
Submitted:
24 June 2025
Posted:
25 June 2025
You are already at the latest version
Abstract
The integration of generative AI into statistical analysis is revolutionizing medical research, offering unprecedented opportunities for enhancing data interpretation and educational methodologies. This paper explores the challenges and potential misuse of AI-generated outputs in statistical data analysis, specifically focusing on t-tests. Through a detailed examination, we highlight the pitfalls associated with over-reliance on AI and propose a robust framework for using AI tools like Julius AI in hypothesis testing. Our findings demonstrate that while AI can significantly aid in understanding and applying statistical tests, it is essential to use these tools correctly to avoid erroneous outputs and misinterpretations. By adopting a step-by-step approach, educators can empower medical students and researchers to leverage AI effectively, thereby improving their analytical skills and critical thinking. This framework not only enhances the learning experience but also ensures accurate and reliable data analysis, ultimately contributing to more robust and valid conclusions in medical research.
Keywords:
Artificial intelligence (AI)
; ChatGPT
; educators
; Julius AI
; medical research
; statistical tests
; teaching statistics
1. Introduction
The unprecedented evolution of artificial intelligence (AI) in recent years, marked by the public release of ChatGPT by OpenAI in November 2022 [1], has changed many areas from understanding human language to analyzing complex data. These new AI systems use large amounts of data and advanced learning techniques to do tasks that used to need human experts. Because these models are easy to access and develop quickly, they have gained worldwide attention and are now being used in many professional fields, including education and research [2].
Generative AI has greatly influenced medical research worldwide, transforming areas like drug discovery, genomics, and personalized medicine. A report by McKinsey states that the global market for generative AI in healthcare was worth USD 1.8 billion in 2023 and is projected to grow at an annual rate of 33.2% from 2024 to 2032 [3]. This growth is due to generative AI’s ability to analyze large datasets, create hypotheses, and speed up the research process. For example, AI models have been used to predict protein structures, find potential drug candidates, and simulate clinical trials, thus reducing the time and cost of traditional research methods [4].
In the African context, the adoption of generative AI in medical research is still emerging but shows promising potential. A scientometric analysis published in 2023 highlighted that AI research in African healthcare is predominantly concentrated in South Africa, Nigeria, and Ghana [5]. The study found that the most common AI tools used in African medical research include deep learning neural networks applied in medical imaging and adaptive neuro-fuzzy inference systems [5]. Despite the limited number of published articles, there is a growing interest and investment in AI technologies across the continent, with a focus on addressing local healthcare challenges such as infectious diseases and resource scarcity [5].
In medical education, generative AI is being added to the curriculum to improve learning and research. A survey in the USA found that medical students use generative AI for tasks like creating learning materials, helping with research, and clinical documentation [6]. For instance, Harvard Medical School has included AI in its courses, teaching students how to use AI tools for medical research and clinical decisions [7]. While African medical schools are beginning to explore the integration of AI into their curricula, the region faces significant challenges such as inadequate infrastructure and limited access to advanced technologies, which hinder the widespread adoption of AI to support traditional teaching methods and provide students with advanced research tools [8].
Generative AI is starting to transform teaching methods by offering real-time assistance, automating basic tasks, and enabling new ways to analyze data. The benefits of these systems, such as providing immediate feedback and generating code or analytical frameworks, are clear. However, there is a growing concern about the potential for over-reliance on AI-generated outputs [9]. Over-reliance on AI can pose several risks, especially in educational and professional settings. When users depend too much on AI-generated outputs, they might not engage deeply with the material, leading to a decline in critical thinking and problem-solving skills. AI systems can make mistakes, and over-reliance can result in users accepting incorrect or incomplete information without questioning it, which can lead to significant errors in decision-making [10].
This concern is particularly critical in medical research, where statistical analyses are fundamental to decision-making processes. Misinterpretation or misuse of statistical tests, such as the t-test, can result in significant errors in clinical conclusions, potentially jeopardizing patient safety [11]. As generative AI tools become more prevalent in health research, there is an urgent need to incorporate comprehensive statistical education that highlights both the strengths and limitations of these technologies. This paper uses the t-test as an example to demonstrate how generative AI can produce erroneous results and provides strategies to avoid these errors in data analysis. By addressing these issues, the paper aims to enhance the proper use generative AI in data analysis.
2. Statistics in Medical Research
Medical research heavily relies on statistical methods to evaluate treatment effects and make critical decisions. Despite the importance of rigorous statistical analysis, the application of these methods has often been fraught with errors and misinterpretations [12]. The advent of generative AI has raised concerns that these problems could be magnified, as researchers may rely on automated outputs without a full understanding of underlying statistical concepts. Numerous studies have documented that nearly 50% of articles in biomedical and dental research are compromised by one or more statistical inaccuracies [13]. These inaccuracies span a range of errors, including sampling bias, inappropriate implementation of null hypothesis significance testing, and a failure to report or interpret effect sizes. Such oversights not only distort the magnitude of research outcomes but also increase the likelihood of type I errors when multiple comparisons are made without appropriate corrections. These methodological flaws jeopardizes the internal validity of studies and misinforms subsequent research and policy decisions.
2.1. Statistical Tests and Assumptions
Statistical tests are indispensable in empirical research, providing a framework for hypothesis testing and inference. These tests, however, are predicated on several critical assumptions, such as normality, homogeneity of variances, and independence of observations [14]. For instance, parametric tests like the t-test and ANOVA assume that the data are normally distributed and that variances are equal across groups. When these assumptions are satisfied, the tests yield valid p-values and confidence intervals, thereby supporting robust conclusions [14].
The violation of these assumptions can lead to substantial analytical issues. Non-normality, for example, can distort test statistics, resulting in inaccurate p-values and potentially erroneous conclusions [15]. Heteroscedasticity, or unequal variances, can inflate type I error rates, increasing the likelihood of falsely rejecting the null hypothesis. Furthermore, the independence assumption is crucial; its violation, often due to autocorrelation, can result in underestimated standard errors and inflated test statistics, thereby compromising the integrity of the analysis. These violations necessitate the use of alternative methods or data transformations to mitigate their impact [14].
To address assumption violations, researchers can employ several strategies. Non-parametric tests, such as the Mann-Whitney U test or the Kruskal-Wallis test, do not require normality and are robust to heteroscedasticity. Data transformations, such as logarithmic or square root transformations, can help stabilize variances and normalize distributions. Additionally, robust statistical methods, like Welch’s ANOVA, can be used when variances are unequal. It is imperative for researchers to thoroughly check and report the assumptions underlying their statistical tests to ensure the validity of their findings and to apply appropriate remedies when assumptions are violated [16].
2.2. T-Tests and Their Assumptions
The independent t-test and paired t-test are both predicated on specific assumptions to ensure the validity of their results. The independent t-test assumes that the data in each group are normally distributed, the variances of the two groups are equal (homogeneity of variances), and the observations are independent of each other. These assumptions are crucial for the test to provide accurate p-values and confidence intervals, thereby supporting robust statistical inferences [14,16].
The paired t-test, on the other hand, assumes that the differences between the paired observations are normally distributed and that there are no extreme outliers in these differences. This test is particularly sensitive to the normality of the differences, as it relies on the assumption that the paired differences follow a normal distribution. Ensuring these assumptions are met is essential for the paired t-test to yield valid and reliable results, allowing researchers to draw meaningful conclusions from their data [14,16].
3. Illustration
Using a hypothetical example, we illustrate how outputs from generative AI can be misleading and how such erroneous outputs can be avoided. To make this illustration engaging, we added a narrative behind the data.
3.1. Data
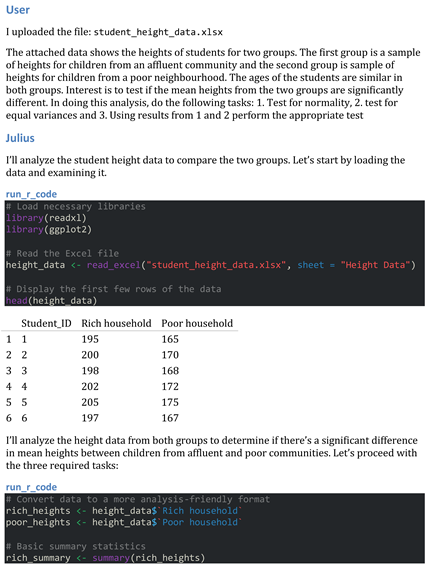
The following data shows the heights of students for two groups. The first group is a sample of heights for children from an affluent community and the second group is sample of heights for children from a poor neighbourhood. The ages of the students are similar in both groups. Interest is to test if the mean heights from the two groups are significantly different.

Table 1.
Hypothetical data.
| Student_ID | Rich household | Poor household |
| 1 | 195.00 | 165.00 |
| 2 | 200.00 | 170.00 |
| 3 | 198.00 | 168.00 |
| 4 | 202.00 | 172.00 |
| 5 | 205.00 | 175.00 |
| 6 | 197.00 | 167.00 |
| 7 | 203.00 | 173.00 |
| 8 | 201.00 | 171.00 |
| 9 | 199.00 | 169.00 |
| 10 | 204.00 | 174.00 |
To analyze these data using AI, it is important to communicate effectively with the large language model. Prompt engineering is the art and science of crafting effective prompts to guide AI models in generating desired outputs. At its core, it involves designing natural language inputs that instruct AI models to produce specific responses. This process is less about coding and more about how instructions are phrased to align with the AI’s understanding of language. The quality of the prompt can significantly influence the accuracy and relevance of the AI’s output. For the purpose of this illustration, we shall use Julius AI.
Julius AI is an advanced AI tool designed to assist with data analysis and visualization. It integrates capabilities from various AI technologies, including natural language processing and machine learning, to provide expert-level insights from data. Julius AI allows users to interact with their data through natural language queries, making it accessible to those without extensive technical expertise. At the time of writing this paper, Julius AI had three models in it which are GPT 4o, Claude 3.5, and Claude 3.7 sonnet. The user can choose between these models. For coding and analysis, the user can choose between R, python and lean python. In this paper we made use of R because R is free and commonly used in data analysis.
Approach 1
A naïve approach would be to ask AI to perform a t-test, based on the realization that the data is continuous and the sample size is small. Using this approach produces the following output as shown in Figure 1. The model used here was the GPT 4o. A similar output was obtained using Claude 3.7 Sonnet.
In this output, Julius AI has not tested the assumptions of the t-test. This output is produced using the equal variances assumption without a formal test. In cases where such assumptions are violated, a wrong output will be produced, which is dangerous. To illustrate this, we introduced some outliers in the heights for students from poor households. We changed the heights for students 1 and 9 to 196 and 186, respectively, and ran the same prompt. Julius AI performed the analysis as previously, yet the normality assumption was violated. The code run was:
Welch Two Sample t-test
data: df$`Rich household` and df$`Poor household`
t = 8.3385, df = 11.244, p-value = 3.801e-06
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
18.56586 31.83414
sample estimates:
mean of x mean of y
200.4 175.2
This is a wrong test and it is a result of not using generative AI correctly.
Approach 2
In this approach, the user assumes no knowledge of statistics and provides as much information as possible to the AI model. In this case, we included the narrative behind the data and then asked AI to analyze. This approach is not reliable either. Initially, the analysis was done using GPT-4o in Julius AI, and the results were the same as in the previous approach. Switching to Claude 3.7 Sonnet produced the correct result. For the rest of this illustration section, we used Claude 3.7 Sonnet. The prompts were the same: we added the narrative from the data and then "Analyze the data." We then requested an MS Word document to be created for the analysis. Figure 2 shows the summary document:
Approach 3
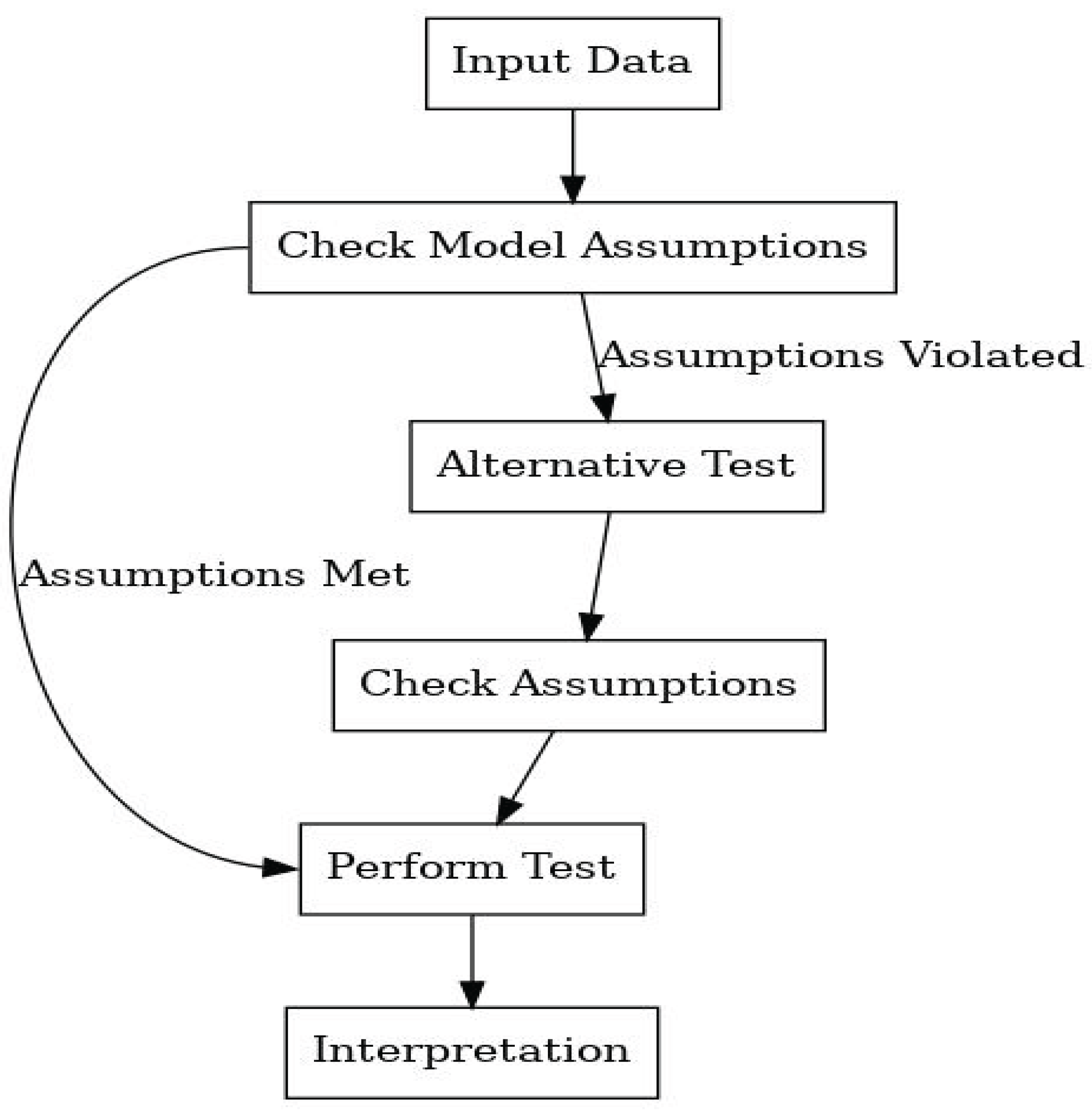
This is a step-by-step approach. The user should break down the analysis into smaller chunks, requiring some knowledge about the test to be performed. The user tells AI exactly what to do in each step, avoiding hallucinations from AI. Since the analysis from this step-by-step approach produced many pages, we decided to put this output in Appendix A. The user first loads the data and then instructs AI on what to do with the data. It can be seen from Appendix A that the task was broken down into smaller chunks. The output is correct, and the interpretation given in the conclusion is appropriate. The user can add more details on the tests for assumptions, such as the test to be used. There are several tests that can be used to test equality for variances. The same applies to testing the normality assumption; others may prefer a visual inspection. From this approach, we propose the following framework for using generative AI in hypothesis testing problems.
In this framework, we assume some knowledge about the statistical test to be performed, as shown in Figure 3. The user should know which assumptions to test and, if there is a preferred test to be used, provide its name in the prompt. The user starts by loading the data, identifying the model to be used, and then testing the assumptions of the model. If the assumptions are met, the user then proceeds to instruct AI to perform the test and interpret the results. If the assumptions are violated, the user then selects an alternative test and tests assumptions again for the alternative test using generative AI. The user can ask AI to suggest alternative tests. For example, if the normality assumption in the example above is violated, a non-parametric test can be performed. We believe that by using this framework, hallucinations and erroneous responses can be avoided from generative AI. Basic knowledge about the test is needed, and it is our view that health researchers in most cases have such basic knowledge. This framework does not apply only to health researchers but to users of statistics in general.
4. Conclusion
The integration of generative AI into the teaching of data analysis offers transformative potential for enhancing statistical education in medical research. AI tools, such as Julius AI, can provide real-time assistance, automate basic tasks, and enable innovative approaches to data analysis. This paper has demonstrated that while AI can significantly aid in the understanding and application of statistical tests, it is crucial to use these tools correctly to avoid erroneous outputs and misinterpretations.
The proposed framework emphasizes a step-by-step approach to using AI in hypothesis testing, ensuring that assumptions are thoroughly checked and appropriate tests are selected. This method not only mitigates the risk of over-reliance on AI but also encourages a deeper engagement with statistical concepts among students. By incorporating this framework into the curriculum, educators can empower students to leverage AI effectively, enhancing their analytical skills and critical thinking.
Generative AI has the potential to revolutionize the teaching of data analysis in medical research by providing robust support and ensuring a comprehensive understanding of statistical principles. The framework proposed in this paper serves as a valuable guide for educators, ensuring that AI is used judiciously and effectively in the classroom. This approach not only enhances the learning experience but also prepares students to navigate the complexities of data analysis with confidence and precision.
Appendix E Julius AI Claude 3.7 Sonnet Output Using Approach 3
References
- AI, O. Introducing ChatGPT. https://openai.com/blog/chatgpt/, 2022. Accessed: April 02, 2025.
- Frey, C.B.; Osborne, M.A. The future of employment: How susceptible are jobs to computerisation? Technological forecasting and social change 2017, 114, 254–280. [Google Scholar] [CrossRef]
- Insights, G.M. Generative AI in Healthcare Market – By Application, By End Use - Global Forecast, 2024 to 2032. https://openai.com/blog/chatgpt/, 2022. Accessed: April 02, 2025. 02 April.
- Ackerman, P.E.; Andrews, E.; Carter, C.M.; DeMaio, C.D.; Knaple, B.S.; Larson, H.; Lonstein, W.; McCreight, R.; Muehlfelder, T.; Mumm, H.C.; et al. Intersection of Biotechnology and AI (Sincavage & Muehlfelder & Carter). Advanced Technologies for Humanity 2024. [Google Scholar]
- Njei, B.; Kanmounye, U.S.; Mohamed, M.F.; Forjindam, A.; Ndemazie, N.B.; Adenusi, A.; Egboh, S.M.C.; Chukwudike, E.S.; Monteiro, J.F.G.; Berzin, T.M.; et al. Artificial intelligence for healthcare in Africa: a scientometric analysis. Health and Technology 2023, 13, 947–955. [Google Scholar] [CrossRef]
- Ichikawa, T.; Olsen, E.; Vinod, A.; Glenn, N.; Hanna, K.; Lund, G.C.; Pierce-Talsma, S.; et al. Generative Artificial Intelligence in Medical Education—Policies and Training at US Osteopathic Medical Schools: Descriptive Cross-Sectional Survey. JMIR Medical Education 2025, 11, e58766. [Google Scholar] [CrossRef] [PubMed]
- Gehrman, E. How Generative AI Is Transforming Medical Education. https://https://magazine.hms.harvard.edu/articles/how-generative-ai-transforming-medical-education, 2024. Accessed: April 02, 2025.
- Andigema, A.; Cyrielle, N.N.T.; Danaëlle, M.K.L.; Ekwelle, E. Transforming african healthcare with AI: paving the way for improved health outcomes. Journal of Translational Medicine & Epidemiology 2024, 7, 1–8. [Google Scholar]
- Cribben, I.; Zeinali, Y. The benefits and limitations of ChatGPT in business education and research: A focus on management science, operations management and data analytics. Operations Management and Data Analytics (March 29, 2023) 2023.
- Zhai, C.; Wibowo, S.; Li, L.D. The effects of over-reliance on AI dialogue systems on students’ cognitive abilities: a systematic review. Smart Learning Environments 2024, 11, 28. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, R.; He, J.; Xiang, Y. Evaluating ChatGPT-4.0’s data analytic proficiency in epidemiological studies: A comparative analysis with SAS, SPSS, and R. Journal of Global Health 2024, 14, 04070. [Google Scholar] [CrossRef] [PubMed]
- Sackett, D.L. Evidence-based medicine. In Proceedings of the Seminars in perinatology. Elsevier, 1997, Vol. 21, pp. 3–5.
- Thiese, M.S.; Arnold, Z.C.; Walker, S.D. The misuse and abuse of statistics in biomedical research. Biochemia medica 2015, 25, 5–11. [Google Scholar] [CrossRef] [PubMed]
- Mann, P.S. Introductory statistics; John Wiley & Sons, 2010.
- Nørskov, A.K.; Lange, T.; Nielsen, E.E.; Gluud, C.; Winkel, P.; Beyersmann, J.; de Uña-Álvarez, J.; Torri, V.; Billot, L.; Putter, H.; et al. Assessment of assumptions of statistical analysis methods in randomised clinical trials: the what and how. BMJ evidence-based medicine 2021, 26, 121–126. [Google Scholar] [CrossRef] [PubMed]
- Kanji, G.K. 100 statistical tests; Sage, 1999.
Figure 1.
Julius AI GPT 4o output for Approach 1.

Figure 2.
Julius AI Claude 3.7 Sonnet output for Approach 2.

Figure 3.
Framework.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



