Submitted:
29 May 2025
Posted:
29 May 2025
You are already at the latest version
Abstract
The rise of machine learning is enhancing various products in the software industry in a variety of ways by applying a diverse set of algorithms. One such application is to verify whether a sentence is grammatically correct or not. We find the use of such applications in Writing Assistance tools, Language Learning platforms, Automated Scoring platforms, Content Moderation platforms, and Email platforms. In our research, we present Sentence Classification using Transfer Learning with BERT (Bidirectional Encoder Representations from Transformers). We leverage transfer learning with the Hugging Face Transformers library to fine-tune the BERT model, incorporating hyperparameter sweeps via Weights and Biases to optimize learning rate, batch size, and the number of epochs. The process involves downloading and preprocessing the dataset, tokenizing sentences with the BERT tokenizer, and preparing input data with special tokens, padding, and attention masks. The dataset is split into training and validation sets, and a custom training loop is implemented to fine-tune the model, logging performance metrics to Weights and Biases. Additionally, a test function is provided to predict the grammaticality of example sentences using the fine-tuned model.
Keywords:
BERT
; Transfer Learning
; Classification
; Fine-Tuning
; Transformers
1. Introduction
The growth of artificial intelligence is fueled by several factors, including abundant data, transformer models, and high-performance computing powered by GPUs. These technological advancements have led to the creation of powerful models, particularly BERT (Bidirectional Encoder Representations from Transformers). After the discovery of the transformer model, the artificial intelligence race has accelerated. The exceptional performance of artificial intelligence models (e.g., BERT) and their access through user-friendly interfaces have brought classification to the forefront of daily and commonplace use. Techniques like classification are involved in building application features like Document Classification. Now, artificial intelligence is transforming the world, driving innovations in a wide range of industries and emerging applications.
The field of natural language processing has significantly advanced with the adoption of BERT-based models for grammatical error correction (GEC), offering robust solutions for improving text quality across various applications. These models harness BERT’s contextual embeddings to accurately detect and correct grammatical errors, enhancing the clarity of written communication. For instance, [1] demonstrates how fine-tuning BERT within an encoder-decoder framework improves GEC performance, making it suitable for applications requiring precise text corrections. The GECToR model, as described in [2], utilizes BERT to predict token-level edit operations, enabling efficient grammar corrections in diverse contexts. Similarly, [3] introduces Seq2Edits, which leverages BERT for span-level edit predictions, addressing complex errors in professional and creative writing. The iterative editing approach in [4] uses BERT to refine text through multiple passes, ideal for high-stakes writing tasks. Additionally, [5] employs BERT with synthetic data to enhance GEC robustness, broadening its applicability across varied linguistic scenarios.
2. Identifying the Research Gap and Contribution
Despite the progress in BERT-based GEC, a notable gap remains in deploying these models in resource-constrained, real-world settings outside of controlled research environments [1]. Existing studies often prioritize model accuracy over practical challenges like computational efficiency and adaptability to diverse text domains. Our research aims to address this in future by developing a BERT-based GEC system optimized for general-purpose applications, utilizing Parameter-Efficient Fine-Tuning (PEFT) techniques such as LoRA and Prompt Tuning to minimize computational overhead. We incorporate zero-shot and few-shot inference strategies to ensure flexibility across different writing styles and genres. Model performance is evaluated using ROUGE and error-type classification metrics, ensuring reliable corrections. This work bridges the divide between theoretical GEC advancements and practical, scalable solutions, enabling broader adoption in professional, creative, and technical writing contexts.
3. Preliminaries of Classification Models for Text Processing
Classification models for text processing aim to categorize or label textual data, enabling tasks such as grammatical error correction (GEC), sentiment analysis, and named entity recognition. These models learn to map input text to discrete outputs, using contextual or sequential patterns in the data. A variety of classification models, including transformer-based models like BERT and non-transformer approaches like LSTMs and CNNs, have been applied to text processing challenges. In this section, we present the preliminaries of these models, as illustrated in Figure 1.
3.1. BERT (Bidirectional Encoder Representations from Transformers)
BERT is a transformer-based model that leverages bidirectional context to understand text, pre-trained on large corpora using masked language modeling and next-sentence prediction. It consists of stacked encoder layers that process input text in parallel, capturing deep contextual relationships. Fine-tuning BERT for classification tasks, such as GEC, involves adding a task-specific layer to predict labels or edit operations. Its bidirectional nature allows it to excel in tasks requiring nuanced understanding of text, making it highly effective for applications like error detection and correction.
3.2. RoBERTa (Robustly Optimized BERT Approach)
RoBERTa builds on BERT by optimizing its pre-training process, using larger datasets, longer training times, and removing the next-sentence prediction objective. It employs dynamic masking and larger batch sizes to improve contextual representations. For classification tasks, RoBERTa’s enhanced embeddings lead to superior performance in applications like GEC and sentiment analysis, offering robustness in handling diverse text inputs. Its architecture remains similar to BERT but delivers improved accuracy due to refined pre-training strategies [6].
3.3. DistilBERT
DistilBERT is a distilled version of BERT, designed to be smaller and faster while retaining most of BERT’s performance. It reduces parameters by 40 percent through knowledge distillation, where a smaller model is trained to mimic BERT’s outputs. This makes DistilBERT ideal for resource-constrained environments, such as real-time text classification or GEC on mobile devices. Despite its reduced size, it maintains strong performance in tasks like error correction and sequence labeling, balancing efficiency and accuracy [7].
3.4. ELECTRA
ELECTRA introduces a novel pre-training approach where the model acts as a discriminator, distinguishing real tokens from generated replacements in a text. Unlike BERT’s generative pre-training, ELECTRA’s discriminative task makes it more sample-efficient, achieving high performance with less computational cost. For classification tasks like GEC, ELECTRA excels in detecting subtle errors and predicting corrections, offering a scalable alternative for text processing applications [8].
3.5. Long Short-Term Memory (LSTM) Networks
LSTMs are recurrent neural networks designed to capture long-term dependencies in sequential data, making them suitable for text classification tasks. They use memory cells and gates to regulate information flow, mitigating issues like vanishing gradients. While less contextually rich than transformers, LSTMs are effective for tasks like sentiment analysis and GEC in resource-limited settings, especially when paired with word embeddings like GloVe or Word2Vec. Their sequential processing suits applications where computational resources are constrained [9].
3.6. Convolutional Neural Networks (CNNs) for Text
CNNs for text processing apply convolutional layers to capture local patterns, such as n-grams, in text data. These models excel in extracting features from fixed-size windows of text, making them efficient for tasks like sentiment classification or topic categorization. While not as adept at capturing long-range dependencies as transformers, CNNs offer computational simplicity and are effective for short-text classification or as a complement to other models in hybrid architectures [10].
The various classification models exhibit different strengths in terms of contextual understanding, computational efficiency, and adaptability to specific tasks. Transformer-based models like BERT, RoBERTa, DistilBERT, and ELECTRA dominate in tasks requiring deep contextual analysis, such as GEC, due to their bidirectional processing and large-scale pre-training. Non-transformer models like LSTMs and CNNs provide lightweight alternatives for simpler tasks or constrained environments. Combining the strengths of these models, where feasible, can enhance performance for complex text processing applications.
4. BERT for Sentence Classification
Sentence classification models like BERT have been widely adopted in educational applications due to their ability to understand contextual nuances in text and classify sentences or text segments with high accuracy. This section provides examples of how BERT and similar models are applied in educational contexts, focusing on practical implementations.
4.1. Student Support and Personalized Learning
BERT-based models are used in educational platforms to classify student responses, feedback, or queries, enabling personalized learning experiences. For example, BERT can analyze open-ended student answers in online assessments to classify them as correct, partially correct, or incorrect, providing immediate feedback. Platforms like Duolingo leverage BERT-like models to classify learner responses in language exercises, identifying error types (e.g., grammar, vocabulary) and tailoring subsequent exercises to address specific weaknesses. Similarly, tools like Quizlet use BERT to classify flashcard responses, adapting difficulty based on user performance.
4.2. Faculty and Administrative Assistance
BERT-based classifiers streamline grading and administrative tasks by automating the evaluation of written responses. For instance, EdX and Coursera employ BERT to classify short-answer responses in MOOCs, categorizing them into predefined rubrics for grading efficiency. These models can also detect sentiment in student feedback forms, helping faculty gauge course satisfaction or identify areas needing improvement. Additionally, BERT-powered chatbots, like those integrated into Canvas LMS, classify student inquiries (e.g., technical issues, course content queries) to route them to appropriate support channels, reducing administrative burden.
4.3. Curriculum Planning and Educational Analytics
In curriculum planning, BERT is used to classify and analyze educational content for alignment with learning objectives. Tools like Turnitin’s AI-powered features use BERT to classify student submissions for plagiarism or originality, while also identifying writing quality issues (e.g., coherence, clarity). Gradescope employs BERT-based models to classify patterns in student submissions, detecting common misconceptions or errors to inform curriculum adjustments. These models also support analytics by classifying student performance data into categories like “at-risk” or “proficient,” enabling targeted interventions.
4.4. Educational Standards Chatbots and Knowledge Access
BERT excels in classifying educational standards and aligning content with frameworks like Common Core or NGSS. For example, tools like Achieve3000 use BERT to classify reading passages by difficulty level and alignment with specific standards, ensuring content matches student needs. BERT-based chatbots, such as those developed by ETS, classify teacher queries about standards, retrieving relevant guidelines or suggesting aligned lesson plans. These models also support inclusive education by classifying text for readability, adapting materials for diverse learners, or detecting cultural biases in content.
4.5. Research Implementation: Sentiment Analysis for Classroom Feedback
Our research showcases a BERT-based sentence classification system for analyzing classroom feedback. Using a fine-tuned BERT model with adapters (e.g., AdapterHub), we classify student and teacher feedback into positive, negative, or neutral sentiments. The system employs transfer learning to adapt pre-trained BERT weights to educational datasets, achieving high accuracy on metrics like F1-score and precision. Toxicity detection is integrated using a secondary BERT classifier to flag inappropriate feedback, ensuring safe and constructive classroom interactions. This implementation demonstrates BERT’s potential for real-time, scalable feedback analysis in educational settings.
5. Design Aspects
The application of transfer learning with BERT has revolutionized natural language processing (NLP) tasks, particularly sentence classification, in educational contexts. Sentence classification, such as sentiment analysis of student feedback, topic categorization of classroom discussions, or automated grading of short-answer responses, benefits from BERT’s ability to capture contextual nuances in text. This section outlines the key design aspects for developing and deploying BERT-based sentence classification systems tailored to educational needs, ensuring scalability, efficiency, and domain-specific performance, as illustrated in Figure 2.
5.1. Model Architecture and Pre-Training
BERT’s transformer-based architecture leverages bidirectional contextual understanding, making it highly effective for sentence classification tasks. Unlike traditional unidirectional models, BERT processes text in both directions, capturing rich semantic relationships critical for educational applications. For instance, in sentiment analysis of student feedback, BERT can discern subtle emotional cues, distinguishing between nuanced responses like “The lecture was challenging but rewarding” and “The lecture was too difficult.”
The pre-trained BERT model, typically trained on large corpora like Wikipedia and BookCorpus, provides a robust foundation for transfer learning. In educational settings, the model is fine-tuned on domain-specific datasets, such as student feedback surveys, classroom discussion transcripts, or assessment responses. The architecture consists of multiple transformer layers, each with self-attention mechanisms, enabling the model to weigh the importance of words in context. For sentence classification, a classification head (e.g., a fully connected layer with softmax activation) is added to the final hidden state of the [CLS] token, which aggregates the sentence’s contextual representation.
Training and fine-tuning BERT require significant computational resources due to its large parameter set (e.g., 110M parameters for BERT-Base, 340M for BERT-Large). High-performance computing infrastructure, such as multi-GPU clusters with NVIDIA’s latest architectures, is essential to handle the computational load. These GPUs support mixed-precision training (e.g., FP16 and FP8), reducing memory usage and accelerating training while maintaining model accuracy through dynamic precision adjustments.
5.2. Fine-Tuning and Customization
Fine-tuning BERT for sentence classification involves adapting the pre-trained model to specific educational tasks. This process requires careful design to balance performance, resource efficiency, and domain relevance.
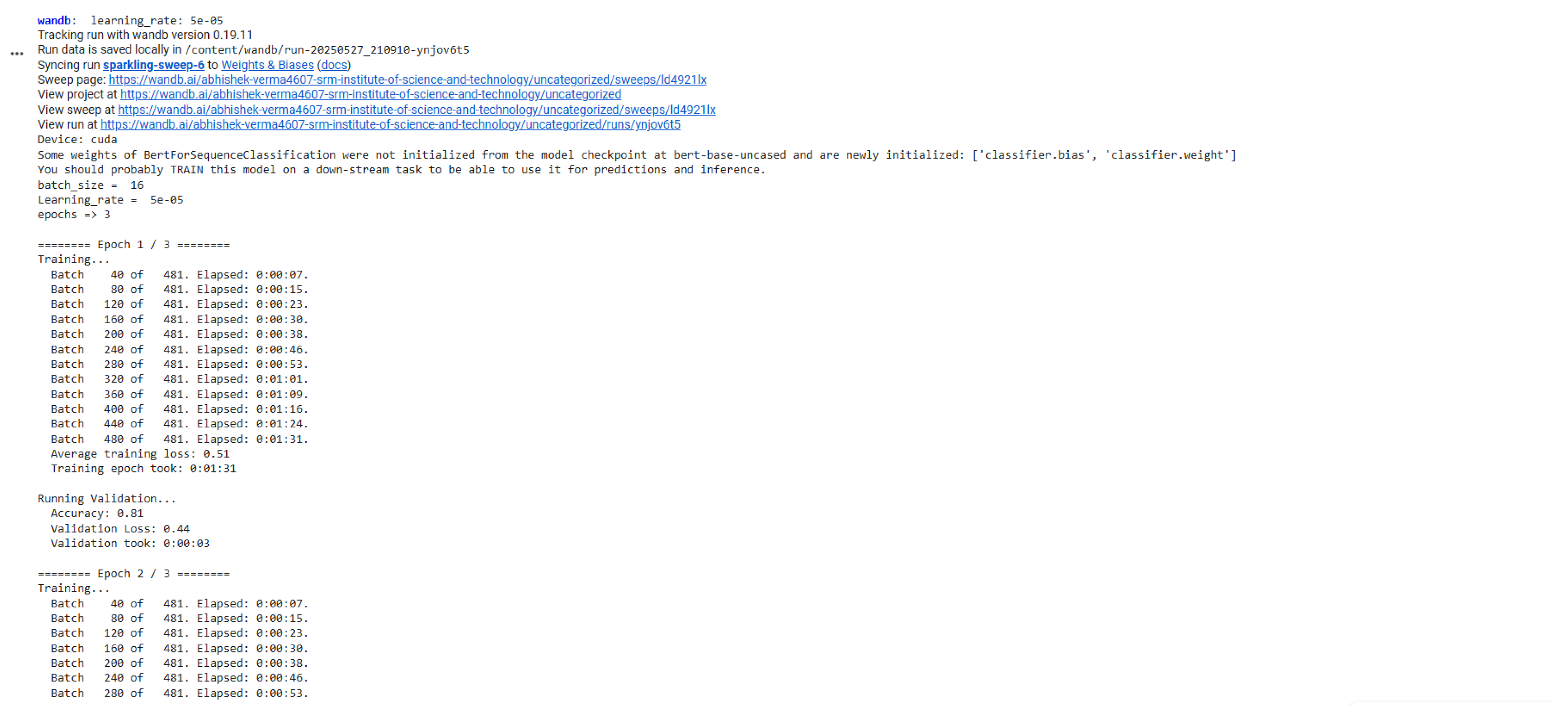
Fine-Tuning Process: Fine-tuning begins with loading a pre-trained BERT model, followed by appending a task-specific classification head. The model is then trained on a labeled dataset relevant to the educational task, such as categorizing student feedback into positive, neutral, or negative sentiments. The dataset is typically split into training, validation, and test sets to optimize hyperparameters (e.g., learning rate, batch size) and prevent overfitting. Techniques like gradient accumulation and learning rate scheduling (e.g., using a linear warmup followed by decay) ensure stable convergence, especially on smaller educational datasets.
Domain-Specific Customization: To enhance performance, the model is fine-tuned on education-specific datasets, such as course evaluations, open-ended quiz responses, or discussion forum posts. For example, a BERT model fine-tuned on a dataset of student essays can classify responses based on clarity or argumentative strength, supporting automated grading systems. Parameter-efficient fine-tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), are employed to update only a small subset of parameters, reducing computational costs while adapting the model to educational contexts.
Ethical Considerations and Bias Mitigation: Fine-tuning must address potential biases in educational datasets, such as skewed sentiment distributions or cultural biases in student responses. Techniques like reinforcement learning with human feedback (RLHF) or adversarial training can mitigate harmful biases, ensuring fair and inclusive outputs. Regular audits of model outputs and dataset curation are essential to maintain fairness.
5.3. Deployment and Inference Optimization
Deploying BERT-based sentence classification models in educational environments requires optimizing for low-latency inference and scalability to support real-time applications, such as live feedback analysis during virtual classes.
Inference Optimization: Techniques like model quantization (e.g., reducing weights to INT8 precision) and knowledge distillation (e.g., training a smaller “student” model from the BERT “teacher”) reduce inference time and resource demands. These optimizations are crucial for applications like real-time sentiment analysis in online learning platforms, where rapid response generation enhances user experience.
System Integration: The classification model is integrated with educational platforms, such as learning management systems (LMS) or virtual tutoring environments. APIs facilitate seamless interaction, allowing the model to process inputs (e.g., student comments) and return classifications (e.g., sentiment labels) in real time.
Scalability and Sustainability: High-performance computing infrastructure supports scalable deployment, leveraging cloud or on-premises GPU clusters to handle large-scale inference tasks. Energy-efficient hardware, such as GPUs with low-power modes, aligns with sustainable computing goals in educational institutions.
5.4. Evaluation and Monitoring
Continuous evaluation and monitoring ensure the BERT-based classifier remains effective and relevant in dynamic educational contexts.
Evaluation Metrics: Model performance is assessed using metrics like accuracy, precision, recall, and F1-score, tailored to the classification task. For imbalanced datasets, such as sentiment analysis with predominantly positive feedback, metrics like macro-F1 or area under the ROC curve (AUC-ROC) provide a balanced evaluation.
Monitoring and Retraining: Post-deployment, the model is monitored for performance drift, which may occur due to evolving educational contexts (e.g., new teaching methods or student demographics). Automated monitoring pipelines detect degradation in classification accuracy, triggering retraining with updated datasets.
6. Case Study: BERT-Based Sentence Classification for Grammatical Correction
In our research, we present Sentence Classification using Transfer Learning with BERT. We leverage transfer learning with the Hugging Face Transformers library to fine-tune the BERT model, incorporating hyperparameter sweeps via Weights and Biases to optimize learning rate, batch size, and the number of epochs. The process involves downloading and preprocessing the dataset, tokenizing sentences with the BERT tokenizer, and preparing input data with special tokens, padding, and attention masks. The dataset is split into training and validation sets, and a custom training loop is implemented to fine-tune the model, logging performance metrics to Weights and Biases. We also implement a prediction method to predict if a sentence is grammatically correct or not.
Figure 3.
Dataset Setup.
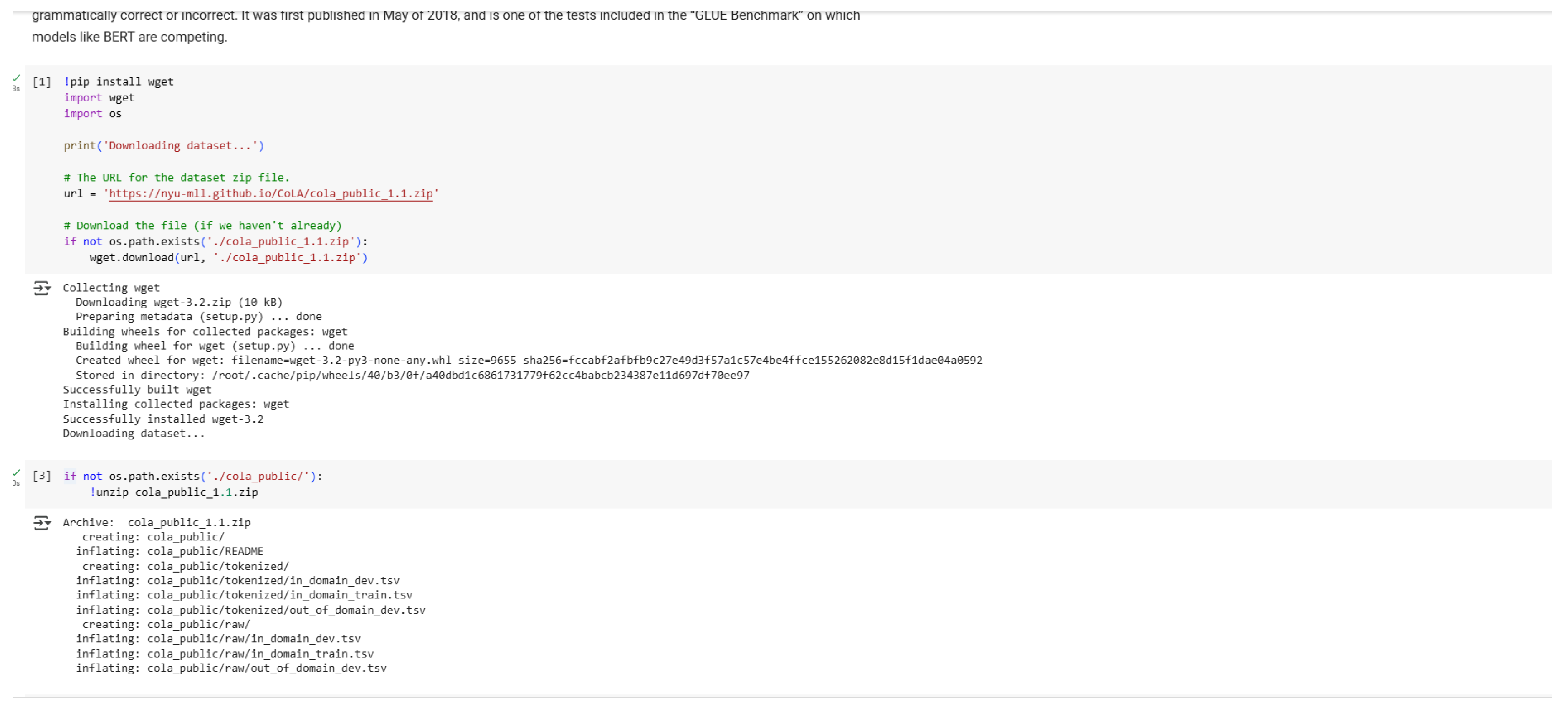
Figure 4.
Loading the Dataset.
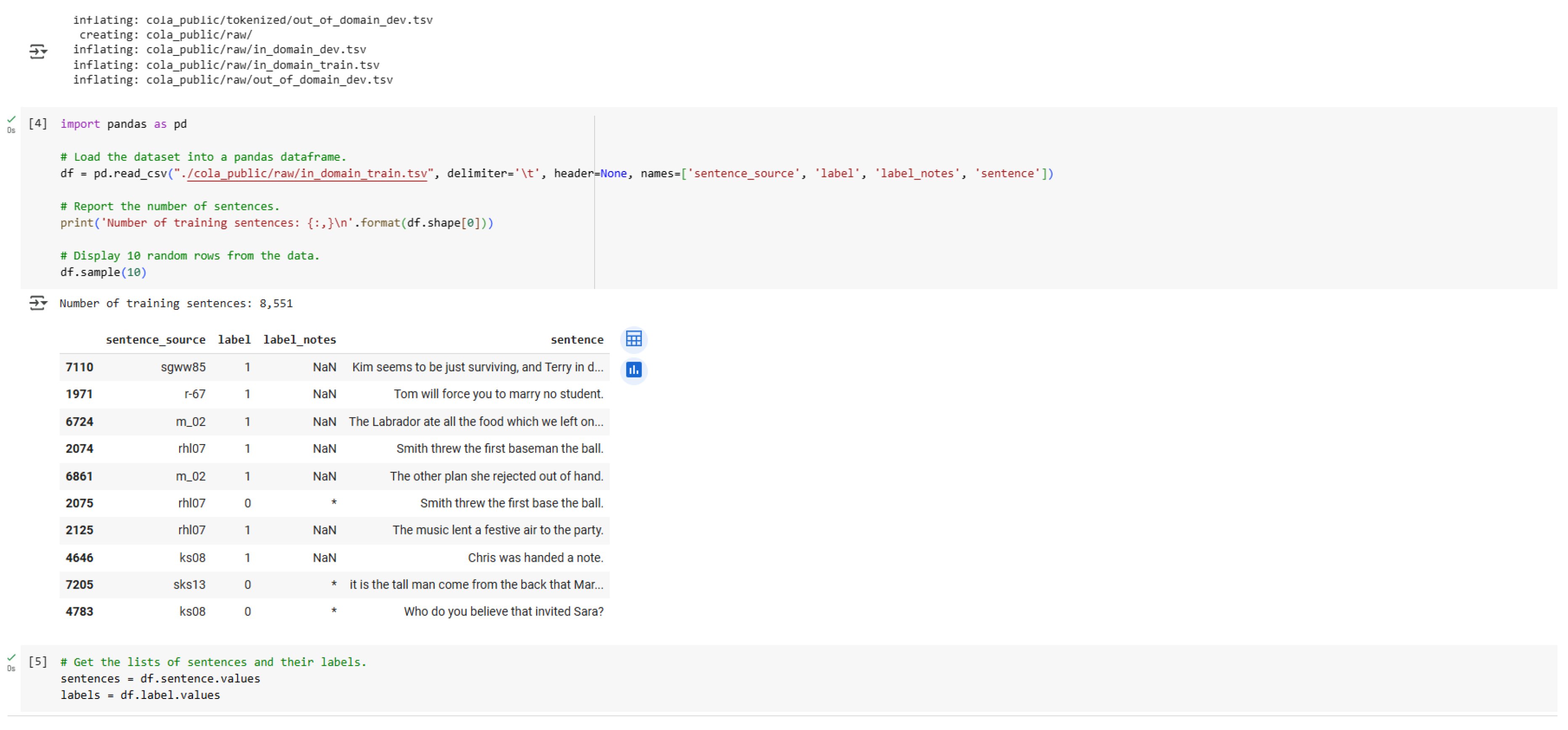
Figure 5.
Tokenization Process.
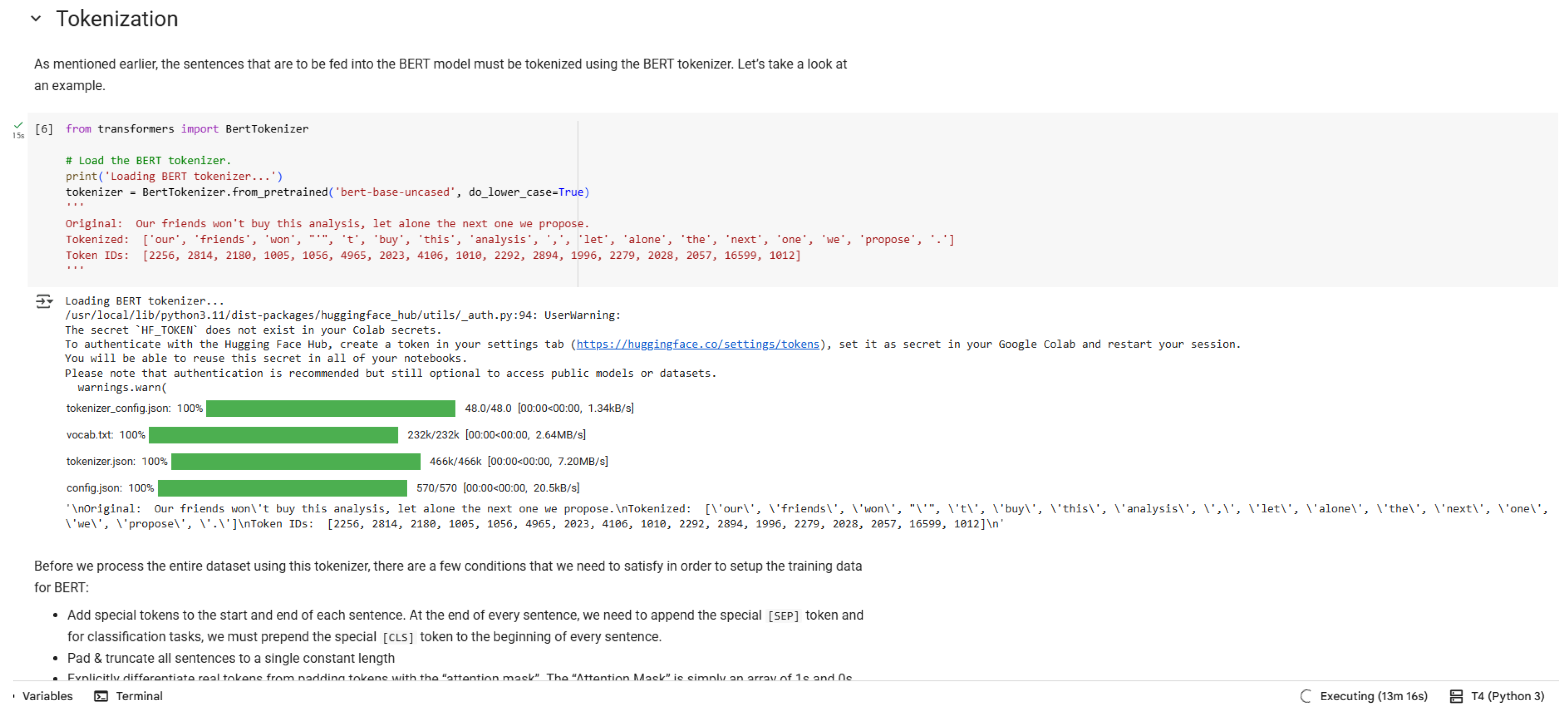
Figure 6.
Determining Maximum Sentence Length.
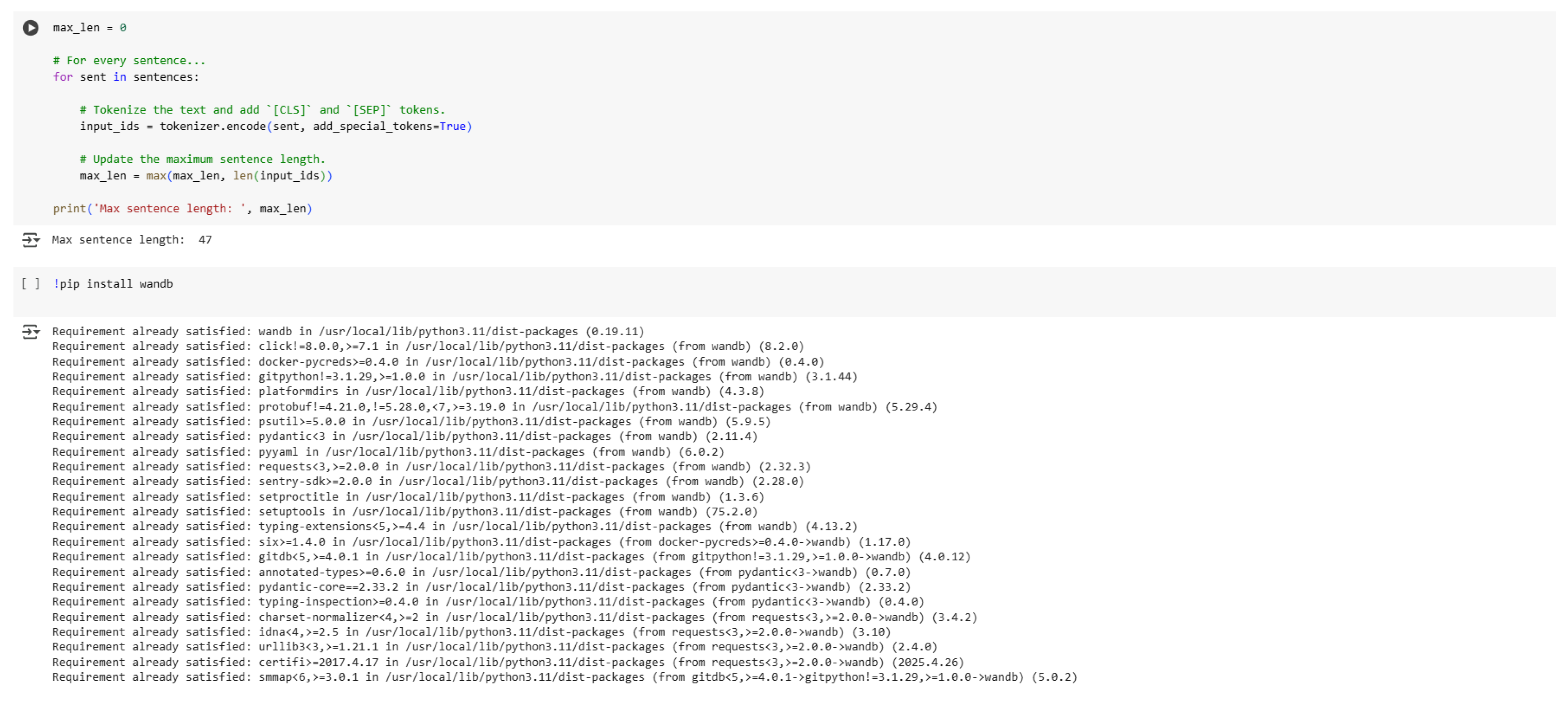
Figure 7.
Weights and Biases Sweep Configurations.
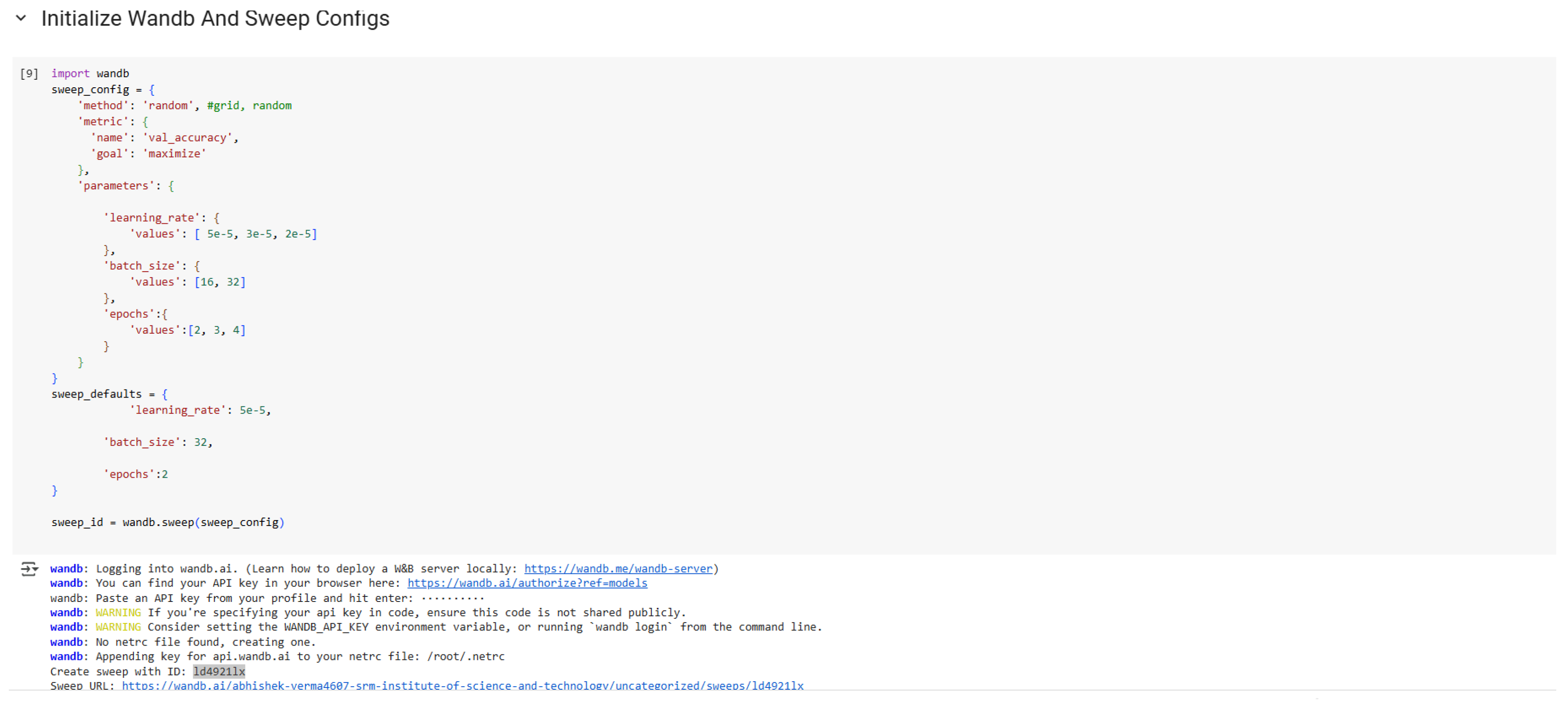
Figure 8.
Tokenization Implementation.
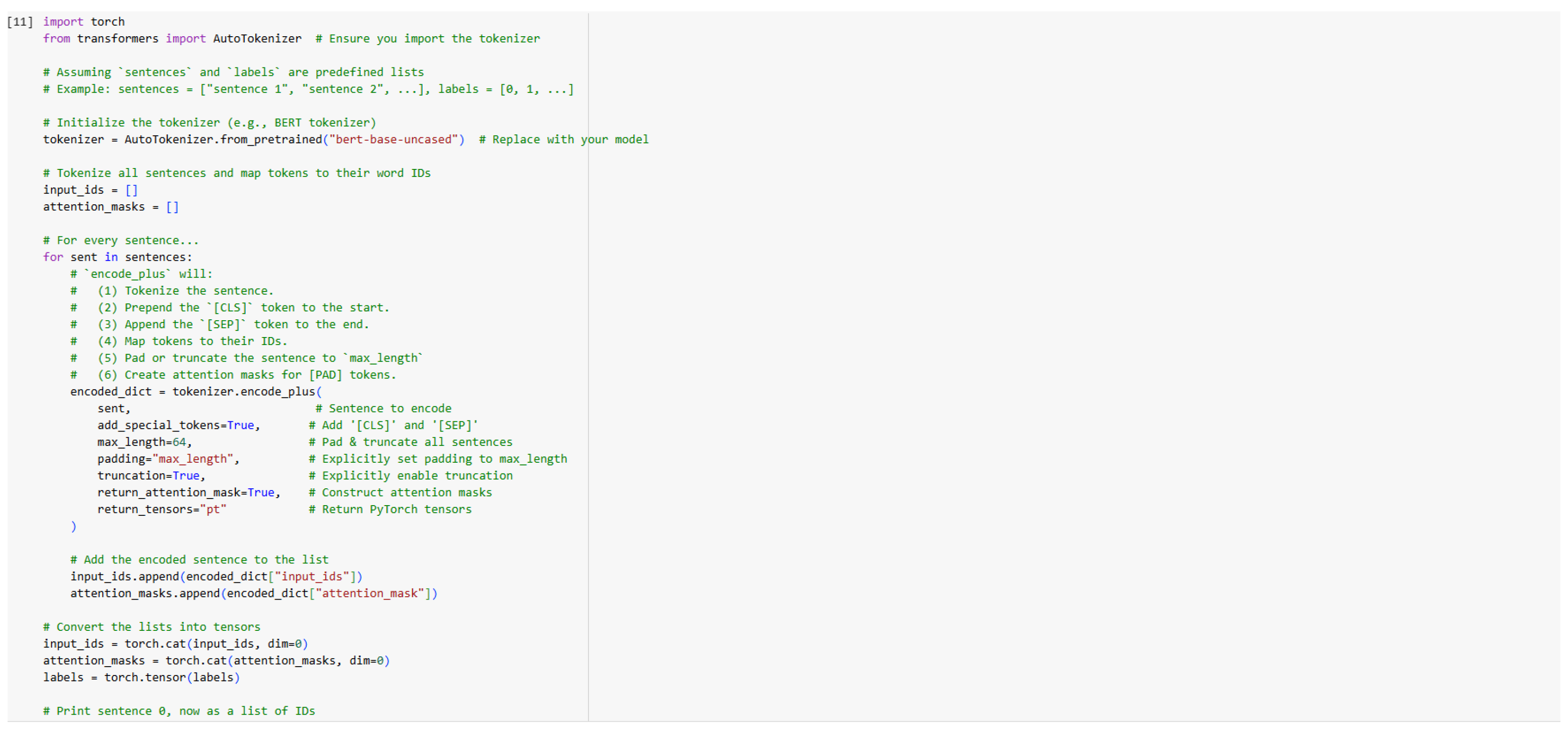
Figure 9.
Train-Test Split.
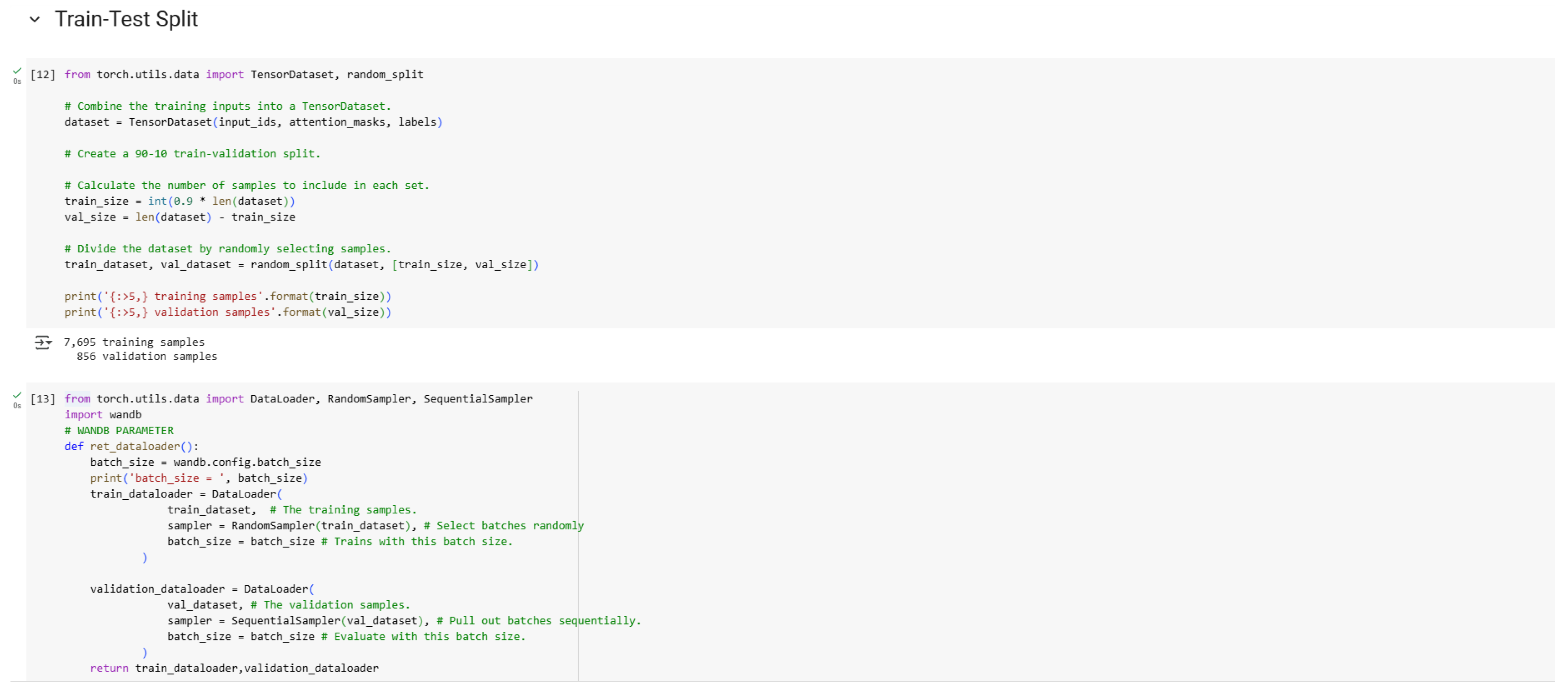
Figure 10.
Loading Pre-trained BERT Model.
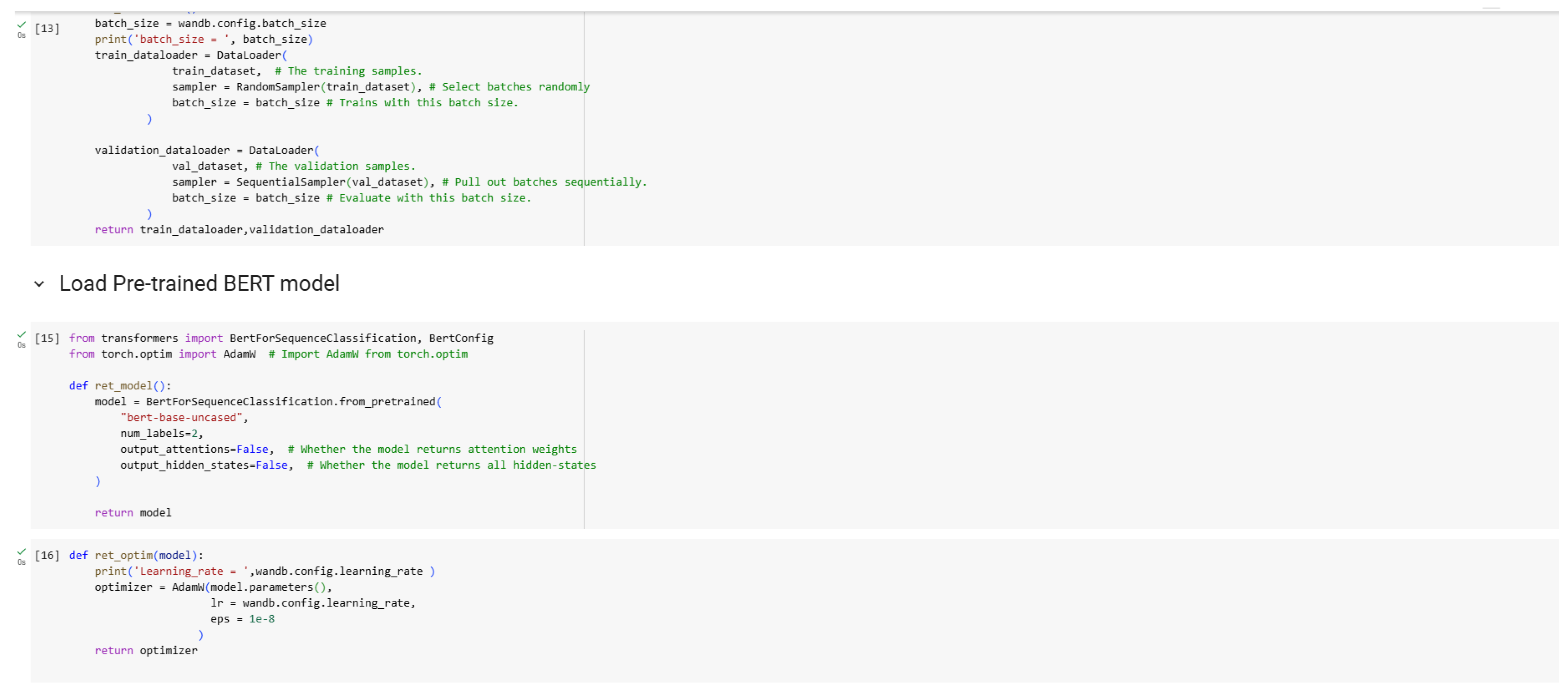
Figure 11.
Scheduler and Accuracy Prediction.
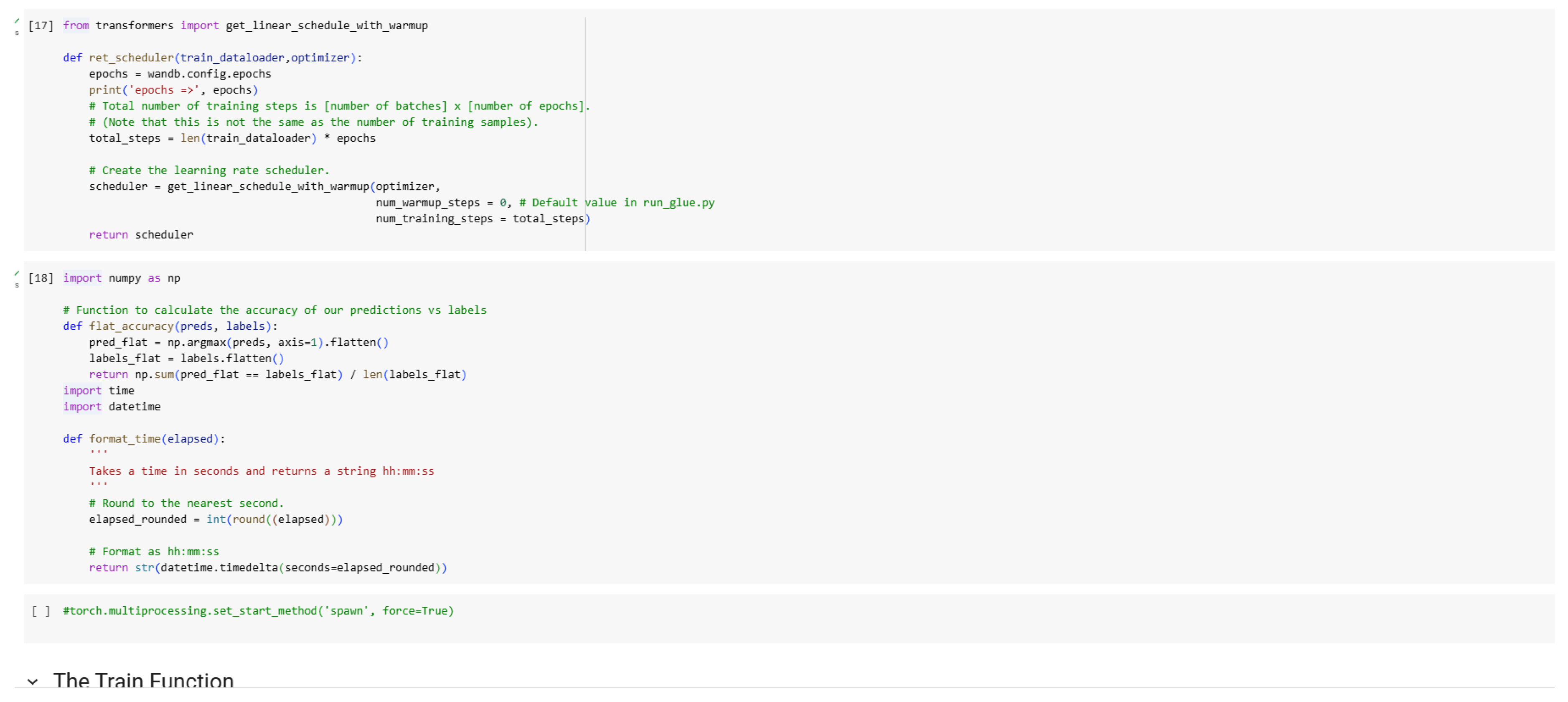
Figure 12.
Training Code (Part 1).
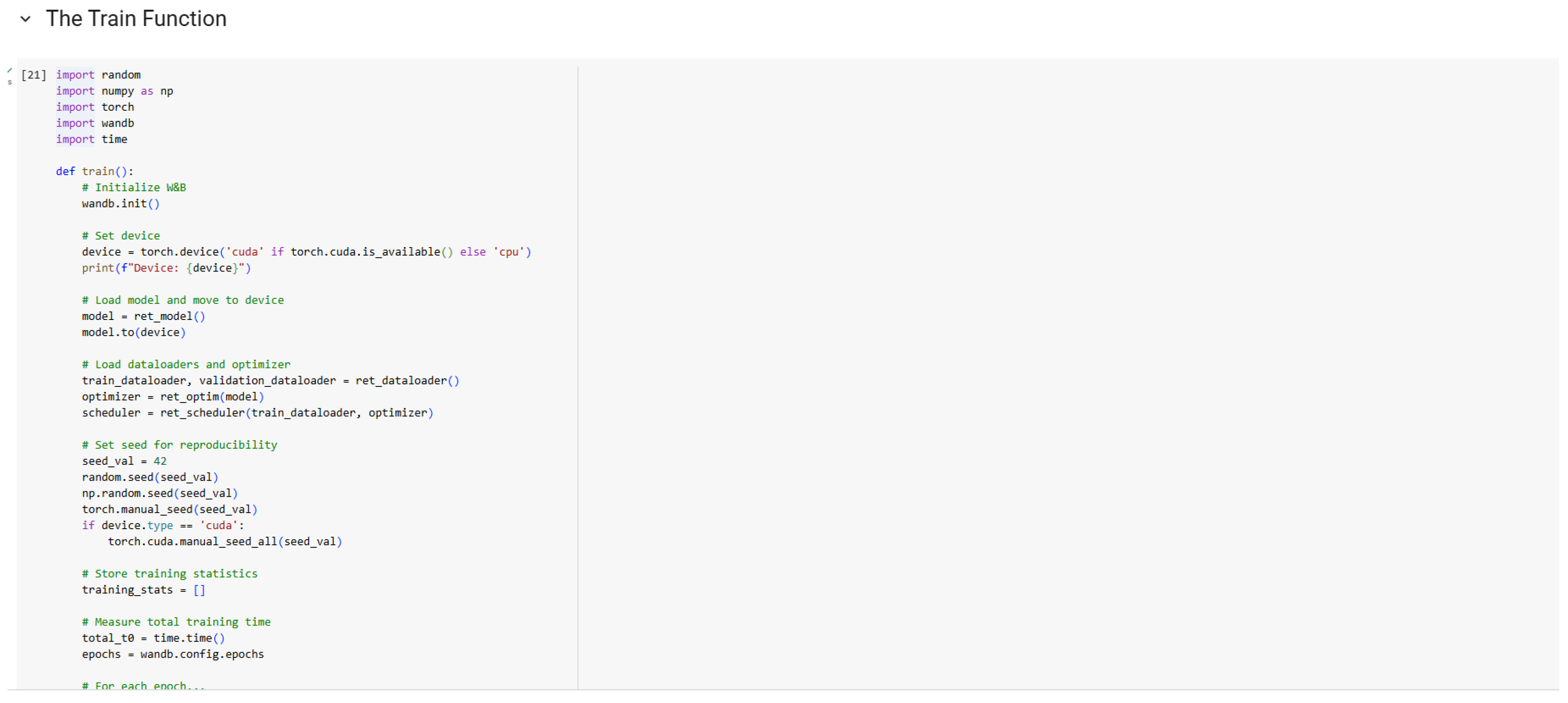
Figure 13.
Training Code (Part 2).
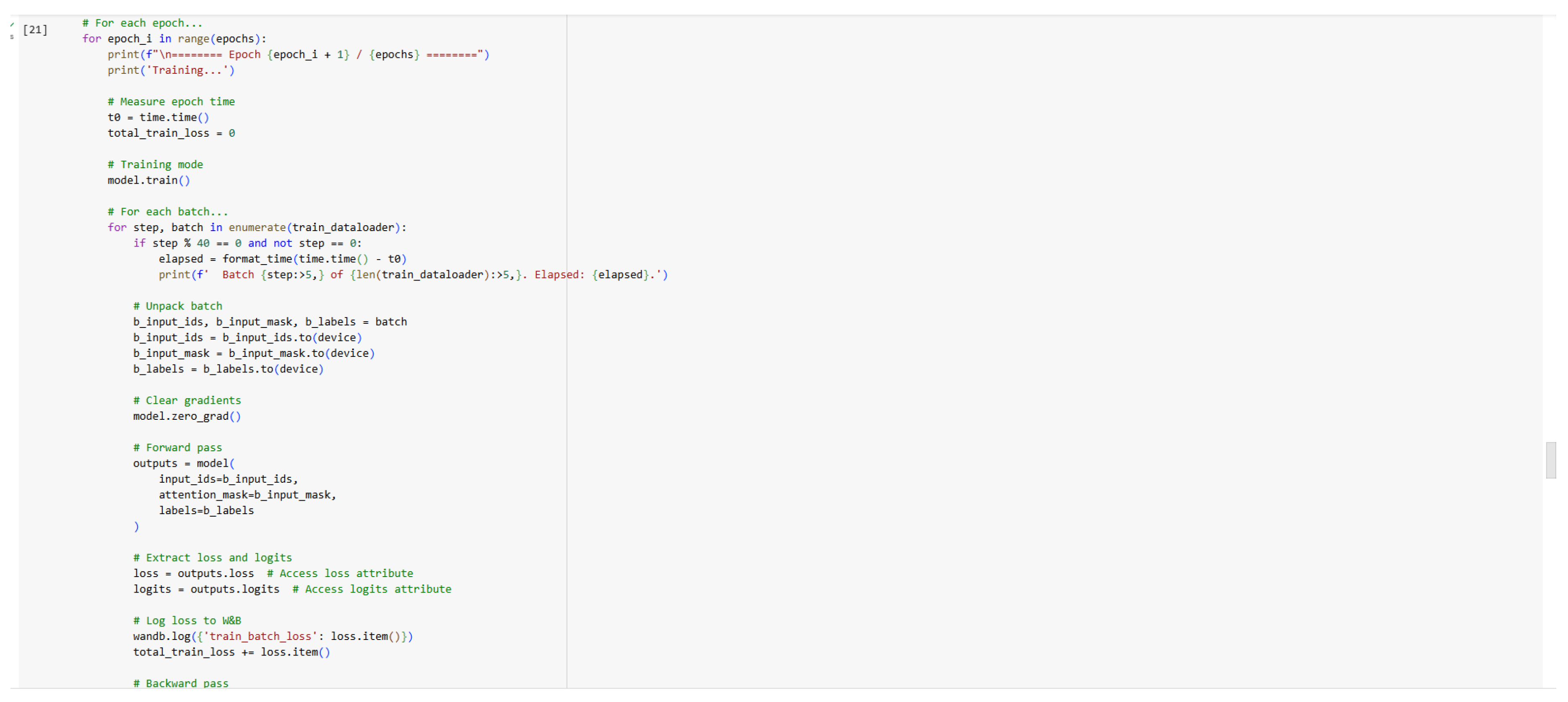
Figure 14.
Training Code (Part 3).
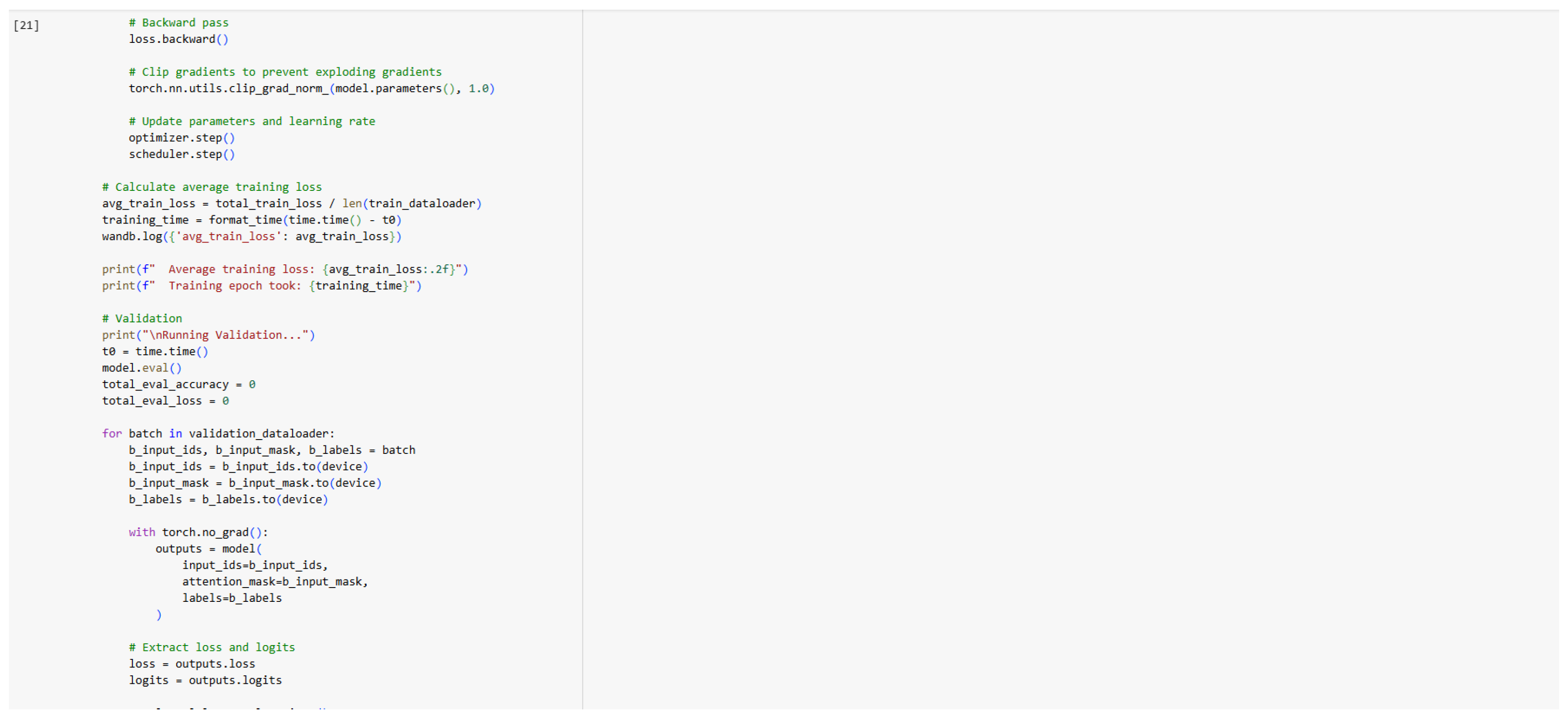
Figure 15.
Training Epochs.
References
- M. Kaneko, M. Mita, S. Kiyono, and J. Suzuki, “Encoder-decoder models can benefit from pre-trained bert for grammatical error correction,” Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020. [Online]. Available: https://aclanthology.org/2020.acl-main.565.
- K. Omelianchuk, V. Atrasevych, A. Chernodub, and Y. Skurzhanskyi, “Gector – grammatical error correction: Tag, don’t rewrite,” Proceedings of the 15th Workshop on Innovative Use of NLP for Building Educational Applications, 2020. [Online]. Available: https://aclanthology.org/2020.bea-1.16.
- F. Stahlberg and S. Kumar, “Seq2edits: Sequence transduction using span-level edit operations with bert,” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020. [Online]. Available: https://aclanthology.org/2020.emnlp-main.393.
- A. Awasthi, S. Sarawagi, and P. Goyal, “Parallel iterative edit models for local sequence transduction,” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. [Online]. Available: https://aclanthology.org/D19-1280.
- J. Lichtarge, A. Dabrowska, C. Alberti, and J. Devlin, “Grammatical error correction with bert-based synthetic data,” Proceedings of the 14th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing), 2020. [Online]. Available: https://arxiv.org/abs/1911.09329.
- Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019. [Online]. Available: https://arxiv.org/abs/1907.11692.
- V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019. [Online]. Available: https://arxiv.org/abs/1910.01108.
- K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pre-training text encoders as discriminators rather than generators,” International Conference on Learning Representations (ICLR), 2020. [Online]. Available: https://arxiv.org/abs/2003.10555.
- S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735.
- Y. Kim, “Convolutional neural networks for sentence classification,” Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014. [Online]. Available: https://aclanthology.org/D14-1181.
Figure 1.
Overview of Classification Models for Text Processing.
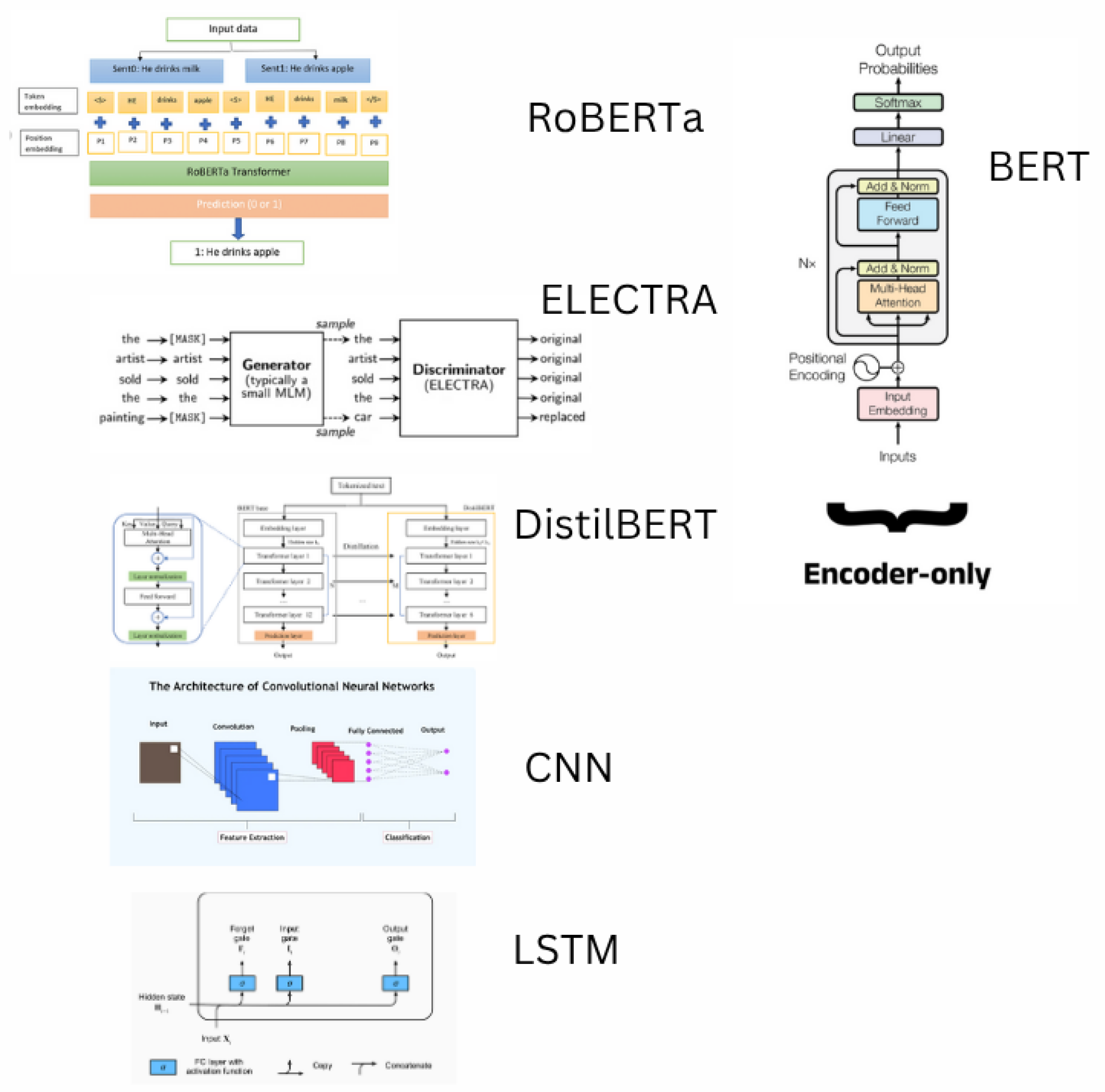
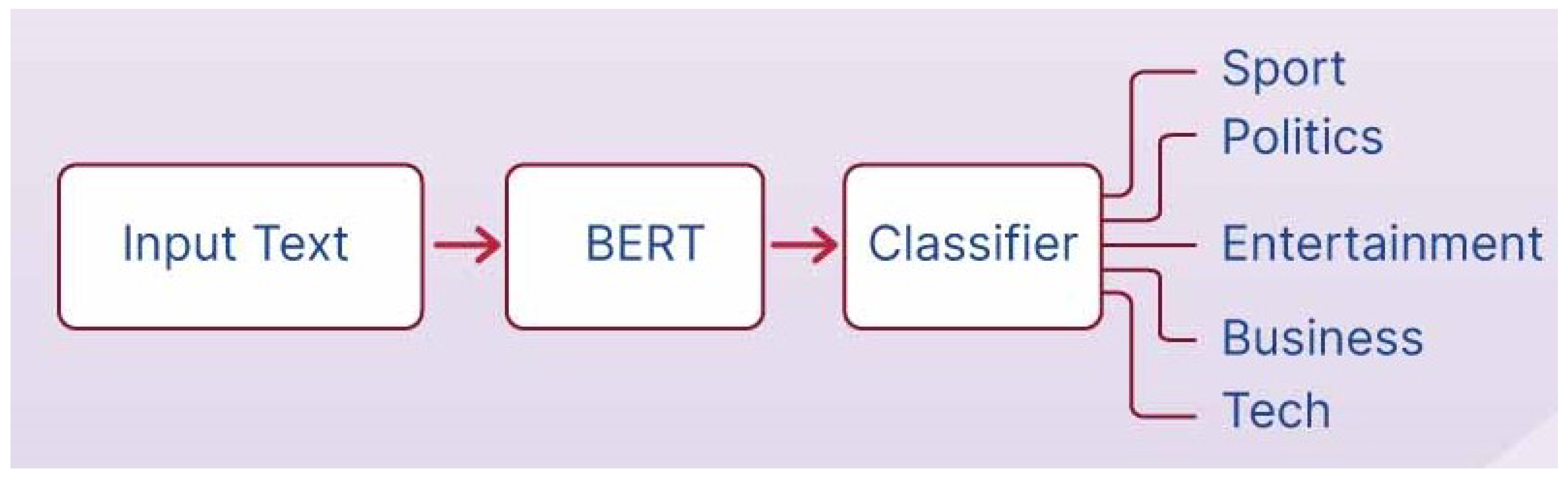
Figure 2.
Overview of the BERT-based sentence classification pipeline for educational applications, such as sentiment analysis or topic categorization.
Figure 2.
Overview of the BERT-based sentence classification pipeline for educational applications, such as sentiment analysis or topic categorization.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



