Submitted:
29 September 2025
Posted:
29 September 2025
You are already at the latest version
Abstract
Data contamination poses a significant challenge to reliable LLM evaluation, where models may achieve high performance by memorizing training data rather than demonstrating genuine reasoning capabilities. We introduce RADAR (Recall vs. Reasoning Detection through Activation Representation), a novel framework that leverages mechanistic interpretability to detect contamination by distinguishing recall-based from reasoning-based model responses. RADAR extracts 37 features spanning surfacelevel confidence trajectories and deep mechanistic properties including attention specialization, circuit dynamics, and activation flow patterns. Using an ensemble of classifiers trained on these features, RADAR achieves 93% accuracy on a diverse evaluation set, with perfect performance on clear cases and 76.7% accuracy on challenging ambiguous examples. This work demonstrates the potential of mechanistic interpretability for advancing LLM evaluation beyond traditional surface-level metrics. The code used in this work is publicly available.
Keywords:
recall vs. reasoning
; activation analysis
; mechanistic interpretability
; representation disentanglement
; semantic recall detection
; reasoning pathway identification
; layer-wise activation analysis
; latent representation mapping
; attention attribution
; causal tracing
; neuron activation profiling
; circuit discovery
; alignment analysis
; large language models
; recommender systems
; retrieval-augmented generation
; hallucination detection
; reasoning robustness
; safety and alignment
; embedding drift
; contamination detection
; semantic genome mapping
; clustering quality metrics
; interpretability benchmark
1. Introduction
Large Language Models (LLMs) show strong performance across tasks, but data contamination remains a major challenge in evaluation. Overlap between training and evaluation sets inflates metrics and obscures the distinction between genuine reasoning and memorization [1,2,3].
Existing detection methods typically compare evaluation data to training corpora, check n-gram overlaps, or flag verbatim outputs [4]. These approaches are limited: they require access to training data, fail with paraphrased contamination, and cannot reveal whether a model solved a task by recall or reasoning.
We propose RADAR, which instead analyzes internal computation dynamics. Leveraging mechanistic interpretability, RADAR extracts features from attention, hidden states, and activation flows [5,6]. Recall exhibits focused attention and rapid confidence convergence, while reasoning shows distributed activation and gradual stabilization.
Our contributions are: (1) We demonstrate that mechanistic features can reliably distinguish recall from reasoning with 93% accuracy, (2) We provide interpretable insights into the internal signatures of these cognitive processes, and (3) We offer a practical tool for contamination detection that works without access to training data.
2. Methodology
2.1. Framework Architecture
RADAR operates through three integrated components: (1) Mechanistic Analyzer that extracts internal model states, (2) Feature Extraction that computes surface and mechanistic features, and (3) Classifier that predicts recall vs. reasoning, , as illustrated in Figure 1..
The Mechanistic Analyzer interfaces with target LLMs (e.g., DialoGPT-medium) configured to output attention weights and hidden states. For each prompt, it analyzes attention patterns across all heads and layers, computing entropy and specialization metrics, and examines hidden state dynamics, including variance, norms, and effective rank.
2.2. Feature Engineering
We extract 37 features organized into two complementary categories:
Surface Features (17): Derived from the model’s output trajectory across layers, these features capture prediction dynamics through confidence statistics (mean, std, max, min, range), convergence properties (layer, speed, slope), entropy measures (mean, change, information gain), and stability metrics.
Mechanistic Features (20): Derived from attention weights and hidden states across all layers and heads, these features capture internal computational mechanisms, including attention specialization (specialized heads, specialization scores, entropy), circuit dynamics (depth, complexity, activation flow), intervention sensitivity (ablation robustness, critical components), working memory (hidden state variance, norm trajectories), and causal effects (logit attribution, mediation scores).
2.3. Classification System
The classification module employs an ensemble of four supervised learning models: Random Forest[7], Gradient Boosting[8], Support Vector Machine (SVM)[9], and Logistic Regression[10]. Each model is trained on the extracted feature vectors after normalization with StandardScaler. The scaling ensures zero mean and unit variance across features:
where and denote the mean and standard deviation of feature i.
For prediction, each base classifier (with ) outputs a hard label and a probability estimate , where corresponds to recall and to reasoning. The ensemble aggregates these outputs as:
The final confidence score is defined consistently with the predicted label:
3. Experiments and Results
3.1. Experimental Setup and Results
We curated two datasets: a balanced training set (30 examples: 15 recall, 15 reasoning) and a diverse test set (100 examples: 20 clear recall, 20 clear reasoning, 30 challenging cases, 30 complex reasoning). The classifier achieved 96.7% cross-validation accuracy during training.
RADAR achieved an overall accuracy of 93.0% on the test set, with task-specific performance of 97.7% on recall tasks and 89.3% on reasoning tasks. A detailed breakdown of performance across different categories is shown in Table 1.
3.2. Feature Analysis
Key discriminative features include specialized attention heads (higher for recall), circuit complexity (higher for reasoning), and confidence convergence patterns (faster for recall). Recall tasks showed a mean Recall Detection Score (RDS) of 0.933 compared to 0.375 for reasoning, demonstrating clear separability, as shown in Figure 2.
Surface features revealed that recall tasks exhibit higher early confidence and faster convergence, whereas reasoning tasks show gradual confidence build-up and later stabilization. Mechanistic features highlighted that recall relies on focused attention patterns and specialized heads, while reasoning engages broader network resources with higher activation flow variance. The scatter plot visualization confirms clear separation between recall and reasoning tasks in the RDS–RCI score space.
4. Discussion and Implications
4.1. Contamination Detection Applications
RADAR’s ability to distinguish recall from reasoning has direct implications for contamination detection. When reasoning-type prompts elicit recall-like internal signatures (high confidence, fast convergence, specialized attention), this indicates potential contamination where the model "knows" rather than "computes" the answer.
Our approach offers several benefits: (1) Works without access to training data, (2) Analyzes computational processes rather than just outputs, (3) Provides interpretable features explaining classifications, (4) Complements existing external detection methods, and (5) Scales to different model architectures.
4.2. Interpretability Insights
The feature analysis confirms that recall and reasoning leave distinct mechanistic signatures. Recall processes exhibit focused attention patterns with rapid confidence convergence, suggesting direct retrieval pathways. Reasoning processes show distributed attention, gradual confidence build-up, and higher circuit complexity, indicating multi-step computational processes engaging broader network resources. Top discriminative features (Specialized Heads, Circuit Complexity, Hidden State Variance) capture fundamental differences in how the model processes information, providing interpretable insights into the underlying cognitive mechanisms.
5. Conclusion
RADAR demonstrates that mechanistic interpretability can effectively detect data contamination by analyzing internal LLM processing signatures. Our framework achieves 93% accuracy in distinguishing recall from reasoning, providing interpretable insights into the cognitive processes underlying model responses. This work opens new directions for LLM evaluation that move beyond surface-level metrics to examine computational mechanisms. The ability to detect contamination without training data access, combined with interpretable mechanistic features, makes RADAR a valuable tool for improving LLM evaluation reliability.
Future work will explore scaling to larger models, developing unsupervised detection methods, and extending to other contamination types. The integration of mechanistic interpretability with traditional evaluation methods promises more robust and trustworthy LLM assessment frameworks.
Appendix A. Implementation Details
Appendix A.1. Model Configuration
The target model (microsoft/DialoGPT-medium) was configured with output_attentions=True and output_hidden_states=True. Analysis focused on input prompt tokens to capture reasoning during comprehension.
Appendix A.2. Feature Computation
Surface features tracked confidence and entropy trajectories across layers. Mechanistic features analyzed attention weight distributions using entropy measures and computed hidden state statistics including effective rank via SVD decomposition.
Appendix A.3. Training Procedure
Features were preprocessed and standardized using StandardScaler. Each ensemble model was trained with k-fold cross-validation for robust performance estimation.
Appendix B. Training and Test Datasets
This appendix provides details on the datasets used for training and evaluating the Enhanced RADAR Framework’s Recall–Reasoning Classifier.
Appendix B.1. Training Dataset
The training dataset was used exclusively for training the classifier. It consists of 30 examples, each containing a prompt and a corresponding label indicating whether the expected response is based on “recall” or “reasoning.” The composition is as follows:

Table A1.
Composition of the training dataset.
| Category | Count |
|---|---|
| Total Examples | 30 |
| Recall Examples | 15 |
| Reasoning Examples | 15 |
This dataset provides the classifier with a basic representation of the internal features and patterns that distinguish factual retrieval from logical inference. Representative examples are shown below:
Table A2.
Sample training dataset prompts and labels.
| Prompt | Label |
|---|---|
| “The capital of France is” | recall |
| “If X is the capital of France, then X is” | reasoning |
| “2 + 2 equals” | recall |
| “If a triangle has angles 60, 60, and X degrees, then X equals” | reasoning |
Appendix B.2. Test Dataset
The test dataset was used only for evaluating the trained classifier on unseen data. It comprises 100 examples, with broader coverage to assess generalization across different levels of difficulty and ambiguity:
Table A3.
Composition of the test dataset.
| Category | Count |
|---|---|
| Total Examples | 100 |
| Clear Recall Examples | 20 |
| Clear Reasoning Examples | 20 |
| Challenging/Ambiguous Cases | 30 |
| Complex Reasoning Cases | 30 |
The inclusion of challenging and complex reasoning cases is important for evaluating robustness, especially in detecting possible data contamination where a reasoning task could be solved by recall.
Examples from each category are shown below:
Table A4.
Sample test dataset prompts by category.
| Category | Example Prompt | Label |
|---|---|---|
| Clear Recall | “The capital of Germany is” | recall |
| Clear Reasoning | “If a rectangle has length 5 and width 3, its area is” | reasoning |
| Challenging/Ambiguous | “What is the sum of 10 and 15?” | reasoning |
| Complex Reasoning | “If a store has 100 items and sells 30% of them, how many items remain?” | reasoning |
Appendix B.3. Why Challenging or Ambiguous Prompts Are Difficult
Challenging or ambiguous prompts are difficult because they blur the line between recall and reasoning.
- Some prompts may appear to require reasoning (e.g., arithmetic) but can be solved by memorized recall if the model has seen similar examples during training.
- Conversely, some factual prompts may trigger reasoning-like processing if the information is incomplete or framed indirectly.
- Ambiguity arises when the surface form of the task does not clearly signal whether the solution requires stored knowledge or active inference.
These cases are crucial for evaluation because they reveal whether the classifier is robust to subtle shifts in task framing and whether it can correctly separate recall-driven answers from reasoning-based ones.
Appendix C. Scoring
In addition to the binary classification, the RADAR Framework computes several continuous scores that provide a more nuanced perspective:
- Recall Detection Score (RDS): Indicates how strongly the analysis suggests a recall-based process, combining specific surface and mechanistic features.
- Reasoning Complexity Index (RCI): Reflects the complexity and depth of processing, suggesting a reasoning-based process. Derived from a combination of surface and mechanistic features.
- Mechanistic Score: Focuses on features related to causal effects and intervention sensitivity.
- Circuit Complexity Score: Based on features describing the depth and complexity of the activated computational graph.
These scores are calculated using predefined formulas that weigh different features according to their relevance to recall and reasoning processes. They provide complementary information to the classifier’s binary output.
Appendix D. Feature Documentation
The RADAR (Recall And Deliberative Analysis of Reasoning) Framework extracts 37 features from language model behavior to distinguish between recall-based and reasoning-based tasks. These features are organized into two categories: Surface Features (16 features) that capture observable trajectory patterns, and Mechanistic Features (21 features) that analyze internal model dynamics through attention patterns and activation analysis.
Appendix D.1. Surface Features (16 Features)
Surface features analyze the confidence and entropy trajectories across all model layers to capture behavioral patterns without requiring deep mechanistic analysis.
Appendix D.1.1. Confidence-Based Features (8 Features)
| Feature | Type | Definition & Computation |
| mean_confidence | float | Mean confidence across all layers: where is the maximum softmax probability at layer l, and L is the total number of layers. |
| std_confidence | float | Standard deviation of confidence trajectory: . Higher values indicate more variable confidence across layers. |
| max_confidence | float | Maximum confidence achieved: . Indicates peak certainty reached by the model. |
| min_confidence | float | Minimum confidence observed: . Represents lowest certainty point in processing. |
| confidence_range | float | Range of confidence values: . Measures the span of confidence variation across layers. |
| convergence_layer | int | Layer index where maximum confidence is achieved: . Earlier convergence may indicate simpler recall tasks. |
| convergence_speed | float | Inverse of convergence layer: . Higher values indicate faster convergence to high confidence. |
| confidence_slope | float | Linear regression slope of confidence trajectory: where . Positive slopes indicate increasing confidence. |
Appendix D.1.2. Trajectory Dynamics Features (4 Features)
| Feature | Type | Definition & Computation |
| oscillation_count | int | Number of sign changes in the discrete confidence derivative. Let for . Then oscillation_count i.e., consecutive derivatives with opposite sign. Zeros in are ignored for sign changes. |
| early_confidence | float | Mean confidence in the first half of layers:
|
| late_confidence | float | Mean confidence in the second half of layers:
|
| prediction_stability | float | Inverse of confidence standard deviation:
|
Appendix D.1.3. Information-Theoretic Features (4 Features)
| Feature | Type | Definition & Computation |
| mean_entropy | float | Average entropy across layers:
|
| entropy_change | float | Change from first to last layer:
|
| information_gain | float | Negative entropy change:
|
| layer_consistency | float | Inverse of entropy standard deviation:
|
Appendix D.2. Mechanistic Features (21 Features)
Mechanistic features analyze internal model dynamics through attention patterns, activation flows, and causal intervention proxies to understand the computational mechanisms underlying different task types.
Appendix D.2.1. Attention Specialization Features (5 Features)
| Feature | Type | Definition & Computation |
| num_specialized_heads | int | Total count of attention heads with entropy below a specialization threshold (typically ):
|
| head_specialization_score | float | Normalized specialization measure:
|
| factual_head_activation | float | Inverse relationship with attention entropy:
|
| reasoning_head_activation | float | Proportional to attention entropy:
|
| attention_entropy | float | Mean entropy across all attention heads:
|
Appendix D.2.2. Circuit Dynamics Features (4 Features)
| Feature | Type | Definition & Computation |
| effective_circuit_depth | float | Number of layers with significant causal effects. Equal to the number of attention layers analyzed. Represents the depth of the computational circuit. |
| circuit_complexity | float | Product of variance and norm growth:
|
| activation_flow_variance | float | Variance in activation magnitudes across layers. Measures how much activation patterns change between layers, indicating computational complexity. |
| causal_path_length | float | Length of the causal computation path. Currently equal to circuit depth, representing the number of processing steps in the causal chain. |
Appendix D.2.3. Intervention Sensitivity Features (4 Features)
| Feature | Type | Definition & Computation |
| ablation_robustness | float | Robustness to component removal:
|
| critical_component_count | int | Number of critical components:
|
| performance_degradation_slope | float | Rate of performance degradation under intervention:
|
| intervention_sensitivity | float | Sensitivity to interventions:
|
Appendix D.2.4. Working Memory Features (4 Features)
| Feature | Type | Definition & Computation |
| hidden_state_variance | float | Variance in hidden state activations. Measures variability in internal representations across layers, indicating working memory usage. |
| norm_growth_trajectory | float | Growth pattern of activation norms. tracks how activation magnitudes change across layers, indicating information accumulation. |
| working_memory_complexity | float | Complexity of working memory usage. Currently uses rank evolution as a proxy for working memory complexity. |
| state_rank_evolution | float | Evolution of representation rank. measures how the effective dimensionality of representations changes across layers. |
Appendix D.2.5. Causal Effect Features (4 Features)
| Feature | Type | Definition & Computation |
| direct_logit_attribution | float | Direct causal effect on output:
|
| indirect_effect_strength | float | Strength of indirect causal effects:
|
| causal_mediation_score | float | Mediation effect strength:
|
| activation_patching_effect | float | Proxy measure for activation patching:
|
Appendix E. Feature Computation Pipeline
Appendix E.1. Surface Feature Extraction
- Extract confidence trajectory:
- Extract entropy trajectory:
- Compute statistical measures: mean, standard deviation, minimum, maximum, and range.
- Analyze trajectory dynamics: slope, oscillations, and convergence properties.
- Calculate information-theoretic measures.
Appendix E.2. Mechanistic Feature Extraction
- Analyze attention patterns across all layers and heads.
- Compute attention entropy for each head:
- Identify specialized heads:
- Analyze activation patterns (variance, norms, and rank evolution).
- Compute proxy causal effects from attention entropy.
- Calculate intervention sensitivity measures.
Appendix F. Important Notes and Limitations
Appendix F.1. Proxy Measures
Several features rely on proxy measures rather than direct computation:
- Causal effects: Derived from attention entropy instead of actual interventions.
- Activation patching: Approximated via attention entropy proxy, not true patching experiments.
- Critical components: Approximated using specialized head counts.
- Working memory: Approximated using rank evolution as a complexity proxy.
Appendix F.2. Computational Considerations
- All features can be computed in a single forward pass.
- No gradient computation is required for feature extraction.
- Attention patterns are analyzed across all layers and heads.
- Surface features require only the output probability distributions.
Appendix G. Usage in Classification
The 37 features are concatenated into a single feature vector:
This vector is then used to train classifiers (Random Forest, Gradient Boosting, SVM, Logistic Regression) to distinguish between recall and reasoning tasks.
References
- Golchin, S.; Surdeanu, M. Time travel in llms: Tracing data contamination in large language models. arXiv preprint arXiv:2308.08493, arXiv:2308.08493 2023.
- Deng, C.; Zhao, Y.; Tang, X.; Gerstein, M. Investigating data contamination in modern benchmarks for large language models. arXiv preprint arXiv:2311.09783, arXiv:2311.09783 2023.
- Feldman, V. Does learning require memorization? a short tale about a long tail. In Proceedings of the Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, 2020, pp.
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21); 2021; pp. 2633–2650. [Google Scholar]
- Elhage, N.; Nanda, N.; Olsson, C.; Henighan, T.; Joseph, N.; Mann, B.; et al. A mathematical framework for transformer circuits. Anthropic 2021. [Google Scholar]
- Olah, C.; Cammarata, N.; Schubert, L.; Goh, G.; Petrov, M.; Carter, S. Zoom in: An introduction to circuits. Distill 2020, 5, e00024–001. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Machine learning 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Annals of statistics, 1189. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Machine learning 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; Wiley, 2013.
Figure 1.
RADAR Framework Architecture: Input prompts are processed by the Mechanistic Analyzer to extract internal states, which are converted to Surface and Mechanistic Features, then classified by an ensemble to predict recall vs. reasoning with confidence scores.
Figure 1.
RADAR Framework Architecture: Input prompts are processed by the Mechanistic Analyzer to extract internal states, which are converted to Surface and Mechanistic Features, then classified by an ensemble to predict recall vs. reasoning with confidence scores.
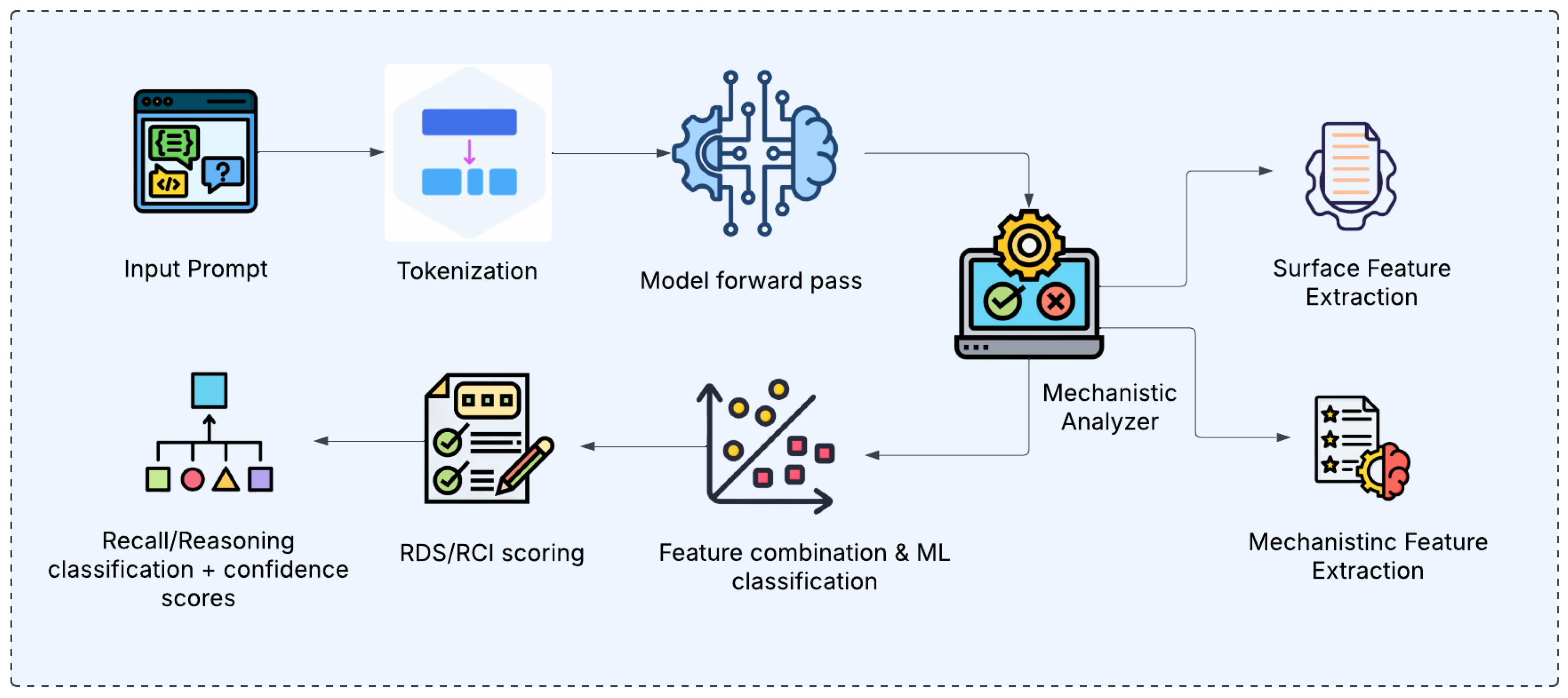
Figure 2.
RADAR Feature Analysis: Comparison of surface and mechanistic features for recall and reasoning tasks, highlighting top discriminative features and RDS–RCI score distribution. The results show recall tasks characterized by early confidence and specialized heads, while reasoning tasks rely on broader circuit complexity and higher activation flow variance. The scatter plot demonstrates strong clustering, with recall tasks in the high-RDS region and reasoning tasks distributed in lower-RDS regions.
Figure 2.
RADAR Feature Analysis: Comparison of surface and mechanistic features for recall and reasoning tasks, highlighting top discriminative features and RDS–RCI score distribution. The results show recall tasks characterized by early confidence and specialized heads, while reasoning tasks rely on broader circuit complexity and higher activation flow variance. The scatter plot demonstrates strong clustering, with recall tasks in the high-RDS region and reasoning tasks distributed in lower-RDS regions.
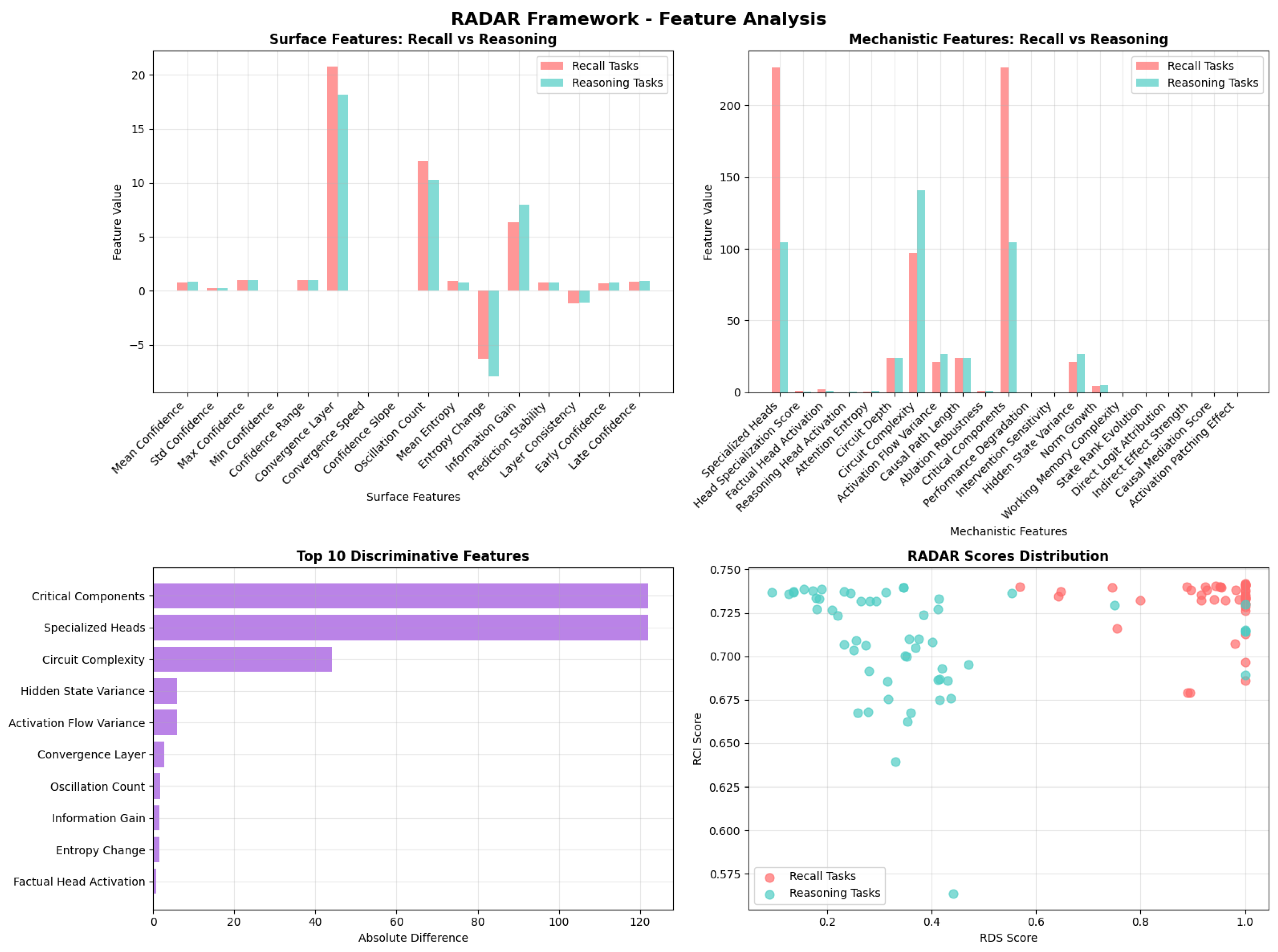
Table 1.
RADAR Performance Results.
| Overall Performance | Category-wise Performance | ||
|---|---|---|---|
| Overall Accuracy | 93.0% | Clear Recall | 100% (20/20) |
| Recall Tasks | 97.7% | Clear Reasoning | 100% (20/20) |
| Reasoning Tasks | 89.3% | Challenging Cases | 76.7% (23/30) |
| Complex Reasoning | 100% (30/30) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



