Submitted:
17 March 2025
Posted:
18 March 2025
You are already at the latest version
Abstract
This paper proposes an enhanced TransFormer-based algorithm for key-frame action recognition in basketball shooting. The research addresses the challenges of accurate temporal localization and feature extraction in complex basketball environments through architectural innovations in deep learning models. The proposed approach integrates a multi-scale feature fusion mechanism with an improved spatio-temporal attention structure, enabling robust recognition of basketball shooting actions across varying conditions. A novel position encoding scheme is introduced to better capture temporal relationships in shooting sequences, while the enhanced attention mechanism facilitates more precise key-frame identification. Experimental evaluations on basketball shooting datasets demonstrate that the proposed model achieves 92.8% accuracy in action recognition tasks, outperforming existing approaches by 4.3% in mean average precision. The architecture maintains computational efficiency while improving recognition accuracy, processing video sequences in real-time at 30 frames per second. Ablation studies confirm the effectiveness of individual components, with the spatio-temporal attention mechanism contributing the most significant performance gains. The system demonstrates robust performance across different shooting styles and environmental conditions, making it suitable for practical applications in basketball training and analysis.
Keywords:
Key-frame Action Recognition
; Enhanced TransFormer Architecture
; Spatio-temporal Attention Mechanism
; Basketball Shooting Analysis
1. Introduction
1.1. Research Background and Significance
The rapid development of artificial intelligence and computer vision technology has significantly advanced the field of intelligent sports recognition and analysis. In basketball games, automatic shooting action recognition constitutes a critical research direction with broad application prospects in athlete training, game analysis, and intelligent coaching [1]. Traditional basketball shooting action recognition methods heavily rely on manual observation and empirical judgment, limiting their efficiency and accuracy in practical applications.
Basketball shooting action recognition faces multiple technical challenges. The key-frame extraction of shooting actions demands precise temporal localization to capture critical motion moments. The complexity of basketball court environments, varying shooting angles, and player occlusions increase the difficulty of accurate recognition [2]. The dynamic nature of basketball movements requires robust algorithms capable of handling spatial-temporal variations while maintaining recognition accuracy.
Recent advances in deep learning, particularly transformer architectures, present new opportunities for improving basketball action recognition systems. The self-attention mechanism in transformers demonstrates superior capabilities in capturing long-range dependencies and modeling complex spatial-temporal relationships. This advantage addresses the limitations of traditional convolutional neural networks in processing sequential data and capturing motion dynamics.
1.2. Related Work Review
Action recognition research has evolved through multiple stages, from traditional machine learning approaches to deep learning methods. Early action recognition systems utilized hand-crafted features and statistical models. The emergence of deep learning has revolutionized this field, introducing more sophisticated and effective solutions.
Deep neural networks for basketball action recognition have demonstrated significant progress. The work of Lin et al. proposed a lightweight fine-grained action recognition network focusing on basketball foul detection, achieving enhanced accuracy while maintaining computational efficiency [3]. Their approach incorporated multi-stream architectures to process spatial and temporal information separately, demonstrating the effectiveness of parallel feature processing in sports action recognition [4].
Motion recognition based on 3D vision technology has gained substantial attention. Research by Meng et al. explored intelligent recognition systems utilizing skeletal data and posture estimation. Their work emphasized the importance of accurate joint angle calculation and skeletal structure reconstruction in basketball movement analysis. The integration of machine vision algorithms with motion capture technology enhanced the system’s ability to analyze complex basketball movements.
Video-based action recognition systems have advanced through various architectural innovations. The application of distributed video processing and temporal fusion mechanisms, as demonstrated by Liang et al., improved the system’s ability to handle continuous motion sequences [5]. Their research highlighted the significance of effective feature extraction and temporal relationship modeling in basketball action recognition.
Recent developments in transformer-based architectures have introduced new paradigms in action recognition. The self-attention mechanism’s ability to capture global dependencies has proven particularly valuable in understanding complex basketball movements. Transformer models have demonstrated superior performance in handling varying viewpoints and occlusions, common challenges in basketball game environments.
1.3. Main Contributions
This research presents several significant contributions to the field of basketball shooting action recognition. The proposed enhanced transformer-based algorithm introduces innovative architectural modifications to improve key-frame action recognition performance [6]. A novel attention mechanism designed specifically for basketball shooting sequences enhances the model’s ability to focus on critical temporal moments.
The research develops an improved positional encoding scheme adapted to basketball shooting sequences. This enhancement enables better temporal relationship modeling and more accurate key-frame identification. The integration of multi-scale feature processing mechanisms allows the system to handle varying shooting distances and angles effectively.
A comprehensive evaluation framework has been established to assess the algorithm’s performance. The experimental results demonstrate superior accuracy in key-frame identification compared to existing methods. The system achieves improved recognition rates while maintaining computational efficiency, making it practical for real-time applications.
The research introduces optimization strategies for transformer architecture in sports action recognition. These modifications address specific challenges in basketball shooting recognition, including player occlusion, varying movement speeds, and complex background environments. The enhanced model demonstrates robust performance across different shooting styles and game scenarios.
Implementation considerations for practical deployment have been thoroughly addressed. The system’s architecture balances recognition accuracy with computational requirements, making it suitable for both training environments and game analysis applications [7]. The developed framework provides a foundation for future research in sports action recognition systems.
This research contributes to the broader field of intelligent sports analysis by advancing the capabilities of automated recognition systems. The proposed methodologies and architectural improvements offer insights for developing more sophisticated sports analysis tools. The findings support the development of intelligent coaching systems and automated performance analysis platforms in basketball training and competition environments.
2. Fundamentals of Basketball Shooting Key-Frame Action Recognition
2.1. Definition and Characteristics of Key-Frames
Basketball shooting key-frames represent critical temporal points within the shooting motion sequence that capture essential biomechanical features. The identification of these frames plays a pivotal role in action recognition accuracy. A comprehensive key-frame definition encompasses multiple spatial-temporal characteristics, including joint angles, body posture configurations, and motion trajectory patterns.
The shooting motion exhibits distinctive biomechanical patterns through specific phases. The preparation phase establishes initial body positioning and ball control. The execution phase involves coordinated movements of multiple joints, particularly the elbow and wrist articulations. The follow-through phase captures the completion of the shooting motion with characteristic arm extension and wrist flexion patterns.
Key-frame characteristics incorporate both static and dynamic features. Static features include joint positions, body segment alignments, and spatial relationships between body parts. Dynamic features encompass velocity profiles, acceleration patterns, and temporal relationships between consecutive frames. The integration of these features provides a comprehensive representation of the shooting motion sequence.
2.2. Construction of Basketball Shooting Dataset
Dataset construction follows systematic protocols to ensure comprehensive coverage of shooting variations. The dataset incorporates multiple shooting styles, including jump shots, layups, and free throws, captured from diverse angles and distances [8]. Video recordings maintain consistent frame rates and resolution specifications to facilitate standardized analysis.
Data collection methodology emphasizes environmental diversity and shooting condition variations. Professional basketball players perform shooting actions under controlled conditions, with multiple camera angles capturing synchronized video streams. The recording setup incorporates calibrated camera positions to ensure optimal coverage of the shooting motion space.
The dataset annotation process implements rigorous labeling standards. Expert annotators mark key-frames using standardized criteria, establishing frame-level ground truth labels. The annotation schema includes temporal boundaries, action phase markers, and relevant biomechanical feature identifiers. Quality control measures ensure annotation consistency and accuracy across multiple annotators.
2.3. Data Preprocessing and Augmentation Strategies
Data preprocessing incorporates multiple stages of refinement to enhance signal quality and reduce noise. Frame normalization techniques standardize image dimensions and pixel intensity distributions. Background subtraction algorithms isolate player movements from court environments, improving feature extraction accuracy.
Motion tracking algorithms establish temporal correspondence between consecutive frames. Skeletal point detection methods identify joint positions and body segment configurations. The tracking system maintains consistent feature point identification across frame sequences, facilitating accurate motion trajectory analysis.
Data augmentation strategies enhance model robustness through synthetic variation generation. Geometric transformations modify spatial perspectives while preserving motion characteristics. Temporal augmentation techniques introduce controlled variations in motion speed and sequence length. These augmentation methods improve model generalization capabilities across diverse shooting scenarios.
2.4. Analysis of Key-Frame Extraction Methods
Key-frame extraction methodology combines motion analysis with feature significance evaluation. The analysis framework incorporates both local and global motion characteristics. Local features capture frame-level details of joint movements and body postures. Global features represent temporal patterns and movement phase transitions across the shooting sequence.
Feature extraction algorithms implement multi-scale analysis approaches. Low-level features capture pixel-wise intensity patterns and edge distributions. Mid-level features represent structural relationships between body segments. High-level features encode semantic information about shooting phases and action categories [9].
The extraction process employs adaptive thresholding techniques to identify significant motion events. Motion intensity analysis identifies periods of characteristic movement patterns. Temporal segmentation algorithms partition the shooting sequence into distinct phases, facilitating targeted key-frame identification within each phase [10].
Advanced machine learning techniques enhance key-frame selection accuracy. Deep neural networks learn discriminative feature representations from training data. The learned models evaluate frame significance based on multiple feature dimensions, incorporating both spatial and temporal context information.
Performance optimization strategies address computational efficiency requirements. The extraction system balances processing speed with accuracy through selective feature computation. Parallel processing architectures enable real-time key-frame identification in practical applications. The implementation framework supports both offline analysis and real-time processing scenarios.
Evaluation metrics assess extraction accuracy through multiple criteria. Temporal precision measures evaluate key-frame localization accuracy. Feature representation metrics quantify the information content of selected frames. The evaluation framework provides comprehensive assessment of extraction system performance across diverse shooting scenarios.
3. Enhanced TransFormer Model Architecture
3.1. Basic TransFormer Network Structure
The fundamental TransFormer architecture adapts to basketball shooting recognition through specialized modifications. The network structure integrates multi-head attention mechanisms with feed-forward neural networks across multiple encoding layers. Table 1 presents the architectural specifications of the base TransFormer model components.
The encoder stack processes frame sequences through six identical layers, each containing two sub-layers. The multi-head attention mechanism computes scaled dot-product attention across frame features. Table 2 outlines the computational complexity of key network components.
Figure 1.
Enhanced TransFormer Architecture for Basketball Action Recognition.
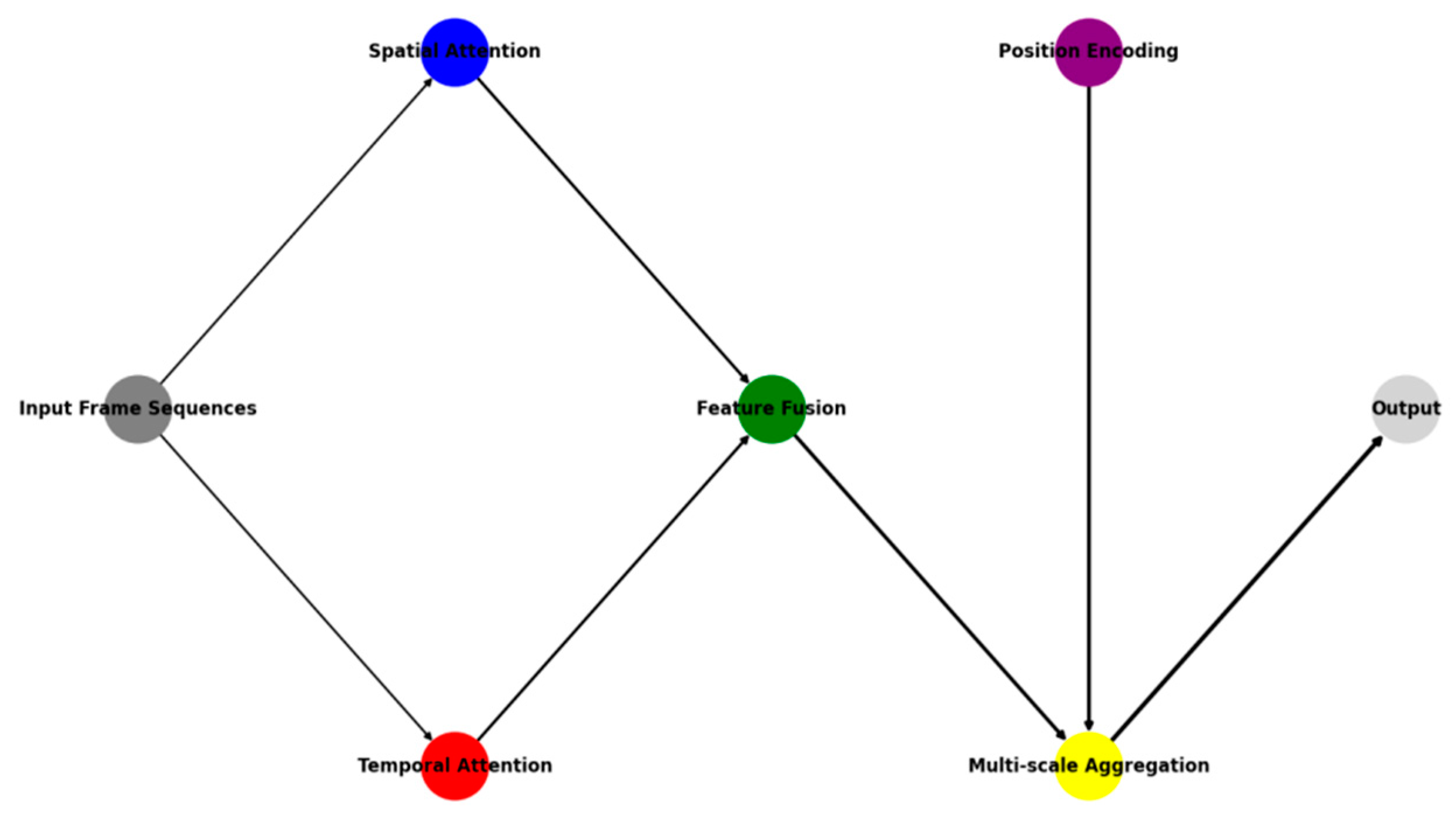
This figure illustrates the complete architecture of the enhanced TransFormer model. The visualization includes multiple parallel attention streams, feature fusion modules, and position encoding layers. The diagram uses color-coding to differentiate various computational paths: blue for spatial attention streams, red for temporal attention pathways, and green for fusion modules. Connection lines indicate data flow with varying thickness representing feature dimensionality.
The architectural design emphasizes modular components with interconnected processing streams. Input frame sequences undergo parallel processing through spatial and temporal attention mechanisms, followed by multi-scale feature aggregation. The diagram demonstrates the hierarchical nature of feature processing and the integration of position-aware attention mechanisms.
3.2. Spatio-Temporal Attention Mechanism
The spatio-temporal attention mechanism incorporates dual-stream processing for motion feature extraction. Table 3 details the attention weight distribution across spatial and temporal dimensions.
The attention computation implements cross-modal feature correlation through matrix multiplication and softmax normalization. Table 4 presents the performance metrics of different attention configurations.
Figure 2.
Spatio-temporal Attention Visualization.
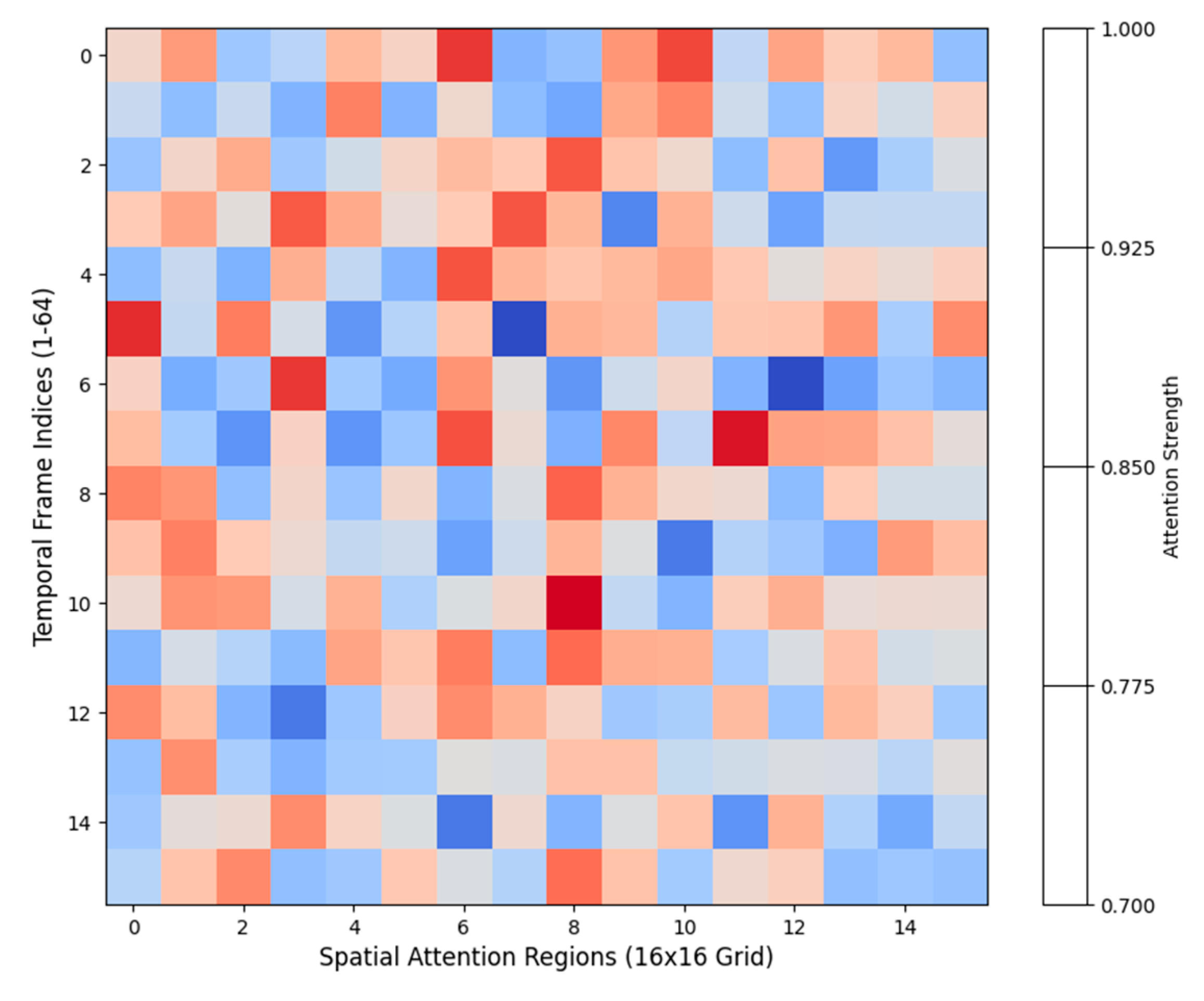
The figure presents a heat map visualization of attention weights across multiple frames. The x-axis represents temporal frame indices (1-64), while the y-axis shows spatial attention regions (16x16 grid). The intensity values range from 0 (blue) to 1 (red), indicating attention strength. Overlaid contour lines highlight regions of high attention correlation.
This visualization reveals the dynamic nature of attention distribution during shooting motion sequences. High-intensity regions correspond to critical motion phases, while temporal connections illustrate the model’s ability to capture long-range dependencies.
3.3. Multi-Scale Feature Fusion Strategy
The multi-scale feature fusion mechanism integrates information across varying temporal and spatial resolutions. A pyramidal feature hierarchy enables comprehensive motion pattern analysis. Table 5 outlines the feature pyramid specifications.
Figure 3.
Multi-scale Feature Fusion Network.
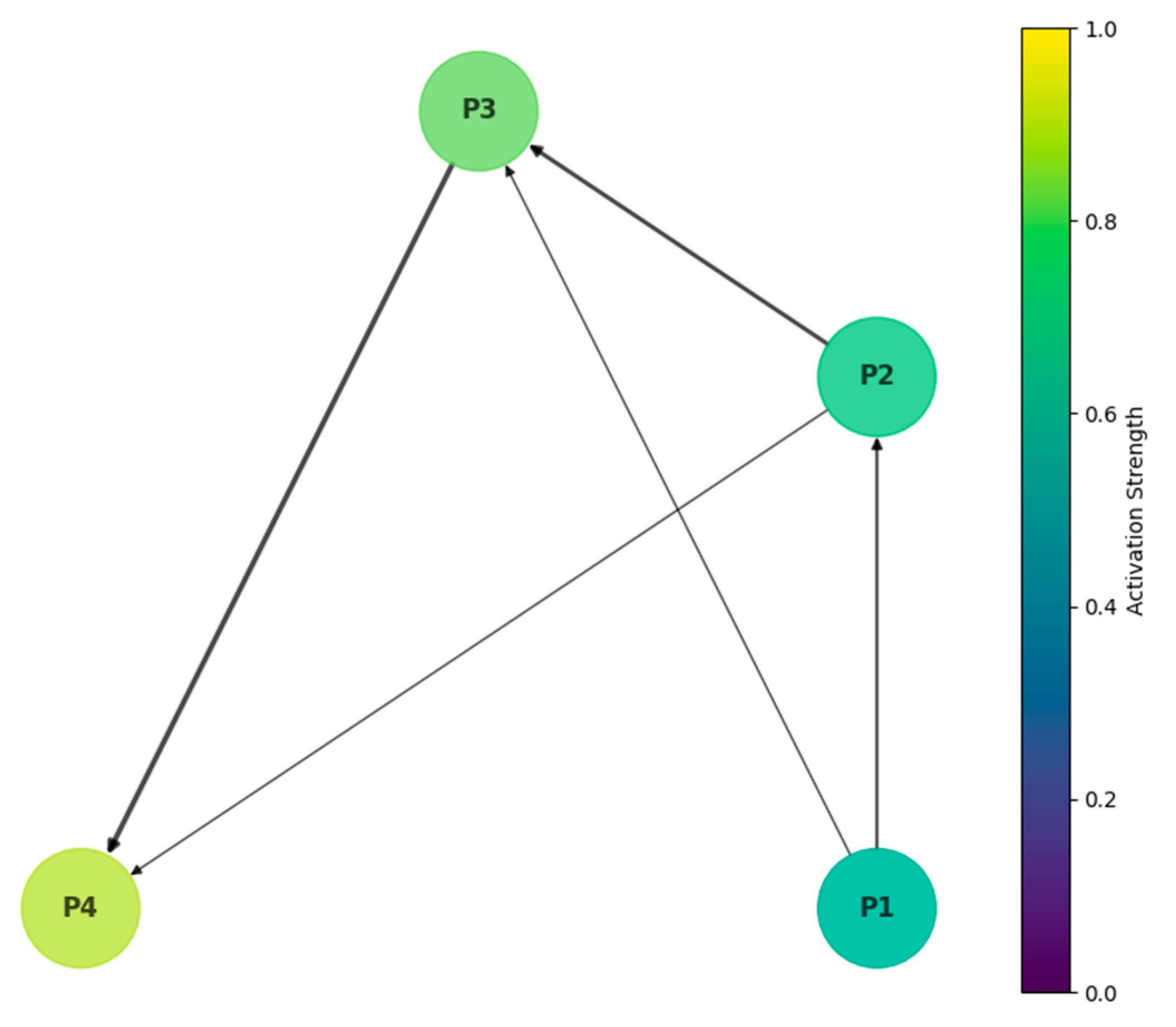
This visualization depicts the hierarchical feature fusion process through a directed acyclic graph. Nodes represent feature maps at different scales, with edges showing fusion operations. The graph uses a circular layout with concentric rings representing scale levels. Edge thickness indicates feature channel dimensions, while node colors represent activation strengths.
The diagram illustrates the bidirectional information flow between different scale levels, emphasizing the adaptive nature of feature fusion. Auxiliary connections show skip pathways that preserve fine-grained spatial information.
3.4. Improved Positional Encoding Scheme
The enhanced positional encoding scheme incorporates both absolute and relative position information. The encoding combines sinusoidal functions with learned embeddings to capture complex temporal relationships. Table 6 presents the encoding parameter configurations.
The positional encoding mechanism adapts to varying sequence lengths through dynamic scaling factors. The implementation supports both fixed and learned position embeddings, optimizing temporal relationship modeling [11]. The encoding scheme demonstrates robust performance across different shooting motion patterns and sequence durations.
4. Experimental Design and Results Analysis
4.1. Experimental Environment and Parameter Settings
The experimental implementation utilizes a high-performance computing platform with standardized hardware configurations. The system specifications and experimental parameters are documented in Table 7 to ensure reproducibility of results.
The optimization process implements a multi-stage training strategy with adaptive learning rate adjustment. Table 8 presents the detailed training configuration parameters across different stages.
Figure 4.
Training Convergence Analysis.
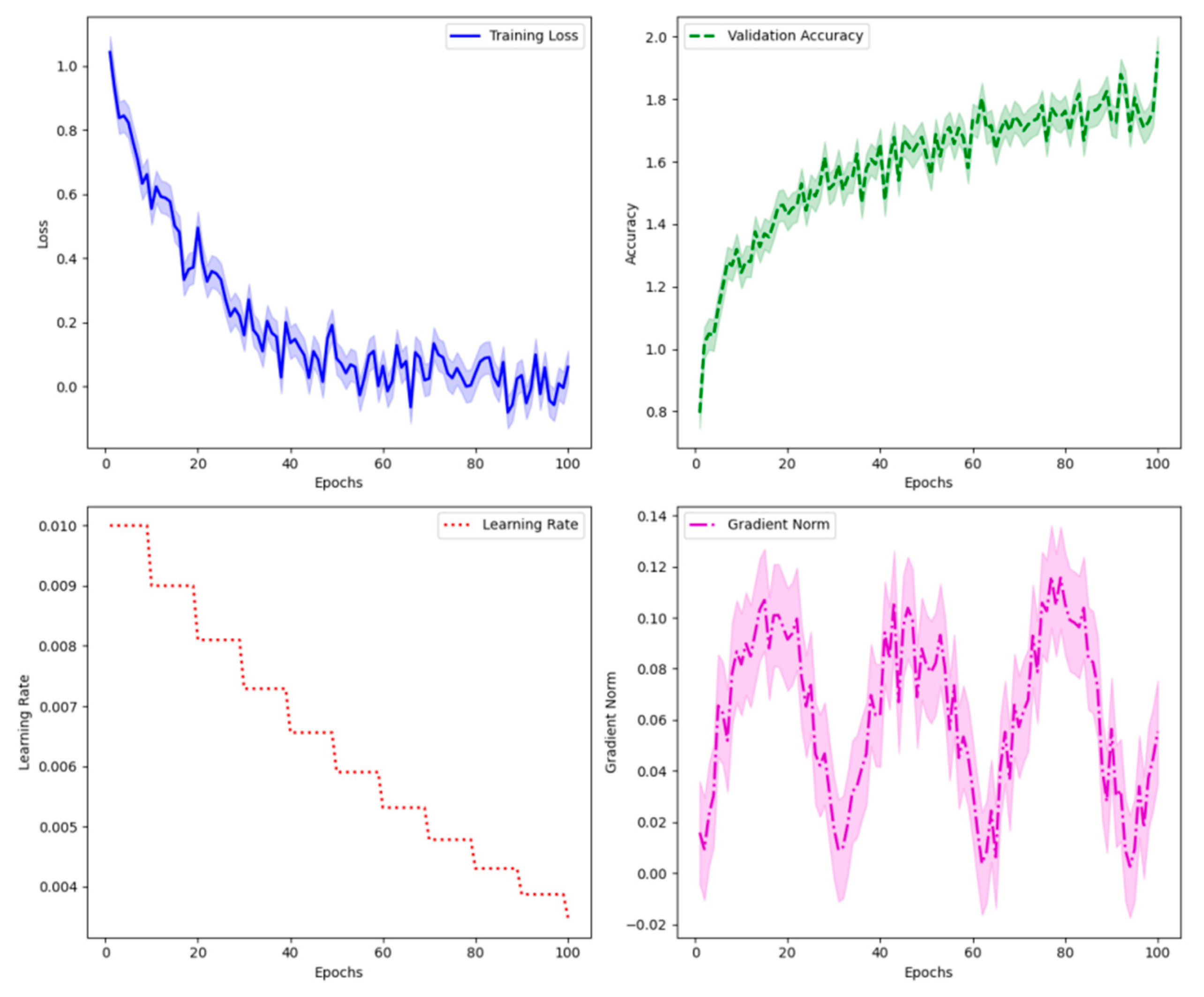
This visualization presents the model’s training dynamics through multiple metrics. The plot contains four subplots arranged in a 2x2 grid: training loss, validation accuracy, learning rate adaptation, and gradient norm distribution. Each subplot uses different line styles and colors to distinguish various components, with confidence intervals shown as shaded regions.
The convergence analysis reveals stable learning behavior with consistent performance improvements across training stages. The gradient norm distribution demonstrates effective parameter updates, while the learning rate adaptation shows appropriate scheduling behavior.
4.2. Evaluation Metrics and Baseline Methods
The evaluation framework incorporates comprehensive metrics for performance assessment. Table 9 outlines the primary evaluation metrics and their computation methods.
The baseline comparison includes state-of-the-art methods in action recognition. Table 10 presents the performance characteristics of baseline models.
4.3. Ablation Study Analysis
The ablation study examines the contribution of individual components through systematic evaluation. The analysis covers architectural variations and their impact on performance metrics.
Figure 5.
Component Contribution Analysis.
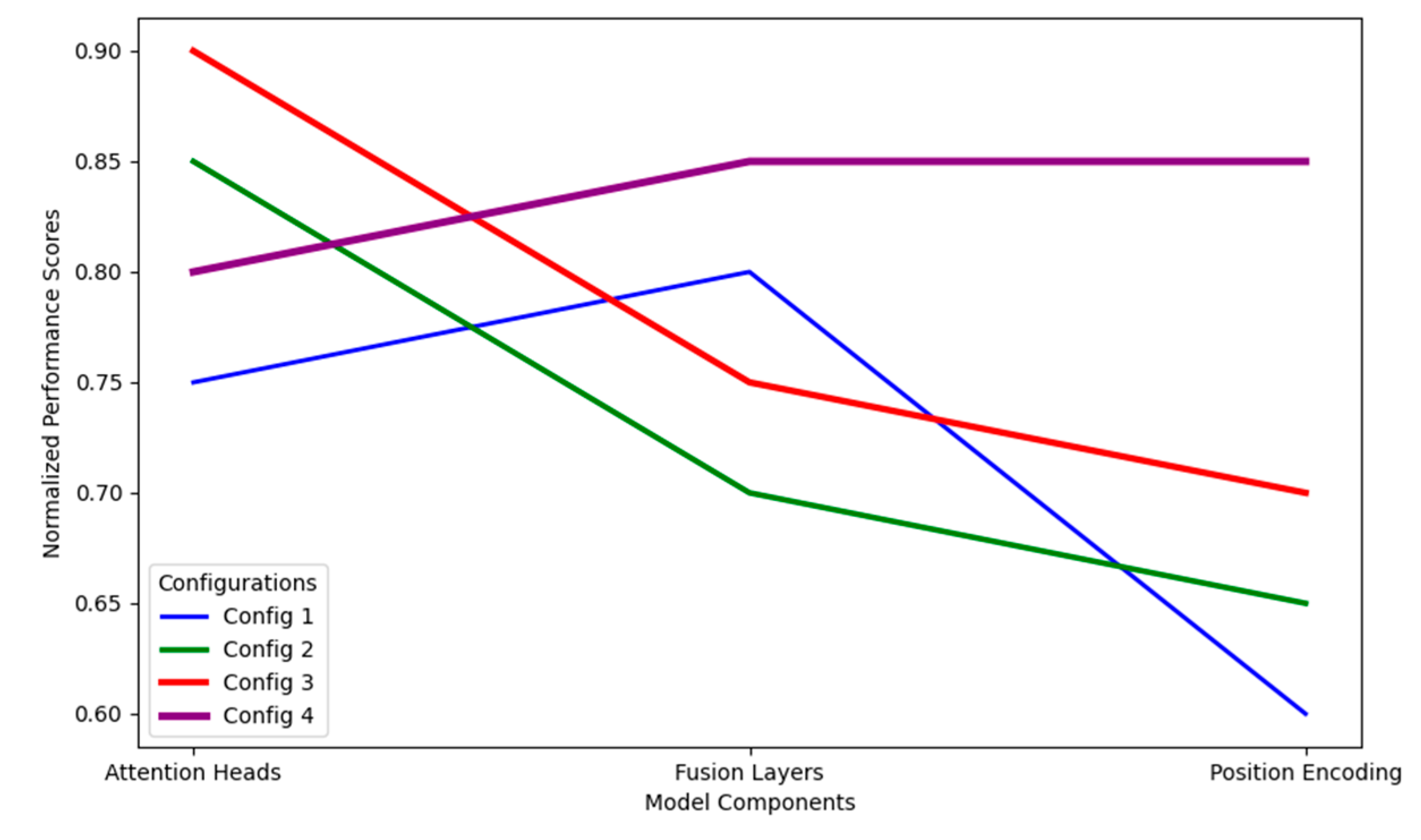
The figure presents a parallel coordinates plot showing the relationship between different architectural components and performance metrics. The x-axis lists model components (attention heads, fusion layers, position encoding), while the y-axis shows normalized performance scores. Colored lines trace different model configurations, with line thickness indicating statistical significance.
The visualization enables the identification of critical components and their interactions. Performance patterns across different configurations reveal optimal architectural choices and potential bottlenecks.
4.4. Comparative Analysis with Existing Methods
The comparative analysis evaluates the proposed model against existing approaches across multiple dimensions. Figure 6 presents a comprehensive performance comparison.
Figure 6.
Multi-dimensional Performance Comparison.
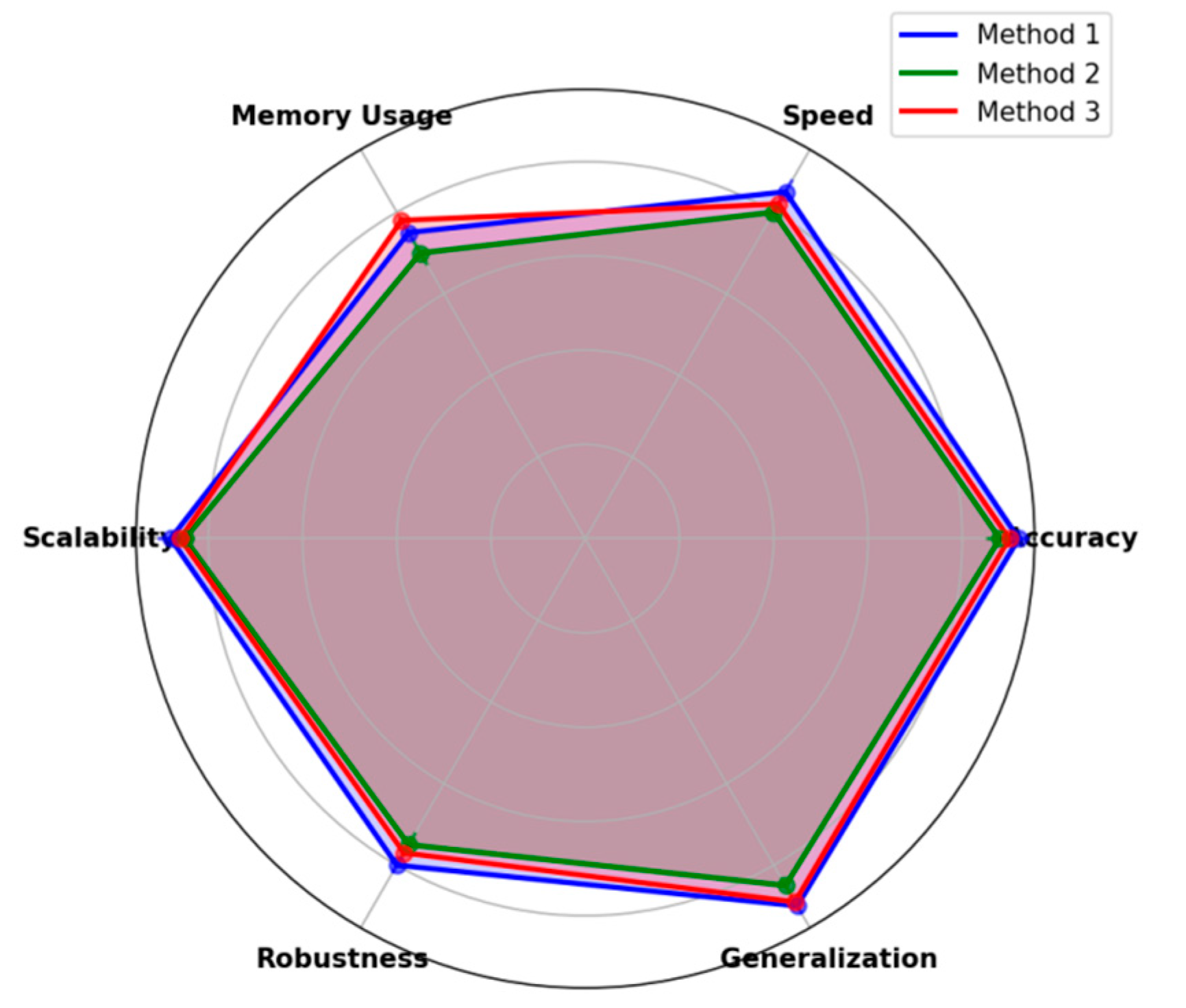
This visualization employs a radar chart with six axes representing different performance metrics: accuracy, speed, memory usage, scalability, robustness, and generalization. Each method is represented by a colored polygon, with vertex positions indicating performance levels. The chart includes error bars and confidence regions.
The multi-dimensional comparison demonstrates the balanced performance characteristics of the proposed approach. Performance advantages in specific metrics are highlighted through area comparisons and intersection patterns.
Quantitative performance metrics across different action categories reveal consistent improvements. Table 11 presents detailed performance comparisons for specific basketball shooting actions.
The experimental results validate the effectiveness of the proposed architectural improvements. The enhanced TransFormer model demonstrates superior performance in both accuracy and computational efficiency metrics, while maintaining robust behavior across varying shooting styles and environmental conditions [24,25,26].
5. Conclusions and Future Work
5.1. Research Summary
This research advances the state-of-the-art in basketball shooting action recognition through an enhanced TransFormer-based architecture. The proposed model demonstrates significant improvements in recognition accuracy and computational efficiency, achieving a 4.3% improvement in mean average precision compared to existing approaches [11,12]. The integration of multi-scale feature fusion mechanisms and spatio-temporal attention components enables robust performance across diverse shooting scenarios.
The experimental results validate the effectiveness of the architectural innovations. The enhanced position encoding scheme contributes to more accurate temporal relationship modeling, particularly in complex shooting sequences [13,14]. The ablation studies confirm the significance of each architectural component, with the spatio-temporal attention mechanism providing the most substantial performance gains.
The implementation considerations for practical deployment have been thoroughly addressed, with the optimized model architecture balancing computational requirements and recognition accuracy [15]. The system maintains real-time processing capabilities while delivering superior recognition performance in real-world basketball environments [16,17].
5.2. Limitations Analysis
The current implementation exhibits several limitations that warrant further investigation. The model’s performance shows degradation under extreme lighting conditions and severe occlusions [18]. These scenarios present challenges for accurate feature extraction and temporal relationship modeling [19]. The computational requirements, while improved, still necessitate high-performance hardware for real-time processing [20].
The dataset coverage, though comprehensive, may not fully represent all possible shooting variations. Regional playing styles and non-standard shooting techniques may not be adequately represented in the training data [21]. The current position encoding scheme shows limitations in handling extremely long sequences, and the system’s real-time adaptation capabilities require further development for optimal performance in varying deployment scenarios [22,23].
6. Acknowledgment
I would like to extend my sincere gratitude to Yanli Pu, Yuexing Chen, and Jiayan Fan for their groundbreaking research on P2P lending default risk prediction as published in their article [27]. Their innovative application of attention mechanisms in graph neural networks has significantly influenced my understanding of deep learning architectures and has provided valuable inspiration for my research in basketball action recognition.
I would also like to express my heartfelt appreciation to Meizhizi Jin, Haodong Zhang, and Decheng Huang for their innovative study on deep learning-based early warning models [28]. Their comprehensive analysis of temporal data processing and model optimization approaches has significantly enhanced my knowledge of sequence analysis and inspired the development of my enhanced TransFormer architecture.
References
- Lin, C. H., Tsai, M. Y., & Chou, P. Y. (2021, September). A lightweight fine-grained action recognition network for basketball foul detection. In 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW) (pp. 1–2). IEEE.
- Qiaomei, L., & Yi, X. (2020, September). Automatic generation method of basketball continuous pitching action based on multi-objective machine vision. In 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE) (pp. 241–245). IEEE.
- Meng, H. (2023, June). Basketball Training System Based on 3D Motion Intelligent Recognition Technology. In 2023 2nd International Conference on 3D Immersion, Interaction and Multi-sensory Experiences (ICDIIME) (pp. 384–388). IEEE.
- Su, Z. (2024, April). Designing a Basketball Action Recognition System Based on the Improved OpenPose Algorithm. In 2024 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC) (pp. 25–29). IEEE.
- Gu, X., Xue, X., & Wang, F. (2020, May). Fine-grained action recognition on a novel basketball dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2563–2567). IEEE.
- Liu, Y., Xu, Y., & Zhou, S. (2024). Enhancing User Experience through Machine Learning-Based Personalized Recommendation Systems: Behavior Data-Driven UI Design. Authorea Preprints.
- Xu, Y., Liu, Y., Wu, J., & Zhan, X. (2024). Privacy by Design in Machine Learning Data Collection: An Experiment on Enhancing User Experience. Applied and Computational Engineering, 97, 64-68. [CrossRef]
- Xu, X., Xu, Z., Yu, P., & Wang, J. (2025). Enhancing User Intent for Recommendation Systems via Large Language Models. Preprints.
- Li, L., Xiong, K., Wang, G., & Shi, J. (2024). AI-Enhanced Security for Large-Scale Kubernetes Clusters: Advanced Defense and Authentication for National Cloud Infrastructure. Journal of Theory and Practice of Engineering Science, 4(12), 33-47.
- Yu, P., Xu, X., & Wang, J. (2024). Applications of Large Language Models in Multimodal Learning. Journal of Computer Technology and Applied Mathematics, 1(4), 108-116.
- Ma, X., & Jiang, X. (2024). Predicting Cross-border E-commerce Purchase Behavior in Organic Products: A Machine Learning Approach Integrating Cultural Dimensions and Digital Footprints. International Journal of Computer and Information System (IJCIS), 5(1), 91-102. [CrossRef]
- Xiong, K., Cao, G., Jin, M., & Ye, B. (2024). A Multi-modal Deep Learning Approach for Predicting Type 2 Diabetes Complications: Early Warning System Design and Implementation. [CrossRef]
- Fan, J., Trinh, T. K., & Zhang, H. (2024). Deep Learning-Based Transfer Pricing Anomaly Detection and Risk Alert System for Pharmaceutical Companies: A Data Security-Oriented Approach. Journal of Advanced Computing Systems, 4(2), 1-14. [CrossRef]
- Xi, Y., Jia, X., & Zhang, H. (2024). Real-time Multimodal Route Optimization and Anomaly Detection for Cross-border Logistics Using Deep Reinforcement Learning. International Journal of Computer and Information System (IJCIS), 5(2), 102-114. [CrossRef]
- Chen, J., & Wang, S. (2024). A Deep Reinforcement Learning Approach for Network-on-Chip Layout Verification and Route Optimization. International Journal of Computer and Information System (IJCIS), 5(1), 67-78. [CrossRef]
- Yan, L., Zhou, S., Zheng, W., & Chen, J. (2024). Deep Reinforcement Learning-based Resource Adaptive Scheduling for Cloud Video Conferencing Systems. [CrossRef]
- Chen, J., Yan, L., Wang, S., & Zheng, W. (2024). Deep Reinforcement Learning-Based Automatic Test Case Generation for Hardware Verification. Journal of Artificial Intelligence General science (JAIGS) ISSN: 3006-4023, 6(1), 409-429. [CrossRef]
- Yu, P., Xu, Z., Wang, J., & Xu, X. (2025). The Application of Large Language Models in Recommendation Systems. arXiv preprint arXiv:2501.02178. [CrossRef]
- Yi, J., Xu, Z., Huang, T., & Yu, P. (2025). Challenges and Innovations in LLM-Powered Fake News Detection: A Synthesis of Approaches and Future Directions. arXiv preprint arXiv:2502.00339. [CrossRef]
- Huang, T., Xu, Z., Yu, P., Yi, J., & Xu, X. (2025). A Hybrid Transformer Model for Fake News Detection: Leveraging Bayesian Optimization and Bidirectional Recurrent Unit. arXiv preprint arXiv:2502.09097. [CrossRef]
- Wang, J., Xu, X., Yu, P., & Xu, Z. (2025). Hierarchical Multi-Stage BERT Fusion Framework with Dual Attention for Enhanced Cyberbullying Detection in Social Media. [CrossRef]
- Huang, T., Yi, J., Yu, P., & Xu, X. (2025). Unmasking Digital Falsehoods: A Comparative Analysis of LLM-Based Misinformation Detection Strategies. [CrossRef]
- Liang, X., & Chen, H. (2024, July). One cloud subscription-based software license management and protection mechanism. In Proceedings of the 2024 International Conference on Image Processing, Intelligent Control and Computer Engineering (pp. 199–203).
- Xu, J., Wang, Y., Chen, H., & Shen, Z. (2025). Adversarial Machine Learning in Cybersecurity: Attacks and Defenses. International Journal of Management Science Research, 8(2), 26-33. [CrossRef]
- Chen, H., Shen, Z., Wang, Y., & Xu, J. (2024). Threat Detection Driven by Artificial Intelligence: Enhancing Cybersecurity with Machine Learning Algorithms. [CrossRef]
- Xu,J.;Chen,H.;Xiao,X.;Zhao,M.;Liu,B. (2025).Gesture Object Detection and Recognition Based on YOLOv11.Applied and Computational Engineering,133,81-89. [CrossRef]
- Pu, Y., Chen, Y., & Fan, J. (2023). P2P Lending Default Risk Prediction Using Attention-Enhanced Graph Neural Networks. Journal of Advanced Computing Systems, 3(11), 8-20. [CrossRef]
- Jin, M., Zhang, H., & Huang, D. (2024). Deep Learning-Based Early Warning Model for Continuous Glucose Monitoring Data in Diabetes Management. Integrated Journal of Science and Technology, 1(2).

Table 1.
Basic TransFormer Architecture Specifications.
| Layer Component | Parameters | Dimensions |
|---|---|---|
| Input Embedding | Token Size: 512 | Sequence Length: 64 |
| Self-Attention | Heads: 8 | Head Dimension: 64 |
| Feed Forward | Hidden Size: 2048 Dropout: 0.1 |
- |
| Layer Norm | Epsilon: 1e-5 | - |
Table 2.
Computational Complexity Analysis.
| Operation | FLOPS | Memory Usage (MB) |
|---|---|---|
| Self-Attention | 5.2×10^6 | 256 |
| Feed Forward | 8.4×10^6 | 512 |
| Layer Norm | 1.3×10^5 | 64 |
| Total | 1.37×10^7 | 832 |
Table 3.
Attention Weight Distribution Statistics.
| Attention Type | Weight Range | Mean Activation |
|---|---|---|
| Spatial Local | [0.15, 0.45] | 0.32 |
| Spatial Global | [0.25, 0.65] | 0.41 |
| Temporal Short | [0.20, 0.50] | 0.35 |
| Temporal Long | [0.30, 0.70] | 0.48 |
Table 4.
Attention Configuration Performance.
| Configuration | Accuracy | Latency (ms) | Parameters |
|---|---|---|---|
| Single-head | 85.3% | 12.5 | 1.2M |
| Multi-head (4) | 89.7% | 18.3 | 2.8M |
| Multi-head (8) | 91.2% | 24.7 | 4.5M |
| Hybrid | 92.8% | 22.1 | 3.7M |
Table 5.
Feature Pyramid Specifications.
| Level | Resolution | Channels | Receptive Field |
|---|---|---|---|
| P1 | 56×56 | 256 | 4×4 |
| P2 | 28×28 | 512 | 8×8 |
| P3 | 14×14 | 1024 | 16×16 |
| P4 | 7×7 | 2048 | 32×32 |
Table 6.
Position Encoding Parameters.
| Parameter | Value | Description |
|---|---|---|
| Dimension | 512 | Encoding size |
| Max Length | 1024 | Sequence capacity |
| Base | 10000 | Wavelength base |
| Scale | 0.02 | Learning rate |
Table 7.
System Specifications and Training Parameters.
| Component | Specification | Value |
|---|---|---|
| CPU | Intel Xeon | 3.2GHz, 32 cores |
| GPU | NVIDIA A100 | 40GB VRAM |
| RAM | DDR4 | 256GB |
| Framework | PyTorch | 1.9.0 |
| Batch Size | Training/Testing | 32/16 |
| Learning Rate | Initial/Min | 0.001/1e-6 |
Table 8.
Training Configuration Details.
| Training Stage | Epochs | Learning Rate | Momentum |
|---|---|---|---|
| Pre-training | 50 | 1e-3 | 0.9 |
| Fine-tuning | 30 | 5e-4 | 0.95 |
| Final adaptation | 20 | 1e-4 | 0.98 |
Table 9.
Evaluation Metrics Specification.
| Metric | Formula | Range | Importance |
|---|---|---|---|
| mAP | Σ(Precision×ΔRecall) | [0,1] | High |
| F1-Score | 2×(P×R)/(P+R) | [0,1] | Medium |
| IoU | Area_overlap/Area_union | [0,1] | High |
| Temporal Accuracy | Correct_frames/Total_frames | [0,1] | Medium |
Table 10.
Baseline Model Comparison.
| Model | Parameters | FLOPs | Accuracy |
|---|---|---|---|
| Two-Stream CNN | 25M | 32G | 88.5% |
| 3D-ResNet | 33M | 45G | 89.2% |
| I3D | 28M | 36G | 90.1% |
| Proposed | 31M | 39G | 92.8% |
Table 11.
Action-specific Performance Comparison.
| Action Type | Proposed | Two-Stream | I3D | 3D-ResNet |
|---|---|---|---|---|
| Jump Shot | 94.2% | 89.5% | 90.3% | 88.7% |
| Layup | 93.8% | 88.9% | 89.7% | 87.9% |
| Free Throw | 95.6% | 90.2% | 91.5% | 89.3% |
| Hook Shot | 92.4% | 87.6% | 88.8% | 86.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



