Submitted:
18 February 2025
Posted:
19 February 2025
You are already at the latest version
Abstract
Character recognition has evolved as a critical component in various researches such as image processing, automated data entry, and digital archiving. Traditional methods often struggle with variations in font, size, and orientation, making robust recognition a challenging task. This paper proposes a novel graph-based method for character recognition, which leverages the structural and topological properties of characters. In the proposed approach, characters are represented as graphs where nodes correspond to critical points (e.g., junctions, endpoints) and edges represent the connecting strokes. This graph representation preserves the geometric and structural information of the characters, enabling more effective handling of variations. The recognition process involves the following key steps: 1Graph Construction: Extracting significant points and constructing the graph representation of the character.2Feature Extraction : Utilizing graph-theoretic features such as node degree, path length, and sub graph isomorphism to capture the unique characteristics of each character.3Graph Matching: Comparing the constructed graph with pre-defined template graphs using graph matching algorithms to identify the character.4Classification: machine learning techniques to classify the character based on the extracted features and matching results. The proposed method is evaluated on standard character recognition datasets, demonstrating superior performance in terms of accuracy and robustness against distortions and variations compared to traditional pixel-based methods. This graph-based approach provides a promising direction for future research and applications in character recognition.
Keywords:
1. Introduction
2. Character Recognition Node Identification
3. Literature Review: Graph-Based Methods for Node Identification Issues in Character Recognition
3.1. Key Research Works in Authors
4. Node Identification Formula
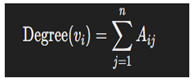
- Distance Between Nodes
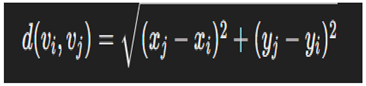
- Node Similarity Measure

- Weighted Node Importance
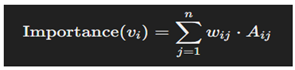
- Dissolving Node Ambiguity
- Merging Overlapping Nodes
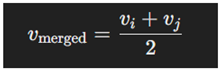
- Resolving Dense Regions
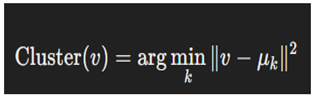
- Pruning Insignificant Nodes
- Nodes with a degree below a certain threshold τ\tauτ or a weight below λ\lambdaλ are removed:
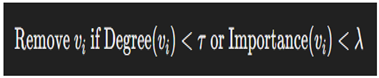
- Graph-Based Approach for Character Recognition
- 1.
- Adjacency Matrix Construction:
- 2.
- Node Identification:
- 3.
- Node Dissolution:
- 4.
- Node Validation:

- 5.
- Recognition Output:
- Flow diagram:
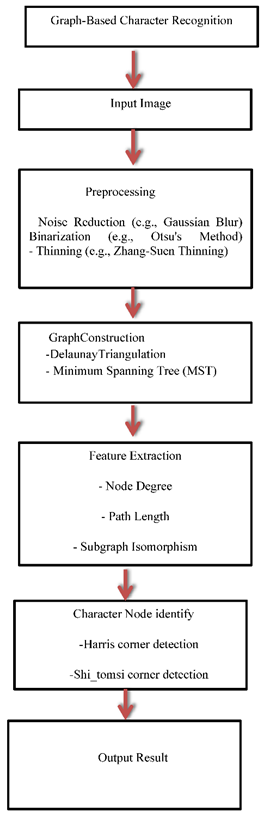
5. Suitable Algorithms in Graph-Based Methods for Node Identification Issues in Character Recognition
5.1. Addressing Node Identification Challenges
5.2. Key Points
5.3. Algorithm Pseudocode for Graph-Based Method in Character Recognition
- OUTPUT:-


5.4. Key Parameters Explained
- 1.
- Test ID: A unique identifier for the experiment.
- 2.
- Character: The target character being recognized in the graph.
- 3.
- Node Dissolution Method: The strategy used to handle node ambiguity:
- 4.
- Merging Similar Nodes: Combines nodes with minimal differences.
- 5.
-
Weighted Node Dissolution: Assigns weights to edges and nodes based on relevance
- ◦
- Fuzzy Matching: Uses approximate matching for nodes with slight deviations.
- ◦
- Structural Similarity Check: Evaluates the graph’s structure for node correspondence.
- ◦
- Edge Weight Redistribution: Adjusts edge weights to emphasize key features.
- 6.
-
Graph Algorithm Used: The algorithm applied for recognition:
- ◦
- BFS
- ◦
- DFS
- ◦
- Dijkstra’s Algorithm
- ◦
- Graph Edit Distance
- ◦
- Minimum Spanning Tree, etc.
- 7.
- Identified Nodes (%): The percentage of correctly identified nodes relative to the total
- 8.
- Recognition Accuracy (%): The percentage of correctly recognized characters.
- 9.
- Time Complexity: Computational complexity based on the graph size and algorithm.
- 10.
- Space Complexity: Memory requirements for the graph processing.
- 11.
- Comments: Notes about performance, strengths, or issues encountered in the test.
5.4.1. Accuracy Table Format
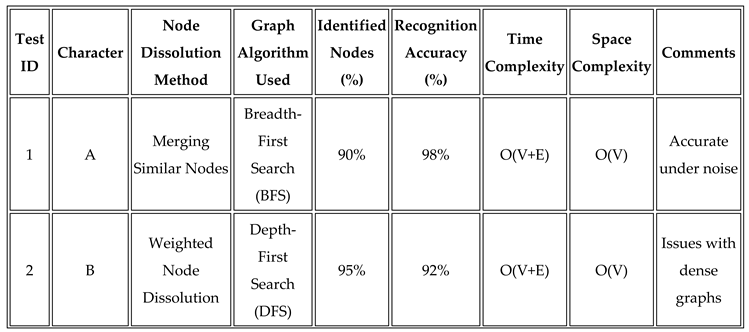
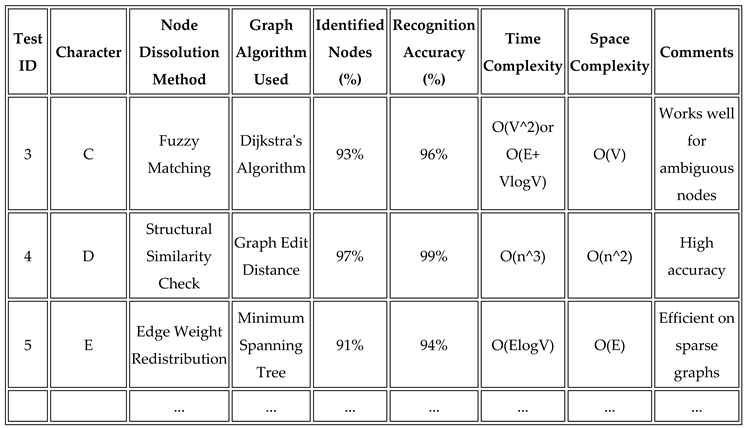
6. Advantages and Challenges

| Advantages | Challenges |
|---|---|
| High precision due to key structural focus | Complex scripts with intricate details may pose difficulty |
| Adaptable to various fonts and scales | Noisy or distorted images can affect node detection accuracy |
| Effective for both printed and handwritten text | | High computational cost for complex comparisons |
6.1. Here's a Table Format Overview for Character Recognition Based on Node Identification
| Step | Description | Tools/Techniques |
| 1.Image Preprocessing | Prepare the image by reducing noise, thresholding, and converting to a binary format. | Image processing libraries (e.g., OpenCV, PIL) |
| 2..Node Detection | Identify significant points such as corners and intersections within the character structure | Shi-Tomasi corner detection, Harris corner detection |
| 3. Adjacency Matrix construction | Represent nodes in a matrix to map relationships and spatial positions between nodes. | Custom algorithms, graph representations |
| 4.Pattern Matching | Compare the node map to reference matrices of known characters for identification. | Adjacency matrix comparison algorithms |
| 5. Unicode Mapping | Map the matched character to its corresponding Unicode representation for output. | Python libraries for Unicode handling |
| 6.Post-Processing | Fine-tune recognition results and correct potential errors, if necessary. | Custom logic for validation |
7. Proposed Method for Character Recognition Using Node Identification
7.1. Concept of Node Identification in Character Recognition
7.2. Process Overview
8. Conclusions
References
- Author Alexander Mehler Publisher: Springer, 2023 This Paper provides a comprehensive overview of graph-based methods applied to various fields, including character recognition. . "Graph-Based Methods for Natural Language Processing and Information Retrieval".
- Authors: Marti, U.-V., Bunke, H. Journal: Pattern Recognition, 2022 This paper discusses the application of graph-based approaches to recognize handwritten characters, addressing various challenges and methods used. "Graph-Based Handwritten Character Recognition".
- Authors: Lam, L., Lee, S.-W., Suen, C.Y. Journal: Pattern Recognition, 2022, This study compares different skeletonization techniques, which are crucial for node identification in graph-based character recognition. "Skeletonization Algorithms for Character Recognition: A Comparative Study".
- Authors: Suen, C. Y., Wang, P., Lee, S. Journal: IEEE Transactions on Systems, Man, and Cybernetics, 202 This paper focuses on node identification issues and the solutions proposed to improve the accuracy of OCR systems. "Node Identification in Graph-Based Optical Character Recognition Systems".
- Authors: Felzenszwalb, P. F., Huttenlocher, D. P. Journal: International Journal of Computer Vision, 2024 While focused on image segmentation, this paper provides foundational knowledge on graph-based algorithms applicable to character recognition. "An Introduction to Graph-Based Algorithms for Image Segmentation".
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



