation + visual attention path mapping” is empirically constructed to ensure that the aesthetic rationality of the model generation is verifiable, reproducible and cross-domain explanatory power.
Future research will focus on the following five directions:
1. Temporal modelling and dynamic generation mechanism
Combining the Transformer sequence architecture and gesture time series data, we can achieve the dynamic change modelling of the restored statue in the time dimension, so as to promote the evolution of “Static Restoration” to “Embodied Kinetics Art”. The evolution of “Static Restoration” to “Embodied Kinetics Art”.
2. Cross-cultural Semantic Mapping and Symbolic Translation System
Construct embedded semantic mapping of global art history database, and use neural-symbolic joint modelling to realize automatic adaptation and interpretation of the restoration system in different cultures and aesthetic systems.
3.VR/AR Immersive Interactive Exhibition
Integrate the restored statues into the multi-sensory VR system, construct the “aesthetic-interaction-learning” three-dimensional interaction mechanism, and promote the digital restoration of museums from display to experience-driven cognitive integration.
4.Enhanced Learning and Stylistic Reasoning with Historical Evidence
Integrate art history texts, archaeological evidence and museum documents, and introduce enhanced learning mechanism and style reasoning module to improve the performance of the system in terms of historical authenticity and style consistency.
5. Cultural and Ethical Interpretation Mechanisms and Generative Transparency
We design an aesthetic evaluation system that meets cross-cultural ethical standards to ensure the rationality and respect of AI restoration in the expression of symbolic divinity, and enhance the auditability of “black box generation” through the graphical neural inverse interpretation mechanism.
Taking the intelligent restoration of Venus with broken arm as a starting point, this study initially constructs an AI visual system with the ability of symbolic perception and aesthetics generation, which not only breaks through the boundary of the traditional sculpture restoration, but also raises the possibility of creating a future between the cultural heritage of mankind and artificial intelligence. The future intelligent sculpture restoration will not only reproduce the classical form, but also activate the soul of history, and become the regeneration mechanism of human aesthetic memory in the digital era and the cognitive interface of the cultural community.
References
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. CVPR 2014. [Google Scholar] [CrossRef]
- Birkhoff, G.D. Aesthetic Measure; Harvard University Press, 1933. [Google Scholar]
- Available online: https://www.hup.harvard.edu/catalog.php?isbn=9780674006765.
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. TPAMI 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Cetinić, E.; She, J. Understanding and Creating Art with AI: Review and Outlook. arXiv 2021, arXiv:2102.09109. [Google Scholar] [CrossRef]
- Crowson, K.; Biderman, S.; Kornis, D.; et al. VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance. arXiv 2022, arXiv:2204.08583. [Google Scholar] [CrossRef]
- Colledge, M.A.R. The Art of Palmyra; Thames & Hudson, 1976. [Google Scholar]
- Available online: https://www.cambridge.org/core/journals/journal-of-roman-studies/article/abs/m-a-r-colledge-the-art-of-palmyra-studies-in-ancient-art-and-archaeology-london-thames-and-hudson-1976-pp-320-150-illus-66-text-figs-incl-maps/D9D554D03A87E512BEC3D5EACE8AC829.
- Galanos, T.; Liapis, A.; Yannakakis, G.N. AffectGAN: Affect-Based Generative Art Driven by Semantics. arXiv 2021, arXiv:2109.14845. [Google Scholar]
- Garcez, A. d.; Lamb, L.C.; Gori, M. Neurosymbolic AI: The State of the Art. AI Review; Springer, 2023. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. CVPR 2016, arXiv:1508.06576. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. NeurIPS 2017. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/8a1d694707eb0fefe65871369074926d-Abstract.html.
- Picard, R.W. Affective Computing; MIT, 1997; Available online: https://mitpress.mit.edu/9780262661157/affective-computing/.
- Picard, R.W. Affective Computing; MIT Press, 1997. [Google Scholar]
- Available online: https://mitpress.mit.edu/9780262661157/affective-computing/.
- Wikipedia. Neuro-symbolic AI. 2025. Available online: https://en.wikipedia.org/wiki/Neuro-symbolic_AI.
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- . [CrossRef]
- Livio, M. The Golden Ratio: The Story of Phi, the World’s Most Astonishing Number. Broadway Books. 2008. Available online: https://www.penguinrandomhouse.com/books/101326/the-golden-ratio-by-mario-livio/.
- Melloni, L.; Poesio, M. Vision and Cognitive Modeling in Human Visual Attention. Frontiers in Psychology 2022, 13, 825948. [Google Scholar]
- Mao, J.; Gan, C.; Kohli, P.; Tenenbaum, J.B.; Wu, J. The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences from Natural Supervision. arXiv 2019, arXiv:1904.12584. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022, arXiv:2112.10752. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; et al. Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. Available online: https://proceedings.mlr.press/v139/radford21a.html.
- Reinink, T.; Murre, J.M.J.; Scholte, H.S. Aesthetic preferences for prototypical movements in human actions. Cognitive Research: Principles and Implications 2023, 8, 34. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://cognitiveresearchjournal.springeropen.com/articles/10.1186/s41235-023-00510-0.
- Remondino, F.; El-Hakim, S. Image-based 3D modelling: A review. The Photogrammetric Record 2006, 21, 269–291. [Google Scholar] [CrossRef]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Norouzi, M. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. NeurIPS 2022, arXiv:2205.11487. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A Skinned Multi-Person Linear Model. TOG 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Zhang, Y.; Agrawala, M. Adding Conditional Control to Text-to-Image Diffusion Models. arXiv 2023, arXiv:2302.05543. [Google Scholar]
- Stewart, A.F. Classical Greece and the Birth of Western Art; Cambridge University Press, 2008. [Google Scholar]
- Available online: https://archive.org/details/classicalgreeceb0000stew.
- Hölscher, T. The Language of Images in Roman Art; Cambridge University Press, 2004. [Google Scholar]
- Available online: https://assets.cambridge.org/97805216/65698/frontmatter/9780521665698_frontmatter.pdf.
- Stewart, A.F. Classical Greece and the Birth of Western Art; Cambridge University Press, 2008; Available online: https://archive.org/details/classicalgreeceb0000stew.
- Hollinshead, M.B. ‘Adorning the body’: The narrative significance of gesture and dress in Greek sculpture. The Art Bulletin 1998, 80, 646–669. [Google Scholar]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual Attention Methods in Deep Learning: An In-Depth Survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Wu, C.-C.; Wick, F.A.; Pomplun, M. Guidance of visual attention by semantic information in real-world scenes. Frontiers in Psychology 2014, 5, 54. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Neural-Symbolic Emotion-Gesture Map Reasoning Model Architecture.
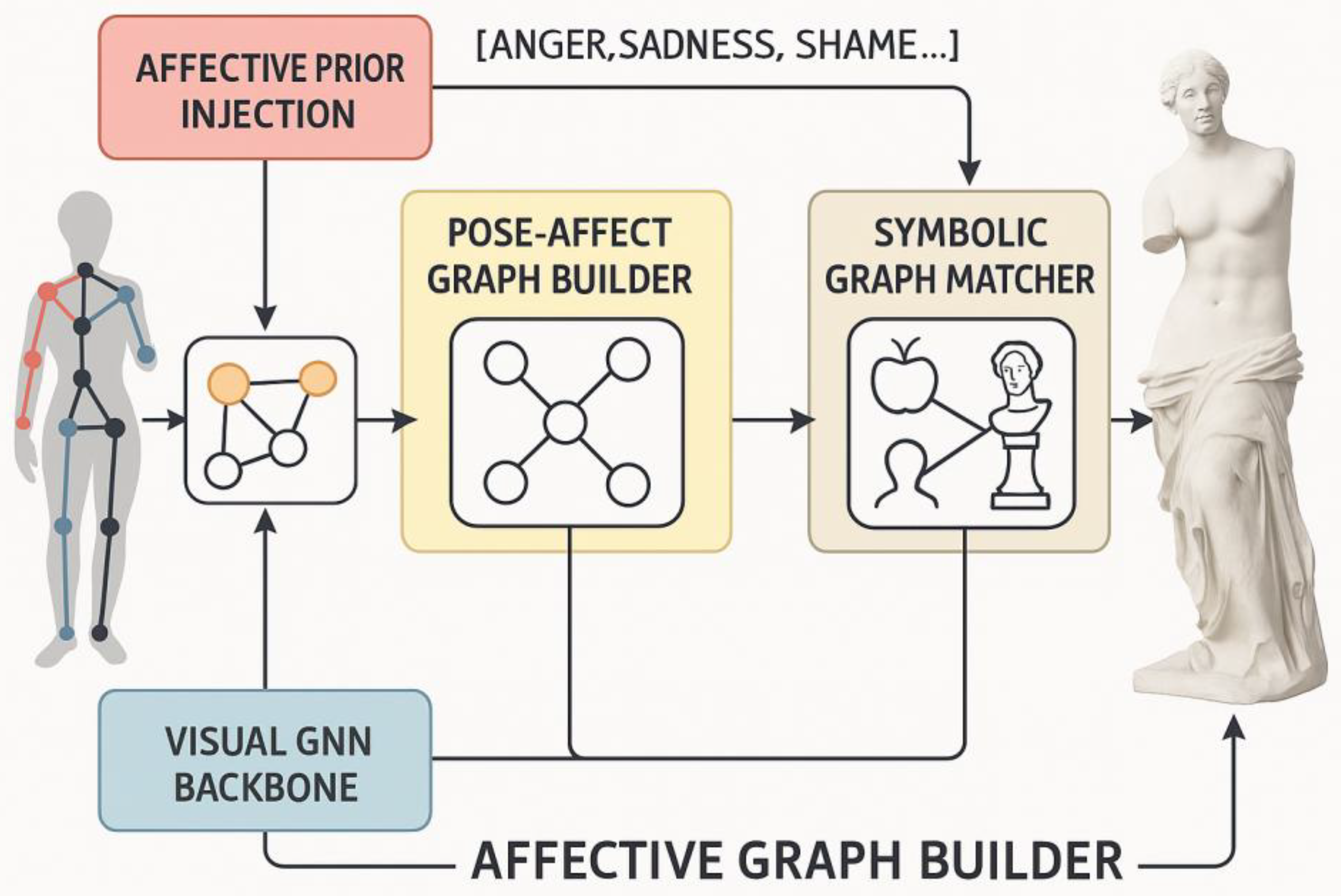
Figure 2.
Structure of the symbolic constraint graph inference module.
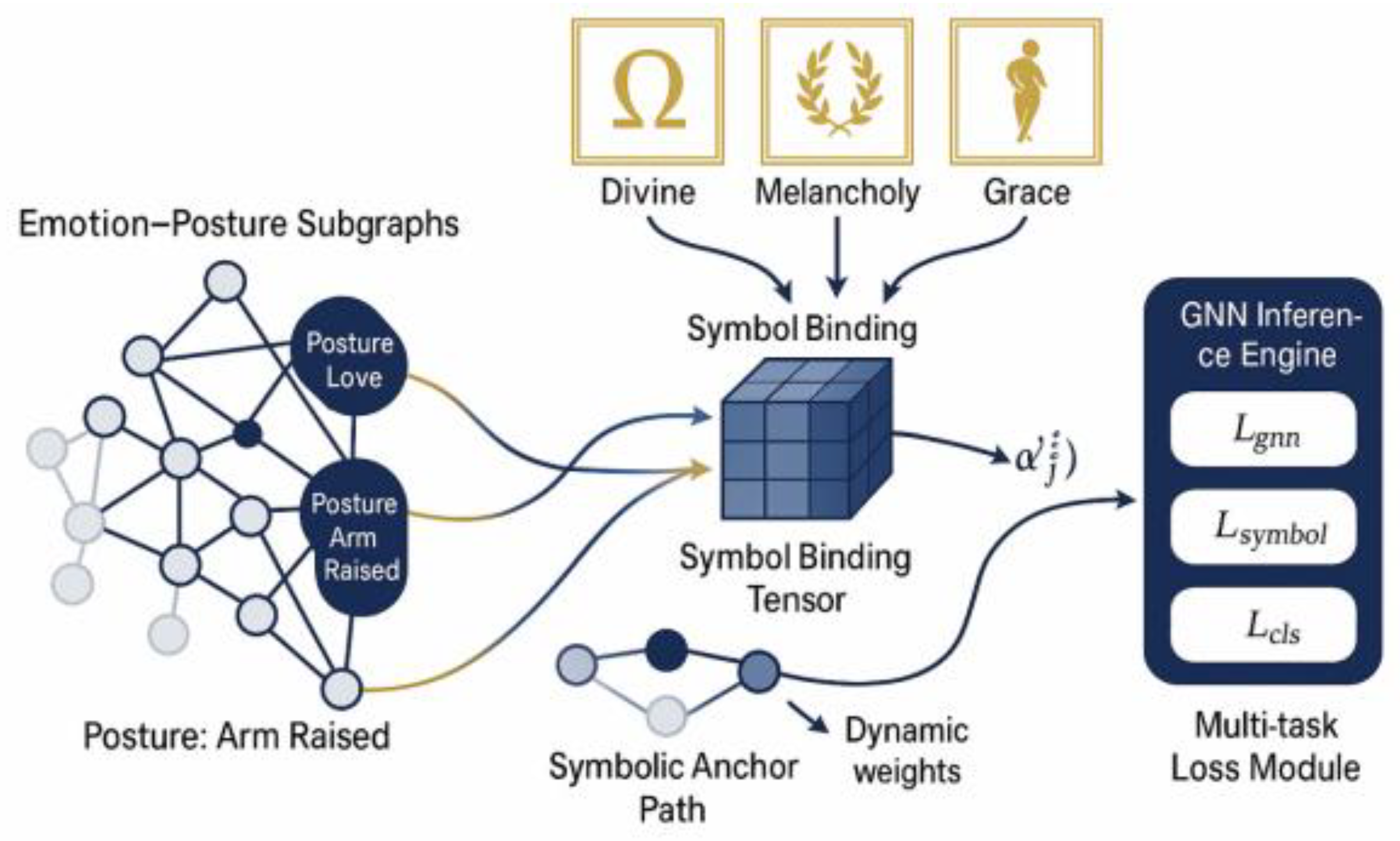
Figure 3.
Aesthetic Cognition A priori Causal Path Map.
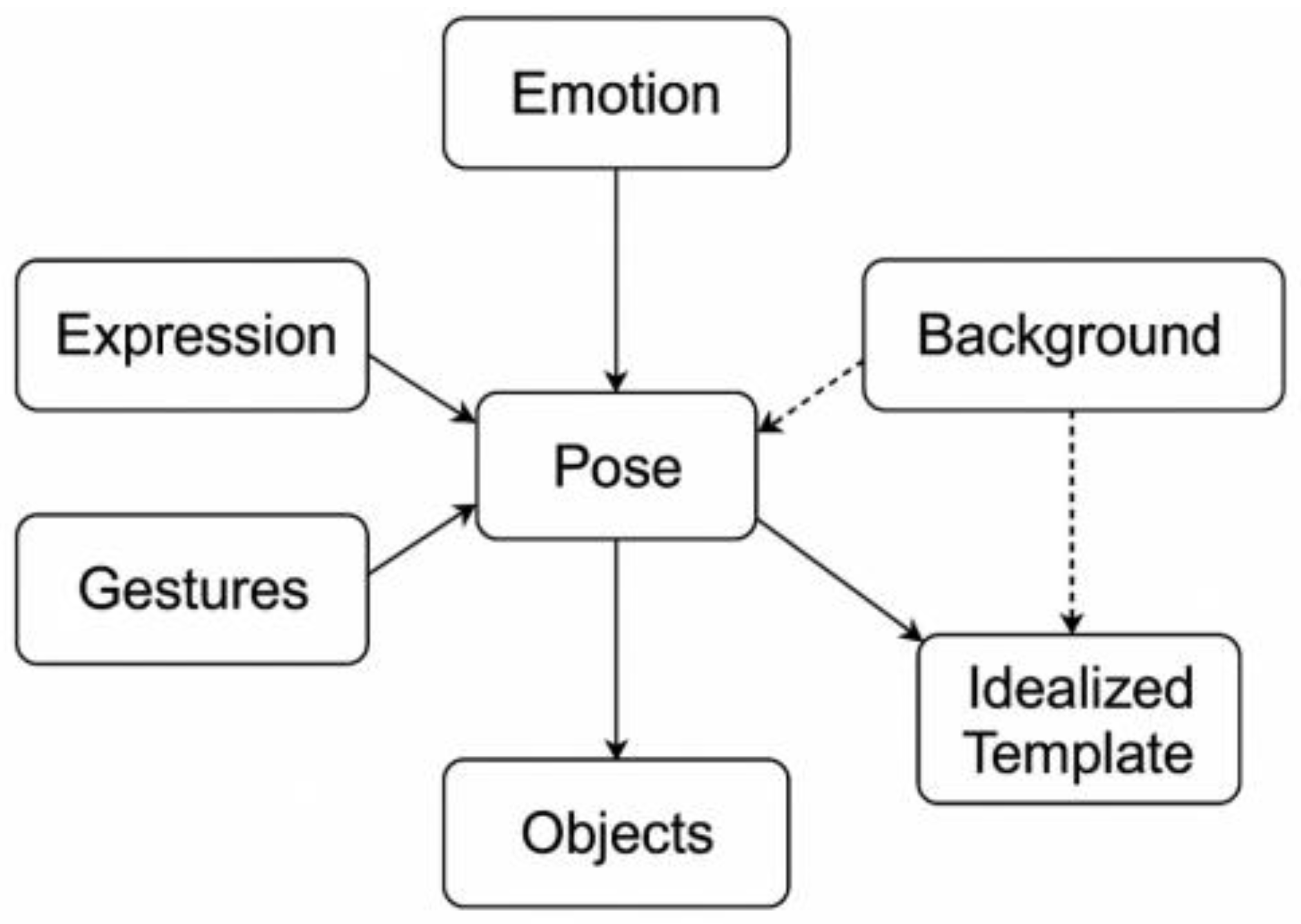
Figure 6.
Preliminary skeleton lines labelling the reconstruction of Venus’ broken arm.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



