Submitted:
12 February 2025
Posted:
12 February 2025
You are already at the latest version
Abstract
Homomorphic Encryption (HE) introduces new dimensions of security and privacy within federated learning (FL) and Internet of Things (IoT) frameworks that allow preservation of user privacy when handling data for FL occurring Smart Grid (SG) technologies. In this paper, we propose a novel SG IoT framework to provide a solution of predicting energy consumption while preserving user-privacy in a smart grid system. The proposed framework is based on the integration of FL, edge computing, and HE principles to provide a robust and secure framework to conduct machine learning workloads end-to-end. In the proposed framework, edge devices are connected to each other using P2P networking and the data exchanged between peers is encrypted using CKKS fully HE. The results obtained show that the system can predict energy consumption as well as preserve user privacy in SG scenarios. The findings provide an insight into the SG IoT framework that can help network researchers and engineers to contribute further towards developing a next generation SG IoT system.
Keywords:
1. Introduction
1.1. Research Challenges
1.2. Research Scope and Contribution
- We propose a novel federated learning smart grid IoT framework using P2PFL and HE principles to secure model parameters (by extension, user data) in the model aggregation process between peers in an EC context. To this end, we provide an analysis of the existing FL IoT framework focusing on privacy-preservation within the realm of SG IoT to identify research gaps and areas for contribution.
- In the context of IoT, we explore a practical application of the framework with IoT devices involving SG energy consumption and optimization using software simulation. To this end, we develop a simulation model for system performance evaluation and validation.
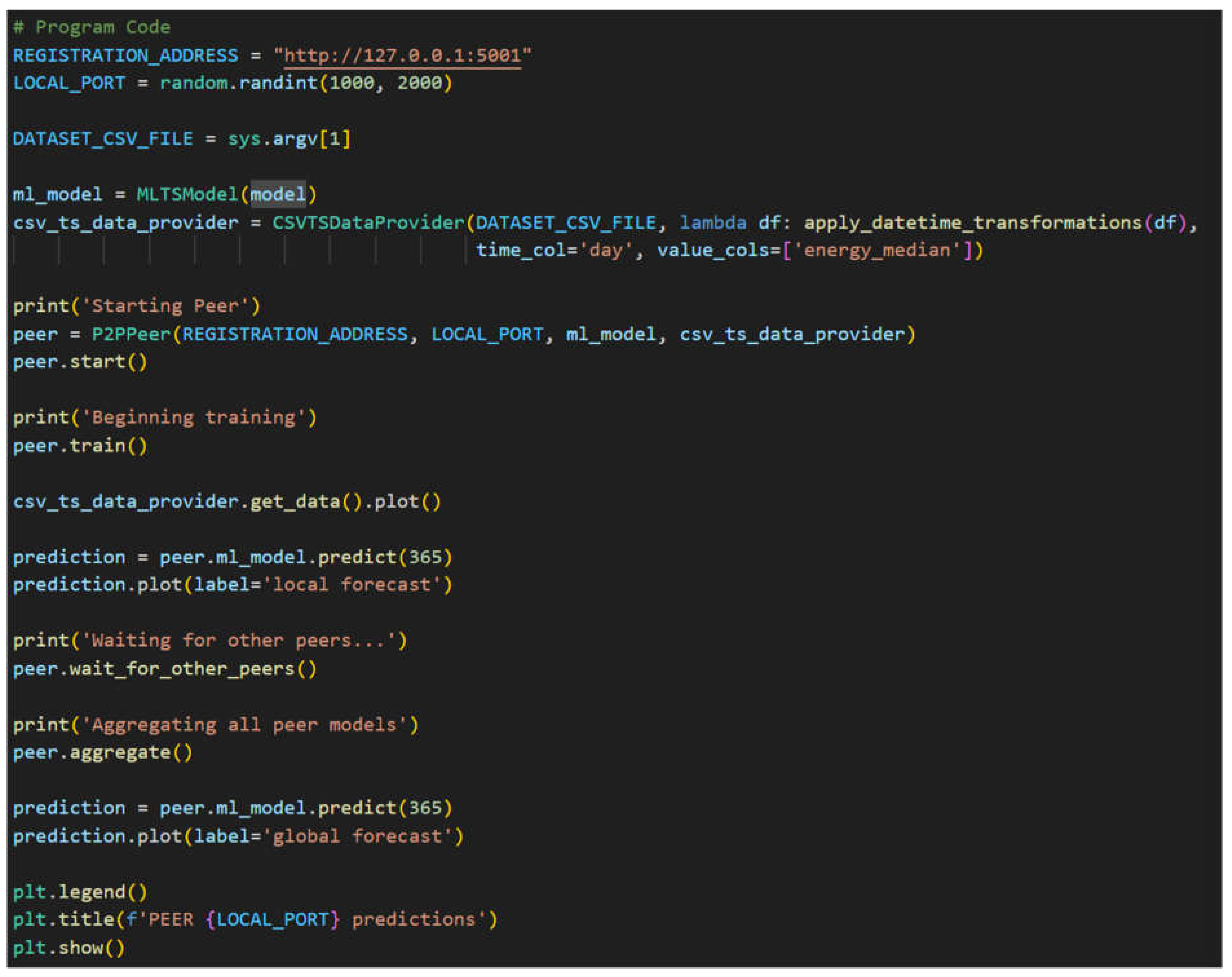
- Finally, we contribute code (written in Python) for system design and practical implementation. To this end, we made our source code publicly available (https://github.com/FilUnderscore/SG-P2PFL-HE) at no costs so that network researchers and engineers can make a substantial contribution to this emerging field, especially energy consumption prediction with privacy-preservation.
1.3. Structure of the Article
2. Related Work
2.1. Research Gaps and Areas for Contribution
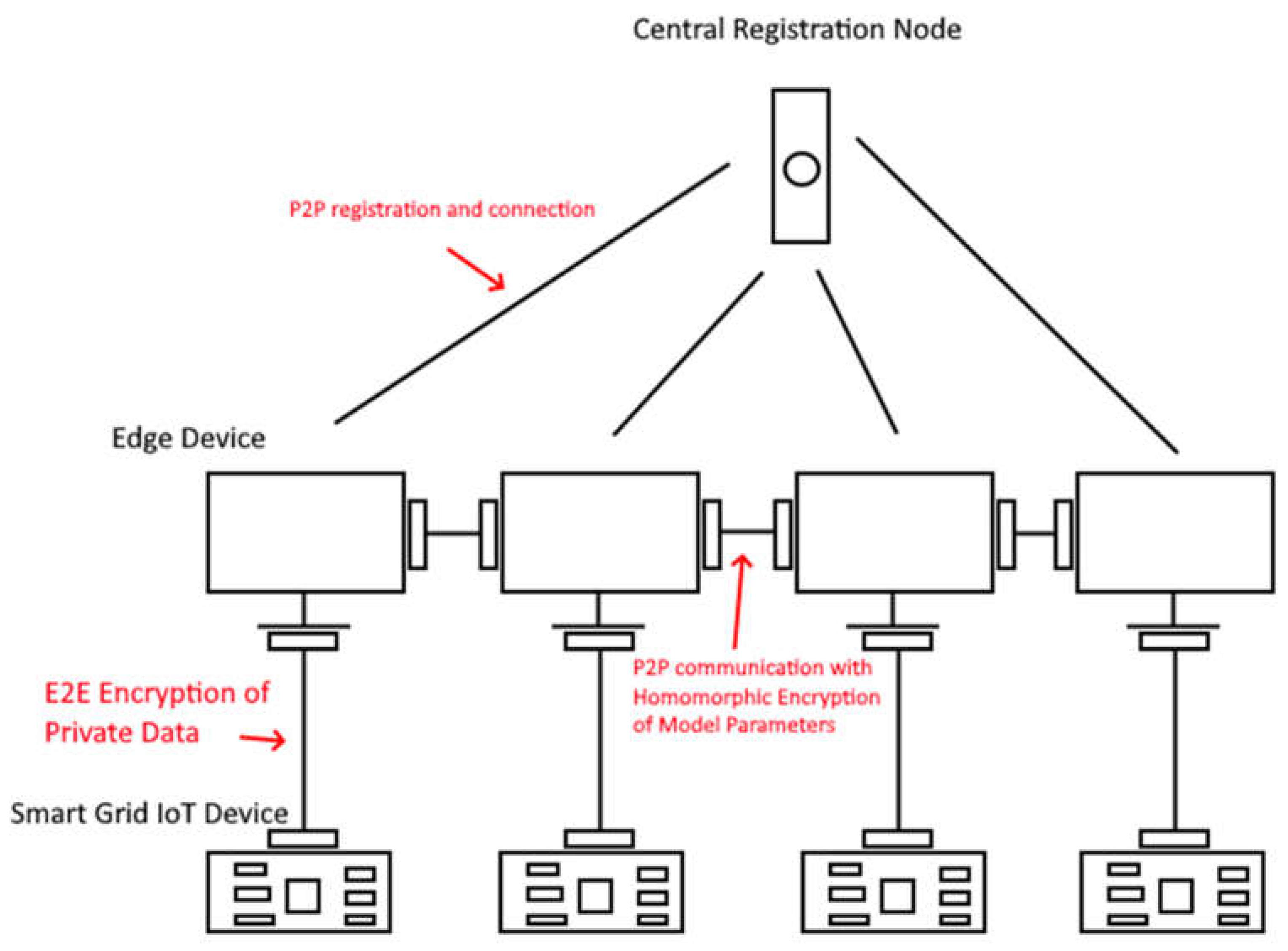
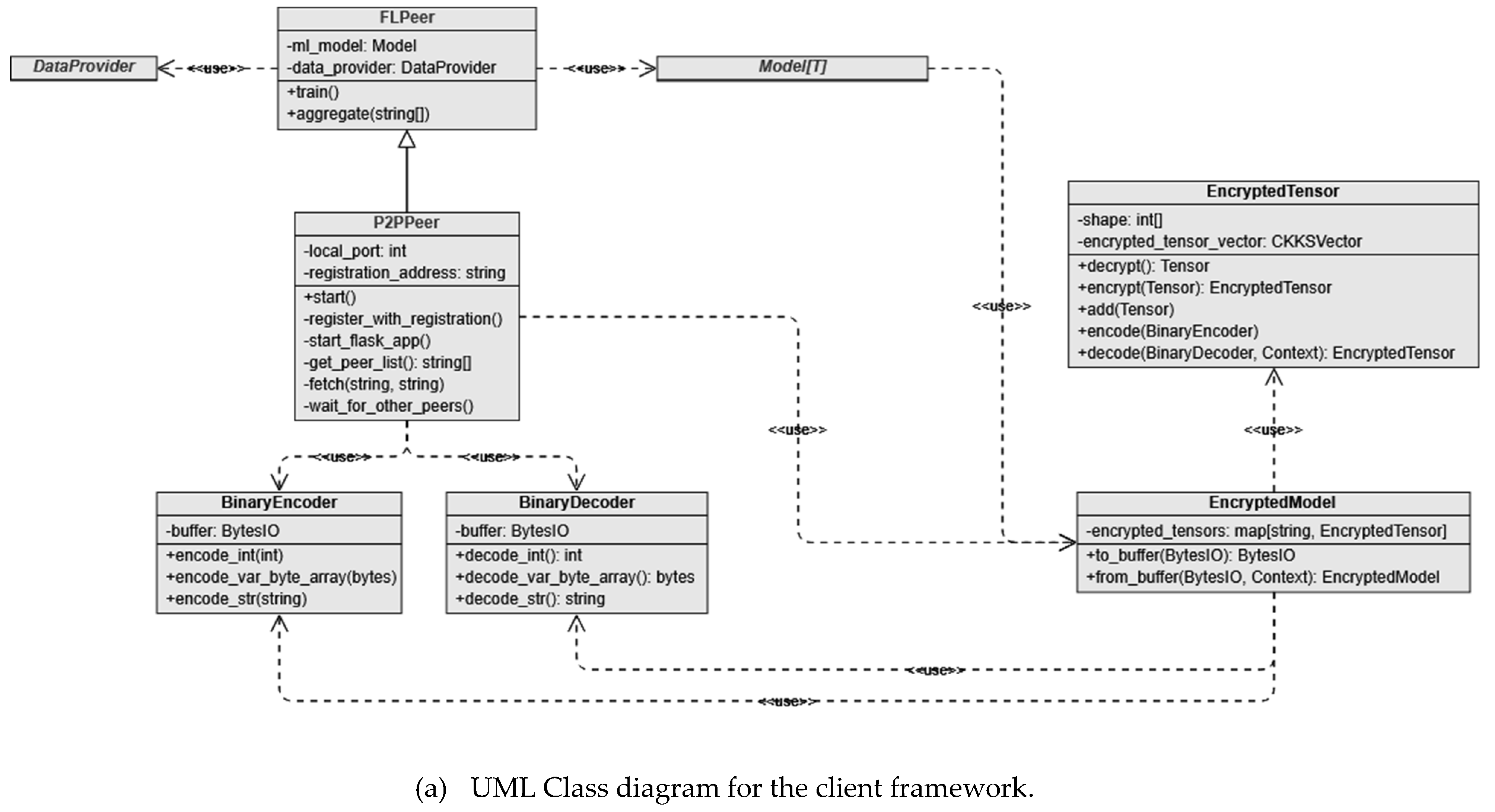
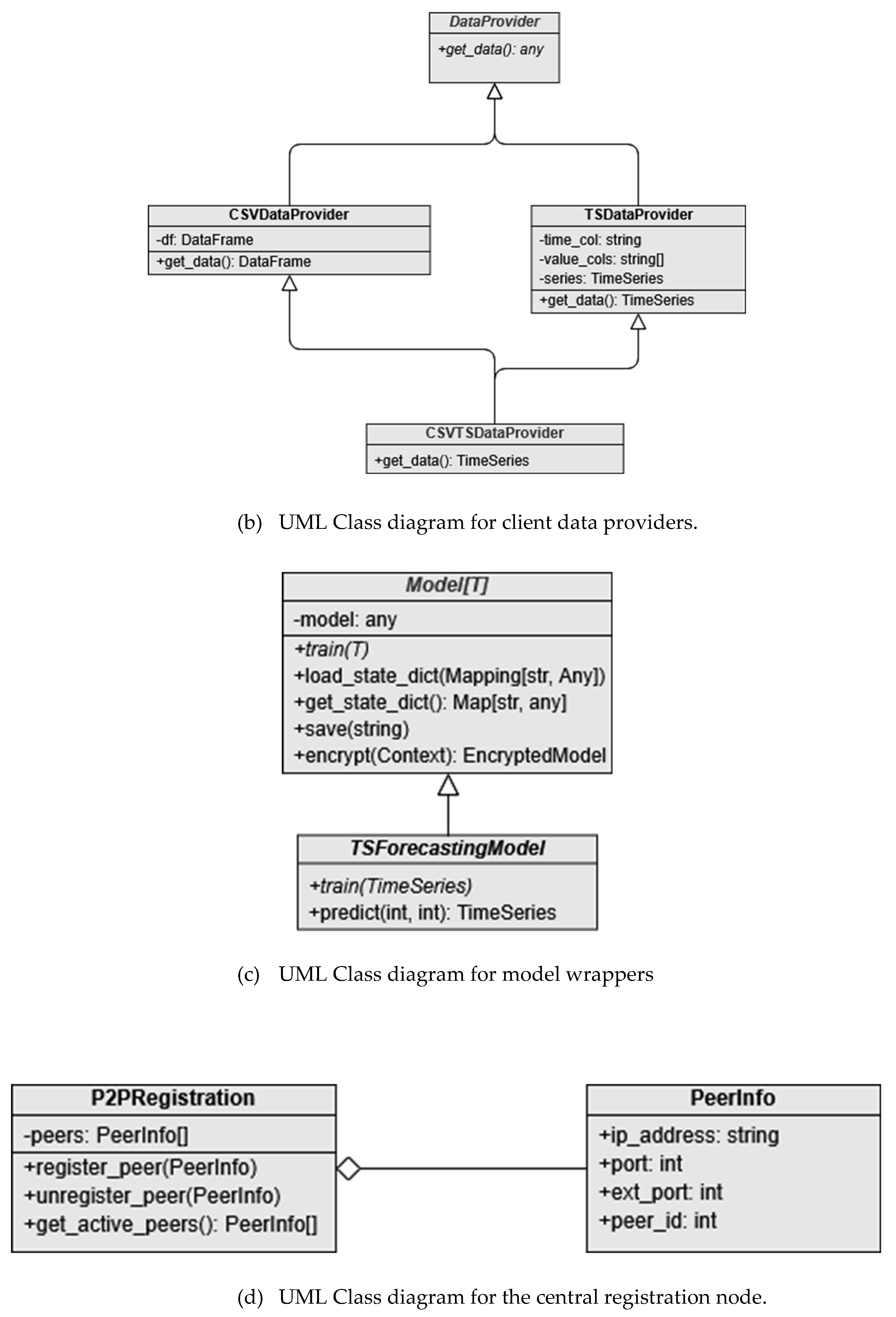
3. Description of the Proposed Framework
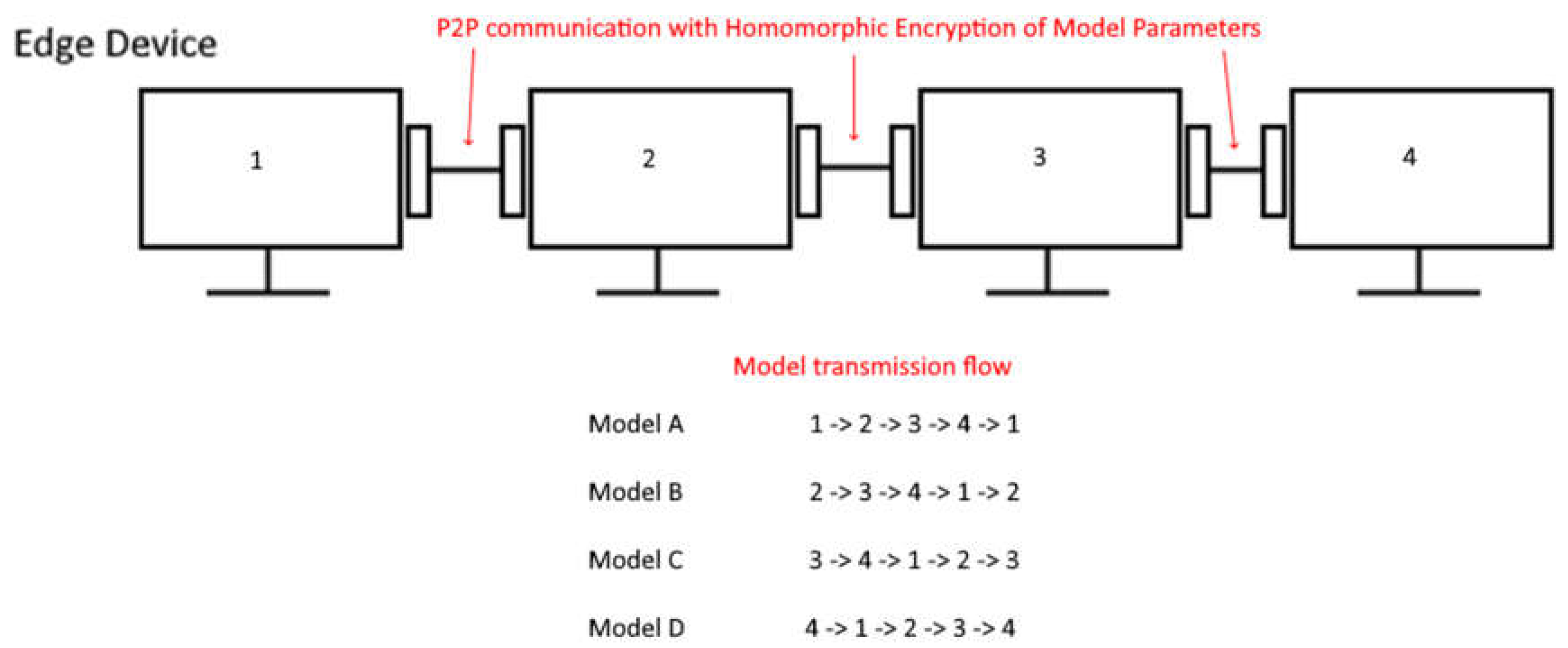
3.1. P2P Communication
4. Implementation Aspect of Fully Homomorphic Encryption
5. Performance Evaluation
5.1. Simulation Environment
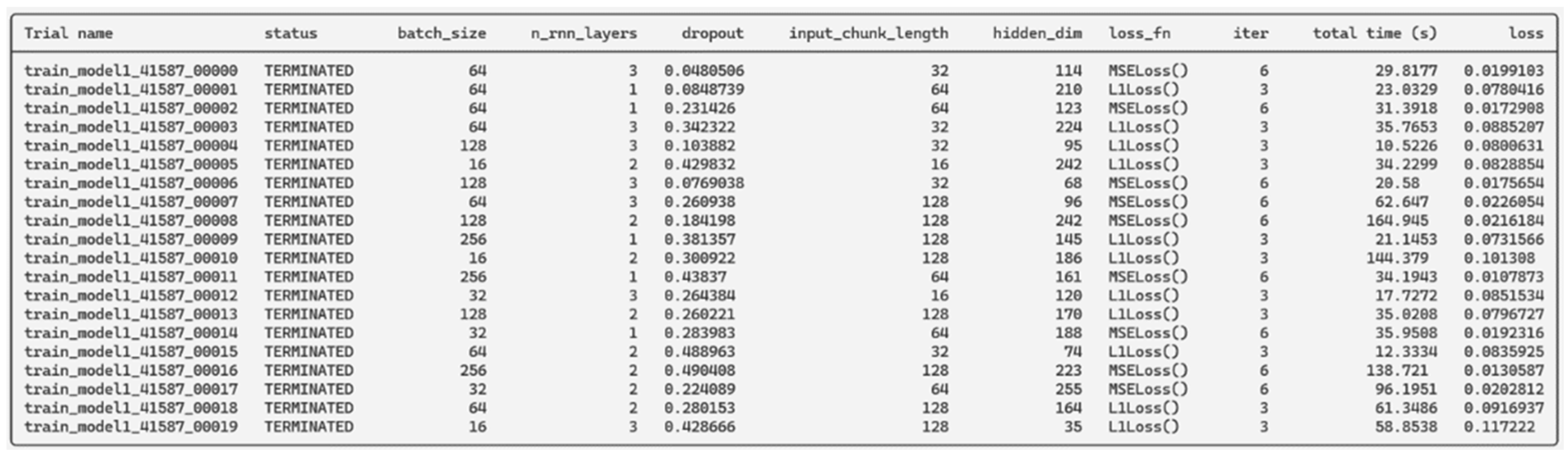
5.2. Hyperparameter Optimization
5.3. Model Validation
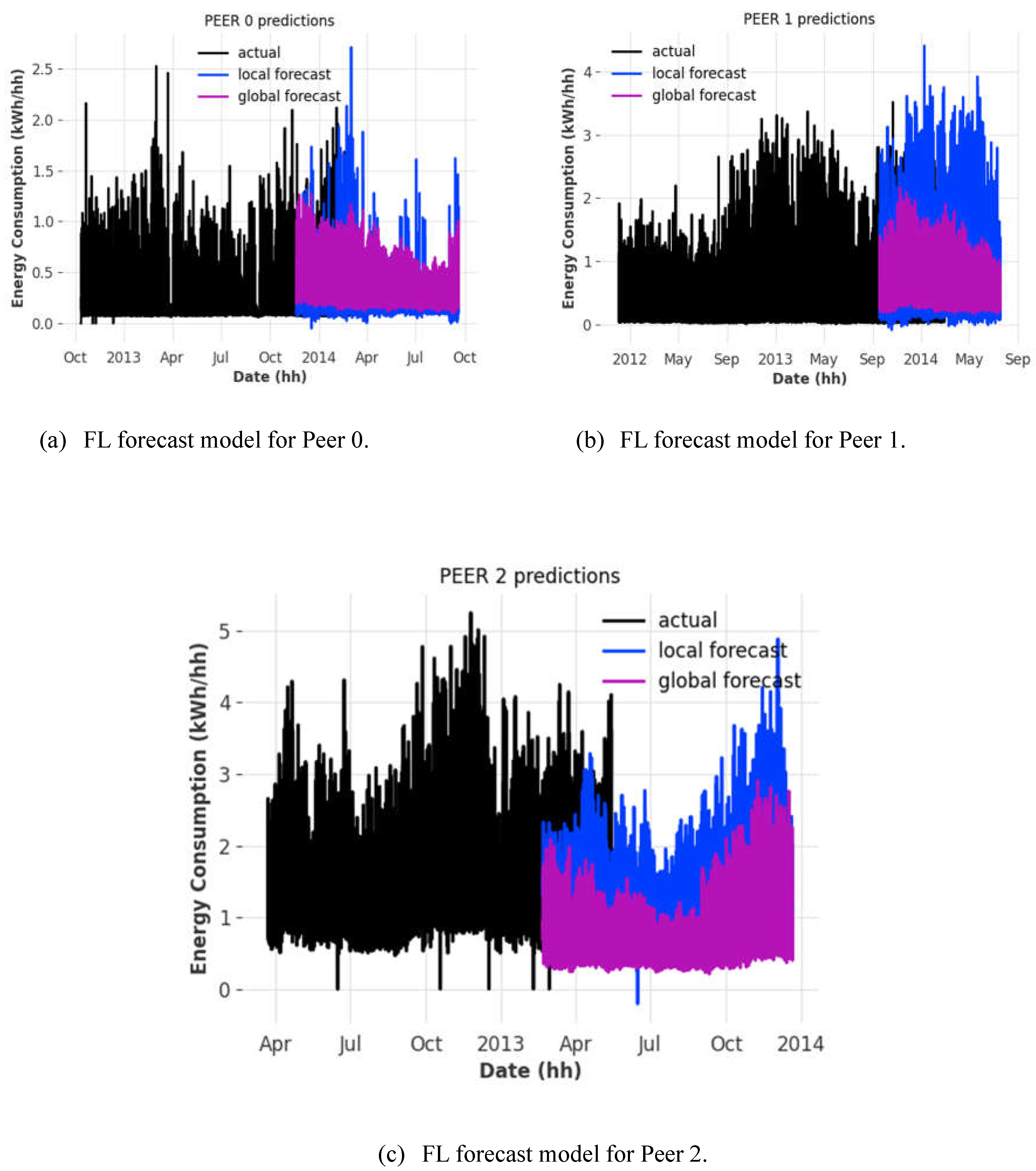
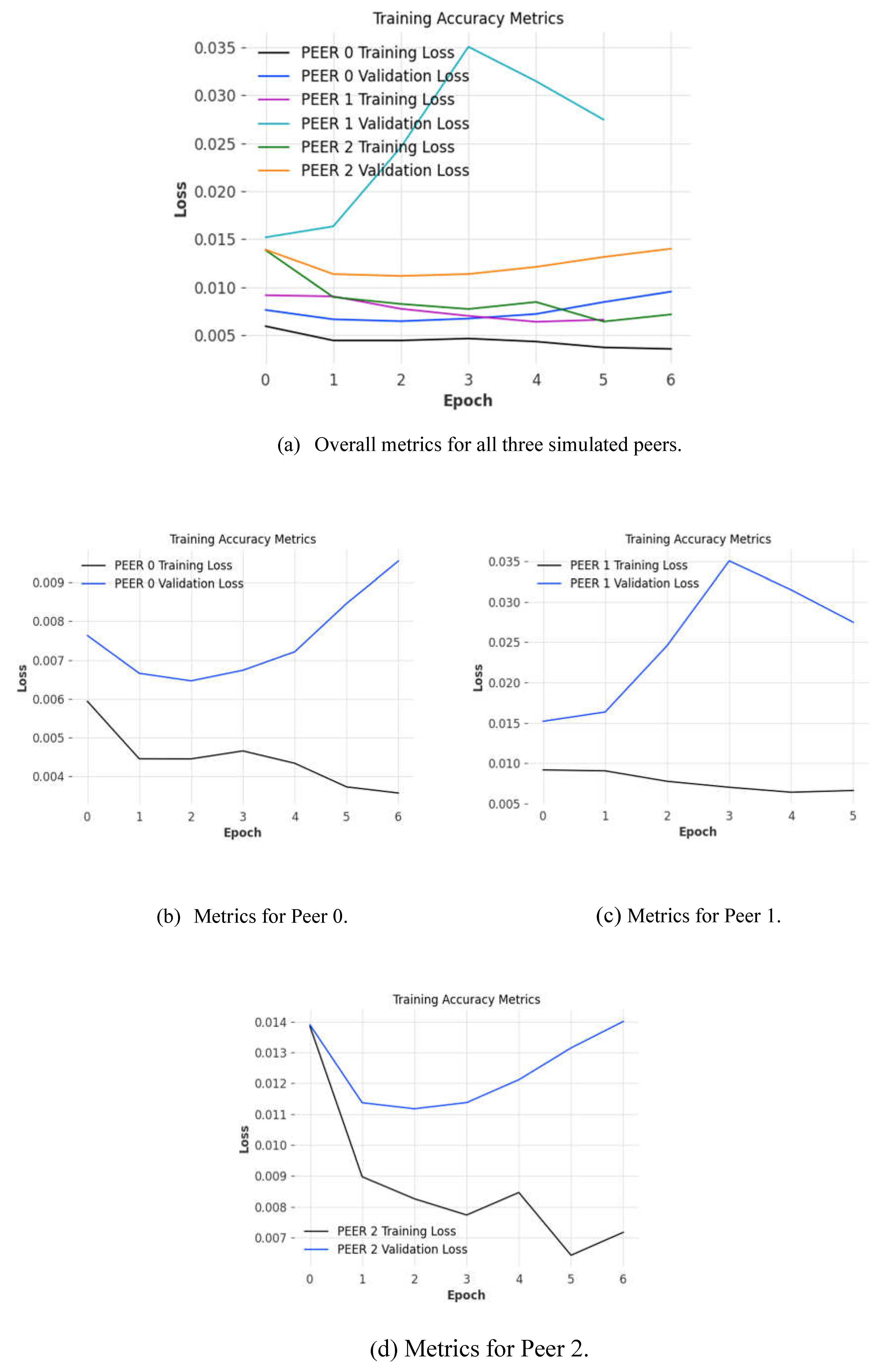
6. Results and Discussion
6.1. Practical System Implications
7. Conclusions
References
- Panigrahi, M.; Bharti, S.; Sharma, A. Federated Learning for Beginners: Types, Simulation Environments, and Open Challenges. In Proceedings of the 2023 International Conference on Computer, Electronics & Electrical Engineering & their Applications (IC2E3); 2023; pp. 1–6.
- Abdulla, N.; Demirci, M.; Ozdemir, S. Smart Meter-Based Energy Consumption Forecasting for Smart Cities Using Adaptive Federated Learning. Sustainable Energy, Grids and Networks 2024, 38, 1–13. [Google Scholar] [CrossRef]
- Zeng, R.; Mi, B.; Huang, D. A Federated Learning Framework Based on CSP Homomorphic Encryption. In Proceedings of the 2023 IEEE 12th Data Driven Control and Learning Systems Conference; Xiangtan; 2023; pp. 196–201. [Google Scholar]
- Liu, Y.; Dong, Z.; Liu, B.; Xu, Y.; Ding, Z. FedForecast: A Federated Learning Framework for Short-Term Probabilistic Individual Load Forecasting in Smart Grid. Electrical Power and Energy Systems 2023, 152, 1–9. [Google Scholar] [CrossRef]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. BrainTorrent: A Peer-to-Peer Environment for Decentralized Federated Learning. 2019.
- Hijazi, N.M.; Aloqaily, M.; Guizani, M. Collaborative IoT Learning with Secure Peer-to-Peer Federated Approach. Comput Commun 2024, 228, 1–13. [Google Scholar] [CrossRef]
- Wen, H.; Liu, X.; Lei, B.; Yang, M.; Cheng, X.; Chen, Z. A Privacy-Preserving Heterogeneous Federated Learning Framework with Class Imbalance Learning for Electricity Theft Detection. Appl Energy 2024, 378, 1–21. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. Fully Homomorphic Encryption without Bootstrapping. 2011.
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. 2023. [CrossRef]
- D., J.-M. Smart Meters in London 2022.
- Networks, U.K.P. SmartMeter Energy Consumption Data in London Households 2015.
- Zhou, T.; Chen, L.; Che, X.; Liu, W.; Zhang, Z.; Yang, X. Multi-Key Fully Homomorphic Encryption Scheme with Compact Ciphertexts. 2021.


| Abbreviation | Notation |
|---|---|
| FL | Federated Learning |
| ML | Machine Learning |
| IoT | Internet of Things |
| SG | Smart Grid |
| EC | Edge Computing |
| E2E | End-to-End |
| P2P | Peer-to-Peer |
| P2PFL | Peer-to-Peer Federated Learning |
| HE | Homomorphic Encryption |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| UML | Unified Modeling Language |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
| MSE | Mean Squared Error |
| CSV | Comma-Separated Values |
| HTTP | Hypertext Transfer Protocol |
| HTTPS | Hypertext Transfer Protocol Secure |
| TLS | Transport Layer Security |
| JSON | JavaScript Object Notation |
| FHE | Fully Homomorphic Encryption |
| MKFHE | Multi-Key Fully Homomorphic Encryption |
| SEAL | Simple Encrypted Arithmetic Library |
| BGV | Brakerski-Gentry-Vaikuntanathan |
| CKKS | Cheon-Kim-Kim-Song |
| Reference | Technologies used | Key contributions | ||||
|---|---|---|---|---|---|---|
| FL | P2P | EC | HE | IoT | ||
| [2] | ✓ | ✕ | ✓ | ✕ | ✓ | Introduces an adaptive FL model using EC architecture which improves privacy-preservation, reduces error rates, and speeds up training times in SG IoT. |
| [4] | ✓ | ✓ | ✓ | ✕ | ✕ | Improves model training by distributing SG forecasting models instead of distributing user data to improve privacy-preservation. |
| [7] | ✓ | ✕ | ✕ | ✓ | ✕ | Introduces a novel data paritioning and aggregation scheme that detects SG energy theft patterns on encrypted data leveraging CKKS FHE. |
| Our work | ✓ | ✓ | ✓ | ✓ | ✓ | Proposes P2PFL EC architecture when forecasting energy consumption in SG IoT using secure peer-peer model aggregation on CKKS FHE-encrypted model data. |
| Parameter | Value |
| No. of peers | 3 |
| ML model | RNN |
| FL algorithm | FedAvg |
| RNN model | LSTM |
| Hidden neuron count | 196 |
| RNN layer count | 2 |
| RNN dropout | 0.22222 |
| Batch size | 128 |
| Input size | 32 |
| Sequence length | 32 |
| Epochs | 100 |
| Learning rate | 0.001 |
| Loss function | MSE |
| Early stopping monitor | Validation Loss |
| Early stopping patience | 5 |
| Early stopping min delta | 0.0005 |
| Early stopping mode | min |
| Training set to validation set ratio | 4:1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



