
Submitted:
05 June 2023
Posted:
06 June 2023
You are already at the latest version
Preprints on COVID-19 and SARS-CoV-2
Abstract
Most studies modelling population mobility and the spread of infectious diseases, particularly using meta-population-multi-patched models, tend to focus on theoretical properties and numerical simulations of such models. There is relatively scanty literature published on fit, inference and uncertainty quantification on epidemic models with population mobility. In this research, we have used three estimation techniques to solve an inverse problem and quantify its uncertainty on a human mobility-based multi-patched epidemic model, using mobile phone sensing data and COVID-19 confirmed positive cases in Hermosillo, Mexico. First, we have utilized a Brownian bridge model using mobile phone GPS data to estimate residence and mobility parameters of the epidemic model. In the second step, we have estimated the optimal model epidemiological parameters by deterministically inverting the model using a Darwinian inspired evolutionary algorithm (EA) known as the genetic algorithm (GA). The third part of the analysis involves performing inference and uncertainty quantification on the epidemic model using two Bayesian Monte Carlo sampling methods: t-walk and Hamiltonian Monte Carlo (HMC). The results show that the estimated model parameters and incidence adequately fit the observed daily COVID-19 incidence in Hermosillo. Moreover, the estimated parameters from HMC result into large credible intervals, improving their coverage for the observed and predicted daily incidences. We also observe improved predictions when using multi-patch model with mobility against the single-patch model.
Keywords:
Epidemics
; Human mobility
; Inference
; Deterministic inversion
; Bayesian inference
1. Introduction
The mathematical modeling of infectious diseases has been a continuously growing research area over the past few decades. This is due to the significant impact that infectious diseases can have on a wide range of important areas, including social, health, and economic development, whose main driving factor is human populationThe mathematical modeling of infectious diseases has witnessed continuous growth as a research area in recent decades. This growth has been primarily motivated by the substantial impact that contagious diseases have on various crucial domains, including social, health, and economic development. [1,2,3,4,5].These domains are intricately linked to human population interaction, which serves as a key driving factor.
Indeed, works such as [6] and [7], raised awareness on the fact that the emergence and re-emergence of infectious diseases had historically been neglected as a significant threat to public health. Understanding the propagation dynamics of infectious diseases has thus become a central issue for epidemiologists and theoreticians [8,9,10,11,12]. Such knowledge would in turn lead to the formulation of robust infection mitigation policies, yielding, in the end, a healthy human population, that significantly contributes to the economic development of their respective nations.Such knowledge would subsequently enable the formulation of effective infection mitigation policies. These policies, in turn, would contribute to maintaining a healthy human population, thereby significantly bolstering the economic development of their respective nations.
Since its advent and declaration as a pandemic in March 2020 by the WHO, COVID-19 has undeniably wrecked havoc and drastically impacted the lives and livelihoods of the global human population. In terms of significance, COVID-19 has been compared to the influenza pandemic of 1948-20, [8] but these are not yet equated in terms of severity. The 1918 influenza pandemic had an estimated death toll of 40 Million lives and infected 1/3 of the world population as compared to COVID-19 which so far has a death toll of 6.6 Million and confirmed cases of 633 Million (less than 10% of total human population) [13]. However, the urgency in the need for more research on COVID-19, and other infectious diseases, is qualified by the warnings from scientists in the recent past about the likelihood of another pandemic striking at any momentHowever, the urgency for conducting further research on COVID-19 and other infectious diseases is underscored by the warnings issued by scientists in recent times regarding the imminent threat of another pandemic. These cautionary alerts emphasize the pressing need to proactively study and understand these diseases to be better prepared for any potential future outbreaks. [14]. These studies seek understanding the dynamics of the infection propagation, control and mitigation strategies. and include but are notThey encompass various aspects, including but not limited to model selection, statistical inference, uncertainty quantification and prediction using empirical epidemiological data. Such studies furnish epidemiologists and policymakers with useful information on the impact of control and eradication measures and formulation of effective response strategies in anticipation of a new pandemic crisis.valuable information in relation to the effectiveness of control and eradication measures. This knowledge facilitates the formulation of proactive response strategies in anticipation of a potential new pandemic crisis.
At the core of the transmission dynamics of infectious and communicable diseases like COVID-19 is human behaviour and interaction. Consequently, it behooves researchers and epidemiologists involved in the study of infectious diseases to accurately incorporate human behaviour as a critical component of the models used in modelling infectious diseases [15]. One such human behaviour that has, over the years, fundamentally shaped person to person transmission of infectious diseases in the face of an outbreak is formulation of human networks, population mobility and travel,One significant human behavior that has consistently influenced person-to-person transmission of infectious diseases during outbreaks is mobility. [10,16,17,18,19,20,21]. The mobility and its travel patterns promote the creation of temporal social connections and networks that both local and global, play a crucial role in the spread of diseases. Human mobility, an undeniably crucial component of human existence and survival, not only plays a critical role in the spread and propagation of an epidemic [18,22,23,24], but it also crucially determines the spreading speed of infectious diseases, [23,25,26]. There is therefore no gainsaying that deep understanding of the role of human mobility in the spread of infectious diseases is central in the quest to have a clear view, for instance, of the impact of control strategies such as mobility restrictions [27,28,29,30,31].
Developments in epidemiological research have confirmed that traditional compartmental epidemic models are deficient in modeling strong heterogeneous disease spread, as they were formulated with the assumption of interaction of a well-mixed homogeneous population [15,32,33]. It is widely recognized that humans do not exhibit homogeneous mobility patterns, [15], which highlights the importance of incorporating heterogeneous population behavioral responses in epidemiological models as emphasized by [34]. The literature is replete with a plethora of proposed models for capturing human heterogeneous mobility and dispersal and most of them are mostly geo-meta-population-multi-patched based, as can be seen inThe scientific literature offers a wide array of proposed models that aim to capture the heterogeneous mobility and dispersal patterns observed among humans. Many of these models consists of human groups of spatially separated populations which interact at some level (geo-meta-population-multi-patched framework), as evidenced by numerous references in the literature [e.g., [26,27,34,35,36,37,38,39,40,41,42]. Although modelling geo-spatial-temporal spread of infectious diseases is a complex task [43], models such as the ones in the mentioned references have crucially attempted to accurately capture human mobility in different settings. Nevertheless, there is still need to incorporate more realistic mobility patterns that reflect more complex mobility scenarios [17], which is an inevitable reality of human behaviour. In some situations, an appropriate approach could be to describe the connection between the spread of infectious diseases and the fraction of time that residents spend in different patches (homogeneous in terms of some characteristic, e.g. risk of infection) in the course of their traveling In certain scenarios, it may be highly desirable to explore the relationship between the spread of infectious diseases and the proportion of time individuals spend in different locations during their travels [44]. This approach considers the impact of human movement on disease transmission and how it relates to the amount of time spent in locations, each having specific characteristics, such as the risk of infection level. These locations, that are homogeneous within them and possibly different between them, are usually referred in the literature as patches. Then, a single-patch model reduces to a model with a well-mixed homogeneous population where every susceptible individual can become infected with the same probability. The concept of multi-patches not only allows to consider locations with different characteristics but helps in capturing the spatial dynamics and interactions, produced by the human mobility, that influence the spread of infectious diseases.
Once an appropriate epidemic model has been formulated, a myriad of analysis relevant to epidemiologists, policy makers and public health officials can be conducted. These include but are not limited to theoretical analysis and numerical simulations [see e.g., [39,40,45,46,47], inference, uncertainty quantification and predictions [see e.g., [14,48,49,50,51,52,53]. Most studies modelling population mobility and the spread of infectious diseases, particularly using meta-population-multi-patched models, have tended to focus on theoretical and global properties and numerical simulations of such models. There is relatively scanty literature published on inference and uncertainty quantification on epidemic models with population mobility. To our knowledge, to this date, the only research work that has come close to performing inference, uncertainty quantification and predictions on a multi-patch epidemic model is [51] who developed and used a projected Stein Variational Gradient Descent (pSVGD) algorithm to model COVID-19 in the states of New Jersey and Texas in the US. However, their model did not incorporate population mobility as they modeled the dynamics and severity of COVID-19 inside and outside long-term care (LTC) facilities where the interaction was introduced through some contact matrix. Other works that have addressed the problem of statistical inference for epidemics on networks are [54] and [55]. These models consider families of networks of contact that remains constant through time. Filling the gap left by the conspicuous lack of literature on uncertainty quantification and Bayesian inverse problems on meta-population-multi-patched epidemic models, forms the central motivation of the present study. To this end, we perform inference and uncertainty quantification, using COVID-19 confirmed cases in Hermosillo, Mexico, on a multi-patched epidemic model with mobility, residency and demography. This model was proposed and theoretical analyzed inTo achieve this objective, we conduct inference and uncertainty quantification using COVID-19 confirmed cases in Hermosillo, Mexico. We employ a multi-patched epidemic model that incorporates mobility, residency, and demography. This model was proposed and theoretically analyzed in [42].
Solving an inverse problem involves the combination of actual observed data and the model to deduce the values of the parameters that characterizes the said modelSolving an inverse problem entails the utilization of both observed data and a model to deduce the parameter values that characterize the dynamics producing the observations [56,57,58]. However, using models that are sufficient and are well posed in capturing heterogeneity and complexity of human behaviour, such as mobility, when modelling the spread of infectious diseases, leads to the introduction of innumerable parametersHowever, employing models that adequately capture the heterogeneity and complexity of human behavior, such as mobility, in modeling the spread of infectious diseases, introduces numerous parameters [51,59] that poses a plethora of challenges when solving . This, in turn, presents a multitude of challenges when addressing inverse problems (fit) and conducting inference (uncertainty quantification). To faceconfront the problems originated by the complex system and its high dimensional parameter space, we divide the problem into two parts. The first one is related to the mobility parameters that describe the proportion of individuals who move, and the time spent in each of the sub regions/patches. The second one, is associated to the numerical fit or statistical inference of the initial conditions and the parameters for the infectious agent and individual evolution of infected individuals.
The rest of this article is organized as follows: In Section 2, we present and describe the epidemic model on which the present analysis is centered. Section 3 discusses how the COVID-19 data used in this work was obtained. In Section 4, a discussion on the estimation of the mobility parameters and residence times of the epidemic model using mobile phone sensing data and the Brownian bridge model, is presented. We elucidate the formulation of the deterministic inversion model and the corresponding results in Section 5. Section 6 entails Bayesian model formulation, inference and the obtaining results. Finally, we give concluding remarks and possible extensions of the present work in Section 7.
2. The multi-patch model with mobility, residency and demography
The emergence and re-emergence of infectious diseases over the past several decades has led to the formulation, by researchers and epidemiologists, of numerous mathematical models that incorporate varied and distinct disease propagation dynamics. The central purpose of such models is to provide fundamental quantitative information and utilitarian guidelines in disease outbreak management and mitigation policy formulations. Provision of such useful information by such models is anchored on their ability to incorporate and capture realistic situations and disease transmission parameters. One such parameter, that has played a crucial role in the spread of infectious diseases, is human population mobility [16,17,18,21,39,40,60].
Several aspects of human history, such as social and economic, have been significantly impacted by the effects of the spread of infectious disease viruses among mobile sectors of human civilization [21]. Undoubtedly, the effects of the current COVID-19 pandemic is a demonstration of the devastating consequences of the interchange between human population mobility and transmission of infectious diseases. For instance, in December 2019, Wuhan, China was the only understood geographical boundary of COVID-19 [61,62,63,64,65]. However, it can be postulated that human mobility within and between cities in China and around the world aided the spread of the pathogen to a significant portion of the planet earth. In a span of three months, the pathogen had posed monumental health, social and economic stress to the point of being declared a pandemic by the WHO on March 11, 2020. Even though the exact nature of the contagion remained unclear, there was recognition of the undeniable interplay between the swift spread of the virus and human mobility through the universally known modes of travel [16,66,67,68,69]. Indeed, besides aiding the spread of COVID-19, such close relationship between population mobility and the spread of infectious diseases has the potential of shaping the emergence of future epidemics. Consequently, in order to formulate robust guidelines to manage both the current ongoing COVID-19 and possible future pandemics, there is dire need to construct appropriate epidemic models that accurately capture population mobility behaviour.
Human mobility, being a geo-spatio-temporal phenomena [17,43,70,71], can be modelled by meta-population-multi-patched models [4,34,39,40,42,44], as traditional homogeneous compartmental models are incapable of capturing such a strong heterogeneous human behaviour [15,17,34,51]. Once such models have been constructed, a wide spectrum of quantitative analysis that leads to deep understanding of the reciprocity of mobility and the spread of infectious diseases can be conducted. For instance, researchers and epidemiologists may focus on theoretical properties and numerical simulations of the model or parameter estimation, uncertainty quantification and predictions. In this research, we focus on the latter, using COVID-19 confirmed cases in Hermosillo, Mexico and a multi-patched SEIRS compartmental epidemic model with residency and demography. The model was proposed, and its theoretical properties analyzed byin [42]. For this model, human mobility is viewed as including not just travel between two locations, but the multiple temporal interactions that people have while traveling to various destinations. It is crucial to emphasize that in for this model human mobility encompasses more than just travel between two locations. It encompasses the multiple temporal interactions that individuals experience while traveling to different destinations.
The following ordinary differential equations (1) constitute the full form of the said patchymulti-patch non-linear model.This model extends the traditional compartmental SEIR model but in also divides the population into different compartments based on their disease status: Susceptible (S), Exposed (E), Infected (I), and Recovered (R). Most individuals start in the susceptible compartment (S) but when one of them comes into contact with an infectious individual, he moves from the susceptible compartment into the exposed compartment (E), meaning that he has been infected but is not yet infectious. This individual leaves the E compartment to enter the I compartment where he can transmit the disease to susceptible individuals. Over time, infected individuals either recover from the disease or may succumb to it. Once individuals recover, they move to the recovered compartment (R), gaining immunity to the disease. In the proposed model, the population dynamic also considers births (into the S compartment) and deaths (not produced by the disease).
Its parameters The parameters of model (1) are described in Table 1. We refer the reader to [42] for a full description of the arguments leading up to this model formulation.
where , and n is the number of patches.
Model (1) is limited to infectious diseases with single strain mutation. That is, in the formulation of the model, [42] assume that the recovered individuals in each patch are conferred with partial immunity, which they lose at a rate . These individuals then reenter the susceptible compartment but it is only in relation to the same strain of the pathogen. However, many infectious diseases, including COVID-19, which is the center of this research, have several pathogenic strains whose dynamic properties should be studied for complete sensible management of emerging and re-emerging outbreaks with multiple variants. To this end, model (1) can be improved to include multiple COVID-19 disease strains.
Works such as [72,73,74,75,76] have considered models that incorporate several disease strains and mutations, with some of them focusing on this property for COVID-19 disease. Even though these works are mostly single-patch based, they provide valuable insights and useful starting point to extend model (1) to this important direction.
3. The data
In 2020, the University of Sonora signed an agreement with the government of the State of Sonora that provided the geo-referenced COVID-19 cases in Hermosillo, Mexico, from 2020-01-01 to 2020-09-06. On the other hand, using mobile phone GPS data from 2020-09-21 to 2020-11-15, [4] estimated mobility parameters and residence times in Hermosillo’s 582 urban AGEBs (Basic Census Geographical Units). As we are interested in modelling the number of cases in four important zones in Hermosillo (each aggregating AGEBs as shown in Figure 1), we use the geo-referenced and GPS information to obtain the number of COVID cases and estimate the mobility and residence within and between zones.Based on an institutional agreement between the University of Sonora (UNISON) and the Secretaría de Salud del Estado de Sonora (SSA), a collaborative effort was undertaken to provide accurate and reliable information to the population of Sonora during the sanitary emergency. As part of this initiative, researchers from the Mathematics Department at UNISON were granted access to georeferenced data pertaining to COVID-19 cases in Hermosillo, Mexico. The dataset encompassed the period from January 1, 2020, to September 6, 2020. It is important to emphasize that the usage of this data is strictly limited to academic activities in accordance with UNISON’s agreements with public institutions, and utmost care has been taken to safeguard sensitive and private information.
Furthermore, on September 14th, 2020, UNISON entered into a specific agreement, referenced as 12615-5700000-000412, to provide statistical consulting services to LUMEX CONSULTORES, S.C. Esteemed research professors from the Mathematics Department, including co-author J.F.E., provided these consulting services. The dataset provided by LUMEX CONSULTORES, S.C. comprised a comprehensive collection of approximately 80 million records, each containing the GPS position and timestamp of nearly 300,000 devices. These devices were geographically located within Hermosillo city between September 21st, 2020, and November 15th, 2020. The usage of this data was explicitly authorized for non-profit and academic activities, with appropriate credits duly acknowledged. Notably, user privacy was carefully protected through the meticulous anonymization of the data, employing distinct alphanumeric IDs for each individual device.
In a separate study, Ramirez et al. (2022) utilized mobile phone GPS data from September 21st, 2020, to November 15th, 2020, to estimate mobility parameters and residence times in Hermosillo’s 582 urban AGEBs (Basic Census Geographical Units) [4]. In alignment with our research objectives of modeling the number of COVID-19 cases in four key zones within Hermosillo, which aggregate AGEBs as illustrated in Figure 1, we employed the geo-referenced and GPS information to obtain the number of COVID-19 cases and estimate mobility and residence patterns within and between these zones.
The two geo-referenced databases only have a small time overlap and using this small period, we would not have sufficient data to learn the quite complex model (1), which has numerous epidemiological parameters to be estimatedThe two geo-referenced databases utilized in this study do not exhibit a temporal overlap, thereby limiting the feasibility of employing the complex model (1), which relies on the estimation of numerous epidemiological parameters. To address this problem, we have elected to use the weighted global COVID-19 data by zonal proportions.
The global confirmed positive COVID-19 cases in Hermosillo (Figure 3) are available in [77], a website managed by Consejo Nacional de Ciencias y Technología (CONACYT), since 2020-02-26. We use the weighted global cases by considering the zonal proportions of the global COVID-19 data, and we justify this selectiona selection we justify as in Figure 2, from which we can observe that the proportions of the available zonal COVID-19 data are approximately stable from June 2020. We therefore project that the data will have the same behaviour within the period for which the mobility parameters and mobility residence times were estimated. The global (Figure 3) and derived zonal COVID-19 cases, however, exhibits high variability. We therefore smoothen it using 7-days moving averages and use the smoothed version for the rest of the analysis.
Most models that have been proposed to analyze and predict COVID-19 incidence, since the emergence of SARS-CoV-2, assume that all infected individuals are observed, which is inexact due to under-reporting of disease incidence. This assumption undermines the accuracy of the models and their predictions. Emerging diseases, such as COVID-19, Typhoid fever, Hepatitis B, Epstein-Barr virus and Zika, that present a large fraction of asymptomatic pathogen carriers, are often characterized by incidence under-reporting during disease surveillance [78,79,80,81]. Coupled with asymptomatic and subclinical carriers, a phase that is prevalent with COVID-19 disease [82,83,84,85], another source of under-counting of disease incidence is lack of systematic testing. It is therefore necessary to account for under-reporting when modeling and fitting COVID-19 disease incidence, as failure to do so will lead to underestimation of epidemiological characteristics of the disease, especially the transmission parameter [86].
In modelling COVID-19 observed incidence for eight American countries, [86] reported an under-reporting of Mexico COVID-19 cases by a factor of 15. This acute under-reportingcases identification problem corroborated the observation in [87], that Mexico has one of the lowest numbers of COVID-19 tests performed per reported cases. We believe that this under-reporting cascaded down to the local Mexico states and cities like Hermosillo. In order to account for this under-reporting, we inflated the smoothed observed COVID-19 incidence, which was obtained from the weighting procedure previously explained, by a factor of 15 to obtain the daily incidence data. We subsequently consider the inflated data (see Figure 4) as the true observed daily COVID-19 incidence in Hermosillo, Mexico, and use it for inference in this research.
In addition to using real count data for model fitting and uncertainty quantification, we also utilized simulated incidence data generated from the model. Our goal was to assess the parameter and initial conditions identifiability of the inverse problem and statistical inference under the model. To this end, we used epidemiological parameters of COVID-19 gathered from various literature as presented in Table 2, and simulated from model (1), daily observed incidences for each zone in Hermosillo. For this simulation, we used epidemiological parameter values close to the ones used by [88], who modelled lockdown relaxation period of COVID-19 in Hermosillo. The parameters and initial condition values used in the simulation can be seen in Table 3. The latter were based on the total population of each zone. After the simulation of the zonal incidence from the model, we added a normal noise , to incorporate variability in the model data. The final simulated incidence for each zone in Hermosillo is presented in Figure 5.
4. Estimation of the mobility and Residence time parameters
The present study involves solving an inverse problem and performing uncertainty quantification on system (1), using 2020 COVID-19 confirmed cases in Hermosillo, Mexico. Such data may not be sufficient in estimating all the mobility and infection parameters, as well the initial conditions present in the system. Moreover, simultaneous estimation of several parameters oftentimes leads to parameter non-identifiability problems [109,110,111,112,113,114,115]. As such, we use the mobile phone sensing data used in [4] for purposes of estimating the mobility vector , and the mobility residence time matrices , , which we will incorporate into system (1). Using mobile consecutive pings,4] estimated the mobility parameters vectors and mobility residence time matrices of 582 urban AGEBs in Hermosillo, Mexico, for three periods, each divided into two parts. In this research, we use the same GPS pings during the Third Period – First Part (2020-09-21 to 2020-10-11). Using this information, we estimate the mobility and residence time matrix of four zones in Hermosillo. Since we are interested in evaluating the forecasting (after November 2020) under the model, this period was selected as its start date was closer to the last period of considered COVID-19 cases. We note that we can also use mobility data from other periods and parts, and employ a similar procedure that we describe next, to estimate mobility and residence times for the four zones, within the period and part of interest.
Solving the inverse problem and performing uncertainty quantification on system (1) for a total number of AGEBs (patches) poses a logical set-up challenge. Thus, using well-defined geographical demarcations of Hermosillo, we group the 582 AGEBs into four main zones. These zones, together with their corresponding total population, are shown in Figure 1. The mobility parameter vector ,and residence times , , were estimated by searching for individuals who activated at least 11 pings and left their AGEBs within and between the zones. For the individual AGEBs, [4] estimates the probability density functions at position z for any individual originating from AGEB/patch r as
where is the patch population size, is the density of the expected time of the j-th individual originating from the r-th patch, is the maximum likelihood estimate of the individual standard deviation of the mobility of the j-th resident from the r-th patch, and is the variance of the geolocation error. After grouping and renaming the composing AGEBs of each of the four zones, we have
where the subscript index indicates that the said quantity is in zone ℓ and represents the total number of AGEBs in the ℓ-th zone.
From (3), we can obtain the estimated probability density function at location z for any individual originating from patch r in zone ℓ as
where . Then the expected occupation time in A of a resident of zone ℓ can thus be obtained, from (4), as
As has been mentioned, for this research, we consider the mobility parameter and the mobility residence matrix for the Third Period – First Part (2020-09-21 to 2020-10-11), which we compute, using the above procedure, and obtain
5. Deterministic inversion
Due to their exponential growth in time, the state variables of the dynamical system (1) are extremely sensitive to the input parameters. This sensitivity cascades uncertainty into the pre-inferred parameter values, which, in turn, may result into blow-up or significant uncertainty in the model outputs. To have a robust and desirable model analysis, it is imperative to avoid such model blow-ups by first determining the optimal model parameters that fits the measured data. Moreover, prior knowledge of point parameter estimates is necessary for meaningful uncertainty quantification. To this end, we begin by deterministically inverting system (1) in this section, and then subsequently perform uncertainty quantification on the inferred point parameters in the next section. Following is an outline of the formulation of the inversion problem and the results.
5.1. Formulation of the model to minimize
Let where , , , and , denote the state variables in system (1) for n patches. Let be the dimension of patch i parameters to be estimated. Then, we have the total number of patch i parameters to be estimated, denoted as . Consequently, the total number of parameters, , for the global system is . System (1) can be viewed as a mapping where , (i.e., maps the parameters to be estimated to the state variables) and it defines an initial value problem of the form;
The function f in the forward problem (6) is continuous and satisfies Lipschitz condition with respect to [116]. Thus, given , problem (6) has a unique solution .
Besides the numerically simulated states , the inverse problem requires, as an input, directly measured state variables at a discrete set of points . In most circumstances, not all of the state variables of the system can be directly observed. For instance, in epidemiology, data on new confirmed cases of infected individuals is readily available compared to data on other epidemiological statuses of the population. For this reason, we use the new cases reported in periods of time (days, weeks, for example) from the model to formulate the inverse problem.
Let , , denote the observed new infected cases in each unit/period of time , for the n patches. Let be the incidence in Patch i, during , derived from the numerical solution of the forward problem (6) with parameter vector . The objective function of the inverse problem is thus defined as
Consequently, the inverse problem becomes: compute such that
where is the feasible region of the parameter .
Problem (8) can be optimized using methods such as Landweber in [116,117,118,119], faster methods such as Levenberg-Marquardt or gradient based numerical non-linear least squares minimization algorithms such as Sequential Least SQuares programming algorithm (SLSQP) in [e.g, [51,120]. Due to the complexity of the forward problem (6), the inverse problem (8) is complex, high dimensional and computationally intensive. As a consequence, problem (8) creates a complex landscape, making it difficult for gradient-based algorithms and other optimization techniques to find the global minima, thereby easily failing to reach the optimal solution. As an alternative, we solve problem (8) using Genetic Algorithm (GA), a type of the diverse machine learning Evolutionary Algorithms (EAs), that uses heuristic search and optimization methods. Besides their efficacy in the optimization of problems involving numerous parameters with large feasible regions (i.e, problems with increased dimensionality) and multiple local optima, GAs do not require gradient computations which may sometimes be computationally challenging or unavailable altogether [121,122].
5.2. Results
Since we are dealing with four zones, we minimize Equation (7) as in (8), for . Besides estimating the epidemiological parameters , we also estimate the initial conditions . Thus, from the deterministic inversion, we estimate a total of 20 parameters; .
Table 4 and Table 5 shows the estimated parameters, while Figure 6 and Figure 7 presents the fitted incidence for the simulated and observed data, respectively. For the simulated incidence, the fit is visibly good, even though there is variation in the estimated parameters from the real ones (see Table 3) and a more important difference on the initial conditions. These disparities can be as a result of the noise that was added to the simulated data, andwhich represent an important modification to the original simulated incidence, especially in the early stages of the outbreak. As in complex models, we can also face the situation where there exists different sets of parameters that would give an equally good fit to the zonal model incidences.
As the estimated parameters from the GA give a good fit for the model incidence, we used them as a guide in specifying the initial sampling points for Stan and t-walk when performing Bayesian inference and uncertainty quantification in the next section. The values were particularly important for t-walk to begin sampling as without them, the algorithm does not converge and completely fails. In addition, as there are no literature that provides the spaces (upper and lower bounds) for the initial conditions of the incubation and prevalence states parameters for Hermosillo, we used the estimates of the said parameters from GA as a guide to set their boundaries in the Bayesian procedure.
6. Bayesian inference
Deterministic inversion of epidemic models have gained prominence in learning the trajectories of the epidemic using measured epidemiological data. However, deterministic inversion ignores inherent uncertainties due to imperfect data, stochasticity, model structural discrepancies and even parameter uncertainties that usually plagues the epidemic model. In order to make robust, valid and reliable decisions regarding management, prediction and forecasts of current and future epidemics, good treatment and quantification of such uncertainties is imperative. In this section, we use Bayesian techniques to quantify uncertainties that characterize the epidemic model (1), its parameters and the observed Hermosillo COVID-19 infection data and provide credible intervals for the model output.
Over the last few decades, Bayesian inference has become an important mechanism by providing an optimal probability platform for learning unknown parameters of a system given observed data. A Bayesian framework learns the trajectories of the unknown parameters by updating their prior distributions to the posterior distribution. Such prior updates and exploitation of the parameter space of the posterior distribution can be achieved using the standard Monte Carlo Markov Chain (MCMC) methods. Moreover, MCMC has somewhat led to approximate estimation of intractable posterior distributions, which often characterizes the modelling of real world phenomena. Estimation of such intractable posterior distribution has been a long-standing challenge in the realm of Bayesian inference, [123]. We use t-walk and Stan, which are MCMC based algorithms, to simulate the posterior distribution. Following is a detailed account on how the Bayesian framework is treated in this section.
6.1. Building the Posterior Distribution
In Bayesian realm, the observed data, is fixed while the state variable and the parameter are considered as random variables. In this setting, the Bayes’ theorem defines the posterior distribution as
where , called the prior distribution, codifies our belief about the unknown parameter before the data is observed and , called the likelihood distribution, codifies all the information available regarding how the observed data was obtained. From the Bayesian perspective, (9) constitutes thean inverse problem which may be solved by using the Maximum a posteriori (MAP), that is thean argument that maximizes the posterior (), or the posterior mean () or posterior median, as the optimal value of .
Since we are dealing with count data, which by their very nature are events that occur between a given period of time, a Poisson process would be a natural and meaningful starting point for modeling and performing inference on the observed cases. However, count data, especially epidemiological observations, usually exhibit more variations than is implied by the Poisson distribution, pointing to inherent over-dispersion in the data. Such variations may be due to sampling, aggregation and environmental variability or a combination of both factors making count data to have inherent over-dispersion. It is therefore not possible that count epidemiological data portrays equal mean-variance relationship, as is contemplated by the Poisson distribution. In fact, [124] posits that most commonly used approaches contemplates a quadratic mean-variance relationship. The mean-variance relationship in modeling count data, like epidemiological data, can adequately be described by the negative-binomial distribution as it has an additional parameter that permits the variance to be larger than the mean [125,126,127]. Moreover, the negative binomial distribution is a mixture of the Poisson and Gamma distribution [127,128], a pointer to the fact that the Poisson distribution is still involved in the modelling even when the negative binomial distribution is used.
We assume that the observed data follows the negative binomial distribution with one dispersion parameter and we write where p is the probability of success. The distribution has the form
where
It is noteworthy that is the additional variance allowed by the Negative Binomial distribution with respect to the Poison distribution, and that the parameter can be viewed as controlling the dispersion of the observed data.
We acknowledge that there are other forms of the Negative binomial distribution. For instance, [49] achieved success in modelling COVID-19 and hospital demand in Mexico using a Negative binomial distribution with two over-dispersion parameters. This distribution was proposed by [124]. However, in a model with numerous parameters to estimate as ours, it is our view that additional parameters would further increase the dimensionality of the already complex optimization problem.
We now construct the posterior distribution for the present multi-patched study. Using the already defined observed data and the variable in the previous section, we assume that the observed cases of each patch follow a negative-binomial distribution with over-dispersion parameter (the number of failures before first success) and success probabilities
where is the theoretical mean of the negative binomial distribution which can be taken as patch i incidence
With this setting in mind, we have that if , represents the incidence in Patch i observed in day j with theoretical mean , as in (11), then we have that
Then the likelihood from Patch i, , corresponds to
Hence, the likelihood of the combined data from the n patches is given as .
To establish the prior distribution, we opt to define the joint prior distribution as the product of the marginal. That is, if we denote , where is the ℓ-parameter associated to Patch i, then
where is the number of parameters for Patch i.
6.2. Results
We note, from the deterministic inversion section, that we are interested in estimating for each zone i, , the transmission, incubation and recovery rates , and as well as the exposed, infected and incidence initial conditions and . For the Bayesian inference, also called probabilistic inversion, there is an addition of four over-dispersion parameters , for each zone’s observed incidence data. The dispersion parameters can be loosely defined as the number of trials before we encounter the first successful infection in each zone. These parameters come with the negative binomial distribution, which we use as the distribution of the observed zonal incidences. We thus have, for the Bayesian inference in this section, a total of 24 parameters,
that we estimate.
An important problem that has been the topic of recent research, is the selection of adequate prior distributions, their corresponding hyperparameters and the delimitations of the parametric spaces of the parameters to be estimated [129,130,131]. In this research, for the epidemiological parameters, we choose prior distributions with 95% of their body falling within the parametric spaces (upper and lower bounds) provided from COVID-19 literature as in Table 2.
In this way, we use the following prior distributions for each of the parameters;
where the hyperparameters for the log Normal prior distributions of the contact parameters are , , , and , while those for the exposed states’ initial conditions are , , , , , , and , . These prior probability distributions, which we have selected using the mentioned criteria, are versatile and allows for the assumption that some parameter values could occur with lower, equal or higher probability densities.
However, to avoid generalizations, it is imperative to perform a diagnostic analysis of the adequacy and correctness of the selected prior distributions before we begin sampling. These prior distributions should be in coherence with our expectations and correspond to the domain knowledge of each parameter as obtained from the deterministic inversion in the previous section. We desire priors that, in accordance with our deterministic inversion domain experience, permits every conceivable configuration of the data while excluding blatantly ludicrous scenarios. Figure 8 shows a graph of the selected prior distributions of the infection, incubation and recovery parameters, vis-à-vis the corresponding posterior distributions. Here we can observe that for most parameters we have allowed for low informative priors and the posterior distributions are within their respective prior probability support. This conforms with the suggestion by [132], that the model should not be overly confined by the priors, which should instead be too wide to encompass a wide variety of situations and data that are incredibly improbable. We thus conclude that our selected prior distributions are adequate and are capable of regularizing our estimates to avoid non-identifiability. We acknowledge that [131] also proposed an interesting criterion for selecting prior distributions together with their corresponding hyperparameters, based on parametric intervals. Applying the assumption of independence of the parameters, the joint prior distribution is .
The likelihood for the four zonal incidence is
where, is the total number of days for which we observe the incidence for each zone ; is the j-th observed incidence for zone i, and is the incidence of model (1). The posterior distribution is thus given as .
The incidences output from the epidemic model (1) are very sensitive and exhibits a lot of uncertainty to slight changes, especially of the contact, incubation and recovery parameters. As a consequence, it was challenging to provide a wide range of values as support of the posterior distribution in Stan and t-walk. We addressed this challenge by beginning with the deterministic inversion of the epidemic model using GA, as is discussed in the previous section. The output of this inversion are given in Table 5. Consequently, we use the point parameter estimates obtained from the GA as the initial sampling points for t-walk and Stan. Moreover, as there is no literature for the parametric spaces of the incubation and prevalence states initial conditions, we delimit their support in the posterior distribution in the neighbourhood of their point parameter estimates obtained from the GA.
After performing the prior predictive checks, using the t-walk package [133], we obtain posterior samples for each of the 24 parameters (13). MCMC methods, from its definition, produces samples that can have high correlation, harboring some level of redundant information. One way of measuring the level of information redundancy in the posterior sample, is by using the effective sample size (ESS). Theoretically, ESS is the sample size we would obtain if we independently sampled the posterior distribution. The ESS and the proportion of ESS (pESS) of the simulated samples are given in the last two columns of Table A1. Going by how low (high) the values of ESS (pESS) are, we can tell that the simulated chains are highly correlated and thus, this MCMC method requires very high number of iterations. In other words, to obtain samples with insignificant auto correlations can require thinning at large lags, which can remarkably reduces the chains sizes. To obtain chains with reasonable sample sizes for analysis, after running this MCMC method for 1,000,000 iterations, we discarded 360,000 burnin samples and thinned the chains at lag 20.
The summary statistics of the generated samples are given in Table A1 (in the Appendix). As can be observed, the presented summary statistics are; the mean, variance, 95% credible interval (CI), median, ESS and pESS. From this table, we can conclude that in general, all the samples exhibited low variability and that their means are close to the estimates obtained from the GA in the previous section. Further, we can conclude that the means (and medians) are all within the 95% CI. The former and the latter observations can be confirmed from Figure 9, which shows the 95% CI of the samples, the mean and the estimates from the GA. Based on the scales of the values in the intervals, we can conclude that the credible intervals (CIs) are generally short, an indication of good estimates.
Figure 10 and Figure 11 represents the posterior predictive checks. The figures graph the incidence simulations of model (1) from 2020-02-26 to 2020-10-17. This period includes the dates within which the incidence data was observed (2020-02-26 to 2020-09-06) and 41 days prediction dates (2020-09-07 to 2020-10-17). Figure 10 shows 30,000 model incidences (grey curves), from the first 30,000 MCMC iterations, the observed incidence and the maximum a posteriori (MAP) model incidence. Here, the MAP model incidence, which is apparently covered by the grey curves, is the model incidence output obtained from the parameter values that maximizes the posterior distribution. We can observe from this figure, that 1) our fitted model produces simulations that are consistent with the observed incidence data and 2) the simulated trajectories do not portray diverse or variable changes. Indeed, the latter observation is consistent with our previous observation that there is low variability in the simulated samples.
Figure 11 shows the 95% posterior confidence intervals (CIs), the mean, median and the MAP of the simulated model incidences. From this figure we observe that most of the observed training incidences for the four zones, fall outside the 95% CI of the simulated model incidence with zone 1 and zone 3 simulated model incidences providing the narrowest 95% CI. In contrast, zones 2 and 4 have larger 95% prediction CI, and they cover more of the observed incidence. Zone 1 model prediction interval provides the worst coverage of the observed prediction incidences in this zone. The proportions of the observed prediction incidence covered by the 95% CI of simulated model incidence from t-walk are presented in Table 8. As the CIs for the four zones are generally not too wide and covers a small proportion of the training observed incidence, and the prediction observed incidences for zones 3 and 4, we can conclude that the point estimates from t-walk seems adequate, but we tend to underestimate the uncertainty associated with the estimated parameters.
We can observe from both Figure 10 and Figure 11 that the model predicts that there will still be some infection levels beyond 2020-09-06, the date when we observed the last incidence. In fact, the figures reveal that in the four zones, some individuals will still be infected up until 2020-10-17, with the median and map incidences being within the 95% CI.
After checking the adequacy of the prior distributions with respect to the posterior distribution and sampling, using the t-walk package, we also performed sampling of the posterior distribution using the Stan package. Stan is a Hamiltonian Monte Carlo (HMC) based package designed for Bayesian statistical analysis. We refer the reader to [134] for more details about the software and [132,135] for an insight on how the package can be used to perform inference and uncertainty quantification of compartmental epidemic models.
For Stan, we used the same support for the prior distribution as used in t-walk, except for the incubation initial conditions. Using the same support for the incubation initial conditions in t-walk led to very low overall proposal acceptance rate. As such, we had to use a different and shorter support range for all the incubation initial conditions prior distributions in t-walk in order to have reasonable proposals acceptance rate for the algorithm. However, in Stan, the support range for the same parameters were larger as Stan is more robust. For the over-dispersion parameters, we used the transformed versions and sampled their inverses in Stan.
For the model at hand, we ran one chain with 1,000 iterations for each of the 24 parameters and took the first 300 iterations as burn-in samples. The number of iterations is not the same as those obtained from t-walk as Stan requires longer periods of time, than t-walk, to complete each iteration. However, from the analysis, we observe that the chains are importantly less correlated, and we can obtain bigger effective sample sizes. Figure 12 and Figure 13 respectively shows the trace plots and the posterior densities of the samples of the estimated parameters. We obtained unit Rhat values from the Stan summary statistics output, an indication that all, except two, of the transitions converged. Additional Stan statistics, particularly, the diagnosis of the pairs plot of a subset of the estimated parameters, (Figure 14), confirms convergence of all, except two of the transitions of the chain during sampling.
Figure 15 shows the 95% CIs of the posterior distributions obtained from Stan. All the parameters, except , , , and , had short CIs. It is noteworthy that just as in t-walk, the samples of the inverse of the over-dispersion parameters, from Stan had very narrow intervals.
The pairs plot in Figure 14 shows the posterior distributions of the infection and recovery parameters (diagonal figures) and scatter plots (off-diagonal figures) showing the relationship between each of the samples. Since there were many (24) parameters to estimate, it was not appealing to have a joint pairs plot for all of them. In as much as this is the ideal procedure, doing this would lead to a figure with very tiny non-visualizable figure entries. We thus chose to pair the infection and recover rates (see Figure 14), as the scatter plots of these parameters exhibited interesting relationships. For instance, we observe from this figure, that there was a strong linear positive posterior correlation between and , and and and . In contrast, the infection parameters for the four zones did not exhibit any important relationship among themselves. This was also the case with the recovery parameters.
The summary statistics of the samples as obtained from Stan are shown in Table A2. These statistics are slightly different from the summary statistics from t-walk as displayed in Table A1. The differences in the statistics of the prevalence initial conditions and the over-dispersion parameters are obvious, as we have already mentioned that besides using different support ranges for thesethe distributions of prevalence initial conditions, we transformed and sampled the inverses of the over-dispersion parameters , . Otherwise, the slight differences in the statistics of the other parameters could have been occasioned by the difference in how the t-walk and Stan packages performs sampling. Notably, these differences would not lead to a different conclusion regarding the potency of COVID-19 infections in Hermosillo in 2020. The statistics in Table A2 reveals that the point estimates of the parameters are within the 95% CIs as is the case with the estimated parameters from t-walk, as can be seen in Table A1.
The differences in the summary statistics of the samples obtained from both packages is further reflected in Figure 11 and Figure 16, which are the posterior predictive check figures from t-walk and Stan respectively. We can observe that the mean, median and the observed incidences for each zone are all covered by the respective 95% CIs. In comparison, we observe from the t-walk output in Figure 11, that whereas the 95% CI of the epidemic model incidences did not cover some observed daily incidences, the same interval from Stan covered all the training observed zonal incidences. We thus conclude that the estimated parameters from Stan can capture a more realistic uncertainty level, compared to those estimated by t-walk. Both Figure 11 and Figure 16 reveals that COVID-19 infections in the four zones, and consequently, the whole of Hermosillo, was at its peak in mid-July 2020, with a prediction of continued infections beyond 2020-09-06, which was the last date of observed training daily incidences.
Table 2 shows the ranges of the parameters of the model as obtained from various COVID-19 literature. Our results, both from the GA, t-walk and Stan packages (see Table 5, Table A1 and Table A2), indicate that the point estimates of the infection and incubation parameters; and , , that best fit the incidences for the four zones, were within the ranges from literature. This is however not the case for the recovery parameters, , whose estimates were obtained as generally averaging close to one day recovery period for the four zones. This result is not surprising, as our incidence data for the four zones were inflated by a large under-reporting factor. This inflation, besides accounting for a possible lack of systematic testing of COVID-19 in Hermosillo, also accounted for the existence of subclinical and asymptomatic COVID-19 patients in the four zones under study. Going by how well the model fits the data, (see Figure 7, Figure 10, Figure 11 and Figure 16), we believe that accounting for incidence under-reporting by a factor of 15, as reported by [86] is realistic.
We further evaluate the prediction capability of the multi-patch model by checking the proportion of the observed zonal prediction incidences that are within the 95% CIs of the zone model incidences. Table 8 shows these proportions obtained from Stan (see Figure 16) and t-walk (see Figure 11). From this table, we can see that Stan produces 95% prediction bands that cover more than 50% of the observed prediction incidences for all the zones. On the other hand, t-walk provides 95% CIs large enough to cover less than 50% of observed prediction incidences for all the four zones, with zone 1 providing the narrowest simulated model incidence CIs that covers only 22.22% of the observed prediction incidence. In effect, we conclude that Stan outperforms t-walk as regards to the percentages of covered observed daily prediction incidence for all the zones.
6.3. Comparison to a single Patch model
To assess the improvement of using a more complex model against the usual single population model, in this section we fit the single-patch model (global SEIRS model) and compare its predictive performance against the multi-patch model with mobility. The systems of differential equations forming the single-patch model are presented in equation (14).
We run the single-patch model using similar values of birth, natural death and disease induced mortality rates used in the multi-patched model. We estimated the infection (), incubation() and recovery() rates and the initial conditions and for the single patch model. The prior distributions of these parameters and the likelihood of the global observed incidence remains the same as the ones used in the multi-patched model. The initial population was taken as the sum of the zones population sizes, shown in Figure 1. That is, .
We use the observed global incidence in the period 2020-02-26 to 2020-09-06 to train the global single-patch model and then use the incidence in the period 2020-10-17 to assess the prediction efficiency of the model. Table 6 shows the summary statistics of the estimated parameters. For comparison purposes with the multi-patch model, we sum all the zones’ predicted mean and median incidences and compute the efficiency measures. The efficiency measures used in this case are the Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE) defined as
where n is the total number of the predicted incidences, is the actual observed incidence and is the predicted incidence, which in this case is the mean and median incidences for both the multi-patch and global single-patched models.
Figure 17 shows the global single-patch predicted incidences together with the 95% credible incidence intervals, and Table 7 shows the efficiency measures of the predictions both from the multi and single-patched models. From this table, and indeed, comparing Figure 16 and Figure 17, we see that the multi-patched model outperforms the global single patch model, as it gives predicted incidences with lower RMSE and MAPE values. Moreover, Figure 16 reveals that a bigger percentage of the observed prediction and model predicted incidences from the multi-patched model are all within the 95% credible incidence interval. We thus conclude that in modelling COVID-19 in Hermosillo, using the multi-patched model with mobility represents an important improvement compared to the single-patch model.
7. Conclusions
In this work, we have utilized three techniques to estimate the parameters and perform inference and uncertainty quantification on a multi-patched epidemic model with mobility, residency and demography. The analysis has been conducted using mobile phone GPS data and confirmed COVID-19 cases in the four zones of Hermosillo, Mexico. The model incorporates two sets of parameters; 20 mobility and residence times parameters and 20 epidemiological parameters (including the incubation and prevalence initial conditions) which have all been estimated.
The complexity of the epidemic model makes it susceptible to the problem of parameter non-identifiability, a problemcomplication we have addressed by using the two distinctive data sets and different estimation techniques to estimate the two sets of parameters separately. In the first step, we have used Brownian Bridge model and mobile phone GPS data to estimate the first set of 20 mobility and residence times for the four zones in Hermosillo. The next set of the model epidemiological parameters have been estimated using confirmed positive COVID-19 cases and two estimation techniques; deterministic inversion using GA and probabilistic inversion, using two different MCMC methods implemented in the t-walk and Stan statistical packages.
The incidence outputs of the epidemic model are very sensitive to slight changes of its parameters, especially the infection, incubation and recovery rates. This necessitated the use of the deterministic inversion technique as the first step of estimation, as it provided us with an idea of the possible parametric values, and model incidences that best fit the observed incidences. This first step of estimation thus presented us with the scope of the parametric space within which to delimit the support of the posterior distribution and the initial sampling values used in the probabilistic inversion stage, using t-walk and Stan.
In this article, we are not concerned with a detailed comparison of t-walk and Stan, as there could be many factors that affect their performance, that undoubtedly vary among different models. Some of these factors may include the chosen parametrization of the model, the prior distribution and initial values from where the sampling starts. We however mention that some literature have established that it may be difficult to use MCMC-based inference tools to model systems of ODEs, since the relevant likelihood function may contain several local minima that causes them to fail the standard regulatory conditions. In these cases, Stan offers high statistical efficiency and, in complex scenarios, may produce more accurate results compared to t-walk. For the presented epidemic model, Stan performs better than t-walk as the posterior distributions are characterized by highly correlated parameter spaces. We have observed this fact in the present study based on the large ESS proportions obtained from Stan compared to those obtained from t-walk.
The results from the estimation in this study shows that the infection and incubation rates for the four zones in Hermosillo were within the ranges postulated in various COVID-19 literature. However, the recovery parameters fell outside the known COVID-19estimated ranges reported in other COVID-19 studies. This deviation has however been justified as possibly emanating from the inflation of the incidences in the four zones by a factor of 15 to account for under-reporting. . Further, from the estimated parameters, the model presents a good fit to COVID-19 infections in the four zones, and consequently, the whole city of Hermosillo, and under the model it also has its peak in mid-July 2020.
The epidemic model and the results in this research can be useful to public health officials as it not only provides better predictions, but alsoit italso explicitly introduces mobility parameters that can be modified to assess the effectiveness of different levels of mobility restrictions. These restrictions can be global or applied to only some patches. We believe the model and methods then can turn into a user-friendly tool to guide public health policies for management and mitigation of emerging and re-emerging infectious diseases.
The epidemic model in this article is confined within the limits of modelling a single strain of the COVID-19 virus. However, like many infectious diseases, multiple strains of COVID-19, resulting from its gene mutation, have emerged. For instance, four mutants of the pathogen were detected within the first one and a half years of the pandemic. It would therefore be relevant to extend the present epidemic model to include the dynamics of several COVID-19 pathogenic strains. This extension would lead to better understanding and management of future infectious outbreaks.
In addition, besides urban mobility, Tthe epidemic model used in this research did not account for government intervention measures like, such as vaccination and regional or national mobility. As the vaccination campaign in Mexico started in December 2020, this factor is absent, but it would be desirable to introduce these, and other mitigation strategies in future models, for modelling futuresubsequent outbreaks of COVID-19 and other infectious diseases.
It is worth noting that the assumptions for the proposed model include those for the ODEs to describe the dynamics within each patch. While ODEs can be effective in approximating dynamics in many scenarios, there are cases where, even with homogeneous mixing, the mathematical system may fail to accurately represent the behavior of a small population.
One reason for this is the assumption of continuous variables and smooth transitions inherent in ODEs. In small populations, discrete effects and stochastic events can have a significant impact on the dynamics. These discrete effects, such as random fluctuations or individual interactions, introduce variability that is not captured by ODEs, leading to the model inaccurately reflecting the true behavior of the system.
To address this, one option for small spatial scales and patch sizes, is to leverage computational techniques such as agent-based modeling. This approach captures the important variability that arises from individual interactions [136,137,138,139,140,141]. Additionally, to reduce the variability of simulations, relevant contact patterns produced by street or building layouts can be incorporated. At a more detailed level, modeling individual interactions as a network of contacts still allows for fitting or performing statistical inference using computer-intensive methods [55,142,143,144]. Because of this, scaling up these methods on slightly larger patches can pose serious challenges that requiere careful considerations.
Author Contributions
Conceptualization, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; methodology,Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; software, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R. and J.F.E; validation, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R. and J.F.E.; formal analysis, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; investigation, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; resources, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R. and J.F.E.; data curation, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R. and J.F.E.; writing—original draft preparation, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; writing—review and editing, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; visualization, Albert Orwa Akuno, L. Leticia Ramírez-Ramírez and Jesús F. EspinozaA.O.A, L.L.R-R.; supervision, L. Leticia Ramírez-RamírezL.L.R-R.; project administration, L. Leticia Ramírez-RamírezL.L.R-R.. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
The global Hermosillo COVID-19 data is publicly available in the CONACyT website https://datos.covid-19.conacyt.mx. The GPS mobility and zonal COVID-19 data used in this study are available on request from the corresponding author. These data are not publicly available since they contain private and personal individual information.The GPS mobility and zonal COVID-19 data utilized in this study are available upon request from the corresponding author. These datasets are not publicly accessible due to the inclusion of private and personal individual information. The geo-referenced COVID-19 data provided by the Secretaría de Salud del Estado de Sonora (SSA) are protected by confidentiality agreements and in accordance with the laws of personal data of Mexico, as they contain sensitive personal information such as medical records and residence locations. Detailed information regarding the processing, analysis, and visualization of this data can be found at https://www.mat.uson.mx/web/index.php/coronavirus-covid-19/, specifically on the official website of the Mathematics Department at UNISON. The codes used in this research are however publicly available at https://github.com/AlbertAkuno/Inference
Acknowledgments
We would like to thank the Super Computers Laboratory at CIMAT for providing us with the necessary computer resources that we used to run the codes in this work, and LUMEX CONSULTORES, S.C. for contributing the mobile phone GPS data and approving its use for academic purposes.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Posterior statistics from t-walk and Stan
Appendix A.1. Posterior statistics from t-walk

Table A1.
Statistics of model parameters estimated using probabilistic (twalk) inversion
| Probabilistic inversion (t-walk) statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Parameters | Mean | SD | ESS | pESS | |||||
| 1.3552 | 0.1039 | 1.1166 | 1.2951 | 1.3724 | 1.4307 | 1.5033 | 25 | 0.0008 | |
| 1.2258 | 0.1014 | 1.0668 | 1.1321 | 1.2366 | 1.3036 | 1.4168 | 22 | 0.0007 | |
| 0.4223 | 0.0663 | 0.3046 | 0.3734 | 0.4225 | 0.4629 | 0.5734 | 28 | 0.0009 | |
| 1.0839 | 0.1404 | 0.8218 | 0.9383 | 1.1300 | 1.1700 | 1.2970 | 18 | 0.0006 | |
| 0.4649 | 0.0368 | 0.3754 | 0.4510 | 0.4757 | 0.4888 | 0.4989 | 233 | 0.0073 | |
| 0.4730 | 0.0294 | 0.4013 | 0.4627 | 0.4811 | 0.4925 | 0.4994 | 112 | 0.0035 | |
| 0.4236 | 0.0575 | 0.2735 | 0.3940 | 0.4320 | 0.4683 | 0.4964 | 122 | 0.0038 | |
| 0.2614 | 0.0401 | 0.1991 | 0.2318 | 0.2526 | 0.2897 | 0.3436 | 21 | 0.0006 | |
| 1.3740 | 0.1082 | 1.1382 | 1.3000 | 1.4047 | 1.4649 | 1.4977 | 22 | 0.0007 | |
| 1.3461 | 0.1243 | 1.1416 | 1.2259 | 1.3920 | 1.4620 | 1.4945 | 20 | 0.0006 | |
| 1.3196 | 0.1551 | 0.9050 | 1.2604 | 1.3547 | 1.4367 | 1.4959 | 32 | 0.0010 | |
| 0.5198 | 0.0673 | 0.4061 | 0.4546 | 0.5358 | 0.5669 | 0.6372 | 18 | 0.0006 | |
| 61.3153 | 3.1875 | 53.1884 | 59.6405 | 62.2854 | 63.8354 | 64.8765 | 92 | 0.0029 | |
| 6.6851 | 2.6790 | 0.6896 | 4.9450 | 7.3324 | 8.9846 | 9.8718 | 175 | 0.0055 | |
| 80.5102 | 3.8104 | 71.4076 | 78.1892 | 81.6369 | 83.5947 | 84.8731 | 88 | 0.0027 | |
| 6.3754 | 2.8778 | 0.3521 | 4.4653 | 7.1644 | 8.8401 | 9.9016 | 75 | 0.0023 | |
| 27.8516 | 1.9766 | 22.5930 | 26.8572 | 28.4460 | 29.3748 | 29.9438 | 160 | 0.0050 | |
| 5.7194 | 2.8518 | 0.3452 | 3.4194 | 6.0118 | 8.2424 | 9.8920 | 288 | 0.0090 | |
| 7.9665 | 1.5100 | 4.2772 | 7.1346 | 8.2710 | 9.1433 | 9.9091 | 87 | 0.0027 | |
| 1.6821 | 1.5480 | 0.0551 | 0.4926 | 1.2054 | 2.3330 | 5.7315 | 70 | 0.0022 | |
| 9.6957 | 0.2948 | 8.8788 | 9.5804 | 9.7863 | 9.9084 | 9.9933 | 226 | 0.0071 | |
| 9.1320 | 0.7812 | 7.3177 | 8.7525 | 9.3166 | 9.7064 | 9.9798 | 141 | 0.0044 | |
| 9.7135 | 0.3543 | 8.9596 | 9.6075 | 9.8080 | 9.9251 | 9.9939 | 147 | 0.0046 | |
| 7.8458 | 1.3651 | 5.2517 | 6.8248 | 7.9591 | 9.0183 | 9.9349 | 35 | 0.0010 | |
Appendix A.2. Posterior statistics from Stan
Table A2.
Statistics of model parameters estimated using probabilistic (Stan) inversion
| Probabilistic inversion (Stan) statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Parameters | Mean | SD | ESS | pESS | |||||
| 1.2476 | 0.1080 | 1.0107 | 1.1807 | 1.2498 | 1.3193 | 1.4317 | 255 | 0.3643 | |
| 1.1591 | 0.0546 | 1.0432 | 1.1294 | 1.1698 | 1.2000 | 1.2460 | 213 | 0.3043 | |
| 0.3811 | 0.0380 | 0.3129 | 0.3543 | 0.3805 | 0.4057 | 0.4536 | 244 | 0.3486 | |
| 0.7728 | 0.0245 | 0.7489 | 0.7548 | 0.7656 | 0.7855 | 0.8440 | 173 | 0.2471 | |
| 0.4409 | 0.0377 | 0.3606 | 0.4166 | 0.4427 | 0.4729 | 0.4976 | 188 | 0.2686 | |
| 0.4660 | 0.0282 | 0.3973 | 0.4501 | 0.4728 | 0.4881 | 0.4985 | 248 | 0.3543 | |
| 0.4019 | 0.0517 | 0.2978 | 0.3641 | 0.4053 | 0.4385 | 0.4930 | 244 | 0.3486 | |
| 0.3766 | 0.0280 | 0.3228 | 0.3578 | 0.3758 | 0.3933 | 0.4365 | 196 | 0.2800 | |
| 1.2275 | 0.1359 | 0.9530 | 1.1274 | 1.2277 | 1.3274 | 1.4783 | 241 | 0.3443 | |
| 1.4091 | 0.0795 | 1.2259 | 1.3692 | 1.4280 | 1.4729 | 1.4980 | 209 | 0.2986 | |
| 1.3743 | 0.0983 | 1.1104 | 1.3161 | 1.3922 | 1.4521 | 1.4958 | 204 | 0.2914 | |
| 0.3550 | 0.0113 | 0.3408 | 0.3472 | 0.3514 | 0.3612 | 0.3846 | 188 | 0.2686 | |
| 94.4414 | 5.1047 | 80.4055 | 92.2135 | 95.8150 | 98.3510 | 99.7569 | 234 | 0.3343 | |
| 6.5046 | 2.5618 | 1.0641 | 4.6339 | 7.0732 | 8.6031 | 9.8693 | 202 | 0.2886 | |
| 94.8808 | 4.5037 | 83.3513 | 92.6637 | 95.9344 | 98.4198 | 99.8949 | 143 | 0.2043 | |
| 5.8008 | 2.8349 | 0.3588 | 3.6777 | 6.1113 | 8.2312 | 9.8222 | 217 | 0.3100 | |
| 43.6993 | 5.1480 | 32.0696 | 40.9228 | 45.1198 | 47.7972 | 49.8012 | 224 | 0.3200 | |
| 5.2505 | 2.8159 | 0.1604 | 2.5964 | 5.4800 | 7.5498 | 9.6372 | 217 | 0.3100 | |
| 9.1961 | 1.9174 | 5.6108 | 7.9395 | 9.2555 | 10.4385 | 12.6814 | 262 | 0.3743 | |
| 0.8923 | 0.9075 | 0.0397 | 0.2712 | 0.6660 | 1.1865 | 3.4709 | 202 | 0.2886 | |
| 9.6200 | 0.3765 | 8.6530 | 9.4789 | 9.7231 | 9.8887 | 9.9887 | 167 | 0.2386 | |
| 8.8543 | 0.7276 | 7.3756 | 8.3520 | 8.9653 | 9.4043 | 9.8811 | 222 | 0.3171 | |
| 7.4251 | 1.1378 | 5.1812 | 6.6442 | 7.4181 | 8.2871 | 9.4924 | 146 | 0.2086 | |
| 7.1626 | 1.0035 | 5.2185 | 6.4972 | 7.1173 | 7.7591 | 9.2361 | 151 | 0.2158 | |
References
- Jašková, D.; Havierniková, K. The human resources as an important factor of regional development. International Journal of Business and Society 2020, 21, 1464–1478. [Google Scholar] [CrossRef]
- Krypa, N. Social economic development and the human resources management. Academic Journal of Interdisciplinary Studies 2017, 6, 73. [Google Scholar] [CrossRef]
- Peterson, E.W.F. The role of population in economic growth. Sage Open 2017, 7, 2158244017736094. [Google Scholar] [CrossRef]
- Ramírez-Ramírez, L.L.; Montoya, J.A.; Espinoza, J.F.; Mehta, C.; Akuno, A.O.; Bui-Thanh, T. Use of mobile phone sensing data to estimate residence and mobility times in urban patches during the COVID-19 epidemic: The case of the 2020 outbreak in Hermosillo, Mexico. Preprint in Research Square 2022. [CrossRef]
- VLAD, C.A.; Ungureanu, G.; Militaru, M. Human resources contribution to economic growth. REVISTA ECONOMICĂ 2012, p. 850.
- Oaks Jr, S.C.; Shope, R.E.; Lederberg, J.; et al. Emerging infections: microbial threats to health in the United States; National Academies Press, 1992.
- Monto, A.S. The Global Threat of New and Reemerging Infectious Diseases: Reconciling US National Security and Public Health Policy, 2003.
- Adiga, A.; Dubhashi, D.; Lewis, B.; Marathe, M.; Venkatramanan, S.; Vullikanti, A. Mathematical models for covid-19 pandemic: A comparative analysis. Journal of the Indian Institute of Science 2020, 100, 793–807. [Google Scholar] [CrossRef] [PubMed]
- Schmidtchen, M.; Tse, O.; Wackerle, S. A multiscale approach for spatially inhomogeneous disease dynamics. arXiv preprint arXiv:1602.05927 2016. arXiv:1602.05927 2016.
- Castillo-Chavez, C.; Bichara, D.; Morin, B.R. Perspectives on the role of mobility, behavior, and time scales in the spread of diseases. Proceedings of the National Academy of Sciences 2016, 113, 14582–14588. [Google Scholar] [CrossRef]
- Rvachev, L.A.; Longini Jr, I.M. A mathematical model for the global spread of influenza. Mathematical biosciences 1985, 75, 3–22. [Google Scholar] [CrossRef]
- Baroyan, O.; Rvachev, L.; Basilevsky, U.; Ermakov, V.; Frank, K.; Rvachev, M.; Shashkov, V. Computer modelling of influenza epidemics for the whole country (USSR). Advances in Applied Probability 1971, 3, 224–226. [Google Scholar] [CrossRef]
- Anifandis, G.; Tempest, H.G.; Oliva, R.; Swanson, G.M.; Simopoulou, M.; Easley, C.A.; Primig, M.; Messini, C.I.; Turek, P.J.; Sutovsky, P.; et al. COVID-19 and human reproduction: A pandemic that packs a serious punch. Systems Biology in Reproductive Medicine 2021, 67, 3–23. [Google Scholar] [CrossRef]
- Prieto, K. Current forecast of COVID-19 in Mexico: A Bayesian and machine learning approaches. PloS one 2022, 17, e0259958. [Google Scholar] [CrossRef]
- Weston, D.; Hauck, K.; Amlôt, R. Infection prevention behaviour and infectious disease modelling: a review of the literature and recommendations for the future. BMC public health 2018, 18, 1–16. [Google Scholar] [CrossRef]
- Luo, M.; Qin, S.; Tan, B.; Cai, M.; Yue, Y.; Xiong, Q. Population Mobility and the Transmission Risk of the COVID-19 in Wuhan, China. ISPRS International Journal of Geo-Information 2021, 10, 395. [Google Scholar] [CrossRef]
- Changruenngam, S.; Bicout, D.J.; Modchang, C. How the individual human mobility spatio-temporally shapes the disease transmission dynamics. Scientific Reports 2020, 10, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Findlater, A.; Bogoch, I.I. Human mobility and the global spread of infectious diseases: a focus on air travel. Trends in parasitology 2018, 34, 772–783. [Google Scholar] [CrossRef] [PubMed]
- Danon, L.; Ford, A.P.; House, T.; Jewell, C.P.; Keeling, M.J.; Roberts, G.O.; Ross, J.V.; Vernon, M.C. Networks and the epidemiology of infectious disease. Interdisciplinary perspectives on infectious diseases 2011, 2011. [Google Scholar] [CrossRef] [PubMed]
- Apostolopoulos, Y.; Sönmez, S.F. Population mobility and infectious disease; Springer, 2007.
- Gushulak, B.D.; MacPherson, D.W. Population mobility and infectious diseases: the diminishing impact of classical infectious diseases and new approaches for the 21st century. Clinical infectious diseases 2000, 31, 776–780. [Google Scholar] [CrossRef]
- Dalziel, B.D.; Pourbohloul, B.; Ellner, S.P. Human mobility patterns predict divergent epidemic dynamics among cities. Proceedings of the Royal Society B: Biological Sciences 2013, 280, 20130763. [Google Scholar] [CrossRef] [PubMed]
- Ni, S.; Weng, W. Impact of travel patterns on epidemic dynamics in heterogeneous spatial metapopulation networks. Physical review E 2009, 79, 016111. [Google Scholar] [CrossRef]
- Tang, M.; Liu, Z.; Li, B. Epidemic spreading by objective traveling. EPL (Europhysics Letters) 2009, 87, 18005. [Google Scholar] [CrossRef]
- Yang, Z.; Cui, A.X.; Zhou, T. Impact of heterogeneous human activities on epidemic spreading. Physica A: Statistical Mechanics and its Applications 2011, 390, 4543–4548. [Google Scholar] [CrossRef]
- Meloni, S.; Perra, N.; Arenas, A.; Gómez, S.; Moreno, Y.; Vespignani, A. Modeling human mobility responses to the large-scale spreading of infectious diseases. Scientific reports 2011, 1, 1–7. [Google Scholar] [CrossRef]
- Wang, B.; Cao, L.; Suzuki, H.; Aihara, K. Safety-information-driven human mobility patterns with metapopulation epidemic dynamics. Scientific reports 2012, 2, 1–8. [Google Scholar] [CrossRef]
- Epstein, J.M.; Goedecke, D.M.; Yu, F.; Morris, R.J.; Wagener, D.K.; Bobashev, G.V. Controlling pandemic flu: the value of international air travel restrictions. PloS one 2007, 2, e401. [Google Scholar] [CrossRef] [PubMed]
- Colizza, V.; Barrat, A.; Barthelemy, M.; Valleron, A.J.; Vespignani, A. Modeling the worldwide spread of pandemic influenza: baseline case and containment interventions. PLoS medicine 2007, 4, e13. [Google Scholar] [CrossRef] [PubMed]
- Bajardi, P.; Poletto, C.; Ramasco, J.J.; Tizzoni, M.; Colizza, V.; Vespignani, A. Human mobility networks, travel restrictions, and the global spread of 2009 H1N1 pandemic. PloS one 2011, 6, e16591. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, N.M.; Cummings, D.A.; Fraser, C.; Cajka, J.C.; Cooley, P.C.; Burke, D.S. Strategies for mitigating an influenza pandemic. Nature 2006, 442, 448–452. [Google Scholar] [CrossRef] [PubMed]
- Keeling, M.; Rohani, P. Model. Infectious Diseases Humans Animals, 2008.
- Frıas-Martınez, E.; Williamson, G.; Frıas-Martınez, V. Agent-based modelling of epidemic spreading using social networks and human mobility patterns. In Proceedings of the Proceedings of the 2011 IEEE third international conference on privacy, security.
- Cota, W.; Soriano-Paños, D.; Arenas, A.; Ferreira, S.C.; Gómez-Gardeñes, J. Infectious disease dynamics in metapopulations with heterogeneous transmission and recurrent mobility. New Journal of Physics 2021, 23, 073019. [Google Scholar] [CrossRef]
- Balcan, D.; Gonçalves, B.; Hu, H.; Ramasco, J.J.; Colizza, V.; Vespignani, A. Modeling the spatial spread of infectious diseases: The GLobal Epidemic and Mobility computational model. Journal of computational science 2010, 1, 132–145. [Google Scholar] [CrossRef] [PubMed]
- Driessche, P.v. Spatial structure: patch models. In Mathematical epidemiology; Springer, 2008; pp. 179–189.
- Herrera-Valdez, M.A.; Cruz-Aponte, M.; Castillo-Chavez, C. Multiple outbreaks for the same pandemic: Local transportation and social distancing explain the different" waves" of A-H1N1pdm cases observed in México during 2009. Mathematical Biosciences & Engineering 2011, 8, 21. [Google Scholar]
- Khan, K.; Arino, J.; Hu, W.; Raposo, P.; Sears, J.; Calderon, F.; Heidebrecht, C.; Macdonald, M.; Liauw, J.; Chan, A.; et al. Spread of a novel influenza A (H1N1) virus via global airline transportation. New England journal of medicine 2009, 361, 212–214. [Google Scholar] [CrossRef]
- Bichara, D.; Kang, Y.; Castillo-Chavez, C.; Horan, R.; Perrings, C. SIS and SIR Epidemic Models Under Virtual Dispersal. Bulletin of Mathematical Biology 2015, 77, 2004–2034. [Google Scholar] [CrossRef]
- Bichara, D.; Abderrahman, I. Multi-patch and multi-group epidemic models: a new framework. Journal of Mathematical Biology 2018, 77, 107–134. [Google Scholar] [CrossRef] [PubMed]
- Riley, S. Large-scale spatial-transmission models of infectious disease. Science 2007, 316, 1298–1301. [Google Scholar] [CrossRef] [PubMed]
- Akuno, A.O.; Ramirez-Ramirez, L.L.; Mehta, C.; Krishnanuni, C.; Bui-Thanh, T.; Montoya, J.A. Multi-patch epidemic models with partial mobility, residency, and demography. Preprint in Research Square 2022. [CrossRef]
- Arino, J.; van den Driessche, P. A multi-city epidemic model. Mathematical Population Studies 2003, 10, 175–193. [Google Scholar] [CrossRef]
- Brauer, F. Mathematical epidemiology: Past, present, and future. Infectious Disease Modelling 2017, 2, 113–127. [Google Scholar] [CrossRef]
- Moualeu, D.; Bowong, S.; Tsanou, B.; Temgoua, A. A patchy model for the transmission dynamics of tuberculosis in sub-Saharan Africa. International journal of dynamics and control 2018, 6, 122–139. [Google Scholar] [CrossRef] [PubMed]
- Salmani, M.; van den Driessche, P. A model for disease transmission in a patchy environment. Discrete & Continuous Dynamical Systems-B 2006, 6, 185. [Google Scholar]
- Phaijoo, G.R.; Gurung, D.B.; et al. Mathematical study of dengue disease transmission in multi-patch environment. Applied Mathematics 2016, 7, 1521. [Google Scholar] [CrossRef]
- Swallow, B.; Birrell, P.; Blake, J.; Burgman, M.; Challenor, P.; Coffeng, L.E.; Dawid, P.; De Angelis, D.; Goldstein, M.; Hemming, V.; et al. Challenges in estimation, uncertainty quantification and elicitation for pandemic modelling. Epidemics 2022, 38, 100547. [Google Scholar] [CrossRef]
- Capistran, M.A.; Capella, A.; Christen, J.A. Forecasting hospital demand in metropolitan areas during the current COVID-19 pandemic and estimates of lockdown-induced 2nd waves. PloS one 2021, 16, e0245669. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, P.; Zhang, S.; Pan, H. Uncertainty Modeling of a Modified SEIR Epidemic Model for COVID-19. Biology 2022, 11, 1157. [Google Scholar] [CrossRef]
- Chen, P.; Wu, K.; Ghattas, O. Bayesian inference of heterogeneous epidemic models: Application to COVID-19 spread accounting for long-term care facilities. Computer Methods in Applied Mechanics and Engineering 2021, 385, 114020. [Google Scholar] [CrossRef]
- Huppert, A.; Katriel, G. Mathematical modelling and prediction in infectious disease epidemiology. Clinical microbiology and infection 2013, 19, 999–1005. [Google Scholar] [CrossRef] [PubMed]
- Márquez Urbina, J.U.; González Farías, G.; Ramírez Ramírez, L.L.; Rodríguez González, D.I. A multi-source global-local model for epidemic management. Plos one 2022, 17, e0261650. [Google Scholar] [CrossRef] [PubMed]
- Groendyke, C.; Welch, D.; Hunter, D.R. Bayesian inference for contact networks given epidemic data. Scandinavian Journal of Statistics 2011, 38, 600–616. [Google Scholar] [CrossRef]
- Dutta, R.; Mira, A.; Onnela, J.P. Bayesian inference of spreading processes on networks. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 2018, 474, 20180129. [Google Scholar] [CrossRef] [PubMed]
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of inverse problems; Vol. 375, Springer Science & Business Media, 1996.
- Tarantola, A. Inverse problem theory and methods for model parameter estimation; SIAM, 2005.
- Vogel, C.R. Computational methods for inverse problems (Frontiers in Applied Mathematics); SIAM, 2002.
- Alexanderian, A. Optimal experimental design for infinite-dimensional Bayesian inverse problems governed by PDEs: A review. Inverse Problems 2021, 37, 043001. [Google Scholar] [CrossRef]
- Wesolowski, A.; Buckee, C.O.; Engø-Monsen, K.; Metcalf, C.J.E. Connecting mobility to infectious diseases: the promise and limits of mobile phone data. The Journal of infectious diseases 2016, 214, S414–S420. [Google Scholar] [CrossRef]
- Wei, J.T.; Liu, Y.X.; Zhu, Y.C.; Qian, J.; Ye, R.Z.; Li, C.Y.; Ji, X.K.; Li, H.K.; Qi, C.; Wang, Y.; et al. Impacts of transportation and meteorological factors on the transmission of COVID-19. International journal of hygiene and environmental health 2020, 230, 113610. [Google Scholar] [CrossRef]
- Silva, P.C.; Batista, P.V.; Lima, H.S.; Alves, M.A.; Guimarães, F.G.; Silva, R.C. COVID-ABS: An agent-based model of COVID-19 epidemic to simulate health and economic effects of social distancing interventions. Chaos, Solitons & Fractals 2020, 139, 110088. [Google Scholar]
- Cartenì, A.; Di Francesco, L.; Martino, M. How mobility habits influenced the spread of the COVID-19 pandemic: Results from the Italian case study. Science of the Total Environment 2020, 741, 140489. [Google Scholar] [CrossRef]
- Ogen, Y. Assessing nitrogen dioxide (NO2) levels as a contributing factor to coronavirus (COVID-19) fatality. Science of the Total Environment 2020, 726, 138605. [Google Scholar] [CrossRef]
- He, G.; Pan, Y.; Tanaka, T. The short-term impacts of COVID-19 lockdown on urban air pollution in China. Nature Sustainability 2020, 3, 1005–1011. [Google Scholar] [CrossRef]
- Iacus, S.M.; Santamaria, C.; Sermi, F.; Spyratos, S.; Tarchi, D.; Vespe, M. Human mobility and COVID-19 initial dynamics. Nonlinear Dynamics 2020, 101, 1901–1919. [Google Scholar] [CrossRef]
- Alessandretti, L. What human mobility data tell us about COVID-19 spread. Nature Reviews Physics 2022, 4, 12–13. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.M.; Paul, K.C.; Hossain, M.A.; Ali, G.M.N.; Rahman, M.S.; Thill, J.C. Machine learning on the COVID-19 pandemic, human mobility and air quality: A review. Ieee Access 2021, 9, 72420–72450. [Google Scholar] [CrossRef] [PubMed]
- Hu, T.; Wang, S.; She, B.; Zhang, M.; Huang, X.; Cui, Y.; Khuri, J.; Hu, Y.; Fu, X.; Wang, X.; et al. Human mobility data in the COVID-19 pandemic: characteristics, applications, and challenges. International Journal of Digital Earth 2021, 14, 1126–1147. [Google Scholar] [CrossRef]
- Lin, C.H.; Wen, T.H. How Spatial Epidemiology Helps Understand Infectious Human Disease Transmission. Tropical Medicine and Infectious Disease 2022, 7, 164. [Google Scholar] [CrossRef]
- Perez, L.; Dragicevic, S. An agent-based approach for modeling dynamics of contagious disease spread. International journal of health geographics 2009, 8, 1–17. [Google Scholar] [CrossRef]
- Lazebnik, T.; Blumrosen, G. Advanced multi-mutation with intervention policies pandemic model. IEEE Access 2022, 10, 22769–22781. [Google Scholar] [CrossRef]
- Fudolig, M.; Howard, R. The local stability of a modified multi-strain SIR model for emerging viral strains. PloS one 2020, 15, e0243408. [Google Scholar] [CrossRef]
- Yusuf, A.; Qureshi, S.; Inc, M.; Aliyu, A.I.; Baleanu, D.; Shaikh, A.A. Two-strain epidemic model involving fractional derivative with Mittag-Leffler kernel. Chaos: An Interdisciplinary Journal of Nonlinear Science 2018, 28, 123121. [Google Scholar] [CrossRef]
- Lazebnik, T.; Bunimovich-Mendrazitsky, S. Generic approach for mathematical model of multi-strain pandemics. PloS one 2022, 17, e0260683. [Google Scholar] [CrossRef]
- Khyar, O.; Allali, K. Global dynamics of a multi-strain SEIR epidemic model with general incidence rates: application to COVID-19 pandemic. Nonlinear dynamics 2020, 102, 489–509. [Google Scholar] [CrossRef] [PubMed]
- Conacyt. Covid-19 México, 2020. Accessed in, 2022.
- Del Valle, S.Y.; McMahon, B.H.; Asher, J.; Hatchett, R.; Lega, J.C.; Brown, H.E.; Leany, M.E.; Pantazis, Y.; Roberts, D.J.; Moore, S.; et al. Summary results of the 2014-2015 DARPA Chikungunya challenge. BMC infectious diseases 2018, 18, 1–14. [Google Scholar] [CrossRef]
- Lai, C.C.; Liu, Y.H.; Wang, C.Y.; Wang, Y.H.; Hsueh, S.C.; Yen, M.Y.; Ko, W.C.; Hsueh, P.R. Asymptomatic carrier state, acute respiratory disease, and pneumonia due to severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2): Facts and myths. Journal of Microbiology, Immunology and Infection 2020, 53, 404–412. [Google Scholar] [CrossRef] [PubMed]
- Kalajdzievska, D.; Li, M.Y. Modeling the effects of carriers on transmission dynamics of infectious diseases. Math. Biosci. Eng 2011, 8, 711–722. [Google Scholar]
- Duffy, M.R.; Chen, T.H.; Hancock, W.T.; Powers, A.M.; Kool, J.L.; Lanciotti, R.S.; Pretrick, M.; Marfel, M.; Holzbauer, S.; Dubray, C.; et al. Zika virus outbreak on Yap Island, federated states of Micronesia. New England Journal of Medicine 2009, 360, 2536–2543. [Google Scholar] [CrossRef]
- Doll, M.E.; Pryor, R.; Mackey, D.; Doern, C.D.; Bryson, A.; Bailey, P.; Cooper, K.; Godbout, E.; Stevens, M.P.; Bearman, G. Utility of retesting for diagnosis of SARS-CoV-2/COVID-19 in hospitalized patients: Impact of the interval between tests. Infection Control & Hospital Epidemiology 2020, 41, 859–861. [Google Scholar]
- Esbin, M.N.; Whitney, O.N.; Chong, S.; Maurer, A.; Darzacq, X.; Tjian, R. Overcoming the bottleneck to widespread testing: a rapid review of nucleic acid testing approaches for COVID-19 detection. Rna 2020, 26, 771–783. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Pei, S.; Chen, B.; Song, Y.; Zhang, T.; Yang, W.; Shaman, J. Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2). Science 2020, 368, 489–493. [Google Scholar] [CrossRef]
- Team, E. The epidemiological characteristics of an outbreak of 2019 novel coronavirus diseases (COVID-19)—China, 2020. China CDC weekly 2020, 2, 113. [Google Scholar]
- Trejo, I.; Hengartner, N.W. A modified Susceptible-Infected-Recovered model for observed under-reported incidence data. PloS one 2022, 17, e0263047. [Google Scholar] [CrossRef] [PubMed]
- Hasell, J.; Mathieu, E.; Beltekian, D.; Macdonald, B.; Giattino, C.; Ortiz-Ospina, E.; Roser, M.; Ritchie, H. A cross-country database of COVID-19 testing. Scientific data 2020, 7, 345. [Google Scholar] [CrossRef]
- Tocto-Erazo, M.R.; Espíndola-Zepeda, J.A.; Montoya-Laos, J.A.; Acuña-Zegarra, M.A.; Olmos-Liceaga, D.; Reyes-Castro, P.A.; Figueroa-Preciado, G. Lockdown, relaxation, and acme period in COVID-19: A study of disease dynamics in Hermosillo, Sonora, Mexico. PloS one 2020, 15, e0242957. [Google Scholar] [CrossRef]
- Lin, Q.; Zhao, S.; Gao, D.; Lou, Y.; Yang, S.; Musa, S.S.; Wang, M.H.; Cai, Y.; Wang, W.; Yang, L.; et al. A conceptual model for the coronavirus disease 2019 (COVID-19) outbreak in Wuhan, China with individual reaction and governmental action. International journal of infectious diseases 2020, 93, 211–216. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Hewings, G.; Wang, S.; Qin, M.; Xiang, X.; Zheng, S.; Li, X. Modelling the situation of COVID-19 and effects of different containment strategies in China with dynamic differential equations and parameters estimation. MedRxiv 2020, pp. 2020–03.
- Chatterjee, K.; Chatterjee, K.; Kumar, A.; Shankar, S. Healthcare impact of COVID-19 epidemic in India: A stochastic mathematical model. Medical Journal Armed Forces India 2020, 76, 147–155. [Google Scholar] [CrossRef]
- Organization, W.H.; et al. Coronavirus disease 2019 (COVID-19): situation report, 73, 2020.
- Ganyani, T.; Kremer, C.; Chen, D.; Torneri, A.; Faes, C.; Wallinga, J.; Hens, N. Estimating the generation interval for coronavirus disease (COVID-19) based on symptom onset data, March 2020. Eurosurveillance 2020, 25, 2000257. [Google Scholar] [CrossRef]
- Linton, N.M.; Kobayashi, T.; Yang, Y.; Hayashi, K.; Akhmetzhanov, A.R.; Jung, S.m.; Yuan, B.; Kinoshita, R.; Nishiura, H. Incubation period and other epidemiological characteristics of 2019 novel coronavirus infections with right truncation: a statistical analysis of publicly available case data. Journal of clinical medicine 2020, 9, 538. [Google Scholar] [CrossRef]
- Wu, J.T.; Leung, K.; Leung, G.M. Nowcasting and forecasting the potential domestic and international spread of the 2019-nCoV outbreak originating in Wuhan, China: a modelling study. The Lancet 2020, 395, 689–697. [Google Scholar] [CrossRef]
- Lauer, S.A.; Grantz, K.H.; Bi, Q.; Jones, F.K.; Zheng, Q.; Meredith, H.R.; Azman, A.S.; Reich, N.G.; Lessler, J. The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: estimation and application. Annals of internal medicine 2020, 172, 577–582. [Google Scholar] [CrossRef]
- Knoema. World data atlas, Mexico, Sonora mortality. https://knoema.com/atlas/Mexico/Sonora/Crude-Death-Rate, 2021.
- Torres-Ibarra, L.; Basto-Abreu, A.; Carnalla, M.; Torres-Alvarez, R.; Reyes-Sanchez, F.; Hernández-Ávila, J.E.; Palacio-Mejia, L.S.; Alpuche-Aranda, C.; Shamah-Levy, T.; Rivera, J.A.; et al. SARS-CoV-2 infection fatality rate after the first epidemic wave in Mexico. International journal of epidemiology 2022, 51, 429–439. [Google Scholar] [CrossRef] [PubMed]
- Organization, W.H.; et al. COVID-19 natural immunity: scientific brief, 10 May 2021. Technical report, World Health Organization, 2021.
- Pilz, S.; Chakeri, A.; Ioannidis, J.P.; Richter, L.; Theiler-Schwetz, V.; Trummer, C.; Krause, R.; Allerberger, F. SARS-CoV-2 re-infection risk in Austria. European journal of clinical investigation 2021, 51, e13520. [Google Scholar] [CrossRef] [PubMed]
- Hansen, C.H.; Michlmayr, D.; Gubbels, S.M.; Mølbak, K.; Ethelberg, S. Assessment of protection against reinfection with SARS-CoV-2 among 4 million PCR-tested individuals in Denmark in 2020: a population-level observational study. The lancet 2021, 397, 1204–1212. [Google Scholar] [CrossRef]
- Kim, P.; Gordon, S.M.; Sheehan, M.M.; Rothberg, M.B. Duration of SARS-CoV-2 natural immunity and protection against the Delta variant: a retrospective cohort study. Clinical Infectious Diseases: An Official Publication of the Infectious Diseases Society of America 2021.
- Spicer, K.B.; Glick, C.; Cavanaugh, A.M.; Thoroughman, D. Protective immunity after natural infection with severe acute respiratory syndrome Coronavirus-2 (SARS-CoV-2)–Kentucky, USA, 2020. International Journal of Infectious Diseases 2022, 114, 21–28. [Google Scholar] [CrossRef]
- Sheehan, M.M.; Reddy, A.J.; Rothberg, M.B. Reinfection rates among patients who previously tested positive for coronavirus disease 2019: a retrospective cohort study. Clinical Infectious Diseases 2021, 73, 1882–1886. [Google Scholar] [CrossRef]
- Mahase, E. Covid-19: Past infection provides 83% protection for five months but may not stop transmission, study finds, 2021.
- Abu-Raddad, L.J.; Chemaitelly, H.; Coyle, P.; Malek, J.A.; Ahmed, A.A.; Mohamoud, Y.A.; Younuskunju, S.; Ayoub, H.H.; Al Kanaani, Z.; Al Kuwari, E.; et al. SARS-CoV-2 antibody-positivity protects against reinfection for at least seven months with 95% efficacy. EClinicalMedicine 2021, 35, 100861. [Google Scholar] [CrossRef]
- Harvey, R.A.; Rassen, J.A.; Kabelac, C.A.; Turenne, W.; Leonard, S.; Klesh, R.; Meyer, W.A.; Kaufman, H.W.; Anderson, S.; Cohen, O.; et al. Association of SARS-CoV-2 seropositive antibody test with risk of future infection. JAMA internal medicine 2021, 181, 672–679. [Google Scholar] [CrossRef] [PubMed]
- Pilz, S.; Theiler-Schwetz, V.; Trummer, C.; Krause, R.; Ioannidis, J.P. SARS-CoV-2 reinfections: Overview of efficacy and duration of natural and hybrid immunity. Environmental research 2022, 209, 112911. [Google Scholar] [CrossRef]
- Capaldi, A.; Behrend, S.; Berman, B.; Smith, J.; Wright, J.; Lloyd, A.L. Parameter estimation and uncertainty quantication for an epidemic model. Mathematical biosciences and engineering 2012, p. 553.
- Anh, D.T.; Bonnet, M.P.; Vachaud, G.; Van Minh, C.; Prieur, N.; Duc, L.V.; et al. Biochemical modeling of the Nhue River (Hanoi, Vietnam): Practical identifiability analysis and parameters estimation. Ecological modelling 2006, 193, 182–204. [Google Scholar]
- Bellman, R.; Åström, K.J. On structural identifiability. Mathematical biosciences 1970, 7, 329–339. [Google Scholar] [CrossRef]
- Evans, N.D.; White, L.J.; Chapman, M.J.; Godfrey, K.R.; Chappell, M.J. The structural identifiability of the susceptible infected recovered model with seasonal forcing. Mathematical biosciences 2005, 194, 175–197. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Moog, C.H. Identifiability of nonlinear systems with application to HIV/AIDS models. IEEE transactions on automatic control 2003, 48, 330–336. [Google Scholar] [CrossRef]
- White, L.; Evans, N.; Lam, T.; Schukken, Y.; Medley, G.; Godfrey, K.; Chappell, M. The structural identifiability and parameter estimation of a multispecies model for the transmission of mastitis in dairy cows. Mathematical biosciences 2001, 174, 77–90. [Google Scholar] [CrossRef] [PubMed]
- Reid, J. Structural identifiability in linear time-invariant systems. IEEE Transactions on Automatic Control 1977, 22, 242–246. [Google Scholar] [CrossRef]
- Prieto, K.; Dorn, O. Sparsity and level set regularization for diffuse optical tomography using a transport model in 2D. Inverse Problems 2016, 33, 014001. [Google Scholar] [CrossRef]
- Prieto, K.; Ibarguen-Mondragon, E. Parameter estimation, sensitivity and control strategies analysis in the spread of influenza in Mexico. Proceedings of the Journal of Physics: Conference Series. IOP Publishing 2019, 1408, 012–020. [Google Scholar] [CrossRef]
- Smirnova, A.; DeCamp, L.; Liu, H. Inverse problems and ebola virus disease using an age of infection model. In Mathematical and Statistical Modeling for Emerging and Re-emerging Infectious Diseases; Springer, 2016; pp. 103–121.
- Capistrán, M.A.; Moreles, M.A.; Lara, B. Parameter estimation of some epidemic models. The case of recurrent epidemics caused by respiratory syncytial virus. Bulletin of mathematical biology 2009, 71, 1890–1901. [Google Scholar] [CrossRef] [PubMed]
- Kraft, D. A software package for sequential quadratic programming. Forschungsbericht- Deutsche Forschungs- und Versuchsanstalt fur Luft- und Raumfahrt 1988.
- Spataru, D. Using a Genetic Algorithm for Parameter Estimation in a Modified SEIR Model of COVID-19 Spread in Ontario. PhD thesis, University of Guelph, 2021.
- Whitley, D. A genetic algorithm tutorial. Statistics and computing 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. Advances in neural information processing systems 2016, 29. [Google Scholar]
- Lindén, A.; Mäntyniemi, S. Using the negative binomial distribution to model overdispersion in ecological count data. Ecology 2011, 92, 1414–1421. [Google Scholar] [CrossRef]
- Bliznashki, S. A Bayesian logistic growth model for the spread of COVID-19 in New York. medRxiv 2020. [Google Scholar]
- Arguedas, Y.N.; Santana-Cibrian, M.; Velasco-Hernández, J.X. Transmission dynamics of acute respiratory diseases in a population structured by age. Mathematical Biosciences and Engineering 2019, 16, 7477–7493. [Google Scholar] [CrossRef]
- Neyens, T.; Faes, C.; Molenberghs, G. A generalized Poisson-gamma model for spatially overdispersed data. Spatial and spatio-temporal epidemiology 2012, 3, 185–194. [Google Scholar] [CrossRef]
- Coly, S.; Yao, A.F.; Abrial, D.; Charras-Garrido, M. Distributions to model overdispersed count data. Journal de la Société Française de Statistique 2016, 157, 39–63. [Google Scholar]
- Gutiérrez-Pulido, H.; Aguirre-Torres, V.; Christen, J.A. A practical method for obtaining prior distributions in reliability. IEEE Transactions on Reliability 2005, 54, 262–269. [Google Scholar] [CrossRef]
- Gutiérrez-Pulido, H.; Aguirre-Torres, V.; Christen, J.A. A Bayesian approach for the determination of warranty length. Journal of quality Technology 2006, 38, 180–189. [Google Scholar] [CrossRef]
- Gutiérrez Pulido, H.; Gutiérrez González, P. Fundamentos y aplicaciones de la estadística Bayesiana. México: Universidad de Guadalajara 2013.
- Grinsztajn, L.; Semenova, E.; Margossian, C.C.; Riou, J. Bayesian workflow for disease transmission modeling in Stan. Statistics in medicine 2021, 40, 6209–6234. [Google Scholar] [CrossRef]
- Christen, J.A.; Fox, C. A General Purpose Sampling Algorithm for Continuous Distributions (the t-walk). Bayesian Analysis 2010, 5, 263–282. [Google Scholar] [CrossRef]
- Carpenter, B.; Gelman, A.; Hoffman, M.D.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.; Guo, J.; Li, P.; Riddell, A. Stan: A probabilistic programming language. Journal of statistical software 2017, 76. [Google Scholar] [CrossRef]
- Chatzilena, A.; van Leeuwen, E.; Ratmann, O.; Baguelin, M.; Demiris, N. Contemporary statistical inference for infectious disease models using Stan. Epidemics 2019, 29, 100367. [Google Scholar] [CrossRef]
- Banks, D.L.; Hooten, M.B. Statistical challenges in agent-based modeling. The American Statistician 2021, 75, 235–242. [Google Scholar] [CrossRef]
- Ju, N.; Heng, J.; Jacob, P.E. Sequential Monte Carlo algorithms for agent-based models of disease transmission. arXiv preprint arXiv:2101.12156 2021. arXiv:2101.12156 2021.
- Shiono, T. Estimation of agent-based models using Bayesian deep learning approach of BayesFlow. Journal of Economic Dynamics and Control 2021, 125, 104082. [Google Scholar] [CrossRef]
- Manzo, G. Agent-based Models and Causal Inference; John Wiley & Sons, 2022.
- Dyer, J.; Cannon, P.; Farmer, J.D.; Schmon, S. Black-box Bayesian inference for economic agent-based models. arXiv preprint arXiv:2202.00625 2022. arXiv:2202.00625 2022.
- Dyer, J.; Cannon, P.; Farmer, J.D.; Schmon, S.M. Calibrating agent-based models to microdata with graph neural networks. arXiv preprint arXiv:2206.07570 2022. arXiv:2206.07570 2022.
- Britton, T. Epidemic models on social networks—With inference. Statistica Neerlandica 2020, 74, 222–241. [Google Scholar] [CrossRef]
- Bu, F.; Aiello, A.E.; Xu, J.; Volfovsky, A. Likelihood-based inference for partially observed epidemics on dynamic networks. Journal of the American Statistical Association 2022, 117, 510–526. [Google Scholar] [CrossRef]
- Murphy, C.; Laurence, E.; Allard, A. Deep learning of contagion dynamics on complex networks. Nature Communications 2021, 12, 4720. [Google Scholar] [CrossRef]
Figure 1.
Hermosillo city and Urban Zones
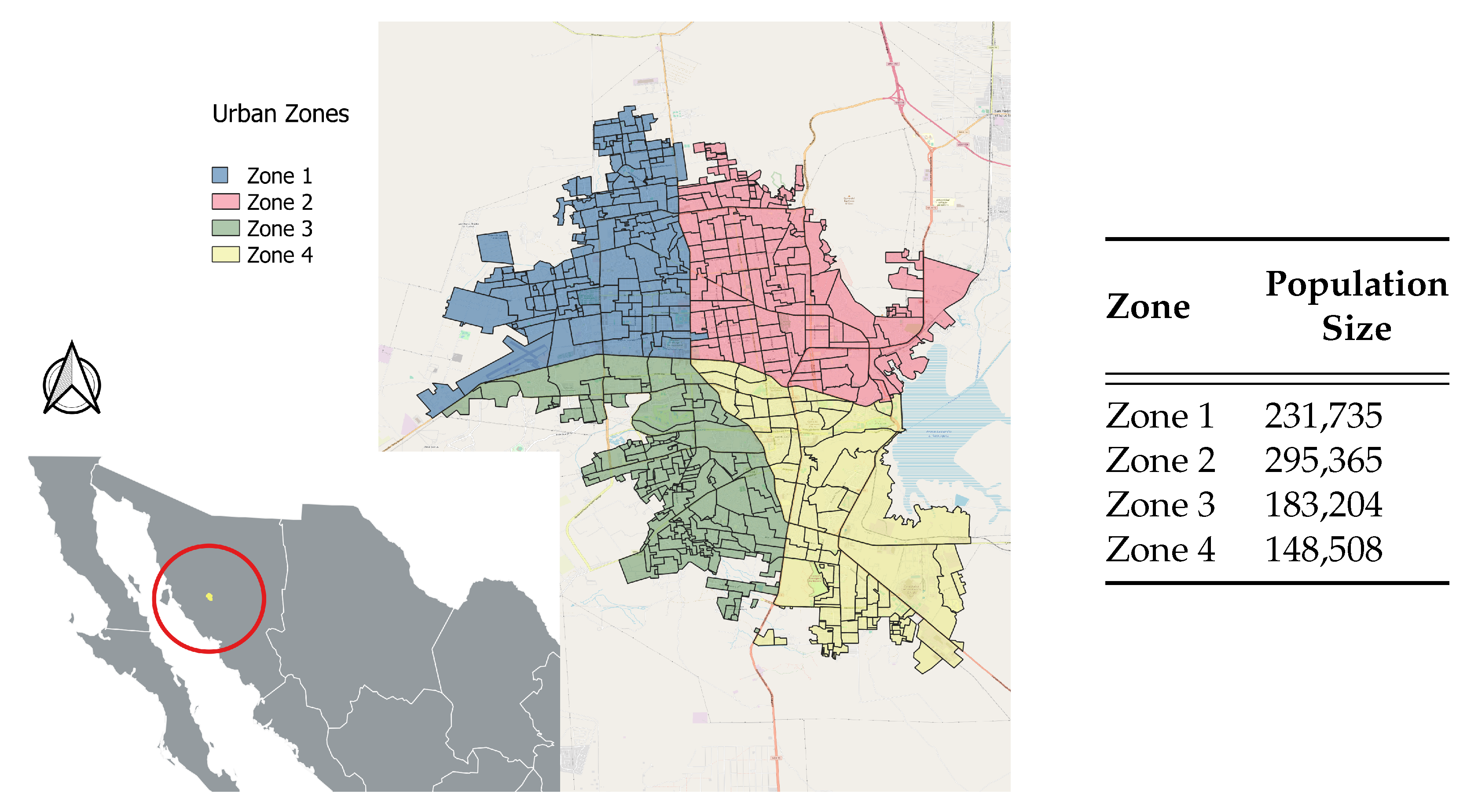
| Zone | Population |
| Size | |
| Zone 1 | 231,735 |
| Zone 2 | 295,365 |
| Zone 3 | 183,204 |
| Zone 4 | 148,508 |
Figure 2.
Proportions of zonal COVID-19 daily (YYYY-MM) cases.
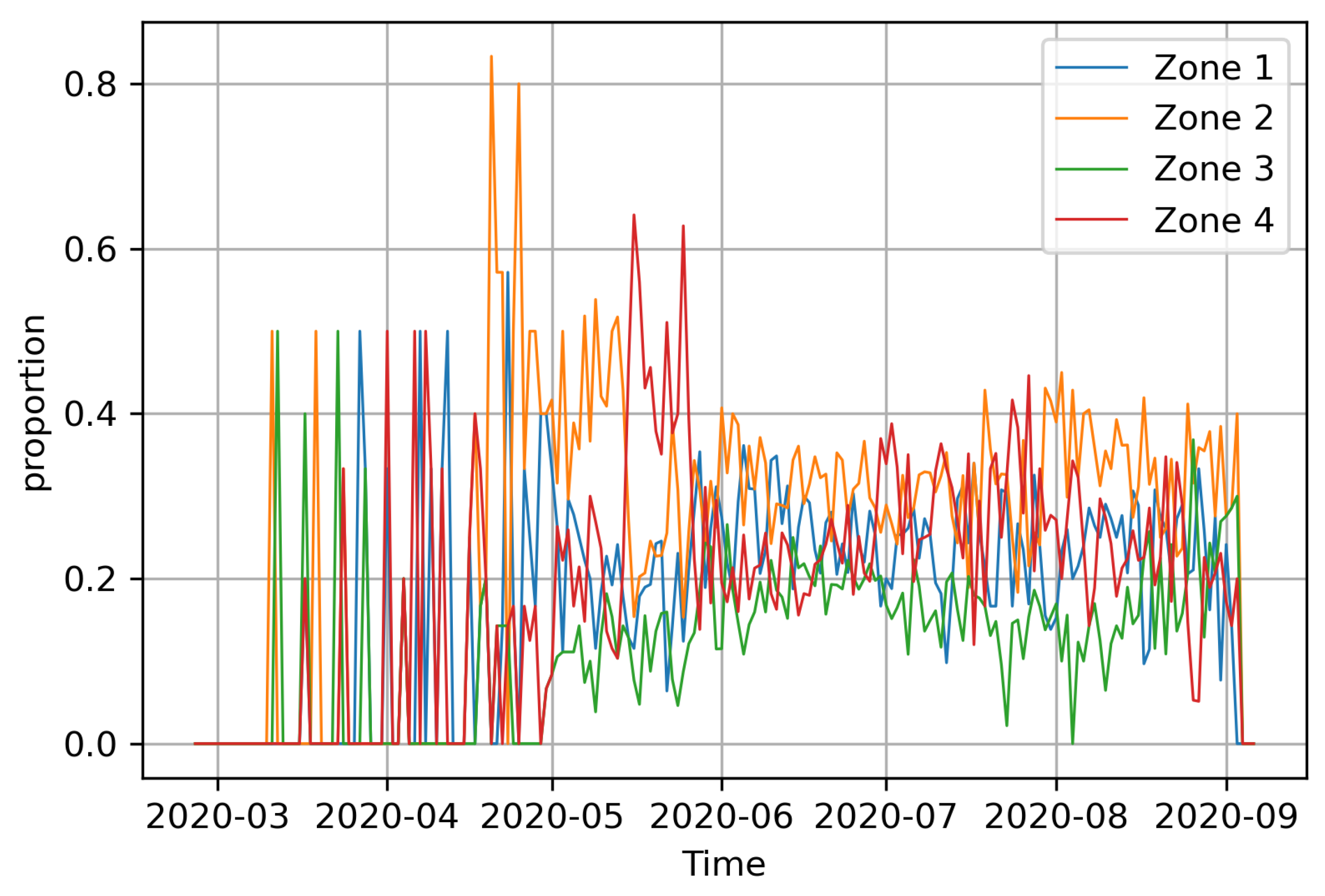
Figure 3.
Hermosillo’s COVID-19 daily (YYYY-MM) cases. Source: https://datos.covid-19.conacyt.mx
Figure 3.
Hermosillo’s COVID-19 daily (YYYY-MM) cases. Source: https://datos.covid-19.conacyt.mx
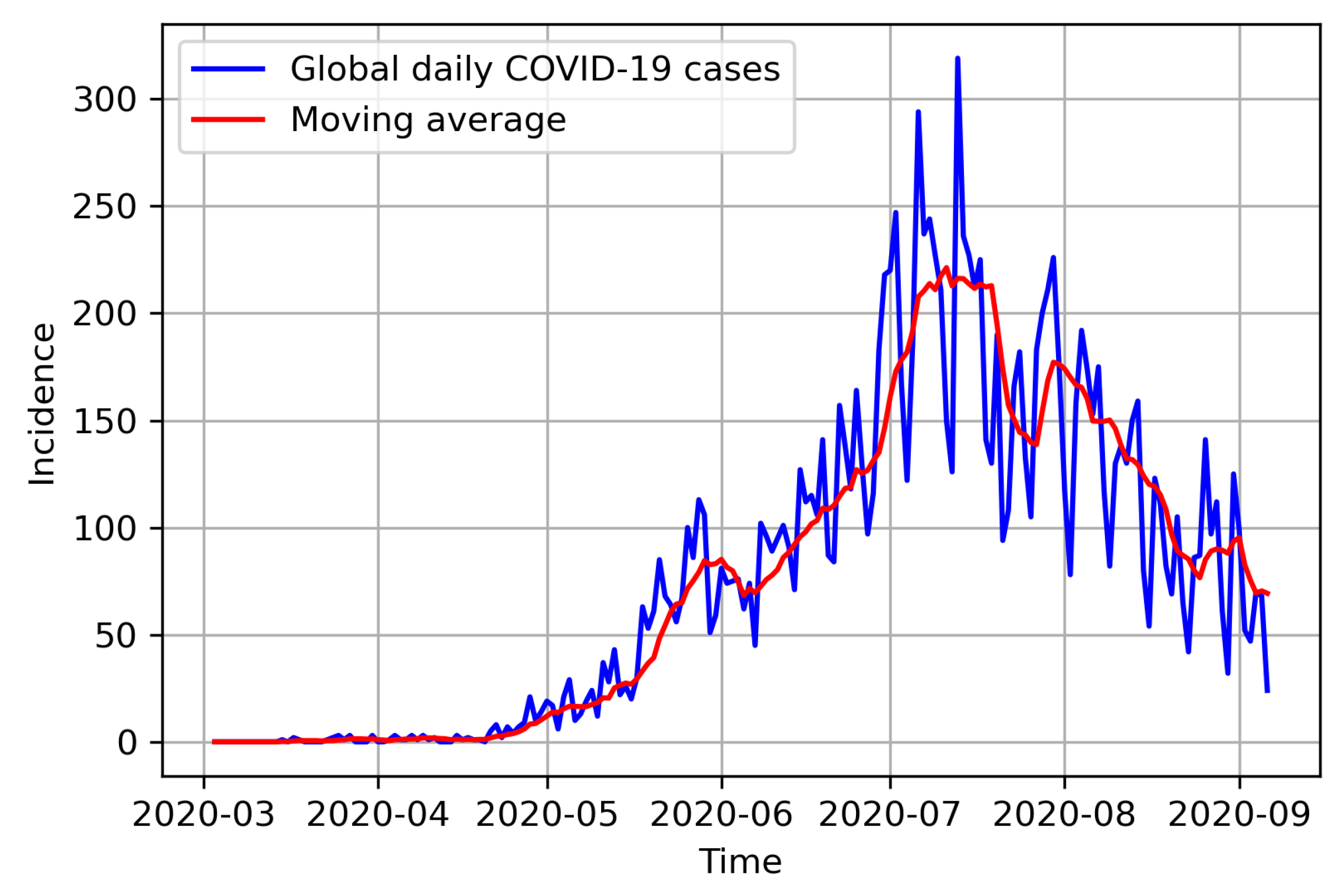
Figure 4.
Observed Hermosillo COVID-19 daily (YYYY-MM) cases. The incidences (blue dots) are inflated by a factor of 15.
Figure 4.
Observed Hermosillo COVID-19 daily (YYYY-MM) cases. The incidences (blue dots) are inflated by a factor of 15.
Figure 5.
Simulated Hermosillo COVID-19 daily (YYYY-MM) cases. The daily model incidence (in blue) have been simulated using the parameters values in Table 3, together with and values in Table 2 and .
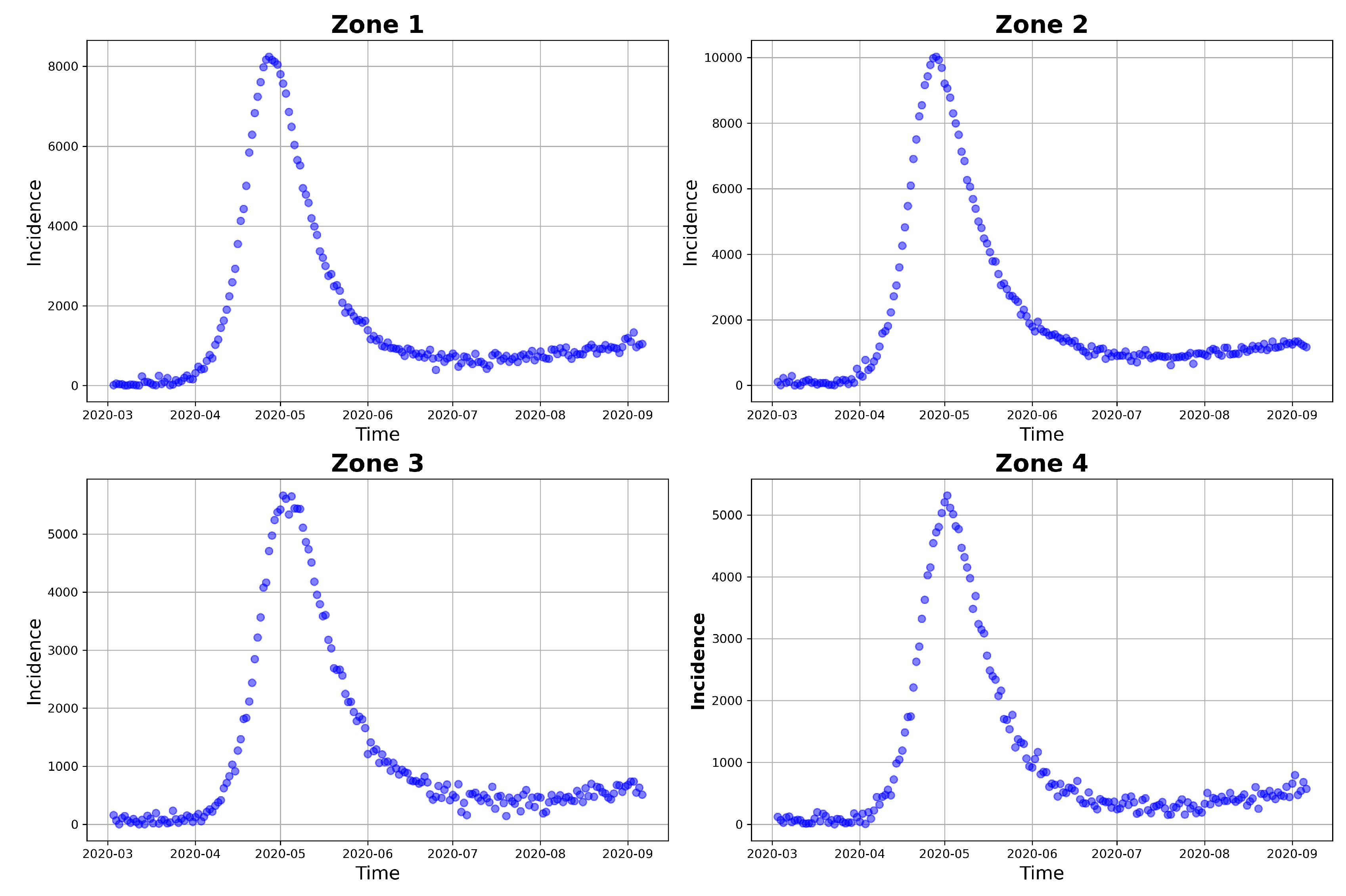
Figure 6.
Fitted model incidence and simulated observed daily incidence.
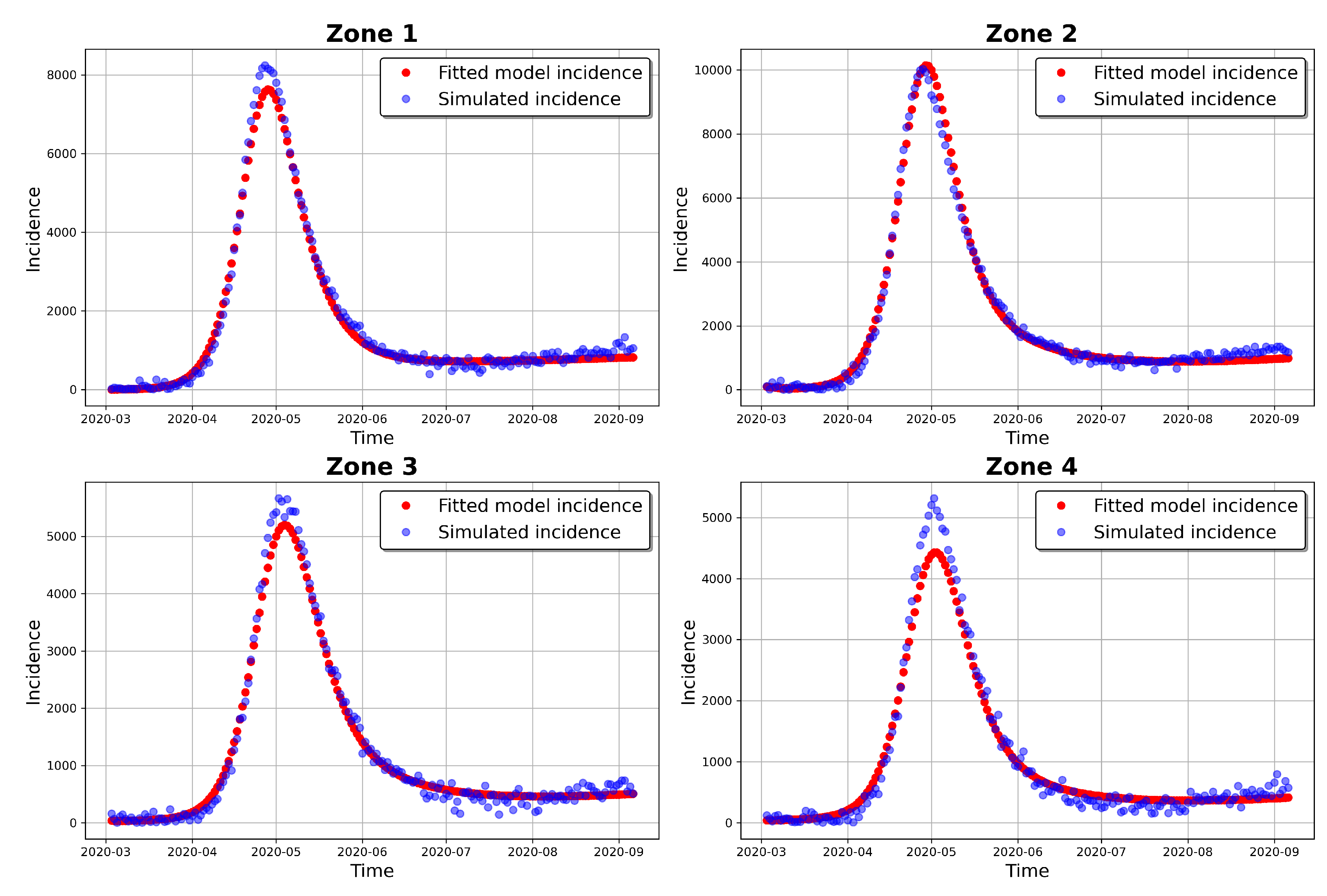
Figure 7.
Fitted model incidence and observed daily incidence.
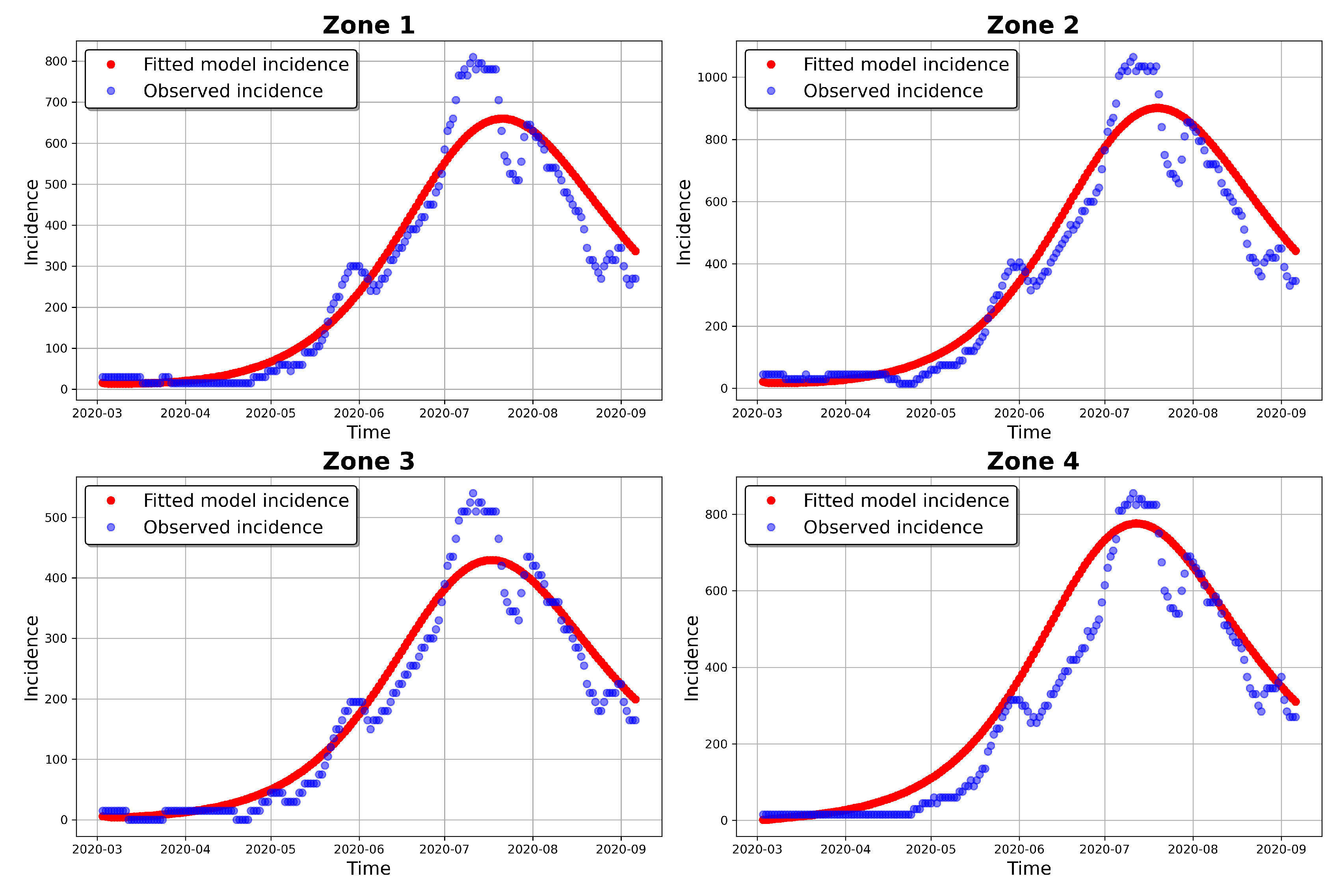
Figure 8.
Prior distributions of the infection, incubation and recovery rates parameters and the corresponding posterior distributions obtained from t-walk.
Figure 8.
Prior distributions of the infection, incubation and recovery rates parameters and the corresponding posterior distributions obtained from t-walk.
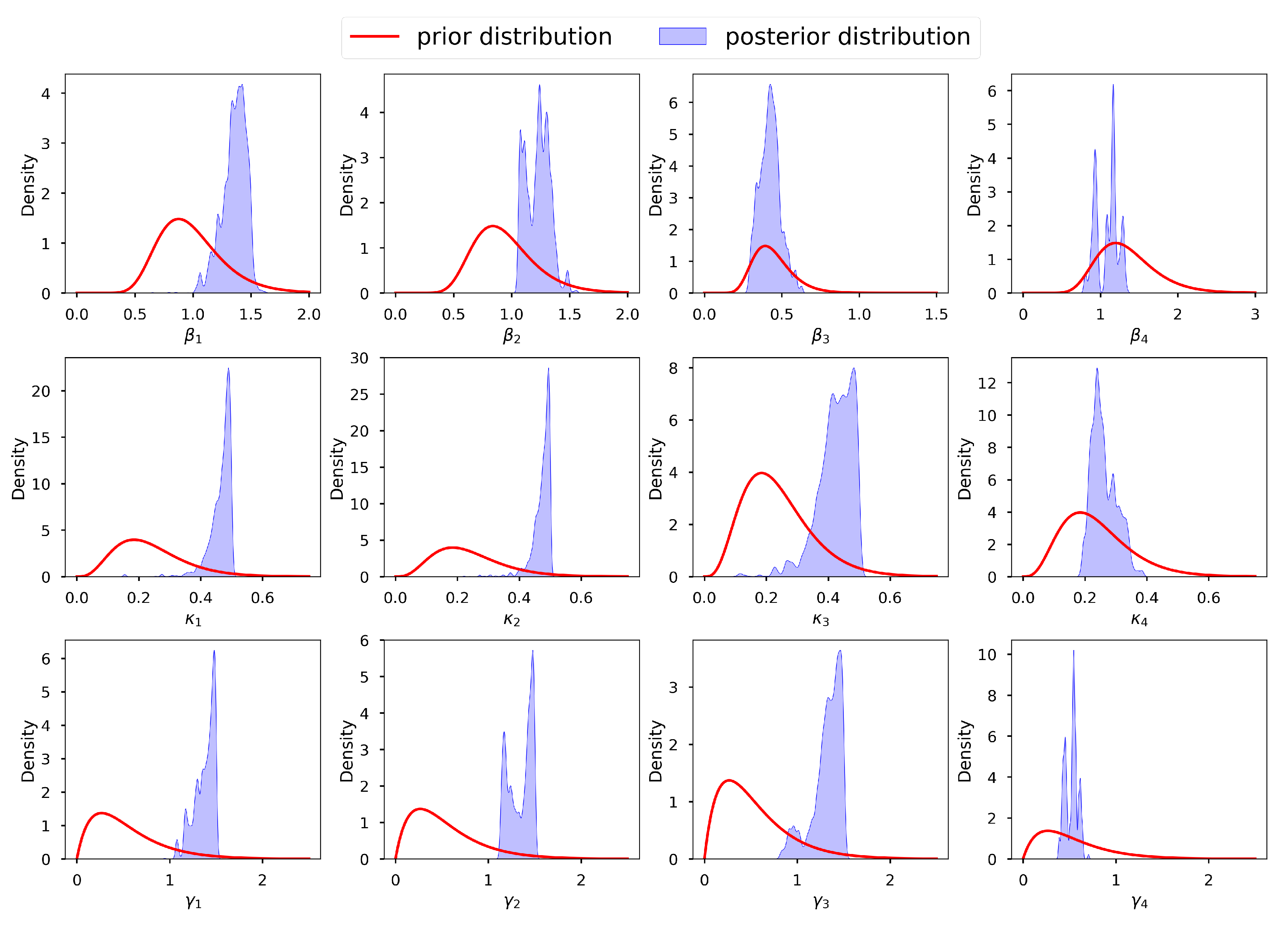
Figure 9.
Credible intervals, means and GA estimates of the incubation and recovery rates, exposed and prevalence initial conditions and dispersion parameters.
Figure 9.
Credible intervals, means and GA estimates of the incubation and recovery rates, exposed and prevalence initial conditions and dispersion parameters.
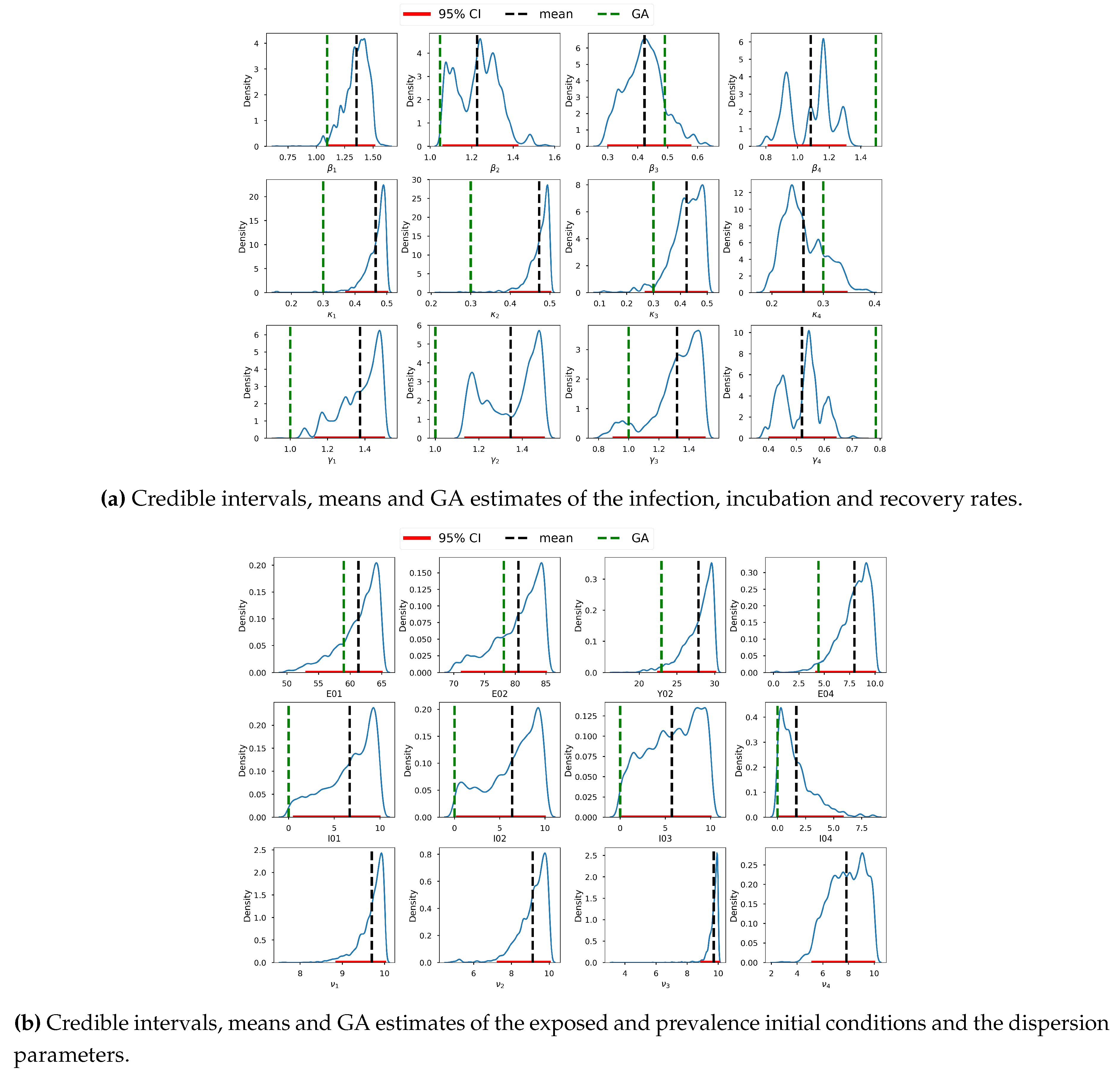
Figure 10.
Observed (red points) and model (gray) incidences. The model incidences were obtained by solving the model using parameters from the first 30,000 iterations of MCMC after burnin.
Figure 10.
Observed (red points) and model (gray) incidences. The model incidences were obtained by solving the model using parameters from the first 30,000 iterations of MCMC after burnin.
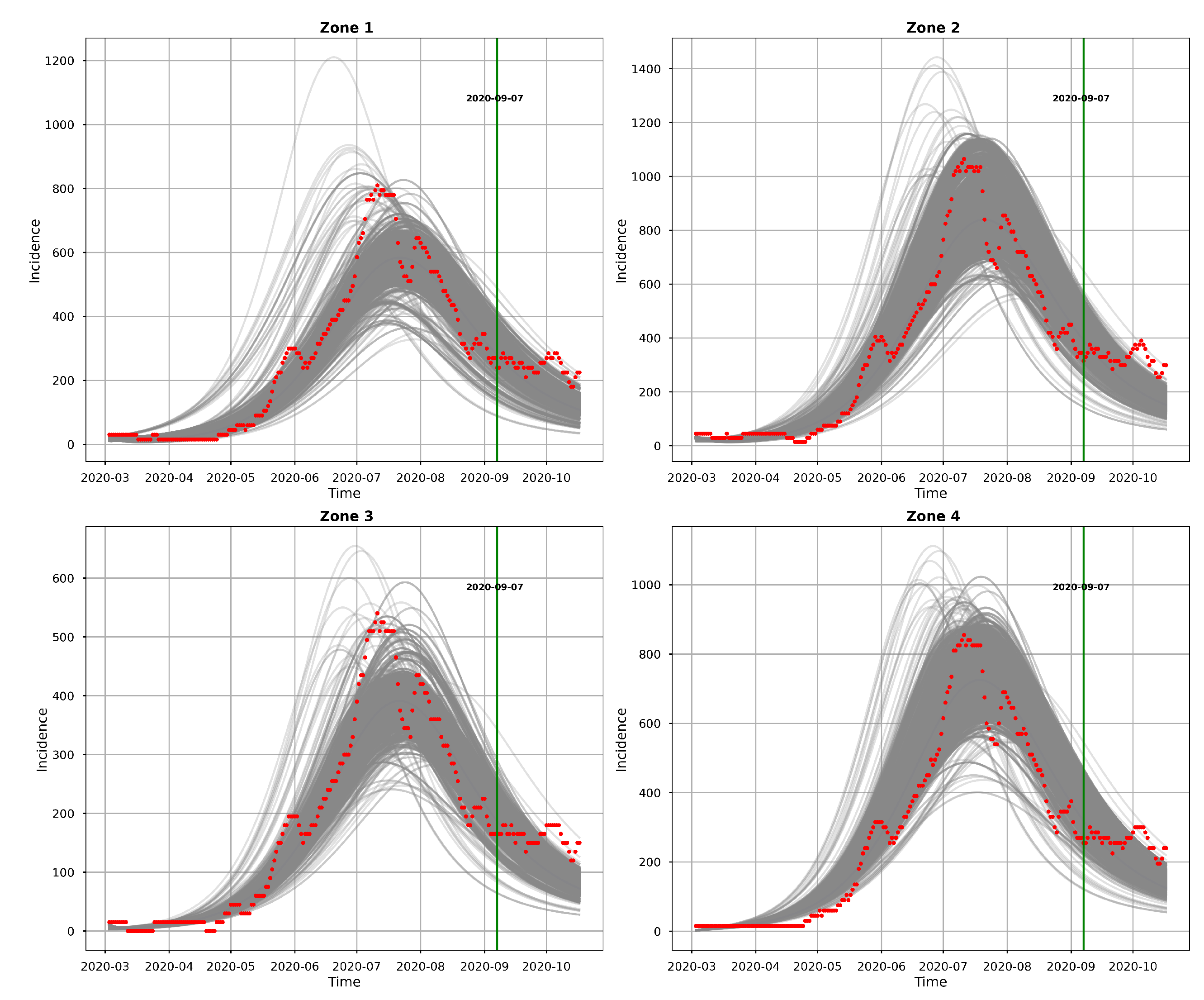
Figure 11.
The mean (black), median (medium blue), MAP (medium violet red) and 95% CI (blue bands) of model incidence obtained from t-walk. The red points are observed daily incidences.
Figure 11.
The mean (black), median (medium blue), MAP (medium violet red) and 95% CI (blue bands) of model incidence obtained from t-walk. The red points are observed daily incidences.
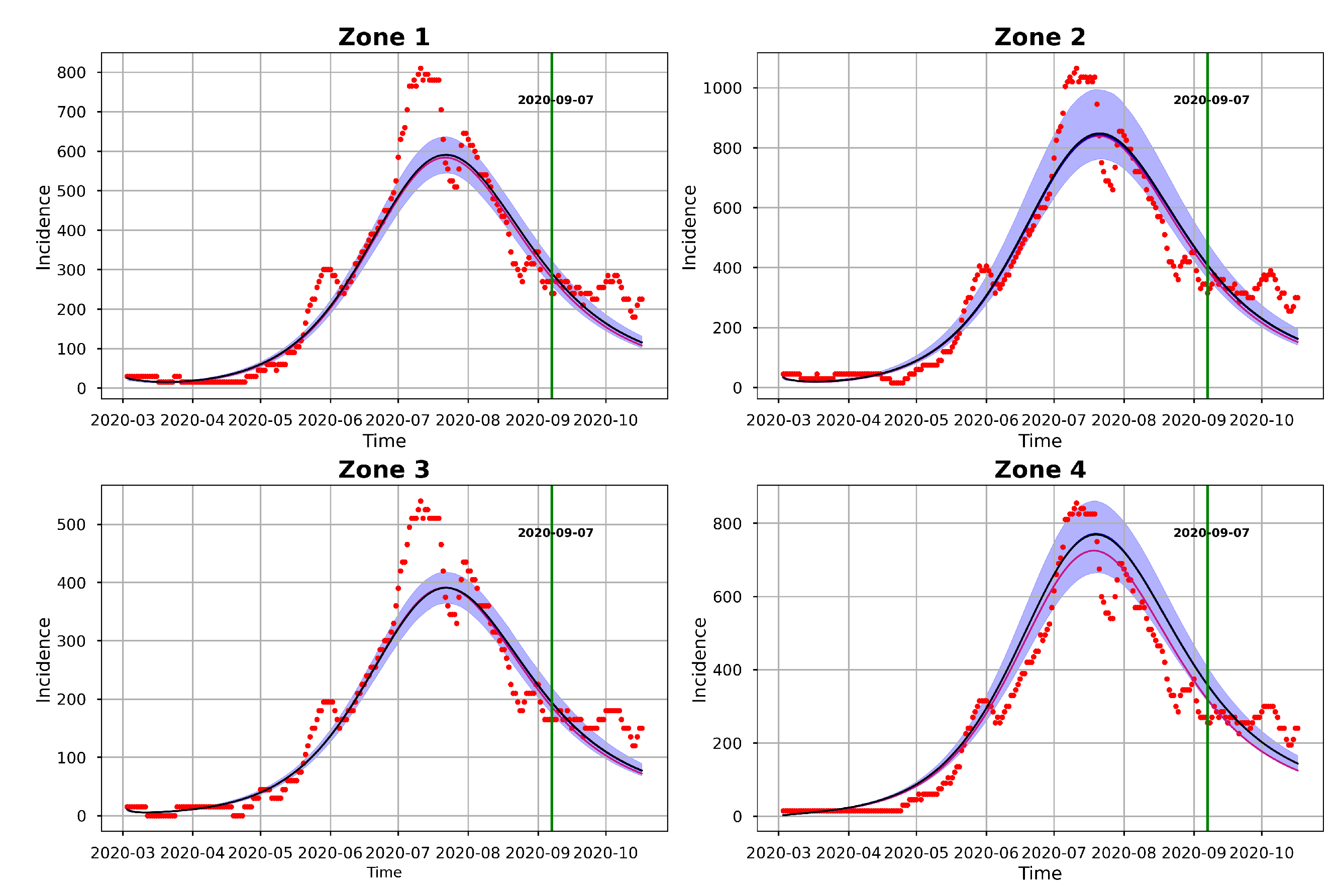
Figure 12.
Posterior distributions of the infection, incubation and recovery rates, exposed and prevalence initial conditions and dispersion parameters as obtained from Stan.
Figure 12.
Posterior distributions of the infection, incubation and recovery rates, exposed and prevalence initial conditions and dispersion parameters as obtained from Stan.
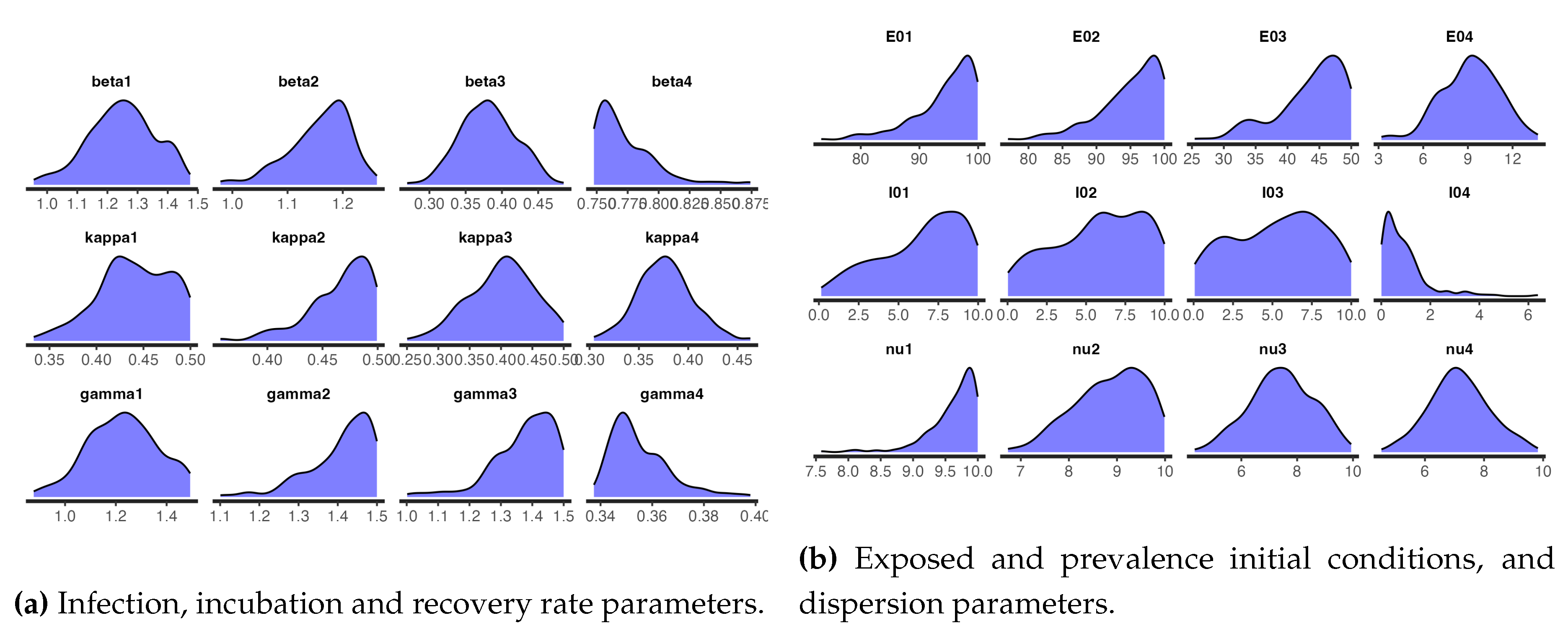
Figure 13.
Traceplots of the samples of infection, incubation and recovery rates, exposed and prevalence initial conditions and over-dispersion parameters as obtained from Stan.
Figure 13.
Traceplots of the samples of infection, incubation and recovery rates, exposed and prevalence initial conditions and over-dispersion parameters as obtained from Stan.
Figure 14.
Pairs plot for the samples of infection and recovery rates as obtained from Stan.
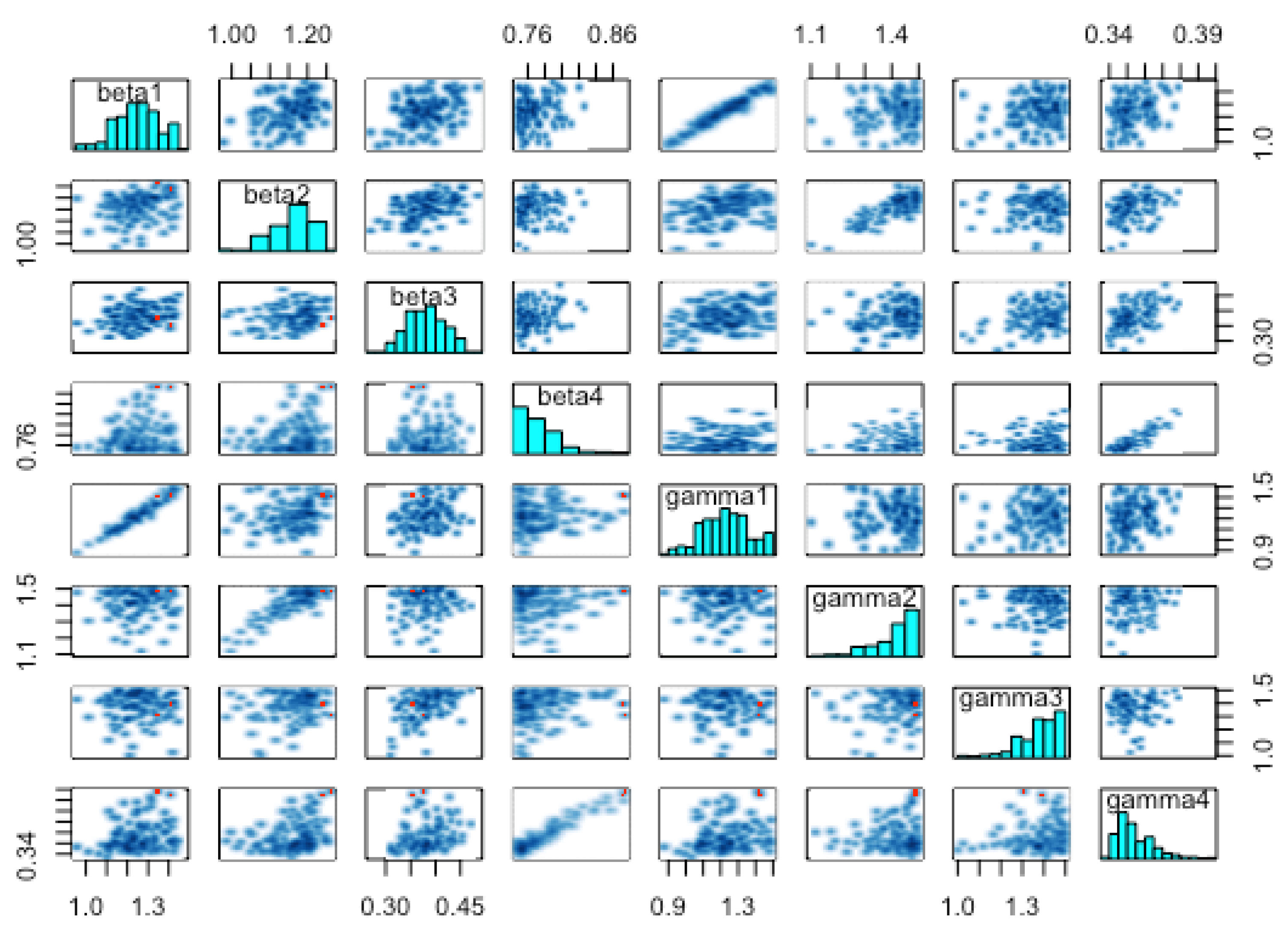
Figure 15.
95% Credible intervals of the infection, incubation and recovery rates, the initial conditions and the over-dispersion parameters as obtained from Stan.
Figure 15.
95% Credible intervals of the infection, incubation and recovery rates, the initial conditions and the over-dispersion parameters as obtained from Stan.
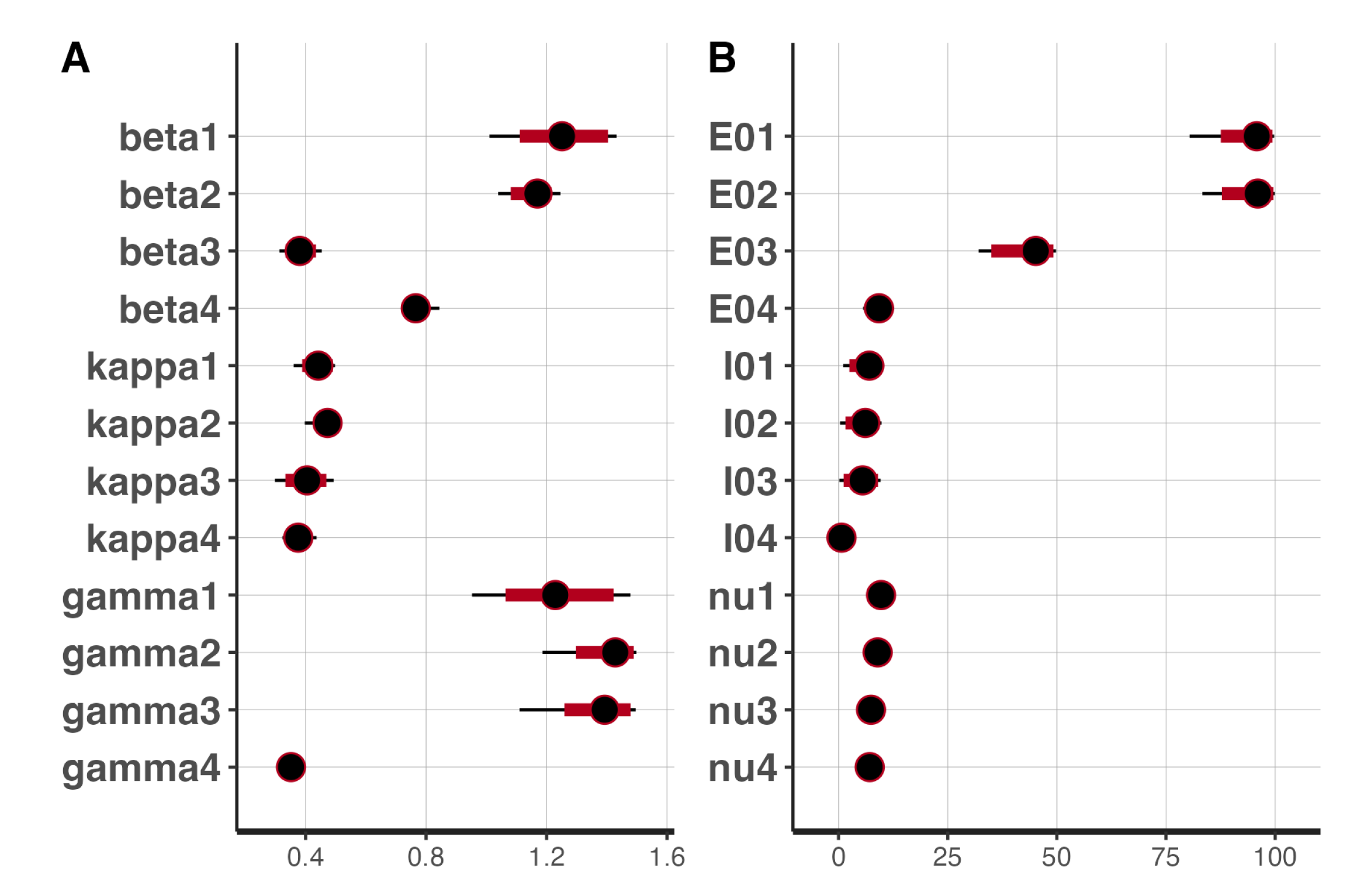
Figure 16.
Observed daily incidence, Posterior incidence predictions and 95% uncertainty bands obtained from Stan.
Figure 16.
Observed daily incidence, Posterior incidence predictions and 95% uncertainty bands obtained from Stan.
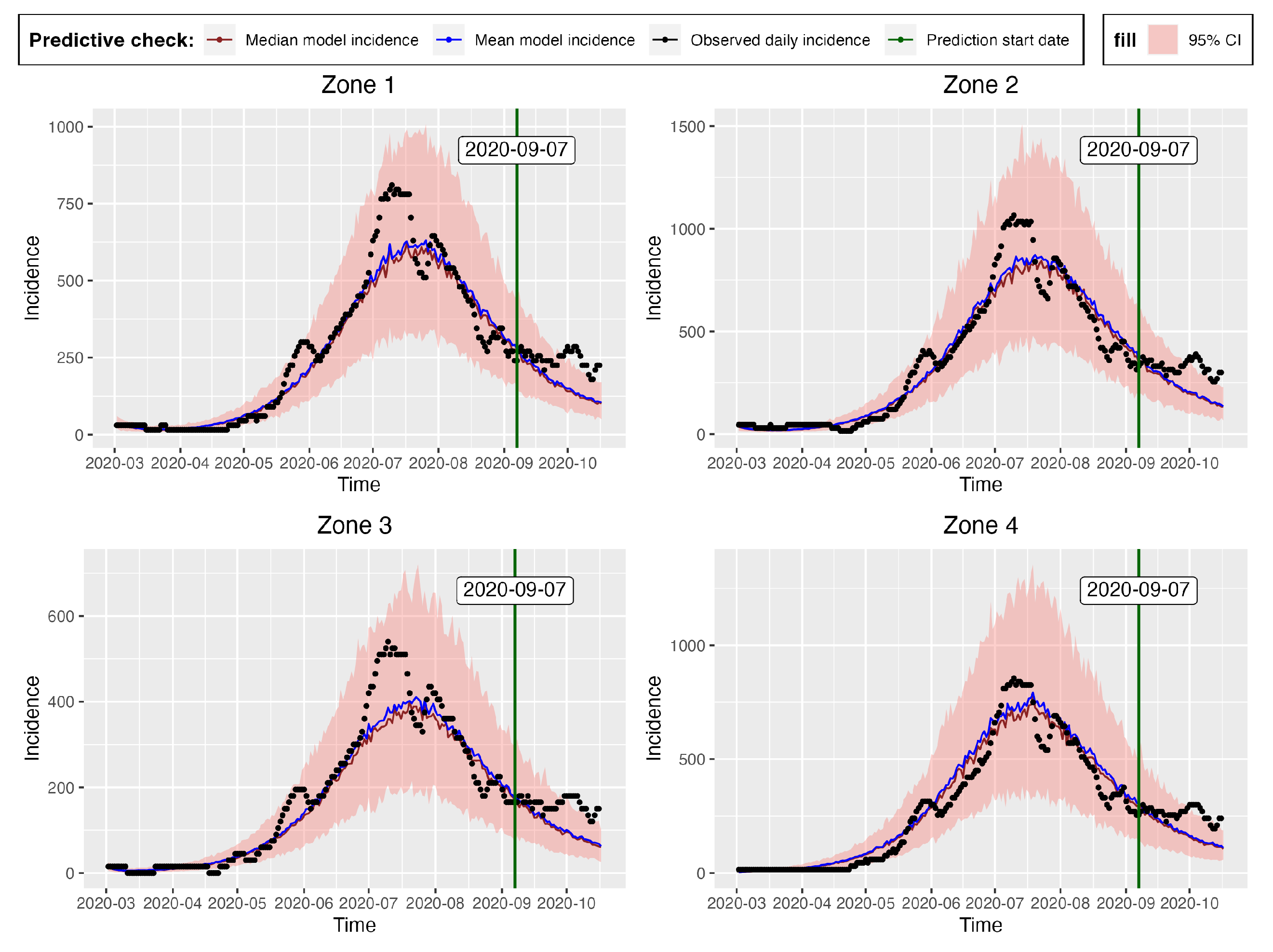
Figure 17.
Global single patched observed and predicted mean and median incidences together with the 95% CI.
Figure 17.
Global single patched observed and predicted mean and median incidences together with the 95% CI.
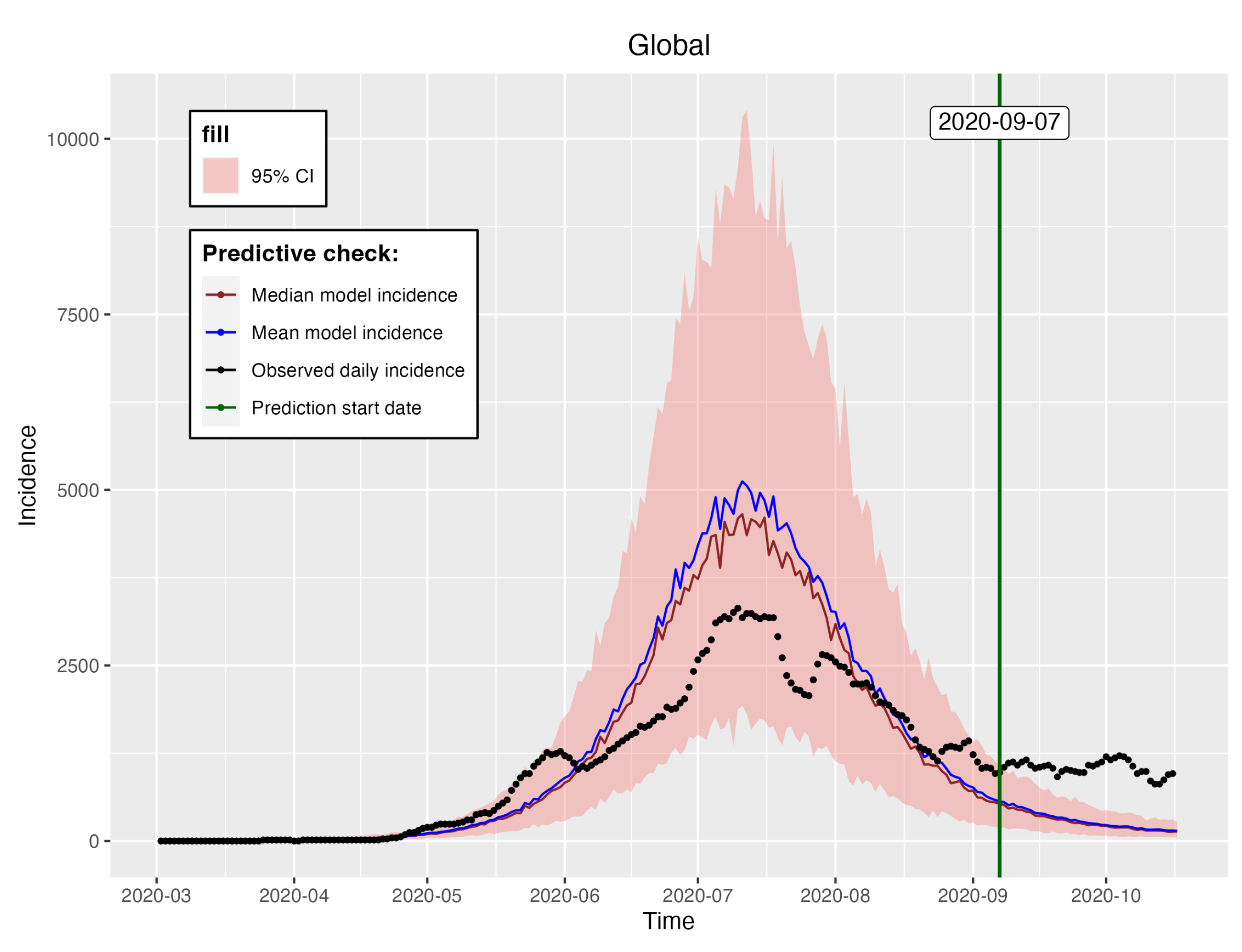
Table 1.
Parameters description.
| Parameters | Description |
|---|---|
| The proportion of individuals that leave their residence patch i | |
| The proportion of time that an individual from patch i spends | |
| in patch j, given that is one individual that leaves its residence patch | |
| Recruitment of Susceptible individuals in Patch i | |
| Instantaneous risk of infection in Patch j | |
| Per capita natural death rate in Patch i | |
| Per capita recovery rate of individuals in Patch i | |
| Per capita loss of immunity rate | |
| Per capita disease induced death rate of Patch i | |
| Per capita rate at which the exposed individuals in patch i becomes infectious |
Table 2.
Epidemiological parameter ranges/values and their associated literature
| Parameters | Range/Value | Literature |
|---|---|---|
| 0.0616 - 1.68 | [88,89,90] | |
| 2 - 14 | [88,91,92,93,94] | |
| 5 - 15.6 | [49,88,90,95,96] | |
| [97] | ||
| (0.0047+0.0030)/2 | [98] | |
| 90 - 300 | [99,100,101,102,103,104,105,106,107,108] |
| Epidemiological | Initial conditions | ||
|---|---|---|---|
| Parameters | Values | Parameters | Values |
| 1.3000 | 10 | ||
| 1.4000 | 1 | ||
| 0.9500 | 1 | ||
| 0.8000 | 20 | ||
| 0.0833 | 2 | ||
| 0.0714 | 2 | ||
| 0.0741 | 5 | ||
| 0.1000 | 0 | ||
| 0.1667 | 0 | ||
| 0.1429 | 5 | ||
| 0.1818 | 0 | ||
| 0.2000 | 0 | ||
Table 4.
Model (1) parameter values estimated from deterministic inversion using Genetic Algorithm (GA). The values are used to obtain the fitted simulated model incidence in Figure 6.
| Epidemiological | Initial conditions | ||
|---|---|---|---|
| Parameters | GA | Parameters | GA |
| 0.8322 | 0.0000 | ||
| 0.7473 | 0.0000 | ||
| 0.5259 | 0.0000 | ||
| 1.4354 | 200.0000 | ||
| 0.0829 | 126.4590 | ||
| 0.5334 | 326.4590 | ||
| 0.1983 | 200.0000 | ||
| 0.2115 | 0.0000 | ||
| 0.0357 | 200.0000 | ||
| 1.0000 | 200.0000 | ||
| 0.4248 | 8.4447 | ||
| 1.0000 | 208.4447 | ||
Table 5.
Model (1) parameter values estimated from deterministic inversion using Genetic Algorithm (GA). The values are used to obtain the fitted model and observed daily incidence in Figure 7.
| Epidemiological | Initial conditions | ||
|---|---|---|---|
| Parameters | GA | Parameters | GA |
| 1.0950 | 58.9925 | ||
| 1.0473 | 0.0000 | ||
| 0.4904 | 58.9925 | ||
| 1.4951 | 78.1313 | ||
| 0.3000 | 0.0000 | ||
| 0.3000 | 78.1313 | ||
| 0.3000 | 22.9404 | ||
| 0.3000 | 0.0000 | ||
| 1.0000 | 22.9404 | ||
| 1.0000 | 4.4192 | ||
| 1.0000 | 0.0000 | ||
| 0.7853 | 4.4192 | ||
Table 6.
Statistics of the single patch model parameters estimated using probabilistic (Stan) inversion.
Table 6.
Statistics of the single patch model parameters estimated using probabilistic (Stan) inversion.
| Probabilistic inversion (Stan) statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Parameters | Mean | SD | ESS | pESS | |||||
| 1.0139 | 0.0972 | 0.8168 | 0.9503 | 1.0191 | 1.0843 | 1.1701 | 244 | 0.0122 | |
| 0.8690 | 0.0847 | 0.6911 | 0.8140 | 0.8798 | 0.9436 | 0.9917 | 301 | 0.0151 | |
| 0.8569 | 0.0862 | 0.6797 | 0.8015 | 0.8640 | 0.9191 | 0.9936 | 244 | 0.0122 | |
| 1.2060 | 0.8259 | 0.0497 | 0.5090 | 1.0952 | 1.7977 | 2.8544 | 296 | 0.0148 | |
| 1.6101 | 0.7787 | 0.1173 | 1.0340 | 1.6587 | 2.2338 | 2.9343 | 237 | 0.0119 | |
| 4.0792 | 0.5313 | 3.0715 | 3.7108 | 4.0322 | 4.4569 | 5.1152 | 264 | 0.0132 | |
Table 7.
Efficiency measures for the predicted mean and median incidences from the multi-patch and single-patch epidemic models.
Table 7.
Efficiency measures for the predicted mean and median incidences from the multi-patch and single-patch epidemic models.
| Multi-patch | Single-patch | |||
|---|---|---|---|---|
| Efficiency measure | Mean | Median | Mean | Median |
| RMSE | 395.61 | 418.61 | 773.98 | 796.06 |
| MAPE | 34.40 | 37.06 | 73.86 | 76.10 |
Table 8.
Proportion of the observed zones prediction incidence covered by the CIs of the model incidence both from t-walk and Stan.
Table 8.
Proportion of the observed zones prediction incidence covered by the CIs of the model incidence both from t-walk and Stan.
| % of observed prediction incidence covered by CIs |
||
|---|---|---|
| Zone | Stan | t-walk |
| Zone 1 | 55.56 | 22.22 |
| Zone 2 | 55.56 | 44.44 |
| Zone 3 | 58.33 | 30.56 |
| Zone 4 | 63.89 | 38.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



