
Submitted:
04 November 2022
Posted:
08 November 2022
You are already at the latest version
Abstract
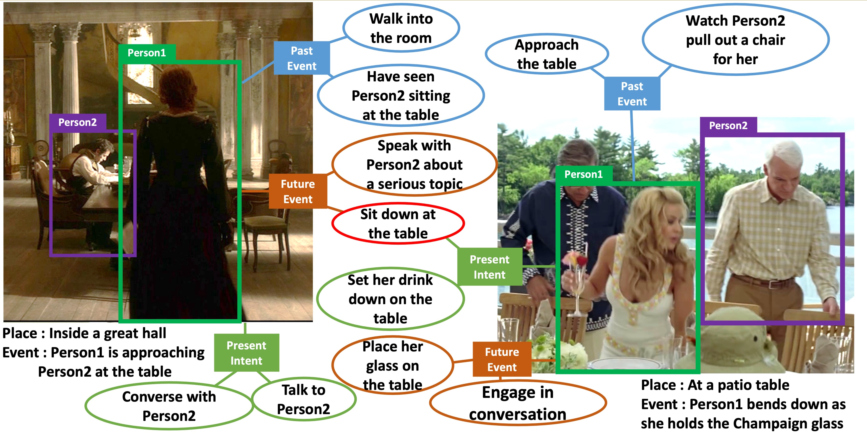
“A Picture is worth a thousand words”. Given an image, humans are able to deduce various cause-and-effect captions of past, current, and future events beyond the image. The task of visual commonsense generation aims at generating three cause-and-effect captions (1) what needed to happen before, (2) what is the current intent, and (3) what will happen after for a given image. However, such a task is challenging for machines owing to two limitations: existing approaches (1) directly utilize conventional vision-language transformers to learn relationships between input modalities, and (2) ignore relations among target cause-and-effect captions but consider each caption independently. We propose Cause-and-Effect BART (CE-BART) which is based on (1) Structured Graph Reasoner that captures intra- and inter-modality relationships among visual and textual representations, and (2) Cause-and-Effect Generator that generates cause-and-effect captions by considering the causal relations among inferences. We demonstrate the validity of CE-BART on VisualCOMET and AVSD benchmarks. CE-BART achieves SOTA performances on both benchmarks, while extensive ablation study and qualitative analysis demonstrate the performance gain and improved interpretability.
Keywords:
Deep Learning
; Visual-Language Reasoning
; Visual Commonsense Generation
; Video-grounded Dialogue
; VisualCOMET
; AVSD
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



