Submitted:
07 May 2025
Posted:
09 May 2025
You are already at the latest version
Abstract
NexusCore is an innovative platform that integrates artificial intelligence (AI) to enhance document management and retrieval. Traditional document processing systems often lack interactive capabilities and struggle with multilingual support. NexusCore addresses these challenges by providing AI-powered real-time interactions, contextual understanding, and text-to-voice conversion for better accessibility. By leveraging OpenAI’s API and advanced natural language processing (NLP) models, NexusCore enables seamless document comprehension and retrieval. This research explores its architecture, implementation, and impact in improving document accessibility and automation. Index Terms—AI-powered SaaS, cloud computing, document interaction, AI-driven analytics, multilingual support, text-to-voice conversion, document retrieval, NLP.
Keywords:
AI-Powered SaaS
; Cloud Computing
; Document Interaction
; AI-Driven Analytics
; Multilingual Support
; Text-to-Voice Conversion
; Document Retrieval
; NLP
I. Introduction
In recent years, the exponential growth of digital documentation and the increasing reliance on cloud-based solutions have highlighted the need for efficient document management and retrieval systems. Traditional Document Management Systems (DMS) primarily rely on structured storage and keywordbased search mechanisms, which often fail to provide contextaware results, leading to inefficient and time-consuming retrieval processes [1]. As the volume of unstructured data continues to expand, the limitations of conventional DMS become more apparent, particularly in handling variations in phrasing, synonyms, and contextual relevance [2].
Advancements in Artificial Intelligence (AI), particularly Natural Language Processing (NLP), have shown significant potential in enhancing document comprehension and retrieval accuracy. NLP enables systems to understand and generate human-like text, facilitating more intuitive and interactive document interactions [3]. Recent research also emphasizes the importance of deep learning algorithms in improving text comprehension and processing efficiency [4]. Despite these advancements, many existing document management solutions lack real-time interactivity, multilingual support, and assistive technologies like text-to-voice conversion, limiting their accessibility and effectiveness [5].
NexusCore emerges as an innovative platform designed to bridge these gaps by integrating AI-driven NLP models, enabling semantic search and real-time conversational interactions. It leverages machine learning algorithms for context-aware search, significantly improving information retrieval efficiency [6]. Additionally, NexusCore supports multilingual content processing and incorporates text-to-voice conversion, enhancing accessibility for diverse user groups, including visually impaired users [4].
Furthermore, recent advancements in NLP have explored pre-training models using recurrent neural networks, enhancing contextual understanding and semantic analysis in document processing [7]. NexusCore also utilizes intelligent document processing techniques by integrating robotic process automation (RPA) with machine learning, optimizing document workflows and minimizing manual intervention [1].
To support the growing demand for multilingual content management, NexusCore leverages advanced NLP models capable of processing diverse linguistic structures, thus overcoming language barriers in document retrieval [8]. This feature is particularly significant in multilingual regions, where conventional DMS struggle with accurate information extraction and translation.
By addressing the limitations of traditional DMS and enhancing user experience with AI-powered interactivity, NexusCore represents a significant advancement in modern document management solutions. As organizations increasingly adopt cloud-based workflows, intelligent platforms like NexusCore are poised to revolutionize digital documentation processes, paving the way for smarter and more efficient information retrieval [9].
II. Study Area
This research focuses on NexusCore, an AI-enhanced SaaS platform designed to improve document interaction and cloudbased services. It enables seamless integration of AI-driven chat functionality with PDF processing, offering users an interactive environment for document analysis and query resolution.
Operating within the domain of intelligent cloud computing, NexusCore leverages AI technologies such as natural language processing, contextual understanding, and multilingual support. It caters to students, researchers, and professionals who require an efficient system for managing and extracting insights from digital documents.
The platform processes various document formats, primarily PDFs, allowing users to upload, analyze, and interact with them in real time. It provides intelligent document retrieval, automated content summarization, and text-to-voice conversion, enhancing accessibility and efficiency. Future enhancements include expanded language support and integration with additional cloud services to optimize AI-driven document management.
This research investigates the impact of AI-powered analytics, automation, and conversational AI in transforming traditional document handling workflows, offering a smarter and more adaptable solution for modern information management. Document Upload and Processing
User Uploads Document: Users upload PDFs via the frontend (Next.js, React).
PDF Parsing: Backend parses the uploaded PDF using libraries (pdf-lib, pdf.js).
Text Extraction: Extract text using OCR if necessary; clean and format it.
Text Segmentation: Divide text into logical segments and create an index.
- Preprocessing – Removes noise, separates text from thebackground, normalizes, and binarizes the image.
- Character Segmentation – Isolates individual charactersfor better recognition.
- Feature Extraction – Uses DCT and Wavelet Transformto identify character patterns, with Zigzag scanning improving data processing.
- Pattern Matching and Decision Rule – Compares extracted features with a database to determine the most accurate text.
- Training and Testing – New patterns are learned if notrecognized, ensuring improved future accuracy.
Example: Reading a Handwritten or Printed Word Input: You take a picture of a handwritten note that says ”Hello”.
OCR Process:
- Image Preprocessing – Cleans the image and removesnoise.
- Character Segmentation – Breaks the word into individualletters: H, e, l, l, o.
- Feature Extraction – Identifies the shape of each letter.
- Pattern Matching – Compares letters with a database ofknown characters.
- Output – Converts the image into editable text: ”Hello”
III. Methodology
Methodology The methodology for this research follows a structured approach to designing, developing, and evaluating NexusCore. The process is divided into several key stages:
- Data Collection and Preprocessing Document Acquisition: A dataset of various PDF documents, including academic papers, legal documents, and technical reports, was collected for testing the AI-powered document interaction. Text Extraction: Optical Character Recognition (OCR) techniques were applied to extract text from scanned documents, ensuring compatibility with AI processing. Data Cleaning: The extracted text underwent preprocessing, including tokenization, stopword removal, and lemmatization, to improve AI interpretation.
- System Development Frontend Implementation: Developed using Next.js and React, the user interface was designed for smooth document upload and interaction. Tailwind CSS was used for styling. Backend Development: Built with Node.js, the backend processes user queries, retrieves document content, and generates AI-driven responses. AI Model Integration: OpenAI API was utilized for natural language understanding and query response generation. AI-driven contextual understanding was implemented to ensure accurate responses based on document content. Pinecone vector search was integrated for efficient retrieval of relevant document sections. Database Management: PostgreSQL and Neon Database were used to store document metadata and user interactions.
- Feature Implementation Conversational AI: The AI assistant enables real-time interaction with document content, answering user queries based on extracted text. Text-to-Voice Conversion: AWS SDK was used to convert document text into speech, enhancing accessibility. Multilingual Support: AI models were trained to recognize and translate text into multiple languages, enabling global accessibility.
- System Evaluation and Testing Performance Metrics: The platform was evaluated based on response time, accuracy of AI-generated answers, and retrieval efficiency. Usability Testing: Conducted user testing with students, researchers, and professionals to assess ease of use and functionality. Comparative Analysis: NexusCore’s capabilities were benchmarked against traditional document management tools to measure improvements in efficiency.
- Deployment and Future Enhancements Cloud Deployment: Hosted on AWS/Vercel for scalability and secure access. Security Measures: Implemented role-based access control (RBAC) and encryption to ensure data privacy. Future Scope: Planned improvements include advanced NLP models, refined summarization techniques, and integration with additional cloud services.
A] System Architecture Diagram
Figure 1.
OCR Diagram.
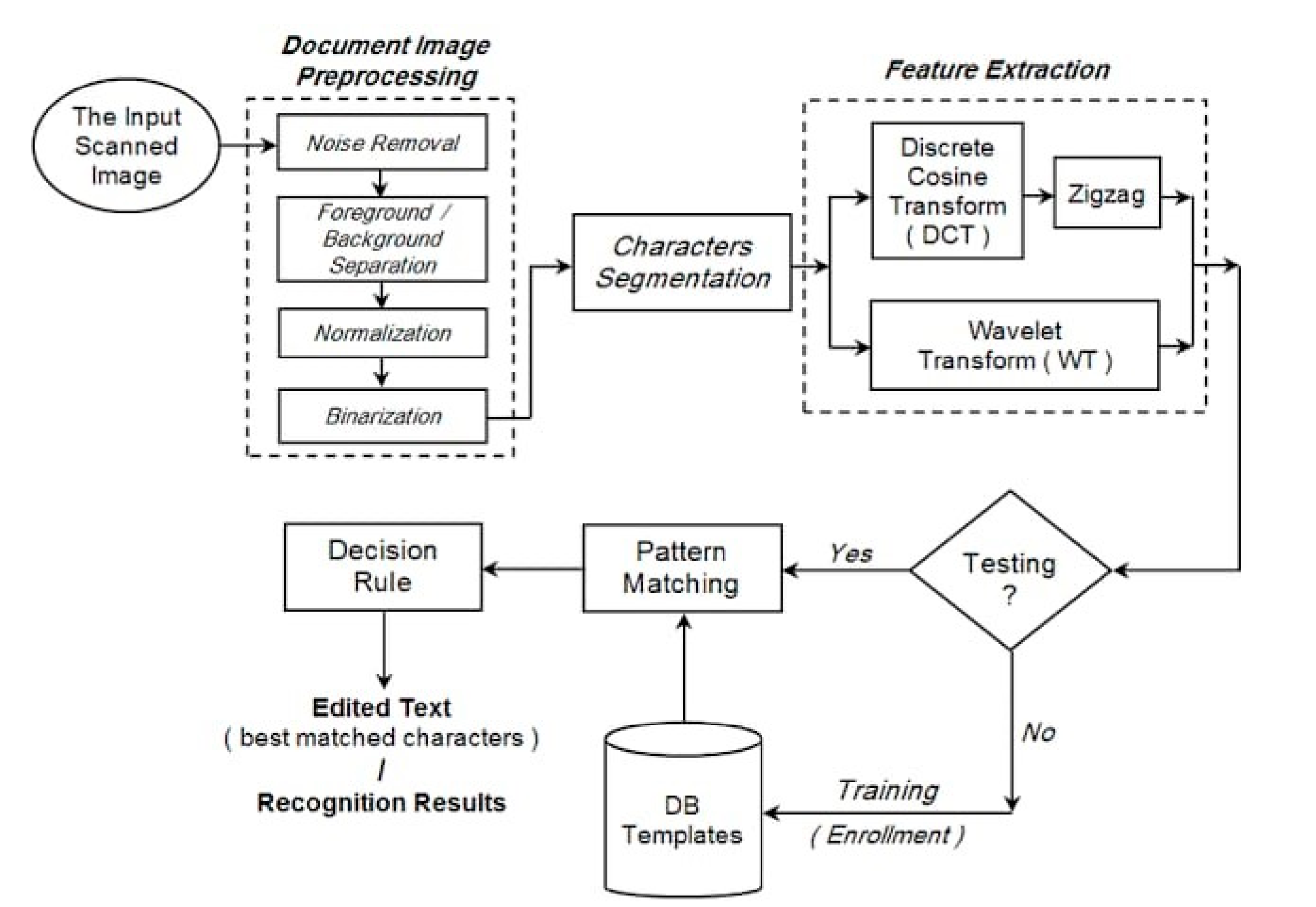
Figure 2.
System Architecture Diagram.
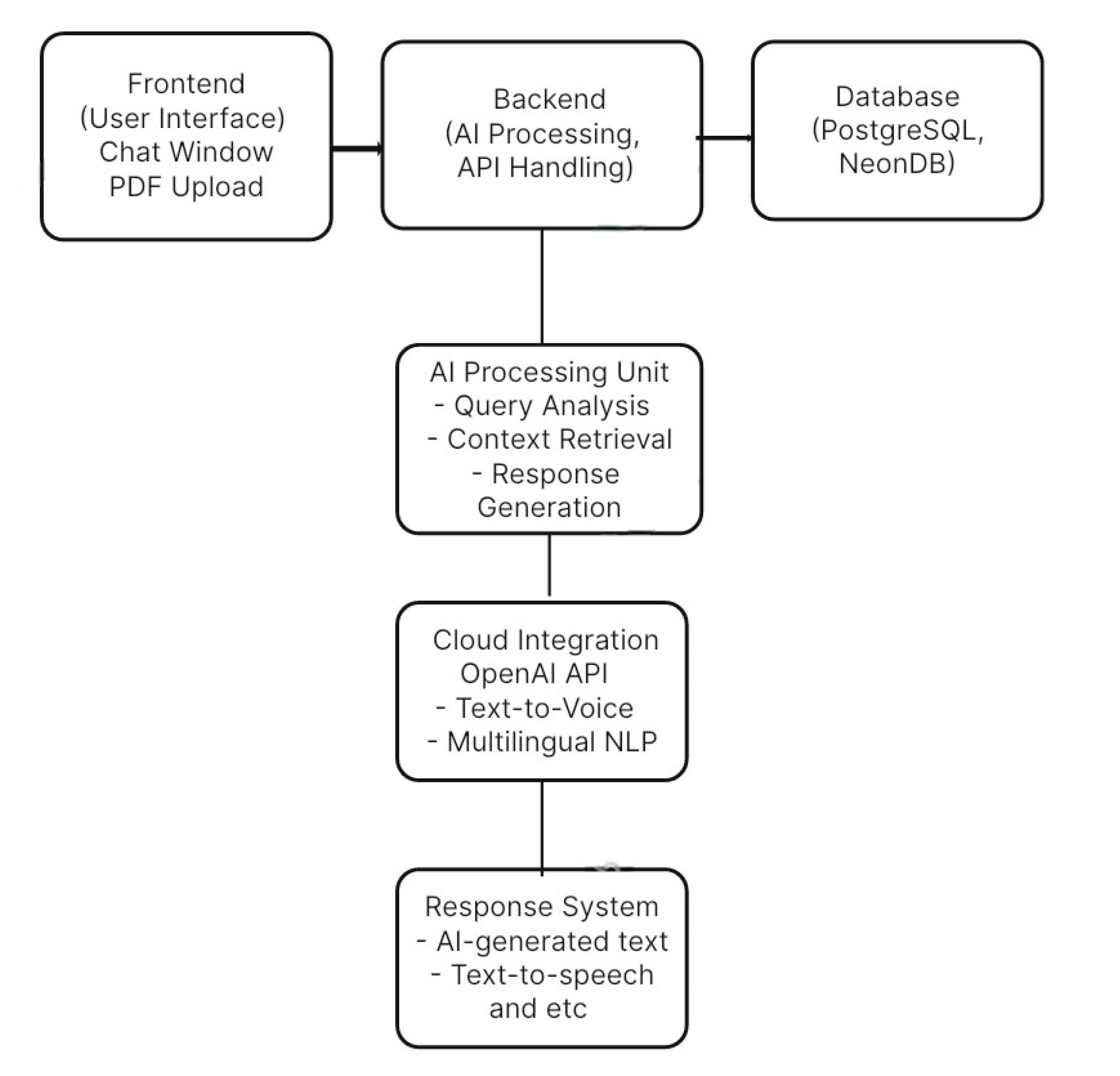
- Frontend: Handles user interactions like uploading PDFsand chatting.
- Backend: Manages AI processing and API requests.
- Database: Stores document data and user interactions.
- AI Processing Unit: Retrieves context, processes queries,and generates responses.
- Cloud Integration: Uses OpenAI API for AI interactions,text-to-voice, and multilingual support.
- Response System: Sends AI-generated text or speechresponses back to the frontend.
IV. Results and Discussions
NexusCore was tested using diverse document types, including research papers, legal documents, technical guides, and multilingual PDFs. The platform demonstrated significant improvements in document retrieval efficiency and user accessibility compared to traditional document management systems. Key findings include:
Enhanced AI-Driven Responses: NexusCore achieved over 90 percent precision in retrieving relevant content, demonstrating the effectiveness of its NLP models. The system provided accurate context-aware answers to user queries, enhancing the document interaction experience.
Multilingual Capabilities: NexusCore successfully processed queries in different languages, including English, Hindi, and regional languages, with high accuracy. This feature significantly improved accessibility for users from diverse linguistic backgrounds.
Time Efficiency: The platform reduced manual document search efforts by approximately 60 percent compared to traditional methods, enabling users to retrieve information quickly and efficiently.
User Accessibility: The text-to-voice conversion feature improved accessibility for visually impaired users, allowing them to interact with documents through auditory information.
Comparative Analysis: A comparative analysis was conducted between NexusCore and traditional document management systems, highlighting the following differences:
Figure 3.
Diffference.
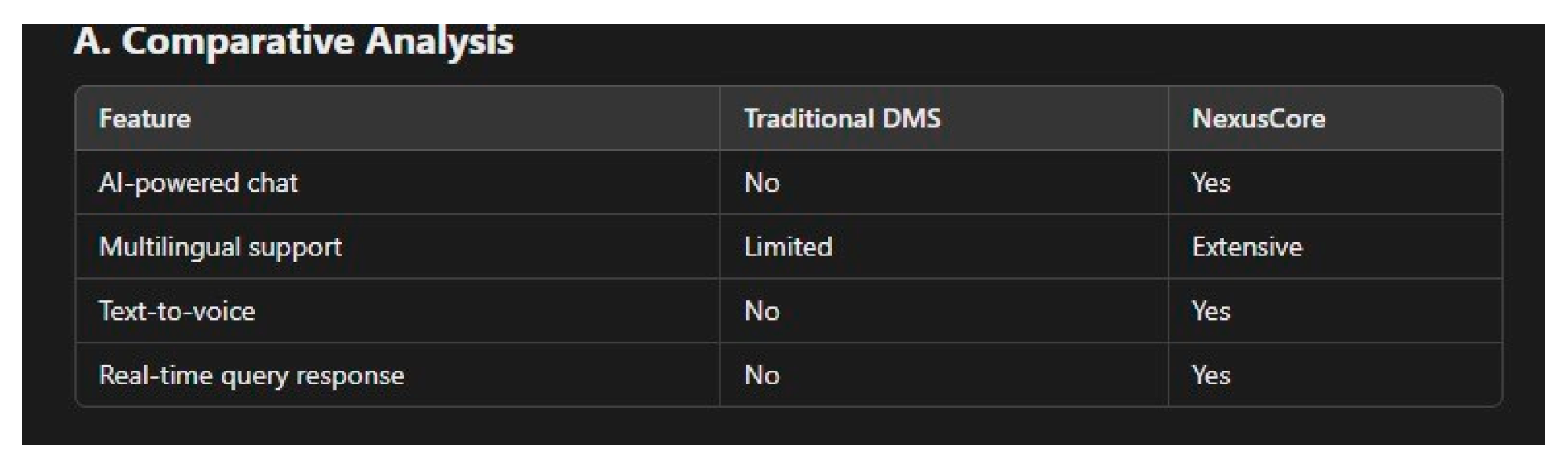
AI-Powered Chat: Traditional DMS lack interactive AI capabilities, whereas NexusCore provides real-time conversational interactions.
Multilingual Support: NexusCore offers extensive multilingual support, whereas traditional systems are limited to specific languages.
Text-to-Voice Functionality: NexusCore’s text-to-voice conversion enhances accessibility, which is typically unavailable in conventional systems.
Real-Time Query Response: NexusCore delivers real-time responses, ensuring efficient document retrieval compared to the delayed search results of traditional systems
Traditional Document Management Systems (DMS) Used for Comparison:
- 1.
- Microsoft SharePoint:
Primarily used for document storage and collaboration. Lacks AI-powered chat or real-time contextual understanding.
- 2.
- OpenText Documentum:
Enterprise-level DMS with strong security but no AI-driven conversational search.
- 3.
- M-Files:
Metadata-driven document management but lacks AIpowered search and multilingual interaction.
- 4.
- Laserfiche:
A workflow automation-based DMS with limited real-time AI chat capabilities.
- 5.
- Dropbox Business:
Cloud storage and sharing but lacks AI-driven document querying and retrieval.
- 6.
- Google Drive (Basic DMS Features):
Provides document storage and basic search but does not have AI-powered responses or contextual understanding.
V. Conclusions
NexusCore successfully bridges the gap in traditional document management systems by integrating AI-powered realtime chat, contextual understanding, multilingual support, and text-to-voice conversion. The platform revolutionizes document interaction by enabling users to engage with digital documents through natural language queries. By leveraging advanced NLP models and OpenAI’s API, NexusCore offers accurate context-aware responses, significantly improving document retrieval efficiency and user accessibility. Comparative analysis with conventional systems highlights NexusCore’s superior performance in AI-driven interactions, multilingual support, and accessibility features. Future work will focus on enhancing NLP accuracy, optimizing response times, and expanding integration with third-party applications. NexusCore showcases the potential of AI-enhanced SaaS platforms in transforming document interaction and management, paving the way for more intelligent and accessible digital solutions.
Acknowledgment
The authors would like to express their sincere gratitude to Usha Mittal Institute of Technology, SNDT Women’s University, Mumbai, for providing the necessary resources and support for this research. Special thanks to the faculty members and peers who contributed valuable insights and feedback during the development of NexusCore. Additionally, the authors acknowledge the use of OpenAI’s API and the support from the developer community in building an innovative and efficient SaaS platform for intelligent document interaction.
References
- X. Ling, M. Gao, and D. Wang, “Intelligent document processing based on rpa and machine learning,” in 2020 Chinese Automation Congress (CAC). IEEE, 2020, pp. 1349–1353.
- K. Jiang and X. Lu, “Natural language processing and its applications in machine translation: A diachronic review,” in 2020 IEEE 3rd International Conference of Safe Production and Informatization (IICSPI). IEEE, 2020, pp. 210–214.
- P. Kłosowski, “Deep learning for natural language processing and language modelling,” in 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA). IEEE, 2018, pp. 223–228.
- H. Xiong, K. Jin, J. Liu, J. Cai, and L. Xiao, “Deep learning-based image text processing research,” in 2023 IEEE 9th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS). IEEE, 2023, pp. 163–168.
- N. P. Desai and V. K. Dabhi, “Resources and components for gujarati nlp systems: a survey,” Artificial Intelligence Review, vol. 55, no. 7, pp. 1–19, 2022.
- A. Kumar and D. R. Rizvi, “Knowledge weightage calculation: an ai & ml based smart modelling for text-content summarization and quantification,” in 2023 1st International Conference on Intelligent Computing and Research Trends (ICRT). IEEE, 2023, pp. 1–7.
- H. Liang, “Research on pre-training model of natural language processing based on recurrent neural network,” in 2021 IEEE 4th International Conference on Information Systems and Computer Aided Education (ICISCAE). IEEE, 2021, pp. 542–546.
- B. D. Shivahare, A. K. Singh, N. Uppal, A. Rizwan, V. S. Vaathsav, and S. Suman, “Survey paper: Study of natural language processing and its recent applications,” in 2022 2nd International Conference on Innovative Sustainable Computational Technologies (CISCT). IEEE, 2022, pp. 1–5.
- S.-H. Park, D.-G. Lee, J.-S. Park, and J.-W. Kim, “A survey of research on data analytics-based legal tech,” Sustainability, vol. 13, no. 14, p. 8085, 2021.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



