
Submitted:
10 May 2023
Posted:
11 May 2023
You are already at the latest version
Abstract
Recent advancements in Artificial Intelligence (AI), Deep Learning (DL), and computer vision have revolutionized various industrial processes through image classification and object detection. State-of-the-art Optical Character Recognition (OCR) and Object Detection (OD) technologies, such as YOLO and PaddleOCR, have emerged as powerful solutions for addressing challenges in recognizing textual and non-textual information on printed stickers. However, a well-established framework integrating these cutting-edge technologies for industrial applications still needs to be discovered. In this paper, we propose an innovative framework that combines advanced OCR and OD techniques to automate visual inspection processes in an industrial context. Our primary contribution is a comprehensive framework adept at detecting and recognizing textual and non-textual information on printed stickers within a company, harnessing the latest AI tools and technologies for sticker information recognition. Our experiments reveal an overall macro accuracy of 0.88 for the sticker OCR across three distinct patterns. Furthermore, the proposed system goes beyond traditional Printed Character Recognition (PCR) by extracting supplementary information, such as barcodes and QR codes present in the image, significantly streamlining industrial workflows and minimizing manual labor demands.
Keywords:
Optical Character Recognition
; Sticker Pattern
; Deep Learning
; Object Detection
; YOLO
; Manufacture Automation
; Paddle OCR
1. Introduction
Recent advancements in artificial intelligence (AI) have paved the way for disruptive innovations, offering effective solutions across a wide range of industries [1]. Many of these innovations harness the power of deep learning (DL) and computer vision algorithms to enhance industrial processes [2]. DL algorithms are capable of learning the most relevant features for distinguishing patterns and can be employed for classification, regression, or other purposes [3,4,5]. Meanwhile, computer vision can be applied to tasks such as image classification and character recognition [3,6,7,8].
Object detection (OD) involves the identification and tracking of desired object instances in images, videos, or real-time applications [7]. A popular technology employed for OD in industrial applications is YOLO (You Only Look Once) [9]. YOLO facilitates real-time object detection by dividing the input image into a grid and predicting bounding boxes (BB) and class probabilities for each grid cell [9]. This process requires a single forward pass through the network, ensuring fast and efficient object detection [7].
Another widespread application of computer vision in industry is Optical Character Recognition (OCR) [10]. Contemporary OCR techniques are primarily rooted in deep learning and aim to recognize various characters or numerals in images [10]. OCR technologies can identify characters in different types of documents, such as printed stickers, and can be utilized for Printed Character Recognition (PCR) and Handwritten Character Recognition (HCR) [11]. PCR is comparatively simpler than HCR due to the limited number of available fonts in PCR as opposed to the diverse handwriting styles found in HCR [12]. However, it is often necessary to identify documents or printed stickers containing arbitrary characters, such as hexadecimal identifiers or passwords with special characters [12].
PaddleOCR (PP-OCR) is a versatile and powerful solution for PCR and HCR, effectively addressing these challenges [13]. This tool offers a comprehensive OCR system comprised of three components: text detection, detection boxes, and text recognition [13]. Text detection identifies text segments, detection boxes correct text orientation, and text recognition classifies each character present in a text segment [13,14].
Industrial applications frequently face challenges related to non-textual and textual information recognition. These challenges can encompass variations in lighting conditions, low-resolution images, and complex image patterns, all of which can negatively impact the performance of OD and OCR systems. To tackle this issue, many industries rely on human visual inspection (VI) for information recognition. However, VI comes with its own set of problems, such as visual fatigue and inconsistent results.
Despite the advancements in sticker textual and non-textual information detection, a well-established framework is yet to be developed. OD integrated with OCR technologies can be harnessed to create a robust industrial application in this area. In this paper, we propose an innovative framework that combines OCR and OD to automate visual inspection processes in an industrial context. Our primary contribution is a comprehensive framework that detects and recognizes both textual and non-textual information on printed stickers within a company. Our system employs the latest AI tools and technologies for OCR, such as YOLOv8 and PaddleOCRv3, and it is capable of processing printed stickers beyond traditional PCR, extracting additional information such as barcodes and QR codes present in the image.
The remainder of this paper is structured as follows: Section 2 introduces the fundamental concepts of OD and OCR, with a particular emphasis on YOLO and PP-OCR. Section 3 outlines the relevant literature. Section 4 describes the databases, the OD approach, and the proposed framework. Section 5 delves into the training outcomes and performance evaluation. Lastly, Section 6 provides concluding remarks and highlights possible avenues for future research.
2. Background
This section aims to provide basic background on the YOLO and PP-OCR technologies, and the ground to understand our proposed framework, in order to enhance the comprehension of the present study.
2.1. You Only Look Once (YOLO)
One of the most widely utilized object detection models currently is YOLO, due to its simple architecture, low complexity, easy implementation, and speed [15]. The authors of YOLO transformed the object detection problem into a regression problem instead of classification. A convolutional neural network predicts the bounding boxes as well as their position. Since this algorithm identifies objects and their positions with the help of bounding boxes by looking at the image only once, it is named You Only Look Once [16].
The YOLO algorithm has undergone numerous versions since its release in 2016, demonstrating consistent improvements to the algorithm’s performance. YOLOv8 was released in 2023 and presents various pre-trained model versions [17,18]. For the development of this study, the YOLOv8n architecture is employed due to its compact size and high performance [15]. One of the key reasons for choosing this YOLO version in our framework is the need to obtain a powerful, lightweight, and state-of-the-art model that can run efficiently on a CPU. We aim to implement the proposed framework in an industrial setting where hardware resources may be limited. Therefore, YOLOv8n was selected for its high accuracy and ability to run in real-time on CPU-based systems.
2.2. Paddle OCR (PP-OCR)
PP-OCR is a framework that integrates the entire process of training, inference, and deployment of OCR models and also provides pre-trained models for use in industrial environments [19]. PP-OCR offers the PP-OCR solution [20], a universal OCR system for text detection and recognition, with various models suitable for industrial implementations, including universal, ultra-light, and multilingual segmentation and recognition models.
In addition to the input and output, it is composed of three modules: text detection, frame correction, and text recognition. The text detection module is composed of a text detection model that returns the areas where text is present in the image. The frame correction module receives the text boxes detected in the previous module and corrects the irregularly shaped boxes into rectangular format, preparing them for text recognition. The direction of the text is also corrected if it is upside down or sideways. Finally, text recognition is performed on the detected and corrected boxes. Currently, there are three versions of PP-OCR proposed by Paddle Paddle, namely PP-OCRv1 [20], PP-OCRv2 [21], and PP-OCRv3 [14], with the latter being the most recent.
We employed PP-OCRv3 in our framework, which utilizes the same structure as PP-OCRv1 but implements new algorithms and optimizations. Specifically, the detection model is optimized based on the same model used in PP-OCR, the Differentiable Binarization (DB), while the base recognition model is replaced by the Single Visual Model for Scene Text Recognition (SVTR), which was previously the Convolutional Recurrent Neural Network (CRNN).
3. Related Work
This section will discuss OD and OCR applications. We also will cover post-processing techniques used with OCR systems.
3.1. Sticker information extraction
Extracting information from product labels in industrial settings is a critical task that has garnered significant attention in recent years [22]. Numerous techniques and technologies have been devised to improve the efficiency and accuracy of information extraction, including OCR systems and various image and data processing methods [23].
One such study is by Subedi et al. [24], who developed a low-cost OCR system grounded in deep learning. Their system accepted code text segment images from real products as inputs. However, their approach did not incorporate OD and failed to address the challenges of extracting information from complex sticker patterns, such as stickers with non-textual data. Another approach by Gromova and Elangovan [25] involved developing an automated system for extracting pertinent information from medication container images. Their system utilized Convolutional Neural Networks (CNN) for sticker extraction and distortion correction, followed by OCR. Relevant information was obtained from the recognized text using Natural Language Processing (NLP) techniques. Nonetheless, their system did not include OD and might not be suitable for extracting information from intricate real-world scenarios Gregory et al. [26] proposed an automatic inventory tracking system that leverages computer vision and DL techniques. Their system locates, processes, and decodes label information, continuously updating the inventory database. Their approach consists of locating the label using an OD algorithm, decoding the barcode, and performing OCR. However, their system may struggle with the complexity of industrial product labels.
In our proposed framework, we integrate OCR with OD based on Santiago Garcia [27]. This integration enables us to accurately extract all relevant data from product stickers, including text, barcodes, and QR codes. Furthermore, our framework is capable of handling multiple sticker patterns, aiming to become a robust solution for an industrial application.
3.2. Paddle OCR System and Post-processing Information
PP-OCR is widely used in various applications, including document analysis, and passport card recognition [27,28]. In the context of industrial visual inspection, PP-OCR offers a robust solution for extracting textual information from product stickers.
The work of Dahlberg et al. [29] demonstrated the effectiveness of PP-OCR in an industrial environment for printed character recognition. Their solution detects stickers from panoramic scans of industrial plants, comparing the performance of different OCR systems, such as Tesseract OCR [30] and PP-OCR, with the latter outperforming the former.
OCR systems can recognize text with high accuracy, but there is still room for improvement, particularly with post-OCR techniques. Post-processing methods can be classified into manual and semi-automatic approaches [31]. Manual post-processing involves reviewing and correcting OCR output, while semi-automatic post-processing combines human inspection and automated resources to enhance OCR accuracy [32]. Semi-automatic techniques can be further divided into isolated-word and context-dependent methods.
Isolated-word post-processing analyzes the word to which OCR has been applied, while context-dependent methods consider all words in a document and analyze surrounding words to correct errors [33]. In the context of post-OCR processing, the transformer-based architecture BERT has been employed in several works, such as Kaló and Sipos [34], which introduces a technique for correcting Tesseract OCR output.
Our proposed framework employs an isolated-word approach for post-processing OCR, as the target label fields are rule-based and have no interdependence. This innovation contributes to post-processing OCR techniques.
4. Methodology
In this section, we will cover the databases utilized to train the object detectors models and to evaluate the OCR system. Then, we explain how the OD methodology for detect sticker, QR code and barcode. We covered Post-OCR algorithm employed to enhance the performance of OCR system output. In metrics, we explain how each AI component of our framework was evaluated. Finally, we cover how all these systems work together in the proposed OCR framework to detect sticker textual and non-textual information.
4.1. Databases
We employed a controlled environment to capture images of three different sticker patterns, A, B, and C, provided by a private company. These patterns are illustrated in Figure 1. It’s important to mention that all fields in the stickers were in Portuguese language.
For the OD algorithms we created two databases, a sticker database and a non textual database (for detecting barcode and QR code) and for validating our models, we used a third database to work as ground truth for the OCR output. We employed a hold-out technique as a validation strategy with a 70/30 training and validation proportion. For the first two databases, we mixed real stickers images and also non sticker images to develop a system capable of detecting the desired objects with another sticker pattern. Additionally, we utilized MakeSenseAI for annotating the images due to its quick and specialized image annotation capabilities for object detection applications [35]. Next, the particular characteristics of the database used in this work will be detailed.
4.1.1. Stickers
The Stickers database consists of modem images that we created with real images of three sticker patterns: A, B and C, making some positioning and lighting modifications in the controlled environment. Additionally, we included some public sticker images available on the internet. Although this OCR system is only validated with A, B, and C modem models, we designed the OCR detectors to be generalist and capable of detecting a new model without the need for retraining. At the end of this process, a database was obtained with 561 different modem images with 580 annotated stickers.
4.1.2. QR code and Barcode
The non-textual (QR code and barcodes) database consists in modem stickers images that have QR codes and barcodes captured in a controlled environment. In addition, to diversify the database, QR code and barcode images unrelated to modem stickers were collected from public sources on the Internet. The criteria was to chose images with different conditions, such as light, distance and angulation. This step was crucial in order to simulate real-world scenarios, as the input for the QR code and barcode detection model is solely the modem sticker image. The process of annotating and labeling the QR code and barcode images was the same as that of the modem sticker images. The resulting database consisted of 963 images, with 555 QR code object and 952 barcode object.
4.1.3. OCR Evaluation
The validation database consists of two components: Sticker Images and the character recognition for each image. The character recognition is presented in a JSON file with the text extracted as well as the information extracted from the QRcodes and Barcodes,
This database serves as the ground truth for quality control of the system. The label data corresponds to the true and reliable information that we wish to predict. This database was generated in a semi-automatic way. First, a visual inspection system developed in the study was employed to generate answers for each label. Then, the generated images were saved, and manual work was done to evaluate and correct the data. There are three types of sticker in the database: A, B and C. Each category represents a different kind of sticker.
Sticker A includes 43 images with 11 fields, 3 barcodes, and 2 QR codes. Sticker B has 40 images with 12 fields, 4 barcodes, and 1 QR code. Sticker C contains 22 images, 10 fields, 3 barcodes, and 1 QR code.
4.2. Sticker, QR code and Barcode detection
This section presents a comprehensive description of the process of detecting objects in modem images, specifically the modem label, QR codes, and barcodes. The process comprises several steps, including image input, object detection, and image processing. We illustrated this process in Figure 2.
This process is crucial to ensure precise identification of both characters present in the image and QR codes and barcodes. It involves segmenting the image into specific areas, identifying characters, and reducing image noise, which significantly improves the accuracy of object detection. The object detection method adopted was YOLOv8. In this step, the input image passes thought the YOLOv8n detection model. This model provides the coordinates of the modem label (bounding boxes). This process is done to isolate only the interesting potion of the image.
For this step, we applied image processing techniques such as smoothing, binarization, and region of interest using available functions from OpenCV library [36]. This helped improve OCR accuracy. For QR code and Barcode object detection, we employed binarization, resizing, and morphological transformations. We used the Zbar library [37] to decode the barcodes and extract the information from the QR codes and the barcodes.
4.3. Sticker character recognition
The objective is to accurately identify the characters the modem images with OCR, enabling further analysis and processing. The OCR module processes the image and identifies characters.
The framework chosen for this step was PP-OCR. The direction classification model was not required in this project since the direction of characters was always correct. The multilingual model of PP-OCR was utilized for text detection and recognition, which takes an image as input and returns a list of detected segments with the recognized text and coordinates inside the image. This approach significantly improved the accuracy of character recognition in images, making it possible to identify characters with precision and efficiency. Figure 3 illustrates this process.
4.4. Post-OCR
Our post-processing approach aimed to extract information from the OCR output and transform it into a structured and organized format. To achieve this, we adopted a key-value format for the fields that needed to be returned, as demonstrated in Table 1. This allowed us to effectively organize the data and facilitate further analysis. Moreover, we also implemented error correction methods to address any inaccuracies that may have arisen during the OCR process.
The input for the Post-OCR is the result of the previous step, which is a list containing each of the text segments detected and converted into characters as well as the position of the segment inside the image, given by another list containing the coordinates (x, y) of the bounding boxes (BB).
For modem stickers, the fields of interest are already specified by the producer company, and the number of characters of each field is fix. Furthermore, depending on the field, the value only receives specific types of characters, such as numerical, alphanumeric, and hexadecimal. This information was used to model the key-value processing step.
To process and retrieve the relevant information from the OCR, a template was implemented in the key-value JSON structure. The keys in the template represent the fields in the sticker that should be returned at the end of the visual inspection process, while the values are a set of rules that model the structure of the values of each field. Since different sticker models have different fields, a template is used for each label type. The template format used for the Sticker C pattern is shown in the Table 1.
The rules used for the values are based on representations and literals. Representations are alphabet characters indicating the types of characters that can appear in the position of the value. For example, "D" represents decimal numbers, and "H" represents hexadecimal. The literal texts are indicated by the symbol "$" and signify that all text contained between the literal symbols will be reproduced as it is. The key processing is performed first. This step aims to detect and extract the text segments that contain the keys of the predetermined fields and divide them into key and value. These keys are those specified in the template shown in Table 1 for Sticker C pattern. For that, three rules were created: the colon rule, the space rule and the size rule.
The colon rule is applied when an item in the results list contains at least one colon character. The method tries to find a match between the OCR key value and the template value, using the colon character’s position as a hint to find the corresponding key. The space rule is applied when the colon rule does not result in a key match. In this case, the method tries to find a key match by splitting the item value into words and testing each word as a possible key. Finally, the size rule is applied when none of the previous rules results in a key match. This rule tries to find a key by comparing the size of the OCR key value with the size of the template key values.
After the key processing step, the value processing is performed. This step aims to fix mistakes that could have happened while the OCR processing. To achieve this, we identified common errors made by the OCR and compiled a list of possible errors based on their representation. Characters that are commonly mistaken for one another, such as "O" and "0", "1", "I", and "/", are corrected by replacing them in the values based on their respective representations. The corrections involve replacing the positions containing literal characters. At the end, a dictionary with textual information is returned. This stage ensures that the values are accurate, and any errors are corrected, resulting in reliable information.
4.5. Evaluation Metrics
In this section, we will cover the metrics that were employed to evaluate the OD results obtained in this study. Additionally, we will introduce the OCR metrics that were utilized to interpret the results.
4.5.1. Object Detection
To evaluate object detection models, the main ways of measuring performance are based on accuracy. The most commonly used metric for evaluating the accuracy of object detection models is mean Average Precision (mAP) [39,40,41].
True Positive (TP) Correct detection of an annotated object (ground truth). False Positive (FP) An incorrect detection of a non-existent object or a wrong detection of an existing object. False Negative (FN) An undetected object. In addition to that. True Negative (TN) is also used for machine learning models. For machine learning models, TN occurs when the model correctly predicts that an instance does not belong to a certain class. In other words, the model correctly classified a negative sample, that is, a sample that does not belong to the class of interest. As there are an infinite number of bounding boxes that should not be detected within a given image in object detection, TN is not employed [41].
It is also important to define what is considered a "correct detection" and an "incorrect detection" along with the above concepts. For this, the Intersection over Union (IoU) is used. The IoU is a measure based on the Jaccard similarity, a similarity coefficient for two data sets [42]. For object detection, the IoU measures the overlapping area between the predicted bounding box and the real bounding box or ground truth, divided by the union area between them, given by Equation 1.
When comparing IoU for a certain threshold t, it is possible to classify detection as correct or incorrect. If IoU > t, the detection is considered correct, and for IoU < t, incorrect. In the literature, the most used threshold values t are 0.5 and the mean of the range from 0.5 to 0.95, varying by 0.05.
The evaluation methods used for object detection models are based on precision and recall. Precision measures the model’s ability to identify only relevant objects. It is the percentage of correct predictions and is given by Equation 2 [41].
Recall measures the model’s ability to find all relevant cases (all true bounding boxes). It is the percentage of correct predictions among all true objects and is given by Equation 3 [41].
An object detector is considered good when precision and recall values remain high even with an increase in the threshold t, while precision remains high for different recall values. AP is the average precision for each recall level. For each class, precision is calculated at various threshold t levels. AP is calculated as the area under the P x R curve obtained by plotting precision against recall and can be obtained by Equation 4 [41].
Where is the AP for the i-th class, and N is the total number of classes. This work uses mAP@0.5 as a metric, with mAP with a threshold equal to 0.5, and mAP@0.5:0.95, which is the mean of mAP for the threshold range from 0.5 to 0.95, with a step of 0.05.
4.5.2. OCR
This work will use three metrics to evaluate the performance of the proposed visual inspection. The first is the sticker-wise accuracy rate, and the other two are character error rate (CER) and field error rate (FER).
The sticker-wise accuracy rate is given by the proportion of stickers that returned all their fields without any error, compared to the ground truth, and also decoded all the barcodes correctly.
The error rate (ER) is a metric that quantifies the minimum number of insertions (I), deletions (D), and substitutions (S) of characters, words, or fields, needed to transform the true text into the OCR output, given by Equation 6.
where N is the total number of characters/words in the true text [43].
4.6. Proposed framework
The proposed process for text label extraction is based on four main steps. The first step is image acquisition, which involves capturing the image of the label using a camera attached to a controlled environment. The second step is detection and image processing, where the label image is extracted from the captured image and processed to reduce noise and correct the image angle. The third step involves information extraction from the label, which is divided into two parts: image decoding of barcodes and QR codes, and Optical Character Recognition (OCR). Finally, the fourth step involves post-processing of the OCR output. This step involves processing the text information obtained from OCR in a structured manner that can be easily used as structured data. Figure 4 illustrates an overview of the framework employed in this study.
5. Results
In this section, we will discuss the outcomes related to the sticker detection. Next, we will proceed to exhibit the results obtained from the Qrcode and Barcode detection. Finally, we will also present the results of the OCR system integrated with our pipeline.
5.1. Sticker detection
In the results section, the label detection model demonstrates outstanding performance, as shown in Table 2. The sticker OD model achieves a remarkable mean Average Precision (mAP) of 0.99 at IoU (Intersection over Union) threshold of 0.5, highlighting the model’s accuracy in detecting stickers. This level of accuracy is crucial, given that the system operates as a cascade, with sticker detection being the first level.
Despite the apparent simplicity of the task for modern OD systems, the dataset in this study contains various sticker patterns. The primary focus of the research, however, is on modem stickers. The model’s performance, as evident in the high precision and recall scores of 0.972 and 0.966, respectively, reflects its ability to accurately identify and distinguish modem stickers from other patterns in the dataset. The mAP score of 0.930 at IoU thresholds ranging from 0.5 to 0.95 further emphasizes the model’s robustness in handling different levels of overlap between predicted and ground truth bounding boxes.
5.2. Barcode and QR code detection
The results for barcode and QR code detection using the validation dataset are illustrated in Table 3. Accurate and precise detection of barcodes and QR codes on stickers is essential for their subsequent decoding and information extraction.
The detection model demonstrates impressive performance, as evidenced by the high precision and recall scores across both QR codes and barcodes. For QR codes, the model achieves a precision of 0.987 and a recall of 0.972, while for barcodes, the precision and recall scores are 0.977 and 0.964, respectively. The high mean Average Precision (mAP) scores of 0.988 and 0.979 at IoU threshold of 0.5 for QR codes and barcodes, respectively, indicate the model’s strong detection capabilities. This value is most significant than the mAP scores at IoU thresholds ranging from 0.5 to 0.95 (0.855 for QR codes and 0.868 for barcodes).
The overall performance of the model, as shown by the results, ensures reliable detection of barcodes and QR codes on stickers, facilitating their successful decoding and information extraction.
5.3. Sticker textual recognition
The performance of the OCR system was evaluated using three different subsets of sticker patterns, namely A, B, and C. Table 4 presents the overall performance metrics for each subset, including Character Error Rate (CER), Field Error Rate (FER), and Sticker Accuracy. Additionaly, the table also presents a macro avarage results for each metric used.
The metrics displayed in the table are interdependent; a misclassified character will affect the CER, which in turn will influence the FER and Sticker Accuracy. It is important to note that a sticker is considered accurate only when there are no errors in any of its fields or characters.
Despite the Sticker Accuracy appearing somewhat unsatisfactory for subset A, the performance should be evaluated within the context of the stringent requirement for complete correctness in fields and characters.
For subset A, we have more characters than others sticker patterns (as the field "IP padrão do terminal: 192.168.0.1"), it justifies the performance of 0.76 accuracy. Meanwhile, subset B demonstrates a marked improvement in Sticker Accuracy, with a value of 0.92. As for subset C, achieved the most favorable outcome, reaching a value of 0.95.
Overall, the OCR system’s performance varies depending on the sticker subset, with the most accurate results observed in subset C. The overall accuracy for all sticker pattern was 0.88.
For a more detailed analysis, Table 5, Table 6 and Table 7 display the CER and FER values for each field of the A, B and C sticker patterns, respectively.
The system achieved error-free performance for most fields, including CM MAC, EMTA MAC, IP address, MODEL, P/N, NETWORK WiFi 2.4GHz, NETWORK WiFi 5GHz, and S/N. However, it encountered some errors in the PASSWORD WiFi and Password fields, with CER values of 1.19% and 1.11%, respectively, and FER values of 9.52% and 14.29%, respectively.
Overall, these results indicate that the system performed effectively on the A sticker database, with only minor errors. The low CER and FER values demonstrate a high level of accuracy and reliability in recognizing fields within the A sticker database.
Most fields in Table 6 exhibit a CER and FER of 0, indicating no recognition errors occurred for those fields. However, the MAC and S/N fields experienced slightly higher CER and FER values, with 0.21% and 0.33% for CER, and 2.50% and 5.00% for FER, respectively. These results suggest that while the majority of fields were accurately recognized, the system encountered minor difficulties with the MAC and S/N fields in the B sticker database.
In comparison to the previous two tables, Table 7 shows that the system performed well for the fields of the C sticker database, with the majority of fields having CER and FER values of 0. The only field with a slightly higher CER and FER was MODEL, with values of 0.31% and 0.34%, respectively.
These results demonstrate that the system was able to accurately recognize fields across all three sticker databases, with only minor discrepancies in a few fields. This highlights the effectiveness of the proposed system in extracting information from diverse product stickers within an industrial setting.
While the method has demonstrated good performance in subsets A, B and C, it has encountered difficulties in certain fields, as evidenced by Table 5, Table 6 and Table 7 and the high standard deviation relative to the mean values. For the A model, a high error rate was observed in the "PASSWORD Wi-Fi" and "Password" fields, which negatively impacted the accuracy per label, despite low average CER and FER values. Upon closer examination of the fields’ formats, it was found that they comprise a mix of alphanumeric characters, with alphabetic characters that can be both uppercase and lowercase, without any discernible structural or lexical pattern. The following errors were identified:
- a)
- Substitution of "q" by "g";
- b)
- Removal of "W" when it appears more than once in a row;
- c)
- Substitution of "j" by "i";
- d)
- Substitution of "t" by "f";
- e)
- Removal of "W" when followed by another "W";
- f)
- Substitution of "vv" by "w";
- g)
- Substitution of "w" by "W";
- h)
- Substitution of "z" by "Z";
- i)
- Removal of "v" when followed by another "v".
Upon analyzing the aforementioned errors, it became evident that the primary errors stem from confusion between similar alphabetical characters (e.g., "j" and "i"), discrepancies between lowercase and uppercase characters with similar appearances (e.g., "z" and "Z"), and issues with character suppression and substitution when characters like "w" and "v" appear consecutively. The errors in the 5657 model, although fewer, were also due to confusion between similar characters.
Figure 5 illustrates these errors, highlighting the impact of factors such as font, character arrangement, and OCR system performance on the final result. For example, consecutive "v" and "w" characters can cause recognition confusion, the physical position of characters and fields within the label can lead to misrecognition when characters are too close or overlapping, and similar characters can create confusion for the OCR model.
6. Conclusion
In this paper, we have presented a groundbreaking framework that amalgamates the capabilities of OCR and OD to automate visual inspection processes within industrial environments. This comprehensive framework adeptly detects and recognizes both textual and non-textual elements on printed stickers used in a company, harnessing cutting-edge AI tools and technologies for sticker information recognition. By transcending traditional Printed Character Recognition (PCR), our system extracts supplementary information, such as barcodes and QR codes, from images.
The experimental results substantiate the effectiveness of our proposed framework over three different sticker patterns, achieving a CER of 0.21 for non-textual recognition on subset A, 0.04 on subset B and 0.31 with an overall sticker accuracy of 0.88, based on the macro accuracy across all subset. For OD, sticker recognition attained a mean Average Precision (mAP) of 0.99 at 0.5 Intersection Over Union (IoU), and 0.98 for barcodes and QR codes using the same metric. Integrating modern OCR with PP-OCRv3 and modern OD with YOLO v8 within our framework enables seamless recognition and interpretation of diverse information types on printed stickers, fostering more efficient visual inspection processes in industrial applications.
However, our framework exhibits certain limitations. It may encounter difficulties recognizing characters in low-resolution images or when characters are distorted due to suboptimal printing quality. Furthermore, our system may struggle with text featuring unconventional fonts. Certain character sequences also pose challenges, as exemplified in Figure 5. These limitations present opportunities for future research to further refine and enhance the proposed framework.
In conclusion, our trailblazing framework provides a reliable and efficient solution for automating visual inspection processes in the industrial sector by fusing OCR and OD technologies. We incorporate the latest and most robust techniques within this framework. By accurately detecting and recognizing both textual and non-textual information on printed stickers, our system significantly streamlines industrial workflows and minimizes manual labor demands. The successful implementation of our framework sets the stage for future progress in automating visual inspection processes and underscores the potential of AI-driven solutions in industrial settings.
Author Contributions
For research articles with several authors, a short paragraph specifying their individual contributions must be provided. The following statements should be used “Conceptualization, G.R., L.C., G.A., N.A. and J.P.O.; methodology, G.R., L.C., R.F. and G.A; software, G.R., L.C. and G.A.; validation, G.R., G.A., L. C and J.P.O.; formal analysis, G.R., G.A., L. C, R.F. and J.P.O.; investigation, G.R., G.A. and L. C; data curation, G.R., G.A., L. C, R.F. and J.P.O.; writing—original draft preparation G.R., G.A., L. C and R.F; writing—review and editing, G.R., G.A., L. C, R.F, H.L. and J.P; visualization, G.R., G.A., L. C, R.F, H.L. and J.P; supervision, I.T., A.P, R.C, C.F and J.P.O; project administration, I.T., A.P, R.C, C.F and J.P.O; funding acquisition, I.T. and A.L.P.
Funding
This paper is a result of TESSERACT Project: “Computer Vision and Artificial Intelligence-Based Assistant System for Improving the Productive Process of Reading Labels on Modems.” developed by the Embedded Systems Laboratory at State University of Amazonas. It is funded by SAGEMCOM BRASIL COMUNICAÇÕES LTDA, under the terms of Brazilian Federal Law nº 8.387/1991, and it’s disclosure is in accordance with the provisions of Article 39 of Decree No. 10.521/2020.
Acknowledgments
This research and development project was supported by Sagemcom, a French industrial group, world leader in high added-value communicating terminals and solutions for the broadband, audio video solutions and energy markets
Conflicts of Interest
The authors declare no conflict of interest.
References
- Peres, R.S.; Jia, X.; Lee, J.; Sun, K.; Colombo, A.W.; Barata, J. Industrial Artificial Intelligence in Industry 4.0 - Systematic Review, Challenges and Outlook. IEEE Access 2020, 8, 220121–220139. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R. Convolutional Neural Network (CNN) for Image Detection and Recognition. 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), 2018, pp. 278–282. [CrossRef]
- Aquino, G.; Costa, M.G.F.; Costa Filho, C.F.F. Explaining One-Dimensional Convolutional Models in Human Activity Recognition and Biometric Identification Tasks. Sensors 2022, 22. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhou, W.; Zhang, X.; Lou, X. An End-to-end Computer Vision System Architecture. 2022 IEEE International Symposium on Circuits and Systems (ISCAS), 2022, pp. 2338–2342. [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. CoRR 2018, abs/1804.02767, [1804.02767].
- Hsu, M.M.; Wu, M.H.; Cheng, Y.C.; Lin, C.Y. An Efficient Industrial Product Serial Number Recognition Framework. 2022 IEEE International Conference on Consumer Electronics - Taiwan, 2022, pp. 263–264. [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. CoRR 2015, abs/1506.02640, [1506.02640].
- Srivastava, S.; Verma, A.; Sharma, S. Optical Character Recognition Techniques: A Review. 2022 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), 2022, pp. 1–6. [CrossRef]
- Plamondon, R.; Srihari, S. Online and off-line handwriting recognition: a comprehensive survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22, 63–84. [Google Scholar] [CrossRef]
- Vinjit, B.M.; Bhojak, M.K.; Kumar, S.; Chalak, G. A Review on Handwritten Character Recognition Methods and Techniques. 2020 International Conference on Communication and Signal Processing (ICCSP), 2020, pp. 1224–1228. [CrossRef]
- Du, Y.; Li, C.; Guo, R.; Yin, X.; Liu, W.; Zhou, J.; Bai, Y.; Yu, Z.; Yang, Y.; Dang, Q.; Wang, H. PP-OCR: A Practical Ultra Lightweight OCR System. CoRR 2020, abs/2009.09941, [2009.09941].
- Li, C.; Liu, W.; Guo, R.; Yin, X.; Jiang, K.; Du, Y.; Du, Y.; Zhu, L.; Lai, B.; Hu, X.; others. PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System. arXiv preprint arXiv:2206.03001 2022.
- Ravi, N.; El-Sharkawy, M. Real-Time Embedded Implementation of Improved Object Detector for Resource-Constrained Devices. Journal of Low Power Electronics and Applications 2022, 12, 21. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: challenges, architectural successors, datasets and applications. Multimedia Tools and Applications 2022, pp. 1–33.
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, N.; Won, C.S. High-Speed Drone Detection Based On Yolo-V8. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–2. [CrossRef]
- Li, C.; Liu, W.L.; Guo, R.; Yin, X. Dive in to OCR; Baidu, PaddlePaddle, 2022.
- Du, Y.; Li, C.; Guo, R.; Yin, X.; Liu, W.; Zhou, J.; Bai, Y.; Yu, Z.; Yang, Y.; Dang, Q.; others. Pp-ocr: A practical ultra lightweight ocr system. arXiv preprint arXiv:2009.09941 2020.
- Du, Y.; Li, C.; Guo, R.; Cui, C.; Liu, W.; Zhou, J.; Lu, B.; Yang, Y.; Liu, Q.; Hu, X.; others. PP-OCRv2: bag of tricks for ultra lightweight OCR system. arXiv preprint arXiv:2109.03144 2021.
- Song, S.; Shi, X.; Song, G.; Huq, F.A. Linking digitalization and human capital to shape supply chain integration in omni-channel retailing. Industrial Management & Data Systems 2021, 121, 2298–2317. [Google Scholar]
- Antonio, J.; Putra, A.R.; Abdurrohman, H.; Tsalasa, M.S. A Survey on Scanned Receipts OCR and Information Extraction.
- Subedi, B.; Yunusov, J.; Gaybulayev, A.; Kim, T.H. Development of a low-cost industrial OCR system with an end-to-end deep learning technology. IEMEK Journal of Embedded Systems and Applications 2020, 15, 51–60. [Google Scholar]
- Gromova, K.; Elangovan, V. Automatic Extraction of Medication Information from Cylindrically Distorted Pill Bottle Labels. Machine Learning and Knowledge Extraction 2022, 4, 852–864. [Google Scholar] [CrossRef]
- Gregory, S.; Singh, U.; Gray, J.; Hobbs, J. A computer vision pipeline for automatic large-scale inventory tracking. Proceedings of the 2021 ACM Southeast Conference, 2021, pp. 100–107.
- Santiago Garcia, E. Country-independent MRTD layout extraction and its applications. Master’s thesis, University of Twente, 2022.
- Li, S.; Ma, X.; Pan, S.; Hu, J.; Shi, L.; Wang, Q. VTLayout: Fusion of Visual and Text Features for Document Layout Analysis. PRICAI 2021: Trends in Artificial Intelligence: 18th Pacific Rim International Conference on Artificial Intelligence, PRICAI 2021, Hanoi, Vietnam, November 8–12, 2021, Proceedings, Part I 18. Springer, 2021, pp. 308–322.
- Dahlberg, E.; Lehtonen, T.; Yllikäinen, M. Tag recognition from panoramic scans of industrial facilities 2022.
- Smith, R. An Overview of the Tesseract OCR Engine. ICDAR ’07: Proceedings of the Ninth International Conference on Document Analysis and Recognition; IEEE Computer Society: Washington, DC, USA, 2007; pp. 629–633. [Google Scholar]
- Nguyen, T.T.H.; Jatowt, A.; Coustaty, M.; Doucet, A. Survey of Post-OCR Processing Approaches; Vol. 54, Association for Computing Machinery, 2021. [CrossRef]
- Mei, J.; Islam, A.; Moh’d, A.; Wu, Y.; Milios, E. Statistical learning for OCR error correction. Information Processing & Management 2018, 54, 874–887. [Google Scholar]
- Khosrobeigi, Z.; Veisi, H.; Ahmadi, H.R.; Shabanian, H. A rule-based post-processing approach to improve Persian OCR performance. Scientia Iranica 2020, 27, 3019–3033. [Google Scholar] [CrossRef]
- Kaló, Á.Z.; Sipos, M.L. Key-Value Pair Searhing System via Tesseract OCR and Post Processing. 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI). IEEE, 2021, pp. 000461–000464.
- Desai, M.; Mewada, H. A novel approach for yoga pose estimation based on in-depth analysis of human body joint detection accuracy. PeerJ Computer Science 2023, 9, e1152. [Google Scholar] [CrossRef] [PubMed]
- Bradski, G. The OpenCV Library. Dr. Dobb’s Journal of Software Tools 2000.
- ZBar Development Team. ZBar: Barcode reader software. https://zbar.sourceforge.net/index.html, 2011.
- RapidAI. RapidOCR: Open-source Optical Character Recognition. https://github.com/RapidAI/RapidOCR, Accessed on 9 May 2023.
- Zhu, H.; Wei, H.; Li, B.; Yuan, X.; Kehtarnavaz, N. A review of video object detection: Datasets, metrics and methods. Applied Sciences 2020, 10, 7834. [Google Scholar] [CrossRef]
- Padilla, R.; Passos, W.L.; Dias, T.L.; Netto, S.L.; Da Silva, E.A. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. 2020 international conference on systems, signals and image processing (IWSSIP). IEEE, 2020, pp. 237–242.
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull Soc Vaudoise Sci Nat 1901, 37, 547–579. [Google Scholar]
- Nguyen, T.T.H.; Jatowt, A.; Coustaty, M.; Doucet, A. Survey of post-OCR processing approaches. ACM Computing Surveys (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
Figure 1.
Subsets Sticker Patterns in Databases

Figure 2.
Modem Label, QR Code, and Barcode Detection Overview
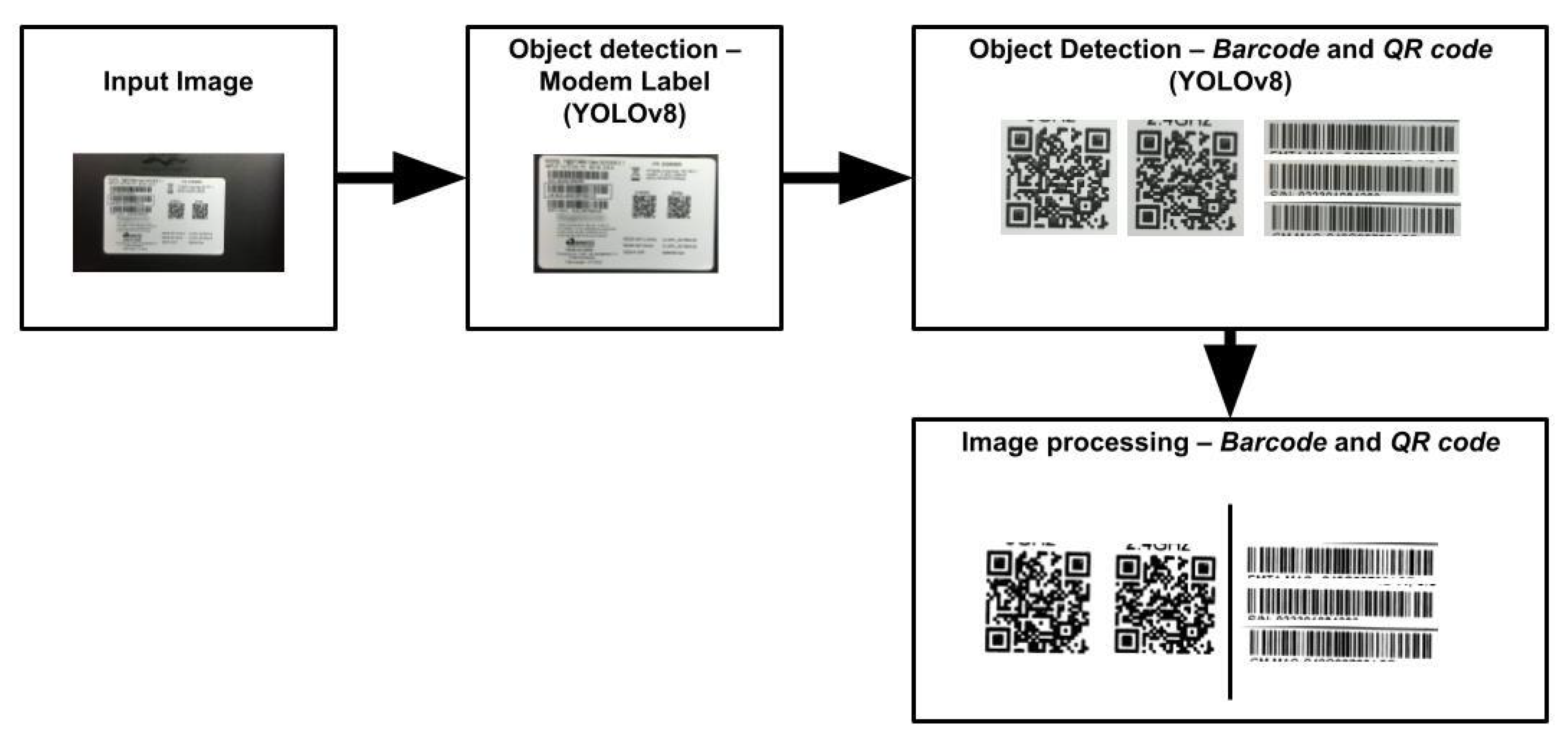
Figure 3.
OCR Process Overview
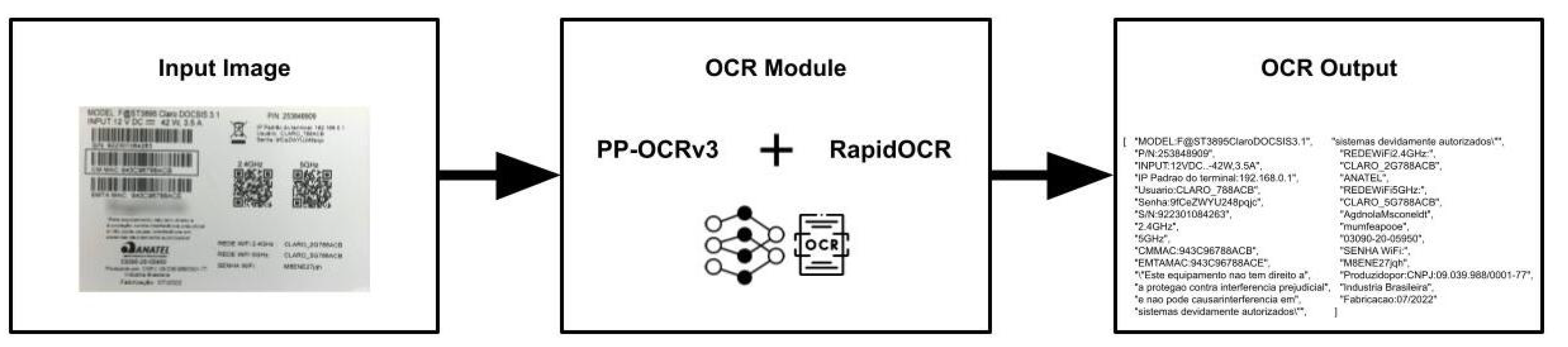
Figure 4.
Proposed Framework Architecture
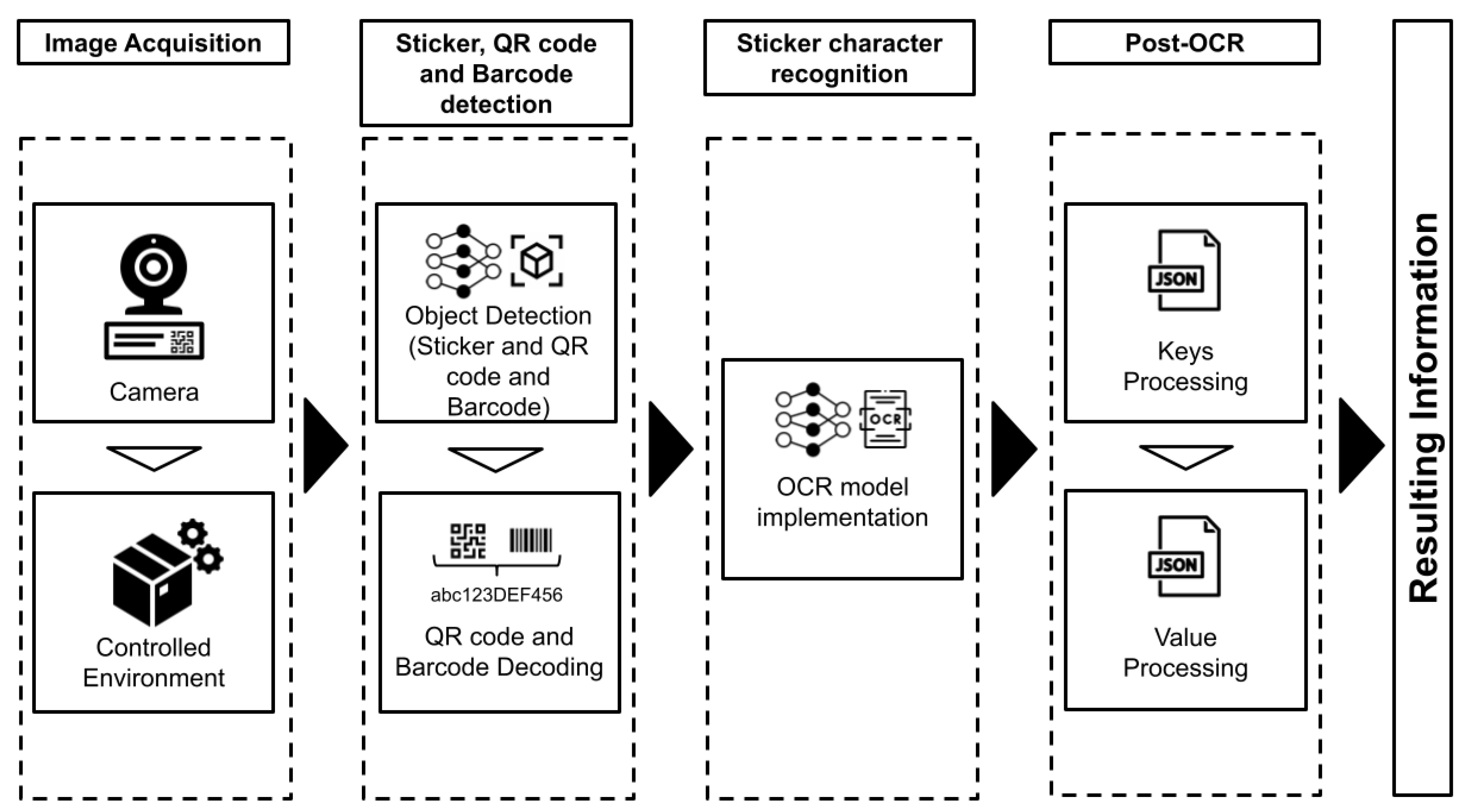
Figure 5.
Examples of modem label errors
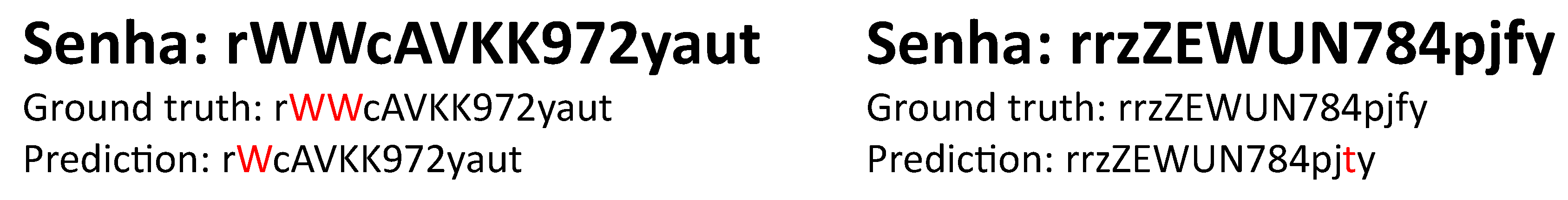

Table 1.
Post-OCR Output in Key-Value Format for Sticker C subset
| Key | Format | Value |
|---|---|---|
| P/N | DDDDDDDDD | 253951842 |
| IP | DDD$.$DDD$.$D$.$D | 192.168.0.1 |
| Usuário | $CLARO_$BBBBBB | CLARO_FDBBD5 |
| Senha | FFFFFFFFFF | ghykmcUG827zxVA |
| S/N | DDDDDDDDDDDD | 929240013008 |
| CM MAC | HHHHHHHHHHHH | B0FC88FDBBD5 |
| EMTA MAC | HHHHHHHHHHHH | B0FC88FDBBD8 |
| REDE Wi-Fi | $CLARO$BBBBBB | CLARO_FDBBD5 |
| SENHA Wi-Fi | FFFFFFFFFFFFFFF | jNyYUUnJtg |
| MODEL | $F@ST3895 Claro DOCSIS 3.1$ | F@ST3896 Claro DOCSIS 3.1 |
Table 2.
Result of the performance evaluation of the label detection model.
| Classes | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| Modem Sticker | 0.972 | 0,966 | 0,992 | 0.930 |
Table 3.
Results for the barcode and qr code detection model
| Classes | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| Todos | 0,982 | 0,968 | 0,984 | 0,861 |
| QR code | 0,987 | 0,972 | 0,988 | 0,855 |
| Barcode | 0,977 | 0,964 | 0,979 | 0,868 |
Table 4.
Performance of the OCR system for the sticker subsets A, B and C. The values within parentheses indicate the standard deviation.
Table 4.
Performance of the OCR system for the sticker subsets A, B and C. The values within parentheses indicate the standard deviation.
| Subset | Number of Images | CER (%) | FER (%) | Sticker Accuracy |
|---|---|---|---|---|
| A | 43 | 0.21 (0,42) | 2.16 (3,87) | 0.76 |
| B | 40 | 0.04 (0,16) | 0.62 (2,19) | 0.92 |
| C | 22 | 0.31 (1,42) | 0.34 (1.56) | 0.95 |
| All | 105 | 0.17 | 1.04 | 0.88 |
Table 5.
Performance evaluation results of the system for sticker subset A.
| Field | CER (%) | FER (%) |
|---|---|---|
| CM MAC | 0 | 0 |
| EMTA MAC | 0 | 0 |
| IP address | 0 | 0 |
| MODEL | 0 | 0 |
| P/N | 0 | 0 |
| NETWORK Wi-Fi 2.4GHz | 0 | 0 |
| NETWORK Wi-Fi 5GHz | 0 | 0 |
| S/N | 0 | 0 |
| PASSWORD Wi-Fi | 1.19 | 9.52 |
| Password | 1.11 | 14.29 |
| User | 0 | 0 |
Table 6.
Result of the performance evaluation of the system for the fields of the B sticker database
Table 6.
Result of the performance evaluation of the system for the fields of the B sticker database
| Field | CER (%) | FER (%) |
|---|---|---|
| IP | 0 | 0 |
| MAC | 0.21 | 2.50 |
| Model | 0 | 0 |
| PN | 0 | 0 |
| PON/ID | 0 | 0 |
| Password | 0 | 0 |
| S/N | 0.33 | 5.00 |
| SAP | 0 | 0 |
| SSID 2.4GHZ | 0 | 0 |
| SSID 5GHZ | 0 | 0 |
| Senha 5GHZ | 0 | 0 |
| User | 0 | 0 |
Table 7.
Result of the performance evaluation of the system for the fields of the C sticker database.
Table 7.
Result of the performance evaluation of the system for the fields of the C sticker database.
| Field | CER (%) | FER (%) |
|---|---|---|
| CM MAC | 0 | 0 |
| EMTA MAC | 0 | 0 |
| IP | 0 | 0 |
| MODEL | 0.31 | 0.34 |
| P/N | 0 | 0 |
| REDE Wi-Fi | 0 | 0 |
| S/N | 0 | 0 |
| SENHA Wi-Fi | 0 | 0 |
| Password | 0 | 0 |
| User | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



