Submitted:
19 February 2023
Posted:
20 February 2023
You are already at the latest version
Abstract
This study aimed to investigate the possibility of using one-shot hyperspectral airborne images to recognize crops for an area with many small plots. The results showed that unsupervised clustering methods could classify crops with an accuracy of 80%, which improved to 90% when restricted to only grain crops, using a single airborne hyperspectral recording. However, additional layers such as NDVI, DTM, slope, and aspect did not improve classification accuracy. For comparison, the accuracy of clustering time series Sentinel-2 images with NDVI layers and DTM-derived data yielded an accuracy of: 74% ,Sentinel-2 time series 68% and single one registration before harvest - 39%. The results of the random forest classification were slightly less accurate due to a lack of sufficient reference data. However, it is challenging to verify the reported accuracy of crop recognition in the literature above 90% due to differences in analysis methodologies, reference data selection, pixel/object approaches, metric choice, and calculation formulas used.
Keywords:
n/a
; airborne hyperspectral images
; Sentinel-2
; k-means
; random forest
; crop recognition
1. Introduction
Agricultural land cover monitoring is performed for various purposes such as yield forecasting [1,2,3], precision farming [4,5], and control of direct agricultural subsidies and sustainable development [6,7]. In Europe, the Integrated Administration Control System (IACS) has been established to manage direct payments in agriculture and monitor the type of agriculture land cover and its area, as well as "cross-compliance" [8]. Cross-compliance aims to encourage farmers to follow high EU standards for public, plant, and animal health and welfare, making European farming more sustainable. Farmers receiving support from the Common Agriculture Policy (CAP) must comply with EU standards for good agricultural and environmental conditions, which is also monitored under the IACS. Efforts to simplify CAP have been made due to the high cost of On-the-Spot checks. This includes projects like Sen4CAP [9] and NIVA [10]. One way to modify the IACS is to replace the On-The-Spot check with remote sensing based on Sentinel-1 (S1) and Sentinel-2 (S2) time series covering the entire country. The control method should be reliable, fast, and simple, with the highest accuracy estimated based on independent reference data. In recognition of agricultural land cover, long-time series data from Sentinel-2 (S2) and Sentinel-1 (S1) covering the entire plant phenological cycle is used. Other data, such as indices calculated from the S1/S2 time series such as the Normalized Differential Vegetation Index (NDVI) [11] and radar backscattering coefficient (SIGMA) [12], as well as cadastral parcels or Digital Elevation Model (DTM), may also be included. Machine learning algorithms, including Random Forest (RF), Support Vector Machine (SVM), Convolutional Neural Network (CNN), Deep Learning (DL), and others, are used exclusively to automatically classify these large data sets. Recently, the majority of research papers on agriculture land cover recognition have focused on using either RF or SVM methods, despite the increasing popularity of DL techniques. This is due to the challenge of obtaining sufficient reference data to support deep learning models. The following bullet points highlight selected publications that employ the RF method. The information provided includes the test region, the data utilized for classification, the types of agriculture land cover, and the Overall Accuracy (OA):
- Italy, L8, S2, NDVI, bare soils, herbaceous, tree crops - 90% [13],
- Germany, Northrhinewestfalia (NRW), S1, topographical and cadastral data, 11 crops (maize, sugar beet, barley, wheat, rye, spring barley, pasture, reapeseed, potato, pea, carrot), S1 - 96.7%, optic data - 91.44% [14],
- China, Yangzi River, S1, S2, L8, (NDVI), wheat, rape, maize - 93% [15],
- China, S1,S2, cotton, spring corn, summer corn, pear, tomato - 86.98% [16],
- Belgium, the whole country (IACS/LPIS), S1,S2 (NDVI), wheat, barley, rapeseed, maize, patatos, beets, flax, grassland - 82% [17].
Selected studies that showcase the results of agriculture land cover classification using the SVM method are similarly summarized:
- Australia, S1,S2, NDVI, annual crops (cotton, rice, maize, canola, wheat, barley), perennial crops (citrus, almond, cherry etc.) - 84.2% [18],
- South Africa, Western Cape Province, S2, canola, lucerne, pasture, wheat, fallow - 82.4% [19],
- India, Sultan Bathery, S1,S2, paddy, rubber, arecanut - 88.94 [20],
In all of these studies, the input data for analysis was time series created from multiple satellite images taken at different points in time. The accuracy of the results was generally greater than 80%. It should be noted that the time series was often generated from a large number of image acquisitions, which is a prevalent trend in research using remote sensing methods for crop recognition. This approach can also be seen in various Copernicus projects, such as the first European agriculture land cover type map based on Sentinel-1 and LUCAS Copernicus in-situ observations [21], and services such as Sen2Agri [22] and Sen4Cap [9] dedicated to agriculture.
However, processing long time series can be time-consuming and requires many unclouded images, which can be a challenge in temperate climates. As a result, methods based on single image acquisition are promising. Our study followed the suggestion of Maponya et.al. [19], who compared the accuracy obtained from time series versus the accuracy that could be achieved from a single image. The highest accuracy from a single image acquisition was achieved about 4 weeks before harvest, at 77.2% (compared to a maximum of 82.4% for time series). We repeated this experiment in the north of Poland, where land plots are relatively large and can be recognized in Sentinel images and obtained similar accuracy for a single registration 79% [23]. This suggests that using optical images from a single acquisition, a recognition accuracy of 80% at the plant level can be achieved for agriculture land cover. Our research was also motivated by the study presented in [24] which highlights the use of deep learning for mapping agriculture land cover during cloudy seasons with a single hyperspectral satellite image and achieved high accuracy (94%). However, the resolution of satellite images could be an issue in areas with highly fragmented agricultural structures, such as southern Poland and other regions globally. Therefore, we have established our research objective as determining the accuracy that can be obtained through the use of a single airborne hyperspectral image in recognizing land cover in areas with small plots and complex structures.
2. Methods and Materials
2.1. Test area
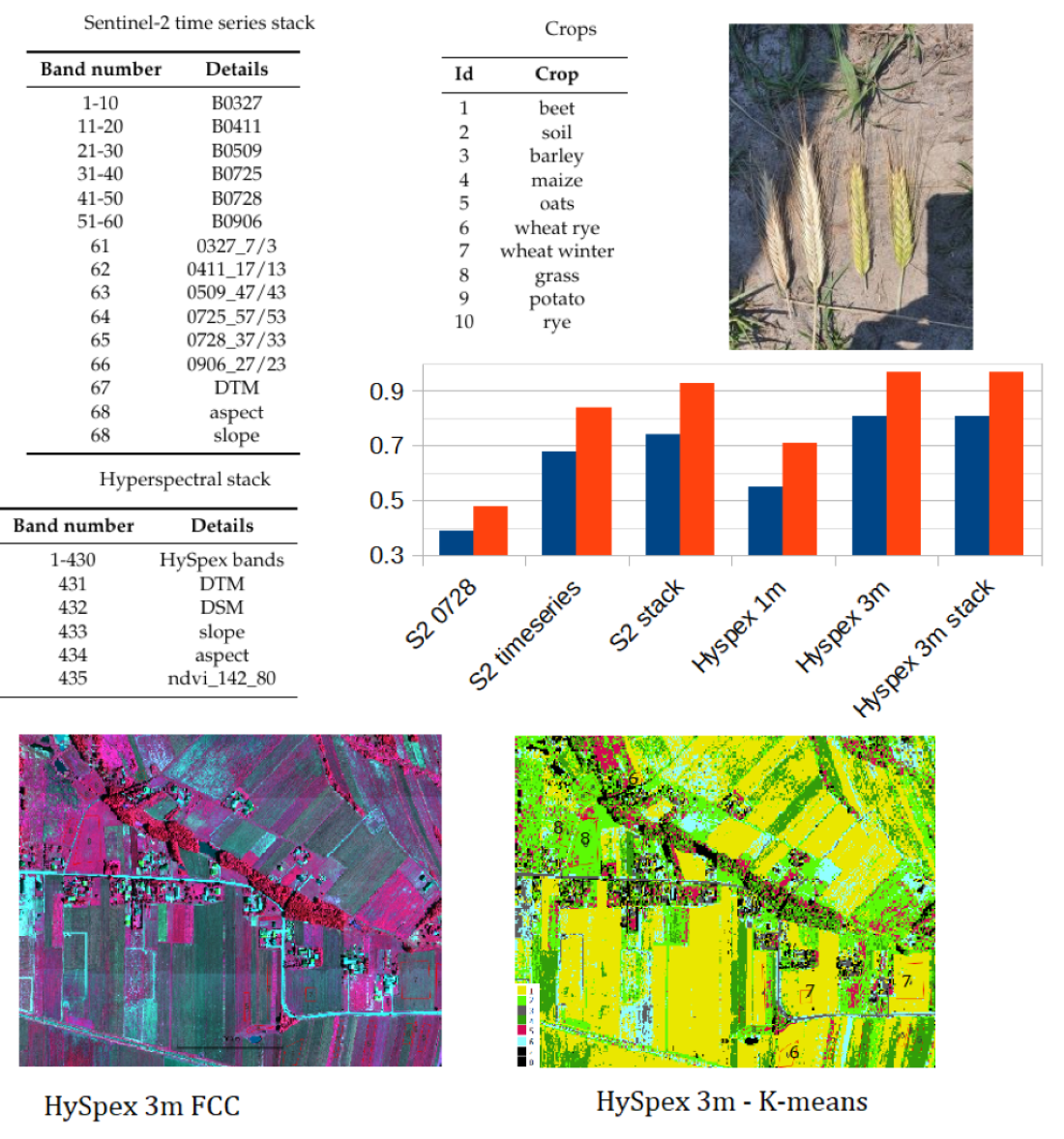
Poland is characterized by a varied agricultural landscape, with large, regularly shaped fields in the northern and central regions and small, elongated and irregular plots in the south. The use of S1/S2 imagery for crop monitoring may prove feasible for fields in the northern and central areas, but could pose difficulties for those in the south. In collaboration with the Agency for Restructuring and Modernisation of Agriculture (ARMA) in Poland, a test area near the town of Kolbuszowa was selected as a representative sample (as shown in Figure 1). Information was obtained from ARMA on the agricultural plots that receive subsidies, with roughly 5000 such plots registered annually (as shown in Figure 2). Most of these plots are small, with 75% of the agricultural plots being less than 1 hectare in size, with a third quartile of 9499 square meters (as shown in Figure 3).
2.2. Data
The choice of data is dependent on its intended usage. For our research aimed at recognizing agricultural land cover types, we needed to consider the phenological stage of the crops on the agricultural plots. Based on a promising suggestion in the literature, we decided to investigate the feasibility of using data collected approximately four weeks before harvest. In Poland, the harvest season typically lasts for 2 months (July and August), starting with the small harvest of rapeseed and winter barley, followed by the large harvest of rye, spring barley, wheat, and oats [25]. To examine the potential of using a single registration for agricultural land cover recognition, a survey campaign was conducted in 2021 that collected the following data: S2 time series, one-shot hyperspectral, in-situ measurement, and topographical data. The data acquisition dates are as follows:
- Sentinel-2 time series during vegetation season 2021 (March-September)
- Hyperspectral data: 5th of July 2021
- in-situ measurements: 7 July 2021
- Shuttle Radar Topography Mission - SRTM
- archival topographic data existing in Central Geodetic and Cartographic Resource
During the 2021 growing season, only six Sentinel-2 registration dates were cloud-free:
- S2B_MSIL2A_20210327T093039_N0214_R136_T34UEA_20210327T120034
- S2A_MSIL2A_20210411T093031_N0300_R136_T34UEA_20210411T122810
- S2B_MSIL2A_20210509T094029_N0300_R036_T34UEA_20210509T120133
- S2B_MSIL2A_20210725T093039_N0301_R136_T34UEA_20210725T115620
- S2B_MSIL2A_20210728T094029_N0301_R036_T34UEA_20210728T125908
- S2B_MSIL2A_20210906T094029_N0301_R036_T34UEA_20210906T113414
Sentinel-2 images were acquired from Copernicus Open Access Hub as granules with a size of 100 per 100 km with a radiometric correction level of 2A in geographical coordinate system EPSG:4326. The images were not further corrected either geometric or radiometric. The pixel size depending on the channel is 10, 20 and 60m. A single S2 scene in SAFE (ESA) format takes approximately 1.2 gigabytes when packed (S2 range in shown in Figure 1).
Hyperspectral data were acquired for the area ca. 5 x 4 km using HySpex VS-725 which is a very small area compared to the S2 range (in red in Figure 1) . The registration was performed at an altitude of 867 - 882 m. The HySpex VS-725 consists of two SWIR-384 scanners and one VNIR-1800 scanner which provide 430 spectral channels (414.13 nm - 2357.43 nm). The test area was covered with 16 strips. Radiometric, geometric (PARGE), atmospheric (ATCOR4) correction was performed using the MODTRAN physical model. The final product, an orthophotomap with a pixel size of 0.5 m was registered in the UTM 34N coordinate system (EPSG:32634) and takes up about 60 gigabytes.
A field visit was conducted to obtain information about the ground truth (the plant that was 2021 grown on the agriculture parcels). Information on 56 agricultural plots was acquired by positioning the location using handheld GPS, 10 classes were defined:
DTM and DSM (Digital Surface Model) were obtained from the national server: geoportal.gov.pl. Three DSM sheets (about 150 megabytes) and 15 DTM sheets (about 160 megabytes) with a pixel size of 1m.
2.3. Data preprocessing
Six Sentinel-2 images were subset and resampled into 10 m. From each Sentinel-2 set 10 bands were selected (B2, B3, B4, B5, B6, B7, B8, B8A, B11 and B12) for area of interest (AOI): 1295 columns x 922 rows (UL: 552250, 5567620 ; LR: 5558400, 5565200 ; EPSG:32634). The channels of all the images prepared in this way were saved in a single TIF file. In addition, NDVI was calculated for each registration date and added to the above mentioned TIF file. Image classification also uses other data that can increase the accuracy of classification, such as numerical terrain models and the slopes/aspects calculated from them. So SRTM was acquired, cropped to the AOI, and resampled to 10m. SRTM and calculated: slope and aspect were added to the TIF file as well. This means that the S2 time series stack consists of 60 Sentinel-2 channels, 6 NDVI images and 3 images containing topography information of the area.
The original Sentinel-2 images are recorded on 12 bits and stored on 16 bits as uint16 (in the metadata there is a size by which DN should be divided to calculate the reflection coefficient: 0-1 as a float32 number, which is 10,000). The values of NDVI coefficients change from -1 to 1 and were stored as float32 numbers.
The SRTM layer is of float32 type and includes for AOI values in the range of 230-310m, slope and aspect are also float 32 type and include values in the range of: 0 to 26 degrees, and 0 to 360 degrees. For the purposes of machine learning, all layers were scaled to a range: 0.0 - 1.0.
Due to the large size of the hyperspectral image, it was cropped of the area where the field visit was conducted and resampled to a pixel size of 1m and 3m. Numerical terrain models were merged and clipped to the extent of the hyperspectral image. In addition, slopes and aspects were calculated from the DTM and NDVI from hiperspectral channels. All rasters were merged into a single TIFF file (5340 cols x 6840 rows, UL: 557062, 5566510 ; LR: 559732, 5563090, 430 bands, NDVI, DTM, DSM, slope and aspect).
The hyperspectral mosaic (9484 rows x 7478 cols, UL: 554995, 5566821 ; LR: 559737, 5563082) made from the processed hyperspectral images has a spatial resolution of 0.5 m, consists of 430 spectral channels (414.13 nm - 2357.43 nm) is registered in the UTM 34N coordinate system (EPSG:32634) and takes up about 60 gigabytes
2.4. Methods
The image data, numerical terrain models and their derivatives were merged using own code in Python as a stack and saved as a single tif file. Separately, one file from the Sentinel-2 time series, at 10m resolution, and one file with hyperspectral data at 3m resolution (the original HySpex 0.5 data was resampled to 3m). There are 68 layers (bands) in the Sentinel-2 time series stack file, Table 2. From 1-60 Sentinel-2 channels, 61 to 66 NDVI for each date (the channels used for calculation are also given), 67-68 DTM, aspect and slope. There are 435 layers (bands) in the Hyperspectral stack file Table 3. From 1-430 HySpex channels, 431-434 DTM, DSM aspect and slope, 435 NDVI (the channels used for calculations are also given).
Image processing was carried out using custom scripts in Python and free plug-ins for QGIS (EnMAP-Box and GRASS). Automatic classification was performed in an unsupervised (K-means method) and supervised (Random Forest method) manner. RF classification accuracy analysis was analyzed by k-fold cross validation in EnMAP-Box. Analysis of the accuracy of the final classification result was done on independent test fields in GRASS.
Clustering in EnMAP proceeds in two stages: FitKMeans and Predict Clustering
FitKMeans in EnMAP-Box is executed using the following script:
Argument of class - "‘k-means++’ : selects initial cluster centroids using sampling based on an empirical probability distribution of the points’ contribution to the overall inertia" (scikit-learn 1.1.2). Number of clusters can be modified (default = 8).
Another issue is standardize features by removing the mean and scaling to unit variance. The standard score of a sample x is calculated as: z = (x - u) / s where u is the mean of the training samples or zero if with_mean=False, and s is the standard deviation of the training samples or one if with_std=False (scikit-learn 1.1.2).
The second step performs , which applies a to a raster.
The resulting clusters were mapped to crop type and analyzed in the context of reference fields to evaluate the effectiveness of the method.
Random Forest in EnMAP in classic approach proceeds using the following script:
The set of reference parcels was divided into two separate sets using stratified random sampling. The learning process was based on the training set. The model’s accuracy, known as validation accuracy, was determined using k-fold cross-validation (defaulting to 3 folds). To select the optimal hyperparameters for our Random Forest (RF) model, we utilized the widely used grid search method through scikit-learn’s Grid Search CV class. Our training phase employed three evaluation metrics - accuracy, balanced accuracy (mean recall), and f1-weighted (weighted average of precision and recall) - to measure the model’s performance. After testing various configurations using 10-fold cross-validation, we ultimately settled on the following classification settings.
- classification:scikit-learnlibrary, sklearn.ensemblemodule, RandomForestClassifier,
- number of trees: 100,
- min_samples_split’: 2,
- min_samples_lef: 2,
- bootstrap: True,
- max_depth: None,
- max_features: None.
In the next stage, we conducted an accuracy analysis based on a test set that was not involved in the learning process. Although accuracy analysis on independent test fields is available in EnMAP-Box, the function from the GRASS plugin was used for technical reasons. Function " tabulates the error matrix of classification result by crossing classified map layer with respect to reference map layer. Both overall kappa (accompanied by its variance) and conditional kappa values are calculated. This analysis program respects the current geographic region and mask settings" (https://ibiblio.org/pub/packages/gis/grass/grass63/manuals/html63_user/r.kappa.html). In this manner, pixel accuracy was determined. In addition, accuracy was analyzed at the plot level by performing an automatic majority class extraction for each polygon (QGIS-Processing tools-Zonal statistic).
Even though researchers have investigated different metrics over the years [26,27,28,29,30,31]), the most commonly recommended metric remains Overall Accuracy (OA) [32], which is defined as OA = TP / (TN + FP + FN) [28]. Therefore, in our study, we limited our analysis to OA.
The study aimed to compare the accuracy of classification results from Sentinel-2 and hyperspectral images captured at significantly different altitudes (10 m for satellites and 1-3 m for aerial images). Processing of single registrations from both types of images as well as time series of Sentinel-2 was conducted to achieve this goal. The complete dataset (stack) was used for classification, and the accuracy was compared to the classification results obtained by excluding NDVI, DEM, and their processing from the remote sensing data.
3. Results
Before presenting the classification results, we would like to showcase the crop structure in the test area, as seen in Figure 5. The plots have a complex and intricate cultivation pattern, with small, elongated, and often irregular shapes. A clearer view can be seen in the False Color Composite (FCC = B8A, B4, B3) of the image captured on July 28th, 2021, just before the first harvest, as shown in Figure 6. The image clearly displays green vegetation (represented in red), buildings and bare soil (in cyan), fields of mature crops (in dark green), forests, and water. The stack data can be seen in Figure A1 to Figure A4.
The best clustering results were obtained from the S2 stack, as shown in Figure 7. The results from clustering other datasets can be found in Appendix A (Figure A5 and Figure A6).
Figure A5 shows correctly classified green vegetation (green) and crops in some fields (yellow). However, a phenomenon of indistinguishability between built-up areas and bare soil (white and gray) can always be noted for a single registration date.
The clustering of the time series, both in the S2 stack (Figure 7) and the S2 time series (Figure A6), allows for the separation of built-up areas (gray), industrial areas (violet), and bare soils (brown). Additionally, mature cereals can be differentiated from green vegetation in the fields (yellow and green). Clustering the time series of remote sensing data alone, however, provides better differentiation within the green vegetation (represented in light green and cyan in Figure 7).
From the clustering results, we extracted classes to mask the areas not analyzed further for crop recognition.
- residential and industrial areas (Figure 7 class 4 and 3),
- forests (Figure 7, class 1 and 6)
- bare soils mixed with industrial areas (Figure A5, Class 8)
The masked clustering crop prediction is shown in Figure 8. For comparison, the results of the Random Forest (RF) classification are presented in Figure 9 and Figure 10 (which are numbered according to the crop ID Table 1). Due to under-representation of classes 1, 3, 4, and 9, the supervised classification was limited to classes 2, 5, 6, 7, and 8.
For hyperspectral data, the best results were obtained when the spatial resolution was reduced to 3m, as shown in Figure 11 and Figure 13. The results of the clustering accuracy analysis are presented in Figure 14, while the accuracy of the RF classification can be analyzed in Figure 15. Detailed results of the accuracy analysis are provided in Appendix A, including Table A1, Table A2 for Sentinel-2 data, and Table A3, Table A4 for HySpex data, along with Figure A11 and Figure A12.
The highest clustering accuracy on the test set was obtained for HySpex 3m with a score of 0.81, and adding additional data did not increase accuracy (Figure 14 blue bars). However, the accuracy of HySpex 1m clustering was low, at 0.55. The maximum accuracy from Sentinel-2 was obtained for the S2 stack, which scored 0.74, for the S2 time series 68% and for single registration S2 0728 39%. For grain crops excluding bare soil and corn ( Figure 14 red bars), the accuracy was above 0.90, with scores of 0.93 for the S2 stack and 0.97 for HySpex 3m. The accuracy of clustering was determined for all reference objects/parcels as no teaching data are required in this case.
The RF method had a greater difference in accuracy between the training pixel set and the test pixel set for Sentinel-2 images than for hyperspectral data (Figure 15). The training accuracy on the S2 stack was 0.97 and the accuracy on the test pixels was 0.70, while the training accuracy for HySpex 3m was 0.85 and the accuracy on the test pixels was 0.73. The object accuracy was slightly less than the pixel accuracy for the S2 stack (0.69), but greater than the pixel accuracy for HySpex 3m (0.75). The effectiveness of the RF method in correctly classifying grain crops excluding bare soil and corn was 100%.
4. Discussion
When comparing classification results, three aspects should be taken into account:
- whether the results concern method validation or testing on independent test data not used for learning
- whether the reference data was divided in a way that prevents data correlation
- which metric was chosen to assess accuracy
Often, articles present the learning process and report only the validation accuracy, which is always higher than the accuracy obtained on independent test data. K-fold cross validation is used to analyze learning effectiveness and results in higher validation accuracy compared to independent test data [33]. Reference data is also often divided in a way that falsely increases accuracy, such as selecting pixels from the same plot for the training and testing sets, which are correlated with each other. To avoid this issue in agriculture land cover recognition, reference set separation should be made at the plot level, not the pixel level. Therefore, for testing, plots that have never been seen during learning should be selected. Finally, it is sometimes reported as OA values that are actually ACC values. Machine learning typically uses four classification results types (TP, TN, FP, FN) and metrics like sensitivity, specificity, and accuracy (ACC=(TP+TN)/(FP+FN+TP+TN) [34]), which is only equal to OA in one-class classification. In multi-class classification, OA is calculated as TP/(TN+FP+FN) [28], while ACC results in much higher accuracy estimates than OA. Examples can be found in journals of both proper and improper use of ACC for classifying features [35,36].
Our article was influenced by a publication [24] that explored the use of one-shot hyperspectral satellite imagery compared to multispectral time series for crop recognition. The authors reported an accuracy of 94%. However, it is important to keep in mind that the accuracy was calculated using OA=(TP+TN)/(TP+TN+FP+FN), which is the de facto ACC accuracy, and only two crops, winter wheat and rapeseed, were tested. This calculation method gives a higher value for ACC compared to OA for many classes OA=TP/(TP+TN+FP+FN) as it takes into account both TPs and TNs.
On the other hand, [37] classified 6 classes with the correct calculation of accuracy, resulting in 95.85% for SVM and an increase in accuracy using deep learning: PCA = 8, epoch = 30 - 97.1%; PCA = 16, epoch = 30 - 98%; and PCA = 24, epoch = 30 - 98.6%. However, the reference data was divided at the pixel level, meaning only selected test pixels were analyzed, which makes it difficult to assess the reported accuracy. As the authors mentioned, potatoes were the worst misclassified crop with a total of 32 pixels misclassified (19 too few and 13 too many). The producer accuracy was 93.04% and user accuracy was 95.15%. However, looking at Figure 16 [37], there is a mismatch between the reference plot with potatoes and the SVM classification results, making it challenging to trust the accuracy based on pixel analysis.
5. Conclusions
The objective of our study was to examine the feasibility of using one-shot hyperspectral airborne images for crop recognition. The following conclusions were drawn from our measurement experiment:
- With a single airborne hyperspectral recording, it was possible to classify crops at 80% accuracy using unsupervised clustering methods. When restricted to only grain crops, accuracy improved to 90%.
- Additional layers (NDVI, DTM, slope and aspect) did not increase the classification accuracy of aerial hyperspectral images.
- The accuracy of S2 stack (S2 Sentinel-2 time series plus NDVI, DTM, slope, and aspect) clustering was relatively high - 74%, especially for an area with a large number of small plots; in comparison, the accuracy of clustering only S2 time series was 68%.
- The accuracy of a single Sentinel-2 recording was surprisingly low, at less than 50%. The reason for this discrepancy is unclear, but it may be related to differences in crop structure in northern Poland where a one-shot FR S2 test had an accuracy of approximately 80% ([23]).
- The results of the random forest classification were slightly less accurate due to a lack of enough reference data. Clustering methods did not require training data, while random forest methods required dividing reference data into learning and test sets.
- The accuracy of crop recognition reported in the literature above 90% is difficult to verify due to differences in accuracy analysis methodologies, reference data selection, pixel/object approaches, metric choice, and calculation formula used.
Author Contributions
Conceptualization, B.H. and P.M.; methodology, B.H. and PK; software, P.K.; validation, P.K.; investigation, P.K. and B.H.; writing—original draft preparation P.K.; writing—review and editing B.H.; visualization, P.K.; supervision, B.H.; funding acquisition BH All authors have read and agreed to the published version of the manuscript.
Funding
Research project supported by program Excellence initiative—research university for the AGH University of Science and Technology no. 501.696.7996. The project title: Integration of remote sensing data for control in the system of direct agricultural subsidies (IACS).
Acknowledgments
The authors thank the editor and anonymous reviewers for their helpful comments and valuable suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RF | Random Forest |
| SVM | Supported Vector Machine |
| CNN | Convolution Neural Network |
| DL | Deep Learning |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| OA | Overall Accuracy=TP/(TP+TN+FP+FN) |
| ACC | Accuracy=(TP+TN)/(TP+TN+FP+FN) |
Appendix A. Results of classifications and accuracy analysis
Figure A1.
S2 NDVI 0728
Figure A2.
SRTM
Figure A3.
SRTM - slope
Figure A4.
SRTM - aspect

Figure A5.
Cluster S2 0728; 1-deciduous forest, 2-maturing cereals, 3-conifer forest, 4-industrial, rocks, 5-mix forest, 6-mature cereals, urban, 7-green vegetation, 8-bare soils
Figure A5.
Cluster S2 0728; 1-deciduous forest, 2-maturing cereals, 3-conifer forest, 4-industrial, rocks, 5-mix forest, 6-mature cereals, urban, 7-green vegetation, 8-bare soils

Figure A6.
Cluster S2 time series; 1-mix forest, 2-mature cereals, 3-industrial, 4-urban, 5-maturing cereals, green vegetation, 6-conifer forest, 7-mature cereals, green vegetation, 8-grass
Figure A6.
Cluster S2 time series; 1-mix forest, 2-mature cereals, 3-industrial, 4-urban, 5-maturing cereals, green vegetation, 6-conifer forest, 7-mature cereals, green vegetation, 8-grass

Table A1.
Object accuracy analysis Sentinel-2 cluster - class mapping
| Id crop | S2 stack | S2 time series | S2 0728 |
|---|---|---|---|
| 2 | 4 | 2 | 8 |
| 2 | 3 | 2 | 4 |
| 2 | 8 | 3 | 4 |
| 2 | 4 | 7 | 2 |
| 2 | 3 | 2 | 8 |
| 2 | 8 | 3 | 8 |
| 5 | 4 | 7 | 6 |
| 5 | 6 | 4 | 2 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 6 |
| 5 | 4 | 7 | 2 |
| 6 | 3 | 2 | 6 |
| 6 | 3 | 2 | 6 |
| 6 | 3 | 2 | 8 |
| 6 | 3 | 2 | 6 |
| 6 | 3 | 2 | 6 |
| 6 | 3 | 4 | 6 |
| 6 | 3 | 2 | 6 |
| 7 | 4 | 2 | 6 |
| 7 | 3 | 2 | 8 |
| 7 | 4 | 7 | 8 |
| 7 | 4 | 7 | 6 |
| 8 | 2 | 5 | 7 |
| 8 | 2 | 5 | 7 |
| 8 | 2 | 5 | 2 |
| 8 | 2 | 5 | 7 |
| 8 | 2 | 5 | 7 |
| OA | 0.74 | 0.68 | 0.39 |
| OA without bare soils | 0.92 | 0.84 | 0.48 |
Figure A7.
Pixel accuracy analysis, confusion matrix S2 stack RF, train, OA=0.97
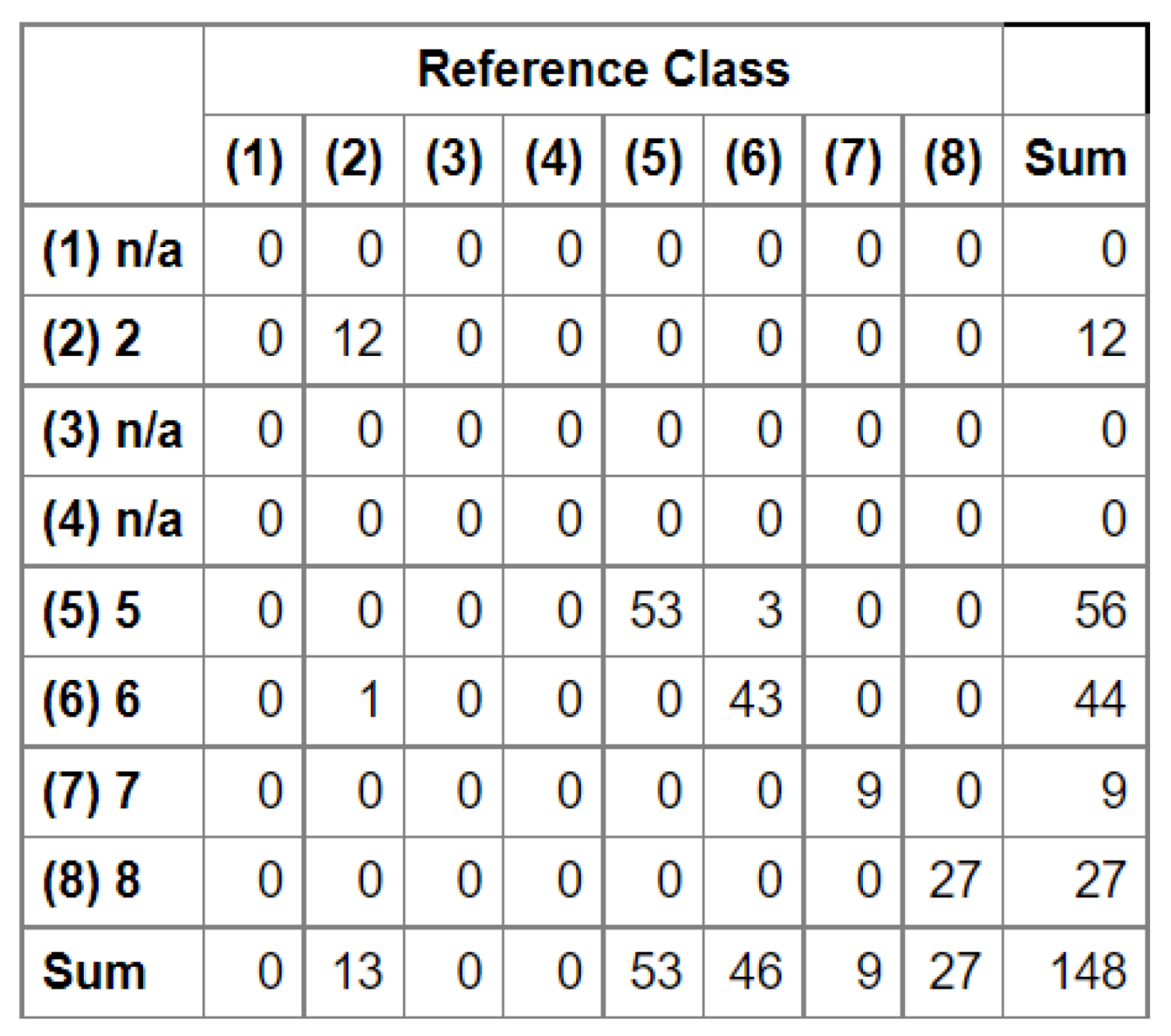
Figure A8.
Pixel accuracy analysis, confusion matrix S2 stack RF, test
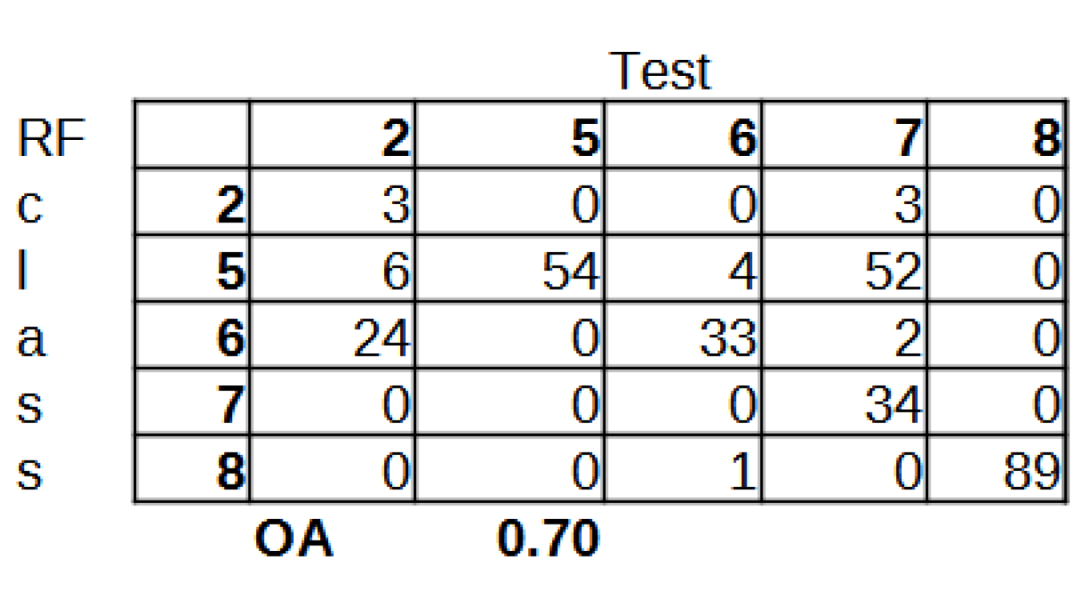
Table A2.
Object accuracy analysis S2 stack RF, test
| Id crop | S2 stack RF |
|---|---|
| 2 | 5 |
| 2 | 6 |
| 2 | 2 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 6 | 6 |
| 6 | 6 |
| 6 | 5 |
| 7 | 5 |
| 7 | 5 |
| 8 | 8 |
| 8 | 8 |
| 8 | 8 |
| OA | 0.69 |
| OA without bare soils and corn merged | 1.00 |
Figure A9.
HySex FCC 1m

Figure A10.
HySex FCC 1m K-means

Figure A11.
Pixel accuracy assessment, confusion matrix HySpex 3m stack RF, train, OA=0.85
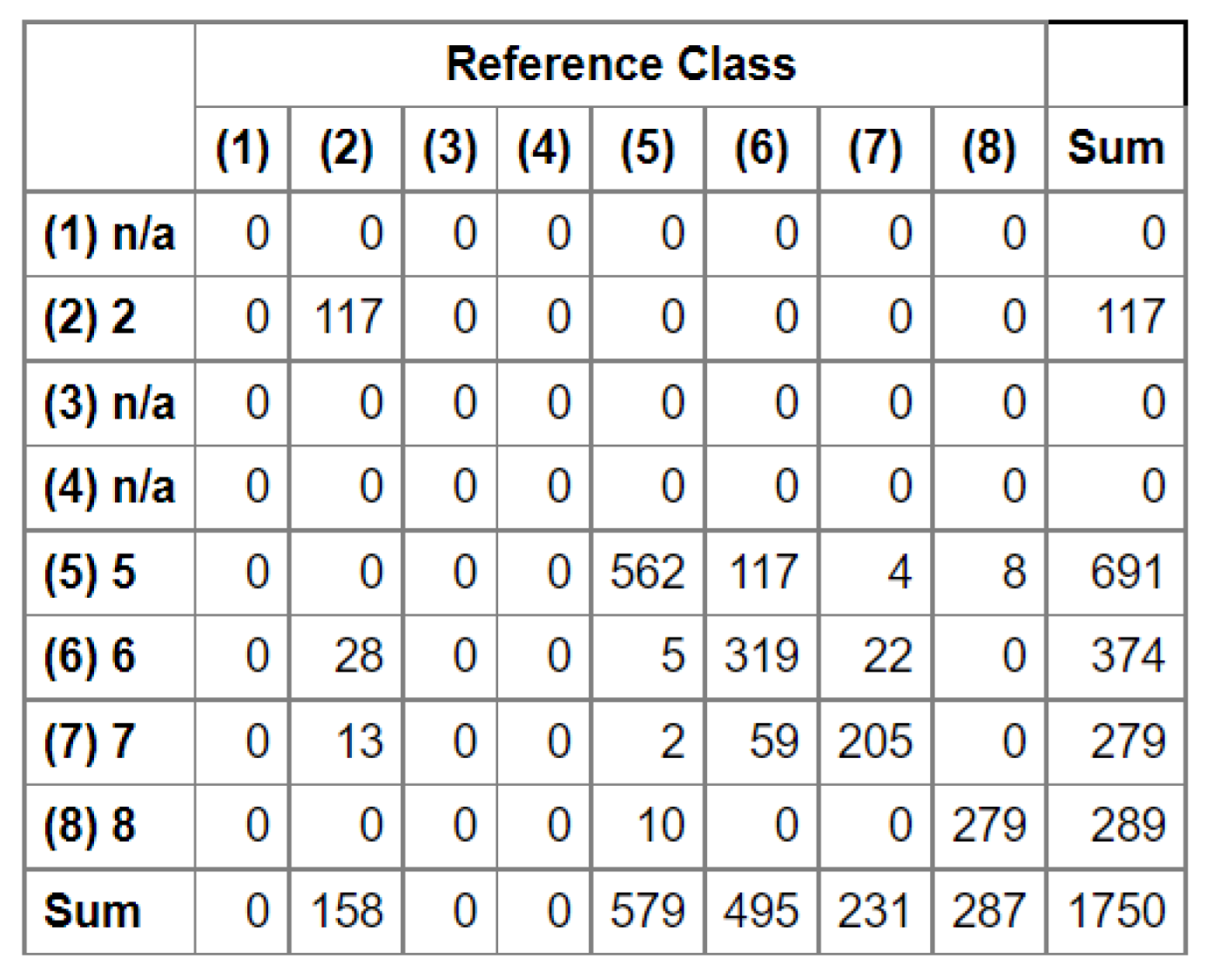
Figure A12.
Pixel accuracy assessment, confusion matrix HySpex 3m stack RF, test, OA=0.73
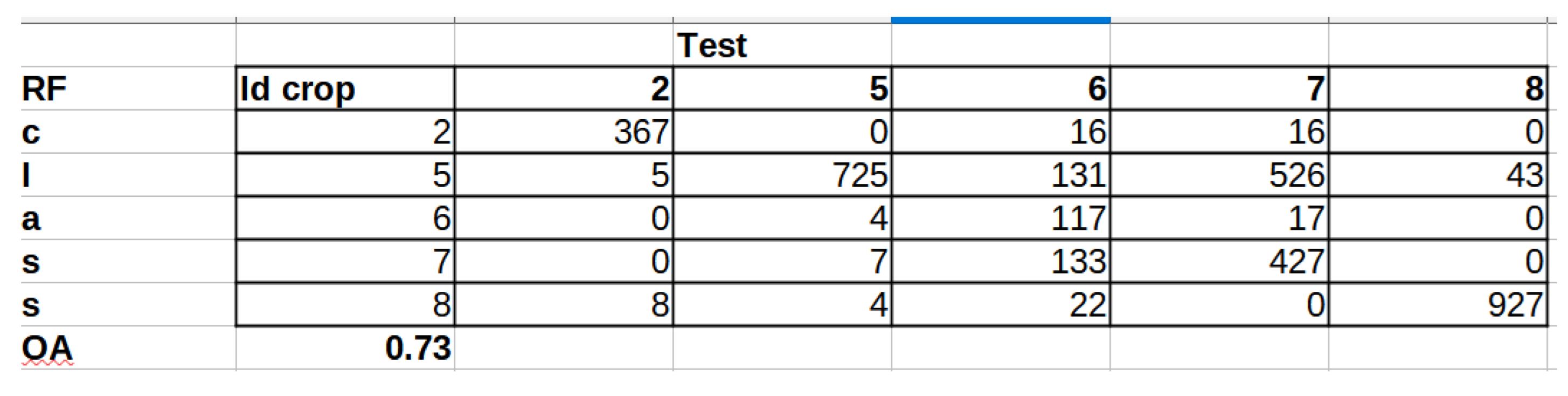
Table A3.
Object accuracy analysis HySpex cluster - class mapping
| Id crop | HySpex 1m | HySpex 3m | HySpex stack |
|---|---|---|---|
| 2 | 6 | 6 | 4 |
| 2 | 1 | 3 | 2 |
| 2 | 7 | 3 | 2 |
| 2 | 1 | 3 | 2 |
| 2 | 1 | 3 | 2 |
| 2 | 7 | 3 | 2 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 5 | 5 | 4 | 1 |
| 6 | 6 | 1 | 6 |
| 6 | 5 | 4 | 1 |
| 6 | 3 | 1 | 6 |
| 6 | 6 | 1 | 6 |
| 6 | 6 | 1 | 6 |
| 6 | 6 | 1 | 6 |
| 6 | 6 | 1 | 6 |
| 7 | 6 | 1 | 6 |
| 7 | 6 | 1 | 6 |
| 7 | 6 | 1 | 6 |
| 7 | 6 | 1 | 6 |
| 8 | 5 | 2 | 3 |
| 8 | 5 | 2 | 3 |
| 8 | 5 | 2 | 3 |
| 8 | 5 | 2 | 3 |
| 8 | 5 | 2 | 3 |
| OA | 0.55 | 0.81 | 0.81 |
| OA corn together | 0.71 | 0.97 | 0.97 |
Table A4.
Object accuracy analysis RF HySpex 3m stack, test
| Id crop | HySpex 3m stack RF |
|---|---|
| 2 | 2 |
| 2 | 2 |
| 2 | 2 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 5 | 5 |
| 6 | 6 |
| 6 | 5 |
| 6 | 7 |
| 7 | 5 |
| 7 | 5 |
| 8 | 8 |
| 8 | 8 |
| 8 | 8 |
| OA | 0.75 |
| OA corn merged | 1.00 |
References
- Cao, J.; Wang, H.; Li, J.; Tian, Q.; Niyogi, D. Improving the Forecasting of Winter Wheat Yields in Northern China with Machine Learning;Dynamical Hybrid Subseasonal-to-Seasonal Ensemble Prediction. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Bojanowski, J.S.; Sikora, S.; Musiał, J.P.; Woźniak, E.; Dąbrowska-Zielińska, K.; Slesiński, P.; Milewski, T.; Łączyński, A. Integration of Sentinel-3 and MODIS Vegetation Indices with ERA-5 Agro-Meteorological Indicators for Operational Crop Yield Forecasting. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Zare, H.; Weber, T.K.D.; Ingwersen, J.; Nowak, W.; Gayler, S.; Streck, T. Combining Crop Modeling with Remote Sensing Data Using a Particle Filtering Technique to Produce Real-Time Forecasts of Winter Wheat Yields under Uncertain Boundary Conditions. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Roma, E.; Catania, P. Precision Oliviculture: Research Topics, Challenges, and Opportunities;A Review. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Ma, C.; Johansen, K.; McCabe, M.F. Monitoring Irrigation Events and Crop Dynamics Using Sentinel-1 and Sentinel-2 Time Series. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Borowiec, N.; Marmol, U. Using LiDAR System as a Data Source for Agricultural Land Boundaries. Remote Sensing 2022, 14. [Google Scholar] [CrossRef]
- Beriaux, E.; Jago, A.; Lucau-Danila, C.; Planchon, V.; Defourny, P. Sentinel-1 Time Series for Crop Identification in the Framework of the Future CAP Monitoring. Remote Sensing 2021, 13. [Google Scholar] [CrossRef]
- Commission, E. Integrated Administration and Control System (IACS), 2022.
- consortium, S. Sentinels for Common Agricultural Policy - Sen4CAP, 2022.
- consortium, N. New IACS Vision in Action - NIVA, 2022.
- Rouse, J.; Haas, R.; Schell, J.; Deering, D.; Harlan, J. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation. NASA/GSFC Type III Final Report, Greenbelt, MD, 371 p. . "https://ntrs.nasa.gov/api/citations/19750020419/downloads/19750020419.pdf", 1974.
- Laur, H.; Bally, P.; Meadows, P.; Sanchez, J.; Schättler, B.; Lopinto, E.; Esteban, D. Derivation of the backscattering coefficient sigma nought in ESA ERS SAR PRI products. Technical Report ES-TN-RS-PM-HL09, ESA, September 1998. Issue 2, Rev. 5b. "https://earth.esa.int/documents/10174/13019/ers_sar_calibration_issue2_5f.pdf", 1994. 19 September.
- Bolognesi, S.; Pasolli, E.; Belfiore, O.; De Michele, C.; D’Urso, G. Harmonized landsat 8 and sentinel-2 time series data to detect irrigated areas: An application in Southern Italy. Remote Sensing 2020, 12. [Google Scholar] [CrossRef]
- Hütt, C.; Waldhoff, G.; Bareth, G. Fusion of sentinel-1 with official topographic and cadastral geodata for crop-type enriched LULC mapping using FOSS and open data. ISPRS International Journal of Geo-Information 2020, 9. [Google Scholar] [CrossRef]
- Sun, C.; Bian, Y.; Zhou, T.; Pan, J. Using of multi-source and multi-temporal remote sensing data improves crop-type mapping in the subtropical agriculture region. Sensors (Switzerland) 2019, 19. [Google Scholar] [CrossRef]
- Sun, L.; Chen, J.; Guo, S.; Deng, X.; Han, Y. Integration of time series sentinel-1 and sentinel-2 imagery for crop type mapping over oasis agricultural areas. Remote Sensing 2020, 12. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar sentinel-1 and optical sentinel-2 imagery for crop mapping: A case study for Belgium. Remote Sensing 2018, 10. [Google Scholar] [CrossRef]
- Brinkhoff, J.; Vardanega, J.; Robson, A. Land cover classification of nine perennial crops using sentinel-1 and -2 data. Remote Sensing 2020, 12. [Google Scholar] [CrossRef]
- Maponya, M.G.; van Niekerk, A.; Mashimbye, Z.E. Pre-harvest classification of crop types using a Sentinel-2 time-series and machine learning. Computers and Electronics in Agriculture 2020, 169. [Google Scholar] [CrossRef]
- Mustak, S.; Uday, G.; Ramesh, B.; Praveen, B. Evaluation of the performance of SAR and SAR-optical fused dataset for crop discrimination. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences - ISPRS Archives, 2019, Vol. 42, pp. 563–571. [CrossRef]
- d’Andrimont, R.; Verhegghen, A.; Lemoine, G.; Kempeneers, P.; Meroni, M.; van der Velde, M. From parcel to continental scale – A first European crop type map based on Sentinel-1 and LUCAS Copernicus in-situ observations. Remote Sensing of Environment 2021, 266, 112708. [Google Scholar] [CrossRef]
- consortium, S.A. SEN2-AGRI SYSTEM, 2022.
- Hejmanowska, B.; Kramarczyk, P.; Głowienka, E.; Mikrut, S. Reliable Crops Classification Using Limited Number of Sentinel-2 and Sentinel-1 Images. Remote Sensing 2021, 13. [Google Scholar] [CrossRef]
- Meng, S.; Wang, X.; Hu, X.; Luo, C.; Zhong, Y. Deep learning-based crop mapping in the cloudy season using one-shot hyperspectral satellite imagery. Computers and Electronics in Agriculture 2021, 186. [Google Scholar] [CrossRef]
- Wikipedia. Żniwa, 2022.
- Hord, M.R.; Brooner, W. Land-Use Map Accuracy Criteria. Photogramm. Eng. Rem. S. 1976, 42. [Google Scholar]
- van Genderen, J.; Lock, B. Testing Land Use Map Accuracy. Photogramm. Eng. Rem. S. 1977, 43. [Google Scholar]
- Russell, G.C. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Canran, L.; Paul, F.; Lalit, K. Comparative assessment of the measures of thematic classification accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Pontus, O.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Foody, G.M. Impacts of Sample Design for Validation Data on the Accuracy of Feedforward Neural Network Classification. Appl. Sci. 2017, 7, 888. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Morales-Barquero, L.; Lyons, M.B.; Phinn, S.R.; Roelfsema, C.M. Trends in Remote Sensing Accuracy Assessment Approaches in the Context of Natural Resources. Remote Sens. 2019, 11. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Mann, H.M.R.; Iosifidis, A.; Jepsen, J.U.; Welker, J.M.; Loonen, M.J.J.E.; Høye, T.T. Automatic flower detection and phenology monitoring using time-lapse cameras and deep learning. Remote Sensing in Ecology and Conservation 2022, 8, 765–777. [Google Scholar] [CrossRef]
- Lake, T.A.; Briscoe Runquist, R.D.; Moeller, D.A. Deep learning detects invasive plant species across complex landscapes using Worldview-2 and Planetscope satellite imagery. Remote Sensing in Ecology and Conservation 2022, 8, 875–889. [Google Scholar] [CrossRef]
- Wan, S.; Yeh, M.L.; Ma, H.L. An innovative intelligent system with integrated CNN and SVM: Considering various crops through hyperspectral image data. ISPRS International Journal of Geo-Information 2021, 10. [Google Scholar] [CrossRef]
Figure 1.
Test area location on the south of Poland, small red area in the background of S2 and SRTM, geographical coordinate system, EPSG:4326
Figure 1.
Test area location on the south of Poland, small red area in the background of S2 and SRTM, geographical coordinate system, EPSG:4326
Figure 2.
Parcels submitted for subsidies each year
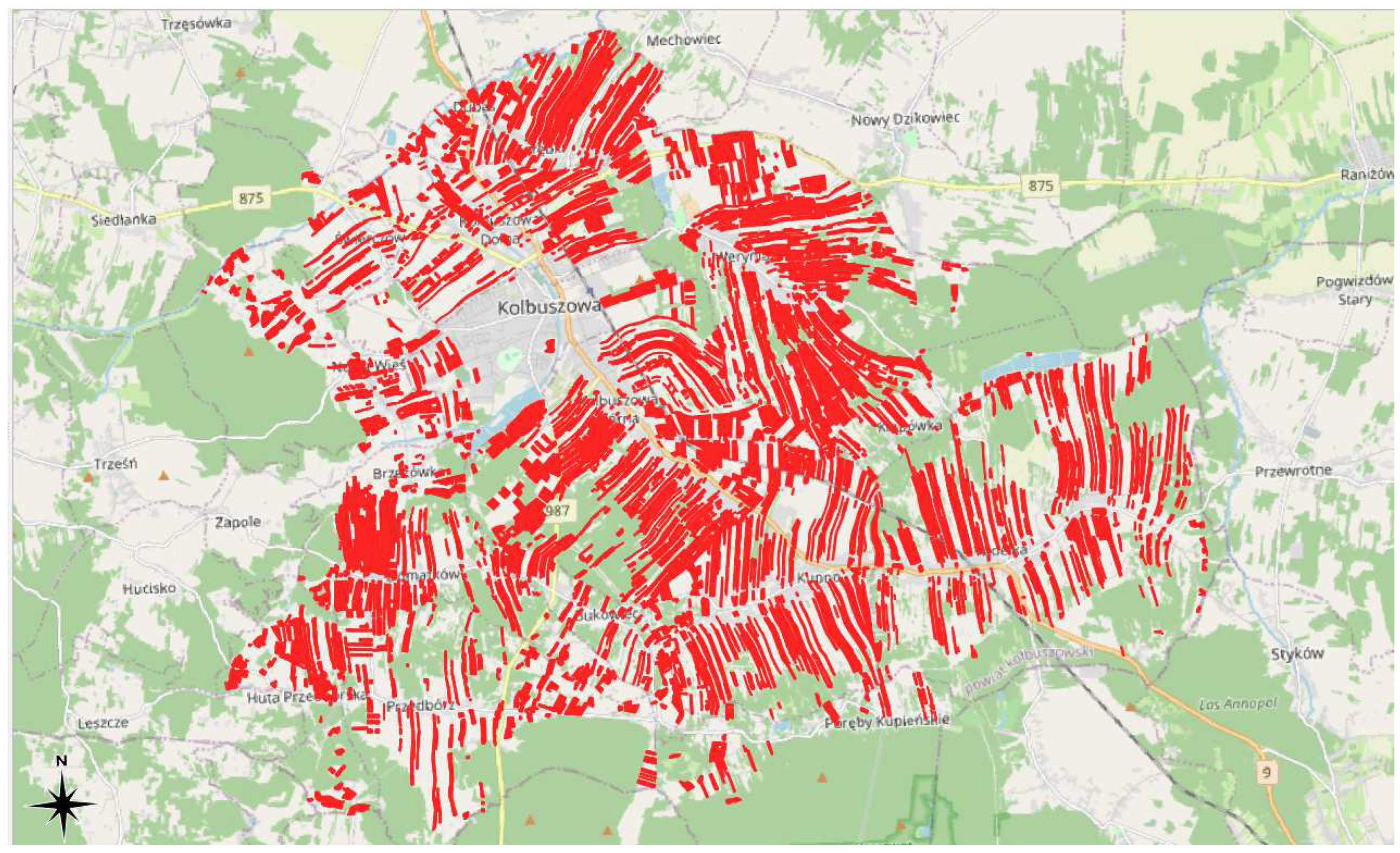
Figure 3.
Histogram of the parcels’ areas
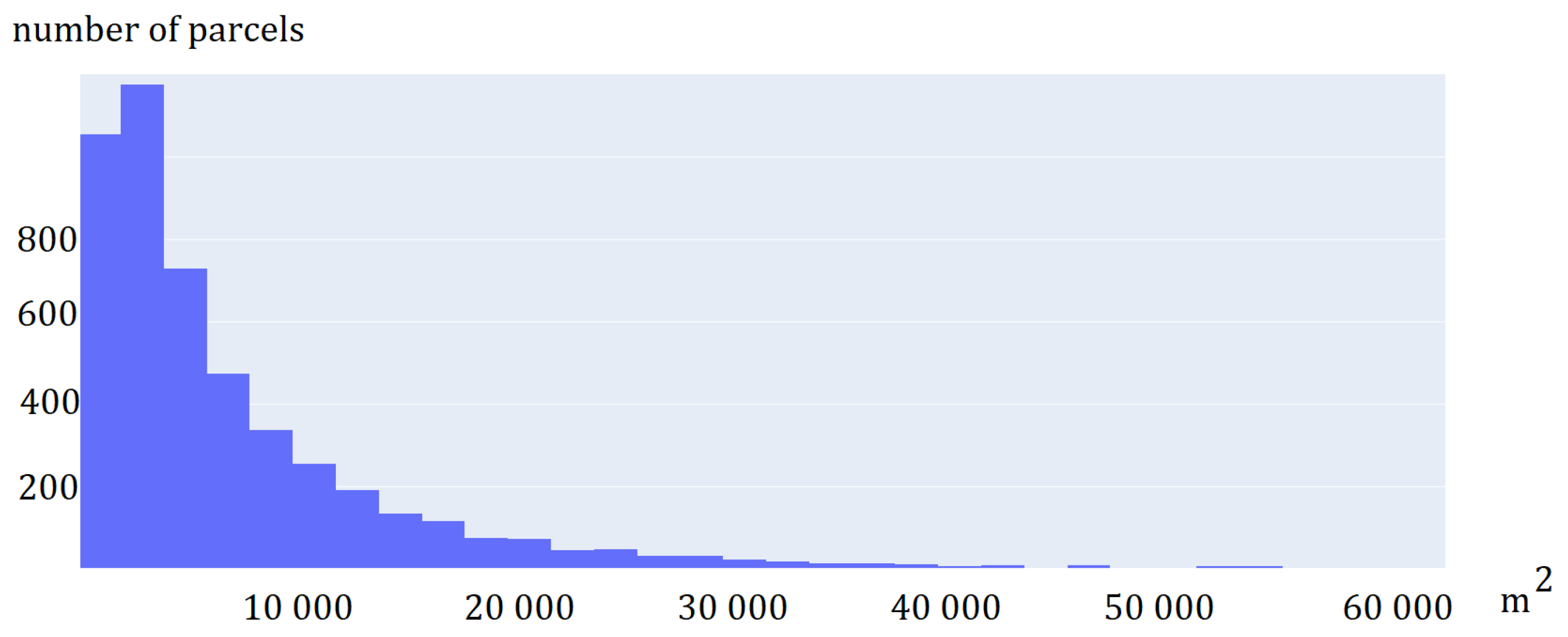
Figure 4.
Parcels visted in the field

Figure 5.
Test area - Google Maps
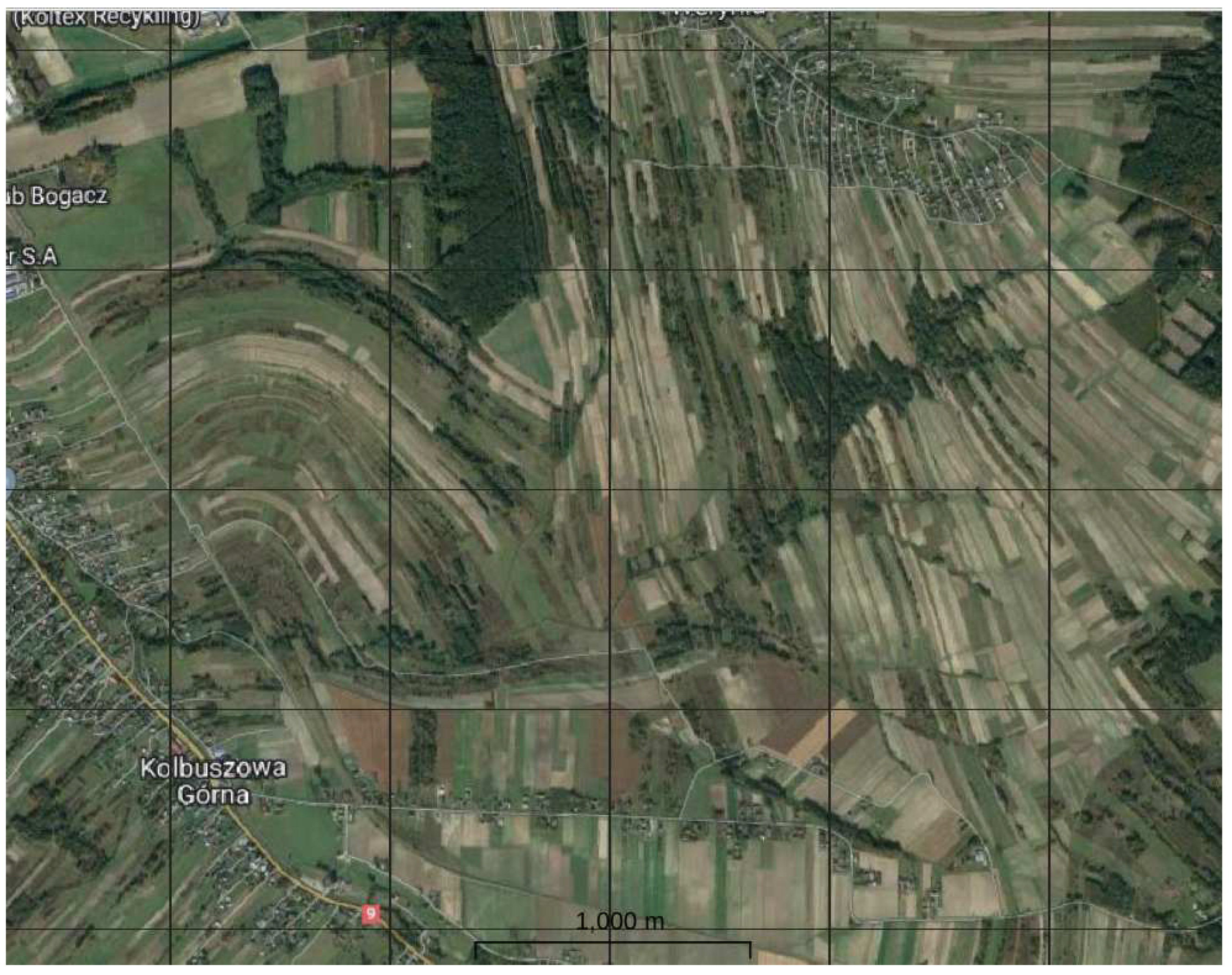
Figure 6.
S2 FCC 0728
Figure 7.
Cluster S2 stack; 1-conifer forest, 2-grass, 3-maturing/mature cereals, 4-maturing/mature cereals, 5-deciduous forest, 6-urban, 7-residual class, 8-industrial
Figure 7.
Cluster S2 stack; 1-conifer forest, 2-grass, 3-maturing/mature cereals, 4-maturing/mature cereals, 5-deciduous forest, 6-urban, 7-residual class, 8-industrial
Figure 8.
Cluster S2 stack masked; 1-conifer forest (masked), 2-grass, 3-maturing/mature cereals, 4-maturing/mature cereals, 5-deciduous forest (masked), 6-urban (masked), 7-residual class (no visible), 8-industrial (masked)
Figure 8.
Cluster S2 stack masked; 1-conifer forest (masked), 2-grass, 3-maturing/mature cereals, 4-maturing/mature cereals, 5-deciduous forest (masked), 6-urban (masked), 7-residual class (no visible), 8-industrial (masked)
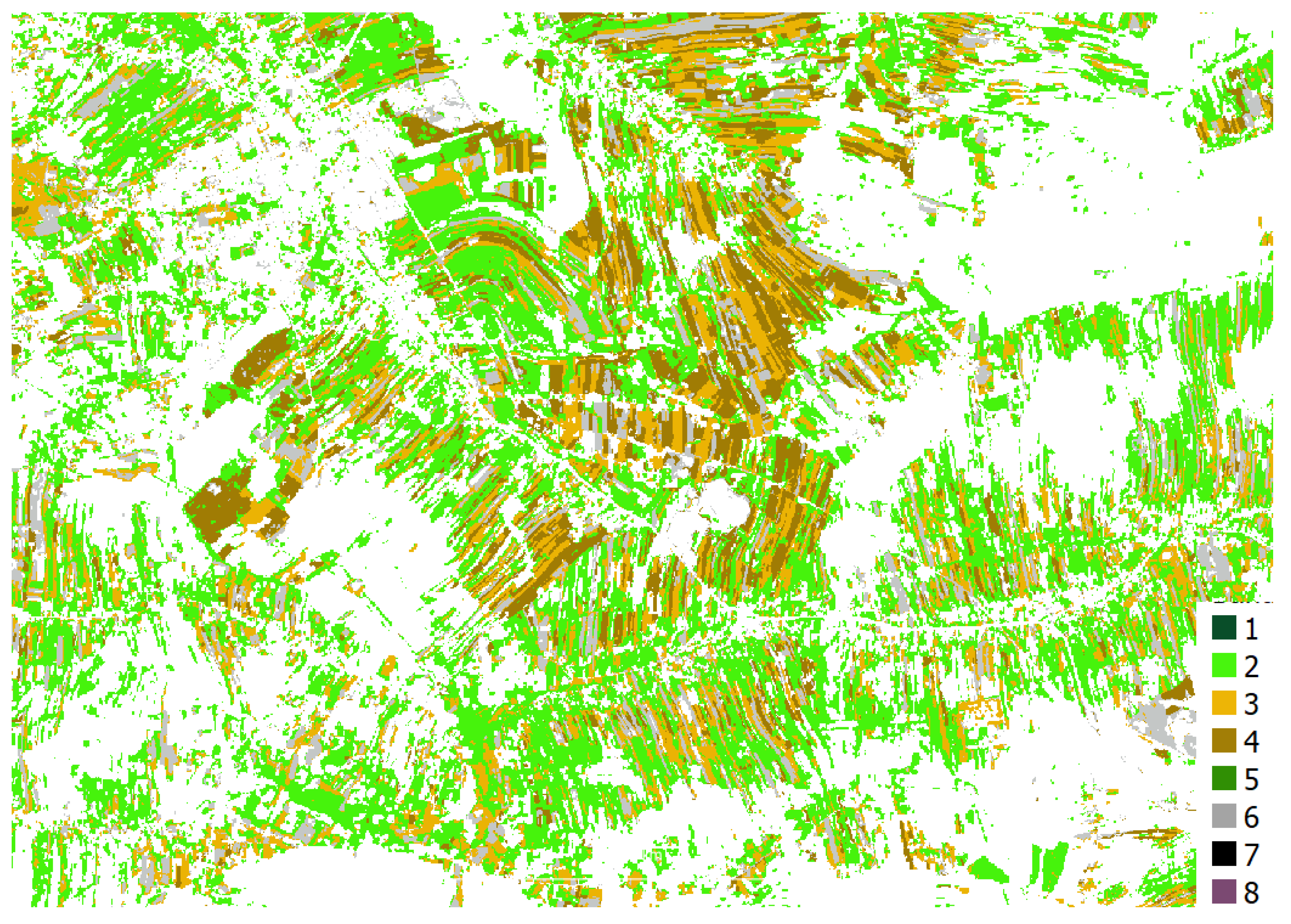
Figure 9.
RF S2 stack masked, classes according Table 1, 2-soil, 5-oats, 6-winter rye, 7- wheat winter, 8-grass
Figure 9.
RF S2 stack masked, classes according Table 1, 2-soil, 5-oats, 6-winter rye, 7- wheat winter, 8-grass
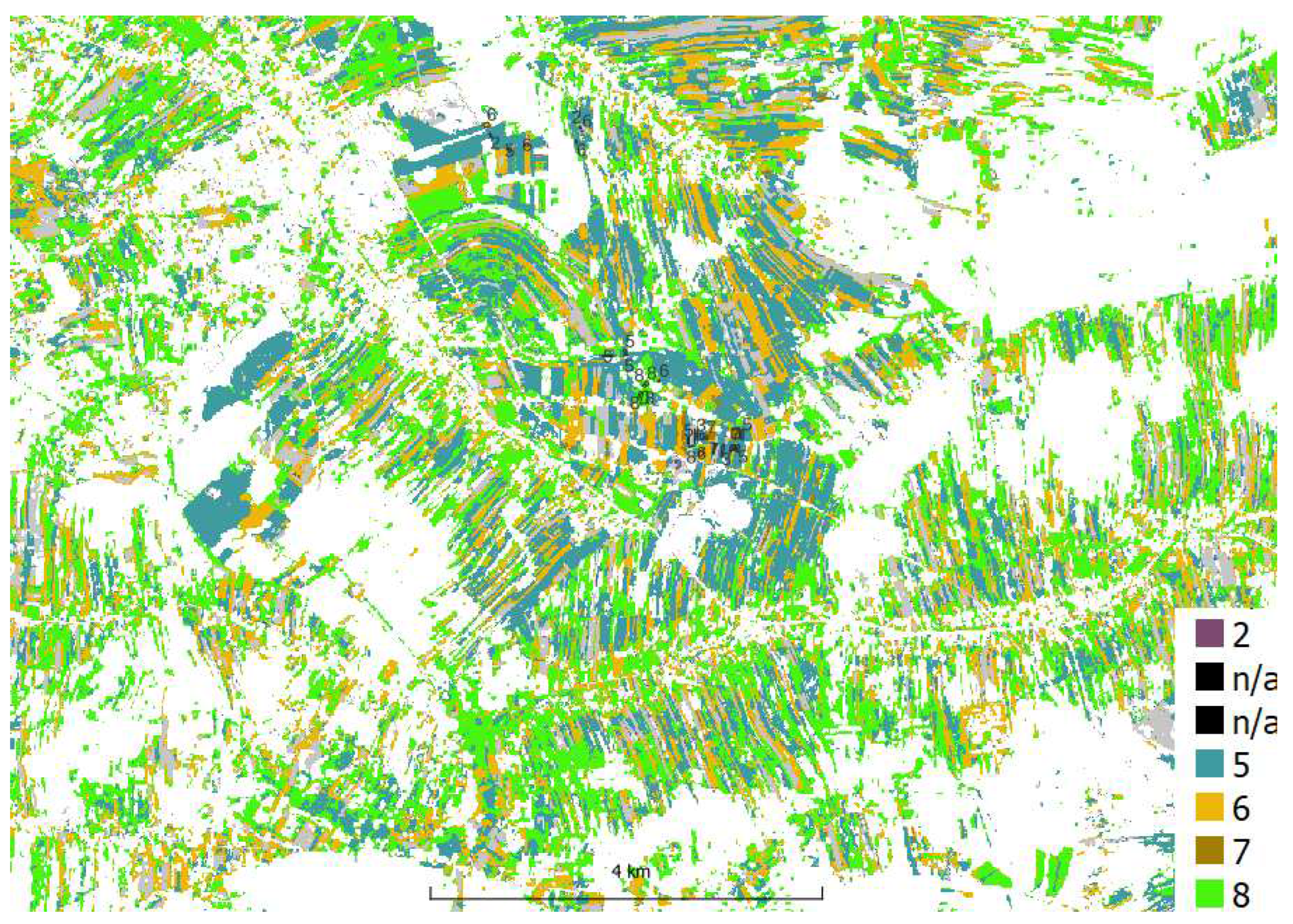
Figure 10.
RF S2 stack masked (zoom); legend and polygon labels - according Table 1, 2-soil, 5-oats, 6-winter rye, 7- wheat winter, 8-grass
Figure 10.
RF S2 stack masked (zoom); legend and polygon labels - according Table 1, 2-soil, 5-oats, 6-winter rye, 7- wheat winter, 8-grass
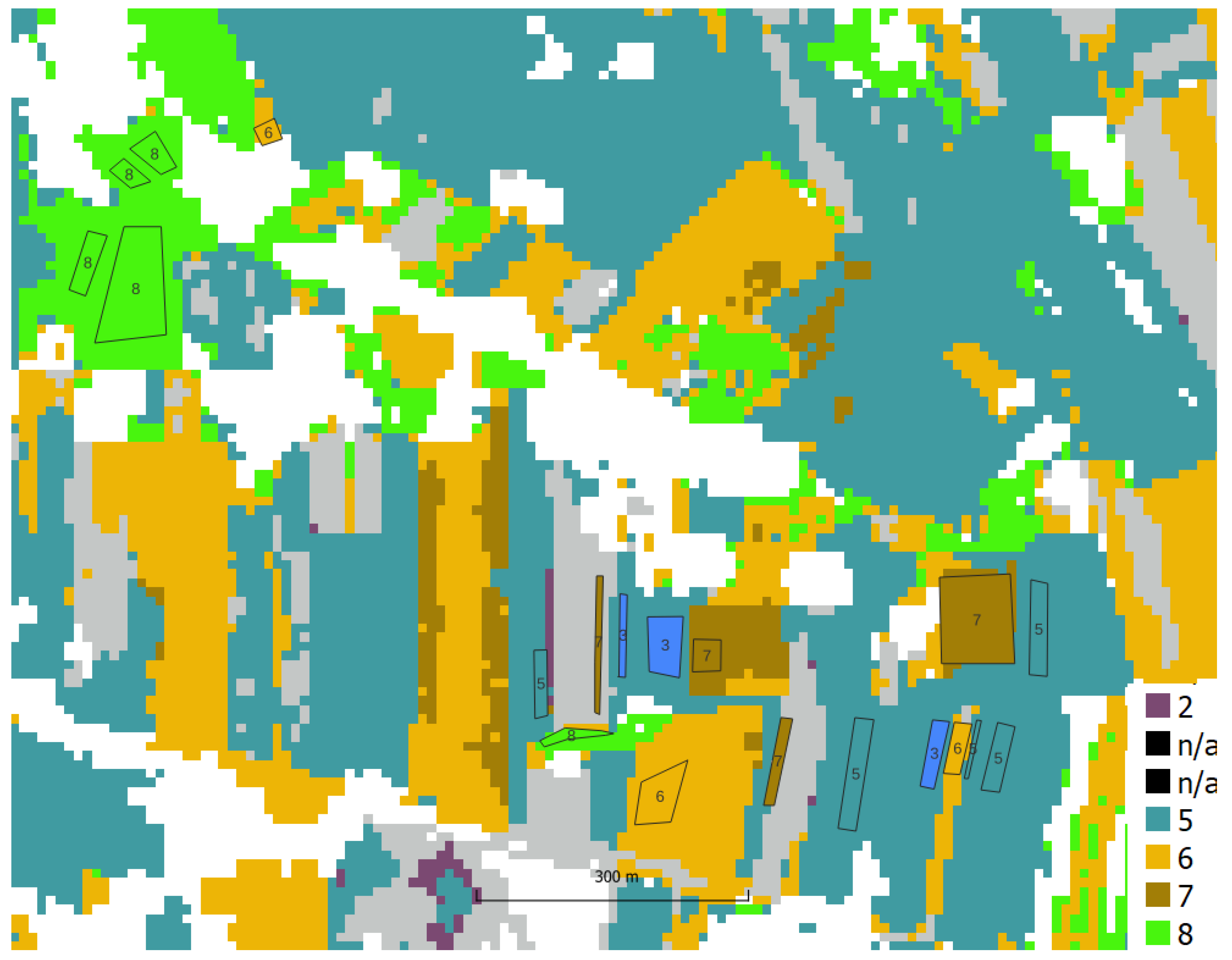
Figure 11.
HySpex FCC 3m

Figure 12.
HySex 3m K-means

Figure 13.
RF HySpex 3m

Figure 14.
Comparison of clustering accuracy - object/parcel level
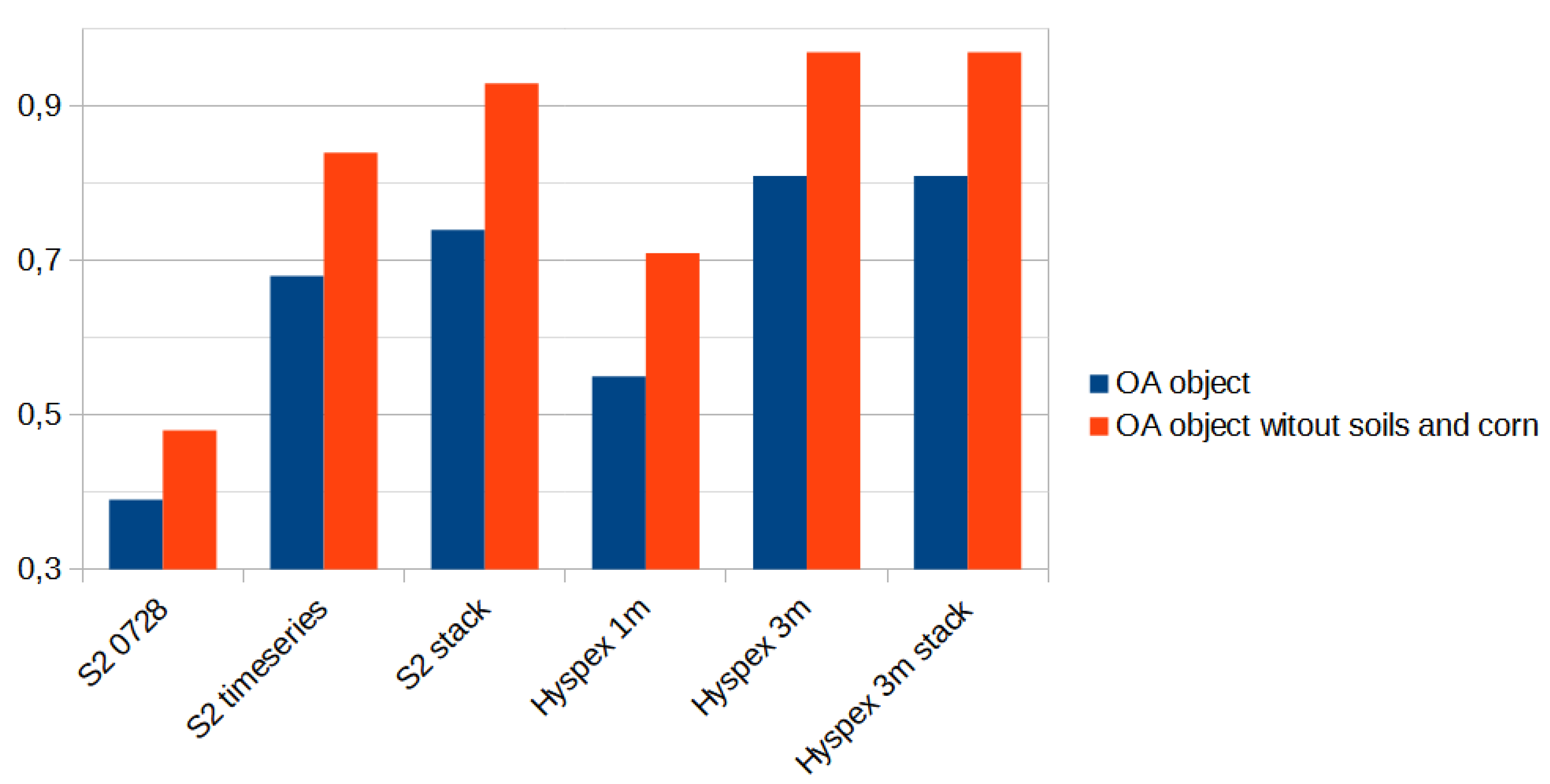
Figure 15.
Comparison of accuracy obtained in RF classification; pixel level: validation and test sets; object/parcels level: test set
Figure 15.
Comparison of accuracy obtained in RF classification; pixel level: validation and test sets; object/parcels level: test set
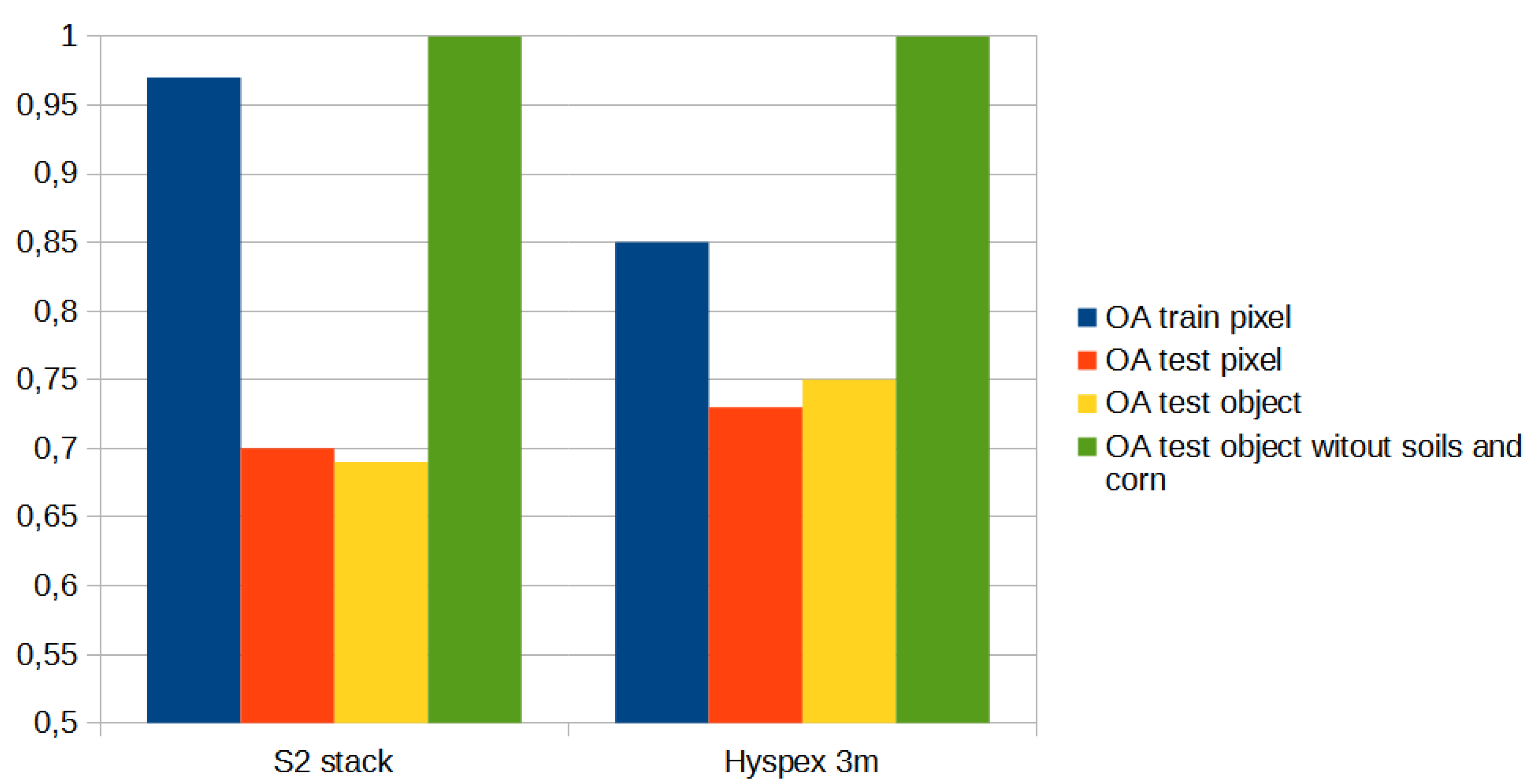
Figure 16.
FCC from hyperspectral image, reference plots and result of SVM classification [37]
Figure 16.
FCC from hyperspectral image, reference plots and result of SVM classification [37]

Table 1.
Crops .
| Id | Crop |
|---|---|
| 1 | beet |
| 2 | soil |
| 3 | barley |
| 4 | maize |
| 5 | oats |
| 6 | wheat rye |
| 7 | wheat winter |
| 8 | grass |
| 9 | potato |
| 10 | rye |
Table 2.
Sentinel-2 time series stack.
| Band number | Details |
|---|---|
| 1-10 | B0327 |
| 11-20 | B0411 |
| 21-30 | B0509 |
| 31-40 | B0725 |
| 41-50 | B0728 |
| 51-60 | B0906 |
| 61 | 0327_7/3 |
| 62 | 0411_17/13 |
| 63 | 0509_47/43 |
| 64 | 0725_57/53 |
| 65 | 0728_37/33 |
| 66 | 0906_27/23 |
| 67 | DTM |
| 68 | aspect |
| 68 | slope |
Table 3.
Hyperspectral stack.
| Band number | Details |
|---|---|
| 1-430 | HySpex bands |
| 431 | DTM |
| 432 | DSM |
| 433 | slope |
| 434 | aspect |
| 435 | ndvi_142_80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



