Submitted:
30 June 2025
Posted:
30 June 2025
You are already at the latest version
Abstract
In the era of AI-driven e-commerce and advertising platforms, market segmentation and personalized recommendation have become essential for improving user conversion rates and marketing effectiveness. By leveraging artificial intelligence to conduct deep analysis of large-scale behavioral data from e-commerce platforms, it is possible to perform precise customer segmentation, identify diverse consumer groups, and develop customized marketing strategies. However, users in real-world recommendation scenarios typically exhibit multiple interaction behaviors—such as clicking, adding to cart, and purchasing—which makes it difficult for traditional single-task models to learn generalized representations without introducing task-specific biases. To address this challenge, we propose a pre-training paradigm designed to decouple task-specific and general knowledge in multi-behavior sequential recommendation (MBSR). Yet, conventional pre-trained models are often too large for practical adaptation by end users. Inspired by the success of prompt learning in the natural language processing field, we introduce CPL4Rec (Customized Prompt Learning for Recommendation), the first framework for customized prompt learning in MBSR. CPL4Rec generates user-specific prompts by integrating semantic embeddings from pre-trained models with diverse user attributes and behavioral information. Furthermore, to address the evolving nature of user interests over time, we incorporate a Progressive Feature Generation (PFG) framework that dynamically fuses multi-layer user representations within the model. To ensure controllability, we apply compactness regularization to constrain the prompt space. Extensive experiments conducted on three real-world datasets demonstrate that CPL4Rec achieves superior performance over state-of-the-art baselines in recommendation accuracy. This research offers a new technical pathway for AI-driven market segmentation and personalized e-commerce marketing, providing strong theoretical and empirical support for practical deployment in intelligent recommendation systems.
Keywords:
sequential recommendation
; pre-trained recommendation
; prompt learning
; personalized marketing
1. Introduction
With the accelerated convergence of artificial intelligence and the digital economy, e-commerce and advertising platforms are evolving toward intelligent, precision-based operations. Leveraging AI to deeply analyze massive user behavior data enables platforms to implement precise market segmentation, identify diverse customer groups, and develop personalized marketing strategies. This approach significantly improves recommendation accuracy, user conversion rates, and overall marketing effectiveness. Within this context, recommender systems have become a core technology for intelligent decision-making in e-commerce platforms. Among them, sequential recommendation (SR), which models historical user interactions as temporally ordered sequences to predict the next item, has garnered considerable attention from both academia and industry [1].
In real-world applications, users exhibit multiple types of behaviors (e.g., clicking, adding to favorites, and purchasing), each reflecting different dimensions of user preference. Modeling the dynamic evolution of these behaviors is critical for improving recommendation accuracy. Multi-Behavior Sequential Recommendation (MBSR) addresses this by incorporating various user actions into a unified model. Existing methods such as MMCLR [2], MBSTR [3], S-MBRec [4], and EHCF [5] have explored integrating multi-behavioral data using transformer or graph-based architectures, often combined with contrastive or meta-learning techniques to enhance the representation of target behaviors.
Despite their effectiveness, these methods face two key limitations. First is representation bias: many models are trained in an end-to-end manner, focusing solely on the target behavior’s loss function. This often results in overfitting to task-specific features and limits the generalization of learned representations across tasks. Second, current approaches lack effective knowledge transfer mechanisms. In practical scenarios such as cold-start user recommendations or multi-objective tasks, shared patterns and knowledge are abundant, yet these are rarely leveraged systematically. Most prior work treats each task as isolated, requiring separate training, which is computationally inefficient and lacks adaptability.
To overcome these challenges, we propose constructing a task-decoupled representation space that facilitates knowledge transfer across tasks. We first pretrain a general recommendation model using large-scale interaction data, where the pretraining objective is to predict the next behavior and next item—analogous to next-token prediction in NLP. This allows the model to learn contextual behavioral semantics. However, directly fine-tuning such large models for downstream tasks is computationally expensive and impractical. This raises the first challenge: how to efficiently adapt pre-trained models to personalized downstream scenarios.
Inspired by prompt learning in NLP, we introduce a novel framework called CPLRec (Customized Prompt Learning for Recommendation). Unlike language tokens in NLP, recommendation data lacks clear semantic anchors. Moreover, user behavior is highly personalized, making it difficult to design universal prompts. Thus, our second challenge is to generate effective, personalized prompts that align with individual user preferences.
To address this, CPLRec utilizes user profiles, behavioral history, and attribute information to generate tailored prompts. We hypothesize that user interest evolves layer by layer in the model hierarchy. Hence, we introduce a Prompt Factor Gate (PFG) network to decompose and integrate prompt information at different layers. This supports the construction of layer-specific prompts that combine shared and task-specific cues. We further enhance controllability and reduce convergence collapse by introducing compactness-based regularization to constrain prompt representations.
2. Related Work
The rapid expansion of digital commerce has heightened the importance of recommender systems (RS) in improving user experience, increasing engagement, and boosting sales. A wide array of approaches has emerged to enhance the accuracy, adaptability, and scalability of RS in e-commerce environments.
Pegah Malekpour Alamdari et al [6]. conducted a systematic review of e-commerce recommender systems, analyzing papers from 2008 to 2019. They categorized algorithms into five types, including Content-Based Filtering, Collaborative Filtering, Demographic-Based Filtering, hybrid filtering, and Knowledge-Based Filtering. By identifying gaps and issues in traditional methods, they provided guidelines for future research. They also compared important issues, advantages, disadvantages, metrics, and review issues of selected papers, offering valuable insights for future studies.
Lijuan Xu et al [7]. proposed an e-commerce platform recommendation model integrating random forest, GBDT and XGBoost to address info overload in online shopping. Experiments showed it reduces recommendation sparsity and boosts accuracy. Irem Islek et al [8]. proposed a hierarchical recommendation system for e - commerce, whose DeepIDRS approach with a two - level structure showed at least 10% better performance than other review - based models, enhancing e - commerce recommendation system performance.
Javed U et al [9]. comprehensively review content-based and context-aware recommender systems (CARS) in their paper, emphasizing core techniques, applications, and integration with semantic web technologies like ontology, OWL, and RDF. The paper focuses on overcoming limitations of traditional recommender systems by incorporating user context such as time, place, and companionship. It proposes semantic reasoning and ontologies to enhance basic keyword-based systems and highlights the importance of contextual information in dynamic environments.
Karn et al [10]. propose a hybrid recommendation system that integrates hybrid sentiment analysis (SA) with a hybrid recommendation model (HRM). While addressing cold start and data sparsity issues, this approach uses sentiment-aware post-filtering to improve recommendation quality, though details are limited due to the article’s retraction.
Bączkiewicz et al [11]. contributed a novel Multi-Criteria Decision-Making (MCDM) framework that combines five methods—TOPSIS-COMET, COCOSO, EDAS, MAIRCA, and MABAC—using the Copeland strategy to rank product alternatives. This hybrid DSS architecture, supported by CRITIC-based objective weighting and sensitivity analysis, enables nuanced product comparisons and enhances consumer decision support, especially in complex purchase scenarios with competing product attributes.
Across these works, several trends are evident: the growing importance of integrating multiple data modalities (behavioral logs, sentiment, metadata), the need for adaptive models to reflect evolving user preferences, and the continued relevance of addressing cold-start and data sparsity challenges. Innovative use of deep learning models (e.g., BERT), fuzzy logic, statistical analysis, and decision-making frameworks reflects a convergence between AI techniques and consumer-centric design in modern RS.
These contributions collectively signal a shift toward hybrid, interpretable, and context-aware recommender systems, capable of balancing algorithmic accuracy with user-centric relevance—ultimately supporting more engaging and efficient e-commerce experiences.
3. Preliminaries
In this section, we begin by presenting the task formulation of multi-behavior sequential recommendation. Subsequently, we introduce our proposed concept of Customized Prompt Learning in the recommendation scenario, which aims to exploit the potential of pre-trained large-scale models through dynamically setting prompts based on individual user characteristics and preferences.
DEFINITION 1. (Behavior-Aware Interaction Sequence) Given the sets of users U, items V, and types of behavior B. For a user , his/her behavior-aware interaction sequence consists of individual triples (v, b, t). Each triple represents the k-th interacted item (ordered by time) under the b-th behavior type at time t. Formally,
Furthermore, we define the behavior type we aim to forecast as the target behavior (e.g., purchase). Other types of user behaviors (e.g., cart, tag-as-favorite) are considered as side information to aid in modeling the patterns of the target behavior. Formally, our studied problem can be formalized as follows:
DEFINITION 2. (Multi-Behavior Sequential Recommendation) Input: the user and his/her Behavior-Aware Interaction Sequence . Output: the item that the user interacts with, specifically in the form of the target behavior, at time .
As shown in Figure 2, in recommendation scenarios, the tokens of the pre-trained model represent item ID information lacking specific semantics. As a result, it is not possible to manually design prompts with these tokens. In addition, personalization plays a crucial role in the recommendation problem. Hence, we introduce a novel concept called Customized Prompt Learning, which involves dynamically setting prompt conditions based on diverse side information specific to each user.
4. Methodology
4.1. Overall Framework
In this section, we introduce our framework CPL4Rec, which possesses personalization, progressiveness, and controllability. This framework represents the pioneering model for addressing the multi-behavioral sequential recommendation problem by leveraging customized prompt learning recommendation. The overall flow of the model is depicted in Figure 3.
4.2. Pre-Trained Model
In this subsection we describe how to train our pre-trained model for multi-behavioral recommendations.
SASRec [22] is a widely recognized pre-trained model that has under-gone extensive validation regarding its effectiveness in sequential recommendation tasks. The model stacks transformer() blocks to encode the historical behavior sequence comprising two sub-modules: a self-attention network and a point-wise feed-forward network. This architecture allows for a comprehensive exploration of the complex relationships between individual behaviors.
The embedding layer of the pre-trained model encodes item information, location information, and behavior information. Firstly, we utilize an item embedding matrix to project high-dimensional one-hot item representations into low-dimensional dense vectors. Secondly, when examining user behaviors, it is crucial to recognize that different behaviors can signify varying degrees of user interest. For instance, while clicks may provide some insight, behaviors such as purchases tend to be more reliable indicators of strong user interest. To address this, we introduce behavior-specific encoding denoted as , where the embedding of each item is mapped to specific behaviors. Thirdly, in order to accurately represent the positional information of a sequence, we utilize a learnable position embedding denoted as . This enables us to effectively capture the inherent sequential characteristics. The number of position vectors M limits the length of the user's historical sequence. Consequently, for each user belonging to the set U, we can derive the input representations of the items in their sequence as follows:
where is the representation of item .
After the embedding layer, the transformer block incorporates the self-attention module to capture the interdependencies among item pairs within the sequence. Furthermore, in order to extract information from distinct subspaces at each position, we employ multi-head self-attention instead of a single attention function. Subsequently, the transformer block imbues the model with non-linearity through a point-wise feed-forward network. To further enhance the model’s capacity for capturing intricate item migrations, we stack multiple transformer blocks, which can be defined as follows:
where we represent the transformer block simply as and where =||. Finally, based on several transformer blocks, we obtain the user representation generated at the L-th layer which L is the number of transformer layers.
In order to optimize the model, we employ the loss function of SASRec. Emulating the pre-training task of predicting the next word of a sentence in NLP, we let the model predict the next user behavior and the next item of interaction, allowing the model to understand the contextual semantics of the sequence, which means that we map the representation of the correct item by the correct behavior matrix. The specific loss functions used in our approach are presented below:
where , are positive and negative sample pairs, respectively.
This training method facilitates comprehensive learning and understanding of contextual semantics within user sequences. By leveraging a substantial amount of training data, it effectively establishes a task-agnostic, generalized representation space.
4.3. Personalized Prompt Generator
After acquiring pre-trained models, retraining them for downstream tasks proves to be challenging due to their large size. Therefore, our initial hurdle is to effectively transfer the pre-trained generic knowledge to these downstream tasks. In order to fully leverage the capabilities of pre-trained models, a crucial aspect of our model is the generation of a highly effective prompt that serves as a bridge between pre-trained models and downstream tasks. Drawing upon the concept of customized prompt learning, we introduce our CPL4Rec model in the context of a multi-behavioral sequential recommendation problem.
In our model, we aim to automatically and effectively generate personalized prompts for each user. To achieve this, we leverage a wide range of user-specific information, including user attributes, behavioral statistics, and additional user behaviors.
In order to obtain user attribute information, such as 'gender' and 'age', we initially perform an embedding operation. For continuous variables, we implement segmental discretization prior to the embedding process. In addition, users demonstrate varying numbers of historical behaviors and possess inconsistent cross-conversion relationships among these behaviors. These variations play a crucial role in user modeling. For instance, when a user has a wealth of target behavior data, it becomes necessary to proportionally reduce the prompts to minimize interference. Conversely, for cold start users, it is important to enhance the prompts in order to fully leverage the user's side information. To capture this variability, we discretize the number of individual behaviors, conversion amounts, and other statistical metrics, and encode them as attribute information within the user representation. Subsequently, we concatenate all the user representation embeddings and encode them within a multi-layer MLP structure to derive the ultimate representation.
In addition, following GRU4Rec [18], we employ a simple and efficient Gated Recurrent Unit structure to generate prompts for diverse behaviors. The inherent reset and update mechanism of GRU aids in filtering out noise present in behavior sequences. In the process of generating prompts about user behavior, we all use the same structure i.e. R-layer GRU to generate the final prompt vector representation. The specific formula is as follows:
where represents the embedding of the first byte of user and represents the generated prompt information regarding the attribute for user using a multi-layer MLP. The behavior sequence input is represented as ], and denotes the hidden state of the last layer at the last step.
5. Experiment
In this section, we conduct experiments to assess the effectiveness of our proposed CPL4Rec framework and answer the following research questions: RQ1: How does our CPL4Rec perform as compared to various state-of-the-art recommendation methods? RQ2: What are the impacts of different components in CPL4Rec? RQ3: How does CPL4Rec perform in other downstream tasks?
5.1. Experimental Setting
5.1.1. Datasets
To comprehensively investigate the performance of CPL4Rec, we conduct experiments on three large-scale real-world recommendation datasets, which are widely utilized in multi-behavioral sequential recommendation research and are considered standard benchmarks.
CIKM. The CIKM dataset is an E-commerce recommendation dataset that was released by Alibaba. It originates from the data mining competition known as CIKM 2019 EComm AI, which specifically focused on the efficient retrieval of user interests for ultra-large-scale recommendations. There are 4 types of user behavior: browsing, like, add to cart and buy.
IJCAI. This dataset is released by IJCAI Contest 2015 for the task of repeat buyers prediction. The user behavior data contains various interactions: click, add-to-cart, add-to-favourite, and purchase.
Taobao. This dataset is collected from Taobao which is one of the largest e-commerce platforms in China. Four types of user-item interactions are included in this dataset, i.e., page view, tag-as-favorite, cart, and buy.
In data processing, the previous method [12,13] predominantly eliminates cold start data from the dataset, potentially leading to a deviation from real-world scenarios. Real-world user interactions typically follow a long-tail distribution, where most user interaction data is sparse. Therefore, our experiment focuses on preserving the original dataset’s distribution as closely as possible to align with the characteristics observed in real-world scenarios. We fo-cused on purchase behavior as the target behavior in our study. We only imposed a minimum requirement of three target behaviors for inclusion in the evaluation of few-shot and zero-shot experi-ments. We performed duplicate record removal and data denoising. This approach aims to enhance the model’s robustness and generalization, ensuring that the pre-training process is not excessively influenced by noisy and outlier-rich instances [14].
5.1.2. Evaluation Metrics.
We evaluate models in terms of the top-K recommendation performance with two metrics, i.e., the Hit Ratio (HR@K) and the Normalized Discounted Cumulative Gain (NDCG@K), which are widely used in related works. HR@K is a recall-based metric that measures the average proportion of right items in the top-K recommendation lists. NDCG@K evaluates the ranking quality of the top-K recommendation lists in a positional way. In our experiments, we adopt the leave-one-out strategy for performance evaluation. For each user, we regard the temporally ordered last purchase as the test samples and the previous ones as validation samples [15].
5.2. Overall Performances
In Table 2, we present a comprehensive performance comparison across different datasets, and we summarize our observations as follows:
Firstly, we observe that compared to traditional single-behavior approaches, more advanced multi-behavior methods often yield superior results. This demonstrates the effectiveness of incorporating multi-behavior data to facilitate the modeling of the target behavior. These diverse behaviors reflect users' preferences across various dimensions and can function as supplementary knowledge to enhance information and enhance recommendation accuracy for the target behavior.
Secondly, we have observed certain exceptional cases where multi-behavior approaches are weaker than single-behavior methods on certain datasets. This weakness may arise from the model's inadequate depth in exploring various actions, as well as the need for the model to handle a substantial amount of behavioral information and its interrelationships. As a result, there is a potential risk of overfitting to additional or high-frequency actions, thereby overlooking the crucial features of the target action.
Thirdly, we applied several transformer architectures as single-behavior models to multi-behavior recommendation tasks. We observed that their performance varied, sometimes yielding positive outcomes while other times falling short. Although these models demonstrated extensive exploration of patterns in multi-behavior scenarios, their lack of efficient fine-tuning hindered their overall effectiveness. PPR, the pioneering work in incorporating prompt learning to address the cold-start problem, faced limitations due to its failure to devise an effective mechanism for incorporating user information. Consequently, it struggled to extend its applicability to the multi-behavior problem.
Last but not least, our CPL4Rec method achieved the best performance across all datasets, indicating that we have not only fully leveraged the potential of the pre-trained model but also effectively transferred it to downstream tasks. Surprisingly, it even approached or surpassed the overall fine-tuning effectiveness to some extent. In addition, CPL4Rec demonstrates parameter efficiency as it requires tuning and storing only a limited number of parameters compared to fine-tuning. As indicated in Table 3, within our datasets, the parameter update count in CPL4Rec amounts to only 1.2%, 1.4%, and 0.8% of that required for fine-tuning. Similarly, the time required for CPL4Rec is merely 8.15%, 12.96%, and 7.43% of that needed for fine-tuning, respectively.
6. Conclusions
This study proposes a pre-training paradigm for multi-behavior sequential recommendation tasks in the context of AI-driven e-commerce and advertising platforms, aiming to support precise market segmentation and personalized marketing strategy optimization. Traditional recommendation systems often fail to capture users’ true and multidimensional preferences, as they overlook the diverse behavioral patterns exhibited by users across different scenarios. To address this limitation, we introduce a Customized Prompt Learning mechanism and develop the CPL4Rec framework. This framework integrates three key design principles—personalization, progressiveness, and controllability—to fully exploit the semantic potential of pre-trained models and effectively transfer general knowledge to downstream recommendation tasks through the generation of user-specific prompts.
Specifically, CPL4Rec leverages user historical behaviors, attribute information, and semantic context features to generate multi-granular prompts for different layers of the model, enabling dynamic modeling of evolving user interests. To prevent over-convergence in the prompt space, a compactness-based regularization term is introduced as a control mechanism, enhancing the model’s generalization and expressive capabilities in multi-task settings. Experiments conducted on multiple real-world e-commerce datasets demonstrate that CPL4Rec consistently outperforms state-of-the-art methods across various downstream tasks, significantly improving recommendation accuracy and personalization. The framework is particularly well-suited for understanding user behavior and delivering precise recommendations on AI-driven e-commerce platforms.
Future work will further refine the theoretical foundation of customized prompt learning to develop more efficient models and broaden their applicability to a wider range of downstream tasks. This will contribute to the development of intelligent decision-support tools for smart e-commerce and digital marketing.
References
- Du H, Shi H, Zhao P, et al. Contrastive learning with bidirectional transformers for sequential recommendation[C]//Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022: 396-405.
- Wu Y, **e R, Zhu Y, et al. Multi-view multi-behavior contrastive learning in recommendation[C]//International conference on database systems for advanced applications. Cham: Springer International Publishing, 2022: 166-182.
- Yuan E, Guo W, He Z, et al. Multi-behavior sequential transformer recommender[C]//Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 2022: 1642-1652.
- Gu S, Wang X, Shi C, et al. Self-supervised Graph Neural Networks for Multi-behavior Recommendation[C]//IJCAI. 2022: 2052-2058.
- Chen C, Zhang M, Zhang Y, et al. Efficient heterogeneous collaborative filtering without negative sampling for recommendation[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(01): 19-26.
- Alamdari P M, Navimipour N J, Hosseinzadeh M, et al. A systematic study on the recommender systems in the E-commerce[J]. Ieee Access, 2020, 8: 115694-115716. [CrossRef]
- Xu L, Sang X. E-Commerce Online Shopping Platform Recommendation Model Based on Integrated Personalized Recommendation[J]. Scientific Programming, 2022, 2022(1): 4823828. [CrossRef]
- Islek I, Oguducu S G. A hierarchical recommendation system for E-commerce using online user reviews[J]. Electronic Commerce Research and Applications, 2022, 52: 101131. [CrossRef]
- Javed U, Shaukat K, Hameed I A, et al. A review of content-based and context-based recommendation systems[J]. International Journal of Emerging Technologies in Learning (iJET), 2021, 16(3): 274-306. [CrossRef]
- Karn A L, Karna R K, Kondamudi B R, et al. RETRACTED ARTICLE: Customer centric hybrid recommendation system for E-Commerce applications by integrating hybrid sentiment analysis[J]. Electronic commerce research, 2023, 23(1): 279-314. [CrossRef]
- Bączkiewicz A, Kizielewicz B, Shekhovtsov A, et al. Methodical aspects of MCDM based E-commerce recommender system[J]. Journal of Theoretical and Applied Electronic Commerce Research, 2021, 16(6): 2192-2229.
- Wei W, Huang C, **a L, et al. Contrastive meta learning with behavior multiplicity for recommendation[C]//Proceedings of the fifteenth ACM international conference on web search and data mining. 2022: 1120-1128.
- Guo L, Hua L, Jia R, et al. Buying or browsing?: Predicting real-time purchasing intent using attention-based deep network with multiple behavior[C]//Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019: 1984-1992.
- Rahman S, Khan S, Porikli F. A unified approach for conventional zero-shot, generalized zero-shot, and few-shot learning[J]. IEEE Transactions on Image Processing, 2018, 27(11): 5652-5667. [CrossRef]
- Alsini A, Huynh D Q, Datta A. Hit ratio: An evaluation metric for hashtag recommendation[J]. arxiv preprint arxiv:2010.01258, 2020.
Figure 2.
Traditional Prompt Learning methods in NLP vs.Customized Prompt Learning.
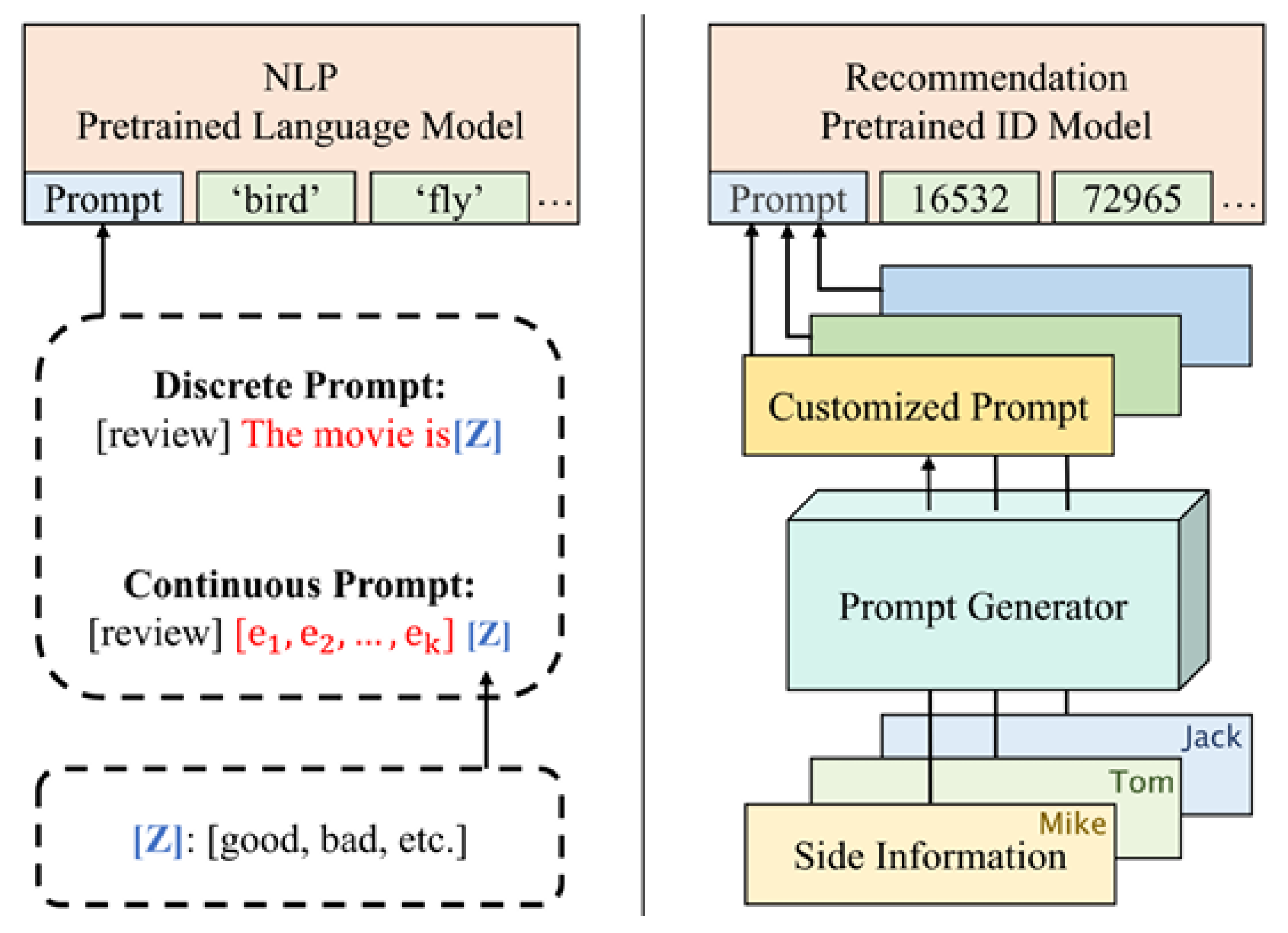
Figure 3.
The overall framework of our CPL4Rec model.
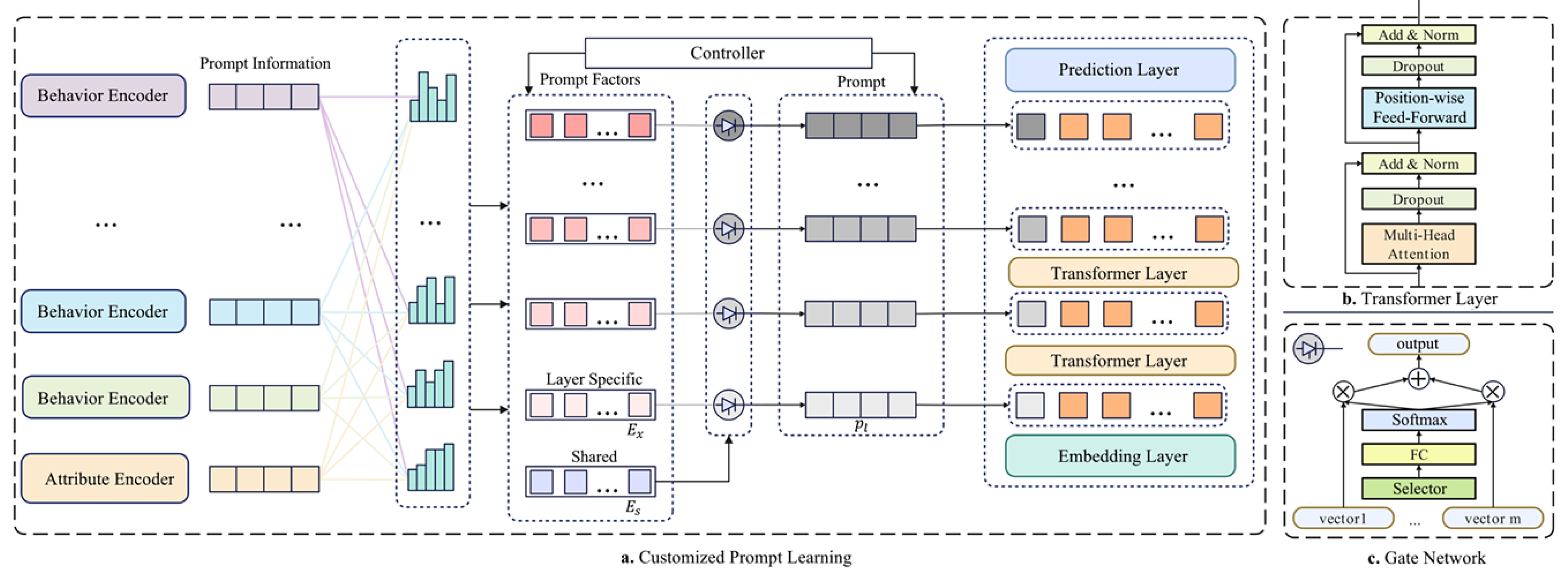

Table 2.
Overall performance comparison of all methods in terms of HR@N and NDCG@N (N = 10,20).
| Model | CIKM | Taobao | IJCAI | |||||||||
| H@10 | N@10 | H@20 | N@20 | H@10 | N@10 | H@20 | N@20 | H@10 | N@10 | H@20 | N@20 | |
| GRU4Rec | 0.293 | 0.169 | 0.338 | 0.195 | 0.266 | 0.150 | 0.290 | 0.169 | 0.322 | 0.178 | 0.397 | 0.226 |
| SASRec | 0.353 | 0.215 | 0.460 | 0.264 | 0.346 | 0.204 | 0.443 | 0.246 | 0.405 | 0.217 | 0.526 | 0.271 |
| Bert4Rec | 0.387 | 0.248 | 0.511 | 0.270 | 0.330 | 0.193 | 0.425 | 0.230 | 0.433 | 0.238 | 0.565 | 0.318 |
| S3Rec | 0.401 | 0.233 | 0.472 | 0.269 | 0.320 | 0.198 | 0.430 | 0.224 | 0.402 | 0.224 | 0.540 | 0.280 |
| CL4Rec | 0.400 | 0.245 | 0.468 | 0.294 | 0.362 | 0.213 | 0.420 | 0.233 | 0.426 | 0.257 | 0.550 | 0.315 |
| MBGCN | 0.454 | 0.261 | 0.552 | 0.299 | 0.403 | 0.224 | 0.501 | 0.267 | 0.480 | 0.257 | 0.614 | 0.328 |
| NMTR | 0.305 | 0.178 | 0.362 | 0.209 | 0.282 | 0.161 | 0.320 | 0.185 | 0.339 | 0.183 | 0.423 | 0.235 |
| MBGMN | 0.431 | 0.253 | 0.550 | 0.332 | 0.418 | 0.242 | 0.468 | 0.275 | 0.388 | 0.229 | 0.494 | 0.300 |
| MBPPR | 0.349 | 0.178 | 0.421 | 0.232 | 0.315 | 0.181 | 0.393 | 0.205 | 0.371 | 0.192 | 0.436 | 0.242 |
| CPL4Rec | 0.483 | 0.280 | 0.613 | 0.365 | 0.498 | 0.268 | 0.566 | 0.307 | 0.550 | 0.299 | 0.696 | 0.379 |
| Improv. | 6.3% | 0.104 | 0.120 | 0.123 | 0.129 | 0.134 | 0.145 | |||||
Table 3.
Efficiency experiments compared to fine-tuning.
| Settings | GRU4Rec | Fine-tuning | Para | Time | |
|
CIKM |
H@10 | 0.483 | 0.469 |
1.25% |
8.15% |
| N@10 | 0.280 | 0.273 | |||
|
Taobao |
H@10 | 0.498 | 0.461 |
1.42% |
12.96% |
| N@10 | 0.268 | 0.267 | |||
|
IJCAI |
R@10 | 0.550 | 0.568 |
0.86% |
7.43% |
| N@10 | 0.299 | 0.301 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



