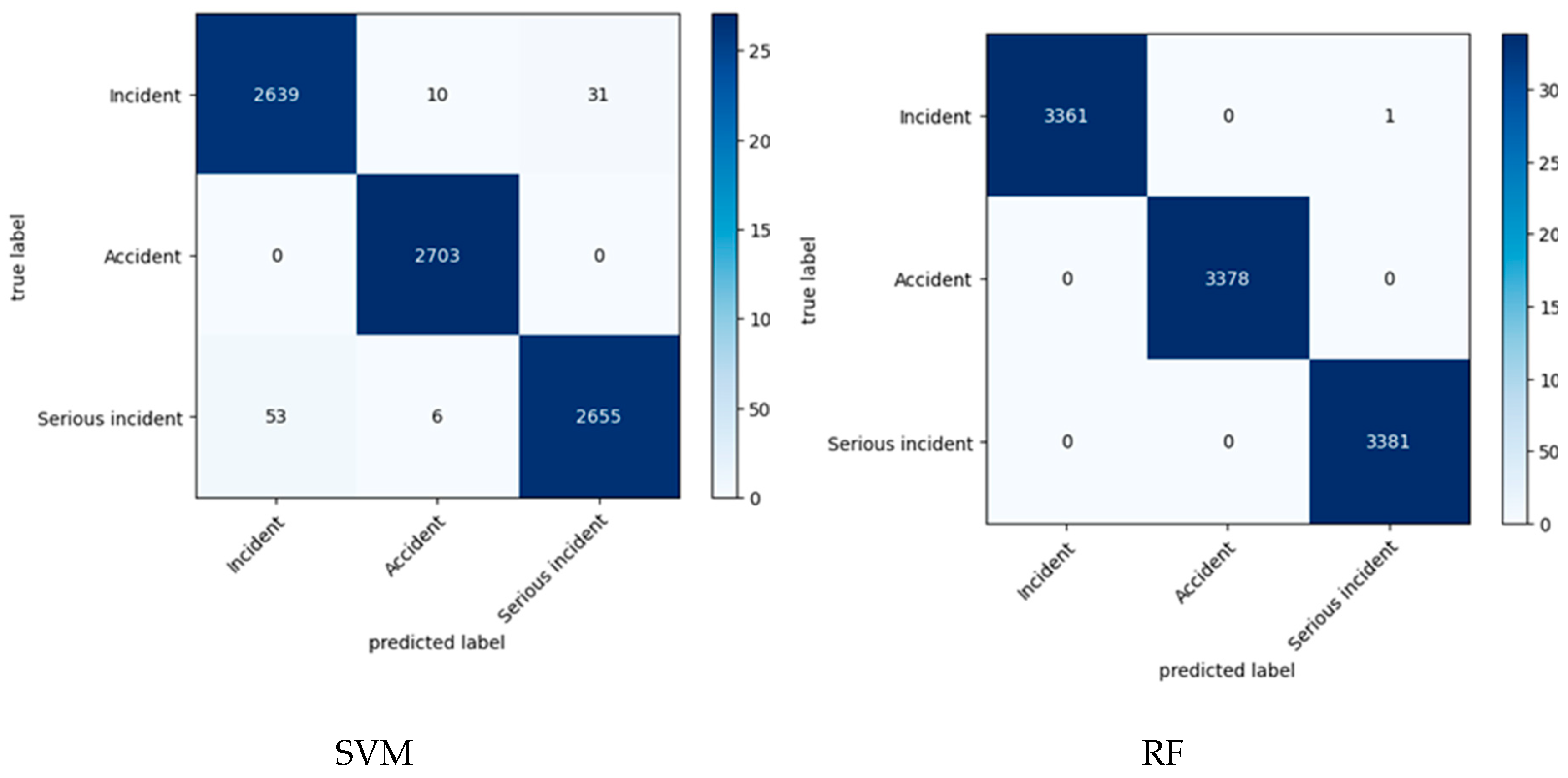
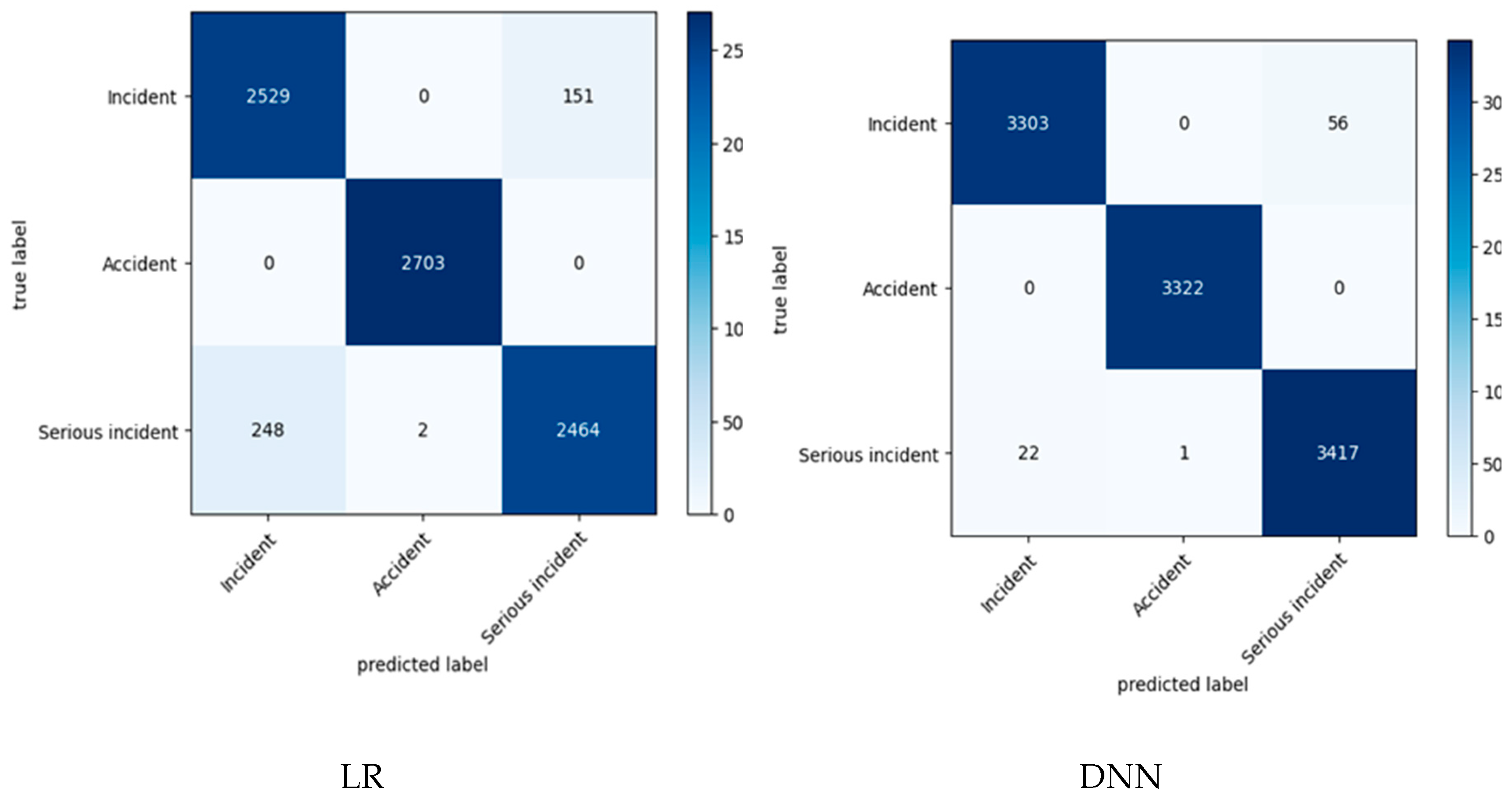
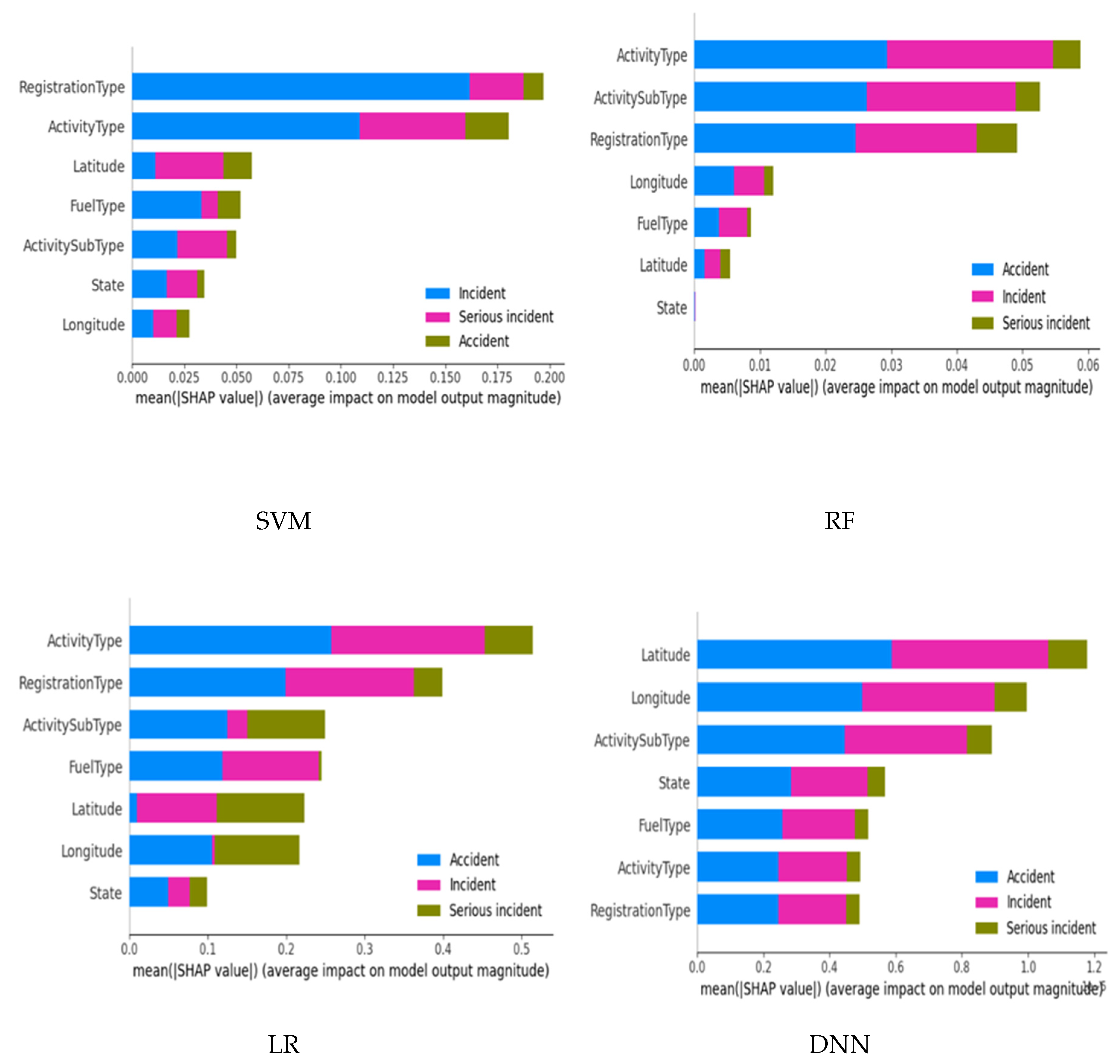
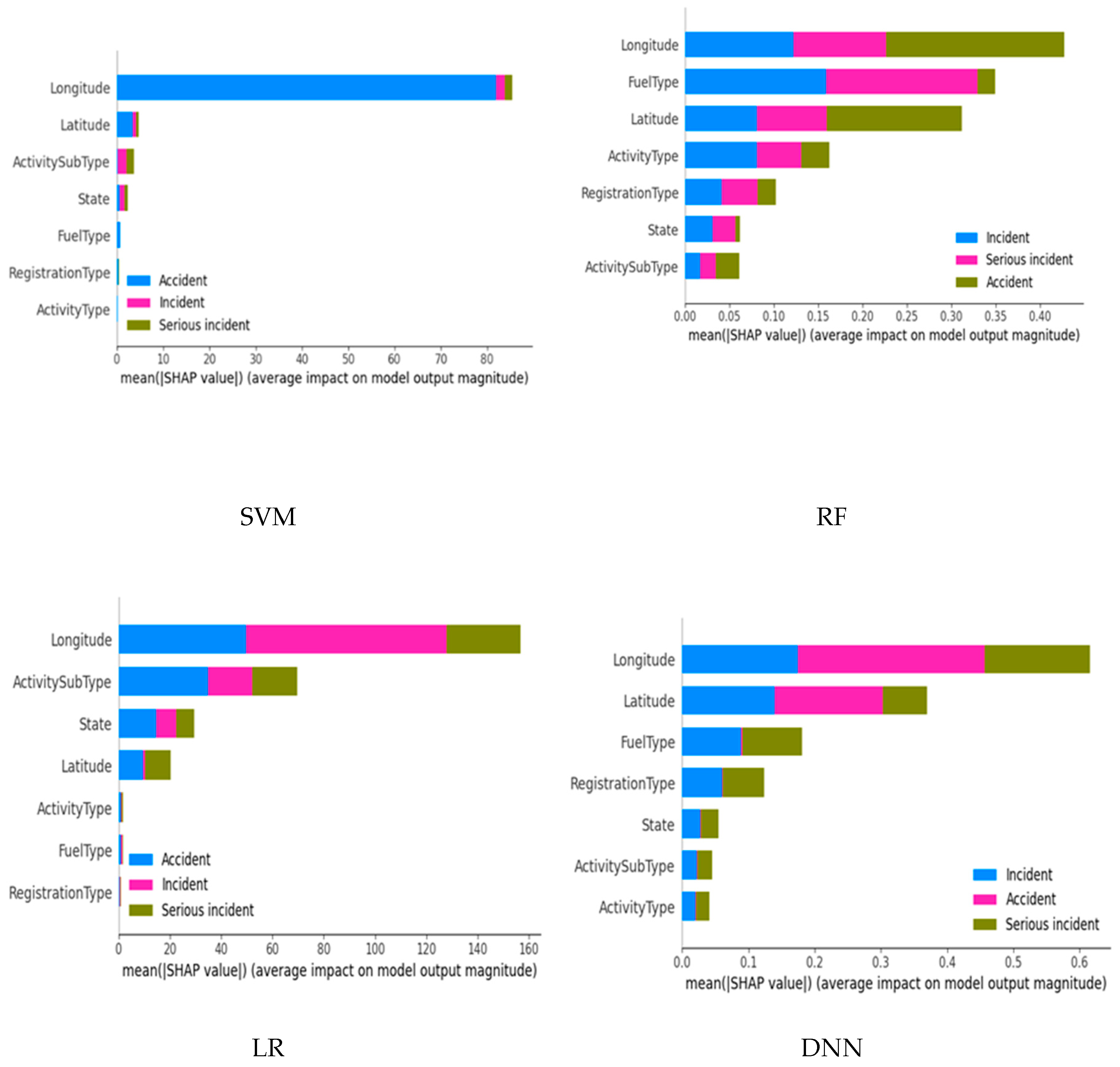
2. Related Work
Despite capturing the attention of many AI researchers across various fields of research, Explainable Artificial Intelligence (XAI) is still in its infant stage, that is, not much has been done to fully explore it for most fields, aviation not being exceptional. This section presents the prior studies whose context was the deployment of XAI to the aviation industry.
A study by [
22] presented a taxonomy of the various levels of XAI relating to the aviation industry that can enhance trust in machine intelligence to human users. The study also gives an insight into the different state-of-the-art XAI approaches highlighting the pros and cons of each and suggesting the most suitable application area for each. However, no quantitative-based experiments are conducted to prove their concept, and consequently, no quantified performance comparison of the approaches for real-world scenarios is done. The work in [
23] proposed a framework for generating human-centric and scientific explanations to enable human users to describe and interpret model predictions in the aviation industry. The authors contextualized XAI at four levels including interactivity with users where the XAI provides interactive explanations, level of observation where XAI is realized by either studying the observed data or the observed model, model structure where explanations are either model-agnostic or specific, and purpose of the explanations.
In a case study, Midtfjord et al. [
24] highlighted the complexities involved in accurately modelling the physical dynamics of runway surface friction incurred by aircraft during landing. This challenge arises due to the complex and nonlinear interactions among the various physical factors influencing surface friction, as well as their time-dependent interdependencies. By incorporating weather data and runway condition reports, the study employed eXtreme Gradient Boosting (XGBoost) models to develop a hybrid assessment framework capable of classifying slippery runway conditions and predicting slipperiness levels. To ensure model transparency and support reliable decision-making for airport operators, the SHAP (SHapley Additive exPlanations) method was applied, offering localized explanations of the model outputs.
By using data provided by the United States Air Force (USAF) spanning from 2010 to 2018, study [
25] trained and assessed several versions of interpretable models based on Bayesian networks, designed to function as decision support systems for selecting USAF candidate pilots. The authors utilized SHAP values alongside split conformal prediction techniques to provide explanations for the resulting black-box model hence facilitating a transparent and manageable assessment of each feature’s impact on the model's prediction, as well as a reliable estimation of the prediction's uncertainty.
The study by Groot et al. [
26] emphasized that in scenarios with high traffic density, analytical conflict resolution methods can lead to airspace instabilities. The authors also highlighted that, despite existing alternative AI-based methods, such as those leveraging deep reinforcement learning, having demonstrated promising results in these settings, they functioned as black-box models, making their decision-making processes challenging to interpret. To address this, the authors explored ways to explain the behavior of a Soft Actor-Critic model trained for vertical conflict resolution within a structured urban airspace. They employed a heat map of chosen actions as a tool to interpret and visualize the learning policy.
Study [
27] introduced a green performance evaluation model for airport buildings, leveraging PCA and hierarchical clustering algorithms within an explainable, semi-supervised AI framework. This approach aimed to minimize reliance on human intervention when assessing green scores. By employing methods such as the scatter coefficient, Psi Index, variation, and permutation to reduce dataset dimensions, alongside divisive and agglomerative hierarchical clustering techniques, the authors were able to derive interpretable decision trees from the corresponding hierarchical dendrograms.
In their study, [
28]developed a deep neural network model aimed at forecasting airport throughput based on both current and anticipated weather and air traffic conditions. To offer insights into which features the model relied upon to generate specific outputs, the authors proposed a method incorporating the explainable principal component analysis (EPCA) algorithm [
29]. This approach enabled users to explore feature vectors derived from processing autoencoder outputs, providing a clearer understanding of the model’s internal processes and decision-making behaviour. Through the proposed method, users could gain insight into both what the model learned and how particular outcomes were achieved. The technique was applied to a real-world case study where deep learning was used to predict the total number of flights—either landings or takeoffs at major US airports within a 15-minute interval.
Zeldam et al., [
30] proposed and applied an automated failure diagnosis model where feasibility was tested using XAI on the RNLAF (Royal Netherlands Air Force) F-16s dataset. Their approach was demonstrated using several learning models---Support Vector Machine (SVM), Random Forest (RF), Naive Bayes (NB), and Neural Network (NN)---and experimental findings showed RF to record a higher performance of ≃ 80%. Their research is also based on XAI for model interpretation and understanding of the assessed diagnosis. The survey conducted in [
5] revealed that LR, SVM, RF, and NN models are better in AI prediction and hence can be used on aviation datasets. Their survey was on AI and XAI in Air Traffic Management (ATM) where they identified the current and future research developments in the same domain. They indicated that LIME and SHAP explanations are now commonly used as they are acceptable to researchers and thus should be used to give more knowledge and understanding to what models give to avoid biases and trust issues among the end users. They also studied the importance of using autoencoders in AI models as explained by Dubot and Olive in their studies specifically regarding air transportation [
31,
32].
In [
33] a CNN (Convolutional Neural Networks) model was developed for the detection of topological defects in automated fiber placement manufacturing. To gain an intuition of the visual features (individual pixels or a group of pixels forming small image segments) that contribute to the model’s decision boundary, three XAI techniques were deployed including Smoothed Integrated Gradients (SIG), Guided Gradient Class activation mapping while the importance of deep learning features was obtained using Shapley Additive Explanations. For visualization of model classifications, SIG and DeepSHAP techniques were deployed. The authors computed and visualized explanations for sample layup defective images while seeing how these explanations correlated with model decisions. Also, study [
34] developed an inception network model (CNN-based model) to discriminate between classes of objects/images. For model explainability, the authors deployed image feature visualization techniques including, visualizing activated neurons, deconvolution, deep dream, and Mask R-CNN segmentation to the output of each layer to extract intermediate information and understand which features are learned for input image discrimination. The authors in [
33] presented a CNN-based semi-supervised model that used an autoencoder component for unsupervised learning and a fully connected network component for supervised learning. The study leveraged Linear adversarial perturbation using the fast gradient sign method (FGSM) to realize input feature perturbation in a bid to understand the impact of each feature on the model classification performance. Also, t-SNE was initialized using PCA (Principal Components Analysis) and then deployed to visualize the high-dimensional latent feature space in a 2D space.
In [
35] a recurrent LSTM-based deep neural network was trained and evaluated on a historic flight dataset collected at the John F. Kennedy International Airport for predicting future unsafe situations. To ensure transparency of model operations, the authors leveraged a combination of input perturbation techniques and an intrinsically explainable hyperplane-based classification model to, in a global approach, explain the decision boundary of the proposed neural network model. The proposed LSTM (Long Short-Term Memory) model recorded 9.4%,12.8%, and 42.3 seconds while the hyperplane-based model recorded 97.2%, 18.0%, and 51.8 seconds in terms of accuracy, miss-detection rate, and duration before the occurrence of the degraded state, respectively.
In a study [
36], Saraf et al. proposed a prototype tool for verifying and validating AI-based aviation systems. A LIME-based technique was used to generate reliable, human-understandable explanations for predictions from the Multiple Kernel Anomaly Detection (MKAD) algorithm, an SMV-based algorithm developed by NASA (National Aeronautics & Space Administration) for aircraft trajectory anomaly detection. Using the enhanced input perturbation technique, the proposed approach located exact anomaly points from the aircraft trajectory images. The authors also proposed a prototype for verifying and validating AI-based aviation systems where they applied XAI for aviation safety applications. Their work gave proof of concept for an explanation as they used XAI to make reasonable interpretations that humans can understand in making decisions based on the models. Hence concluded that the application of XAI can be used by subject matter experts (SMEs) and is useful concerning users accepting the decision made by AI-based support tools.
In the study [
37], a genetic algorithm-based conflict resolution algorithm for ATM was proposed to determine the best aircraft trajectories. Model explainability was evaluated by assessing the degree to which the controller understood its operations. Flight trajectory data was collected via flight simulations with nine controllers and the authors designed questionnaires to get feedback from each controller. To get fine-grained details, the authors also designed and utilized semi-structured questionnaires to assess the explanations at four levels, that is, at a Black box level where only the selected solution was presented, at a heat map level where a combination of potential solutions was demonstrated and at a storytelling level where human-centric explanations in form of storytelling were used.
Despite many of the above studies emphasizing the importance of working with explainable and interpretable models in safety-critical fields, no prior studies have explored explainable models in the classification of aviation incidents using the ATSB aviation incident reports, while the few that have studied aviation incidents using this dataset have not considered the impact of its imbalanced distribution on model performance. This study closes this knowledge gap by training and evaluating the performance of various classic machine learning models and a deep learning model in classifying aviation incidents in the Australian Aviation industry while giving an insight into how the various features influence model predictions for both balanced and imbalanced learning.